【黑马程序员】Python文件、异常、模块、包
文章目录
- 文件操作
- 文件编码
- 什么是编码
- 为什么要使用编码
- 文件的读取
- open
- model常用的三种基础访问模式
- 读操作相关方法
- 文件的写入
- 注意
- 代码示例
- 异常
- 定义
- 异常捕获
- 捕获指定异常
- 捕获多个异常
- 捕获所有异常
- 异常else
- 异常finally
- 异常的传递
- python 模块
- 定义
- 模块的导入
- import模块名
- from 模块名 import 功能名
- 使用*导入time的sleep功能
- 使用as给特定功能加上别名
- 自定义模块
- 创建自定义模块举例
- `__name__` 变量
- `__all__` 变量
- 注意
- Python包
- 自定义包
- 定义
- 创建包
- 导入包
- 使用import导入
- 使用from import导入
- 导入模块中
- 安装第三方包
- 常见第三方包
- 安装第三方包
- 综合练习
- 需求
- 实现
文件操作
文件编码
什么是编码
-
编码就是一种规则集合,记录了内容和二进制间进行互相转换的规则
-
最常用的是UTF-8编码
为什么要使用编码
-
计算机内部保存的都是0和1,所以需要将内容全部转换为0和1才能识别
-
读取时需要将计算机中保存的0和1转为内容
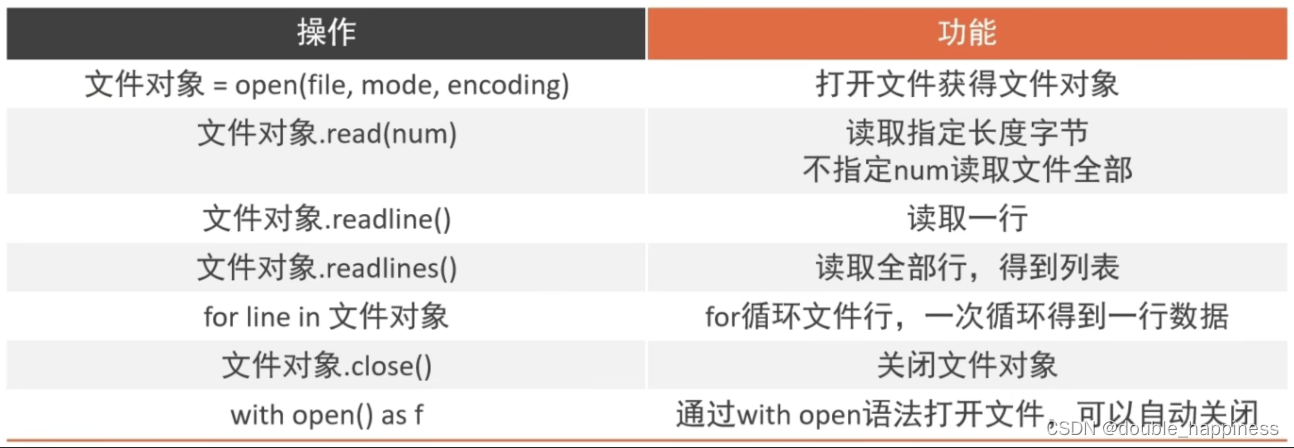
文件的读取
open
- 语法
open(name, mode, encoding)
name 要打开的目标文件名的字符串
mode 打开文件的模式:只读、写入、追加
encoding 编码格式,推荐使用UTF8
model常用的三种基础访问模式

