使用阿里云试用Elasticsearch学习:3.6 处理人类语言——同义词
词干提取是通过简化他们的词根形式来扩大搜索的范围,同义词 通过相关的观念和概念来扩大搜索范围。 也许没有文档匹配查询 “英国女王“ ,但是包含 “英国君主” 的文档可能会被认为是很好的匹配。
用户搜索 “美国” 并且期望找到包含 美利坚合众国 、 美国 、 美洲 、或者 美国各州 的文档。 然而,他们不希望搜索到关于 国事 或者 政府机构 的结果。
这个例子提供了宝贵的经验,它向我们阐述了,区分不同的概念对于人类是多么简单而对于纯粹的机器是多么棘手的事情。通常我们会对语言中的每一个词去尝试提供同义词以确保任何一个文档都是可发现的,以保证不管文档之间有多么微小的关联性都能够被检索出来。
这样做是不对的。就像我们更喜欢不用或少用词根而不是过分使用词根一样,同义词也应该只在必要的时候使用。 这是因为用户可以理解他们的搜索结果受限于他们的搜索词,如果搜索结果看上去几乎是随机时,他们就会变得无法理解(注:大规模使用同义词会导致查询结果趋向于让人觉得是随机的)。
同义词可以用来合并几乎相同含义的词,如 跳 、 跳越 或者 单脚跳行 ,和 小册子 、 传单 或者 资料手册 。 或者,它们可以用来让一个词变得更通用。例如, 鸟 可以作为 猫头鹰 或 鸽子 的通用代名词,还有, 成人 可以被用于 男人 或者 女人 。
同义词似乎是一个简单的概念,但是正确的使用它们却是非常困难的。在这一章,我们会介绍使用同义词的技巧和讨论它的局限性和陷阱。
同义词扩大了一个匹配文件的范围。正如 词干提取 或者 部分匹配 ,同义词的字段不应该被单独使用,而应该与一个针对主字段的查询操作一起使用,这个主字段应该包含纯净格式的原始文本。 在使用同义词时,参阅 多数字段 的解释来维护相关性。
使用同义词
同义词可以取代现有的语汇单元或 通过使用 同义词 语汇单元过滤器,添加到语汇单元流中:
PUT /my_index
{"settings": {"analysis": {"filter": {"my_synonym_filter": {"type": "synonym", "synonyms": [ "british,english","queen,monarch"]}},"analyzer": {"my_synonyms": {"tokenizer": "standard","filter": ["lowercase","my_synonym_filter" ]}}}}
}
- 首先,我们定义了一个 同义词 类型的语汇单元过滤器。
- 我们在 同义词格式 中讨论同义词格式。
- 然后我们创建了一个使用 my_synonym_filter 的自定义分析器。
同义词可以使用 synonym 参数来内嵌指定,或者必须 存在于集群每一个节点上的同义词文件中。 同义词文件路径由 synonyms_path 参数指定,应绝对或相对于 Elasticsearch config 目录。参照 更新停用词(Updating Stopwords) 的技巧,可以用来刷新的同义词列表。
通过 analyze API 来测试我们的分析器,显示如下:
GET /my_index/_analyze
{"text": ["Elizabeth is the English queen"],"analyzer": "my_synonyms","explain": true
}
Pos 1: (elizabeth)
Pos 2: (is)
Pos 3: (the)
Pos 4: (british,english)
Pos 5: (queen,monarch)
- 所有同义词与原始词项占有同一个位置。
这样的一个文件将匹配任何以下的查询: English queen 、British queen 、 English monarch 或 British monarch 。 即使是一个短语查询也将会工作,因为每个词项的位置已被保存。
在索引和搜索中使用相同的同义词语汇单元过滤器是多余的。 如果在索引的时候,我们用 english 和 british 这两个术语代替 English , 然后在搜索的时候,我们只需要搜索这些词项中的一个。或者,如果在索引的时候我们不使用同义词,然后在搜索的时候,我们将需要把对 English 的查询转换为 english 或者 british 的查询。
是否在搜索或索引的时候做同义词扩展可能是一个困难的选择。我们将探索更多的选择 扩展或收缩。
同义词格式
同义词最简单的表达形式是 逗号分隔:
- “jump,leap,hop”
如果遇到这些词项中的任何一项,则将其替换为所有列出的同义词。例如:
原始词项: 取代:
────────────────────────────────
jump → (jump,leap,hop)
leap → (jump,leap,hop)
hop → (jump,leap,hop)
或者, 使用 => 语法,可以指定一个词项列表(在左边),和一个或多个替换(右边)的列表:
"u s a,united states,united states of america => usa"
"g b,gb,great britain => britain,england,scotland,wales"
原始词项: 取代:
────────────────────────────────
u s a → (usa)
united states → (usa)
great britain → (britain,england,scotland,wales)
如果多个规则指定同一个同义词,它们将被合并在一起,且顺序无关,否则使用最长匹配。以下面的规则为例:
"united states => usa",
"united states of america => usa"
如果这些规则相互冲突,Elasticsearch 会将 United States of America 转换为词项 (usa),(of),(america) 。否则,会使用最长的序列,即最终得到词项 (usa) 。
扩展或收缩
在 同义词格式 中,我们看到了可以通过 简单扩展 、 简单收缩 、或_类型扩展_ 来指明同义词规则。 本章节我们将在这三者间做个权衡比较。
本节仅处理单词同义词。多词同义词又增添了一层复杂性,在 多词同义词和短语查询 中,我们将会讨论。
简单扩展
通过 简单扩展 ,我们可以把同义词列表中的任意一个词扩展成同义词列表 所有 的词:
"jump,hop,leap"
扩展可以应用在索引阶段或查询阶段。两者都有优点 (⬆)︎ 和缺点 (⬇)︎。到底要在哪个阶段使用,则取决于性能与灵活性:
索引 查询索引的大小 ⬇︎ 大索引。因为所有的同义词都会被索引,所以索引的大小相对会变大一些。 ⬆︎ 正常大小。关联 ⬇︎ 所有同义词都有相同的 IDF(至于什么是 IDF ,参见 什么是相关性?),这意味着通用的词和较常用的词都拥有着相同的权重。 ⬆︎ 每个同义词 IDF 都和原来一样。性能 ⬆︎ 查询只需要找到查询字符串中指定单个词项。 ⬇︎ 对一个词项的查询重写来查找所有的同义词,从而降低性能。灵活性 ⬇︎ 同义词规则不能改变现有的文件。对于有影响的新规则,现有的文件都要重建(注:重新索引一次文档)。 ⬆︎ 同义词规则可以更新不需要索引文件。简单收缩
简单收缩 ,把 左边的多个同义词映射到了右边的单个词:
- “leap,hop => jump”
它必须同时应用于索引和查询阶段,以确保查询词项映射到索引中存在的同一个值。
相对于简单扩展方法,这种方法也有一些优点和一些缺点:
索引的大小
⬆︎ 索引大小是正常的,因为只有单一词项被索引。
关联
⬇︎ 所有词项的 IDF 是一样的,所以你不能区分比较常用的词、不常用的单词。
性能
⬆︎ 查询只需要在索引中找到单词的出现。
灵活性
⬆︎ 新同义词可以添加到规则的左侧并在查询阶段使用。例如,我们想添加 bound 到先前指定的同义词规则中。那么下面的规则将作用于包含
bound 的查询或包含 bound 的文档索引:
- “leap,hop,bound => jump”
似乎对旧有的文档不起作用是么?其实我们可以把上面这个同义词规则改写下,以便对旧有文档同样起作用: - “leap,hop,bound => jump,bound”
当你重建索引文件,你可以恢复到上面的规则(注: leap,hop,bound => jump )来获得查询单个词项的性能优势(注:因为上面那个规则相比这个而言,查询阶段就只要查询一个词了)。
类型扩展
类型扩展是完全不同于简单收缩 或扩张, 并不是平等看待所有的同义词,而是扩大了词的意义,使被拓展的词更为通用。以这些规则为例:
“cat => cat,pet”,
“kitten => kitten,cat,pet”,
“dog => dog,pet”
“puppy => puppy,dog,pet”
通过在索引阶段使用类型扩展:
- 一个关于 kitten 的查询会发现关于 kittens 的文档。
- 查询一个 cat 会找到关于 kittens 和 cats 的文档。
- 一个 pet 的查询将发现有关的 kittens、cats、puppies、dogs 或者 pets 的文档。
或者在查询阶段使用类型扩展, kitten 的查询结果就会被拓展成涉及到 kittens、cats、dogs。
您也可以有两全其美的办法,通过在索引阶段应用类型扩展同义词规则,以确保类型在索引中存在。然后,在查询阶段, 你可以选择不采用同义词(使 kitten 查询只返回 kittens 的文件)或采用同义词, kitten 的查询操作就会返回包括 kittens、cats、pets(也包括 dogs 和 puppies)的相关结果。
前面的示例规则,对 kitten 的 IDF 将是正确的,而 cat 和 pet 的 IDF 将会被 Elasticsearch 降权。然而, 这是对你有利的,当一个针对 kitten 的查询被拓展成了针对 kitten OR cat OR pet 的查询, 那么 kitten 相关的文档就应该排在最上方,其次是 cat 的文件, pet 的文件将被排在最底部。
同义词和分析链
在 同义词格式 一章中,我们使用 u s a 来举例阐述一些同义词相关的知识。那么为什么 我们使用的不是 U.S.A. 呢?原因是, 这个 同义词 的语汇单元过滤器只能接收到在它前面的语汇单元过滤器或者分词器的输出结果(这里看不到原始文本)。
假设我们有一个分析器,它由 standard 分词器、 lowercase 的语汇单元过滤器、 synonym 的语汇单元过滤器组成。文本 U.S.A. 的分析过程,看起来像这样的:
original string(原始文本) → "U.S.A."
standard tokenizer(分词器) → (U),(S),(A)
lowercase token filter(语汇单元过滤器) → (u),(s),(a)
synonym token filter(语汇单元过滤器) → (usa)
如果我们有指定的同义词 U.S.A. ,它永远不会匹配任何东西。因为, my_synonym_filter 看到词项的时候,句号已经被移除了,并且字母已经被小写了。
这其实是一个非常需要注意的地方。如果我们想同时使用同义词特性与词根提取特性,那么 jumps 、 jumped 、 jump 、 leaps 、 leaped 和 leap 这些词是否都会被索引成一个 jump ? 我们 可以把同义词过滤器放置在词根提取之前,然后把所有同义词以及词形变化都列举出来:
- “jumps,jumped,leap,leaps,leaped => jump”
但更简洁的方式将同义词过滤器放置在词根过滤器之后,然后把词根形式的同义词列举出来:
- “leap => jump”
大小写敏感的同义词
通常,我们把同义词过滤器放置在 lowercase 语汇单元过滤器之后,因此,所有的同义词 都是小写。 但有时会导致奇怪的合并。例如, CAT 扫描和一只 cat 有很大的不同,或者 PET (正电子发射断层扫描)和 pet 。 就此而言,姓 Little 也是不同于形容词 little 的 (尽管当一个句子以它开头时,首字母会被大写)。
如果根据使用情况来区分词义,则需要将同义词过滤器放置在 lowercase 筛选器之前。当然,这意味着同义词规则需要列出所有想匹配的变化(例如, Little、LITTLE、little )。
相反,可以有两个同义词过滤器:一个匹配大小写敏感的同义词,一个匹配大小写不敏感的同义词。例如,大小写敏感的同义词规则可以是这个样子:
"CAT,CAT scan => cat_scan"
"PET,PET scan => pet_scan"
"Johnny Little,J Little => johnny_little"
"Johnny Small,J Small => johnny_small"
大小不敏感的同义词规则可以是这个样子:
"cat => cat,pet"
"dog => dog,pet"
"cat scan,cat_scan scan => cat_scan"
"pet scan,pet_scan scan => pet_scan"
"little,small"
大小写敏感的同义词规则不仅会处理 CAT scan ,而且有时候也可能会匹配到 CAT scan 中的 CAT (注:从而导致 CAT scan 被转化成了同义词 cat_scan scan )。出于这个原因,在大小写敏感的同义词列表中会有一个针对较坏替换情况的特异规则 cat_scan scan 。
