【模拟string函数的实现】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
模拟string函数的实现
浅拷贝
深拷贝
vs和g++下string结构的说明
总结
前言
模拟string函数的实现
浅拷贝
深拷贝
总结
前言
世上有两种耀眼的光芒,一种是正在升起的太阳,一种是正在努力学习编程的你!一个爱学编程的人。各位看官,我衷心的希望这篇博客能对你们有所帮助,同时也希望各位看官能对我的文章给与点评,希望我们能够携手共同促进进步,在编程的道路上越走越远!
提示:以下是本篇文章正文内容,下面案例可供参考
模拟string函数的实现
string.h#pragma once
#include <assert.h>
//string其实就是一个字符顺序表,唯一的区别就是在有效字符后面加了一个\0
namespace bit
{class string{public:typedef char* iterator;//把类型重命名成iterator,然后让类域隔开typedef const char* const_iterator;//const_iterator其实就是const char*const_iterator begin() const{return _str;}const_iterator end() const//const修饰的是this{return _str + _size;}//函数的类型是无法支持函数的重载iterator begin(){return _str;//返回的是字符串第一个字符的下标}iterator end(){return _str + _size;//返回的是'\0'的下标}//无参的构造函数//string()// :_str(nullptr)//不能给str空指针,怕返回空指针// //如果给str赋值 nullptr,采用c语言的接口,返回的字符串是空指针,打印空指针会报错的// ,_size(0)// ,_capacity(0)//{}//c++兼容c,我们要用c语言的接口:返回字符串const char* c_str() const{return _str;}所以,我们要给str开一个空间,并赋值'\0',返回字符的地址,这是可以的//string()// :_str(new char[1])// , _size(0)// , _capacity(0)//{// _str[0] = '\0';//}//带参的构造函数/*string(const char* str)//strlen:遍历字符串,遇到 \0 就停止,不易多调用:_size(strlen(str)),_str(new char[strlen(str)+1]),_capacity(strlen(str))//capacity:不包含 \0 {strcpy(_str, str);}*///以上的无参和带参的构造函数合二为一:全缺省的构造函数(即可传参,也可不传传参)//第一种情况://string(const char* str = nullptr)//如果传的是无参,strlen(str):遍历字符串时,会对指针指向的内容解引用,str指向的是空指针//第二种情况://string(const char* str = '\0')//也不能给str赋值 '\0',左右两边的类型要匹配;右边类型:char 左边类型:const char*//第三种情况://string(const char* str = "\0")//字符串是"\0",但是结束时,还会再加一个 \0//第四种情况:string(const char* str = "")//缺省值给一个空字符串:_size(strlen(str)){_capacity = _size;//capacity:存有效的字符空间,有效的字符是0个,但是还开了一个空间,用来存\0 _str = new char[_capacity + 1];strcpy(_str, str);}size_t capacity() const{return _capacity;}//遍历size_t size() const{return _size;//返回有效字符串的个数}//函数的声明和定义在一块,本质就相当于是内联char& operator[](size_t pos){assert(pos < _size);return _str[pos];//这些数据在堆区上,出来作用域也不会销毁,可以返回别名}//函数重载,上面的和下面的各用各的const char& operator[](size_t pos) const{//只能获取pos位置的字符,但是不能修改assert(pos < _size);return _str[pos];//这些数据在堆区上,出来作用域也不会销毁,可以返回别名}//s2(s1):深拷贝(拷贝构造函数)string(const string& s){_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}//s2(s1)string(const string& s){string tmp(s._str);swap(tmp);}//赋值运算符重载(s1 = s3):也会出现浅拷贝的问题string& operator=(const string& s){char* tmp = new char[s._capacity + 1];strcpy(tmp, s._str);delete[] _str;//把s1原来空间释放掉_str = tmp;_size = s._size;_capacity = s._capacity;return *this;}//析构函数~string(){delete[] _str;_str = nullptr;_size = _capacity = 0;}void resize(size_t n, char ch = '\0')//半缺省函数,有实参会替换缺省值{//保留前n个数据if (n <= _size){_str[n] = '\0';_size = n;}else{reserve(n);//n > capacity,就扩容for (size_t i = _size; i < n; i++){_str[i] = ch;}_str[n] = '\0';_size = n;}}void reserve(size_t n){if (n > _capacity){//手动扩容char* tmp = new char[n + 1];//开空间永远要多开一个,多开的一个是给'\0'准备的strcpy(tmp, _str);//拷贝数据delete[] _str;//释放旧空间_str = tmp;//指针指向新空间_capacity = n;}}void push_back(char ch){// 扩容2倍/*if (_size == _capacity){reserve(_capacity == 0 ? 4 : 2 * _capacity);}_str[_size] = ch;++_size;_str[_size] = '\0';*/insert(_size, ch);//复用insert()函数}void append(const char* str){// 扩容//size_t len = strlen(str);//if (_size + len > _capacity)//{// //_size:当前字符串的长度;len:插入的字符串的长度;'\0'会单独开空间存放// reserve(_size + len);//}insert(_size, str);//复用insert()函数}string& operator+=(char ch){push_back(ch);return *this;}string& operator+=(const char* str){append(str);return *this;}void insert(size_t pos, char ch){assert(pos <= _size);// 扩容2倍if (_size == _capacity){reserve(_capacity == 0 ? 4 : 2 * _capacity);}//挪动数据方法一:/*int end = _size;//while (end >= pos)//end:有符号;pos:无符号;有符号会向无符号提升while (end >= (int)pos)//这里的循环是把包括pos位置和end位置之间的数据往后挪动{//如果一个运算符两边的操作数的类型不同的时候,会发生类型提升(范围小的向范围大的提升)_str[end + 1] = _str[end];--end;}*//*_str[pos] = ch;++_size;*///挪动数据方法二:size_t end = _size + 1;while (end > pos){_str[end] = _str[end - 1];--end;}_str[pos] = ch;++_size;}void insert(size_t pos, const char* str){assert(pos <= _size);//pos=size--->就相当于尾插size_t len = strlen(str);if (_size + len > _capacity){// 扩容reserve(_size + len);}size_t end = _size + len;while (end > pos + len - 1){_str[end] = _str[end - len];end--;}strncpy(_str + pos, str, len);_size += len;}void erase(size_t pos, size_t len = npos){assert(pos < _size);//不用删除\0//if (len == npos || len + pos >= _size)//假如len == npos-1,npos是-1,是无符号整型的最大值,再加pos,可能会存在溢出的风险if (len == npos || len >= _size - pos){_str[pos] = '\0';_size = pos;}else{strcpy(_str + pos, _str + pos + len);_size -= len;}}void swap(string& s){// 我们已经用 using namespace std;将std命名空间域给展开了,为什么还要加 std:: 呢?