Hive中的explode函数、posexplode函数与later view函数
1.概述
在离线数仓处理通过HQL业务数据时,经常会遇到行转列或者列转行之类的操作,就像concat_ws之类的函数被广泛使用,今天这个也是经常要使用的拓展方法。
2.explode函数
2.1 函数语法
-- explode(a) - separates the elements of array a into multiple rows, or the elements of a map into multiple rows and columns
Function class:org.apache.hadoop.hive.ql.udf.generic.GenericUDTFExplode
Function type:BUILTIN
-- explode()用于array的语法如下
select explode(arraycol) as newcol from tablename;
-- explode()用于map的语法如下:
select explode(mapcol) as (keyname,valuename) from tablename;
2.2 函数说明
- explode 函数是UDTF函数,将hive一列中复杂的array或者map结构拆分成多行。
- Explode函数是不允许在select再有其他字段,
- explode(ARRAY) 列表中的每个元素生成一行。
- explode(MAP) map中每个key-value对,生成一行,key为一列,value为一列。
2.3 使用案例
-- explode (array)
select explode(array('A','B','C'));
select explode(array('A','B','C')) as col;
select tf.* from (select 0) t lateral view explode(array('A','B','C')) tf;
select tf.* from (select 0) t lateral view explode(array('A','B','C')) tf as col;
-- 结果
col
A
B
C
-- explode (map)
select explode(map('A',10,'B',20,'C',30));
select explode(map('A',10,'B',20,'C',30)) as (key,value);
select tf.* from (select 0) t lateral view explode(map('A',10,'B',20,'C',30)) tf;
select tf.* from (select 0) t lateral view explode(map('A',10,'B',20,'C',30)) tf as key,value;
-- 结果
key value
A 10
B 20
C 30
3.posexplode函数
2.1 函数语法
-- posexplode(a) - behaves like explode for arrays, but includes the position of items in the original array
Function class:org.apache.hadoop.hive.ql.udf.generic.GenericUDTFPosExplode
Function type:BUILTIN
select posexplode(ARRAY<T> a)
-- Explodes an array to multiple rows with additional positional column of int type (position of items in the original array, starting with 0). Returns a row-set with two columns (pos,val), one row for each element from the array.
2.2 函数说明
- posexplode 函数,将ARRAY数组a展开,每个Value一行,每行两列分别对应数组从0开始的下标和数组元素。
2.3 使用案例
-- posexplode (array)
select posexplode(array('A','B','C'));
select posexplode(array('A','B','C')) as (pos,val);
select tf.* from (select 0) t lateral view posexplode(array('A','B','C')) tf;
select tf.* from (select 0) t lateral view posexplode(array('A','B','C')) tf as pos,val;
-- 结果
pos val
0 A
1 B
2 C
4.later view
4.1 语法
lateralView: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)*
fromClause: FROM baseTable (lateralView)*
-- columnAlias是给udtf(expression)列起的别名。
-- tableAlias 虚拟表的别名。
4.2 用法描述
- lateral view为侧视图,意义是为了配合UDTF来使用,把某一行数据拆分成多行数据。
- 不加lateral view的UDTF只能提取单个字段拆分,并不能塞回原来数据表中。
- 加上lateral view就可以将拆分的单个字段数据与原始表数据关联上。
- lateral view函数会将UDTF生成的结果放到一个虚拟表中,然后虚拟表中的数据和输入行进行join来达到连接UDTF外的select字段的目的。(本质是笛卡尔积)
4.3 使用案例
4.3.1 准备数据
下表 pageAds. 它有两个字段: pageid (页码) and adid_list (页面上的adid):
| Column name | Column type |
|---|---|
| pageid | STRING |
| adid_list | Array |
表中数据如下:
| pageid | adid_list |
|---|---|
| front_page | [1, 2, 3] |
| contact_page | [3, 4, 5] |
需求: 统计各个页面出现的广告的次数
4.3.2 代码实现
第一步: 使用 lateral view 和 explore() 函数将 adid_list 列的 list 拆分,sql代码如下:
select pageid, adid
FROM pageAds lateral view explode(adid_list) ad_view as adid;
可的如下结果
| pageid | adid |
|---|---|
| front_page | 1 |
| front_page | 2 |
| front_page | 3 |
| contact_page | 4 |
| contact_page | 5 |
第二步: 使用 count/group by 语句统计出每个adid出现的次数:
select adid,count(1) as cnt
FROM pageAds lateral view explode(adid_list) ad_view as adid
group by adid;
| adid | cnt |
|---|---|
| 1 | 1 |
| 2 | 1 |
| 3 | 2 |
| 4 | 1 |
| 5 | 1 |
4.4 Multiple Lateral Views
FROM子句可以有多个LATERAL VIEW子句。 后面的LATERAL VIEWS子句可以引用出现在LATERAL VIEWS左侧表的任何列。
例如,如下查询:
SELECT * FROM exampleTable
