Rabbit MQ详解
写在前面,由于Rabbit MQ涉及的内容较多,赶在春招我个人先按照我认为重要的内容进行一定总结,也算是个学习笔记吧。主要参考官方文档、其他优秀文章、大模型问答。自己边学习边总结。后面有时间我会慢慢把所有内容补全,分享出来也是希望可以给需要的同学提供一点儿帮助,想关注后续完整文章的可以点个关注丫,后续我会把现有文章全部重新补充和优化。
Rabbit MQ官网介绍
官网地址: RabbitMQ: One broker to queue them all | RabbitMQ
RabbitMQ is a message broker: it accepts and forwards messages. You can think about it as a post office: when you put the mail that you want posting in a post box, you can be sure that the letter carrier will eventually deliver the mail to your recipient. In this analogy, RabbitMQ is a post box, a post office, and a letter carrier.
The major difference between RabbitMQ and the post office is that it doesn't deal with paper, instead it accepts, stores, and forwards binary blobs of data ‒ messages.
RabbitMQ, and messaging in general, uses some jargon.
简单翻译
RabbitMQ 是一个消息代理:它接受和转发消息。你可以把它想象成一个邮局:当你把你想投递的邮件放在一个邮箱里时,你可以确定信使最终会把邮件送到你的收件人手中。在这个类比中,RabbitMQ 是一个邮箱、一个邮局和一个信箱。
RabbitMQ 和邮局之间的主要区别在于它不处理纸张,而是接受、存储和转发二进制数据 blob 数据 ‒ 消息。
RabbitMQ 和一般的消息传递使用一些行话。
消息队列是什么?
消息队列是一种中间件技术,主要用于处理应用之间的通信、解耦和异步处理等问题。
有什么用?什么场景下会用?
消息队列的主要作用是在分布式系统中实现不同服务之间的数据传输和通信。它允许不同的组件在不同的时间点处理消息,从而实现了系统的异步处理能力。
-
解耦:消息队列允许发送者和接收者独立工作,不需要直接交互,从而降低了系统各部分之间的耦合度。
-
异步处理:发送者可以将消息放入队列后立即继续执行其他任务,而不必等待接收者处理完毕。
-
负载均衡:通过智能地分配消息到不同的接收者,可以平衡系统的负载。
-
容错:如果接收者暂时不可用,消息可以保留在队列中,直到接收者准备好处理它们。
-
可扩展性:可以根据需要增加接收者的数量来处理更多的消息。
-
顺序保证:某些消息队列提供消息的顺序保证,确保消息的发送和接收顺序一致。
-
传输保障:消息队列通常提供消息持久化的功能,即使系统崩溃,消息也不会丢失。
-
事件驱动架构:消息队列是实现事件驱动架构的关键组件,允许系统响应各种事件和触发相
优点?
- 提高系统的可扩展性:消息队列可以帮助系统更好地应对流量高峰,通过缓冲和批量处理消息,减少对后端服务的冲击。
- 增强系统的鲁棒性:即使某个服务暂时不可用,消息也可以在队列中等待,直到服务恢复后再进行处理,从而保证消息不会丢失。
- 简化系统设计:通过使用消息队列,可以将复杂的系统交互简化为生产者和消费者模型,降低了系统间的直接依赖,使得系统更加模块化。
缺点?
- 增加了系统的复杂性:需要正确配置和维护消息队列,这可能会增加系统的复杂性和运维成本。
- 可能引入延迟:虽然消息队列可以提供异步处理能力,但在某些情况下,这可能会导致额外的延迟,特别是在高负载时,消息可能会在队列中排队等待较长时间。
- 需要处理一致性问题:在使用消息队列的系统中,需要确保最终一致性,这可能需要额外的逻辑来处理可能出现的数据不一致问题。
常见的消息队列技术?
RabbitMQ、RocketMQ、ActiveMQ、Kafka
-
RabbitMQ: 由Pivotal Software开发,使用Erlang语言编写。它支持多种协议,提供了可靠的消息传递模式,并且具有灵活的路由和负载均衡功能。
-
RocketMQ: 由阿里巴巴开发的分布式消息中间件,能够处理大规模的消息传输,具有良好的扩展性和高吞吐量。
-
ActiveMQ: 是Apache的一个开源项目,基于Java实现。它支持JMS规范,提供了丰富的消息模型和可靠性级别。
-
Kafka: 最初由LinkedIn开发,是一个分布式流处理平台,适合处理高吞吐量的数据流。Kafka具有高可扩展性和持久性,常用于日志收集和实时数据管道。
Hello World示例

