R语言数据操纵:常用函数
目录
处理循环的函数
lapply函数
apply函数
mapply函数
tapply函数
split函数
排序的函数
sort函数与order函数
总结数据信息的函数
head函数与tail函数
summary函数
str函数
table函数
any函数
all函数
xtab函数
object.size函数
这篇文章主要介绍R语言中处理循环,排序,总结重要信息的常用函数。
rnorm函数是R语言中用来生成正态分布随机数的函数。这个函数非常有用,特别是在需要模拟正态分布数据或进行统计测试时。
rnorm函数的基本结构如下:
rnorm(n, mean = 0, sd = 1)
各个参数的含义如下:
- n:需要生成的随机数的数量。
- mean:生成的正态分布的均值,默认值为0。
- sd:生成的正态分布的标准差,默认值为1。
举个例子,如果你想生成一个包含100个随机数的向量,这些随机数来自于均值为5,标准差为2的正态分布,你可以这样使用rnorm函数:
set.seed(123) # 设置随机数种子以确保结果可重复 random_numbers <- rnorm(100, mean = 5, sd = 2)
这段代码首先设置了一个随机数种子,确保每次运行时生成的随机数序列是相同的,然后使用rnorm函数生成了所需的随机数。
处理循环的函数
lapply函数
这个函数就是俗称的一句话循环函数,不同于while循环或者for循环,这个函数可以实现一句话就是一个循环的效果。
具体格式为lapply(列表名,函数,其它参数),其中列表名告诉lapply我们要处理的对象,如果传的不是列表而是向量等数据结构类型,lapply会自动转换成列表结构。第二个参数:函数告诉lapply要对列表进行怎样的操作。lapply的返回值是一个列表。
举个例子,创建一个名为x的列表

x包含两个元素,他们均为向量。接着使用lapply函数对x进行求平均值的操作(求平均值的函数是mean),结果如图

发现确实是求出了a元素和b元素的平均值
再来看一个例子,假如有一个向量x

runif的功能是从一个均匀分布的总体里抽取若干个数出来,默认是从0到100进行抽取。在上一个代码的基础上再加两个参数,表示从0到100中进行抽取。结果如图
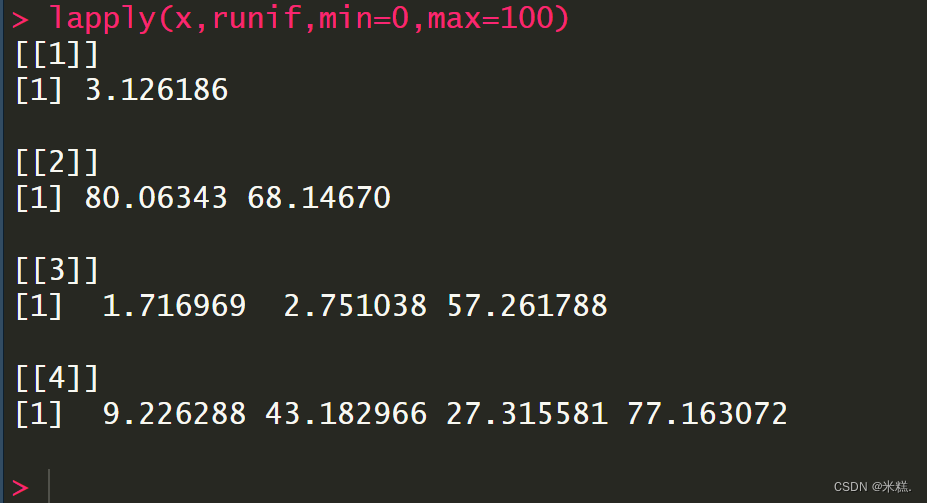
借助lapply函数,我们只用一行代码就对列表x的每一个元素都进行了函数runif的处理。
lapply参数中的函数,还可以是我们自定义的函数,比如有这样的一个列表x

列表x包含两个元素,这两个元素均为矩阵,然后执行这句代码

我们发现此时lapply函数的对象是x,对x中每个元素要进行的操作由后面的函数决定,function(m)代表这是一个自定义函数,m类似于C语言中的形参,后面的m[1,]就是这个函数的功能,也就是C语言中的函数体,m[1,]表示提取m的第一行。在运行的时候lapply函数会用x列表的每一个元素依次替代掉m,因此这句代码的意思就是对列表x的每个元素(这里是x的元素是矩阵)进行提取第一行的操作,运行结果也的确如此。返回的是一个列表,第一个元素是一个向量,也就是x列表第一个元素的第一行,第二个元素也是一个向量,表示x列表第二个元素的第一行。

apply函数
apply用于沿着数组的某一维度处理数据,比如沿着矩阵的行或列进行处理。
函数原型为apply(数组,维度,函数/函数名)
举个例子

首先创建了一个简单的矩阵,然后对矩阵x的按列求平均值,其中第二个参数写2代表按照列进行处理。当然apply函数的功能远远不止于此,实际上对于矩阵x每列的和,平均值等等可以使用rowSums(x),rowMeans(x)这样的函数来更高效的实现。

quantile函数用于求百分位点,后面的probs参数表示要求的是0.25和0.75位点。
再来看一个更加复杂的例子

有一个三维的数组,第三个维度的第一个元素是一个两行三列的矩阵,第二,三,四个元素也是。对于这样一个三维的数据,怎么用apply函数呢?比如有这样一个代码与运行结果

