机器学习知识点
1鸢尾花分类
鸢尾花分类问题是一个经典的机器学习问题,旨在根据鸢尾花的花萼长度、花萼宽度、花瓣长度和花瓣宽度等特征,将鸢尾花分成三个品种:山鸢尾(setosa)、变色鸢尾(versicolor)和维吉尼亚鸢尾(virginica)。
这个问题常用的解决方法是使用机器学习算法来构建一个分类器,然后使用该分类器对新的鸢尾花样本进行分类。常用的分类算法包括支持向量机(SVM)、K近邻(K-Nearest Neighbors)、决策树(Decision Tree)等。
在解决鸢尾花分类问题时,通常采取以下步骤:
-
数据获取与准备: 首先,需要收集包含鸢尾花样本的数据集,常用的是经典的鸢尾花数据集,例如
iris数据集。然后,对数据进行预处理,包括数据清洗、特征选择、特征缩放等。 -
选择模型: 选择适合问题的分类模型,常见的包括支持向量机(SVM)、K近邻(K-Nearest Neighbors)、决策树(Decision Tree)、随机森林(Random Forest)等。
-
训练模型: 使用训练数据对选择的模型进行训练,这一过程会使模型根据数据学习到相应的规律或模式。
-
模型评估: 使用测试数据评估模型的性能,通常使用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值等指标来评估模型的表现。
-
模型调优: 根据评估结果,对模型进行调优,例如调整模型的超参数、选择更合适的特征等,以提高模型的性能。
-
模型应用: 最终,将训练好的模型用于实际问题中,对新的鸢尾花样本进行分类预测。
题目描述:
要求: 鸢尾花分类问题,我们可以通过python的sklearn库,给出预测结果和实际值的对比,并且给出正确率评分。
- 1、导入sklearn库,包括需要用到的数据集dataset.load_iris()、svm分类器工具和、模型用到的数据集拆分工具。
- 2、使用python命令导入数据,并且设置好训练集和测试集。
- 3、创建svm.LinearSVC分类器
- 4、使用分类器clf的fit方法进行拟合训练
- 5、使用分类器clf的predict方法对测试集数据进行预测
- 6、对比测试集的预测结果和测试集的真实结果,并且使用clf的score方法获得预测准确率。
代码:
from sklearn import datasets # 导入数据集模块
from sklearn import svm # 导入支持向量机模块
from sklearn.model_selection import train_test_split # 导入数据集拆分工具
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data # 特征数据
y = iris.target # 类别标签
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 创建线性支持向量机分类器
clf = svm.LinearSVC()
# 使用训练集训练分类器
clf.fit(X_train, y_train)
# 对测试集进行预测
y_predict = clf.predict(X_test)
# 对比预测结果和真实结果,并输出
comparison = ['预测值: ' + str(a) + ' 实际类别: ' + str(b) for a, b in zip(y_predict, y_test)]
for comp in comparison:print(comp)
# 输出分类器在测试集上的准确率
print(f'准确率:{clf.score(X_test, y_test)}') 结果如图: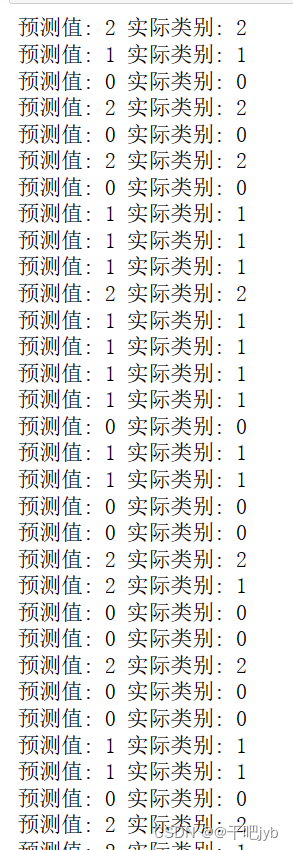
2 KNN算法
K近邻(K-Nearest Neighbors,KNN)算法是一种基本的分类和回归方法。其基本思想是:对于新的样本数据,通过计算其与训练集中的样本的距离,然后选取距离最近的K个样本,根据这K个样本的类别(对于分类问题)或者值(对于回归问题),通过多数表决或者加权平均的方式确定新样本的类别或者值。
在KNN算法中,K是一个用户定义的常数,表示选择最近邻的数量。K的选择会直接影响到算法的性能,一般来说,K值越小,模型对噪声和孤立点的敏感度越高,而K值越大,模型的平滑程度越高,但也可能导致模型欠拟合。
KNN算法不需要显式的训练过程,而是将训练集中的数据保存起来,当需要对新的样本进行预测时,直接在保存的数据集中进行搜索和计算。因此,KNN算法是一种懒惰学习(lazy learning)算法。
KNN算法的优点包括简单易懂、易于实现以及在训练集较大的情况下表现良好。然而,KNN算法的缺点也很明显,主要包括对数据集的高度依赖、计算复杂度高、对于高维数据和大规模数据集的效率低下等。
题目描述:
使用K近邻算法,构建一个预测鸢尾花种类的模型。
要求
- 加载鸢尾花数据集
