Tensorflow2.0+部署(tensorflow/serving)过程备忘记录Windows
Tensorflow2.0+部署(tensorflow/serving)过程备忘记录
部署思路:采用Tensorflow自带的serving进模型部署,采用容器docker
1.首先安装docker
下载地址(下载windows版本):https://desktop.docker.com/
- docker安装
安装就按正常流程一步一步安装即可 - window环境检查
win10,win11版本及以上
虚拟化是否开启(用处不知道,反正大家都开启了,网上有教程,可以搜搜)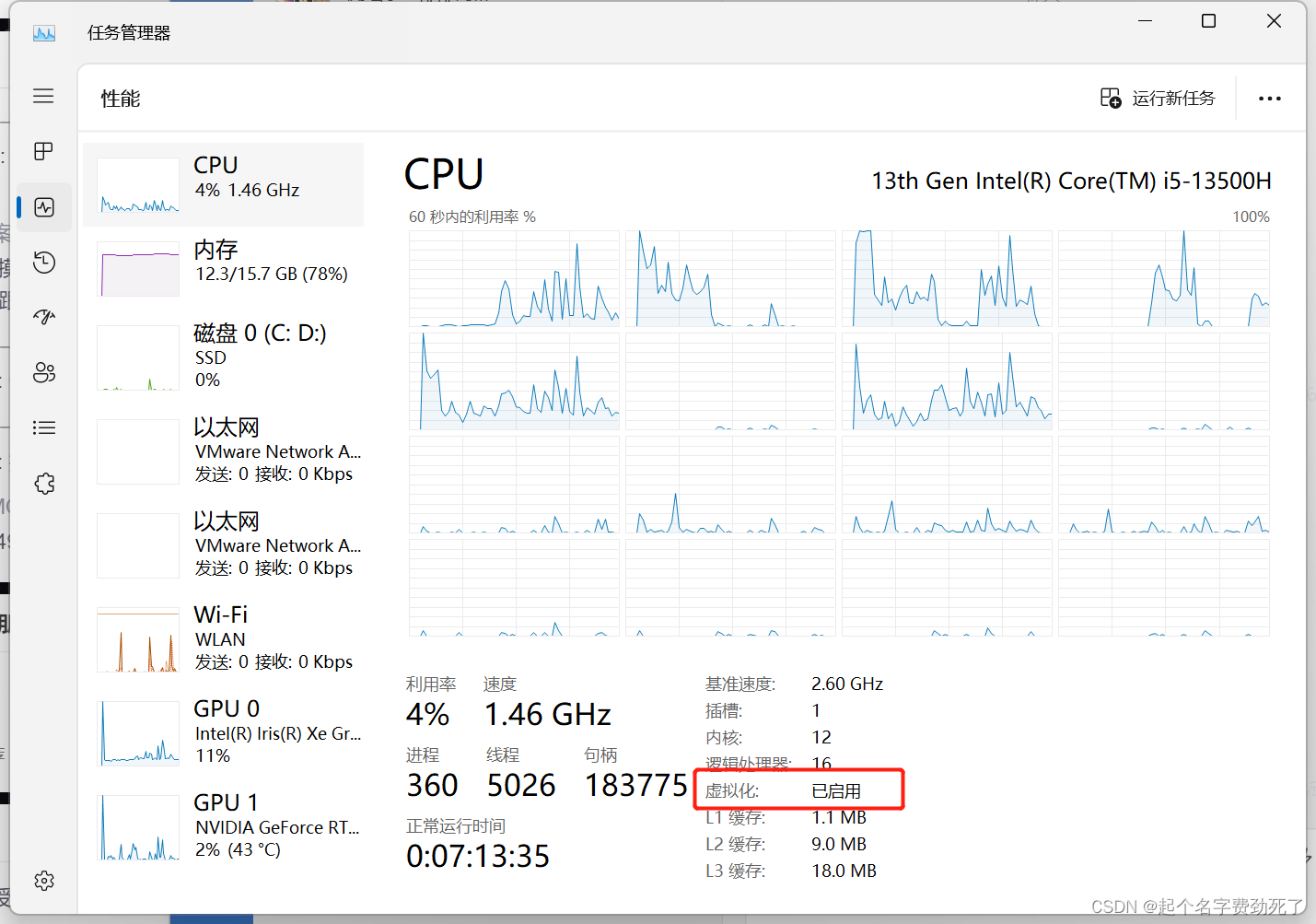
- 安装wsl
下图是截别人的图
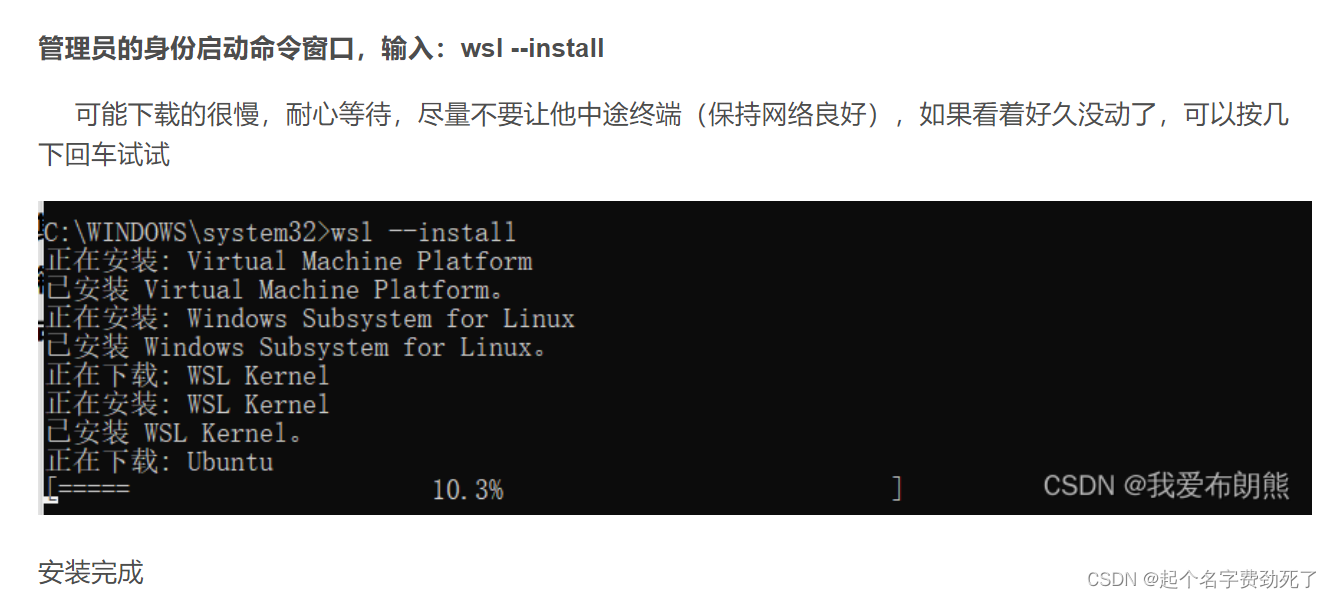
- 安装docker成功
(1)桌面会出现Docker Desktop图标,点击进入后界面如下
(2)给docker添加阿里云镜像源,为了后续下载东西更方便
注册、登录阿里云(支付宝、淘宝扫码都可)