Sending

public class Send {//队列名private final static String QUEUE_NAME = "hello";public static void main(String[] argv) throws Exception {...}
}//创建到服务器的连接
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
try (Connection connection = factory.newConnection();Channel channel = connection.createChannel()) {}//参数依次为:队列名、是否持久化、是否独占、是否自动删除、其他属性。
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
String message = "Hello World!";
//交换机名称(这里为空字符串,表示使用默认的交换机)、队列名、路由键(这里为空,表示使用默认的路由键)、消息体(需要将字符串转换为字节数组)
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");完整代码
public class Send {private final static String QUEUE_NAME = "hello";public static void main(String[] argv) throws Exception {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");try (Connection connection = factory.newConnection();Channel channel = connection.createChannel()) {channel.queueDeclare(QUEUE_NAME, false, false, false, null);String message = "Hello World!";channel.basicPublish("", QUEUE_NAME, null, message.getBytes(StandardCharsets.UTF_8));System.out.println(" [x] Sent '" + message + "'");}}
}Receiving

public class Recv {private final static String QUEUE_NAME = "hello";public static void main(String[] argv) throws Exception {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");Connection connection = factory.newConnection();Channel channel = connection.createChannel();//参数依次为:队列名、是否持久化、是否独占、是否自动删除、其他属性。channel.queueDeclare(QUEUE_NAME, false, false, false, null);System.out.println(" [*] Waiting for messages. To exit press CTRL+C");}
}
回调函数
DeliverCallback deliverCallback = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), "UTF-8");System.out.println(" [x] Received '" + message + "'");
};//用于消费指定队列中的消息。
//消费的队列的名称。
//自动确认消息。如果设置为true,则在消费者成功处理消息后会自动发送确认信号给RabbitMQ服务器;如果设置为false,则需要手动发送确认信号。
//deliverCallback: 这是一个回调函数,用于处理接收到的消息。当有新的消息到达时,该回调函数将被调用。
//consumerTag -> {}: 这是一个Lambda表达式,表示一个空的消费者标签(Consumer Tag)。消费者标签是一个唯一标识符,用于标识消费者实例。
channel.basicConsume(QUEUE_NAME, true, deliverCallback, consumerTag -> { });完整代码
public class Recv {private final static String QUEUE_NAME = "hello";public static void main(String[] argv) throws Exception {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");Connection connection = factory.newConnection();Channel channel = connection.createChannel();channel.queueDeclare(QUEUE_NAME, false, false, false, null);System.out.println(" [*] Waiting for messages. To exit press CTRL+C");DeliverCallback deliverCallback = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), StandardCharsets.UTF_8);System.out.println(" [x] Received '" + message + "'");};channel.basicConsume(QUEUE_NAME, true, deliverCallback, consumerTag -> { });}
}publish/subscribe模型(发布/订阅模型)
Exchanges
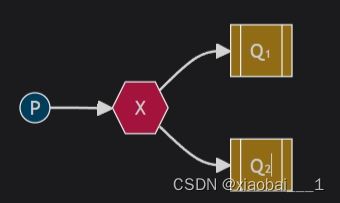
类型
-
扇形交换机(Fanout Exchange):采用广播模式,它会将消息路由到所有绑定的队列,不考虑路由键。这适用于需要将消息发送给多个消费者的情况。
-
直连交换机(Direct Exchange):它根据消息的路由键(Routing Key)进行匹配,将消息传递给与之绑定的队列。这种类型的交换机适用于一对一的消息传递场景,如日志处理或任务分发。
-
主题交换机(Topic Exchange):此类型允许使用模式匹配来路由消息。路由键可以包含特定的符号,如
#表示一个或多个词,*表示一个词,这样可以实现更复杂的消息分发逻辑。
-
头交换机(Headers Exchange):这种类型的交换机不处理路由键,而是根据发送消息内容中的headers属性进行匹配。这为基于消息内容的路由提供了灵活性。
Fanout
Fanout交换机在RabbitMQ中用于实现发布/订阅模式,它能够将消息广播到所有绑定的队列。
