如何使用 Grafana 监控文件系统状态
当 JuiceFS 文件系统部署完成并投入生产环境,接下来就需要着手解决一个非常重要的问题 —— 如何实时监控它的运行状态?毕竟,它可能正在为关键的业务应用或容器工作负载提供持久化存储支持,任何小小的故障或性能下降都可能造成不利的影响。
JuiceFS 启动后会实时发布自身的运行状态数据,只需结合 Granafa 和 Prometheus 这两款开源工具即可相对轻松地建立一套监控系统。它将会通过采集文件系统的关键指标,例如读写吞吐量、IOPS、延迟、存储利用率、请求分布等,并汇集到一个直观的仪表板,让用户能够实现全方位的监控和可视化。
本文将详细介绍如何使用 Grafana 来监控 JuiceFS,在后续的系列文章中将为大家深入解读 JuiceFS 状态指标,敬请期待。
Grafana 是一个开源的监控和分析时间序列数据的仪表板和可视化工具,它主要用于互联网的基础设施和应用分析,传感器数据、应用程序分析以及监控。用户可以根据自己的需求创建和定制 Grafana 仪表盘来显示最关心的数据,跟踪和分析关键性能指标(KPIs)。
Grafana 支持多种数据源,包括 Prometheus、InfluxDB、Elasticsearch 等,可以从多个来源汇集数据,在统一的界面中进行分析和可视化。借助简单易用的查询编辑器,用户能够更深入地了解数据,并从中得到更多的信息。

JuiceFS 默认通过 9567 端口实时输出文件系统的状态指标,用户可以通过 Prometheus 收集这些这些指标数据,然后通过 Grafana 将这些指标以图形化的方式展现出来。

Prometheus 和 Grafana 都是开源软件,可以自行下载部署使用。但部署和维护这些系统会增加运维工作量,如果想更简单便捷地为 JuiceFS 构建可视化状态监控系统,可以尝试用 Grafana Cloud,它一站式地提供了所需地系统,而且包含一定的免费额度,足以满足起步阶段的使用需求。
Grafana Cloud

Grafana Cloud 是一项 SaaS 服务,提供免费、按量付费(Pay as you go)和高级三种订阅计划。不同的订阅计划包含不同的资源,免费与付费的主要差别在于指标数据的保留时长,免费计划会保留 14 天,付费计划则会保留 13 个月。
Grafana Cloud 的优势在于它通过 SaaS 服务直接为用户提供了 Prometheus 和 Grafana,这样就一站式地解决了数据的收集和可视化需求,而且后期维护和规模扩展都不需要用户介入。
通过 Grafana Cloud 为 JuiceFS 搭建监控系统的过程大致如下:
-
准备并挂载 JuiceFS 文件系统
-
注册 Grafana Cloud 账号,创建 Stack 资源;
-
在本地安装配置 grafana-agent,启动资源上报;
-
配置 JuiceFS Dashboard,开始使用。
第一步 准备 JuiceFS 文件系统
JuiceFS 的社区版和云服务版都会实时发布 Prometheus 格式的状态指标数据,不过这里需要注意区分:
-
社区版默认通过客户端所在主机的 http://127.0.0.1:9567 发布 Prometheus 格式的状态指标
-
云服务会通过 SaaS 平台地址同时发布 Prometheus 和 JSON 两种格式的指标(需将地址中的 VOLUME_NAME 替换为文件系统名,将 API_TOKEN 替换为对应的 token)。
-
Prometheus 格式地址
-
JSON 格式地址

如上图,JuiceFS 云服务控制台可以查看文件系统最近 7 天的状态指标,箭头所指的超链接对应前述的两个状态发布地址,可以直接复制给 Prometheus 使用。
另外,只有挂载的文件系统才有状态指标,所以在开始之前需要先准备好文件系统。
对于 JuiceFS 文件系统的创建方法,社区版和云服务略有差别,但原理相同。如果还不熟悉相关操作,可以先查阅官方文档了解详情。
第二步 注册 Grafana Cloud 账号

