面试笔记——Java集合篇
Java集合框架体系
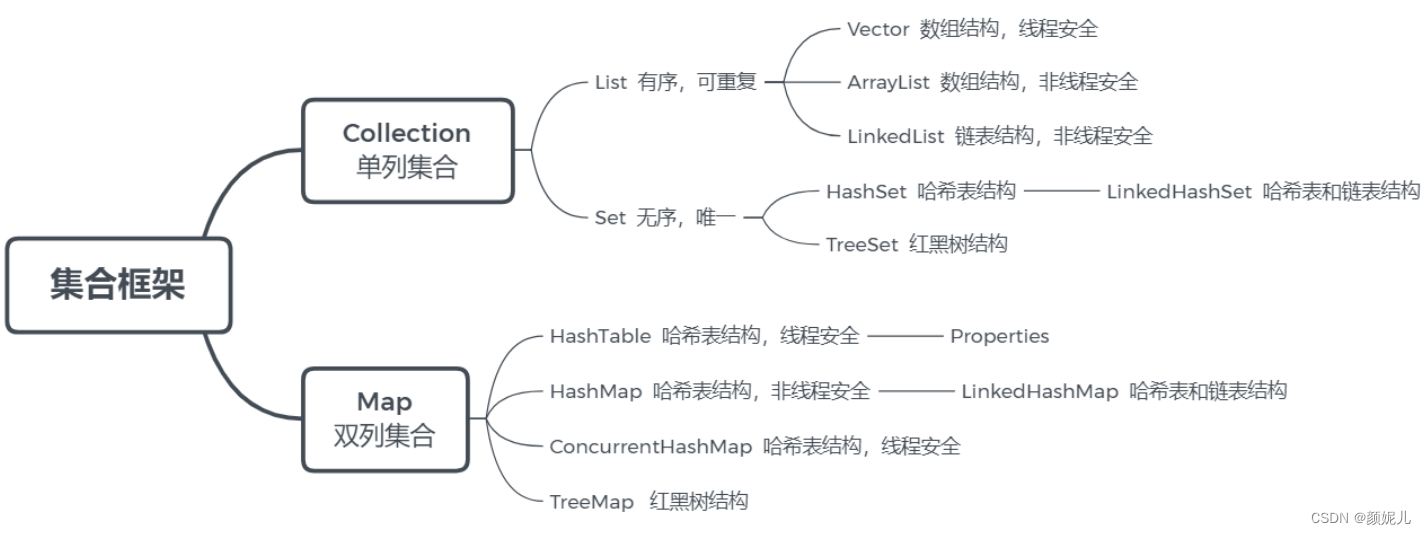
重点:单列集合——ArrayList、LinkedList;双列集合——HashMap、ConcurrentHashMap。
List相关
数组(Array) 是一种用连续的内存空间存储相同数据类型数据的线性数据结构。
数组获取其他元素:
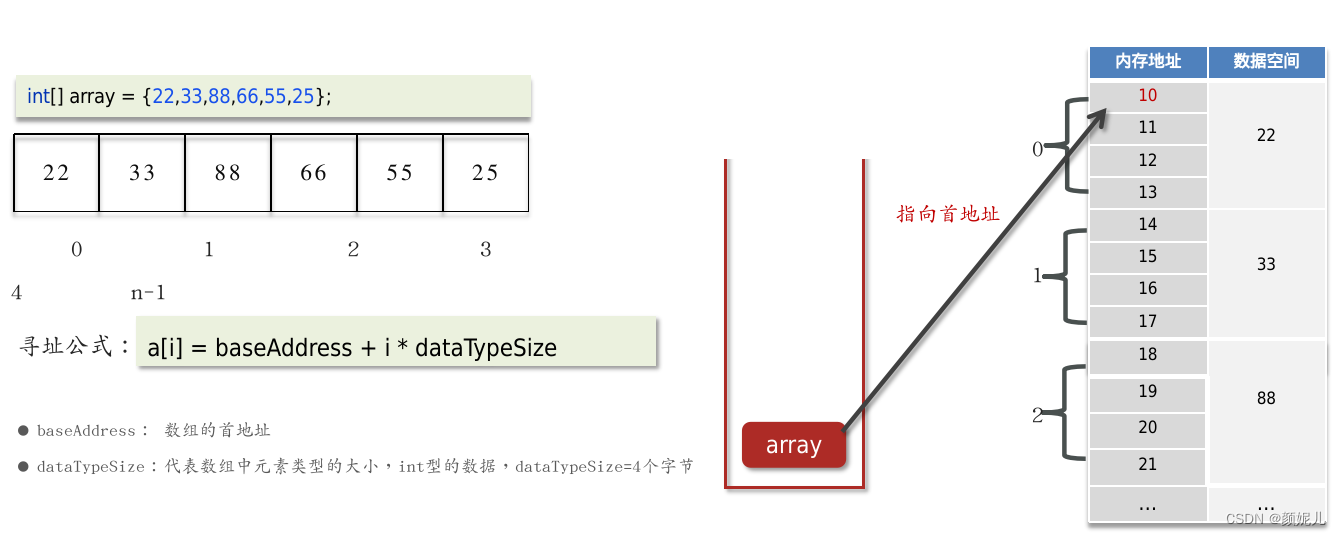
为什么数组索引从0开始呢?假如从1开始不行吗?
- 在根据数组索引获取元素的时候,会用索引和寻址公式来计算内存所对应的元素数据,寻址公式是:数组的首地址+索引乘以存储数据的类型大小在这里插入图片描述

