TEASEL: A transformer-based speech-prefixed language model
文章目录
- TEASEL:一种基于Transformer的语音前缀语言模型
- 文章信息
- 研究目的
- 研究内容
- 研究方法
- 1.总体框图
- 2.BERT-style Language Models(基准模型)
- 3.Speech Module
- 3.1Speech Temporal Encoder
- 3.2Lightweight Attentive Aggregation (LAA)
- 4.训练过程
- 4.1预训练阶段
- 4.2微调阶段
- 4.3TEASEL模型训练的算法伪代码
- 结果与讨论
- 代码和数据集
- 附录
TEASEL:一种基于Transformer的语音前缀语言模型
总结:论文提出了一种基于 Transformer 的语音前缀语言模型 TEASEL,实际本质是用了一个 RoBERTa 模型作为框架,然后加入了一个 LAA 模块(LAA模块就是将音频特征编码为 RoBERTa 编码器的前缀 token)。在训练的时候主要是训练 LAA 模块的参数,当 LAA 模块的参数收敛后,在CMU-MOSI数据集上面微调整个模型。
该论文在2021年就挂在arXiv上面了,但是一直没有发表,看了这篇论文之后,终于知道为什么没有发表了,论文里面有一些错误的地方,而且对自己方法的介绍稀里糊涂的,一些词用的很偏僻,很难以理解。但是最奇怪的是,作者没有提供代码,GitHub上面有人根据算法的思想实现了这个模型,并且在 MSA 任务上的一些指标竟然是 SOTA 的结果。所以本人参考代码,以及论文的思想,终于把这篇论文挖掘出来了。如果大家有不同的看法,欢迎留言 😃
文章信息
作者:Mehdi Arjmand,Mohammad Javad Dousti
单位:University of Tehran(德黑兰大学-伊朗)
会议/期刊:arXiv
题目:TEASEL: A transformer-based speech-prefixed language model
年份:2021
研究目的
解决在多模态语言学习(包括多模态情感分析与多模态情感识别)中,由于数据不足,难以训练一个关于多模态语言学习的自监督Transformer模型的问题。(换句话说,作者想要在不训练完整的Transformer模型的情况下,训练一个关于多模态语言学习的自监督 Transformer模型。)
研究内容
提出了一种基于Transformer的语音前缀语言模型TEASEL。与传统的语言模型相比,增加了语音模态作为动态前缀。该模型可以达到与花费较长时间重新训练Transformer相同的性能水平,而无需训练完整的Transformer模型。
研究方法
1.总体框图
该模型利用传统的预训练语言模型(指的就是RoBERTa)作为跨模态注意力模块。从根本上来说,TEASEL 模型专注于将语音特征表示为RoBERTa的前缀(参考图中的 C A C_A CA)。

训练包含两个阶段:预训练和微调。
- 在预训练阶段,使用 LAA 模块学习语音模态的表征,以便在 RoBERTa 中插入语音模态,训练步骤相对较少(总共 8000 步)。(预训练阶段做的事情,就是对 LAA 模块进行训练)
- 在微调阶段,固定了 LAA 模块的大部分内容,并在 CMU-MOSI 数据集上微调了 RoBERTa 模型,将其作为多模态情感分析下游任务的跨模态 Transformer。(微调阶段做的事情,就是对 RoBERTa 模型进行了调参)
2.BERT-style Language Models(基准模型)
将 RoBERTa 模型作为 BERT-style Language Models(选择RoBERTa作为基准模型是因为RoBERTa是专门针对 MaskedLM 任务训练的)。
RoBERTa tokenizer标记器将句子 L 分解为:
{ [ C L S ] , l 1 , l 2 , … , l T L , [ S E P ] } = t o k e n i z e r ( L ) \{[CLS],l_{1},l_{2},\ldots,l_{T_{\mathbf{L}}},[SEP]\}=tokenizer(L) {[CLS],l1,l2,…,lTL,[SEP]}=tokenizer(L)
| 符号 | 含义 |
|---|---|
| l i ∈ R d l_i \in R_d li∈Rd | 每个token |
| T L T_L TL | 文本模态的时间步数(序列的长度) |
| [CLS] | 代表序列的开始,只关注[CLS]对应的输出 |
| [SEP] | 代表分割 |
| [MASK] | 代表屏蔽的token |
3.Speech Module
3.1Speech Temporal Encoder
选择 wav2vec 预先训练好的固定参数的 CNN 作为音频特征编码器,来提取音频特征。
{ z 1 , z 2 , … , z T A ; z i ∈ R d A } = C N N θ w ( ψ ) \{z_1,z_2,\ldots,z_{T_{\mathbf{A}}};z_i\in\mathbb{R}^{d_A}\}=\mathrm{CNN}_{\theta_{\mathbf{w}}}(\psi) {z1,z2,…,zTA;zi∈RdA}=CNNθw(ψ)
| 符号 | 含义 |
|---|---|
| ψ \psi ψ | 原始的语音数据 |
| z i z_i zi | 第i个时间步对应的特征 |
3.2Lightweight Attentive Aggregation (LAA)
轻量级注意力聚合模块 LAA 的目的是将 Z(Z就是经过CNN提取的音频特征) 编码为 RoBERTa 编码器的前缀 token。

