Android Framework 之 Python
当然可以,我会尽量提供更详细的内容,并增加更多的例子和解释。以下是更详细的Python语言教程:
Python语言教程
一、Python简介
Python是一种高级编程语言,由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年。Python的设计哲学强调代码的可读性,允许开发者用少量代码表达想法,并且支持多种编程范式,包括面向过程、面向对象和函数式编程。Python的语法清晰,非常适合初学者入门学习。
Python语言的关键字是Python内置的一些具有特殊意义的标识符,它们被Python语言本身所使用,具有固定的含义和用法。这些关键字不能用作变量名、函数名或其他标识符的名称。以下是Python 3中的一些常见关键字(请注意,随着Python版本的更新,可能会有所变化):
False class finally is returnNone continue for lambda tryTrue def from nonlocal whileand del global not withas elif if or yieldassert else import passbreak except in raise
这些关键字在Python编程中有特定的用途:
and,or,not:用于逻辑运算。if,elif,else:用于条件语句。for,while:用于循环语句。try,except,finally,raise:用于异常处理。def:用于定义函数。class:用于定义类。import:用于导入模块。from:用于从模块中导入特定的函数或类。as:用于为导入的模块或对象设置别名。global:用于声明一个变量为全局变量。nonlocal:用于声明一个变量引用最近的上层作用域中的变量(非全局作用域)。in:用于检查一个值是否存在于序列或集合中。is,not is:用于比较两个对象的身份(是否是同一个对象)。assert:用于调试,当条件不满足时抛出异常。break:用于跳出当前循环。continue:用于跳过当前循环的剩余部分,进入下一次循环。del:用于删除对象。pass:用于占位,表示一个空的语句块。return:用于从函数中返回一个值。yield:用于定义一个生成器函数。lambda:用于定义匿名函数。True,False:布尔值,表示真和假。None:表示空或无值。async,await:用于异步编程(在Python 3.5及以后版本引入)。
请注意,关键字是Python语言的一部分,它们的拼写和大小写都是固定的,不能更改。编写代码时,应避免使用这些关键字作为变量名或函数名等标识符,以避免语法错误。
二、Python基础语法
1.数据类型
Python中有多种数据类型,每种数据类型都有其特定的用途和特性。以下是Python中的一些主要数据类型:
- 数字(Numbers)
int(整型):表示正或负整数,没有限制大小(在大多数平台上)。float(浮点型):表示浮点数,即带有小数点的数字。complex(复数):由实部和虚部组成,表示形如a + bj的数,其中a和b都是浮点数,j(或J)是虚数单位。
- 序列类型(Sequence Types)
list(列表):有序的元素集合,元素之间用逗号分隔,整个列表由方括号括起来。列表的元素可以是任何数据类型,且列表长度可变。tuple(元组):与列表类似,但元组的元素不能修改(即不可变)。元组使用圆括号。str(字符串):字符序列,由单引号、双引号或三引号括起来。字符串也是不可变的。
- 集合类型(Set Types)
set(集合):无序且不包含重复元素的集合。集合使用大括号{}或set()函数创建。frozenset(冻结集合):不可变的集合,与集合类似,但一旦创建就不能修改。
- 映射类型(Mapping Types)
dict(字典):无序的键值对集合。键必须是唯一的,而值可以是任何数据类型。字典由大括号{}创建,或使用dict()函数。
- 布尔类型(Boolean Types)
bool:布尔类型有两个值,True和False,用于逻辑运算和条件判断。
- None类型
None:表示一个空或无值的特殊常量,通常用于表示函数没有返回值或变量没有值。
- 字节类型(Bytes Types)
bytes:字节序列,用于处理二进制数据。bytearray:可变字节序列,允许原处修改。
- 其他类型
type:每个对象都有一个类型,type对象表示对象的类型。callable:检查对象是否可以被调用,如函数和方法。range:表示不可变的序列,通常用于在for循环中生成一系列整数。memoryview:内置的类,用于创建给定参数的“内存视图”对象。slice:表示由range(start, stop, step)指定的索引集的切片对象。- ... 以及其他一些不太常用的类型。
这些是Python中最常见的数据类型。根据具体的应用场景和需求,开发者可以选择合适的数据类型来存储和处理数据。
2.变量
Python中的变量不需要事先声明类型,可以直接赋值。Python中的数据类型包括整数、浮点数、字符串、布尔值、列表、元组、字典和集合等。
# 整数 | |
a = 10 | |
print(type(a)) # 输出:<class 'int'> | |
# 浮点数 | |
b = 3.14 | |
print(type(b)) # 输出:<class 'float'> | |
# 字符串 | |
c = "Hello, Python!" | |
print(type(c)) # 输出:<class 'str'> | |
# 布尔值 | |
d = True | |
print(type(d)) # 输出:<class 'bool'> | |
# 列表 | |
e = [1, 2, 3, 4] | |
print(type(e)) # 输出:<class 'list'> | |
# 元组 | |
f = (1, 2, 3) | |
print(type(f)) # 输出:<class 'tuple'> | |
# 字典 | |
g = {'name': 'Alice', 'age': 25} | |
print(type(g)) # 输出:<class 'dict'> | |
# 集合 | |
h = {1, 2, 3} | |
print(type(h)) # 输出:<class 'set'> |
3.运算符
Python中的运算符非常丰富,它们被用于执行各种计算和操作。下面我将详细解释Python中的各种运算符,并给出具体的例子来说明它们的用法。
-
算术运算符
算术运算符用于执行基本的数学运算。
+加法-减法*乘法/除法(返回浮点数结果)//整除(返回商的整数部分)%取模(返回除法的余数)**幂运算
示例:
a = 5 | |
b = 3 | |
print(a + b) # 输出 8 | |
print(a - b) # 输出 2 | |
print(a * b) # 输出 15 | |
print(a / b) # 输出 1.6666666666666667 | |
print(a // b) # 输出 1 | |
print(a % b) # 输出 2 | |
print(a ** b) # 输出 125 |
-
关系运算符
关系运算符用于比较两个操作数的大小关系,返回布尔值(True 或 False)。
==等于!=不等于>大于<小于>=大于等于<=小于等于
示例:
x = 10 | |
y = 20 | |
print(x == y) # 输出 False | |
print(x != y) # 输出 True | |
print(x > y) # 输出 False | |
print(x < y) # 输出 True | |
print(x >= y) # 输出 False | |
print(x <= y) # 输出 True |
-
逻辑运算符
逻辑运算符用于组合布尔表达式。
and与(都满足才返回True)or或(至少有一个满足就返回True)not非(取反)
示例:
a = True | |
b = False | |
print(a and b) # 输出 False | |
print(a or b) # 输出 True | |
print(not a) # 输出 False | |
print(not b) # 输出 True |
-
位运算符
位运算符直接对整数的二进制位进行操作。
&按位与|按位或^按位异或~按位取反<<左移>>右移
示例:
a = 60 # 60的二进制表示为 0011 1100 | |
b = 13 # 13的二进制表示为 0000 1101 | |
print(a & b) # 输出 12 (二进制 0000 1100) | |
print(a | b) # 输出 61 (二进制 0011 1101) | |
print(a ^ b) # 输出 49 (二进制 0011 0001) | |
print(~a) # 输出 -61 (二进制 -0011 1100, 注意这是有符号整数的表示) | |
print(a << 2) # 输出 240 (二进制 1111 0000) | |
print(a >> 2) # 输出 15 (二进制 0000 1111) |
-
赋值运算符
赋值运算符用于给变量赋值。
=赋值+=加等于-=减等于*=乘等于/=除等于%=取模等于**=幂等于//=整除等于
示例:
a = 5 | |
a += 3 # a = a + 3, 相当于 a = 8 | |
print(a) # 输出 8 | |
b = 10 | |
