Machine Learning机器学习之K近邻算法(K-Nearest Neighbors,KNN)
目录
前言
背景介绍:
思想:
原理:
KNN算法关键问题
一、构建KNN算法
总结:
博主介绍:✌专注于前后端、机器学习、人工智能应用领域开发的优质创作者、秉着互联网精神开源贡献精神,答疑解惑、坚持优质作品共享。本人是掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战,深受全网粉丝喜爱与支持✌有需要可以联系作者我哦!
🍅文末三连哦🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
前言
背景介绍:
K近邻算法最早由美国的科学家 Thomas Cover 和 Peter Hart 在 1967 年提出,并且在之后的几十年中得到了广泛的研究和应用。KNN 算法是一种基于实例的学习方法,它不像其他算法一样需要对数据进行假设或者参数拟合,而是直接利用已知的数据样本进行预测。
思想:
KNN 算法的思想是基于特征空间中的样本点之间的距离来进行分类。它假设相似的样本在特征空间中具有相似的类别,即距离较近的样本更可能属于同一类别。KNN 算法通过找到样本点周围的 K 个最近邻样本,根据它们的类别进行投票或者加权投票来确定新样本所属的类别。
原理:
-
距离度量: KNN 算法通常使用欧氏距离、曼哈顿距离、闵可夫斯基距离等方法来度量样本点之间的距离。
这里简要介绍一下三种常见的距离度量:
欧氏距离(Euclidean Distance):是最常见的距离度量方法,表示两个点之间的直线距离。
公式:
其中,
和
是两个点的特征向量,
是特征的维度。
曼哈顿距离(Manhattan Distance):表示两个点在各个坐标轴上的绝对距离之和。
公式:
闵可夫斯基距离(Minkowski Distance):是欧氏距离和曼哈顿距离的一种泛化形式,可以表示为两点在各个坐标轴上的距离的
次方。
公式:
其中,是一个正整数
时,就是曼哈顿距离;当
时,就是欧氏距离。
-
K个最近邻: 对于给定的新样本,找到离它最近的 K 个训练样本。
-
投票决策: 对于分类问题,根据 K 个最近邻样本的类别进行投票,将新样本归为票数最多的类别。对于回归问题,可以计算 K 个最近邻样本的平均值来预测新样本的输出。
KNN算法关键问题
距离度量方法: KNN 算法需要计算样本之间的距离,常见的距离度量方法包括欧氏距离、曼哈顿距离、闵可夫斯基距离等。
邻居选择规则: 在给定一个新样本时,需要选择它的 K 个最近邻样本。通常采用的方法是基于距离的排序,选择距离最近的 K 个样本。
类别判定规则: 对于分类问题,KNN 采用多数表决的方式确定新样本的类别,即根据 K 个最近邻样本中所属类别的频率来决定新样本的类别。对于回归问题,通常采用平均值的方式来预测新样本的输出。
K 值选择: K 值的选择对 KNN 算法的性能影响较大。较小的 K 值可能会使模型过拟合,而较大的 K 值可能会使模型欠拟合。因此,需要通过交叉验证等方法来选择合适的 K 值。
特征标准化: 在使用 KNN 算法之前,通常需要对特征进行标准化处理,以确保不同特征的尺度相同,避免某些特征对距离计算的影响过大。
算法复杂度分析: KNN 算法的时间复杂度主要取决于样本数量和特征维度,因为需要计算新样本与所有训练样本的距离。因此,KNN 算法在处理大规模数据集时可能会效率较低。
应用领域: KNN 算法广泛应用于分类和回归问题,特别是在图像识别、推荐系统、医疗诊断等领域有着重要的应用价值。
一、构建KNN算法
基于Python 实现 K 近邻算法,包括了数据准备、距离度量、邻居选择、类别判定规则和模型评估等操作步骤:
我们首先定义了一个 KNN 类,其中包括了初始化方法、训练方法(fit)、预测方法(predict)和评估方法(evaluate)。然后,我们使用一个简单的示例数据集进行了演示。在示例用法中,我们首先准备了训练集和测试集数据,然后初始化了 KNN 模型并进行了训练,接着使用测试集进行了预测,并计算了模型的准确率。
import numpy as np
from collections import Counterclass KNN:def __init__(self, k=3):self.k = kdef fit(self, X_train, y_train):self.X_train = X_trainself.y_train = y_traindef predict(self, X_test):predictions = []for x in X_test:# 计算测试样本与所有训练样本的距离distances = [np.linalg.norm(x - x_train) for x_train in self.X_train]# 找到距离最近的 K 个邻居的索引nearest_neighbors_indices = np.argsort(distances)[:self.k]# 获取这 K 个邻居的类别nearest_neighbors_labels = [self.y_train[i] for i in nearest_neighbors_indices]# 对 K 个邻居的类别进行多数表决,确定测试样本的类别most_common_label = Counter(nearest_neighbors_labels).most_common(1)[0][0]predictions.append(most_common_label)return predictionsdef evaluate(self, X_test, y_test):predictions = self.predict(X_test)accuracy = np.mean(predictions == y_test)return accuracy# 示例用法
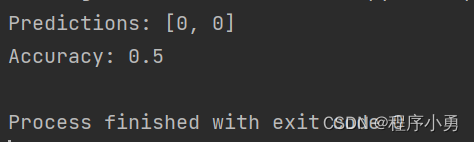
if __name__ == "__main__":# 准备数据集X_train = np.array([[1, 2], [2, 3], [3, 4], [4, 5]])y_train = np.array([0, 0, 1, 1])X_test = np.array([[2, 2], [3, 3]])# 初始化和训练模型knn = KNN(k=2)knn.fit(X_train, y_train)# 预测和评估模型predictions = knn.predict(X_test)print("Predictions:", predictions)accuracy = knn.evaluate(X_test, np.array([0, 1]))print("Accuracy:", accuracy)
执行结果:
总结:
KNN 算法是一种简单有效的分类和回归算法,算法的核心思想是“近朱者赤,近墨者黑”,即认为与新样本距离较近的训练样本更可能具有相同的类别或者输出。它的基本假设是“相似的样本在特征空间中具有相似的类别”。因此,KNN 算法不需要对数据进行假设或者参数拟合,而是直接利用已有的数据进行预测。它没有显式地对数据进行假设或参数拟合,因此在处理复杂、非线性的问题时具有一定的优势。然而,KNN 算法的计算复杂度较高,特别是在处理大规模数据集时,因为需要计算样本之间的距离。此外,KNN 算法对异常值和噪声敏感,需要进行适当的数据预处理和参数调节。
相关文章:
Machine Learning机器学习之K近邻算法(K-Nearest Neighbors,KNN)
目录 前言 背景介绍: 思想: 原理: KNN算法关键问题 一、构建KNN算法 总结: 博主介绍:✌专注于前后端、机器学习、人工智能应用领域开发的优质创作者、秉着互联网精神开源贡献精神,答疑解惑、坚持优质作品共…...