LLA 在提取的语音特征的顶部执行双向门控循环单元(BiGRU),以双向行为捕捉信息。然后利用聚合模块(Aggregation Module)将 BiGRU 的输出进行动态加权求和。
整体过程如下所示:(公式在原论文的基础上进行了修改,个人认为作者的公式在动态加权求和的时候有问题)
Z ^ = L a y e r N o r m ( Z ) ( 1 ) Φ = B i G R U ( W 1 ⊺ Z ^ + b 1 ) , ( 2 ) Φ = { { ϕ 1 , 1 , … , ϕ 1 , T A } , { ϕ 2 , 1 , … , ϕ 2 , T A } } , ( 3 ) u k , i = σ ( W A g g 1 T ϕ k , i + b A g g 1 ) , k ∈ { 1 , 2 } , i ∈ { 1 , T } ( 4 ) α k , i = S o f t m a x ( W A g g 2 I u k , i + b A g g 2 ) , α k , i ∈ [ 0 , 1 ] ( 5 ) C A = ∑ i = 1 T α k , i ϕ k , i ( 6 ) \begin{gathered} \hat{Z}=LayerNorm(Z)\quad(1)\\ \\ \Phi=BiGRU(W_{1}^{\intercal}\hat{Z}+b_{1}), \quad(2)\\ \\ \Phi=\{\{\phi_{\mathbf{1},1},\ldots,\phi_{\mathbf{1},T_{\mathbf{A}}}\},\{\phi_{\mathbf{2},1},\ldots,\phi_{\mathbf{2},T_{\mathbf{A}}}\}\}, \quad(3)\\ \\ u_{k,i}=\sigma(W_{Agg_1}^\mathsf{T}\phi_{k,i}+b_{Agg_1}),k\in\{1,2\},i \in {\{1,T\}}\quad(4)\\ \\ \alpha_{k,i}=Softmax(W_{Agg_2}^{\mathsf{I}}u_{k,i}+b_{Agg_2}),\alpha_{k,i}\in[0,1]\quad(5)\\ \\ \mathcal{C}_\mathbf{A}=\sum_{i=1}^T\alpha_{k,i}\phi_{k,i} \quad(6) \end{gathered} Z^=LayerNorm(Z)(1)Φ=BiGRU(W1⊺Z^+b1),(2)Φ={{ϕ1,1,…,ϕ1,TA},{ϕ2,1,…,ϕ2,TA}},(3)uk,i=σ(WAgg1Tϕk,i+bAgg1),k∈{1,2},i∈{1,T}(4)αk,i=Softmax(WAgg2Iuk,i+bAgg2),αk,i∈[0,1](5)CA=i=1∑Tαk,iϕk,i(6)
| 符号 | 含义 |
|---|---|
| Φ ∈ A 2 × T A × d A \Phi\in\mathbf{A}^{2\times T_{A}\times d_{A}} Φ∈A2×TA×dA | Bi-GRU的输出序列 |
| σ \sigma σ | 激活函数 |
| C A ∈ R 2 × d a \mathcal{C}_\mathbf{A}\in\mathbb{R}^{2\times d_a} CA∈R2×da | 两个可用于 RoBERTa 的语音前缀token |
4.训练过程
4.1预训练阶段
输入序列 { [ C L S ] , l 1 , l 2 , … , l T L , [ S E P ] } \{[CLS],l_{1},l_{2},\ldots,l_{T_{\mathbf{L}}},[SEP]\} {[CLS],l1,l2,…,lTL,[SEP]}给预先训练好的 RoBERTa 模型,然后只计算语音输出token(也就是 C A C_A CA)的损失函数,梯度只影响 LAA 模块。
使用 LIBRISPEECH 数据集对 LAA 模块进行了 8000 步训练(通过实验观察,进行8000步,模型收敛,F1分数趋于稳定,故训练8000步)。每 2,000 步保存一次模型,并对保存的参数进行微调,以便在 CMU-MOSI 数据集上进行高效的多模态情感分析。