(3)进入后,可以看到自己独立的镜像加速器,是一个网址,最下方一行是给docker配置镜像源的方法,或者直接在Docker Desktop里面,添加那一行命令即可
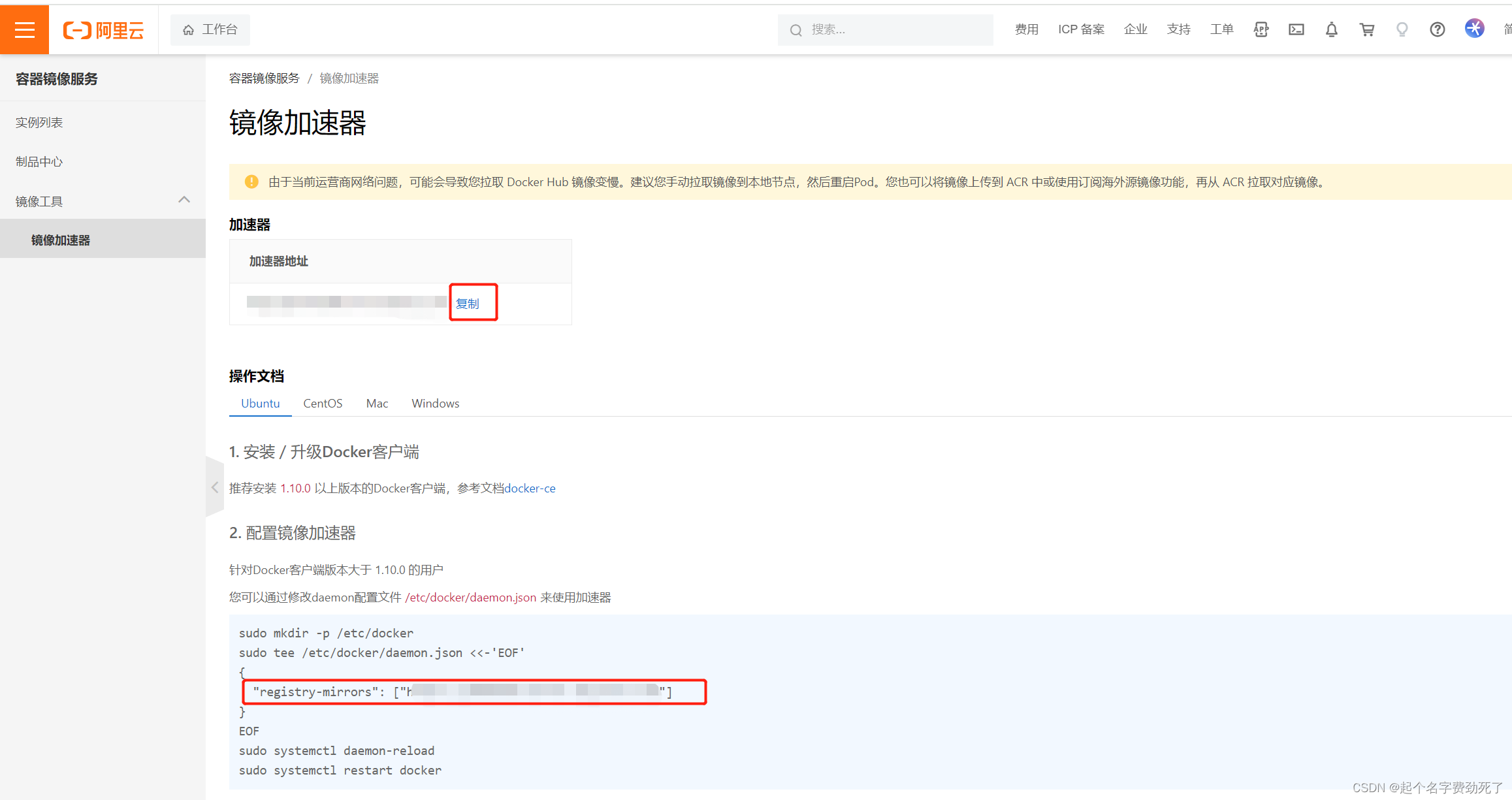
(4)打开Docker Desktop ,点击设置,Docker Engine,添加上图中的代码到窗口中,点击应用和重启按钮即可
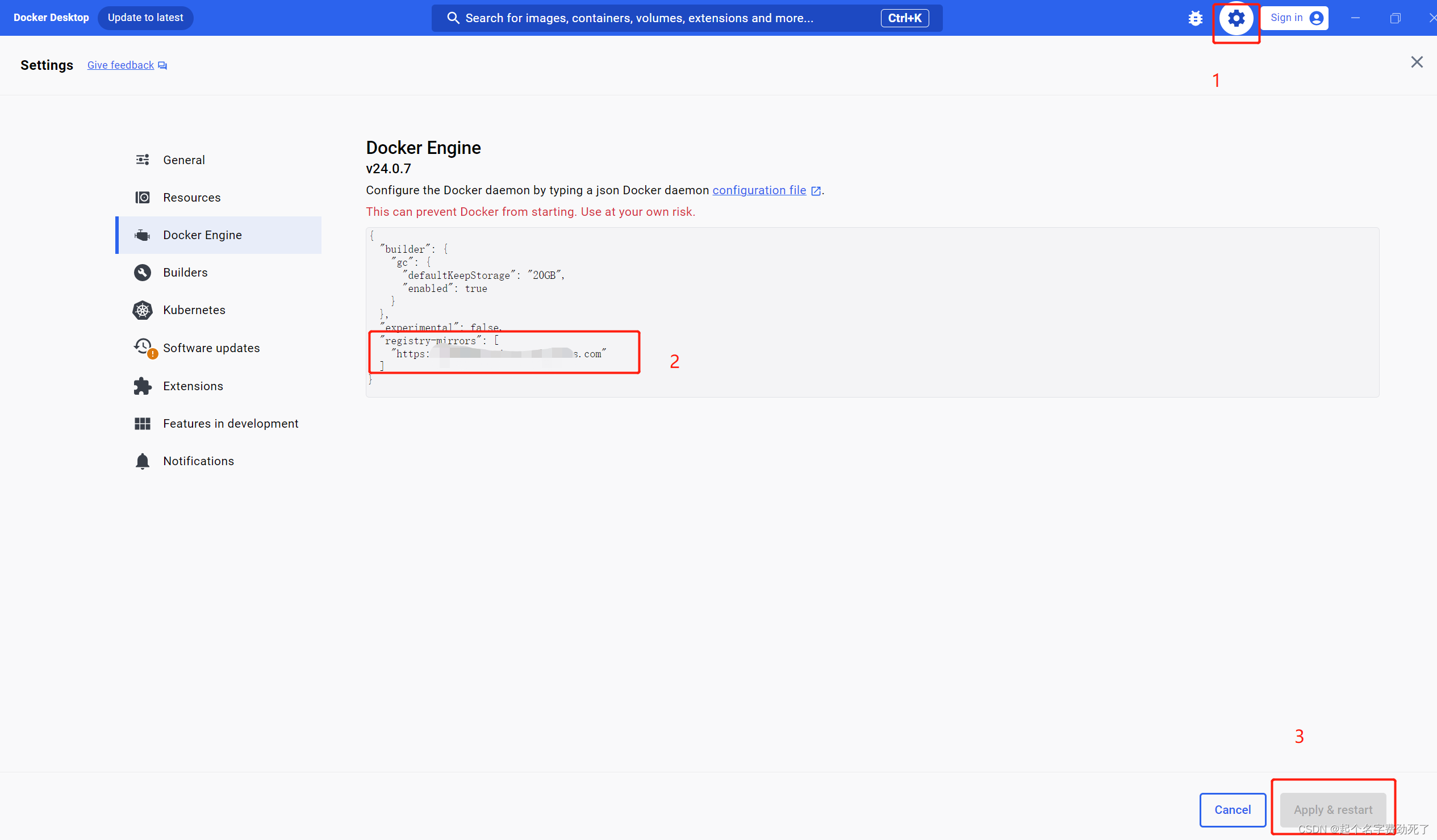
(5)win+R,打开命令行,输入docker info,查看是否应用成功
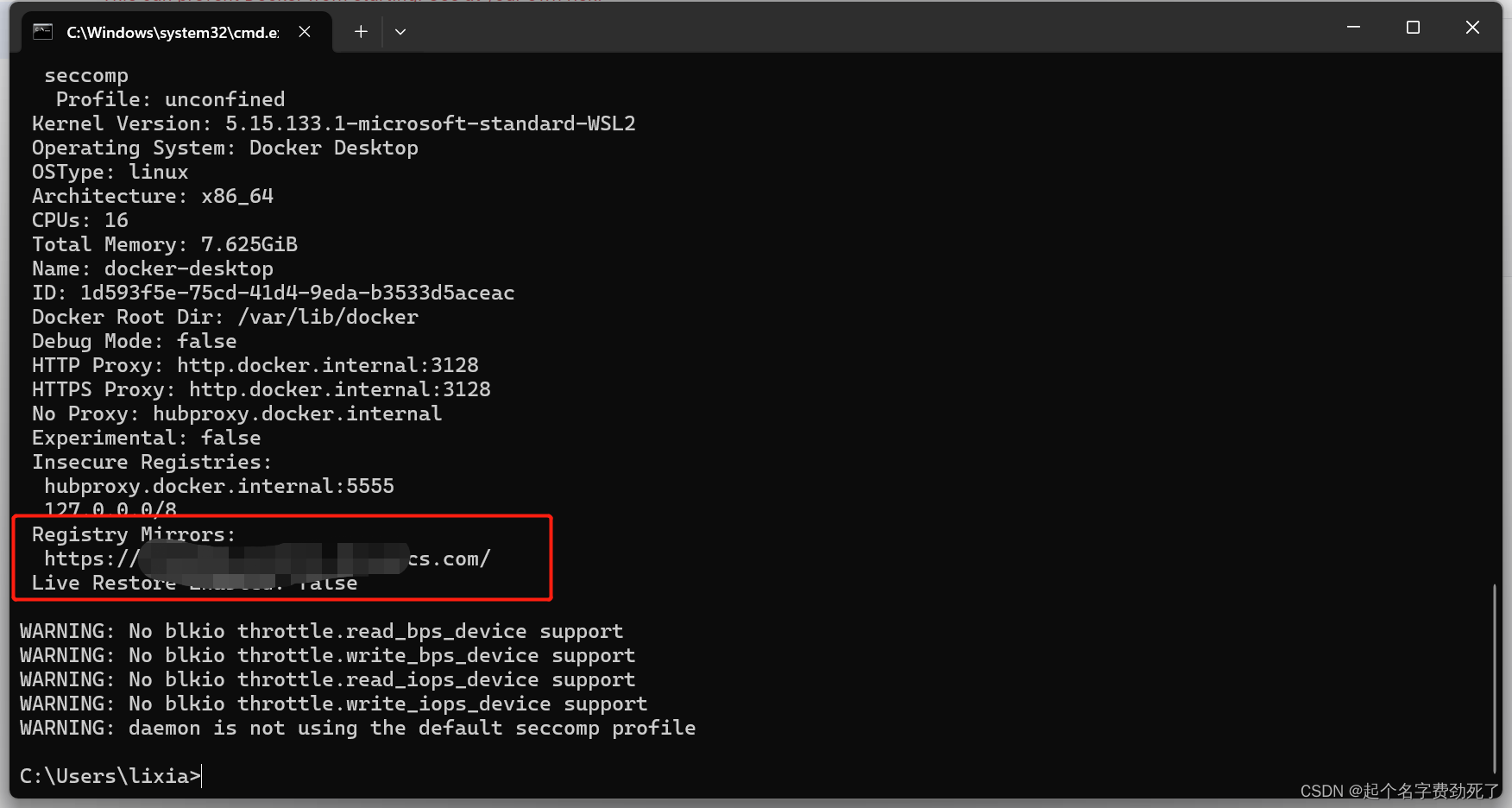
2.安装tensorflow/serving服务
1.docker 拉取tensorflow/serving服务
安装tensorflow 2.6.0的GPU服务
docker pull tensorflow/serving:2.6.0-gpu
安装tensorflow 2.6.0的CPU服务
docker pull tensorflow/serving:2.6.0
2.查看是否拉取成功,其中,GPU版本比较大
docker images