读操作相关方法
- read方法
文件对象.read(num)
num 表示要从文件中读取的数据长度,单位是字节,如果没有传,读取文件中所有的数据
-
readlines():可以按照行的方式把整个文件的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素
-
readline()读取文件的一行
-
for循环读取文件行
-
close()关闭文件对象
-
with open语法:用于打开文件并在使用完毕后自动关闭文件
- 代码示例
# *_*coding:utf-8 *_*
# 打开文件
f = open("./read_file.py", 'r', encoding="UTF-8")
# 读取文件
print(f'读取50个字节的结果{f.read(50)}')
# 在程序中多次调用read,下一次会从上一次读的偏移结尾继续读
print(f'读取全部字节的结果{f.read()}')# readlines读取文件的全部行,封装到列表中
print(f'读取文件的全部行{f.readlines()}')# readline一次读取文件一行
line1 = f.readline()
line2 = f.readline()
line3 = f.readline()
print(f'第一行数据是:{line1}')
print(f'第二行数据是:{line2}')
print(f'第三行数据是:{line3}')# 关闭文件
f.close()# for循环读取文件行
for line in open("./read_file.py", "r"):print(line)# with open语法
with open("./read_file.py", "r", encoding="UTF-8") as f:print(f'{f.readlines()}')
文件的写入
注意
-
直接调用write方法,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
-
当调用flush的时候,内容会真正写入文件
-
目的:避免频繁磁盘操作,导致效率下降
-
close方法内置了flush功能
-
w模式
-
文件不存在则创建
-
文件存在则清空
-
-
a模式
-
文件不存在则创建
-
文件存在则追加尾部写
-
代码示例
# *_*coding:utf-8 *_*# open打开文件,使用覆盖写操作
f = open("test.txt", "w", encoding="UTF-8")
# write写入
f.write("123456789")
# flush刷新
f.flush()
# 关闭文件
f.close()# open打开文件,使用追加写操作
f = open("test1.txt", "a", encoding="UTF-8")
# write写入
f.write("123456789")
# flush刷新
f.flush()
# 关闭文件
f.close()
异常
定义
- 当检测到一个错误时,Python解释器就无法继续运行了,反而出现一些错误的提示,这就是所谓的异常
异常捕获
-
作用:提前假设某处会出现异常,做好提前准备,当真的出现异常时,可以有后续手段
-
基本语法
try:可能发生异常的代码块
except:出现异常后的代码块
- 代码示例:打开一个不存在的文件
try:f = open("xxx.txt", 'r')
except:print("open file err")
捕获指定异常
-
注意:
-
如果尝试执行的代码的异常类型和捕获的异常类型不一致,则无法捕获异常
-
一般try下面只放一行尝试执行的代码
-
-
语法:
try:print(name)
except NameError as e:print('name变量名称未定义错误')
- 代码示例
try:print(name)
# as e是给NameError类型起别名
except NameError as e:print('name变量未定义错误')
捕获多个异常
- 代码示例
# 捕获多个异常
try:print(name)
# as e是给NameError类型起别名,e中记录了异常的具体信息
except (NameError, ZeroDivisionError) as e:print('name变量未定义错误或者除0异常')
捕获所有异常
- 代码示例
# 捕获所有异常
try:print(name)
# 方式一:通过捕获Exception异常,Exception是顶级异常
except Exception as e:print('name变量未定义错误')try:print(name)
# 方式二:不指定具体的异常直接捕获
except:print('name变量未定义错误')
异常else
-
else表示的是如果没有异常要执行的代码
-
代码示例
# 异常else
try:print(name)
# as e是给NameError类型起别名,e中记录了异常的具体信息
except (NameError, ZeroDivisionError) as e:print('name变量未定义错误或者除0异常')
else:print("未发生异常")
异常finally
-
finally表示的是无论是否异常都要执行的代码
-
代码示例
# 异常finally
try:print(name)
# as e是给NameError类型起别名,e中记录了异常的具体信息
except (NameError, ZeroDivisionError) as e:print('name变量未定义错误或者除0异常')
else:print("未发生异常")
finally:print("总会执行我")
异常的传递
-
异常是具有传递性的
-
内层的异常如果没有被捕获会沿着调用链一直向上抛直到main函数
-
代码示例
# *_*coding:utf-8 *_*def func1():print("func1 start")1 / 0print("func1 end")def func2():print("func2 start")func1()print("func2 end")def main():try:func2()except Exception as e:print(e)main()
python 模块
定义
-
Python模块是一个Python文件,以.py结尾,模块能定义类、函数和变量,模块里面也能包含可执行的代码
-
作用:模块就是一个工具包
模块的导入
-
模块在使用之前需要先导入
-
语法
[from 模块名] import [模块|类|变量|函数|*] [as 别名]
- 常用组合方式
import 模块名
from 模块名 import 类、变量、方法等
from 模块名 import *
import 模块名 as 别名
from 模块名 import 功能名 as 别名
import模块名
- 基本语法
import 模块名
import 模块名1,模块名2
- 代码示例
# 导入时间模块
import timeprint("satrt")
# 程序睡眠3s
time.sleep(3)
print("end")
from 模块名 import 功能名
- 代码示例
from time import sleepprint("satrt")
# 程序睡眠3s
sleep(3)
print("end")
使用*导入time的sleep功能
- 代码示例
from time import *print("satrt")
# 程序睡眠3s
sleep(3)
print("end")
使用as给特定功能加上别名
- 代码示例
import time as tprint("satrt")
# 程序睡眠3s
t.sleep(3)
print("end")
自定义模块
创建自定义模块举例
- 创建
my_module.py
def test(a, b):print(a + b)
- 创建
test_my_module.py
import my_modulemy_module.test(1, 2)
__name__ 变量
-
在当前模块中执行时,才会生效,外部导入时不会执行
-
代码示例
def test(a, b):print(a + b)if __name__ == '__main__':test(1, 1)
__all__ 变量
-
如果一个模块中有
__all__变量,当使用from xxx import *,时只能导入这个列表中的元素,没有all时默认导入的是所有,有all时只导入all中的 -
创建
my_module.py
__all__ = ['test1']def test(a, b):print(a + b)def test1(a, b):print(a + b)
- 创建
test_my_module.py
from my_module import *test1(1, 1)
# NameError: name 'test' is not defined
# test(1, 1)
注意
- 不同模块,同名的功能,如果都被导入,那么后导入的会覆盖先导入的
Python包
自定义包
定义
-
从物理上看,包就是一个文件夹,在该文件夹下包含了一个
__init__.py文件,该文件夹可用于包含多个模块文件 -
从逻辑上看,包的本质依然是模块
创建包
-
右键New->Python Package->输入包名
-
编写对应模块文件
- 新建
my_module1.py
# *_*coding:utf-8 *_* def info_print1():print('my_module1')- 新建
my_module2.py
# *_*coding:utf-8 *_*def info_print2():print('my_module2') - 新建
导入包
使用import导入
- 在
my_package同级创建一个test_my_package.py文件
# *_*coding:utf-8 *_*
import my_package.my_module1
import my_package.my_module2# 包中的my_module1模块的info_print方法
my_package.my_module1.info_print1()
# 包中的my_module2模块的info_print方法
my_package.my_module2.info_print2()
使用from import导入
from my_package import my_module1
from my_package import my_module2my_module1.info_print1()
my_module2.info_print2()
导入模块中
from my_package.my_module1 import info_print1
from my_package.my_module2 import info_print2info_print1()
info_print2()
安装第三方包
常见第三方包

