深度学习相关概念及术语总结
目录
- 1.CNN
- 2.RNN
- 3.LSTM
- 4.NLP
- 5.CV
- 6.正向传播
- 7.反向传播
- 8.sigmoid 函数
- 9.ReLU函数
- 10.假设函数
- 11.损失函数
- 12.代价函数
1.CNN
CNN 是卷积神经网络(Convolutional Neural Network)的缩写。卷积神经网络是一种深度学习模型,专门用于处理具有网格状结构的数据,例如图像和视频。CNN 最初被广泛应用于图像识别领域,但随后也扩展到其他领域,如自然语言处理等。
CNN 的核心特点包括:
- 卷积层:CNN 使用卷积层来提取输入数据的特征。卷积操作通过滤波器(或称为卷积核)在输入数据上滑动,计算出每个位置的特征值。
- 池化层:CNN 使用池化层来减小特征图的尺寸,同时保留最重要的信息。池化操作通常包括最大池化或平均池化。
- 全连接层:在卷积和池化层之后,CNN 通常包括全连接层,用于将提取的特征映射到输出类别。
CNN 在图像识别、目标检测、人脸识别等领域取得了巨大成功,并且在自然语言处理领域的文本分类、情感分析等任务中也取得了显著的成果。由于其对图像和序列数据的强大特征提取能力,CNN 已成为深度学习领域中最重要和广泛应用的模型之一。
2.RNN
RNN是循环神经网络(Recurrent Neural Network)的缩写。循环神经网络是一种专门用于处理序列数据(如文本、音频、时间序列等)的神经网络模型。
RNN的核心特点包括:
- 循环结构:RNN具有循环的结构,使其能够对序列数据进行逐个元素的处理,并在处理每个元素时保留之前的状态信息。
- 时间展开:为了更好地理解RNN的工作原理,通常可以将RNN在时间上展开,形成一个循环结构的网络,每个时间步都有相同的网络结构,共享参数。
- 状态传递:RNN能够在处理序列数据时传递状态信息,这意味着它可以记忆之前的输入,并在当前时间步使用这些信息。
RNN在自然语言处理、语音识别、时间序列预测等领域中得到了广泛的应用。然而,传统的RNN模型存在梯度消失和梯度爆炸等问题,为了克服这些问题,后来出现了许多改进的RNN变体,如长短时记忆网络(LSTM)和门控循环单元(GRU)等。
总的来说,RNN以其对序列数据的处理能力而闻名,成为了深度学习领域中重要的模型之一。
3.LSTM
LSTM是长短时记忆网络(Long Short-Term Memory)的缩写。它是一种循环神经网络(RNN)的变体,旨在克服传统RNN模型中的长期依赖问题,并能更好地处理和记忆序列数据。
LSTM的核心特点包括:
- 遗忘门(Forget Gate):LSTM引入了遗忘门来控制前一个时间步的记忆状态是否被遗忘。
- 输入门(Input Gate):LSTM使用输入门来控制当前时间步的输入如何被加入到记忆状态中。
- 输出门(Output Gate):LSTM使用输出门来控制记忆状态如何影响当前时间步的输出。
通过这些门控机制,LSTM可以更好地处理长序列数据,并能够更有效地传递和记忆长期依赖关系。因此,在自然语言处理、时间序列分析、语音识别等领域,LSTM已经成为了一种非常有用的模型。
总的来说,LSTM的设计使其能够更好地处理和记忆序列数据中的长期依赖关系,因此在处理具有长期依赖的序列数据时具有很强的表现力。
4.NLP
NLP 是自然语言处理(Natural Language Processing)的缩写。自然语言处理是一种人工智能领域,专门研究计算机与人类自然语言之间的交互、理解和处理。
NLP 主要涉及以下内容:
- 语言理解:NLP 旨在使计算机能够理解和解释人类语言的含义,包括语音识别、文本理解、语义分析等。
- 语言生成:NLP 还包括使计算机能够生成人类可理解的自然语言,比如文本生成、对话系统、自动摘要等。
