Kafka高级面试题-2024
Kafka中的Topic和Partition有什么关系?
在Kafka中,Topic和Partition是两个密切相关的概念。
- Topic是Kafka中消息的逻辑分类,可以看作是一个消息的存储类别。它是按照不同的主题对消息进行分类,并且可以用于区分和筛选数据。每个Topic可以有多个Partition,每个Partition都是Topic的一个子集,包含了一部分特定的消息。
- Partition则是Kafka 中实际保存数据的单位。每个Topic可以被划分为多个Partition,而这些 Partition 会尽量平均的分配到各个 Broker 上。当一条消息发送到Kafka时,它会被分配到一个特定的Partition中,并最终写入 Partition 对应的日志文件里。这个分配过程是根据Partition的规则来完成的,比如可以按照消息的某个属性进行哈希或者按照时间戳进行排序等。
因此,Topic和Partition的关系是,Topic是消息的逻辑分类,用于区分和筛选数据,而Partition则是Topic的物理划分,用于将消息分配到不同的部分中以便于处理和存储。Topic 和 Partition 的设计对于高吞吐量和横向扩展非常有用。因为生产者和消费者只需要根据 Topic 进行具体的业务实现,而不用关心消息在集群内的分布情况。而在集群内部,这些 Partition 会尽量平均的分布在不同的 Broker节点上,从而提高了系统 整体的性能和可伸缩性。
Kafka的消费消息是如何传递的?
消息的传递主要涉及三个环节:生产者生产消息、broker保存消息和消费者消费消息。
- 生产者生产消息:生产者负责将消息发布到Kafka broker。在发布消息时,生产者需要指定目标主题。消息被写入后,将被存储在指定分区的当前副本中。当发送消息失败时,生产者还会提供确认以及重试机制,以保证消息能够正确的发送到 Broker 上。
- broker保存消息:Kafka broker接收到生产者发送的消息后,会将其存储在内部的缓冲区中,等待消费者拉取。当消费者向broker发送拉取请求时,broker会从缓冲区中获取消息并返回给消费者。Kafka broker能够保证消息的可靠性和顺序性,即使在异常情况下(如服务器崩溃),也能够保证消息不会丢失。
- 消费者消费消息:消费者从Kafka broker中订阅指定的主题,并拉取消息进行消费。消费者可以以同步或异步的方式拉取消息,并对拉取到的消息进行处理。当消费者处理完消息后,会向Kafka broker发送确认消息,表示消息已经被成功处理。这样可以保证消息被正确处理且不会重复消费。
总体来说,Kafka通过生产者、Kafka broker和消费者的协同工作,实现了高吞吐量、高可靠性和高可扩展性的消息传递。
Kafka如何保证消息可靠?
- 数据冗余:Kafka通过将消息副本(replica)的方式来实现数据冗余,每个topic都可以配置副本数量,副本数量越多,数据可靠性越高,但会占用更多的存储空间和网络带宽。在 Kafka 中,针对每个 Partition,会选举产生一个 Leader 节点,负责响应客户端的请求,并优先保存消息。而其他节点则作为 Follower 节点,负责备份 Master 节点上的消息。
- 消息发送确认机制:Kafka支持对生产者发送过来的数据进行校验,以检查数据的完整性。可以通过设置生产者端的参数(例如:acks)来配置校验方式。配置为 0,则不校验生产者发送的消息是否写入 Broker。配置为 1,则只要消息在 Leader 节点上写入成功后就向生产者返回确认信息。配置为-1 或 all,则会等所有 Broker 节点上写入完成后才向生产者返回确认信息。
- ISR机制:针对每个 Partition,Kafka 会维护一个 ISR 列表,里面记录当前处于同步状态的所有Partition。并通过 ISR 机制确保消息不会在Master 故障时丢失。
- 消息持久化:Kafka将消息写入到磁盘上,而不是仅在内存中缓存。这样可以保证即使在系统崩溃的情况下,消息也不会丢失。并且使用零拷贝技术提高消息持久化的性能。
- 消费者确认机制:Kafka消费者在处理完消息后会向Kafka broker发送确认消息,表示消息已经被成功处理。如果消费者未发送确认消息,则Kafka broker会保留消息并等待消费者再次拉取。这样可以保证消息被正确处理且不会重复消费。
Kafka中的消费者偏移量是如何管理的?
在Kafka中,消费者偏移量是指消费者在处理消息过程中所处的位置。Kafka中的消费者偏移量由两部分组成:Topic和Partition。对于每个消费者组,Kafka都会为其维护在每个 Partition 上的偏移量,以便在处理消息时可以准确地跟踪进度。
消费者偏移量的管理可以通过以下方式进行:
- 手动提交偏移量:消费者可以通过调用commitSync或commitAsync方法手动提交偏移量到Kafka。手动提交偏移量的方式需要开发者在适当的时机调用提交方法,确保消费者处理完消息后再提交偏移量。这种方式对于灵活性和精确控制偏移量非常有用,但需要开发者自行考虑提交的时机和异常处理。
- 自动提交偏移量:消费者可以配置为在后台自动提交偏移量。这意味着消费者会定期自动将已经处理的消息的偏移量提交给Kafka,而不需要开发者手动处理。通过配置参数enable.auto.commit为true,以及设置auto.commit.interval.ms参数来控制自动提交的频率。自动提交偏移量简化了管理,但可能会导致消息的重复处理或丢失,因此需要根据具体业务场景谨慎配置。
