机器学习-可解释性机器学习:支持向量机与fastshap的可视化模型解析
一、引言
支持向量机(Support Vector Machine, SVM)作为一种经典的监督学习方法,在分类和回归问题中表现出色。其优点之一是生成的模型具有较好的泛化能力和可解释性,能够清晰地展示特征对于分类的重要性。
fastshap是一种用于快速计算SHAP值(SHapley Additive exPlanations)的工具,通过近似SHAP值的计算加速了模型的解释过程,使得模型的解释更为高效和可视化。
综上所述,本文将探讨支持向量机和fastshap在可解释性机器学习中的作用。通过结合支持向量机和fastshap,我们可以深入分析模型的决策过程,解释模型的预测结果,从而提高模型的可解释性和可信度。
二、SVM简介
2.1 SVM的原理和优点
支持向量机(Support Vector Machine, SVM)的原理是通过寻找最大间隔超平面来进行分类或回归。在二分类情况下,SVM的目标是找到一个能够将不同类别的数据点分开的超平面,并且使得该超平面到最近的数据点(支持向量)的距离最大化。这种最大化间隔的方法使得SVM具有较强的泛化能力。
对于线性不可分的情况,SVM可以通过核函数将数据映射到高维空间,从而在高维空间中找到一个线性可分的超平面,从而解决非线性分类问题。
-
「泛化能力强」:SVM通过最大化间隔的方式进行分类,因此对未知数据的泛化能力较强,有较好的预测性能。 -
「高维空间的处理能力」:SVM可以通过核函数将数据映射到高维空间,从而处理线性不可分的问题。 -
「对特征的依赖较小」:SVM在模型训练过程中主要依赖支持向量,对于非支持向量的数据点不敏感,可以避免维度灾难和过拟合问题。 -
「有效处理小样本数据」:SVM在小样本数据情况下表现出色,可以有效地进行分类和回归。 总的来说,SVM具有较强的泛化能力、高维空间处理能力以及对特征的不敏感性等优点,使其成为机器学习中广泛应用的方法之一。
2.2 SVM在机器学习中的应用场景
-
文本分类:SVM可以用于对文本进行分类,如垃圾邮件识别、情感分析等。 -
识别:SVM可以应用于图像分类和目标检测等领域,例如人脸识别、车牌识别等。 -
生物信息学:SVM在基因分类、蛋白质分类等生物信息学领域有着重要应用。
综上所述,支持向量机作为一种强大的监督学习方法,在文本分类、图像识别、生物信息学等领域展现出了良好的应用前景,同时其高维空间处理能力和泛化能力也使其成为解决复杂问题的重要工具。
三、fastshap方法封装
FastSHAP 是一个用于加速 SHAP(SHapley Additive exPlanations)计算的工具,旨在提高模型可解释性的效率和准确性。
library(magrittr)
library(tidyverse)
library(fastshap)
plot_shap <- function(model,newdata){
shap <- explain(rf,X=newdata,nsim=10,
pred_wrapper = function(model,newdata){
predict(rf, newdata = newdata, type = "class")
})
shap_handle <- shap %>% as.data.frame() %>% mutate(id=1:n()) %>% pivot_longer(cols = -(ncol(train_data[,-10])+1),values_to="shap") # 长宽数据转换
data2 <- newdata %>% mutate(id=1:n()) %>% pivot_longer(cols = -(ncol(newdata)+1))
shap_scale <- shap_handle %>%
left_join(data2)%>%
rename("feature"
="name")%>%
group_by(feature)%>%
mutate(value=(value-min(value))/(max(value)-min(value))) %>% sample_n(200)
p <- ggplot(data=shap_scale, aes(x=shap, y=feature, color=value)) +
geom_jitter(size=2, height=0.1, width=0) +
scale_color_gradient(low="#FFCC33", high="#6600CC", breaks=c(0, 1), labels=c("Low", "High"),
guide=guide_colorbar(barwidth=2, barheight=30),
name="Feature value",
aesthetics = c("color")) + theme_bw()
return(p)
}
四、实例展示
-
「数据集准备」
library(survival)
head(gbsg)
结果展示:
pid age meno size grade nodes pgr er hormon rfstime status
1 132 49 0 18 2 2 0 0 0 1838 0
2 1575 55 1 20 3 16 0 0 0 403 1
3 1140 56 1 40 3 3 0 0 0 1603 0
4 769 45 0 25 3 1 0 4 0 177 0
5 130 65 1 30 2 5 0 36 1 1855 0
6 1642 48 0 52 2 11 0 0 0 842 1
-
「示例数据集介绍」
> str(gbsg)
'data.frame': 686 obs. of 10 variables:
$ age : int 49 55 56 45 65 48 48 37 67 45 ...
$ meno : int 0 1 1 0 1 0 0 0 1 0 ...
$ size : int 18 20 40 25 30 52 21 20 20 30 ...
$ grade : int 2 3 3 3 2 2 3 2 2 2 ...
$ nodes : int 2 16 3 1 5 11 8 9 1 1 ...
$ pgr : int 0 0 0 0 0 0 0 0 0 0 ...
$ er : int 0 0 0 4 36 0 0 0 0 0 ...
$ hormon : int 0 0 0 0 1 0 0 1 1 0 ...
$ rfstime: int 1838 403 1603 177 1855 842 293 42 564 1093 ...
$ status : Factor w/ 2 levels "0","1": 1 2 1 1 1 2 2 1 2 2 ...
age:患者年龄
meno:更年期状态(0表示未更年期,1表示已更年期)
size:肿瘤大小
grade:肿瘤分级
nodes:受累淋巴结数量
pgr:孕激素受体表达水平
er:雌激素受体表达水平
hormon:激素治疗(0表示否,1表示是)
rfstime:复发或死亡时间(以天为单位)
status:事件状态(0表示被截尾,1表示事件发生)
-
「划分训练集和测试集」
# 划分训练集和测试集
set.seed(123)
data <- gbsg[,c(-1)]
# 划分训练集和测试集
set.seed(123)
train_indices <- sample(x = 1:nrow(data), size = 0.7 * nrow(data), replace = FALSE)
test_indices <- sample(setdiff(1:nrow(data), train_indices), size = 0.3 * nrow(data), replace = FALSE)
train_data <- data[train_indices, ]
test_data <- data[test_indices, ]
train_data_feature <- train_data[,-10]
train_data_label <- as.numeric(as.character(train_data$status))
-
「模型拟合」
library(e1071)
library(pROC)
model <- svm(train_data_feature, train_data_label)
pred_prob <- predict(model, newdata =train_data_feature,type="raw",threshold = 0.001)
# 计算ROC曲线的参数
roc <- roc(train_data_label, pred_prob)
plot(roc, col = "blue", main = "ROC Curve", xlab = "False Positive Rate", ylab = "True Positive Rate", print.auc = TRUE, legacy.axes = TRUE)
# 绘制shap图
plot_shap(model,train_data_feature)