// 将 std 命名空间域展开(相当于:小王家开了一个通告,说你们可以拿我家的菜),// 但是顺序还是不变的:局部域----->全局域----->命名空间域// 加 std::是为了防止 swap()函数在局部域找swap()函数的定义出处时,发生事故;// 不加 std:: 的话,swap()函数会先找到 swap(string& s)的,但是参数的类型不一样,会发生报错 std::swap(_str, s._str);//调用库里的模板,这里是交换了堆区空间的地址std::swap(_size, s._size);std::swap(_capacity, s._capacity);}//找字符size_t find(char ch, size_t pos = 0) const{assert(pos < _size);for (size_t i = pos; i < _size; i++){if (_str[i] == ch)return i;}return npos;}//找字符串size_t find(const char* sub, size_t pos = 0) const{assert(pos < _size);const char* p = strstr(_str + pos, sub);if (p){return p - _str;//指针 - 指针 == 两个指针之间的元素个数(返回的是下标)}else{return npos;}}string substr(size_t pos = 0, size_t len = npos){string sub;//if (len == npos || len >= _size-pos)if (len >= _size - pos){for (size_t i = pos; i < _size; i++){sub += _str[i];}}else{for (size_t i = pos; i < pos + len; i++){sub += _str[i];}}return sub;}//只清理空间中的数据,并不会缩容void clear(){_size = 0;_str[_size] = '\0';}private://初始化列表初始化的顺序和声明的顺序一样char* _str;size_t _size;size_t _capacity;public:static const int npos;//npos:是一个公有的静态成员变量};const int string::npos = -1;//string中的非成员函数void swap(string& x, string& y){x.swap(y);}//全局函数bool operator==(const string& s1, const string& s2){int ret = strcmp(s1.c_str(), s2.c_str());return ret == 0;}bool operator<(const string& s1, const string& s2){int ret = strcmp(s1.c_str(), s2.c_str());return ret < 0;}bool operator<=(const string& s1, const string& s2){return s1 < s2 || s1 == s2;}bool operator>(const string& s1, const string& s2){return !(s1 <= s2);}bool operator>=(const string& s1, const string& s2){return !(s1 < s2);}bool operator!=(const string& s1, const string& s2){return !(s1 == s2);}//流插入(必须是全局函数,没有访问类中的私有成员变量,所以不需要设置成友元函数)ostream& operator<<(ostream& out, const string& s){for (auto ch : s){out << ch;}return out;}//流提取(是一个覆盖)istream& operator>>(istream& in, string& s)//提取的字符放入string类型的对象中,所以不需要要用const来修饰{//s是s1和s2的别名,s对象中有s1或s2的字符串内容,流提取是一个覆盖;//此时流提取只会在字符串的尾部插入数据,所以我们要先把s对象中的数据清理掉s.clear();char ch;//in >> s[i];//不能这么写,对象s中还没有写入字符,还没有数据//in >> ch;//c++的cin和c语言的scanf是读元素的时候,是读不到空格和换行的//(他们认为空格或换行是多个元素之间的分割符,会自动把空格或换行符给忽略掉)//c语言应该用 getchar/getc;但是c++是不能用的//(因为c语言和c++的iostream流不是同一个,他们都有各自的缓存区)ch = in.get();//所以用它来取字符char buff[128];//1、在栈上开空间比在堆上开空间要快一些;2、出了函数作用域空间就销毁了,不会一直浪费空间size_t i = 0;//流插入和流提取遇到 空格或换行 就默认结束while (ch != ' ' && ch != '\n'){//buff:字符数组,一段一段往对象s中加buff[i++] = ch;// [0,126]if (i == 127){buff[127] = '\0';s += buff;//把前127个字符加入对象s中i = 0;}ch = in.get();}if (i > 0){buff[i] = '\0';s += buff;//把有效的数据个数加入对象s中}return in;}//流提取(是一个覆盖)//istream& operator>>(istream& in, string& s)//提取的字符放入string类型的对象中,所以不需要要用const来修饰//{// //s是s1和s2的别名,s对象中有s1或s2的字符串内容,流提取是一个覆盖;// //此时流提取只会在字符串的尾部插入数据,所以我们要先把s对象中的数据清理掉// s.clear();// char ch;// //in >> s[i];//不能这么写,对象s中还没有写入字符,还没有数据// //in >> ch;// //c++的cin和c语言的scanf是读元素的时候,是读不到空格和换行的// //(他们认为空格或换行是多个元素之间的分割符,会自动把空格或换行符给忽略掉)// //c语言应该用 getchar/getc;但是c++是不能用的// //(因为c语言和c++的iostream流不是同一个,他们都有各自的缓存区)// ch = in.get();//所以用它来取字符// s.reserve(128);// //流插入和流提取遇到 空格或换行 就默认结束// while (ch != '\n' && ch != ' ')// {// s += ch;// ch = in.get();// }// return in;//}//获取一行istream& getline(istream& in, string& s){s.clear();char ch;//in >> ch;ch = in.get();char buff[128];size_t i = 0;while (ch != '\n'){buff[i++] = ch;// [0,126]if (i == 127){buff[127] = '\0';s += buff; i = 0;}ch = in.get();}if (i > 0){buff[i] = '\0';s += buff;}return in;}
