Advanced RAG 02:揭开 PDF 文档解析的神秘面纱
编者按: 自 2023 年以来,RAG 已成为基于 LLM 的人工智能系统中应用最为广泛的架构之一。由于诸多产品的关键功能(如:领域智能问答、知识库构建等)严重依赖RAG,优化其性能、提高检索效率和准确性迫在眉睫,成为当前 RAG 相关研究的核心问题。如何高效准确地从PDF等非结构化数据中提取信息并加以利用,是其中一个亟待解决的重要问题。本文比较分析了多种解决方案的优缺点,着重探讨了这一问题的应对之策。
文章首先介绍了基于规则的解析方法,如pypdf,指出其无法很好地保留文档结构。接着作者评估了基于深度学习模型的解析方法,如 Unstructured 和 Layout-parser ,阐述了这种方法在提取表格、图像和保留文档布局结构等方面的优势,但同时也存在一些局限性。对于具有双列(double-column)等复杂布局的 PDF 文档,作者提出了一种经过改进的重排序算法。此外,作者还探讨了利用多模态大模型直接从 PDF 文档中提取信息的可能性。
这篇文章系统地分析了 PDF 文档解析中的各种挑战,并给出了一系列解决思路和改进算法,为进一步提高非结构化数据解析的质量贡献了有价值的见解,同时也指出了未来 PDF 文档解析的发展方向。
作者 | Florian June
编译 | 岳扬
对于 RAG 系统而言,从文档中提取信息是一种不可避免的情况。确保能够从源文件中有效地提取内容,对于提高最终输出的质量至关重要。
切勿低估这一流程的重要性。在使用 RAG 系统时,如果在文档解析过程中信息提取不力,会导致对 PDF 文件中所含信息的理解和利用受限。
解析流程(Pasing process)在 RAG 系统中的位置如图 1 所示:
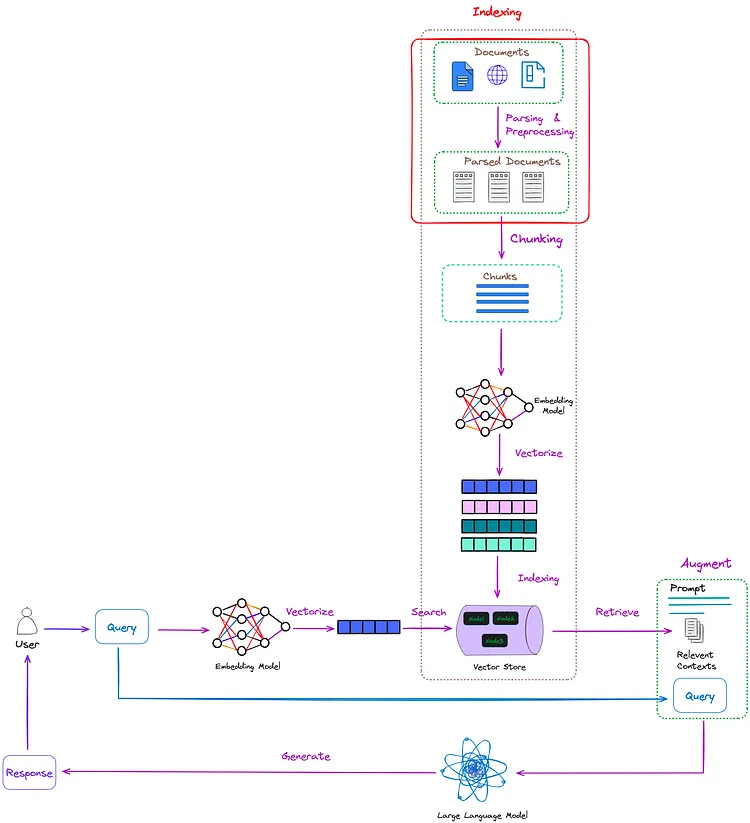
图 1:解析流程(Pasing process)在 RAG 系统中的位置。Image by author。
在实际工作场景中,非结构化数据远比结构化数据丰富。但如果这些海量数据不能被解析,其巨大价值将无法发掘,其中 PDF 文档尤为突出。
在非结构化数据中,PDF 文档占绝大多数。有效处理 PDF 文档对管理其他类型的非结构化文档也有很大帮助。
本文主要介绍解析 PDF 文档的方法,包括但不限于如何有效解析 PDF 文档、如何尽可能提取更多有用信息等相关问题的算法和建议。
01 解析 PDF 将会面临的挑战
PDF 文档是非结构化文档的代表性格式,然而,从 PDF 文档中提取信息是一个极具挑战性的过程。
与其说 PDF 是一种数据格式,不如将其描述为一系列打印指令的集合更为准确。PDF 文件由一系列指令组成,这些指令指示 PDF 阅读器或打印机在屏幕或纸张上如何安排各种符号、文字的位置和显示方式。 这与 HTML 和 docx 等文件格式截然不同,这些文件格式使用 <p>、<w:p>、<table> 和 <w:tbl> 等标签来组织不同的逻辑结构,如图 2 所示:
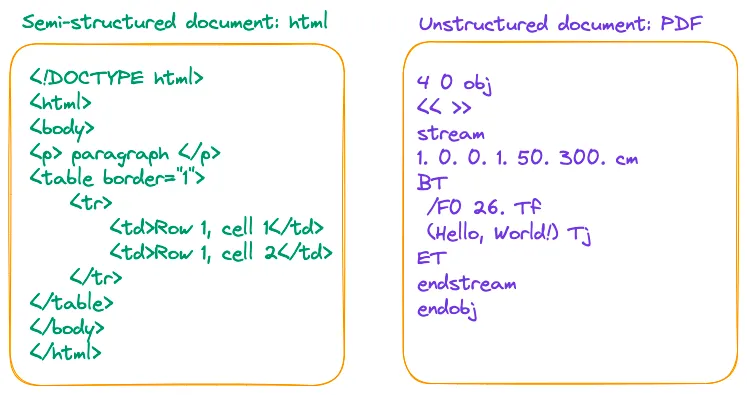
图 2:Html vs PDF. Image by author.
解析 PDF 文档的挑战在于准确提取整个页面的布局,并将所有内容(包括表格、标题、文本段落和图像)转化为文本形式。 在这个过程中,会出现文本提取不准确、图像识别不精确以及混淆表格中的行列关系等挑战。
02 如何解析 PDF 文档
一般来说,解析 PDF 文档有三种方法,它们各有优缺点,适用于不同的场景:
- 基于规则的解析方法(Rule-based approach) :根据文档的组织特征确定 PDF 文档中每个部分的样式和内容。不过,这种方法的通用性不强,因为 PDF 的类型和布局繁多,难以通过预定义的规则覆盖所有情况。
- 基于深度学习模型的解析方法:例如结合目标检测(object detection)和 OCR 模型的解决方案。
- 基于多模态大模型解析复杂结构或提取 PDF 中的关键信息。
2.1 基于规则的解析方法(Rule-based approach)
pypdf[1] 是这种方法最具代表性的工具之一,它是一种被广泛使用的基于规则的 PDF 解析工具。在 LangChain[2] 和 LlamaIndex[3] 等库中,被作为解析 PDF 文件的标准方法使用。
下面是使用 pypdf 尝试解析《Attention Is All You Need》[4]论文第 6 页的案例。该页面如图 3 所示。