- 如果数组的索引从1开始,寻址公式中,就需要增加一次减法操作,对于CPU来说就多了一次指令,性能不高。

查找的时间复杂度: - 随机(通过下标)查询的时间复杂度是O(1)
- 查找元素(未知下标)的时间复杂度是O(n)
- 查找元素(未知下标但排序)通过二分查找的时间复杂度是O(logn)
插入和删除时间复杂度:
- 插入和删除的时候,为了保证数组的内存连续性,需要挪动数组元素,平均时间复杂度为O(n)
ArrayList源码分析
成员变量:
/*** 默认初始的容量(CAPACITY)*/private static final int DEFAULT_CAPACITY = 10;/*** 用于空实例的共享空数组实例*/private static final Object[] EMPTY_ELEMENTDATA = {};/*** 用于默认大小的空实例的共享空数组实例。* 我们将其与 EMPTY_ELEMENTDATA 区分开来,以了解添加第一个元素时要膨胀多少*/private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};/*** 存储 ArrayList 元素的数组缓冲区。 ArrayList 的容量就是这个数组缓冲区的长度。* 当添加第一个元素时,任何具有 elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA 的空 ArrayList* 都将扩展为 DEFAULT_CAPACITY* 当前对象不参与序列化*/transient Object[] elementData; // non-private to simplify nested class access/*** ArrayList 的大小(它包含的元素数量)** @serial*/private int size;
构造方法:
构造方法1——带初始化容量的构造函数:
public ArrayList(int initialCapacity) {if (initialCapacity > 0) {this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {this.elementData = EMPTY_ELEMENTDATA;} else {throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);}}
构造方法2——无参构造函数,默认创建空集合:
public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}
构造方法3——将collection对象转换成数组,然后将数组的地址的赋给elementData
:
public ArrayList(Collection<? extends E> c) {Object[] a = c.toArray();if ((size = a.length) != 0) {if (c.getClass() == ArrayList.class) {elementData = a;} else {elementData = Arrays.copyOf(a, size, Object[].class);}} else {// replace with empty array.elementData = EMPTY_ELEMENTDATA;}}
关键方法
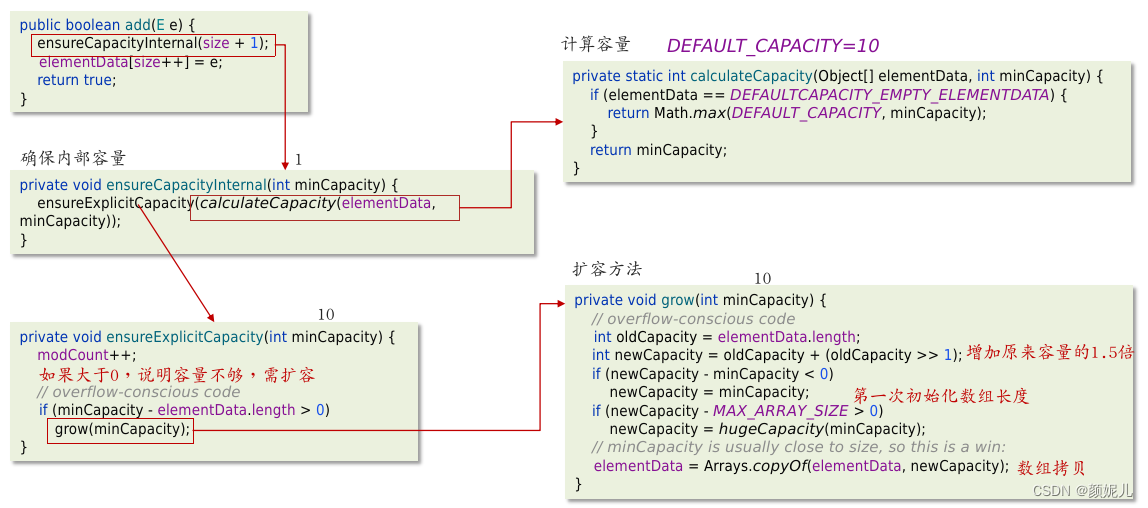
第一次添加数据(调用add方法添加数据)流程:
第十次添加数据:
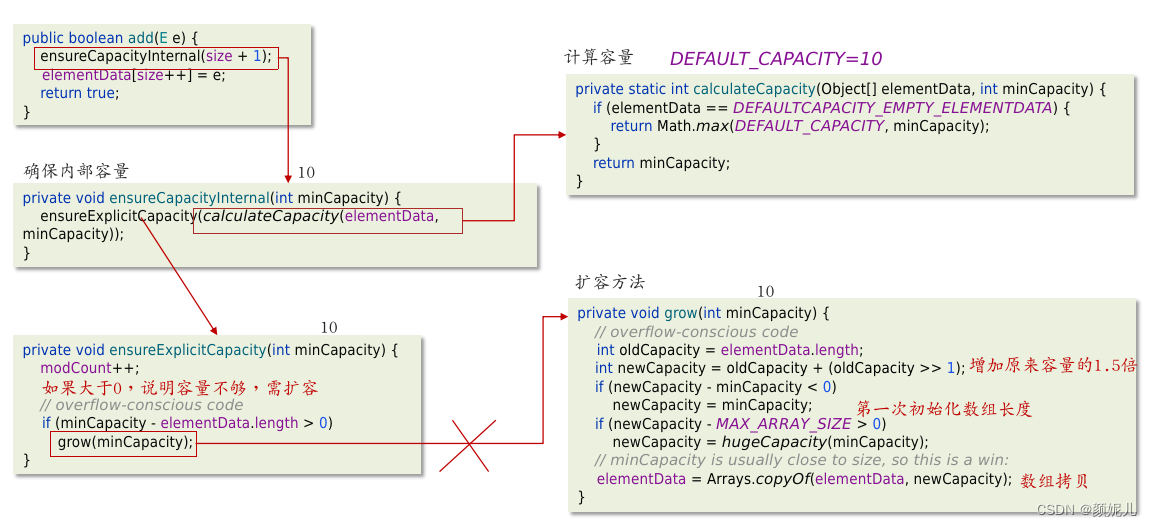
第十一次添加数据:
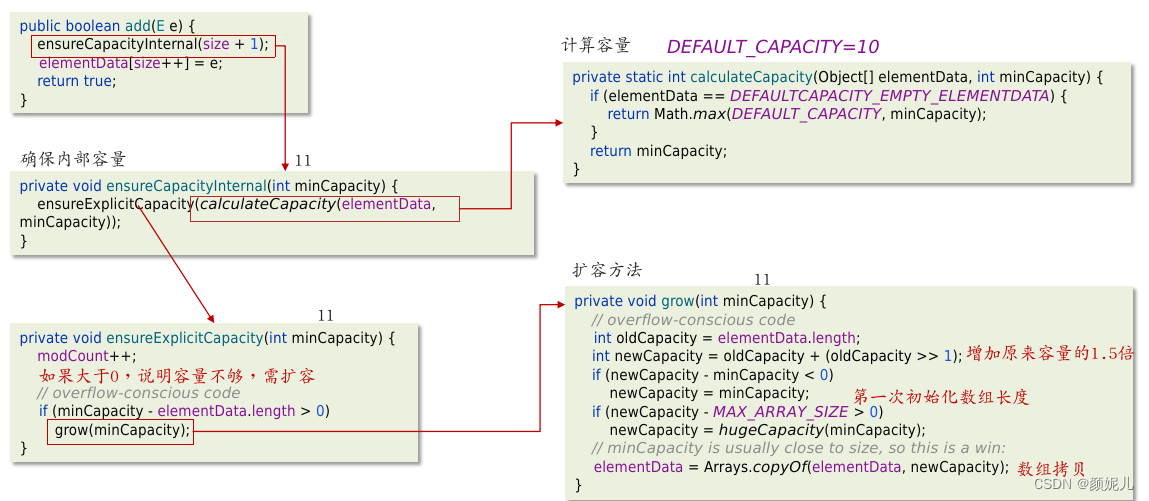
总结:
- ArrayList的底层使用动态的数组实现的;
- 它的初始容量为0,当第一次添加数据的时,会初始化容量为10;
- 在扩容后,容量是原来容量的1.5倍,每次扩容都需要拷贝数据;
- 添加逻辑:
- 确保数组已使用长度(size)加1之后足够存下下一个数据
- 计算数组的容量,如果当前数组已使用长度+1后的大于当前的数组长度,则调用grow方法扩容(原来的1.5倍)
- 确保新增的数据有地方存储之后,则将新元素添加到位于size的位置上。
- 返回添加成功布尔值。
问题: ArrayList list=new ArrayList(10)中的list扩容几次?
回答: 该语句只是声明和实例了一个 ArrayList,指定了容量为 10,未扩容。
Array与List相互转换
- 数组转List ,使用JDK中java.util.Arrays工具类的asList方法
- List转数组,使用List的toArray方法。无参toArray方法返回 Object数组,传入初始化长度的数组对象,返回该对象数组。