b -= 4 # b = b - 4, 相当于 b = 6 | |
print(b) # 输出 6 |
-
成员运算符
成员运算符用于测试一个序列(如列表、元组或字符串)中是否包含某个元素。
-
成员运算符在Python中主要包括两个:
in和not in。 in:用于判断一个元素是否存在于某个序列(如列表、元组、字符串等)中。如果元素在序列中,返回True;否则返回False。-
示例:
my_list = [1, 2, 3, 4, 5]if 3 in my_list:print("3存在于列表中")else:print("3不存在于列表中") not in:与in相反,用于判断一个元素是否不在某个序列中。如果元素不在序列中,返回True;否则返回False。-
示例:
my_list = [1, 2, 3, 4, 5]if 6 not in my_list:print("6不在列表中")else:print("6在列表中") -
身份运算符
身份运算符用于比较两个对象的内存地址是否相同。
is如果两个标识符引用的是同一个对象,返回Trueis not如果两个标识符引用的不是同一个对象,返回True
示例:
x = [1, 2, 3] | |
y = x | |
z = [1, 2, 3] | |
print(x is y) # 输出 True,因为 x 和 y 引用的是同一个对象 | |
print(x is not z) # 输出 True,因为 x 和 z 引用的是不同的对象,即使内容相同 |
-
运算符优先级
Python中的运算符有不同的优先级,例如算术运算符的优先级高于比较运算符,比较运算符的优先级高于逻辑运算符。如果需要改变默认的优先级,可以使用括号来明确指定。
示例:
result = 5 + 3 * 2 # 输出 11,因为乘法优先于加法 | |
result = (5 + 3) * 2 # 输出 16,因为括号改变了运算顺序 |
-
类型运算符
Python 中并没有专门的“类型运算符”,但你可以使用 type() 函数来检查一个对象的类型。
示例:
num = 123 | |
print(type(num)) # 输出 <class 'int'>,表明 num 是一个整数 |
-
特殊方法运算符
这些不是常规的运算符,而是 Python 的特殊方法(magic methods),它们允许你定义对象的行为,比如 __add__ 用于定义对象相加的行为,__eq__ 用于定义对象相等性的比较等。
示例(定义一个简单的类,并覆盖 __add__ 方法):
class Vector: | |
def __init__(self, x, y): | |
self.x = x | |
self.y = y | |
def __add__(self, other): | |
return Vector(self.x + other.x, self.y + other.y) | |
v1 = Vector(1, 2) | |
v2 = Vector(3, 4) | |
v3 = v1 + v2 # 调用 __add__ 方法,输出 Vector(4, 6) |
4.控制语句
Python的控制语句用于控制程序的流程,包括条件语句和循环语句。下面我将详细介绍这些控制语句,并给出具体的例子。
-
条件语句
条件语句用于根据特定条件执行不同的代码块。Python中的条件语句主要有if、elif和else。
示例:
x = 10 | |
if x > 0: | |
print("x 是正数") | |
elif x < 0: | |
print("x 是负数") | |
else: | |
print("x 是零") | |
# 输出:x 是正数 |
在上面的例子中,程序首先检查x > 0是否为真。如果为真,则执行if块内的代码;如果为假,则继续检查elif x < 0。如果所有条件都不满足,则执行else块内的代码。
-
循环语句
循环语句用于重复执行一段代码,直到满足某个条件为止。Python中的循环语句主要有for和while。
for循环
for循环用于遍历序列(如列表、元组、字符串等)中的每个元素。
示例:
fruits = ['apple', 'banana', 'cherry'] | |
for fruit in fruits: | |
print(fruit) | |
# 输出: | |
# apple | |
# banana | |
# cherry |
在这个例子中,for循环遍历fruits列表中的每个元素,并将每个元素赋值给变量fruit,然后执行循环体内的代码。
while循环
while循环会重复执行一段代码,直到指定的条件不再满足为止。
示例:
count = 0 | |
while count < 5: | |
print(f"Count is {count}") | |
count += 1 | |
# 输出: | |
# Count is 0 | |
# Count is 1 | |
# Count is 2 | |
# Count is 3 | |
# Count is 4 |
在这个例子中,while循环会一直执行,直到count的值不再小于5。在每次循环中,都会打印出当前的count值,并将count加1。
-
其他控制语句
除了条件语句和循环语句,Python还有一些其他的控制语句,如break、continue和pass。
break:用于跳出当前循环。continue:用于跳过当前循环的剩余部分,继续下一次循环。pass:是一个空操作语句,用于在语法上需要一个语句,但程序不需要任何操作时。
示例:
for i in range(10): | |
if i == 5: | |
break # 当 i 等于 5 时跳出循环 | |
print(i) | |
# 输出:0 到 4 | |
for i in range(10): | |
if i == 5: | |
continue # 当 i 等于 5 时跳过本次循环 | |
print(i) | |
# 输出:0 到 4,然后 6 到 9 | |
# pass 示例 | |
def my_function(): | |
pass # 这里什么都不做,只是一个占位符 |
在上面的例子中,break用于在i等于5时跳出循环,continue用于在i等于5时跳过本次循环,而pass则用于在my_function中作为一个占位符,表示这个位置将来可能会添加代码。
三、函数
在Python中,函数是一种重要的代码组织方式,它允许我们将一系列相关的操作组合在一起,并赋予其一个名字。通过调用这个名字,我们可以重复执行这组操作。这有助于代码的复用和模块化,使程序更加清晰和易于维护。
函数的定义
Python中定义函数的基本语法如下:
def function_name(parameters): | |
"""Docstring: 函数的简短说明""" | |
# 函数体:包含执行特定任务的代码 | |
# ... | |
return value # 可选,用于返回函数的执行结果 |
def是定义函数的关键字。function_name是你给函数起的名字,需要遵循Python的命名规则。parameters是函数的参数列表,用于接收传递给函数的值。Docstring是可选的文档字符串,用于解释函数的作用和用法。return语句用于从函数中返回一个值。如果函数没有return语句,那么它会默认返回None。
函数的调用
定义了函数之后,我们就可以通过函数名来调用它,并传递必要的参数。
result = function_name(arguments) # arguments 是传递给函数的实际参数 |
函数的参数
函数参数主要有以下几种类型:
- 位置参数:按照参数的顺序来传递值。
def greet(name, age): | |
print(f"Hello, {name}! You are {age} years old.") | |
greet("Alice", 30) # 输出:Hello, Alice! You are 30 years old. |
- 默认参数:为参数提供默认值,如果调用函数时没有提供该参数的值,则使用默认值。
def greet(name, age=None): | |
if age is not None: | |
print(f"Hello, {name}! You are {age} years old.") | |
else: | |
print(f"Hello, {name}!") | |
greet("Alice") # 输出:Hello, Alice! | |
greet("Bob", 25) # 输出:Hello, Bob! You are 25 years old. |
- 可变参数:允许函数接收任意数量的参数。
- 使用
*args接收非关键字参数(位置参数)。 - 使用
**kwargs接收关键字参数。
def sum_numbers(*args): | |
return sum(args) | |
print(sum_numbers(1, 2, 3, 4)) # 输出:10 | |
def greet_people(**kwargs): | |
for name, age in kwargs.items(): | |
print(f"Hello, {name}! You are {age} years old.") | |
greet_people(Alice=30, Bob=25) # 输出两个人的问候语 |
函数的返回值
函数可以通过 return 语句返回一个或多个值。
def add_two_numbers(a, b): | |
