#LLM入门|Prompt#3.3_存储_Memory
在与语言模型交互时,一个关键问题:记忆缺失使得对话缺乏真正的连续性。
因此,接下来介绍 LangChain 中的储存模块,即如何将先前的对话嵌入到语言模型中的,使其具有连续对话的能力。
当使用 LangChain 中的储存(Memory)模块时,它旨在保存、组织和跟踪整个对话的历史,从而为用户和模型之间的交互提供连续的上下文。
LangChain 提供了多种储存类型。缓冲区储存允许保留最近的聊天消息,摘要储存则提供了对整个对话的摘要。实体储存则允许在多轮对话中保留有关特定实体的信息。
这些记忆组件都是模块化的,可与其他组件组合使用,从而增强机器人的对话管理能力。
储存模块可以通过简单的 API 调用来访问和更新,允许开发人员更轻松地实现对话历史记录的管理和维护。
此次课程主要介绍其中四种储存模块,其他模块可查看文档学习。
- 对话缓存储存 (ConversationBufferMemory)
- 对话缓存窗口储存 (ConversationBufferWindowMemory)
- 对话令牌缓存储存 (ConversationTokenBufferMemory)
- 对话摘要缓存储存 (ConversationSummaryBufferMemory)
短期记忆在LangChain中的大语言模型(LLM)里的重要知识点包括:
- 长期记忆与短期记忆的区别:LLM通过训练获得长期记忆,而短期记忆是用户与模型互动时产生的。
- 参数不变性:LLM的长期参数在训练完成后不会因用户输入而改变。
- 对话中的信息处理:LLM在对话过程中会暂时记住用户的输入和自己的输出,以便进行下一步的预测和生成响应。
- 信息的临时性:一旦LLM完成输出,它会“遗忘”之前的用户输入和自己的输出,这些信息仅作为短期记忆存在。
- 短期记忆的作用:短期记忆帮助LLM在特定会话中维持上下文的连贯性和相关性。
为了延长 LLM 短期记忆的保留时间,则需要借助一些外部储存方式来进行记忆,以便在用户与 LLM 对话中,LLM 能够尽可能的知道用户与它所进行的历史对话信息。
一、对话缓存储存
1.1 初始化对话模型
让我们先来初始化对话模型。
from langchain.chains import ConversationChain
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory# 这里我们将参数temperature设置为0.0,从而减少生成答案的随机性。
# 如果你想要每次得到不一样的有新意的答案,可以尝试增大该参数。
llm = ChatOpenAI(temperature=0.0)
memory = ConversationBufferMemory()# 新建一个 ConversationChain Class 实例
# verbose参数设置为True时,程序会输出更详细的信息,以提供更多的调试或运行时信息。
# 相反,当将verbose参数设置为False时,程序会以更简洁的方式运行,只输出关键的信息。
conversation = ConversationChain(llm=llm, memory = memory, verbose=True )
1.2 第一轮对话
当我们运行预测(predict)时,生成了一些提示,如下所见,他说“以下是人类和 AI 之间友好的对话,AI 健谈“等等,这实际上是 LangChain 生成的提示,以使系统进行希望和友好的对话,并且必须保存对话,并提示了当前已完成的模型链。
conversation.predict(input=“你好, 我叫皮皮鲁”)
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.Current conversation:Human: 你好, 我叫皮皮鲁
AI:> Finished chain.'你好,皮皮鲁!很高兴认识你。我是一个AI助手,可以回答你的问题和提供帮助。有什么我可以帮你的吗?'
1.3 第二轮对话
当我们进行第二轮对话时,它会保留上面的提示
conversation.predict(input=“1+1等于多少?”)
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.Current conversation:
Human: 你好, 我叫皮皮鲁
AI: 你好,皮皮鲁!很高兴认识你。我是一个AI助手,可以回答你的问题和提供帮助。有什么我可以帮你的吗?
Human: 1+1等于多少?
AI:> Finished chain.'1+1等于2。'
1.4 第三轮对话
为了验证他是否记忆了前面的对话内容,我们让他回答前面已经说过的内容(我的名字),可以看到他确实输出了正确的名字,因此这个对话链随着往下进行会越来越长。
conversation.predict(input=“我叫什么名字?”)
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.Current conversation:
Human: 你好, 我叫皮皮鲁
AI: 你好,皮皮鲁!很高兴认识你。我是一个AI助手,可以回答你的问题和提供帮助。有什么我可以帮你的吗?
Human: 1+1等于多少?
AI: 1+1等于2。
Human: 我叫什么名字?
AI:> Finished chain.'你叫皮皮鲁。'
1.5 查看储存缓存
储存缓存(buffer),即储存了当前为止所有的对话信息
print(memory.buffer)
Human: 你好, 我叫皮皮鲁
AI: 你好,皮皮鲁!很高兴认识你。我是一个AI助手,可以回答你的问题和提供帮助。有什么我可以帮你的吗?
Human: 1+1等于多少?
AI: 1+1等于2。
Human: 我叫什么名字?
AI: 你叫皮皮鲁。
也可以通过load_memory_variables({})打印缓存中的历史消息。这里的{}是一个空字典,有一些更高级的功能,使用户可以使用更复杂的输入,具体可以通过 LangChain 的官方文档查询更高级的用法。
print(memory.load_memory_variables({})) {‘history’: ‘Human: 你好, 我叫皮皮鲁\nAI: 你好,皮皮鲁!很高兴认识你。我是一个AI助手,可以回答你的问题和提供帮助。有什么我可以帮你的吗?\nHuman: 1+1等于多少?\nAI: 1+1等于2。\nHuman: 我叫什么名字?\nAI: 你叫皮皮鲁。’}
1.6 直接添加内容到储存缓存
我们可以使用save_context来直接添加内容到buffer中。
memory = ConversationBufferMemory()
memory.save_context({"input": "你好,我叫皮皮鲁"}, {"output": "你好啊,我叫鲁西西"})
memory.load_memory_variables({})
{‘history’: ‘Human: 你好,我叫皮皮鲁\nAI: 你好啊,我叫鲁西西’}
继续添加新的内容
memory.save_context({"input": "很高兴和你成为朋友!"}, {"output": "是的,让我们一起去冒险吧!"})
