chabot项目介绍
项目介绍
- 整体的目录如下所示:
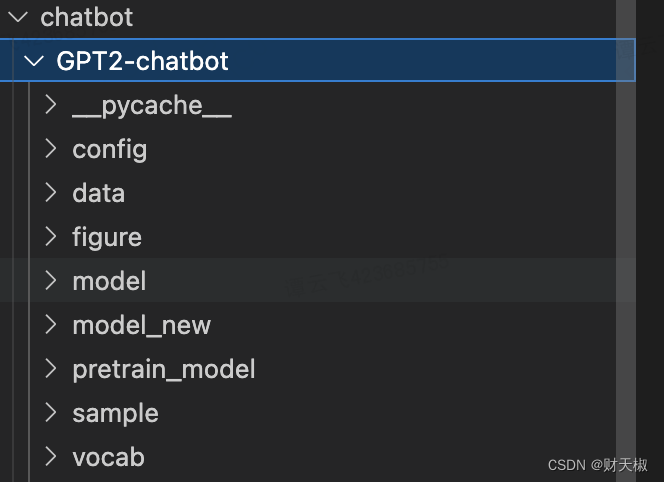
- 上述的项目结构中出了model是必须的外,其他的都可以根据训练的代码参数传入进行调整,有些不需要一定存在
- data
- train.pkl:对原始训练语料进行tokenize之后的文件,存储一个list对象,list的每条数据表示一个多轮对话,表示一条训练数据
- model:存放对话生成的模型
- config.json:模型参数的配置文件
- pytorch_model.bin:模型文件 - vocab
- vocab.txt:字典文件。默认的字典大小为13317,若需要使用自定义字典,需要将confog.json文件中的vocab_size字段设为相应的大小。
- sample:存放人机闲聊生成的历史聊天记录
- train.py:训练代码
- interact.py:人机交互代码
- preprocess.py:数据预处理代码
项目的整体运行流程
- 第一步:数据模块, 根据后面的数据集地址介绍进行数据集的下载,里面有各个地方的数据集来源以及数据合并的代码
- 第二步:将得到的数据通过preprocess.py文件进行训练数据处理,得到train.pkl文件,得到后再整个项目目录下创建data文件夹,并将得到的train.pkl文件移动到data文件夹下面
- 第三步:去huggingface网站上面下载gpt2预训练模型下的文件,具体需要下载的文件如下所示:
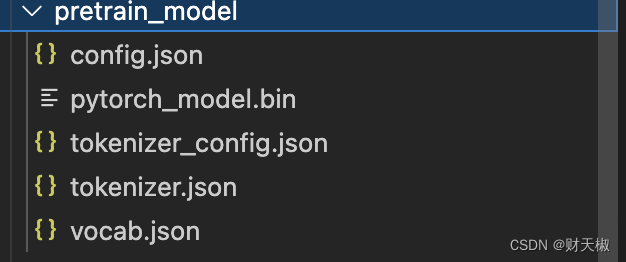
- 第四步:运行train.py文件训练得到再收集的数据集上面的微调模型
- 第五步:通过chatbot.py对模型进行人机交互和推理
数据集地址
- https://github.com/codemayq/chinese-chatbot-corpus, 安装上面的readme运行就可以得到相应的数据集
- 然后再运行上面的preprocess.py就可以得到相关的训练数据集train.pkl
训练代码train.py
import argparse
import math
import time
import torch
import torch.nn.functional as F
import torch.optim as optim
import logging
from datetime import datetime
import os
from torch.utils.data import Dataset, DataLoader
from os.path import join, exists
from torch.nn import CrossEntropyLoss
from tqdm import tqdm
from torch.nn import DataParallel
import transformers
import pickle
import sys
from pytorchtools import EarlyStopping
from sklearn.model_selection import train_test_split
from data_parallel import BalancedDataParallel
from transformers import GPT2TokenizerFast, GPT2LMHeadModel, GPT2Config
from transformers import BertTokenizerFast
import pandas as pd
import torch.nn.utils.rnn as rnn_utils
import numpy as np
from dataset import MyDatasetdef set_args():parser = argparse.ArgumentParser()parser.add_argument('--device', default='3', type=str, required=False, help='设置使用哪些显卡')parser.add_argument('--no_cuda', action='store_true', help='不使用GPU进行训练')parser.add_argument('--vocab_path', default='vocab/vocab.txt', type=str, required=False,help='词表路径')parser.add_argument('--model_config', default='config/config.json', type=str, required=False,help='设置模型参数')parser.add_argument('--train_path', default='data/train.pkl', type=str, required=False, help='训练集路径')parser.add_argument('--max_len', default=150, type=int, required=False, help='训练时,输入数据的最大长度')parser.add_argument('--log_path', default='data/train.log', type=str, required=False, help='训练日志存放位置')parser.add_argument('--log', default=True, help="是否记录日志")parser.add_argument('--ignore_index', default=-100, type=int, required=False, help='对于ignore_index的label token不计算梯度')# parser.add_argument('--input_len', default=200, type=int, required=False, help='输入的长度')parser.add_argument('--epochs', default=20, type=int, required=False, help='训练的最大轮次')parser.add_argument('--batch_size', default=64, type=int, required=False, help='训练的batch size')parser.add_argument('--gpu0_bsz', default=10, type=int, required=False, help='0号卡的batch size')parser.add_argument('--lr', default=2.6e-5, type=float, required=False, help='学习率')parser.add_argument('--eps', default=1.0e-09, type=float, required=False, help='衰减率')parser.add_argument('--log_step', default=1, type=int, required=False, help='多少步汇报一次loss')parser.add_argument('--gradient_accumulation_steps', default=4, type=int, required=False, help='梯度积累')parser.add_argument('--max_grad_norm', default=2.0, type=float, required=False)parser.add_argument('--save_model_path', default='model_new', type=str, required=False,help='模型输出路径')parser.add_argument('--pretrained_model', default='./pretrained_model', type=str, required=False,help='预训练的模型的路径')# parser.add_argument('--seed', type=int, default=None, help='设置种子用于生成随机数,以使得训练的结果是确定的')parser.add_argument('--num_workers', type=int, default=0, help="dataloader加载数据时使用的线程数量")parser.add_argument('--patience', type=int, default=0, help="用于early stopping,设为0时,不进行early stopping.early stop得到的模型的生成效果不一定会更好。")