python写爬虫爬取京东商品信息

工具库
爬虫有两种方案:
- 第一种方式是使用request模拟请求,并使用bs4解析respond得到数据。
- 第二种是使用selenium和无头浏览器,selenium自动化操作无头浏览器,由无头浏览器实现请求,对得到的数据进行解析。
第一种方案部署简单,效率高,对于静态页面效果较好,对于动态页面效果较差。【可以理解为直接与服务器对接,申请什么数据完全由你自己来决定】
对于网页来说,可以分为静态网页和动态网页,二者的区别是静态网页是对于你的申请切切实实存在一个html网页文件,将这个文件发给你,你浏览器进行渲染。而动态网页则是存在一个服务器框架,处理你的请求,临时组合成一个html网页发给你,你浏览器进行渲染,你得到的是服务器框架的产物。
因此网页的数据来源也可以分为:
1、静态网页内的,
2、通过Ajax接口申请的,例如商品的评价数量,加载网页时不随网页一块儿得到,而是额外申请
3、通过JS脚本运行+Ajax接口申请的,例如商品的具体评价,只有你点评论栏,JS脚本才会向服务器申请数据
第二种方案部署稍微麻烦,需要安装无头浏览器,但是爬取效果较好,因为是真实的浏览器申请,selenium是模拟真人进行操作,对于反爬虫效果较好。
本文使用的是第一种,所需的工具库:
Python库:
Beautifulsoup
request
json
方法:
1、登录京东,获取登录cookie
2、搜索,得到搜索链接
3、使用request向搜索链接发送请求,得到respond
4、使用bs4解析respond
5、定位想要的数据所在的tag
6、对于一些动态数据,在浏览器开发者工具的network中找到相应的服务器地址,使用request模拟请求,并使用json解析服务器的respond
代码
import requests, json
from bs4 import BeautifulSoup# 基类,后续可以在此之上扩展
class AbstractWebPage:def __init__(self, cookie, use_cookie=True):if use_cookie:self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/80.0.3987.149 Safari/537.36','cookie': cookie}else:self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/80.0.3987.149 Safari/537.36'}self.sess = requests.session()self.sess.headers.update(self.headers)# 目录类,用来表示搜索结果
class Content(AbstractWebPage):def __init__(self, cookie, keyword, end_page):super(Content, self).__init__(cookie)start_url = 'https://search.jd.com/Search?keyword=' + keyword + '&enc=utf-8&wq=' + keywordself.url_list = [start_url + '&page=' + str(j) for j in range(1, end_page + 1)]self.end_page = end_pagedef print(self):print(self.url_list, sep='\n')def get_item_info(self):item_pages_list = []with open("good_info.txt", 'w', encoding='utf-8') as f:f.write("产品名称" + '\t' + '价格' + '\t' + '销量' + '\t' '店铺' + '\n')f.write("*" * 50 + '\n')for url in self.url_list:res = self.sess.get(url)res.encoding = 'utf-8'res = res.text# 定位搜索结果主体,并获取所有的商品的标签soup = BeautifulSoup(res, 'html.parser').select('#J_goodsList > ul')good_list = soup[0].select('[class=gl-i-wrap]')# 循环获取所有商品信息for temp in good_list:# 获取名称信息name_div = temp.select_one('[class="p-name p-name-type-2"]')good_info = name_div.text.strip() + '\t'# 价格信息price_div = temp.select_one('[class=p-price]')good_info += price_div.text.strip() + '\t'# 评价信息comment_div = temp.select_one('[class=p-commit]').find('strong').find('a')comment_url = comment_div.get('href')good_id = comment_url.replace('//item.jd.com/', '').replace('.html#comment', '')# 评价信息没有在主页面内,而是需要另外发送GET获取,服务器地址如下# 这里面的uuid是唯一标识符,如果运行程序发现报错或者没有得到想要的结果# commit_start_url = f'https://api.m.jd.com/?appid=item-v3&functionId' \# '=pc_club_productCommentSummaries&client=pc&clientVersion=1.0.0&t' \# f'=1711091114924&referenceIds={good_id}&categoryIds=9987%2C653%2C655' \# '&loginType=3&bbtf=&shield=&uuid=181111935.1679801589641754328424.1679801589' \# '.1711082862.1711087044.29'commit_start_url = f'https://api.m.jd.com/?appid=item-v3&functionId' \'=pc_club_productCommentSummaries&client=pc&clientVersion=1.0.0&t' \f'=1711091114924&referenceIds={good_id}&categoryIds=9987%2C653%2C655'# 发送请求,得到结果comment_res = self.sess.get(commit_start_url)# 编码方式是GBK国标编码comment_res.encoding = 'gbk'comment_res_json = comment_res.json()# 解析得到评论数量good_info += comment_res_json['CommentsCount'][0]['CommentCountStr'] + '\t'# 店铺信息shop_div = temp.select_one('[class=p-shop]')good_info += shop_div.get_text().strip() + '\t'f.write(good_info + '\n')f.write("*" * 50 + '\n')f.close()return item_pages_listif __name__ == "__main__":# cookie,用于验证登录状态,必须要有cookie,否则京东会提示网络繁忙请重试# 获取方法:使用浏览器登录过后按F12,点击弹出界面中最上方的network选项,name栏里面随便点开一个,拉到最下面就有cookie,复制到cookie.txt中# 注意,不要换行,前后不要有空格,只需要复制cookie的值,不需要复制“cookie:”这几个字符# 上面的看不懂的话,看这个:https://blog.csdn.net/qq_46047971/article/details/121694916# 然后就可以运行程序了cookie_str = ''with open('cookie.txt') as f:cookie_str = f.readline()# 输入cookie,关键词,输入结束页数content_page = Content(cookie_str, '手机', 2)content_page.print()urls = content_page.get_item_info()相关文章:

python写爬虫爬取京东商品信息
工具库 爬虫有两种方案: 第一种方式是使用request模拟请求,并使用bs4解析respond得到数据。第二种是使用selenium和无头浏览器,selenium自动化操作无头浏览器,由无头浏览器实现请求,对得到的数据进行解析。 第一种方…...

使用Linux别名简化命令输入
Linux定义命令别名,解决经常重复输入长命令 在Linux环境下工作时,我们经常需要输入长长的命令,这不仅耗时而且容易出错。Linux提供了一种名为“别名(alias)”的功能,可以让我们为这些长命令定义简短的名称…...

34.网络游戏逆向分析与漏洞攻防-游戏网络通信数据解析-登录数据包的监视与模拟
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 如果看不懂、不知道现在做的什么,那就跟着做完看效果 内容参考于:易道云信息技术研究院VIP课 上一个内容:33.游戏登录数据…...

rust - 对文件夹进行zip压缩加密
本文提供了一种对文件夹进行zip压缩并加密的方法。 添加依赖 cargo add anyhow cargo add walkdir cargo add zip cargo add zip-extensions计算文件夹的大小 目的是对需要压缩的文件夹的大小做一个限制。当然如果资源足够的话,可以去掉此限制。 let mut total_s…...
ETL数据倾斜与资源优化
1.数据倾斜实例 数据倾斜在MapReduce编程模型中比较常见,由于key值分布不均,大量的相同key被存储分配到一个分区里,出现只有少量的机器在计算,其他机器等待的情况。主要分为JOIN数据倾斜和GROUP BY数据倾斜。 1.1GROUP BY数据倾…...

Python的asyncio:异步编程的利器
在Python中,asyncio模块为开发者提供了强大的异步编程支持,使得编写高效且并发的代码变得更加容易。本文将深入探讨asyncio的核心概念、工作原理以及如何快速入门,通过文字与代码结合,带您领略异步编程的魅力。 1. 协程与事件循环…...
nodejs+vue高校奖助学金系统python-flask-django-php
高校奖助学金系统的目的是让使用者可以更方便的将人、设备和场景更立体的连接在一起。能让用户以更科幻的方式使用产品,体验高科技时代带给人们的方便,同时也能让用户体会到与以往常规产品不同的体验风格。 与安卓,iOS相比较起来,…...