memory.load_memory_variables({})
{‘history’: ‘Human: 你好,我叫皮皮鲁\nAI: 你好啊,我叫鲁西西\nHuman: 很高兴和你成为朋友!\nAI: 是的,让我们一起去冒险吧!’}
可以看到对话历史都保存下来了!
当我们在使用大型语言模型进行聊天对话时,大型语言模型本身实际上是无状态的。语言模型本身并不记得到目前为止的历史对话。每次调用API结点都是独立的。储存(Memory)可以储存到目前为止的所有术语或对话,并将其输入或附加上下文到LLM中用于生成输出。如此看起来就好像它在进行下一轮对话的时候,记得之前说过什么。
二、对话缓存窗口储存
随着对话变得越来越长,所需的内存量也变得非常长。将大量的tokens发送到LLM的成本,也会变得更加昂贵,这也就是为什么API的调用费用,通常是基于它需要处理的tokens数量而收费的。
针对以上问题,LangChain也提供了几种方便的储存方式来保存历史对话。其中,对话缓存窗口储存只保留一个窗口大小的对话。它只使用最近的n次交互。这可以用于保持最近交互的滑动窗口,以便缓冲区不会过大。
2.1 添加两轮对话到窗口储存
我们先来尝试一下使用ConversationBufferWindowMemory来实现交互的滑动窗口,并设置k=1,表示只保留一个对话记忆。接下来我们手动添加两轮对话到窗口储存中,然后查看储存的对话。
from langchain.memory import ConversationBufferWindowMemory# k=1表明只保留一个对话记忆
memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "你好,我叫皮皮鲁"}, {"output": "你好啊,我叫鲁西西"})
memory.save_context({"input": "很高兴和你成为朋友!"}, {"output": "是的,让我们一起去冒险吧!"})
memory.load_memory_variables({})
{‘history’: ‘Human: 很高兴和你成为朋友!\nAI: 是的,让我们一起去冒险吧!’}
通过结果,我们可以看到窗口储存中只有最后一轮的聊天记录。
2.2 在对话链中应用窗口储存
接下来,让我们来看看如何在ConversationChain中运用ConversationBufferWindowMemory吧!
llm = ChatOpenAI(temperature=0.0)
memory = ConversationBufferWindowMemory(k=1)
conversation = ConversationChain(llm=llm, memory=memory, verbose=False )print("第一轮对话:")
print(conversation.predict(input="你好, 我叫皮皮鲁"))print("第二轮对话:")
print(conversation.predict(input="1+1等于多少?"))print("第三轮对话:")
print(conversation.predict(input="我叫什么名字?"))
第一轮对话:
你好,皮皮鲁!很高兴认识你。我是一个AI助手,可以回答你的问题和提供帮助。有什么我可以帮你的吗?
第二轮对话:
1+1等于2。
第三轮对话:
很抱歉,我无法知道您的名字。
注意此处!由于这里用的是一个窗口的记忆,因此只能保存一轮的历史消息,因此AI并不能知道你第一轮对话中提到的名字,他最多只能记住上一轮(第二轮)的对话信息
三、对话字符缓存储存
使用对话字符缓存记忆,内存将限制保存的token数量。如果字符数量超出指定数目,它会切掉这个对话的早期部分 以保留与最近的交流相对应的字符数量,但不超过字符限制。
添加对话到Token缓存储存,限制token数量,进行测试
from langchain.llms import OpenAI
from langchain.memory import ConversationTokenBufferMemory
memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=30)
memory.save_context({"input": "朝辞白帝彩云间,"}, {"output": "千里江陵一日还。"})
memory.save_context({"input": "两岸猿声啼不住,"}, {"output": "轻舟已过万重山。"})
memory.load_memory_variables({})
{‘history’: ‘AI: 轻舟已过万重山。’}
ChatGPT 使用一种基于字节对编码(Byte Pair Encoding,BPE)的方法来进行 tokenization (将输入文本拆分为token)。BPE 是一种常见的 tokenization 技术,它将输入文本分割成较小的子词单元。 OpenAI 在其官方 GitHub 上公开了一个最新的开源 Python 库 tiktoken(https://github.com/openai/tiktoken),这个库主要是用来计算%EF%BC%8C%E8%BF%99%E4%B8%AA%E5%BA%93%E4%B8%BB%E8%A6%81%E6%98%AF%E7%94%A8%E6%9D%A5%E8%AE%A1%E7%AE%97) tokens 数量的。相比较 HuggingFace 的 tokenizer ,其速度提升了好几倍。 具体 token 计算方式,特别是汉字和英文单词的 token 区别,具体可参考知乎文章(https://www.zhihu.com/question/594159910)。%E3%80%82)
四、对话摘要缓存储存
对话摘要缓存储存,使用 LLM 对到目前为止历史对话自动总结摘要,并将其保存下来。
4.1 使用对话摘要缓存储存
我们创建了一个长字符串,其中包含某人的日程安排。
from langchain.chains import ConversationChain
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationSummaryBufferMemory# 创建一个长字符串
schedule = "在八点你和你的产品团队有一个会议。 \
你需要做一个PPT。 \
上午9点到12点你需要忙于LangChain。\
Langchain是一个有用的工具,因此你的项目进展的非常快。\
中午,在意大利餐厅与一位开车来的顾客共进午餐 \
走了一个多小时的路程与你见面,只为了解最新的 AI。 \
确保你带了笔记本电脑可以展示最新的 LLM 样例."llm = ChatOpenAI(temperature=0.0)
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=100)
memory.save_context({"input": "你好,我叫皮皮鲁"}, {"output": "你好啊,我叫鲁西西"})
memory.save_context({"input": "很高兴和你成为朋友!"}, {"output": "是的,让我们一起去冒险吧!"})