- 对数据集进行划分:参数test_size=0.2,random_state=2
- 构建KNN模型:调用sklearn中的函数进行构建
- 训练模型
- 预测模型:选取测试集中的第3组数据(下标为2)进行预测
- 输出得到的预测值和真实值
代码:
from sklearn import datasets # 导入数据集模块# 加载鸢尾花数据集
iris = datasets.load_iris()
x = iris.data # 特征数据
y = iris.target # 类别标签# 划分数据集
from sklearn.model_selection import train_test_split
# 将数据集划分为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=2)# 构建模型
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3) # 使用K近邻算法,设置邻居数为3# 训练模型
knn.fit(x_train, y_train)# 模型预测
x_to_predict = x_test[2].reshape(1, -1) # 选取测试集中的第3组数据(下标为2)进行预测
y_predicted = knn.predict(x_to_predict)# 输出预测值和真实值
print("预测值:" + str(y_predicted)) # 输出预测的类别
print("真实值:" + str(y_test[2])) # 输出该样本在测试集中的真实类别结果如图:
3策树分类模型
决策树是一种基于树状结构的监督学习算法,用于解决分类和回归问题。在决策树中,每个内部节点表示一个特征属性上的判断条件,每个分支代表一个判断结果,每个叶子节点表示最终的分类结果或数值预测结果。
决策树的构建过程是一个递归地选择最佳特征进行分裂的过程,直到满足停止条件为止。在构建决策树时,一般会使用信息增益、基尼不纯度等指标来选择最佳的特征进行分裂,以使得每次分裂后的数据集更加纯净(即同一类别的样本更加集中)。
以下是决策树分类的一些重要知识点:
-
节点与叶子节点:决策树由节点和叶子节点组成。节点表示一个特征属性上的判断条件,叶子节点表示最终的分类结果。
-
分裂准则:在构建决策树时,需要确定节点分裂的准则。常用的准则包括信息增益、基尼不纯度等,用于选择最佳的特征进行分裂。
-
剪枝:为了避免过拟合,决策树需要进行剪枝操作。剪枝可以分为预剪枝(在构建树的过程中进行剪枝)和后剪枝(在构建完整棵树后再进行剪枝)。
-
特征选择:在每个节点上,需要选择最佳的特征进行分裂。常用的特征选择方法有信息增益、基尼指数、方差等。
-
决策树的优缺点:
- 优点:易于理解和解释,可视化效果好,能够处理数值型和类别型数据,对缺失值不敏感。
- 缺点:容易过拟合,对噪声数据敏感,不稳定,需要进行剪枝操作。
-
集成学习中的应用:决策树常被用于集成学习方法中,如随机森林和梯度提升树。这些方法通过组合多个决策树来提高分类准确率和泛化能力。
题目描述:
对红酒数据集创建决策树分类模型,并输出每个特征的评分。
要求
- 从sklearn的datasets模块中导入load_wine 包,读取红酒数据集,
- 转换为DataFrame格式,将数据集划分为特征样本和标签样本,
- 使用该数据集建立决策树分类模型,树深设置为5,随机种子设置为1,其他值设置为默认值
- 将数据放入模型中进行训练,要求输出每个特征的评分。
代码:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_wine# 加载红酒数据集
wine = load_wine()# 创建DataFrame格式的特征样本和标签样本
x_train = pd.DataFrame(data=wine["data"], columns=wine["feature_names"]) # 特征样本
y_train = wine["target"] # 标签样本# 建立决策树分类模型
model = DecisionTreeClassifier(max_depth=5, random_state=1)
model.fit(x_train, y_train) # 模型训练# 输出每个特征的评分(特征重要性)
print("每个特征的评分(特征重要性):")
for feature, importance in zip(wine["feature_names"], model.feature_importances_):print(f"{feature}:{importance:.4f}") # 对每个特征列进行评分相关文章:
机器学习知识点
1鸢尾花分类 鸢尾花分类问题是一个经典的机器学习问题,旨在根据鸢尾花的花萼长度、花萼宽度、花瓣长度和花瓣宽度等特征,将鸢尾花分成三个品种:山鸢尾(setosa)、变色鸢尾(versicolor)和维吉尼亚…...

