【机器学习】《机器学习算法竞赛实战》思考练习(更新中……)
文章目录
- 第2章 问题建模
- (一)对于多分类问题,可否将其看作回归问题进行处理,对类别标签又有什么要求?
- (二)目前给出的都是已有的评价指标,那么这些评价指标(分类指标和回归指标)的损失函数如何实现?
- (三)解决样本分布不均衡问题时,尝试用代码实现样本加权、类别加权和采样算法等几种方式,并对比使用权重前后的分数变化。
- (四)在对不均衡的数据集进行采样时,是否会影响训练集和测试集之间的独立同分布关系?
- (五)在进行K折交叉验证的时候,对于K值的选取,是否越大越好呢?
- (六)在大多数情况下,我们会选择使用K折交叉验证,那么K折交叉验证为什么能够帮助提升效果呢?
- 第3章 数据探索
- 第7章 用户画像
- (一)你觉得用户画像是想体现用户的共性还是个性,为什么?
- (二)就你日常使用的App,思考其算法与运营团队会如何给你画像呢?
- (三)文本挖掘算法也是非常多的,尝试整理这些算法调用方法,并且结合原理去熟悉参数的设置。
- (四)嵌入方式被广泛应用,除了Word2Vec和Deep Walk以外,还有哪些嵌入算法,具体原理是什么样的?
- (五)相似度计算方法非常多,但要从大量数据中检索出最为相似的或者相似度排前N位的并不是件容易的事情,所以有什么好的检索算法吗?
- (六)内容摘要/总结
最近在看《机器学习算法竞赛实战》,虽然很多看不懂,但是我觉得学习就是看不懂、然后就厚着脸皮反复看呗,我不是一次就能看懂、学会的天才。
思考练习里面的内容我基本都答不上来,答案来自CodeGeeX。仅供参考。
第2章 问题建模
(一)对于多分类问题,可否将其看作回归问题进行处理,对类别标签又有什么要求?
CodeGeeX:
对于多分类问题,可以将它们看作回归问题进行处理。但是,为了 successful,会对类别标签提出以下要求:
1、每个类别都有一个唯一的数值标签。
2、类别标签必须是 continuous 且 non-negative。
3、类别标签不能存在空值或缺失值。
满足这些要求的类别标签可以使用进行回归问题处理。但是,请注意,这种方法可能会降低 model 的性能,因为多分类问题通常需要 special handling。
【翻译】
continuous:连续性
negative:负类
non-negative:非负类
special handling:特殊处理
(二)目前给出的都是已有的评价指标,那么这些评价指标(分类指标和回归指标)的损失函数如何实现?
CodeGeeX:
在机器学习中,指标(如 F1-score、Accuracy、MSE 等)通常用于评估模型的性能。这些指标可以使用损失函数(如 Log-loss、MSE-loss 等)实现。在神经网络训练过程中,模型会根据输入数据计算损失函数,并根据损失函数的大小更新模型参数。
我:
我觉得这个问题,CodeGeeX回答的不太好。依据我看书后的理解和总结如下:
1、分类问题常见的评价指标:
①错误率与精度
要点:加总等于1。
②准确率与召回率
要点:同时使用,此消彼长。
③F1-score
要点:调和平均②,介于[0,1]区间。
④ROC曲线
要点:正负样本不均衡时依然能够保持不变。该指标不常用。
⑤AUC
要点:极常见的指标。定义为ROC曲线下的面积。取值范围0.5-1之间。
是数值,值越大==>分类器效果越好。
⑥对数损失
要点:常见指标。取值0-1之间。
2、AUC和对数损失对比
同样是概率。
AUC侧重于模型将正样本排到前面的能力。比如广告排序效果。
我理解的是,如果要考察排在前几位的,就用AUC。比如热度前十,增长前十这类的……评价这类的预测用AUC比较好。
对数损失反映平均偏差,更偏向于将样本数量多的那类划分准确。评价模型预测的概率是否足够准确。
3、如何实现,大概就是代码问题了,书上给了准确率、召回率、F1-score:
from sklearn.metrics import precision_score, recall_score, f1_score
precision = precision_score(y_train, y_pred)
recall = recall_score(y_train, y_pred)
f1 = f1_score(y_train, y_pred)
代码很简单:导入模块,然后直接使用方法,参数就那两个,直接放进去 就好啦。
4、回归指标
①平均绝对误差(MAE,Mean Absolute Error),又称为L1范数损失
残差的基础上,弄了个绝对值。所谓的“绝对”就是绝对值的意思。
②均方误差(MSE,Mean Squared Error),又称为L2范数损失
残差基础上,弄了个平方。
③均方根误差
在均方误差基础上弄了个开方。
④平均绝对百分比误差(MAPE)
在平均绝对误差(MAE)基础上除以预测值y’。弥补了MAE的不足,真实值越大,误差越小。