总之,Kafka 消费者的偏移量管理是确保消息传递的可靠性和一致性的重要部分。它允许消费者灵活地管理消息的消费进度,以满足不同的应用需求。无论您选择自动还是手动管理偏移量,都需要确保偏移量的正确提交,以避免消息的重复消费。
Kafka中的消息如何分配给不同的消费者?
Kafka中的消息是通过分区(Partition)分配给不同的消费者的。Kafka将每个Topic划分为多个Partition,每个Partition存储一部分消息。消费者通过订阅Topic来消费消息,而Kafka将Partition中的消息按照一定的分配策略分配给消费者组中的不同消费者。
Kafka提供了多种分区分配策略,用于确定如何将分区分配给消费者。例如:
- RoundRobin 轮询策略:Kafka将Partition按照轮询的方式分配给消费者组中的不同消费者,每个消费者依次获得一个Partition,直到所有Partition被分配完毕。当消费者数量发生变化时,Kafka会重新分配Partition。
- Range 范围策略:Kafka将Partition按照Range的方式分配给消费者组中的不同消费者,每个消费者负责处理指定范围内的Partition。这种分配方式适用于Topic的Partition数量较少,而消费者数量较多的情况。
- Sticky 粘性策略: 尽量保持每个消费者在一段时间内消费相同的分区,以减少分区重新分配的频率
当消费者处理完一个Partition中的所有消息后,它会向Kafka发送心跳请求,Kafka会将该Partition分配给其他消费者进行处理。这种机制确保了消息在不同的消费者之间负载均衡,并提高了容错性。如果一个消费者出现故障,其他消费者可以继续处理Partition中的消息,而不会导致消息丢失或重复处理。
什么是“零拷贝”?有什么作用?
零拷贝有两种实现方式,mmap文件映射和sendfile文件复制。
- mmap机制主要依赖于内存区域映射技术,可以减少一次 IO 操作中,内核态与用户态之间的数据传输,从而减少因为上下文切换而带来的 CPU 性能开销。mmap机制通常适合于对大量小文件的 IO 操作,Kafka 大量的运用 mmap 机制加速 Partition 日志文件的读写过程。
- sendfile主要依赖于 DMA 数据传输技术,采用一组单独的指令集来进行负责数据在内存不同区域之间的拷贝过程。这样就不再需要 CPU 来进行复制,从而减少 CPU 性能消耗,让 CPU 可以用于更重要的计算任务。sendfile通常适合于大文件的拷贝传输操作,Kafka 大量的运用 sendfile 机制,加速消息从 Partition 文件到网卡的传输过程。
总之,零拷贝是由操作系统提供的一种高效的文件读写技术,而 Kafka 则大量的运用了零拷贝技术,从而极大的提升了 Kafka 整体的工作性能。
Kafka中的消息是如何存储的?
Kafka 中的消息是以文件的方式持久化到磁盘中进行存储的,这是 Kafka 的一个关键特性,确保消息的可靠性和可用性。Kafka中的消息是通过以下方式进行存储的:
- Partition 分区:Partition是Kafka中消息存储的基本单位,每个Topic下的消息都会被划分成多个Partition进行管理。每个Partition都是一个有序的、不变的消息队列,消息按照追加的顺序被添加到队列尾部。
- Segment 分块:Partition会被进一步划分成多个Segment,Segment是逻辑上的文件组,方便进行数据的管理和查找。每个Segment里都包含多个文件,这些文件名相同且被集合在一起。
- 文件索引:Segment中的每个文件都有自己的索引文件和数据文件,索引文件存储了当前数据文件的索引信息,而数据文件则存储了当前索引文件名对应的数据信息。
- 消息偏移:Kafka中的每个消息都会被分配到一个特定的Partition中,然后根据Partition内的Segment划分,被存储到对应的数据文件中。消息的偏移量信息则会被记录在索引文件中。
- 持久化:Kafka中的每个消息都包含一个64位的偏移量,该偏移量表示消息在Partition中的位置。当消费者读取消息时,可以通过偏移量信息来确定需要从哪个位置开始读取。
Kafka 的消息存储是基于日志文件和分区的,确保了消息的可靠性、持久性和高吞吐量。消息被追加到日志文件中,每个消息都有唯一的偏移量,分区和副本机制保证了数据的冗余存储和可用性。这种设计使 Kafka 成为一个可信赖的消息传递系统,适用于各种实时数据处理、日志聚合和事件驱动应用程序。
为什么需要消息队列?
1、屏蔽异构平台的细节:发送方、接收方系统之间不需要了解双方,只需认识消息。
2、异步:消息堆积能力;发送方接收方不需同时在线,发送方接收方不需同时扩容(削峰)。
3、解耦:防止引入过多的API给系统的稳定性带来风险;调用方使用不当会给被调用方系统造成压力,被调用方处理不当会降低调用方系统的响应能力。
4、复用:一次发送多次消费。
5、可靠:一次保证消息的传递。如果发送消息时接收者不可用,消息队列会保留消息,直到成功地传递它。
6、提供路由:发送者无需与接收者建立连接,双方通过消息队列保证消息能够从发送者路由到接收者,甚至对于本来网络不易互通的两个服务,也可以提供消息路由。
相关文章:

Kafka高级面试题-2024
Kafka中的Topic和Partition有什么关系? 在Kafka中,Topic和Partition是两个密切相关的概念。 Topic是Kafka中消息的逻辑分类,可以看作是一个消息的存储类别。它是按照不同的主题对消息进行分类,并且可以用于区分和筛选数据。每个…...
)
Qt——Qt文本读写之QFile与QTextStream的使用总结(打开文本文件,修改内容后保存至该文件中)
【系列专栏】:博主结合工作实践输出的,解决实际问题的专栏,朋友们看过来! 《项目案例分享》 《极客DIY开源分享》 《嵌入式通用开发实战》 《C++语言开发基础总结》 《从0到1学习嵌入式Linux开发》 《QT开发实战》 《Android开发实战》...

掌握Java中的super关键字
super 是 Java 中的一个关键字,它在继承的上下文中特别有用。super 引用了当前对象的直接父类,它可以用来访问父类中的属性、方法和构造函数。以下是 super 的几个主要用途: 1. 调用父类的构造函数 在子类的构造函数中,你可以使…...
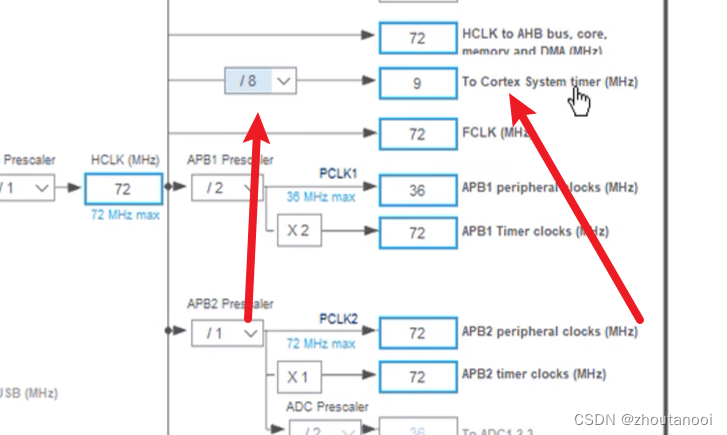
STM32之HAL开发——系统定时器(SysTick)
系统定时器(SysTick)介绍 SysTick—系统定时器是属于 CM3 内核中的一个外设,内嵌在 NVIC 中。系统定时器是一个 24bit的向下递减的计数器,计数器每计数一次的时间为 1/SYSCLK,一般我们设置系统时钟 SYSCLK等于 72M。当…...
Redis 不再“开源”:中国面临的挑战与策略应对
Redis 不再“开源”,使用双许可证 3 月 20 号,Redis 的 CEO Rowan Trollope 在官网上宣布了《Redis 采用双源许可证》的消息。他表示,今后 Redis 的所有新版本都将使用开源代码可用的许可证,不再使用 BSD 协议,而是采用…...
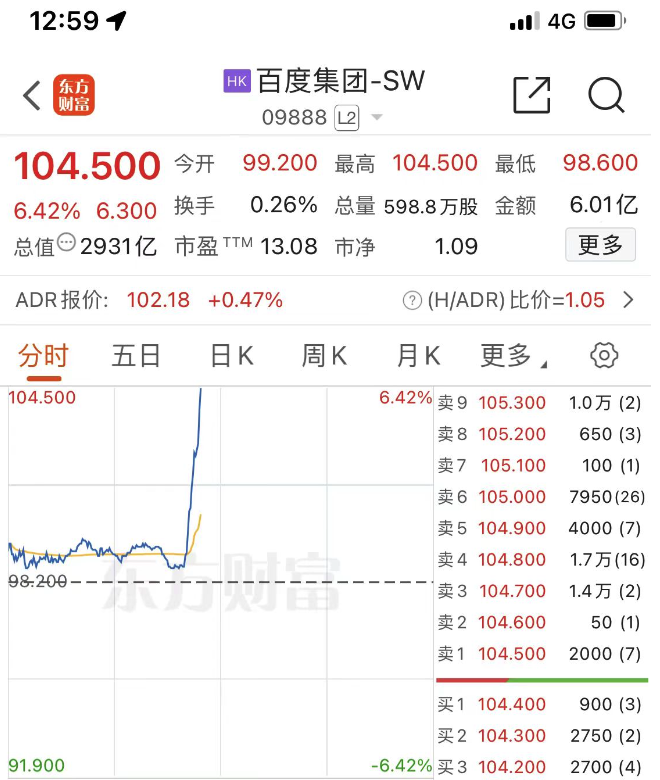
刚刚,百度和苹果宣布联名
百度 Apple 就在刚刚,财联社报道,百度将为苹果今年发布的 iPhone16、Mac 系统和 iOS18 提供 AI 功能。 苹果曾与阿里以及另外一家国产大模型公司进行过洽谈,最后确定由百度提供这项服务,苹果预计采取 API 接口的方式计费。 苹果将…...