SQL注入利用学习-Union联合注入
联合注入的原理 在SQL语句中查询数据时,使用select 相关语句与where 条件子句筛选符合条件的记录。 select * from person where id 1; #在person表中,筛选出id1的记录如果该id1 中的1 是用户可以控制输入的部分时,就有可能存在SQL注入漏洞…...

zookeeper源码(12)命令行客户端
zkCli.sh脚本 这个命令行脚本在bin目录下: ZOOBIN"${BASH_SOURCE-$0}" ZOOBIN"$(dirname "${ZOOBIN}")" ZOOBINDIR"$(cd "${ZOOBIN}"; pwd)"# 加载zkEnv.sh脚本 if [ -e "$ZOOBIN/../libexec/zkEnv.sh&qu…...

深度学习的数学基础--Homework2
学习资料:https://www.bilibili.com/video/BV1mg4y187qv/?spm_id_from333.788.recommend_more_video.1&vd_sourced6b1de7f052664abab680fc242ef9bc1 神经网络的特点:它不是一个解析模型,它的储存在一堆参数里面(确定一个超平…...

什么是HW,企业如何进行HW保障?
文章目录 一、什么是HW二、HW行动具体采取了哪些攻防演练措施三、攻击方一般的攻击流程和方法四、企业HW保障方案1.建意识2.摸家底3.固城池4.配神器5.增值守 一、什么是HW 网络安全形势近年出现新变化,网络安全态势变得越来越复杂,黑客攻击入侵、勒索病…...

【Redis系列】Spring Boot 集成 Redis 实现缓存功能
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
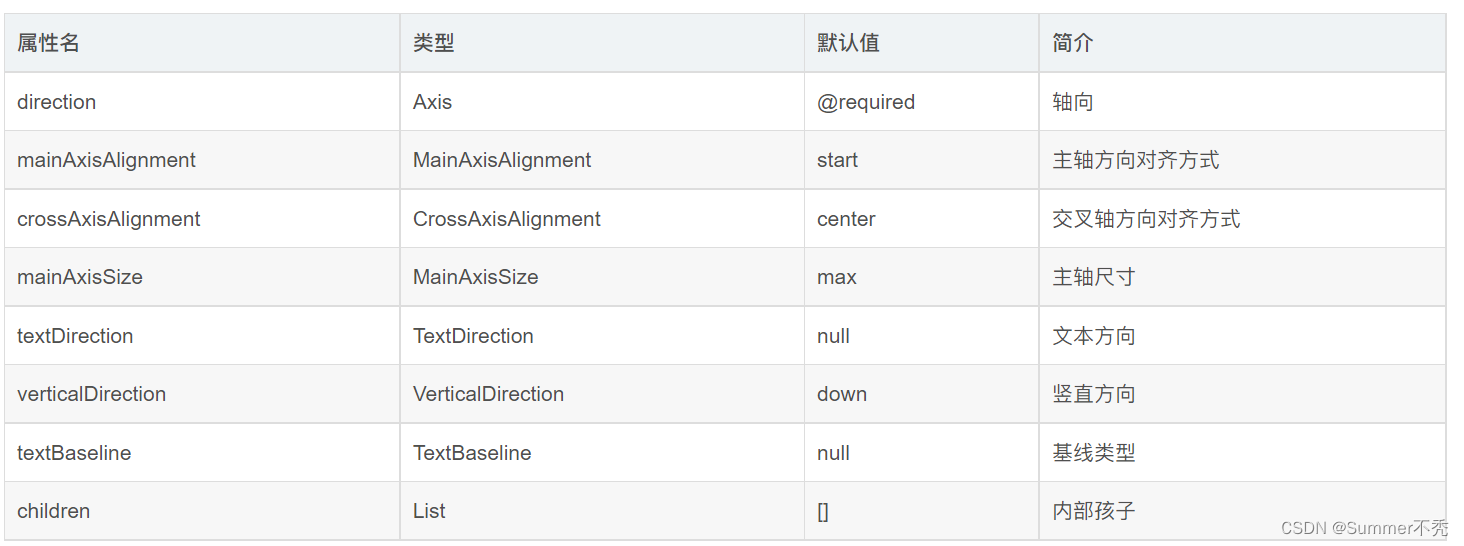
Flutter之Flex组件布局
目录 Flex属性值 轴向:direction:Axis.horizontal 主轴方向:mainAxisAlignment:MainAxisAlignment.center 交叉轴方向:crossAxisAlignment:CrossAxisAlignment 主轴尺寸:mainAxisSize 文字方向:textDirection:TextDirection 竖直方向排序:verticalDirection:VerticalDir…...
【Linux】TCP编程{socket/listen/accept/telnet/connect/send}
文章目录 1.TCP接口1.1socket文档 1.2listen拓:端口号8080 1.3accept拓:今天全局函数 1.4读写接口1.5telnet1.一个客户端2.两个客户端 1.6ulimit -a1.7常识回顾1.8connect1.9拓:客户端的ip和地址什么时候被分配?1.10拓:…...