五、总结
总结支持向量机(Support Vector Machine, SVM)与FastSHAP在可解释性机器学习中的作用:
「支持向量机(SVM)」:
-
SVM是一种常用的机器学习算法,主要用于分类和回归任务。 -
在可解释性方面,SVM的决策边界可以清晰地将不同类别的数据分开,使得模型的预测过程相对容易理解。 -
可以通过观察支持向量等方式来解释SVM模型的预测结果,帮助用户理解模型的决策依据。
「FastSHAP」:
-
FastSHAP是一种加速版的SHAP(SHapley Additive exPlanations)计算方法,用于解释复杂模型的预测过程。 -
通过FastSHAP可以有效地计算特征的SHAP值,帮助用户理解模型对于不同特征的依赖程度。 -
FastSHAP在提高SHAP值计算效率的同时,也能保持解释性的优势,使得解释性机器学习更加实用。
*「未经许可,不得以任何方式复制或抄袭本篇文章之部分或全部内容。版权所有,侵权必究。」
相关文章:
机器学习-可解释性机器学习:支持向量机与fastshap的可视化模型解析
一、引言 支持向量机(Support Vector Machine, SVM)作为一种经典的监督学习方法,在分类和回归问题中表现出色。其优点之一是生成的模型具有较好的泛化能力和可解释性,能够清晰地展示特征对于分类的重要性。 fastshap是一种用于快速计算SHAP值(…...