4.2微调阶段
将语音前缀和文本token输入到 RoBERTa 模型,根据[CLS]对应的输出,对 RoBERTa 模型进行微调。

4.3TEASEL模型训练的算法伪代码

结果与讨论
⚠ 斜体是消融实验
- 通过与一些仅限于文本的流行Transformer方法、基于Transformer的冻结特征方法、为下游任务微调Transformer的方法进行对比,TEASEL在Corr、ACC-2与F1分数上的表现是最佳的。
- 在相同的条件下,对预训练TEASEL的不同步数下的参数进行微调,表明了预训练 LAA 模块是有效的,也证明了训练8000步是刚刚好的。
- 通过对微调部分应该固定 LAA 模块的哪些部分进行了详尽的实验,证明了不需要对整个 LAA 模块进行微调。
- 对测试集中的某个随机数据的注意力激活层进行可视化,证明了语音前缀的有效性。
代码和数据集
此代码是别人复现的,论文作者并没有提供。
代码:https://github.com/tjdevWorks/TEASEL
数据集:CMU-MOSI
实验环境:GitHub上面,有人复现这个代码,使用Tesla V100都显示CUDA内存不足。
附录
MaskedLM 任务:旨在使用句子中未屏蔽的全部词语来预测随机屏蔽的标记。标准的 MaskedLM 80% 的时间使用 [MASK] token,10% 的时间使用random token,10% 的时间使用unchanged token,迫使语言模型顺利地预测输出标记。
wav2vec模型:wav2vec模型利用五层卷积神经网络(CNN)作为时间特征编码器,并利用BERT-style Transformer作为上下文编码器。
BiGRU单元:BiGRU单元指的是双向门控循环单元(Bidirectional Gated Recurrent Unit)。它是一种特殊的循环神经网络(RNN)结构,用于处理序列数据。BiGRU通过结合两个GRU层来工作,一个处理正向时间序列(从开始到结束),另一个处理反向时间序列(从结束到开始)。这种结构允许网络同时学习过去和未来的上下文信息,提高了对序列数据的理解能力。GRU单元结构:

😃😃😃
相关文章:
TEASEL: A transformer-based speech-prefixed language model
文章目录 TEASEL:一种基于Transformer的语音前缀语言模型文章信息研究目的研究内容研究方法1.总体框图2.BERT-style Language Models(基准模型)3.Speech Module3.1Speech Temporal Encoder3.2Lightweight Attentive Aggregation (LAA) 4.训练…...
机器学习之分类回归模型(决策数、随机森林)
回归分析 回归分析属于监督学习方法的一种,主要用于预测连续型目标变量,可以预测、计算趋势以及确定变量之间的关系等。 Regession Evaluation Metrics 以下是一些最流行的回归评估指标: 平均绝对误差(MAE):目标变量的预测值与实际值之间的平均绝对差…...

