K8S Pod 水平自动扩缩容 HPA
介绍
HPA(Horizontal Pod Autoscaler)水平扩缩意味着可根据观察到的CPU、内存使用率或自定义度量标准来自动扩展或缩容Pod的数量(Deployment、StatefulSet 或其他类似资源)。与“垂直”扩缩不同,对于 K8S, 垂直扩缩意味着将更多资源(例如:内存或 CPU)分配给已经为工作负载运行的 Pod。HPA不适用于无法缩放的对象。(例如:DaemonSet)
安装Metrics Server
要实现HPA自动扩缩容需要安装Metrics Server插件
Metrics Server 官网,根据自己K8S版本安装合适的插件。
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
安装好以后测试如下
[root@master01 ~]# kubectl top po -n kube-system
NAME CPU(cores) MEMORY(bytes)
calico-kube-controllers-54cbfb689f-stf9f 3m 44Mi
calico-node-2v2pk 20m 178Mi
calico-node-djvsw 23m 201Mi
calico-node-gfjw9 26m 182Mi
calico-node-hhsnx 24m 176Mi
calico-node-z9mrv 28m 170Mi
coredns-65599ffb58-jx78h 2m 23Mi
metrics-server-6b7745d9f-dfk7f 5m 36Mi
部署 php-apache 服务
为了演示 HPA,首先启动一个 Deployment 用 hpa-example 镜像运行一个容器
apiVersion: apps/v1
kind: Deployment
metadata:name: php-apache
spec:selector:matchLabels:run: php-apachetemplate:metadata:labels:run: php-apachespec:containers:- name: php-apacheimage: deis/hpa-exampleports:- containerPort: 80resources:limits:cpu: 500mrequests:cpu: 200m
---
apiVersion: v1
kind: Service
metadata:name: php-apachelabels:run: php-apache
spec:ports:- port: 80selector:run: php-apache
创建 HPA
使用 kubectl 创建自动扩缩器。 kubectl autoscale 创建 HPA 的命令, 该 HPA 维护由你在这些说明的第一步中创建的 php-apache Deployment 控制的 Pod 存在 1 到 20 个副本。
创建HPA:
目前支持的资源度量指标为CPU和内存,并且基本都是用CPU,内存在有一些java项目上面会有问题,比如Java项目访问量激增以后内存使用率上去了,但是访问量下来以后内存使用率并不会下来。
# 基于CPU使用率扩容的
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=20
查看创建的HPA
[root@master01 ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 20 1 24s
注意当前的 CPU 利用率是 0%,这是由于我们尚未发送任何请求到服务器 (TARGET 列显示了相应 Deployment 所控制的所有 Pod 的平均 CPU 利用率)。
增加负载
启动一个不同的 Pod 作为客户端。 客户端 Pod 中的容器在无限循环中运行,向 php-apache 服务发送查询。
# 在单独的终端中运行它
# 以便负载生成继续,你可以继续执行其余步骤
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
测试完以后按 Ctrl+C 结束
kubectl get hpa php-apache -w
负载升高HPA自动扩容
[root@master01 ~]# kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 49%/50% 1 20 1 6m22s
php-apache Deployment/php-apache 250%/50% 1 20 1 6m30s
php-apache Deployment/php-apache 250%/50% 1 20 4 6m45s
php-apache Deployment/php-apache 250%/50% 1 20 5 7m
php-apache Deployment/php-apache 251%/50% 1 20 5 7m15s
php-apache Deployment/php-apache 249%/50% 1 20 5 7m30s
结束请求以后自动缩容
一旦 CPU 利用率降至 0,HPA 会自动将副本数缩减为 1。自动扩缩完成副本数量的改变可能需要几分钟的时间。
[root@master01 ~]# kubectl get hpa -n apps -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 49%/50% 1 20 1 6m22s
php-apache Deployment/php-apache 250%/50% 1 20 1 6m30s
php-apache Deployment/php-apache 250%/50% 1 20 4 6m45s
php-apache Deployment/php-apache 250%/50% 1 20 5 7m
php-apache Deployment/php-apache 251%/50% 1 20 5 7m15s
php-apache Deployment/php-apache 249%/50% 1 20 5 7m30s
php-apache Deployment/php-apache 124%/50% 1 20 5 7m45s