32.768K晶振X1A000141000300适用于无人驾驶汽车电子设备
科技的发展带动电子元器件的发展电子元器件-“晶振”为现代的科技带来了巨大的贡献,用小小的身体发挥着大大的能量。 近两年无人驾驶汽车热度很高,不少汽车巨头都已入局。但这项技术的难度不小,相信在未来几年里,无人驾驶汽车这项…...

利用autodl服务器跑模型
1. 租用服务器 本地改模型 服务器 将改进好的、数据集处理好的模型压缩为zip文件上传到阿里云盘打开服务器AUTODL服务器,在主页中选择容器实例 在此位置进行开关机操作,若停止服务器,必须关机,不然会一直扣钱 2. 运行模型 选择…...
【微服务】分布式调度框架PowerJob使用详解
目录 一、前言 二、定时任务调度框架概述 2.1 为什么需要定时任务调度框架 2.2 定时任务调度使用场景 三、PowerJob 介绍 3.1 PowerJob 概述 3.2 PowerJob 功能特性 3.3 PowerJob 应用场景 3.4 PowerJob 与其他同类产品对比 四、PowerJob 部署 4.1 PowerJob 架构 4.…...

一命通关广度优先遍历
前言 在这篇文章之前,已对非线性结构遍历的另一种方法——深度优先遍历进行了讲解,其中很多概念词都是共用的。为了更好的阅读体验,最好先在掌握或起码了解dfs的基础上,再来阅读本文章,否则因为会有很多概念词看不明白…...