Fanout交换机的主要作用是将接收到的消息无条件地广播到所有与之绑定的队列中。这种类型的交换机不关心消息的内容,也不使用路由键(Routing Key)来决定消息的路由,而是简单地将消息复制到所有绑定的队列中。
以下是Fanout交换机的一些典型应用场景:
- 实时消息分发:当系统需要将实时消息分发给多个消费者时,如实时新闻推送或股票市场更新。
- 日志收集系统:在日志收集系统中,可以使用Fanout交换机将日志信息分发到不同的处理队列中,以便进行并行处理和分析。
- 事件驱动的系统:在事件驱动架构中,Fanout交换机可以用来广播事件,让不同的服务或组件接收并响应这些事件。
Fanout交换机的优点包括:
- 简单性:Fanout交换机的工作机制非常简单,易于理解和实现。
- 解耦:生产者和消费者之间不需要直接交互,只需与Fanout交换机打交道,这有助于降低系统各部分之间的耦合度。
然而,Fanout交换机也有一些缺点:
- 资源消耗:由于消息会被广播到所有绑定的队列,这可能会导致资源的浪费,尤其是当某些队列不需要某些消息时。
- 无选择性:无法根据消息内容选择性地发送给特定的队列,这可能会导致一些队列收到无关的消息。
总的来说,Fanout交换机适用于需要广泛分发消息的场景,但需要注意其资源使用效率和消息筛选的限制。
生产者
public class FanoutProducer {//定义要使用的交换机名名称,这次的队列就叫fanout-exchangeprivate static final String EXCHANGE_NAME = "fanout-exchange";public static void main(String[] argv) throws Exception {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");try (Connection connection = factory.newConnection();Channel channel = connection.createChannel()) {//声明fanout类型的交换机channel.exchangeDeclare(EXCHANGE_NAME, "fanout");Scanner sc = new Scanner(System.in);while (sc.hasNext()) {String message = sc.nextLine();//将消息发送到指定的交换机channel.basicPublish(EXCHANGE_NAME, "", null, message.getBytes("UTF-8"));System.out.println(" [x] Sent '" + message + "'");}}}
}
消费者
public class FanoutConsumer {private static final String EXCHANGE_NAME = "fanout-exchange";public static void main(String[] argv) throws Exception {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");Connection connection = factory.newConnection();//创建两个通道Channel channel1 = connection.createChannel();Channel channel2 = connection.createChannel();//声明交换机channel1.exchangeDeclare(EXCHANGE_NAME,"fanout");//创建队列1String queueName = "fanoutTest1";channel1.queueDeclare(queueName,true,false,false,null);channel1.queueBind(queueName,EXCHANGE_NAME,"");//创建队列2String queueName2 = "fanoutTest2";channel2.queueDeclare(queueName2,true,false,false,null);channel2.queueBind(queueName2,EXCHANGE_NAME,"");System.out.println(" [*] Waiting for messages. To exit press CTRL+C");//创建交付回调函数1DeliverCallback deliverCallback1 = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), "UTF-8");System.out.println(" [喜羊羊] Received '" + message + "'");};//创建交付回调函数2DeliverCallback deliverCallback2 = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), "UTF-8");System.out.println(" [美羊羊] Received '" + message + "'");};//开始消费消息队列1channel1.basicConsume(queueName, true, deliverCallback1, consumerTag -> { });channel2.basicConsume(queueName2, true, deliverCallback2, consumerTag -> { });}
}
Direct
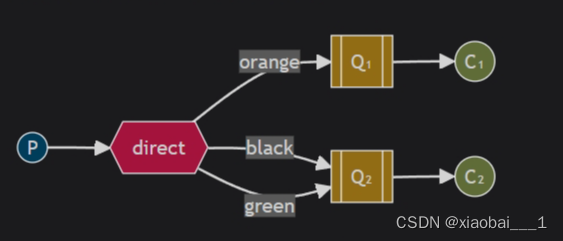
Direct交换机在RabbitMQ中用于根据消息的路由键将消息发送到与之完全匹配的队列上。
Direct交换机是RabbitMQ中常用的一种交换机类型,它属于AMQP(高级消息队列协议)的一部分。这种类型的交换机会根据消息携带的路由键(Routing Key)来决定消息的路由。只有当队列绑定到Direct交换机时指定了与消息完全相同的路由键,该队列才会接收到消息。这种方式确保了只有特定的队列能够接收到特定的消息,实现了精确的消息传递。
Direct交换机的典型应用场景包括:
- 精确匹配的消息分发:当系统设计要求只有特定的队列能够接收特定类型的消息时,可以使用Direct交换机。
- 任务分配:在任务分配系统中,可以使用Direct交换机确保特定的任务只能被特定的工作节点接收处理。
Direct交换机的优点包括:
- 简单直接:相对于其他类型的交换机,Direct交换机的工作原理和配置相对简单直观。
- 精确控制:可以实现对消息路由的精确控制,确保消息只发送到指定的队列。
然而,Direct交换机也存在一些缺点:
- 灵活性有限:与Topic交换机相比,Direct交换机只能进行精确匹配,不支持通配符或模式匹配,这在一定程度上限制了其灵活性。
- 维护成本:随着系统规模的扩大,可能需要维护大量的路由键和队列绑定关系,这会增加系统的复杂性和维护成本。
生产者
