C++的一些基础语法

前言:
本篇将结束c++的一些基础的语法,方便在以后的博客中出现,后续的一些语法将在涉及到其它的内容需要用到的时候具体展开介绍;其次,我们需要知道c++是建立在c的基础上的,所以c的大部分语法都能用在c++上。
目录
1.域作用限定符
2.关键字namespace
3.流插入和流提取
4.缺省(默认)参数与缺省值
a.全缺省参数
b.半缺省参数
c.注意
5.函数重载
6.指针和引用
a.语法
b.应用
c.常引用
d.指针和引用的区别
7.内联函数inline
a.复习宏
b.使用
c.内联函数的性质
8.关键字auto
a.语法
b.缺点
c.特性
d.typedef的缺点(附加)
9.范围for(c++11)
10.关键字nullptr
总结:
只介绍了c++中一些常见的基础语法,精进需要结合后面的内容,毕竟只学习语法却不了解应用是学不好的,本文如有错误请指正并会及时回复。
1.域作用限定符
首先,认识一下域作用限定符:
#include <iostream>int main()
{
std::cout<<"hello world"<<std::endl;
return 0;}代码中域作用限定符就是::,当我们遇到在用一个项目组中使用了相同的命名的时候,除了改该怎么办?我们可以指定对应的域中去找相应的重复命名的内容,例如去某个结构体或者类中去找(类在后面会介绍);其次记住一点,如果域作用限定符的左侧为空,就是去全局里面去找。
2.关键字namespace
#include <iostream>
using namespace std;
int main()
{cout<<"hello world"<<endl;return 0;
}首先可以明显的看到,函数里面的内容少了点什么,这就是因为我们加上了一句using namespace std;,为什么呢?
这里就开始介绍初学c++为什么要这样写程序了,因为大部分人学会使用了c++却连开始为什么要这样写都说不上一二,就有些尴尬了,首先介绍开始的头文件: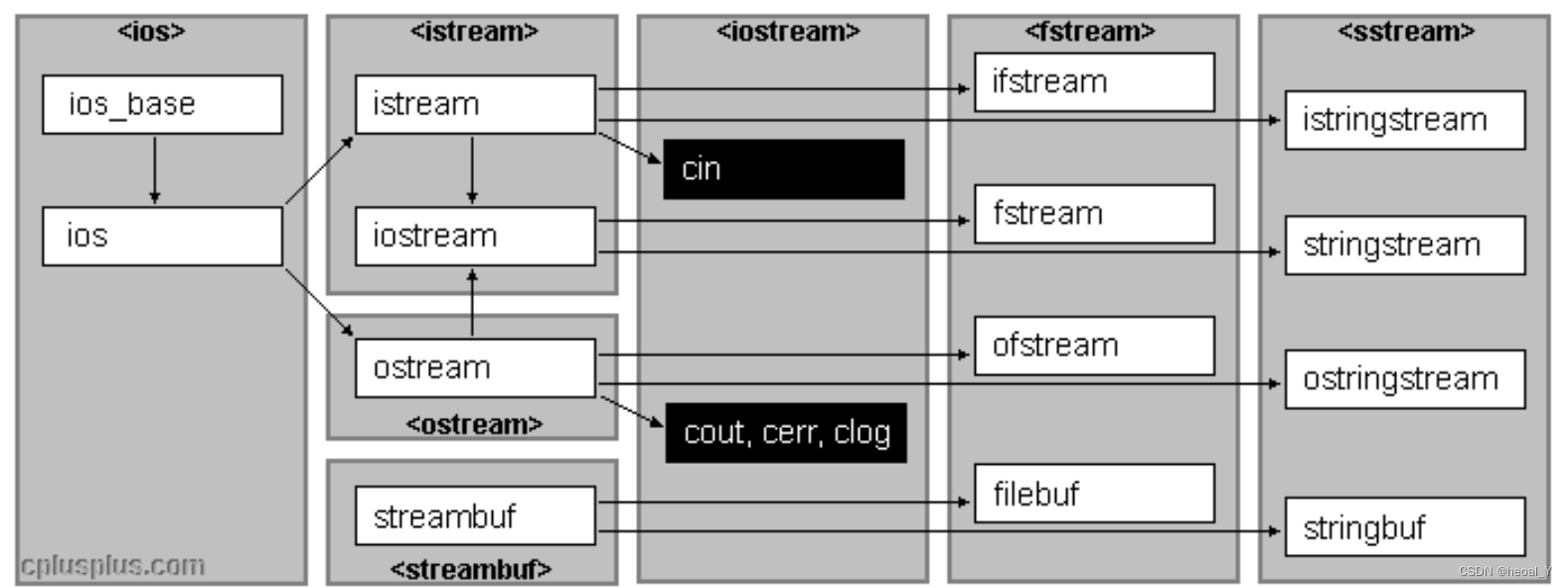
我们查阅文档可知(来源:https://legacy.cplusplus.com/reference/)iostream中包含了cin和cout等(其实它们都是iostream的对象),所以我们要想使用cout和cin等就要包含这个头文件。
那cout和cin等又是什么?我们目前记住它们是用来显示屏幕的信息和提取屏幕的信息的,分别需要搭配流插入<<和流提取>>,所以它们就都相当于c中的printf和scanf,但是不同的是它们不是库函数,而是某个类的对象,后面再提,以及与printf,scanf的区别也在后面再提。
然后endl只需要知道它是换行的意思即可。
然后就是我们的命名空间这一行,这一行是什么意思呢?首先我们需要知道
- 用法:namespace name
{}
- 命名空间---命名空间域,只影响使用,不影响生命周期,在多个文件使用相同的命名空间会被认为是同一个
然后我们需要知道std是c++标准库的名字,也就是说如果我们想用封装在c++标准库中的内容就需要展开这个命名空间,也就是展开标准库所在的域,这样才能使用库中的内容,如果不这样使用,cout等就会不被编译器所认识。
但是需要注意,你会在一些人的代码中发现是这样写的:
std::cout<<"hello world"<<std::endl为什么呢?首先我们知道了命名空间的存在其实就是为了封装起你写的内容,避免其他的重复命名出现导致出问题,而如果要让标准库中的域展开,那就破坏了这道防线,因为其实封装的目的就是防止你的命名与标准库中的冲突,再使用与标准库中同名的就不行了,所以就有了这样的写法(平时练习可以直接展开,但比较大的项目中不建议这样用)。
如果我们将上方的写法称为全部展开,那下面的写法就为部分展开:
using std::cout;
using std::endl;也就是让比较常用的展开,避免一个一个写。
3.流插入和流提取
刚刚我们已经提到了它们,例如cout<<endl就是让换行符流到控制台上,再看一个流提取的例子:
int n=0;
double* a=(double*)malloc(sizeof(double));
if(a==NULL)
{perror("malloc fail");exit(-1);
}
for(int i=0;i<n;++i)
{cin>>a[i];
}
for(int i=0;i<n;++i)
{cout<<a[i]<<endl;
}这是一个输入数组元素,然后打印出来的例子,从中我们可以看到cout和cin的用法,但是我们也可以发现我们在使用cout和cin的时候好像不用管a是一个double类型的数组唉?
这就是流的特性:
- 流会自动识别类型,不需要%d%f等输入输出
至于为什么,我们将在流的内容与运算符重载中在提。
4.缺省(默认)参数与缺省值
我们知道,在c语言中,函数的参数是不能赋值的,也就是说你传来的什么就是什么,而c++有创造了一个新的玩法:
void func(int a=0){cout<<a<<endl;}int main(){func(1);//传参就是打印传的值,也就是1func();//不传就是打印默认值0return 0;}
至于有什么用,我们在以后再说(减少重载函数的数量,简化函数的调用过程)。
a.全缺省参数
全缺省就是所以参数都缺省:
void Func(int a = 10, int b = 20, int c = 30)
{cout << "a=" << a << endl;cout << "a=" << b << endl;cout << "a=" << c << endl;cout << endl;
}int main()
{Func(1, 2, 3);return 0;
}需要注意的是,只能从右往左缺省,且要连续,为什么呢?
因为如果你要写成:
void Func(int a = 10, int b = 20, int c )
那你传两个参数的时候,c对应的位置必须要有一个传过来的参数(因为没缺省嘛),那第一个实参是对应的a还是b,不仅编译器会报错,意义也不明;参数从右往左缺省就不会出现这样的问题。
然后就是使用缺省值要从右往左(因为参数是从右往左缺省的)连续使用,像这样不连续的就不行:
Func(,1,2);b.半缺省参数
也就是参数可以不完全缺省,规则也和全缺省一样(从右往左连续缺省),不同的是不能不传参数,如果传一个参数就是对应最左边的参数
c.注意
- 不能在声明和定义中同时给缺省参数,要在声明中给(如果声明和定义的缺省值不同,编译器无法确定,放在声明中也减少了其他源文件重复定义;还有些人说是为了保护代码的安全,因为别人copy了源码却不知道缺省值)
- 缺省值必须是常量或者是全局变量,c语言不支持缺省参数
5.函数重载
在c中,我们知道使用函数名相同的函数是行不通的,所以本贾尼博士又发明了一个新的语法,允许函数名可以相同,但是参数的个数或者返回类型或者类型的顺序要不同的同名函数存在。
void Add(int a,int b);
void Add(int a,int b,int c);void Add(int a,int b);
void Add(double a,double b);void Add(int a,int b);
void Add(int b,int a);那具体是怎么实现相同的函数名能找到对应的函数呢?
c++对函数名进行了修饰(此为linux的修饰规则,不同平台的修饰规则不同),例如void Add(int a,int b),会修饰成_Z3Addii,void Add(double a,double b)会修饰成_Z3Adddd,其中_Z是固定的,3是函数名长度,再加上函数名,再加上形参的类型缩写,通过不同的函数名修饰加上编译时产生的地址,就能区别出调用哪个了(浮点数默认为double)
另外还需要注意:
- 返回值不同的,其他都相同,不构成重载,因为编译器识别不出来,不是因为修饰名没有返回值而识别不出,而是调用函数的时候没写返回值(call这个函数的地址的时候没有返回值),区分不出来
- 编译时就已经确定了调用那个函数 ,编译速度可能变慢,但是运行速度不会变慢
6.指针和引用
a.语法