parser.add_argument('--warmup_steps', type=int, default=4000, help='warm up步数')# parser.add_argument('--label_smoothing', default=True, action='store_true', help='是否进行标签平滑')parser.add_argument('--val_num', type=int, default=8000, help='验证集大小')args = parser.parse_args()return argsdef create_logger(args):"""将日志输出到日志文件和控制台"""logger = logging.getLogger(__name__)logger.setLevel(logging.INFO)formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')# 创建一个handler,用于写入日志文件file_handler = logging.FileHandler(filename=args.log_path)file_handler.setFormatter(formatter)file_handler.setLevel(logging.INFO)logger.addHandler(file_handler)# 创建一个handler,用于将日志输出到控制台console = logging.StreamHandler()console.setLevel(logging.DEBUG)console.setFormatter(formatter)logger.addHandler(console)return loggerdef collate_fn(batch):input_ids = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=0)labels = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=-100)return input_ids, labels# def padding_batch(data_list, pad_id):
# """
# 使用pad_id将data_list的每条数据,填充至data_list中最长的长度
# :param data_list:
# :param pad_id:
# :return:
# """
# # 统计data_list中的最大长度
# max_len = 0
# for data in data_list:
# max_len = max_len if max_len > len(data) else len(data)
#
# # 对数据进行padding
# new_data_list = []
# for data in data_list:
# new_data = data + [pad_id] * (max_len - len(data))
# new_data_list.append(new_data)
# return new_data_listdef load_dataset(logger, args):"""加载训练集和验证集"""logger.info("loading training dataset and validating dataset")train_path = args.train_pathwith open(train_path, "rb") as f:input_list = pickle.load(f)# 划分训练集与验证集val_num = args.val_numinput_list_train = input_list[val_num:]input_list_val = input_list[:val_num]# test# input_list_train = input_list_train[:24]# input_list_val = input_list_val[:24]train_dataset = MyDataset(input_list_train, args.max_len)val_dataset = MyDataset(input_list_val, args.max_len)return train_dataset, val_datasetdef train_epoch(model, train_dataloader, optimizer, scheduler, logger,epoch, args):model.train()device = args.device# pad_id = args.pad_id# sep_id = args.sep_idignore_index = args.ignore_indexepoch_start_time = datetime.now()total_loss = 0 # 记录下整个epoch的loss的总和# epoch_correct_num:每个epoch中,output预测正确的word的数量# epoch_total_num: 每个epoch中,output预测的word的总数量epoch_correct_num, epoch_total_num = 0, 0for batch_idx, (input_ids, labels) in enumerate(train_dataloader):# print(f"the input_ids is: {input_ids}, and the labels is : {labels} !!!")# 捕获cuda out of memory exceptiontry:input_ids = input_ids.to(device)labels = labels.to(device)outputs = model.forward(input_ids, labels=labels)logits = outputs.logitsloss = outputs.lossloss = loss.mean()# 统计该batch的预测token的正确数与总数batch_correct_num, batch_total_num = calculate_acc(logits, labels, ignore_index=ignore_index)# 统计该epoch的预测token的正确数与总数epoch_correct_num += batch_correct_numepoch_total_num += batch_total_num# 计算该batch的accuracybatch_acc = batch_correct_num / batch_total_numtotal_loss += loss.item()if args.gradient_accumulation_steps > 1:loss = loss / args.gradient_accumulation_stepsloss.backward()# 梯度裁剪torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)# 进行一定step的梯度累计之后,更新参数if (batch_idx + 1) % args.gradient_accumulation_steps == 0:# 更新参数optimizer.step()# 更新学习率scheduler.step()# 清空梯度信息optimizer.zero_grad()if (batch_idx + 1) % args.log_step == 0:logger.info("batch {} of epoch {}, loss {}, batch_acc {}, lr {}".format(batch_idx + 1, epoch + 1, loss.item() * args.gradient_accumulation_steps, batch_acc, scheduler.get_lr()))del input_ids, outputsexcept RuntimeError as exception:if "out of memory" in str(exception):logger.info("WARNING: ran out of memory")if hasattr(torch.cuda, 'empty_cache'):torch.cuda.empty_cache()else:logger.info(str(exception))raise exception# 记录当前epoch的平均loss与accuracyepoch_mean_loss = total_loss / len(train_dataloader)epoch_mean_acc = epoch_correct_num / epoch_total_numlogger.info("epoch {}: loss {}, predict_acc {}".format(epoch + 1, epoch_mean_loss, epoch_mean_acc))# save modellogger.info('saving model for epoch {}'.format(epoch + 1))model_path = join(args.save_model_path, 'epoch{}'.format(epoch + 1))if not os.path.exists(model_path):os.mkdir(model_path)model_to_save = model.module if hasattr(model, 'module') else modelmodel_to_save.save_pretrained(model_path)logger.info('epoch {} finished'.format(epoch + 1))epoch_finish_time = datetime.now()logger.info('time for one epoch: {}'.format(epoch_finish_time - epoch_start_time))return epoch_mean_lossdef validate_epoch(model, validate_dataloader, logger, epoch, args):logger.info("start validating")model.eval()device = args.device# pad_id = args.pad_id# sep_id = args.sep_idignore_index = args.ignore_indexepoch_start_time = datetime.now()total_loss = 0# 捕获cuda out of memory exceptiontry:with torch.no_grad():for batch_idx, (input_ids, labels) in enumerate(validate_dataloader):input_ids = input_ids.to(device)labels = labels.to(device)outputs = model.forward(input_ids, labels=labels)logits = outputs.logitsloss = outputs.lossloss = loss.mean()total_loss += loss.item()del input_ids, outputs# 记录当前epoch的平均lossepoch_mean_loss = total_loss / len(validate_dataloader)logger.info("validate epoch {}: loss {}".format(epoch+1, epoch_mean_loss))epoch_finish_time = datetime.now()logger.info('time for validating one epoch: {}'.format(epoch_finish_time - epoch_start_time))return epoch_mean_lossexcept RuntimeError as exception:if "out of memory" in str(exception):logger.info("WARNING: ran out of memory")if hasattr(torch.cuda, 'empty_cache'):torch.cuda.empty_cache()else:logger.info(str(exception))raise exceptiondef train(model, logger, train_dataset, validate_dataset, args):train_dataloader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=args.num_workers, collate_fn=collate_fn,drop_last=True)validate_dataloader = DataLoader(validate_dataset, batch_size=args.batch_size, shuffle=True,num_workers=args.num_workers, collate_fn=collate_fn, drop_last=True)early_stopping = EarlyStopping(args.patience, verbose=True, save_path=args.save_model_path)t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.epochsoptimizer = transformers.AdamW(model.parameters(), lr=args.lr, eps=args.eps)# scheduler = transformers.WarmupLinearSchedule(optimizer, warmup_steps=args.warmup_steps, t_total=t_total)scheduler = transformers.get_linear_schedule_with_warmup(optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total)logger.info('starting training')# 用于记录每个epoch训练和验证的losstrain_losses, validate_losses = [], []# 记录验证集的最小lossbest_val_loss = 10000# 开始训练for epoch in range(args.epochs):# ========== train ========== #train_loss = train_epoch(model=model, train_dataloader=train_dataloader,optimizer=optimizer, scheduler=scheduler,logger=logger, epoch=epoch, args=args)train_losses.append(train_loss)# ========== validate ========== #validate_loss = validate_epoch(model=model, validate_dataloader=validate_dataloader,logger=logger, epoch=epoch, args=args)validate_losses.append(validate_loss)# 保存当前困惑度最低的模型,困惑度低,模型的生成效果不一定会越好if validate_loss < best_val_loss:best_val_loss = validate_losslogger.info('saving current best model for epoch {}'.format(epoch + 1))model_path = join(args.save_model_path, 'min_ppl_model'.format(epoch + 1))if not os.path.exists(model_path):os.mkdir(model_path)model_to_save = model.module if hasattr(model, 