我们知道apply的第二个参数代表维度,那为什么上面这个维度还成个向量了呢?难不成是又对第一个维度求平均值,又对第二个维度求平均值吗?从结果来看显然不是,因为如果是像上面说的那样对两个维度分别求平均值,结果应该是两个向量,就好像在空间直角坐标系当中对一些散点的横坐标和纵坐标分别求平均值一样,但是这里返回的结果是一个矩阵,因此实际上这样维度这个参数传c(1,2)的时候是在对几个矩阵求平均值,对哪几个矩阵求平均值呢?我们说三维数组在展示的时候都是站在第三个维度的视角来展示的,创建数组的时候第三个维度的数值是几,就展示几个矩阵,这里在创建数组x的时候第三个维度的数字是4,那就展示四个矩阵,而apply求得也是这四个矩阵的平均值。
或者说这样理解,传的维度是c(1,2),那就是要求这样一个维度的平均值,这代表二维的矩阵,那就是求这些矩阵的平均值。
mapply函数
参数为mapply(函数/函数名,数据,函数相关的参数)
对于mapply的应用可以举这样一个例子

上面的代码创建了这样一个列表x,x的第一个元素是四个1,第二个元素是3个2,第三个元素是2个3,第四个元素是一个4。实际上这个代码可以直接使用mapply代替掉,如图

其中第一个参数指定了要用的函数是rep,第二个参数和第三个参数分别指定rep的参数,也就是说rep的参数刚上来时1,4,在接下来是2,3等等。
再举个例子,写一个函数用来从随机分布的总体里抽取指定个数的数据。

其中n是要抽取的个数,mean是均值,std是标准差。比如s(4,0,1)就是从均值为0,标准差为1的数据中抽取4个样本。
使用mapply函数,第一个参数传s,表示要把某些参数应用于函数s,第二个参数和第三个参数分别代表要传给s的第一二个参数,也就是说要传给s的第一个参数也就是提取的个数分别是1到5,第二个参数也就是均值分别是5到1,第三个参数也就是标准差一直是2

第一个元素来自于均值为5,标准差为2的总体,提取了一个数
第二个元素来自于均值为4,标准差为2的总体,提取了两个数
以此类推,第五个元素来自于均值为1,标准差为2的总体,提取了五个数
tapply函数
这个函数的作用是对向量的子集进行操作,函数原型如下
tapply(向量,因子/因子列表,函数/函数名)
首先构建一个向量x

向量x一共含有15个元素,前五个元素是均值为0标准差为1的均匀分布随机数,中间五个是(0,1)上的均匀分布随机数,最后五个是均值为1,标准差为1的正态分布随机数。
再来创建一个因子f

创建因子使用的函数是gl,表示创建了三个水平的因子,每个水平有五个元素
下面将使用tapply函数对向量x按照因子f进行分组,对每一组求平均值

可以看到分成了三组,因为因子f有三个水平。每个因子水平有五个元素,分成三组,需要向量有15个元素,而向量x恰好有15个元素。因此可以正确的分组并求平均值。
如果我们在tapply中引入第三个参数simplify并把它设置成FALSE(simplify默认是T,顾名思义就是起到一个简化的作用,当simplify是T的时候会把tapply的结果简化成一个向量)
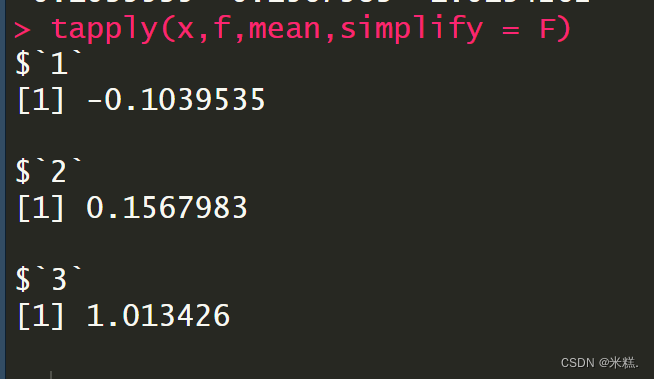
这样tapply的结果就是一个没有没简化过的,可以看到是一个列表
split函数
这个函数用于根据因子或因子列表将向量或其他对象分组。通常要与lapply一起使用。函数原型为:
split(向量/列表/数据框,因子/因子列表,.......)
举个例子,仍然使用前面的向量x(x包含15个元素)与因子f (f包含三个levels)

可以看到根据因子的levels把向量x分成了三组,每组五个元素
为什么说split函数要经常与lapply函数一起使用呢?