- 语言处理应用:NLP 在许多实际应用中发挥作用,包括情感分析、机器翻译、信息检索、问答系统等。
NLP 的目标是使计算机能够理解和处理人类的自然语言,使其能够与人类进行自然、智能的交互。在近年来,由于深度学习和大数据的发展,NLP 已经取得了巨大的进步,使得计算机在处理和理解自然语言方面取得了显著的成就。
5.CV
CV通常指的是“Computer Vision”(计算机视觉)。计算机视觉是一种人工智能领域,致力于使计算机能够理解、分析和解释图像和视频数据。它涉及图像处理、模式识别、机器学习等技术,用于实现图像识别、物体检测、人脸识别、视频分析等应用。
计算机视觉的目标是开发算法和技术,使计算机能够模拟人类的视觉系统,从图像或视频中提取有用的信息,并做出相应的决策。计算机视觉在许多领域都有广泛的应用,包括医学影像分析、自动驾驶、安防监控、工业质检、增强现实等。
在学术和工业界,计算机视觉一直是一个活跃的研究领域,并且随着深度学习和大数据的发展,计算机视觉技术取得了显著的进步,为图像和视频分析提供了更准确和高效的解决方案。
6.正向传播
正向传播(Forward Propagation)或叫向前传播 是神经网络中的一个重要概念,用于描述信号在网络中从输入到输出的传播过程。在训练神经网络时,正向传播是指输入数据通过神经网络的各层,逐层计算并传播,最终得到输出结果的过程。
在正向传播过程中,输入数据首先经过输入层,然后通过隐藏层(可能有多个)进行加权求和、激活函数处理,最终得到输出层的输出。每一层的输出都作为下一层的输入,这样信号就会依次传播至输出层。
具体来说,正向传播包括以下步骤:
- 输入数据通过输入层传递至第一个隐藏层,进行加权求和和激活函数处理,得到第一个隐藏层的输出。
- 第一个隐藏层的输出作为输入传递至下一个隐藏层,同样进行加权求和和激活函数处理,得到下一个隐藏层的输出。
- 最终,经过所有隐藏层的处理后,数据传递至输出层,进行加权求和和激活函数处理,得到神经网络的输出结果。
正向传播是神经网络训练中的第一步,它将输入数据经过网络中的权重和偏置,通过激活函数的处理,最终得到网络的输出结果。这个输出结果可以与真实标签进行比较,从而计算出预测值与真实值之间的误差,进而进行反向传播(Backward Propagation)来更新网络参数,从而逐步优化网络的预测能力。
7.反向传播
反向传播(Backward Propagation)或向后传播是神经网络中的一个重要概念,用于调整网络中权重和偏置的过程。它是在训练神经网络时使用的一种优化算法,通过计算损失函数对神经网络参数的梯度,然后根据梯度下降法来更新网络中的参数,以使损失函数达到最小值。
在反向传播过程中,首先通过正向传播计算出网络的输出,然后计算输出与真实标签之间的误差。接着,误差会反向传播回网络,计算每个参数对误差的贡献,进而根据梯度下降法来更新网络的权重和偏置。
具体来说,反向传播包括以下步骤:
- 计算损失函数对网络输出的梯度。
- 将梯度反向传播回输出层,计算每个参数对损失函数的梯度。
- 将梯度继续反向传播至隐藏层,计算每个参数对损失函数的梯度。
- 根据梯度下降法,更新网络中的权重和偏置。
通过反向传播,神经网络可以利用梯度下降法逐步调整参数,以最小化损失函数,从而提高网络的预测能力。
反向传播是神经网络训练中至关重要的一部分,它使得神经网络能够根据数据动态地调整参数,从而更好地适应不同的任务和数据。
8.sigmoid 函数
Sigmoid函数是一种常用的数学函数,通常用于机器学习中的分类模型,尤其是逻辑回归模型。Sigmoid函数的数学表达式如下:
σ ( z ) = 1 1 + e − z σ(z) =\frac{1}{1+e^{−z}} σ(z)=1+e−z1
其中,( e ) 是自然对数的底数,( x ) 是输入的实数。