图 3:《Attention Is All You Need》论文第 6 页
具体代码如下:
import PyPDF2
filename = "/Users/Florian/Downloads/1706.03762.pdf"
pdf_file = open(filename, 'rb')reader = PyPDF2.PdfReader(pdf_file)page_num = 5
page = reader.pages[page_num]
text = page.extract_text()print('--------------------------------------------------')
print(text)pdf_file.close()
代码运行结果为(为简洁起见,省略其余部分):
(py) Florian:~ Florian$ pip list | grep pypdf
pypdf 3.17.4
pypdfium2 4.26.0(py) Florian:~ Florian$ python /Users/Florian/Downloads/pypdf_test.py
--------------------------------------------------
Table 1: Maximum path lengths, per-layer complexity and minimum number of sequential operations
for different layer types. nis the sequence length, dis the representation dimension, kis the kernel
size of convolutions and rthe size of the neighborhood in restricted self-attention.
Layer Type Complexity per Layer Sequential Maximum Path Length
Operations
Self-Attention O(n2·d) O(1) O(1)
Recurrent O(n·d2) O(n) O(n)
Convolutional O(k·n·d2) O(1) O(logk(n))
Self-Attention (restricted) O(r·n·d) O(1) O(n/r)
3.5 Positional Encoding
Since our model contains no recurrence and no convolution, in order for the model to make use of the
order of the sequence, we must inject some information about the relative or absolute position of the
tokens in the sequence. To this end, we add "positional encodings" to the input embeddings at the
bottoms of the encoder and decoder stacks. The positional encodings have the same dimension dmodel
as the embeddings, so that the two can be summed. There are many choices of positional encodings,
learned and fixed [9].
In this work, we use sine and cosine functions of different frequencies:
PE(pos,2i)=sin(pos/100002i/d model)
PE(pos,2i+1)=cos(pos/100002i/d model)
where posis the position and iis the dimension. That is, each dimension of the positional encoding
corresponds to a sinusoid. The wavelengths form a geometric progression from 2πto10000 ·2π. We
chose this function because we hypothesized it would allow the model to easily learn to attend by
relative positions, since for any fixed offset k,PEpos+kcan be represented as a linear function of
PEpos.
...
...
...
根据 PyPDF 的检测结果,可以发现它将 PDF 中的字符序列(character sequences)序列化为一个单一的长序列,而不保留结构信息。换句话说,它将文档中的每一行都视为由换行符"\n "分隔的序列,因此无法准确识别文本段落或表格。
这种限制是基于规则的 pdf 解析方法的固有特征。
2.2 基于深度学习模型的解析方法
这种方法的优点在于能够准确识别文档的整体布局(包括表格和文本段落),甚至可以理解表格的内部结构。说明这种方法可以将文档划分为定义明确、完整的信息单元,同时还可以保留预期的含义和结构。
不过,这种方法也存在一定的局限性。目标检测(object detection)和 OCR 阶段可能比较耗时。因此,建议使用 GPU 或其他用于加速特定计算任务的硬件,并采用多个进程和线程并行处理。
这种方法需要使用目标检测(object detection)技术和 OCR 模型,我已经测试了几个最具代表性的开源框架:
- Unstructured[5]:该框架已经被集成到 langchain[6] 中。在 infer_table_structure 为 True 的情况下,hi_res 策略的表格识别效果很好。然而,fast 策略由于没有使用目标检测模型,错误地识别了许多图像和表格,因此表现不佳。
- Layout-parser[7]:如果需要识别结构复杂的 PDF,建议使用框架中最大规模的模型,这样准确率会更高,不过速度可能会稍慢一些。此外,Layout-parser 的模型[8]似乎在过去两年中没有更新过。
- PP-StructureV2[9]: 采用了各种模型组合进行文档分析,性能高于平均水平。其架构如图 4 所示:

图 4:作者提出的 PP-StructureV2 框架。它包含两个子系统:布局信息提取(layout information extraction)和关键信息提取(key information extraction)。来源:PP-StructureV2[9]。
除了前文提到的那些开源工具外,还存在像 ChatDOC 这样需要付费才能使用的商业工具,这些商业工具利用基于文档布局的识别和OCR(光学字符识别)方法来解析PDF文档。
接下来,我们将详细说明如何使用开源的 unstructured[10] 框架来解析 PDF,解决下面这三个关键挑战。
挑战 1:如何从表格和图片中提取数据
在本小节,我们将以 unstructured[10] 框架为例。检测到的表格数据可以直接导出为 HTML。相关代码如下:
from unstructured.partition.pdf import partition_pdffilename = "/Users/Florian/Downloads/Attention_Is_All_You_Need.pdf"# infer_table_structure=True automatically selects hi_res strategy
elements = partition_pdf(filename=filename, infer_table_structure=True)
tables = [el for el in elements if el.category == "Table"]print(tables[0].text)
print('--------------------------------------------------')
print(tables[0].metadata.text_as_html)
通过跟踪 partition_pdf 函数的内部代码逻辑,绘制了如图 5 的基本代码流程图。
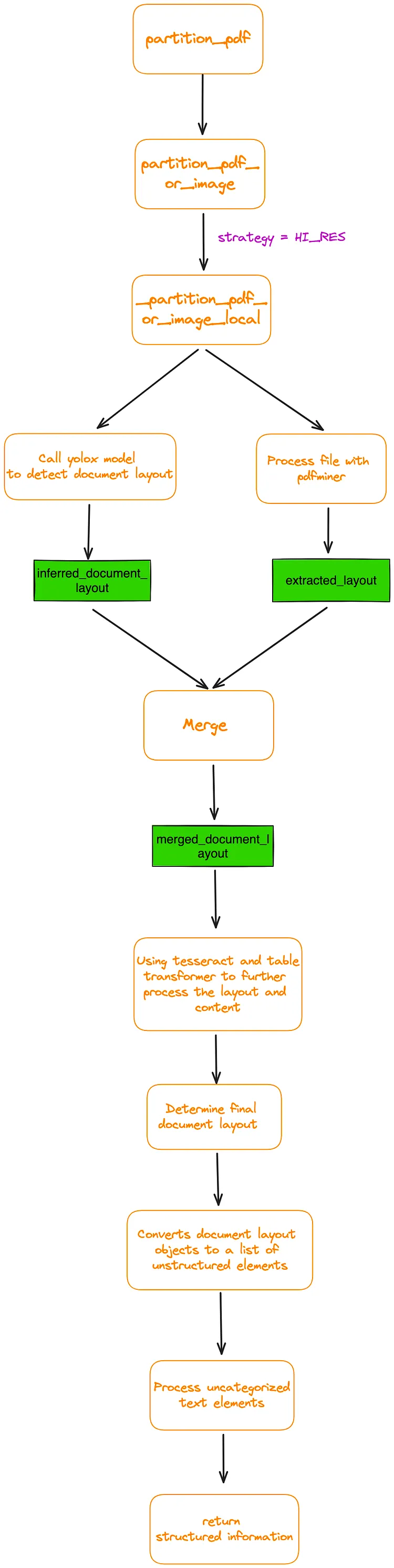
图 5:partition_pdf 函数的内部代码逻辑。Image by author。
代码运行的结果如下:
Layer Type Self-Attention Recurrent Convolutional Self-Attention (restricted) Complexity per Layer O(n2 · d) O(n · d2) O(k · n · d2) O(r · n · d) Sequential Maximum Path Length Operations O(1) O(n) O(1) O(1) O(1) O(n) O(logk(n)) O(n/r)
--------------------------------------------------
<table><thead><th>Layer Type</th><th>Complexity per Layer</th><th>Sequential Operations</th><th>Maximum Path Length</th></thead><tr><td>Self-Attention</td><td>O(n? - d)</td><td>O(1)</td><td>O(1)</td></tr><tr><td>Recurrent</td><td>O(n- d?)</td><td>O(n)</td><td>O(n)</td></tr><tr><td>Convolutional</td><td>O(k-n-d?)</td><td>O(1)</td><td>O(logy(n))</td></tr><tr><td>Self-Attention (restricted)</td><td>O(r-n-d)</td><td>ol)</td><td>O(n/r)</td></tr></table>
复制 HTML 标签并将它们保存为 HTML 文件。然后,使用 Chrome 打开它,如图 6 所示:

图 6:图 3 中表格 1 的内容提取。Image by author。
可以看出,unstructured 算法基本准确提取了整个表格的数据。
挑战 2:如何重新排列检测到的数据块?特别是如何处理双列(double-column) PDF
在处理双列(double-column) PDF 时,我们以《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》[11]论文为例。红色箭头表示阅读顺序:

图 7:Double-column page
确定布局后,unstructured 框架会将每个页面划分为若干矩形块,如图 8 所示。

图 8:布局检测结果的可视化。Image by author。
每个矩形块的详细信息可以按以下格式获取:
[LayoutElement(bbox=Rectangle(x1=851.1539916992188, y1=181.15073777777613, x2=1467.844970703125, y2=587.8204599999975), text='These approaches have been generalized to coarser granularities, such as sentence embed- dings (Kiros et al., 2015; Logeswaran and Lee, 2018) or paragraph embeddings (Le and Mikolov, 2014). To train sentence representations, prior work has used objectives to rank candidate next sentences (Jernite et al., 2017; Logeswaran and Lee, 2018), left-to-right generation of next sen- tence words given a representation of the previous sentence (Kiros et al., 2015), or denoising auto- encoder derived objectives (Hill et al., 2016). ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.9519357085227966, image_path=None, parent=None), LayoutElement(bbox=Rectangle(x1=196.5296173095703, y1=181.1507377777777, x2=815.468994140625, y2=512.548237777777), text='word based only on its context. Unlike left-to- right language model pre-training, the MLM ob- jective enables the representation to fuse the left and the right context, which allows us to pre- In addi- train a deep bidirectional Transformer. tion to the masked language model, we also use a “next sentence prediction” task that jointly pre- trains text-pair representations. The contributions of our paper are as follows: ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.9517233967781067, image_path=None, parent=None), LayoutElement(bbox=Rectangle(x1=200.22352600097656, y1=539.1451822222216, x2=825.0242919921875, y2=870.542682222221), text='• We demonstrate the importance of bidirectional pre-training for language representations. Un- like Radford et al. (2018), which uses unidirec- tional language models for pre-training, BERT uses masked language models to enable pre- trained deep bidirectional representations. This is also in contrast to Peters et al. (2018a), which uses a shallow concatenation of independently trained left-to-right and right-to-left LMs. ', source=<Source.YOLOX: 'yolox'>, type='List-item', prob=0.9414362907409668, image_path=None, parent=None), LayoutElement(bbox=Rectangle(x1=851.8727416992188, y1=599.8257377777753, x2=1468.0499267578125, y2=1420.4982377777742), text='ELMo and its predecessor (Peters et al., 2017, 2018a) generalize traditional word embedding re- search along a different dimension. They extract context-sensitive features from a left-to-right and a right-to-left language model. The contextual rep- resentation of each token is the concatenation of the left-to-right and right-to-left representations. When integrating contextual word embeddings with existing task-specific architectures, ELMo advances the state of the art for several major NLP benchmarks (Peters et al., 2018a) including ques- tion answering (Rajpurkar et al., 2016), sentiment analysis (Socher et al., 2013), and named entity recognition (Tjong Kim Sang and De Meulder, 2003). Melamud et al. (2016) proposed learning contextual representations through a task to pre- dict a single word from both left and right context using LSTMs. Similar to ELMo, their model is feature-based and not deeply bidirectional. Fedus et al. (2018) shows that the cloze task can be used to improve the robustness of text generation mod- els. ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.938507616519928, image_path=None, parent=None), LayoutElement(bbox=Rectangle(x1=199.3734130859375, y1=900.5257377777765, x2=824.69873046875, y2=1156.648237777776), text='• We show that pre-trained representations reduce the need for many heavily-engineered task- specific architectures. BERT is the first fine- tuning based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outper- forming many task-specific architectures. ', source=<Source.YOLOX: 'yolox'>, type='List-item', prob=0.9461237788200378, image_path=None, parent=None), LayoutElement(bbox=Rectangle(x1=195.5695343017578, y1=1185.526123046875, x2=815.9393920898438, y2=1330.3272705078125), text='• BERT advances the state of the art for eleven NLP tasks. The code and pre-trained mod- els are available at https://github.com/ google-research/bert. ', source=<Source.YOLOX: 'yolox'>, type='List-item', prob=0.9213815927505493, image_path=None, parent=None), LayoutElement(bbox=Rectangle(x1=195.33956909179688, y1=1360.7886962890625, x2=447.47264000000007, y2=1397.038330078125), text='2 Related Work ', source=<Source.YOLOX: 'yolox'>, type='Section-header', prob=0.8663332462310791, image_path=None, parent=None), LayoutElement(bbox=Rectangle(x1=197.7477264404297, y1=1419.3353271484375, x2=817.3308715820312, y2=1527.54443359375), text='There is a long history of pre-training general lan- guage representations, and we briefly review the most widely-used approaches in this section. ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.928022563457489, image_path=None, parent=None), LayoutElement(bbox=Rectangle(x1=851.0028686523438, y1=1468.341394166663, x2=1420.4693603515625, y2=1498.6444497222187), text='2.2 Unsupervised Fine-tuning Approaches ', source=<Source.YOLOX: 'yolox'>, type='Section-header', prob=0.8346447348594666, image_path=None, parent=None), LayoutElement(bbox=Rectangle(x1=853.5444444444446, y1=1526.3701822222185, x2=1470.989990234375, y2=1669.5843488888852), text='As with the feature-based approaches, the first works in this direction only pre-trained word em- (Col- bedding parameters from unlabeled text lobert and Weston, 2008). ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.9344717860221863, image_path=None, parent=None), LayoutElement(bbox=Rectangle(x1=200.00000000000009, y1=1556.2037353515625, x2=799.1743774414062, y2=1588.031982421875), text='2.1 Unsupervised Feature-based Approaches ', source=<Source.YOLOX: 'yolox'>, type='Section-header', prob=0.8317819237709045, image_path=None, parent=None), LayoutElement(bbox=Rectangle(x1=198.64227294921875, y1=1606.3146266666645, x2=815.2886352539062, y2=2125.895459999998), text='Learning widely applicable representations of words has been an active area of research for decades, including non-neural (Brown et al., 1992; Ando and Zhang, 2005; Blitzer et al., 2006) and neural (Mikolov et al., 2013; Pennington et al., 2014) methods. Pre-trained word embeddings are an integral part of modern NLP systems, of- fering significant improvements over embeddings learned from scratch (Turian et al., 2010). To pre- train word embedding vectors, left-to-right lan- guage modeling objectives have been used (Mnih and Hinton, 2009), as well as objectives to dis- criminate correct from incorrect words in left and right context (Mikolov et al., 2013). ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.9450697302818298, image_path=None, parent=None), LayoutElement(bbox=Rectangle(x1=853.4905395507812, y1=1681.5868488888855, x2=1467.8729248046875, y2=2125.8954599999965), text='More recently, sentence or document encoders which produce contextual token representations have been pre-trained from unlabeled text and fine-tuned for a supervised downstream task (Dai and Le, 2015; Howard and Ruder, 2018; Radford et al., 2018). The advantage of these approaches is that few parameters need to be learned from scratch. At least partly due to this advantage, OpenAI GPT (Radford et al., 2018) achieved pre- viously state-of-the-art results on many sentence- level tasks from the GLUE benchmark (Wang language model- Left-to-right et al., 2018a). ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.9476840496063232, image_path=None, parent=None)]
其中 (x1, y1) 是左上顶点的坐标,而 (x2, y2) 是右下顶点的坐标:
(x_1, y_1) --------| || || |---------- (x_2, y_2)
此时,你可以选择重新调整(reshape)页面的阅读顺序。Unstructured 框架已经内置了排序算法,但我发现在处理 double-column 的情况时,排序结果并不令我满意。
因此,有必要设计一种算法处理这种情况。最简单的方法是首先按照左上顶点的横坐标进行排序,如果横坐标相同,则按纵坐标进行排序。其伪代码如下:
layout.sort(key=lambda z: (z.bbox.x1, z.bbox.y1, z.bbox.x2, z.bbox.y2))
不过,我们发现,即使是同一列中的图块,其横坐标也可能存在变化。如图 9 所示,紫线指向的 block 横坐标 bbox.x1 实际上更靠左。进行排序时,它的位置会在绿线指向的 block 之前,这显然违反了文档的阅读顺序。