'module') else modelmodel_to_save.save_pretrained(model_path)# 如果patience=0,则不进行early stoppingif args.patience == 0:continueearly_stopping(validate_loss, model)if early_stopping.early_stop:logger.info("Early stopping")breaklogger.info('training finished')logger.info("train_losses:{}".format(train_losses))logger.info("validate_losses:{}".format(validate_losses))def caculate_loss(logit, target, pad_idx, smoothing=True):if smoothing:logit = logit[..., :-1, :].contiguous().view(-1, logit.size(2))target = target[..., 1:].contiguous().view(-1)eps = 0.1n_class = logit.size(-1)one_hot = torch.zeros_like(logit).scatter(1, target.view(-1, 1), 1)one_hot = one_hot * (1 - eps) + (1 - one_hot) * eps / (n_class - 1)log_prb = F.log_softmax(logit, dim=1)non_pad_mask = target.ne(pad_idx)loss = -(one_hot * log_prb).sum(dim=1)loss = loss.masked_select(non_pad_mask).mean() # average laterelse:# loss = F.cross_entropy(predict_logit, target, ignore_index=pad_idx)logit = logit[..., :-1, :].contiguous().view(-1, logit.size(-1))labels = target[..., 1:].contiguous().view(-1)loss = F.cross_entropy(logit, labels, ignore_index=pad_idx)return lossdef calculate_acc(logit, labels, ignore_index=-100):logit = logit[..., :-1, :].contiguous().view(-1, logit.size(-1))labels = labels[..., 1:].contiguous().view(-1)_, logit = logit.max(dim=-1) # 对于每条数据,返回最大的index# 进行非运算,返回一个tensor,若labels的第i个位置为pad_id,则置为0,否则为1non_pad_mask = labels.ne(ignore_index)n_correct = logit.eq(labels).masked_select(non_pad_mask).sum().item()n_word = non_pad_mask.sum().item()return n_correct, n_worddef main():# 初始化参数args = set_args()# 设置使用哪些显卡进行训练os.environ["CUDA_VISIBLE_DEVICES"] = args.deviceargs.cuda = not args.no_cudaif args.batch_size < 2048 and args.warmup_steps <= 4000:print('[Warning] The warmup steps may be not enough.\n' \'(sz_b, warmup) = (2048, 4000) is the official setting.\n' \'Using smaller batch w/o longer warmup may cause ' \'the warmup stage ends with only little data trained.')# 创建日志对象logger = create_logger(args)# 当用户使用GPU,并且GPU可用时args.cuda = torch.cuda.is_available() and not args.no_cudadevice = 'cuda:0' if args.cuda else 'cpu'args.device = devicelogger.info('using device:{}'.format(device))# 初始化tokenizertokenizer = BertTokenizerFast(vocab_file=args.vocab_path, sep_token="[SEP]", pad_token="[PAD]", cls_token="[CLS]")args.sep_id = tokenizer.sep_token_idargs.pad_id = tokenizer.pad_token_idargs.cls_id = tokenizer.cls_token_id# 创建模型的输出目录if not os.path.exists(args.save_model_path):os.mkdir(args.save_model_path)# 创建模型if args.pretrained_model: # 加载预训练模型model = GPT2LMHeadModel.from_pretrained(args.pretrained_model)else: # 初始化模型model_config = GPT2Config.from_json_file(args.model_config)model = GPT2LMHeadModel(config=model_config)model = model.to(device)logger.info('model config:\n{}'.format(model.config.to_json_string()))assert model.config.vocab_size == tokenizer.vocab_size# 并行训练模型if args.cuda and torch.cuda.device_count() > 1:model = DataParallel(model).cuda()# model = BalancedDataParallel(args.gpu0_bsz, model, dim=0).cuda()logger.info("use GPU {} to train".format(args.device))# 计算模型参数数量num_parameters = 0parameters = model.parameters()for parameter in parameters:num_parameters += parameter.numel()logger.info('number of model parameters: {}'.format(num_parameters))# 记录参数设置logger.info("args:{}".format(args))# 加载训练集和验证集# ========= Loading Dataset ========= #train_dataset, validate_dataset = load_dataset(logger, args)train(model, logger, train_dataset, validate_dataset, args)if __name__ == '__main__':main()
dataset.py文件
from torch.utils.data import Dataset
import torch