HTTP系列之HTTP缓存 —— 强缓存和协商缓存
文章目录 HTTP缓存强缓存协商缓存状态码区别缓存优先级如何设置强缓存和协商缓存使用场景 HTTP缓存 HTTP缓存时利用HTTP响应头将所请求的资源在浏览器进行缓存,缓存方式分两种:强缓存和协商缓存。 浏览器缓存是指将之前请求过的资源在浏览器进行缓存&am…...
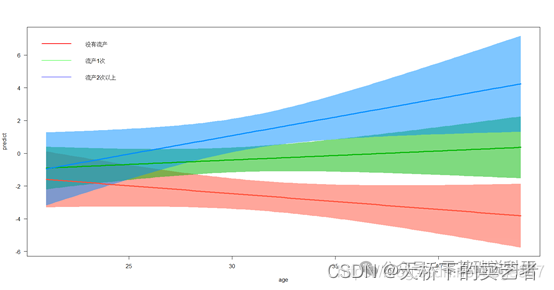
代码+视频,R语言logistic回归交互项(交互作用)的可视化分析
交互作用效应(p for Interaction)在SCI文章中可以算是一个必杀技,几乎在高分的SCI中必出现,因为把人群分为亚组后再进行统计可以增强文章结果的可靠性,不仅如此,交互作用还可以使用来进行数据挖掘。在既往文章中,我们已…...