算法二刷day3
203.移除链表元素 class Solution { public:ListNode* removeElements(ListNode* head, int val) {ListNode *dummyHead new ListNode(0);dummyHead->next head;ListNode *cur dummyHead;while (cur->next ! nullptr) {if (cur->next->val val) {ListNode *tm…...
面具安装LSP模块时提示 Unzip error错误的解决办法
面具(Magisk Delta)安装LSP模块时提示 Unzip error错误的解决办法 如果前面的配置都正常的话,可能是LSP版本有问题重新去Github下载一个最新版的吧;我是这么解决的。 我安装1.91那个版本的LSP就是死活安装不上,下载了1.92的版本一次就…...

HarmonyOS 关系型数据 整体测试 进行 初始化 增删查改 操作
好啊 前面的文章 HarmonyOS 数据持久化 关系型数据库之 初始化操作 HarmonyOS 数据持久化 关系型数据库之 增删改逻辑编写 HarmonyOS 数据持久化 关系型数据库之 查询逻辑编写 我们分别编写了 初始化数据库表 增删查改操作 的逻辑代码 那么 下面我们就来整体操作一下 然后 这…...
软件杯 垃圾邮件(短信)分类算法实现 机器学习 深度学习
文章目录 0 前言2 垃圾短信/邮件 分类算法 原理2.1 常用的分类器 - 贝叶斯分类器 3 数据集介绍4 数据预处理5 特征提取6 训练分类器7 综合测试结果8 其他模型方法9 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 垃圾邮件(短信)分类算…...