php-apache Deployment/php-apache 0%/50% 1 20 4 8m15s
php-apache Deployment/php-apache 0%/50% 1 20 4 12m
php-apache Deployment/php-apache 0%/50% 1 20 2 12m
php-apache Deployment/php-apache 1%/50% 1 20 1 13m
查看生成的HPA yaml文件
查看命令
kubectl get hpa php-apache -oyaml
HPA yaml 文件
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler # 资源类型
metadata:name: php-apache # HPA对象的名称是"php-apache
spec:maxReplicas: 20 # 指定了可以扩展到的最大Pod数量,这里是20个metrics:- resource:name: cpu # 度量标准的名称是CPU target:averageUtilization: 50 # 目标CPU利用率是50%type: Utilization # 度量标准的类型是利用率type: ResourceminReplicas: 1 # 这指定了可以扩展到的最小Pod数量,这里是1个scaleTargetRef:apiVersion: apps/v1 # Deployment对象的API版本kind: Deployment # 目标资源的类型是Deploymentname: php-apache # 目标资源的名称是"php-apache
基于多项度量指标和自定义度量指标自动扩缩
Pod 度量指标
这些指标从某一方面描述了 Pod, 在不同 Pod 之间进行平均,并通过与一个目标值比对来确定副本的数量。 它们的工作方式与资源度量指标非常相像,只是它们仅支持 target 类型为 AverageValue。
type: Pods
pods:metric:name: packets-per-secondtarget:type: AverageValueaverageValue: 1k
Object 度量指标
这些度量指标用于描述在相同名字空间中的别的对象,而非 Pod。 注意这些度量指标不一定来自某对象,它们仅用于描述这些对象。 对象度量指标支持的 target 类型包括 Value 和 AverageValue。 如果是 Value 类型,target 值将直接与 API 返回的度量指标比较, 而对于 AverageValue 类型,API 返回的度量值将按照 Pod 数量拆分, 然后再与 target 值比较。 下面的 YAML 文件展示了一个表示 requests-per-second 的度量指标。
type: Object
object:metric:name: requests-per-seconddescribedObject:apiVersion: networking.k8s.io/v1kind: Ingressname: main-routetarget:type: Valuevalue: 2k
基于Ingress的请求速率这样的度量标准,您可能需要实现一个自定义metrics API,该API能够监控Ingress对象的请求速率,并将这些数据暴露给Kubernetes的metrics server或HPA。然后,您可以在HPA的配置中引用这个自定义度量标准,以便根据Ingress的请求速率来自动扩展Pod。
示例:
如果你指定了多个上述类型的度量指标,HorizontalPodAutoscaler 将会依次考量各个指标。 HorizontalPodAutoscaler 将会计算每一个指标所提议的副本数量,然后最终选择一个最高值。
比如,如果你的监控系统能够提供网络流量数据,你可以通过 kubectl edit 命令将上述 Horizontal Pod Autoscaler 的定义更改为:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:name: php-apache
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apacheminReplicas: 1maxReplicas: 10metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 50 # CPU使用率- type: Podspods:metric:name: packets-per-secondtarget:type: AverageValueaverageValue: 1k # 每秒请求1000个数据包- type: Objectobject:metric:name: requests-per-seconddescribedObject:apiVersion: networking.k8s.io/v1kind: Ingressname: main-routetarget:type: Valuevalue: 10k # 请求服务总数达到每秒10000次
这样,你的 HorizontalPodAutoscaler 将会尝试确保每个 Pod 的 CPU 利用率在 50% 以内, 每秒能够服务 1000 个数据包请求, 并确保所有在 Ingress 后的 Pod 每秒能够服务的请求总数达到 10000 个。
基于与 K8S 对象无关的度量指标
例如,如果你的应用程序处理来自主机上消息队列的任务, 为了让每 30 个任务有 1 个工作者实例,你可以将下面的内容添加到 HorizontalPodAutoscaler 的配置中。
- type: Externalexternal:metric:name: queue_messages_readyselector:matchLabels:queue: "worker_tasks"target:type: AverageValueaverageValue: 30
推荐使用定制度量指标而不是外部度量指标,因为这便于让系统管理员加固定制度量指标 API。 而外部度量指标 API 可以允许访问所有的度量指标。 当暴露这些服务时,系统管理员需要仔细考虑这个问题。
相关文章:

K8S Pod 水平自动扩缩容 HPA
介绍 HPA(Horizontal Pod Autoscaler)水平扩缩意味着可根据观察到的CPU、内存使用率或自定义度量标准来自动扩展或缩容Pod的数量(Deployment、StatefulSet 或其他类似资源)。与“垂直”扩缩不同,对于 K8S,…...

Spring日志框架
前言 本文我们简单说说关于Spring中的日志框架,以及对应的注解 我们知道,公司服务器在运行的时候,一定会打印日志,有很多优点,比如预防报警,或者是某重大事故尝试修复等等都需要查看日志 应该说日志对我们来说并不陌生,我们在之前刷题或者是程序遇到bug的时候也经常会将程序的状…...

(九)关系数据理论
函数依赖:设R(U)是属性集U上的关系模式。X、Y是属性集U的子集。若对于R(U)的任意一个可能的关系r,r中不可能存在两个元组在X上的属性值相等,而在Y上的属性值不等,则称X函数确定Y或Y函数依赖于X,记作X→Y。(即只要X 上的…...

【经验分享】Ubuntu下如何解决问题arm-linux-gcc:未找到命令
【经验分享】Ubuntu下如何解决问题arm-linux-gcc:未找到命令 前言问题分析解决方法 前言 在编译过程中发现一个问题,明明之前安装了gcc-4.6版本,版本信息都是正常显示的,刚安装上去的时候也是可以用的。但不知道什么原因突然不能…...

【算法刷题day10】Leetcode:232.用栈实现队列、225. 用队列实现栈
文章目录 Leetcode 232.用栈实现队列解题思路代码总结 Leetcode 225. 用队列实现栈解题思路代码总结 stack、queue和deque对比 草稿图网站 java的Deque Leetcode 232.用栈实现队列 题目:232.用栈实现队列 解析:代码随想录解析 解题思路 一个栈负责进&a…...

sql注入详解
ps:简单说下这里只写了我能理解的明白的,后面的二阶注入,堆叠注入没写 手工sql注入 1.存在sql注入本质上就是数据库过滤的不严格或者未进行过滤,1 and 11,返回正常,1 and 12 返回不正常,说明带到数据库里面…...

[蓝桥杯 2022 省 B] 李白打酒加强版
题目链接 [蓝桥杯 2022 省 B] 李白打酒加强版 题目描述 话说大诗人李白,一生好饮。幸好他从不开车。 一天,他提着酒壶,从家里出来,酒壶中有酒 2 2 2 斗。他边走边唱: 无事街上走,提壶去打酒。 逢店加一倍…...
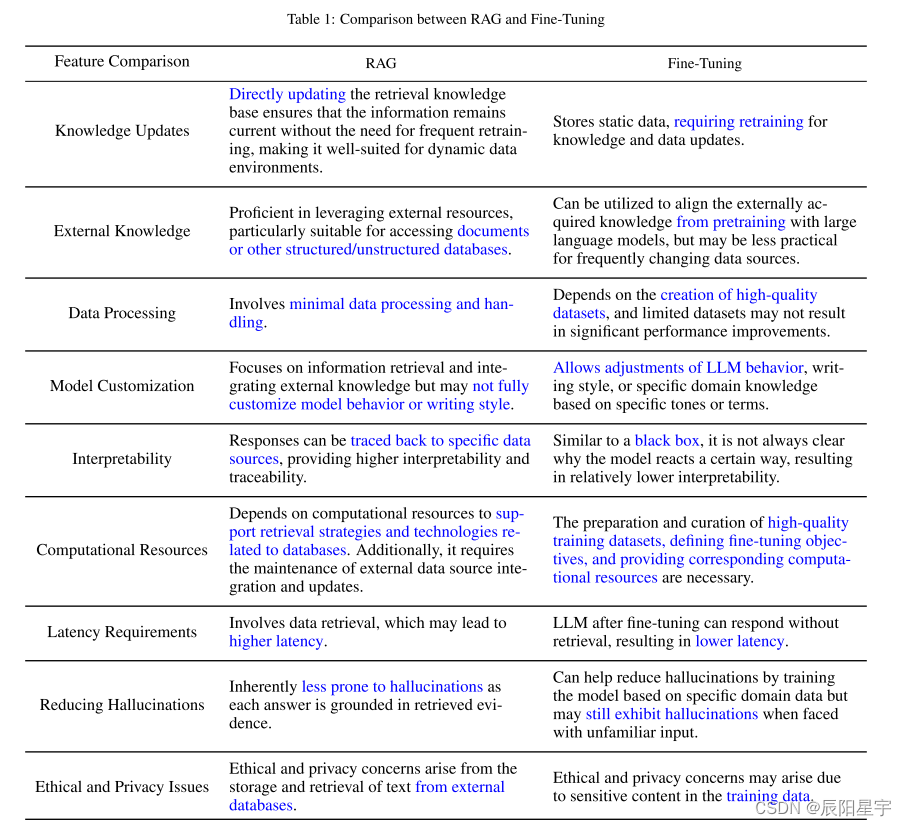
【检索增强】Retrieval-Augmented Generation for Large Language Models:A Survey
本文简介 1、对最先进水平RAG进行了全面和系统的回顾,通过包括朴素RAG、高级RAG和模块化RAG在内的范式描述了它的演变。这篇综述的背景下,更广泛的范围内的法学硕士研究RAG的景观。 2、确定并讨论了RAG过程中不可或缺的核心技术,特别关注“…...
EVM Layer2 主流解决方案
深度解析主流 EVM Layer 2 解决方案:zk Rollups 和 Optimistic Rollups 随着以太坊网络的不断演进和 DeFi 生态系统的迅速增长,以太坊 Layer 2 解决方案日益受到关注。 其中,zk Rollups 和 Optimistic Rollups 作为两种备受瞩目的主流 EVM&…...
go中结构体标签:omitempty、json꞉“name“、 gorm꞉“column꞉name“、yaml꞉“name“
在Go语言中,结构体标签(Struct Tags)提供了一种在编译时附加到结构体字段上的元数据,这些标签可以被运行时的反射(reflection)机制读取。结构体标签的存在意义和用途非常广泛,主要包括ÿ…...