力扣4寻找两个正序数组的中位数
1.实验内容 给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。 2.实验目的 算法的时间复杂度应该为 O(log (mn)) 。 3.基本思路 碰到时间复杂度要求log的,肯定用二分查找&…...
jmeter之常用函数-第六天
1.常见函数: _counter 计数器函数 TRUE(每个用户都有自己的计数器) FALSE(所有用户共用一个计数器) _Random 随机数函数 参数1:取值范围最小值(包含) 参数2:取值范围最大值(包含) _time 获取当前时间的函数 无参: 获取的是距离 1970/01/01 00:00:00 的毫秒值 参…...
原创!分解+集成思想新模型!VMD-CNN-BiGRU-Attention一键实现时间序列预测!以风速数据集为例
声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~ 目录 数据介绍 模型流程 创新点 结果展示 部…...
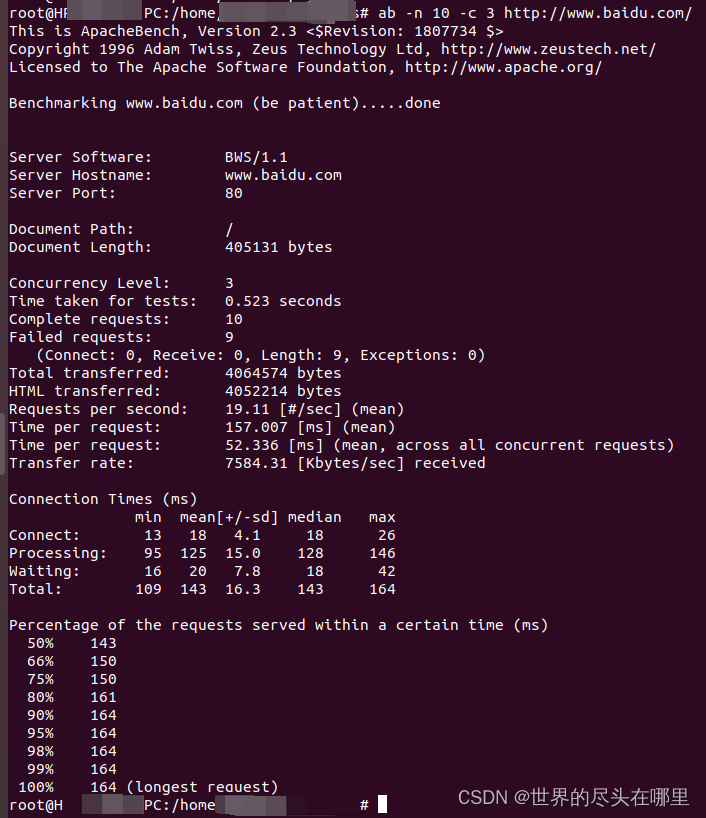
ab (Apache benchmark) - 压力/性能测试工具
Apache benchmark(ab) 安装window安装使用方法 - bin目录运行使用方法 - 任意目录运行 linux安装 基本命令介绍常用参数:输出结果分析: ab的man手册 安装 window安装 官网下载链接:https://www.apachehaus.com/cgi-bin/download…...
除了Confluence,有没有其他工具一样好用?
每个团队都需要一个协同工作工具,以更有效地管理任务、跟踪进度和分享知识。这就是Atlassian的Confluence发挥作用的地方。然而,尽管它相当强大,其昂贵的价格和复杂的界面可能会让某些用户望而却步。所以,还有其他工具可以替代Con…...
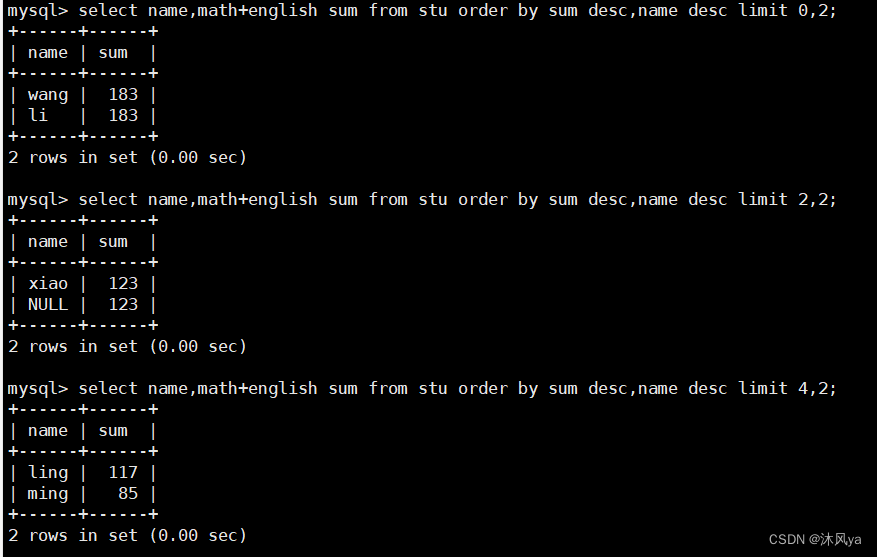
查询表中数据(全列/特定列/表达式,where子句(比较/逻辑运算符),order by子句,limit筛选分页),mysql执行顺序
目录 select 全列查询 特定列查询 用表达式查询 (as) 名字 distinct 去重 where子句 比较运算符 列数据之间的比较 编辑 别名不能参与比较 null查询 between and in ( ... , ...) 模糊匹配 逻辑运算符 order by子句 可以使用别名 总结mysql执行顺…...
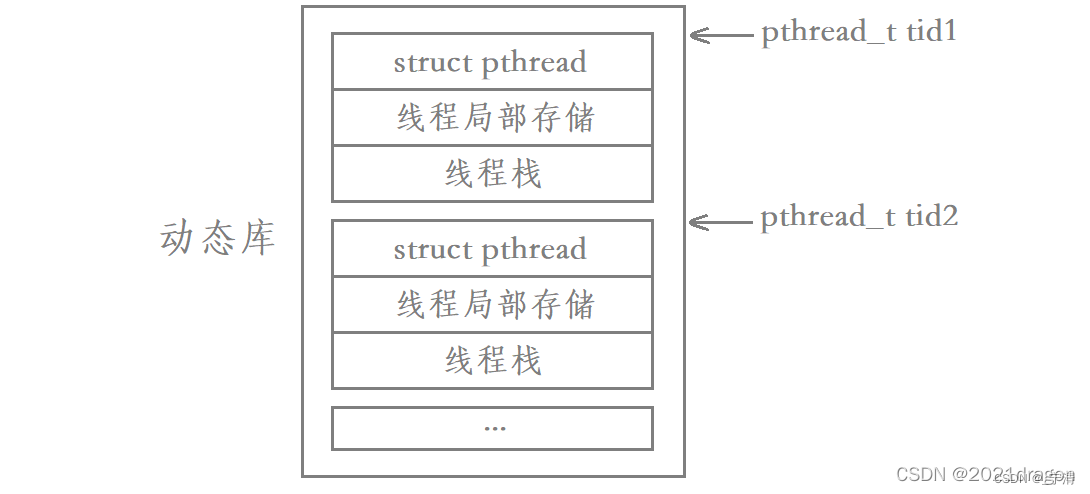
【Linux】多线程概念 | POSIX线程库
文章目录 一、线程的概念1. 什么是线程Linux下并不存在真正的多线程,而是用进程模拟的!Linux没有真正意义上的线程相关的系统调用!原生线程库pthread 2. 线程和进程的联系和区别3. 线程的优点4. 线程的缺点5. 线程异常6. 线程用途 二、二级页…...