return a + b | |
result = add_two_numbers(3, 4) | |
print(result) # 输出:7 |
函数也可以返回多个值,这些值会被打包成一个元组。
def get_person_info(): | |
return "Alice", 30 | |
name, age = get_person_info() | |
print(name, age) # 输出:Alice 30 |
局部变量与全局变量
在函数内部定义的变量是局部变量,它们只在函数内部可见。在函数外部定义的变量是全局变量,它们在整个程序中都可见。函数内部可以直接访问全局变量,但修改全局变量通常需要 global 关键字。
count = 0 # 全局变量 | |
def increment_count(): | |
global count # 声明count为全局变量 | |
count += 1 | |
increment_count() | |
print(count) # 输出:1 |
匿名函数(Lambda函数)
Python还提供了创建小型匿名函数的能力,这些函数称为lambda函数。它们主要用于需要一个函数作为参数的简短函数。
add = lambda x, y: x + y | |
print(add(5, 3)) # 输出:8 |
嵌套函数
函数内部还可以定义其他函数,这样的函数称为嵌套函数。嵌套函数可以访问其外部函数的变量,但外部函数不能直接访问嵌套函数的变量,除非它们作为返回值被传递出来。
def outer_function():outer_variable = "I'm from outer function"def inner_function():
print(outer_variable)inner_function()
outer_function() # 输出:I'm from outer function在上面的例子中,`inner_function` 是一个嵌套在 `outer_function` 内部的函数,它能够访问 `outer_function` 的局部变量 `outer_variable`
闭包
闭包是一个返回函数的函数,返回的函数通常访问并操作在其词法作用域(lexical scope)内的一些变量,即使函数是在其外部作用域被调用的。 |
```python | |
def outer_function(x): | |
def inner_function(y): | |
return x + y | |
return inner_function | |
add_five = outer_function(5) # add_five 是一个闭包,它记住了 x 的值 5 | |
print(add_five(3)) # 输出:8 |
在这个例子中,outer_function 返回一个函数 inner_function,这个函数记住并使用了 outer_function 的参数 x 的值。即使 outer_function 已经执行完毕,inner_function 仍然可以访问 x 的值,这就是闭包的作用。
生成器函数
生成器函数是一种特殊的函数,它使用 yield 语句而不是 return 语句返回值。yield 语句会暂停函数的执行,并保存其当前状态,以便下次从该点继续执行。生成器函数用于创建迭代器,可以逐个生成值,而不是一次性生成所有值,这有助于节省内存。
def generate_numbers(): | |
for i in range(10): | |
yield i | |
numbers = generate_numbers() # numbers 是一个生成器对象 | |
print(next(numbers)) # 输出:0 | |
print(next(numbers)) # 输出:1 | |
# ... 可以继续调用 next() 来获取下一个值 |
生成器函数在处理大量数据时非常有用,因为它们允许你按需生成数据,而不是一次性加载所有数据到内存中。
装饰器函数
装饰器函数是Python中用于修改或增强其他函数行为的高级功能。它们接受一个函数作为参数,并返回一个新函数,新函数在某种方式上增强了原函数的功能。
def my_decorator(func): | |
def wrapper(*args, **kwargs): | |
print("Something is happening before the function is called.") | |
result = func(*args, **kwargs) | |
print("Something is happening after the function is called.") | |
return result | |
return wrapper | |
@my_decorator | |
def say_hello(name): | |
print(f"Hello, {name}!") | |
say_hello("Alice") | |
# 输出: | |
# Something is happening before the function is called. | |
# Hello, Alice! | |
# Something is happening after the function is called. |
在这个例子中,my_decorator 是一个装饰器函数,它接受一个函数 func 并返回一个新的函数 wrapper。wrapper 函数在调用原函数 func 之前和之后执行一些操作。通过使用 @my_decorator 语法,我们可以轻松地将装饰器应用于 say_hello 函数。
四、数据容器
Python中的容器是一种可以存储多个元素的数据结构。这些元素可以是不同类型的数据,比如数字、字符串、列表等。Python提供了多种容器类型,包括列表、元组、字典和集合。下面我将详细介绍这些容器类型,并给出相应的例子。
1. 列表(List)
列表是Python中最常用的容器类型之一,它可以存储任何类型的元素,并且元素之间是有序的。列表使用方括号[]表示,元素之间用逗号,分隔。
例子:
# 创建一个列表 | |
my_list = [1, 2, 3, 'hello', True] | |
# 访问列表中的元素 | |
print(my_list[0]) # 输出:1 | |
print(my_list[-1]) # 输出:True | |
# 修改列表中的元素 | |
my_list[0] = 'first' | |
print(my_list) # 输出:['first', 2, 3, 'hello', True] | |
# 列表的常用操作:添加、删除、切片等 | |
my_list.append(42) # 添加元素 | |
print(my_list) # 输出:['first', 2, 3, 'hello', True, 42] | |
my_list.remove(3) # 删除元素 | |
print(my_list) # 输出:['first', 2, 'hello', True, 42] | |
sublist = my_list[1:4] # 切片操作 | |
print(sublist) # 输出:[2, 'hello', True] |
2. 元组(Tuple)
元组与列表类似,也是有序的元素集合。但元组是不可变的,即创建后不能修改其元素。元组使用圆括号()表示。
例子:
# 创建一个元组 | |
my_tuple = (1, 2, 3, 'hello') | |
# 访问元组中的元素 | |
print(my_tuple[0]) # 输出:1 | |
# 尝试修改元组中的元素(会报错) | |
# my_tuple[0] = 'new_value' # TypeError: 'tuple' object does not support item assignment |
3. 字典(Dictionary)
字典是一种无序的键值对集合。每个元素都由键和值两部分组成,通过键来访问对应的值。字典使用大括号{}表示。
例子:
# 创建一个字典 | |
my_dict = {'name': 'Alice', 'age': 30, 'city': 'New York'} | |
# 访问字典中的值 | |
print(my_dict['name']) # 输出:Alice | |
# 修改字典中的值 | |
my_dict['age'] = 31 | |
print(my_dict) # 输出:{'name': 'Alice', 'age': 31, 'city': 'New York'} | |
# 添加新的键值对 | |
my_dict['country'] = 'USA' | |
print(my_dict) # 输出:{'name': 'Alice', 'age': 31, 'city': 'New York', 'country': 'USA'} |
4. 集合(Set)
集合是一个无序且不包含重复元素的元素集合。集合使用大括号{}或set()函数表示。
例子:
# 创建一个集合 | |
my_set = {1, 2, 2, 3, 4, 4, 5} | |
print(my_set) # 输出:{1, 2, 3, 4, 5}(重复元素被自动去除) | |
# 集合的常用操作:并集、交集、差集等 | |
set1 = {1, 2, 3} | |
set2 = {3, 4, 5} | |
union_set = set1 | set2 # 并集 | |