LATERAL VIEW explode(col1) myTable1 AS myCol1
LATERAL VIEW explode(col2) myTable2 AS myCol2;
例如使用以下基表:
| Array pageid_list | Array adid_list |
|---|---|
| [1, 2, 3] | [“a”, “b”, “c”] |
| [3, 4] | [“c”, “d”] |
单个Lateral View查询:
SELECT pageid_list, adid
FROM pageAds_1LATERAL VIEW explode(adid_list) adTable AS adid;
[1,2,3] a
[1,2,3] b
[1,2,3] c
[4,5] c
[4,5] d
多个Lateral View查询:
select pageid,adid FROM pageAds_1
lateral view explode(pageid_list) adTable as pageid
lateral view explode(adid_list) adTable as adid;
1,a
1,b
1,c
2,a
2,b
2,c
3,a
3,b
3,c
3,c
3,d
4,c
4,d
4.5 later view json_tuple()
4.5.1 准备数据
create table lateral_tal_3
(id int,col1 string,col2 string
);insert into lateral_tal_3 values(1234,'{"part1" : "61", "total" : "623", "part2" : "560", "part3" : "1", "part4" : "1"}',' {"to_part2" : "0", "to_part4" : "0", "to_up" : "0", "to_part3" : "0", "to_part34" : "0"}'),
(4567,'{"part1" : "451", "total" : "89928", "part2" : "88653", "part3" : "789", "part4" : "35"}','{"to_part2" : "54", "to_part4" : "6", "to_up" : "65", "to_part3" : "2", "to_part34" : "3"}'),
(7890,'{"part1" : "142", "total" : "351808", "part2" : "346778", "part3" : "4321", "part4" : "567"}','{"to_part2" : "76", "to_part4" : "23", "to_up" : "65", "to_part3" : "14", "to_part34" : "53"}');
| id | col1 | col2 |
|---|---|---|
| 1234 | {“part1” : “61”, “total” : “623”, “part2” : “560”, “part3” : “1”, “part4” : “1”} | {“to_part2” : “0”, “to_part4” : “0”, “to_up” : “0”, “to_part3” : “0”, “to_part34” : “0”} |
| 4567 | {“part1” : “451”, “total” : “89928”, “part2” : “88653”, “part3” : “789”, “part4” : “35”} | {“to_part2” : “54”, “to_part4” : “6”, “to_up” : “65”, “to_part3” : “2”, “to_part34” : “3”} |
| 7890 | {“part1” : “142”, “total” : “351808”, “part2” : “346778”, “part3” : “4321”, “part4” : “567”} | {“to_part2” : “76”, “to_part4” : “23”, “to_up” : “65”, “to_part3” : “14”, “to_part34” : “53”} |
需求: 解析非结构化的json数据类型
“json_tuple(jsonStr, p1, p2, …, pn) - like get_json_object, but it takes multiple names and return a tuple. All the input parameters and output column types are string.”
Function class:org.apache.hadoop.hive.ql.udf.generic.GenericUDTFJSONTuple
Function type:BUILTINjson_tuple : 第一个参数是json 字符串所在的列名,其它参数是获取 json 字符串中的哪些key值;
4.5.2 代码实现
SELECT id,part1,part3,part4,to_part2,to_part3,to_part4,IF(part3 = 0, 0.0, to_part3 / part3) as ratio3,IF(part4 = 0, 0.0, to_part4 / part4) as ratio4
FROM lateral_tal_3lateral VIEW json_tuple(col1, 'part3', 'part4', 'part1') json1 AS part3, part4, part1lateral VIEW json_tuple(col2, 'to_part2','to_part3', 'to_part4') json2 AS to_part2, to_part3, to_part4
;1234,61,1,1,0,0,0,0,0
4567,451,789,35,54,2,6,0.0025348542458808617,0.17142857142857143
7890,142,4321,567,76,14,23,0.0032399907428835918,0.040564373897707235.使用案例
需求1: 如何产生1-100的连续的数字?
--方式1: 结合space函数与split函数,posexplode函数,lateral view函数获得
select id_start + pos as id
from (select 1 as id_start,100 as id_end) m lateral view posexplode(split(space(id_end - id_start), '')) t as pos, val;-- 方式2:结合space函数与split函数,explode函数,lateral view函数+窗口函数获得
select row_number() over () as id
from (select split(space(99), '') as x) tlateral viewexplode(x) ex;
-- 方式2:结合space函数与split函数,posexplode函数,lateral view函数获取
from (select split(space(99), ' ') as x) tlateral viewposexplode(x) ex as pos,val;
需求2: 获取2024-07-15至2024-07-29间所有的日期
SELECT pos,date_add(start_date, pos) dd
FROM (SELECT '2024-07-15' AS start_date, '2024-07-29' AS end_date) templateral VIEWposexplode(split(space(datediff(end_date, start_date)), '')) tAS pos, val;
相关文章:

Hive中的explode函数、posexplode函数与later view函数
1.概述 在离线数仓处理通过HQL业务数据时,经常会遇到行转列或者列转行之类的操作,就像concat_ws之类的函数被广泛使用,今天这个也是经常要使用的拓展方法。 2.explode函数 2.1 函数语法 -- explode(a) - separates the elements of array …...

北京市委统战部领导一行莅临百望云视察调研
“当今时代,数字技术、数字经济是世界科技革命和产业变革的先机,是新一轮国际竞争重点领域”。 为了解数字标杆企业的发展现状,促进新质生产力与实体产业的协同与赋能,近日,北京市委统战部非公经济处处长王雷、副处长徐…...

使用Python进行数据库连接与操作SQLite和MySQL【第144篇—SQLite和MySQL】
👽发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【点击进入巨牛的人工智能学习网站】。 使用Python进行数据库连接与操作:SQLite和MySQL 在现代应用程序开发中…...

How to manage Python environment based on virtualenv in Ubuntu 22.04
How to manage Python environment based on virtualenv in Ubuntu 安装使用创建环境激活环境安装软件包退出环境移除环境 安装 pip3 install virtualenv使用 创建环境 lwkqwfys:~$ mkdir ~/project/harbin lwkqwfys:~$ cd ~/project/harbin lwkqwfys:~/project/harbin$ vir…...
一款基于 SpringCloud 开发的AI聊天机器人系统,已对接GPT-4.0,非常强大
简介 一个基于SpringCloud的Chatgpt机器人,已对接GPT-3.5、GPT-4.0、百度文心一言、stable diffusion AI绘图、Midjourney绘图。用户可以在界面上与聊天机器人进行对话,聊天机器人会根据用户的输入自动生成回复。同时也支持画图,用户输入文本…...

