Re62:读论文 GPT-2 Language Models are Unsupervised Multitask Learners
诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文全名:Language Models are Unsupervised Multitask Learners
论文下载地址:https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
官方博文:
Better language models and their implications
GPT-2: 6-month follow-up
GPT-2: 1.5B release
官方GitHub项目:openai/gpt-2: Code for the paper “Language Models are Unsupervised Multitask Learners”
对代码的整理和用代码实现GPT-2的解决方案请参考本文第4章
本文是OpenAI于2019年推出的GPT-2论文,核心思想是用无监督思路构建的语言模型来直接解决NLP问题,做一个通用大模型而非领域专家。
GPT-2本身也是个纯英文的模型。
GPT-1:Re45:读论文 GPT-1 Improving Language Understanding by Generative Pre-Training
GPT-2是因果/单向LM,预训练目标是通过前文预测下一个单词。
huggingface提供的在线试用GPT-2-large的平台:https://transformer.huggingface.co/doc/gpt2-large
打字后按Tab获得提示。

文章目录
- 1. 研究背景
- 2. 模型
- 3. 实验
- 3.1 数据集
- 3.2 实验结果
- LM实验结果
- 下游任务实验结果
- Generalization vs Memorization
- OOD生成样例
- 4. 复现
- 4.1 官方代码
- 4.2 基于transformers实现GPT-2
- 4.2.1 基于GPT2LMHeadModel + PyTorch原生框架实现S2S任务微调和推理
- 4.2.2 基于GPT2LMHeadModel + transformers.Trainer微调GPT-2
- 5. 本文撰写过程中参考的其他网络资料
1. 研究背景
现在的有监督方法的缺点:有监督模型不鲁棒,只能在IID测试集上表现良好。当前已经开始研究多任务通用模型,但多任务学习表现不好,而且要求高标注量。
现在的预训练方法还需要有监督微调。
2. 模型
语言模型:
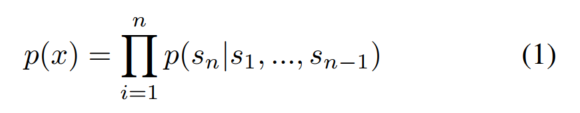
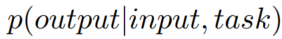
可以用文本生成任务来建模所有NLP任务,这种思路统一了无监督和有监督任务的形式。
不同大小的GPT-2:

- tokenization
Byte Pair Encoding (BPE) 改造版:原始BPE是贪心,这导致重复相似词出现,导致非最优和占空间。本文改为不让它在字节序列之间合并。 - Layer normalization:加到每个sub-block输入,和最后一个self-attention block后
- 词表、上下文长度、batchsize增大
- 学习率是手动调整的,目标使测试集(5% WebText)perplexity最低
- 模型仍未收敛
- 位置向量
绝对位置编码,默认pad到右边。
3. 实验
3.1 数据集
语料:WebText
来源于爬虫
在预训练时删掉了非英语网页(所以翻译效果不好也很正常)
语料中蕴含的翻译知识:

下游多任务:
阅读理解:CoQA
翻译:WMT-14 Fr-En
摘要:CNN and Daily Mail
QA:Natural Questions
3.2 实验结果
LM实验结果
基本上都是模型尺寸越大,效果越好。
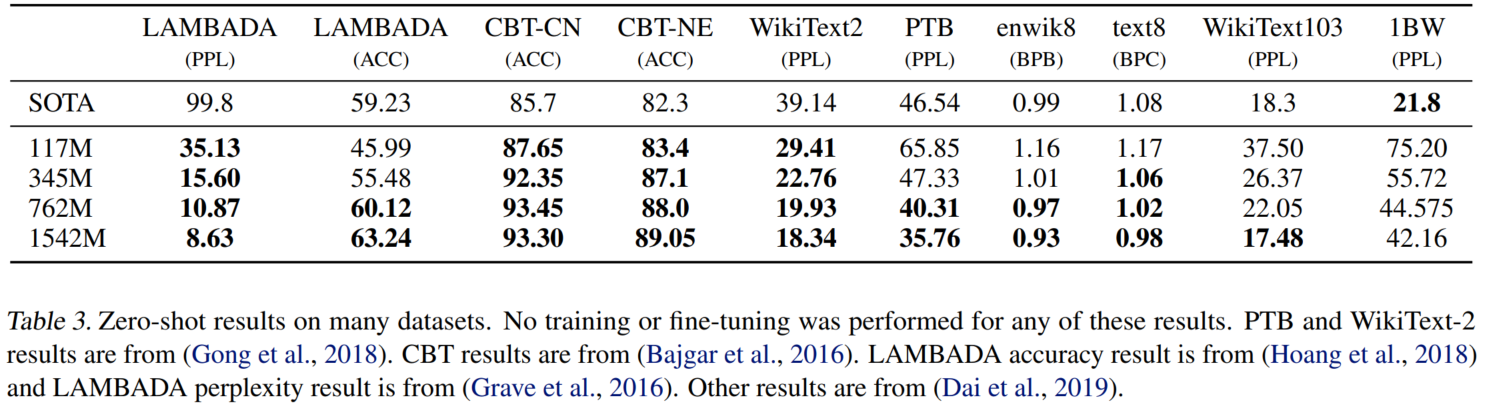
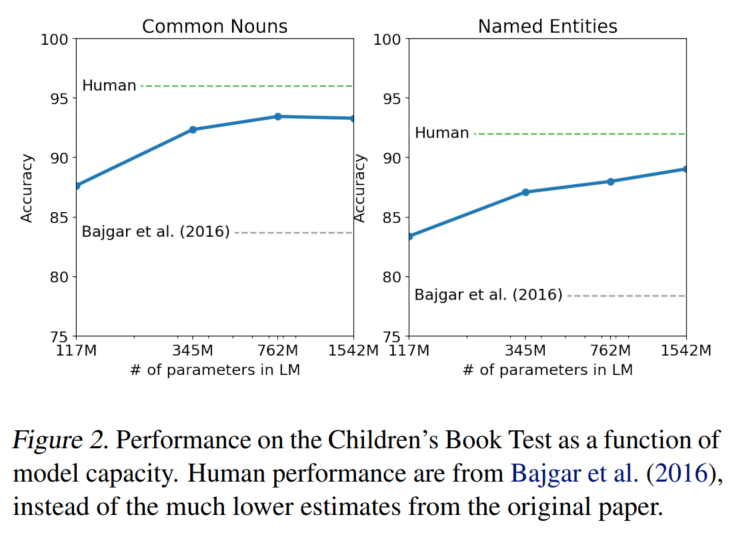
CBT:
LAMBADA
Winograd Schema Challenge:commonsense reasoning

