C++:STL - set map
C++:STL - set & map
- 关联式容器
- pair
- set
- 模板参数
- typedef的类型
- 构造函数
- 迭代器
- 常规接口
- 特殊接口
- multiset
- map
- 模板参数
- typedef的类型
- 常规接口
- 特殊接口
- multimap
关联式容器
关联式容器是C++标准库提供的一种数据结构,用于存储操作键值对(key-value)。每个键值对都包含一个键和一个关联的值。关联式容器提供了通过键快速查找和访问值的功能。
C++98标准库提供了四种树形结构的关联式容器:set、multiset、map和multimap。
-
set:set是一个无序集合,存储唯一的元素。内部实现使用红黑树,因此元素是按照特定的顺序进行存储。查找和插入操作的平均时间复杂度为O(log n)。 -
multiset:multiset和set类似,不同之处在于它可以存储重复的元素。 -
map:map是一个键值对的集合,其中的键是唯一的。内部实现也是使用红黑树。查找和插入操作的平均时间复杂度为O(log n)。 -
multimap:multimap和map类似,不同之处在于它可以存储重复的键。
后续C++11又提供了哈希结构的关联式容器,此博客不做讲解。
关联式容器与序列式容器的区别在于元素的顺序。关联式容器内部使用二叉搜索树(如红黑树)实现,因此元素是按照特定的顺序进行存储。而序列式容器内部使用动态数组或链表实现,元素按照插入的顺序进行存储。
pair
在讲解map与set之前,我们要先了解一个类:pair。
pair是一个模板类,封装了两个成员变量first,second,用于存储两个不同类型的值。它被定义在头文件<utility>中。
pair类的定义如下:
template <class T1, class T2>
struct pair
{T1 first;T2 second;
};
pair类有两个模板参数T1和T2,分别表示两个值的类型。
pair类有两个成员变量first和second,分别表示两个值。
pair类的构造函数有多个重载形式,可以根据需要来创建pair对象。其中,最常用的是以下几种:
- pair():默认构造函数,创建一个
pair对象,默认初始化first和second。 - pair(const T1& x, const T2& y):构造函数,初始化
first为x,second为y。
pair类还支持拷贝构造函数、移动构造函数和赋值运算符重载,以及比较运算符重载。
使用pair类可以方便地将两个不同类型的值组合在一起,便于传递和操作。例如:
pair<int, string> p1(1, "hello");
cout << p1.first << " " << p1.second << endl;pair<double, char> p2;
p2.first = 3.14;
p2.second = 'a';
cout << p2.first << " " << p2.second << endl;
输出结果为:
1 hello
3.14 a
另外的,C++还提供了一个函数make_pair用于创建pair对象,需要时直接传入两个参数,分别对应first和second,make_pair内部会自动推演参数类型,返回一个pair对象。
auto p = make_pair("hello world", 10);
此时make_pair就会推演对象的类型为pair<const char*, int>。
因为pair可以存储任意两个不同类型的数据,所以任何需要封装两个变量的地方,都可以使用pair。而我们的key - value结构,就是需要封装两个变量key和value,所以map和set的底层都是使用pair来完成的。
set
set是一种集合容器。它是基于红黑树实现的,它可以存储不重复的元素,并且会自动按照元素的大小进行排序。
下面是一些set的概念和特点:
- 不重复的元素:
set中的元素是不重复的,每个元素只能出现一次。- 自动排序:
set中的元素会根据元素的大小进行自动排序。默认情况下,set按照升序排列。你也可以通过传入自定义的比较函数来进行降序排序。- 红黑树实现:
set内部使用红黑树(一种自平衡二叉搜索树)来存储元素。这个数据结构保证了素的快速插入、查找和删除,时间复杂度为O(logn)。- 迭代器支持:
set提供了迭代器,可以用于遍历集合中的元素。- 查找和插入的效率高:由于
set是基于红黑树实现,查找和插入操作的平均时间复杂度为O(logn),效率比较高。- 元素的值是不可修改的:在
set中,元素的值是不可修改的。如果需要修改元素的值,需要先删除旧的元素,然后插入新的元素。
接下来我们讲解set的接口使用以及注意事项。
模板参数
set的模板如下:
template < class T, class Compare = less<T>> class set;
其有两个模板参数:
T:代表value值的类型
Compare:代表了比较规则的仿函数
也就是说,我们在定义set的时候,可以在模板参数中传入仿函数,用于制定规则:
template <class T>
struct comp
{bool operator()(const T& t1, const T& t2) const{return T1 > T2;}
};int main()
{set<int, comp<int>> s1;return 0;
}
其中,s1通过仿函数comp完成了逆序排列,而set的模板参数有缺省值Compare = less<T>,所以set的默认情况是升序排列。