实验3 中文分词
必做题: 数据准备:academy_titles.txt为“考硕考博”板块的帖子标题,job_titles.txt为“招聘信息”板块的帖子标题,使用jieba工具对academy_titles.txt进行分词,接着去除停用词,然后统计词频,最…...
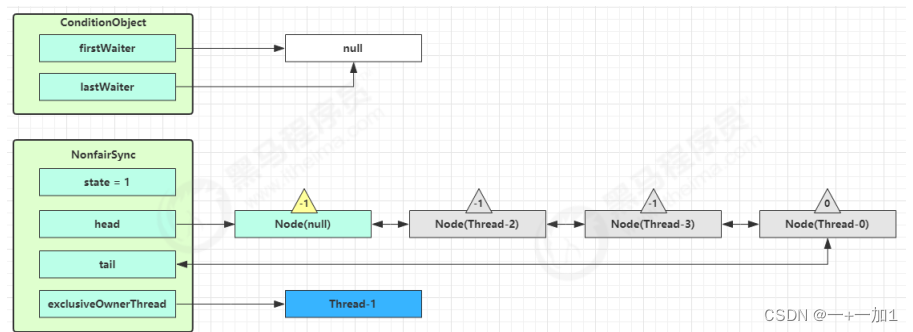
ReentrantLock 原理
(一)、非公平锁实现原理 1、加锁解锁流程 先从构造器开始看,默认为非公平锁实现 public ReentrantLock() {sync new NonfairSync(); } NonfairSync 继承自 AQS 没有竞争时 加锁流程 构造器构造,默认构造非公平锁(无竞争,第一个线程尝试…...
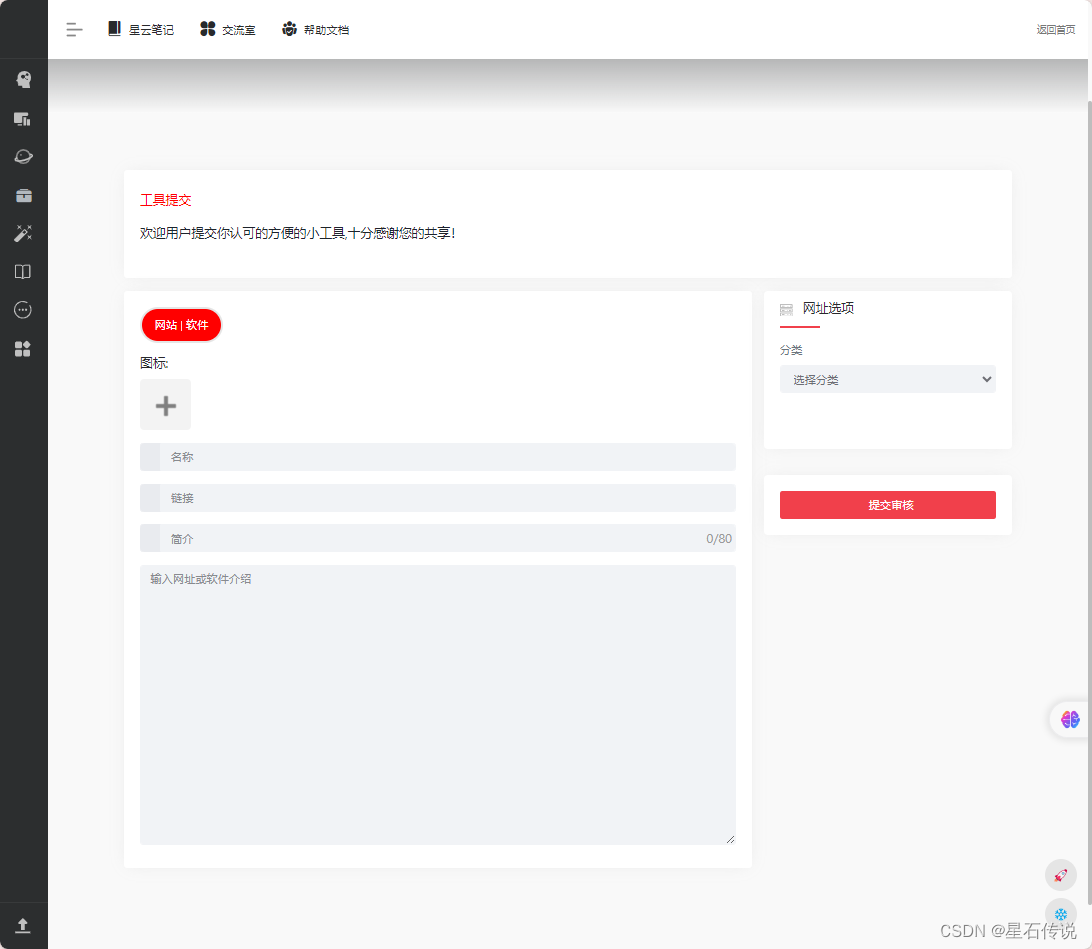
星云小窝项目1.0——项目介绍(一)
星云小窝项目1.0——项目介绍(一) 文章目录 前言1. 介绍页面2. 首页2.1. 游客模式2.2. 注册用户后 3. 星云笔记3.1. 星云笔记首页3.2. 星云笔记 个人中心3.2. 星云笔记 系统管理3.3. 星云笔记 文章展示3.3. 星云笔记 新建文章 4. 数据中心5. 交流评论6. …...

