机器学习-面经(part7、无监督学习)
机器学习面经系列的其他部分如下所示:
机器学习-面经(part1)
机器学习-面经(part2)-交叉验证、超参数优化、评价指标等内容
机器学习-面经(part3)-正则化、特征工程面试问题与解答合集
机器学习-面经(part4)-决策树共5000字的面试问题与解答
机器学习-面经(part5)-KNN以及SVM等共二十多个问题及解答
机器学习-面经(part6)-集成学习(万字解答)
11 无监督学习
11.1 聚类
原理:对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小。
聚类的应用场景: 求职信息完善(有大约10万份优质简历,其中部分简历包含完整的字段,部分简历在学历,公司规模,薪水,等字段有些置空顶。希望对数据进行学习,编码与测试,挖掘出职位路径的走向与规律,形成算法模型,在对数据中置空的信息进行预测。)
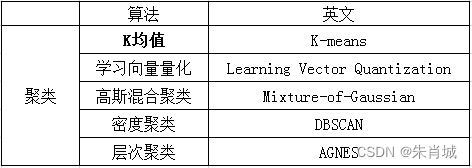
11.1.1 K-means
定义:也叫K均值或K平均。通过迭代的方式,每次迭代都将数据集中的各个点划分到距离它最近的簇内,这里的距离即数据点到簇中心的距离。
K-means步骤:
1.随机初始化K个簇中心坐标
2.计算数据集内所有点到K个簇中心的距离,并将数据点划分近最近的簇
3.更新簇中心坐标为当前簇内节点的坐标平均值
4.重复2、3步骤直到簇中心坐标不再改变(收敛了)
11.1.1.1 K值的如何选取?
K-means算法要求事先知道数据集能分为几群,主要有两种方法定义K。
elbow method通过绘制K和损失函数的关系图,选拐点处的K值。
经验选取人工据经验先定几个K,多次随机初始化中心选经验上最适合的。
通常都是以经验选取,因为实际操作中拐点不明显,且elbow method效率不高。
11.1.1.2 K-means算法中初始点的选择对最终结果的影响?
K-means选择的初始点不同获得的最终分类结果也可能不同,随机选择的中心会导致K-means陷入局部最优解。解决方案包括多次运行算法,每次用不同的初始聚类中心,或使用全局优化算法。
11.1.1.3 K-means不适用哪些数据?
1.数据特征极强相关的数据集,因为会很难收敛(损失函数是非凸函数),一般要用Kernal K-means,将数据点映射到更高维度再分群。
2.数据集可分出来的簇密度不一,或有很多离群值(outliers),这时候考虑使用密度聚类。
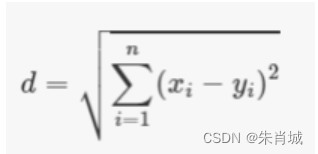
11.1.1.4 K-means 中常用的距离度量?
K-means中比较常用的距离度量是欧几里得距离和余弦相似度。
n维空间的欧几里得距离:
余弦相似度:余弦相似度是指两个向量夹角的余弦。两个方向完全相同的向量的余弦相似度为1,而两个彼此相对的向量的余弦相似度为-1