Java Spring AOP代码3分钟快速入手
AOP Spring入门(十):Spring AOP使用讲解 - 掘金 maven的依赖: <dependency><groupId>org.springframework</groupId><artifactId>spring-aop</artifactId> </dependency> <!--aspectj支持--> <dependen…...
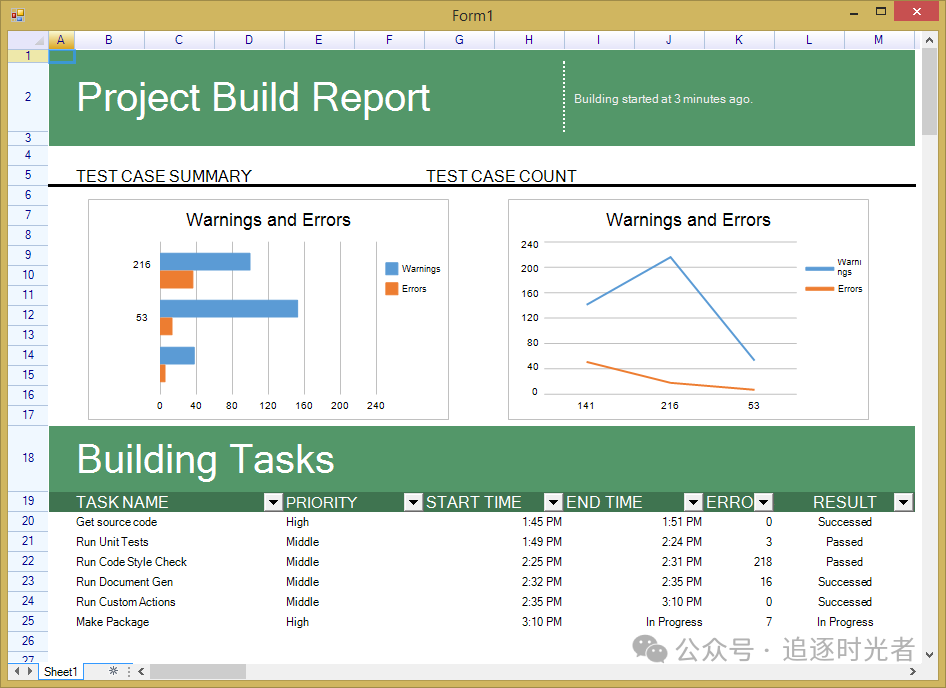
.NET开源快速、强大、免费的电子表格组件
今天大姚给大家分享一个.NET开源(MIT License)、快速、强大、免费的电子表格组件,支持数据格式、冻结、大纲、公式计算、图表、脚本执行等。兼容 Excel 2007 (.xlsx) 格式,支持WinForm、WPF和Android平台:ReoGrid。 项…...
docker一键部署若依前后端分离版本
比如这里把文件放到/xin/docker/jiaoZ/的目录下,jar包和下面的配置文件都放在这个文件夹下。 注意要把jar端口改为你实际启动的,映射端口也可以改为你想要的。 这里的映射端口为:nginx监听80端口,jar在8620端口,mysq…...