cnpm install报错:报错Error: certificate has expired ,淘宝镜像证书过期了解决办法
方案1: 不校验证书 cnpm install --insecure; 方案2: 替换镜像源,比如换成华为的 cnpm confg set registry https://mirrors.huaweicloud.com/repository/npm/ 方案3: 使用http作为镜像源 cnpm confg set registry http://re…...
生成式 AI:使用 Pytorch 通过 GAN 生成合成数据
导 读 生成对抗网络(GAN)因其生成图像的能力而变得非常受欢迎,而语言模型(例如 ChatGPT)在各个领域的使用也越来越多。这些 GAN 模型可以说是人工智能/机器学习目前主流的原因; 因为它向每个人࿰…...
C#/WPF 清理任务栏托盘图标缓存
在我们开发Windows客户端程序时,往往会出现程序退出后,任务还保留之前程序的缓存图标。每打开关闭一次程序,图标会一直增加,导致托盘存放大量缓存图标。为了解决这个问题,我们可以通过下面的程序清理任务栏托盘图标缓存…...
java SSM科研管理系统myeclipse开发mysql数据库springMVC模式java编程计算机网页设计
一、源码特点 java SSM科研管理系统是一套完善的web设计系统(系统采用SSM框架进行设计开发,springspringMVCmybatis),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S…...
C# OpenCvSharp 图片批量改名
目录 效果 项目 代码 下载 C# OpenCvSharp 图片批量改名 效果 项目 代码 using NLog; using OpenCvSharp; using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Windows.Forms; namespace OpenCvSharp_Demo { publi…...
大数据开发-Hive介绍以及安装配置
文章目录 数据库和数据仓库的区别Hive安装配置Hive使用方式Hive日志配置 数据库和数据仓库的区别 数据库:传统的关系型数据库主要应用在基本的事务处理,比如交易,支持增删改查数据仓库:主要做一些复杂的分析操作,侧重…...
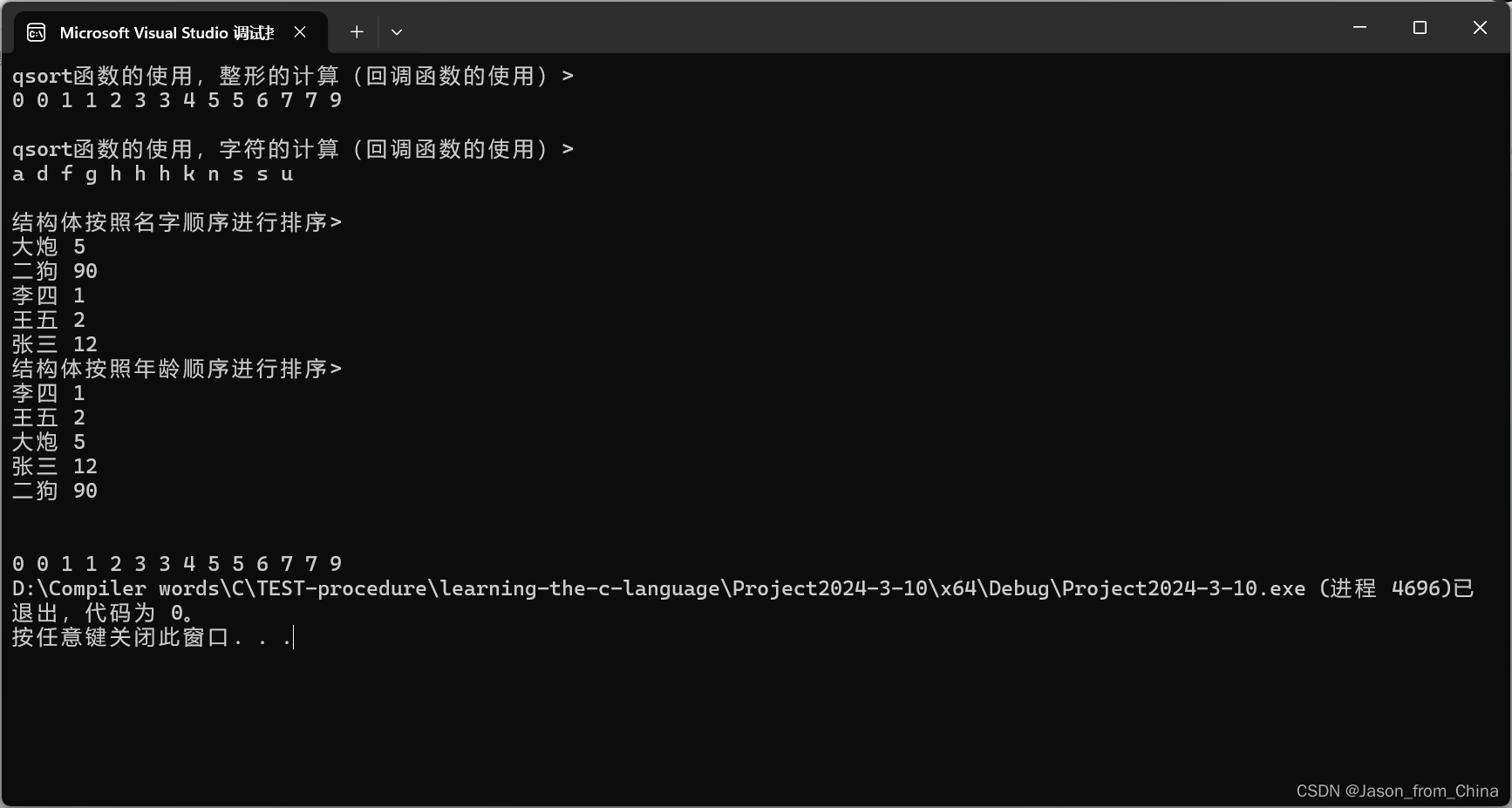
指针篇章-(4)+qsort函数的模拟
学习目录 ———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————…...

接口测试实战--使用docker方案去部署jenkins并搭建接口自动化项目
一、搭建环境 1.几个概念 CI:持续集成 CD:持续交付 DevOps(development and operations):是一个框架,是一种方法论,并不是一套工具,包括一系列基本原则和实践,核心价值在于更快速的交付和响应市场变化。 jenkins:一个开源框架,需要操作什么流程,就下载什么插件 2…...

Day 8.TCP包头和HTTP
TCP包头 1.序号:发送端发送数据包的编号 2.确认号:已经确认接收到的数据的编号(只有当ACK为1时、确认号才有用); TCP为什么安全可靠 1.在通信前建立三次握手 SYP SYPACK ACK 2.在通信过程中通过序列号和确认号和…...

