大数据开发(Hive面试真题-卷三)
大数据开发(Hive面试真题)
- 1、Hive的文件存储格式都有哪些?
- 2、Hive的count的用法?
- 3、Hive得union和unionall的区别?
- 4、Hive的join操作原理,left join、right join、inner join、outer join的异同?
- 5、Hive的mapjoin?
- 6、Hive Shuffle的具体过程?
- 7、UDF是怎么在Hive里执行的?
- 8、Hive HQL:行转列、列转行?
1、Hive的文件存储格式都有哪些?
- 文本文件格式(TextFile):以文本形式存储数据,每一行都是一个记录,字段之间使用分隔符进行分割。
- 序列文件格式(SequenceFile):一种二进制文件格式,数据以键值对的形式存储,适用于大数据量的存储和读取。
- 列式存储格式(Columnar formats):例如Parquet和ORC等,以列为单位存储数据,提供更高的压缩比和查询性能。
- Avro格式:一种数据序列化系统,支持动态类型,适用于复杂数据结构的存储。
- RCFile格式(Record Columnar File):一种列式存储格式,将每个列的数据存储在单独的文件中,提供高效的读取和查询性能。
- JSON格式(JsonFile):以JSON格式存储数据,适用于半结构化数据的存储。
- CSV格式:以逗号分割的文本文件格式,适用于简单的表格数据存储。
2、Hive的count的用法?
- Hive中的count函数用于计算指定列或整个表中的行数。它的用法如下:
SELECT COUNT(*) FROM table_name;
- 计算指定列的非空值的个数:
SELECT COUNT(column_name) FROM table_name;
- 计算指定列的唯一值的个数:
SELECT COUNT(DISTINCT column_name) FROM table_name;
3、Hive得union和unionall的区别?
Hive中的UNION和UNION ALL都是用于合并多个查询结果集的操作,但它们之间有一些区别。
- UNION会删除重复的行,而UNION ALL会保留所有行,包括重复的行。
- UNION操作符会对两个查询结果的列进行匹配,要求它们的数据类型和顺序完全一致,而UNION ALL不会进行列匹配。
- UNION操作符会对结果进行排序,以消除重复行,而UNION ALL不会进行排序,因此性能上可能会更快一些。
- UNION操作符默认会去除NULL值,而UNION ALL会保留NULL值。
因此,如果你需要合并多个结果集并消除重复行,你可以使用UNION操作符。而如果你想保留所有行,包括重复的行,可以使用UNION ALL操作符。
4、Hive的join操作原理,left join、right join、inner join、outer join的异同?
- Inner Join(内连接):它返回两个表中满足连接条件的记录。只有在两个表中都有匹配的记录时,才会返回结果。
- Left Join(左连接):它返回左表中所有记录以及与右边匹配的记录。如果右表中没有匹配的记录,则返回NULL。
- Right Join(右连接):它返回右表中所有记录以及与左表匹配的记录。如果左表中没有匹配的记录,则返回NULL。
- Outer Join(外连接):它返回左表和右表中的所有记录。如果两个表中没有匹配的记录,则返回NULL。
5、Hive的mapjoin?
Hive的mapjoin是一种优化技术,用于加快Hive查询的速度。它通过将小表加载到内存中,然后在Map阶段将大表的数据与小表的数据进行连接,从而减少了磁盘读写操作和网络传输开销。
具体来说,Hive的mapjoin分为两种类型:
- Map端的mapjoin(Map-side Join):当一个表的数据量足够小,可以将其全部加载到内存中时,Hive会将这个表的数据复制到所有的Map任务中,然后在Map任务中直接进行连接操作。这样可以避免Shuffle阶段的数据传输和磁盘I/O,大大提高了查询速度。
- Bucket Map端的mapjoin:当两个表都被分桶时,Hive可以使用Bucket Map端的mapjoin。它将两个表的桶按照相同的桶号分发到同一个Map任务中,然后再Map任务中进行连接操作。这样可以减少Shuffle阶段的数据传输和磁盘I/O,提高查询效率。
需要注意的是,使用mapjoin的前提是小表可以完全加载到内存中,否则可能会导致内存不足的问题。此外,mapjoin也只适用于等值连接(Equi-Join),不支持其它类型的连接操作。
6、Hive Shuffle的具体过程?
Hive的Shuffle过程是在Hive执行MapReduce任务时发生的数据重分区和排序过程。它是为了将具有相同键的数据项聚集再同一个Reducer任务中,以便进行数据的合并和计算。
具体的Hive Shuffle过程如下:
- Map阶段:在Map阶段,输入数据会根据指定的分区键进行哈希分区,即根据分区键的哈希值将数据分配到对应的Reducer任务中。同时,Map阶段会对每个分区键进行局部排序,保证每个分区内的数据按照分区键的顺序排列。