这样就对根据f对x分的每一组都进行了求平均值的操作
再来看一个比较复杂的例子,就是我们前面使用过的airquality这个数据框,他里面有一列是Month,先来看看这列是什么样的

我们发现Month只有五种取值,就像一个有五个levels的因子一样,那我们就可以使用airquality$Month这一列对前面的airquality进行分组。虽然split的第二个参数应该是因子,但是我们传一个向量也是兼容的,split函数会自动把这个向量解释为因子类型。分组之后的部分结果展示如图(太长了就不展示全了)

结果是airquality这个数据框被按照所谓的“因子”Month(其实Month不是一个因子,而是一个长得很像因子的向量)的levels分割成了五个组,也就是说本来airquality是一个一百多行的数据框,现在根据Month被分成了好几个数据框。
然后使用下面这句代码求分的每一组的这三列的平均值

运行结果如图

我们发现了一个问题,就是每一组的Ozone的均值结果均为NA,这是因为在每一组在计算Ozone这行均值的时候都有某一行有个缺失值,这将导致colMeans函数不知道怎么计算,因此返回值就是NA。为了避免这个结果的出现,我们只需要在colMeans函数中调用第三个参数na.rm即可,如图

运行结果如图

na.rm=T这个参数的意义为在计算平均值的时候不要包括那些缺失值。
当然还可以使用sapply函数让结果展示的更加清楚

参数与apply一致,sapply函数的运行结果如下

这个例子也证明了在我们拿到一个数据集的时候,处理缺失值非常重要。
排序的函数
sort函数与order函数
sort函数:对向量进行排序,返回结果是排序好的内容。默认是以升序进行排列
order函数:返回排好序的内容的下标,允许使用多个标准排序
举例说明用法。首先创建一个这样的数据框x

结果如图

如果我们想要对v2这一列按照升序进行排序,应该怎么做?
答案是直接使用sort函数即可,sort函数默认就是按照升序的方式进行排列的。

如果要按照降序的方式进行排列,只需要在sort函数中引入第二个参数即可,如图

也可以使用order函数进行排列,如图

order函数返回的是下标,默认是升序,也就是说下标4对应的元素是最小的,下标1对应的元素是最大的。利用order函数的结果可以使我们按照升序的方式提取子集

order函数允许使用多个条件进行排序,比如我先按照v4的升序进行排序,如果v4中有两个相同的数,在按照v2的升序进行排序,如图

如果想要按照降序进行排序,只需要在order函数中引入参数decreasing=T即可
总结数据信息的函数
head函数与tail函数
还是以airquality这个数据集为例,先来看看他的前10行长什么样

head函数用于查看一个数据集的前几行,默认是前6行,并允许使用第二个参数指定要查看多杀行。如果查看的对象是列表或者向量这种一维的数据结构,可以认为查看的是前六个元素
类似的也有函数tail用于查看数据集后六行或者后六个元素
summary函数

从运行结果来看,summary函数返回了传给他的数据集中的每一个变量的最小值,最大值,0.25分位点,0.75分位点,均值等等信息,可以让我们对变量总体有一个大致的把握。
str函数

这个函数就是对传给他的数据集进行一个整体的总结,比如这个airquality是一个数据框类型,有153次记录(行),6个变量(列),还列出了每个变量的部分信息比如这些变量是什么类型的,前几次记录的值。
table函数

当我们给table这个函数传了一个Month向量,table函数会统计这个向量中不同的元素出现的次数,比如这里的结果代表Month中5出现了31次,6出现了30次等等。这个函数默认情况下会跳过所给参数中的缺失值,如果想要连带缺失值一起统计,只需要在table函数中再引入一个参数useNA="ifany"。
同时table函数允许对两个参数进行统计,此时返回的就是一个二维的表,表中的任何数字都要满足横竖两个方向的要求
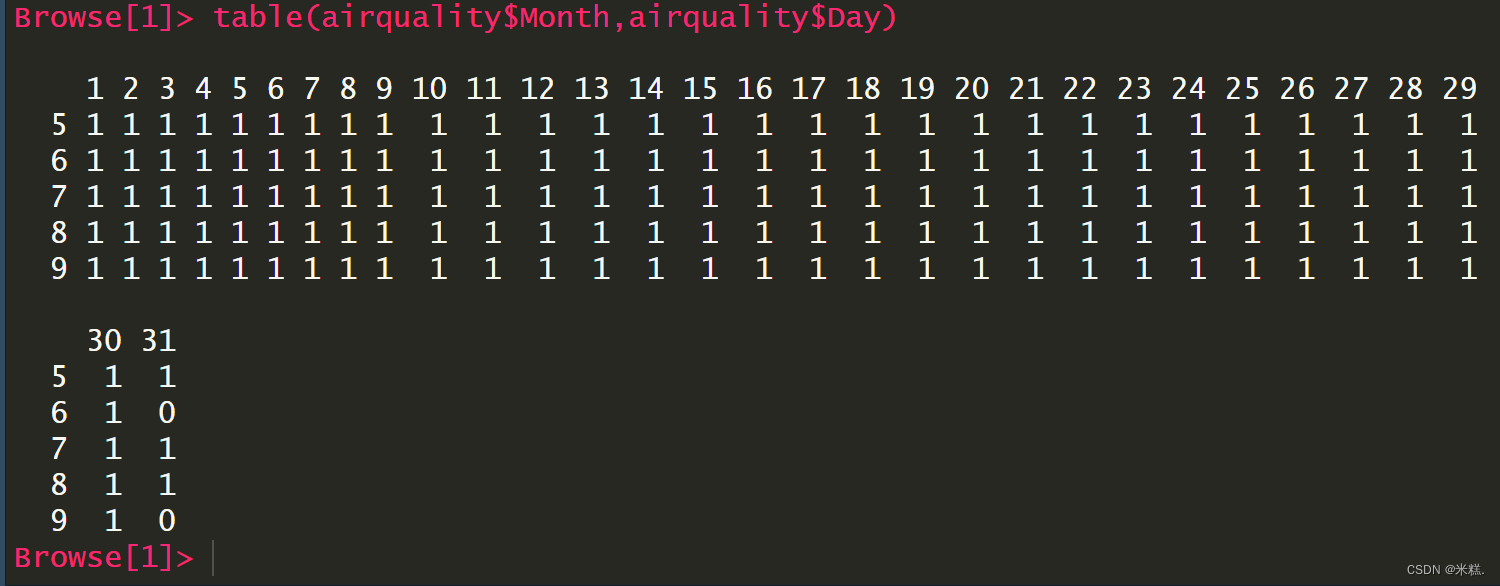
其中第一个数值代表是五月,且是一号的记录出现了几次,显然是1次。
any函数
前面介绍过is.na这个函数可以判断所给参数中是否有缺失值,但是is.na函数展示是否存在缺失值的方式是:如果是缺失值则在对应下标的位置返回一个TRUE,当我们只是想要知道这个数据集中是否有缺失值,知识想要一个有或者没有这样的答案的时候,就可以在is.na函数的外部再套一个any函数,这样就可以判断这个数据集中有无缺失值。如果有缺失值,返回结果就是一个TRUE,否则就是FALSE