四、在数据库里建库
一、查库 ##1)库:一个库就是一个excell文档,库里含有表,一个表就是一个excell的sheet. ##2)查看数据库实例中有哪些库 MariaDB [(none)]> show databases; -------------------- | Database | -------------------- | informat…...

蓝桥杯-网络安全比赛(2)基础学习-正则表达式匹配电话号码、HTTP网址、IP地址、密码校验
正则表达式(Regular Expression):定义:一种强大的文本处理工具,用于描述、匹配和查找字符串中的特定模式。应用:密码验证、文本搜索和替换、数据清洗等。特点:通过特定的元字符和规则来构建复杂…...

如何创建azure pipeline
Azure Pipelines是一种持续集成和持续交付(CI/CD)工具,可以帮助开发团队自动化构建、测试和部署应用程序。以下是创建Azure Pipeline的步骤: 登录到Azure DevOps(https://dev.azure.com/)。在Azure DevOps…...

缓存菜品、套餐、购物车相关功能
一、缓存菜品 通过缓存的方式提高查询性能 1.1问题说明 大量的用户访问导致数据库访问压力增大,造成系统响应慢,用户体验差 1.2 实现思路 优先查询缓存,如果缓存没有再去查询数据库,然后载入缓存 将菜品集合序列化后缓存入red…...