- Combiner阶段:如果在Hive查询中定义了Combiner函数,那么在Map阶段的输出结果会经过Combiner函数的合并操作。Combiner函数可以对相同分区键的数据进行合并,以减少数据传输量和提高性能。
- Partitioner阶段:在Map阶段结束后,Hive会调用Partitioner函数对Map输出结果进行再次分区。Partitioner函数决定了数据项如何分布到不同的Reducer任务中。通常情况下,Partitioner函数会根据分区键的哈希值将数据项均匀地分配到不同的Reducer任务中。
- Sort阶段:在Partitioner阶段之后,Hive会对每个Reducer任务的输入数据进行全局排序。这个排序操作保证了每个Reducer任务的输入数据按照分区键的顺序进行处理。
- Reduce阶段:在Reduce阶段,每个Reducer任务会接收到属于自己分区的数据块,并进行最终的聚合和计算操作。Reducer任务会对输入数据进行迭代处理,输出最终的结果。
7、UDF是怎么在Hive里执行的?
UDF是在Hive中执行的一种自定义函数。当在Hive中定义一个UDF后,它可以在Hive查询中使用,以对数据进行转换、计算或其它操作。
执行过程如下:
- 首先,开发人员需要使用Java或其它编程语言编写UDF的代码。UDF代码需要实现Hive UDF接口,并定义输入和输出参数的类型。
- 然后,将编写的UDF代码编译成可执行的JAR文件。
- 接下来,将JAR文件上传到Hive的集群环境中,并将其添加到Hive的类路径中。
- 在Hive中创建一个函数,将该数据与上传的JAR文件中的UDF代码关联起来。这可以通过使用Hive的CREATE FUNCTION语句来完成。
- 一旦函数创建完毕,就可以在Hive查询中调用该函数,并将其应用于数据。
- 当Hive查询中调用UDF时,Hive会根据函数的定义和输入参数类型,调用上传的JAR文件中的对应UDF代码。
- UDF代码将执行相应的计算或转换操作,并返回结果给Hive查询。
8、Hive HQL:行转列、列转行?
Hive HQL中可以使用Pivot操作实现行转列和列转行的功能。
行转列(行数据转为列):
在 Hive 中,可以使用 Pivot 操作将行数据转为列。Pivot 操作需要使用聚合函数和 CASE WHEN 语句来实现。
例如,假设我们有一个表格包含以下数据:
+----+------+-------+
| ID | Name | Value |
+----+------+-------+
| 1 | A | 10 |
| 1 | B | 20 |
| 2 | A | 30 |
| 2 | B | 40 |
+----+------+-------+
我们可以使用 Pivot 操作将上述数据按 ID 列进行行转列:
SELECT ID,
MAX(CASE WHEN Name = 'A' THEN Value END) AS Value_A,
MAX(CASE WHEN Name = 'B' THEN Value END) AS Value_B
FROM table_name
GROUP BY ID;
执行上述查询后,可以得到如下结果:
+----+---------+---------+
| ID | Value_A | Value_B |
+----+---------+---------+
| 1 | 10 | 20 |
| 2 | 30 | 40 |
+----+---------+---------+
列转行(列数据转为行):
Hive 中可以使用 UNION ALL 操作将列数据转为行数据。
假设我们有一个表格包含以下数据:
+----+------+-------+
| ID | Name | Value |
+----+------+-------+
| 1 | A | 10 |
| 1 | B | 20 |
| 2 | A | 30 |
| 2 | B | 40 |
+----+------+-------+
我们可以使用 UNION ALL 操作将上述数据按 Name 列进行列转行:
SELECT ID, 'A' AS Name, Value FROM table_name WHERE Name = 'A'
UNION ALL
SELECT ID, 'B' AS Name, Value FROM table_name WHERE Name = 'B';
执行上述查询后,可以得到如下结果:
+----+------+-------+
| ID | Name | Value |
+----+------+-------+
| 1 | A | 10 |
| 2 | A | 30 |
| 1 | B | 20 |
| 2 | B | 40 |
+----+------+-------+
这样我们就可以将列数据转为行数据。.
相关文章:
)
大数据开发(Hive面试真题-卷三)
大数据开发(Hive面试真题) 1、Hive的文件存储格式都有哪些?2、Hive的count的用法?3、Hive得union和unionall的区别?4、Hive的join操作原理,left join、right join、inner join、outer join的异同࿱…...

