海山数据库(He3DB)原理剖析:浅析Doris跨源分析能力
-
Doris湖仓分析背景:

Doris多数据源功能演进
Doris的生态近年来围绕湖仓分析做了较多工作,Doris一直在积极拓宽大数据生态的OLAP分析市场,Doris2.0之后为了满足湖仓分析场景,围绕multi-catalog、数据缓存、容错、pipeline资源管理等做了不少改进。
首先在multi-catalog之前,Doris访问Hive表需要单表映射或者整库映射,如果用户的Hive库特别多的话,库级别的一一映射对于用户也很繁琐,索引在库的上层加一个catalog级别(catalog多数据源应该都是学习的Presto),一个catalog对应一个数据源(所有库和表),简化用户从Doris访问外部数据源的方式。 Hive社区(HiveServer2引擎)之前也想去做这种catalog的方式进行跨源查询,但受限于架构改造太以及社区内本身对该功能呼声并不高,所以只做到了database整库级别的外部数据源映射,且主要是jdbc数据源。
可以说目前多catalog的这种架构已经成为跨源联邦分析的标准架构,这种架构以Trino/Presto为典型代表,近两年流行的OLAP引擎在跨源改造方面基本上都会向Presto看齐,满足自身架构的跨源分析能力。

Doris multi-catalog支持的主要数据源
Apache Hive数据源是Doris较早支持也是投入开发最多的一个外部数据源,支持hive表的查询分区/分桶过滤,支持搜集hive表统计信息做cbo优化(典型的join优化,使用统计信息做join reorder,加速复杂join查询),基本上内部表能用的优化特性,在以Hive/Iceberg表为代表的主流湖格式上都用到了。
我们可以看到无论是Apache Hive还是Trino/Spark集成Iceberg表,都会去利用Iceberg丰富的元数据信息(如min/max)做统计信息优化cbo,该优化已经成为业内的共识。但计算引擎不仅可以利用Iceberg这种湖格式自身的元数据进行cbo优化,还可以考虑对湖格式元数据进一步扩展,获取更细粒度的统计信息,如Trino社区使用puffin存储Iceberg统计信息,做更好地优化。所以Doris如果考虑深度集成数据湖表格式,需要考虑怎么利用湖格式的元数据信息做最大化的优化。

Doris复用Trino的connector
湖仓联邦分析本质上是跨源分析,做跨源最专业的莫过于Trino,而Doris绝大多数围绕联邦分析的能力/技术点都合Trino非常类似,所以在这种联邦分析场景上Doris想要进一步发展:
1)Doris兼容Trino语义
Trino在大数据领域OLAP发展多年,生态做的很好,有较广泛的用户,如何取代Trino的部分业务场景一直是Doris尝试去做的事情。取代Trino业务,重要的是用户的Trino业务无缝迁移至Doris,对于用户修改业务SQL是最繁琐的事,兼容Trino的SQL语义自然是Doris首要想做的事情。这里Doris内部解析Trino SQL语法树,最后转成Doris自己的语法,完成用户业务的无感迁移。
2)Doris复用Trino connector(该特性还未做)
Trino是业内专业跨源分析的标杆,而Trino的可插拔connector机制允许任何数据源去实现然后利用Trino算力计算。那么能够复用Trino丰富的connector来增强Doris的跨源能力将是一个非常巧妙的事情。一个是用户现有的connector不需要任何改动放到Doris上就可以查询;另一个是Doris自身不需要维护众多的connector,可以大大减少Doris开发人员的工作量。
业内有不少案例,做跨源分析时都会围绕Trino做文章,有部分厂商甚至考虑在OLAP中内部启动一个Trino集群做跨源分析,相当于直接复用Trino全部能力,省时省事!
一、multi-catalog基本使用
简单贴一些Doris multi-catalog的使用方式,以提供一个直观认识:
1.创建一个hive catalog,名称为hive(可用其他名),可以既可以查询hive表,也可以查询iceberg/hudi/paimon表
CREATE CATALOG hive PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://localhost:9083',
'hadoop.username' = 'hive'
);
2.创建iceberg的catalog,只允许看到库下的iceberg表
CREATE CATALOG iceberg PROPERTIES (
'type'='iceberg',
'iceberg.catalog.type'='hms',
'hive.metastore.uris' = 'thrift://localhost:9083',
'hadoop.username' = 'hive'
);
3.catalog.db.tbl三级目录定位联邦查询查询多个catalog,和Presto使用体验一样
select * from hive.testdb.tbl01 a join iceberg.testdb.tbl02 b on a.id = b.id;
总体而言,针对Hive/Iceberg这种湖格式,从功能层面以及性能优化层面,Doris做的算是较完善,跨源功能点的开发基本上都会优先聚焦于这种湖格式。我们也看到近年来的趋势,越来越多的中小企业更喜欢使用简单的大数据分析架构进行数据分析,兼具实时分析以及湖仓分析能力的Doris自然会成为众多企业优先考虑对象。尤其是在企业数据源多种多样的情况下,利用Doris这种多catalog能力进行加速分析/湖仓分析,一定程度上为企业带来降本增效的益处。
二、外部元数据管理