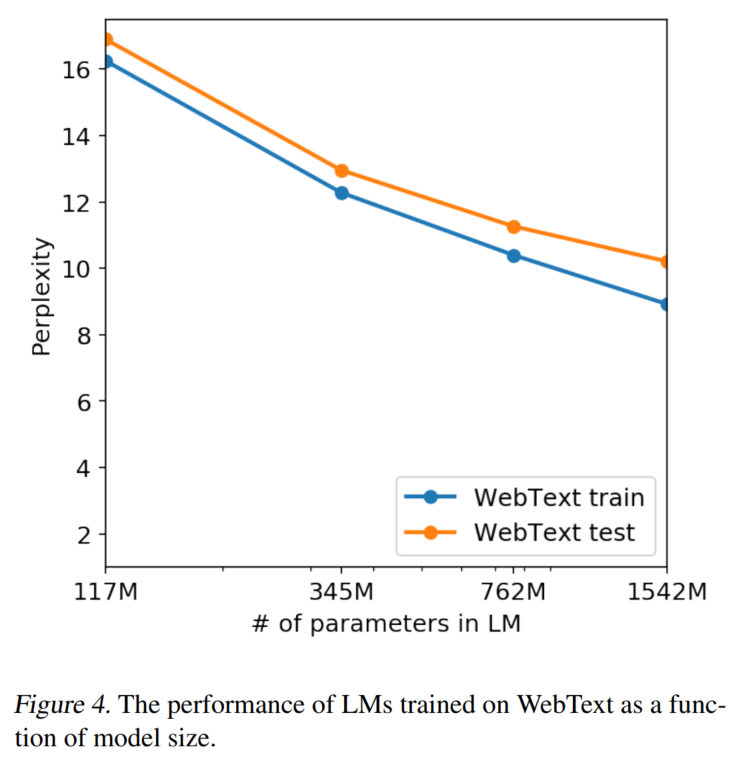
下游任务实验结果
零样本多任务,模型尺寸越大,效果越好:
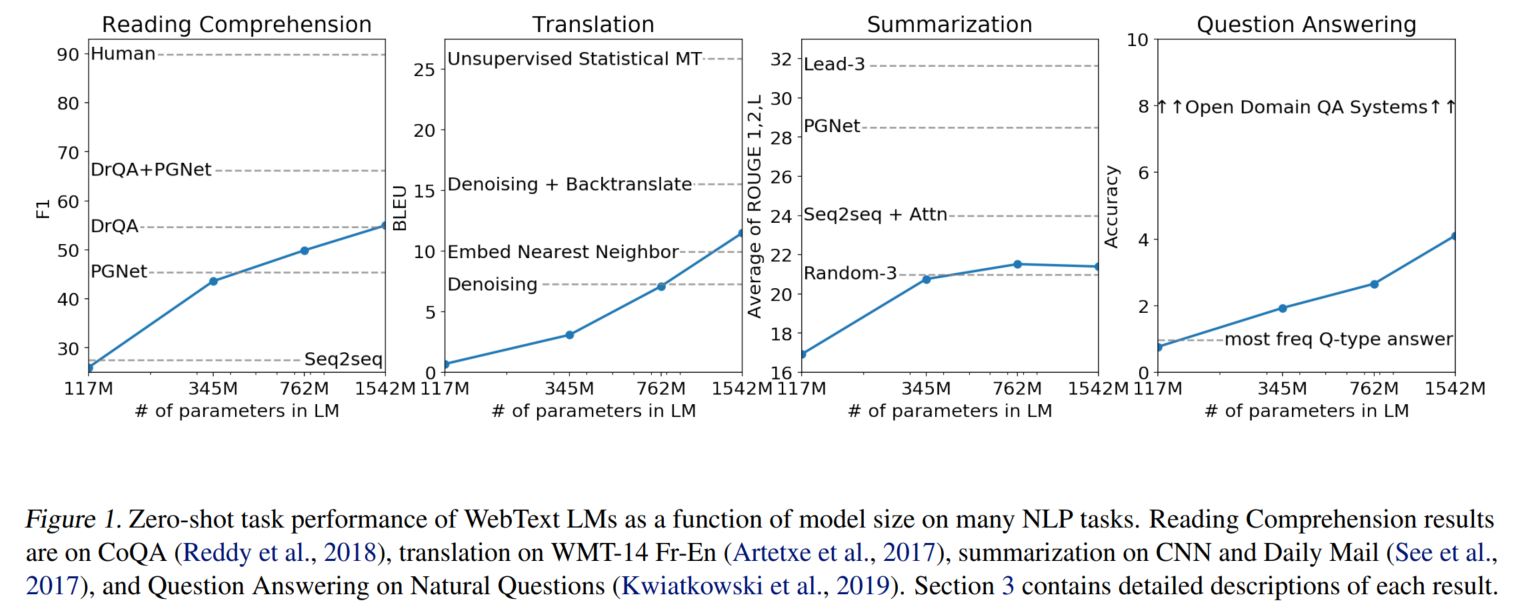
生成摘要的prompt:TL;DR:
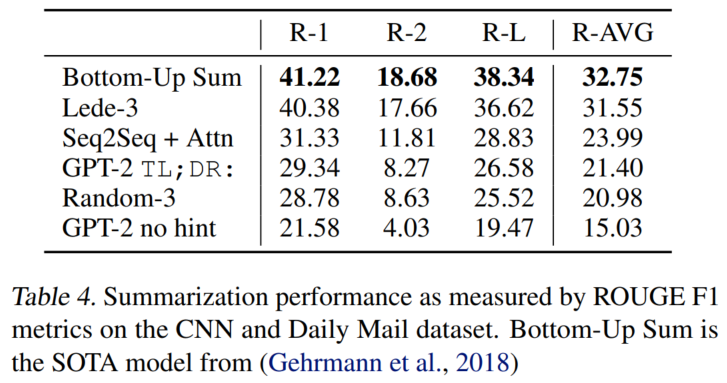
翻译给出少样本上下文(english sentence = french sentence)和prompt(english sentence =)
QA:
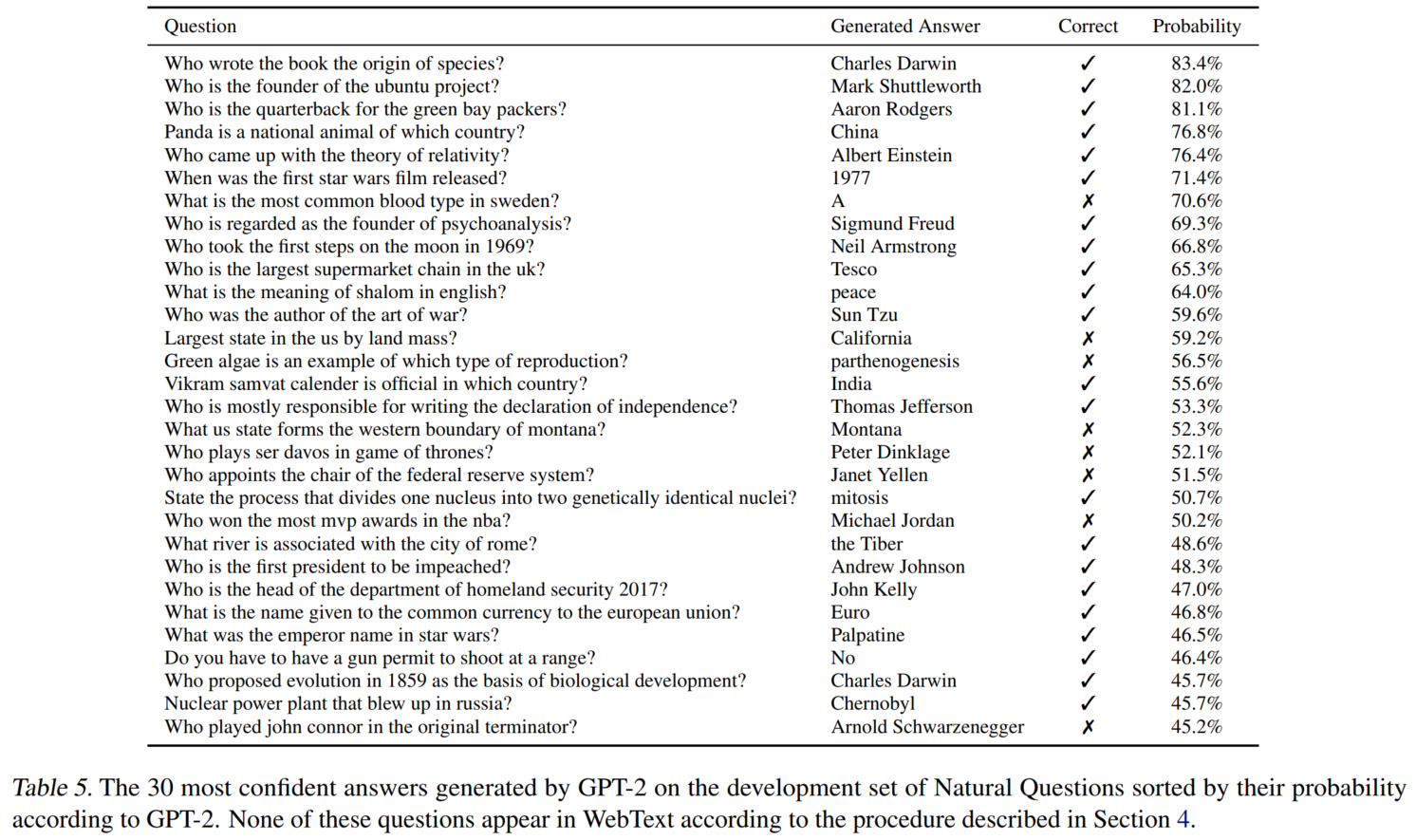