class MyDataset(Dataset):""""""def __init__(self, input_list, max_len):self.input_list = input_listself.max_len = max_lendef __getitem__(self, index):input_ids = self.input_list[index]input_ids = input_ids[:self.max_len]input_ids = torch.tensor(input_ids, dtype=torch.long)return input_idsdef __len__(self):return len(self.input_list)
训练数据处理代码preprocess.py
from tokenizers import BertWordPieceTokenizer
from transformers import BertTokenizer
from transformers import BertTokenizerFast
import argparse
import pandas as pd
import pickle
from tqdm import tqdm
from transformers import GPT2TokenizerFast, GPT2LMHeadModel
import logging
import numpy as npdef create_logger(log_path):"""将日志输出到日志文件和控制台"""logger = logging.getLogger(__name__)logger.setLevel(logging.INFO)formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')# 创建一个handler,用于写入日志文件file_handler = logging.FileHandler(filename=log_path)file_handler.setFormatter(formatter)file_handler.setLevel(logging.INFO)logger.addHandler(file_handler)# 创建一个handler,用于将日志输出到控制台console = logging.StreamHandler()console.setLevel(logging.DEBUG)console.setFormatter(formatter)logger.addHandler(console)return loggerdef preprocess():"""对原始语料进行tokenize,将每段对话处理成如下形式:"[CLS]utterance1[SEP]utterance2[SEP]utterance3[SEP]""""# 设置参数parser = argparse.ArgumentParser()parser.add_argument('--vocab_path', default='vocab/vocab.txt', type=str, required=False,help='词表路径')parser.add_argument('--log_path', default='data/preprocess.log', type=str, required=False, help='训练日志存放位置')parser.add_argument('--train_path', default='50w_qa_data', type=str, required=False, help='训练日志存放位置')parser.add_argument('--save_path', default='data/train.pkl', type=str, required=False, help='tokenize的训练数据集')args = parser.parse_args()# 初始化日志对象logger = create_logger(args.log_path)# 初始化tokenizertokenizer = BertTokenizerFast(vocab_file=args.vocab_path, sep_token="[SEP]", pad_token="[PAD]", cls_token="[CLS]")sep_id = tokenizer.sep_token_idcls_id = tokenizer.cls_token_idlogger.info("preprocessing data,data path:{}, save path:{}".format(args.train_path, args.save_path))# 读取训练数据集with open(args.train_path, 'rb') as f:data = f.read().decode("utf-8")# 需要区分linux和windows环境下的换行符if "\r\n" in data:train_data = data.split("\r\n\r\n")else:train_data = data.split("\n")logger.info("there are {} dialogue in dataset".format(len(train_data)))# 开始进行tokenize# 保存所有的对话数据,每条数据的格式为:"[CLS]utterance1[SEP]utterance2[SEP]utterance3[SEP]"dialogue_len = [] # 记录所有对话tokenize之后的长度,用于统计中位数与均值dialogue_list = []with open(args.save_path, "w", encoding="utf-8") as f:for index, dialogue in enumerate(tqdm(train_data)):if "\r\n" in data:utterances = dialogue.split("\r\n")else:utterances = dialogue.split("\t")input_ids = [cls_id] # 每个dialogue以[CLS]开头for utterance in utterances:input_ids += tokenizer.encode(utterance, add_special_tokens=False)input_ids.append(sep_id) # 每个utterance之后添加[SEP],表示utterance结束dialogue_len.append(len(input_ids))dialogue_list.append(input_ids)# len_mean = np.mean(dialogue_len)# len_median = np.median(dialogue_len)# len_max = np.max(dialogue_len)with open(args.save_path, "wb") as f:pickle.dump(dialogue_list, f)# logger.info("finish preprocessing data,the result is stored in {}".format(args.save_path))# logger.info("mean of dialogue len:{},median of dialogue len:{},max len:{}".format(len_mean, len_median, len_max))if __name__ == '__main__':preprocess()
相关文章:
chabot项目介绍
项目介绍 整体的目录如下所示: 上述的项目结构中出了model是必须的外,其他的都可以根据训练的代码参数传入进行调整,有些不需要一定存在data train.pkl:对原始训练语料进行tokenize之后的文件,存储一个list对象,list的每条数据表…...
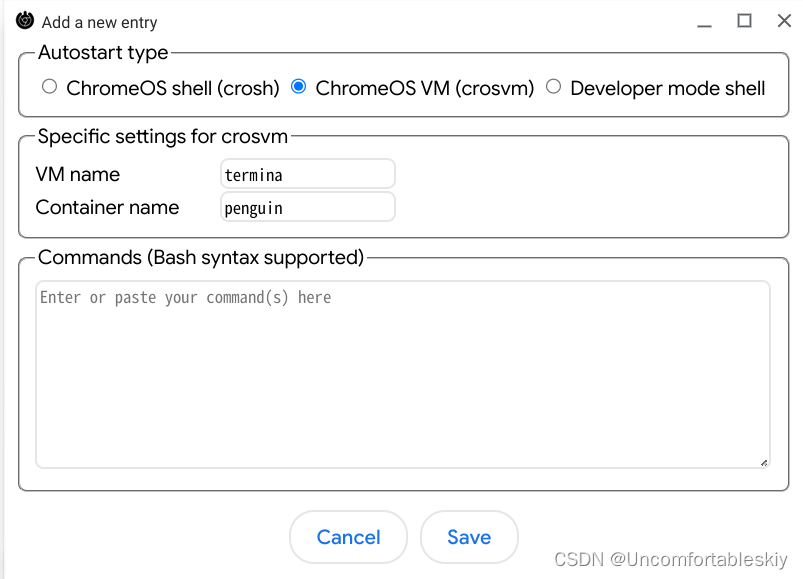
ChromeOS 中自启动 Fcitx5 和托盘 stalonetray
ChromeOS 更新的飞快,旧文章的方法也老是不好用,找遍了也没找到很好的可以开机自启动 Linux VM 和输入法、托盘的方法。 研究了一下(不,是很久),终于找到个丑陋的实现。 方法基于 ChromeOS 123.0.6312.94…...
画图理解JVM相关内容
文章目录 1. JVM视角下,内存划分2. 类内存分布硬核详解1. 获取堆内存参数2. 扫描堆内存,定位实例3. 查看实例所在地址的数据4. 找到实例所指向的类信息的地址5. 查看class信息6. 结论 3. Java的对象创建流程4. 垃圾判别算法4.1 引用计数法4.2 可达性分析…...