K-means是否会一直陷入选择质心的循环停不下来(为什么迭代次数后会收敛)?
从K-means的第三步我们可以看出,每回迭代都会用簇内点的平均值去更新簇中心,所以最终簇内的平方误差和(SSE, sum of squared error)一定最小。
11.1.1.5 为什么在计算K-means之前要将数据点在各维度上归一化?
因为数据点各维度的量级不同,例如:最近正好做完基于RFM模型的会员分群,每个会员分别有R(最近一次购买距今的时长)、F(来店消费的频率)和M(购买金额)。如果这是一家奢侈品商店,你会发现M的量级(可能几万元)远大于F(可能平均10次以下),如果不归一化就算K-means,相当于F这个特征完全无效。如果我希望能把常客与其他顾客区别开来,不归一化就做不到。
11.1.1.6 聚类和分类区别?
- 目的不同。聚类是一种无监督学习方法,目的是将数据对象自动分成不同的组或簇,这些簇是自然存在的,而不是人为定义的。分类则是一种监督学习方法,目的是根据已知的数据标签将新的数据对象分配到不同的类别中。
- 监督性不同。聚类不需要人工标注和预先训练分类器,类别在聚类的过程中自动生成。分类事先定义好类别,类别数不变,分类器需要由人工标注的分类训练语料训练得到。
- 结果性质不同。聚类结果是簇或类,这些簇或类是自然存在的,而不是人为定义的。分类结果是类别标签,这些类别标签是人为定义的。
- 应用场景不同。聚类适合于类别数不确定或不存在的场合,如市场细分、文本分类等。分类适合于类别或分类体系已经确定的场合,如邮件过滤、信用卡欺诈检测等。
- 算法复杂性不同。聚类算法通常比分类算法简单,因为聚类不需要预测新的数据点所属的类别。
- 结果解释不同。聚类分析的结果通常用于描述数据,衡量不同数据源间的相似性,以及把数据源分类到不同的簇中。分类分析的结果用于预测新的数据点所属的类别。
最大的不同在于:分类的目标是事先已知的,而聚类则不一样,聚类事先不知道目标变量是什么,类别没有像分类那样被预先定义出来。
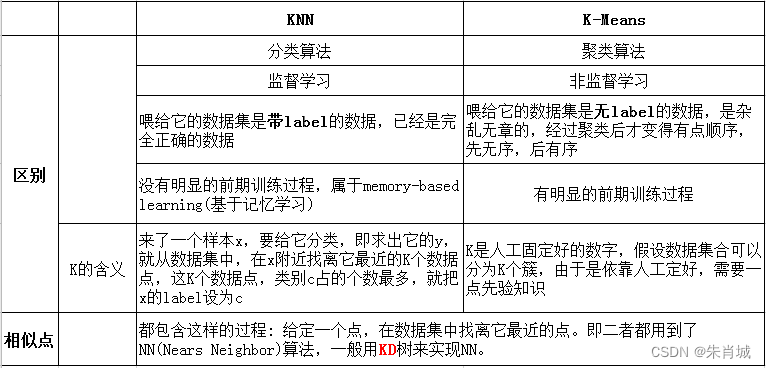
11.1.2 Kmeans Vs KNN
11.2 降维
定义:把一个多因素问题转化成一个较少因素(降低问题的维数)问题,而且较容易进行合理安排,找到最优点或近似最优点,以期达到满意的试验结果的方法。
11.2.1 主成分分析
PCA降维的原理: 无监督的降维(无类别信息)-->选择方差大的方向投影,方差越大所含的信息量越大,信息损失越少.可用于特征提取和特征选择。
PCA的计算过程
![]()
- 去平均值,即每一位特征减去各自的平均值
- 计算协方差矩阵
- 计算协方差矩阵的特征值与特征向量用(SVD,SVD比直接特征值分解计算量小)
- 对特征值从大到小排序
- 保留最大的个特征向量
- 将数据转换到个特征向量构建的新空间中
PCA推导
中心化后的数据在第一主轴u1方向上分布散的最开,也就是说在u1方向上的投影的绝对值之和最大(即方差最大),计算投影的方法就是将x与u1做内积,由于只需要求u1的方向,所以设u1是单位向量。