public class DirectProducer {//定义要使用的交换机名名称private static final String EXCHANGE_NAME = "direct-exchange";public static void main(String[] argv) throws Exception {//创建连接工厂ConnectionFactory factory = new ConnectionFactory();//主机地址为本机factory.setHost("localhost");//创建连接并创建通道try (Connection connection = factory.newConnection();Channel channel = connection.createChannel()) {//声明交换机,类型为directchannel.exchangeDeclare(EXCHANGE_NAME, "direct");/* //拿路由键和消息内容String severity = getSeverity(argv);String message = getMessage(argv);*/Scanner sc = new Scanner(System.in);while (sc.hasNext()) {String str = sc.nextLine();String[] strings = str.split(" ");// 输入内容不符合要求,继续下一行if (strings.length < 1) {continue;}//获取消息内容和路由键String message = strings[0];String routingKey = strings[1];//发布消息到交换机//EXCHANGE_NAME: 这是一个字符串常量,表示要发布消息的交换机的名称。//severity: 路由键(Routing Key),用于确定消息应该被发送到哪个队列。//null: 表示没有使用任何消息属性。//message.getBytes("UTF-8"): 这是将要发送的消息内容,通过调用getBytes方法将其转换为字节数组,并指定字符编码为UTF-8。channel.basicPublish(EXCHANGE_NAME, routingKey, null, message.getBytes("UTF-8"));System.out.println(" [x] Sent '" + routingKey + "':'" + message + "'"); }}}
}
消费者
public class DirectConsumer {//定义正在监听的交换机名名称private static final String EXCHANGE_NAME = "direct-exchange";public static void main(String[] argv) throws Exception {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");Connection connection = factory.newConnection();Channel channel = connection.createChannel();//声明交换机,类型为directchannel.exchangeDeclare(EXCHANGE_NAME, "direct");// 创建队列,绑定到 xiaoming 路由键String queueName = "xiaoming_queue";channel.queueDeclare(queueName, true, false, false, null);channel.queueBind(queueName, EXCHANGE_NAME, "xiaoming");// 创建队列,绑定到 xiaohong 路由键String queueName2 = "xiaohong_queue";channel.queueDeclare(queueName, true, false, false, null);channel.queueBind(queueName, EXCHANGE_NAME, "xiaohong");System.out.println(" [*] Waiting for messages. To exit press CTRL+C");//创建一个 DeliverCallback 实例来处理接收到的消息(xiaoming)DeliverCallback xiaomingdeliverCallback = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), "UTF-8");System.out.println(" [xiaoming] Received '" +delivery.getEnvelope().getRoutingKey() + "':'" + message + "'");};//创建一个 DeliverCallback 实例来处理接收到的消息(xiaohong)DeliverCallback xiaohongdeliverCallback = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), "UTF-8");System.out.println(" [xiaohong] Received '" +delivery.getEnvelope().getRoutingKey() + "':'" + message + "'");};//开始消息队列中的消息,设置自动确认消息已经被消费(xiaoming)channel.basicConsume(queueName, true, xiaomingdeliverCallback, consumerTag -> {});//开始消息队列中的消息,设置自动确认消息已经被消费(xiaohong)channel.basicConsume(queueName, true, xiaomingdeliverCallback, consumerTag -> {});}
}
Topic
Topic交换机在RabbitMQ中用于实现模式匹配的消息路由。
Topic交换机是RabbitMQ中的一种交换机类型,它允许更复杂的路由规则。与Direct交换机不同,Topic交换机不是基于精确匹配的路由键,而是使用模式匹配的方式来决定消息应该被发送到哪个队列。这种类型的交换机非常灵活,因为它可以基于多个标准进行路由。
以下是Topic交换机的一些典型应用场景:
- 日志系统:在一个多级别的日志系统中,可以使用Topic交换机来根据日志的级别和类型将消息路由到不同的队列。
- 多类别事件处理:对于需要处理多种类型事件的应用,如订单处理、用户行为跟踪等,可以使用Topic交换机来确保不同类型的事件被正确分发到相应的处理队列。
Topic交换机的优点包括:
- 灵活性高:支持使用通配符的模式匹配,可以实现更加复杂的路由策略。
- 解耦设计:通过Topic交换机,生产者和消费者之间不必事先协调好固定的路由键,这有助于降低系统各部分之间的耦合度。
然而,Topic交换机也存在一些缺点:
- 配置复杂性:由于需要使用模式匹配来定义路由规则,这可能会增加配置的复杂性。
- 性能影响:在某些情况下,复杂的模式匹配可能会对性能产生一定的影响。
总的来说,Topic交换机适用于需要基于多个标准或模式匹配来路由消息的场景,它提供了比Direct交换机更高的灵活性,但同时也带来了配置上的复杂性和潜在的性能影响。
Headers
Headers交换机在RabbitMQ中用于基于消息的头信息而非路由键来进行消息路由。