void test_string1(){string s1("hello world");string s2;cout << s1.c_str() << endl;cout << s2.c_str() << endl;for (size_t i = 0; i < s1.size(); i++){s1[i]++;}cout << endl;//遍历:下标+[]for (size_t i = 0; i < s1.size(); i++){//s1:既能调用const的函数,也可以调用非const的函数//s1.operator[](i)cout << s1[i] << "";}cout << endl;const string s3("xxxx");//只能调用const char& operator[](size_t pos) const这个函数for (size_t i = 0; i < s3.size(); i++){//s3[i]++;cout << s3[i] << " ";}cout << endl;数组的越界是很不好检查的://int a[10];数组的读是检查不出来的//a[10];//a[11];数组的写不一定能检查出来。因为数组的越界检查是一种抽查//a[10] = 1;}void test_string2(){string s3("hello world");//范围for是一个替换机制(会自动替换成迭代器,这个地方是写死的,迭代器中必须要有iterator、begin、end)://自动取对象s3里面的数据赋值给ch,自动迭代,自动加加for (auto ch : s3)//s3是普通对象,范围for替换成普通迭代器{cout << ch << " ";}cout << endl;//迭代器(像指针,但不一定是指针)string::iterator it3 = s3.begin();while (it3 != s3.end()){*it3 -= 1;cout << *it3 << " ";++it3;}cout << endl;const string s4("xxxx");string::const_iterator it4 = s4.begin();while (it4 != s4.end()){//*it4 += 3;cout << *it4 << " ";++it4;}cout << endl;//s4是const对象,范围for替换成const迭代器(class类中必须声明iterator、begin、end)for (auto ch : s4){cout << ch << " ";}cout << endl;}void test_string3(){string s3("hello world");s3.push_back('1');s3.push_back('2');cout << s3.c_str() << endl;s3 += 'x';s3 += "yyyyyy";cout << s3.c_str() << endl;string s1("hello world");s1.insert(11, 'x');cout << s1.c_str() << endl;s1.insert(0, 'x');cout << s1.c_str() << endl;}void test_string4(){string s1("hello world");cout << s1.c_str() << endl;s1.erase(6, 3);cout << s1.c_str() << endl;s1.erase(6, 30);cout << s1.c_str() << endl;s1.erase(3);cout << s1.c_str() << endl;string s2("hello world");cout << s2.c_str() << endl;s2.resize(5);cout << s2.c_str() << endl;s2.resize(20, 'x');cout << s2.c_str() << endl;}void test_string5(){string s1("hello world");cout << s1.c_str() << endl;//此时,这里是 浅拷贝/值拷贝;s1和s2中的_str所指向的空间是同一块,析构函数释放数据会释放两次,//并且改动数据,对两个都有影响string s2(s1);cout << s2.c_str() << endl;s1[0] = 'x';cout << s1.c_str() << endl;cout << s2.c_str() << endl;string s3("xxxxx");s1 = s3;cout << s1.c_str() << endl;cout << s3.c_str() << endl;}void test_string6(){string s1("hello world");cout << s1.c_str() << endl;s1.insert(6, "xxx");cout << s1.c_str() << endl;string s2("xxxxxxx");cout << s1.c_str() << endl;cout << s2.c_str() << endl;swap(s1, s2);//调用库里面的swap模板,代价:三次拷贝构造+一次析构(涉及到深拷贝,释放和申请空间的次数太多)s1.swap(s2);//高效的方法:交换两个堆区空间的地址,不需要多次释放和申请空间cout << s1.c_str() << endl;cout << s2.c_str() << endl;}void test_string7(){string url1("https://legacy.cplusplus.com/reference/string/string/substr/");string url2("http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=65081411_1_oem_dg&wd=%E5%90%8E%E7%BC%80%20%E8%8B%B1%E6%96%87&fenlei=256&rsv_pq=0xc17a6c03003ede72&rsv_t=7f6eqaxivkivsW9Zwc41K2mIRleeNXjmiMjOgoAC0UgwLzPyVm%2FtSOeppDv%2F&rqlang=en&rsv_dl=ib&rsv_enter=1&rsv_sug3=4&rsv_sug1=3&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&inputT=1588&rsv_sug4=6786");string protocol, domain, uri;size_t i1 = url1.find(':');if (i1 != string::npos){protocol = url1.substr(0, i1 - 0);cout << protocol.c_str() << endl;}// strcharsize_t i2 = url1.find('/', i1 + 3);if (i2 != string::npos){domain = url1.substr(i1 + 3, i2 - (i1 + 3));cout << domain.c_str() << endl;uri = url1.substr(i2 + 1);cout << uri.c_str() << endl;}// strstr size_t i3 = url1.find("baidu");cout << i3 << endl;}void test_string8(){string s1("hello world");string s2("hello world");cout << (s1 == s2) << endl;cout << ("hello world" == s2) << endl;//左边是调用构造成员函数,类型是 const char*//左边不能是一个成员函数,他必须是一个对象,对象才能调用成员函数//(解释赋值运算符重载为什么是全局函数,如果是成员函数的话,第一个参数是 this,是对象的地址)cout << (s1 == "hello world") << endl;//单参数的构造函数可以支持隐式类型转换(const char*转换成string类型)cout << s1 << endl;cout << s2 << endl;//c++中的cout和cin的缓存区也不是同一个,所以cout出去的,不会影响cin进来的cin >> s1 >> s2;cout << s1 << endl;cout << s2 << endl;getline(cin, s1);cout << s1 << endl;}void test_string9(){string s1;cin >> s1;cout << s1.capacity() << endl;}void test_string10(){string s1("hello world");string s2(s1);cout << s1 << endl;cout << s2 << endl;}
}
test.cpp#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
#include<string>
#include"string.h"int main()
{bit::test_string1();return 0;
}//内置类型为什么支持流插入和流提取呢?
//因为库里面直接就把内置类型重载了,直接掉库里面的函数;又可以自动识别类型,是因为这些函数有互相构成了函数重载
tmp要初始化为nullptr,否则当swap交换之后,tmp指向空,出了函数的作用域之后,会调用析构函数,析构函数会对tmp局部变量销毁,如果tmp是随机值会报错,而是nullptr的话,就不会有问题。传统写法和现代写法效率基本都一样。
拷贝构造是用一个存在的对象去构造另外一个要初始化的对象,那另外一个对象是没有空间的。
赋值是两个对象都已经存在了。
栈上开空间要比堆区上开空间要快,而且成本更低。
浅拷贝
浅拷贝:也称位拷贝,编译器只是将对象中的值拷贝过来。如果对象中管理资源,最后就会导致多个对象共享同一份资源,当一个对象销毁时就会将该资源释放掉,而此时另一些对象不知道该资源已经被释放,以为还有效,所以当继续对资源进项操作时,就会发生发生了访问违规。
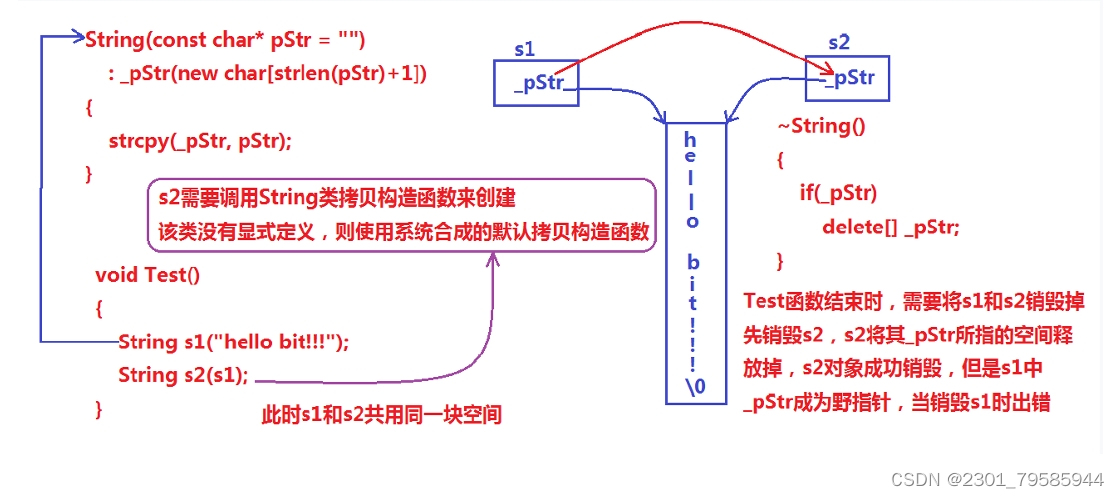
说明:
上述String类没有显式定义其拷贝构造函数与赋值运算符重载,此时编译器会合成默认的,当用s1构 造s2时,编译器会调用默认的拷贝构造。最终导致的问题是,s1、s2共用同一块内存空间,在释放时同一块 空间被释放多次而引起程序崩溃,这种拷贝方式,称为浅拷贝。
深拷贝



