Transformer代码从零解读【Pytorch官方版本】
文章目录
- 1、Transformer大致有3大应用
- 2、Transformer的整体结构图
- 3、如何处理batch-size句子长度不一致问题
- 4、MultiHeadAttention(多头注意力机制)
- 5、前馈神经网络
- 6、Encoder中的输入masked
- 7、完整代码
- 补充知识:
1、Transformer大致有3大应用
1、机器翻译类应用:Encoder和Decoder共同使用,
2、只使用Encoder端:文本分类BERT和图片分类VIT,
3、只使用Decoder端:生成类模型,
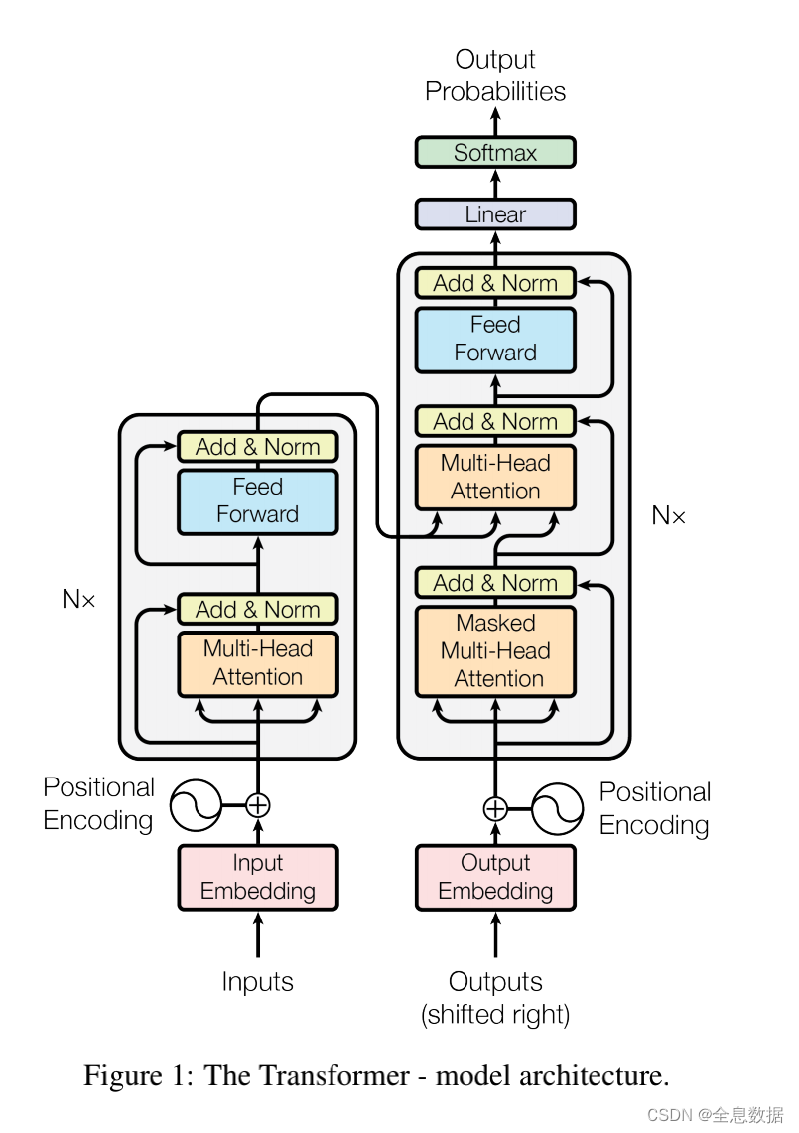
2、Transformer的整体结构图
Transformer整体结构有2个输入,1个输出,具体过程可参考这个链接:详情请点击,
如下图,左边是Encoder,右边是Decoder,2个输入分别是Encoder的输入,Decoder的输入,
先看左边的Encoder,输入经过词向量层和位置编码层,得到最终的输入,通过多头注意力机制和前馈神经网络得到Encoder的输出,该输出会与Decoder进行交互,
再看右边的Decoder,输入经过词向量层和位置编码层,得到最终的输入,通过掩码注意力机制,然后交互注意力机制与Encoder的输出做交互,Encoder的输出做K矩阵、V矩阵,Decoder的值做Q矩阵,再经过前馈神经网络层,得到Decoder的输出,
如下图一共有2个输入,分别是“我爱你”和“S I LOVE YOU”,“我爱你”这个句子是3个token,token翻译成词元,“S I LOVE YOU”中的 S 是特殊字符,“I LOVE YOU E”是解码端的真实标签,与输出结果计算损失,
解码端是没法并行的,因为输入【S】,输出【I】,然后输出的【I】作为下一阶段的输入,这一次的输入取决于上一次的输出,所以解码端无法并行,
但是为了加快训练速度和收敛速度,我们使用Teacher forcing,就是把真实标签作为一种输入,把当前输入单词后面所有的单词全部 mask 掉,

“ich mochte ein bier P”是编码端的德语输入,“S i want a beer"是解码端的英语输入,“i want a beer E”是解码端的真实标签,一般在训练时为了加快训练速度,需要增加batch-size,

3、如何处理batch-size句子长度不一致问题
以中文为例,batch-size为4,如下图所示每一行句子代表每个batch-size中的第一个句子,代表Encoding的输入,Decoding的输入和标签值下图已省略,
1个batch在被模型处理的时候,为了加快速度常使用矩阵的方式来计算,但是如果一个batch中句子长度不一致,就组不成一个有效的矩阵,为了解决这个问题,一个常规的操作就是给每个句子设置 max-length,