安装第三方包
-
命令:
pip install 包名 -
示例

综合练习
需求

实现
-
新建
my_utils包 -
新建
str_utils.py文件
# *_*coding:utf-8 *_*def str_reverse(s):reversed(s)return sdef substr(s, x, y):return s[x:y]- 新建
file_utils.py文件
# *_*coding:utf-8 *_*def print_file_info(file_name):try:f = open(file_name, "r", encoding='UTF-8')except Exception as e:print(e)finally:f.close()def append_to_file(file_name, data):f1 = open(file_name, 'a', encoding='UTF-8')f1.write(data)f1.close()
- 测试:在my_utils同级新建
test_my_utils.py
# *_*coding:utf-8 *_*from my_utils import str_util
from my_utils import file_utilprint(f'反转后的结果是:{str_util.str_reverse("abc")}')
print(f'取子串后后的结果是:{str_util.substr("123456789", 2, 7)}')file_util.print_file_info("aa.txt")
file_util.append_to_file("aa.txt", "这是一条追加内容")相关文章:
【黑马程序员】Python文件、异常、模块、包
文章目录 文件操作文件编码什么是编码为什么要使用编码 文件的读取openmodel常用的三种基础访问模式读操作相关方法 文件的写入注意代码示例 异常定义异常捕获捕获指定异常捕获多个异常捕获所有异常异常else异常finally 异常的传递 python 模块定义模块的导入import模块名from …...
导入fetch_california_housing 加州房价数据集报错解决(HTTPError: HTTP Error 403: Forbidden)
报错 HTTPError Traceback (most recent call last) Cell In[3], line 52 from sklearn.datasets import fetch_california_housing3 from sklearn.model_selection import train_test_split ----> 5 X, Y fetch_california_housing(retu…...
后勤管理系统|基于SSM 框架+vue+ Mysql+Java+B/S架构技术的后勤管理系统设计与实现(可运行源码+数据库+设计文档+部署说明+视频演示)
目录 文末获取源码 前台首页功能 员工注册、员工登录 个人中心 公寓信息 员工功能模块 员工积分管理 管理员登录 编辑管理员功能模块 个人信息 编辑员工管理 公寓户型管理 编辑公寓信息管理 系统结构设计 数据库设计 luwen参考 概述 源码获取 文末获取源…...
【办公类-40-01】20240311 用Python将MP4转MP3提取音频 (家长会系列一)
作品展示: 背景需求: 马上就要家长会,我负责做会议前的照片滚动PPT,除了大量照片视频,还需要一个时间很长的背景音乐MP3 一、下载“歌曲串烧” 装一个IDM 下载三个“串烧音乐MP4”。 代码展示 家长会背景音乐: 歌曲串…...