【机器学习】支持向量机 | 支持向量机理论全梳理 对偶问题转换,核方法,软间隔与过拟合
支持向量机走的路和之前介绍的模型不同 之前介绍的模型更趋向于进行函数的拟合,而支持向量机属于直接分割得到我们最后要求的内容 1 支持向量机SVM基本原理 当我们要用一条线(或平面、超平面)将不同类别的点分开时,我们希望这条…...

【JS】APIs:事件流、事件委托、其他事件、页面尺寸、日期对象与节点操作
1 事件流 捕获阶段:从父到子 冒泡阶段:从子到父 1.1 事件捕获 <body> <div class"fa"><div class"son"></div> </div> <script>const fadocument.querySelector(.fa);const sondocument.qu…...

定制红酒:如何根据客户需求调整红酒口感与风格
在云仓酒庄洒派,云仓酒庄洒派深知不同消费者对于红酒的口感与风格有着不同的喜好和需求。因此,云仓酒庄洒派根据消费者的具体要求,灵活调整红酒的口感与风格,以满足他们的期望。 首先,云仓酒庄洒派会与消费者进行深入的…...

利用excel批量修改图片文件名
今天同事提出需求要实现利用excel批量修改某文件夹下的图片重命名,衡量到各种条件,最后还是选择了vbs来实现。代码如下 代码 创建Excel对象 Set objExcel CreateObject("Excel.Application") objExcel.Visible False 隐藏Excel窗口 打开Ex…...
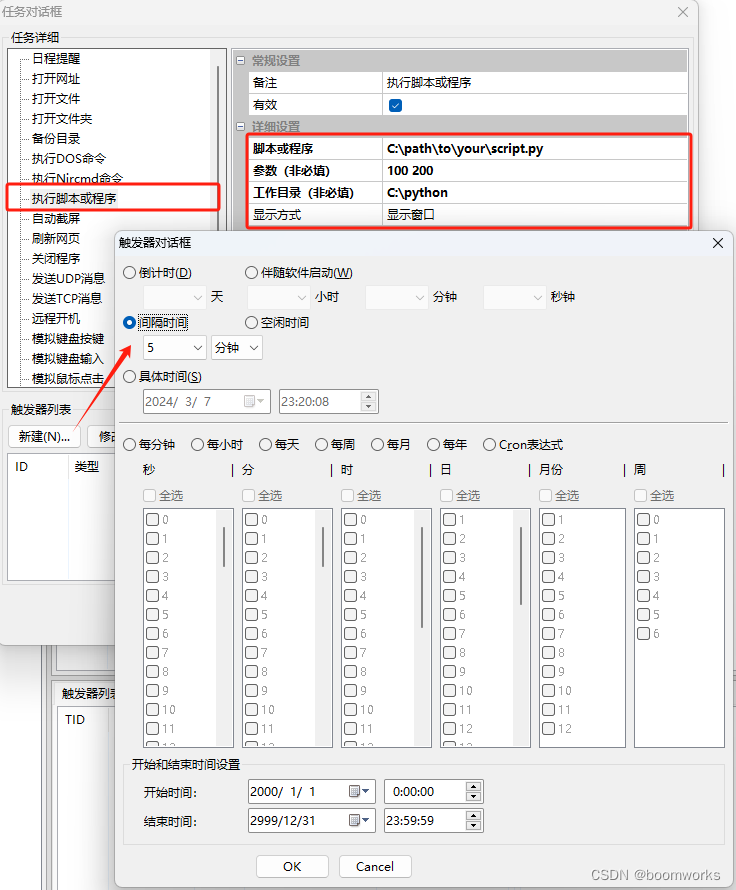
间隔5分钟执行1次Python脚本设置步骤 —— 定时执行专家
《定时执行专家》是一款制作精良、功能强大、毫秒精度、专业级的定时任务执行软件,用于在 Windows 系统上定时执行各种任务,包括执行脚本或程序。 下面是使用 "定时执行专家" 软件设置定时执行 Python 脚本的步骤: 步骤 1: 设置 P…...