图 9:同一列的横坐标可能会有变化。Image by author。
在这种情况下,一种具备可行性的算法如下:
- 首先,对所有左上顶点 x 坐标 x1 进行排序,得到 x1_min
- 然后,对所有右下顶点 x 坐标 x2 进行排序,得到 x2_max
- 接下来,确定页面中心线的 x 坐标为:
x1_min = min([el.bbox.x1 for el in layout])
x2_max = max([el.bbox.x2 for el in layout])
mid_line_x_coordinate = (x2_max + x1_min) / 2
之后,如果 bbox.x1 < mid_line_x_coordinate,则将该 block 划为左列的一部分。否则,将其视为右列的一部分。
分类完成后,根据它们的 y 坐标对每列内的每个 block 进行排序。最后,将右侧列连接到左侧列的右侧。
left_column = []
right_column = []
for el in layout:if el.bbox.x1 < mid_line_x_coordinate:left_column.append(el)else:right_column.append(el)left_column.sort(key = lambda z: z.bbox.y1)
right_column.sort(key = lambda z: z.bbox.y1)
sorted_layout = left_column + right_column
值得一提的是,这一算法改进也能兼容单栏 PDF 的解析。
挑战 3:如何提取多级标题
提取标题(包括多级标题)的目的是增强 LLM 所提供回复内容的准确性。
例如,如果用户想了解图 9 中第 2.1 节的大意,只需准确提取出第 2.1 节的标题,并将其与相关内容一起作为上下文发送给 LLM,最终所得到的回复内容的准确性就会大大提高。
该算法仍然依赖于图 9 所示的布局块(layout blocks)。我们可以提取 type=’Section-header’ 的 block,并计算高度差值(bbox.y2 - bbox.y1)。高度差值(height difference)最大的 block 对应一级标题,其次是二级标题,然后是三级标题。
2.3 基于多模态大模型解析 PDF 中的复杂结构
在多模态模型得到快速发展和广泛应用之后,也可以利用多模态模型来解析表格。有几种选择[12]:
- 检索相关图像(PDF 页面)并将它们发送到 GPT4-V ,以响应用户向系统提交的问题或需求。
- 将每个 PDF 页面视为一张图像,让 GPT4-V 对每个页面进行图像推理。通过图像推理构建 Text Vector Store index (译者注:应当是对文本向量进行索引和检索的数据结构或存储空间)。使用 Image Reasoning Vectore Store (译者注:应当为用于存储图像推理向量的数据库或仓库)查询答案。
- 使用 Table Transformer 从检索到的图像中裁剪表格信息,然后将这些裁剪后的图像发送到 GPT4-V 以响应用户向系统提交的问题或需求。
- 对裁剪后的表格图像使用 OCR 技术进行识别,然后将数据发送到 GPT4 / GPT-3.5 ,以回答用户向系统提交的问题。
经过测试,确定第三种方法最为有效。
此外,我们还可以使用多模态模型从图像中提取或总结关键信息(因为 PDF 文件可轻松转换为图像),如图 10 所示。
图 10:从图像中提取或总结关键信息。来源:GPT-4 with Vision: Complete Guide and Evaluation[13]
03 Conclusion
一般几乎所有的非结构化文档都具有高度的灵活性,需要各种各样的解析技术。然而,业界目前还没有就使用哪种方法达成共识。
在这种情况下,建议选择最适合项目需求的方法,根据不同类型的 PDF 文件,采取特定的处理方法。例如,论文、书籍和财务报表等非结构性文档可能会根据其特点进行独特的布局设计。
尽管如此,如果条件允许,仍建议选择基于深度学习或多模态的方法。这些方法可以有效地将文档分割成定义明确、完整的信息单元,从而最大限度地保留文档的原意和结构。
Thanks for reading!
————
Florian June
An artificial intelligence researcher, mainly write articles about Large Language Models, data structures and algorithms, and NLP.
END
参考资料
[1]https://github.com/py-pdf/pypdf
[2]https://github.com/langchain-ai/langchain/blob/v0.1.1/libs/langchain/langchain/document_loaders/pdf.py
[3]https://github.com/run-llama/llama_index/blob/v0.9.32/llama_index/readers/file/docs_reader.py
[4]https://arxiv.org/pdf/1706.03762.pdf
[5]http://unstructured-io.github.io/unstructured/
[6]https://github.com/langchain-ai/langchain/blob/master/libs/langchain/langchain/document_loaders/pdf.py
[7]http://github.com/Layout-Parser/layout-parser
[8]https://layout-parser.github.io/platform/
[9]https://arxiv.org/pdf/2210.05391.pdf
[10]https://github.com/Unstructured-IO/unstructured
[11]https://arxiv.org/pdf/1810.04805.pdf
[12]https://docs.llamaindex.ai/en/stable/examples/multi_modal/multi_modal_pdf_tables.html
[13]https://blog.roboflow.com/gpt-4-vision/
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接:
https://pub.towardsai.net/advanced-rag-02-unveiling-pdf-parsing-b84ae866344e
相关文章:
Advanced RAG 02:揭开 PDF 文档解析的神秘面纱
编者按: 自 2023 年以来,RAG 已成为基于 LLM 的人工智能系统中应用最为广泛的架构之一。由于诸多产品的关键功能(如:领域智能问答、知识库构建等)严重依赖RAG,优化其性能、提高检索效率和准确性迫在眉睫&am…...