vs和g++下string结构的说明
注意:下述结构是在32位平台下进行验证,32位平台下指针占4个字节。
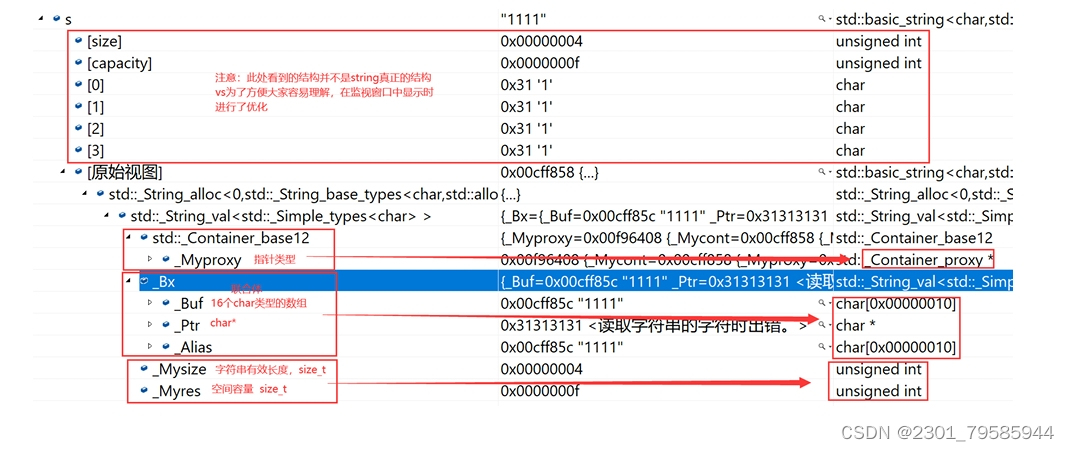
- vs下string的结构
string总共占28个字节,内部结构稍微复杂一点,先是有一个联合体,联合体用来定义string中字 符串的存储空间:
- 当字符串长度小于16时,使用内部固定的字符数组来存放
- 当字符串长度大于等于16时,从堆上开辟空间
union _Bxty{ // storage for small buffer or pointer to larger onevalue_type _Buf[_BUF_SIZE];pointer _Ptr;char _Alias[_BUF_SIZE]; // to permit aliasing} _Bx;这种设计也是有一定道理的,大多数情况下字符串的长度都小于16,那string对象创建好之后,内 部已经有了16个字符数组的固定空间,不需要通过堆创建,效率高。
其次:还有一个size_t字段保存字符串长度,一个size_t字段保存从堆上开辟空间总的容量
最后:还有一个指针做一些其他事情。
故总共占16+4+4+4=28个字节。
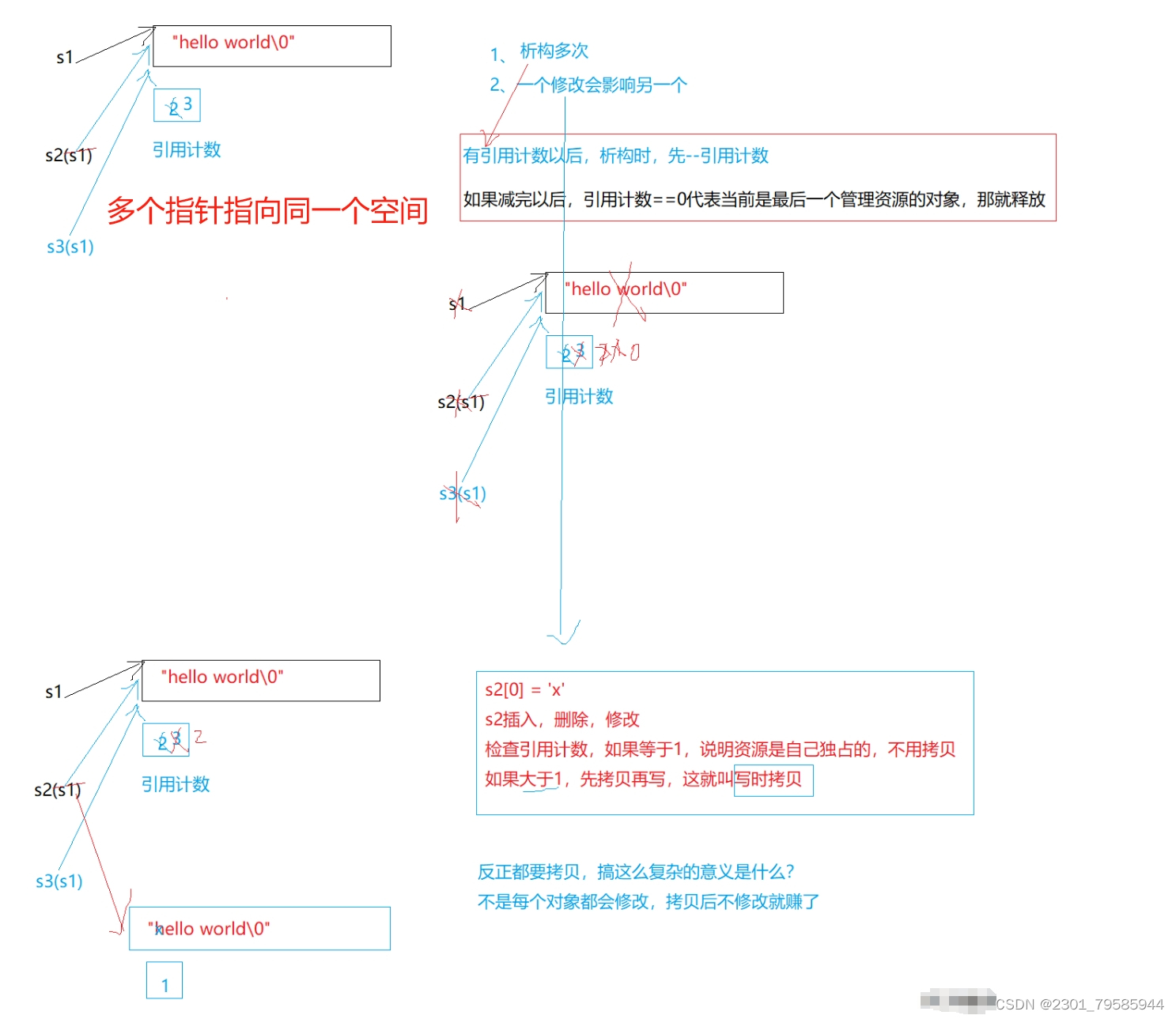
- g++下string的结构
G++下,string是通过写时拷贝实现的,string对象总共占4个字节,内部只包含了一个指针,该指 针将来指向一块堆空间,内部包含了如下字段:
- 空间总大小
- 字符串有效长度
- 引用计数
struct _Rep_base{size_type _M_length;size_type _M_capacity;_Atomic_word _M_refcount;};
- 指向堆空间的指针,用来存储字符串。