VR虚拟仿真在线模拟旅游专业情景
旅游专业运用VR虚拟仿真教学的教学优势主要包括: 1. 增强教学效果:VR技术能够提供身临其境的体验,使学生更容易理解和记住某些概念和理论。例如,学生可以通过虚拟旅行来了解某个国家的文化、历史和景点,这将比传统的课…...
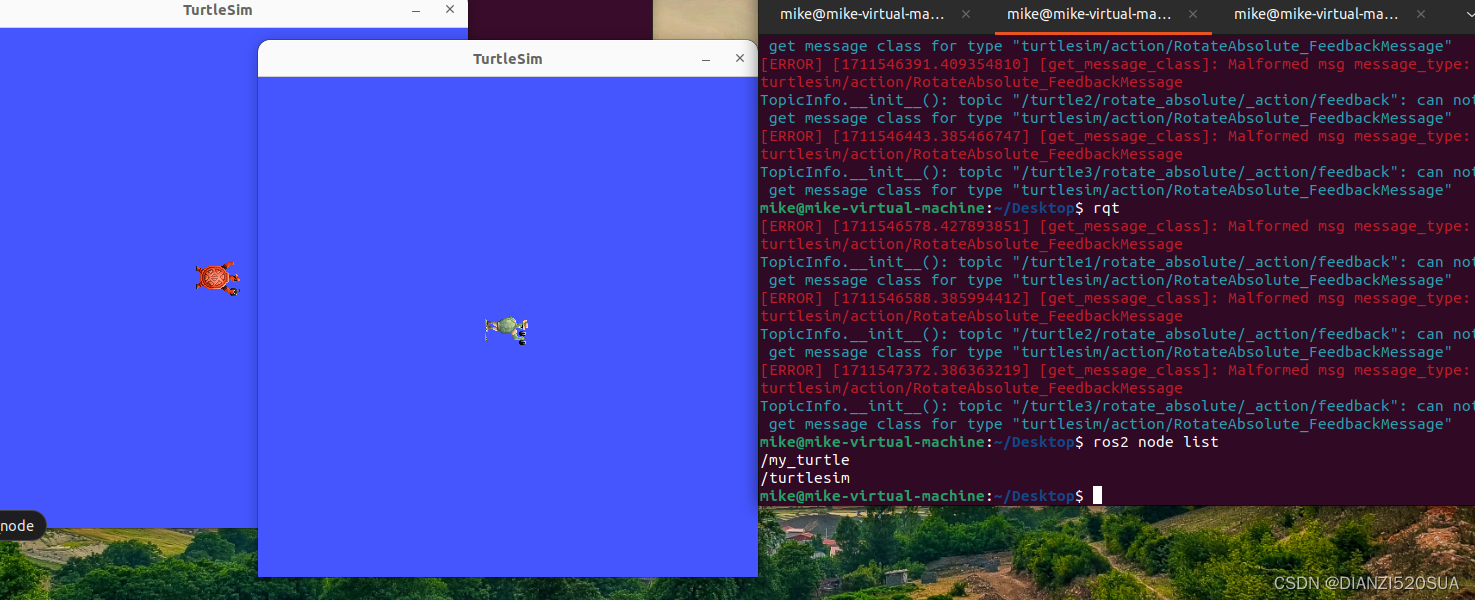
ROS 2边学边练(3)-- 何为节点(nodes)
在接触节点这个概念之前,我们先来看看下面这张动态图,更方便我们理解一些概念和交互过程。 (相信大家的英文基础哈) 概念 如上图所示,这里面其实涉及到了三个概念(功能),分别是节点…...