3.准备模型测试
1.先拿官方例子测试一下,先下载一下tensorflow/serving2.6.0,然后在该目录结构下,找到 saved_model_half_plus_two_gpu例子,整体拷贝到想要放置的位置
2.开始发布一下该服务
(1)GPU版本,–gpus all 标注了下使用机器的所有GPU,我这边不加提示找不到GPU
注意:
下面的绝对路径表示模型存放的实际路径,最后一个参数项需要指定运行的容器和版本,里面的其他参数照猫画虎吧,很好理解,具体参数项也比较复杂
docker run --gpus all -t --rm -p 8501:8501 -v "C:/Users/lixia/.docker/tf_serving/saved_model_half_plus_two_gpu:/models/saved_model_half_plus_two_gpu" -e MODEL_NAME=saved_model_half_plus_two_gpu tensorflow/serving:2.6.0-gpu
出现了如下图,则表示发布成功
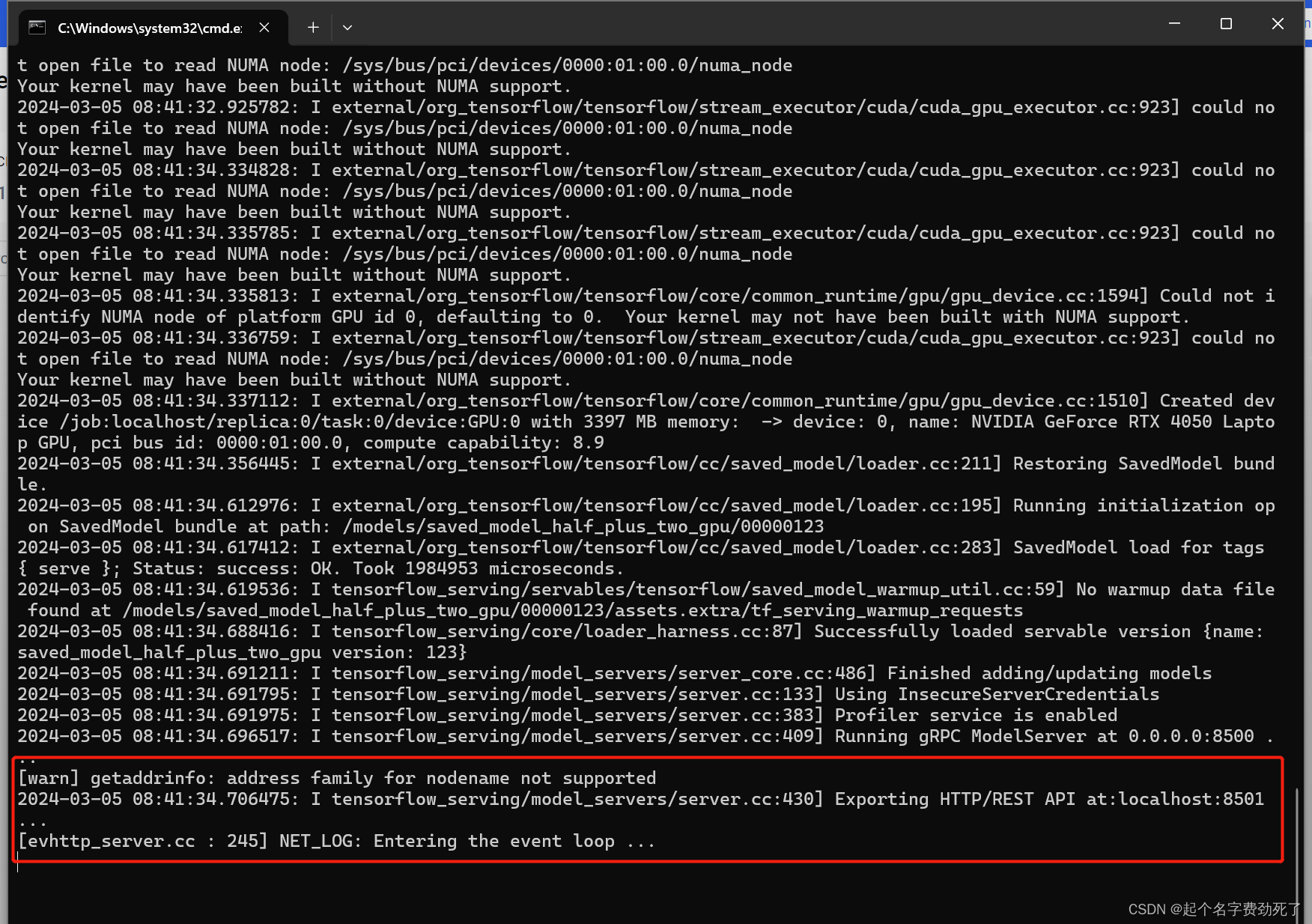
此时,在Docker Desktop中可以看到该服务信息
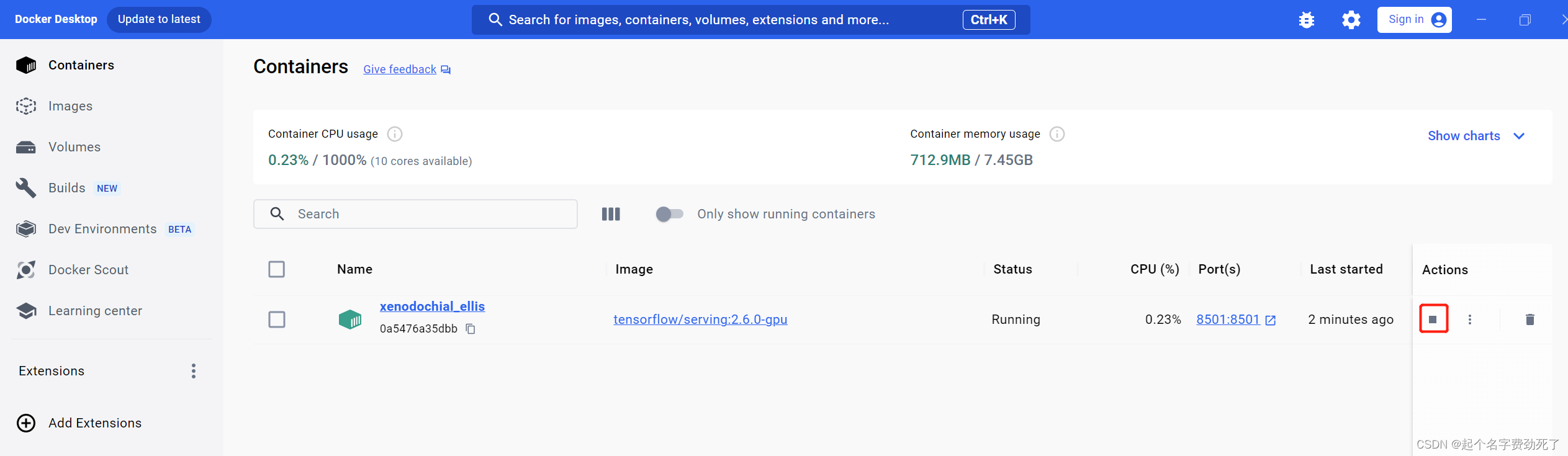
此时,浏览器访问localhost:8501,看是否能连通
http://localhost:8501/v1/models/saved_model_half_plus_two_gpu
出现该信息,则表示可以正常连通和访问了
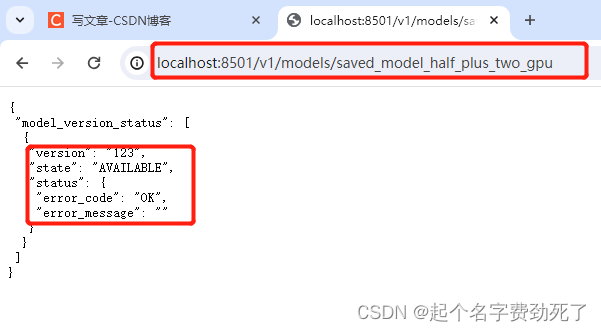
3.测试调用一下该服务,是否能正常返回结果
#调用官方例子 线性回归小例子 y=0.5*x+2.0
import requests
import jsonurl='http://localhost:8501/v1/models/saved_model_half_plus_two_gpu:predict'
pdata = {"instances":[1.0, 2.0, 3.0]}
param = json.dumps(pdata)
res = requests.post(url, data= param)
print(res.text)
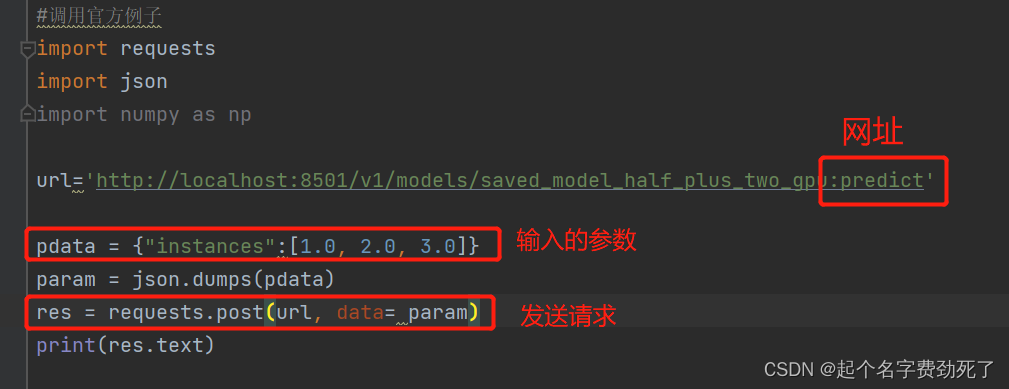
出现该结果表示部署成功