可以看到k是i的引用,并且地址是一样的,所以我们又说k是i的别名。
同时我们还可以看到,直接赋值地址是不一样的,因为是又开辟了新的栈帧。
引用在后面的应用有很大的作用。
注意:
- 引用在定义时必须初始化
- 一个变量可以有多个引用
- 引用一旦引用一个实体,再不能引用其他实体
b.应用
- 应用1(输出型参数)---实参影响形参的情况,例如改变实参的值就要传实参的地址,从而形参要用指针
void Swap(int& x,int& y)//形参是实参的别名,地址一样,不用取地址{int tmp=x;x=y;y=tmp}
- 应用2(做返回值)
首先,先引入传值返回:

我们可以看到:
返回的n先存到(拷贝给)一个临时变量(可能是寄存器也可能是上一层栈帧),然后count栈帧销毁,这个临时变量再给给ret,如果n是个静态的变量放在静态区,也是先存到临时变量,也不会直接返回n,此为传值返回(用于变量出了作用域就不在的情况)
如果使用传引用返回:

返回n的别名,减少了拷贝,因为n已经是静态的了,但返回时还要拷贝到一个临时变量,返回n的别名就减少了拷贝(可以理解产生了一个临时变量,但这个临时变量是n的别名,也就是n,就减少了拷贝 ),只要出了count作用域这个变量还在,就可以用传引用返回
所以使用传引用返回,我们可以得到以下结论:
- 减少拷贝
- 调用者可以直接修改返回的对象
我们再来看一个错误的例子:
int& Add(int a,int b)
{int c=a+b;return c;
}int main()
{int ret=Add(1,2);//正确的int& ret=Add(1,2);//错误的
}返回c的别名,ret又是c这块空间的别名,但是c这块空间销毁了,访问ret也是找到销毁的空间,如果c的空间被覆盖就是随机值,没有就还是那块空间
总结:
如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用引用返回(性能上有一定的提升),如果已经还给系统了,则必须使用传值返回,以此理解全局变量二者都可以(因为全局变量也是存在静态区的,所以也是先拷贝给临时变量)。
c.常引用
const int c=2;const int& d=c;const int* p1=NULL;const int* p2=p1;const int m=1;int n=m;int count{int n=1;return n;}const int& ret=count();int i=0;const double& rd=i;从前两个例子我们可以知道d是c的别名,c是不可改的,那d也应该是不可改的;同理指针也是(*p不能修改,但是p可以修改,需要根据const的位置,在c专栏中有介绍到这一点),
赋值或初始化,权限可以缩小(只有别名是const修饰),但是不能放大。
而第三个例子就仅仅赋值,所以n的改变不会影响到m。
第四个例子是count的返回值是n先拷贝给临时变量,再给ret,返回的这个临时变量(在此过程中)也不可改变,它的别名也要用const修饰。
第五个例子是隐式类型转换,类型转换会产生临时变量,i先给给double类型的临时变量,临时变量再给给rd,所以rd是这个临时变量的别名,而这个临时变量(因为在这个过程里面这个临时变量肯定不变嘛)具有常性,所以要加const。
d.指针和引用的区别
首先我们需要知道:
- 从语法的角度,引用不开空间,指针需要开空间;而从底层的角度,从汇编来看二者过程一模一样,引用也是需要开空间的
其次不同点:

这里的安全是从引用没有空引用个定义必须初始化出发的,因为有时指针的一些错误不会直接报错。
7.内联函数inline
a.复习宏
c++推荐使用enum和const代替宏常量,inline代替宏函数。
我们来复习一下宏的优缺点:
优点:
- 类型可以不固定
- 不用建立栈帧
缺点:
不能调试
没有类型安全的检查
有些场景非常复杂(例如add宏函数)
#define ADD(x,y)((x)+(y))
1.为什么x+y要加括号,因为宏只是替换,例如ADD(1,2)*3;不加括号就达不到效果了
2.为什么里面的x和y分别要加括号?因为例如ADD(a|b,a&b);宏会替换成a|b+a&b,而加号
优先级更高,也达不到想要的效果
3.加分号也不行ADD(1,2)*3;宏会替换成((1)+(2));*3;会报错
b.使用
inline int Add(int x,int y){int z=x+y;return z;}
用汇编查看可知在调用内联函数时就展开了函数的逻辑,不用建立栈帧:
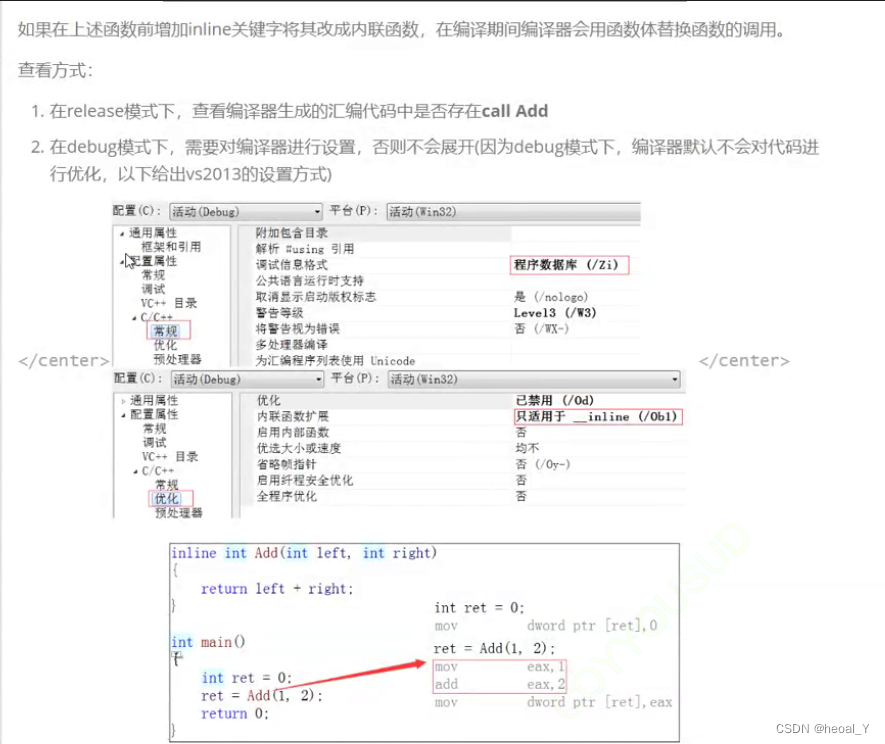 如果存在call Add就是没有展开函数,也就不是内联;红色箭头指向的就是没有call 这个函数的地址,直接展开函数体,使用了内联。
如果存在call Add就是没有展开函数,也就不是内联;红色箭头指向的就是没有call 这个函数的地址,直接展开函数体,使用了内联。
c.内联函数的性质

关于第三点:
假设在头文件中声明一个内联函数,再在函数实现文件中定义一个内联函数,此时在主函数中使用内联函数就会链接报错,因为虽然主函数引用了头文件,但是内联函数是直接展开的,没有地址,头文件只定义了内联函数,但找不到内联函数的地址(也就是出现在了声明中,但是展开时找不到函数体),所以建议定义和声明都在头文件里。
注意:
如果成员函数在类中定义,编译器可能会将它当做内联函数处理。
所以在stl源码里面有些短小的函数直接就放在类里面定义了,就是当做了内联函数
有些大一点的函数就类中声明,类外定义,源码就这样搞的,所以声明定义分离还是有一定的道理的。
8.关键字auto
a.语法
int a=0;
auto b=a;
auto c=&a;cout<<typeid(b).name<<endl;//int
cout<<typeid(c).name<<endl;//int*实际价值是为了简化类型很长的代码。
b.缺点
- 不能做形参
- 不能声明数组
- 定义变量必须初始化
c.特性
- auto后加*或者&就是限定类型为指针或者是引用
auto a=1,b=2; auto c=1,b=2.0;//报错同一行定义多个变量时,这些变量必须是相同的类型,否则编译器会报错,因为编译器是根据第一个类型进行推导,再用推导出来的类型定义其他的。
d.typedef的缺点(附加)
typedef char* pstring;
int main()
{const pstring p1;//报错,需要初始化const pstring* p2;//正确
}这里所说的缺点就是如果是const char* p1,就不会报错,因为const修饰的是p1指向的空间,可以不对p1赋初始值,但是使用typedef就不行了,这里会被误解为const char p1,const修饰的是p1,要对p1赋初始值。
9.范围for(c++11)
int array[]={0,1,2,3};for(auto e:array)//自动依次数组中的数据赋值给e对象,自动判断结束,所以e的改{cout<<e<<" "; //变不会改变数组的值,想改数组值用auto& e}cout<<endl;
c++11提供的语法糖,底层其实是迭代器,知道怎么使用就行(分号前是范围内用于迭代的变量,右边是被迭代的范围)