Doris 数据湖元数据缓存/同步
数据湖本身具备完善的元数据体系,Doris查询的数据湖数据的时候,需要考虑如何统一管理数据湖元数据,这里我的直观感受采用和Presto一样常规的做法,拉取数据湖元数据缓存至内存,通过手动设置、定时任务刷新缓存解决元数据缓存和远端元数据同步问题。
但Doris这里做的比较好的一点是针对HMS的各种action(drop table/Drop database等)做了事件同步(Apache Impala也有类似能力),可以最大程度做到细粒度的元数据实时同步更新。但是这种HMS的事件监听同样会对HMS带来一定的高负载,比如单表分区很多时进行分区修改/删除,HMS的瞬时负载会很高。所以我们可以看到,大数据生态中很多时候针对某一个问题并没有完美的解决方案,更多的是一种trade-off。
三、一致性数据缓存&CN节点

local cache加速
湖仓分析可以避免用户把数据ETL搬迁到Doris内部存储,用户分析更加灵活,但湖仓分析架构其实属于存算分离架构的一个典型,而存算分离主要的问题是可能会带来一定的数据读取网络消耗,一定程度上会影响查询延时。
这里Local cache是一种常见的远端数据拉取加速手段,可以有效减少跨网络数据传输带来的延时以及带宽消耗。针对外部数据源,Doris在be侧做了一致性file block local cache,缓存热点数据,一致性哈希的使用主要有两点好处:
1)由于远端数据不属于Doris内部数据,所以查询不会访问be侧的存储,所以Doris fe端在针对外部数据源做查询规划的时候,其实会随机be进行查询,这样每次查询可能会使用不同的be,be侧都会重新拉取一份缓存,会降低查询效率。一致性hash则可以尽可能的让查询发送到已经存在缓存的be节点上,避免查询的不稳定性。
2)Doris的CN(compute node)节点是针对数据湖这种外部数据源(Doris CN节点目前不能查询内部存储表),CN节点只负责计算,没有存储,CN节点带来好处是可以方便k8s容器化部署以及基于k8s的弹性伸缩,若使用CN节点访问数据湖数据,不停的扩缩节点,会导致缓存数据的重分布。一致性hash则可以尽可能的避免在CN节点扩缩的时候缓存重分布。
一致性hash缓存似乎是所有存算分离下的云数仓标配,如doris、hashdata。是否有更好的替代方案?
我们看到专注缓存能力开发的Alluxio社区做了一个非常好的功能,提供了一个标准的sdk,引擎实现部分接口,就可以使用Alluxio做local cache,而不需要部署Alluxio集群,其实这个能力就是两年前Alluxio贡献给PrestoDB的功能(PrestoDB代号RaptorX工程),只是Alluxio现在把这个功能抽象独立于引擎之外了,可以允许其他引擎方便使用Alluxio做本地的cache。那么Doris是否可以考虑抽象缓存接口对接外部缓存系统?
当前Doris其实还都是本地节点缓存,带来的一个缺点是节点丢失缓存也会丢失,丢失的缓存数据下次还需要重新拉取;而且如果考虑存算分离多计算集群下,每个集群都会缓存同样的数据,如果有了分布式缓存是不是就不需要考虑这种一致性hash,同时解决存算分离下多集群数据缓存重复?
Doris社区提到未来存算分析架构下可能会把be做成一个分布式缓存,来彻底解决缓存数据和节点耦合的情况。
四、湖仓查询/即席负载隔离/查询稳定性建设