Grafana Cloud 将提供给用户的资源称之为 Stack(技术栈),因为它在 Grafana 的基础上还额外提供 Prometheus、Loki 等许多监控相关的服务。
注册账号后就会获得一个 xxx.grafana.net 专属 URL,比如 https://juicefs.grafana.net ,这个地址可以直接访问自己的 Grafana 控制台。
第三步 配置 Prometheus 代理程序
拥有了 Grafana Cloud 账号和 Stack,接下来就可以开始配置数据源了,如下图所示,Grafana Cloud 提供了一系列可以连接的数据源。

JuiceFS 默认通过 Prometheus 格式公开状态信息,因此这里选择 Hosted Prometheus metrics,然后在 Configuration Details 中根据实际情况进行配置。
1. 选择收集指标的方法

这里有两种可选的方式:
-
第一种是在本地安装 Grafana Agent 客户端,由它负责将 JuiceFS 的状态指标上传到云上的 Prometheus 服务。
-
第二种是从本地维护的 Prometheus 复制数据到云端。
第一种的特点是指标数据完全保存在云端,本地没有数据副本,可以结合 Grafana Cloud 的警报服务一起使用。第二种则需要在本地自行部署和维护 Prometheus 实例,数据完全保存在本地,同时会拷贝一个副本到云端使用。
本文会以第一种方式为例来介绍。另外,如果要在 Kubernetes 环境种使用,可以点击相关的按钮查看说明,本文不做相关介绍。
2. 选择系统及架构

因为要将这个 Grafana Agent 安装到本地 JuiceFS 客户端所在的主机,因此需要根据本地主机的系统和架构进行选择。
3. 下载 Grafana Agent 客户端

将这里的代码复制并粘贴到 JuiceFS 所在的本地主机运行,这段代码会将 grafana-agent 客户端下载到当前目录并赋予可执行权限。而这个 grafana-agent 程序本质上就是一个经过定制的 Prometheus 客户端。
4. 创建配置文件

这一步将为 grafana-agent 生成一个配置文件,如下图所示,这其实就是一个 Prometheus 的配置文件,但它将 Grafana Cloud 平台提供的服务地址以及相关的设置都配置好了。

将生成的命令粘贴到 JuiceFS 所在的主机,它会把相关配置信息写入当前目录的 agent-config.yaml 文件。
为了让它能够收集 JuiceFS 文件系统的状态指标,需要进一步修改这个配置文件,一方面要添加 JuiceFS 发布状态指标的地址,另一方面要调整数据 scrape_interval 抓取数据的频率。
前面已有介绍,社区版 JuiceFS 默认通过 9567 端口发布状态指标,如下图。

但是,在同一台主机上同时用不同的访问方式挂载文件系统,JuiceFS 就会随机分配一个端口给第二个访问方式。如下图,这个主机以经通过 mount 方式挂载了文件系统,同时又通过 WebDAV 方式进行挂载,这时就会分配一个随机的端口给 WebDAV 协议用做状态指标发布。

根据查到的实际信息编辑 agent-config.yaml,可以参考下面这个修改后的示例:
metrics:global:scrape_interval: 15sconfigs:- name: hosted-prometheusscrape_configs:- job_name: nodestatic_configs:- targets: ['localhost:9100']- job_name: juicefsstatic_configs:- targets: ["localhost:9567", "localhost:35013"]remote_write:- url: https://prometheus-prod-36-prod-us-west-0.grafana.net/api/prom/pushbasic_auth:username: 1480721password: glc_eyJvIjo`</pre>
-
第三行,scrape_interval 修改为 15s (或更小)可以确保抓到 JuiceFS 的实时状态变化;
-
第十行,添加 juicefs 相关的配置,在 targets 部分的数组中可以根据实际情况添加所有发布状态指标的地址。
5. 启动 agent