//数组转Listpublic static void testArray2List() {String[] strs = {"aaa", "bbb", "ccc"};List<String> list = Arrays.asList(strs);for (String s : list) {System.out.println(s);}}//List转数组public static void testList2Array() {List<String> list = new ArrayList<String>();list.add("aaa");list.add("bbb");list.add("ccc");String[] array = list.toArray(new String[list.size()]);for (String s : array) {System.out.println(s);}}
注意:
-
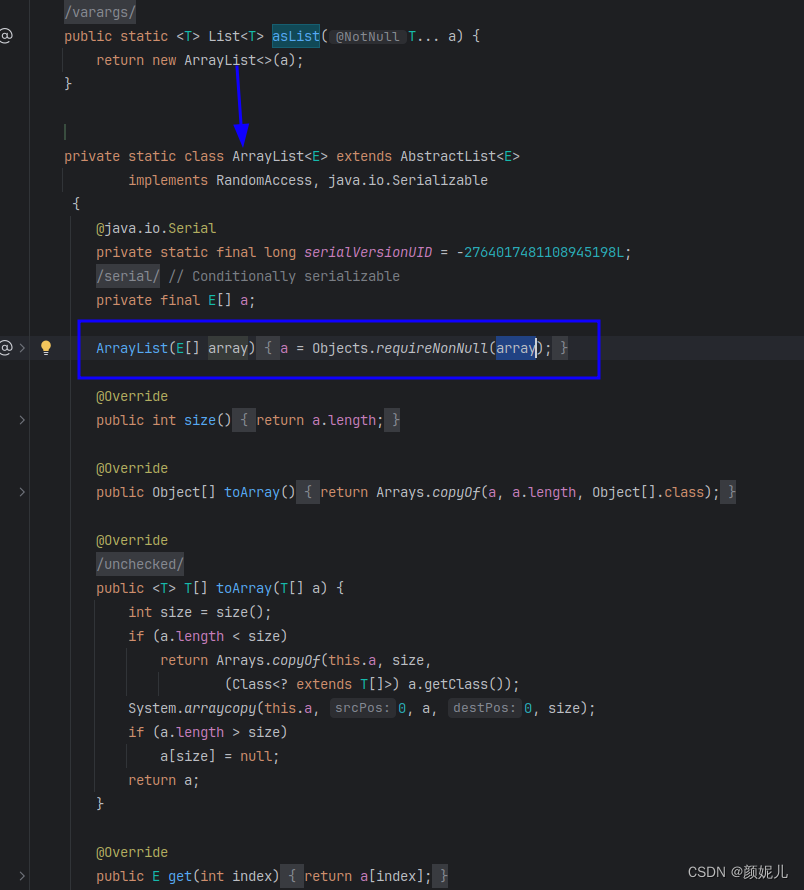
Arrays.asList转换list之后,如果修改了数组的内容,list会受影响,因为它的底层使用的Arrays类中的一个内部类ArrayList来构造的集合,在这个集合的构造器中,把我们传入的这个集合进行了包装而已,最终指向的都是同一个内存地址。源码如下图所示:
-
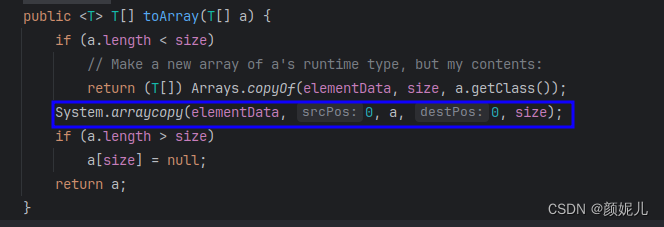
list用了toArray转数组后,如果修改了list内容,数组不会影响,当调用了toArray以后,在底层是它是进行了数组的拷贝,跟原来的元素就没啥关系了,所以即使list修改了以后,数组也不受影响。源码如下图所示:
测试代码:
//数组转Listpublic static void testArray2List() {String[] strs = {"aaa", "bbb", "ccc"};List<String> list = Arrays.asList(strs);for (String s : list) {System.out.println(s);}strs[1] = "ddd";System.out.println("================");for (String s : list) {System.out.println(s);}}//List转数组public static void testList2Array() {List<String> list = new ArrayList<String>();list.add("aaa");list.add("bbb");list.add("ccc");String[] array = list.toArray(new String[list.size()]);for (String s : array) {System.out.println(s);}list.add("ddd");System.out.println("================");for (String s : array) {System.out.println(s);}}ArrayList和LinkedList的区别
-
底层数据结构:
- ArrayList 使用动态数组实现,它内部维护一个 Object 数组,在添加或删除元素时会涉及到数组的扩容和拷贝操作。
- LinkedList 使用双向链表实现,它的每个元素都包含了对前后元素的引用,添加或删除元素时只需要修改相邻节点的引用,不涉及数组的扩容和拷贝操作。
-
访问效率:
- ArrayList 支持随机访问(通过索引访问),因为它是基于数组实现的,可以通过索引直接定位到元素。因此,对于随机访问的操作效率比较高,时间复杂度为 O(1)。
- LinkedList 不支持随机访问,因为它是基于链表实现的,需要从头节点或尾节点开始顺序查找,时间复杂度为 O(n),其中 n 为链表长度。但在插入和删除操作上,LinkedList 由于不涉及数组的扩容和拷贝,且只需修改相邻节点的引用,因此插入和删除操作的效率较高,时间复杂度为 O(1)。
-
新增和删除:
- ArrayList尾部插入和删除,时间复杂度是O(1);其他部分增删需要挪动数组,时间复杂度是O(n)。
- LinkedList头尾节点增删时间复杂度是O(1),其他都需要遍历链表,时间复杂度是O(n)。
-
空间复杂度:
- ArrayList 在添加元素时可能需要进行数组的扩容,而扩容操作需要重新分配内存空间并将原数组的元素拷贝到新数组中,因此可能会导致额外的内存消耗。
- LinkedList 每个元素都需要额外的空间来存储前后节点的引用,因此相比 ArrayList 需要更多的内存空间。
-
线程安全:
- ArrayList和LinkedList都不是线程安全的。
- 如果需要保证线程安全,有两种方案:
- 在方法内使用,局部变量则是线程安全的
- 使用线程安全的ArrayList和LinkedList,如