已解决redis.clients.jedis.exceptions.JedisMovedDataException异常的正确解决方法,亲测有效!!!
已解决redis.clients.jedis.exceptions.JedisMovedDataException异常的正确解决方法,亲测有效!!! 目录 问题分析 报错原因 解决思路 解决方法 使用JedisCluster自动处理MOVED错误 手动更新客户端缓存 总结 博主vÿ…...
政安晨:【深度学习实践】【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(五)—— Dropout和批归一化
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: TensorFlow与Keras实战演绎 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! Dropout和批归一化是深度学习领域中常用的正则化技术…...

nodejs+vue高校会议室预订管理系统python-flask-django-php
伴随着我国社会的发展,人民生活质量日益提高。于是对系统进行规范而严格是十分有必要的,所以许许多多的信息管理系统应运而生。此时单靠人力应对这些事务就显得有些力不从心了。所以本论文将设计一套高校会议室预订管理系统,帮助学校进行会议…...

文件夹读取不到文件:深度解析与高效恢复策略
一、遭遇文件夹读取难题:文件离奇失踪 在日常使用电脑或移动设备的过程中,我们有时会遇到一个令人头疼的问题:原本存储着重要数据的文件夹突然变得“空空如也”,其中的文件仿佛凭空消失一般,无法正常读取。这种文件夹…...
python—接口编写部分
最近准备整理一下之前学过的前端小程序知识笔记,形成合集。顺便准备学一学接口部分,希望自己能成为一个全栈嘿嘿。建议关注收藏,持续更新技术文档。 目录 前端知识技能树http请求浏览器缓存 后端知识技能树python_api:flaskflask…...

手机IP地址如何更换
手机IP地址的修改方法可以通过以下几种方式实现: 1. 手动更改IP地址:打开手机设置,进入网络设置页面,找到IP地址更改选项。在此页面输入新的IP地址和子网掩码,并启用DHCP服务器。请注意,并非所有手机都支持…...