可以看出GPT-2置信度高的样本准确率确实高。
Generalization vs Memorization
训练集与测试集重复度较低,所以可以认为模型是真的实现了泛化,而不是单纯的记忆。
语料训练集与测试集的重复程度:(第一行是原始数据的训练集,第二行是WebText的训练集)
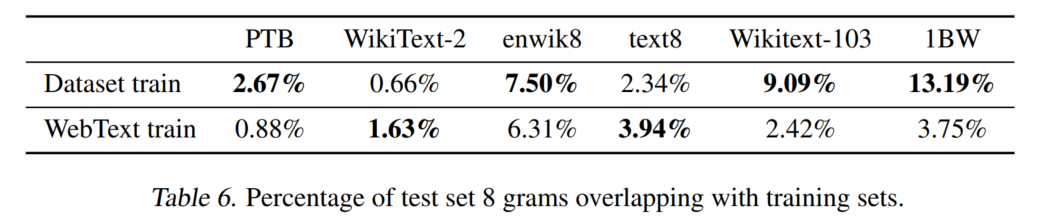
文字描述的下游数据上的重复率略。
这个是通过8-gram布隆过滤器计算的,具体略。
8-gram覆盖率
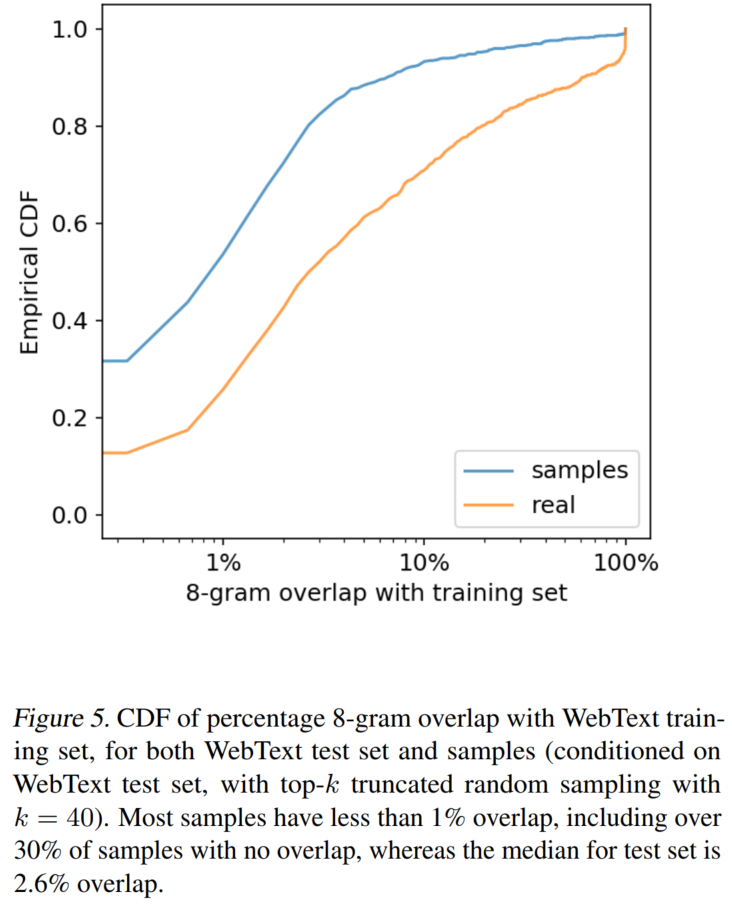
OOD生成样例