【WPF应用33】WPF基本控件-TabControl的详解与示例
在Windows Presentation Foundation(WPF)中,TabControl控件是一个强大的界面元素,它允许用户在多个标签页之间切换,每个标签页都可以显示不同的内容。这种控件在组织信息、提供选项卡式界面等方面非常有用。在本篇博客…...

[C语言]——动态内存管理
目录 一.为什么要有动态内存分配 二.malloc和free 1.malloc 2.free 三.calloc和realloc 1.calloc 2.realloc 3.空间的释放编辑 四.常见的动态内存的错误 1.对NULL指针的解引用操作 2.对动态开辟空间的越界访问 3.对非动态开辟内存使用free释放 4.使用free释放⼀块…...
C++ 学习笔记
文章目录 【 字符串相关 】C 输入输出流strcpy_s() 字符串复制输出乱码 【 STL 】各个 STL 支持的常见方法 ? : 运算符switch case 运算符 switch(expression) {case constant-expression :statement(s);break; // 可选的case constant-expression :statement(s);break; //…...

本科生学深度学习一残差网络,解决梯度消失和爆炸
看到订阅的激励还在继续,今天写下残差网络 1、梯度爆炸和梯度消失 梯度爆炸和梯度消失是两种常见的问题,由神经网络的结构和参数初始化方式引起。它们都与深度神经网络中的反向传播过程相关。 梯度爆炸:这是指在反向传播期间,梯度逐渐增大并最终超出了有效范围。这通常发…...

初识SpringMVC
一、什么是MVC MVC是一种软件架构模式(是一种软件架构设计思想,不止Java开发中用到,其它语言也需要用到),它将应用分为三块: M:Model(模型)V:View(…...

【Leetcode】2009. 使数组连续的最少操作数
文章目录 题目思路代码复杂度分析时间复杂度空间复杂度 结果总结 题目 题目链接🔗 给你一个整数数组 n u m s nums nums 。每一次操作中,你可以将 n u m s nums nums 中 任意 一个元素替换成 任意 整数。 如果 n u m s nums nums 满足以下条件&…...

LeetCode-347. 前 K 个高频元素【数组 哈希表 分治 桶排序 计数 快速选择 排序 堆(优先队列)】
LeetCode-347. 前 K 个高频元素【数组 哈希表 分治 桶排序 计数 快速选择 排序 堆(优先队列)】 题目描述:解题思路一:哈希表记录出现次数,然后用最小堆取,因为每次都是弹出最小的,剩下的一定是K…...