4.服务停止
(1)去Docker Desktop界面端中,手动终止,上面有图
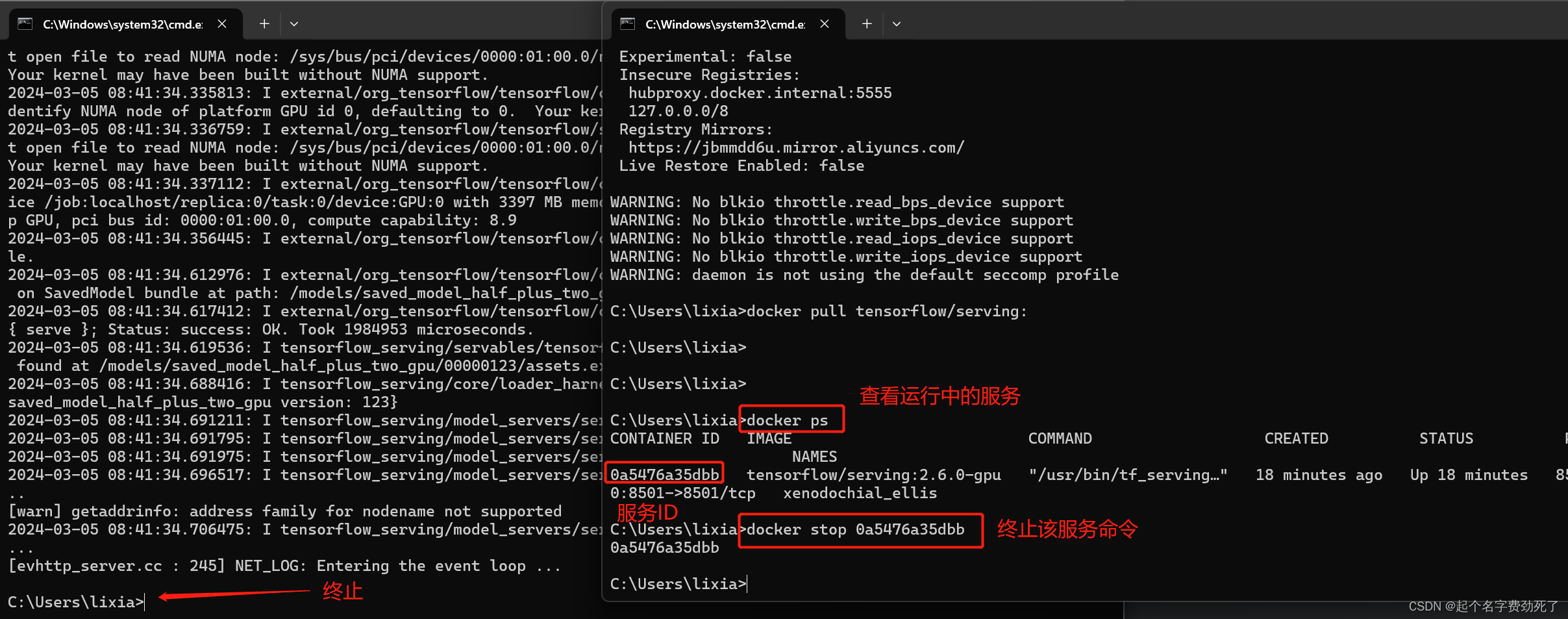
(2)命令行的形式停止
查看运行中的服务
docker ps
终止服务 ****表示ID
docker stop ******
4.准备自己的模型部署测试
准备一个部署练习代码:是否佩戴口罩检测(YOLOv5)
1.首先需要有一个训练好的模型文件,如下图,是我训练好的一个模型