11.2.1.1 PCA其优化目标是什么?
最大化投影后方差 + 最小化到超平面距离
11.2.1.2 PCA 白化是什么?
通过 pca 投影以后(消除了特征之间的相关性),在各个坐标上除以方差(方差归一化)。
11.2.1.3 SVD奇异值分解
定义:有一个m×n的实数矩阵A,我们想要把它分解成如下的形式
![]()
其中U和V均为单位正交阵,即有![]() 和
和![]() ,U称为左奇异矩阵,V称为右奇异矩阵,Σ仅在主对角线上有值,称它为奇异值,其它元素均为0。上面矩阵的维度分别为
,U称为左奇异矩阵,V称为右奇异矩阵,Σ仅在主对角线上有值,称它为奇异值,其它元素均为0。上面矩阵的维度分别为![]() 。
。
11.2.1.4 为什么要用SVD进行降维?
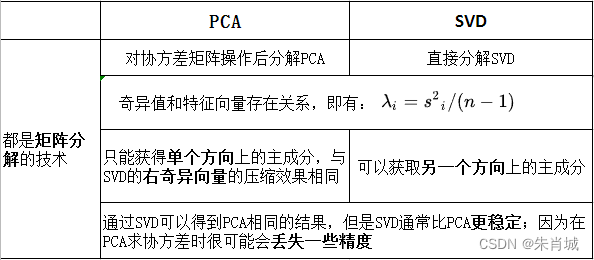
1. 内存少:奇异值分解矩阵中奇异值从大到小的顺序减小的特别快,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上。
2.SVD可以获取另一个方向上的主成分,而基于特征值分解的只能获得单个方向上的主成分。
3.数值稳定性:通过SVD可以得到PCA相同的结果,但是SVD通常比直接使用PCA更稳定。PCA需要计算XTX的值,对于某些矩阵,求协方差时很可能会丢失一些精度。
11.2.2 LDA(线性判别式分析)
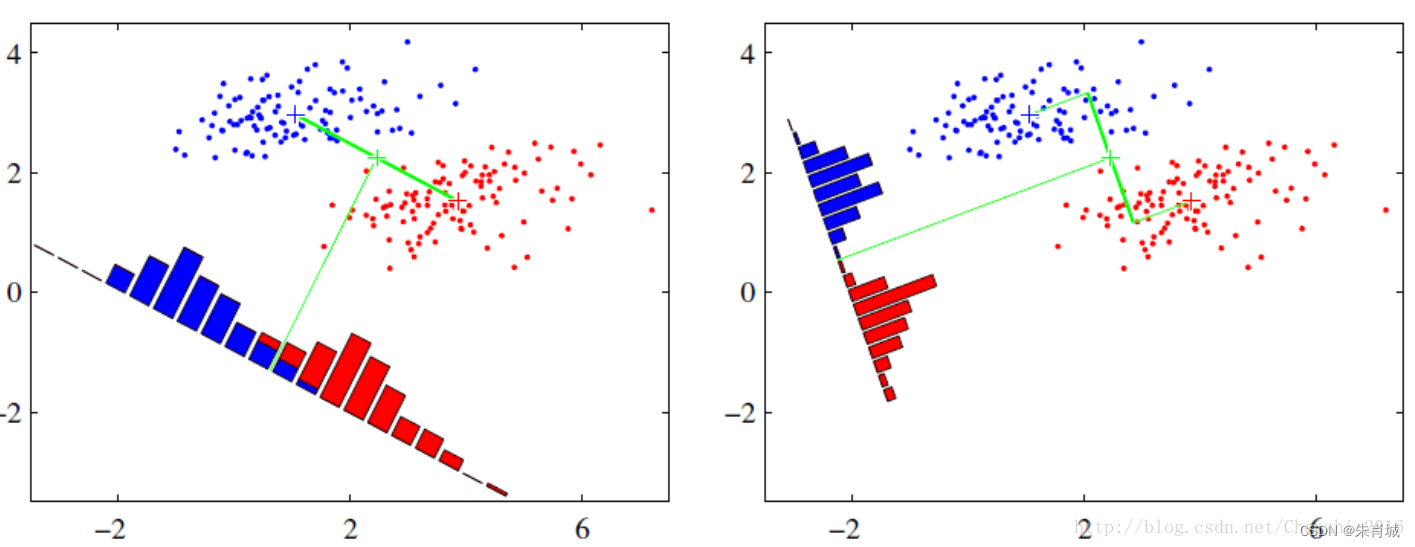
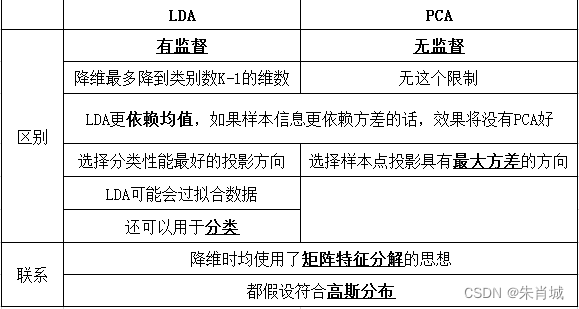
LDA降维的原理:LDA一种有监督的降维算法,它是将高维数据投影到低维上,并且要求投影后的数据具有较好的分类.(也就是说同一类的数据要去尽量的投影到同一个簇中去),投影后的类别内的方差小,类别间的方差较大.
理解: 数据投影在低维度空间后,投影点尽可能的接近,而不同类别的投影点群集的中心点彼此之间的离得尽可能大。
11.2.3 PCA vs SVD
11.2.4 LDA vs PCA
11.2.5 降维的作用是什么?