Sigmoid函数的特点包括:
- 值域在(0, 1)之间:Sigmoid函数的输出值总是在0到1之间,这使得它特别适用于表示概率或将实数映射到概率值的问题。
- 平滑性:Sigmoid函数是连续可导的,并且具有良好的平滑性,这在优化算法中非常有用。
- 应用于逻辑回归:在逻辑回归中,Sigmoid函数通常用作激活函数,将线性模型的输出映射到0到1之间的概率值。
在机器学习中,Sigmoid函数经常用于将模型的输出转化为概率值,以便进行分类预测或计算分类的概率。sigmoid函数在神经网络中也有一些应用,尤其是在早期的神经网络模型中,作为激活函数使用。然而,随着时间的推移,一些新的激活函数,如ReLU(Rectified Linear Unit),已经取代了Sigmoid函数在神经网络中的常规使用。
9.ReLU函数
ReLU(Rectified Linear Unit)函数是一种常用的激活函数,用于神经网络中的前向传播过程。ReLU函数定义如下:
R e L U ( x ) = m a x ( x , 0 ) ReLU(x)=max(x,0) ReLU(x)=max(x,0)
换句话说,当输入 (x) 大于0时,ReLU函数返回 (x),否则返回0。
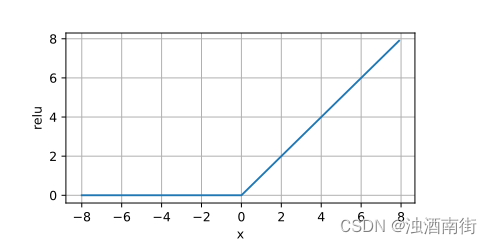
ReLU函数的特点包括:
- 非线性:ReLU函数是非线性的,这对于神经网络的表示能力至关重要。
- 稀疏性:在反向传播过程中,对于负的输入,ReLU函数的导数为0,这意味着一些神经元将被置为非活跃状态,从而实现了网络的稀疏性。
- 克服梯度消失问题:与一些传统的激活函数相比,ReLU函数有助于克服梯度消失问题,使得训练更加稳定。
ReLU函数在深度学习中得到了广泛的应用,尤其是在卷积神经网络(CNN)等模型中。它的简单性、非线性和稀疏性等特点使得它成为了许多深度学习模型的首选激活函数。然而,ReLU函数也有一些问题,如死亡神经元问题(Dead Neurons),即一些神经元可能在训练过程中永远不会被激活,这一问题后续被一些改进版本的激活函数所解决,如Leaky ReLU和ELU。
10.假设函数
假设函数(Hypothesis Function)是机器学习中的一个重要概念,特别是在监督学习中的回归和分类问题中经常出现。假设函数是指根据输入变量(特征)预测输出变量的函数。在不同的机器学习算法和模型中,假设函数可能会有不同的形式和表示方式。
- 线性回归:
在线性回归中,假设函数是一个线性函数,通常表示为:
h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . . . . + θ n x n h_θ(x) = θ_0 + θ_1x_1 +θ_2x_2 + ......+ θ_nx_n hθ(x)=θ0+θ1x1+θ2x2+......+θnxn
其中 ( x 1 , x 2 , . . . . . . x n x_1, x_2,...... x_n x1,x2,......xn ) 是输入特征,( θ 0 , θ 1 , . . . . . . , θ n θ_0, θ_1, ......, θ_n θ0,θ1,......,θn ) 是模型参数(也称为权重),( h θ ( x ) h_θ(x) hθ(x) ) 是预测的输出。
- 逻辑回归:
在逻辑回归中,假设函数是用于估计输入变量属于正类别的概率,通常表示为:
h θ ( x ) = 1 1 + e − ( θ 0 + θ 1 x 1 + θ 2 x 2 + . . . . . . + θ n x n ) h_θ(x) = \frac{1}{1 + e^{-(θ_0 +θ_1x_1 + θ_2x_2 + ...... + θ_nx_n)}} hθ(x)=1+e−(θ0+θ1x1+θ2x2+......+θnxn)1
其中 ( x 1 , x 2 , . . . . . . x n x_1, x_2,...... x_n x1,x2,......xn ) 是输入特征,( θ 0 , θ 1 , . . . . . . , θ n θ_0, θ_1, ......, θ_n θ0,θ1,......,θn) 是模型参数,( h θ ( x ) h_θ(x) hθ(x) ) 是预测属于正类别的概率。
在机器学习中,假设函数用于表示模型对输入数据的预测。通过合适的参数学习和训练,假设函数可以对新的未知数据进行预测。在训练过程中,模型的目标是找到最佳的参数,使得假设函数能够对数据做出准确的预测。
11.损失函数
损失函数(Loss Function)是在机器学习和优化问题中经常用到的一个重要概念。它用来量化模型预测与实际值之间的差距或损失程度,是模型优化过程中的关键组成部分。在训练模型的过程中,优化算法的目标通常是最小化损失函数,以便使模型的预测更加接近实际值。
不同的机器学习问题和模型会使用不同的损失函数,以下是一些常见的损失函数:
均方误差(Mean Squared Error, MSE):
在回归问题中常用的损失函数,用于衡量模型预测值与实际值之间的平方差。它的数学表达式为:
L ( y , y ^ ) = ( y i − y ^ i ) 2 L(y, \hat{y}) =(y_i - \hat{y}_i)^2 L(y,y^)=(yi−y^i)2
其中 ( y i y_i yi) 是真实值,( y ^ i \hat{y}_i y^i) 是模型的预测值。
交叉熵损失(Cross Entropy Loss):
在分类问题中常用的损失函数,特别是在逻辑回归和神经网络中。对于二分类问题,交叉熵损失函数的数学表达式为:
L ( y , y ^ ) = ( y i log ( y ^ i ) + ( 1 − y i ) log ( 1 − y ^ i ) ) L(y, \hat{y}) = (y_i \log(\hat{y}_i) + (1-y_i) \log(1-\hat{y}_i)) L(y,y^)=(yilog(y^i)+(1−yi)log(1−y^i))
其中 ( y i y_i yi ) 是真实标签(0或1),( y ^ i \hat{y}_i y^i ) 是模型的预测概率。
Hinge Loss:
用于支持向量机(SVM)中的损失函数,适用于分类问题。Hinge Loss函数的数学表达式为:
L ( y , y ^ ) = max ( 0 , 1 − y ⋅ y ^ ) L(y, \hat{y}) = \max(0, 1 - y \cdot \hat{y}) L(y,y^)=max(0,1−y⋅y^)
其中 ( y ) 是真实标签(-1或1),( y ^ \hat{y} y^ ) 是模型的预测值。
这些都是常见的损失函数,但实际应用中会根据具体问题和模型的特性选择合适的损失函数。通过优化算法(如梯度下降)来最小化损失函数,可以使模型更好地拟合训练数据,提高预测的准确性。
12.代价函数
代价函数(Cost Function)是机器学习中的一个重要概念,用于衡量模型预测与实际值之间的误差。代价函数是模型优化过程中的关键组成部分,通常在训练过程中被最小化,以便使模型的预测更加接近实际值。
在监督学习中,代价函数用于量化模型的预测误差,以下是一些常见的代价函数:
均方误差(Mean Squared Error, MSE):
均方误差是常用的代价函数,用于回归问题。它衡量了模型预测值与真实值之间的平方差的平均值,其数学表达式为:
J ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta) = \frac{1}{2m} \sum_{i=1}^{m} (h_{\theta}(x^{(i)}) - y^{(i)})^2 J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2
其中 ( h θ ( x ( i ) ) ) 是模型对样本 ( x ( i ) h_{\theta}(x^{(i)}) ) 是模型对样本 ( x^{(i)} hθ(x(i)))是模型对样本(x(i) ) 的预测值,( y ( i ) y^{(i)} y(i) ) 是样本的真实值,( m ) 是样本数量。
交叉熵损失(Cross Entropy Loss):
交叉熵损失函数通常用于分类问题,特别是在逻辑回归和神经网络中。对于二分类问题,交叉熵损失函数的数学表达式为:
J ( θ ) = − 1 m ∑ i = 1 m ( y ( i ) log ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ) J(\theta) = -\frac{1}{m} \sum_{i=1}^{m} (y^{(i)} \log(h_{\theta}(x^{(i)})) + (1-y^{(i)}) \log(1-h_{\theta}(x^{(i)}))) J(θ)=−m1i=1∑m(y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i))))
其中 ( h θ ( x ( i ) ) ) 是模型对样本 ( x ( i ) h_{\theta}(x^{(i)}) ) 是模型对样本 ( x^{(i)} hθ(x(i)))是模型对样本(x(i) ) 的预测概率,( y ( i ) y^{(i)} y(i) ) 是样本的真实标签,( m ) 是样本数量。
代价函数的选择取决于具体的机器学习问题和模型类型。通过最小化代价函数,可以使模型更好地拟合训练数据,提高预测的准确性。
持续更新中!!!!
相关文章:
深度学习相关概念及术语总结
目录 1.CNN2.RNN3.LSTM4.NLP5.CV6.正向传播7.反向传播8.sigmoid 函数9.ReLU函数10.假设函数11.损失函数12.代价函数 1.CNN CNN 是卷积神经网络(Convolutional Neural Network)的缩写。卷积神经网络是一种深度学习模型,专门用于处理具有网格状…...
uniapp发行H5获取当前页面query
阅读uni的文档大致可得通过 onLoad与 onShow()的形参都能获取页面传递的参数,例如在开发时鼠标移动到方法上可以看到此方法的简短介绍 实际这里说的是打开当前页面的参数,在小程序端的时候测试并无问题,但是发行到H5时首页加载会造成参数获取…...