2.将.h5模型转换为.pb模型
直接使用TF自带的函数转(tf.keras.models.save_model),我的模型初始化+参数加载都在yolo.YOLO()中完成了
import tensorflow as tf
import yolodef export_serving_model(path,version=1):"""导出标准的模型格式:param path::return:"""#路径+模型名字+版本export_path = './yolov5_mask_detection/1'#调用模型,指定训练好的.h5文件model = yolo.YOLO()#导出模型tf.keras.models.save_model(model.yolo_model,export_path,overwrite=True,include_optimizer=True,save_format=None,signatures=None,options=None)
运行完后,会生产出下面文件结构的模型.pb文件,直接拷贝上上级整体目录结构即可yolov5_mask_detection
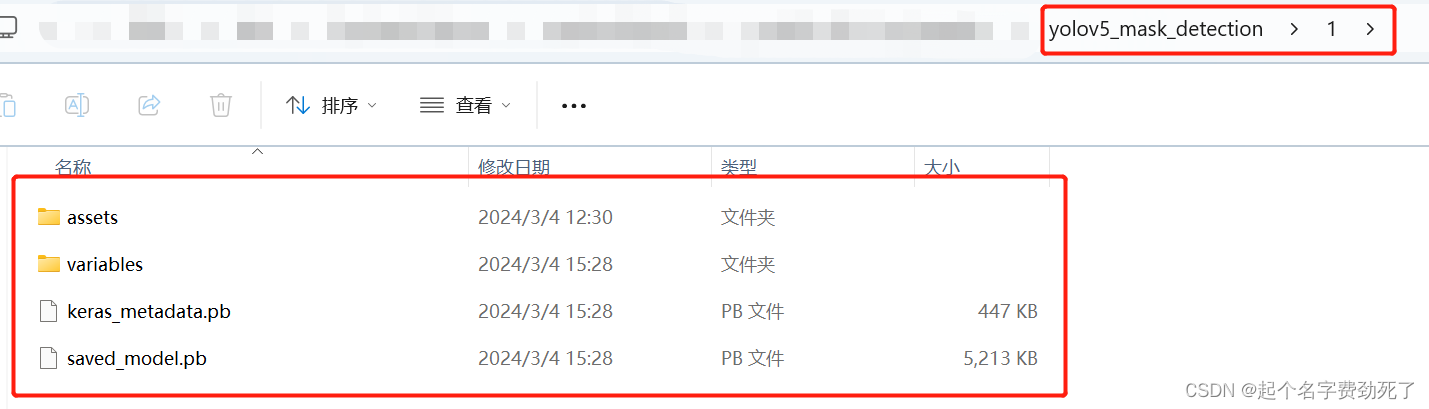
3.将pb模型发布服务
(1)我直接拷贝到D盘根目录

(2)发布GPU服务
docker run --gpus all -t --rm -p 8501:8501 -v "D:/yolov5_mask_detection:/models/yolov5_mask_detection" -e MODEL_NAME=yolov5_mask_detection tensorflow/serving:2.6.0-gpu
(3)发布CPU服务
直接发布即可,发现GPU模型直接可以在CPU使用
docker run -t --rm -p 8501:8501 -v "D:/yolov5_mask_detection:/models/yolov5_mask_detection" -e MODEL_NAME=yolov5_mask_detection tensorflow/serving:2.6.0
出现如下,表示发布成功

4.调用模型
(1)新建一个裸的python环境,最好和tf用的版本一致,保不齐会出现问题啥的,如果缺少requests 、numpy、PIL库,pip install安装即可;
(2)调用代码前,如果不知道输入输出是啥,需要看下
进行conda环境,激活tf虚拟环境,输入命令查看
#打开anaconda命令行输入
conda activate tensorflow-gpu
#产看模型的输入输出和网络结构,绝对路径表示模型存放路径
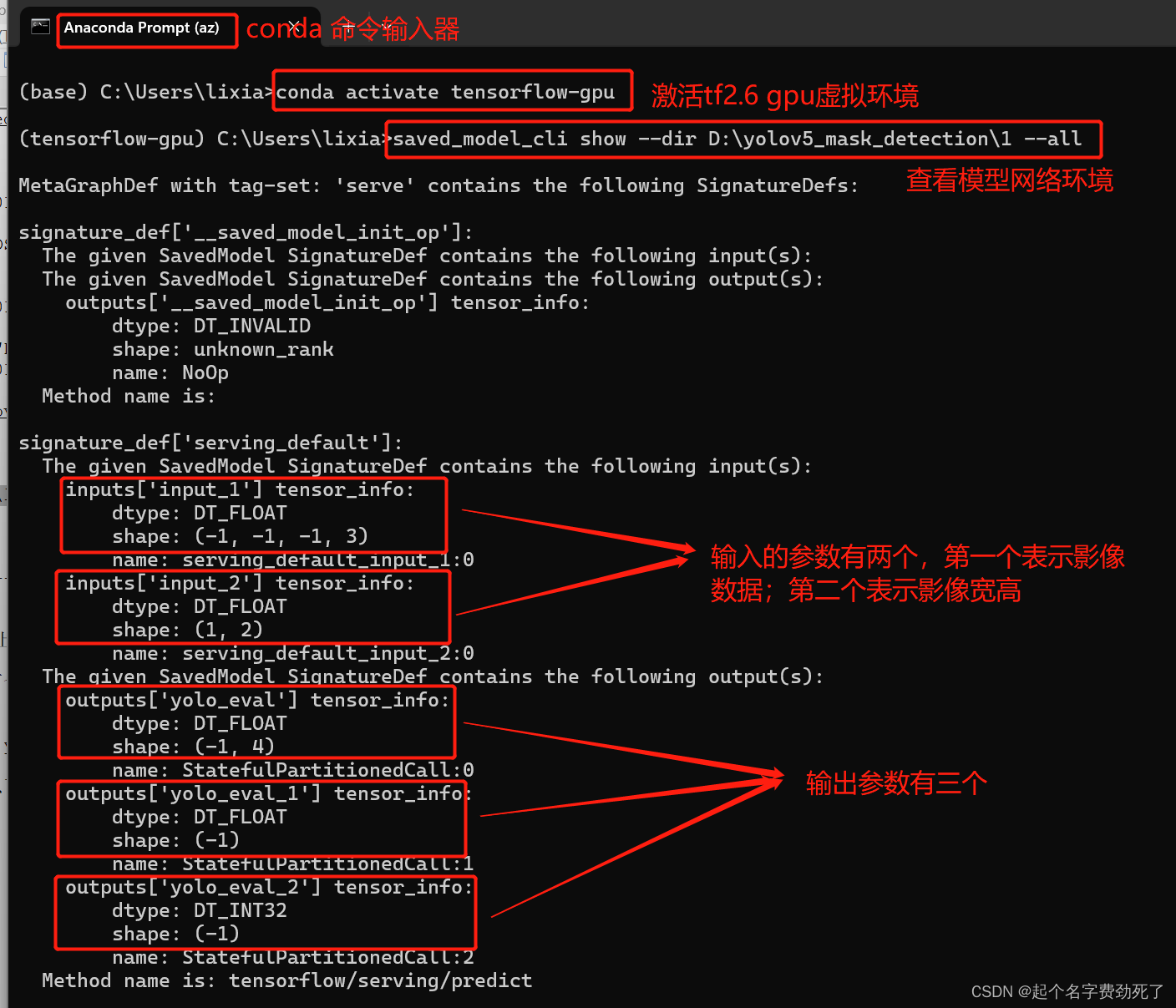
saved_model_cli show --dir D:\yolov5_mask_detection\1 --all
输出参数包含三个,yolo_eval_1表示概率值;yolo_eval_2表示标签值;yolo_eval表示目标检测框
(3)调用代码,核心代码和上述官方例子一致,只不过加了些影像读取+预处理代码
代码如下:
import json
import time
import requests
import numpy as np
from PIL import Image
import ujson#---------------------------------------------------#
# 对输入图像进行resize,模型训练过程也采用了同样的方法
#---------------------------------------------------#
def resize_image(image, size, letterbox_image):iw, ih = image.sizew, h = sizeif letterbox_image:scale = min(w/iw, h/ih)nw = int(iw*scale)nh = int(ih*scale)image = image.resize((nw,nh), Image.BICUBIC)new_image = Image.new('RGB', size, (128,128,128))new_image.paste(image, ((w-nw)//2, (h-nh)//2))else:new_image = image.resize((w, h), Image.BICUBIC)return new_image
#---------------------------------------------------#
# 对输入图像进行归一化,模型训练过程也采用了同样的方法
#---------------------------------------------------#
def preprocess_input(image):image /= 255.0return image
#服务网址
url = 'http://localhost:8501/v1/models/yolov5_mask_detection:predict'
#计时器
tt1 = time.time()
#输入的影像路径
image = Image.open("1.jpg")
#影像需要重采样成640*640
image_data = resize_image(image, (640, 640), True)
#维度扩展,和模型训练保持一致
image_data = np.expand_dims(preprocess_input(np.array(image_data, dtype='float32')), 0)
#原始影像大小,主要是为了将描框放缩到初始影像大小时用到的参数
input_image_shape = np.expand_dims(np.array([image.size[1], image.size[0]], dtype='float32'), 0)
#构造输入的参数类型,有两个参数,第一个表示影像数据1*640*640*3,第二个表示初始影像宽高
# data = json.dumps({
# "signature_name": "serving_default",
# "inputs":
# {"input_1": image_data.tolist(), "input_2": input_image_shape.tolist()}
# })
#换一种json解析方法,速度更快
data = ujson.dumps({"signature_name": "serving_default","inputs":{"input_1": image_data.tolist(), "input_2": input_image_shape.tolist()}})
#构造headers
headers = {"content-type":"application/json"}
#发送请求
r = requests.post(url, data=data, headers=headers)
#计时器终止
tt2 = time.time()
print(tt2-tt1)
#打印返回的结果,这里表示所有框的位置
print(r.text)
注意:
实际测试中发现,大影像转json时,效率偏低,可以直接使用ujson进行替换,其他更优的办法暂时也不过多探讨
**1.安装ujson
pip install ujson