List<Object> syncArrayList = Collections.synchronizedList(new ArrayList<>()); List<Object> syncLinkedList = Collections.synchronizedList(new LinkedList<>());
HashMap相关
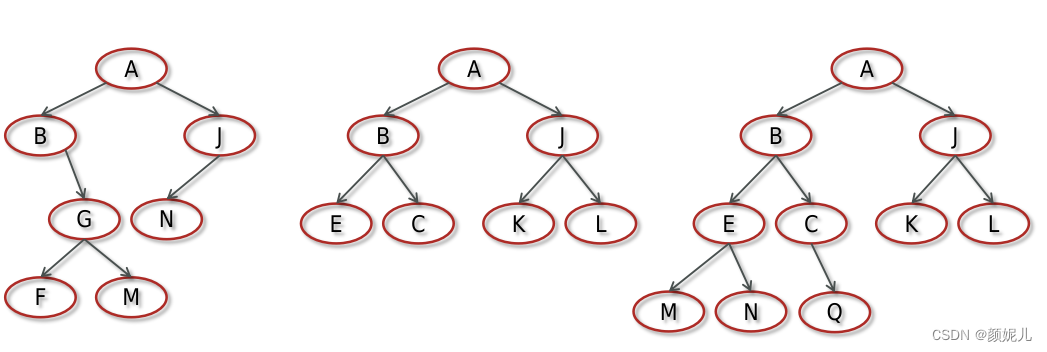
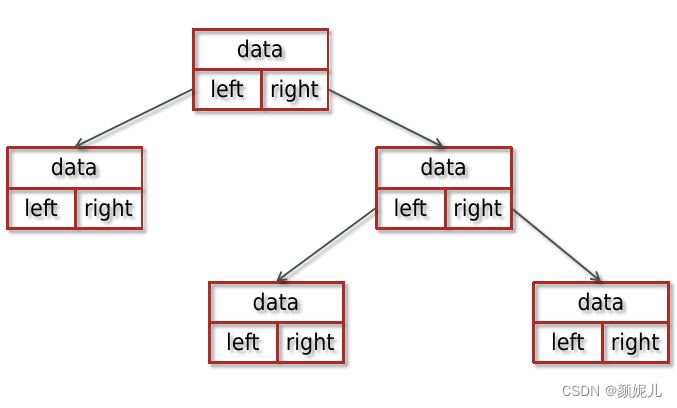
二叉树:每个节点最多有两个“叉”,也就是两个子节点,分别是左子节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只有左子节点,有的节点只有右子节点。
二叉树每个节点的左子树和右子树也分别满足二叉树的定义。
如图所示:
Java中有两个方式实现二叉树:数组存储,链式存储。
基于链式存储的树的节点可定义如下:
public class TreeNode {int val;TreeNode left;TreeNode right;TreeNode() {}TreeNode(int val) {this.val = val;}TreeNode(int val, TreeNode left, TreeNode right) {this.val = val;this.left = left;this.right = right;}}
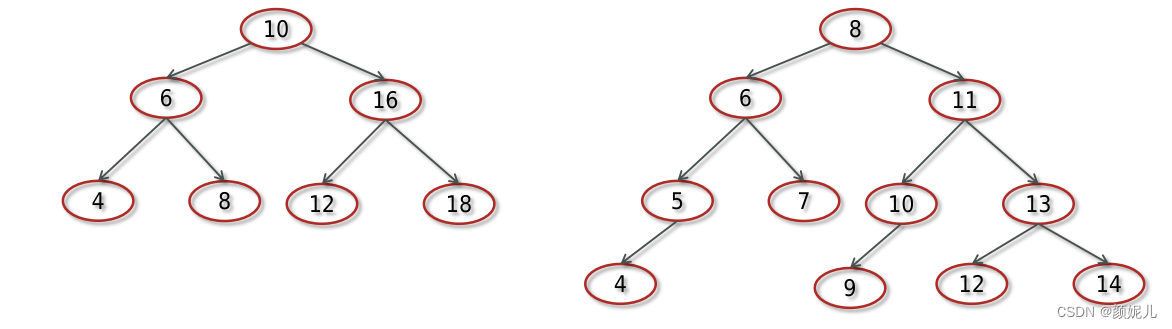
在二叉树中,比较常见的二叉树有:
- 满二叉树
- 完全二叉树
- 二叉搜索树
- 红黑树
二叉搜索树(Binary Search Tree,BST) 又名二叉查找树,有序二叉树或者排序二叉树,是二叉树中比较常用的一种类型。
二叉查找树要求,在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值。
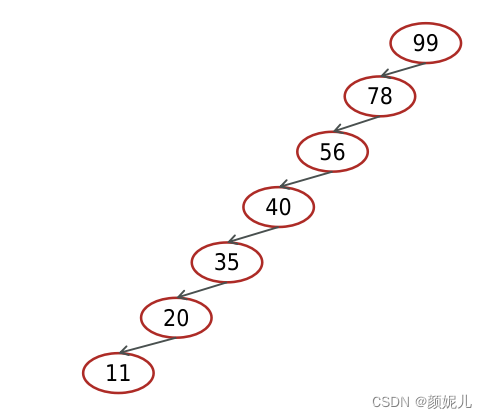
二叉树的插入,查找,删除的时间复杂度O(logn),最坏的情况下,二叉树会退化成链表,此时的查找时间复杂度为O(n),如图:
红黑树(Red Black Tree):也是一种自平衡的二叉搜索树(BST),之前叫做平衡二叉B树(Symmetric Binary B-Tree),它在每个节点上增加了一个额外的表示节点颜色的属性,可以是红色或黑色,如下图所示。红黑树通过一系列的规则确保了树的平衡,从而保证了在最坏情况下的基本操作(如查找、插入和删除)具有较低的时间复杂度。
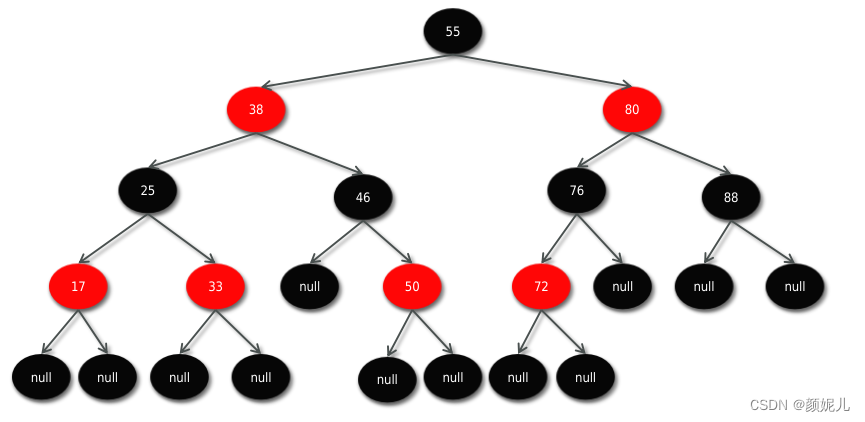
红黑树具有以下特性:
- 节点颜色:每个节点都是红色或黑色。
- 根节点:根节点是黑色的。
- 叶子节点:叶子节点(NIL 节点或空节点)是黑色的。
- 红色节点:红色节点的两个子节点都是黑色的。
- 路径规则:从任一节点到其每个叶子节点的路径上,黑色节点的数量相同。
当插入和删除操作可能会破坏红黑树的特性,因此需要进行修正,以恢复树的平衡。
红黑树的复杂度:
- 查找:
红黑树也是一棵BST(二叉搜索树)树,查找操作的时间复杂度为:O(log n) - 添加:
添加先要从根节点开始找到元素添加的位置,时间复杂度O(log n)
添加完成后涉及到复杂度为O(1)的旋转调整操作
故整体复杂度为:O(log n) - 删除:
首先从根节点开始找到被删除元素的位置,时间复杂度O(log n)
删除完成后涉及到复杂度为O(1)的旋转调整操作
故整体复杂度为:O(log n)
HashMap
散列表: 散列表(Hash Table)又名哈希表/Hash表,是根据键(Key)直接访问在内存存储位置值(Value)的数据结构,它是由数组演化而来的,利用了数组支持按照下标进行随机访问数据的特性。
如图:
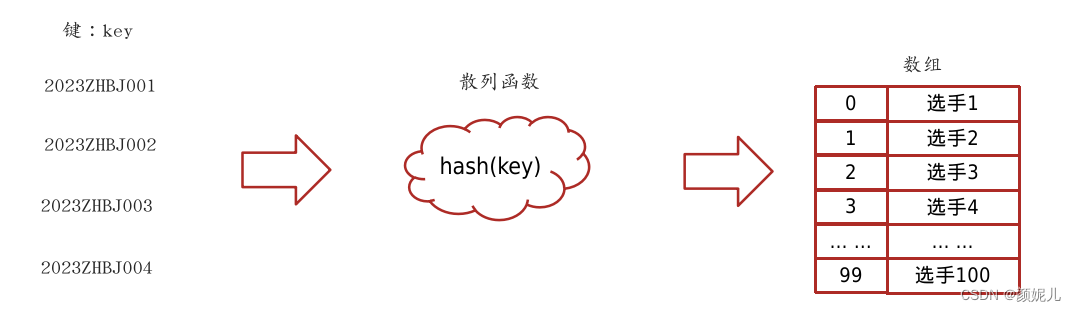
将键(key)映射为数组下标的函数叫做散列函数。 可以表示为:hashValue = hash(key)。
散列函数的基本要求:
- 散列函数计算得到的散列值必须是大于等于0的正整数,因为hashValue需要作为数组的下标。
- 如果key1==key2,那么经过hash后得到的哈希值也必相同即:hash(key1) == hash(key2)
- 如果key1 != key2,那么经过hash后得到的哈希值也必不相同即:hash(key1) != hash(key2)——但不太好实现
实际的情况下想找一个散列函数能够做到对于不同的key计算得到的散列值都不同几乎是不可能的,即便像著名的MD5,SHA等哈希算法也无法避免这一情况,这就是散列冲突(或者哈希冲突,哈希碰撞,就是指多个key映射到同一个数组下标位置) 。
避免Hash冲突——拉链法:在散列表中,数组的每个下标位置我们可以称之为桶(bucket)或者槽(slot),每个桶(槽)会对应一条链表, 所有散列值相同的元素我们都放到相同槽位对应的链表中。如图所示:

基于拉链法,分析散列表的时间复杂度:
- 插入操作:
- 通过散列函数计算出对应的散列槽位,将其插入到对应链表中即可,插入的时间复杂度是 O(1)
- 查找、删除操作:
- 当查找、删除一个元素时,同样通过散列函数计算出对应的槽,然后遍历链表查找或者删除
- 平均情况下基于链表法解决冲突时查询的时间复杂度是O(1)
- 散列表可能会退化为链表,查询的时间复杂度就从 O(1) 退化为 O(n)
- 将链表法中的链表改造为其他高效的动态数据结构,比如红黑树,查询的时间复杂度是 O(logn)
- 当查找、删除一个元素时,同样通过散列函数计算出对应的槽,然后遍历链表查找或者删除
HashMap实现原理
HashMap的数据结构: 底层使用hash表数据结构,即数组和链表或红黑树 。
- 当我们往HashMap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
- 存储时,如果出现hash值相同的key,此时有两种情况。
a. 如果key相同,则覆盖原始值;
b. 如果key不同(出现冲突),则将当前的key-value放入链表或红黑树中 - 获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
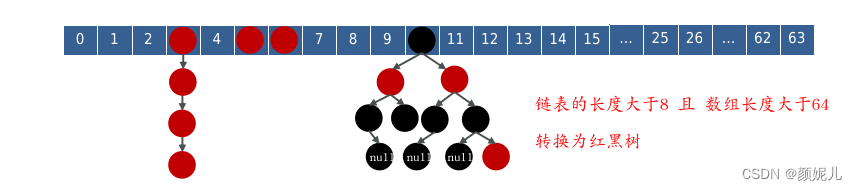
HashMap的jdk1.7和jdk1.8有什么区别:
- JDK1.8之前采用的是拉链法。拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
- JDK1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8) 时并且数组长度达到64时,将链表转化为红黑树,以减少搜索时间。扩容 resize( ) 时,红黑树拆分成的树的结点数小于等于临界值6个,则退化成链表。
HashMap的put方法的具体流程
HashMap常见属性:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
transient HashMap.Node<K,V>[] table;
transient int size;
DEFAULT_INITIAL_CAPACITY 默认的初始容量
DEFAULT_LOAD_FACTOR 默认的加载因子扩容阈值 == 数组容量 * 加载因子
其中 table变量的所属类:
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}public final boolean equals(Object o) {if (o == this)return true;return o instanceof Map.Entry<?, ?> e&& Objects.equals(key, e.getKey())&& Objects.equals(value, e.getValue());}}
HashMap的无参构造方法:
public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}
说明:
- HashMap是懒惰加载,在创建对象时并没有初始化数组
- 在无参的构造函数中,设置了默认的加载因子是0.75
添加数据的流程图:
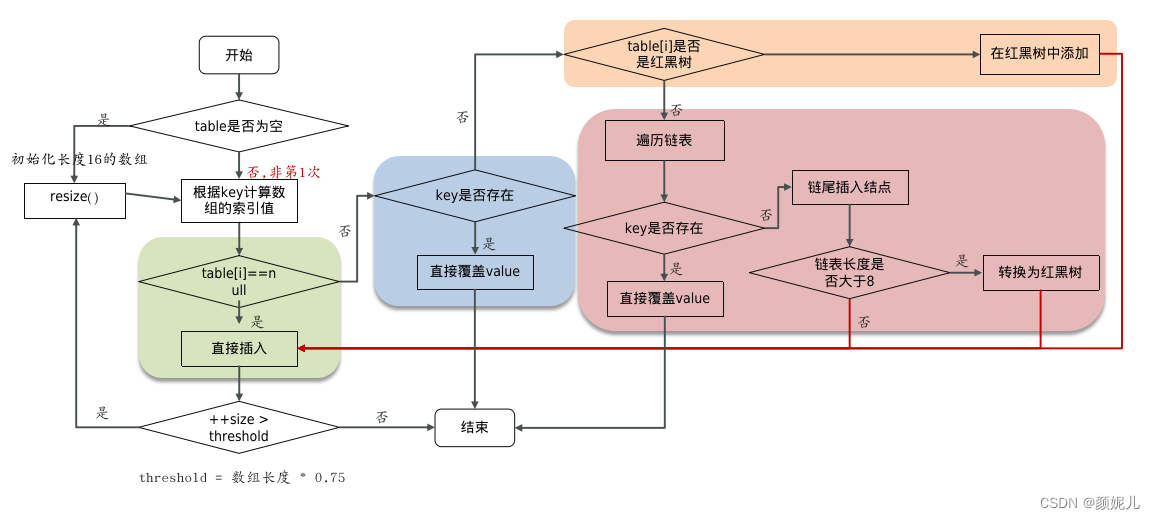
- 判断键值对数组table是否为空或为null,否则执行resize()进行扩容(初始化)
- 根据键值key计算hash值得到数组索引
- 判断table[i]==null,条件成立,直接新建节点添加
- 如果table[i]==null ,不成立
- 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
- 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对
- 遍历table[i],链表的尾部插入数据,然后判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操 作,遍历过程中若发现key已经存在直接覆盖value
- 插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold(数组长度*0.75),如果超过,进行扩容。
put方法流程
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;//判断数组是否未初始化if ((tab = table) == null || (n = tab.length) == 0)//如果未初始化,调用resize方法 进行初始化n = (tab = resize()).length;//通过 & 运算求出该数据(key)的数组下标并判断该下标位置是否有数据if ((p = tab[i = (n - 1) & hash]) == null)//如果没有,直接将数据放在该下标位置tab[i] = newNode(hash, key, value, null);//该数组下标有数据的情况else {Node<K,V> e; K k;//判断该位置数据的key和新来的数据是否一样if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))//如果一样,证明为修改操作,该节点的数据赋值给e,后边会用到e = p;//判断是不是红黑树else if (p instanceof TreeNode)//如果是红黑树的话,进行红黑树的操作e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//新数据和当前数组既不相同,也不是红黑树节点,证明是链表else {//遍历链表for (int binCount = 0; ; ++binCount) {//判断next节点,如果为空的话,证明遍历到链表尾部了if ((e = p.next) == null) {//把新值放入链表尾部p.next = newNode(hash, key, value, null);//因为新插入了一条数据,所以判断链表长度是不是大于等于8if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st//如果是,进行转换红黑树操作treeifyBin(tab, hash);break;}//判断链表当中有数据相同的值,如果一样,证明为修改操作if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;//把下一个节点赋值为当前节点p = e;}}//判断e是否为空(e值为修改操作存放原数据的变量)if (e != null) { // existing mapping for key//不为空的话证明是修改操作,取出老值V oldValue = e.value;//一定会执行 onlyIfAbsent传进来的是falseif (!onlyIfAbsent || oldValue == null)//将新值赋值当前节点e.value = value;afterNodeAccess(e);//返回老值return oldValue;}}//计数器,计算当前节点的修改次数++modCount;//当前数组中的数据数量如果大于扩容阈值if (++size > threshold)//进行扩容操作resize();//空方法afterNodeInsertion(evict);//添加操作时 返回空值return null;
}
HashMap的扩容
流程图:
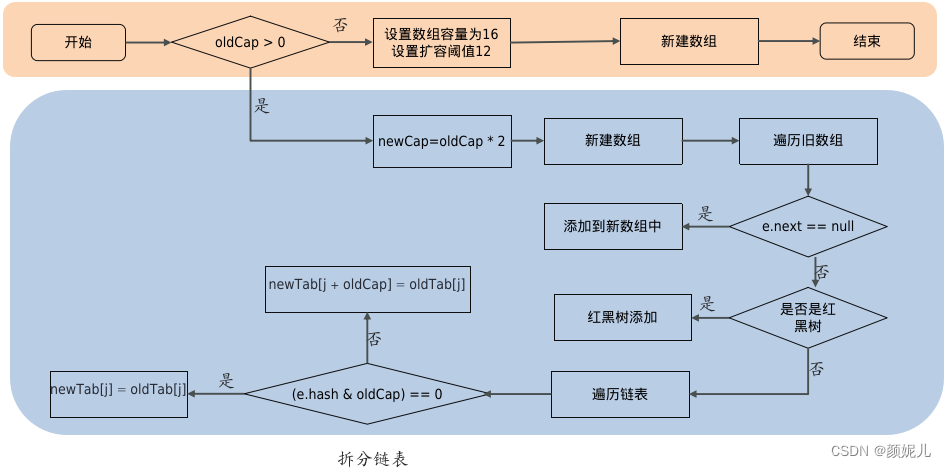
- 在添加元素或初始化的时候需要调用resize方法进行扩容,第一次添加数据初始化数组长度为16,以后每次每次扩容都是达到了扩容阈值(数组长度 * 0.75)
- 每次扩容的时候,都是扩容之前容量的2倍;
- 扩容之后,会新创建一个数组,需要把老数组中的数据挪动到新的数组中
- 没有hash冲突的节点,则直接使用 e.hash & (newCap - 1) 计算新数组的索引位置
- 如果是红黑树,走红黑树的添加
- 如果是链表,则需要遍历链表,可能需要拆分链表,判断(e.hash & oldCap)是否为0,该元 素的位置要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上
扩容
//扩容、初始化数组
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;//如果当前数组为null的时候,把oldCap老数组容量设置为0int oldCap = (oldTab == null) ? 0 : oldTab.length;//老的扩容阈值int oldThr = threshold;int newCap, newThr = 0;//判断数组容量是否大于0,大于0说明数组已经初始化if (oldCap > 0) {//判断当前数组长度是否大于最大数组长度if (oldCap >= MAXIMUM_CAPACITY) {//如果是,将扩容阈值直接设置为int类型的最大数值并直接返回threshold = Integer.MAX_VALUE;return oldTab;}//如果在最大长度范围内,则需要扩容 OldCap << 1等价于oldCap*2//运算过后判断是不是最大值并且oldCap需要大于16else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold 等价于oldThr*2}//如果oldCap<0,但是已经初始化了,像把元素删除完之后的情况,那么它的临界值肯定还存在, 如果是首次初始化,它的临界值则为0else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;//数组未初始化的情况,将阈值和扩容因子都设置为默认值else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}//初始化容量小于16的时候,扩容阈值是没有赋值的if (newThr == 0) {//创建阈值float ft = (float)newCap * loadFactor;//判断新容量和新阈值是否大于最大容量newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}//计算出来的阈值赋值threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})//根据上边计算得出的容量 创建新的数组 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//赋值table = newTab;//扩容操作,判断不为空证明不是初始化数组if (oldTab != null) {//遍历数组for (int j = 0; j < oldCap; ++j) {Node<K,V> e;//判断当前下标为j的数组如果不为空的话赋值个e,进行下一步操作if ((e = oldTab[j]) != null) {//将数组位置置空oldTab[j] = null;//判断是否有下个节点if (e.next == null)//如果没有,就重新计算在新数组中的下标并放进去newTab[e.hash & (newCap - 1)] = e;//有下个节点的情况,并且判断是否已经树化else if (e instanceof TreeNode)//进行红黑树的操作((TreeNode<K,V>)e).split(this, newTab, j, oldCap);//有下个节点的情况,并且没有树化(链表形式)else {//比如老数组容量是16,那下标就为0-15//扩容操作*2,容量就变为32,下标为0-31//低位:0-15,高位16-31//定义了四个变量// 低位头 低位尾Node<K,V> loHead = null, loTail = null;// 高位头 高位尾Node<K,V> hiHead = null, hiTail = null;//下个节点Node<K,V> next;//循环遍历do {//取出next节点next = e.next;//通过 与操作 计算得出结果为0if ((e.hash & oldCap) == 0) {//如果低位尾为null,证明当前数组位置为空,没有任何数据if (loTail == null)//将e值放入低位头loHead = e;//低位尾不为null,证明已经有数据了else//将数据放入next节点loTail.next = e;//记录低位尾数据loTail = e;}//通过 与操作 计算得出结果不为0else {//如果高位尾为null,证明当前数组位置为空,没有任何数据if (hiTail == null)//将e值放入高位头hiHead = e;//高位尾不为null,证明已经有数据了else//将数据放入next节点hiTail.next = e;//记录高位尾数据hiTail = e;}} //如果e不为空,证明没有到链表尾部,继续执行循环while ((e = next) != null);//低位尾如果记录的有数据,是链表if (loTail != null) {//将下一个元素置空loTail.next = null;//将低位头放入新数组的原下标位置newTab[j] = loHead;}//高位尾如果记录的有数据,是链表if (hiTail != null) {//将下一个元素置空hiTail.next = null;//将高位头放入新数组的(原下标+原数组容量)位置newTab[j + oldCap] = hiHead;}}}}}//返回新的数组对象return newTab;}
HashMap的get 方法
public V get(Object key) {Node<K,V> e;//hash(key),获取key的hash值//调用getNode方法,见下面方法return (e = getNode(hash(key), key)) == null ? null : e.value;
}final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;//找到key对应的桶下标,赋值给first节点if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {//判断hash值和key是否相等,如果是,则直接返回,桶中只有一个数据(大部分的情况)if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;if ((e = first.next) != null) {//该节点是红黑树,则需要通过红黑树查找数据if (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);//链表的情况,则需要遍历链表查找数据do {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;
}
HashMap的寻址算法
在HashMap中,计算hash值时用到的关键方法:

计算hash值时用到的两个技巧:
- 将key的hashCode右移16位后再进行异或运算——(h = key.hashCode()) ^ (h >>> 16),这称为扰动算法,使hash值更加均匀,从而减少hash冲突。
- (n-1)&hash : 得到数组中的索引,代替取模,性能更好(运算结果与取模运算一样)。数组长度必须是2的n次幂
HashMap的数组长度一定是2的次幂:
- 计算索引时效率更高:如果是 2 的 n 次幂可以使用位与运算代替取模
- 扩容时重新计算索引效率更高: hash & oldCap == 0 的元素留在原来位置 ,否则新位置 = 旧位置 + oldCap
相关文章:
面试笔记——Java集合篇
Java集合框架体系 重点:单列集合——ArrayList、LinkedList;双列集合——HashMap、ConcurrentHashMap。 List相关 数组(Array) 是一种用连续的内存空间存储相同数据类型数据的线性数据结构。 数组获取其他元素: 为什…...

在 IntelliJ IDEA 中使用 Terminal 执行 git log 命令后的退出方法
前言 IntelliJ IDEA 是一款广受欢迎的集成开发环境,它内置了强大的终端工具,使得开发者无需离开IDE就能便捷地执行各种命令行操作,包括使用 Git 进行版本控制。在 IDEA 的 Terminal 中执行 git log 命令时,由于该命令会显示项目的…...
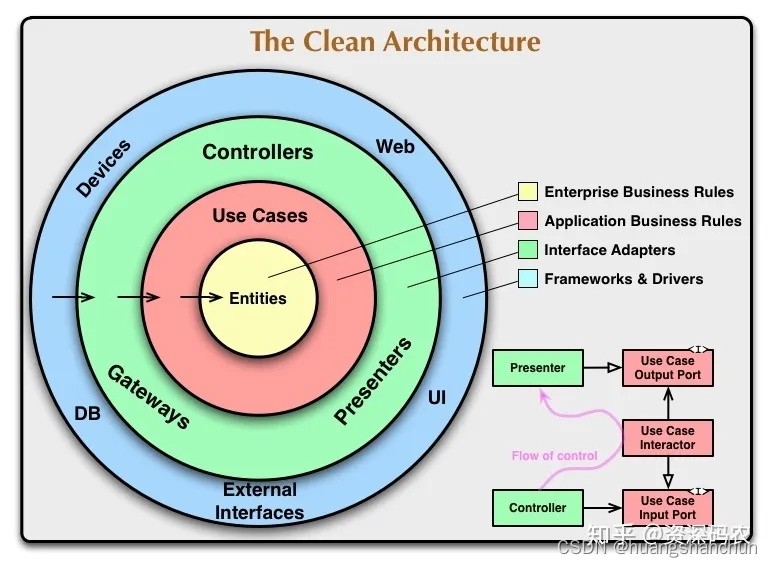
架构整洁之道-读书总结
1 概述 1.1 关于本书 《架构整洁之道》(Clean Architecture: A Craftsman’s Guide to Software Structure and Design)是由著名的软件工程师Robert C. Martin(又称为Uncle Bob)所著。这本书提供了软件开发和架构设计的指导原则…...

蓝桥杯学习笔记(贪心)
在很久很久以前,有几个部落居住在平原上,依次编号为1到n。第之个部落的人数为 t 有一年发生了灾荒,年轻的政治家小蓝想要说服所有部落一同应对灾荒,他能通过谈判来说服部落进行联台。 每次谈判,小蓝只能邀请两个部落参…...

【无标题】如何使用 MuLogin 设置代理
如何使用 MuLogin 设置代理 使用 MuLogin 浏览器设置我们的代理,轻松管理多个社交媒体或电子商务帐户。 什么是MuLogin? MuLogin 是一款虚拟反检测浏览器,使用户能够管理多个电子商务、社交媒体和广告帐户,而无需验证码或 IP 禁…...