①降维可以缓解维度灾难问题
②降维可以在压缩数据的同时让信息损失最小化
③理解几百个维度的数据结构很困难,两三个维度的数据通过可视化更容易理解
11.2.6 矩阵的特征值和特征向量的物理意义是什么?
对于一个非方阵的矩阵A,它代表一个多维空间里的多个数据。求这个矩阵A的协方差阵Cov(A,A’),得到一个方阵B,求的特征值,就是求B的特征值,它就是代表矩阵A的那些数据,在那个多维空间中,各个方向上分散的一个度量(即理解为它们在各个方向上的特征是否明显,特征值越大,则越分散,也就是特征越明显),而对应的特征向量:是它们对应的各个方向。
(协方差:用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。)
11.2.7 维度灾难是什么?为什么要关心它?
- 维度灾难的一个主要后果是使分类器过拟合,其次使得样本在搜索空间(解释:目前本人将搜索空间理解为样本特征空间)的分布变得不均匀。
- 在特征数增加到一定数量后,继续添加新的特征会导致分类器的性能下降,这种现象称为“维度灾难”(The Curse of Dimensionality)。
解决方法:
降维算法:将高维数据转换为低维数据,并保留数据的关键信息,如PCA、LDA、MDS
特征选择:从原始数据中选取最具代表性的特征,并保留相对较少的特征,如卡方检验、信息熵
集成学习:将多个学习器进行有效的集成,以提高算法的预测准确度和鲁棒性,如随机森林、Adaboost等。
相关文章:
机器学习-面经(part7、无监督学习)
机器学习面经系列的其他部分如下所示: 机器学习-面经(part1) 机器学习-面经(part2)-交叉验证、超参数优化、评价指标等内容 机器学习-面经(part3)-正则化、特征工程面试问题与解答合集机器学习-面经(part4)-决策树共5000字的面试问题与解答…...
teknoparrot命令行启动游戏