**2.测试记录
import ujson
****tt2 = time.time()# 构造输入的参数类型,有两个参数,第一个表示影像数据1*640*640*3,第二个表示初始影像宽高# -------------------------------------------------------------------------------------data = json.dumps({"signature_name": "serving_default","inputs":{"input_1": image_data.tolist(), "input_2": input_image_shape.tolist()}})tt21 = time.time()print("json方式:",tt21 - tt2)# ------------------------------------------------------------------------------------data = ujson.dumps({"signature_name": "serving_default","inputs":{"input_1": image_data.tolist(), "input_2": input_image_shape.tolist()}})tt22 = time.time()print("ujson方式:",tt22 - tt21)
效率大概提升一倍多,可以一定程度提升推理速度,大数据情况可以考虑,小数据无所谓

直接右键运行,得到结果,表示该程序检测出了9个目标,概率值+标签+目标框像素位置如下,通过解析json,可以得到目标检测结果
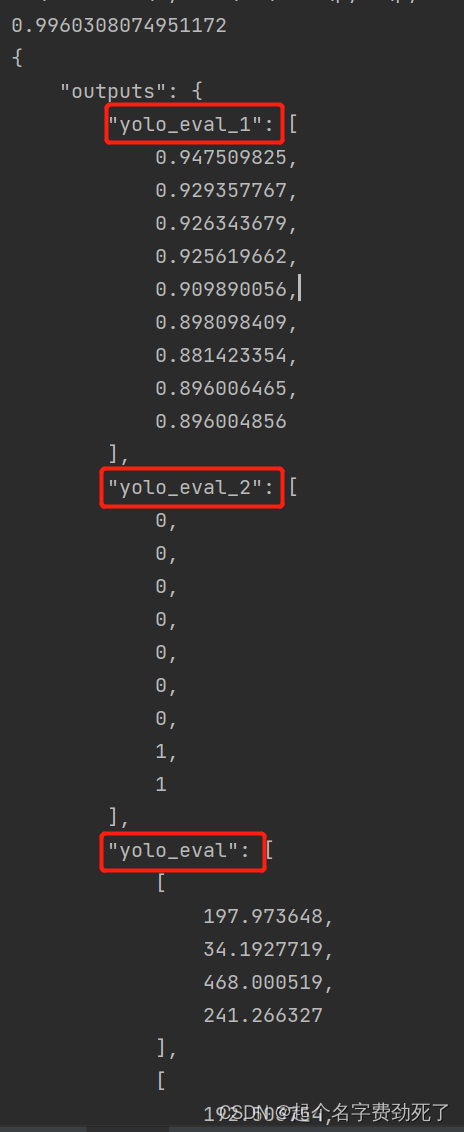
(4)我们看下,将检测结果标记到图上后,效果如下:

换个图片试一下

5.将docker环境整体打包到其他电脑测试(待续…)
有空了试试
6.一些备忘记录
1.conda 环境整体打包移植
//----------------------------------------------------------------------------------------------------------
conda 环境打包到其他电脑要将 Conda 环境打包并迁移到其他电脑上使用,可以按照以下步骤进行操作:导出 Conda 环境: 在源电脑上使用以下命令导出 Conda 环境的配置信息到一个 YAML 文件中:conda env export > environment.yml
复制环境文件: 将生成的 environment.yml 文件复制到目标电脑上。创建 Conda 环境: 在目标电脑上使用以下命令根据导出的环境文件创建相同的 Conda 环境:conda env create -f environment.yml
激活环境: 激活新创建的 Conda 环境:conda activate <environment_name>
相关文章:
Tensorflow2.0+部署(tensorflow/serving)过程备忘记录Windows
Tensorflow2.0部署(tensorflow/serving)过程备忘记录 部署思路:采用Tensorflow自带的serving进模型部署,采用容器docker 1.首先安装docker 下载地址(下载windows版本):https://desktop.docke…...