这里auto加上了引用是因为数据量大且涉及深拷贝(以后还会介绍)。
10.关键字nullptr
c++里NULL(NULL是一个宏)被定义为0,识别出来是int,实际c++不定义应该是((void*)0)

总结:
只介绍了c++中一些常见的基础语法,精进需要结合后面的内容,毕竟只学习语法却不了解应用是学不好的,本文如有错误请指正并会及时回复。
相关文章:
C++的一些基础语法
前言: 本篇将结束c的一些基础的语法,方便在以后的博客中出现,后续的一些语法将在涉及到其它的内容需要用到的时候具体展开介绍;其次,我们需要知道c是建立在c的基础上的,所以c的大部分语法都能用在c上。 目…...

mysql 技术100问?
什么是软件架构?它的定义和目的是什么?软件架构设计的基本原则是什么?请解释一下模块化架构和分层架构的区别。为什么重视可伸缩性在软件架构中的作用?请讨论一下微服务架构和单体应用架构的区别和优劣。如何选择适合项目的软件架…...

APK漏洞扫描工具
一、APKDeepLens是一个基于python的工具,旨在扫描Android应用程序,专门针对OWASP TOP 10移动漏洞。 工具:python3.8或者以上版本 安装 git clone https://github.com/d78ui98/APKDeepLens/tree/main cd /APKDeepLens python3 -m venv venv…...
ReactNative项目构建分析与思考之react-native-gradle-plugin
前一段时间由于业务需要,接触了下React Native相关的知识,以一个Android开发者的视角,对React Native 项目组织和构建流程有了一些粗浅的认识,同时也对RN混合开发项目如何搭建又了一点小小的思考。 RN环境搭建 RN文档提供了两种…...

LeetCode454 四数相加
给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 < i, j, k, l < n nums1[i] nums2[j] nums3[k] nums4[l] 0 示例 1: 输入:nums1 [1,2], nu…...
Kafka消费者重平衡
「(重平衡)Rebalance本质上是一种协议,规定了一个Consumer Group下的所有Consumer如何达成一致,来分配订阅Topic的每个分区」。 比如某个Group下有20个Consumer实例,它订阅了一个具有100个分区的Topic。 正常情况下&…...
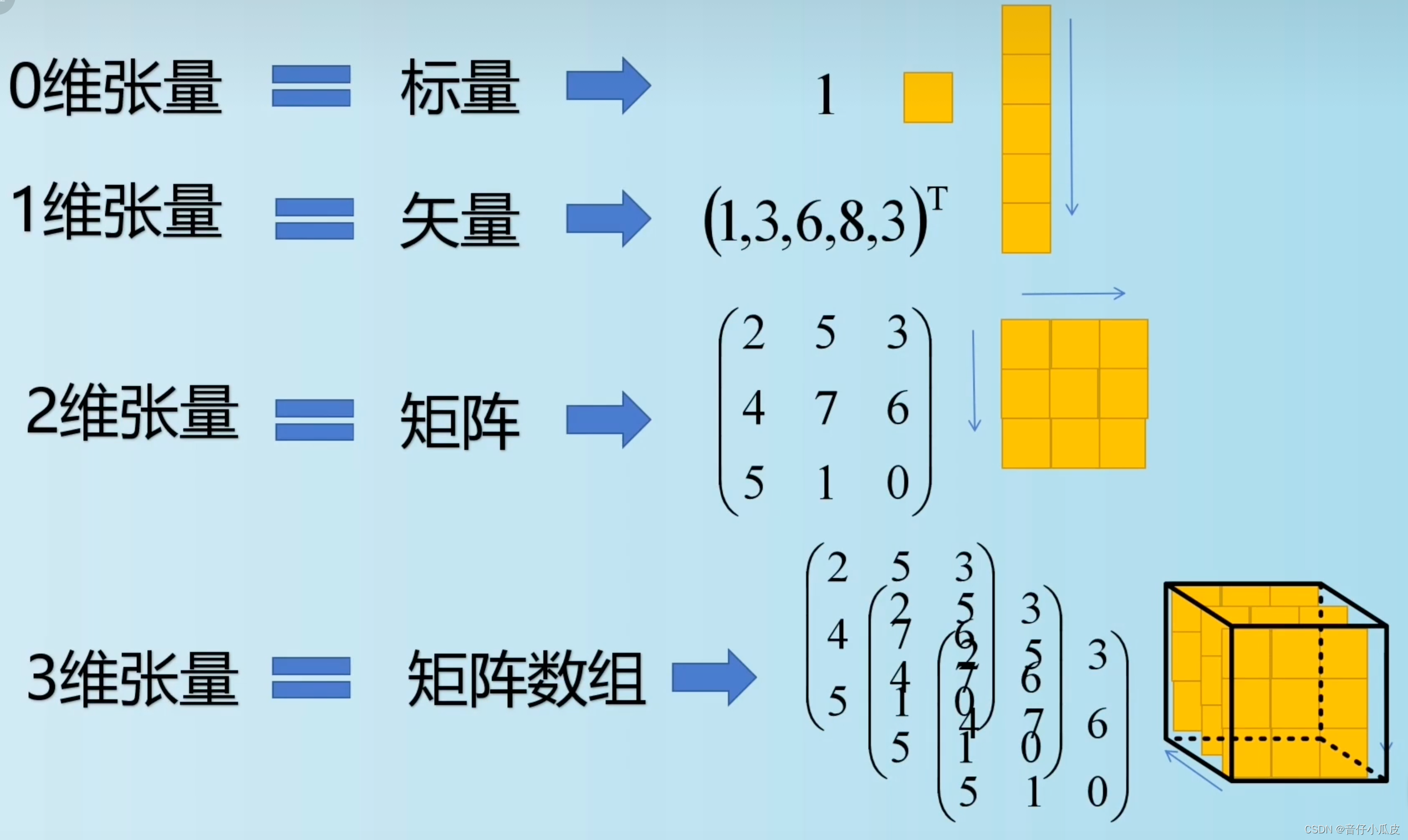
【线代基础】张量、向量、标量、矩阵的区别
1、标量(Scalar) 纯数字,无方向性、无维度概念。因此也叫 标量张量、零维张量、0D张量 例如,x18,x21.34 x1、x2即为标量 2、张量(tensor) 具有方向性,可以理解为一个多维数组&a…...