5、这些指标的损失函数……这个我就不太理解了,貌似书上只说了这些指标啊,它们还有损失函数吗?以后再说吧……
(现实情况是,我还没啰嗦完,面试官:可以滚了,下一位……)
(三)解决样本分布不均衡问题时,尝试用代码实现样本加权、类别加权和采样算法等几种方式,并对比使用权重前后的分数变化。
CodeGeeX:
在解决样本分布不均衡问题时,可以使用以下几种方式来处理:
1、样本加权:为不同类别的样本分配不同的权重,以便于对不同类别进行均衡采样。
2、类别加权:为不同类别的样本分配不同的数量,以便于对不同类别进行均衡训练。
3、采样算法:使用算法来生成平衡的样本分布,例如adasyn、balance_dataset、ClassBalancedSampler 等。
4、使用权重前缀:在计算损失函数时,使用权重前缀来调整不同类别的重要性。例如,在 softmax 损失函数中,可以使用权重前缀来调整预测概率的权重。
5、使用 focal loss:focal loss 是一种针对样本分布不均衡问题的损失函数,它可以有效地提高识别困难样本的能力。
6、使用 gradient reverse algorithm:GRAD 是一种通过调整学习率来解决样本分布不均衡问题的方法,它通过最大化正负样本的差值来提高困难样本的训练强度。
我:
看不懂……遇到具体问题的时候再说吧……代码实现?没有没有……
(四)在对不均衡的数据集进行采样时,是否会影响训练集和测试集之间的独立同分布关系?
CodeGeeX:
在某些情况下,对不均衡的数据集进行采样可能会影响训练集和测试集之间的独立同分布关系。具体来说,这取决于采样算法的设计和数据集的性质。一些采样算法,如 undersampling(欠采样) 和 oversampling(过采样),可以确保训练集和测试集之间的独立同分布关系保持不变。然而,一些算法,如 balanced sampling(平衡取样;对称抽样),可能会改变独立同分布关系。
因此,在对不均衡的数据集进行采样时,需要根据实际需求和数据集的性质来选择合适的采样算法,以保持训练集和测试集之间的独立同分布关系。
(五)在进行K折交叉验证的时候,对于K值的选取,是否越大越好呢?
CodeGeeX:
通常情况下,K值的选取不是越大越好。在K折交叉验证中,K值越大,意味着每个验证集的大小越小,XTrain和XTest之间的独立同分布关系越小,这可能会导致模型泛化能力不足。因此,K值的选取需要根据实际需求和数据集的性质来选择。在某些情况下,K值可能需要减小到接近于1的值,以提高模型的泛化能力。
我:
K值过大,计算量过大。一般K=5或10。
(六)在大多数情况下,我们会选择使用K折交叉验证,那么K折交叉验证为什么能够帮助提升效果呢?
CodeGeeX:
K折交叉验证是一种常用的评估方法,它可以帮助我们评估模型的泛化能力。与直接使用整个训练集作为验证集相比,K折交叉验证可以在不暴露测试集的情况下估计模型的性能,从而更准确地评估模型的效果。通过K折交叉验证,我们可以看到不同训练集下的模型性能,从而更好地理解和优化模型。
第3章 数据探索
(我跳着看的,晚些回来补充……)
第7章 用户画像
(一)你觉得用户画像是想体现用户的共性还是个性,为什么?
CodeGeeX:
用户画像通常是想体现用户的共性。用户画像的主要目的是为了更好地了解和满足用户的需求,icheck 平台通过分析用户在产品使用过程中的行为数据(如浏览记录、购买记录、搜索记录等)来构建用户的画像,从而为后续的营销策略提供参考。用户画像是基于共性来提取特征,从而进行分类的。
我:icheck平台,没查到什么相关的资料,不重要……
(二)就你日常使用的App,思考其算法与运营团队会如何给你画像呢?
我:呵呵……虽然我在学习给用户画像,但我不希望被画像……
(三)文本挖掘算法也是非常多的,尝试整理这些算法调用方法,并且结合原理去熟悉参数的设置。
CodeGeeX:
文本挖掘算法有以下几种:
1、深度学习算法:如BERT、GPT等,这些算法采用深度学习技术和大规模语言模型训练,能够更好地理解和处理文本数据。
2、机器学习算法:如分类模型、回归模型等,这些算法采用机器学习技术,对文本数据进行训练和优化,以实现对文本数据的分类或预测。
3、自然语言处理算法:如分词、词性标注、命名实体识别等,这些算法主要用于处理文本数据,以提取关键信息。
4、信息检索算法:如TF-IDF、BM25、LDA等,这些算法主要用于处理文档数据,以实现对大量文本数据的检索。
5、情感分析算法:如正面情感分析、负面情感分析等,这些算法主要用于处理文本数据,以实现对用户情感的识别和分析。
6、文本生成算法:如机器翻译、文本摘要等,这些算法主要用于处理文本数据,以实现文本的生成和转换。
7、文本分类算法:如主题模型、sentence-transformers等,这些算法主要用于处理文本数据,以实现文本的分类和聚类。