Java项目开发之fastjson详解
Fastjson 是由阿里巴巴公司开发的一个 Java 语言编写的高性能 JSON 处理库。它主要用于 Java 对象与 JSON 数据格式之间的转换,提供了简单易用的 API 来实现序列化(Java 对象转 JSON 字符串)和反序列化(JSON 字符串转 Java 对象&a…...

面试算法-62-盛最多水的容器
题目 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明:你不能倾斜容器。…...

【智能算法】海洋捕食者算法(MPA)原理及实现
目录 1.背景2.算法原理2.1算法思想2.2算法过程 3.结果展示4.参考文献 1.背景 2020年,Afshin Faramarzi 等人受到海洋生物适者生存启发,提出了海洋捕食者算法(Marine Predators Algorithm,MPA)。 2.算法原理 2.1算法思想 MPA根据模拟自然界…...
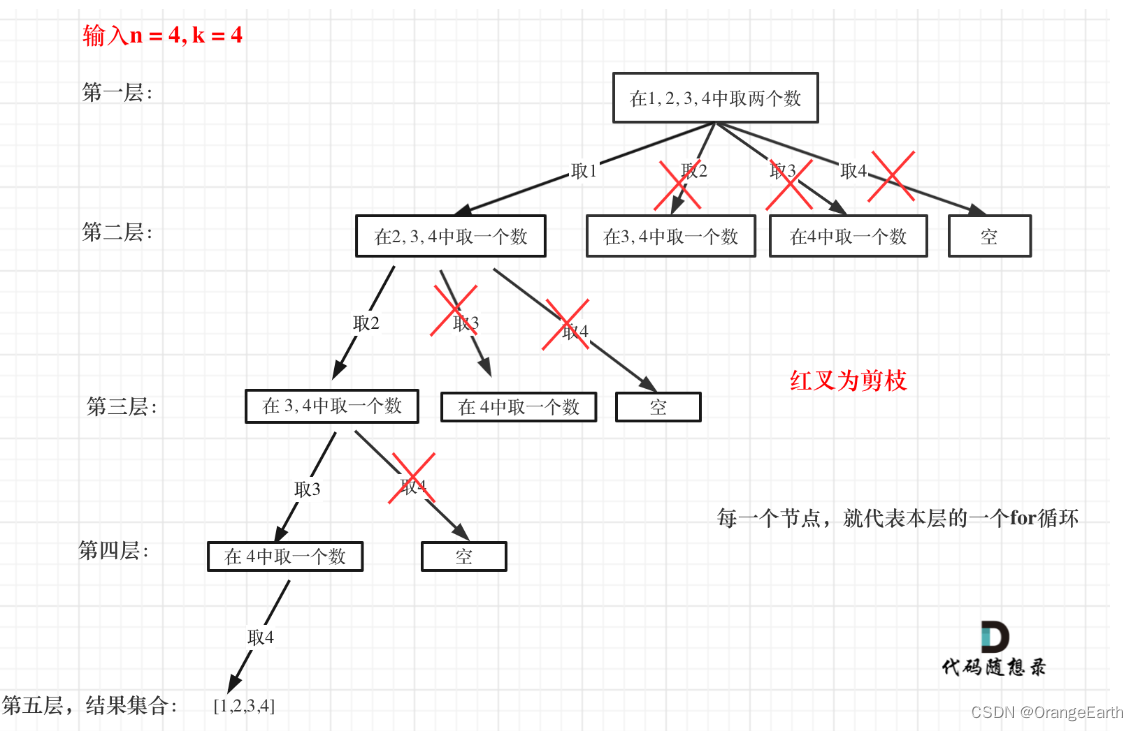
刷题DAY24 | LeetCode 77-组合
1 回溯法理论基础 回溯法也可以叫做回溯搜索法,它是一种搜索的方式。回溯是递归的副产品,只要有递归就会有回溯。 所以以下讲解中,回溯函数也就是递归函数,指的都是一个函数。 1.1 回溯法的效率 回溯法的性能如何呢࿰…...