Doris新一代Pipeline执行引擎
multi-catalog功能层面上集成开发相对比较容易,比较困难的是如何保证跨源查询尤其是大数据量的湖仓查询的稳定性?
个人认为稳定性建设是评估一个引擎能不能持久吸引用户的一个最重要指标。湖仓查询的主要特征是数据量很大,查询很复杂,如果OLAP引擎内核不够健壮,一个湖仓的查询可能就会把OLAP所有节点宕掉。Doris最初的架构满足不了这种查询,Doris2.0之后,社区做了内核层面上的一些演进,以满足Doris在多种类型负载下的稳定查询。这里主要聚焦于针对集群稳定建设Doris所做的资源精细化管理的一些工作。Doris原有的火山模型计算模型并不能很好地处理大查询尤其是湖仓大数据分析,该模型在集群资源上能力较弱,且较多依赖于人工调优,Doris2.0的pipeline引入一个是可以集群自动根据负载调整计算并行度避免过多人工干预;
另一个更重要的是pipeline可以精细化控制单个节点内的资源管理,以及可以对算子进行更多的控制,比如大查询需要用的spill task(算子落盘,轻量级容错能力)来进行稳定查询,那么有了pipeline框架,就可以做更好的资源管理、算子控制,可以更多地稳定数据湖的海量数据查询。但是虽然可以做到一定的单节点资源精细化管理,对于用户要求业务SLA高的情况,存算分离下的云数仓一般还是需要起多个计算集群,实现读写分离,这也是selectdb、hahsdata目前云上数仓的形态,这样可以做到绝对的物理资源隔离。

Doris 资源管理模型
WorkLoad Group资源软限是基于pipeline执行模型。这种资源隔离有点类似yarn队列形式,可以对单个节点内部进行cpu/mem的细粒度拆分,能够更好地应该不同的工作负载(etl/adhoc),尤其是湖仓大查询下,尽可能细粒度限制不同查询使用资源,保证并发查询能够顺利进行。相较于之前的resource group,能最大化利用集群资源并能做到相对好的控制,保证集群的整体稳定性。
这里我们可以看到,Doris为了更好的支持多种负载的并发稳定调度,内核调度/资源管理层面做了很大优化。尤其Pipeline计算模型、资源细粒度管理、算子落盘等能力是实现湖仓融合查询稳定建设的第一步,这些优化在Presto中已经演进了多年,Presto本身就是Pipeline计算架构,在资源管理层面也做了多种细粒度控制;
Presto尤其针对算子容错做了更多的优化,如中间结果物化/分组执行,query级别/task级别的恢复,更有Presto on Spark这种复用Spark shuffle能力来解决大查询的容错问题,所以各家OLAP引擎都在用类似的手段进行湖仓查询稳定性建设。
五、湖仓一体高阶特性