七月论文审稿GPT第4版:通过paper-review数据集微调Mixtral-8x7b,对GPT4胜率超过80%
前言 在此之前,我司论文审稿项目组已经通过我司处理的paper-review数据集,分别微调了RWKV、llama2、gpt3.5 16K、llama2 13b、Mistral 7b instruct、gemma 7b 七月论文审稿GPT第1版:通过3万多篇paper和10多万的review数据微调RWKV七月论文审…...

【QT学习】1.qt初识,创建qt工程,使用按钮,第一个交互按钮
1.初识qt--》qt是个框架,不是语言 1.学习路径 一 QT简介 ,QTCreator ,QT工程 ,QT的第一个程序,类,组件 二 信号与槽 三 对话框 四 QT Desiner 控件 布局 样式 五 事件 六 GUI绘图 七 文件 八 …...

JavaScript_与html结合方式
JavaScript_语法 ECMAScript:客户端脚本语言的标准 1.基本语法 1.1 与html结合方式(2种) 1. 内部JS 定义<script>,标签体内容就是js代码 2. 外部JS 定义<script>,通过src属性引入外部的 js文件 注意: 1.<script>…...

WPF —— 动画
wpf动画类型 1<类型>Animation这些动画称为from/to/by动画或者叫基本动画,他们会在起始值或者结束值进行动画处理,常用的例如 <DoubleAnimation> 2 <类型>AnimationUsingKeyFrames: 关键帧动画,功能要比from/to这些动画功…...

前端二维码生成工具小程序:构建营销神器的技术解析
摘要: 随着数字化营销的不断深入,二维码作为一种快速、便捷的信息传递方式,已经广泛应用于各个领域。本文旨在探讨如何通过前端技术构建一个功能丰富、操作简便的二维码生成工具小程序,为企业和个人提供高效的营销支持。 一、引言…...

光伏发电量预测(Python代码,CNN结合LSTM,TensorFlow框架)
1.数据集(开始位置),数据集免费下载链接:https://download.csdn.net/download/qq_40840797/89051099 数据集一共8列,第一列是时间,特征列一共有6列:"WindSpeed" - 风速 "Sunshi…...

GPT带我学-设计模式11-组合模式
设计模式类型 结构型设计模式 使用场景 将对象组合成树状结构来表现"部分-整体"的层次结构。这种模式能够使得客户端对单个对象和组合对象的使用具有一致性。这句话太抽象了,拿一个实际的网站菜单树例子来说。 例子:网页菜单树 一个网站的…...