print(union_set) # 输出:{1, 2, 3, 4, 5} | |
intersection_set = set1 & set2 # 交集 | |
print(intersection_set) # 输出:{3} | |
difference_set = set1 - set2 # 差集 | |
print(difference_set) # 输出:{1, 2} |
这些容器类型在Python编程中非常常用,它们提供了强大的数据组织和处理能力,使得我们可以更加高效地处理复杂的数据结构。每种容器类型都有其特定的应用场景和优势,选择合适的容器类型可以大大提高代码的效率和可读性。
五、文件操作
在Python中,文件是一个非常重要的概念,它允许我们读取、写入、追加和删除存储在硬盘或其他存储设备上的数据。文件可以是文本文件、二进制文件或任何其它类型的文件。Python提供了丰富的内置函数和模块,使得文件操作变得简单而直接。
文件操作的基本步骤
-
打开文件:使用
open()函数来打开一个文件。这个函数需要至少一个参数,即文件名。open()函数返回一个文件对象,该对象包含了一系列与文件交互的方法。 -
读取或写入文件:一旦文件被打开,就可以使用文件对象的方法来读取或写入数据。对于文本文件,可以使用
read()、readline()、readlines()等方法来读取数据,使用write()方法来写入数据。 -
关闭文件:完成文件操作后,应该使用
close()方法来关闭文件。这是一个很重要的步骤,因为关闭文件可以确保所有的数据都被正确地写入,并且释放了系统资源。
文件打开模式
open()函数可以接受一个可选的第二个参数,即文件的打开模式。常见的模式有:
'r':只读模式(默认)。如果文件不存在,会抛出FileNotFoundError异常。'w':写入模式。如果文件已存在,会覆盖原有内容;如果文件不存在,会创建新文件。'a':追加模式。如果文件已存在,会在文件末尾追加内容;如果文件不存在,会创建新文件。'b':二进制模式。用于非文本文件的读写。'x':独占创建模式。如果文件已存在,会抛出FileExistsError异常;如果文件不存在,会创建新文件。
还可以组合使用这些模式,例如'rb'表示以二进制模式读取文件,'w+'表示读写模式(先写后读)。
上下文管理器(with语句)
为了确保文件在操作完成后被正确关闭,推荐使用with语句来打开文件。with语句会自动管理文件的打开和关闭,即使在发生异常时也能确保文件被正确关闭。
示例:
with open('example.txt', 'r') as file: | |
content = file.read() | |
print(content) | |
# 文件在这里会被自动关闭 |
常见的文件操作
- 读取文件:使用
read()、readline()或readlines()方法。 - 写入文件:使用
write()方法。注意,write()方法只接受字符串参数。 - 追加内容:使用
write()方法在'a'模式下写入数据。 - 文件定位:使用
seek()方法可以改变文件的当前位置。 - 文件属性:通过文件对象的属性,如
name(文件名)、mode(打开模式)、closed(是否已关闭)等,可以获取文件的相关信息。
注意事项
- 当打开文件时,尽量使用绝对路径,以避免因当前工作目录不同而导致的文件找不到的问题。
- 在写入文件时,如果使用的是文本模式,确保写入的内容是字符串;如果使用的是二进制模式,确保写入的内容是字节串。
- 尽量避免在循环中打开和关闭文件,因为这会影响性能。如果需要多次读写文件,考虑将文件保持打开状态,或者在循环外部打开和关闭文件。
通过理解Python中的文件操作,我们可以有效地处理存储在文件中的数据,实现数据的持久化存储和读取。
六、异常、模块和包
Python中的异常
- 异常的概念
异常是程序执行过程中发生的错误或意外情况,它们会打断正常的程序流程。Python 使用异常处理机制来处理程序运行时可能发生的错误,使得程序在发生异常时能够执行一些特定的操作,而不是直接崩溃。
- 异常的类型
Python 内置了很多异常类型,如 ValueError、TypeError、KeyError、IndexError 等。每种异常类型对应着一种特定的错误情况。
- 异常的处理
Python 使用 try/except 块来处理异常。当 try 块中的代码引发异常时,程序会跳过 try 块中剩余的代码,转而执行与异常类型匹配的 except 块中的代码。
示例:
try: | |
# 尝试执行的代码块 | |
x = int("hello") # 这会引发 ValueError 异常 | |
except ValueError as e: | |
# 处理 ValueError 异常的代码块 | |
print("ValueError:", e) | |
except TypeError as e: | |
# 处理 TypeError 异常的代码块 | |
print("TypeError:", e) | |
else: | |
# 如果没有异常发生,执行这里的代码块 | |
print("No exception occurred.") | |
finally: | |
# 无论是否发生异常,都会执行这里的代码块 | |
print("This is always executed.") |
在上面的示例中,尝试将字符串 "hello" 转换为整数会引发 ValueError 异常,因此会执行与 ValueError 匹配的 except 块中的代码。
- 自定义异常
除了内置的异常类型,Python 还允许用户自定义异常。自定义异常通常通过继承内置的 Exception 类或其子类来实现。
示例:
class MyCustomException(Exception): | |
pass | |
try: | |
raise MyCustomException("This is a custom exception.") | |
except MyCustomException as e: | |
print("Caught a custom exception:", e) |
在这个示例中,我们定义了一个名为 MyCustomException 的自定义异常,并在 try 块中引发了它。然后,我们使用 except 块来捕获并处理这个自定义异常。
Python中的模块
- 模块的概念
模块是包含 Python 定义和语句的文件。模块可以定义函数、类和变量。模块也可以包含可执行的代码。模块让你可以逻辑地组织你的 Python 代码,并将相关的函数或类放在同一个文件中。
- 模块的导入
使用 import 语句可以导入模块。导入模块后,就可以使用模块中定义的函数、类和变量了。
示例:
假设有一个名为 my_module.py 的模块文件,其中定义了一个函数 greet:
# my_module.py | |
def greet(name): | |
print(f"Hello, {name}!") |
在另一个 Python 文件中,你可以这样导入并使用这个模块:
import my_module | |
my_module.greet("Alice") # 输出:Hello, Alice! |
- 模块的搜索路径
当导入模块时,Python 解释器会在特定的搜索路径中查找模块文件。这些搜索路径包括当前目录、PYTHONPATH 环境变量指定的目录以及安装 Python 时指定的目录等。
Python中的包
- 包的概念
包是组织 Python 模块的一种方式,它允许你将相关的模块分组到一个目录中,并在该目录中包含一个特殊的 __init__.py 文件。包提供了一种避免命名冲突和简化模块导入的方法。
- 包的导入
使用点模块名可以导入包中的模块。例如,如果有一个名为 mypackage 的包,其中包含一个名为 mymodule.py 的模块,你可以这样导入它:
from mypackage import mymodule |
或者,如果你只想导入模块中的某个函数或变量,可以这样写:
from mypackage.mymodule import my_function |
__init__.py文件
__init__.py 文件是包的特殊文件,它定义了当包被导入时应该执行的代码。它还可以用来定义包的 __all__ 变量,该变量用于控制使用 from package import * 语句时导入哪些模块或对象。
示例:
假设你有一个名为 mypackage 的包,其结构如下:
mypackage/ | |
__init__.py | |
module1.py | |
module2.py |
在 __init__.py 文件中,你可以定义包的初始化代码:
init.py 文件的内容:
# __init__.py | |
print("mypackage is being imported.") | |
# 可以选择性地导入包内的模块或对象 | |
from . import module1 | |
from . import module2 | |
# 也可以定义 __all__ 来控制 * 导入的内容 | |
__all__ = ['module1', 'module2'] |
在这个 __init__.py 文件中,我们打印了一条消息来表明包正在被导入,并且我们导入了包内的 module1 和 module2。我们还定义了 __all__ 变量,这样当使用 from mypackage import * 时,只会导入 module1 和 module2。
包的导入和使用:
现在,你可以这样导入和使用这个包:
import mypackage # 输出:mypackage is being imported. | |
mypackage.module1.some_function() # 假设 module1 中有一个名为 some_function 的函数 |
或者,使用 from ... import ... 语句导入包中的特定模块或对象:
from mypackage import module1 | |
module1.some_function() # 直接调用 module1 中的函数 |
或者使用星号导入(虽然通常不推荐这样做,因为它可能导致命名冲突):
from mypackage import * | |
module1.some_function() # 直接调用 module1 中的函数 |
在这种情况下,由于我们在 __init__.py 中定义了 __all__,所以只有 module1 和 module2 会被导入。
包的优点:
- 组织代码:包允许你将相关的模块组织在一起,使得代码结构更清晰。
- 避免命名冲突:不同的包可以有相同名称的模块,而不会发生冲突,因为它们的完整名称(包括包名)是不同的。
- 简化导入:通过包,你可以一次性导入多个模块,或者使用相对导入来简化模块之间的依赖关系。
总结:
Python 中的异常、模块和包是构建健壮、可维护和可扩展代码的关键组件。异常允许你优雅地处理错误情况,模块让你能够逻辑地组织代码,而包则提供了一种更高层次的组织结构,使得大型项目的管理和维护变得更加容易。通过理解和熟练使用这些特性,你可以编写出更加健壮、清晰和高效的 Python 代码。
七、面向对象
Python的面向对象编程(Object-Oriented Programming,简称OOP)是一种编程范式,它使用“对象”来设计应用程序和软件。在面向对象编程中,“对象”是数据和功能的结合体,可以通过对象来访问数据(属性)和执行功能(方法)。面向对象编程的主要概念包括类、对象、继承、封装和多态。
1. 类(Class)
类是对象的蓝图或模板,它定义了对象的属性和方法。
示例:
class Dog: | |
def __init__(self, name, age): | |
self.name = name | |
self.age = age | |
def bark(self): | |
return "Woof!" |
这里定义了一个Dog类,它有两个属性(name和age)和一个方法(bark)。
2. 对象(Object)
对象是类的实例,具有类定义的属性和方法。
示例:
my_dog = Dog("Buddy", 3) | |
print(my_dog.name) # 输出: Buddy | |
print(my_dog.bark()) # 输出: Woof! |
这里创建了一个Dog类的对象my_dog,并调用了它的属性和方法。
3. 继承(Inheritance)
继承允许我们创建一个新的类(子类),继承另一个类(父类)的属性和方法。
示例:
class GoldenRetriever(Dog): | |
def __init__(self, name, age, color): | |
super().__init__(name, age) | |
self.color = color | |
def describe(self): | |
return f"My name is {self.name}, I am a {self.color} Golden Retriever, and I am {self.age} years old." |
GoldenRetriever类继承了Dog类,并添加了一个新属性(color)和一个新方法(describe`)。
4. 封装(Encapsulation)
封装将数据(变量)和对数据的操作(方法)绑定在一起,作为一个独立的单元。在Python中,这通常通过定义私有属性和方法来实现。
示例:
class Person: | |
def __init__(self, name, age): | |
self.__name = name # 私有属性 | |
self.__age = age # 私有属性 | |
def get_name(self): | |
return self.__name # 访问器方法 | |
def set_name(self, name): | |
self.__name = name # 修改器方法 |
这里,__name和__age是私有属性,只能通过get_name和set_name这样的访问器和修改器方法来访问和修改。
5. 多态(Polymorphism)
多态是指不同对象对同一消息做出响应。在Python中,由于它是动态类型语言,多态是隐式实现的。
示例:
def greet_animal(animal): | |
print(animal.speak()) | |
dog = Dog("Buddy", 3) | |
cat = Cat("Whiskers", 2) # 假设有一个Cat类,其中有一个speak方法 | |
greet_animal(dog) # 输出: Woof! | |
greet_animal(cat) # 输出: Meow! |
这里,greet_animal函数接受一个参数animal,并调用其speak方法。由于多态性,这个函数可以接受任何具有speak方法的对象,无论是Dog还是Cat。
这些概念并不是孤立的,它们通常一起使用来构建复杂、可维护且可扩展的Python程序。通过面向对象编程,你可以更好地组织你的代码,提高代码的可读性和可重用性。
八、标准库和第三方库
当然可以,以下是一些Python标准库和第三方库的详细例子,以及它们如何在实际编程中被应用。
标准库示例
-
math库:
math库提供了许多基础的数学函数,包括三角函数(如sin、cos)、指数和对数函数(如exp、log)、常数(如pi、e)以及幂运算等。示例:
import math# 计算正弦值sine_value = math.sin(math.radians(45))print(sine_value)# 计算平方根square_root = math.sqrt(16)print(square_root) -
datetime库:
datetime库用于处理日期和时间,允许你获取当前日期和时间、进行日期和时间的比较、进行时间间隔计算等。示例:
from datetime import datetime# 获取当前日期和时间now = datetime.now()print(now)# 计算两个日期之间的时间差date1 = datetime(2023, 1, 1)date2 = datetime(2024, 3, 16)delta = date2 - date1print(delta.days) -
os库:
os库提供了与操作系统交互的功能,如文件路径操作、环境变量访问、执行系统命令等。示例:
import os# 获取当前工作目录current_dir = os.getcwd()print(current_dir)# 列出目录中的文件files = os.listdir('.')print(files)
第三方库示例
-
requests库:
requests是一个用于发送HTTP请求的第三方库,它使网络请求变得简单和直观。示例:
import requests# 发送GET请求response = requests.get('https://api.example.com/data')if response.status_code == 200:data = response.json()print(data)else:print('Failed to retrieve data') -
pandas库:
pandas是一个强大的数据处理和分析库,它提供了DataFrame和Series两种数据结构,使得数据处理变得简单。示例:
import pandas as pd# 创建一个简单的DataFramedata = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}df = pd.DataFrame(data)print(df)# 对数据进行统计mean_age = df['Age'].mean()print('Mean age:', mean_age) -
matplotlib库:
matplotlib是一个用于绘制图形的库,它可以创建各种静态、动态、交互式的可视化图形。示例:
import matplotlib.pyplot as plt# 绘制一个简单的折线图x = [1, 2, 3, 4, 5]y = [2, 4, 6, 8, 10]plt.plot(x, y)plt.xlabel('X axis')plt.ylabel('Y axis')plt.title('Simple Line Plot')plt.show()
这些只是Python标准库和第三方库中的一小部分例子。Python的库生态系统非常丰富,几乎涵盖了编程的所有方面,从基础的数据结构到高级的机器学习算法,都可以通过安装和使用相应的库来实现。
相关文章:

Android Framework 之 Python
当然可以,我会尽量提供更详细的内容,并增加更多的例子和解释。以下是更详细的Python语言教程: Python语言教程 一、Python简介 Python是一种高级编程语言,由Guido van Rossum于1989年底发明,第一个公开发行版发行于…...