Qwen3-ASR-1.7B效果实测:1.7B参数量带来的上下文联想能力提升验证
Qwen3-ASR-1.7B效果实测:1.7B参数量带来的上下文联想能力提升验证 1. 语音识别新标杆:Qwen3-ASR-1.7B深度解析 语音识别技术正在经历一场静默的革命。当我们还在为0.6B参数模型的准确率感到惊喜时,Qwen3-ASR-1.7B已经以近乎三倍的参数量重新…...

本体论与知识图谱,从 1 亿条杂乱数据到 3400 万高质量节点:这篇论文重新定义知识图谱构建
介绍一篇关于知识图谱和本体论的工作。 作者关注的问题很明确:当人们把一个超大规模、开放编辑的知识库(例如 Wikidata)变成一个“可用的属性图(typed property graph)”时,真正困难的不是把数据导出来&am…...

如何快速获取百度网盘提取码:开源工具的终极实战指南
如何快速获取百度网盘提取码:开源工具的终极实战指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘分享链接的提取码而烦恼吗?每次遇到需要密码的资源,你都要在多个网页间来…...

现代AI系统架构全景解析
人工智能系统已从单一算法演进为复杂的多组件协作架构。本文将深入解析现代AI系统的核心构成要素——从大型语言模型(LLM)到智能体(Agent),从检索增强生成(RAG)到模型上下文协议(MCP…...
大型空间设计电解式除湿器模块,专为电气柜与大型展柜微环境 恒温恒湿方案)
M-7J1R(ROSAHL)大型空间设计电解式除湿器模块,专为电气柜与大型展柜微环境 恒温恒湿方案
在工业电气柜、博物馆大型展柜和通信基站的庞大箱体中,由湿气引发的设备故障或文物损坏,其代价往往是巨大的。像传统除湿的有半导体冷凝式和传统的压缩机式除湿方案,在噪音、振动、冷凝水维护等方面很难达到效果,而 RO SAHL 的 M-…...

手把手教学:基于Wan2.2-I2V-A14B镜像,快速搭建你的AI视频生成服务
手把手教学:基于Wan2.2-I2V-A14B镜像,快速搭建你的AI视频生成服务 1. 准备工作:了解你的AI视频生成利器 Wan2.2-I2V-A14B是一款强大的文生视频模型,能够将文字描述转化为高质量视频内容。相比从零开始搭建环境,使用预…...

零基础小白也能搞定!PyTorch 2.9-CUDA镜像保姆级入门教程
零基础小白也能搞定!PyTorch 2.9-CUDA镜像保姆级入门教程 你是不是也遇到过这样的情况:看到别人用PyTorch做AI项目很酷,自己也想试试,结果第一步就被“环境配置”给劝退了?CUDA版本、PyTorch版本、各种依赖包……光是…...

Genymotion模拟器安装与配置全攻略:从零开始搭建高效Android开发环境
1. 为什么选择Genymotion模拟器 如果你正在开发Android应用,肯定知道测试环节有多重要。官方模拟器虽然稳定,但那个启动速度和卡顿简直让人抓狂。我最早用Android Studio自带的模拟器,每次启动都要等上几分钟,调试时还经常卡死。后…...

如何快速恢复PL2303老芯片兼容性:Windows 10/11终极驱动解决方案
如何快速恢复PL2303老芯片兼容性:Windows 10/11终极驱动解决方案 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 还在为那些老式PL2303串口设备在Windows 1…...

告别if-else地狱!在Godot 4.4里用状态机重构你的2D角色控制器
告别if-else地狱!在Godot 4.4里用状态机重构你的2D角色控制器 当你的2D平台游戏角色开始拥有跑跳、攻击、滑铲等复杂动作时,脚本里层层嵌套的if-else判断会像野草般疯长。上周我接手一个项目,发现玩家控制器脚本竟有200多行条件判断——添加新…...