芒果YOLOv8改进135:主干篇GCNet,统一为全局上下文建模global context结构,即插即用,助力小目标检测,轻量化的同时精度性能涨点
该专栏完整目录链接: 芒果YOLOv8深度改进教程 芒果专栏 基于 GCNet 的改进结构,改进源码教程 | 详情如下🥇 💡本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可 即插即用 结构。博客 包括改进所需的 核心结构代码 文件 论文:https://arxiv.org/a…...
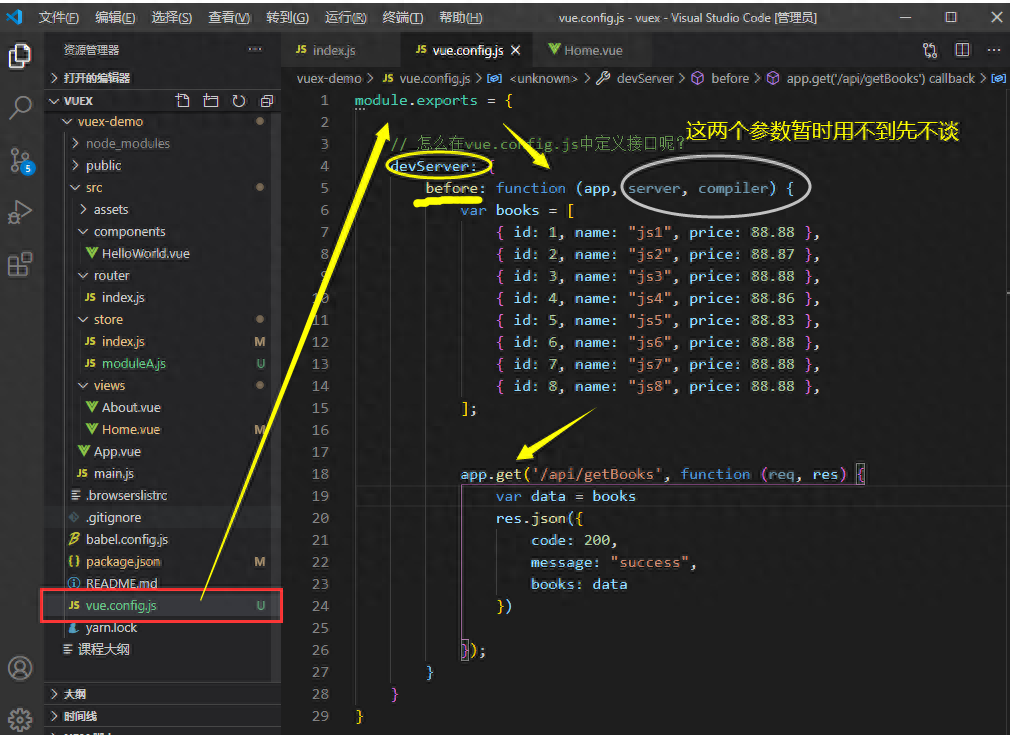
全面:vue.config.js 的完整配置
vue.config.js是Vue项目的配置文件,用于配置项目的构建、打包和开发环境等。 在Vue CLI 3.0之后,项目的配置文件从原来的build和config目录下的多个配置文件,合并成了一个vue.config.js文件。这个文件可以放在项目的根目录下,用于…...

海量数据处理项目-账号微服务注册Nacos+配置文件增加
海量数据处理项目-账号微服务注册Nacos配置文件增加 导入生成好的代码 model (为啥不放common项目,如果是确定每个服务都用到的依赖或者类才放到common项目) mapper 类接口拷贝 resource/mapper文件夹 xml脚本拷贝 controller service 不拷贝 Mybatis plus配置控制…...

DNS 服务 Unbound 部署最佳实践
文章目录 安装unbound-control配置启动服务测试 参考: 官网地址:https://nlnetlabs.nl/projects/unbound/about/ 详细文档:https://unbound.docs.nlnetlabs.nl/en/latest/index.html DNS服务Unbound部署于使用 https://cloud.tencent.com/…...
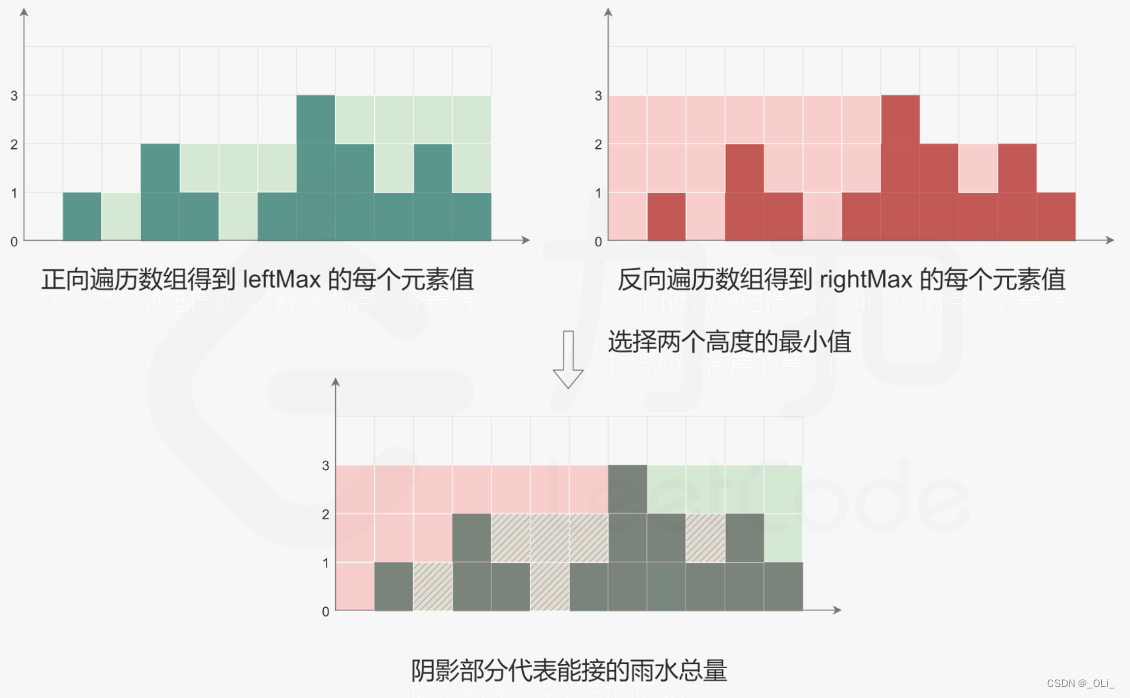
力扣HOT100 - 42. 接雨水
解题思路: 动态规划 感觉不是很好想 class Solution {public int trap(int[] height) {int n height.length;if (n 0) return 0;int[] leftMax new int[n];leftMax[0] height[0];for (int i 1; i < n; i) {leftMax[i] Math.max(leftMax[i - 1], height[i…...
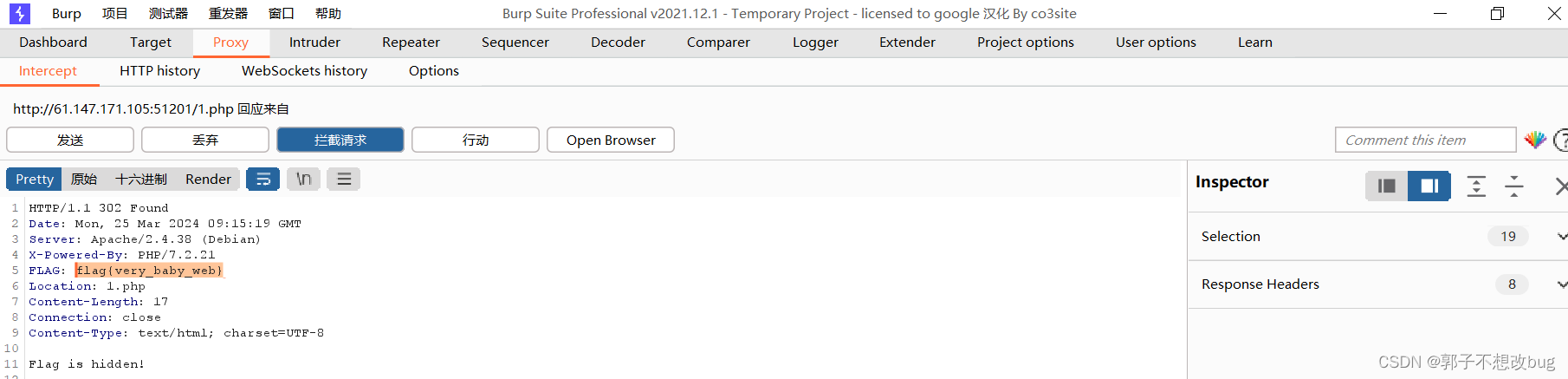
攻防世界-baby_web
题目信息 相关知识 使用bp进行抓包 解题过程 题目界面如下所示: 试图找index界面: 发现又跳转到http://61.147.171.105:51201/1.php页面,因此说明61.147.171.105:51201/index.php是存在的(因为笔者试了,不存在的页面会直接报…...
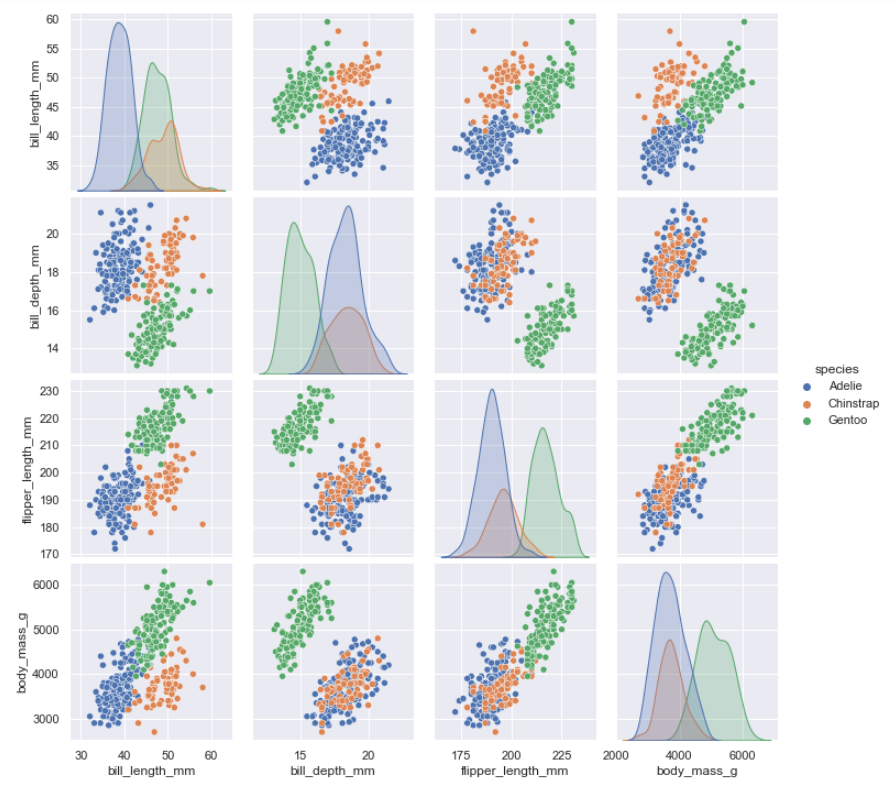
数据可视化基础与应用-04-seaborn库从入门到精通01-02
总结 本系列是数据可视化基础与应用的第04篇seaborn,是seaborn从入门到精通系列第1-2篇。本系列的目的是可以完整的完成seaborn从入门到精通。主要介绍基于seaborn实现数据可视化。 参考 参考:数据可视化-seaborn seaborn从入门到精通01-seaborn介绍与load_datas…...