用chatgpt写论文重复率高吗?如何降低重复率?
ChatGPT写的论文重复率很低 ChatGPT写作是基于已有的语料库和文献进行训练的,因此在写作过程中会不可避免地引用或借鉴已有的研究成果和观点。同时,由于ChatGPT的表述方式和写作风格与人类存在一定的差异,也可能会导致论文与其他文章相似度高…...

字节跳动也启动春季校园招聘了(含二面算法原题)
字节跳动 - 春招启动 随着各个大厂陆续打响春招的响头炮,字节跳动也官宣了春季校园招聘的正式开始。 还是那句话:连互联网大厂启动校招计划尚且争先恐后,你还有什么理由不马上行动?! 先来扫一眼「春招流程」和「面向群…...
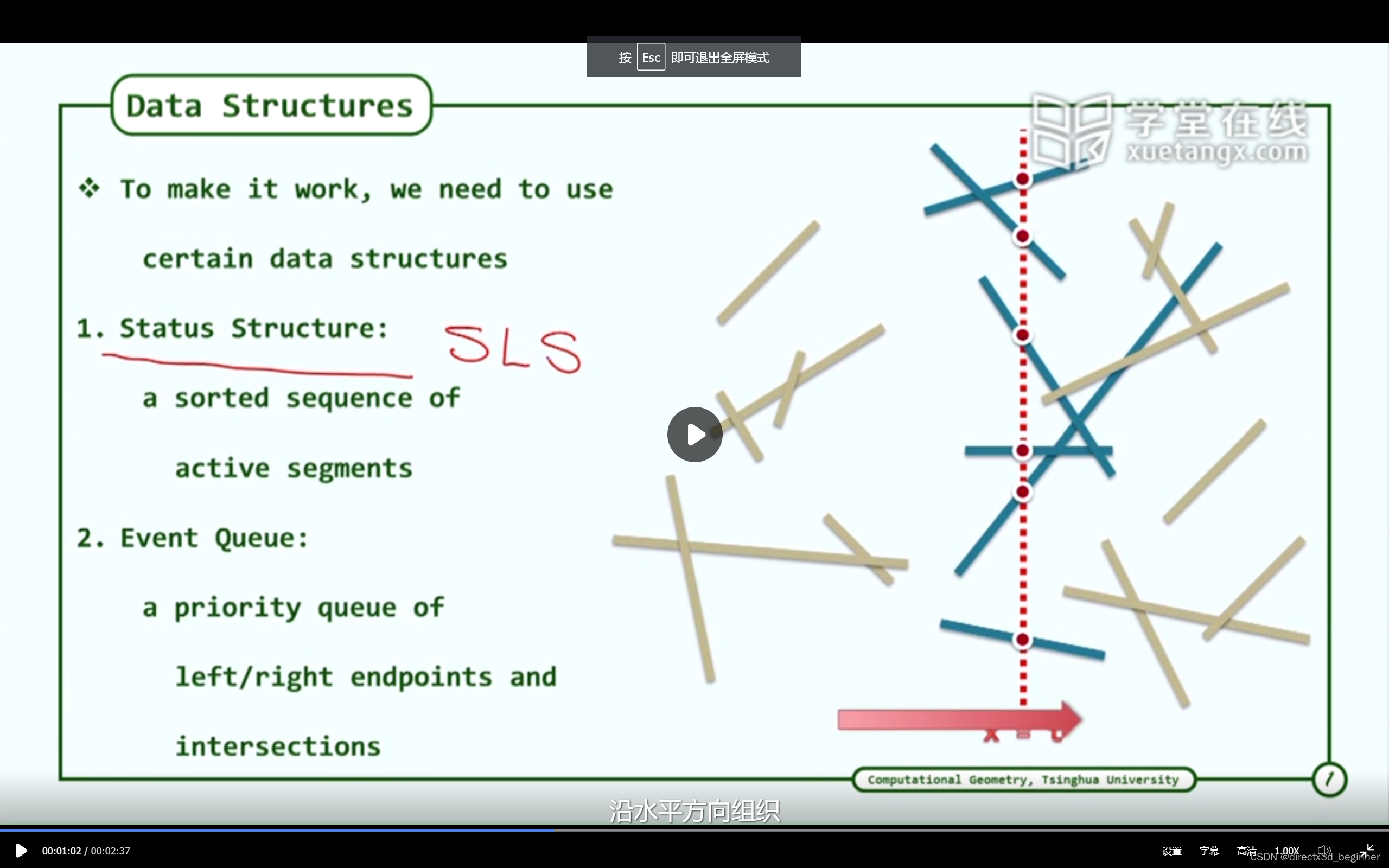
二,几何相交---4,BO算法---(3)数据结构
数据结构分两块,一个是某一时间状态的局部相交线段。一个是事件队列,是某一时刻局部相交线段的集合。...

