机器学习之分类回归模型(决策数、随机森林)
回归分析
回归分析属于监督学习方法的一种,主要用于预测连续型目标变量,可以预测、计算趋势以及确定变量之间的关系等。
Regession Evaluation Metrics
以下是一些最流行的回归评估指标:
平均绝对误差(MAE):目标变量的预测值与实际值之间的平均绝对差值。
均方误差(MSE):目标变量的预测值与实际值之间的平均平方差。
均方根误差(RMSE):均方根误差的平方根。
Huber Loss:一种混合损失函数,在较大误差时从MAE过渡到MSE,在鲁棒性和MSE对异常值的敏感性之间提供平衡。
均方根对数误差
R2-Score
分类模型
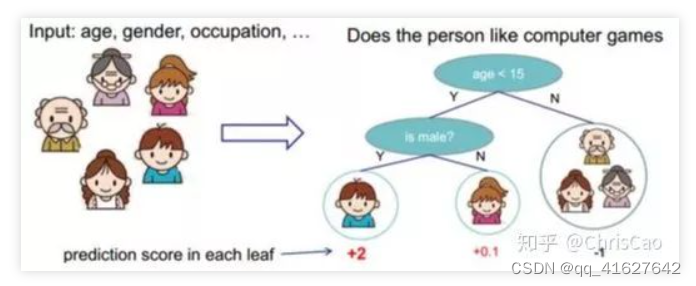
决策树(监督分类回归模型)
分类树:该树用于确定目标变量在连续时最有可能落入哪个“类”。
回归树:用于预测连续变量的值。
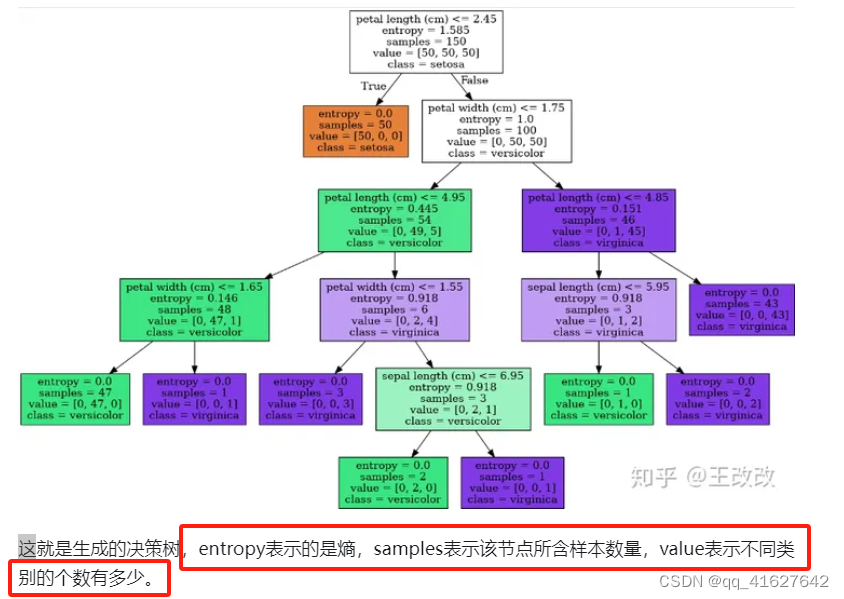
在决策树中,节点根据属性的阈值划分为子节点。将根节点作为训练集,并根据最优属性和阈值将其分割为两个节点。此外,子集也使用相同的逻辑进行分割。这个过程一直持续,直到在树中找到最后一个纯子集,或者在该生长的树中找到最大可能的叶子数。
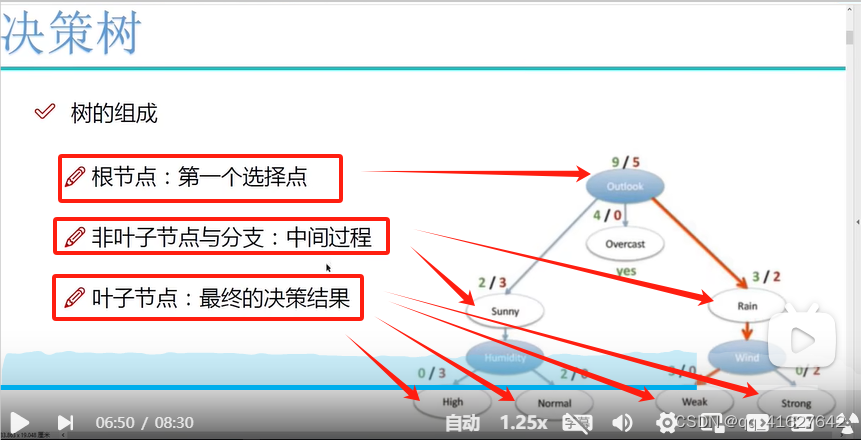

根据分割指标和分割方法,可分为:ID3、C4.5、CART算法。
(1)ID3算法:以信息增益为准则来选择最优划分属性
信息增益的计算是基于信息熵(度量样本集合纯度的指标)


(2)C4.5基于信息增益率准则 选择最有分割属性的算法

3. CART:以基尼系数为准则选择最优划分属性,可用于分类和回归
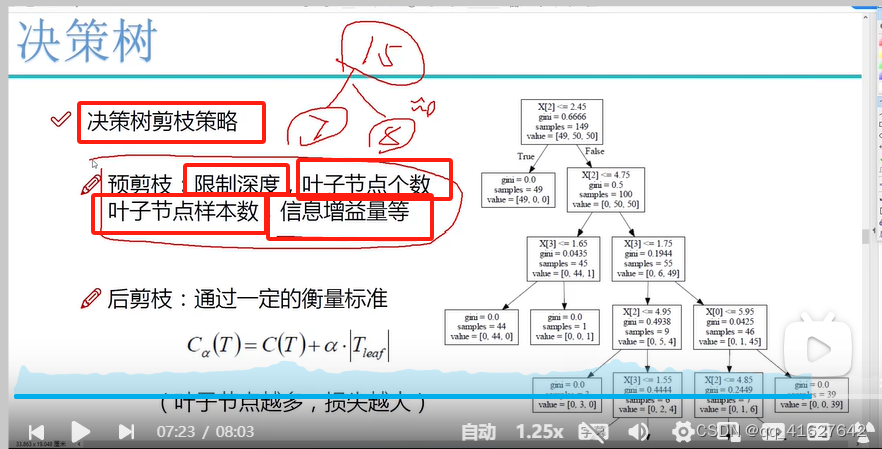
基尼杂质-基尼杂质测量根据多数类标记的子集对随机实例进行错误分类的概率。基尼不纯系数越低,意味着子集的纯度越高。分割标准- CART算法评估每个节点上的所有潜在分割,并选择最能减少结果子集的基尼杂质的分割。这个过程一直持续,直到达到一个停止条件,比如最大树深度或叶子节点中的最小实例数。