总结
好了,本篇博客到这里就结束了,如果有更好的观点,请及时留言,我会认真观看并学习。
不积硅步,无以至千里;不积小流,无以成江海。
相关文章:
【模拟string函数的实现】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 模拟string函数的实现 浅拷贝 深拷贝 vs和g下string结构的说明 总结 前言 模拟string函数的实现 浅拷贝 深拷贝 总结 前言 世上有两种耀眼的光芒&#…...
智能合约开发基础知识:最小信任机制、智能合约、EVM
苏泽 大家好 这里是苏泽 一个钟爱区块链技术的后端开发者 本篇专栏 ←持续记录本人自学两年走过无数弯路的智能合约学习笔记和经验总结 如果喜欢拜托三连支持~ 专栏的前面几篇详细了介绍了区块链的核心基础知识 有兴趣学习的小伙伴可以看看http://t.csdnimg.cn/fCD5E关于区块…...
程序人生——Java泛型和反射的使用建议
目录 引出泛型和反射建议93:Java的泛型是类型擦除的建议94:不能初始化泛型参数和数组建议95:强制声明泛型的实际类型 建议96:不同的场景使用不同的泛型通配符建议97:警惕泛型是不能协变和逆变的 建议98:建议…...

JavaSE-----认识异常【详解】
目录 一.异常的概念与体系结构: 1.1异常的概念: 1.2一些常见的异常: 1.3异常的体系结构: 1.4异常的分类: 二.异常的处理机制: 2.1 抛出异常: 2.2异常的捕获: 2.3try-catch-&…...
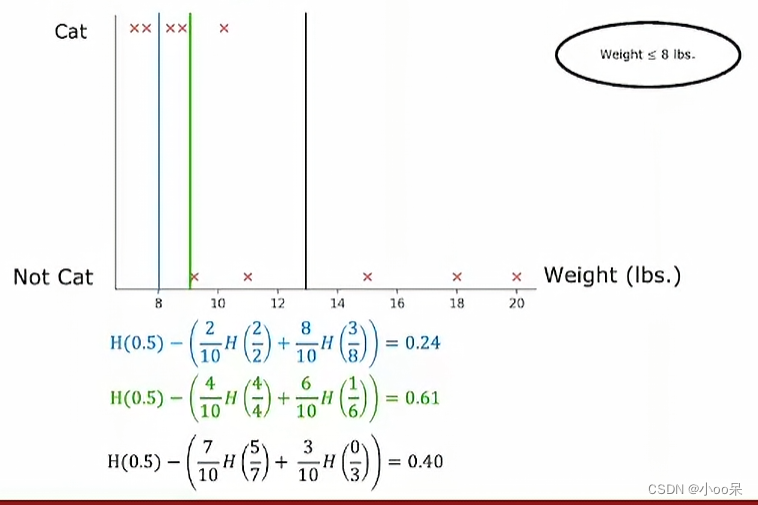
【机器学习300问】34、决策树对于数值型特征如果确定阈值?
还是用之前的猫狗二分类任务举例(这个例子出现在【机器学习300问】第33问中),我们新增一个数值型特征(体重),下表是数据集的详情。如果想了解更多决策树的知识可以看看我之前的两篇文章: 【机器…...