Headers交换机的使用场景包括但不限于:
- 多属性路由:当需要根据消息的多个属性来决定消息的投递时,可以使用Headers交换机。
- 灵活的匹配规则:如果路由逻辑较为复杂,或者需要更灵活的匹配方式,Headers交换机提供了这样的能力。
- 无字符串限制:由于Headers交换机不依赖于字符串类型的路由键,因此它允许使用不同数据类型的值作为路由依据。
然而,Headers交换机也存在一些缺点:
- 性能问题:与Direct交换机相比,Headers交换机的性能较差。在实际使用中,Headers交换机的性能可能不如其他类型的交换机。
- 较少使用:因为Headers交换机的复杂性和性能问题,它在实际应用中的使用频率较低。
总的来说,虽然Headers交换机提供了一种基于消息头信息的灵活路由机制,但由于其性能上的不足和实际使用场景的限制,它并不是RabbitMQ中最常用的交换机类型。
核心特性
消息过期机制
RabbitMQ的消息过期机制,也称为TTL(Time To Live),是指可以对消息或队列设置一个过期时间,一旦超过这个时间,消息将被视为dead letter(死信)并可被删除或转移到死信队列。
该机制的用途包括但不限于:
- 自动处理超时任务:如订单超时未付款自动取消等场景。
- 实现定时任务执行器:结合死信队列使用,可以在特定时间后触发某些操作。
- 控制消息的生命周期:确保消息在一定时间内被消费,否则认为是不再需要的数据。
在应用场景中,消息过期机制特别适用于以下情况:
- 限时活动通知:活动通知只在活动期间有效,过时则不再需要。
- 临时数据存储:某些数据只在短期内有用,过期后可以自动清理以释放资源。
优点包括:
- 自动化处理:无需手动干预,系统会自动处理过期消息。
- 资源管理:有助于避免队列中堆积过多不必要的消息,从而节省存储空间。
- 提高可靠性:确保消费者只处理相关和及时的消息。
然而,它也存在一些缺点:
- 配置复杂性:需要正确配置TTL,以确保消息在预期的时间内过期。
- 可能的数据丢失:如果TTL设置不当,可能会导致消费者未能及时消费的有效消息被误删除。
消息确认机制
ack: 消费成功
nack: 消费失败
rejiect: 拒绝
支持配置autoack,自动执行 ack 命令, 接受到消息立刻就成功
channel.basicConsume(queueName, true, xiaomingdeliverCallback, consumerTag -> { });指定确认某条消息
//getEnvelope(): 是delivery对象的一个方法,用于获取消息的信封信息。
//getDeliveryTag(): 是Envelope对象的一个方法,用于获取消息的唯一标识符(即消息ID)。
//false: 表示是否批量确认消息。如果为true,则表示批量确认;如果为false,则表示只确认当前消息。
channel.basicAck(delivery.getEnvelope().getDeliveryTag(),false);拒绝某条消息
//getEnvelope(): 是delivery对象的一个方法,用于获取消息的信封信息。
//getDeliveryTag(): 是Envelope对象的一个方法,用于获取消息的唯一标识符(即消息ID)。
//false: 表示是否批量拒绝消息。如果为true,则表示批量拒绝;如果为false,则表示只拒绝当前消息。
//false: 表示是否将消息重新放回队列。如果为true,则表示将消息重新放回队列;如果为false,则表示将消息丢弃。
channel.basicNack(delivery.getEnvelope().getDeliveryTag(),false,false);RabbitMQ的消息确认机制确保消息的可靠传递和处理,主要通过发布确认(Publish Confirm)和消费确认(Consumer Acknowledgement)来实现。
发布确认指的是生产者发送消息后,等待RabbitMQ服务器返回确认消息的过程,以确保消息已经被成功地发送到RabbitMQ服务器。而消费确认则是确认消费者是否成功消费了队列中的消息。
这种机制在以下场景下会用到:
- 防止消息丢失:在分布式系统中,由于网络故障、硬件故障或其他原因,消息可能会在传输过程中丢失。消息确认机制可以确保消息被正确接收和处理,从而防止消息丢失。
- 防止消息重复:在消息发送过程中,可能会因为网络超时、消费者故障等原因导致消息重复发送。消息确认机制可以避免消费者多次处理同一条消息,保证数据的一致性。
- 监控和调试:通过确认机制,生产者和消费者可以更好地监控系统的消息传递状态,便于问题的排查和系统的优化。
优点包括:
- 提高消息传递的可靠性:通过确认消息是否成功投递到交换器和队列,以及消费者是否正确消费,降低了消息丢失的风险。
- 增强系统的健壮性:在出现故障时,可以通过确认信息来重发消息或采取其他补救措施,保证系统的稳定运行。
然而,它也存在一些缺点:
- 增加系统复杂性:实现和维护消息确认机制需要额外的代码和逻辑,这可能会增加系统的复杂性。
- 性能影响:在高并发的情况下,确认机制可能会对性能产生一定的影响,因为需要等待确认信息的处理。
总的来说,RabbitMQ的消息确认机制是一个强大的工具,可以帮助确保消息的可靠传递和处理,适用于对消息可靠性要求较高的场景。但是,它也需要合理设计和优化,以减少对系统性能的影响。
死信队列
RabbitMQ中的死信队列(Dead-Letter-Exchange,简称DLX)是一种专门用于处理无法被正常消费的消息的队列。
死信队列的作用主要是接收那些因为各种原因无法被消费者正确处理的消息,这些原因可能包括消息过期、队列达到最大长度、消息被拒绝等。当这些消息成为所谓的“死信”时,它们可以被重新发布到另一个交换机,即死信队列中,从而可以进行后续的特殊处理或分析。
以下是一些典型的使用场景:
- 订单业务:在订单系统中,如果一个消息因为某些原因无法被处理,比如支付超时,可以将该消息放入死信队列中,以便后续进行异常处理或补偿操作。
- 消息过期处理:如果消息因为TTL(Time To Live)设置过期而未被消费,可以将其转移到死信队列中进行后续处理。
- 队列满时的处理:当队列达到最大长度无法再添加新消息时,新来的消息可以被转发到死信队列中。
- 消息被拒绝:如果消费者主动拒绝某个消息(使用
basic.reject或basic.nack),并且设置requeue=false,那么这个消息会被发送到死信队列。
优点包括:
- 提高系统的健壮性:通过死信队列,系统设计者可以确保即使在消费者处理失败的情况下,消息也不会丢失,从而可以在后续进行补救措施。
- 灵活的错误处理:死信队列提供了一种机制来自定义处理失败的消息,而不是简单地丢弃它们。
然而,死信队列也有其缺点:
- 增加复杂性:实现和维护死信队列需要额外的配置和代码,这可能会增加系统的复杂性。
- 性能影响:如果死信队列中积累了大量消息,可能会对系统性能产生影响,因此需要定期监控和清理。
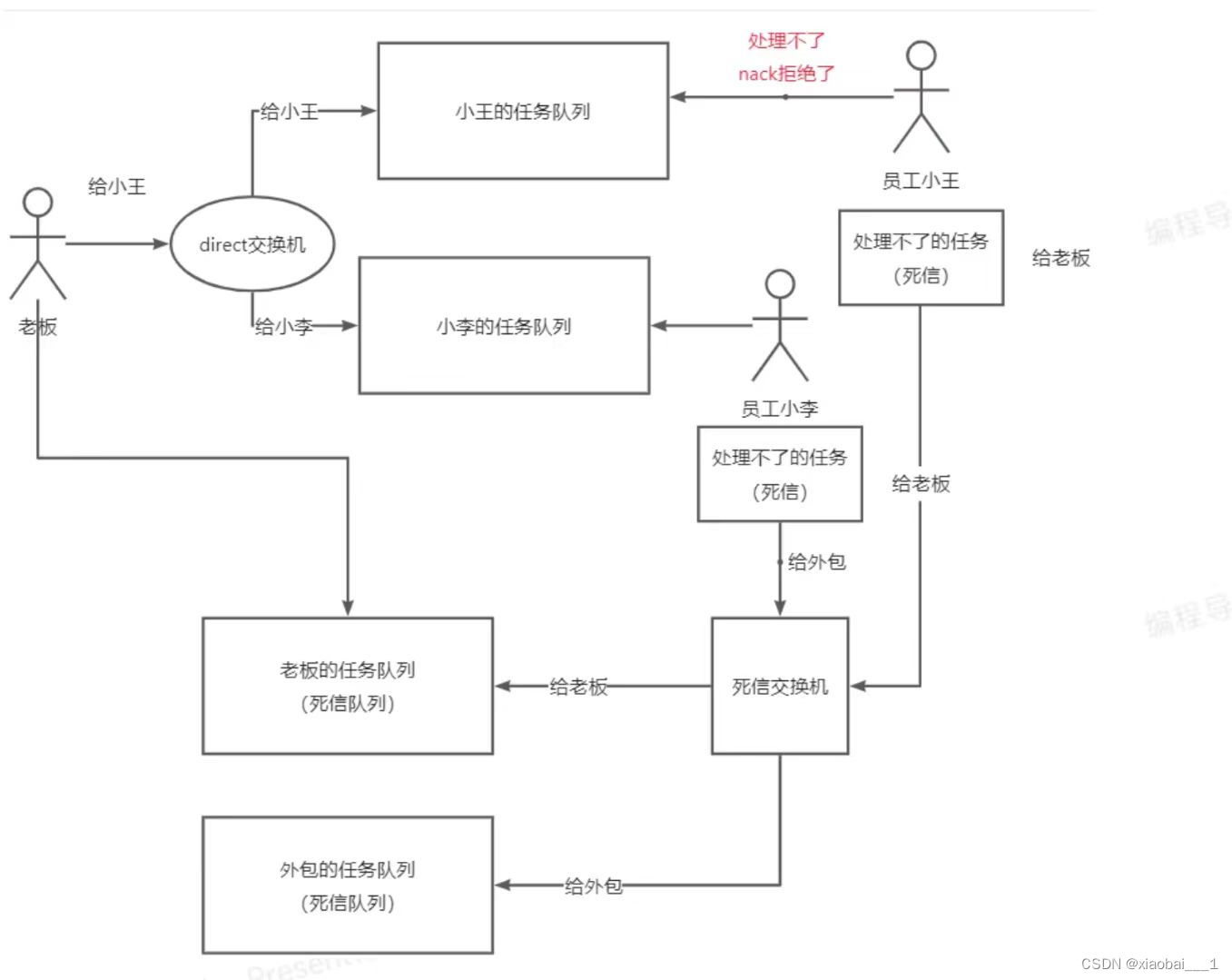
图源来自编程导航( 仅用于学习 侵删)
相关文章:
Rabbit MQ详解
写在前面,由于Rabbit MQ涉及的内容较多,赶在春招我个人先按照我认为重要的内容进行一定总结,也算是个学习笔记吧。主要参考官方文档、其他优秀文章、大模型问答。自己边学习边总结。后面有时间我会慢慢把所有内容补全,分享出来也是希望可以给…...