Docker的安装跟基础使用一篇文章包会
目录 国内源安装新版本 1、清理环境 2、配置docker yum源 3、安装启动 4、启动Docker服务 5、修改docker数据存放位置 6、配置加速器 现在我们已经完成了docker的安装和初始配置。以下为基本测试使用 自带源安装的版本太低 docker官方源安装的话速度太慢了 所以本篇文…...
SQL技巧笔记(一):连续3人的连号问题—— LeetCode601.体育馆的人流量
SQL 技巧笔记 前言:我发现大数据招聘岗位上的应聘流程都是需要先进行笔试,其中占比很大的部分是SQL题目,经过一段时间的学习之后,今天开了一个力扣年会员,我觉得我很有必要去多练习笔试题目,这些题目是有技…...
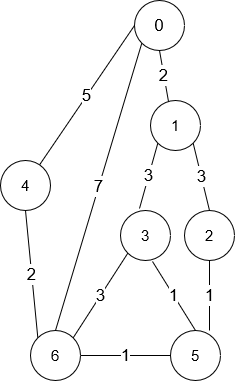
LeetCode 1976.到达目的地的方案数:单源最短路的Dijkstra算法
【LetMeFly】1976.到达目的地的方案数:单源最短路的Dijkstra算法 力扣题目链接:https://leetcode.cn/problems/number-of-ways-to-arrive-at-destination/ 你在一个城市里,城市由 n 个路口组成,路口编号为 0 到 n - 1 ÿ…...
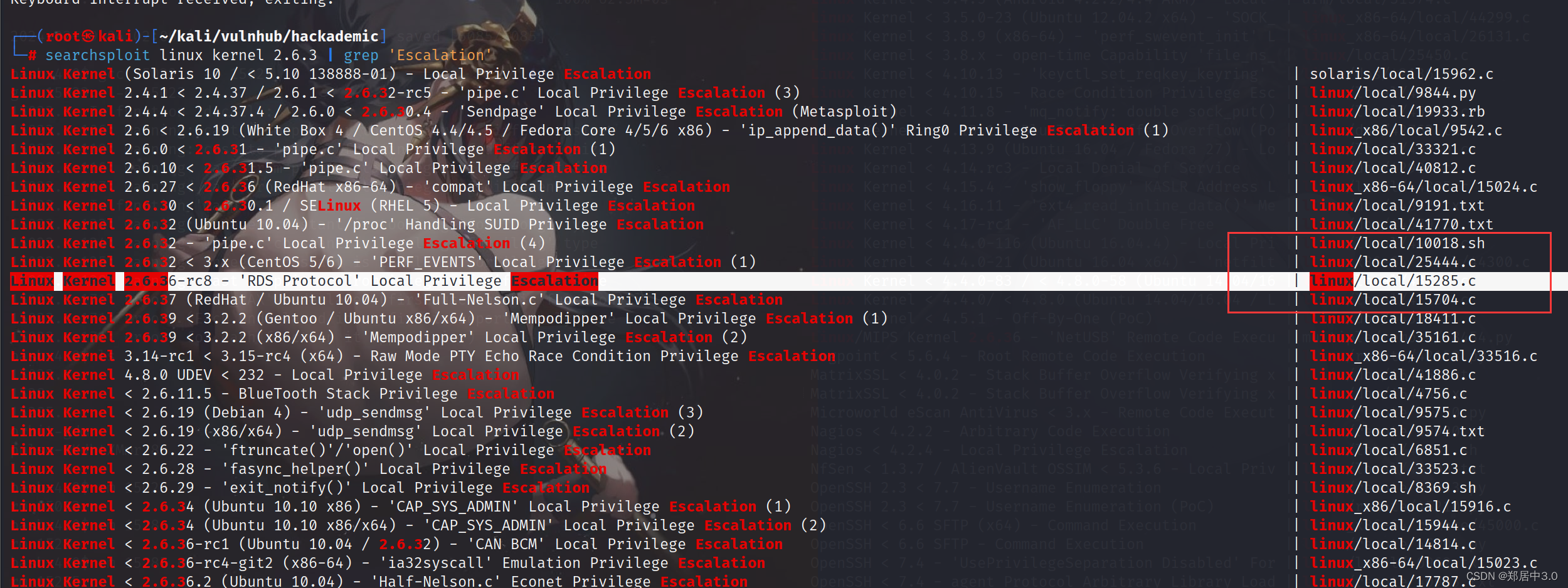
vulnhub-----Hackademic靶机
文章目录 1.C段扫描2.端口扫描3.服务扫描4.web分析5.sql注入6.目录扫描7.写马php反弹shell木马 8.反弹shell9.内核提权 1.C段扫描 kali:192.168.9.27 靶机:192.168.9.25 ┌──(root㉿kali)-[~] └─# arp-scan -l Interface: eth0,…...

十秒学会Ubuntu命令行:从入门到进阶
一、引言 在使用Ubuntu操作系统时,命令行界面(CLI)是不可或缺的一部分。对于初学者来说,掌握基本的命令行操作可以帮助他们更高效地管理系统和软件。 本文将介绍一些常见的Ubuntu命令以及如何解决与命令行相关的问题。 目录 一、…...
华为智慧教室3.0的晨光,点亮教育智能化变革
“教室外有更大的世界,但世界上没有比教室更伟大的地方。” 我们在求学阶段,都听说过这句话,但往往是在走出校园之后,才真正理解了这句话。为了让走出校园的孩子能够有能力,有勇气探索广阔的世界。我们应该准备最好的教…...

深度学习预测分析API:金融领域的Game Changer
🚀 引言 在这个AI遍地开花的时代,谁能成为金融领域的真正Game Changer?那必然是是深度学习预测分析API。如大脑般高效运转的系统不仅颠覆了传统操作,更是以无与伦比的速度和精度赋予了金融数据以全新的生命。 💼 广泛…...

外贸网站做Google SEO 用wordpress模板的优势
易于优化:WordPress模板是专门为搜索引擎优化(SEO)设计的。从一开始,WordPress模板就考虑到了搜索引擎的因素,因此在构建网站时已经考虑了如何优化网站的结构和内容。使用WordPress模板可以简化优化过程,让您的网站更容易被搜索引…...

后端面试题整理-1
1.Maven 依赖传递产生版本冲突怎么解决? 升级或降级依赖版本:通过修改相关依赖的版本号,选择与项目其他依赖兼容的版本。可以通过查看 Maven 依赖树来确定哪些依赖冲突,并找出合适的版本号进行调整。排除依赖:对于特定…...

Python图像处理之光斑分析
文章目录 质心目标截取光斑半径 python图像处理教程:初步📷插值变换📷形态学处理📷滤波 光斑是工程中经常出现的图像数据,其特点是目标明确,分布清晰。对光斑图像的分析,主要包括质心定位、目标…...

软件测试 - 测试用例基本理论
1. 概念 为了特定的目的(该目的是检验代码是否满足用户需求)而设计的文档,文档包含测试输入、执行条件、预期结果等。文档的形式一般是excel表格。 比如说我们买了一台电脑,新买的笔记本检查完外观之后第一步需要查看电脑是否能够正常开机,…...