Scikit-Learn K均值聚类
Scikit-Learn K均值聚类 1、K均值聚类1.1、K均值聚类及原理1.2、K均值聚类的优缺点1.3、聚类与分类的区别2、Scikit-Learn K均值聚类2.1、Scikit-Learn K均值聚类API2.2、K均值聚类初体验(寻找最佳K)2.3、K均值聚类案例1、K均值聚类 K-均值(K-Means)是一种聚类算法,属于无…...

蓝桥杯 - 受伤的皇后
解题思路: 递归 回溯(n皇后问题的变种) 在 N 皇后问题的解决方案中,我们是从棋盘的顶部向底部逐行放置皇后的,这意味着在任何给定时间,所有未来的行(即当前行之下的所有行)都还没…...

AcWing---乌龟棋---线性dp
312. 乌龟棋 - AcWing题库 思路: 原来没有碰到过类似的题: dp数组为思维:dp[i][j][k][r],分别表示用了i个第一类型卡片,j个第二类型卡片...所到的格子数的最大分数,为啥不用记录乌龟到了哪里呢࿱…...

python代码使用过程中使用快捷键注释时报错
1.代码 2.代码报错 3.代码注释后的结果 4. 原因...

go之web框架gin
介绍 Gin 是一个用 Go (Golang) 编写的 Web 框架。 它具有类似 martini 的 API,性能要好得多,多亏了 httprouter,速度提高了 40 倍。 如果您需要性能和良好的生产力,您一定会喜欢 Gin。 安装 go get -u github.com/gin-gonic/g…...
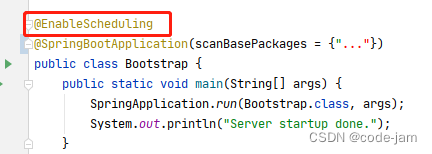
SpringBoot 定时任务实践、定时任务按指定时间执行
Q1. springboot怎样创建定时任务? 很显然,人人都知道,Scheduled(cron ".....") Q2. 如上所示创建了定时任务却未能执行是为什么? 如果你的cron确定没写错的话 cron表达式是否合法,可参考此处,…...