计算机二级(Python)真题讲解每日一题:《绘制雪花》
在横线处填写代码,完成如下功能…...

Rust 的 Arc<Mutex<T>> 的用法示例源代码
在 Rust 中,Arc<Mutex<T>> 是一种组合类型,它结合了 Arc(原子引用计数)和 Mutex(互斥锁)。Arc 用于在多个所有者之间共享数据,而 Mutex 用于确保在任意时刻只有一个线程可以访问被保…...

【NR 定位】3GPP NR Positioning 5G定位标准解读(十六)-UL-AoA 定位
前言 3GPP NR Positioning 5G定位标准:3GPP TS 38.305 V18 3GPP 标准网址:Directory Listing /ftp/ 【NR 定位】3GPP NR Positioning 5G定位标准解读(一)-CSDN博客 【NR 定位】3GPP NR Positioning 5G定位标准解读(…...

如何理解闭包
闭包是编程语言中一个重要的概念,特别是在函数式编程中常常会遇到。以下是对闭包的理解: 1. 定义: 闭包是一种函数,它引用了在其定义范围之外的自由变量(非全局变量),并且这些引用的变量在函数被调用时仍然保持活跃状态。2. 构成: 闭包通常由两部分组成:内部函数(函…...

python知识点总结(一)
这里写目录标题 一、什么是WSGI,uwsgi,uWSGI1、WSGI2、uWSGI3、uwsgi 二、python中为什么没有函数重载?三、Python中如何跨模块共享全局变量?四、内存泄露是什么?如何避免?五、谈谈lambda函数作用?六、写一个函数实现字符串反转,尽可能写出你知道的所…...
【Poi-tl Documentation】区块对标签显示隐藏改造
前置说明: <dependency><groupId>com.deepoove</groupId><artifactId>poi-tl</artifactId><version>1.12.1</version> </dependency>模板: 删除行表格测试.docx 改造前测试效果 package run.siyuan…...

第十四届蓝桥杯 三国游戏
一开始的思路就是想着暴力,但是呢,如果真的用暴力一个一个列的话,连30%的数据都搞定不了,所以这里需要考虑别的办法。 这道题的思路就是贪心。 我们这样想:既然要满足至少一个国X>YZ,那么我们何不变成…...
数据结构——通讯录项目
1.通讯录的介绍 顺序表是通讯录的底层结构。 通讯录是将顺序表的类型替换成结构体类型来储存用户数据,通过运用顺序表结构来实现的。 用户数据结构: typedef struct PersonInfo {char name[12];char sex[10];int age;char tel[11];char addr[100]; }…...
学点Java打小工_Day4_数组_冒泡排序
1 数组基本概念 程序算法数据结构 算法:解决程序的流程步骤 数据结构:将数据按照某种特定的结构来存储 设计良好的数据结构会导致良好的算法。 ArrayList、LinkedList 数组是最简单的数据结构。 数组:存放同一种类型数据的集合,在…...