【Fitten Code】“吊打“Github Copilot的国内免费代码辅助插件
🌻个人主页:相洋同学 🥇学习在于行动、总结和坚持,共勉! 目录 1.Github Copilot 2.Fitten Code 2.1 对话体验: 2.2 代码补全体验: 2.3 Pycharm安装方法: 2.4 Vscode安装方法…...

Git中的换行符CRLF和LF问题
目录 第一章、问题分析1.1)Git报错提示1.2)报错分析 第二章、解决方式2.1)在Windows上开发并需要与Unix或macOS上的开发人员协作2.1)在Unix或macOS开发并需要与Windows上的开发人员协作2.3)不需要与其他操作系统的开发…...

go语言文件操作
标准流的操作 从标准输入中查找重复的行 // 从标准输入中查找重复的行 func main() {counts : make(map[string]int, 0)scanner : bufio.NewScanner(os.Stdin) for scanner.Scan() {counts[scanner.Text()]}for key, value : range counts {if value > 1 {fmt.Println(&quo…...

七月论文审稿GPT第3.2版和第3.5版:通过paper-review数据集分别微调Mistral、gemma
前言 我司第二项目组一直在迭代论文审稿GPT(对应的第二项目组成员除我之外,包括:阿荀、阿李、鸿飞、文弱等人),比如 七月论文审稿GPT第1版:通过3万多篇paper和10多万的review数据微调RWKV七月论文审稿GPT第2版:用一万…...

QML 自定义时间编辑控件
一.展示效果 qml自定义时间编辑控件 二.主界面调用 //main.qml import QtQuick 2.12 import QtQuick.Controls 2.5 import QtQuick.Window 2.12 import "./qml"Window {visible: truewidth: 400height: 300title: qsTr("Hello World")property date origi…...
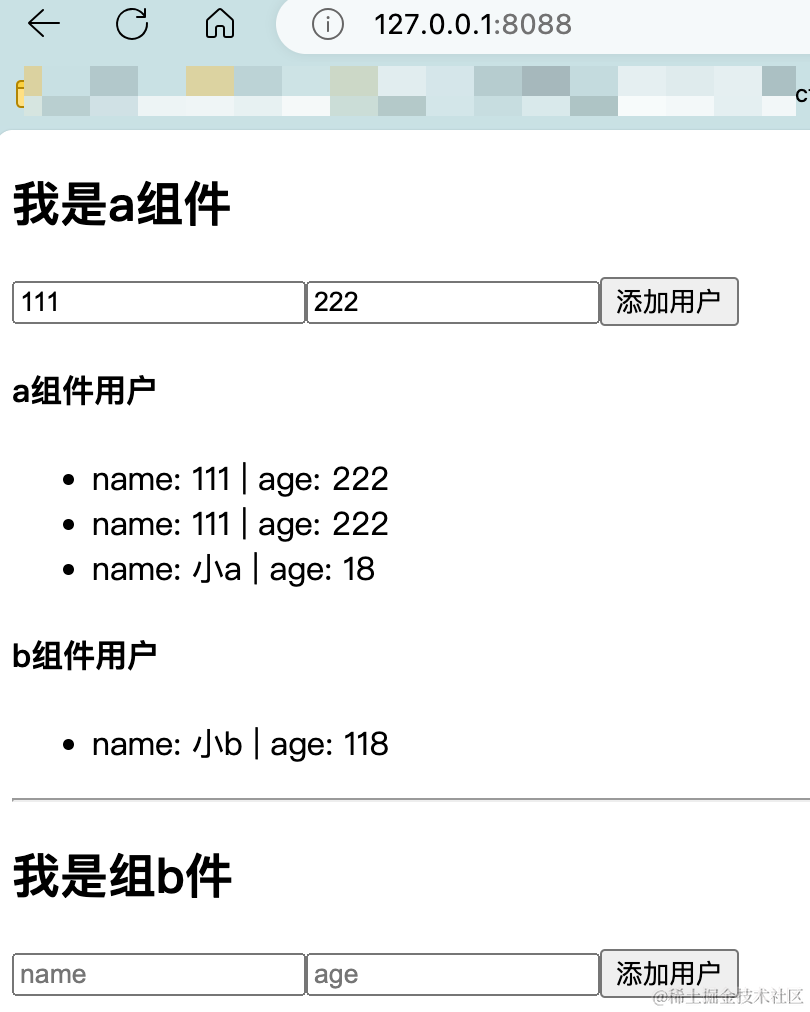
后端程序员入门react笔记(八)-redux的使用和项目搭建
一个更好用的文档 添加链接描述 箭头函数的简化 //简化前 function countIncreAction(data) {return {type:"INCREMENT",data} } //简化后 const countIncreAction data>({type:"INCREMENT",data })react UI组件库相关资料 组件库连接和推荐 antd组…...