更多示例见论文附录和官方博客,我就不列出来了。
4. 复现
4.1 官方代码
官方代码是5年前的TensorFlow 1,想想就知道我不可能会。TensorFlow是不可能学的,这辈子都不可能学TensorFlow的,PyTorch又好用,社区丰富,超喜欢这里的。
BPE tokenize:https://github.com/openai/gpt-2/blob/master/src/encoder.py
建模:https://github.com/openai/gpt-2/blob/master/src/model.py
生成:https://github.com/openai/gpt-2/blob/master/src/sample.py
无条件生成文本:https://github.com/openai/gpt-2/blob/master/src/generate_unconditional_samples.py
有条件(基于prompt)生成文本:https://github.com/openai/gpt-2/blob/master/src/interactive_conditional_samples.py
4.2 基于transformers实现GPT-2
GPT-2是AR语言模型,所以要用语言模型(AutoModelWithLMHead)来实现各项任务。不是seq2seq模型,所以应该不能用seq2seq模型的框架……
不过我也没试过那么干就是了……
官方提供的GPT-2权重(都是纯英文的):
openai-community/gpt2 · Hugging Face:OpenAI官方提供的最小的GPT-2权重
https://huggingface.co/openai-community/gpt2-medium
https://huggingface.co/openai-community/gpt2-large
https://huggingface.co/openai-community/gpt2-xl
https://huggingface.co/distilbert/distilgpt2
4.2.1 基于GPT2LMHeadModel + PyTorch原生框架实现S2S任务微调和推理
数据集构建:https://github.com/PolarisRisingWar/Math_Word_Problem_Collection/blob/master/codes/finetune/gpt2/GPT2DataSet.py
微调:https://github.com/PolarisRisingWar/Math_Word_Problem_Collection/blob/master/codes/finetune/gpt2/finetune.py
推理:https://github.com/PolarisRisingWar/Math_Word_Problem_Collection/blob/master/codes/finetune/gpt2/test.py
关于generate()函数的使用可以参考这篇博文:文本生成解码策略及其在transformers中的代码实现 及配套的代码,展示了不同解码方案输出的效果:https://github.com/PolarisRisingWar/all-notes-in-one/blob/main/decode_examples_in_GPT2.ipynb
4.2.2 基于GPT2LMHeadModel + transformers.Trainer微调GPT-2
参考代码:https://github.com/PolarisRisingWar/Math_Word_Problem_Collection/blob/master/codes/finetune/gpt2/finetune_w_Trainer.py
5. 本文撰写过程中参考的其他网络资料
- OpenAI GPT2
- https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-generation/run_generation.py:这个是transformers的AR语言模型的示例
- Fine-tune a non-English GPT-2 Model with Huggingface:用德语语料训练GPT-2的示例,本文撰写基于Trainer微调时参考了这篇博文的代码
- python - How to build a dataset for language modeling with the datasets library as with the old TextDataset from the transformers library - Stack Overflow:这篇的意义就是跳转到下面这个讨论↓
- Help understanding how to build a dataset for language as with the old TextDataset - 🤗Datasets - Hugging Face Forums
- 图解GPT-2 | The Illustrated GPT-2 (Visualizing Transformer Language Models)-CSDN博客:这篇具体介绍了GPT-2原理
我之前写的Transformer和GPT-1的博文其实也有涵盖,但是没有这篇这么有针对性。而且这篇对attention的介绍与我写的理解角度不同,可资参考。补充的点在于 ① 最后一个block输出与embedding相乘得到logits,对这个logits进行采样得到预测token ② GPT-2一般用top-k=40 - 图解自注意力机制_masked self-attention-CSDN博客:上文中的自注意力部分独立成章
这个masked attention图画得挺到位的,带了数字而且颜色更好看:
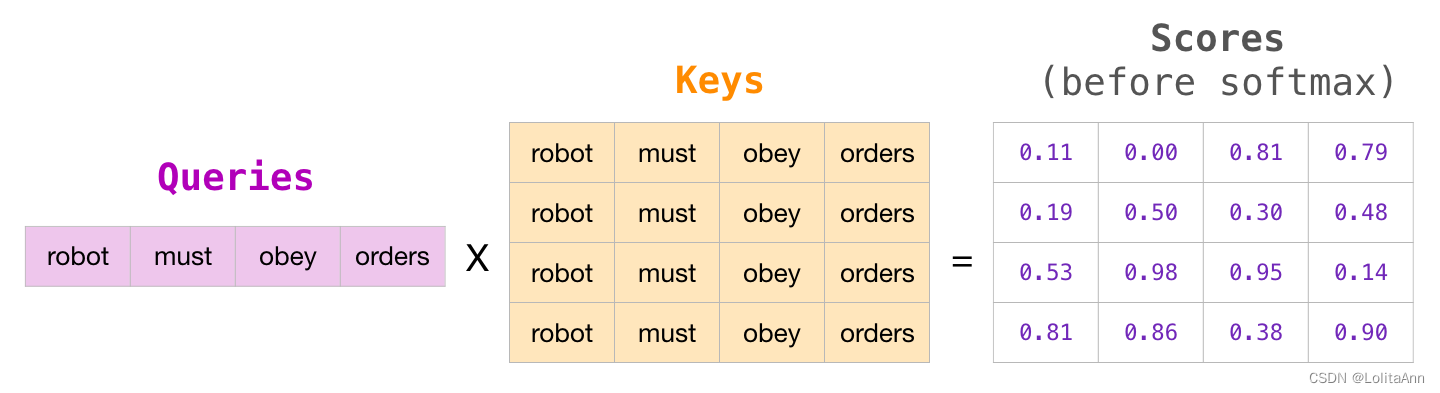