提示: 可以看到它们可以多么轻易地变得复杂。同平时一样, analyze API 是帮手,用它来检查分析器是否正确配置。参阅 测试分析器。
多词同义词和短语查询
至此,同义词看上去还挺简单的。然而不幸的是,复杂的部分才刚刚开始。 为了能使 短语查询 正常工作, Elasticsearch 需要知道每个词在初始文本中的位置。多词同义词会严重破坏词的位置信息,尤其当新增的同义词标记长度各不相同的时候。
我们创建一个同义词语汇单元过滤器,然后使用下面这样的同义词规则:
"usa,united states,u s a,united states of america"
PUT /my_index
{"settings": {"analysis": {"filter": {"my_synonym_filter": {"type": "synonym","synonyms": ["usa,united states,u s a,united states of america"]}},"analyzer": {"my_synonyms": {"tokenizer": "standard","filter": ["lowercase","my_synonym_filter"]}}}}
}GET /my_index/_analyze
{"text": ["The United States is wealthy"],"analyzer": "my_synonyms","explain": true
}
如果你用上面这个同义词语汇单元过滤器索引一个文档,然后执行一个短语查询,那你就会得到惊人的结果,下面这些短语都不会匹配成功:
- The usa is wealthy
- The united states of america is wealthy
- The U.S.A. is wealthy
但是这些短语会:
- United states is wealthy
- Usa states of wealthy
- The U.S. of wealthy
- U.S. is america
如果你是在查询阶段使同义词,那你就会看到更加诡异的匹配结果。看下这个 validate-query 查询:
查询关键字会被同义词语汇单元过滤器处理成类似这样的信息:
“(usa united u united) (is states s states) (wealthy a of) america”
这会匹配包含有 u is of america 的文档,但是匹配不出任何含有 america 的文档。
使用简单收缩进行短语查询
避免这种混乱的方法是使用 简单收缩, 用单个词项表示所有的同义词, 然后在查询阶段,就只需要针对这单个词进行查询了:
PUT /my_index
{"settings": {"analysis": {"filter": {"my_synonym_filter": {"type": "synonym","synonyms": ["united states,u s a,united states of america=>usa"]}},"analyzer": {"my_synonyms": {"tokenizer": "standard","filter": ["lowercase","my_synonym_filter"]}}}}
}GET /my_index/_analyze
{"text": ["The United States is wealthy"],"analyzer": "my_synonyms","explain": true
}
上面那个查询信息就会被处理成类似下面这样:
Pos 1: (the)
Pos 2: (usa)
Pos 3: (is)
Pos 5: (wealthy)
现在我们再次执行我们之前做过的那个 validate-query 查询,就会输出一个简单又合理的结果:
“usa is wealthy”
这个方法的缺点是,因为把 united states of america 转换成了同义词 usa, 你就不能使用 united states of america 去搜索出 united 或者 states 。 你需要使用一个额外的字段并用另一个解析器链来达到这个目的。
符号同义词
最后一节内容我们来阐述下怎么对符号进行同义词处理,这和我们前面讲的同义词处理不太一样。 符号同义词 是用别名来表示这个符号,以防止它在分词过程中被误认为是不重要的标点符号而被移除。
虽然绝大多数情况下,符号对于全文搜索而言都无关紧要,但是字符组合而成的表情,或许又会是很有意义的东西,甚至有时候会改变整个句子的含义,对比一下这两句话:
- 我很高兴能在星期天工作。
- 我很高兴能在星期天工作 😦 (注:难过的表情)
标准 (注:standard)分词器或许会简单地消除掉第二个句子里的字符表情,致使两个原本意思相去甚远的句子变得相同。
我们可以先使用 映射字符过滤器,在文本被递交给分词器处理之前, 把字符表情替换成符号同义词 emoticon_happy 或者 emoticon_sad :
PUT /my_index
{"settings": {"analysis": {"char_filter": {"emoticons": {"type": "mapping","mappings": [ ":) => emoticon_happy",":( => emoticon_sad"]}},"analyzer": {"my_emoticons": {"char_filter": "emoticons","tokenizer": "standard","filter": [ "lowercase" ]]}}}}
}
GET /my-index-000001/_analyze
{"tokenizer": "keyword","char_filter": [ "my_mappings_char_filter" ],"text": "I'm delighted about it :("
}
{"tokens": [{"token": "I'm delighted about it _sad_","start_offset": 0,"end_offset": 25,"type": "word","position": 0}]
}
很少有人会搜 emoticon_happy 这个词,但是确保类似字符表情的这类重要符号被存储到索引中是非常好的做法,在进行情感分析的时候会很有用。当然,我们也可以用真实的词汇来处理符号同义词,比如: happy 或者 sad 。
提示: 映射 字符过滤器是个非常有用的过滤器,它可以用来对一些已有的字词进行替换操作, 你如果想要采用更灵活的正则表达式去替换字词的话,那你可以使用 pattern_replace 字符过滤器。
相关文章:

使用阿里云试用Elasticsearch学习:3.6 处理人类语言——同义词
词干提取是通过简化他们的词根形式来扩大搜索的范围,同义词 通过相关的观念和概念来扩大搜索范围。 也许没有文档匹配查询 “英国女王“ ,但是包含 “英国君主” 的文档可能会被认为是很好的匹配。 用户搜索 “美国” 并且期望找到包含 美利坚合众国 、…...
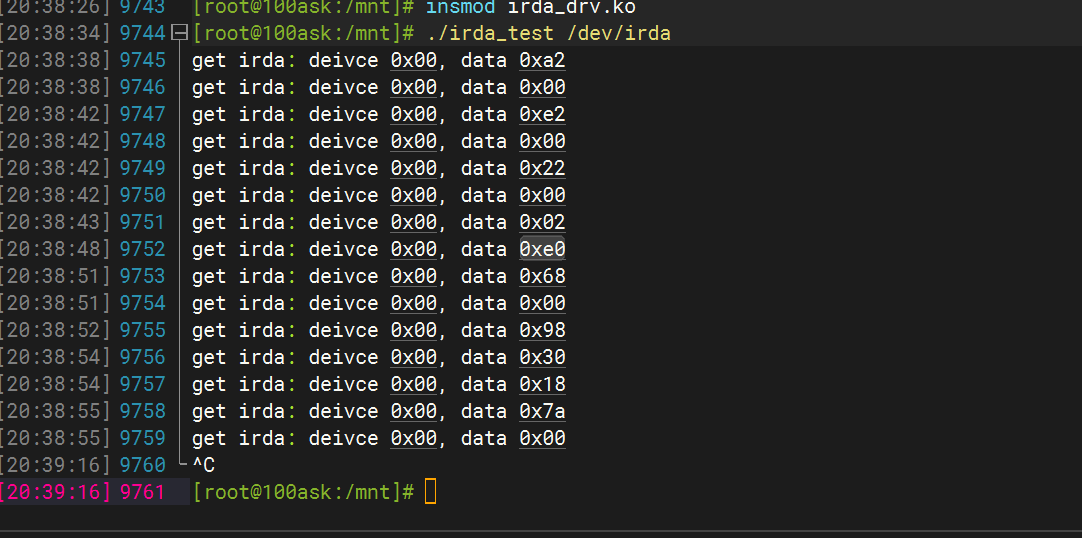
018——红外遥控模块驱动开发(基于HS0038和I.MX6uLL)
目录 一、 模块介绍 1.1 简介 1.2 协议 二、 驱动代码 三、 应用代码 四、 实验 五、 程序优化 一、 模块介绍 1.1 简介 红外遥控被广泛应用于家用电器、工业控制和智能仪器系统中,像我们熟知的有电视机盒子遥控器、空调遥控器。红外遥控器系统分为发送端和…...
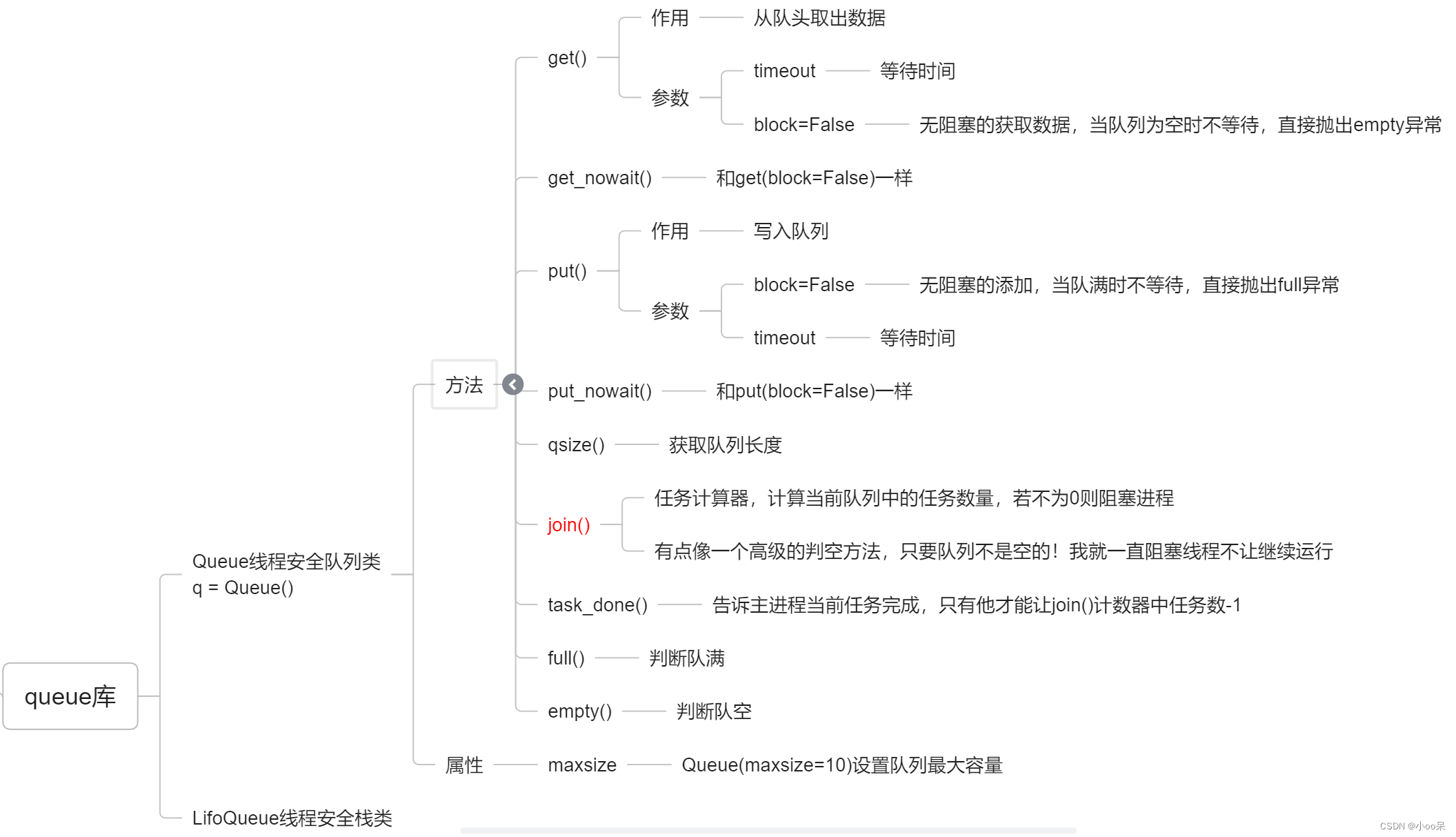
【学习心得】Python中的queue模块使用
一、Queue模块的知识点思维导图 二、Queue模块常用函数介绍 queue模块是内置的,不需要安装直接导入就可以了。 (1)创建一个Queue对象 import queue# 创建一个队列实例 q queue.Queue(maxsize20) # 可选参数,默认为无限大&am…...