Spring Boot为什么默认使用CGLIB动态代理
兼容性: 1. CGLIB 动态代理可以代理任何类型的目标类,无论它是否实现了接口;[注意的是,类被 final 修饰,那么该不可被继承,即不可被代理;同样,类中 final 修饰的方法&am…...

Android 11开发避坑:为什么你的App获取的Wifi MAC地址总是变?手把手教你配置固定MAC
Android 11开发实战:彻底解决Wifi MAC地址随机化问题最近在开发一个设备管理系统时,遇到了一个棘手的问题:我们的App在Android 11设备上获取的Wifi MAC地址每次都不一样,导致基于MAC地址的设备识别功能完全失效。经过一周的深入研…...

IPD的势、道、法、术、器
目录 简介 一、势:为什么 IPD 是必然选择? 二、道:IPD 的底层哲学 三、法与术:从战略到执行的具体路径 四、器:让流程真正落地的工具与组织 不是每家公司都需要全套 IPD,但每家公司都需要 IPD 思维 简…...

钱钟书《围城》第1-5章阅读笔记:一场关于人生困境的提前预演
前言 钱钟书先生的《围城》被誉为"新儒林外史",是中国现代文学史上风格独特的讽刺经典。这部创作于20世纪40年代的长篇小说,以抗战初期为背景,通过主人公方鸿渐的人生轨迹,深刻揭示了知识分子群体的精神困境与人性弱点。…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...

Arduino ADC自检:用RC电路诊断模数转换器故障
1. 项目概述:当你的体重秤开始“说谎”你有没有遇到过这样的情况:站上家里的电子体重秤,屏幕上跳出来的数字让你瞬间怀疑人生?要么是轻得离谱,要么是重得吓人,更诡异的是,它可能只在两个固定的、…...

理想二极管控制器:用MOSFET实现毫伏级压降的电源管理方案
1. 理想二极管控制器:告别传统二极管的压降损耗 在电源设计、电池保护、太阳能板并联这些领域里,二极管是个再常见不过的元件。我们用它来防反接、做整流、实现“或”逻辑供电,几乎不假思索。但如果你设计过一个需要处理大电流、低电压的系统…...

【C++】零基础入门 · 第 5 节:函数基础
前面四节我们写的代码都集中在 main 函数里。随着程序变复杂,所有逻辑堆在一起会越来越难维护。函数就是用来解决这个问题的——它把一段代码「打包」起来,取个名字,需要的时候调用就行。 1. 为什么需要函数 假设你需要在程序的不同地方打印一行分隔线: cout << &…...

3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验
3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hive…...

Windows 11终极优化指南:一键清理系统,释放51%性能潜力
Windows 11终极优化指南:一键清理系统,释放51%性能潜力 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to decl…...

将Taotoken作为统一AI网关整合进企业现有微服务架构的实践思路
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将Taotoken作为统一AI网关整合进企业现有微服务架构的实践思路 在构建以AI能力驱动的现代应用时,中型及以上的企业常面…...