这篇补充多头注意力机制peojection过程是不改变维度的 - https://github.com/huggingface/transformers/blob/870ff9e1dab249e4ffd8363ce132aa5145c94604/src/transformers/models/gpt2/modeling_gpt2.py:transformers官方实现
代码集成性太高了,一下子看不懂,以后有时间慢慢研究吧 - GPT-2 论文+代码笔记 | Yam:这篇对论文做了解读,同时对GPT-2原代码做了解读,内容很全面。
用Conv1d做线性转换这事真奇怪啊…… - GPT-2代码解读[2]:Attention_gpt attention qpv-CSDN博客:这篇主要的特色是对GPT-2原代码中attention部分进行解读
↑虽然但是,我也不用TF 1……总之是值得在需要时进一步了解的。但是,有没有PyTorch实现更简洁的解读啊 - Training CodeParrot 🦜 from Scratch:这篇博文涵盖了更多大模型训练技巧,包括对多卡的处理。由于我暂时用不到所以没细看,如果有需要可以看看。
相关文章:
Re62:读论文 GPT-2 Language Models are Unsupervised Multitask Learners
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类 论文全名:Language Models are Unsupervised Multitask Learners 论文下载地址:https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learner…...

stm32-编码器测速
一、编码器简介 编码电机 旋转编码器 A,B相分别接通道一和二的引脚,VCC,GND接单片机VCC,GND 二、正交编码器工作原理 以前的代码是通过触发外部中断,然后在中断函数里手动进行计次。使用编码器接口的好处就是节约软件资源。对于频…...