微信小程序的页面交互1
一、page()函数 每个页面的s代码全部写入对应的js文件的page()函数里面。点击编译,就可以显示js代码的运行效果。注意,每个页面的page()函数是唯一的。 page(ÿ…...

win10 docker zookeeper和kafka搭建
好久没用参与大数据之类的开发了,近日接触到一个项目中使用到kafka,因此要在本地搭建一个简易的kafka服务。时间比较紧急,之前有使用docker的经验,因此本次就使用docker来完成搭建。在搭建过程中出现的一些问题,及时记…...
【Redis】快速入门 数据类型 常用指令 在Java中操作Redis
文章目录 一、简介二、特点三、下载与安装四、使用4.1 服务器启动4.2 客户端连接命令4.3 修改Redis配置文件4.4 客户端图形化界面 五、数据类型5.1 五种常用数据类型介绍5.2 各种数据类型特点 六、常用命令6.1 字符串操作命令6.2 哈希操作命令6.3 列表操作命令6.4 集合操作命令…...
【tingsboard开源平台】下载数据库,IDEA编译,项目登录
一, PostgreSQL 下载 需要看官网的:点此下载直达地址:点此进行相关学习:PostgreSQL 菜鸟教程 二,PostgreSQL 安装 点击安装包进行安装 出现乱码错误: There has been an error. Error running C:\Wind…...

Web3:探索区块链与物联网的融合
引言 随着科技的不断发展,区块链技术和物联网技术都成为了近年来备受瞩目的前沿技术。而当这两者结合在一起,将产生怎样的化学反应呢?本文将深入探讨Web3时代中区块链与物联网的融合,探索其意义、应用场景以及未来发展趋势。 1. …...
[BT]BUUCTF刷题第9天(3.27)
第9天(共2题) [护网杯 2018]easy_tornado 打开网站就是三个txt文件 /flag.txt flag in /fllllllllllllag/welcome.txt render/hints.txt md5(cookie_secretmd5(filename))当点进flag.txt时,url变为 http://b9e52e06-e591-46ad-953e-7e8c5f…...

html页面使用@for(){},@if(){},利用jquery 获取当前class在列表中的下标
基于以前的项目进行修改优化,前端代码根据List元素在html里进行遍历显示 原先的代码: 其中,noticeGuide.Id是标识noticeGuide的唯一值,但是不是从0开始的【是数据库自增字段】 但是在页面初始化加载的时候,我们只想…...

pulsar: 批量接收消息
接收消息时,和kafka类似,如果topic有多个分区,则只能保证分区内数据的接收有序,不能保证全局有序。 一、发送消息 package cn.edu.tju.test1;import org.apache.pulsar.client.api.*;public class BatchProducer01 {private sta…...
LNMP架构之mysql数据库实战
mysql安装 到官网www.mysql.com下载源码版本 实验室使用5.7.40版本 tar xf mysql-boost-5.7.40.tar.gz #解压 cd mysql-boost-5.7.40/ yum install -y cmake gcc-c bison #安装依赖性 cmake -DCMAKE_INSTALL_PREFIX/usr/local/mysql -DMYSQL_DATADIR/data/mysql -DMYSQL_…...
aws使用记录
数据传输(S3) 安装命令行 安装awscli: https://docs.aws.amazon.com/zh_cn/cli/latest/userguide/getting-started-install.html#getting-started-install-instructions 直到 aws configure list 可以运行 身份验证: 运行: aws config…...

区块链食品溯源案例实现(二)
引言 随着前端界面的完成,我们接下来需要编写后端代码来与区块链网络进行交互。后端将负责处理前端发送的请求,调用智能合约的方法获取食品溯源信息,并将结果返回给前端。 通过前后端的整合,我们可以构建一个食品溯源系统…...
RabbitMQ(简单模式)
2种远程服务调用 1openFeign: 优点:能拿到被调用的微服务返回的数据,系统系耦度高,系统稳定。 缺点:同步调用,如果有很多服务需要被调用,耗时长。 MQ,消息队列,RabbitMQ是消息we…...