memory.save_context({"input": "今天的日程安排是什么?"}, {"output": f"{schedule}"})print(memory.load_memory_variables({})['history'])
System: The human introduces themselves as Pipilu and the AI introduces themselves as Luxixi. They express happiness at becoming friends and decide to go on an adventure together. The human asks about the schedule for the day. The AI informs them that they have a meeting with their product team at 8 o’clock and need to prepare a PowerPoint presentation. From 9 am to 12 pm, they will be busy with LangChain, a useful tool that helps their project progress quickly. At noon, they will have lunch with a customer who has driven for over an hour just to learn about the latest AI. The AI advises the human to bring their laptop to showcase the latest LLM samples.
4.2 基于对话摘要缓存储存的对话链
基于上面的对话摘要缓存储存,我们新建一个对话链。
conversation = ConversationChain(llm=llm, memory=memory, verbose=True)
conversation.predict(input="展示什么样的样例最好呢?")
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.Current conversation:
System: The human introduces themselves as Pipilu and the AI introduces themselves as Luxixi. They express happiness at becoming friends and decide to go on an adventure together. The human asks about the schedule for the day. The AI informs them that they have a meeting with their product team at 8 o'clock and need to prepare a PowerPoint presentation. From 9 am to 12 pm, they will be busy with LangChain, a useful tool that helps their project progress quickly. At noon, they will have lunch with a customer who has driven for over an hour just to learn about the latest AI. The AI advises the human to bring their laptop to showcase the latest LLM samples.
Human: 展示什么样的样例最好呢?
AI:> Finished chain.'展示一些具有多样性和创新性的样例可能是最好的选择。你可以展示一些不同领域的应用,比如自然语言处理、图像识别、语音合成等。另外,你也可以展示一些具有实际应用价值的样例,比如智能客服、智能推荐等。总之,选择那些能够展示出我们AI技术的强大和多样性的样例会给客户留下深刻的印象。'
print(memory.load_memory_variables({})) # 摘要记录更新了
{‘history’: “System: The human introduces themselves as Pipilu and the AI introduces themselves as Luxixi. They express happiness at becoming friends and decide to go on an adventure together. The human asks about the schedule for the day. The AI informs them that they have a meeting with their product team at 8 o’clock and need to prepare a PowerPoint presentation. From 9 am to 12 pm, they will be busy with LangChain, a useful tool that helps their project progress quickly. At noon, they will have lunch with a customer who has driven for over an hour just to learn about the latest AI. The AI advises the human to bring their laptop to showcase the latest LLM samples. The human asks what kind of samples would be best to showcase. The AI suggests that showcasing diverse and innovative samples would be the best choice. They recommend demonstrating applications in different fields such as natural language processing, image recognition, and speech synthesis. Additionally, they suggest showcasing practical examples like intelligent customer service and personalized recommendations to impress the customer with the power and versatility of their AI technology.”}
通过对比上一次输出,发现摘要记录更新了,添加了最新一次对话的内容总结。
相关文章:

#LLM入门|Prompt#3.3_存储_Memory
在与语言模型交互时,一个关键问题:记忆缺失使得对话缺乏真正的连续性。 因此,接下来介绍 LangChain 中的储存模块,即如何将先前的对话嵌入到语言模型中的,使其具有连续对话的能力。 当使用 LangChain 中的储存(Memory)…...
基于SSM+Vue的龙腾公司员工信息管理系统设计与实现
1 绪论 1.1研究背景 当前社会各行业领域竞争压力非常大,随着当前时代的信息化,科学化发展,让社会各行业领域都争相使用新的信息技术,对行业内的各种相关数据进行科学化,规范化管理。这样的大环境让那些止步不前&a…...
使用点链云管家创建瑜伽约课小程序
点链云管家 点链云管家是由上海点链科技开发的门店管理系统,为线下门店商家提供一站式门店运营服务平台解决方案,适用于瑜伽健身、美业、新零售会员制电商、母婴店、宠物店、按摩养生、服装、美容、美甲、汽车服务、商超零售、餐饮、KTV娱乐、干洗等18个…...

【Node.js从基础到高级运用】八、Express 框架入门
Express 框架入门 Express 是一个灵活且广泛使用的 Node.js web 应用框架,它提供了一系列强大特性来帮助开发者创建各种 Web 和移动设备应用。在这一节中,我们将介绍如何安装和配置 Express,并简单探讨其路由和中间件的概念。 安装 Express…...
Unity Timeline学习笔记(2) - PlayableTrack
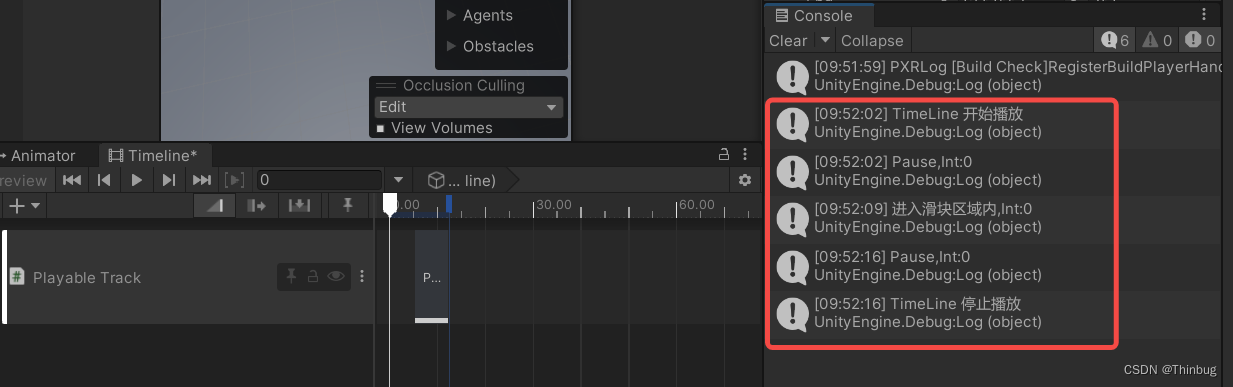
PlayableTrack 是可自定义播放的轨道。我们可以通过进入轨道后调用自己的函数方法,使用起来也是比较顺手的。 添加轨道 我们点击加号添加 这样就有一个空轨道了,然后我们创建两个测试脚本。 添加脚本 分别是Playable Behaviour和PlayableAsset脚本。…...
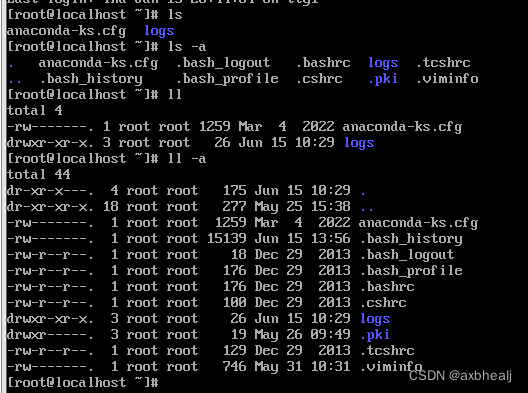
Linux的一些常用指令
一、文件中 r w x - 的含义 r(read)是只读权限, w(write)是写的权限, x(execute)是可执行权限, -是没有任何权限。 二、一些指令 # 解压压缩包 tar [-zxvf] 压缩包名…...