全国各省市县统计年鉴/中国环境统计年鉴/中国工业企业数据库/中国专利数据库/污染排放数据库
统计年鉴是指以统计图表和分析说明为主,通过高度密集的统计数据来全面、系统、连续地记录年度经济、社会等各方面发展情况的大型工具书来获取统计数据资料。 统计年鉴是进行各项经济、社会研究的必要前提。而借助于统计年鉴,则是研究者常用的途径。目前国…...
MacOS和Win安装)
【LAMMPS学习】二、LAMMPS安装(2)MacOS和Win安装
2. LAMMPS安装 您可以将LAMMPS下载为可执行文件或源代码。 在下载LAMMPS源代码时,还必须构建LAMMPS。但是对于在构建中包含或排除哪些特性,您有更大的灵活性。当您下载并安装预编译的LAMMPS可执行文件时,您只能安装可用的LAMMPS版本以及这些…...

如何解决网络中IP地址发生冲突故障?
0、前言 本专栏为个人备考软考嵌入式系统设计师的复习笔记,未经本人许可,请勿转载,如发现本笔记内容的错误还望各位不吝赐教(笔记内容可能有误怕产生错误引导)。 1、个人IP地址冲突解决方案 首先winR,调出…...

机器学习常用框架
机器学习是人工智能的一个重要分支,它通过让计算机系统利用数据自我学习来改进任务执行的能力。在机器学习领域,有许多成熟的框架被广泛使用,这些框架提供了构建和训练机器学习模型的工具。以下是一些常用的机器学习框架: Tensor…...

计算机网络——物理层(信道复用技术)
计算机网络——物理层(信道复用技术) 信道复用技术频分多址与时分多址 频分复用 FDM (Frequency Division Multiplexing)时分复用 TDM (Time Division Multiplexing)统计时分复用 STDM (Statistic TDM)波分复用码分复用 我们今天接着来看信道复用技术&am…...