MYSQL数据库故障排除与优化
目录 MySQL 单实例故障排查 MySQL 主从故障排查 MySQL 优化 MySQL 单实例故障排查 故障现象 1 ERROR 2002 (HY000): Cant connect to local MySQL server through socket /data/mysql/mysql.sock (2) 问题分析:以上这种情况一般都…...
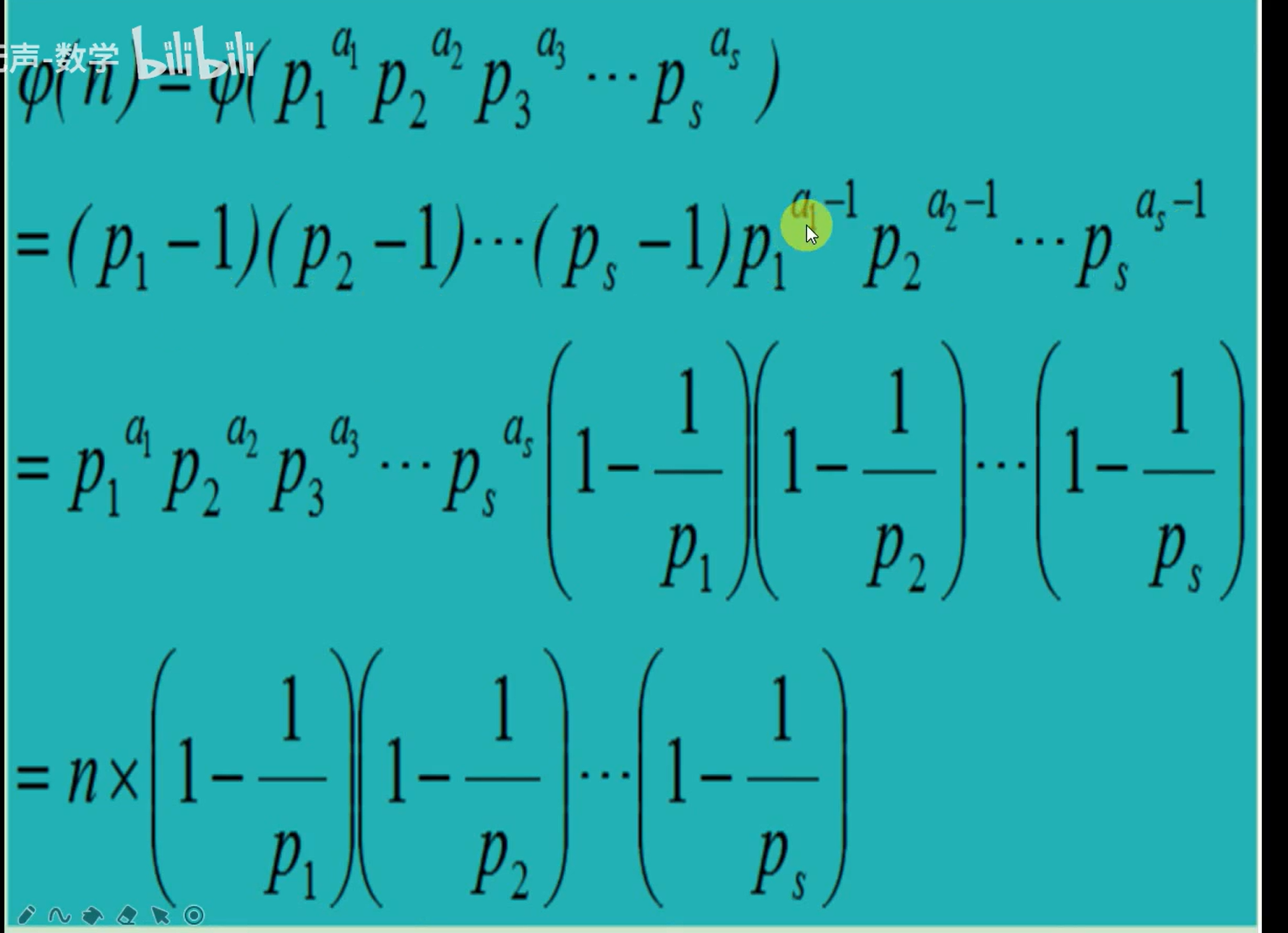
算法-数论-蓝桥杯
算法-数论 1、最大公约数 def gcd(a,b):if b 0:return areturn gcd(b, a%b) # a和b的最大公约数等于b与a mod b 的最大公约数def gcd(a,b):while b ! 0:cur aa bb cur%bpassreturn a欧几里得算法 a可以表示成a kb r(a,b,k,…...

222.完全二叉树节点个数
给你一棵 完全二叉树 的根节点 root ,求出该树的节点个数。 完全二叉树 的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最…...

C++中的string类操作详解
引言 针对C中的string,本文主要讲解如何对其进行插入、删除、查找、比较、截断、分割以及与数字之间的相互转换等。 字符串插入 1. append方法 std::string str "hello"; str.append(7, w); // 在末尾添加7个字符w str.append("wwwwwww");…...

Java绘图坐标体系
一、介绍 下图说明了Java坐标系。坐标原点位于左上角,以像素为单位。在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐…...
【MATLAB源码-第38期】基于OFDM的块状导频和梳状导频误码率性能对比,以及LS/LMMSE两种信道估计方法以及不同调制方式对比。
操作环境: MATLAB 2022a 1、算法描述 块状导频和梳状导频都是用于无线通信系统中信道估计的方法。 块状导频: 定义: 在频域上,块状导频是连续放置的一组导频符号。这意味着所有的导频符号都集中在一个短的时间段内发送。 优点…...
javaWeb车辆管理系统设计与实现
摘 要 随着经济的日益增长,车辆作为最重要的交通工具,在企事业单位中得以普及,单位的车辆数目已经远远不止简单的几辆,与此同时就产生了车辆资源的合理分配使用问题。 企业车辆管理系统运用现代化的计算机管理手段,不但可以对车辆的使用进行合理的管理,…...
【DM8】间隔分区
是范围分区的一个扩展 如果使用了间隔函数做分区,在数据插入的时候,如果没有合适的分区,数据库会自动创建一个新的分区。 –year往后推两年 SELECT SYSDATE numtoyminterval(2,‘YEAR’); –month往后推两年 SELECT SYSDATE numtoyminterv…...