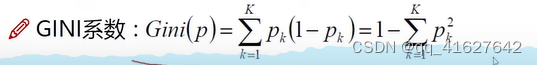



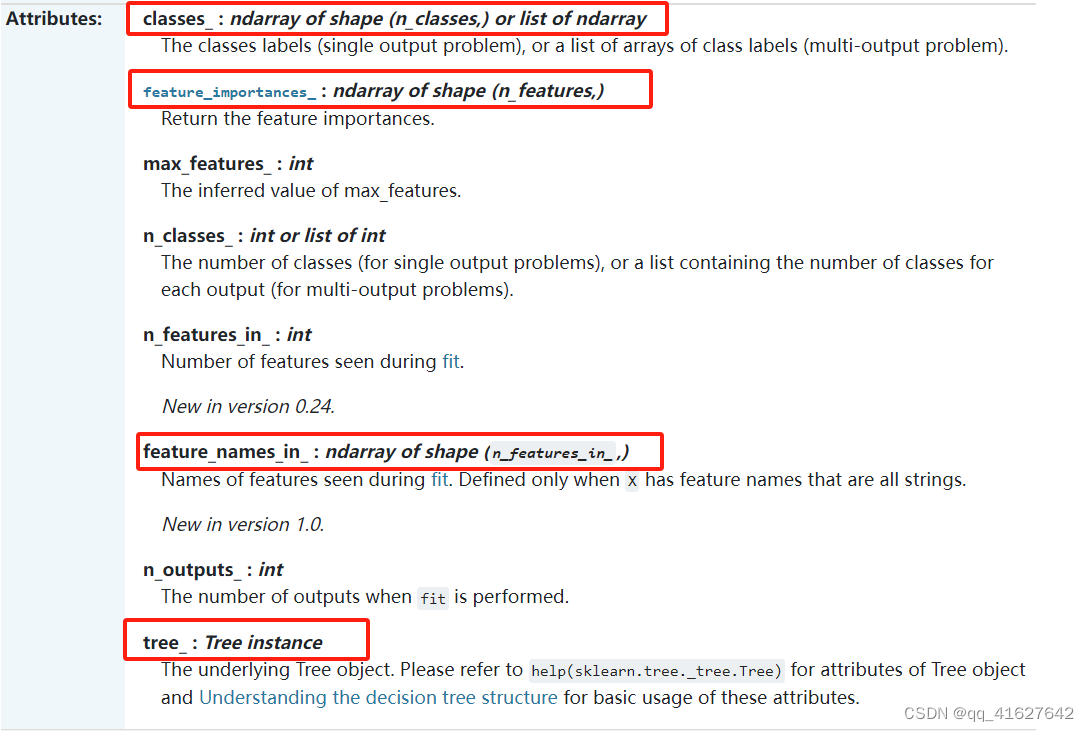
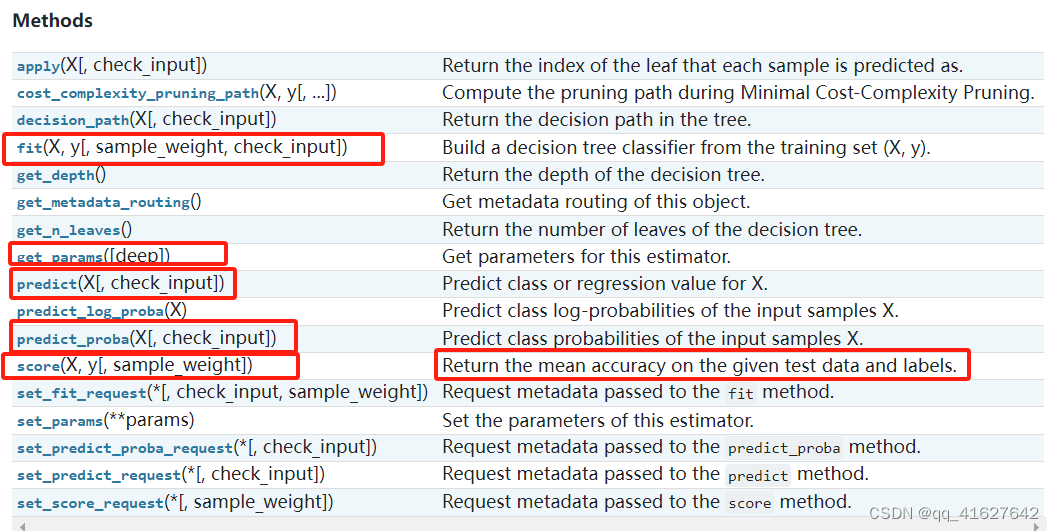
sklearn.tree.DecisionTreeClassifier(分类)
class sklearn.tree.DecisionTreeClassifier(*, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0)[source]