8、文本匹配算法:如字符串匹配、向量匹配等,这些算法主要用于处理文本数据,以实现文本的相似性匹配。
9、文本嵌入算法:如Word2Vec、GloVe、BERT等,这些算法主要用于处理文本数据,以实现文本的向量表示和嵌入。
10、文本分区算法:如分水岭算法、聚类算法等,这些算法主要用于处理文本数据,以实现文本的分区。
这些算法的调用方法取决于具体的应用场景和需求。在实际应用中,可以根据需要选择合适的算法进行学习和实践。
我:晕了晕了……混个脸熟先……
(四)嵌入方式被广泛应用,除了Word2Vec和Deep Walk以外,还有哪些嵌入算法,具体原理是什么样的?
CodeGeeX:
除了Word2Vec和Deep Walk之外,还有以下几种嵌入算法:
1、GloVe:是一种基于图的嵌入方法,通过训练来学习图中节点之间的相似度,并将这些相似度转换为低维的向量表示。
2、BERT:是一种基于Transformer的预训练语言模型,能够学习语言模式和知识,并将它们嵌入到低维空间中。
3、Transformer:是一种基于自注意力机制的深度神经网络模型,用于处理序列数据,可以实现词嵌入、句嵌入和文档嵌入。
4、GCN:是一种基于图卷积神经网络的嵌入方法,可以学习图中的节点关系,并将这些关系转换为低维的向量表示。
5、DNN:是一种基于深度神经网络的嵌入方法,可以学习大量数据的模式,并将它们转换为低维的向量表示。
6、CDSSM:是一种基于局部上下文的嵌入方法,可以学习文本中的局部特征,并将它们转换为低维的向量表示。
7、LSTM:是一种基于长短期记忆网络的嵌入方法,可以学习文本中的长期依赖关系,并将它们转换为低维的向量表示。
8、GLM:是一种基于生成式模型的嵌入方法,可以学习大规模语言模型中的词嵌入,并将它们转换为低维的向量表示。
9、向量空间模型:是一种基于概率模型的嵌入方法,可以学习大规模语言模型中的词嵌入,并将它们转换为低维的向量表示。
10、概率模型:是一种基于概率模型的嵌入方法,可以学习大规模语言模型中的词嵌入,并将它们转换为低维的向量表示。
这些算法的原理有所不同,具体原理可以参考相关文献或教程。在实际应用中,可以根据需要选择合适的算法进行学习和实践。
我:呃……为什么(9、向量空间模型)和(10、概率模型)的解释完全相同?
先不去管它了,反正看到这么多生词,脑瓜子嗡嗡的……
还得补充一下,书中提到,词嵌入:Word2Vec衍生的Item2Vec,以及图嵌入:LINE、Node2Vec、SDNE。
(五)相似度计算方法非常多,但要从大量数据中检索出最为相似的或者相似度排前N位的并不是件容易的事情,所以有什么好的检索算法吗?
CodeGeeX:
文本检索算法有很多,以下是一些常见的算法:
1、基于向量的检索方法:如TF-IDF、BM25、LDA等,这些算法主要用于处理文档数据,以实现对大量文本数据的检索。
2、基于概率模型的检索方法:如概率模型、向量空间模型等,这些算法主要用于学习大规模语言模型中的词嵌入,并将它们转换为低维的向量表示。
3、深度学习算法:如BERT、GPT等,这些算法采用深度学习技术和大规模语言模型训练,能够更好地理解和处理文本数据。
4、局部模型:如CNN、RNN等,这些算法用于处理短文本数据,可以实现词嵌入、句嵌入和文档嵌入。
5、全局模型:如Transformer、GLM等,这些算法用于处理长文本数据,可以实现全局特征的抽取。
6、嵌入模型:如Word2Vec、GloVe等,这些算法用于学习文本数据的模式,并将它们转换为低维的向量表示。
7、主题模型:如LDA、LSI等,这些算法用于处理文档数据,可以实现对文本数据的自动分类和聚类。
8、感分析算法:如正面情感分析、负面情感分析等,这些算法用于处理文本数据,以实现对用户情感的识别和分析。
9、文本生成算法:如机器翻译、文本摘要等,这些算法用于处理文本数据,以实现文本的生成和转换。
10、文本分类算法:如主题模型、sentence-transformers等,这些算法用于处理文本数据,以实现文本的分类和聚类。
这些算法的应用场景和需求不同,可以根据需要选择合适的算法进行学习和实践。
我:……所以并没有回答究竟那个检索算法更好。
此外我发现两个事,CodeGeeX 最多就是罗列10个答案……只有top10啊~
还有,这些算法和上面的差不多,所以,文本挖掘算法主要的也就这么些了,不要害怕不要害怕~~~~
(六)内容摘要/总结
这一章干货还是挺多的,想了想还是做了个笔记。详见
【机器学习】《机器学习算法竞赛实战》第7章用户画像
(更新中……)
CodeGeeX:
相关文章:
)
【机器学习】《机器学习算法竞赛实战》思考练习(更新中……)
文章目录 第2章 问题建模(一)对于多分类问题,可否将其看作回归问题进行处理,对类别标签又有什么要求?(二)目前给出的都是已有的评价指标,那么这些评价指标(分类指标和回归…...