09-设计模式 企业场景 面试题
目录 1.简单工厂模式 编辑 2.工厂方法模式 3.抽象工厂模式 4.策略模式 5.登录案例(工厂模式+策略模式) 6.责任链设计模式 7.单点登录怎么是实现的? 8.权限认证是如何实现的 9.上传数据的安全性你们怎么控制? 10.你负责项目的时候遇到了哪些比较棘手的问题?怎…...
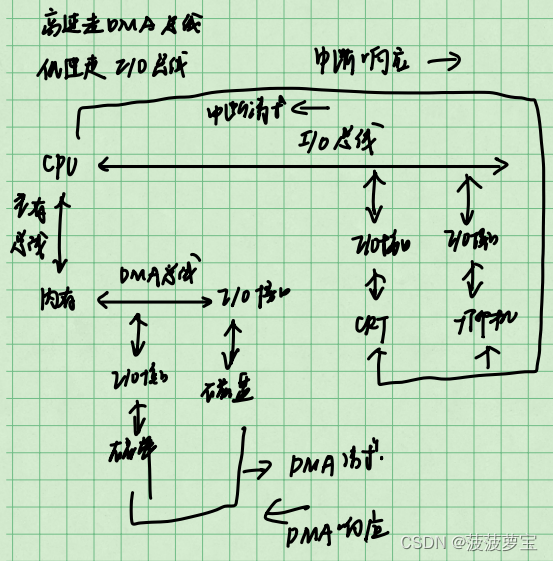
计算机组成原理-练手题集合【期末复习|考研复习】
前言 总结整理不易,希望大家点赞收藏。 给大家整理了一下计算机组成原理中的各章练手题,以供大家期末复习和考研复习的时候使用。 参考资料是王道的计算机组成原理和西电的计算机组成原理。 计算机组成原理系列文章传送门: 第一/二章 概述和数…...