Doris技术会议-湖仓能力开发规划
现在流行的数据湖格式如Iceberg,其最亮眼的地方莫过于其多版本元数据管理能力,基于其多版本元数据,上层计算引擎可以做很多有意思的功能,比如timetravel、比如git风格的branch&tag特性,版本回滚等高阶能力。这种能力给用户带来了较多业务开发上的高效以及容错。比如用户数据误删可以进行版本回溯,比如用户在业务上线之前可以切多个branch分支,在分支上进行数据增删改,而切分支是一个metadata操作不涉及到数据拷贝,不像传统hive表开发需要复制一个新表测试(涉及到数据的二次拷贝)。
cdc能力,这里指数据湖格式具备cdc能力,如iceberg本身已经具备cow的cdc数据,那么如果用户想要对这种Iceberg表进行灾备复制,就可以读取其cdc数据进行增量备份。这种cdc集成是比较好做的,多数只涉及到读,调用湖格式开发的接口即可。似乎很多引擎都在考虑做这种高阶特性,如databend、hashdata。Apache Hive和Apache Spark通过集成iceberg已经完成这种git方式的元数据操作。高阶特性在引擎集成完善之后,然后赋能数据开发用户,我相信数据开发流程也会变得更加高效和有趣。
六、小结
Doris2.0之后围绕湖仓多源分析做了不少的工作,这些改造补全了Doris之前架构的部分短板,虽然基本上Doris围绕湖仓跨源分析的工作(pipeline/资源隔离/multi-catalog/容错)在Trino社区早已经做完且做的更完善,但Doris在多源分析上本身处于一个快速演进中,相信不久也会功能更加完善性能更加高效稳定。所以Doris社区整个发展的态势上更像是一个后来居上的三好学生,集百家之长应用在自身。
说几点和Trino差异较大的几个点:
1)更丰富的数据源connector。Doris数据源较少,Trino的很多且功能相对完善;
2)Doris目前没有一个相对彻底的容错架构;Trino有本地shuffle风格的容错框架(注意Trino为了支持shuffle容错支持了另一种调度模型,不同于其默认的pipeline)--典型应用:公有云spot instance竞价实例上运行计算;以及PrestoDB的on spark项目;
3)更完善的算子下推能力:Doris2之后针对数据湖查询做了一些优化;Trino/Presto相对做的更加完善,可以尽可能在scan阶段减少数据;
4)核心架构上的一个存算分离:Doris目前存算分离还没做好;Trino本身就是一个彻底的存算分离架构,灵活性更好;
5)C++ native执行引擎 VS Java:Doris的核心优势,C++ 向量化,计算加速起飞;而Trino一直坚持使用最新版本JDK进行向量化计算,当前已经开始默认JDK21,JDK21可以更直接调用vector向量计算;PrestoDB社区目前则全面拥抱C++ native引擎(velox,intel的人也在搞spark结合gluten+velox做native引擎计算);
6)社区文化:Trino社区开发除了部分主力,还有国内外大厂持续贡献,可以在PR或者issue上看到多年前的详细讨论,多数功能点都有据可循,社区文化(Github&Slack)开放且活跃;Doris的GitHub上PR&issue多数上的讨论很少,主要是国内开发者基本上线上微信或者线下沟通,个人感觉这种社区文化只能在国内持续,国外的人很难参与,一定程度影响Doris国际化。
七、参考
(注意:文中图片主要来源于Doris公开技术会议)
1)Doris内存管理:
https://www.infoq.cn/article/1e9fghrhs6rvvpkerms2
2)存算分离新架构:
https://zhuanlan.zhihu.com/p/646999190 Doris
3)数据湖分析:
https://www.bilibili.com/video/BV13y4y1c7WH/?spm_id_from=333.337.searchcard.all.click&vd_source=62c3915345dce64bde0eb3a73508f6d6 Doris submit asia
4)Doris2.0 特性解读:
https://www.bilibili.com/video/BV15p4y1A7bw/?spm_id_from=333.337.search-card.all.click
5)Doris2.0 pipeline执行模型设计文档:
https://cwiki.apache.org/confluence/display/DORIS/DSIP-027%3A+Support+Pipeline+Exec+Engine
八、作者介绍
张步涛,中国移动云能力中心数据库产品部-OLAP数据库开发工程师。主要参与OLAP内核优化/湖仓一体分析的研发。
相关文章:
海山数据库(He3DB)原理剖析:浅析Doris跨源分析能力
Doris湖仓分析背景: Doris多数据源功能演进 Doris的生态近年来围绕湖仓分析做了较多工作,Doris一直在积极拓宽大数据生态的OLAP分析市场,Doris2.0之后为了满足湖仓分析场景,围绕multi-catalog、数据缓存、容错、pipeline资源管理…...

第十三届蓝桥杯大赛软件赛省赛C/C++ 大学 B 组 题解
VP比赛链接 : 数据加载中... - 蓝桥云课 1 . 九进制 转 十进制 直接模拟就好了 #include <iostream> using namespace std; int main() {// 请在此输入您的代码int x 22*92*81*9;cout << x << endl ;return 0; } 2 . 顺子日期 枚举出每个情况即可 : …...