【R包开发:包的组件】 第4章 包的元数据
DESCRIPTION(描述文件) 的作用是存储包中重要的元数据。当第一次开发包时, 你会 使用这个文件记录包运行时所需要的包。然而,随着时间的流逝,当开始与他人分享包 时,元数据文件变得越来越重要,因为它指定了谁可以使用它…...
Office办公软件之word的使用(一)
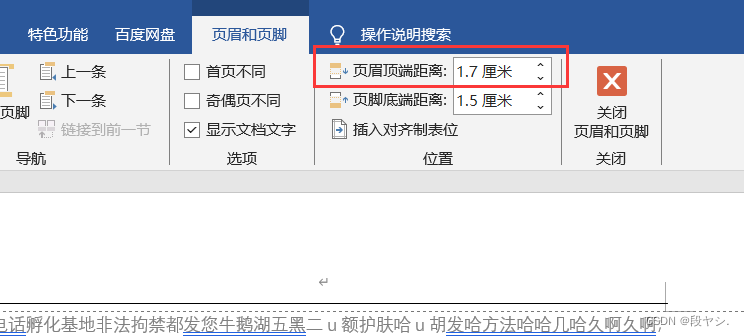
前几天调整公司招标文件的格式,中途遇到一些问题,感觉自己还不是太熟悉操作,通过查阅资料,知道了正确的操作,就想着给记下来。如果再次遇到,也能很快地找到解决办法。 一、怎么把标题前的黑点去掉 解决办法…...
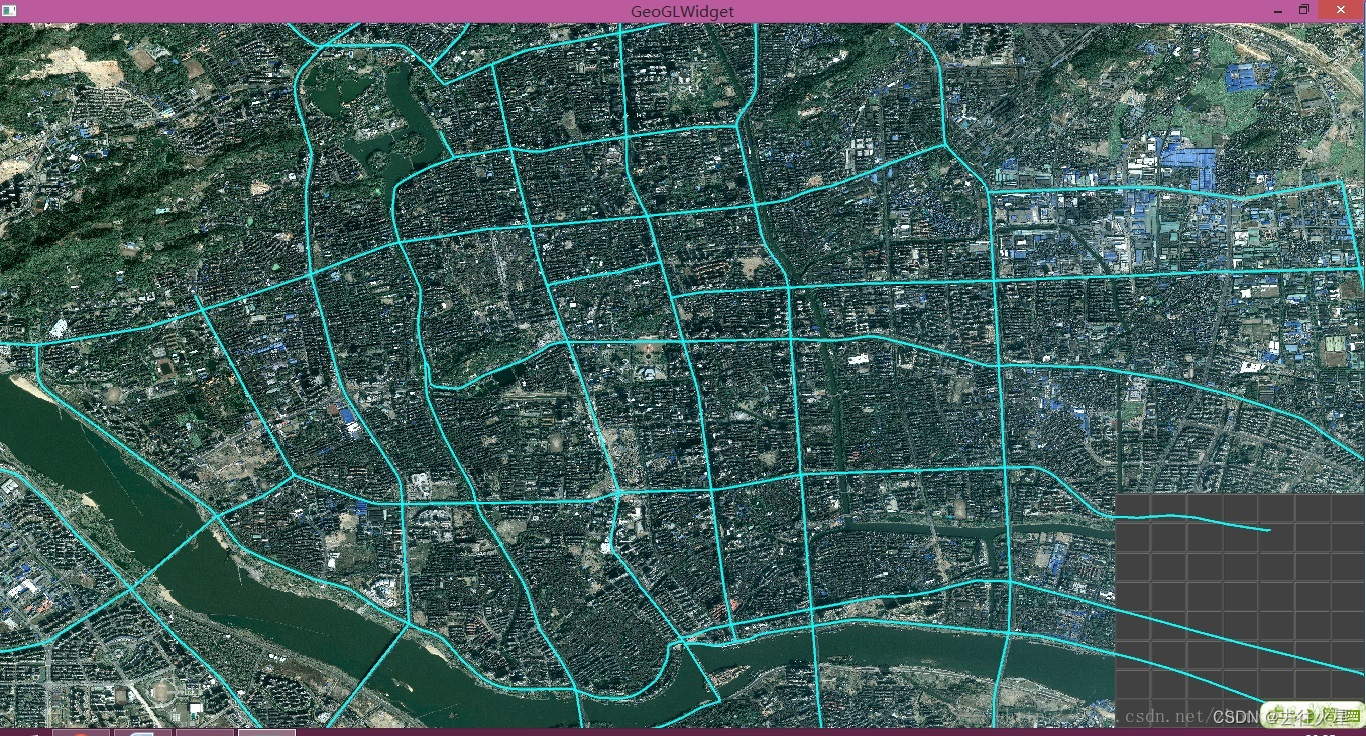
OpenGL+QT实现矢量和影像的叠加绘制
一、QT下OpenGL框架的初始化 OpenGL的介绍我在这里就没有必要介绍了,那OpenGL和QT的结合在这里就有必要先介绍一下,也就是怎么使用QT下的OpenGL框架。要想使用QT下的OpenGL框架,就必须要子类化QGLWidget,然后实现。 void initia…...
)
vue基础——java程序员版(vuex)
vuex可以定义共享数据。 1、主要结构 src/store/index.js 是使用vuex的核心js文件。 定义数据:state 修改数据(同步):mutations 修改数据(异步):action调用>mutations 下面定义了一个公共数据msg ,mutations方法setName…...
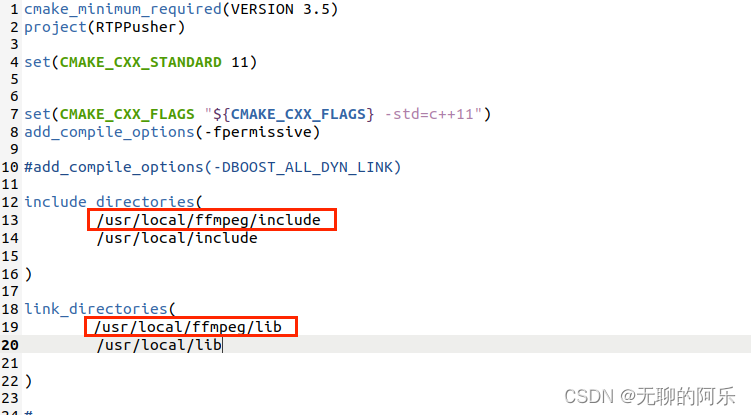
ubuntu20.04安装 ffmpeg 开发环境
参考:参考1 一些相关软件包,已打包整理好,如下 源码包 1、安装步骤 创建安装目录 sudo mkdir -p /usr/local/ffmpeg/lib 解压源码 tar -jxf ffmpeg-4.3.2.tar.bz2 到指定ffmpeg目录进行配置 cd ffmpeg-4.3.2/ 配置:会报错很多…...
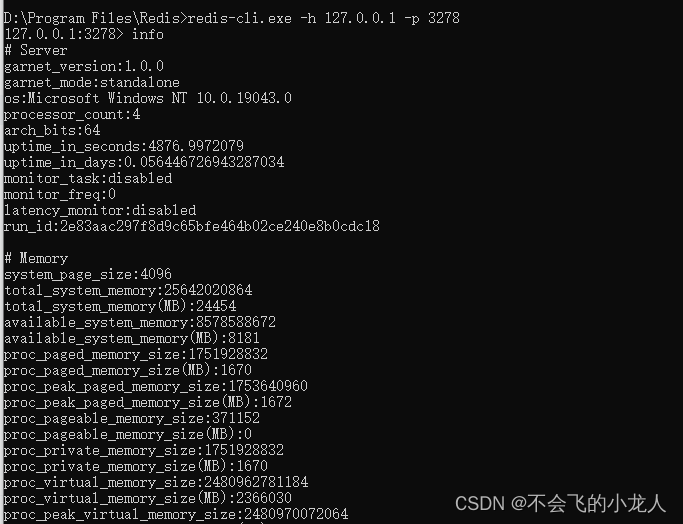
微软开源Garnet高性能缓存服务安装
Garnet介绍 Garnet是一款微软研究院基于C#开发而开源的高性能缓存服务,支持Windows、Linux多平台部署,Garnet兼容Redis服务API,在性能和使用架构上较Redis有很大提升(官方说法),并提供与Redis一样的命令操…...
)
云计算系统管理(ADMIN)
01. 公司需要将/opt/bjcat3目录下的所有文档打包备份,如何实现? 答案: # tar -czf /tmp/bjcat3.tar.gz /opt/bjcat302. 简述创建crontab计划任务的流程 答案: 利用crontab –e -u 用户名 进入计划任务编辑模式 分 时 日 月 周 …...

CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测
CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测无人机技术的普及带来了新的安全挑战,从隐私侵犯到关键设施威胁,反无人机技术正成为计算机视觉领域的热点。CVPR 2023反无人机竞赛提供的开源数据集和基线模型…...

30岁裸辞后,我用两个月拿下AI应用认证,现在OFFER选择困难症犯了
30岁裸辞那天,我最怕的不是没收入,而是突然发现:过去积累的经验,正在被AI重新定价。以前会写方案、做表格、跟项目,算是职场硬通货;到了2026年,招聘JD里开始频繁出现AI工具应用、智能工作流、Pr…...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...

Agent开发面试通关攻略:吃透稳拿offer
阅读前置:2026年当下最卷也最缺人的AI岗位,一定是AI Agent开发。最近刷遍CSDN、牛客、力扣最新面经,发现一个非常明显的招聘趋势:普通大模型微调岗位饱和内卷,而AI Agent开发岗位人才严重缺口,薪资更高、竞…...

长期使用Taotoken聚合服务对项目月度账单的可预测性提升
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对项目月度账单的可预测性提升 在AI驱动的项目开发与运营中,成本控制与预算规划是团队管理者…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

人类防伪指南:为什么你越写错字,HR越信你是真人?
前言各位码农、算法侠、CtrlC/V十级学者请注意:你有没有过这样的经历?辛辛苦苦肝了一晚上文档,逻辑严密、语法丝滑、连Markdown都对齐得像军训方阵,结果老板幽幽来一句:“这真是你自己写的?”那一刻&#x…...

基于ESP8266与MQTT的家庭水压自动控制系统设计与实现
1. 项目概述与核心需求解析家里水压不稳、供水时断时续,这大概是很多朋友都遇到过的烦心事。我所在的城市供水情况就很不理想,为了解决这个问题,我不得不自己动手,搭建了一套基于ESP8266微控制器的家庭水压增压与储水自动控制系统…...

具身智能:面向新兴交叉学科建设的思考与建议 2026
这份由 CCF YOCSEF 长三角五地学术委员会 2026 年 5 月发布的白皮书,聚焦具身智能作为新兴交叉学科的建设,明确其并非 AI 与机器人学的简单拼接,而是围绕物理交互中的智能行为形成的新问题域,提出 “三大基本问题 一个应用需求”…...