K8S Deployment HA
文章目录 K8S Deployment HA1.机器规划2.前期准备2.1 安装ansible2.2 修改 hostname2.3 配置免密2.4 时间同步2.5 系统参数调整2.6 安装 Docker2.7 部署 HaproxyKeepalived 3. 部署 K8S3.1 安装 k8s命令3.2 k8s初始化3.3 添加其他master节点3.4 添加 Node节点3.5 安装 CNI3.6 查…...

【Linux】linux 在指定根目录下,查找wav文件并删除
要在Linux的指定根目录下查找.wav文件并删除它们,您可以使用find命令结合-exec选项来执行删除操作。请注意,这个操作是不可逆的,所以在执行之前请确保您知道自己在做什么,并且已经备份了重要数据。 以下是一个示例命令࿰…...
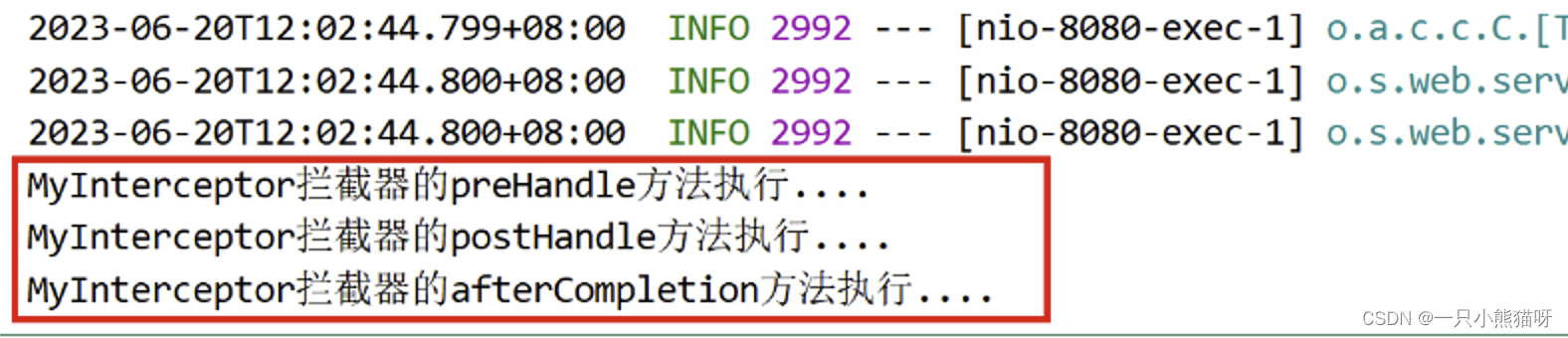
三、SpringBoot3 整合 SpringMVC
本章概要 实现过程web 相关配置静态资源处理自定义拦截器(SpringMVC 配置) 3.1 实现过程 创建程序引入依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www…...
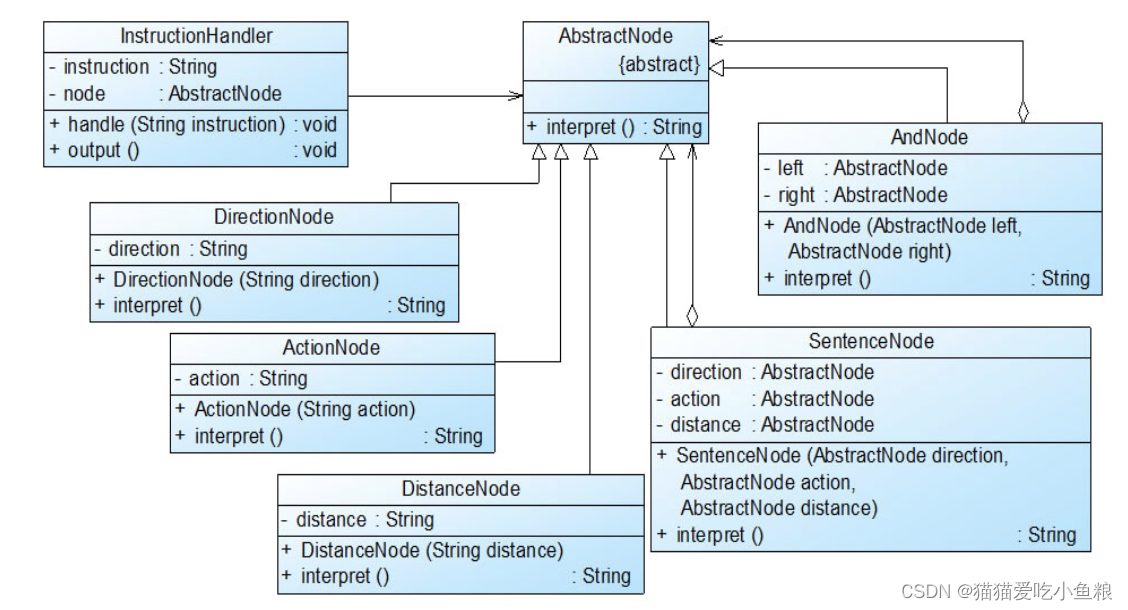
设计模式之解释器模式(上)
解释器模式 1)概述 1.定义 定义一个语言的文法,并且建立一个解释器来解释该语言中的句子,这里的“语言”是指使用规定格式和语法的代码。 2.结构图 3.角色 AbstractExpression(抽象表达式):在抽象表达…...