Flutter中动画的实现
动画三要素 控制动画的三要素:Animation、Tween、和AnmaitionController Animation: 产生的值的序列,有CurveAnimation等子类,, 可以将值赋值给Widget的宽高或其他属性,进而控制widget发生变化 Tween&#…...
Elasticsearch从入门到精通-03基本语法学习
Elasticsearch从入门到精通-03基本语法学习 👏作者简介:大家好,我是程序员行走的鱼 📖 本篇主要介绍和大家一块学习一下ES基本语法,主要包括索引管理、文档管理、映射管理等内容 1.1 了解Restful ES对数据进行增、删、改、查是以…...
【黑马程序员】STL实战--演讲比赛管理系统
文章目录 演讲比赛管理系统需求说明比赛规则程序功能 创建管理类功能描述创建演讲比赛管理类 菜单功能添加菜单成员函数声明菜单成员函数实现菜单功能测试 退出功能添加退出功能声明退出成员函数实现退出功能测试 演讲比赛功能功能分析创建选手类比赛成员属性添加初始化属性创建…...
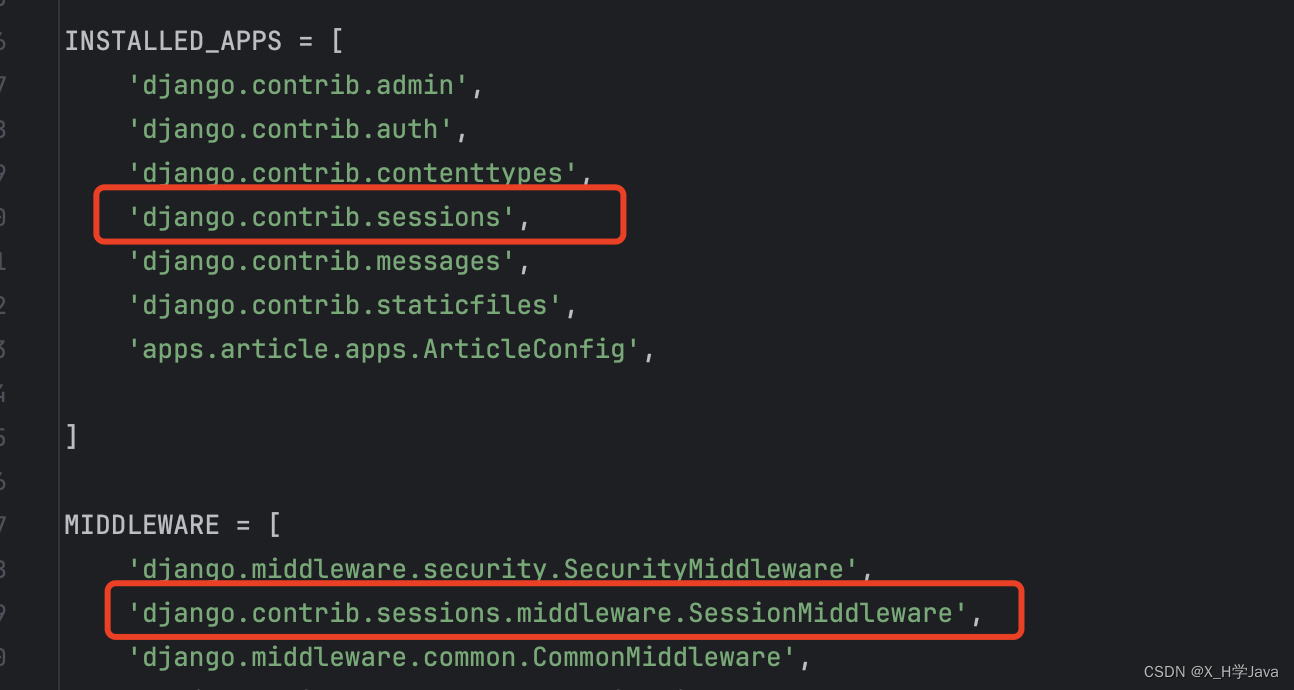
一文帮助快速入门Django
文章目录 创建django项目应用app配置pycharm虚拟环境打包依赖 路由传统路由include路由分发namenamespace 视图中间件orm关系对象映射操作表数据库配置model常见字段及参数orm基本操作 cookie和sessiondemo类视图 创建django项目 指定版本安装django:pip install dj…...
基于springboot实现图书推荐系统项目【项目源码+论文说明】计算机毕业设计
基于springboot实现图书馆推荐系统演示 摘要 时代的变化速度实在超出人类的所料,21世纪,计算机已经发展到各行各业,各个地区,它的载体媒介-计算机,大众称之为的电脑,是一种特高速的科学仪器,比…...