中间件MQ面试题之Kafka
MQ相关面试题 Kafka面试题 (1)rockermq和kafka 的区别在哪里? 使用场景有什么不一样? 不同点: 数据可靠性 不同: RocketMQ:支持异步实时刷盘、同步刷盘、同步复制、异步复制;kafka:使用异步刷盘方式,异步复制/同步复制。性能对比:kafka单机写入TPS比较高单机支持…...

Prometheus 安装部署
文章目录 1.部署Prometheus1.1.修改配置文件1.2.配置告警规则1.3.运行Docker 2.部署Alertmanager2.1.修改配置文件2.2.Prometheus监控配置2.3.运行Docker 3.部署Grafana3.1.运行Docker3.2. 配置数据源3.3. 配置dashboard 开源中间件 # Prometheushttps://iothub.org.cn/docs/m…...

龙芯杯赛道-学习过程记录
Preface&免责声明: 由于参赛资料企业并未开源,所以我不能开放出有关参赛的资料 但是我会在这里记录参赛时看不懂的一系列知识补充 ------------------------------------------------------------------------------------------------------- TSEN…...
)
76. 最小覆盖子串-力扣hot100(C++)
76. 最小覆盖子串s 初始化和特判 //本题做题思想 //从头开始,首先找到一个包含所有字母的字串,将i移动到包含字串字母的位置,然后更新长度和字符串ans后, //i的位置加1,j的位置也加1,从新开始上面的流程&…...

vue的生命周期有那些
1.v-text 相当于js的innerText <div v-text"姓名:name"></div>const name ref(张三); //声明 2.v-html 相当于js的innerHTML <div v-html"html"></div>const html ref(<s>这是一段文字</s>) 3.v-bin…...

OpenStack安装步骤
一、准备OpenStack安装环境 1、创建实验用的虚拟机实例。 内存建议16GB(8GB也能运行)CPU(处理器)双核且支持虚拟化硬盘容量不低于200GB(!)网络用net桥接模式 运行虚拟机 2、禁用防火墙与SELin…...

如何借助CRM系统获得直观的业务洞察?CRM系统图表视图解析!
Zoho CRM管理系统在优化客户体验方面持续发力,新年新UI,一波新功能正在赶来的路上。今天要介绍的新UI功能在正式推出之前,已经通过早鸟申请的方式给部分国际版用户尝过鲜了。Zoho CRM即将推出图表视图,将原始数据转换为直观的图表…...
制作图片马:二次渲染(upload-labs第17关)
代码分析 $im imagecreatefromjpeg($target_path);在本关的代码中这个imagecreatefromjpeg();函数起到了将上传的图片打乱并重新组合。这就意味着在制作图片马的时候要将木马插入到图片没有被改变的部分。 gif gif图的特点是无损,我们可以对比上传前后图片的内容…...