机场数据治理系列介绍(5)民用机场智慧能源系统评价体系设计
目录 一、背景 二、体系设计 1、评价体系设计维度 2、评价体系相关约定 3、评价指标体系框架设计 4、能源利用评价指标 5、环境友好评价指标 6、智慧管控评价指标 7、安全保障评价指标 三、具体落地措施 一、背景 在“双碳”国策之下,各类机场将能源系统建…...

[LeetCode][LCR190]加密运算——全加器的实现
题目 LCR 190. 加密运算 计算机安全专家正在开发一款高度安全的加密通信软件,需要在进行数据传输时对数据进行加密和解密操作。假定 dataA 和 dataB 分别为随机抽样的两次通信的数据量: 正数为发送量负数为接受量0 为数据遗失 请不使用四则运算符的情况…...

Linux: linux常见操作指令
目录 01.ls 指令 02. pwd命令 03. cd 指令 04. touch指令 05.mkdir指令(重要) 06.rmdir指令 && rm 指令(重要) 07.man指令(重要) 07.cp指令(重要) 08.mv指令&#…...

【BPNN】BP神经网络代码
主代码 %function main() clc clear close all %% 1.原始数据 %输入 SR1[20.55 22.44 25.37 27.13 29.45 30.10 30.96 34.06 36.42 38.09 39.13 39.99 ...41.93 44.59 47.30 52.89 55.73 56.76 59.17 60.63]; SR2[0.6 0.75 0.85 0.9 1.05 1.35 1.45 1.6 1.7 1.85 2.15 2.2 2.2…...

基于mqtt的物联网控制移动应用程序开发
具体实现问题 MQTT模型、特点、服务质量、报文、消息类型表 java实现mqtt两种方式:Paho Java原生库、spring boot MQTT与HTTP:哪一个最适合物联网? mqtt协议和http协议区别 应用是如何实现mqtt协议 通过调用安卓的MQTT库来实现MQTT协议&…...
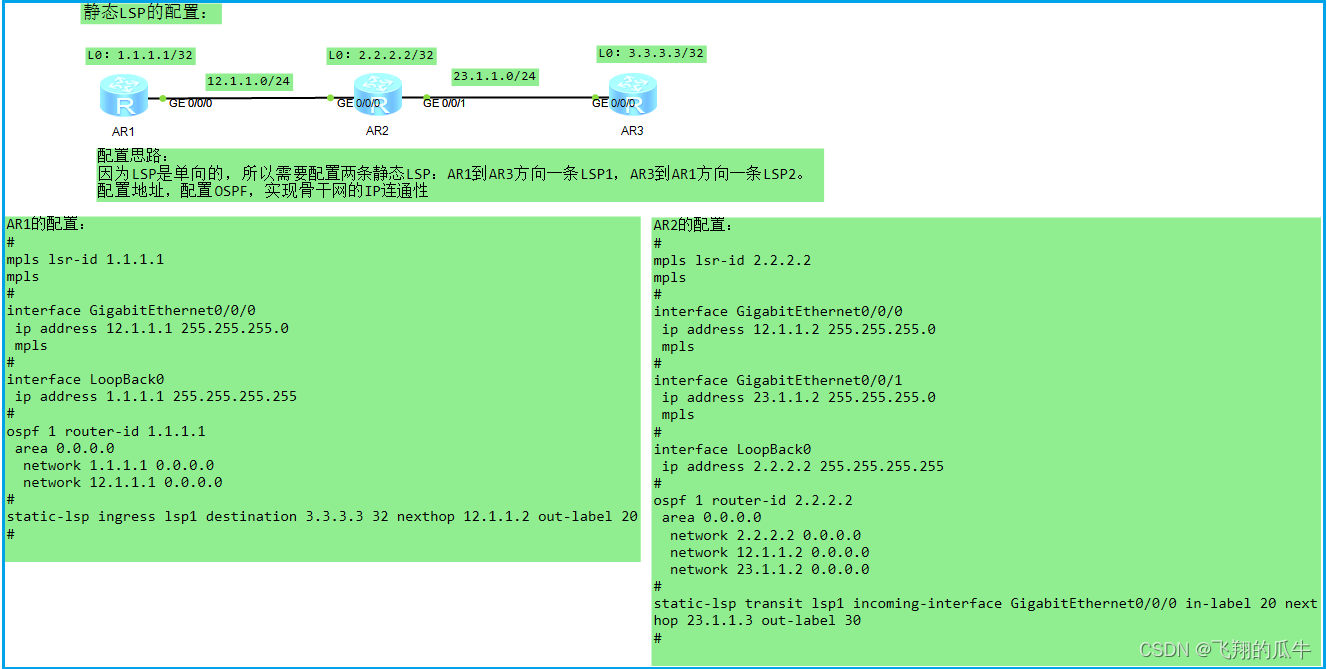
MPLS-基础、LSR、LSP、标签、体系结构
MPLS技术 MPLS基础 MPLS:转发数据时,只在网络边缘分析IP报文头,不在每一跳都分析,节约了转发时间。 MPLS:Multiprotocol Label Switching,多协议标签交换骨干网技术。主要应用:VPN、流量工程…...