如果我们想要知道这个数据集中有多少个缺失值,可以再is.na函数的外面套一个sum函数,sum函数可以统计参数中TRUE的个数,这里代表的也就是NA的个数

all函数
如果我们想要知道某个变量的所有取值是否都满足某个条件,比如上面的月份取值是否均小于12,就可以使用all函数

结果显示airquality中的Month变量的所有取值均小于12,。
再来举个例子,对R中自带的数据集Titanic进行一系列的数据信息总结

首先是把Titanic转换成数据框,然后可以查看前六行,还可以查看这个数据框的维度,还可以对titanic进行一系列的信息总结,最后还创建了一个交叉表,运行结果如下

交叉表中显示头等舱中有6个儿童,319个成年人。
xtab函数
在R语言中,xtabs函数是一种用于创建交叉表的函数,它主要用于统计分析中的频数统计。该函数来自于stats包,它可以方便地对分类变量进行汇总,并生成一个或多个因子的频数表(即交叉表)。这是进行探索性数据分析时非常有用的工具,尤其是当你需要理解不同分类变量之间的关系时。
格式
基本的xtabs函数的格式如下:
xtabs(formula, data, subset, na.action)
- formula: 是一个对象公式,通常形式为 ~ x + y 或 x ~ y,其中 x 和 y 是数据框中的列名。左边是要汇总的值(可以是频数或某个变量的总和),右边是因子,用于形成表的行和列。
- data: 是一个数据框(data.frame)或者列表(list),其中包含了用于制作表的变量。
- subset: 这是一个可选参数,用于指定一个逻辑条件,该条件定义了哪些行应该被包括在内。
- na.action: 指定如何处理数据中的NA值,比如可以设置为na.pass以包括NA值。
功能
xtabs函数的主要功能是创建一个高维表格,它使用公式接口来指定表格中各维度的因子。这个功能特别适合于快速汇总数据并查看各分类层级间的交互作用。例如,如果你想了解不同性别(男性、女性)在不同治疗组(对照组、实验组)中的人数分布,你可以使用xtabs来快速生成这样的频数表。
object.size函数
这个函数用于查看参数的大小,比如我们要查看airquality这个数据集的大小,可以这样

相关文章:
R语言数据操纵:常用函数
目录 处理循环的函数 lapply函数 apply函数 mapply函数 tapply函数 split函数 排序的函数 sort函数与order函数 总结数据信息的函数 head函数与tail函数 summary函数 str函数 table函数 any函数 all函数 xtab函数 object.size函数 这篇文章主要介绍R语言中处理…...

图论做题笔记:bfs
Leetcode - 433:最小基因变化 题目: 基因序列可以表示为一条由 8 个字符组成的字符串,其中每个字符都是 A、C、G 和 T 之一。 假设我们需要调查从基因序列 start 变为 end 所发生的基因变化。一次基因变化就意味着这个基因序列中的一个字符发生了变化…...

群集服务器与主机托管区别
1、首先什么群集服务器? 通俗的来说,它是指很多台服务器把它们集中在一起来进行同一种服务,而在我们在客户端看,却只能看见一个服务器;集群服务器也可以由很多个的计算机并行去计算,这样可以获得非常高的计算速度;同时也可以用很多个计算机来…...

Linux锁的使用
一、临界资源与临界区 多线程会共享例如全局变量等资源,我们把会被多个执行流访问的资源称为临界资源,我们是通过代码访问临界资源的,而我们访问临界资源的那部分代码称为临界区。 实现一个抢票系统 只有一个线程抢票时 #include <ios…...

go语言学习--2.函数
目录 1.函数分类 2.函数的声明和定义 3.函数传参 4.函数返回值 5.递归调用 为完成某一功能的程序指令(语句)的集合,称为函数。 1.函数分类 在Go语言中,函数是第一类对象,我们可以将函数保持到变量中。函数主要有具名和匿名之分&#x…...