Spring面试题pro版-1
Spring框架是由于软件开发的复杂性而创建的。Spring使用的是基本的JavaBean来完成以前只可能由EJB完成的事情。然而,Spring的用途不仅仅限于服务器端的开发。从简单性、可测试性和松耦合性角度而言,绝大部分Java应用都可以从Spring中受益。 Spring是什么…...

6 Reverse Linked List
分数 20 作者 陈越 单位 浙江大学 Write a nonrecursive procedure to reverse a singly linked list in O(N) time using constant extra space. Format of functions: List Reverse( List L ); where List is defined as the following: typedef struct Node *PtrToNo…...

【随笔】Git 高级篇 -- 相对引用2 HEAD~n(十三)
💌 所属专栏:【Git】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! 💖 欢迎大…...

2024免费Mac电脑用户的系统清理和优化软件CleanMyMac
作为产品营销专家,对于各类产品的特性与优势有着深入的了解。CleanMyMac是一款针对Mac电脑用户的系统清理和优化软件,旨在帮助用户轻松管理、优化和保护Mac电脑。以下是关于CleanMyMac的详细介绍: CleanMyMac X2024全新版下载如下: https://…...
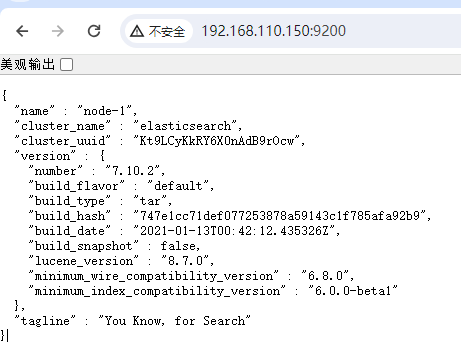
Centos7源码方式安装Elasticsearch 7.10.2单机版
版本选择参考:Elasticsearch如何选择版本-CSDN博客 下载 任选一种方式下载 官网7.10.2版本下载地址: https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.10.2-linux-x86_64.tar.gz 网盘下载链接 链接:https://pan…...

mysql的安装和部署
##官网下载mysql 我下载的是一个mysql-5.7.38-linux-glibc2.12-x86_64.tar.gz 可以通过xshell 或者xftp传送 xshell则是先下载一个lrzsz 执行以下的命令 yum install lrzsz -y #安装好我下面有个一键安装的脚本 #!/bin/bash#解决软件的依赖关系 yum install cmake ncurses…...

大数据基本名词
目录[-] 1.1. 1. Hadoop1.2. 2. Hive1.3. 3. Impala1.4. 4. Hbase1.5. 5.hadoop hive impala hbase关系1.6. 6. Spark1.7. 7. Flink1.8. 8. Spark 和 Flink 的应用场景 1. Hadoop 开源官网:https://hadoop.apache.org/ Hadoop是一个由Apache基金会所开发的分…...

网站网页客服、微信公众号客服、H5客服、开源源码与高效部署的完美结合
随着互联网技术的飞速发展,企业与客户之间的沟通方式也在持续变革。在线客服系统作为一种新兴的沟通工具,已经成为提升企业服务质量、增强客户满意度的重要手段。本文将详细介绍在线客服系统的优势、功能以及如何高效部署,特别是推荐一款名为…...

1、Qt UI控件 -- qucsdk
前言:Qt编写的自定义控件插件的sdk集合,包括了各个操作系统的动态库文件以及控件的头文件和sdk使用demo。类似于Wpf中的LivChart2控件库,都是一些编译好的控件,可以直接集成到项目中。该控件是飞扬青云大神多年前开发的࿰…...