typedef的类型
| 类型 | 含义 | 缺省值 |
|---|---|---|
key_type | 第一个模板参数T的类型,即value的类型 | |
value_type | 第一个模板参数T的类型,即value的类型 | |
key_compare | 第二个模板参数的类型,即用于比较的仿函数的类型 | less<key_type> |
value_compare | 第二个模板参数的类型,即用于比较的仿函数的类型 | less<value_type> |
由于在set中,key和value是一致的,所以以上表格中,key_type和value_type是一致的,key_compare与value_compare是一致的。
而key_compare与value_compare的缺省值是 less<key_type>,即升序排序的仿函数。
构造函数
默认构造:
explicit set (const key_compare& comp = key_compare());
迭代器区间构造:
template <class InputIterator>
set (InputIterator first, InputIterator last,const key_compare& comp = key_compare());
通过一个迭代器区间来构造set,由于是模板,所以可以是其它容器的迭代器。
迭代器
set的迭代器用法与其它容器一致,就是通过begin和end来进行遍历,或者说使用反向迭代器。值得注意的是容器set的迭代器走中序遍历,得到的是有序的数据。
常规接口
empty:
bool empty() const;
即返回这个set是否为空,如果为空返回true,不为空返回false。
size:
size_type size() const;
返回当前set存储的节点个数。
swap:
void swap (set& x);
交换两个set的根节点指针。
clear:
void clear();
清空当前set。
key_comp 与 value_comp:
key_compare key_comp() const;
value_compare value_comp() const;
可以看到,两者的返回类型分别是key_compare 与value_compare ,也就是比较key与value的仿函数,这两个函数的功能就是返回当前比较set的仿函数。
find:
iterator find (const value_type& val) const;
find函数用于查找val值的节点,如果找到了,返回指向val的迭代器;如果没找到,则返回end()处的迭代器。
count:
size_type count (const value_type& val) const;
count函数用于检测set中存在几个val值的节点,但是由于set不可以存在重复的元素,所以这个函数的返回值只有可能是1或0。返回类型为size_type即size_t无符号整型。
特殊接口
lower_bound 与 upper_bound:
iterator lower_bound (const value_type& val) const;
iterator upper_bound (const value_type& val) const;
两者都传入一个val值,返回值一个iterator迭代器,它们的功能如下:
lower_bound:返回第一个>=val节点的迭代器
upper_bound:返回第一个>val节点的迭代器
在STL设计中,都是利用左闭右开的区间特性,而迭代器也利用了此特性,我们可以使用lower_bound 与upper_bound配合得到一个一开一闭的迭代器区间,从而进行遍历,删除等等操作。
比如现在我们想遍历一个set中[3, 20]的闭区间,你会如何查找迭代器?
假设我们有一个名为s1的set,看一段代码:
auto it1 = s1.find(3);
auto it2 = s2.find(21);while(it1 != it2)
{cout << *it1 << endl;++it1;
}
请问这个代码正确吗?
以上代码存在两个问题:
- 在
s1中可能不存在值为3或者21的节点,find有可能是失败的,此时我们就无法遍历到[3, 20]了。- 由于我们要遍历
[3, 20],迭代器遵循左闭右开的特性,所以我们找了一个比20大的迭代器21来遍历。但是如果我们的set存储的是float类型的数据,20与21之间可能还会存在其它节点,此时我们可能就会多遍历到其它节点。
因此我们可以利用lower_bound 与upper_bound配合来得到迭代器:
auto it1 = s1.lower_bound(3);
auto it2 = s2.upper_bound(21);while(it1 != it2)
{cout << *it1 << endl;++it1;
}
以上代码中lower_bound(3)可以得到第一个>=3节点的迭代器,这样就不怕3节点不存在的情况了,如果3存在,此函数得到3,如果不存在,就得到大于3的下一个节点。
而upper_bound(21)则是得到第一个>21节点的迭代器,如果我们存储了float类型的数据,而刚好存储了一个21.0001的数据,那么此时upper_bound(21)就刚刚好返回这个只大21一点点的节点。
通过两者配合,我们就可以得到一个等效的左闭右开迭代器区间,后续方便操作。
erase:
set的erase存在三个重载:
void erase (iterator position);
这个erase用于删除迭代器指向的节点,迭代器必须有效。
void erase (iterator first, iterator last);
这个erase用于删除整个迭代器区间[first, last),迭代器必须有效。
size_type erase (const value_type& val);
这个erase用于删除val值的节点,val值可以不存在,删除后返回删除节点的个数。在set中,由于不存在重复节点,所以返回值只可能是0或1。
insert:
set的insert也存在三个重载:
iterator insert (iterator position, const value_type& val);
这个重载用于提高插入效率,如果迭代器position位于插入val值的节点之前,那么此次插入val的效率会提高,但是如果迭代器position与插入val节点无关,那么与一般的插入一致。
template <class InputIterator>
void insert (InputIterator first, InputIterator last);
这个重载用于插入一整个迭代器区间[first, last)。
pair<iterator,bool> insert (const value_type& val);
这是最常用的插入,其用于直接插入一个val值的节点,但是其返回值比较特别:pair<iterator,bool>
如果原先
val存在,此时iterator指向原先的val节点,bool值返回false表示插入失败
如果原先val不存在,此时iterator指向新插入的val节点,bool值返回true表示插入失败
但是函数不能一次性返回两个值,于是把iterator和bool两个值封装进pair中返回。这样我们就既可以得到迭代器,又可以检测是否插入成功了。
multiset
multiset是一个允许存在重复元素的set,其它的效果与set完全一致。
但是有几个接口还是值得注意:
find:
对multiset使用find时,由于一个val可能有多个节点,此时返回中序遍历的第一个节点。
count:
对于set而言,count用于返回某个val值的个数,由于set不能重复,所以这个count接口没有多大意义。而对于multiset才有用,可以检测val的个数。
map
map是一种关联容器,用于存储键-值对(key-value)。map中的每个元素都由一个键和一个与之关联的值组成,键和值可以是任意类型。其将key和value封装进了pair中,所以每一个节点都是一个pair<key, value>。
模板参数
set的模板如下:
template < class Key, class T, class Compare = less<Key> >class map
其有三个模板参数:
Key:代表key值的类型
T:代表value值的类型
Compare:代表了比较规则的仿函数
同样的,map也可以在模板参数中定义仿函数,与set相似。
typedef的类型
| 类型 | 含义 | 缺省值 |
|---|---|---|
key_type | 第一个模板参数Key的类型,即key的类型 | |
mapped_type | 第二个模板参数T的类型,即value的类型 | |
value_type | 将key与value封装后 pair<const key_type,mapped_type>的类型 | |
key_compare | 第二个模板参数的类型,即用于比较的仿函数的类型 | less<key_type> |
在map中,value的类型是mapped_type,而value_type却是pair<const key_type,mapped_type>的类型,这是值得注意的。
常规接口
由于map的很多接口和set一致,这里就用一张表格概括:
| 函数 | 声明 | 功能 | 注意事项 |
|---|---|---|---|
| 迭代器 | begin , end等 | 遍历map | 走中序遍历,得到有序数据 |
| empty | bool empty() const; | 判空 | - |
| size | size_type size() const; | 返回元素个数 | - |
| erase | void erase (iterator position); | 删除迭代器指向的节点 | 迭代器必须有效 |
| size_type erase (const key_type& k); | 删除key值的节点 | key值可以不存在 | |
| void erase (iterator first, iterator last); | 删除迭代器区间 | - | |
| swap | void swap (map& x); | 交换两棵树根节点指针 | - |
| clear | void clear(); | 清空map | - |
| key_comp | key_compare key_comp() const; | 得到比较key的仿函数 | - |
| value_comp | value_compare value_comp() const; | 得到比较value的仿函数 | - |
| find | iterator find (const key_type& k); | 得到key位置的迭代器 | 如果没有找到,返回end()等效的迭代器 |