from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state=42)
tree = DecisionTreeClassifier(random_state=0)
tree.fit(X_train, y_train)
print("Accuracy on training set: {:.3f}".format(tree.score(X_train, y_train)))
print("Accuracy on test set: {:.3f}".format(tree.score(X_test, y_test)))
tree = DecisionTreeClassifier(max_depth=4, random_state=0)
tree.fit(X_train, y_train)print("Accuracy on training set: {:.3f}".format(tree.score(X_train, y_train)))
print("Accuracy on test set: {:.3f}".format(tree.score(X_test, y_test)))
fig, axes = plt.subplots(2, 3, figsize=(20, 10))
for i, (ax, tree) in enumerate(zip(axes.ravel(), forest.estimators_)):ax.set_title("Tree {}".format(i))mglearn.plots.plot_tree_partition(X_train, y_train, tree, ax=ax)mglearn.plots.plot_2d_separator(forest, X_train, fill=True, ax=axes[-1, -1],alpha=.4)
axes[-1, -1].set_title("Random Forest")
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
def plot_feature_importances_cancer(model):n_features = cancer.data.shape[1]plt.barh(np.arange(n_features), model.feature_importances_, align='center')plt.yticks(np.arange(n_features), cancer.feature_names)plt.xlabel("Feature importance")plt.ylabel("Feature")plt.ylim(-1, n_features)plot_feature_importances_cancer(tree)
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import LabelEncoder# Define the features and target variable
features = [["red", "large"],["green", "small"],["red", "small"],["yellow", "large"],["green", "large"],["orange", "large"],
]
target_variable = ["apple", "lime", "strawberry", "banana", "grape", "orange"]# Flatten the features list for encoding
flattened_features = [item for sublist in features for item in sublist]# Use a single LabelEncoder for all features and target variable
le = LabelEncoder()
le.fit(flattened_features + target_variable)# Encode features and target variable
encoded_features = [le.transform(item) for item in features]
encoded_target = le.transform(target_variable)# Create a CART classifier
clf = DecisionTreeClassifier()# Train the classifier on the training set
clf.fit(encoded_features, encoded_target)# Predict the fruit type for a new instance
new_instance = ["red", "large"]
encoded_new_instance = le.transform(new_instance)
predicted_fruit_type = clf.predict([encoded_new_instance])
decoded_predicted_fruit_type = le.inverse_transform(predicted_fruit_type)
print("Predicted fruit type:", decoded_predicted_fruit_type[0])
DecisionTreeRegressor(回归)
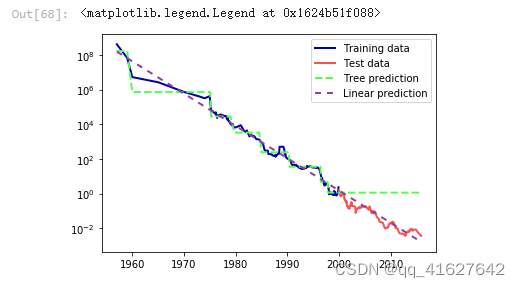
import os
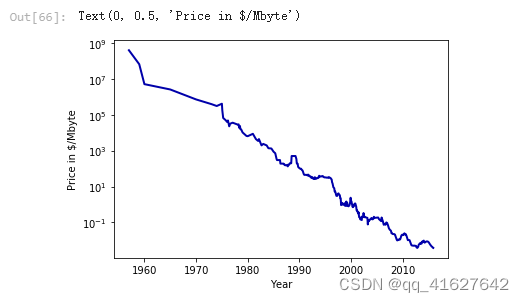
ram_prices = pd.read_csv(os.path.join(mglearn.datasets.DATA_PATH, "ram_price.csv"))plt.semilogy(ram_prices.date, ram_prices.price)
plt.xlabel("Year")
plt.ylabel("Price in $/Mbyte")
from sklearn.tree import DecisionTreeRegressor
# use historical data to forecast prices after the year 2000
data_train = ram_prices[ram_prices.date < 2000]
data_test = ram_prices[ram_prices.date >= 2000]# predict prices based on date
X_train = data_train.date[:, np.newaxis]
# we use a log-transform to get a simpler relationship of data to target
y_train = np.log(data_train.price)tree = DecisionTreeRegressor(max_depth=3).fit(X_train, y_train)
linear_reg = LinearRegression().fit(X_train, y_train)# predict on all data
X_all = ram_prices.date[:, np.newaxis]pred_tree = tree.predict(X_all)
pred_lr = linear_reg.predict(X_all)# undo log-transform
price_tree = np.exp(pred_tree)
price_lr = np.exp(pred_lr)
plt.semilogy(data_train.date, data_train.price, label="Training data")
plt.semilogy(data_test.date, data_test.price, label="Test data")
plt.semilogy(ram_prices.date, price_tree, label="Tree prediction")
plt.semilogy(ram_prices.date, price_lr, label="Linear prediction")
plt.legend()
随机森林(集成学习)
先补充组合分类器的概念,将多个分类器的结果进行多票表决或取平均值,以此作为最终的结果。
每个决策树都有很高的方差,但是当我们将它们并行地组合在一起时,结果的方差就会很低,因为每个决策树都在特定的样本数据上得到了完美的训练,因此输出不依赖于一个决策树,而是依赖于多个决策树。在分类问题的情况下,使用多数投票分类器获得最终输出。在回归问题的情况下,最终输出是所有输出的平均值。这部分称为聚合。
1.构建组合分类器的好处:
(1)提升模型精度:整合各个模型的分类结果,得到更合理的决策边界,减少整体错误呢,实现更好的分类效果:
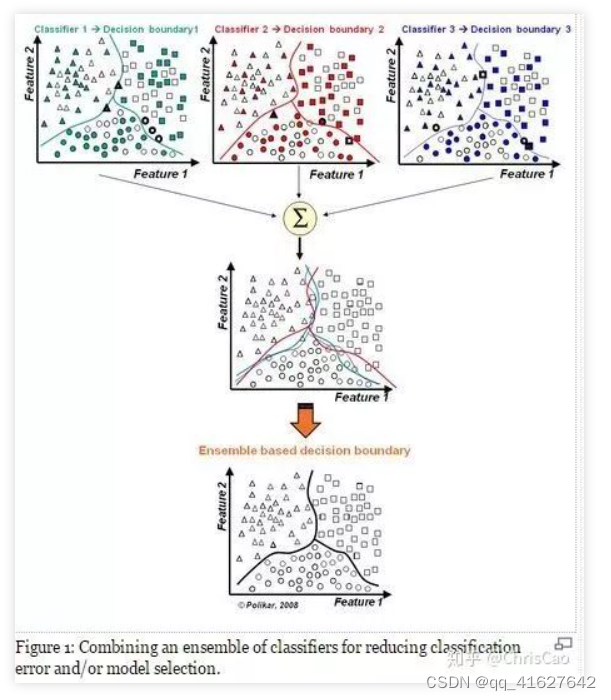
(2)处理过大或过小的数据集:数据集较大时,可将数据集划分成多个子集,对子集构建分类器;当数据集较小时,通过自助采样(bootstrap)从原始数据集采样产生多组不同的数据集,构建分类器。
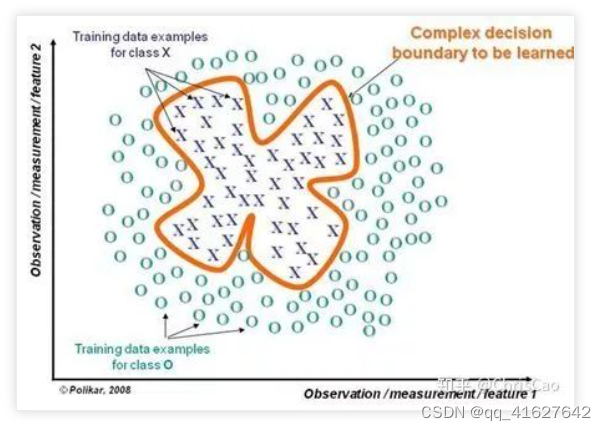
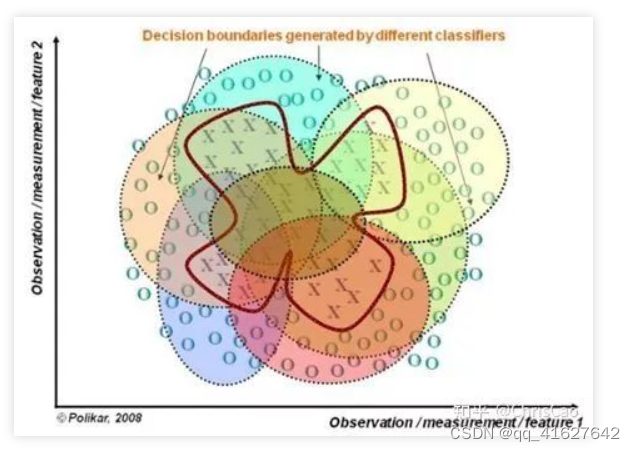
(3)若决策边界过于复杂,则线性模型不能很好地描述真实情况。因此,现对于特定区域的数据集,训练多个线性分类器,再将他们集成。
(4)比较适合处理多源异构数据(存储方式不同(关系型、非关系型),类别不同(时序型、离散型、连续型、网络结构数据))
随机森林是一个多决策树的组合分类器,随机主要体现在两个方面:数据选取的随机性和特征选取的随机性。
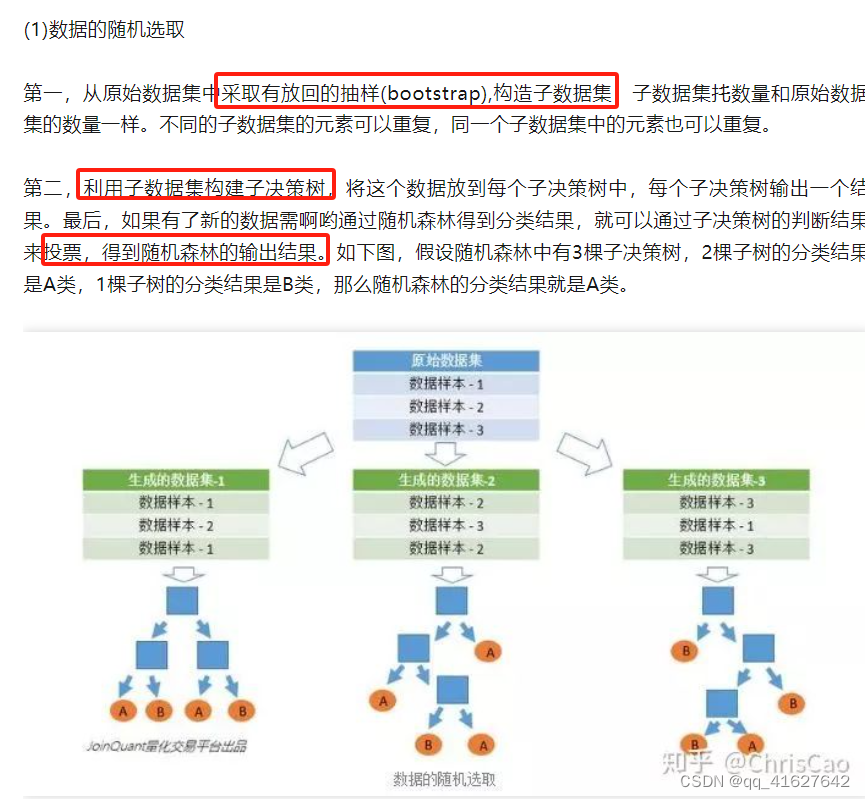
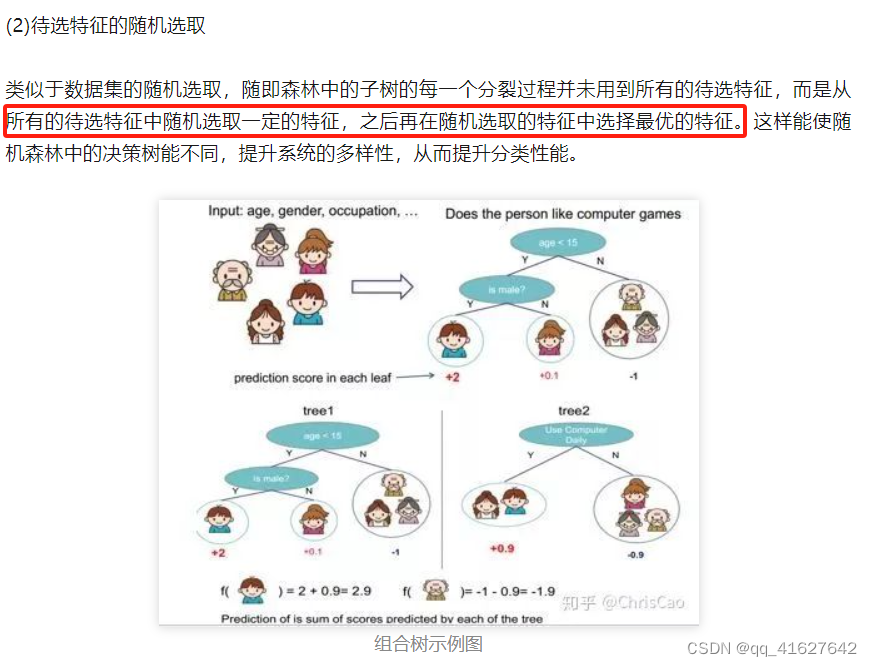
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_moonsX, y = make_moons(n_samples=100, noise=0.25, random_state=3)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y,random_state=42)forest = RandomForestClassifier(n_estimators=5, random_state=2)