假设设置max-length为8,句子的长度大于8的删除,小于8的用P替换,如下图,
需要注意的是,PAD这种方法不仅用在在Encoder的输入,也用在Decoder的输入,

位置编码公式:
P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE(pos,2i)=sin(pos/10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE(pos,2i+1)=cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
两个共有的部分: e − ( 2 i ) / d m o d e l ∗ l o g ( 10000 ) = 1 / 1000 0 2 i / d m o d e l e^{-(2i)/d_{model}*log(10000)}=1/10000^{2i/d_{model}} e−(2i)/dmodel∗log(10000)=1/100002i/dmodel,这里POS代表的是每个字符在整个句子中的索引,512是整个句子最大长度,和2i对应的Embedding维度512要区分开,位置编码和Embedding相加即可得到整个输出的内容,
位置编码公式代码如下:
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout=0.1, max_len=5000):super(PositionalEncoding, self).__init__()# 位置编码的实现其实很简单,直接对照着公式去敲代码就可以,下面这个代码只是其中一种实现方式;# 从理解上来讲,需要注意的就是偶数和奇数在公式上有一个共同部分,我们使用log函数把次方拿下来,方便计算;# pos代表的是单词在句子中的索引,这点需要注意;比如max_len是128个,那么索引就是从0,1,2,...,127# 假设我的d_model是512,2i那个符号中i从0取到了255,那么2i对应取值就是0,2,4,...,510self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # shape:[max_len,1]div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # shape:[d_model/2]pe[:, 0::2] = torch.sin(position * div_term) # 这里需要注意的是pe[:, 0::2]这个用法,就是从0开始到最后面,步长为2,其实代表的就是偶数位置pe[:, 1::2] = torch.cos(position * div_term) # 这里需要注意的是pe[:, 1::2]这个用法,就是从1开始到最后面,步长为2,其实代表的就是奇数位置# 上面代码获取之后得到的pe.shape:[max_len, d_model]# 下面这个代码之后,我们得到的pe形状是:[max_len, 1, d_model]pe = pe.unsqueeze(0).transpose(0, 1)self.register_buffer('pe', pe) # 定一个缓冲区,其实简单理解为这个参数不更新就可以def forward(self, x):"""x: [src_len, batch_size, d_model]"""x = x + self.pe[:x.size(0), :]return self.dropout(x)
为什么需要告诉后面模型哪些位置被PAD填充
注意力机制公式:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
下图是 Q K T QK^T QKT相乘后的矩阵,还没有经过softmax计算,表示每个单词和其他所有单词的相似性,应该能看到不应该把PAD参与计算,

如何去掉PAD信息?利用符号矩阵,不是PAD置为0,是PAD的置为1,

代码:
把PAD为0的元素置为True,
# 比如说,我现在的句子长度是5,在后面注意力机制的部分,我们在计算出来QK转置除以根号之后,softmax之前,我们得到的形状
# len_input * len*input 代表每个单词对其余包含自己的单词的影响力# 所以这里我需要有一个同等大小形状的矩阵,告诉我哪个位置是PAD部分,之后在计算计算softmax之前会把这里置为无穷大;# 一定需要注意的是这里得到的矩阵形状是batch_size x len_q x len_k,我们是对k中的pad符号进行标识,并没有对k中的做标识,因为没必要# seq_q 和 seq_k 不一定一致,在交互注意力,q来自解码端,k来自编码端,所以告诉模型编码这边pad符号信息就可以,解码端的pad信息在交互注意力层是没有用到的;def get_attn_pad_mask(seq_q, seq_k):batch_size, len_q = seq_q.size()batch_size, len_k = seq_k.size()# eq(zero) is PAD tokenpad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k, one is maskingreturn pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k
4、MultiHeadAttention(多头注意力机制)
如下图,batch-size为1,src_len为2(即有2个单词), d m o d e l d_{model} dmodel为4,