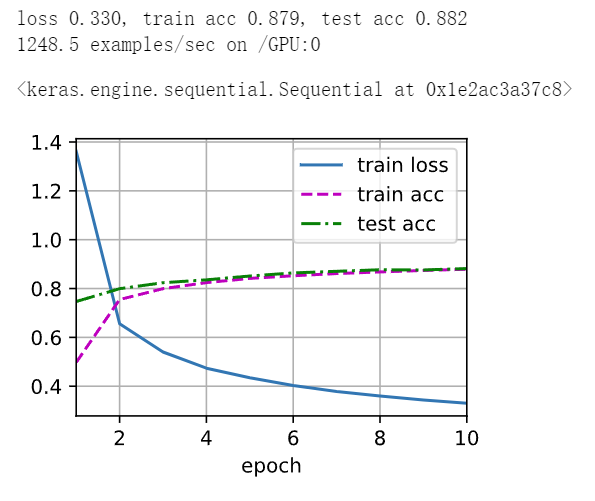
深度学习 精选笔记(13.2)深度卷积神经网络-AlexNet模型
学习参考: 动手学深度学习2.0Deep-Learning-with-TensorFlow-bookpytorchlightning ①如有冒犯、请联系侵删。 ②已写完的笔记文章会不定时一直修订修改(删、改、增),以达到集多方教程的精华于一文的目的。 ③非常推荐上面(学习参考&#x…...
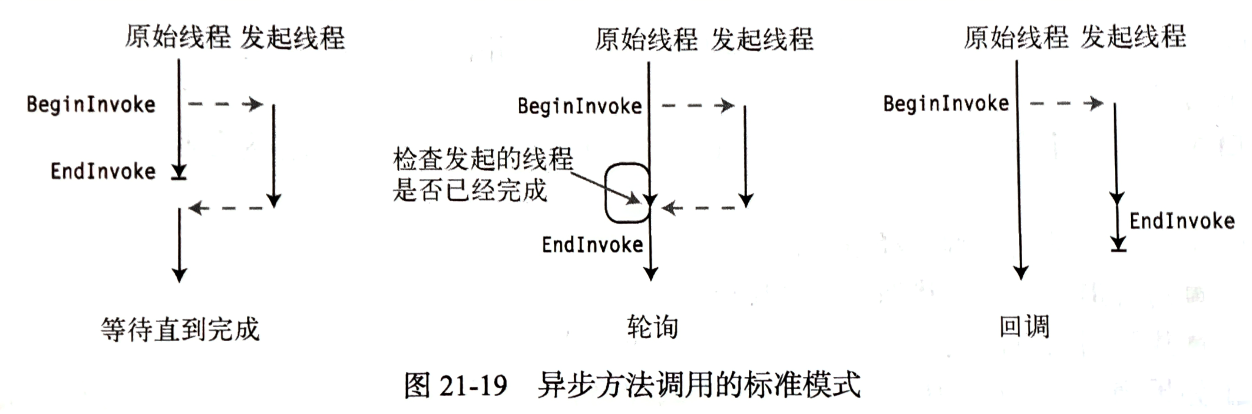
【C#图解教程】笔记
文章目录 1. C#和.NET框架.NET框架的组成.NET框架的特点CLRCLICLI的重要组成部分各种缩写 2. C#编程概括标识符命名规则: 多重标记和值格式化数字字符串对齐说明符格式字段标准数字格式说明符标准数字格式说明符 表 3. 类型、存储和变量数据成员和函数成员预定义类型…...
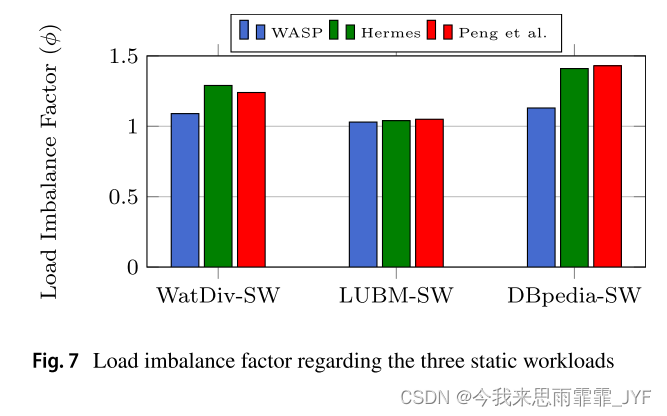
A Workload‑Adaptive Streaming Partitioner for Distributed Graph Stores(2021)
用于分布式图存储的工作负载自适应流分区器 对象:动态流式大图 划分方式:混合割 方法:增量重划分 考虑了图查询算法,基于动态工作负载 考虑了双动态:工作负载动态;图拓扑结构动态 缺点:分配新顶…...

鸿蒙Harmony应用开发—ArkTS声明式开发(基础手势:Search)
搜索框组件,适用于浏览器的搜索内容输入框等应用场景。 说明: 该组件从API Version 8开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 子组件 无 接口 Search(options?: { value?: string, placeholder?: Reso…...

GPIO八种工作模式实践总结
到目前为止我还是没搞懂,GPIO口输入输出模式下,PULLUP、PULLDOWN以及NOPULL之间的区别,从实践角度讲,也就是我亲自测试来看,能划分的区别有以下几点: GPIO_INPUT 在输入模式下使用HAL_GPIO_WritePin不能改变…...
ElementUI两个小坑
1.form表单绑定的是一个对象,表单里的一个输入项是对象的一个属性之一,修改输入项,表单没刷新的问题, <el-form :model"formData" :rules"rules" ref"editForm" class"demo-ruleForm"…...

前端基础——HTML傻瓜式入门(2)
该文章Github地址:https://github.com/AntonyCheng/html-notes 在此介绍一下作者开源的SpringBoot项目初始化模板(Github仓库地址:https://github.com/AntonyCheng/spring-boot-init-template & CSDN文章地址:https://blog.c…...
操作系统(AndroidIOS)图像绘图的基本原理
屏幕显示图像的过程 我们知道,屏幕是由一个个物理显示单元组成,每一个单元我们可以称之为一个物理像素点,而每一个像素点可以发出多种颜色。 而图像,就是在不同的物理像素点上显示不同的颜色构成的。 像素点的颜色 像素的颜色是…...
测试用例的设计(2)
目录 1.前言 2.正交排列(正交表) 2.1什么是正交表 2.2正交表的例子 2.3正交表的两个重要性质 3.如何构造一个正交表 3.1下载工具 3.1构造前提 4.场景设计法 5.错误猜测法 1.前言 我们在前面的文章里讲了测试用例的几种设计方法,分别是等价类发,把测试例子划分成不同的类…...

HTML与CSS
前言 Java 程序员一提起前端知识,心情那是五味杂陈,百感交集。 说不学它吧,说不定进公司以后,就会被抓壮丁去时不时写点前端代码说学它吧,HTML、CSS、JavaScript 哪个不得下大功夫才能精通?学一点够不够用…...