20240324-1-集成学习面试题EnsembleLearning
集成学习面试题 1. 什么是集成学习算法? 集成学习算法是一种优化手段或者策略,将多个较弱的模型集成模型组,一般的弱分类器可以是决策树,SVM,KNN等构成。其中的模型可以单独进行训练,并且它们的预测能以某…...

默克尔(Merkle)树 - 原理及用途
默克尔(Merkle)树的原理以及用途 引言 在当今数字化时代,确保数据的完整性是至关重要的。默克尔树作为一种高效的数据结构,被广泛应用于网络安全、分布式系统以及加密货币等领域,用于验证大量数据的完整性和一致性 数…...

设计模式:迭代器模式
迭代器模式的示例可以涵盖各种数据结构的遍历,包括数组、列表、树、图等。下面是一些不同场景下迭代器模式的示例及其代码实现。 示例 1: 数组遍历 使用迭代器模式遍历数组。 // 迭代器接口 interface Iterator<T> {boolean hasNext();T next(); }// 数组迭…...

Navicat Premium 16常用快捷键
打开一个新的查询窗口: Ctrl Q 关闭当前窗口: Ctrl W 运行当前窗口的SQL语句: Ctrl R 运行选中的SQL语句: Ctrl Shift R 注释选中的SQL语句: Ctrl / 取消注释SQL: Ctrl Shift / 保存连接&…...

LeetCode笔记——1042.不邻接植花
题目 有 n 个花园,按从 1 到 n 标记。另有数组 paths ,其中 paths[i] [xi, yi] 描述了花园 xi 到花园 yi 的双向路径。在每个花园中,你打算种下四种花之一。 另外,所有花园 最多 有 3 条路径可以进入或离开. 你需要为每个花园…...

Centos7搭建 Skywalking 单机版
介绍 Skywalking是应用性能监控平台,可用于分布式系统,支持微服务、云原生、Docker、Kubernetes 等多种架构场景。 整体架构如图 Agent :在应用中,收集 Trace、Log、Metrics 等监控数据,使用 RPC、RESTful API、Kafk…...

定制您的设备体验:如何更改Android启动动画
“bootanim"通常是指在操作系统启动过程中显示的动画,尤其是在移动设备或某些定制的Linux发行版中较为常见。这个术语并不是一个标准的命令或工具名称,而是通常用来描述"启动动画”(boot animation)的简称。在Android设备中,启动动…...

Docker日常系列
一、如何build双架构(AMDRAM)镜像 (1) 需求描述 当k8s集群的硬件资源为ARMAMD混合架构时,镜像需要同时支持2种架构,如何构建镜像。 (2) 操作 准备工作:需要将代码在不同架构下build为镜像,以下默认我们…...