人类的谋算与量子计算
量子计算并不等价于并行计算。量子计算和并行计算是两种不同的计算模型。 在经典计算中,通过增加计算机的处理器核心和内存等资源,可以实现并行计算,即多个任务同时进行。并行计算可以显著提高计算速度,尤其是对于可以被细分为多个…...
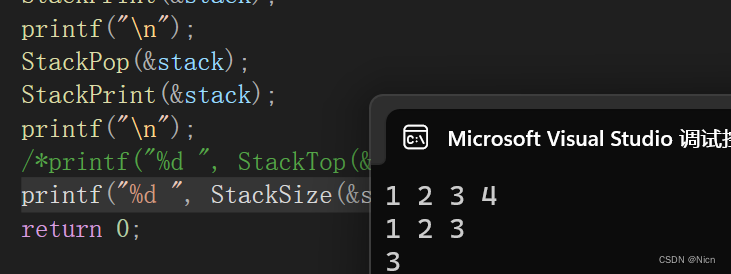
【数据结构和算法初阶(C语言)】栈的概念和实现(后进先出---后来者居上的神奇线性结构带来的惊喜体验)
目录 1.栈 1.1栈的概念及结构 2.栈的实现 3.栈结构对数据的处理方式 3.1对栈进行初始化 3.2 从栈顶添加元素 3.3 打印栈元素 3.4移除栈顶元素 3.5获取栈顶元素 3.6获取栈中的有效个数 3.7 判断链表是否为空 3.9 销毁栈空间 4.结语及整个源码 1.栈 1.1栈的概念及结构 栈&am…...
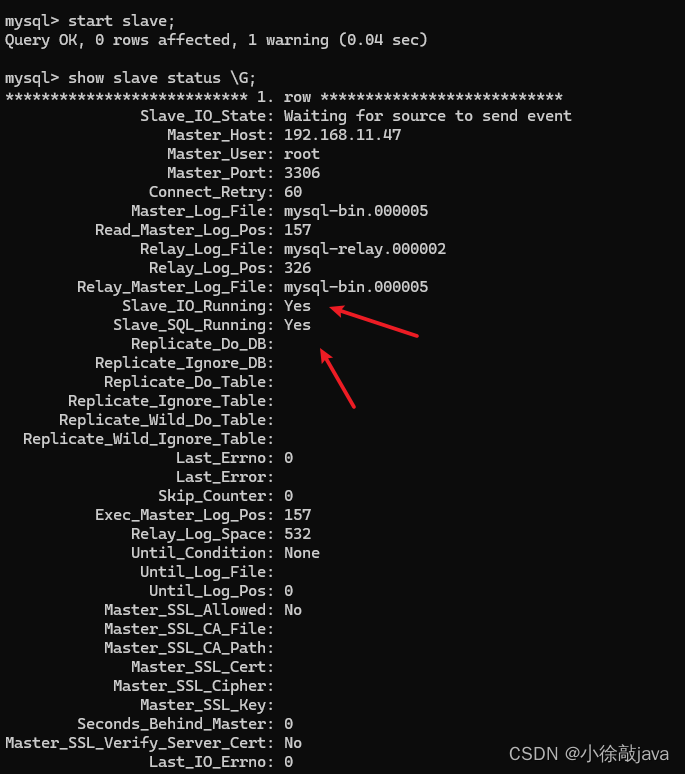
搭建mysql主从复制(主主复制)
1:设主库允许远程连接(注意:设置账号密码必须使用的插件是mysql_native_password,其他的会连接失败) #切换到mysql这个数据库,修改user表中的host,使其可以实现远程连接 mysql>use mysql; mysql>update user se…...
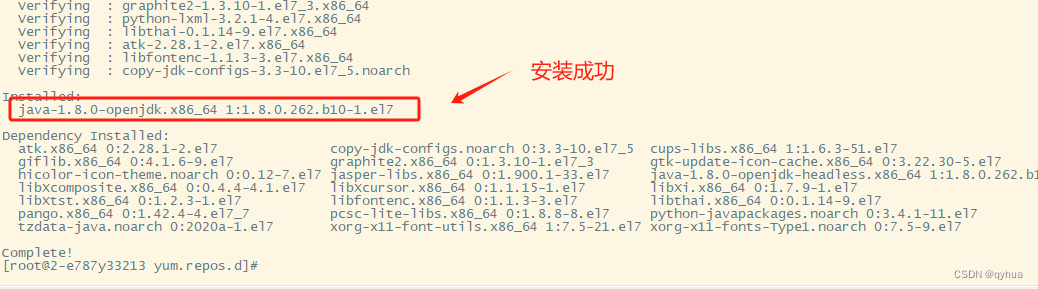
centos 系统 yum 无法安装(换国内镜像地下)