代码:
class MultiHeadAttention(nn.Module):def __init__(self):super(MultiHeadAttention, self).__init__()# 输入进来的QKV是相等的,我们会使用映射linear做一个映射得到参数矩阵Wq, Wk, Wvself.W_Q = nn.Linear(d_model, d_k * n_heads)self.W_K = nn.Linear(d_model, d_k * n_heads)self.W_V = nn.Linear(d_model, d_v * n_heads)self.linear = nn.Linear(n_heads * d_v, d_model)self.layer_norm = nn.LayerNorm(d_model)def forward(self, Q, K, V, attn_mask):# 这个多头分为这几个步骤,首先映射分头,然后计算atten_scores,然后计算atten_value;# 输入进来的数据形状: Q: [batch_size x len_q x d_model], K: [batch_size x len_k x d_model],👇# V: [batch_size x len_k x d_model], attn_mask.shape:[batch_size, src_len_q, src_len_k]residual, batch_size = Q, Q.size(0)# (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)# 下面这个就是先映射,后分头;一定要注意的是q和k分头之后维度是一致的,所以一看这里都是dkq_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]# 输入进行的attn_mask形状是 batch_size x len_q x len_k,👇# 然后经过下面这个代码得到 新的attn_mask : [batch_size x n_heads x len_q x len_k],# 就是把pad信息重复了n个头上attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)# 然后我们计算 ScaledDotProductAttention 这个函数,去7.看一下# 得到的结果有两个:context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q x len_k]context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)# context: [batch_size x len_q x n_heads * d_v]context = context.transpose(1, 2).contiguous().view(batch_size, -1,n_heads * d_v)output = self.linear(context)return self.layer_norm(output + residual), attn # output: [batch_size x len_q x d_model]
Encoder代码:
class EncoderLayer(nn.Module):def __init__(self):super(EncoderLayer, self).__init__()self.enc_self_attn = MultiHeadAttention()self.pos_ffn = PoswiseFeedForwardNet()def forward(self, enc_inputs, enc_self_attn_mask):# 下面这个就是做自注意力层,输入是enc_inputs,形状是[batch_size x seq_len_q x d_model] 需要注意的是最初始的QKV矩阵是等同于这个输入的,# 去看一下enc_self_attn函数 6.enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs,enc_self_attn_mask) # enc_inputs to same Q,K,Venc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size x len_q x d_model]return enc_outputs, attndef get_attn_pad_mask(seq_q, seq_k):batch_size, len_q = seq_q.size()batch_size, len_k = seq_k.size()# eq(zero) is PAD tokenpad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k, one is maskingreturn pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_kclass PositionalEncoding(nn.Module):def __init__(self, d_model, dropout=0.1, max_len=5000):super(PositionalEncoding, self).__init__()# 位置编码的实现其实很简单,直接对照着公式去敲代码就可以,下面这个代码只是其中一种实现方式;# 从理解上来讲,需要注意的就是偶数和奇数在公式上有一个共同部分,我们使用log函数把次方拿下来,方便计算;# pos代表的是单词在句子中的索引,这点需要注意;比如max_len是128个,那么索引就是从0,1,2,...,127# 假设我的d_model是512,2i那个符号中i从0取到了255,那么2i对应取值就是0,2,4,...,510self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term) # 这里需要注意的是pe[:, 0::2]这个用法,就是从0开始到最后面,补长为2,其实代表的就是偶数位置pe[:, 1::2] = torch.cos(position * div_term) # 这里需要注意的是pe[:, 1::2]这个用法,就是从1开始到最后面,补长为2,其实代表的就是奇数位置# 上面代码获取之后得到的pe:[max_len*d_model]# 下面这个代码之后,我们得到的pe形状是:[max_len*1*d_model]pe = pe.unsqueeze(0).transpose(0, 1)self.register_buffer('pe', pe) # 定一个缓冲区,其实简单理解为这个参数不更新就可以def forward(self, x):"""x: [seq_len, batch_size, d_model]"""x = x + self.pe[:x.size(0), :]return self.dropout(x)class Encoder(nn.Module):def __init__(self):super(Encoder, self).__init__()# nn.Embedding:https://blog.csdn.net/raelum/article/details/125462028?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171029892316800211559494%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171029892316800211559494&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-125462028-null-null.142^v99^pc_search_result_base8&utm_term=nn.Embedding&spm=1018.2226.3001.4187self.src_emb = nn.Embedding(src_vocab_size, d_model) # 这个其实就是去定义生成一个矩阵,大小是 src_vocab_size * d_model,👇# src_vocab_size=src_len,d_model是词向量的维度,self.pos_emb = PositionalEncoding(d_model) # 位置编码情况,这里是固定的正余弦函数,也可以使用类似词向量的nn.Embedding获得一个可以更新学习的位置编码self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) # 使用ModuleList对多个encoder进行堆叠,因为后续的encoder并没有使用词向量和位置编码,所以抽离出来;def forward(self, enc_inputs):# 这里我们的 enc_inputs 形状是: [batch_size * src_len]# 下面这个代码通过src_emb进行索引定位,enc_outputs输出形状是[batch_size, src_len, d_model]enc_outputs = self.src_emb(enc_inputs)# 这里就是位置编码,把两者相加放入到了这个函数里面,从这里可以去看一下位置编码函数的实现;3.enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1)# get_attn_pad_mask是为了得到句子中pad的位置信息,给到模型后面,在计算自注意力和交互注意力的时候去掉pad符号的影响,去看一下这个函数 4.enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)enc_self_attns = []for layer in self.layers:# 去看EncoderLayer 层函数 5.enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)enc_self_attns.append(enc_self_attn)return enc_outputs, enc_self_attns
5、前馈神经网络
代码:
class PoswiseFeedForwardNet(nn.Module):def __init__(self):super(PoswiseFeedForwardNet, self).__init__()self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)self.layer_norm = nn.LayerNorm(d_model)def forward(self, inputs):residual = inputs # inputs : [batch_size, len_q, d_model]output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))output = self.conv2(output).transpose(1, 2)return self.layer_norm(output + residual)
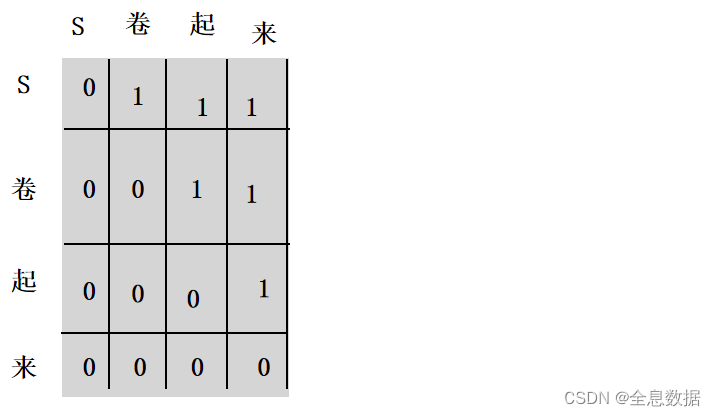
6、Encoder中的输入masked
如果当前输入为【S】,则后面的【卷起来】被遮挡,当输入为【S卷】时,后面的【起来】被遮挡,形成上三角矩阵为1的矩阵,
7、完整代码
# from https://github.com/graykode/nlp-tutorial/tree/master/5-1.Transformerimport numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import mathdef make_batch(sentences):input_batch = [[src_vocab[n] for n in sentences[0].split()]]output_batch = [[tgt_vocab[n] for n in sentences[1].split()]]target_batch = [[tgt_vocab[n] for n in sentences[2].split()]]return torch.LongTensor(input_batch), torch.LongTensor(output_batch), torch.LongTensor(target_batch)# 10
def get_attn_subsequent_mask(seq):"""seq: [batch_size, tgt_len]"""attn_shape = [seq.size(0), seq.size(1), seq.size(1)]# attn_shape: [batch_size, tgt_len, tgt_len]subsequence_mask = np.triu(np.ones(attn_shape), k=1) # 生成一个上三角矩阵subsequence_mask = torch.from_numpy(subsequence_mask).byte()return subsequence_mask # [batch_size, tgt_len, tgt_len]# 7. ScaledDotProductAttention