【RV1126】Ubuntu22.04下sdk编译问题汇集
对于新版本Ubuntu系统来编译SDK,尤其是buildroot ,是一个巨大考验,发现问题如下: 1. c-stack.c的SIGSTKSZ错误 buildroot 报错:c-stack.c:55:26:error:missing binary operator before token “(“55 在buildroot目录中找到c-s…...
51单片机使用uart串口和助手简单调试
基础知识 参考 特殊功能寄存器PCON(控制波特率是否加倍SMOD)、TMOD(T0,T1计时器的功能方式)、TCON(T0,T1计时器的控制)、串口中断、SCON(串口数据控制寄存器) 关闭定时器1中断&…...
:b站弹幕)
Python网络爬虫(五):b站弹幕
上一篇对b站的视频评论爬取进行了探讨,这一篇是弹幕。直接上代码: import csv import json import re import chardet import requestsheaders = {user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Saf…...

Docker环境安装Postgresql数据库Posrgresql 15.6
宿主机是ubuntu 22.04版本 ubuntu宿主机上安装docker,参见官方文档https://docs.docker.com/engine/install/ubuntu/, docker-ce是社区版 docker-ee是企业版 1、检查Docker是否安装 rootODS1SPGOFSDEV:~# docker Command docker not found, but can be installed …...

当代软件专业大学生与青年在新质生产力背景下的发展探究
在新质生产力的浪潮中,信息技术以前所未有的速度革新,为软件专业的大学生和青年带来了丰富的机遇,同时也伴随着一系列的挑战。他们如何把握时代的脉搏,实现个人的发展,成为了值得深入探讨的话题。 一、新质生产力背景下的机遇 随着新质生产力的不断发展,信息技术在各个领…...

MATLAB——知识点备忘
最近在攻略ADC建模相关方面,由好多零碎的知识点,这里写个备忘录。 Matlab 判断一个数是否为整数 1. isinteger 函数 MATLAB中,可以使用 isinteger 函数来判断一个数是否为整数,例如:要判断x是否为整数可以采用以下代…...
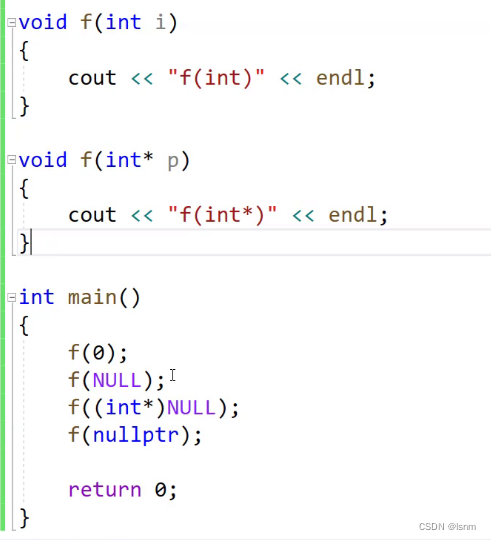
C++入门(以c为基础)——学习笔记2
1.引用 引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空 间。在语法层面,我们认为它和它引用的变量共用同一块内存空间。 可以取多个别名,也可以给别名取别名。 b/c/d本质都是别名&#…...
)
设计模式-单例模式(懒汉式)
1. 概念 保证一个类只有一个实例并为该实例提供一个全局唯一的访问节点 2. 懒汉式-方式一 2.1 代码示例(方式一) 示例 public class Singleton03 {/*** 构造器私有化*/private Singleton03() {}/*** 成员变量*/private static Singleton03 INSTANCE;…...