ubuntu-server部署hive-part4-部署hive
参照 https://blog.csdn.net/qq_41946216/article/details/134345137 操作系统版本:ubuntu-server-22.04.3 虚拟机:virtualbox7.0 部署hive 下载上传 下载地址 http://archive.apache.org/dist/hive/ apache-hive-3.1.3-bin.tar.gz 以root用户上传至…...
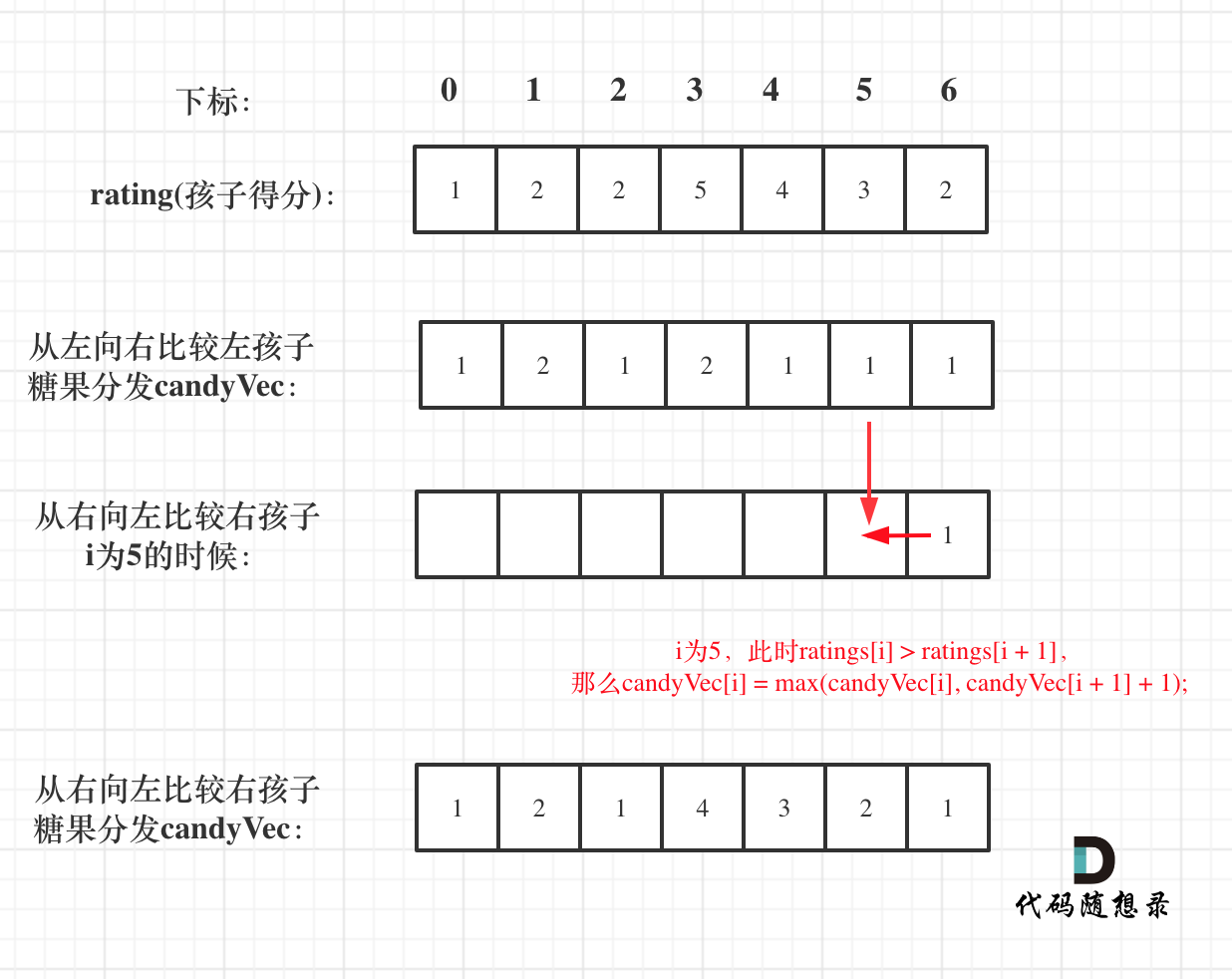
贪心算法|135.分发糖果
力扣题目链接 class Solution { public:int candy(vector<int>& ratings) {vector<int> candyVec(ratings.size(), 1);// 从前向后for (int i 1; i < ratings.size(); i) {if (ratings[i] > ratings[i - 1]) candyVec[i] candyVec[i - 1] 1;}// 从后…...
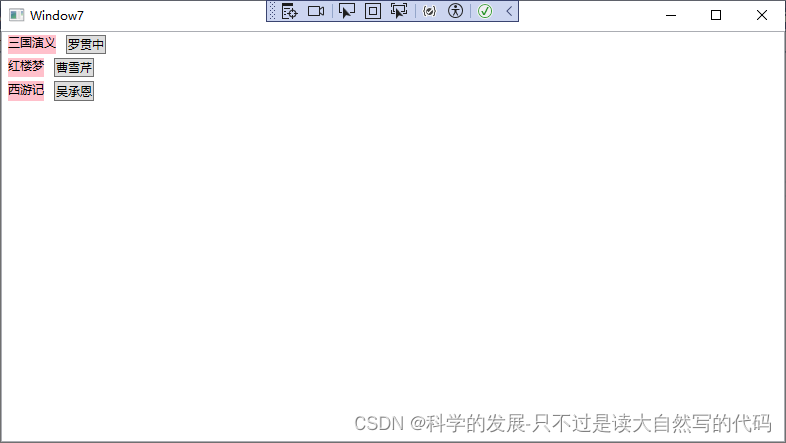