uniapp 写安卓app,运行到手机端 调试
手机 设置》关于手机》点击版本号 4-5次,弹出手机锁屏页面,输入手机锁屏密码 2.手机 设置中 》搜索 开发人员选项 》 调试》打开USB调试 同页面 找到 选择USB配置》选择 MIDIhbuilder 编辑器 点击 》运行》运行到手机或模拟器》运行到Android App基座 》…...

uniapp 实现双击点赞出现特效
更新一下 老板改了需求要加上特效 1. 创建点赞按钮 首先,在你的页面中创建一个点赞按钮 全局点赞的话就写在最外面的标签就行了。你可以使用 <button> 组件或者自定义一个视图组件。 <template> <view class"container"> <but…...
分布式搜索引擎elasticsearch(2)
1.DSL查询文档 elasticsearch的查询依然是基于JSON风格的DSL来实现的。 1.1.DSL查询分类 Elasticsearch提供了基于JSON的DSL([Domain Specific Language](https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html))来定义查…...

如何实现一个栈或队列?
如何实现一个栈或队列? 栈(Stack)和队列(Queue)是两种常见的数据结构,它们在编程中经常被使用。下面我将分别解释如何使用Python来实现这两种数据结构。 1. 栈的实现 栈是一种后进先出(LIF…...
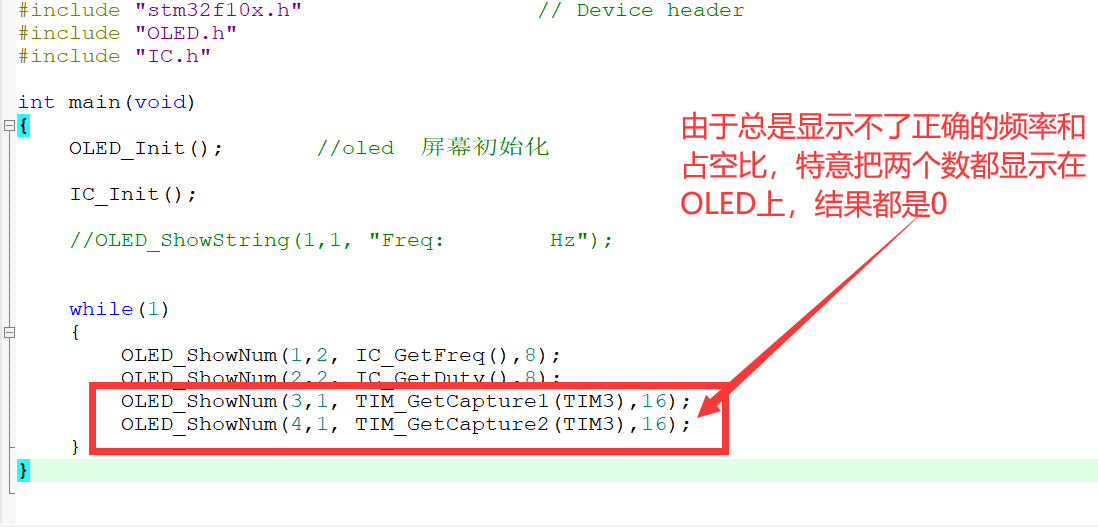
STM32输入捕获频率和占空比proteus仿真失败
这次用了两天的时间来验证这个功能,虽然实验没有成功,但是也要记录一下,后面能解决了,回来再写上解决的办法: 这个程序最后的实验结果是读取到的CCR1和CCR2的值都是0,所以没有办法算出来频率和占空比。 还…...