[安卓逆向]常见调试和反调试及解决方案
写在前面 我们在逆向软件时难免会遇到一些反调试策略,这篇文章就来详细总结下,现阶段比较流行的几种反调试策略及解决方案。 特定文件检测 反调试功能: 通过检测文件方式,检测android_server文件是否存在设备中的指定目录/data/l…...

uni-app(H5)论坛 | 社区 表情选择 UI组件
项目源码请移步:bbs 效果 实现思路 表情切换 人物、动物、小黄人不同表情之间的切换实际就是组件的切换 emoji表情 emoji表情本身就是一种字符 如需其他emoji表情可参考 EmojiAll中文官方网站 需要注意的就是数据库的存储格式需要支持emoji表情,我项…...

基于SpringBoot+vue的在线商城系统+论文+免费远程调试
基于SpringBootvue的在线商城系统034(含源码 数据库文档免费送) 开发系统:Windows10 架构模式:MVC/前后端分离 JDK版本: Java JDK1.8 开发工具:IDEA 数据库版本: mysql8.0 数据库可视化工具: navicat 服务器: SpringBoot自带 apache tomcat 主要技术: Java,Springb…...
mac中创建的证书提示是无效或者是证书不受信任的解决办法
mac中创建的证书提示是无效或者是证书不受信任的解决办法 原因: (1)可能是由于自己的误删除将Apple worldwide Developer Relatioans Certification Authority删除掉了 (2) 由于签发的认证的证书到期了 (3)其它未知原…...

LangChain Demo | 如何调用stackoverflow并结合ReAct回答代码相关问题
背景 楼主决定提升与LLM交互的质量,之前是直接prompt->answer的范式,现在我希望能用上ReAct策略和能够检索StackOverflow,让同一款LLM发挥出更大的作用。 难点 1. 怎样调用StackOverflow step1 pip install stackspi step 2 from la…...
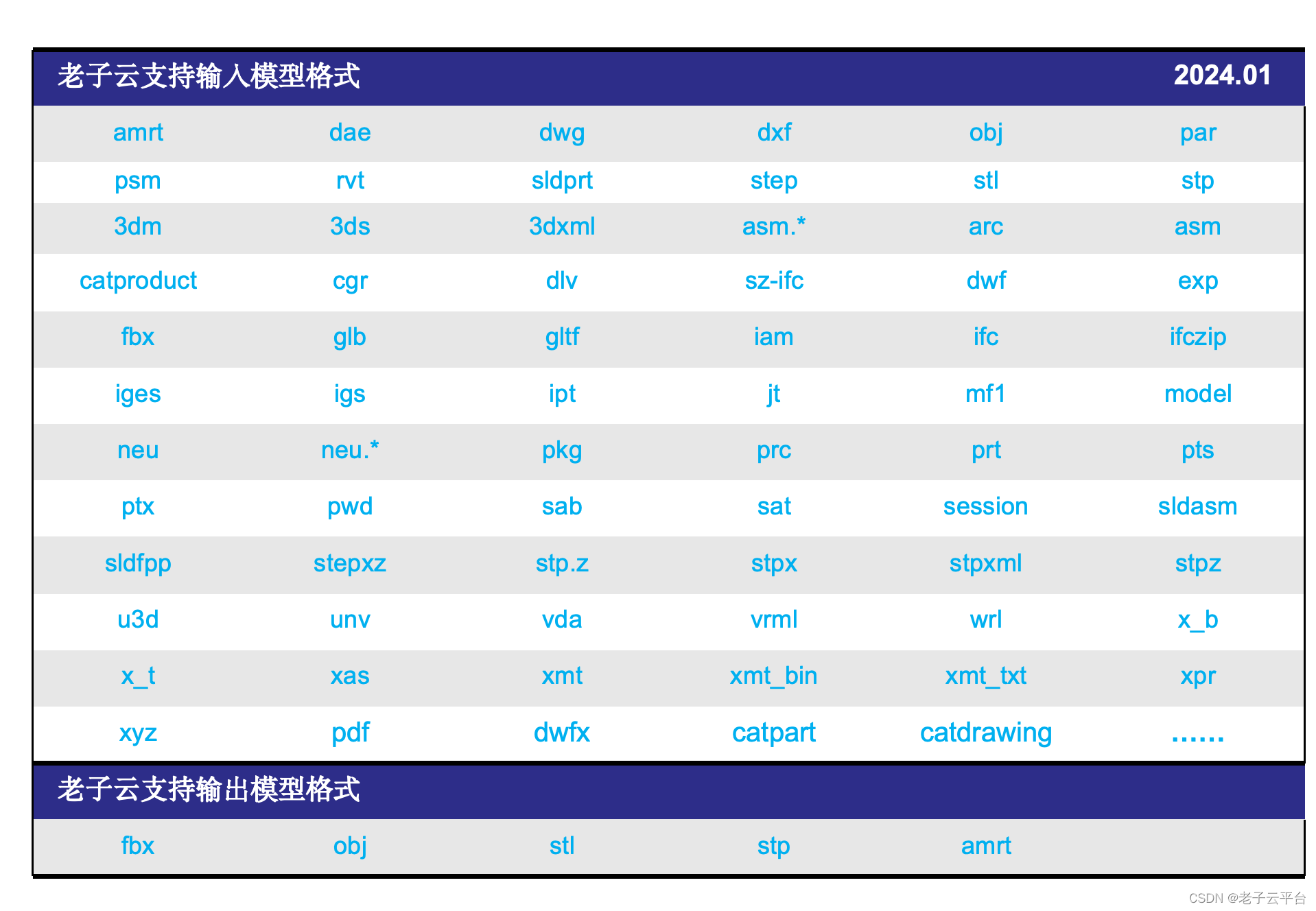
老子云、AMRT3D、眸瑞科技
老子云概述 老子云3D可视化快速开发平台,集云压缩、云烘焙、云存储云展示于一体,使3D模型资源自动输出至移动端PC端、Web端,能在多设备、全平台进行展示和交互,是全球领先、自主可控的自动化3D云引擎。 平台架构 平台特性 1、基…...
2023.4.7 机器学习周报
目录 引言 Abstract 文献阅读 1、题目 2、引言 3、过去方案和Motivation 4、Segment Anything模型 5、创新点 6、实验过程 7、实验结果 1、评价绩效 2、检测评价 3、跟踪评价 8、 结论 总结 引言 本周阅读了一篇关于高效的任意分割模型的文献,用于自…...