0基础如何进入IT行业?
目录 0基础如何进入IT行业? 一、学习路径 二、技能培养 三、实践经验 0基础如何进入IT行业? 对于没有任何相关背景知识的人来说,成功进入IT行业可能看起来是一个遥不可及的目标。然而,只要有正确的方法和坚持不懈的努力&#…...
C#将Console写至文件,且文件固定最大长度
参考文章 将C#的Console.Write同步到控制台和log文件输出 业务需求 在生产环境中,控制台窗口不便展示出来。 为了在生产环境中,完整记录控制台应用的输出,选择将其输出到文件中。 但是,一次性存储所有输出的话,文件会…...

《CSS 知识点》仅在文本有省略号时添加 tip 信息
html <div ref"btns" class"btns"><div class"btn" >这是一段很短的文本.</div><div class"btn" >这是一段很短的文本.</div><div class"btn" >这是一段很长的文本.有省略号和tip.<…...

吴哥窟水文测试:验证古代水库管理AI的智慧
一、从古代水利到现代AI测试的跨越吴哥窟,这座位于柬埔寨的古代都城遗址,以其宏伟的寺庙建筑群闻名于世。然而,鲜为人知的是,支撑这座城市繁荣数百年的,是一套复杂而精密的水管理系统。这套建于9至13世纪的水利工程&am…...

RIS辅助无人机通信的能效优化与深度强化学习应用
1. 项目概述:RIS辅助无人机通信的能效革命在应急救灾、偏远地区覆盖等场景中,无人机(UAV)通信系统常面临两大核心挑战:一是复杂地形导致的信号遮挡问题,二是无人机有限的续航能力制约了长期作业。传统解决方案如增加中继节点会引入…...

Contextcore:轻量高性能的框架无关状态管理核心
1. 项目概述:一个为现代前端应用量身定制的状态管理核心 如果你正在开发一个中大型的React、Vue或任何现代前端应用,并且对现有状态管理库的复杂性、样板代码量或者性能优化感到头疼,那么 lucifer-ux/Contextcore 这个项目很可能就是你一直…...

别再为MATLAB+Amesim联合仿真装环境发愁了!保姆级VS2019+2022a+2021.1安装避坑指南
MATLABAmesim联合仿真环境搭建全攻略:从零避坑到一次成功 当第一次接触MATLAB与Amesim联合仿真时,许多工程师和研究生都会在环境搭建阶段遭遇各种"玄学问题"——明明按照教程操作,却总是卡在某个环节无法继续。本文将分享一套经过…...
Translumo:Windows平台实时屏幕翻译神器,打破语言障碍的终极解决方案
Translumo:Windows平台实时屏幕翻译神器,打破语言障碍的终极解决方案 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/…...

Flowframes:3分钟掌握Windows平台AI视频插帧完整指南
Flowframes:3分钟掌握Windows平台AI视频插帧完整指南 【免费下载链接】flowframes Flowframes Windows GUI for video interpolation using DAIN (NCNN) or RIFE (CUDA/NCNN) 项目地址: https://gitcode.com/gh_mirrors/fl/flowframes 你是否曾经观看24帧视频…...

观察 Taotoken 在多地域请求下的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察 Taotoken 在多地域请求下的延迟与稳定性表现 对于依赖大模型 API 进行开发的团队而言,服务的延迟与稳定性是影响开…...

mRNA疫苗序列生物信息学分析:从密码子优化到免疫原性预测
1. 项目概述:解码两大mRNA疫苗的“核心蓝图”作为一名在生物信息学和基因组学领域摸爬滚打了十多年的“老码农”,我见过太多令人兴奋的数据集,但当我第一次在GitHub上看到这个名为“Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-se…...

从PUMA560到你的项目:手把手教你将经典DH建模流程迁移到自定义机械臂
从PUMA560到自定义机械臂:DH建模实战迁移指南 当机械臂从教科书案例走向真实项目时,最令人头疼的莫过于面对一个全新构型却不知如何下手。本文将以工业界经典的PUMA560为跳板,拆解一套可迁移的DH建模方法论,带您跨越从理论到实践的…...

LangGraph 并发执行不是开 Goroutine 那么简单:状态竞争与事务处理
LangGraph 并发执行不是开 Goroutine 那么简单:状态竞争与事务处理深度解析 元数据 关键词:LangGraph, 大语言模型工作流, 有状态并发, 状态一致性, 事务处理, 多Agent系统, 分布式状态管理 摘要:很多开发者初次接触LangGraph的并发特性时,会下意识将其等同于传统协程/线程…...