Kafka-SSL笔记整理
创建密钥仓库以及CA 创建密匙仓库,用户存储证书文件keytool -keystore server.keystore.jks -alias hello_kafka -validity 100000 -genkey创建CAopenssl req -new -x509 -keyout ca-key -out ca-cert -days 100000将生成的CA添加到客户端信任库keytool -keystore client.trus…...

Mysql挂掉怎么办
思路 从库处理,relaylog,讲从库升级主库。 待主机恢复后,主机替换为从库。 具体操作 简介: 主库宕机 Master DOWN机-企业场景一主多从宕机从库切换主继续和从同步过程详解 登陆从库,show processlist; 查看两个线…...
》)
《工厂模式(极简c++)》
本文章属于专栏《设计模式(极简c版)》 继续上一篇《设计原则》。本章简要说明工厂模式。本文分为模式说明、本质思想、实践建议、代码示例四个部分。 模式说明: 简单工厂模式 方案:对象不直接new,而是通过另一个类&am…...

前端学习笔记|JavaScript基础
JS基础 数据类型 基于动力节点视频。 Number、String、Boolean、object 强制转换 Number 强转,boolean强转(undefined、null、NaN都是转成false),String强转 myAge Number("123445"); Boolean(0); String(123);parseInt、parseFloat 遇到非数字&…...

springcloud五大组件:Eureka:注册中心、Zuul:服务网关、Ribbon:负载均衡、Feign:服务调用、Hystix:熔断器
你提到的这些组件都是Spring Cloud生态系统中非常关键和常用的组件。但是,关于这些组件的命名,有一点需要更正: Eureka 应该是 Eureka 或者 Eureka Server:Eureka是Netflix开源的一个服务发现组件,它本身是一个基于RE…...

Python的Selenium库中的模块、类和异常的汇总
这些是 Selenium Python 库中的模块、类和异常,用于实现自动化 Web 浏览器测试和网页操作。以下是它们的简单解释:Python Module Index — Selenium 4.18.1 documentation 1. selenium.common.exceptions:包含了 Selenium 中可能出现的异常。…...

智慧交通:构建智慧城市的重要一环
随着信息技术的飞速发展,智慧城市已成为现代城市发展的重要方向。作为智慧城市的重要组成部分,智慧交通以其高效、便捷、环保的特性,成为推动城市现代化进程的关键力量。本文将从智慧交通的概念、发展现状、面临挑战以及未来趋势等方面&#…...

BFS 求解 最小高度树 【妙用】
310. 最小高度树 链接 :题目链接 思路 常规解法是树形dp,两个dfs解决,这里不再赘述新颖解法bfs,而且实现更加简单,大体思路就是每次都从叶子节点一步步往中心爬,最后一批留在队列中的节点就为本题意的答案…...
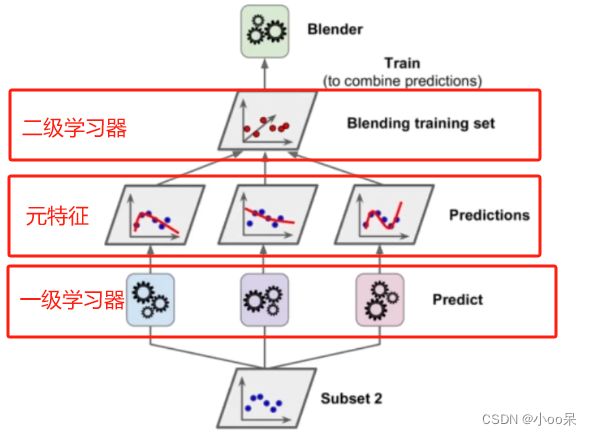
【机器学习300问】36、什么是集成学习?
一、什么是集成学习? (1)它的出现是为了解决什么问题? 提高准确性:单个模型可能对某些数据敏感或者有概念偏见,而集成多个模型可以提高预测的准确性。让模型变稳定:一些模型,如决策…...