c# wpf template itemtemplate+ListBox
1.概要 2.代码 <Window x:Class"WpfApp2.Window7"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/winfx/2006/xaml"xmlns:d"http://schemas.microsoft.com/expression/blend/…...
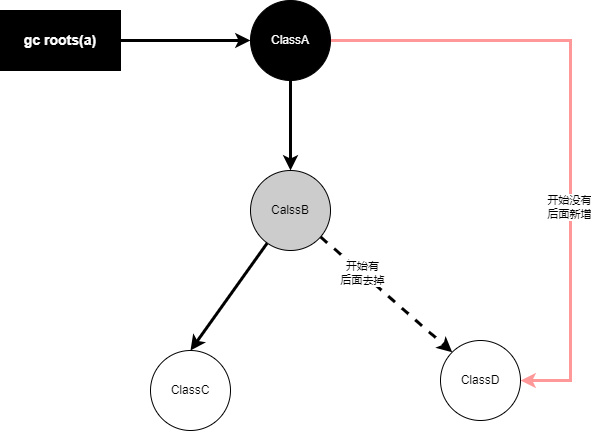
关于JVM-三色标记算法剖析
相关系列 深入理解JVM垃圾收集器-CSDN博客 深入理解JVM垃圾收集算法-CSDN博客 深入理解jvm执行引擎-CSDN博客 jvm优化原则-CSDN博客 jvm流程图-CSDN博客 三色标记产生的原因? 在并发标记的过程中,因为标记期间应用线程还在继续跑,对象间的引…...
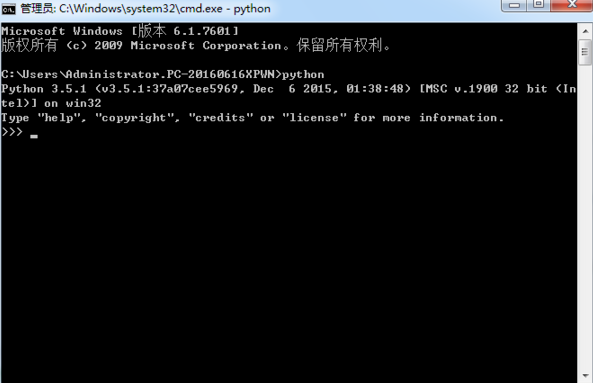
怎么看有没有装python
windows系统,运行——cmd,进入dos窗口,输入python,安装成功的话可以看到版本信息并进入编程模式。 如下图(我安装的版本是python 3.5.1):...