如何将平板或手机作为电脑的外接显示器?
先上官网链接:ExtensoDesk 家里有一台华为平板,自从买回来以后除了看视频外,基本没什么作用,于是想着将其作为我电脑的第二个屏幕,提高我学习办公的效率,废物再次利用。最近了解到华为和小米生态有多屏协同…...
Tuxera NTFS for Mac2023绿色免费版 免费的ntfs for mac 免费读写硬盘U盘工具
Tuxera NTFS 2023 Mac免费版是款适合Mac用户使用的磁盘读写工具。Tuxera NTFS 2023 Mac可以很好的帮助用户在Mac上打开、编辑、复制、移动或删除存储在Windows NTFS格式的USB驱动器上的文件。并且Tuxera NTFS 2023 Mac还可以无阻碍地使用各种文件系统磁盘,还能解决磁…...

使用阿里云试用Elasticsearch学习:3.6 处理人类语言——同义词
词干提取是通过简化他们的词根形式来扩大搜索的范围,同义词 通过相关的观念和概念来扩大搜索范围。 也许没有文档匹配查询 “英国女王“ ,但是包含 “英国君主” 的文档可能会被认为是很好的匹配。 用户搜索 “美国” 并且期望找到包含 美利坚合众国 、…...
018——红外遥控模块驱动开发(基于HS0038和I.MX6uLL)
目录 一、 模块介绍 1.1 简介 1.2 协议 二、 驱动代码 三、 应用代码 四、 实验 五、 程序优化 一、 模块介绍 1.1 简介 红外遥控被广泛应用于家用电器、工业控制和智能仪器系统中,像我们熟知的有电视机盒子遥控器、空调遥控器。红外遥控器系统分为发送端和…...
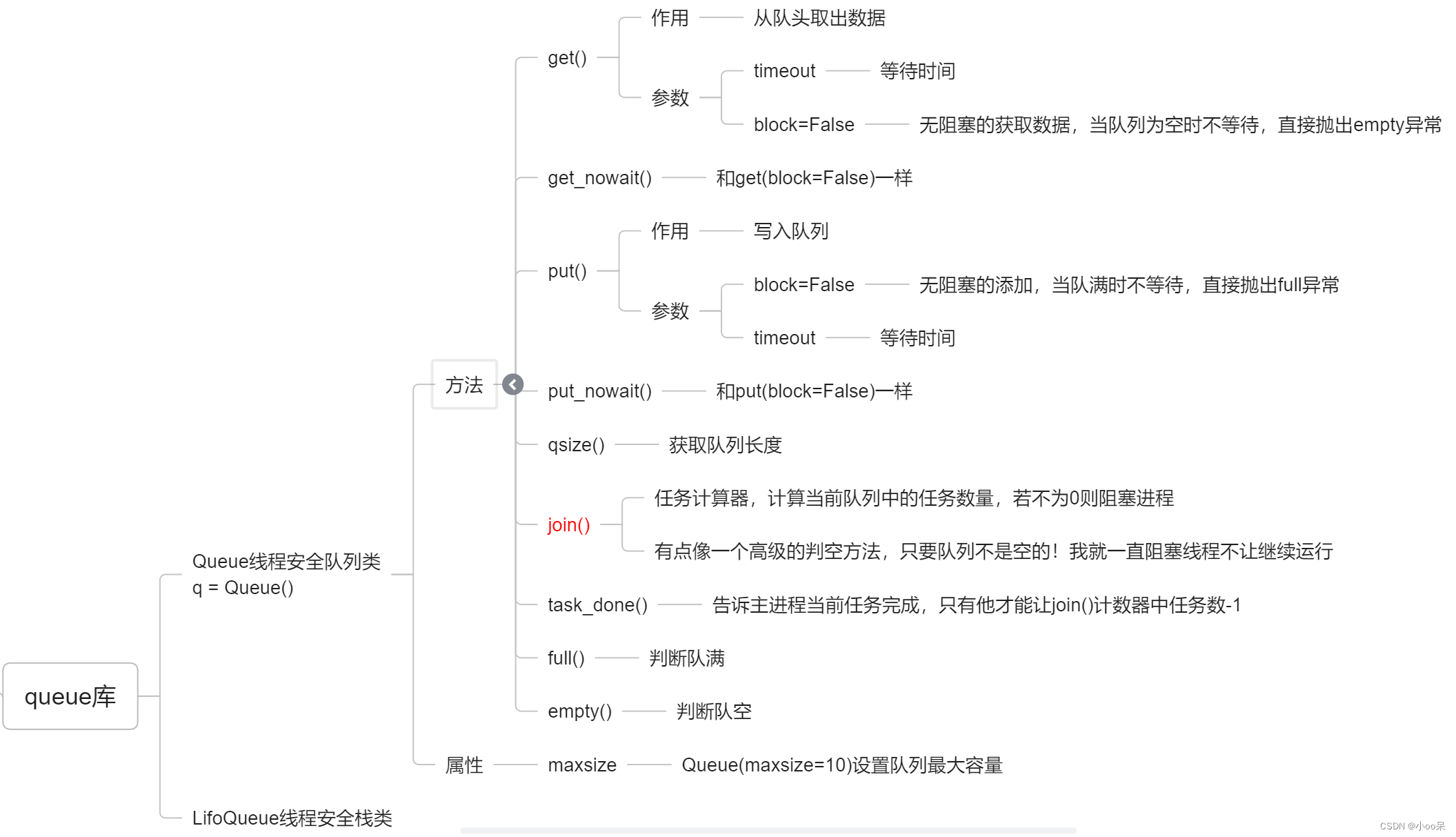
【学习心得】Python中的queue模块使用
一、Queue模块的知识点思维导图 二、Queue模块常用函数介绍 queue模块是内置的,不需要安装直接导入就可以了。 (1)创建一个Queue对象 import queue# 创建一个队列实例 q queue.Queue(maxsize20) # 可选参数,默认为无限大&am…...