内存分配方式?
内存分配方式主要有三种: 静态存储区分配:这种方式在程序编译的时候就已经分配好内存,并且这块内存在程序的整个运行期间都存在。全局变量和静态变量通常就是在静态存储区分配的。这种分配方式效率高,因为内存在程序开始执行前就已…...
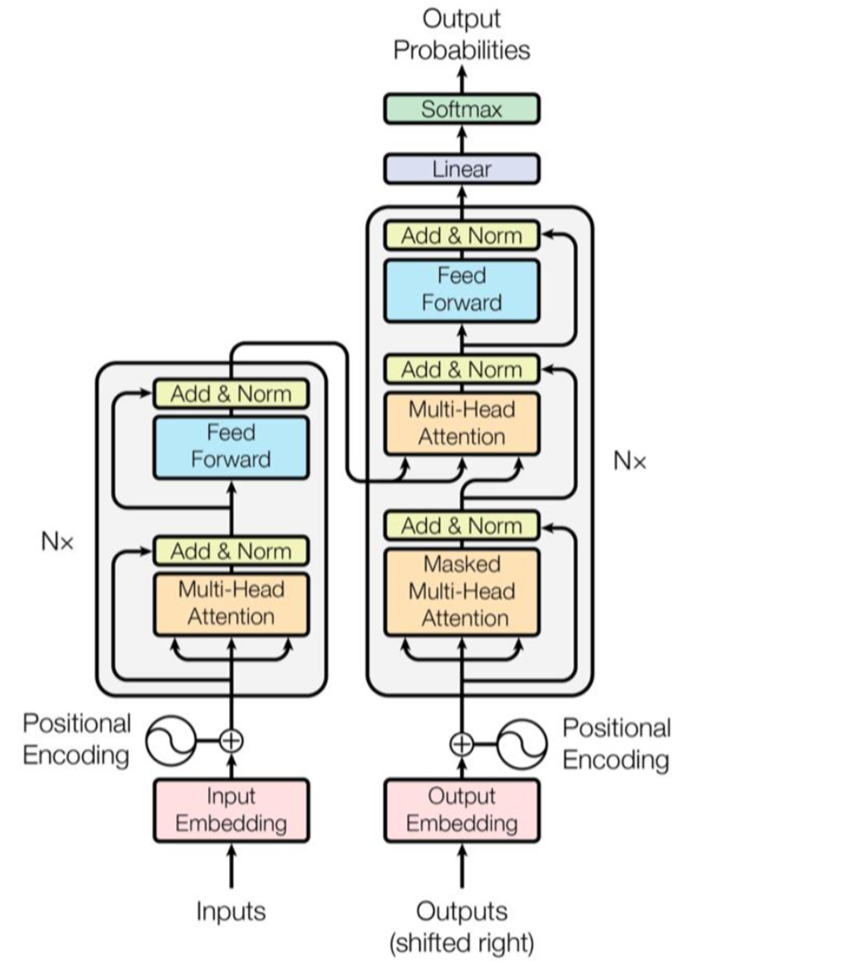
2024/3/17周报
文章目录 摘要Abstract文献阅读题目引言模型架构编码器和解码器堆栈AttentionPosition-wise Feed-Forward NetworksEmbeddings and SoftmaxPositional Encoding 实验数据实验结果 深度学习TransformerEncoderDecoder 总结 摘要 本周阅读了Transformer的开山之作《Attention Is…...