class ScaledDotProductAttention(nn.Module):def __init__(self):super(ScaledDotProductAttention, self).__init__()def forward(self, Q, K, V, attn_mask):# 输入进来的维度分别是 [batch_size x n_heads x len_q x d_k] K: [batch_size x n_heads x len_k x d_k]👇# V: [batch_size x n_heads x len_k x d_v], attn_mask : [batch_size x n_heads x len_q x len_k]# 首先经过matmul函数得到的scores形状是 : [batch_size x n_heads x len_q x len_k]scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)# 然后关键词地方来了,下面这个就是用到了我们之前重点讲的attn_mask,把被mask的地方置为无限小,softmax之后基本就是0,对q的单词不起作用scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is one.attn = nn.Softmax(dim=-1)(scores)context = torch.matmul(attn, V)return context, attn# 6. MultiHeadAttention
class MultiHeadAttention(nn.Module):def __init__(self):super(MultiHeadAttention, self).__init__()# 输入进来的QKV是相等的,我们会使用映射linear做一个映射得到参数矩阵Wq, Wk, Wvself.W_Q = nn.Linear(d_model, d_k * n_heads)self.W_K = nn.Linear(d_model, d_k * n_heads)self.W_V = nn.Linear(d_model, d_v * n_heads)self.linear = nn.Linear(n_heads * d_v, d_model)self.layer_norm = nn.LayerNorm(d_model)def forward(self, Q, K, V, attn_mask):# 这个多头分为这几个步骤,首先映射分头,然后计算atten_scores,然后计算atten_value;# 输入进来的数据形状: Q: [batch_size x len_q x d_model], K: [batch_size x len_k x d_model],👇# V: [batch_size x len_k x d_model], attn_mask.shape:[batch_size, src_len_q, src_len_k]residual, batch_size = Q, Q.size(0)# (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)# 下面这个就是先映射,后分头;一定要注意的是q和k分头之后维度是一致的,所以一看这里都是dkq_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]# 输入进行的attn_mask形状是 batch_size x len_q x len_k,👇# 然后经过下面这个代码得到 新的attn_mask : [batch_size x n_heads x len_q x len_k],# 就是把pad信息重复了n个头上attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)# 然后我们计算 ScaledDotProductAttention 这个函数,去7.看一下# 得到的结果有两个:context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q x len_k]context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)# context: [batch_size x len_q x n_heads * d_v]context = context.transpose(1, 2).contiguous().view(batch_size, -1,n_heads * d_v)output = self.linear(context)return self.layer_norm(output + residual), attn # output: [batch_size x len_q x d_model]# 8. PoswiseFeedForwardNet
class PoswiseFeedForwardNet(nn.Module):def __init__(self):super(PoswiseFeedForwardNet, self).__init__()self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)self.layer_norm = nn.LayerNorm(d_model)def forward(self, inputs):residual = inputs # inputs : [batch_size, len_q, d_model]output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))output = self.conv2(output).transpose(1, 2)return self.layer_norm(output + residual)# 4. get_attn_pad_mask# 比如说,我现在的句子长度是5,在后面注意力机制的部分,我们在计算出来QK转置除以根号之后,softmax之前,我们得到的形状
# len_input * len*input 代表每个单词对其余包含自己的单词的影响力# 所以这里我需要有一个同等大小形状的矩阵,告诉我哪个位置是PAD部分,之后在计算计算softmax之前会把这里置为无穷大;# 一定需要注意的是这里得到的矩阵形状是batch_size x len_q x len_k,我们是对k中的pad符号进行标识,并没有对k中的做标识,因为没必要# seq_q 和 seq_k 不一定一致,在交互注意力,q来自解码端,k来自编码端,所以告诉模型编码这边pad符号信息就可以,解码端的pad信息在交互注意力层是没有用到的;def get_attn_pad_mask(seq_q, seq_k):batch_size, len_q = seq_q.size()batch_size, len_k = seq_k.size()# eq(zero) is PAD tokenpad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # shape:[batch_size, 1, len_k], one is maskingreturn pad_attn_mask.expand(batch_size, len_q, len_k) # shape:[batch_size, len_q, len_k]# 3. PositionalEncoding 代码实现
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout=0.1, max_len=5000):super(PositionalEncoding, self).__init__()# 位置编码的实现其实很简单,直接对照着公式去敲代码就可以,下面这个代码只是其中一种实现方式;# 从理解上来讲,需要注意的就是偶数和奇数在公式上有一个共同部分,我们使用log函数把次方拿下来,方便计算;# pos代表的是单词在句子中的索引,这点需要注意;比如max_len是128个,那么索引就是从0,1,2,...,127# 假设我的d_model是512,2i那个符号中i从0取到了255,那么2i对应取值就是0,2,4,...,510self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # shape:[max_len,1]div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # shape:[d_model/2]pe[:, 0::2] = torch.sin(position * div_term) # 这里需要注意的是pe[:, 0::2]这个用法,就是从0开始到最后面,步长为2,其实代表的就是偶数位置pe[:, 1::2] = torch.cos(position * div_term) # 这里需要注意的是pe[:, 1::2]这个用法,就是从1开始到最后面,步长为2,其实代表的就是奇数位置# 上面代码获取之后得到的pe.shape:[max_len, d_model]# 下面这个代码之后,我们得到的pe形状是:[max_len, 1, d_model]pe = pe.unsqueeze(0).transpose(0, 1)self.register_buffer('pe', pe) # 定一个缓冲区,其实简单理解为这个参数不更新就可以def forward(self, x):"""x: [src_len, batch_size, d_model]"""x = x + self.pe[:x.size(0), :]return self.dropout(x)# 5. EncoderLayer :包含两个部分,多头注意力机制和前馈神经网络
class EncoderLayer(nn.Module):def __init__(self):super(EncoderLayer, self).__init__()self.enc_self_attn = MultiHeadAttention()self.pos_ffn = PoswiseFeedForwardNet()def forward(self, enc_inputs, enc_self_attn_mask):# 下面这个就是做自注意力层,输入是enc_inputs,形状是[batch_size, seq_len_q, d_model], 需要注意的是最初始的QKV矩阵是等同于这个输入的,# 去看一下enc_self_attn函数 6.enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs,enc_self_attn_mask) # enc_inputs to same Q,K,Venc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size x len_q x d_model]return enc_outputs, attn# 2. Encoder 部分包含三个部分:词向量embedding,位置编码部分,注意力层及后续的前馈神经网络