centos 系统 yum 因为无法连接到国外的官网而无法安装,问题如下图: 更换阿里镜像,配置文件路径:/etc/yum.repos.d/CentOS-Base.repo(如果目录有多余的文件可以移动到子目录,以免造成影响) bas…...
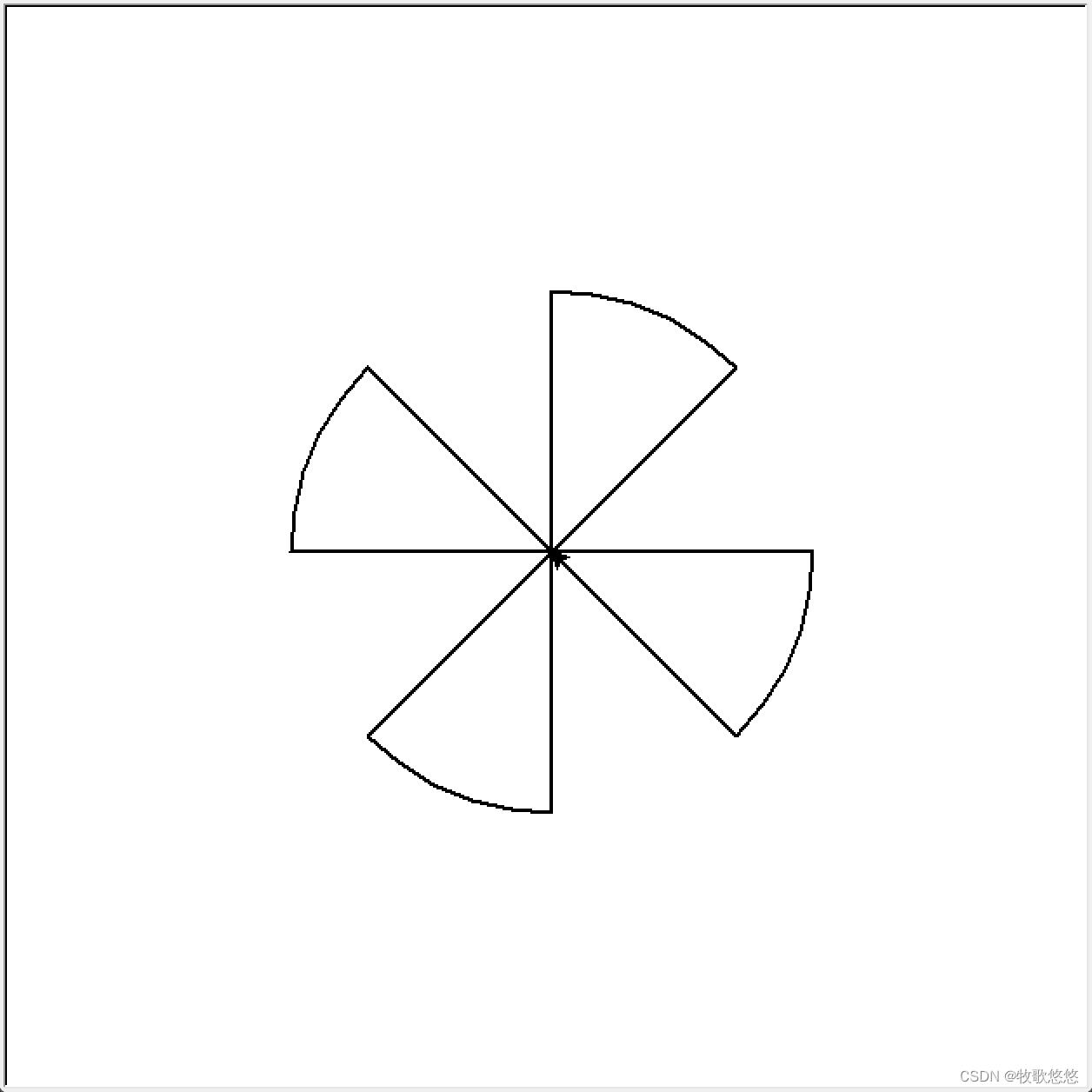
【python绘图】turle 绘图基本案例
文章目录 0. 基础知识1. 蟒蛇绘制2. 正方形绘制3. 六边形绘制4. 叠边形绘制5. 风轮绘制 0. 基础知识 资料来自中国mooc北京理工大学python课程 1. 蟒蛇绘制 import turtle turtle.setup(650, 350, 200, 200) turtle.penup() turtle.fd(-250) turtle.pendown() turtle.pen…...
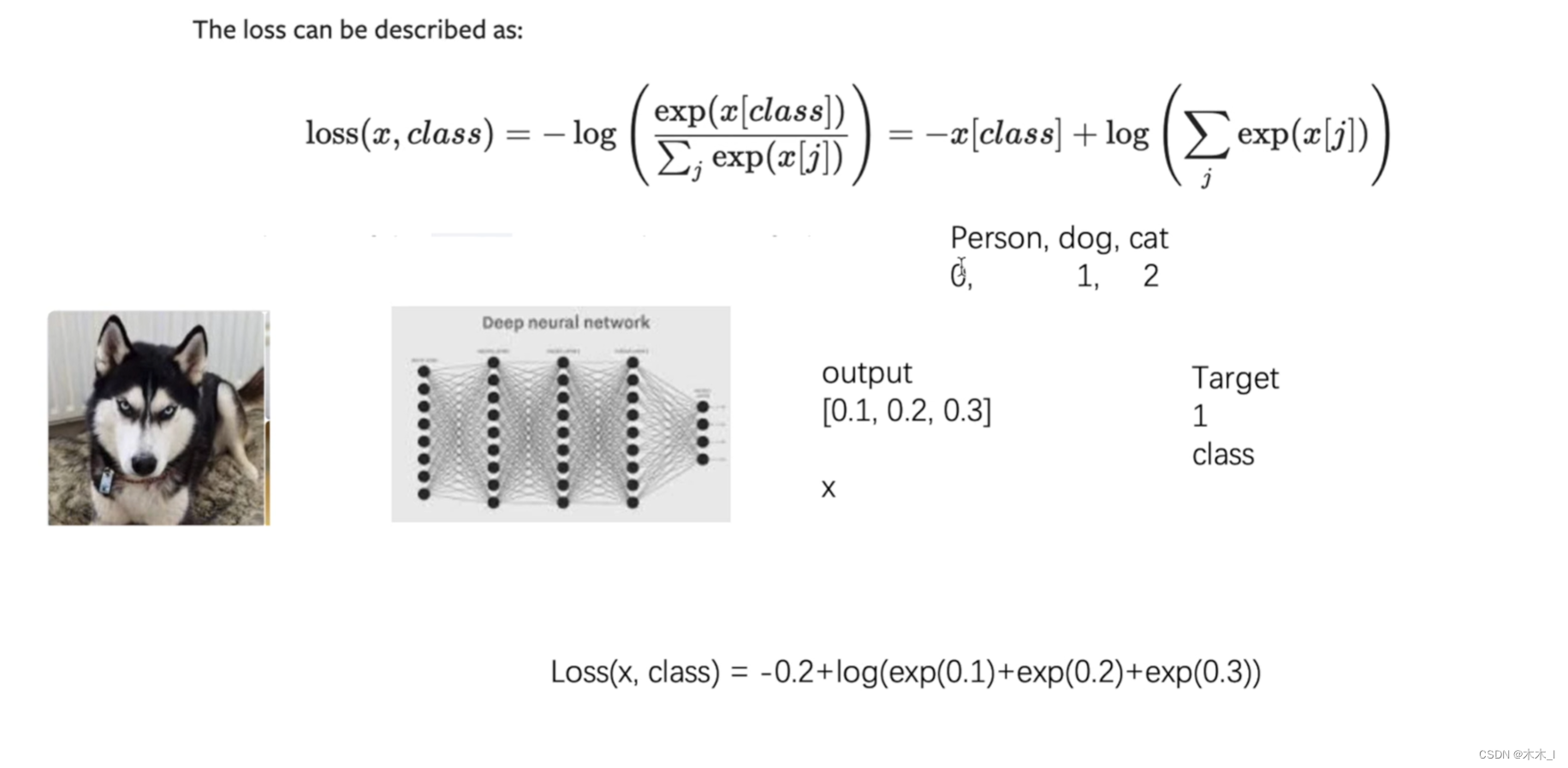
损失函数和反向传播
1. 损失函数的基础 import torch from torch.nn import L1Loss from torch import nninputs torch.tensor([1, 2, 3], dtypetorch.float32) targets torch.tensor([1, 2, 5], dtypetorch.float32)inputs torch.reshape(inputs, (1, 1, 1, 3)) targets torch.reshape(targe…...