VS CODE环境安装和hello world
SAP UI5 demo walkthrough tutorial step1 hello word 首先要安装nodejs,然后才能执行下面的操作 nodejs vscode 安装ui5 npm install --global ui5/cli报错解决: idealTree:npm: sill idealTree buildDeps 这个信息说明npm正在构建,如一直停留在这个…...

mysql性能索引调优易混点总结
文章目录 一、 前言二、explain相关三、索引优化相关联合索引索引下推排序和分组相关优化分页优化表关联优化嵌套循环连接 Nested-Loop Join(NLJ) 算法in和exsits优化 一、 前言 近几年看了很多和mysql相关的书,文章或视频,但仍然有一些点,看…...

区块链与数字身份:探索Facebook的新尝试
在数字化时代,随着区块链技术的崛起,数字身份成为了一个备受关注的话题。作为全球最大的社交媒体平台之一,Facebook一直在探索如何利用区块链技术来改善数字身份管理和用户数据安全。本文将深入探讨Facebook在这一领域的新尝试,探…...
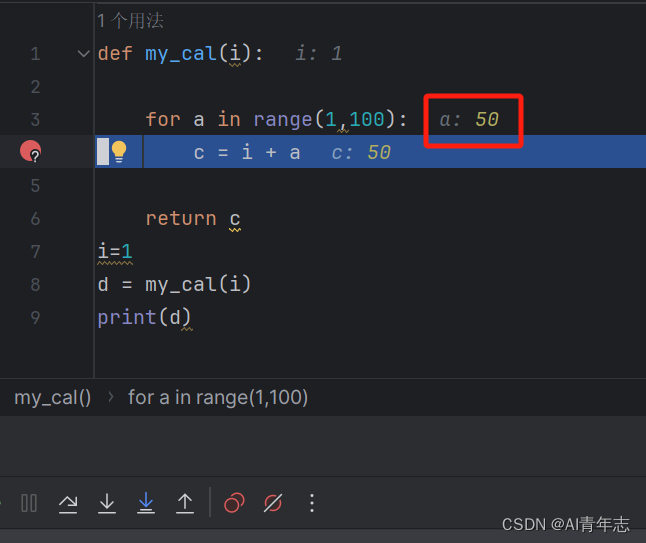
【pycharm】在debug循环时,如何快速debug到指定循环次数
【pycharm】在debug循环时,如何快速debug到指定循环次数 【先赞后看养成习惯】求关注收藏点赞😀 在 PyCharm 中,可以使用条件断点来实现在特定循环次数后停止调试。这可以通过在断点处右键单击,然后选择 “Add Breakpoint” -&g…...