在 Flutter 中使用 flutter_gen 简化图像资产管理
你是否厌倦了在 Flutter 项目中手动管理图像资产的繁琐任务? 告别手工输入资源路径的痛苦,欢迎使用“Flutter Gen”高效资源管理的时代。在本文中,我将带您从手动处理图像资源的挫折到动态生成它们的便利。 选择1:痛苦手动添加–…...
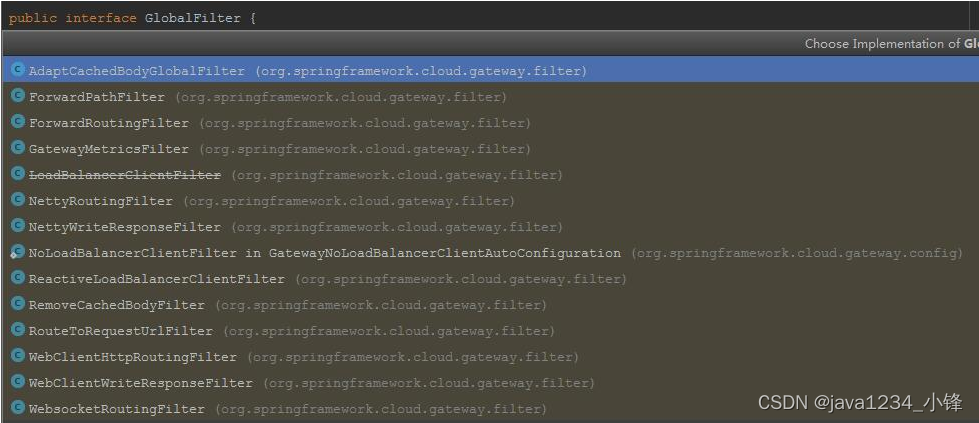
两天学会微服务网关Gateway-Gateway过滤器
锋哥原创的微服务网关Gateway视频教程: Gateway微服务网关视频教程(无废话版)_哔哩哔哩_bilibiliGateway微服务网关视频教程(无废话版)共计17条视频,包括:1_Gateway简介、2_Gateway工作原理、3…...
图像处理 mask掩膜
1,图像算术运算 图像的算术运算有很多种,比如两幅图像可以相加,相减,相乘,相除,位运算,平方根,对数,绝对值等;图像也可以放大,缩小,旋…...
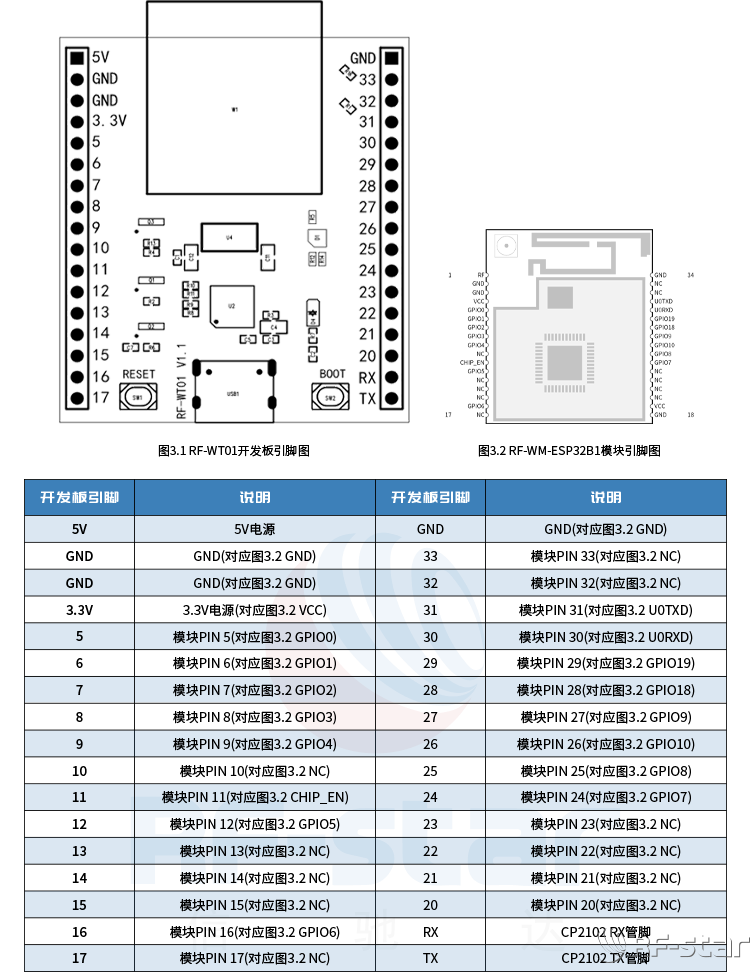
信驰达ESP32-C3/RTL8720CM WiFi开发板RF-WT01上线
为方便客户快速选型和验证WiFi模块,深圳市信驰达科技有限公司推出了WiFi开发板RF-WT01,支持适配信驰达RF-WM-ESP32B1、RF-WM-20CMB1、RF-WM-11AFB1、RF-WM-20DNB1 4款WiFi串口模块使用,方便客户实现对信驰达WiFi模块的快速测试和评估。 图1RF…...

【产品经理方法论——产品的基本概念】
1. 产品学三元素 产品学有三个元素:用户、需求、产品 产品学的内容:根据用户的需求设计产品,使用产品服务用户 仅仅通过三个元素无法说明每个元素的概念,因为三个元素互为说明关系。 通过引入人/群体来说明三个元素的关系。 需…...
V2 查询用户信息)
推特API(Twitter API)V2 查询用户信息
前面章节已经介绍使用code换取Token的整个流程了,这里不再重复阐述了,下面我们介绍如何使用Token查询用户信息等操作。 1.引入相关依赖Maven <dependency> <groupId>oauth.signpost</groupId> <artifactId>signpost-co…...

在Elasticsearch IK分词器中更新、停用某些专有名词
在Elasticsearch IK分词器中更新、停用某些专有名词 目前IK分词器对于现有的新名词或者流行语没有做区分比如"白嫖" “奥利给”,或者对一些没有用的字比如 “的” "地"进行分词其实没有必要过多的分词只会占用宝贵的内存空间,所以如…...

时钟显示 html JavaScript
sf.html <!DOCTYPE html> <html><head><meta charset"UTF-8"><title>时间</title><script>function showTime(){var timenew Date();var datetime.getDate();var yeartime.getFullYear();var monthtime.getMonth()1;var …...

水质在线监测系统嵌入式工控机选型与实战指南
1. 水质在线监测:从传统抽检到智慧物联的必然之路水,是生命之源,也是城市运行的命脉。过去,我们了解水源地的水质状况,主要依赖人工定期采样、送回实验室分析。这种方式周期长、成本高,面对突发性污染事件&…...

解析日本工程塑料厂家代理新日铁住金产品的核心价值与
在众多日本工程塑料供应商中,新日铁住金凭借其在特种工程塑料领域的技术积累和稳定品质,成为众多制造企业的优选合作伙伴。对于寻求高性价比、稳定供应的塑胶制品厂、精密注塑厂及汽车零部件厂商而言,选择专业代理商是平衡品质与成本的关键。…...
)
linux文件基本操作作业(含文件基本操作的重点知识内容及截图)
文件基本操作 1 要求:请简要描述各操作所使用命令 文章目录文件基本操作查看文件新建和修改文件进入指定目录查看文件信息查找文件位置、指定内容内容排序、去除重复行统计创建目录文件的复制、移动和删除文件链接(软/硬) 查看文件 1、通过文…...

为什么你的Windows Phone需要解锁引导加载程序?深度解析WPinternals的3大核心价值
为什么你的Windows Phone需要解锁引导加载程序?深度解析WPinternals的3大核心价值 【免费下载链接】WPinternals Tool to unlock the bootloader and enable Root Access on Windows Phones 项目地址: https://gitcode.com/gh_mirrors/wp/WPinternals 你是否…...

SegFormer凭什么不用位置编码?深入拆解Mix-FFN与重叠Patch Merging的设计哲学
SegFormer革命性设计:为何抛弃位置编码仍能称霸语义分割? 在视觉Transformer的浪潮中,SegFormer以其独特的设计哲学脱颖而出——它大胆摒弃了传统Transformer中视为标配的位置编码(Positional Encoding),却…...

DreamTalk与3DMM参数:如何提取和利用面部表情风格特征
DreamTalk与3DMM参数:如何提取和利用面部表情风格特征 【免费下载链接】dreamtalk Official implementations for paper: DreamTalk: When Expressive Talking Head Generation Meets Diffusion Probabilistic Models 项目地址: https://gitcode.com/gh_mirrors/d…...
)
ADAU1452/1467硬件设计避坑:手把手教你从原理图到SigmaStudio的通道映射(含AD1938实例)
ADAU1452/1467硬件设计实战:从原理图到SigmaStudio的通道映射全解析 在嵌入式音频系统设计中,ADAU1452和ADAU1467作为业界广泛使用的数字信号处理器,其硬件接口配置一直是工程师面临的典型挑战。特别是当系统需要连接多通道编解码器ÿ…...

程序员的职场心态:如何应对代码bug和项目延期
在软件研发的全流程中,测试与开发如同孪生兄弟,紧密协作又时常因问题产生摩擦。作为软件测试从业者,我们既是bug的“捕手”,也是项目进度的“监督者”,更需要成为程序员职场心态的“理解者”与“协同者”。深入剖析程序…...

语法错误秒级定位,Perplexity查询调试实战手册,一线SRE团队内部流出!
更多请点击: https://intelliparadigm.com 第一章:Perplexity语法查询功能概览 Perplexity 是一款面向开发者与数据分析师设计的轻量级语法感知型查询工具,其核心能力在于对结构化与半结构化文本(如 SQL、JSON Schema、YAML 配置…...

极为罕见!35米宽小行星近距离掠过地球
【环球时报特约记者 陈山】据美国全国广播公司(NBC)网站19日报道,一颗直径约50到115英尺(1英尺约合0.3米)的小行星于18日近距离飞掠地球,成为近年来非常罕见的一幕。小行星从地球附近掠过的概念图。欧洲航天…...