forest.fit(X_train, y_train)
fig, axes = plt.subplots(2, 3, figsize=(20, 10))
for i, (ax, tree) in enumerate(zip(axes.ravel(), forest.estimators_)):ax.set_title("Tree {}".format(i))mglearn.plots.plot_tree_partition(X_train, y_train, tree, ax=ax)mglearn.plots.plot_2d_separator(forest, X_train, fill=True, ax=axes[-1, -1],alpha=.4)
axes[-1, -1].set_title("Random Forest")
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
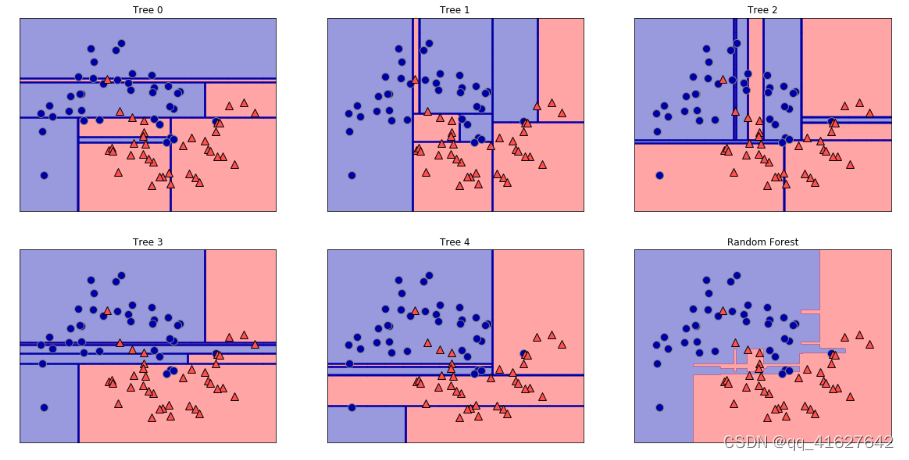
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=0)
forest = RandomForestClassifier(n_estimators=100, random_state=0)
forest.fit(X_train, y_train)print("Accuracy on training set: {:.3f}".format(forest.score(X_train, y_train)))
print("Accuracy on test set: {:.3f}".format(forest.score(X_test, y_test)))
plot_feature_importances_cancer(forest)
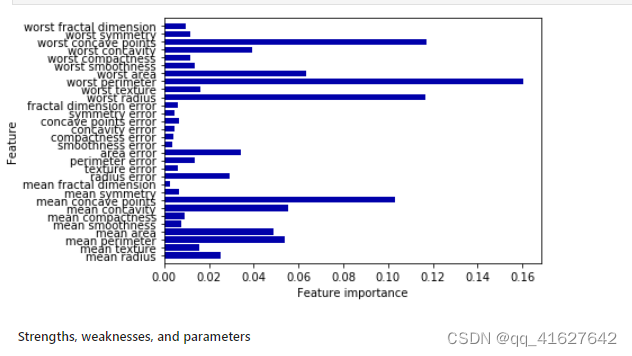
我们举一个线性回归的例子。我们有一个住房数据集,我们想预测房子的价格。下面是它的python代码。
# Python code to illustrate
# regression using data set
import matplotlib
matplotlib.use('GTKAgg')import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
import pandas as pd# Load CSV and columns
df = pd.read_csv("Housing.csv")Y = df['price']
X = df['lotsize']X=X.values.reshape(len(X),1)
Y=Y.values.reshape(len(Y),1)# Split the data into training/testing sets
X_train = X[:-250]
X_test = X[-250:]# Split the targets into training/testing sets
Y_train = Y[:-250]
Y_test = Y[-250:]# Plot outputs
plt.scatter(X_test, Y_test, color='black')
plt.title('Test Data')
plt.xlabel('Size')
plt.ylabel('Price')
plt.xticks(())
plt.yticks(())
# Create linear regression object
regr = linear_model.LinearRegression()# Train the model using the training sets
regr.fit(X_train, Y_train)# Plot outputs
plt.plot(X_test, regr.predict(X_test), color='red',linewidth=3)
plt.show()
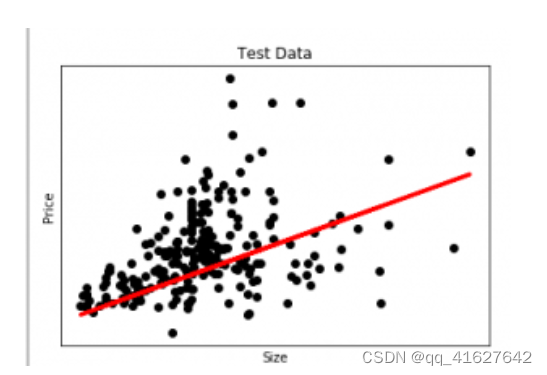
在这张图中,我们绘制了测试数据。红线表示预测价格的最佳拟合线。使用线性回归模型进行个体预测:
print( str(round(regr.predict(5000))) )
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn
import warningsfrom sklearn.preprocessing import LabelEncoder
from sklearn.impute import KNNImputer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import f1_score
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_scorewarnings.filterwarnings('ignore')
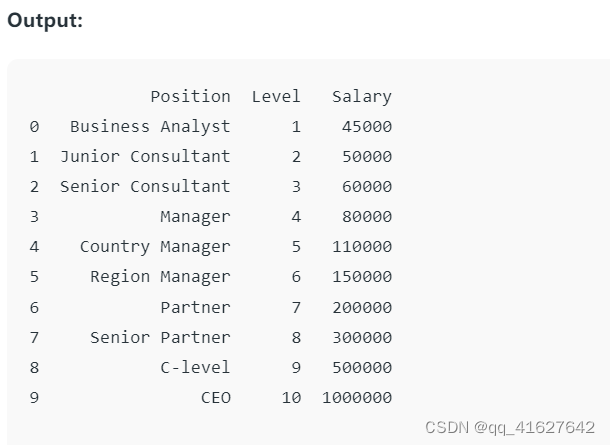
df= pd.read_csv('Salaries.csv')
print(df)
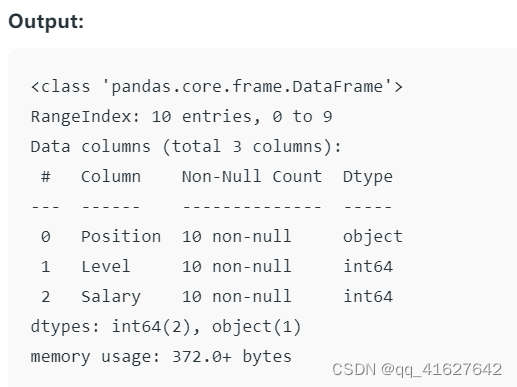
Here the .info() method provides a quick overview of the structure, data types, and memory usage of the dataset.
df.info()
# Assuming df is your DataFrame
X = df.iloc[:,1:2].values #features
y = df.iloc[:,2].values # Target variable
step 4: Random Forest Regressor model代码对分类数据进行数字编码处理,将处理后的数据与数字数据结合起来,使用准备好的数据训练Random Forest Regression模型。
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import LabelEncoderCheck for and handle categorical variables
label_encoder = LabelEncoder()
x_categorical = df.select_dtypes(include=['object']).apply(label_encoder.fit_transform)
x_numerical = df.select_dtypes(exclude=['object']).values
x = pd.concat([pd.DataFrame(x_numerical), x_categorical], axis=1).values# Fitting Random Forest Regression to the dataset
regressor = RandomForestRegressor(n_estimators=10, random_state=0, oob_score=True)# Fit the regressor with x and y data
regressor.fit(x, y)
# Evaluating the model
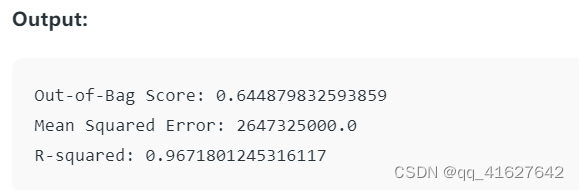
from sklearn.metrics import mean_squared_error, r2_score# Access the OOB Score
oob_score = regressor.oob_score_
print(f'Out-of-Bag Score: {oob_score}')# Making predictions on the same data or new data
predictions = regressor.predict(x)# Evaluating the model
mse = mean_squared_error(y, predictions)
print(f'Mean Squared Error: {mse}')r2 = r2_score(y, predictions)
print(f'R-squared: {r2}')
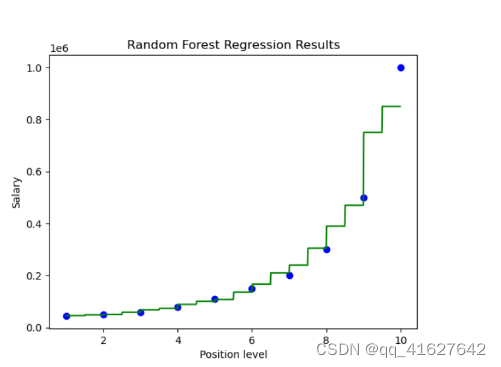
import numpy as np
X_grid = np.arange(min(X),max(X),0.01)
X_grid = X_grid.reshape(len(X_grid),1) plt.scatter(X,y, color='blue') #plotting real points
plt.plot(X_grid, regressor.predict(X_grid),color='green') #plotting for predict pointsplt.title("Random Forest Regression Results")
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()
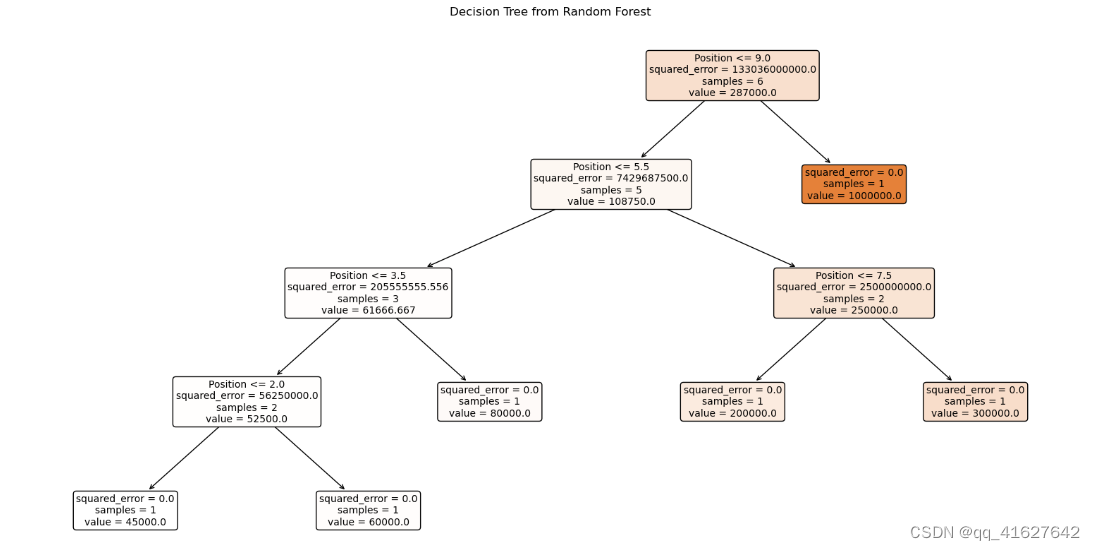
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt# Assuming regressor is your trained Random Forest model
# Pick one tree from the forest, e.g., the first tree (index 0)
tree_to_plot = regressor.estimators_[0]# Plot the decision tree
plt.figure(figsize=(20, 10))
plot_tree(tree_to_plot, feature_names=df.columns.tolist(), filled=True, rounded=True, fontsize=10)
plt.title("Decision Tree from Random Forest")
plt.show()
相关文章:
机器学习之分类回归模型(决策数、随机森林)
回归分析 回归分析属于监督学习方法的一种,主要用于预测连续型目标变量,可以预测、计算趋势以及确定变量之间的关系等。 Regession Evaluation Metrics 以下是一些最流行的回归评估指标: 平均绝对误差(MAE):目标变量的预测值与实际值之间的平均绝对差…...