| count | size_type count (const key_type& k) const; | 返回值为key的节点个数 | - |
| lower_bound | iterator lower_bound (const key_type& k); | 返回第一个>=key值节点的迭代器 | - |
| upper_bound | iterator upper_bound (const key_type& k); | 返回第一个>key值节点的迭代器 | - |
特殊接口
insert:
对于map而言,insert的功能其实和set是一致的,但是不一样的是我们需要插入pair<key, value>,所以此处拿出来额外讲解。
重点看到以下insert的重载:
pair<iterator,bool> insert (const value_type& val);
其插入的值val的类型时候value_type,而我们先前说明过,value_type就是pair<key, value>的类型。也就是说,我们要构造出一个pair插入进去。
现在我们有map<string, int>:
map<string, int> m;
现在我们对其进行插入:
- 利用匿名对象插入:
m.insert(pair<string, int>("hello", 100));
以上代码,我们利用pair<string, int>("hello", 100)这种语法构造了一个匿名对象,然后进行插入。
- 利用多参数默认构造的类型转化:
m.insert({ "hello", 100 });
由于pair具有一个多参数的默认构造,具有类型转化的功能,所以我们可以利用隐式类型转化进行传参。而我们有多个参数,所以要把这些参数用{}括起来。
- 利用
make_pair进行插入:
m.insert(make_pair("hello", 100));
即利用make_pair函数,让其自动推导类型构造pair。
operator[ ]:
map还重载了[],这个重载比较复杂,但是非常有用,我们先看到声明:
mapped_type& operator[] (const key_type& k);
其接收一个key_type类型的参数,也就是接受一个key,然后返回一个mapped_type&,也就是一个value的引用。其功能为:接受一个key值,然后返回这个key对应的value的引用。
其等效于下面的代码:
(*((this->insert(make_pair(k,mapped_type()))).first)).second
现在我们来解读以上代码,我们将其拆解为四个部分:make_pair(k, mapped_type( )) + this->insert( ) + ( ).first + (*( )).second,我们一层层解析。
第一层:
make_pair(k, mapped_type( ))
可以看出,这是在利用参数
k,通过make_pair构造一个pair,而这个pair的value使用了mapped_type( )(mapped_type就是value的类型)来调用默认构造。这样我们最后就得到了一个pair<key, value>。
第二层:
this->insert( )
上一层我们构造了一个
pair<key, value>,然后它被作为参数,传入到这个insert中,相当于把刚刚构造的节点插入进map中。map的插入后,不论成功与否,都会返回一个pair<iterator, bool>,iterator用于指向key的迭代器,bool用于标识插入是否成功。所以这一层最后得到了一个pair,分别存储了指向key的迭代器和bool。
第三层:
( ).first
上一层中我们得到了
pair<iterator, bool>,这一层访问它的first,也就是访问了iterator,所以这一层得到了指向key值的迭代器。
第四层:
(*( )).second
我们上一层拿到了指向
key的迭代器,这一层先对迭代器解引用*( ),此时就得到了一个map的节点。而map的节点是pair<key, value>,所以我们解引用得到了一个pair,随后通过( ).second访问pair<key, value>的second,也就是value。最后返回这个value的引用。
所以我们最后得到了key对应的value的引用。那么这有什么用呢?
假设我们有一个map<string, string>类型的字典dict,通过这个来展示operator[ ]的功能:
- 插入一个key值:
dict["left"];
以上语句在dict中插入了一个key = "left"但是没有value的节点
- 插入一对
key - value:
dict["left"] = "左边";
由于operator[ ]返回的是对应的引用,因此我们可以直接给返回值赋值,此时我们就插入了一个节点key = "left" - value = "左边"
- 修改
key对应的value:
dict[“coffe”] = "咖啡";
如果我们的dict原先就存在key = "coffe"的节点,以上代码可以修改这个key的value值
- 得到
key对应的value:
cout << dict["coffe"] << endl;
由于我们拿到的是value的引用,我们也可以把它作为一个值赋值给别人或者输出
可以看到,operator[]的功能非常丰富,整体来说还是一个很好用的重载。
multimap
原本的map同一个key只能存在一个value,而multimap则可以存在多个key相同的节点,不过多赘述了。
相关文章:

C++:STL - set map
C:STL - set & map 关联式容器pairset模板参数typedef的类型构造函数迭代器常规接口特殊接口 multisetmap模板参数typedef的类型常规接口特殊接口 multimap 关联式容器 关联式容器是C标准库提供的一种数据结构,用于存储操作键值对(key-v…...
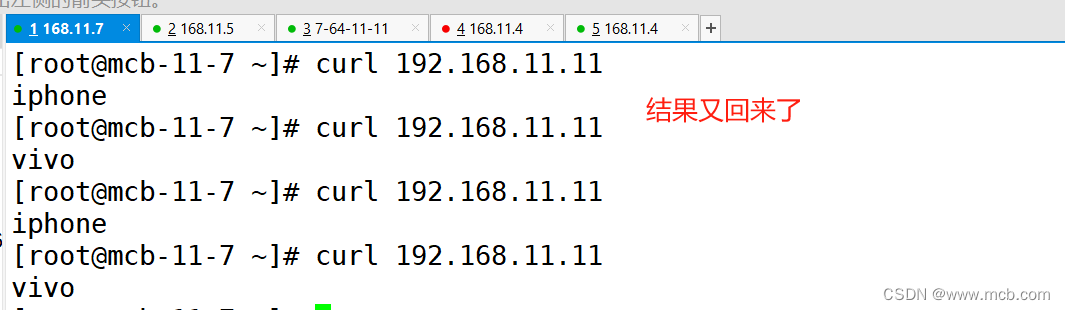
一招鲜吃遍天之Haproxy集群
四层: LVS:Linux Virtual Server Nginx: HAProxy:High Availability Proxy 七层: HAProxy Nginx 硬件: F5 F5 | 多云安全和应用交付 Netscaler NetScaler: Application Delivery at Scale Array 北京华耀科技…...
数据库的筛选条件
【一】筛选过滤条件 【1】完整的查询语句 -- 查询当前表中的全部数据select * from 表名 where 筛选条件;-- 查询当前表中的指定字段的数据select 字段名,字段名 from 表名 where 筛选条件;# 执行顺序from where select select 你选择的列1, 你选择的列2, ... from 查询的…...
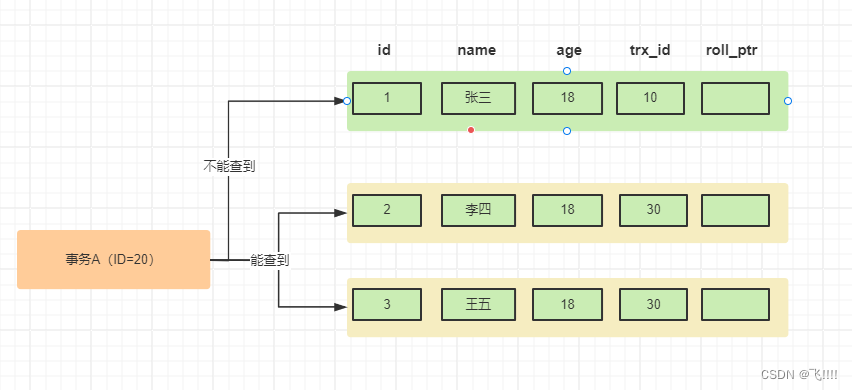
MySQL学习笔记(一)数据库事务隔离级别与多版本并发控制(MVCC)
一、数据库事务隔离级别 数据库事务的隔离级别有4种,由低到高分别为Read uncommitted (读未提交)、Read committed(读提交) 、Repeatable read(可重复读) 、Serializable (串行化&a…...