MySQL的主从复制和读写分离
目录 相关知识: 1. 主从复制和读写分离 2. mysql 支持的复制类型 对比: 一. 主从复制 1. 原理和工作过程 工作过程: 注意: 中继日志(Relay Log): 2. 一些理解问题 2.1 为什么要复制 …...

C# 多态 派生类 abstract virtual new
静态多态函数重载运算符重载 动态多态abstract 和 virtual的区别定义与用途:成员实现:继承与重写:与接口的区别: 使用抽象类的好处主要体现在以下几个方面:代码重用:设计灵活性:接口定义&#x…...
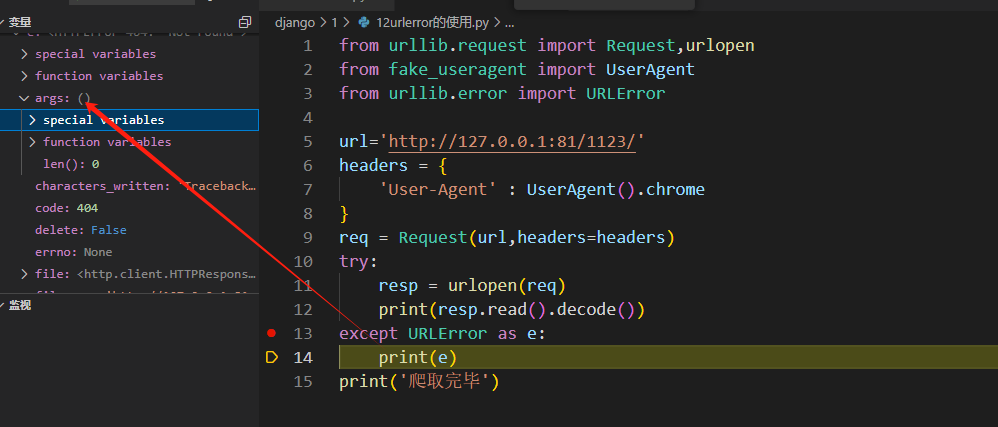
【爬虫基础】第10讲 urlerror的使用及捕获异常
URLError是Python中的一个异常类,用于处理与URL相关的错误。它是urllib.error模块中的一个类。 URLError通常在以下情况下被引发: 网络连接问题:例如无法连接到服务器、超时等。URL不正确:例如无效的URL、无法解析主机名等。服务…...

绍兴越城中墙建材蒸压加气混凝土砌块使用注意事项可送塔山府山北海蕺山城南稽山迪荡灵芝东湖皋埠马山斗门鉴湖东浦孙端陶堰富盛
绍兴越城中墙建材蒸压加气混凝土砌块使用注意事项可送塔山府山北海蕺山城南稽山迪荡灵芝东湖皋埠马山斗门鉴湖东浦孙端陶堰富盛 使用蒸压加气混凝土砌块时需要注意以下事项: 选择符合国家标准的产品:选购时应查看产品质量证明书,确保产品符合…...

吴渔夫:AI技术引领游戏产业革命,小团队有大作为
AI技术的突飞猛进,游戏产业正在经历一场前所未有的变革。中国网游先锋,火石控股创始人吴渔夫,近日在接受第一财经日报的采访,对AI在游戏制作中的应用和未来趋势有着深刻的见解。 吴渔夫指出,AI技术的引入极大地降低了游…...
)
深入探索C++对象模型(二)
类对象占用的空间 #include "pch.h" #include <iostream> using namespace std;class A {public: };//类对象所占用的空间 int main() {//std::cout << "Hello World!\n"; A obja;int ilen = sizeof(obja); cout << ilen << endl…...