Midjourney该怎么用?从零基础到落地实践
前言 从注册登录到基本的操作界面,提示词组成后缀介绍,到主流的生成图片的方式,以及最重要的提示词咒语分享,还有一些我的使用心得,希望对大家有帮助! 喜欢的话欢迎关注我,欢迎点赞收藏评论&am…...
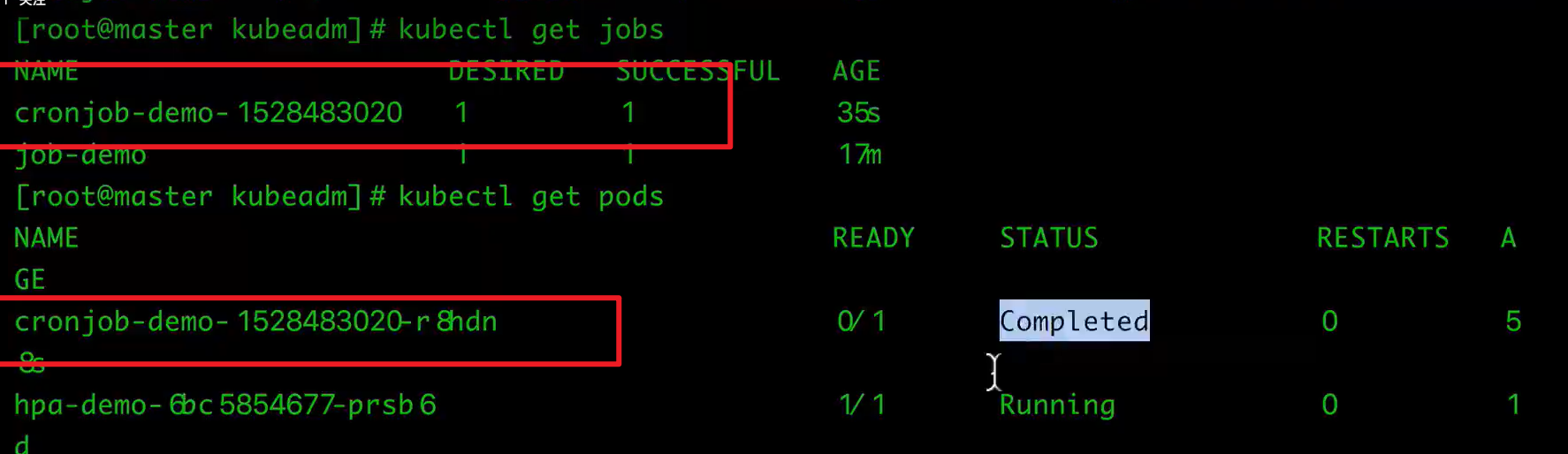
K8S:常用资源对象操作
文章目录 一、使用Replication Controller(RC)、Replica Set(RS) 管理Pod1 Replication Controller(RC)2 Replication Set(RS) 二、Deployment的使用1 创建2 滚动升级3 回滚Deployment三、 Pod 自动扩缩容HPA1 使用kubectl autosc…...

算法刷题应用知识补充--基础算法、数据结构篇
这里写目录标题 枚举结 排序结 模拟结 二分题结 高精度加、乘题结 减题结 除题结 结 位运算(均是拷贝运算,不会影响原数据,这点要注意)&、|、^位运算特性细节知识补充对于n-1的理解异或来实现数字交换找到只出现一次的数据&am…...

ngnix的反向代理是什么?有什么作用?
1、Nginx的反向代理是什么? Nginx的反向代理是一种网络架构模式,其中Nginx服务器作为前端服务器,接收客户端的请求,然后将这些请求转发给后端服务器(例如Java应用程序服务器)。在这个过程中,客…...

Windows程序设计课程作业-1
文章目录 1. 作业内容2. 设计思路分析与难点3. 代码实现3.1 接口定义3.2 工厂类实现3.3 委托和事件3.4 主函数3.5 代码运行结果 4. 代码地址5. 总结&改进思路6. 阅读参考 1. 作业内容 使用 C# 编码(涉及类、接口、委托等关键知识点),实现…...

2024年河北省网络建设与运维-省赛-nginx 和tomcat 服务服务步骤
题目: 5.nginx 和tomcat 服务 任务描述:利用系统自带tomcat,搭建 Tomcat网站。 (1)配置 linux2 为 nginx 服务器,网站目录为/www/nginx,默认文档 index.html 的内容为“HelloNginx”…...
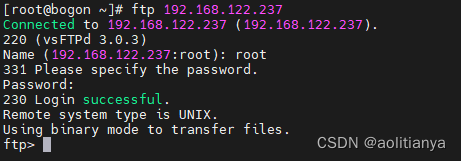
CentOS下部署ftp服务
要在linux部署ftp服务首先需要安装vsftpd服务 yum install vsftpd -y 安装完成后需要启动vsftpd服务 systemctl start vsftpd 为了能够访问ftp的端口,需要在防火墙中开启ftp的端口21,否则在使用ftp连接的时候会报错No route to host. 执行如下命令为f…...
伦敦银几点开盘?为什么交易不了?
近期是西方的假期,伦敦银市场因而休市。很多朋友看到之前伦敦银上涨那么厉害,正摩拳擦掌准备入场大展拳脚,然而现在却吃了一个大瘪:怎么我刚准备好大展拳脚,结果却没有开盘呢?到底伦敦银几点开盘࿱…...

快手开放平台对接内容管理demo
其中包括用户授权,获取accessToken,获取用户信息,自动上传视频,发布视频,视频列表,删除视频等 <?php namespace app\controller;use app\BaseController; use think\Exception; use think\facade\App;…...