算法| ss 回溯
39.组合总数46.全排列—478.子集79.单词搜索—1连续差相同的数字—1 39.组合总数 /*** param {number[]} candidates* param {number} target* return {number[][]}*/ // 思路 // dfs传参,传idx, 剩余target // dfs返回: 0 收集,…...
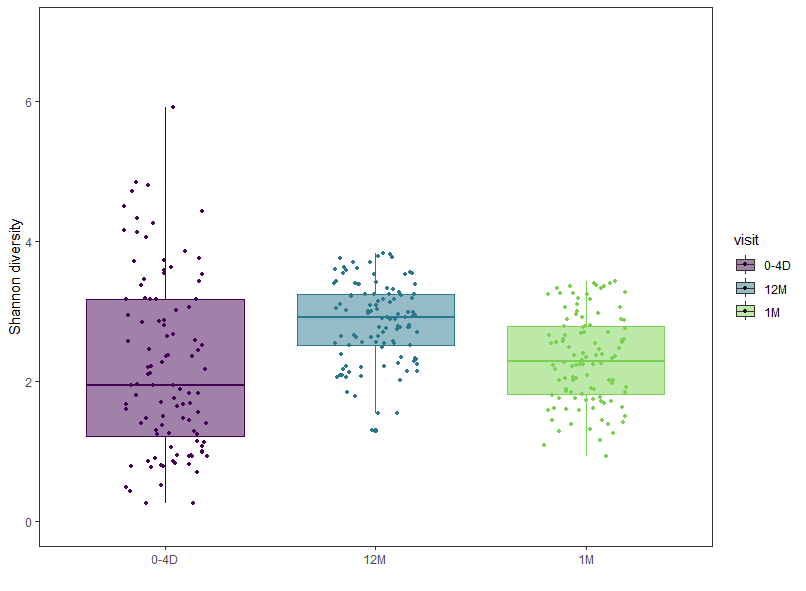
基于R语言绘制-散点小提琴图
原文链接:R语言绘图 | 散点小提琴图 本期教程 写在前面 本期的图形来自发表在Nature期刊中的文章,这样的基础图形在日常分析中使用频率较高。 获得本期教程数据及代码,后台回复关键词:20240405 绘图 设置路径 setwd("You…...
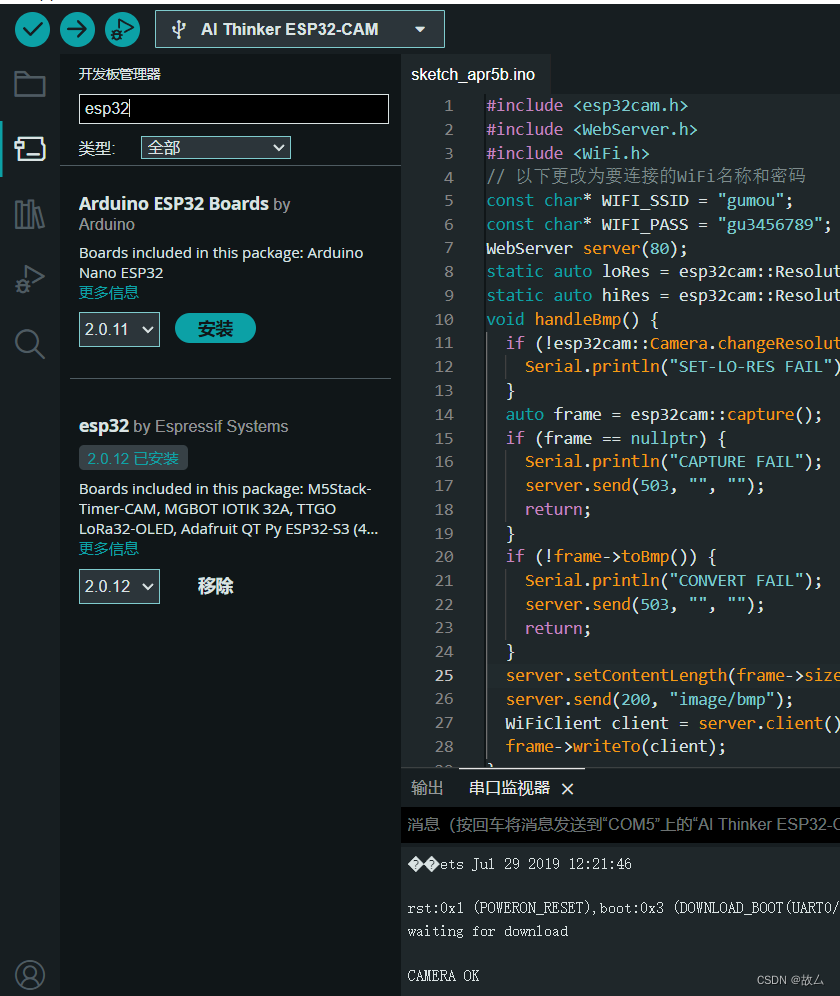
Arduino开发 esp32cam+opencv人脸识别距离+语音提醒
效果图 低于20厘米语音提醒字体变红 Arduino代码 可直接复制使用(修改自己的WIFI) #include <esp32cam.h> #include <WebServer.h> #include <WiFi.h> // 设置要连接的WiFi名称和密码 const char* WIFI_SSID "gumou"; const char* …...
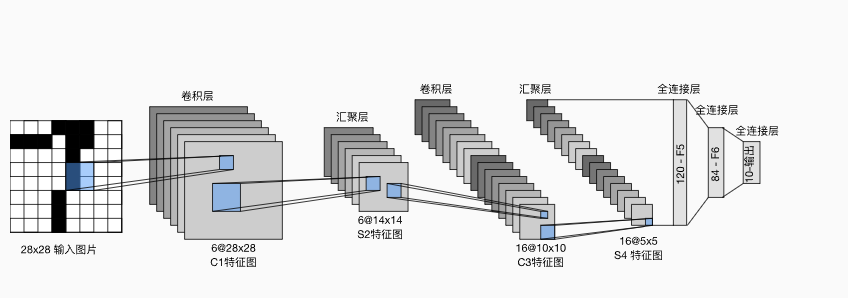
LeNet卷积神经网络
文章目录 简介conv2d网络层的结构 简介 它是最早发布的卷积神经网络之一 conv2d 这个卷积成的参数先进行介绍一下: self.conv1 nn.Conv2d(in_channels3, out_channels10, kernel_size3, stride1, padding1)先看一下in_channels 输入的通道数,out_cha…...
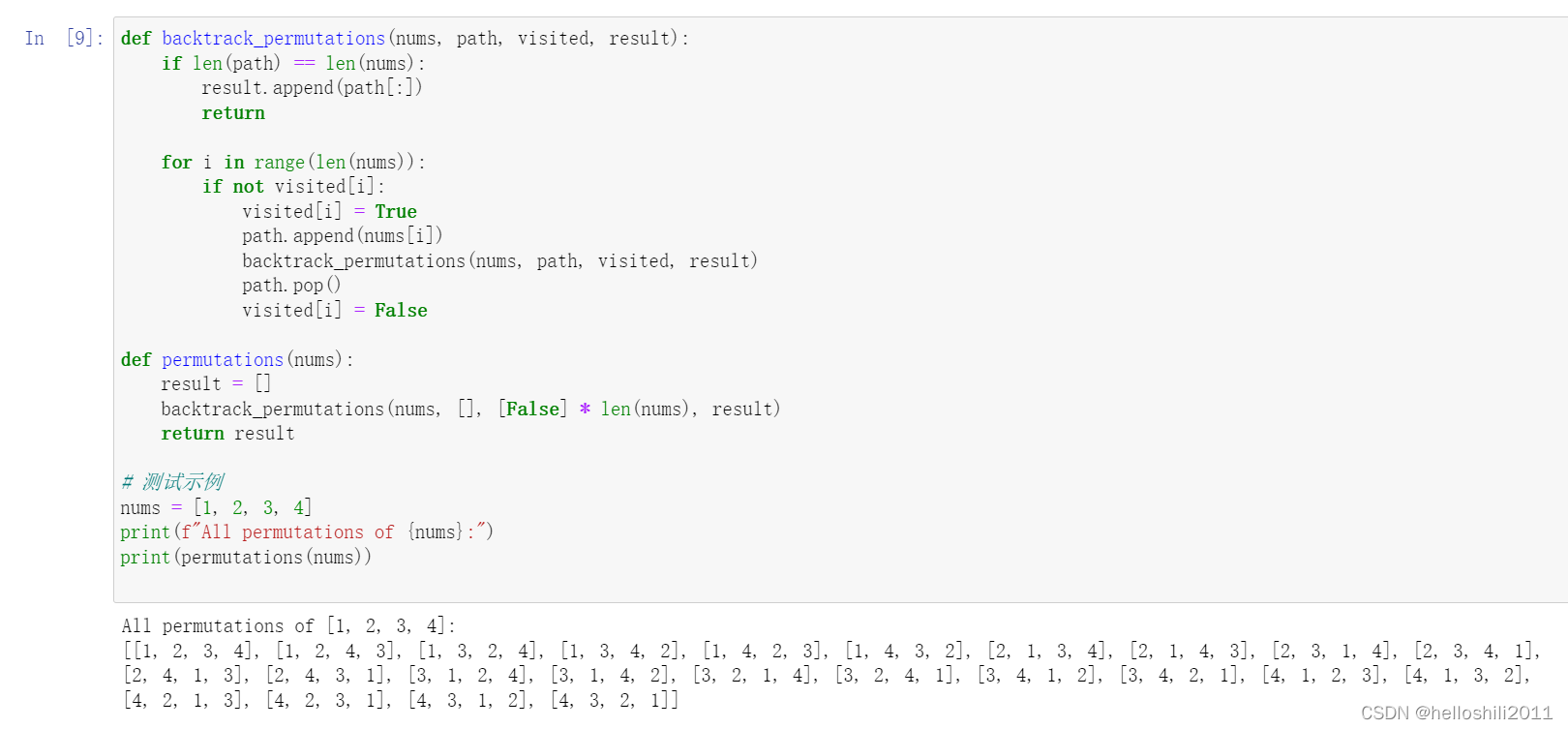
Python常用算法思想--回溯算法思想详解【附源码】
通过回溯算法解决“组合”问题、“排序”问题、“搜索”之八皇后问题、“子集和”之0-1背包问题、字符串匹配等六个经典案例进行介绍: 一、解决“组合”问题 从给定的一组元素中找到所有可能的组合,这段代码中的 backtrack_combinations 函数使用了回溯思想,调用 backtrack…...