【蓝桥杯每日一题】4.8 公约数
题目来源: 4199. 公约数 - AcWing题库 问题描述: 找到最大整数x,需满足下面两个条件 x x x是 a a a, b b b的公约数 l < x < r l<x<r l<x<r 思路: 找到 a a a, b b b两个数的最大公约数 g c g c d (…...

【MySQL学习】MySQL的慢查询日志和错误日志
꒰˃͈꒵˂͈꒱ write in front ꒰˃͈꒵˂͈꒱ ʕ̯•͡˔•̯᷅ʔ大家好,我是xiaoxie.希望你看完之后,有不足之处请多多谅解,让我们一起共同进步૮₍❀ᴗ͈ . ᴗ͈ აxiaoxieʕ̯•͡˔•̯᷅ʔ—CSDN博客 本文由xiaoxieʕ̯•͡˔•̯᷅ʔ 原创 CSDN …...

# C++之functional库用法整理
C之functional库用法整理 注:整理一些突然学到的C知识,随时mark一下 例如:忘记的关键字用法,新关键字,新数据结构 C 的function库用法整理 C之functional库用法整理一、functional库的内建仿函数1. 存储和调用函数2. 存…...
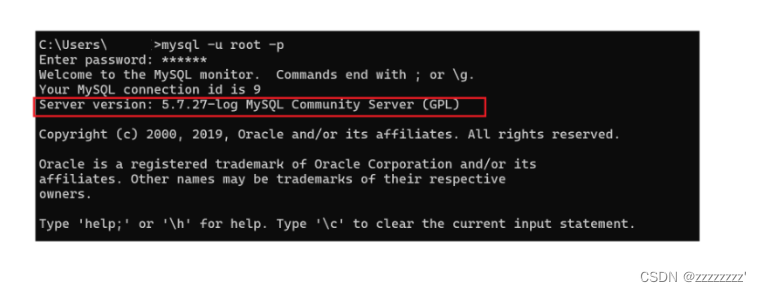
查看MySQL版本的方式
文章目录 一、使用cmd输入命令行查看二、在mysql客户端服务器里查询 一、使用cmd输入命令行查看 1、打开 cmd ,输入命令行: mysql --version 2、还是打开cmd,输入命令行:mysql -V (注意了,此时的V是个大写的V) 二、…...

k8s_入门_命令详解
命令详解 kubectl是官方的CLI命令行工具,用于与 apiserver进行通信,将用户在命令行输入的命令,组织并转化为 apiserver能识别的信息,进而实现管理k8s各种资源的一种有效途径 1. 帮助 2. 查看版本信息 3. 查看资源对象等 查看No…...

腾讯、阿里、字节….等大厂都更喜欢什么样的简历?
我985毕业,为什么筛选简历时输给了一个普通一本? 我投了20份简历,为什么没有一个大厂回我? 每次HR收到简历就没下文了,是我的简历有问题吗? 诚然,在求职时,简历往往就是我们给予H…...

OpenHarmony实战:帆移植案例(中)
OpenHarmony实战:帆移植案例(上) Audio服务介绍 服务节点 基于ADM框架的audio驱动对HDI层提供三个服务hdf_audio_render、hdf_audio_capture、hdf_audio_control。 开发板audio驱动服务节点如下: console:/dev # ls -al hdf_au…...

武汉星起航:创始人张振邦智慧领航,孵化伙伴共绘跨境新蓝图!
在风起云涌的跨境电商行业中,武汉星起航电子商务有限公司如同一颗璀璨的明星,引领着众多创业者迈向成功的彼岸。而这一切的背后,都离不开公司创始人张振邦先生的卓越领导与深厚经验。他凭借着在电子商务行业多年的深耕与积累,为武…...
)
告别烦人警告!Pandas 1.5+ 连接MySQL数据库的正确姿势(SQLAlchemy保姆级教程)
Pandas与MySQL交互的现代化实践:从DBAPI2到SQLAlchemy的平滑迁移 当你在Jupyter Notebook中运行那段熟悉的pymysql.connect代码时,突然跳出的黄色警告框是否让你心头一紧?这个看似无害的UserWarning实际上标志着Pandas生态正在经历一次重要的…...

MPC-HC播放器:3步打造你的专属影院级视听体验
MPC-HC播放器:3步打造你的专属影院级视听体验 【免费下载链接】mpc-hc MPC-HCs main repository. For support use our Trac: https://trac.mpc-hc.org/ 项目地址: https://gitcode.com/gh_mirrors/mpc/mpc-hc MPC-HC(Media Player Classic Home …...

TegraRcmGUI:Switch RCM注入工具新手完全指南
TegraRcmGUI:Switch RCM注入工具新手完全指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI TegraRcmGUI是一款专为Nintendo Switch设计的图形化…...

RK3588核心板赋能无人机智能飞控:异构计算与AI视觉实践
1. 项目概述:当高性能核心板遇上无人机最近在折腾一个挺有意思的项目,核心是把一块高性能的核心板——迅为的RK3588,塞进无人机里,让它成为飞控大脑。这听起来可能有点“大材小用”,毕竟RK3588这玩意儿算力不低&#x…...

基于Wasp全栈框架的SaaS启动模板:快速构建多租户应用
1. 项目概述:一个为独立开发者量身定制的开源SaaS蓝图 如果你是一名独立开发者,或者是一个小团队的创始人,心里揣着一个SaaS产品的想法,却总在技术选型、架构设计和持续交付的迷宫里打转,那么 wasp-lang/open-saas …...

如何用OpenCore Legacy Patcher让老旧Mac焕发新生:5分钟快速上手指南
如何用OpenCore Legacy Patcher让老旧Mac焕发新生:5分钟快速上手指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为你的老旧Mac无法升级到…...

基于Adafruit FLORA的红外遥控胸针DIY:从嵌入式编程到可穿戴艺术
1. 项目概述:一个藏在时尚配饰里的“电视终结者”几年前,我在一个朋友聚会上,发现大家明明在聊天,眼睛却总是不自觉地瞟向角落里那个正在播放无聊广告的电视。直接走过去关掉显得有点突兀,找遥控器又太麻烦。那一刻我就…...

3分钟完成30分钟任务:词达人自动化助手终极指南
3分钟完成30分钟任务:词达人自动化助手终极指南 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 你是否厌倦了每周在词达人平台上花费数小时完成枯燥的…...

Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞!
Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Windows系统…...

Rulebook-AI:用规则引擎为AI智能体构建可控决策框架
1. 项目概述:一个基于规则的AI智能体框架最近在探索如何让AI智能体(Agent)的行为更可控、更符合业务逻辑时,我遇到了一个挺有意思的开源项目:botingw/rulebook-ai。乍一看这个名字,可能会觉得它又是一个试图…...