2024年32款数据分析工具分五大类总览
数据分析工具在现代商业和科学中扮演着不可或缺的角色,为组织和个人提供了深入洞察和明智决策的能力。这些工具不仅能够处理大规模的数据集,还能通过强大的分析和可视化功能揭示隐藏在数据背后的模式和趋势。数据分析工具软件主要可以划分为以下五个类别…...

基于ARM嵌入式平台与AI视觉的输电线路智能巡检系统设计与实现
1. 项目概述:输电线路巡检的智能化转型 输电线路作为电力系统的“大动脉”,其安全稳定运行至关重要。传统的线路巡检主要依赖人工,巡检人员需要跋山涉水,通过望远镜、红外测温仪等设备进行观测和记录。这种方式不仅劳动强度大、效…...

【依赖冲突实战】Java NoSuchFieldError:从版本地狱到优雅解决
1. 当Java程序突然崩溃:NoSuchFieldError的典型症状 那天下午我正在调试一个微服务项目,突然控制台抛出个鲜红的异常: java.lang.NoSuchFieldError: MAX_RETRY_COUNT这个错误看似简单,却让我花了三小时才找到根源。项目里明明有MA…...

Markmap 思维导图转换工具:3种方案解决Markdown可视化难题
Markmap 思维导图转换工具:3种方案解决Markdown可视化难题 【免费下载链接】markmap Build mindmaps with plain text 项目地址: https://gitcode.com/gh_mirrors/ma/markmap 在信息爆炸的时代,如何将结构化的Markdown笔记高效转换为直观的思维导…...

游戏存档管理终极指南:告别背包焦虑的5大解决方案
游戏存档管理终极指南:告别背包焦虑的5大解决方案 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 还在为游戏中的装备堆积如山而烦恼吗?每次冒险归来…...

Hanime1Plugin终极指南:打造纯净Android动漫观影体验的免费神器
Hanime1Plugin终极指南:打造纯净Android动漫观影体验的免费神器 【免费下载链接】Hanime1Plugin Android插件(https://hanime1.me) (NSFW) 项目地址: https://gitcode.com/gh_mirrors/ha/Hanime1Plugin 你是否厌倦了在Android设备上看动漫时被各种广告打断&a…...

使用taotoken后matlab调用大模型api的延迟与稳定性体验分享
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用taotoken后matlab调用大模型api的延迟与稳定性体验分享 1. 背景与接入动机 在数据处理与科学计算项目中,我们经常…...

终极无人机仿真平台XTDrone:从入门到精通的完整指南
终极无人机仿真平台XTDrone:从入门到精通的完整指南 【免费下载链接】XTDrone UAV Simulation Platform based on PX4, ROS and Gazebo 项目地址: https://gitcode.com/gh_mirrors/xt/XTDrone XTDrone是一款基于PX4飞控、ROS机器人操作系统和Gazebo物理引擎的…...

第20章:Skill ≠ Prompt——从提示词到可复用技能的范式升级
第20章:Skill ≠ Prompt——从提示词到可复用技能的范式升级 20.1 问题定义:为什么"保存Prompt"不够 很多团队的做法是:把常用的Prompt保存在文档或笔记中,需要时复制粘贴。这看起来合理,但存在三个根本问题: 不可版本化:Prompt是散落的文本片段,没有版本号…...

Arch Linux Hyprland自动化安装脚本:高效打造现代化Wayland桌面环境
Arch Linux Hyprland自动化安装脚本:高效打造现代化Wayland桌面环境 【免费下载链接】Arch-Hyprland For automated installation of Hyprland on Arch Linux or any Arch Linux-based distros 项目地址: https://gitcode.com/gh_mirrors/ar/Arch-Hyprland A…...

前端新玩具:用几行JavaScript在网页上控制你的游戏手柄和绘图板
前端新玩具:用几行JavaScript在网页上控制你的游戏手柄和绘图板 当游戏手柄的震动反馈通过网页触发,当数位板的压感数据实时映射到Canvas画布——这些曾需要原生应用才能实现的交互,如今在浏览器中只需几行JavaScript代码。Web HID API的诞生…...