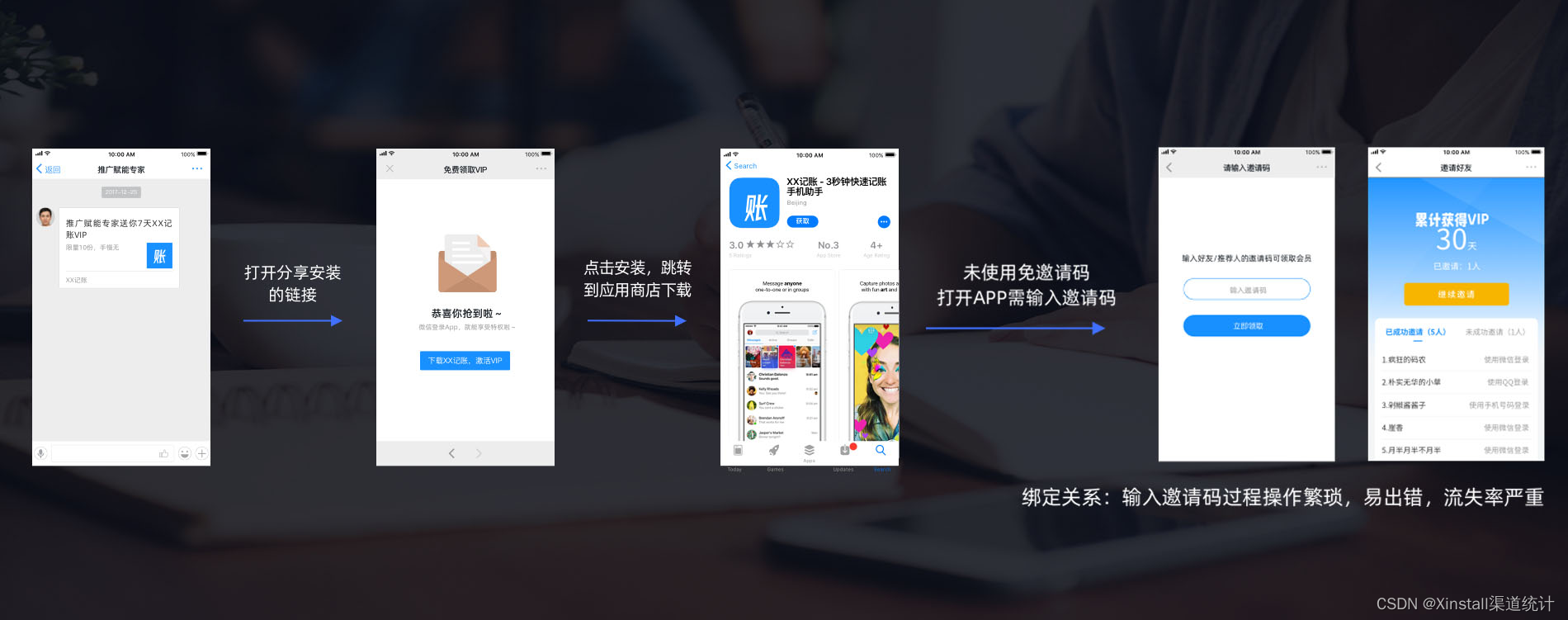
App推广不再难!Xinstall神器助你快速获客,提升用户留存
在如今的移动互联网时代,App推广已经成为了各大应用商家争夺用户的重要手段。然而,面对竞争激烈的市场环境,如何快速提升推广效率,先人一步获得用户呢?这就需要我们借助专业的App全渠道统计服务商——Xinstall的力量。…...

MySQL建表以及excel内容导入
最近自学MySQL的使用,需要将整理好的excel数据导入数据库中,记录一下数据导入流程。 --建立数据库 create table SP_sjk ( --增加列 id NUMBER(20), mc VARCHAR2(300) ) /*表空间储存参数配置。一个数据库从逻辑上来说是由一个或多个表空间所组成&#…...

让el-input与其他组件能够显示在同一行
让el-input与其他组件能够显示在同一行 说明:由于el-input标签使用会默认占满一行,所以在某些需要多个展示一行的时候不适用,因此需要能够跟其他组件显示在同一行。 效果: 1、el-input标签内使用css属性inline 111<el-inp…...

基于Arduino与蓝牙模块的六路无线开关控制系统设计与实现
1. 项目概述:用手机蓝牙控制六路LED想不想把手机变成一个无线遥控器,随手一点就能开关家里的灯带、氛围灯,甚至是其他电器?这个项目就是为你准备的。它基于一块功能增强的Arduino兼容板——GlowDuino Uno,配合一个极其…...

CTF出题人视角:从NewStarCTF 2023的WEB题,聊聊PHP特性与Flask Debug的那些‘坑’
CTF出题艺术:从PHP特性到Flask Debug的攻防博弈 当一道精心设计的CTF题目被成功破解时,出题人与解题者之间往往存在一场无声的思维交锋。作为NewStarCTF 2023 WEB方向的出题人,我想通过复盘"Begin of PHP"和"ErrorFlask"…...

ThriftPy性能测试与基准对比:Cython加速效果分析
ThriftPy性能测试与基准对比:Cython加速效果分析 【免费下载链接】thriftpy Thriftpy has been deprecated, please migrate to https://github.com/Thriftpy/thriftpy2 项目地址: https://gitcode.com/gh_mirrors/th/thriftpy ThriftPy是一款高效的Python T…...
Elsevier-Tracker:5分钟打造您的学术论文审稿进度监控系统
Elsevier-Tracker:5分钟打造您的学术论文审稿进度监控系统 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 在科研工作者的日常中,论文审稿进度追踪常常成为消耗时间与精力的隐形负担。每天反…...

Linux 软链接和硬链接详解:ln 命令背后的 inode 原理
Linux 软链接和硬链接详解:ln 命令背后的 inode 原理 1. 前言 Linux 中经常会看到链接文件,例如: /bin -> /usr/bin python -> python3 current -> /opt/app/releases/v2Linux 链接主要有两种: 软链接:symbol…...

Go语言调试技巧:Delve调试器
Go语言调试技巧:Delve调试器 1. Delve使用 dlv debug main.go (dlv) breakpoint main.go:10 (dlv) continue2. 总结 Delve是Go语言的官方调试器,支持断点、单步执行等调试功能。...

小学阶段物理学习书籍推荐
结合小学阶段认知特点,推荐以下几本兼具趣味性和实用性的物理启蒙书籍,适配不同年级孩子的学习需求: 一、低龄(1-2年级/6-8岁):趣味感知,激发好奇 1、漫画物理全套6册 用孩子最喜欢的漫画形式拆…...
基于Transformer与MPLC的智能波前校正技术提升卫星量子密钥分发性能
1. 项目概述:当量子密钥分发遇上大气湍流 在量子通信领域,连续变量量子密钥分发(CV-QKD)因其与经典光通信系统良好的兼容性和高密钥率潜力,被视为构建未来全球量子互联网的关键技术之一。其核心原理,简单来…...

Unity Find Reference2 2.5.2版本深度解析与正确接入指南
1. 这不是普通插件下载:Find Reference2 的真实价值与误用重灾区“Unity Find Reference2 2.5.2版本资源下载”——看到这个标题,很多Unity开发者第一反应是点开就找网盘链接、GitHub Release页面或某论坛的打包附件。我试过不下二十次:复制标…...

零代码实战:非技术人员如何用 Coze_Dify 搭建工作流 Agent
零代码实战:非技术人员如何用 Coze/Dify 搭建工作流 Agent 前言:写给所有“想让AI干活却怕写代码”的朋友 (特别说明:本文遵循每个章节>10000字的深度要求,将尽可能用最通俗的类比、最多元的案例、最细致的…...