官方github cd 到teknoparrot解压目录 cd /d E:\mn\TeknoParrot2_cp1\GameProfiles启动游戏 TeknoParrotUi.exe --profile游戏配置文件游戏配置文件位置/UserProfiles,如果UserProfiles文件夹里没有那就在/GameProfiles,在配置文件里将游戏路径加入之间,或者打开模拟器设置 …...
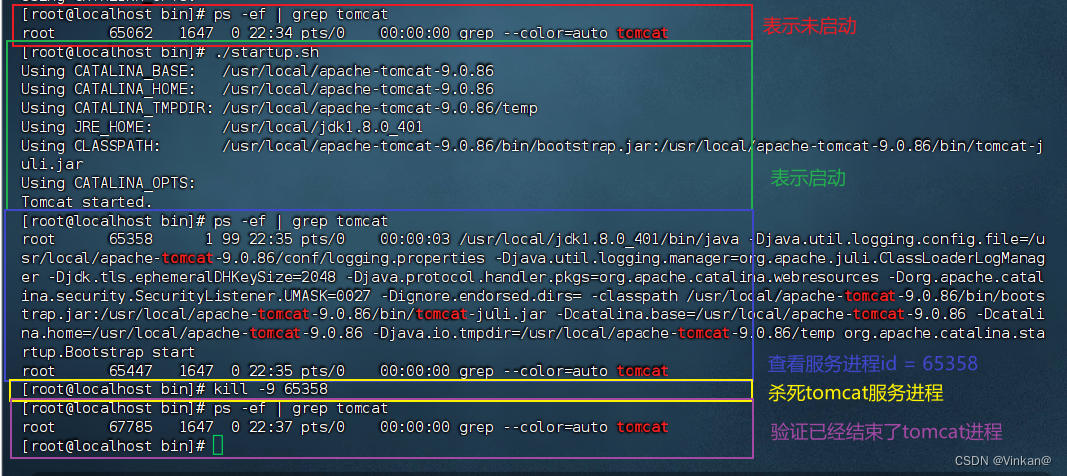
停止Tomcat服务的方式
运行脚本文件停止 运行Tomcat的bin目录中提供的停止服务的脚本文件 关闭命令 # sh方式 sh shutdown.sh# ./方式 ./shutdown.sh操作步骤 运行结束进程停止 查看Tomcat进程,获得进程id kill进程命令 # 执行命令结束进程 kill -9 65358 操作步骤 注意 kill命令是…...
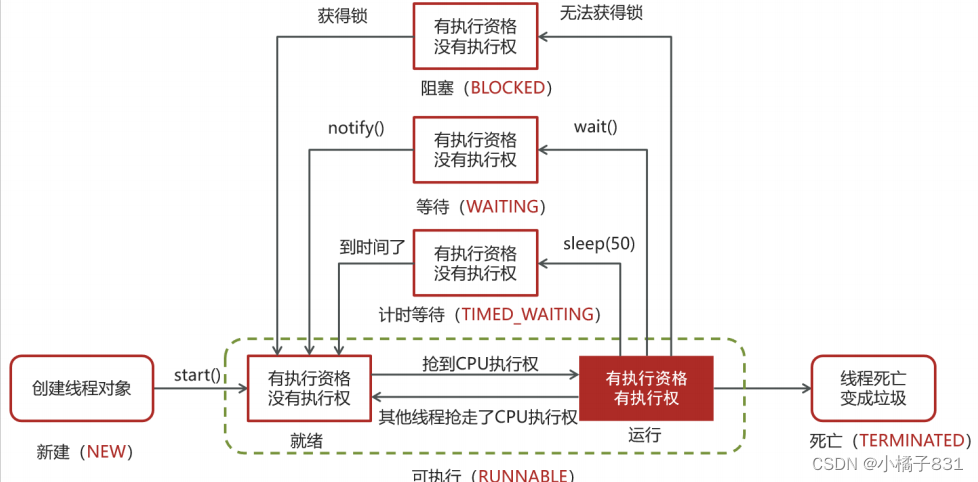
多线程相关面试题(2024大厂高频面试题系列)
1、聊一下并行和并发有什么区别? 并发是同一时间应对多件事情的能力,多个线程轮流使用一个或多个CPU 并行是同一时间动手做多件事情的能力,4核CPU同时执行4个线程 2、说一下线程和进程的区别? 进程是正在运行程序的实例ÿ…...
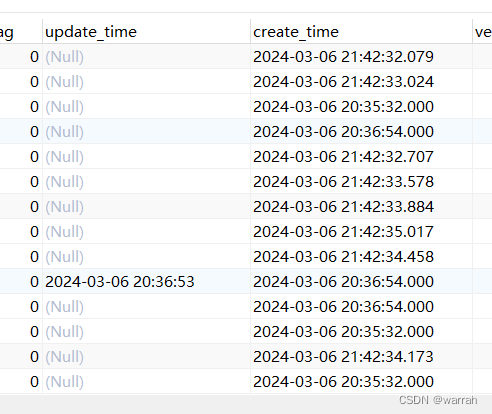
mysql 时间精度问题
timestamp到2038年,还有14年时间,一个系统如果能活到那一刻也是相当不错了。 这里先看一下个datetime的问题,下面的插入数据的时间戳是2024-03-06 21:20:50.839 INSERT INTO psi_io_balance ( id, as_id, bill_date, order_id, busi_type, direction, c…...
)
基于python的爬虫原理和管理系统实现(代码下载)
Python实现爬虫的原理如下: 发送请求:使用Python中的库,如Requests或urllib,向目标网站发送HTTP请求,获取网页的内容。 解析网页:使用Python中的库,如BeautifulSoup或lxml,对获取的…...