【Qt问题】使用QSlider创建滑块小部件无法显示
问题描述: 使用QSlider创建滑块小部件用于音量按钮的时候,无法显示,很奇怪,怎么都不显示 一直是这个效果,运行都没问题,但是就是不出现。 一直解决不了,最后我在无意中,在主程序中…...
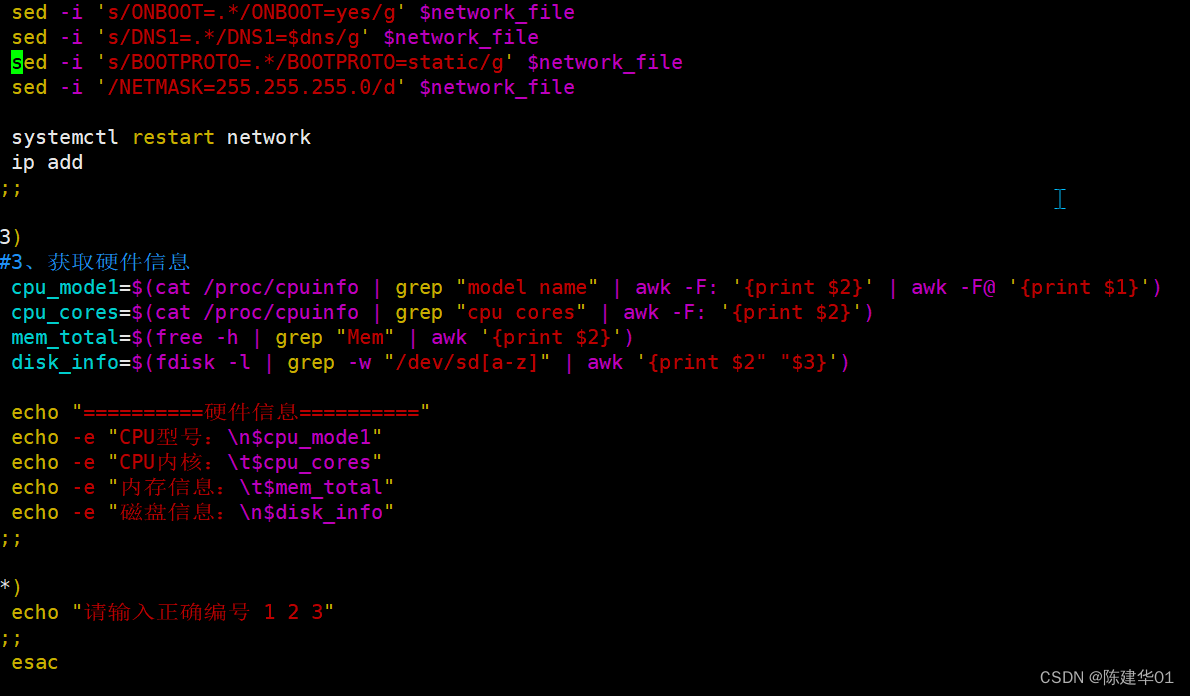
Linux--Shell脚本安装 httpd 和 修改IP
shell脚本 关闭防火墙、安装httpd、启动httpd [rootnode11 ~]# mkdir shell[rootnode11 ~]# vim abc.sh #!/bin/bash#安装httpd服务#1、挂载 准备yum源 mount /dev/sr0 /mnt &> /dev/nulldf$(df -h | grep /dev/sr0 | awk {print $6})if [ "$df" "/mn…...

mysql 常见问题
1、count(*) 、 count(1) 和 count(字段)区别 在MySQL中,COUNT(*)、COUNT(1) 和 COUNT(字段) 是用于统计行数的函数,它们的主要区别在于: COUNT(*):会统计符合条件的所有行的数量,不管这些行中…...

考研机试题
目录 头文件与STL动态规划最大数组子串和最长公共子序列最长连续公共子串最长递增子序列最大上升子序列和0-1背包多重背包多重背包问题 I整数拆分最小邮票最大子矩阵 数学问题朴素法筛素数线性筛素数快速幂 石子合并锯木棍并查集Dijkstra单源最短路Python进制转换(整数无限大)全…...
)
Java基础知识总结(6)
String类中常用的类方法: 方法名称描述format(String format, Object... args)使用指定的格式字符串和参数返回一个格式化字符串。 format - 格式字符串 args - 格式字符串中由格式说明符引用的参数。如果还有格式说明符以外的参数,则忽略这些额外的参数…...

JAVA基础—关于Java的反射机制
1. Java的反射机制是什么? 反射(reflection) 当我们谈及反射,可以将其比作正在照镜子的行为。就像你可以在禁止中看到自己的反射一样,程序在运行时可以检查自身的机构和行为。这意味这程序可以动态地了解自己地组成部分,比如类、…...

Hive中的explode函数、posexplode函数与later view函数
1.概述 在离线数仓处理通过HQL业务数据时,经常会遇到行转列或者列转行之类的操作,就像concat_ws之类的函数被广泛使用,今天这个也是经常要使用的拓展方法。 2.explode函数 2.1 函数语法 -- explode(a) - separates the elements of array …...

北京市委统战部领导一行莅临百望云视察调研
“当今时代,数字技术、数字经济是世界科技革命和产业变革的先机,是新一轮国际竞争重点领域”。 为了解数字标杆企业的发展现状,促进新质生产力与实体产业的协同与赋能,近日,北京市委统战部非公经济处处长王雷、副处长徐…...

使用Python进行数据库连接与操作SQLite和MySQL【第144篇—SQLite和MySQL】
👽发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【点击进入巨牛的人工智能学习网站】。 使用Python进行数据库连接与操作:SQLite和MySQL 在现代应用程序开发中…...

How to manage Python environment based on virtualenv in Ubuntu 22.04
How to manage Python environment based on virtualenv in Ubuntu 安装使用创建环境激活环境安装软件包退出环境移除环境 安装 pip3 install virtualenv使用 创建环境 lwkqwfys:~$ mkdir ~/project/harbin lwkqwfys:~$ cd ~/project/harbin lwkqwfys:~/project/harbin$ vir…...
一款基于 SpringCloud 开发的AI聊天机器人系统,已对接GPT-4.0,非常强大
简介 一个基于SpringCloud的Chatgpt机器人,已对接GPT-3.5、GPT-4.0、百度文心一言、stable diffusion AI绘图、Midjourney绘图。用户可以在界面上与聊天机器人进行对话,聊天机器人会根据用户的输入自动生成回复。同时也支持画图,用户输入文本…...