如何在Linux上为PyCharm创建和配置Desktop Entry
在Linux操作系统中,.desktop 文件是一种桌面条目文件,用于在图形用户界面中添加程序快捷方式。本文将指导您如何为PyCharm IDE创建和配置一个 .desktop 文件,从而能够通过应用程序菜单或桌面图标快速启动PyCharm。 步骤 1: 确定PyCharm安装路…...

Igraph入门指南 4
二、图的创建 图分有向图和无向图,所以图的创建有各自的实现方式。 1、手工创建图: 1-1 通过文本创建:graph_from_literal 通过每项提供两个顶点名(或ID号)作为一条边的格式,手动创建图,顶点…...
外包干了30天,技术明显退步。。
🍅 视频学习:文末有免费的配套视频可观看 🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 这次来聊一个大家可能也比较关心的问题,那就是就业城市选择的问题。而谈到这个问题&a…...
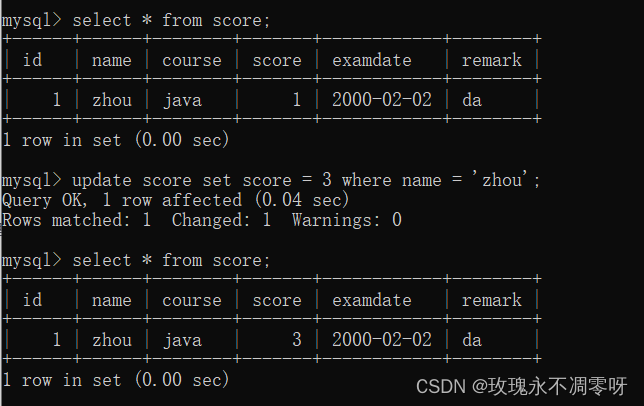
数据库 — 增删查改
一、操作数据库、表 显示 show databases;创建 create database xxx;使用 use xxx; 删除 drop database xxx;查看表; show tables; 查看表结构 desc 表名; 创建 create table 表名(字段1 类型1,字段2 类型2,.... ); 删除 drop table 表名; 二…...
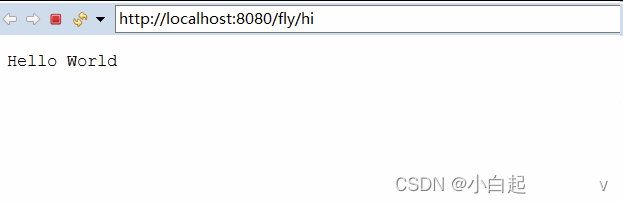
eclipse搭建java web项目
准备条件 eclipsejdk1.8 (配置jdk环境)apache-tomcat-8.5.97(记住安装位置) 一 点击完成 开始创建javaweb项目 import java.io.IOException; import java.io.PrintWriter;import javax.servlet.ServletException; import javax.s…...