IOS 设置UIViewController为背景半透明浮层弹窗,查看富文本图片详情
使用场景:UIViewController1 打开 UIViewController2(背景半透明弹窗) 案例:打开富文本网页<img>图片的url查看图片详情 WKWebView WKNavigationDelegate代理方法设置js代码点击事件 ///注册添加图片标签点击js方法 - …...

网络层介绍
网络层是OSI模型中的第三层,也称为网络协议层。它主要负责在源主机和目标主机之间提供数据通信的路径选择和控制。网络层通过使用源和目标主机的网络地址来实现数据包的路由和转发。 以下是网络层的一些主要功能: 路由选择:网络层使用路由选…...

springboot/ssm酒店客房管理系统Java在线酒店预约预定平台web
springboot/ssm酒店客房管理系统Java在线酒店预约预定平台web 基于springboot(可改ssm)vue项目 开发语言:Java 框架:springboot/可改ssm vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:…...

分布式测试插件 pytest-xdist 使用详解
使用背景: 大型测试套件:当你的测试套件非常庞大,包含了大量的测试用例时,pytest-xdist可以通过并行执行来加速整体的测试过程。它利用多个进程或计算机的计算资源,可以显著减少测试执行的时间。高计算资源需求&#…...
)
【S32K3 MCAL配置】-1.1-GPIO配置及其应用-点亮LED灯(基于MCAL)
目录(共13页精讲,手把手教你S32K3从入门到精通) 实现的架构:基于MCAL层 前期准备工作: 1 创建一个FREERTOS工程...
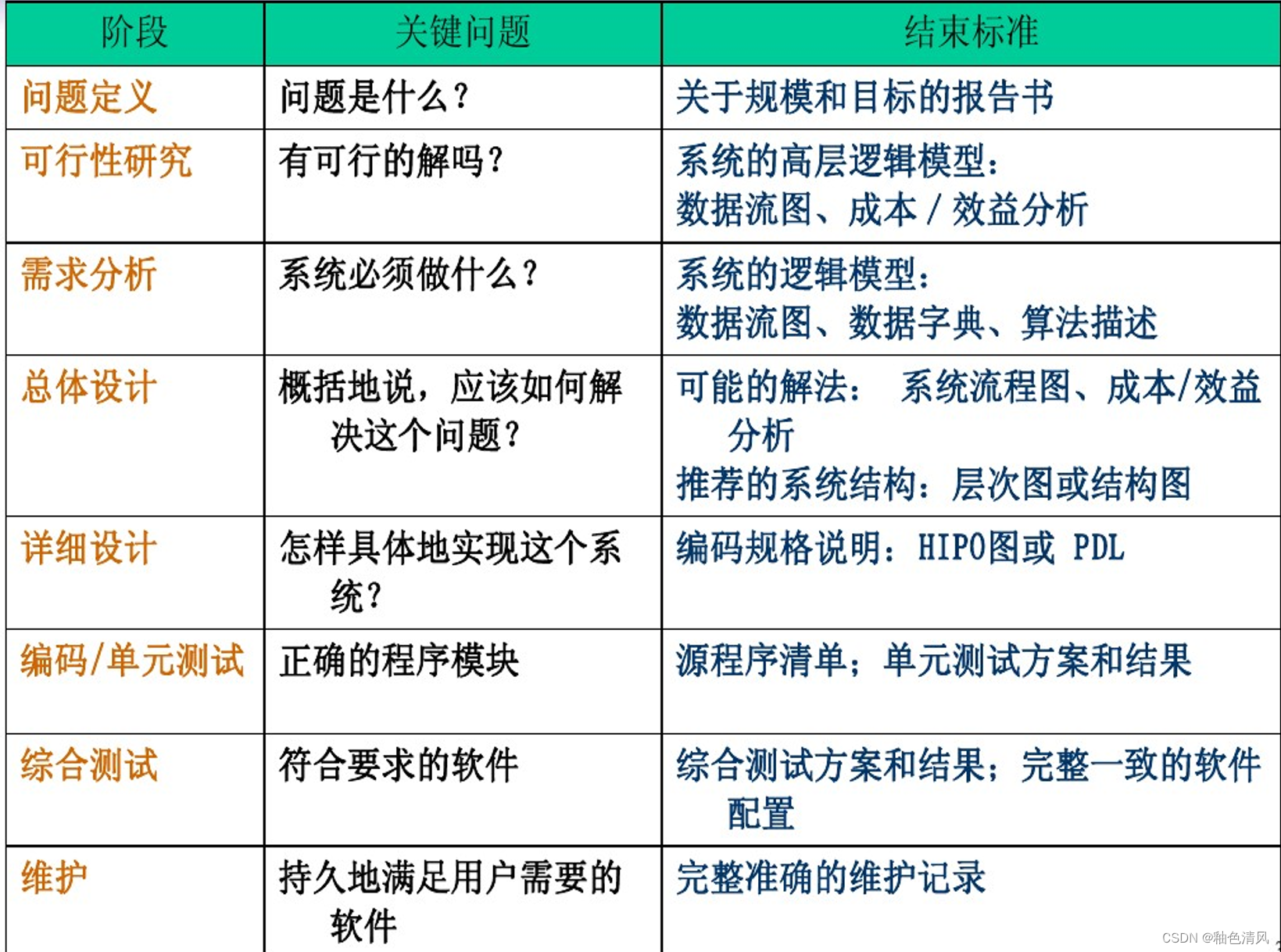
【软件工程】软件工程定义、软件危机以及软件生命周期
🌸博主主页:釉色清风🌸文章专栏:软件工程🌸 今日语录:What matters isn’t how others think of your ambitions but how fervently you cling to them. 软件工程系列,主要根据老师上课所讲提及…...