class Encoder(nn.Module):def __init__(self):super(Encoder, self).__init__()# nn.Embedding:https://blog.csdn.net/raelum/article/details/125462028?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171029892316800211559494%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171029892316800211559494&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-125462028-null-null.142^v99^pc_search_result_base8&utm_term=nn.Embedding&spm=1018.2226.3001.4187self.src_emb = nn.Embedding(src_vocab_size, d_model) # 这个其实就是去定义生成一个矩阵,大小是 src_vocab_size * d_model,👇# src_vocab_size=src_len,d_model是词向量的维度,self.pos_emb = PositionalEncoding(d_model) # 位置编码情况,这里是固定的正余弦函数,也可以使用类似词向量的nn.Embedding获得一个可以更新学习的位置编码self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) # 使用ModuleList对多个encoder进行堆叠,因为后续的encoder并没有使用词向量和位置编码,所以抽离出来;def forward(self, enc_inputs):# 这里我们的 enc_inputs 形状是: [batch_size, src_len]# 下面这个代码通过src_emb进行索引定位,enc_outputs输出形状是[batch_size, src_len, d_model]enc_outputs = self.src_emb(enc_inputs)# 这里就是位置编码,把两者相加放入到了这个函数里面,从这里可以去看一下位置编码函数的实现;3.# enc_outputs.shape:[batch_size, src_len, d_model]enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1)# get_attn_pad_mask是为了得到句子中pad的位置信息,给到模型后面,在计算自注意力和交互注意力的时候去掉pad符号的影响,去看一下这个函数 4.# enc_self_attn_mask.shape:[batch_size, src_len_q, src_len_k]enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)enc_self_attns = []for layer in self.layers:# 去看EncoderLayer 层函数 5.enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)enc_self_attns.append(enc_self_attn)return enc_outputs, enc_self_attns# 10.
class DecoderLayer(nn.Module):def __init__(self):super(DecoderLayer, self).__init__()self.dec_self_attn = MultiHeadAttention()self.dec_enc_attn = MultiHeadAttention()self.pos_ffn = PoswiseFeedForwardNet()def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)dec_outputs = self.pos_ffn(dec_outputs)return dec_outputs, dec_self_attn, dec_enc_attn# 9. Decoder
class Decoder(nn.Module):def __init__(self):super(Decoder, self).__init__()self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)self.pos_emb = PositionalEncoding(d_model)self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])def forward(self, dec_inputs, enc_inputs, enc_outputs): # dec_inputs : [batch_size x target_len]dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, tgt_len, d_model]# get_attn_pad_mask 自注意力层的时候的pad部分dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs)# get_attn_subsequent_mask 这个做的是自注意层的mask部分,就是当前单词之后看不到,使用一个上三角为1的矩阵dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs)# 两个矩阵相加,大于0的为1,不大于0的为0,为1的在之后就会被fill到无限小dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0)# 这个做的是交互注意力机制中的mask矩阵,enc的输入是k,我去看这个k里面哪些是pad符号,给到后面的模型;注意哦,我q肯定也是有pad符号,但是这里我不在意的,👇# 之前说了好多次了哈dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)dec_self_attns, dec_enc_attns = [], []for layer in self.layers:dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask,dec_enc_attn_mask)dec_self_attns.append(dec_self_attn)dec_enc_attns.append(dec_enc_attn)return dec_outputs, dec_self_attns, dec_enc_attns# 1. 从整体网路结构来看,分为三个部分:编码层,解码层,输出层
class Transformer(nn.Module):def __init__(self):super(Transformer, self).__init__()self.encoder = Encoder() # 编码层self.decoder = Decoder() # 解码层self.projection = nn.Linear(d_model, tgt_vocab_size,bias=False) # 输出层d_model是我们解码层每个token输出的维度大小,之后会做一个tgt_vocab_size大小的softmaxdef forward(self, enc_inputs, dec_inputs):# 这里有两个数据进行输入,一个是enc_inputs,形状为[batch_size, src_len],主要是作为编码段的输入,一个是dec_inputs,形状为[batch_size, tgt_len],👇# 主要是作为解码端的输入;# enc_inputs作为输入,形状为[batch_size, src_len],输出由自己的函数内部指定,想要输出什么就可以指定输出什么,可以是全部tokens的输出,可以是特定每一层的输出;👇# 也可以是中间某些参数的输出;# enc_outputs就是主要的输出,enc_self_attns这里没记错的是QK转置相乘之后softmax之后的矩阵值,代表的是每个单词和其他单词相关性;enc_outputs, enc_self_attns = self.encoder(enc_inputs)# dec_outputs 是decoder主要输出,用于后续的linear映射; dec_self_attns类比于enc_self_attns,是查看每个单词对decoder中输入的其余单词的相关性;# dec_enc_attns是decoder中每个单词对encoder中每个单词的相关性;dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)# dec_outputs做映射到词表大小dec_logits = self.projection(dec_outputs) # dec_logits : [batch_size x src_vocab_size x tgt_vocab_size]return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attnsif __name__ == '__main__':# 句子的输入部分,P是指PAD# 这3个句子分别代表Encoding的输入,Decoding的输入,Decoding的真实标签,sentences = ['ich mochte ein bier P', 'S i want a beer', 'i want a beer E']# Transformer Parameters# Padding Should be Zero# 构建Encoding词表(Vocabulary)src_vocab = {'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4}src_vocab_size = len(src_vocab)# 构建Decoding词表(Vocabulary)tgt_vocab = {'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'S': 5, 'E': 6}tgt_vocab_size = len(tgt_vocab)src_len = 5 # length of sourcetgt_len = 5 # length of target# 模型参数d_model = 512 # Embedding Size,每个字符转换为Embedding的大小d_ff = 2048 # FeedForward dimensiond_k = d_v = 64 # dimension of K(=Q), Vn_layers = 6 # number of Encoder of Decoder Layern_heads = 8 # number of heads in Multi-Head Attentionmodel = Transformer()criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.001)enc_inputs, dec_inputs, target_batch = make_batch(sentences)for epoch in range(20):optimizer.zero_grad()outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)loss = criterion(outputs, target_batch.contiguous().view(-1))print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))loss.backward()optimizer.step()补充知识:
torch.repeat和torch.expand的区别,
代码:
import torch
a=torch.arange(0, 9).view(3, 3)
print(a)
b=a.eq(0)
print(b)
c=b.unsqueeze(1)
print(c)
d=c.expand(3, 3, 3)
print(d)
e=c.repeat(1, 3, 1)
print(e)
输出:
tensor([[0, 1, 2],[3, 4, 5],[6, 7, 8]])
tensor([[ True, False, False],[False, False, False],[False, False, False]])
tensor([[[ True, False, False]],[[False, False, False]],[[False, False, False]]])
tensor([[[ True, False, False],[ True, False, False],[ True, False, False]],[[False, False, False],[False, False, False],[False, False, False]],[[False, False, False],[False, False, False],[False, False, False]]])
tensor([[[ True, False, False],[ True, False, False],[ True, False, False]],[[False, False, False],[False, False, False],[False, False, False]],[[False, False, False],[False, False, False],[False, False, False]]])
参考:
1、nn.Embedding:CSDN链接,
2、哔哩哔哩视频,
相关文章:
Transformer代码从零解读【Pytorch官方版本】
文章目录 1、Transformer大致有3大应用2、Transformer的整体结构图3、如何处理batch-size句子长度不一致问题4、MultiHeadAttention(多头注意力机制)5、前馈神经网络6、Encoder中的输入masked7、完整代码补充知识: 1、Transformer大致有3大应…...