探索 Spring 框架:企业级应用开发的强大工具
CSDN-个人主页:17_Kevin-CSDN博客 收录专栏:《Java》 目录 一、引言 二、Spring 框架的历史 三、Spring 框架的核心模块 四、Spring 框架的优势 五、Spring 框架的应用场景 六、结论 一、引言 在当今数字化时代,企业级应用开发的需求日…...
java数据结构与算法刷题-----LeetCode47. 全排列 II
java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846 文章目录 1. 暴力回溯2. 分区法回溯 此题为46题的衍生题,在46题…...

✅技术社区—MySQL和ES的数据同步策略
使用Canal框架实现MySQL与Elasticsearch(ES)的数据同步确实可以提高实时搜索的准确性和效率。Canal通过模拟MySQL的binlog日志订阅和解析,实现了数据的实时同步。在这样的同步机制下,ES中的数据可以非常接近于MySQL数据库中的实时…...

LinearLayout和RelativeLayout对比
LinearLayout和RelativeLayout是Android中应用最为广泛的两种布局, 绝大部分UI均可以通过两种布局中的任何一种进行实现,其对比如下: LinearLayout: 1. LinearLayout可以实现子View按照权重分配显示区域,RelativeLayou…...
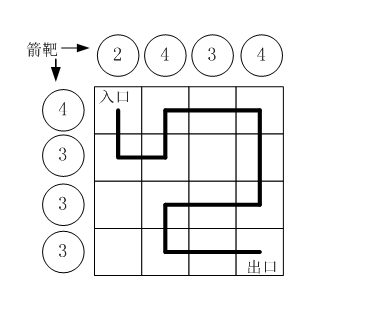
蓝桥杯深度优先搜索|剪枝|N皇后问题|路径之谜(C++)
搜索:暴力法算法思想的具体实现 搜索:通用的方法,一个问题如果比较难,那么先尝试一下搜索,或许能启发出更好的算法 技巧:竞赛时遇到不会的难题,用搜索提交一下,说不定部分判题数据很…...

大门对楼梯,怎么办?
中国是一个非常重视风水的国家,风水学发扬和流传已有几千年的历史,很多懂风水的人都知道,大门风水是其中非常重要的一环,因为大门风水直接影响全家人的各种运势。大门风水好,能帮助你一臂之力;若大门风…...

解决驱动开发中<stdlib.h> no such file 的问题
前言 在进行驱动开发时,需要使用malloc等函数,导入C库<stdlib.h>出现bug。 嵌入式驱动学习专栏将详细记录博主学习驱动的详细过程,未来预计四个月将高强度更新本专栏,喜欢的可以关注本博主并订阅本专栏,一起讨论…...

Find My工牌|苹果Find My技术与工牌结合,智能防丢,全球定位
工作牌一般是由公司发行的,带有相关工作号及佩戴人信息的卡牌,一般由塑料制作而成。具有醒目.增强内部员工归属感等作用。主要构成为公司名字背景图片员工名字照片。胸牌是一种悬挂或串扣于上衣左方的一种工号牌或介绍小标牌,大多数佩戴在西装…...

Springboot解决跨域问题
跨域问题 在Spring Boot中解决跨域问题的原因是因为浏览器的同源策略(Same-Origin Policy)限制了从一个源加载的文档或脚本如何与来自另一个源的资源进行交互。如果前端页面和后端服务不在同一个源(域名、协议、端口号都不相同)&…...

UE5 C++ TPS开发 学习记录(10
p22 这节课把创建,查找,加入游戏房间的菜单类,以及插件内的系统类给补完了.说实话这节课有点绕,因为需要一直使用委托进行传值,先由菜单类Menu向系统类Subsystem发送函数传值请求,然后监听Subsystem的委托回调,同时系统类Subsystem向Session的工具发送请求,监听回调,再返回给M…...