[23年蓝桥杯] 买二赠一
题目描述 【问题描述】 某商场有 N 件商品,其中第 i 件的价格是 A i 。现在该商场正在进行 “ 买二 赠一” 的优惠活动,具体规则是: 每购买 2 件商品,假设其中较便宜的价格是 P (如果两件商品价格一样, 则…...

在Python项目中集成多模型API实现智能对话功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Python项目中集成多模型API实现智能对话功能 对于需要在应用中集成AI对话能力的Python开发者而言,直接对接多个模型厂…...

Linux应用层直接操作硬件寄存器:原理、实现与安全实践
1. 项目概述:为什么要在应用层操作寄存器? 在嵌入式Linux开发或者驱动调试的日常工作中,我们常常会遇到一个看似“越界”的需求:在用户空间的应用层程序里,直接去读写某个硬件寄存器的值。这听起来有点“离经叛道”&am…...

告别‘数据孤岛’的幻想:深入拆解联邦学习Non-IID问题的根源与EMD度量
告别“数据孤岛”的幻想:联邦学习Non-IID问题的本质与实战应对 当企业兴奋地部署联邦学习系统时,常会遭遇这样的尴尬:模型在各方本地数据上表现优异,聚合后却性能骤降。这背后隐藏着一个被低估的真相——数据天然独立同分布&#…...

期权量化交易基础库:模块化设计与回测实战指南
1. 项目概述:一个为期权交易者打造的“地基” 如果你在量化交易或者期权策略开发领域摸爬滚打过一段时间,大概率会和我有同样的感受:每次想测试一个新想法,都得从零开始搭建数据接口、计算希腊字母、管理仓位、回测框架……这些重…...

QMCDump终极指南:快速免费解锁QQ音乐加密文件,重获数字音乐自由 [特殊字符]
QMCDump终极指南:快速免费解锁QQ音乐加密文件,重获数字音乐自由 🎵 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.co…...

Taotoken多模型聚合平台助力每日大赛选手灵活选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken多模型聚合平台助力每日大赛选手灵活选型 对于每日参与算法或创意大赛的选手而言,赛题往往多变,需…...

不止于仿真:用Vivado自带的仿真器做FPGA设计验证与快速迭代
从仿真到验证:Vivado仿真器在FPGA设计中的高阶应用 在FPGA开发领域,仿真环节常常被工程师视为"不得不做"的流程性工作,而非设计验证的核心手段。这种认知导致许多项目陷入"烧录-调试-修改"的循环中,消耗大量时…...

5秒无损转换B站缓存视频:m4s-converter完整使用指南
5秒无损转换B站缓存视频:m4s-converter完整使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了珍贵的学习…...

3个维度深度解析:UABEA如何重塑Unity资源处理生态
3个维度深度解析:UABEA如何重塑Unity资源处理生态 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 在Unity游戏开发和资源处理的复杂生态中,开发者常常面临一个核心挑战…...

ARM Cortex-X4/X925处理器仿真模型与指令集详解
1. ARM Cortex-X4/X925处理器仿真模型概述处理器仿真模型在现代芯片设计中扮演着至关重要的角色,特别是在Arm架构的生态系统中。作为Arm最新一代高性能核心,Cortex-X4和X925的Iris仿真组件提供了完整的指令集和微架构行为建模,使开发者能够在…...