算法二刷day3
203.移除链表元素 class Solution { public:ListNode* removeElements(ListNode* head, int val) {ListNode *dummyHead new ListNode(0);dummyHead->next head;ListNode *cur dummyHead;while (cur->next ! nullptr) {if (cur->next->val val) {ListNode *tm…...
面具安装LSP模块时提示 Unzip error错误的解决办法
面具(Magisk Delta)安装LSP模块时提示 Unzip error错误的解决办法 如果前面的配置都正常的话,可能是LSP版本有问题重新去Github下载一个最新版的吧;我是这么解决的。 我安装1.91那个版本的LSP就是死活安装不上,下载了1.92的版本一次就…...

HarmonyOS 关系型数据 整体测试 进行 初始化 增删查改 操作
好啊 前面的文章 HarmonyOS 数据持久化 关系型数据库之 初始化操作 HarmonyOS 数据持久化 关系型数据库之 增删改逻辑编写 HarmonyOS 数据持久化 关系型数据库之 查询逻辑编写 我们分别编写了 初始化数据库表 增删查改操作 的逻辑代码 那么 下面我们就来整体操作一下 然后 这…...
软件杯 垃圾邮件(短信)分类算法实现 机器学习 深度学习
文章目录 0 前言2 垃圾短信/邮件 分类算法 原理2.1 常用的分类器 - 贝叶斯分类器 3 数据集介绍4 数据预处理5 特征提取6 训练分类器7 综合测试结果8 其他模型方法9 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 垃圾邮件(短信)分类算…...