学习 zustand
学习 zustand https://github.com/pmndrs/zustand告别繁杂的状态管理:Zustand 的简洁之道Zustand 状态库:轻便、简洁、强大的 React 状态管理工具关于 zustand 的一些最佳实践 代码库 https://gitee.com/nian_zuo_chen/learnrect/tree/master/zustand 安…...
竞赛 opencv python 深度学习垃圾图像分类系统
0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 opencv python 深度学习垃圾分类系统 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:3分创新点:4分 这是一个较为新颖的竞…...

vsto worksheet中查找关键字【关键字】获取对应的整列 union成一个range
要在 VSTO 中的工作表中查找包含特定关键字的单元格,并将这些单元格所在列合并为一个范围,可以使用以下代码:csharp using Excel Microsoft.Office.Interop.Excel;// 在工作表中查找包含特定关键字的单元格,并返回这些单元格所在…...
flask_restful规范返回值之参数设置
设置重命名属性和默认值 使用 attribute 配置这种映射 , 比如: fields.String(attributeusername) 使用 default 指定默认值,比如: fields.String(defaultsxt) from flask import Flask,render_template from flask_restful import A…...
基于java+springboot+vue实现的超市管理系统(文末源码+Lw+ppt)23-354
摘 要 系统根据现有的管理模块进行开发和扩展,采用面向对象的开发的思想和结构化的开发方法对超市管理的现状进行系统调查。采用结构化的分析设计,该方法要求结合一定的图表,在模块化的基础上进行系统的开发工作。在设计中采用“自下而上”…...

AI大模型学习:开启智能时代的新篇章
随着人工智能技术的不断发展,AI大模型已经成为当今领先的技术之一,引领着智能时代的发展。这些大型神经网络模型,如OpenAI的GPT系列、Google的BERT等,在自然语言处理、图像识别、智能推荐等领域展现出了令人瞩目的能力。然而&…...

【字符串】字符串哈希
因为习惯了STL,所以一直没有接触这块儿的内容,今天cf碰到学着用了一下发现还蛮好用的 单哈希 字符串哈希 简单来说就是把一个字符串对应到一个数上,且一个字符串唯一对应一个数,一个数也唯一对应一个字符串 怎么进行这个操作呢…...

MacOS快速安装FFmpeg、ffprobe、ffplay
文章目录 一、工具简介二、mac 安装ffprobe、FFmpeg等相关工具2.1 方法一:使用Homebrew安装FFmpeg2.2 从官网下载FFmpeg安装包,源码安装2.3 macOS 无法验证开发者时安装 一、工具简介 这些工具都是与多媒体处理和流媒体相关的开源工具,它们都…...

5步解决Windows包管理器Winget安装难题:专业修复指南
5步解决Windows包管理器Winget安装难题:专业修复指南 【免费下载链接】winget-install Install WinGet using PowerShell! Prerequisites automatically installed. Works on Windows 10/11 and Server 2019/2022. 项目地址: https://gitcode.com/gh_mirrors/wi/w…...

DS4Windows终极指南:3步让PS4手柄在PC上完美工作
DS4Windows终极指南:3步让PS4手柄在PC上完美工作 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 想要在电脑上使用PS4手柄玩游戏,却总是遇到兼容性问题?…...

智能电表数据填补技术对比:从Holt-Winters到Time-MoE的实战指南
1. 项目概述:当智能电表数据“断片”时,我们如何“脑补”?在能源管理和智能电网的日常运维中,我们这些从业者最头疼的问题之一,就是拿到手的智能电表数据“缺斤短两”。想象一下,你正试图分析一个居民区的用…...

服务器被入侵后如何应急响应:安全运维实战指南
1. 这不是演习:当告警邮件凌晨三点弹出来时,你手边该有什么 “服务器CPU持续100%、SSH登录异常增多、/tmp目录下出现陌生可执行文件”——这类告警我见过太多次。不是在靶场演练,不是在CTF赛题里,而是真实发生在某次金融客户核心A…...
Spark Transformer:稀疏激活优化与计算效率提升
1. Spark Transformer 核心设计解析Transformer架构在自然语言处理领域展现出卓越性能,但其计算密集型特性也带来了显著的资源消耗。传统Transformer模型的前馈网络(FFN)和注意力机制采用全连接计算模式,导致FLOPs(浮点运算次数)居高不下。Spark Transfo…...

符号回归在超快磁动力学研究中的应用:从数据中挖掘物理规律
1. 项目概述:当机器学习遇见超快磁动力学 在自旋电子学这个前沿领域,我们一直在与时间赛跑。从纳秒级的磁畴翻转,到飞秒级的超快退磁,理解磁性材料在不同时间尺度下的行为,是设计下一代高速、高密度存储器和逻辑器件的…...

机器学习势函数结合DFT:揭示缺陷如何降低半赫斯勒化合物晶格热导率
1. 项目概述与核心问题在热电材料的研究领域,半赫斯勒化合物一直是个“明星选手”,它们拥有不错的电学性能,但一个长期困扰研究者的难题是:理论计算出的晶格热导率总是比实验测量值高出一大截。这可不是个小问题,晶格热…...

多智能体系统内存架构:共享与分布式内存的挑战与混合实践
1. 项目概述:当多智能体系统遇上计算机内存模型最近在折腾一个多智能体协作的项目,遇到了一个挺有意思的瓶颈:当几十个甚至上百个智能体(Agent)同时在一个环境里跑起来,试图共享信息、协同决策时࿰…...

随机计算与ViT硬件加速:混合架构如何突破AI芯片能效墙
1. 项目概述:当ViT遇见随机计算最近在硬件加速领域,一个名为“ASCEND”的项目引起了我的注意。这本质上是一个专门为Vision Transformer(ViT)模型设计的硬件加速器,但其核心创新点在于采用了“随机计算”这种非常规的电…...
别再傻等下载了!手把手教你用wget离线部署sentence-transformers模型(以all-MiniLM-L6-v2为例)
离线部署sentence-transformers模型的终极指南:以all-MiniLM-L6-v2为例你是否曾在下载Hugging Face模型时遭遇网络中断,眼睁睁看着进度条卡在99%却无能为力?本文将彻底解决这一痛点,教你用wget命令行工具实现模型的离线部署。不同…...