微信小程序实现上拉加载更多
一、前情提要 微信小程序中实现上拉加载更多,其实就是pc端项目的分页。使用的是scroll-view,scroll-view详情在微信开发文档/开发/组件/视图容器中。每次上拉,就是在原有数据基础上,拼接/合并上本次上拉请求得到的数据。这里采用…...
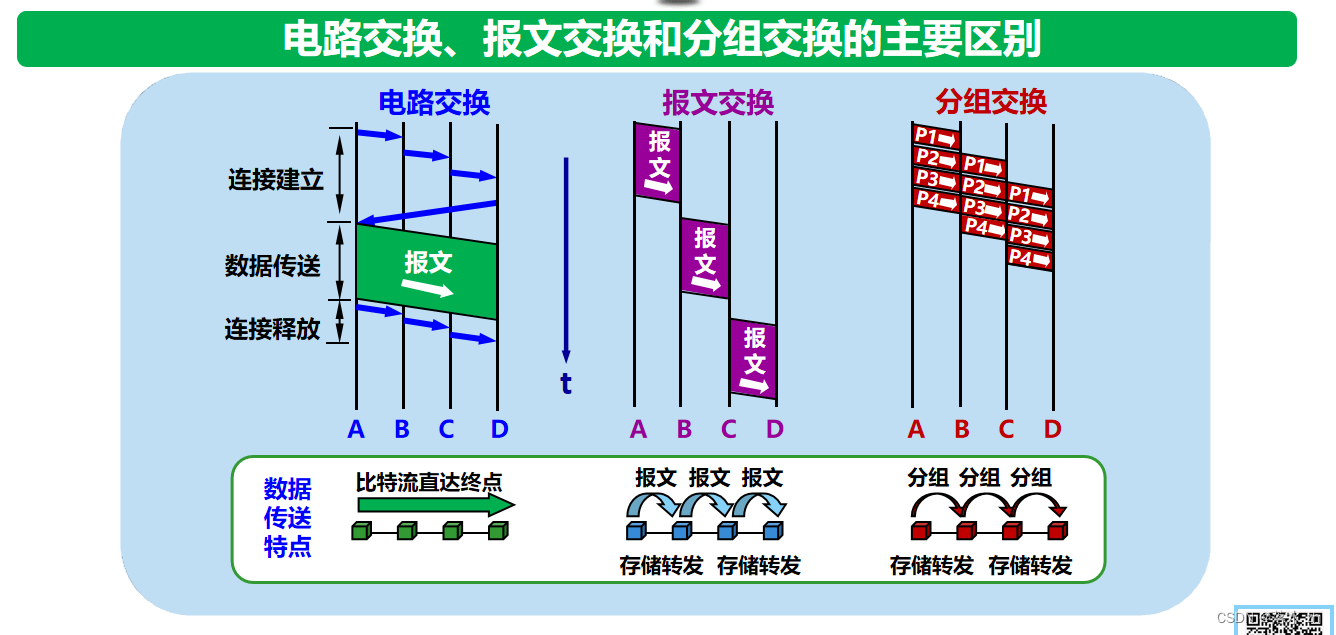
计算机网络——概述
计算机网络——概述 计算机网络的定义互连网(internet)互联网(Internet)互联网基础结构发展的三个阶段第一个阶段——APPANET第二阶段——商业化和三级架构第三阶段——全球范围多层次的ISP结构 ISP的作用终端互联网的组成边缘部分…...