gitlab-ci_cd语法CICD
工作原理 1、将代码托管在git 2、在项目根目录创建ci文件.gitlan-ci.yml 在文件中指定构建,测试和部署脚本 3、gitlab将检测到他并使用名为git Runner的工具运行脚本 4、脚本被分组为作业,他们共同组成了一个管道gitlab-ci的脚本执行,需要自…...

python 蓝桥杯之动态规划入门
文章目录 DFS滑行(DFS 记忆搜索) 思路: 要思考回溯怎么写(入参与返回值、递归到哪里,递归的边界和入口) DFS 滑行(DFS 记忆搜索) 代码分析: 学会将输入的数据用二维列表…...
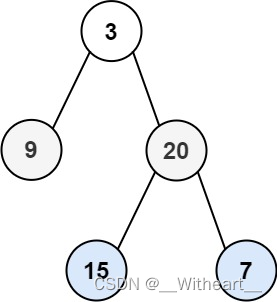
[LeetCode][102]二叉树的层序遍历——遍历结果中每一层明显区分
题目 102. 二叉树的层序遍历 给定二叉树的根节点 root,返回节点值的层序遍历结果。即逐层地,从左到右访问所有节点。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]] 示例 2: 输入…...

GIS之深度学习10:运行Faster RCNN算法
(未完成,待补充) 获取Faster RCNN源码 (开源的很多,论文里也有,在这里不多赘述) 替换自己的数据集(图片标签文件) (需要使用labeling生成标签文件…...

appium2的一些配置
appium-desktop不再维护之后,需要使用appium2。 1、安装appium2 命令行输入npm i -g appium。安装之后输入appium或者appium-server即可启动appium 2、安装安卓/ios的驱动 安卓:appium driver install uiautomator2 iOS:appium driver i…...
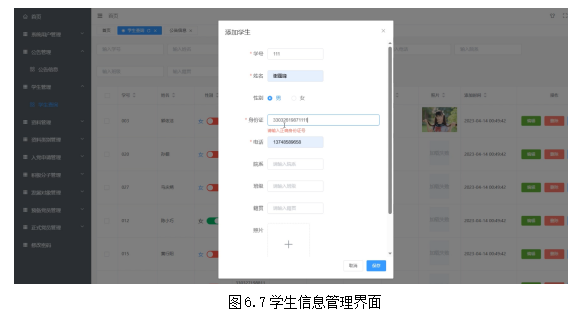
基于springboot+vue实现高校学生党员发展管理系统项目【项目源码+论文说明】
基于springboot实现高校学生党员发展管理系统演示 摘要 随着高校学生规模的不断扩大,高校内的党员统计及发展管理工作面临较大的压力,高校信息化建设的不断优化发展也进一步促进了系统平台的应用,借助系统平台可以实现更加高效便捷的党员信息…...
Java代码审计安全篇-常见Java SQL注入
前言: 堕落了三个月,现在因为被找实习而困扰,着实自己能力不足,从今天开始 每天沉淀一点点 ,准备秋招 加油 注意: 本文章参考qax的网络安全java代码审计,记录自己的学习过程,还希望…...

C#实现快速排序算法
C#实现快速排序算法 以下是C#中的快速排序算法实现示例: using System;class QuickSort {// 快速排序入口函数public static void Sort(int[] array){QuickSortRecursive(array, 0, array.Length - 1);}// 递归函数实现快速排序private static void QuickSortRecu…...
upload-labs通关记录
文章目录 前言 1.pass-012.pass-023.pass-034.pass-045.pass-056.pass-067.pass-078.pass-089.pass-0910.pass-1011.pass-1112.pass-1213.pass-1314.pass-1415.pass-1516.pass-1617.pass-1718.pass-1819.pass-19 前言 本篇文章记录upload-labs中,所有的通过技巧和各…...
Nginx实现高并发
注:文章是4年前在自己网站上写的,迁移过来了。现在看我之前写的这篇文章,描述得不是特别详细,但描述了Nginx的整体架构思想。如果对Nginx玩得透得或者想了解深入的,可以在网上找找其他的文章。 ......................…...