ubuntu-server部署hive-part4-部署hive
参照 https://blog.csdn.net/qq_41946216/article/details/134345137 操作系统版本:ubuntu-server-22.04.3 虚拟机:virtualbox7.0 部署hive 下载上传 下载地址 http://archive.apache.org/dist/hive/ apache-hive-3.1.3-bin.tar.gz 以root用户上传至…...
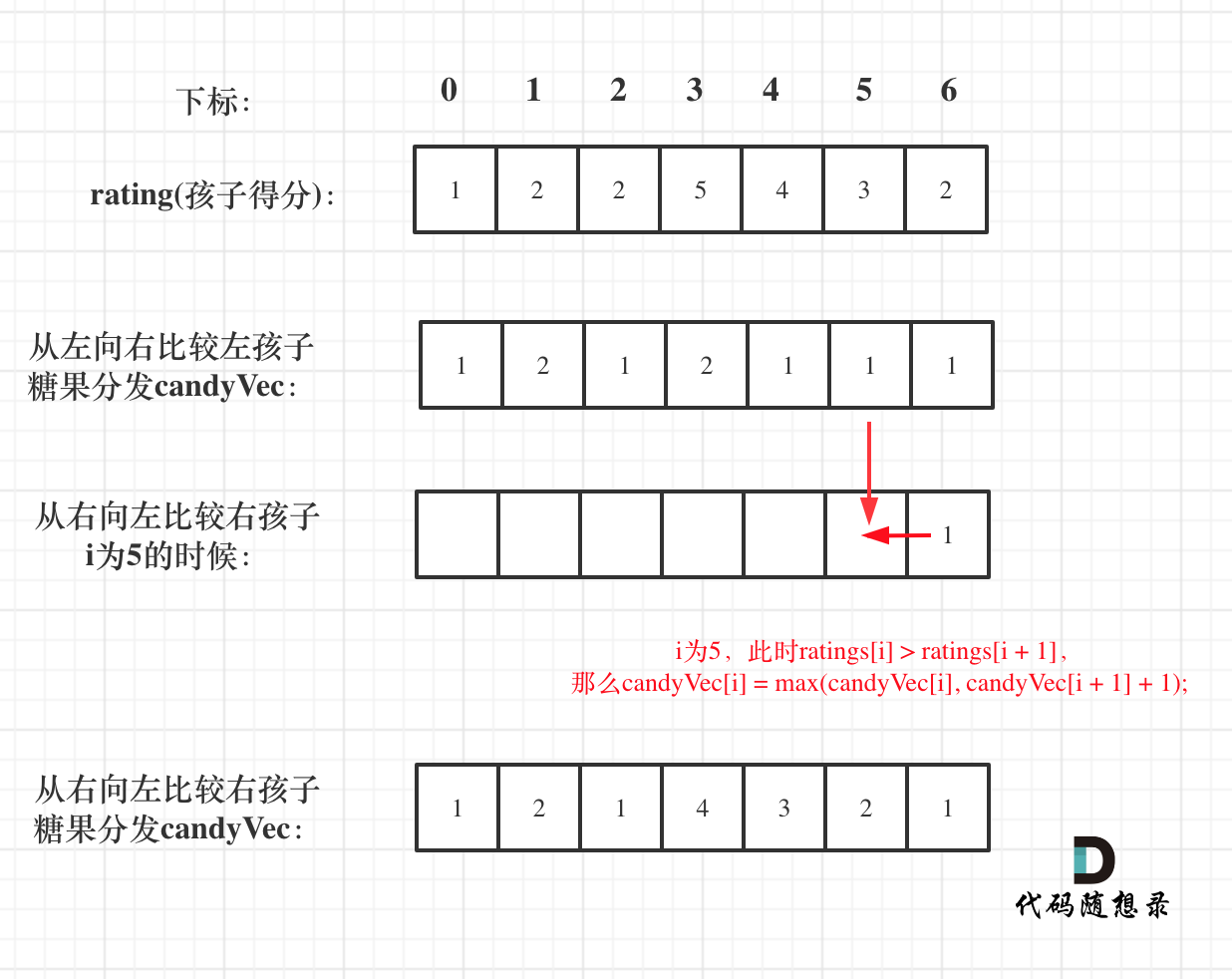
贪心算法|135.分发糖果
力扣题目链接 class Solution { public:int candy(vector<int>& ratings) {vector<int> candyVec(ratings.size(), 1);// 从前向后for (int i 1; i < ratings.size(); i) {if (ratings[i] > ratings[i - 1]) candyVec[i] candyVec[i - 1] 1;}// 从后…...
c# wpf template itemtemplate+ListBox
1.概要 2.代码 <Window x:Class"WpfApp2.Window7"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/winfx/2006/xaml"xmlns:d"http://schemas.microsoft.com/expression/blend/…...