Oracle数据库SQL开发规范
Oracle数据库SQL开发规范是为了保证SQL代码的质量、可读性和性能而遵循的一系列准则和最佳实践。以下是一些常见的Oracle SQL开发规范要点: 1. 命名规范 使用有意义且一致的命名约定,例如表名采用TBL_MODULE_NAME,视图采用VW_MODULE_VIEW等…...

FreeRTOS 消息队列
1. 队列简介 1.1 队列的概念 队列是任务到任务、任务到中断、中断到任务数据交流的一种机制(消息传递) 类似全局变量?假设有一个全局变量a 0,现有两个任务都在写这个变量 a: 大家想象一下如果任务 1 运行一次&#…...

如何在Python中实现列表推导式?并给出一个例子
如何在Python中实现列表推导式?并给出一个例子 Python的列表推导式(List Comprehension)是一种强大且简洁的创建列表的方法。它允许我们在一行代码中完成循环和条件判断,从而生成所需的列表。列表推导式不仅提高了代码的可读性&a…...

Flask中的Blueprints:模块化和组织大型Web应用【第142篇—Web应用】
👽发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【点击进入巨牛的人工智能学习网站】。 Flask中的Blueprints:模块化和组织大型Web应用 在构建大型Web应用时࿰…...

如何通过idea搭建一个SpringBoot的Web项目(最基础版)
通过idea搭建一个SpringBoot的Web项目 文章目录 通过idea搭建一个SpringBoot的Web项目一、打开idea,找到 create new project二、创建方式三、配置项目依赖四、新建项目模块五、总结 一、打开idea,找到 create new project 方式1 方式2 二、创建方式 新…...

Python和FastAPI语义分析和文本图像
要点 使用FastAPI开发RESTful API,创建端点,自定义响应,结构化多路由。Pydantic数据验证库数据建模,创建依赖项注入。开发数据库和对象关系映射,SQLAlchemy,Tortoise ORM,MongoDB。建立权限和安…...

centos系统ssh7.4升级9.6
编译安装 OpenSSL 下载 OpenSSL 源代码: wget https://www.openssl.org/source/openssl-1.1.1w.tar.gz这个命令从 OpenSSL 的官方网站下载指定版本(1.1.1w)的源代码压缩包。 解压源代码: tar zxvf openssl-1.1.1w.tar.gz使用 tar…...
excel所有知识点
1要加双引号 工作表(.xlsx) 单击右键→插入,删除,移动、重命名、复制、设置标签颜色,选定全部工作表 工作表的移动:两个表打开→右键→移动(如果右键是灰色的,可能是保护工作表了)…...

显卡基础知识及元器件原理分析
显卡应该算是是目前最为火热的研发方向了,其中的明星公司当属英伟达。 当地时间8月23日,英伟达发布截至7月30日的2024财年第二财季财报,营收和利润成倍增长,均超市场预期。 财报显示,第二财季英伟达营收为135.07 亿美…...
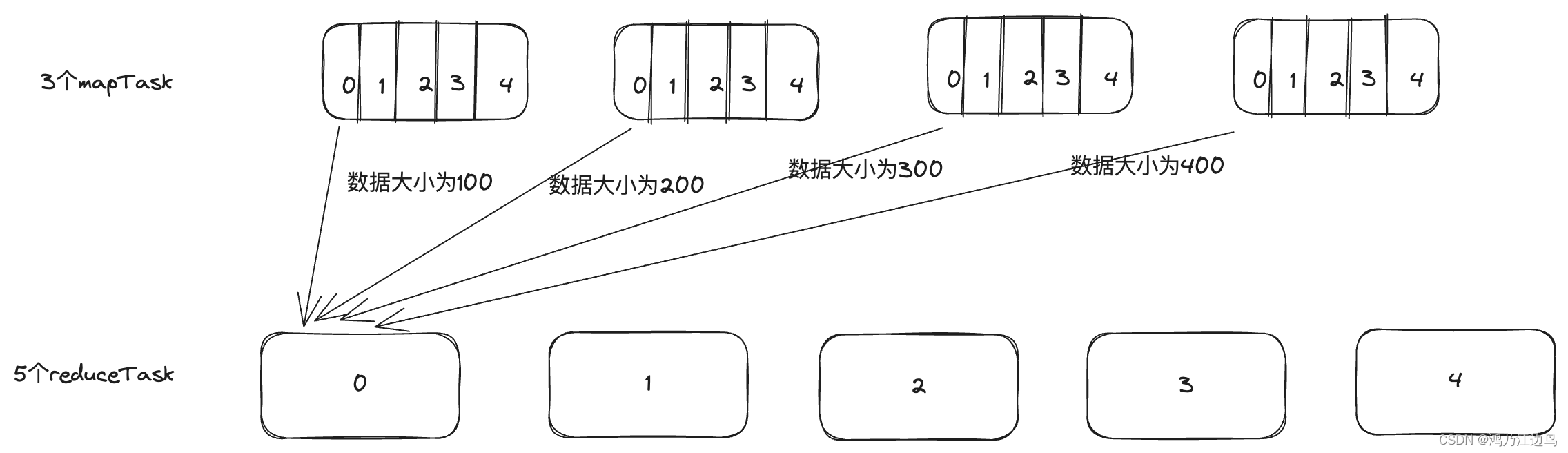
Spark Rebalance hint的倾斜的处理(OptimizeSkewInRebalancePartitions)
背景 本文基于Spark 3.5.0 目前公司在做小文件合并的时候用到了 Spark Rebalance 这个算子,这个算子的主要作用是在AQE阶段的最后写文件的阶段进行小文件的合并,使得最后落盘的文件不会太大也不会太小,从而达到小文件合并的作用,…...
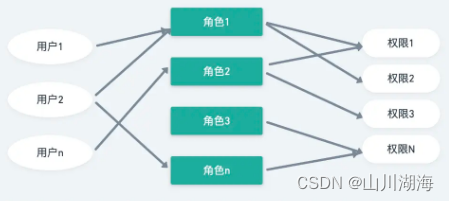
Vue 3中实现基于角色的权限认证实现思路
一、基于角色的权限认证主要步骤 在Vue 3中实现基于角色的权限认证通常涉及以下几个主要步骤: 定义角色和权限:首先需要在后端服务定义不同的角色和它们对应的权限。权限可以是对特定资源的访问权限,比如读取、写入、修改等。用户认证&#…...