XGB-20:XGBoost中不同参数的预测函数
有许多在XGBoost中具有不同参数的预测函数。 预测选项 xgboost.Booster.predict() 方法有许多不同的预测选项,从 pred_contribs 到 pred_leaf 不等。输出形状取决于预测的类型。对于多类分类问题,XGBoost为每个类构建一棵树,每个类的树称为…...
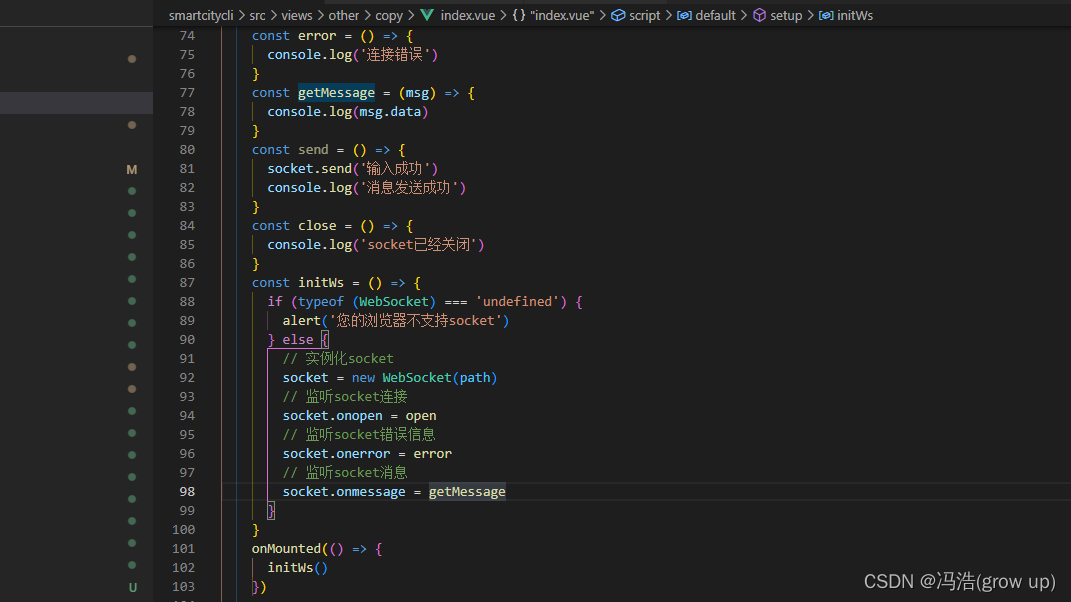
websocket 使用示例
websocket 使用示例 前言html中使用vue3中使用1、安装websocket依赖2、代码 vue2中使用1、安装websocket依赖2、代码 前言 即时通讯webSocket 的使用 html中使用 以下是一个简单的 HTML 页面示例,它连接到 WebSocket 服务器并包含一个文本框、一个发送按钮以及 …...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

我们公司全员把 Cursor 换成了自研的 全开源AtomCode
【引子】这是一篇实录——一位 CTO 用 28 天,用 Claude GLM 双模型调度,造出了一个让全公司放弃 Cursor 的工具。然后我意识到我们正在经历的事情,比"换工具"大得多。【读者承诺】接下来 15 分钟,你会拿到三件东西:一个真实案例(28 天 1,146 commits 是怎么做出来的…...

终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词
终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了在听歌时手动搜索歌词…...

BetterNCM安装器终极指南:5分钟解锁网易云音乐无限潜能
BetterNCM安装器终极指南:5分钟解锁网易云音乐无限潜能 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 你是否觉得网易云音乐PC版功能有限,界面单调?…...

Unity中实现深度遮挡:LingBot-Depth实战接入与优化
1. 这不是“加个插件就完事”的AR效果——为什么LingBot-Depth在Unity里值得专门写一篇实战教程你肯定见过那种AR应用:虚拟椅子摆在真实地板上,但当你绕到椅子后面,它依然完整显示,完全无视身后那堵真实的墙;或者一只3…...

机器学习力场攻克Peierls相变动力学:从对称性描述符到畴生长标度律
1. 项目概述:当机器学习遇见Peierls相变在凝聚态物理和材料科学的前沿,我们常常被一个核心问题所困扰:如何精确地模拟那些由电子和晶格(原子)强烈耦合所驱动的复杂动力学过程?这类系统,比如电荷…...

如何高效使用开源电路仿真工具:CircuitJS1桌面版新手快速入门指南
如何高效使用开源电路仿真工具:CircuitJS1桌面版新手快速入门指南 【免费下载链接】circuitjs1 Standalone (offline) version of the Circuit Simulator with small modifications based on modified NW.js. 项目地址: https://gitcode.com/gh_mirrors/circ/circ…...

Office RibbonX Editor:5分钟学会定制你的Office功能区界面
Office RibbonX Editor:5分钟学会定制你的Office功能区界面 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-e…...

QGroundControl终极指南:5步掌握开源无人机地面站完整使用教程
QGroundControl终极指南:5步掌握开源无人机地面站完整使用教程 【免费下载链接】qgroundcontrol Cross-platform ground control station for drones (Android, iOS, Mac OS, Linux, Windows) 项目地址: https://gitcode.com/gh_mirrors/qg/qgroundcontrol 想…...