通过curl命令调试与验证大模型API连接状态
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令调试与验证大模型API连接状态 基础教程类,针对需要在无SDK环境或快速排错的开发者,详细说明如…...

Kubernetes轻量级服务网格Cetus:核心流量治理与Sidecar代理实践
1. 项目概述:一个为Kubernetes而生的智能代理如果你正在管理一个规模不小的Kubernetes集群,并且对服务网格(Service Mesh)的复杂性望而却步,或者觉得像Istio这样的“巨无霸”方案有些杀鸡用牛刀,那么你很可…...

利用 Taotoken 多模型能力为 AIGC 应用构建降级容灾方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 多模型能力为 AIGC 应用构建降级容灾方案 当你的 AIGC 应用从内部测试走向面向真实用户的生产环境时,服…...

3分钟告别浏览器Markdown阅读困境:这款扩展如何重塑你的技术文档体验
3分钟告别浏览器Markdown阅读困境:这款扩展如何重塑你的技术文档体验 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer 你是否曾面对浏览器中杂乱的Markdown源代码感到困…...

数据笔记:LargeST——如何构建与评估一个面向未来的大规模交通预测基准数据集
1. 为什么我们需要LargeST这样的交通预测基准数据集 交通预测是智慧城市建设的核心技术之一,但长期以来这个领域面临一个尴尬局面:算法模型越来越复杂,却缺乏足够规模和质量的数据来验证其真实效果。这就像给赛车手一辆玩具车来测试性能——模…...

别再只盯着永恒之蓝打靶了!用Metasploit实战MS17-010的5个高阶后渗透技巧
实战MS17-010后渗透:5个提升内网横向移动效率的专业技巧 当Meterpreter会话成功建立后,真正的挑战才刚刚开始。许多安全研究员在渗透测试中往往止步于初始入侵,却忽略了后渗透阶段才是红队演练的核心战场。本文将分享五个经过实战检验的高阶…...

颠覆性创新:为什么Upkie开源轮式双足机器人正在重新定义机器人开发范式
颠覆性创新:为什么Upkie开源轮式双足机器人正在重新定义机器人开发范式 【免费下载链接】upkie Open-source wheeled biped robots 项目地址: https://gitcode.com/gh_mirrors/up/upkie 在传统机器人设计面临轮式与足式两难选择的今天,一个革命性…...

3大突破性功能:如何用QtScrcpy彻底改变你的Android投屏体验
3大突破性功能:如何用QtScrcpy彻底改变你的Android投屏体验 【免费下载链接】QtScrcpy Android real-time display control software 项目地址: https://gitcode.com/GitHub_Trending/qt/QtScrcpy 你是否曾经为了在电脑上操作手机而烦恼?无论是游…...

DownKyi技术架构解析:构建高性能B站视频下载引擎的工程实践
DownKyi技术架构解析:构建高性能B站视频下载引擎的工程实践 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...

Blitz.js全栈开发框架:零API理念与Next.js深度集成实战
1. 项目概述:一个颠覆性的全栈开发框架如果你和我一样,在过去的几年里,一直在React生态圈里打转,从Create React App到Next.js,再到尝试自己搭建一套包含身份验证、数据层、API路由的完整应用,那你一定对那…...