Stargo 管理部署 Starrocks 集群
配置主机间 ssh 互信 ssh-copy-id hadoop02 ssh-copy-id hadoop03配置系统参数 ############################ Swap检查 ############################ echo 0 | sudo tee /proc/sys/vm/swappiness########################### 内核参数检查 ########################## echo…...
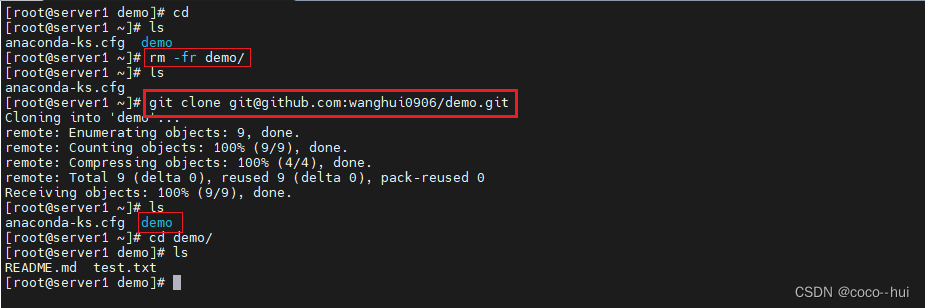
CI/CD实战-git工具使用 1
版本控制系统 本地版本控制系统 集中化的版本控制系统 分布式版本控制系统 git官网文档:https://git-scm.com/book/zh/v2 Git 有三种状态:已提交(committed)、已修改(modified) 和 已暂存(sta…...
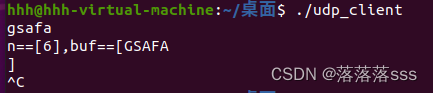
Linux中udp服务端,客户端的开发
UDP通信相关函数: ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen); 函数说明:接收信息 参数说明:sockfd:套接字buf:要接收的缓冲区len:缓冲区…...
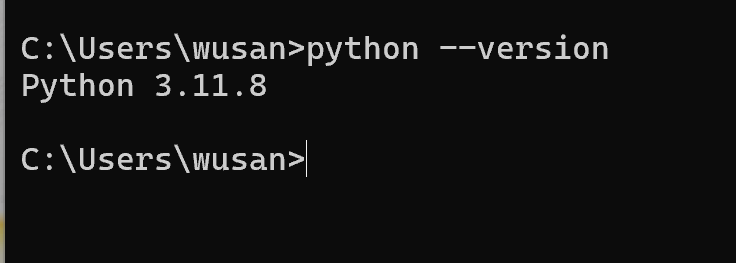
1.python安装
1.检查是否已经安装python 打开cmd 输入 python --version查看是否有返回版本,没有返回则环境变量未设置好,或者未安装 2.下载安转python https://www.python.org/downloads/windows/ 勾选配置环境变量路径 安装成功...

【Flink SQL】Flink SQL 基础概念(三):SQL 动态表 连续查询
《Flink SQL 基础概念》系列,共包含以下 5 篇文章: Flink SQL 基础概念(一):SQL & Table 运行环境、基本概念及常用 APIFlink SQL 基础概念(二):数据类型Flink SQL 基础概念&am…...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

C++中显示与隐式加载dll的使用与区别
一、什么是 DLL?DLL(Dynamic Link Library) 是 Windows 下的动态链接库,包含可被多个程序共享的函数、资源或类。使用 DLL 可以实现代码复用、模块化设计和插件机制。在 C 中,调用 DLL 中的函数有两种主要方式…...

Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度
Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对抗中经历过这样的挫败:同时按下左右方向键时角色卡…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

Burp Suite深度解析:从流量抓包到业务逻辑漏洞挖掘
1. 这不是“学个插件”——Burp Suite 是渗透测试的呼吸系统 很多人第一次听说 Burp Suite,是在某篇“三步拿下登录框”的速成教程里:装好Java、拖进浏览器代理、点几下Repeater就弹出密码明文。结果真去测一个中型SaaS后台,不到十分钟就卡在…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

浏览器指纹识别机制深度剖析与反识别技术实现
一、浏览器指纹技术基础认知1.1 浏览器指纹的核心定义在数字化时代,每一台接入互联网的设备都会留下独特的数字标识,浏览器指纹便是其中最关键的识别凭证之一。浏览器指纹是网站通过 JavaScript 脚本、HTTP 请求头、硬件接口调用等多种技术手段ÿ…...

危急时刻的六条基本安全提示
人机协作,AI模型:Deepseek 仅供参考 危急时刻的六条基本安全提示 以下内容仅为通用性安全建议,供在紧急情况下保持冷静、保护自身安全时参考。所有建议均基于常理和公共安全常识,不包含任何具体操作细节或可能被不当使用的信息…...
)
【2025】AWVS安装保姆级教程(最新25.1.2可用)
【2025】AWVS安装保姆级教程(最新25.1.2可用) 文章目录 工具下载Host 重定向AWVS安装AWVS查看安装失败原因 工具下载 点击下载即可 下载完的工具后缀格式为.apk,需要将其改为.zip,然后将其解压得到以下工具后续安装使用 Host 重…...

三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南
三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 还在为小爱音箱的"人工智障&q…...