安卓性能优化面试题 31-35
31. 简述Handler导致的内存泄露的原因以及如何解决 ?在Android开发中,Handler对象可能导致内存泄漏的主要原因是由于Handler持有对外部类对象的隐式引用,从而导致外部类无法被垃圾回收,进而引发内存泄漏。下面是导致Handler内存泄漏的几种常见情况及相应的解决方法: 1. 长…...

QML与C++通信
一、QML中如何使用C的类和对象 前提条件: 1.从 QObject 或 QObject 的派生类继承 2.使用 Q_OBJECT 宏 这两个条件是为了让一个类能够进入 Qt 强大的元对象系统(meta-object system)中,只有使用元对象系统,一个类的某些…...

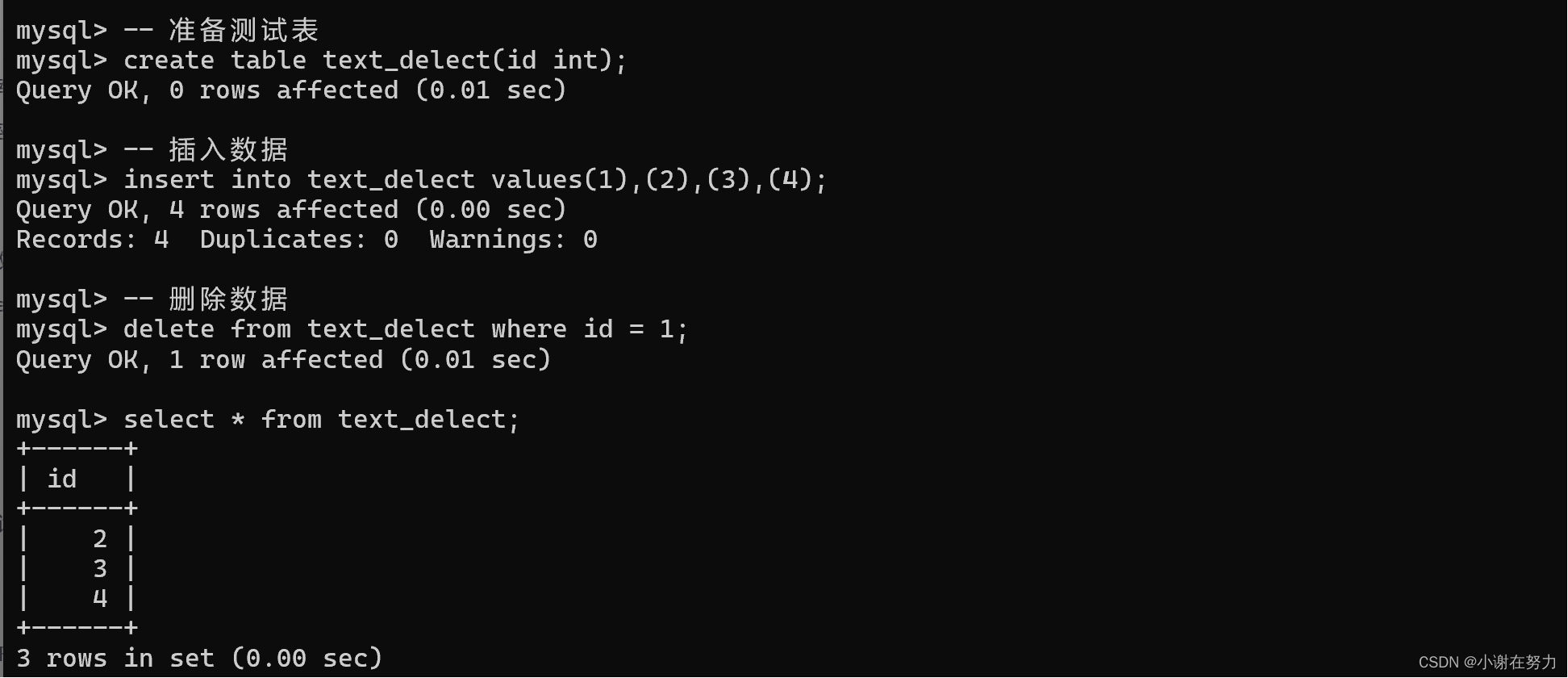
Explain详解与索引优化最佳实践
Explain工具介绍 使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析你的查询语句或是结构的性能瓶颈 在select语句之前增加explain关键字,MySQL会在查询前设置一个标记,执行查询会返回执行计划的信息,而不是执行这条SQL 注意: 如果from中包含子查询,仍会执行该子查询,将结果…...
Spring Boot轻松整合Minio实现文件上传下载功能【建议收藏】
一、Linux 安装Minio 安装 在/root/xxkfz/soft目录下面创建文件minio文件夹,进入minio文件夹,并创建data目录; [rootxxkfz soft]# mkdir minio [rootxxkfz soft]# cd minio [rootxxkfz minio]# mkdir data执行如下命令进行下载 [rootxxkf…...
MySql入门教程--MySQL数据库基础操作
꒰˃͈꒵˂͈꒱ write in front ꒰˃͈꒵˂͈꒱ ʕ̯•͡˔•̯᷅ʔ大家好,我是xiaoxie.希望你看完之后,有不足之处请多多谅解,让我们一起共同进步૮₍❀ᴗ͈ . ᴗ͈ აxiaoxieʕ̯•͡˔•̯᷅ʔ—CSDN博客 本文由xiaoxieʕ̯•͡˔•̯᷅ʔ 原创 CSDN …...