Nginx:配置拦截/禁用ip地址
分析nginx日志 1、分析截止目前为止访问量最高的ip排行 awk {print $1} access.log |sort |uniq -c|sort -nr |head -20过滤出access.log日志文件中访问量前20的ip sort :将文件进行排序,并将排序结果标准输出uniq -nr : 去重并在右边显示…...
css超出部分显示省略号
目录 前言 一、CSS单行实现 二、CSS多行实现(CSS3出的,兼容性需要注意) 三、微信小程序超过2行出现省略号实现 四、JavaScript脚本实现 前言 CSS文本溢出就显示省略号,就是在样式中指定了盒子的宽度与高度,有可能出现某些内…...

python-0001-安装虚拟环境
版本 软件版本python3.9.10django2.2.5sqlite33.45.1pycharm2023.3.4 安装python3.9.10 升级sqlite3 下载地址:https://download.csdn.net/download/qq_41833259/88944701 升级命令: tar -zxvf sqlite-autoconf-3399999.tar.gz cd sqlite-autoconf-…...
Python爬虫:原理与实战
引言 在当今的信息时代,互联网上的数据如同浩瀚的海洋,充满了无尽的宝藏。Python爬虫作为一种高效的数据抓取工具,能够帮助我们轻松地获取这些数据,并进行后续的分析和处理。本文将深入探讨Python爬虫的原理,并结合实战…...
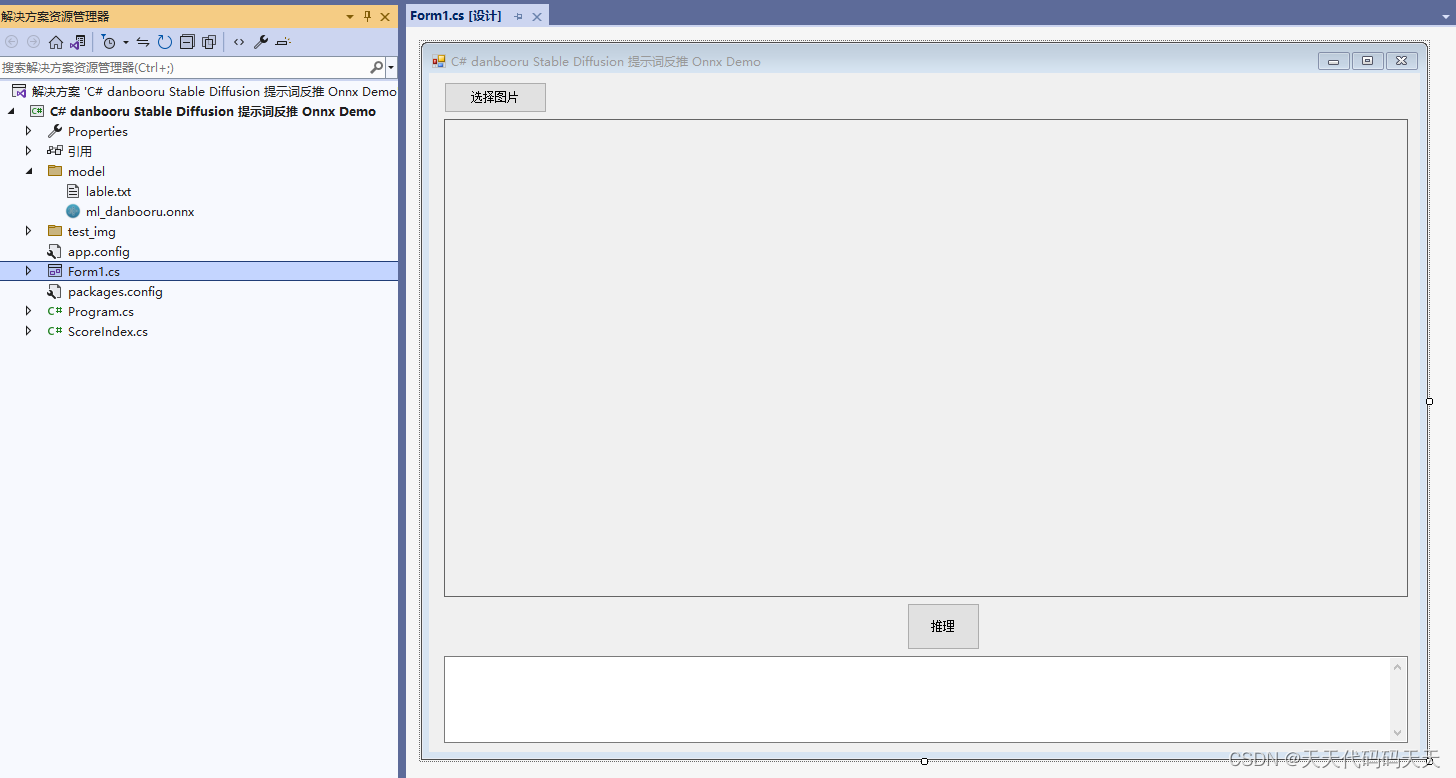
C# danbooru Stable Diffusion 提示词反推 Onnx Demo