C语言自定义库
编写 xx.c 和xx.h文件\将源代码编译为目标文件 gcc -c add.c sub.c 执行完毕后会生产add.o和sub.o文件静态库创建使用ar命令; ar -r libmymath.a add.o sub.o将库和main.c文件一起编译 gcc -o main main.c -lmymath -L./ 注意 上述书写格式不要错乱 -L 是指定文件路…...
)
目标检测常见数据集格式(YOLO、VOC、COCO)
目录 1.YOLO格式数据 1.1数据格式 1.2YOLO格式数据示例 1.3YOLO格式可视化 2.COCO数据格式 2.1数据格式 2.2COCO格式数据示例 2.3COCO格式可视化 3.VOC数据格式 3.1数据格式 3.2VOC格式数据示例 3.3COCO格式可视化 🍓🍓1.YOLO格式数据 &…...

24/7运行指南:OpenClaw+GLM-4-7-Flash树莓派部署与看门狗配置
24/7运行指南:OpenClawGLM-4-7-Flash树莓派部署与看门狗配置 1. 为什么选择树莓派作为OpenClaw的宿主设备? 去年冬天,当我第一次尝试让OpenClaw在我的主力开发机上24小时运行时,遭遇了严重的资源冲突问题。半夜运行的自动化任务…...

Matlab 实现 DES 与 RSA 双重加密及可视化界面搭建
基于matlab上的DES和RSA两种算法的双重加密,附带显示界面,可更改DES密钥,明文消息(在显示界面中),可在代码中更改RSA对应的p,q,e等数据,代码可附加注释和对应要求修改。在…...

从sipML5到现代框架:FreeSWITCH WebRTC客户端升级指南与选型建议
从sipML5到现代框架:FreeSWITCH WebRTC客户端升级指南与选型建议 如果你正在维护一个基于sipML5的FreeSWITCH WebRTC前端项目,可能已经感受到了技术债的压力——浏览器兼容性问题频发、功能扩展困难、社区支持几乎为零。这不是你的错,sipML5作…...

仿真模型中硅胶减震器的特征频率与谐振频率的受力分析
COMSOL仿真模型硅胶减震器减振器特征频率谐振频率受力分析仿真模型最近在研究硅胶减震器的特性,发现用COMSOL来仿真这东西还挺有意思的。硅胶减震器嘛,主要就是用来减振的,比如在一些精密仪器或者机械设备上,防止振动对设备造成损…...

FRCRN模型结构解析:频域卷积+循环网络如何协同提升信噪比
FRCRN模型结构解析:频域卷积循环网络如何协同提升信噪比 1. 引言:语音降噪的挑战与突破 语音降噪技术一直面临着"既要又要"的难题:既要彻底消除背景噪声,又要完整保留人声细节。传统的降噪方法往往在这两者之间难以平…...

Simple Runtime Window Editor:突破窗口分辨率限制的技术实现与应用指南
Simple Runtime Window Editor:突破窗口分辨率限制的技术实现与应用指南 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 一、场景化问题诊断:分辨率调整的现实挑战 1.1 专业设计工作流的…...

2026论文降重神器盘点!毕业论文“AIGC痕迹”怎么破?
【CSDN技术引言:拒绝“开源背调”式的学术翻车】 哈喽各位同行和科研圈的战友们。最近后台私信快炸了,今年这届硕博生仿佛遭遇了“灭顶之灾”。某985高校前天出炉的抽检结果直接把大家看傻了:明明自己逐字逐句手敲的论文,知网查重…...

提升开发效率:用快马一键生成快速排序多版本性能对比工具
今天在优化一个数据处理模块时,遇到了需要选择合适排序算法的问题。不同数据特征下,快速排序的各种变体表现差异很大,手动测试效率实在太低。于是我用InsCode(快马)平台快速搭建了一个性能对比工具,整个过程比想象中简单很多。 需…...

ThreadLocal 源码分析与内存泄漏问题
前言 ThreadLocal 是 Java 中实现线程局部变量的重要工具,被广泛应用于事务管理、链路追踪、用户上下文等场景。然而,面试中关于 ThreadLocal 的追问往往直指其底层设计和内存泄漏问题。 本文将深入分析 ThreadLocal 的源码实现,揭示内存泄…...
)
vLLM实战:手把手教你用LLMEngine构建高效推理服务(附代码解析)
vLLM实战:从零构建高性能大模型推理服务的工程指南 当大语言模型从实验室走向生产环境时,如何实现高吞吐、低延迟的推理服务成为工程化落地的关键挑战。vLLM作为当前最受关注的开源推理框架之一,其核心组件LLMEngine的设计理念值得每一位AI工…...