ES集群部署的注意事项
文章目录 引言I ES集群部署前期工作II 部署ES2.1 配置安全组2.2 创建ES用户和组2.3 下载安装ES2.4 修改内存相关配置III es集群添加用户安全认证功能3.1 生成 elastic-certificates.p123.2 创建 Elasticsearch 集群密码3.2 设置kibana的 elasticsearch帐号角色和密码3.3 logsta…...
Etcd 基本入门
1:什么是 Etcd ? Etcd 是 CoreOS 团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,Etcd基于 Go 语言实现。 名字由来,它源于两个方面,…...
PPT没保存怎么恢复?3个方法(更新版)!
“我刚做完一个PPT,正准备保存的时候电脑没电自动关机了,打开电脑后才发现我的PPT没保存。这可怎么办?还有机会恢复吗?” 在日常办公和学习中,PowerPoint是制作演示文稿的重要工具。我们会在各种场景下使用它。但有时候…...

在数据分析和报告自动化场景中集成Taotoken调用大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在数据分析和报告自动化场景中集成Taotoken调用大模型 数据分析与报告生成是许多团队日常工作中的高频任务。传统流程中࿰…...

深入理解Android中startActivity的完整流程:聚焦IPC机制与Binder原理
引言 在Android开发中,startActivity() 方法是启动新Activity的核心API,它贯穿了应用的生命周期管理。理解其内部流程,不仅有助于优化性能、避免常见错误,还能提升开发者在面试中的竞争力。本文将以“一次完整的 startActivity 到底经历了什么”为主题,深入探讨整个流程,…...
)
别再只算差异了!用Cytoscape给Hub Gene分析加个‘可视化Buff’(附脑网络实战图)
别再只算差异了!用Cytoscape给Hub Gene分析加个‘可视化Buff’(附脑网络实战图) 在生物信息学分析中,差异基因筛选往往是研究的第一步,但如何从海量差异基因中找出真正具有生物学意义的"关键调控者"…...

鸿蒙备考题库页面构建:学习进度可视化与练习模式网格设计
鸿蒙备考题库页面构建:学习进度可视化与练习模式网格设计 前言 在 HarmonyOS 6.0 应用开发中,在线教育类页面的核心挑战在于如何将学习进度、练习入口、知识图谱等多维信息高效整合。本文将以“备考题库”应用的主页面为例,深入解析如何在鸿…...

2026年长沙美缝施工团队哪家强?专业之选等你来揭秘!
在长沙高端住宅、别墅装修领域,美缝施工是提升家居质感的关键环节。面对众多美缝施工团队,业主们常常不知如何选择。今天,我们就来揭秘2026年长沙值得信赖的美缝施工团队——长沙匠心徐师傅美缝团队,看看它有哪些独特的优势。一、…...

吃透Agent Runtime九大核心设计,从基础跑通到工业级稳定落地
在当下人工智能飞速发展的时代,智能Agent已经成为大模型落地应用最主流的形态之一。从日常智能问答,自动化办公脚本,到复杂的项目工程自主开发,业务流程自主运维,各行各业都在尝试借助Agent解放人力成本,提…...

Unity角色移动手感优化:从WASD输入到物理移动的完整链路
1. 这不是“写个Input.GetAxis”就能跑通的移动逻辑在Unity项目里,只要角色需要被玩家操控,WASDQEShift这套组合键几乎就是默认配置——它不依赖鼠标、不强制视角绑定、兼容手柄映射,是PC端第三人称/第一人称角色最基础也最易被低估的交互层。…...

解锁洛可可美学密码:用Midjourney V6实现蓬巴杜夫人级繁复纹样、柔光质感与粉金配色的5步精准控制法
更多请点击: https://intelliparadigm.com 第一章:洛可可美学的数字转译本质与Midjourney V6语义解码机制 洛可可美学以繁复卷曲的曲线、轻盈的不对称构图、粉金柔色调与自然母题(如贝壳、藤蔓、云朵)为标志,其核心并…...

Angular Signal Forms:以状态为先,革新表单验证、UI 更新与状态管理
Angular Signal Forms:为表单管理引入以状态为先的模型表单通常是前端应用中状态最复杂的部分,负责捕获用户输入、运行验证逻辑、跟踪交互状态,并协调更改在 UI 中传播。随着表单规模增大,保持内容同步所需代码量会迅速增加。Angu…...

在Taotoken模型广场中根据任务需求挑选最合适的大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken模型广场中根据任务需求挑选最合适的大模型 1. 模型广场:统一查看与筛选的起点 当我们需要为特定的开发任务…...