C语言自定义库
编写 xx.c 和xx.h文件\将源代码编译为目标文件 gcc -c add.c sub.c 执行完毕后会生产add.o和sub.o文件静态库创建使用ar命令; ar -r libmymath.a add.o sub.o将库和main.c文件一起编译 gcc -o main main.c -lmymath -L./ 注意 上述书写格式不要错乱 -L 是指定文件路…...
)
目标检测常见数据集格式(YOLO、VOC、COCO)
目录 1.YOLO格式数据 1.1数据格式 1.2YOLO格式数据示例 1.3YOLO格式可视化 2.COCO数据格式 2.1数据格式 2.2COCO格式数据示例 2.3COCO格式可视化 3.VOC数据格式 3.1数据格式 3.2VOC格式数据示例 3.3COCO格式可视化 🍓🍓1.YOLO格式数据 &…...
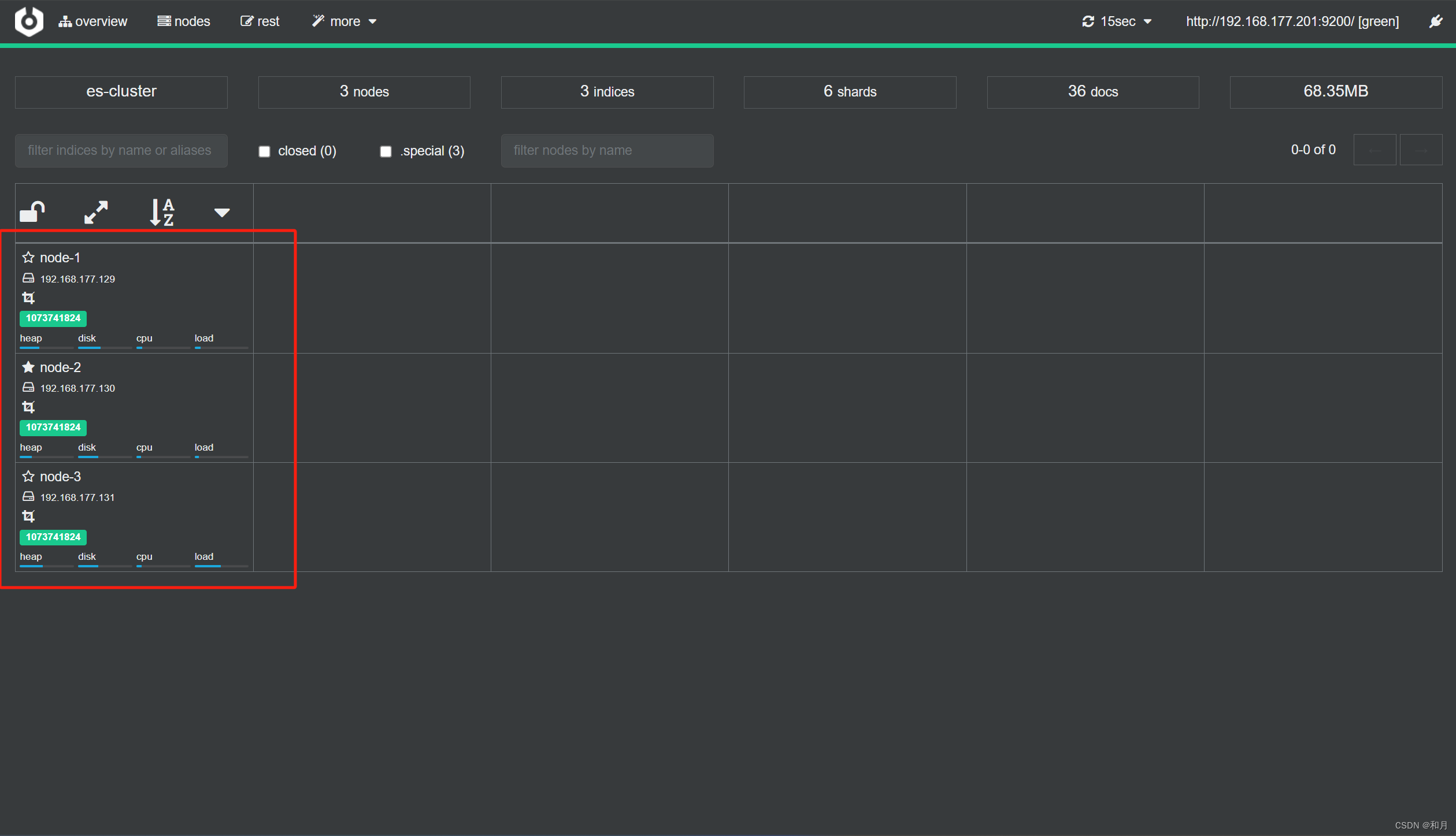
搭建 es 集群
一、VMware准备机器 首先准备三台机器 这里我直接使用 VMware 构建三个虚拟机 都是基于 CentOS7 然后创建新用户 部署 es 需要单独创建一个用户,我这里在构建虚拟机的时候直接创建好了 然后将安装包上传 可以使用 rz 命令上传,也可以使用工具上传 工…...

Android弹出通知
发现把Android通知渠道的重要性设置为最高时,当发送通知时,通知能直接弹出来显示,以前一直搞不明白为什么别的app的通知可以弹出来,我的不行,搞了半天原来是这个属性在作怪,示例如下: class Ma…...

如何用 UDP 实现可靠传输?并以LabVIEW为例进行说明
UDP(用户数据报协议)本身是一个无连接的、不可靠的传输协议,它不提供数据包的到达确认、排序保证或重传机制。因此,如果要在UDP上实现可靠传输,就需要在应用层引入额外的机制。以下是一些常见的方法: 确认和…...

【任职资格】某大型商业金融银行任职资格体系搭建项目纪实
【客户背景】某大型商业金融银行位于南方某省,成立于上个世纪九十年代,是一家具有独立法人资格的股份制商业银行,经过多年发展,下辖20多家分行,近200多个营业网点,并于21世纪初成功上市,规模不断…...