kafka Interceptors and Listeners
Interceptors ProducerInterceptor https://www.cnblogs.com/huxi2b/p/7072447.html Producer拦截器(interceptor)是个相当新的功能,它和consumer端interceptor是在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑。 对于producer而言&…...

【面试题】mysql常见面试题及答案总结
事务中的ACID原则是什么? Mysql是如何实现或者保障ACID的? ACID原则是数据库事务管理中必须满足的四个基本属性,确保了数据库事务的可靠性和数据完整性。 简写全称解释实现A原子性(Atomicity)一个事务被视为一个不可分割的操作序列&#…...

C++ 类的前向声明的用法
我们知道C的类应当是先定义,然后使用。但在处理相对复杂的问题、考虑类的组合时,很可能遇到俩个类相互引用的情况,这种情况称为循环依赖。 例如: class A { public:void f(B b);//以B类对象b为形参的成员函数//这里编译错位&…...
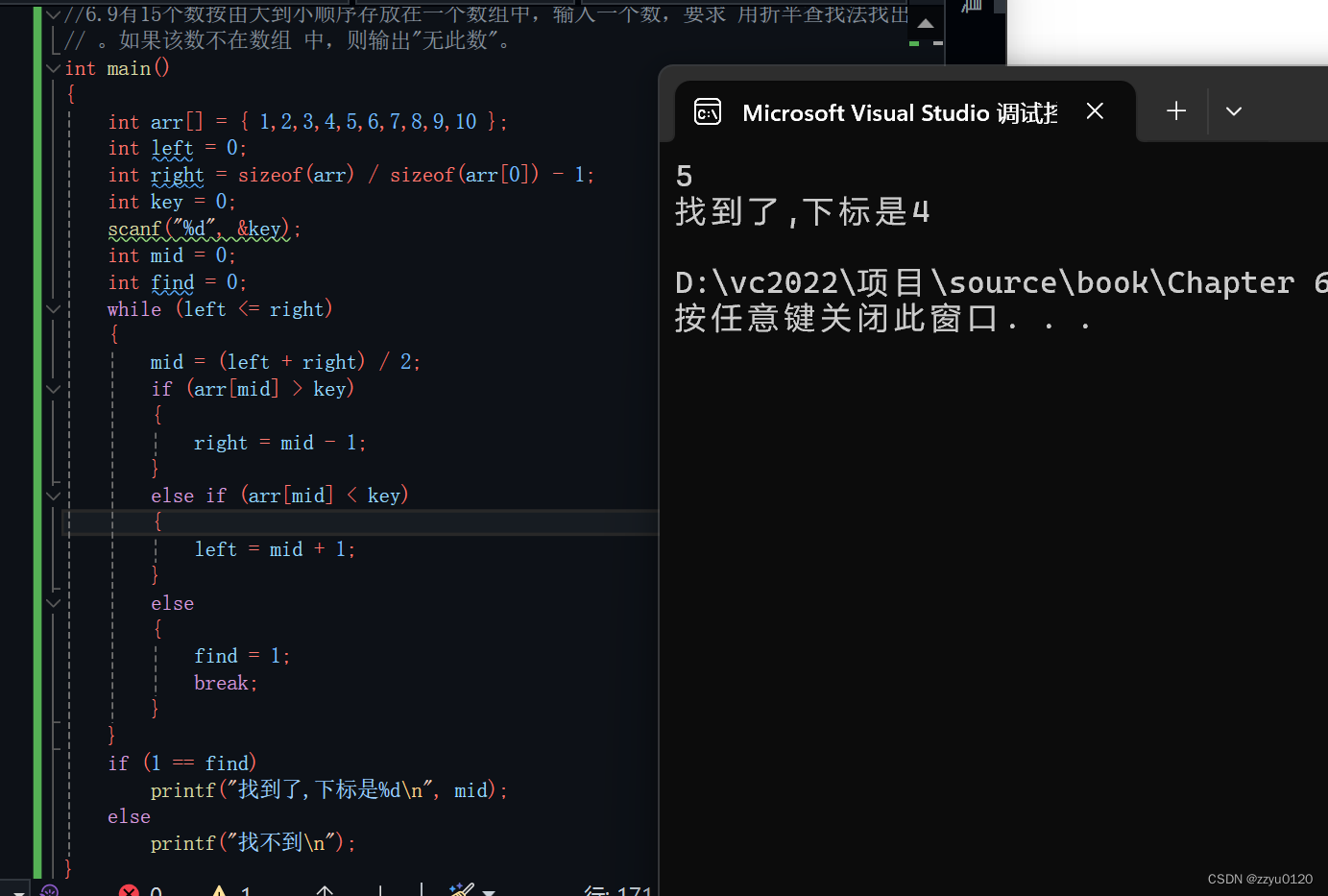
二分查找(c语言)
二分查找 一.什么是二分查找二.代码实现 一.什么是二分查找 在⼀个升序的数组中查找制定的数字n,很容易想到的⽅法就是遍历数组,但是这种⽅法效率⽐较低, ⽐如我买了⼀双鞋,你好奇问我多少钱,我说不超过300元。你还是好…...

【记录31】elementUI el-tree 虚线、右键、拖拽
父组件 <eltree :treeData"treeData"></eltree>import eltree from "../../components/tree.vue"; export default {name: ,components: { // org_tree ,eltree},watch: {},data() {return {orgFormchoose: {},orgForm: { type: 0, limits: 1…...

【C++】函数重载
🦄个人主页:修修修也 🎏所属专栏:C ⚙️操作环境:Visual Studio 2022 目录 📌函数重载的定义 📌函数重载的三种类型 🎏参数个数不同 🎏参数类型不同 🎏参数类型顺序不同 📌重载…...