鸿蒙Harmony应用开发—ArkTS声明式开发(基础手势:Slider)
滑动条组件,通常用于快速调节设置值,如音量调节、亮度调节等应用场景。 说明: 该组件从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 子组件 无 接口 Slider(options?: SliderOption…...

第五十六回 徐宁教使钩镰枪 宋江大破连环马-飞桨图像分类套件PaddleClas初探
宋江等人学会了钩镰枪,大胜呼延灼。呼延灼损失了很多人马,不敢回京,一个人去青州找慕容知府。一天在路上住店,马被桃花山的人偷走了,于是到了青州,带领官兵去打莲花山。 莲花山的周通打不过呼延灼…...

springboot/ssm企业内部人员绩效量化管理系统Java员工绩效管理系统web
springboot/ssm企业内部人员绩效量化管理系统Java员工绩效管理系统web 基于springboot(可改ssm)vue项目 开发语言:Java 框架:springboot/可改ssm vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库&…...

XML语言的学习记录2-XMLHttpRequest
学习笔记:XMLHttpRequest 特点: 在不重新加载页面的情况下更新网页在页面已加载后从服务器请求数据在页面已加载后从服务器接收数据在后台向服务器发送数据创建XMLHttpRequest对象 xmlhttpnew XMLHttpRequest();IE5 和 IE6,使用 …...

力扣爆刷第95天之hot100五连刷61-65
力扣爆刷第95天之hot100五连刷61-65 文章目录 力扣爆刷第95天之hot100五连刷61-65一、131. 分割回文串二、51. N 皇后三、35. 搜索插入位置四、74. 搜索二维矩阵五、34. 在排序数组中查找元素的第一个和最后一个位置 一、131. 分割回文串 题目链接:https://leetcod…...