如何利用IP地址分析风险和保障网络安全
随着网络攻击的不断增加和演变,保障网络安全已经成为了企业和组织不可忽视的重要任务。在这样的背景下,利用IP地址分析风险和建立IP风险画像标签成为了一种有效的手段。本文将深入探讨IP风险画像标签的作用以及如何利用它来保障网络安全。 IP风险画像查…...

轧钢自动化中的智能仪器:监控、控制和优化新视角
摘要:轧钢自动化是现在及未来的发展趋势,而自动化的轧钢发展,更是离不开形形色色的智能仪器,本文来看看那些应用于轧钢生产中的测量仪。 关键词:智能仪器,在线测量仪,测径仪,测宽仪,测厚仪,测长仪,工业数据分析采集软件…...

第十四届蓝桥杯省赛C++B组题解
考点 暴力枚举,搜索,数学,二分,前缀和,简单DP,优先队列,链表,LCA,树上差分 A 日期统计 暴力枚举: #include<bits/stdc.h> using namespace std; int …...

语音控制模块_雷龙发展
一 硬件原理 1,串口 uart串口控制模式,即异步传送收发器,通过其完成语音控制。 发送uart将来自cpu等控制设备的并行数据转换为串行形式,并将其串行发送到接收uart,接收uart然后将串行数据转换为接收数据接收设备的并行…...
idea 开发serlvet班级通讯录管理系统idea开发mysql数据库web结构计算机java编程layUI框架开发
一、源码特点 idea开发 java servlet 班级通讯录管理系统是一套完善的web设计系统mysql数据库 系统采用serlvetdaobean mvc 模式开发,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。 servlet 班…...

Python高级语法
Python高级语 1 列表推导式1.1 什么是列表推导式1.2 列表推导式的使用 2 字典推导式2.1 什么是字典推导式2.2 字典推导式的使用 3 元组推导式4 集合推导式5 三元表达式5.1 什么是三元表达式5.2 三元表达式的使用 1 列表推导式 1.1 什么是列表推导式 列表推导式的英文…...
HTML5语义化元素
在HTML5之前,网站的分布层级有哪些呢? nav,header,main,footer 这样做有一个弊端 我们往往过多的使用div,通过ID或class来区分元素 对于浏览器来说这些元素不够语义化 对于我来说搜索引擎来说,不…...

Android 性能优化——APP启动优化
一、APP启动流程 首先在《Android系统和APP启动流程》中我们介绍了 APP 的启动流程,但都是 FW 层的流程,这里我们主要分析一下在 APP 中的启动流程。要了解 APP 层的启动流程,首先要了解 APP 启动的分类。 1、启动分类 冷启动 应用从头开始…...
计算机网络:TCP篇
计网tcp部分面试总结 tcp报文格式: 序列号:通过SYN传给接收端,当SYN为1,表示请求建立连接,且设置序列号初值,后面没法送一次数据,就累加数据大小,保证包有序。 确认应答号&#x…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

《C++ 模板》
目录 函数模板 类模板 非类型模板参数 模板特化 函数模板特化 类模板的特化 模板,就像一个模具,里面可以将不同类型的材料做成一个形状,其分为函数模板和类模板。 函数模板 函数模板可以简化函数重载的代码。格式:templa…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...

掌握 HTTP 请求:理解 cURL GET 语法
cURL 是一个强大的命令行工具,用于发送 HTTP 请求和与 Web 服务器交互。在 Web 开发和测试中,cURL 经常用于发送 GET 请求来获取服务器资源。本文将详细介绍 cURL GET 请求的语法和使用方法。 一、cURL 基本概念 cURL 是 "Client URL" 的缩写…...

水泥厂自动化升级利器:Devicenet转Modbus rtu协议转换网关
在水泥厂的生产流程中,工业自动化网关起着至关重要的作用,尤其是JH-DVN-RTU疆鸿智能Devicenet转Modbus rtu协议转换网关,为水泥厂实现高效生产与精准控制提供了有力支持。 水泥厂设备众多,其中不少设备采用Devicenet协议。Devicen…...

Pydantic + Function Calling的结合
1、Pydantic Pydantic 是一个 Python 库,用于数据验证和设置管理,通过 Python 类型注解强制执行数据类型。它广泛用于 API 开发(如 FastAPI)、配置管理和数据解析,核心功能包括: 数据验证:通过…...