Centos7 elasticsearch-7.7.0 集群搭建,启用x-pack验证 Kibana7.4用户管理
前言 Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。 环境准备 软件 …...

[CSS]中子元素在父元素中居中
元素居中 对于当行文字居中,比较简单,设置text-align:center和text-height为盒子高度即可 对于父元素中子元素居中,要实现的话有以下几个方法 方法1:利用定位margin:auto <style>.father {width: 500px;heig…...

电脑突然死机怎么办?
死机是电脑常见的故障问题,尤其是对于老式电脑来说,一言不合电脑画面就静止了,最后只能强制关机重启。那么你一定想知道是什么原因造成的吧,一般散热不良最容易让电脑死机,还有系统故障,比如不小心误删了系…...

3秒定位Windows热键冲突:Hotkey Detective终极检测工具完整指南
3秒定位Windows热键冲突:Hotkey Detective终极检测工具完整指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

别再手动加下划线了!AD原理图封装库字体设置,这个隐藏功能一键搞定
Altium Designer原理图封装库字体设置:高效处理上下划线的专业技巧 在硬件设计领域,原理图符号的规范性和一致性直接影响团队协作效率和设计质量。Altium Designer作为行业主流EDA工具,其字体自定义功能常被工程师忽视,特别是处理…...

PX4倾转垂起固定翼混控配置与硬件适配实战
1. PX4倾转垂起固定翼的核心概念解析 第一次接触倾转垂起固定翼的朋友可能会被这个名词吓到,其实它的原理并不复杂。简单来说,这是一种既能像多旋翼一样垂直起降,又能像固定翼飞机一样高效巡航的混合飞行器。我经手过的项目中,这种…...
)
手把手教你给天邑TY1608机顶盒刷机(S905L3B芯片,支持RTL8822CS/MT7668无线模块)
天邑TY1608机顶盒刷机全攻略:从零开始玩转S905L3B芯片 第一次拿到天邑TY1608机顶盒时,你可能被它原厂系统的各种限制所困扰——预装软件无法卸载、广告弹窗频繁出现、存储空间严重不足。这款搭载Amlogic S905L3B芯片的设备,配合RTL8822CS或MT…...

基于LLM的MBTI人格模拟对话实验:从系统设计到工程实践
1. 项目概述:当MBTI遇上AI,一次关于人格的深度对话实验最近在GitHub上看到一个挺有意思的项目,叫“Kali-Hac/ChatGPT-MBTI”。光看名字,你可能觉得这又是一个用ChatGPT玩MBTI性格测试的简单脚本。但当我真正clone下来,…...

终极指南:如何快速筛选高质量免费股票资源的5大核心标准
终极指南:如何快速筛选高质量免费股票资源的5大核心标准 【免费下载链接】awesome-stock-resources :city_sunrise: A collection of links for free stock photography, video and Illustration websites 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-s…...

不止于配置:深入理解AVL Cruise与Matlab Simulink联合仿真的DLL机制
不止于配置:深入理解AVL Cruise与Matlab Simulink联合仿真的DLL机制 在汽车工程仿真领域,AVL Cruise与Matlab Simulink的联合仿真已成为动力系统开发的标准工具链。大多数教程停留在环境配置层面,而真正影响仿真效率与可靠性的,往…...

AIKit:基于容器的一站式开源大语言模型部署与微调平台
1. AIKit项目概述:一站式开源大语言模型部署与微调平台 如果你和我一样,在尝试将Llama、Mistral这类开源大语言模型(LLM)真正用起来时,被复杂的依赖、环境配置和性能优化搞得焦头烂额,那么AIKit的出现&…...

开源提示词库:提升AI协作效率的实战指南与核心设计解析
1. 项目概述:一个开源提示词库的价值与定位如果你也经常使用大型语言模型,无论是用于编程辅助、内容创作还是日常问答,那么你一定遇到过这样的困境:面对一个空白的输入框,明明心里有明确的需求,却不知道如何…...

用AG9311芯片DIY一个多功能Type-C扩展坞:从原理图到PCB布局的保姆级指南
用AG9311芯片DIY多功能Type-C扩展坞:从原理图到PCB布局全解析 Type-C扩展坞早已成为现代数字生活的必需品,但市面上成品往往价格高昂或功能单一。对于硬件爱好者而言,自己动手打造一款多功能扩展坞不仅能节省成本,更能深度掌握高速…...