cnpm install报错:报错Error: certificate has expired ,淘宝镜像证书过期了解决办法
方案1: 不校验证书 cnpm install --insecure; 方案2: 替换镜像源,比如换成华为的 cnpm confg set registry https://mirrors.huaweicloud.com/repository/npm/ 方案3: 使用http作为镜像源 cnpm confg set registry http://re…...
生成式 AI:使用 Pytorch 通过 GAN 生成合成数据
导 读 生成对抗网络(GAN)因其生成图像的能力而变得非常受欢迎,而语言模型(例如 ChatGPT)在各个领域的使用也越来越多。这些 GAN 模型可以说是人工智能/机器学习目前主流的原因; 因为它向每个人࿰…...
C#/WPF 清理任务栏托盘图标缓存
在我们开发Windows客户端程序时,往往会出现程序退出后,任务还保留之前程序的缓存图标。每打开关闭一次程序,图标会一直增加,导致托盘存放大量缓存图标。为了解决这个问题,我们可以通过下面的程序清理任务栏托盘图标缓存…...
java SSM科研管理系统myeclipse开发mysql数据库springMVC模式java编程计算机网页设计
一、源码特点 java SSM科研管理系统是一套完善的web设计系统(系统采用SSM框架进行设计开发,springspringMVCmybatis),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S…...
C# OpenCvSharp 图片批量改名
目录 效果 项目 代码 下载 C# OpenCvSharp 图片批量改名 效果 项目 代码 using NLog; using OpenCvSharp; using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Windows.Forms; namespace OpenCvSharp_Demo { publi…...
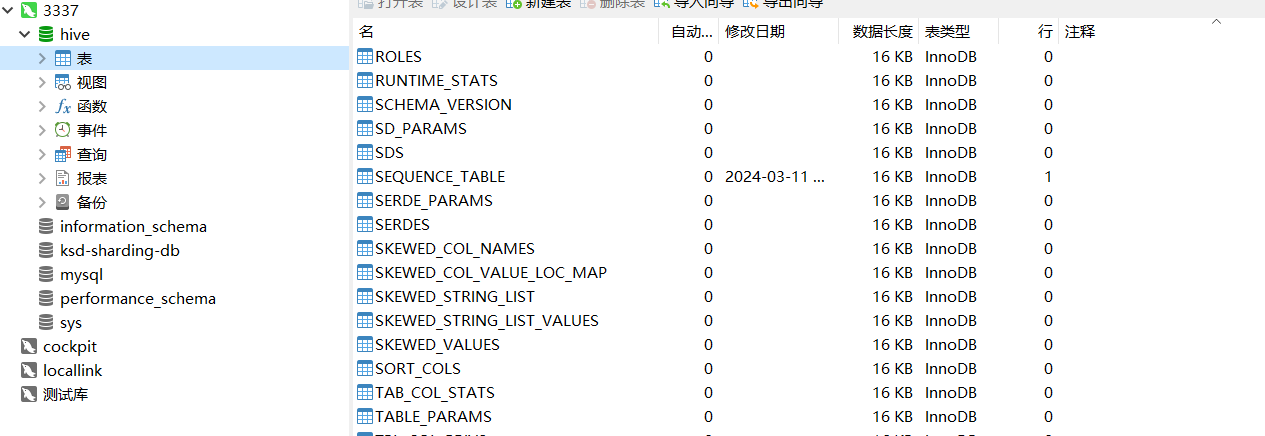
大数据开发-Hive介绍以及安装配置
文章目录 数据库和数据仓库的区别Hive安装配置Hive使用方式Hive日志配置 数据库和数据仓库的区别 数据库:传统的关系型数据库主要应用在基本的事务处理,比如交易,支持增删改查数据仓库:主要做一些复杂的分析操作,侧重…...
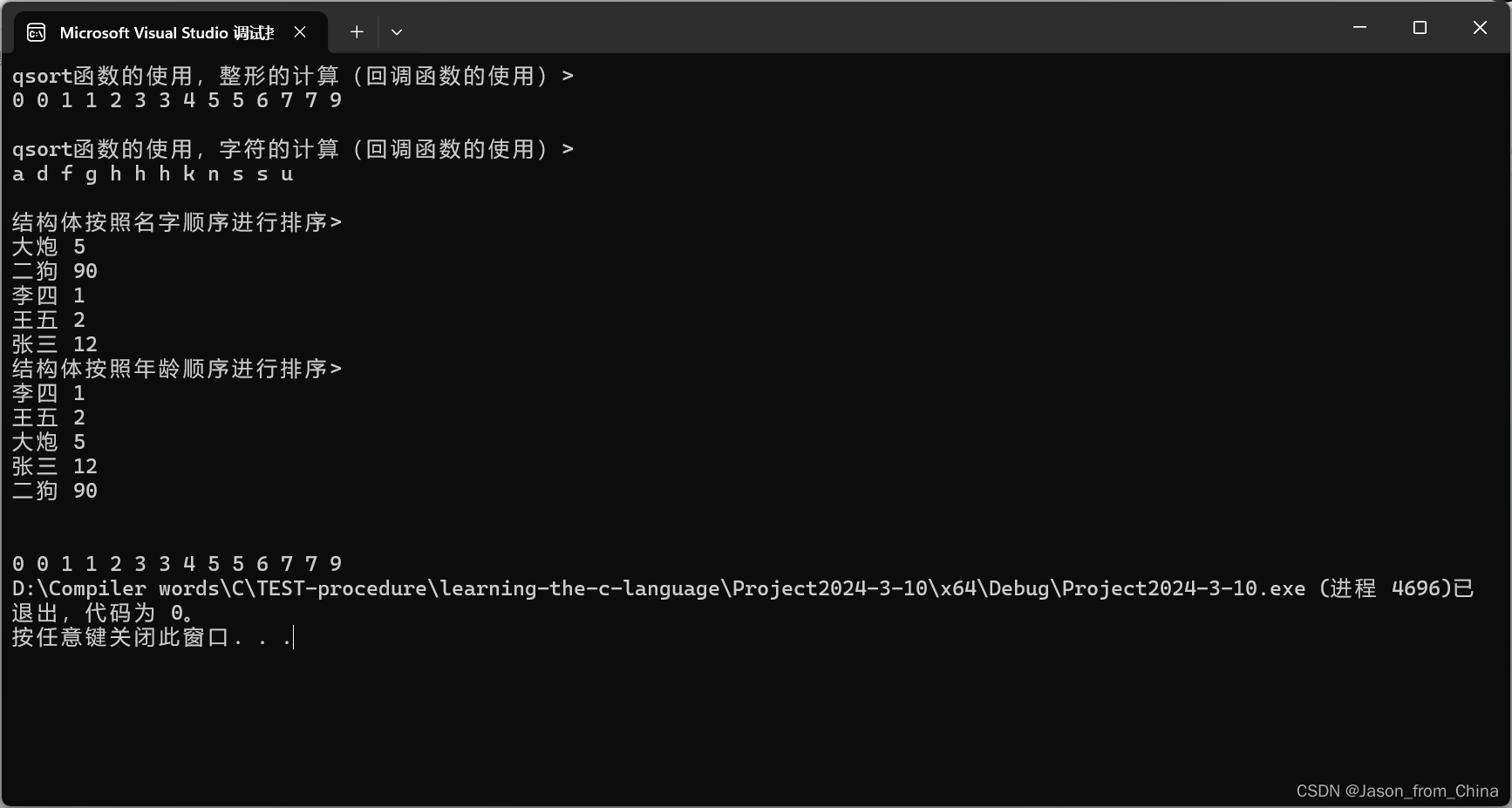
指针篇章-(4)+qsort函数的模拟
学习目录 ———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————…...