Visual Studio 2022进行文件差异比较
前言 Visual Studio 2022在版本17.7.4中发布在解决方案资源管理器中比较文件的功能,通过使用此功能,可以轻松地查看两个文件之间的差异,包括添加、删除和修改的代码行。可以逐行查看差异,并根据需要手动调整和编辑文件内容以进行…...
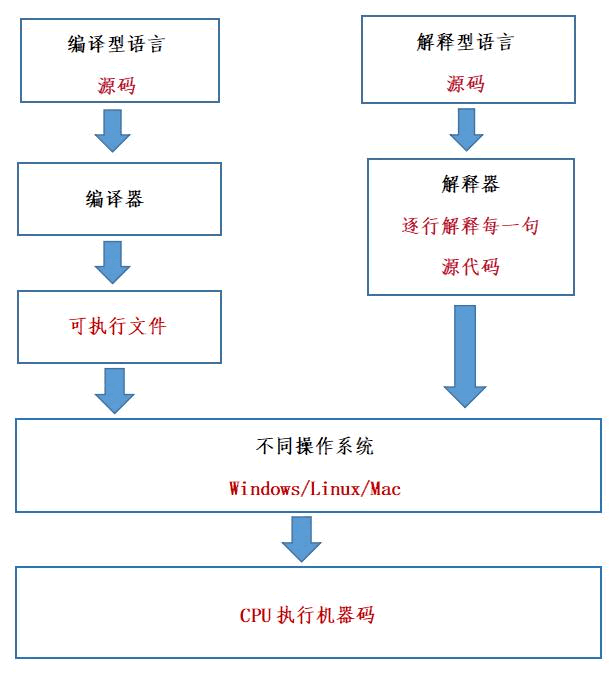
1.2 编译型语言和解释型语言的区别
编译型语言和解释型语言的区别 通过高级语言编写的源码,我们能够轻松理解,但对于计算机来说,它只认识二进制指令,源码就是天书,根本无法识别。源码要想执行,必须先转换成二进制指令。 所谓二进制指令&…...

C语言-常量
什么是常量? 答:常量是在程序执行过程中,其值不发生改变的量,常量分为直接常量和符号常量两种。 其中直接常量又可以分为整型常量、实型常量、字符型常量、字符串常量。 直接常量 1.整型常量 整型常量即整数,包括正整数,负整数和0。c语言中常量可以用八进制,十进制和十六…...