目录 说明 效果 模型信息 项目 代码 下载 C# danbooru Stable Diffusion 提示词反推 Onnx Demo 说明 模型下载地址:https://huggingface.co/deepghs/ml-danbooru-onnx 效果 模型信息 Model Properties ------------------------- ----------------------…...
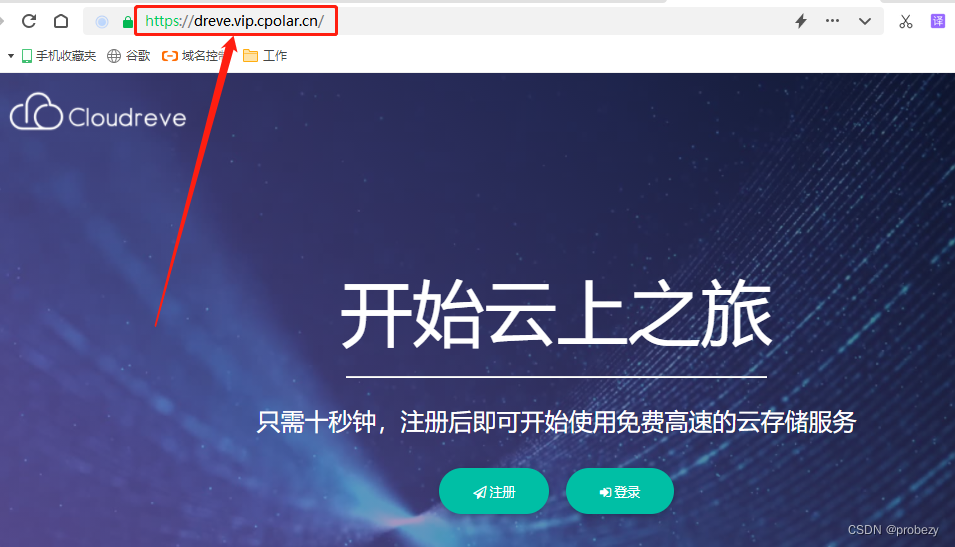
Windows系统搭建Cloudreve结合内网穿透打造可公网访问的私有云盘
目录 ⛳️推荐 1、前言 2、本地网站搭建 2.1 环境使用 2.2 支持组件选择 2.3 网页安装 2.4 测试和使用 2.5 问题解决 3、本地网页发布 3.1 cpolar云端设置 3.2 cpolar本地设置 4、公网访问测试 5、结语 ⛳️推荐 前些天发现了一个巨牛的人工智能学习网站ÿ…...
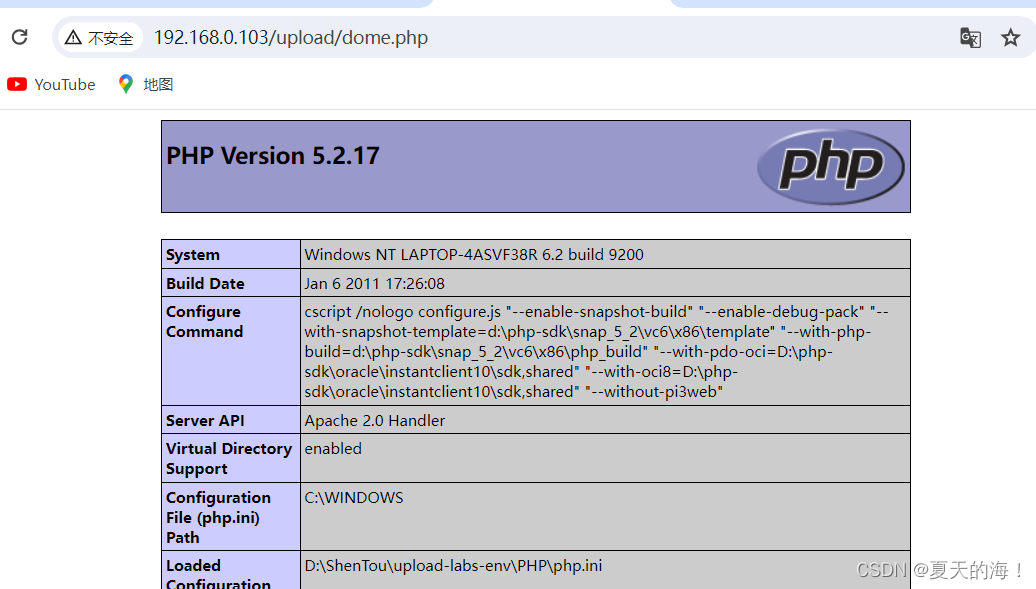
upload-labs 0.1 靶机详解
下载地址https://github.com/c0ny1/upload-labs/releases Pass-01 他让我们上传一张图片,我们先尝试上传一个php文件 发现他只允许上传图片格式的文件,我们来看看源码 我们可以看到它使用js来限制我们可以上传的内容 但是我们的浏览器是可以关闭js功能的…...
react 综合题-旧版
一、组件基础 1. React 事件机制 javascript 复制代码<div onClick{this.handleClick.bind(this)}>点我</div> React并不是将click事件绑定到了div的真实DOM上,而是在document处监听了所有的事件,当事件发生并且冒泡到document处的时候&a…...