接口测试实战--使用docker方案去部署jenkins并搭建接口自动化项目
一、搭建环境 1.几个概念 CI:持续集成 CD:持续交付 DevOps(development and operations):是一个框架,是一种方法论,并不是一套工具,包括一系列基本原则和实践,核心价值在于更快速的交付和响应市场变化。 jenkins:一个开源框架,需要操作什么流程,就下载什么插件 2…...

Day 8.TCP包头和HTTP
TCP包头 1.序号:发送端发送数据包的编号 2.确认号:已经确认接收到的数据的编号(只有当ACK为1时、确认号才有用); TCP为什么安全可靠 1.在通信前建立三次握手 SYP SYPACK ACK 2.在通信过程中通过序列号和确认号和…...

【机器学习】支持向量机 | 支持向量机理论全梳理 对偶问题转换,核方法,软间隔与过拟合
支持向量机走的路和之前介绍的模型不同 之前介绍的模型更趋向于进行函数的拟合,而支持向量机属于直接分割得到我们最后要求的内容 1 支持向量机SVM基本原理 当我们要用一条线(或平面、超平面)将不同类别的点分开时,我们希望这条…...

【JS】APIs:事件流、事件委托、其他事件、页面尺寸、日期对象与节点操作
1 事件流 捕获阶段:从父到子 冒泡阶段:从子到父 1.1 事件捕获 <body> <div class"fa"><div class"son"></div> </div> <script>const fadocument.querySelector(.fa);const sondocument.qu…...

定制红酒:如何根据客户需求调整红酒口感与风格
在云仓酒庄洒派,云仓酒庄洒派深知不同消费者对于红酒的口感与风格有着不同的喜好和需求。因此,云仓酒庄洒派根据消费者的具体要求,灵活调整红酒的口感与风格,以满足他们的期望。 首先,云仓酒庄洒派会与消费者进行深入的…...

利用excel批量修改图片文件名
今天同事提出需求要实现利用excel批量修改某文件夹下的图片重命名,衡量到各种条件,最后还是选择了vbs来实现。代码如下 代码 创建Excel对象 Set objExcel CreateObject("Excel.Application") objExcel.Visible False 隐藏Excel窗口 打开Ex…...
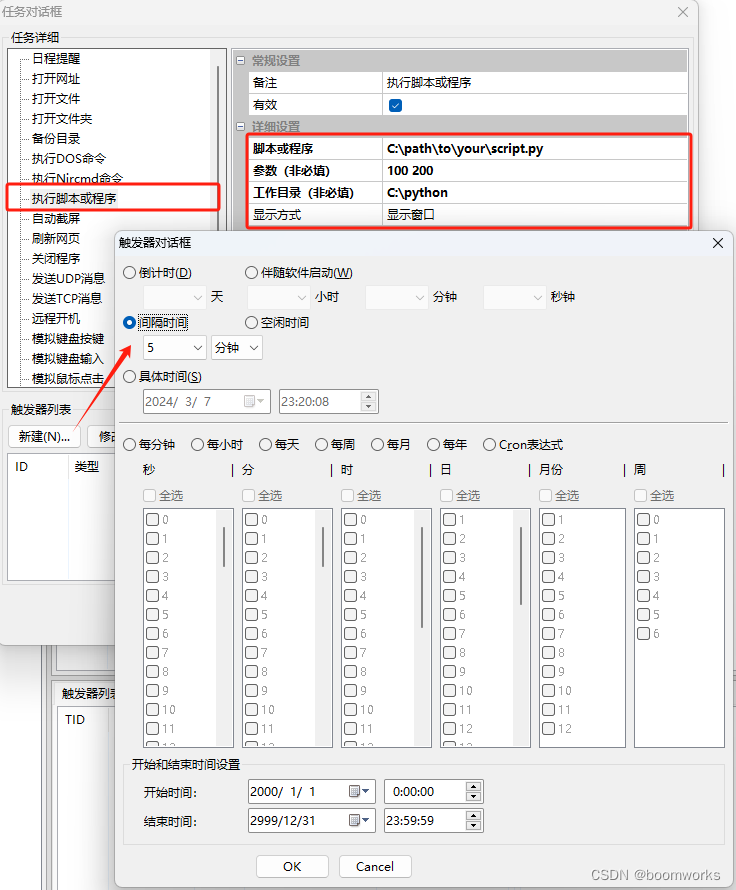
间隔5分钟执行1次Python脚本设置步骤 —— 定时执行专家
《定时执行专家》是一款制作精良、功能强大、毫秒精度、专业级的定时任务执行软件,用于在 Windows 系统上定时执行各种任务,包括执行脚本或程序。 下面是使用 "定时执行专家" 软件设置定时执行 Python 脚本的步骤: 步骤 1: 设置 P…...
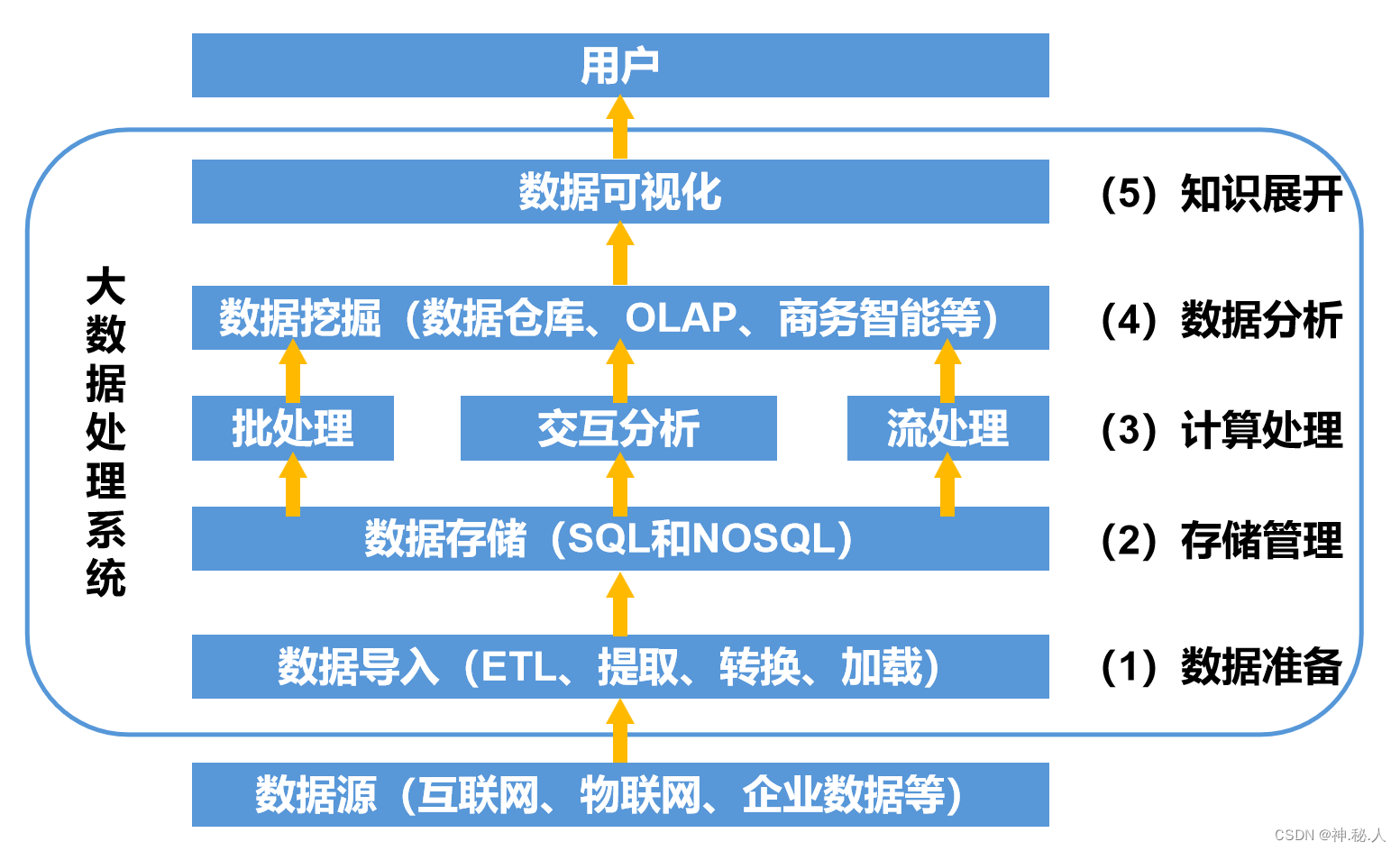
计算机网络基础【信息系统监理师】
计算机网络基础【信息系统监理师】 1、OSI七层参考模型2、TCP/IP协议3、网络拓扑结构分类4、网络传输介质分类5、网络交换技术6、网络存储技术7、网络规划技术8、综合布线系统8.1、综合布线工程内容8.1、隐蔽工程-金属线槽安装8.2、隐蔽工程-管道安装槽道与各种管线间的最小净距…...