聊聊powerjob的执行机器地址
序 本文主要研究一下powerjob的执行机器地址(designatedWorkers) SaveJobInfoRequest powerjob-common/src/main/java/tech/powerjob/common/request/http/SaveJobInfoRequest.java Data public class SaveJobInfoRequest {/*** id of the job. set null to create or non-…...

Android Kotlin知识汇总(三)Kotlin 协程
Kotlin的重要优势及特点之——结构化并发 Kotlin 协程让异步代码像阻塞代码一样易于使用。协程可大幅简化后台任务管理,例如网络调用、本地数据访问等任务的管理。本主题介绍如何使用 Kotlin 协程解决以下问题,从而让您能够编写出更清晰、更简洁的应用代…...

JVM垃圾收集器-serial.parNew,parallelScavnge,serialOld,parallelOld,CMS,G1
垃圾收集器 分代模型 适用于新生代: serial parNew parallel Scaavenge 适用于老年代: CMS serial Old(msc) paraller Old 分区模型 适用于超大容量: G1 分代模型 serial /serial Old收集器 1.单线程收集器 2.收集时会暂停其他线程&…...

docker搭建upload-labs
Upload-labs 是一个专门设计用于学习和练习文件上传安全的开源工具。它提供了各种场景的文件上传漏洞,供用户通过实践来学习如何发现和利用这些漏洞,同时也能学习到防御措施。使用 Docker 来搭建 upload-labs 环境是一种快速、简便的方法,它可…...

超详细外贸单证汇总!
今天给大家汇总了外贸单证的种类与使用相关知识,东西齐全,赶紧码住! 1、合同 CONTRACT是统称,买卖双方均可出具。如系卖方制作,可称为销售确认书,买方出具则可称为采购。 买卖双方均可出具合同。卖方出具的,可称为销售确认书(Sales Confir…...
Docker部署ChatGLM3、One API、FastGPT
创建并运行chatglm3容器 docker run --name chatglm3 -p 8000:8000 registry.cn-hangzhou.aliyuncs.com/ryyan/chatglm.cpp:chatglm3-q5_1 创建并运行one-api容器 (其中挂载路径 D:\one-api 可以选择你自己喜欢的目录) docker run --name oneapi -d -p 3000:3000 -e TZAsia…...
【Linux-网络编程】
Linux-网络编程 ■ 网络结构■ C/S结构■ B/S结构 ■ 网络模型■ OSI七层模型■ TCP/IP四层模型 ■ TCP■ TCP通信流程■ TCP三次握手■ TCP四次挥手 ■ 套接字:socket 主机IP 主机上的进程(端口号)■ TCP传输文件 ■ 网络结构 ■ C/S结构…...
win10虚拟机安装驱动教程
在虚拟机菜单栏中选择安装VMware Tools: 安装好后,在虚拟机中打开此电脑,双击DVD驱动器进行安装: 一直点击下一步: 安装完成: 此时重启虚拟机,发面小屏幕页面的虚拟机自动占满了全部屏幕&#x…...
SpringBoot实战项目——博客笔记项目
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、项目介绍二、项目的整体框架 2.1 数据库模块 2.2 前端模块 2.3 后端模块三、项目图片展示四、项目的实现 4.1 准备工作 4.…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

无机布防火卷帘门价格怎么算?按尺寸定制,按需报价
无机布防火卷帘门作为建筑防火分区的核心设备,价格一直是工程采购的关注重点。很多用户在询价时,会发现不同厂家的报价差异较大,这是因为无机布防火卷帘门的价格并非按统一单价计算,而是完全根据项目的实际需求定制化核算。 &…...

量子计算中Loschmidt回声相位测量的创新方法
1. 量子计算中的Loschmidt回声相位测量方法概述Loschmidt回声是量子动力学中一个重要的概念,它描述了量子系统在时间反演演化后与初始状态的相似程度。在量子计算领域,精确测量Loschmidt回声的相位信息对于理解量子系统的非平衡态行为、计算能量本征值以…...

从入门到上岗,Java+AI 复合型人才养成攻略
当下编程行业格局正在悄然改变,纯 Java 后端岗位内卷日趋严重,薪资增长逐步放缓;纯粹的 AI 算法岗门槛居高不下,对学历、数理功底要求严苛,普通开发者很难入局。 而Java+AI 复合型开发顺势成为行业刚需岗位,既依托成熟的 Java 体系承接业务开发,又能融入人工智能技术实…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

基于ESP32与MQTT的家庭环境监测系统:从传感器选型到数据可视化实战
1. 项目概述与核心价值最近几年,我身边越来越多的朋友开始关注家里的空气质量、温湿度这些看不见摸不着,但又实实在在影响生活舒适度和健康的环境指标。从新装修的房子担心甲醛,到有老人小孩的家庭在意PM2.5和二氧化碳浓度,再到南…...

告别Postman!用APIfox搞定接口测试+自动化,这份保姆级教程带你从环境配置到报告生成
从Postman到APIfox:接口测试自动化的高效迁移指南如果你还在为接口测试中的重复劳动和多环境切换头疼,是时候考虑从Postman迁移到APIfox了。作为一名经历过这个转型过程的开发者,我想分享一些实战经验,帮助你平滑过渡并最大化利用…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

国内大学生常用的AI写作辅助平台有哪些?
国内高校学生常用的 AI 写作辅助平台,以本土化全流程工具为主,结合通用大模型与专项功能模块,覆盖选题构思、大纲搭建、初稿撰写、语言润色、降重处理、查重检测及格式排版等关键环节,以下是主流平台详解与对比: 一、本…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...