函数连续性和Lipschitz连续性
摘要: 直观上,Lipschitz连续性的含义是函数图像的变化速度有一个全局的上限,即函数的增长速率不会无限增加。这种性质确保了函数在任何地方都不会过于陡峭,有助于分析函数的行为,并且在优化、动力系统理论、机器学习等…...
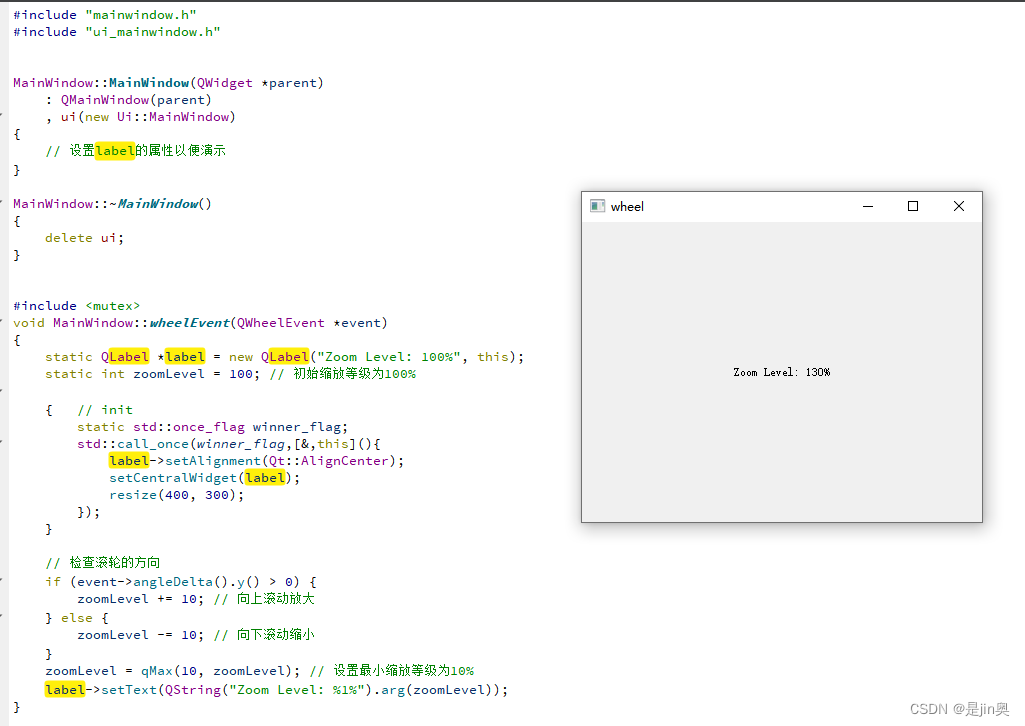
Qt 鼠标滚轮示例
1.声明 void wheelEvent(QWheelEvent *event) override;2.实现(方便复制、测试起见用静态变量) #include <mutex> void MainWindow::wheelEvent(QWheelEvent *event) {static QLabel *label new QLabel("Zoom Level: 100%", this);st…...
【Unity】进度条和血条的三种做法
前言 在使用Unity开发的时候,进度条和血条是必不可少的,本篇文章将简单介绍一下几种血条的制作方法。 1.使用Slider Slider组件由两部分组成:滑动区域和滑块。滑动区域用于显示滑动条的背景,而滑块则表示当前的数值位置。用户可…...
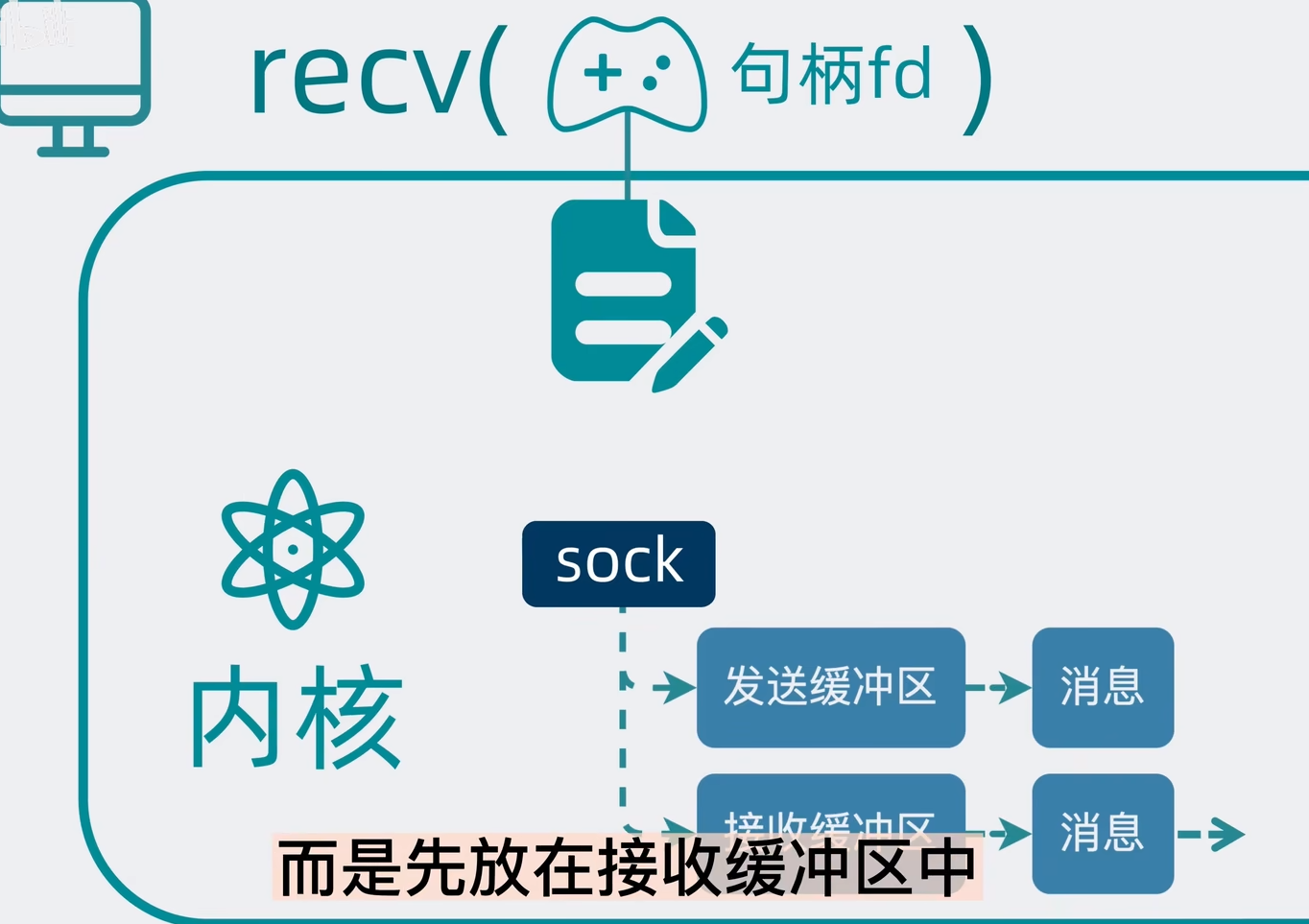
多人聊天室 (epoll - Linux网络编程)
文章目录 零、效果展示一、服务器代码二、客户端代码三、知识点1.connect()2.socket()3.bind()4.send()5.recv() 四、改进方向五、跟练视频 零、效果展示 一个服务器作为中转站,多个客户端之间可以相互通信。至少需要启动两个客户端。 三个客户端互相通信 一、服务…...

如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。
如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。 Word中脚注线不会删?这里有妙招!,教育,职业教育,好看视频...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...

3步深度解锁:网络设备权限管理工具的实战手册
3步深度解锁:网络设备权限管理工具的实战手册 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾面对功能受限的网络设备感到束手无策?当默认配置锁死了硬…...

轻量化部署,异地机房快速接入,多机房管理不用再大动干戈
随着业务拓展,不少企业、单位陆续建起异地分部机房、多区域节点机房。传统资产管理系统部署复杂、对接困难,异地机房接入成本高、周期长,改造繁琐,让很多运维团队望而却步,只能继续沿用分散人工管理,资产混…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...

终极键盘重映射解决方案:3分钟实现职业级游戏操作精度
终极键盘重映射解决方案:3分钟实现职业级游戏操作精度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对抗中,你是否曾因键盘按键冲突而错失关键操作?当同时按下…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南
Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南 【免费下载链接】Graphin 🌌 A React toolkit for graph visualization based on G6. 项目地址: https://gitcode.com/gh_mirrors/gr/Graphin 在当今数据驱动的时代,图可视化…...

机器学习加速分子晶体偏振拉曼光谱模拟:非谐效应与准谐效应的分离
1. 项目概述:当机器学习遇见偏振拉曼光谱 偏振-取向拉曼光谱(PO-Raman)一直是我在材料光谱分析领域里觉得既迷人又头疼的技术。它就像给材料的“分子指纹”加上了方向滤镜,能揭示出振动模式在空间中的对称性和各向异性,…...

基于Shapley值与随机森林的印度CPI通胀预测与特征重要性分析
1. 项目概述与核心价值在宏观经济预测领域,通胀预测的准确性直接关系到货币政策制定、市场预期管理乃至社会民生稳定。传统的计量经济学模型,如基于菲利普斯曲线的线性回归,虽然具有良好的可解释性,但在捕捉现实世界中复杂、非线性…...