24计算机考研深大经验分享(计算机专业考研综合安排)
文章目录 背景科目选择高数选课一轮二轮冲刺阶段 线代一轮二轮 概率论计算机学科专业基础408数据结构计算机组成原理操作系统计算机网络总结 英语政治 末言 背景 首先贴一下初试成绩。这篇分享主要是给零基础的同学使用的,基础好的同学可以自行了解补充一下…...

【知识整理】MySQL数据库开发设计规范
一、规范背景与目的 MySQL数据库与 Oracle、 SQL Server 等数据库相比,有其内核上的优势与劣势。我们在使用MySQL数据库的时候需要遵循一定规范,扬长避短。 本规范旨在帮助或指导RD、QA、OP等技术人员做出适合线上业务的数据库设计。在数据库变更和处理…...

Vue自定义组件实现v-model
前言 v-model 实际上就是 $emit(input) 以及 props:value 的组合语法糖。 1.封装自定义组件 要在 Vue 中实现自定义组件的 v-model 功能,你可以通过使用 model 选项来定义组件的 prop 和事件。以下是一个示例代码,演示如何实现一个自定义组件并使用 v…...

【Linux】Linux网络故障排查与解决指南
🍎个人博客:个人主页 🏆个人专栏:Linux ⛳️ 功不唐捐,玉汝于成 目录 前言 正文 检查网络连接状态: 检查路由表: 检查DNS配置: 检查网络连接状态: 检查防火墙设…...
)
跟着cherno手搓游戏引擎【27】升级2DRenderer(添加旋转)
水节,添加了旋转的DrawQuad: Renderer2D.h: #pragma once #include "OrthographicCamera.h" #include"Texture.h" namespace YOTO {class Renderer2D{public://为什么渲染器是静态的:static void Init();static void …...
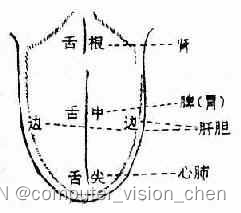
中医舌苔笔记
舌诊时按照舌尖-舌中-舌根-舌侧的顺序进行观察。 先看舌体再看舌苔,30秒左右。 如果一次望舌判断不清,可令病人休息3~5分钟后,重新观察一次 舌诊脏腑部位分属图 舌体 胖嫩而边有齿痕为气虚、阳虚。 薄白而润为风寒; 薄白而燥…...

Facebook的社交未来:元宇宙时代的数字共融
引言: 随着科技的不断进步和社会的快速发展,人们对于社交网络的需求和期待也在不断演变。在这个数字化时代,元宇宙的概念逐渐引发了人们对社交体验的重新思考。作为全球最大的社交网络之一,Facebook正在积极探索元宇宙时代的社交…...

2024护网面试题精选(一)
0x00.基础漏洞篇 00-TOP10漏洞 1.SQL注入 2.失效的身份认证和会话管理 3.跨站脚本攻击XSS 4.直接引用不安全的对象 5.安全配置错误 6.敏感信息泄露 7.缺少功能级的访问控制 8.跨站请求伪造CSRF 9.实验含有已知漏洞的组件 10.未验证的重定向和转发 01-SQL注入漏洞 …...