基于ElasticSearch存储海量AIS数据:AIS数据索引机制篇
文章目录 引言I 预备知识1.1 索引结构1.2 AIS信息项II AIS数据索引2.1 AIS数据静态数据索引2.2 AIS数据动态信息索引2.3 引入静态信息的AIS数据轨迹信息索引引言 AIS数据信息根据其不同更新频率可分为静态和动态信息。索引结构设计包含了静态、动态和轨迹信息索引。同时,为了…...

IDEA中返回上一步和下一步快捷键失效【Ctrl+Alt+左箭头】
原因与解决方法 快捷键失效的缘故,和其它软件的快捷键冲突。方法:改变快捷键。如果不知道哪个软件影响的,一个一个关闭软件,然后再去IDEA中尝试快捷键是否生效。 【提示:我的是QQ音乐软件打开影响的】...

山东防爆监控哪个品牌好用
在当前的工业生产环境中,尤其是矿山、石化、制药等高危行业,防爆监控设备已成为确保安全生产的重要工具。然而,面对市场上琳琅满目的品牌和产品,企业往往难以做出最佳选择。本次推荐的5家[主体类型],均在山东防爆监控领…...

【Linux驱动开发】第12天:Linux设备树核心:树形结构+节点+属性 完整全解
目录 设备树树形结构概述节点(Node)全解:命名规范标准节点常用设备节点属性(Property)全解:类型核心属性总线专用属性标签与节点引用:设备树复用的核心常见错误与注意事项总结:驱动…...

从实战出发:聊聊Serial口静态路由在老旧网络设备迁移中的那些事儿
从实战出发:聊聊Serial口静态路由在老旧网络设备迁移中的那些事儿 第一次在机房里见到那台积满灰尘的Cisco 1841时,我差点以为这是个博物馆展品。但客户坚持说这台服役超过15年的老伙计承载着他们最重要的生产线控制数据,任何闪失都可能造成六…...

如何快速解决Windows 11区域模拟问题:完整API钩子技术指南
如何快速解决Windows 11区域模拟问题:完整API钩子技术指南 【免费下载链接】Locale_Remulator System Region and Language Simulator. 项目地址: https://gitcode.com/gh_mirrors/lo/Locale_Remulator Locale Remulator是一款强大的系统区域和语言模拟工具&…...

AI知识擦除:Gemini3.1Pro能否真正遗忘危险?
概念擦除:能否从 Gemini 3.1 Pro 中删除特定危险知识?——理性看待“遗忘”与“可控”在 2026 年的 AI 热点语境下,“可控”和“可验证”成为讨论主线。除了提升模型能力,人们也更关心另一件事:**当模型掌握了不希望被…...

为你的大模型应用快速接入Taotoken,Python调用只需三步
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的大模型应用快速接入Taotoken,Python调用只需三步 对于希望在自己的应用中集成大模型能力的开发者而言࿰…...

3分钟快速上手Vin象棋:基于YOLOv5的智能中国象棋连线工具终极指南
3分钟快速上手Vin象棋:基于YOLOv5的智能中国象棋连线工具终极指南 【免费下载链接】VinXiangQi Xiangqi syncing tool based on Yolov5 / 基于Yolov5的中国象棋连线工具 项目地址: https://gitcode.com/gh_mirrors/vi/VinXiangQi 你是否厌倦了手动记录棋局的…...

二刷hot100-101.对称二叉树
递归写法;终止条件有很多,左右节点都为空,返回true;有一方为空或者值不相等,返回false;如果都不满足,进入下一层递归:左的左和右的右比较,左的右和右的左比较;…...

如何在Windows上让DualShock 3控制器重获新生?DsHidMini虚拟HID驱动技术解析
如何在Windows上让DualShock 3控制器重获新生?DsHidMini虚拟HID驱动技术解析 【免费下载链接】DsHidMini Virtual HID Mini-user-mode-driver for Sony DualShock 3 Controllers 项目地址: https://gitcode.com/gh_mirrors/ds/DsHidMini 在Windows平台使用索…...

Unity中Spine动画高效集成的四大关键断层
1. 为什么Spine不是“换个插件就完事”的动画方案?在Unity 2D项目里,当美术开始交付第一版Spine动画资源时,很多团队会下意识地把它当成“比SpriteRenderer高级一点的图片播放器”——拖进场景、挂个SpineAnimation组件、调个AnimationName&a…...