雷达信号处理实战:当SDIF算法遇到脉冲丢失和TOA重叠时,我是如何调试和优化的?
雷达信号处理实战:SDIF算法在脉冲丢失与TOA重叠场景下的调试优化 1. 问题背景与挑战 在电子侦察和雷达对抗系统中,信号分选算法的可靠性直接决定了后续分析的准确性。SDIF(Sequential Difference Histogram)作为CDIF算法的改进版本…...

3个步骤解决老Mac无法升级新系统的困境:OpenCore Legacy Patcher完整指南
3个步骤解决老Mac无法升级新系统的困境:OpenCore Legacy Patcher完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想象一下,你…...
---命令解析和工具映射张)
【GUI-Agent】阶跃星辰 GUI-MCP 解读---()---命令解析和工具映射张
先回顾:三次握手(建立连接)核心流程(实际版) 为了让挥手流程衔接更顺畅,咱们先快速回顾三次握手的实际核心,避免上下文脱节: 第一步(客户端→服务器)…...

如何为EmulatorJS贡献代码:从问题报告到PR提交的完整流程
如何为EmulatorJS贡献代码:从问题报告到PR提交的完整流程 【免费下载链接】EmulatorJS A web-based frontend for RetroArch 项目地址: https://gitcode.com/GitHub_Trending/em/EmulatorJS EmulatorJS是一个基于Web的RetroArch前端项目,允许用户…...
Transformer+RoPE如何让GVHMR处理超长视频?深入解读Relative Transformer的设计与实现
TransformerRoPE如何让GVHMR处理超长视频?深入解读Relative Transformer的设计与实现 在计算机视觉领域,处理长序列视频数据一直是个棘手的问题。想象一下,当你需要分析一段长达数小时的监控视频或完整电影片段中的人体动作时,传统…...

LS-WVL系统安装全攻略:从修复模式到中文配置一步到位
LS-WVL系统安装全攻略:从修复模式到中文配置一步到位 当你第一次拿到LS-WVL这台NAS设备时,可能会被它略显复杂的安装流程难住。别担心,这篇指南将带你从零开始,一步步完成从系统安装到中文配置的全过程。不同于市面上那些泛泛而谈…...
和谷歌地图(lyrs=s/m)的URL参数到底怎么用?一篇讲清所有地图瓦片服务调用细节)
天地图(T=img_w/c)和谷歌地图(lyrs=s/m)的URL参数到底怎么用?一篇讲清所有地图瓦片服务调用细节
天地图与谷歌地图URL参数全解析:从瓦片调用到坐标系实战 当你需要在项目中集成地图服务时,是否曾被各种URL参数搞得一头雾水?Timg_w和Timg_c有什么区别?lyrss和lyrsm又代表什么?本文将彻底拆解两大主流地图服务的URL设…...

如何高效处理生命科学图像数据:Bio-Formats完全实战指南
如何高效处理生命科学图像数据:Bio-Formats完全实战指南 【免费下载链接】bioformats Bio-Formats is a Java library for reading and writing data in life sciences image file formats. It is developed by the Open Microscopy Environment. Bio-Formats is re…...
)
单片机开发者必看:从蓝桥杯真题学电源电路设计(BUCK电路详解版)
单片机开发者必看:从蓝桥杯真题学电源电路设计(BUCK电路详解版) 在电子设计竞赛和实际项目开发中,电源电路的设计往往是决定系统稳定性的关键因素。作为一名长期参与蓝桥杯赛事指导的工程师,我发现许多参赛者在BUCK电路…...
的架构设计与实战解析)
点云自监督学习新范式:掩码自编码器(MAE)的架构设计与实战解析
1. 点云自监督学习为何需要MAE? 点云数据在自动驾驶、机器人导航、工业检测等领域越来越重要,但标注成本高得吓人。我去年参与过一个室内场景重建项目,光是标注1000帧点云就花了团队两周时间。这时候自监督学习就成了救命稻草——它能让模型从…...