华为荣耀终端机试真题
文章目录 一 、字符展开(200分)1.1 题目描述1.2 解题思路1.3 解题代码二、共轭转置处理(100分)2.1 题目描述2.3 源码内容一 、字符展开(200分) 1.1 题目描述 // 64 位输出请用 printf(“%lld”)给定一个字符串,字符串包含数字、大小写字母以及括号(包括大括号、中括号…...

别再只盯着batch-size了!用Tesla V100训练YOLO时,这些隐藏的显存杀手和监控技巧你知道吗?
别再只盯着batch-size了!用Tesla V100训练YOLO时,这些隐藏的显存杀手和监控技巧你知道吗? 当你手握一块Tesla V100这样的顶级GPU,却发现训练YOLO时依然频频遭遇"爆显存"的尴尬,这感觉就像开着跑车却堵在早高…...
)
STM32CubeMX实战:5分钟为你的HAL库工程添加Modbus RTU主机功能(兼容FreeModbus从机)
STM32CubeMX实战:5分钟为HAL库工程集成Modbus RTU主机功能 Modbus RTU作为工业自动化领域最常用的通信协议之一,其简单可靠的特性使其在嵌入式系统中广泛应用。许多开发者已经熟悉使用FreeModbus实现从机功能,但当需要主动控制其他设备时&…...

程序员上手 Rust 2 年后感悟:它的确强大,但想要取代 C 还远着呢
作者 | Nabil Elqatib 译者 | 平川 策划 | 刘燕 本文最初发布于 Nabil Elqatib 的个人博客。 接触 Rust 开发快两年了。我觉得,回顾下自己在这个过程中的一些感想和汲取的经验教训,应该会很有趣。 下图是我第一次向一个 Rust 存储库提交代码。虽然时间是…...

VCS仿真效率提升:用UCLI/TCL脚本实现FSDB波形按需抓取与分段存储
VCS仿真效率革命:UCLI/TCL脚本实现FSDB波形智能管理实战 在芯片验证的浩瀚海洋中,波形文件就像航海日志,记录着每一次仿真的完整轨迹。但当我们面对TB级规模的验证环境时,传统的全量波形抓取方式就像用集装箱运送一瓶矿泉水——效…...

Windows Cleaner:彻底告别C盘爆满的免费系统优化方案
Windows Cleaner:彻底告别C盘爆满的免费系统优化方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款专为Windows用户设计的开源…...

一键转换:Save Image as Type终极指南 - 3秒解决浏览器图片格式难题
一键转换:Save Image as Type终极指南 - 3秒解决浏览器图片格式难题 【免费下载链接】Save-Image-as-Type Save Image as Type is an chrome extension which add Save as PNG / JPG / WebP to the context menu of image. 项目地址: https://gitcode.com/gh_mirr…...

番茄小说下载器:5分钟打造个人离线图书馆的终极指南
番茄小说下载器:5分钟打造个人离线图书馆的终极指南 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在通勤地铁上、旅行途中或网络信号不佳的地方…...

从 CMS 到 ZGC,JVM 是如何将停顿时间压缩到 1 毫秒的?
要理解 GC 的演进,我们打个极度通俗的比方:JVM 的堆内存就是一家正在营业的“疯狂大餐厅”,里面挤满了客人(活着的对象),同时也满地都是别人吃剩的骨头和纸巾(死掉的垃圾对象)。 垃圾…...
的正确写法)
CSS3 按钮悬停时显示手型光标(cursor- pointer)的正确写法
CSS 中 cursor: pointer 需配合伪类 :hover 使用,直接在 button 元素上声明不会生效;正确做法是为 button:hover 单独设置该样式。 css 中 cursor: pointer 需配合伪类 :hover 使用,直接在 button 元素上声明不会生效;正确做…...

Windows Cleaner终极指南:5分钟解决C盘爆红问题,快速释放空间提升电脑性能
Windows Cleaner终极指南:5分钟解决C盘爆红问题,快速释放空间提升电脑性能 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleane…...