开源的OCR工具基本使用:PaddleOCR/Tesseract/CnOCR
前言 因项目需要,调研了一下目前市面上一些开源的OCR工具,支持本地部署,非调用API,主要有PaddleOCR/CnOCR/chinese_lite OCR/EasyOCR/Tesseract/chineseocr/mmocr这几款产品。 本文主要尝试了EasyOCR/CnOCR/Tesseract/PaddleOCR这…...
vue3实现输入框短信验证码功能---全网始祖
组件功能分析 1.按键删除,清空当前input,并跳转prevInput & 获取焦点,按键delete,清空当前input,并跳转nextInput & 获取焦点。按键Home/End键,焦点跳转first/最后一个input输入框。ArrowLeft/ArrowRight键点击…...
[C#]winformYOLO区域检测任意形状区域绘制射线算法实现
【简单介绍】 Winform OpenCVSharp YOLO区域检测与任意形状区域射线绘制算法实现 在现代安全监控系统中,区域检测是一项至关重要的功能。通过使用Winform结合OpenCVSharp库,并结合YOLO(You Only Look Once)算法,我们…...

个人网站制作 Part 14 添加网站分析工具 | Web开发项目
文章目录 👩💻 基础Web开发练手项目系列:个人网站制作🚀 添加网站分析工具🔨使用Google Analytics🔧步骤 1: 注册Google Analytics账户🔧步骤 2: 获取跟踪代码 🔨使用Vue.js&#…...
划分的方法)
数据按设定单位(分辨率)划分的方法
1. 问题描述 需要将使用公式计算后的float数值换算到固定间隔数轴的对应位置上的数据,比如2.186这个数据,将该数据换算到以0.25为间隔的数轴上,换算后是2.0,还是2.25呢?该方法就是解决这个问题。 2. 方法 输入&…...
 —— SPI相关概念)
STM32单片机学习(27) —— SPI相关概念
文章目录概述SPI通信的核心特性I2C和SPI的简单对比SPI学习的补充说明SPI硬件电路设计SPI的四条通信线SPI通信的片选线低电平选中不支持广播通信SPI通信的时序结构(重点)SPI通信的比特序通信空闲状态,SPI时钟极性采样时机,SPI时钟相…...

别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单
别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单当你花了三天三夜精心雕琢的Blender模型,导入Unity后却变成了一团旋转错乱、贴图闪烁的"抽象艺术",那种崩溃感每个3D开发者都懂。本文将用实战经验帮你建立一…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...

基于Netburner NANO54415构建工业级嵌入式Web服务器:从硬件选型到广域监控实战
1. 项目概述:一个为广域与本地监控而生的嵌入式Web服务器如果你正在寻找一个能部署在野外、工厂角落或者任何需要远程数据采集与控制场景下的嵌入式Web服务器方案,并且对市面上那些要么性能孱弱、要么开发门槛极高的开发板感到厌倦,那么这个基…...

用图神经网络做缺陷定位,准确率比传统方法高出30%
在现代软件工程的复杂迷宫中,缺陷定位始终是测试团队面临的核心挑战。想象这样一个场景:一个电商系统在特定压力条件下偶发订单丢失,日志中只留下泛泛的超时错误,问题可能深藏在上百个微服务的调用链、分布式事务的竞态条件或某个…...

如何在5分钟内使用CrewAI Studio快速搭建AI工作流:零代码AI智能体开发终极指南
如何在5分钟内使用CrewAI Studio快速搭建AI工作流:零代码AI智能体开发终极指南 【免费下载链接】CrewAI-Studio A user-friendly, multi-platform GUI for managing and running CrewAI agents and tasks. Supports Conda and virtual environments, no coding need…...

量子机器学习与傅里叶分析:革新期权定价的混合计算范式
1. 项目概述:当量子机器学习遇见金融定价在金融工程的核心地带,期权定价一直是个计算密集型的硬骨头。传统的蒙特卡洛模拟虽然通用,但为了达到足够的精度,动辄需要百万甚至千万次的路径模拟,计算成本高昂。近年来&…...
)
用ESP32-C3的PWM做个RGB呼吸灯吧:从配置结构体到色彩渐变(乐鑫ESP-IDF实战)
ESP32-C3 RGB呼吸灯实战:从PWM配置到色彩渐变算法 当智能家居的灯光不再只是简单的开关控制,而是能像呼吸般自然渐变时,整个空间的氛围立刻变得生动起来。ESP32-C3凭借其出色的LED PWM控制器(LEDC)外设,为开…...

观察Token消耗明细,Taotoken用量看板如何帮助控制预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Token消耗明细,Taotoken用量看板如何帮助控制预算 对于个人开发者或项目管理者而言,在使用大模型API时…...

实战解锁:在Blender中掌握专业级MMD动画制作全流程
实战解锁:在Blender中掌握专业级MMD动画制作全流程 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools MMD …...