Sora是什么?Sora怎么使用?Sora最新案例视频以及常见问题答疑
Sora 是什么? 2024年2月16日,OpenAI 在其官网上面正式宣布推出文本生成视频的大模型Sora 这样说吧给你一段话, 让你写一篇800字的论文,你的理解很可能都有偏差,那么作为OpenAi要做文生视频到底有多难,下面…...
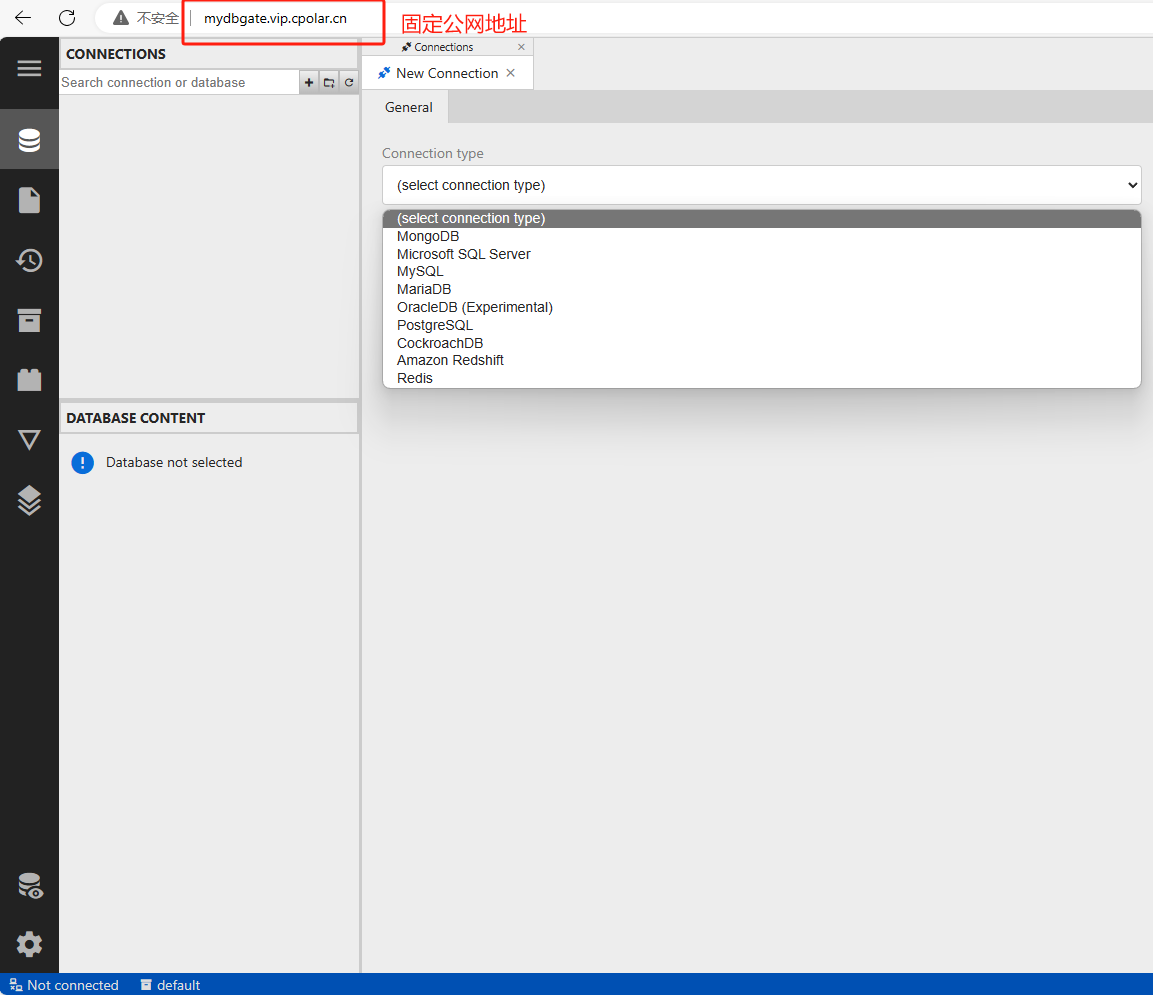
如何在Ubuntu系统使用docker部署DbGate容器并发布至公网可访问
文章目录 1. 安装Docker2. 使用Docker拉取DbGate镜像3. 创建并启动DbGate容器4. 本地连接测试5. 公网远程访问本地DbGate容器5.1 内网穿透工具安装5.2 创建远程连接公网地址5.3 使用固定公网地址远程访问 本文主要介绍如何在Linux Ubuntu系统中使用Docker部署DbGate数据库管理工…...
解决 VSCode 编辑器点击【在集成终端中打开】出现新的弹框
1、问题描述 在 VSCode 的项目下,鼠标右键,点击【在集成终端中打开】,出现新的一个弹框。新版的 VSCode 会有这个问题,一般来说我们都希望终端是在 VSCode 的控制台中打开的,那么如何关闭这个弹框呢? 2、解…...

从零开始:构建、打包并上传个人前端组件库至私有npm仓库的完整指南
文章目录 一、写组件1、注册全局组件方法2、组件13、组件2 二、测试三、发布1、配置package.json2、生成库包3、配置发布信息4、发布 四、使用1、安装2、使用 五、维护1、维护和更新2、注意事项 一、写组件 确定组件库的需求和功能:在开始构建组件库之前,…...

Ant Design Vue 表单验证手机号的正则
代码: pattern: /^1[3456789]\d{9}$/ 1. <a-form-item label"原手机号" v-bind"validateInfos.contactTel"><a-inputstyle"width: 600px"allow-clear:maxlength"20"placeholder"请输入原手机号"v-mo…...
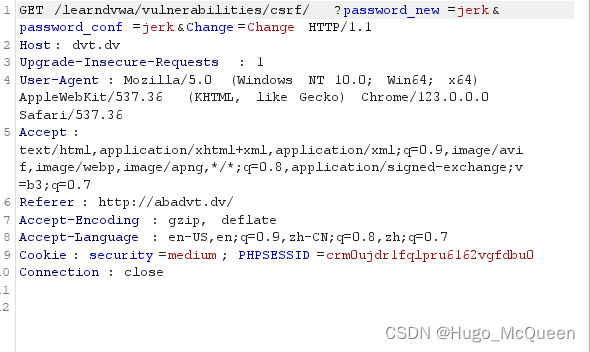
[dvwa] CSRF
CSRF 0x01 low 跨站,输入密码和确认密码直接写在url中,将连接分享给目标,点击后修改密码 社工方式让目标点击短链接 伪造404页,在图片中写路径为payload,目标载入网页自动请求构造链接,目标被攻击 http…...