【深度学习模型】6_3 语言模型数据集
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图 6.3 语言模型数据集(周杰伦专辑歌词) 本节将介绍如何预处理一个语言模型数据集,并将其转换成字符级…...

技术选型思考:分库分表和分布式DB(TiDB/OceanBase) 的权衡与抉择
码到三十五 : 个人主页 心中有诗画,指尖舞代码,目光览世界,步履越千山,人间尽值得 ! 在当今数据爆炸的时代,数据库作为存储和管理数据的核心组件,其性能和扩展性成为了企业关注的重点。随着业…...

React改变数据【案例】
State传统方式 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>React Demo</title> <!--…...
ChatGPT Plus 自动扣费失败,如何续订
ChatGPT Plus 自动扣费失败,如何续订 如果您的 ChatGPT Plus 订阅过期或扣费失败,本教程将指导您如何重新订阅。 本周更新 ChatGPT Plus 是一种每月20美元的订阅服务。扣费会自动进行,如果您的账户余额不足,OpenAI 将在一次扣费…...

Rust: Channel 代码示例
在 Rust 中,通道(Channel)通常使用 std::sync::mpsc(多生产者单消费者)或 tokio::sync::mpsc(在异步编程中,特别是使用 Tokio 运行时)来创建。下面是一个使用 std::sync::mpsc 的简单…...

终极视频下载助手:一键抓取网页视频的完整解决方案
终极视频下载助手:一键抓取网页视频的完整解决方案 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法下载网页视频而烦恼…...

BERT中文文本分割镜像部署教程:Docker Compose编排多模型协同服务
BERT中文文本分割镜像部署教程:Docker Compose编排多模型协同服务 1. 引言:为什么需要智能文本分割? 想象一下,你刚刚参加完一场长达两小时的线上会议,录音转文字工具生成了一份密密麻麻、长达万字的文稿。没有段落&…...
)
别再手动点点点了!用MeterSphere一站式搞定接口、性能与测试管理(附Docker部署避坑指南)
MeterSphere实战指南:从Docker部署到全流程测试自动化 在软件测试领域,重复劳动如同西西弗斯推石上山的永恒惩罚——测试人员不断编写用例、执行回归、分析结果,周而复始。传统测试工具各自为政,接口测试用Postman,性能…...
)
别再花钱买云笔记了!用Typora+GitHub打造你的免费、私有知识库(附完整Git命令清单)
零成本构建私有知识库:Typora与GitHub的完美协作指南 在信息爆炸的时代,知识管理已成为现代人的刚需。市面上各类云笔记应用层出不穷,但要么需要持续付费订阅,要么对免费用户限制功能,更令人担忧的是数据隐私问题——…...

EdgeRemover:彻底卸载Microsoft Edge的智能PowerShell解决方案
EdgeRemover:彻底卸载Microsoft Edge的智能PowerShell解决方案 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRemover …...

DS4Android:如何通过可视化学习让数据结构从抽象概念变为直观体验?
DS4Android:如何通过可视化学习让数据结构从抽象概念变为直观体验? 【免费下载链接】DS4Android 看得见的数据结构Android版---Show the Data_Structure power by Android View 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Android 你是否曾…...
彻底告别‘万向死锁’的烦恼)
从无人机飞控到机械臂:工程师如何用四元数(Quaternion)彻底告别‘万向死锁’的烦恼
从无人机飞控到机械臂:工程师如何用四元数彻底告别万向死锁 想象一下,你正在调试一架无人机的飞控系统。当飞机俯仰角接近90度时,突然发现滚转和偏航控制开始互相干扰,原本独立的三个轴向操作突然"锁死"成两个——这就是…...

QMCDecode终极指南:3分钟解锁QQ音乐加密文件,释放你的音乐自由
QMCDecode终极指南:3分钟解锁QQ音乐加密文件,释放你的音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

拆解一个经典数电密码锁:从555脉冲到74LS190计数,再到7485比较的完整信号流分析
经典数字密码锁系统全链路信号解析:从时钟生成到密码比对的工程思维训练 在电子技术快速迭代的今天,传统数字电路设计依然是理解计算机底层逻辑的必修课。这个由555定时器、74LS190计数器和7485比较器构建的密码锁系统,堪称数字电路教学的&q…...

网易云音乐NCM格式终极解密指南:5分钟解放你的加密音乐库
网易云音乐NCM格式终极解密指南:5分钟解放你的加密音乐库 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾为网易云音乐下载的NCM格式文件无法在其他设备播放而烦恼?那些精心收藏的歌曲,只…...