ES6(一):let和const、模板字符串、函数默认值、剩余参数、扩展运算符、箭头函数
一、let和const声明变量 1.let没有变量提升,把let放下面打印不出来,放上面可以 <script>console.log(a);let a1;</script> 2.let是一个块级作用域,花括号里面声明的变量外面找不到 <script>console.log(b);if(true){let b1;}//und…...

Docker使用及部署流程
文章目录 1. 准备Docker环境2. 准备应用的Docker镜像3. 在服务器上运行Docker容器方法一:Docker Hub方法二:从构建环境传输镜像4. 管理和维护使用Docker Compose(可选)主要区别步骤 1: 安装Docker ComposeLinuxWindowMac步骤 2: 创建docker-compose.yml文件步骤 3: 使用Doc…...

翻译工具:AI跨语言执行任务
翻译工具:AI跨语言执行任务📝 本章学习目标:本章聚焦工具系统,让AI Agent具备丰富的执行能力。通过本章学习,你将全面掌握"翻译工具:AI跨语言执行任务"这一核心主题。一、引言:为什么…...

字节Seed基座GR3机器人的专属控制内核,具备柔性物体操控、人体姿态复刻、工业闭环作业等功能
全称:Gesture Real-Time Reinforcement Learning 全域实时姿态强化学习具身控制框架 内部代号:GR-RL V5.9.2 稳态正式版 隶属体系:字节Seed基座GR3机器人专属控制内核 核心用途:全品类柔性物体操控、人体仿生姿态复刻、工业高精度…...

Tomcat隐藏Server响应头的三种实战方案
1. 为什么连Tomcat默认的版本号都得藏起来?你有没有在浏览器开发者工具的Network面板里,随手点开一个Java Web应用的响应头,就看到这么一行:Server: Apache-Coyote/1.1或者更直白的Server: Apache Tomcat/9.0.83?我第一…...

OmenSuperHub:惠普OMEN游戏本终极性能控制软件完全指南
OmenSuperHub:惠普OMEN游戏本终极性能控制软件完全指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 想要彻底掌控你的惠普OMEN游戏本性能吗…...

深度 | 昇腾NPU MoE算子实现:从TopKGating到Expert并行,稀疏激活的硬件适配
引言 MoE(Mixture of Experts,混合专家)是大模型近年来最重要的架构演进之一。GPT-4、Mixtral-87B、Qwen1.5-MoE——几乎所有宣称"超大规模"的新模型都在用 MoE。核心逻辑很简单:用多个独立的"专家"网络替代…...

数据标注中的权力博弈与主观性:从规则制定到模型偏见的全链路解析
1. 项目概述:当数据标注不再是“客观”的技术活“数据标注”,在很多人眼里,可能就是一个坐在电脑前,对着图片画框、打标签的“体力活”或“技术活”。它听起来中立、客观,是人工智能模型训练前一道标准化的工序。然而&…...
)
Hexo 排坑记:删除所有文章后首页无法访问(Cannot GET)
背景 最近在使用 Hexo Butterfly 主题搭建个人博客时,遇到一个奇怪的问题:我把 source/_posts 下的所有文章都删掉后,重新生成并启动本地服务器,访问 http://localhost:4000 竟然直接显示 Cannot GET /,首页完全打不开…...

《论三生原理》对《周易》《道德经》的一次根本性重写?
AI辅助创作:一、关于《周易》来历根源的推断属于文化创新实验,是对《周易》来历、性质、底层逻辑的一次根本性重写?《论三生原理》关于《周易》来历根源的推断,确实属于一次大胆的文化创新实验,并且是对《周易》的来历…...

使用Python为你的数据分析脚本添加Taotoken大模型智能总结功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Python为你的数据分析脚本添加Taotoken大模型智能总结功能 在数据分析工作中,生成图表后,我们常常需要…...
)
14000华夏之光永存:开源:华为五大全栈硬核技术揭榜课题完整梳理(预刊抽取篇)
开源:华为五大全栈硬核技术揭榜课题完整梳理(预刊抽取篇) 摘要 本文完整收录黄大年茶思屋珠峰会战第八期5项前沿技术揭榜难题,原样保留技术背景、技术挑战、现有方案、现存缺陷与量化技术诉求,不做内容删减与篡改。本文…...