只为兴趣,2024年你该学什么编程?
讲动人的故事,写懂人的代码 当你想学编程但不是特别关心找工作的时候,选哪种语言学完全取决于你自己的目标、兴趣和能找到的学习资料。一个很重要的点,别只学一种语言啊!毕竟,"门门都懂,样样皆通",每种编程语言都有自己的优点和适合的用途,多学几种可以让你的…...
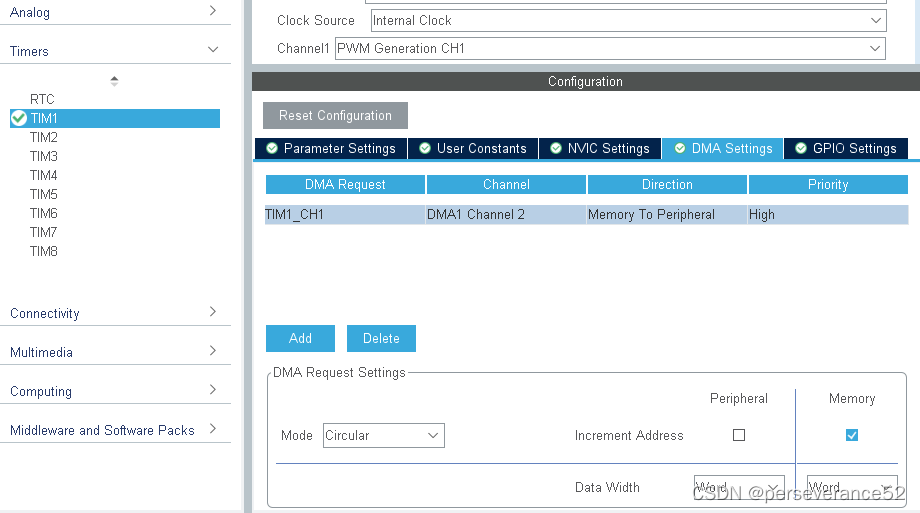
HAL STM32 定时器PWM DMA输出方式
HAL STM32 定时器PWM DMA输出方式 🧨遗留问题:当配置RCR重复计数器,配置为2时,在定义了3组PWM参数情况下,只能输出第二组参数的PWM波形。(HAL_TIM_PWM_Start_DMA(&htim1, TIM_CHANNEL_1, aCCValue_Buff…...

博客部署004-centos安装mysql及redis
1、如何查看当前centos版本? cat /etc/os-release 2、安装mysql 我的是centos8版本,使用dnf命令 2.1 CentOS 7/8: sudo yum install -y mysql-community-server 或者在CentOS 8上,使用DNF:🌟 sudo dnf install -y mysql-ser…...

Hive 之 UDF 运用(包会的)
文章目录 UDF 是什么?reflect静态方法调用实例方法调用 自定义 UDF(GenericUDF)1.创建项目2.创建类继承 UDF3.数据类型判断4.编写业务逻辑5.定义函数描述信息6.打包与上传7.注册 UDF 函数并测试返回复杂的数据类型 UDF 是什么? H…...

朱雀越严,我这个工具越好用|亲测稳过
很多内容从业者对朱雀的第一反应是恐慌,模板失效、爆文文案不好用了,连正常润色都担心「误伤」。但真正跑了一段之后,我的体感反而是,越严苛的检测,越倒逼你回到「表达本身」,而一些为 AI 原生创作设计的平…...

使用格子玻尔兹曼方法模拟方腔流:生成流线、速度、压力图并保存动态展示的研究结果
使用格子玻尔兹曼方法(LBM)模拟方腔流,生成流线、速度、压力图,并可保存动图.今天咱们来玩点流体力学的小把戏——用格子玻尔兹曼方法(LBM)整一个方腔流动模拟。这玩意儿比传统NS方程解法有意思多了&#x…...

毕业神器怎么选?国内篇看“毕业之家”
我为你梳理了毕业之家、PaperRed的核心信息,并推荐了两款专注于英文论文写作的高效工具。 📊 两款中文主力工具速览 这两款工具都非常适合中文学术写作的全流程,各有侧重: 工具名称官网信息与核心优势主要特点适合人群毕业之家…...

2026家长自查手册:为孩子选择DHA,您是否问对了这五个问题?
2026家长自查手册:为孩子选择DHA,您是否问对了这五个问题?在信息过载的今天,为孩子选择一款DHA或“补脑”产品,可能比解答一道数学压轴题更让家长困惑。品牌故事、明星代言、纯度竞赛……营销声音震耳欲聋。然而&#…...

Git急救指南:误操作全拯救
Git误操作急救手册大纲常见误操作场景误删本地分支或文件误提交敏感信息(如密码、密钥)误覆盖或强制推送导致远程分支丢失误执行git reset或git rebase导致提交历史混乱数据恢复方法找回误删的分支或提交 使用git reflog查看操作记录,找到误删…...

湘潭品牌设计公司权威推荐榜单
在当今竞争激烈的市场环境中,品牌已成为企业最核心的资产之一。一个专业、系统、富有战略性的品牌设计,不仅能提升企业的市场辨识度,更能成为驱动业务增长的强大引擎。对于湘潭及周边地区的企业而言,选择一家专业、可靠的品牌设计…...

Kafka消息幂等性实战指南
Kafka 通过 生产者端机制 与 消费者端应用设计 协同保障消息处理的幂等性(即重复操作不影响最终结果)。需注意:Kafka 本身不提供“端到端全自动幂等”,需结合配置与业务逻辑实现。核心方案如下:🔒 一、生产…...

【亲测免费】 SCUT_thesis 开源项目使用教程
SCUT_thesis 开源项目使用教程 【免费下载链接】SCUT_thesis 华南理工大学硕博士学位论文LaTeX模板。Latex templates for the thesis of South China University of Technology 项目地址: https://gitcode.com/gh_mirrors/sc/SCUT_thesis 1. 项目的目录结构及介绍 SCU…...

为什么选择Pebble模板引擎?5大核心优势解析
为什么选择Pebble模板引擎?5大核心优势解析 【免费下载链接】pebble Java Template Engine 项目地址: https://gitcode.com/gh_mirrors/peb/pebble Pebble是一款功能强大的Java模板引擎,专为构建动态网页和文档而设计。它结合了简洁的语法与强大的…...

7个JavaScript面向对象编程原则:从基础到实战的完整指南
7个JavaScript面向对象编程原则:从基础到实战的完整指南 【免费下载链接】curriculum TheOdinProject/curriculum: The Odin Project 是一个免费的在线编程学习平台,这个仓库是其课程大纲和教材资源库,涵盖了Web开发相关的多种技术栈…...