【javaWeb 第三篇】Vue快速入门
VUE vue是一套前端框架,免除原生的js的DOM操作,简化书写 基于MVVM(model-view-viewmodel)思想,实现数据的双向绑定,将编程的关注放在数据上。 什么是框架: 框架相当于一个半成品,是一…...

DamoFD与数据结构优化:提升人脸检测效率50%的实战技巧
DamoFD与数据结构优化:提升人脸检测效率50%的实战技巧 1. 效果惊艳的开场 如果你正在为人脸检测模型的推理速度发愁,那么今天的内容绝对能让你眼前一亮。DamoFD-0.5G作为达摩院推出的轻量级人脸检测模型,本身已经相当高效,但通过…...

免费EDA工具全解析:从电路仿真到PCB设计
1. 电路设计软件的选择困境与免费方案的价值 作为一名在电子设计行业摸爬滚打多年的工程师,我深知专业工具对项目成败的决定性影响。行业主流EDA工具如Altium Designer、Cadence往往价格不菲,单用户年费动辄数万元,这对独立开发者、学生群体和…...

WMatrix 7语料库分析工具上线:隐喻识别高效精准,语言学研究利器
温馨提示:文末有联系方式WMatrix 7:专为语料库驱动隐喻分析优化的实用工具 WMatrix 7是当前广受语言学研究者青睐的语料库分析平台,内置强大词性标注、搭配提取与语义域分类功能,尤其在隐喻识别(如MVU框架适配…...

GCN在推荐系统中的应用:如何用图神经网络提升电商个性化推荐效果
GCN在电商推荐系统中的实战指南:从二部图构建到A/B测试全流程 当你在电商平台浏览商品时,那些"猜你喜欢"的推荐背后,可能正运行着一套基于图神经网络(GCN)的复杂算法系统。与传统的协同过滤不同,GCN能够捕捉用户-商品交…...

终极指南:如何彻底解决Colab运行text-generation-webui的Matplotlib后端错误
终极指南:如何彻底解决Colab运行text-generation-webui的Matplotlib后端错误 【免费下载链接】text-generation-webui The original local LLM interface. Text, vision, tool-calling, training, and more. 100% offline. 项目地址: https://gitcode.com/GitHub_…...

单片机入门指南:硬件工程师成长路径与实战技巧
1. 单片机入门:从零开始的硬件工程师成长之路作为一名在嵌入式领域摸爬滚打多年的工程师,我见过太多初学者在单片机学习路上走弯路。单片机确实是个神奇的东西——它体积小、价格低,却能控制各种电子设备,从智能家居到工业自动化无…...

2026年的具身智能:不再“讲故事”,而是拼“分数”?
作者:刘致呈编辑:Evin审核:徐徐出品:互联网江湖最近,具身智能行业发生了两件大事:一是行业标杆——宇树科技要IPO了。二是中国信息通信研究院联合40余家单位共同起草的具身智能领域首个行业标准,正式发布了…...

开源堡垒机Guacamole二次开发实战:SFTP与录屏功能深度优化
1. Guacamole堡垒机二次开发背景与挑战 Guacamole作为一款优秀的开源堡垒机,在企业远程办公和运维管理中扮演着重要角色。但在实际生产环境中,我们常常会遇到一些原生功能无法满足需求的情况。比如在分布式部署场景下,guacd服务与Java后端分离…...

3分钟夺回你的数字音乐资产:Unlock Music浏览器解密全攻略 [特殊字符]
3分钟夺回你的数字音乐资产:Unlock Music浏览器解密全攻略 🎵 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web…...

QuickBMS深度解析:游戏资源逆向工程与批量处理技术实践
QuickBMS深度解析:游戏资源逆向工程与批量处理技术实践 【免费下载链接】QuickBMS QuickBMS by aluigi - Github Mirror 项目地址: https://gitcode.com/gh_mirrors/qui/QuickBMS 作为游戏逆向工程领域的瑞士军刀,QuickBMS以其卓越的文件格式解析…...