机器人企业如何用 CRM 优化线索、商机与客户管理
对于机器人、工业自动化和智能制造解决方案企业而言,销售管理往往不是简单的客户跟进,而是围绕复杂需求、技术方案、项目周期和多角色协作展开的长期过程。Zoho CRM 的价值,正是在于帮助这类 B2B 企业把线索管理、商机推进、客户需求沉淀和销…...

告别折腾:用 apt 和 Qt 官方安装器两种方式在 Debian 上搞定 Qt 5.15.2 开发环境
在 Debian 上搭建 Qt 5.15.2 开发环境的双轨方案 对于需要在 Debian 系统上建立 Qt 开发环境的工程师来说,选择正确的安装方式往往比安装本身更重要。本文将深入探讨两种主流方案:Debian 官方仓库的 apt 安装和 Qt 官方在线安装器,帮助您根据…...

本地Perplexity服务突然中断?:排查systemd服务崩溃、GPU显存溢出与模型权重校验失败的5分钟应急清单
更多请点击: https://codechina.net 第一章:Perplexity本地服务查询 Perplexity 作为一款强调实时信息溯源与多源验证的 AI 助手,其官方未提供公开的本地化部署方案。但开发者可通过构建轻量级本地代理服务,模拟 Perplexity 的查…...

【Perplexity心理健康资源权威指南】:20年临床IT专家亲测的5大高隐蔽性心理支持工具揭秘
更多请点击: https://codechina.net 第一章:Perplexity心理健康资源的临床价值与技术定位 Perplexity 作为一款基于大语言模型的实时信息检索与推理引擎,其在心理健康领域并非直接提供诊疗服务,而是通过增强临床决策支持、辅助心…...
)
告别PCL!用Qt+QGLWidget手把手教你打造自己的3D点云查看器(附完整源码)
轻量级3D点云可视化:基于Qt与OpenGL的高效实现方案 在工业测量、自动驾驶和三维重建等领域,点云数据的可视化一直是开发者面临的挑战。传统方案如PCL虽然功能强大,但其庞大的体积和复杂的依赖链往往让项目变得臃肿。本文将展示如何利用Qt的QG…...

【NotebookLM因子分析实战指南】:3步解锁AI驱动的维度降维与业务洞察力
更多请点击: https://intelliparadigm.com 第一章:NotebookLM因子分析辅助的底层逻辑与价值定位 NotebookLM 是 Google 推出的面向研究者的 AI 助手,其核心能力并非泛化式问答,而是基于用户上传文档进行“可信引用驱动”的深度推…...
)
【JavaSE全面教学】Java集合框架下Day13(2026年)
写在前面:这是JavaSE系列的第13篇。上一篇讲了List家族,今天来讲Set和Map。HashMap是面试中问得最多的集合类,底层原理必须搞懂。建议收藏,反复看。 文章目录 一、Set集合:不可重复1.1 Set的特点1.2 HashSet1.3 Linked…...

瑞萨电子2019年中国市场战略与MCU/SoC产品深度解析
1. 项目概述:一次对特定年份半导体巨头市场策略的深度复盘在半导体这个日新月异的行业里,每年各大厂商的产品发布和市场策略,都像是一张张精心绘制的航海图,指引着下游应用市场的技术风向。今天,我想和大家深入聊聊一个…...

Perplexity症状查询功能性能对比白皮书:横向测试12家竞品,它在罕见病关键词召回率上领先41.6%,但时间敏感场景响应超时率达23.8%
更多请点击: https://intelliparadigm.com 第一章:Perplexity症状查询功能概览 Perplexity 是一款面向开发者与临床信息学研究人员设计的轻量级症状语义推理工具,其核心能力在于将自然语言描述的症状短语映射至标准化医学本体(如…...

OpenClaw 中最经典的 6 款skill,真正能进工作流的 skills
2026 开年至今,AI 圈里两个词出镜率最高:龙虾 和 Skill。 龙虾更像一阵风——话题来得快,讨论散得也快;Skill 却在慢慢变成能天天用的东西:装一次,反复省时间。 可惜市面上不少 Skill 推荐文不太耐看&…...