SEO排名专家的工作内容是什么_如何成为一名出色的SEO排名专家
<h2>SEO排名专家的工作内容是什么</h2> <p>SEO排名专家,全称搜索引擎优化专家,是一类致力于提升网站在搜索引擎中排名的专业人士。他们的工作内容涵盖了广泛的技术和策略,旨在让网站在搜索结果中获得更高的曝光率ÿ…...

Welch‘s t-test实战指南:从原理到Python实现
1. 为什么你需要Welchs t-test? 做数据分析时,经常会遇到这样的场景:你想比较两组数据的平均值是否有显著差异,但发现这两组数据的方差不一样,样本量也不同。这时候传统的Students t-test就不太适用了,因为…...

Easy-Scraper:革新性HTML数据提取库的技术突破与实战应用
Easy-Scraper:革新性HTML数据提取库的技术突破与实战应用 【免费下载链接】easy-scraper Easy scraping library 项目地址: https://gitcode.com/gh_mirrors/ea/easy-scraper 在数据驱动决策的时代,网页数据采集已成为企业获取市场情报、科研机构…...
)
IDEA插件开发实战:手把手教你开发首个效率工具(附GitHub源码)
IDEA插件开发实战:从零打造你的专属效率工具 JetBrains系列IDE的强大之处不仅在于其核心功能,更在于其开放的插件生态系统。作为一名Java开发者,你是否曾想过为IDEA添加一个能提升自己工作效率的专属工具?本文将带你从零开始&…...

OpenRGB:一键终结RGB灯光混乱,开源免费的多品牌设备统一控制方案
OpenRGB:一键终结RGB灯光混乱,开源免费的多品牌设备统一控制方案 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/CalcProgra…...

WiFi热图绘制工具:用Python为你的无线网络做一次“CT扫描“ [特殊字符][特殊字符]
WiFi热图绘制工具:用Python为你的无线网络做一次"CT扫描" 🏥📶 【免费下载链接】wifi-heat-mapper whm also known as wifi-heat-mapper is a Python library for benchmarking Wi-Fi networks and gather useful metrics that can…...

移动端语音交互避坑指南:录音超时截取、倒计时提醒与MP3转换的完整方案
移动端语音交互避坑指南:录音超时截取、倒计时提醒与MP3转换的完整方案 在即时通讯和语音输入场景中,流畅的录音体验直接影响用户留存。数据显示,超过83%的用户会因为录音功能卡顿或操作复杂而放弃使用语音功能。本文将深入解析三个关键体验优…...
)
Python异步I/O终极调优手册(含strace+py-spy+asyncio debug mode三重追踪链路图)
第一章:Python异步I/O性能瓶颈的本质洞察Python的async/await语法虽大幅简化了异步编程模型,但其底层性能瓶颈并非源于语法糖本身,而根植于事件循环调度机制、GIL对CPU密集型任务的制约,以及I/O等待与协程切换之间的隐式开销。事件…...

【仿真】Carla跨平台部署指南:从零到一,附ROS2与Autoware.auto连接实战
1. Carla仿真平台概述 Carla是一款开源的自动驾驶仿真平台,基于虚幻引擎构建,能够提供高度逼真的城市环境和交通场景。我第一次接触Carla是在2018年,当时它还处于早期开发阶段,但已经展现出惊人的潜力。经过多年发展,现…...

基于S7-200 PLC与组态王的大棚控制系统:产品原理图与IO分配详解
基于S7-200 PLC和组态王温室大棚控制 我们主要的后发送的产品有,带解释的梯形图接线图原理图图纸,io分配,组态画面 菜农张叔上周还给我打电话吐槽:“小王啊,上周那场降温加突然转晴,我三点爬起来盖半层棉被…...