在 JuiceFS 所在的主机上粘贴并运行命令,grafana-agent 程序即可开始工作。
如有需要,还可以把 grafana-agent 客户端配置成 systemd 服务开机自动运行,下面是一个 grafana-agent.service 的配置文件示例:
[Unit]
Description=Grafana Agent
After=network-online.target[Service]
ExecStart=/opt/grafana-agent/grafana-agent-linux-amd64 --config.file=/opt/grafana-agent/agent-config.yaml
Restart=always
User=root
Group=root[Install]
WantedBy=multi-user.target
使用该自启动配置时,需要把 grafana-agent-linux-amd64 程序和配置文件 agent-config.yaml 拷贝到 /opt/grafana-agent 目录;
第四步 配置 Grafana Dashborad
前面三个步骤将本地的 JuiceFS 与 Grafana Cloud 提供的 Prometheus 服务进行了连通,grafana-agent 程序会按照配置每隔 15s 抓取一次 JuiceFS 的状态指标,然后将数据实时推送到云端。
有了实时收集的状态数据,接下来要把它们用图形化的方式展现出来,这就需要在 Grafana 上创建 Dashboard 来实现。

创建 Dashboard 有两种常用的方式:
- 第一种,是创建一个全新 Dashboard,自己根据实际的监控需要来定义查询、图表、状态、表格等。
- 第二种,是导入一个预先创建好的的 Dashboard 模板,可以使用 json 格式的文件模板,也可以使用 Grafana 官方库提供的公共模板。
1. 使用 Dashboard 模板
JuiceFS 官方提供了预定义的 Grafana Dashboard 模板 grafana_template.json 用于展示挂载点、S3 网关、Kubernetes 及 Hadoop Java SDK 的指标。该模板已经收录在 Grafana 官方 Dashboard 仓库,你可以直接使用这个 URL 载入,也可以使用编号 20794 载入。


在导入模板时,可以自定义 Dashboard 的名称和存放的位置,通常保持默认即可。

如上图,官方模板中包含了大量的状态信息,界面中堆叠的一个个信息块叫做 Panel,用户可以根据需要调整这些 Panel 的位置、样式或增删。
2. 手动创建 Dashboard
你可以从零开始创建一个全新的 Dashboard,也可以在 JuiceFS Dashboard 模板的基础上进行改造。
Dashboard 是由一系列 Panel 所组成的(Grafana 中也把 Panel 叫做 Visualization),添加一个 Visualization 就是添加一个 Panel。

一个 Panel 用来展示一个状态指标,在右上角的下拉菜单中可以选择数据展现的形式,比如 Chart、table 或 stat 等。
在下方的 Query 区域,选择 Data source,即收集了 JuiceFS 状态指标的 Prometheus 服务。然后在 Metrics browser 中选择要查询的指标。侧栏有一系列选项可以对显示的内容做细节微调,比如颜色,条件格式等。

如下图,你可以自由切换 Dashboard 中的 Panel,比如将 JuiceFS 官方模板中部分 Chart 图表改成 Stat 类型,当然,也可以为同一个指标创建多个不同展现形式的 Panel。

至此,JuiceFS 的可视化监控系统就搭建完毕了,你可以参考这篇文档了解各个状态指标的含义。限于篇幅,我们会另写文章来专门解读 JuiceFS 各个状态指标,欢迎感兴趣的读者保持关注。
总结
本文主要介绍了如何使用 Grafana Cloud 为 JuiceFS 搭建可视化的状态监控系统,为了满足不同经验背景的读者需要,每个环节尽量选择最简单的方式来实现。
事实上,任何 IT 系统的搭建都是一个个选择堆叠而成。不难发现,在本文介绍的步骤中,有很多环节是可以有其他的选择,比如,Prometheus 的数据上报方式,文中选择了 Grafana Agent,而读者还可以选择用本地自建的 Prometheus。所以,本文只是抛砖引玉,最终的部署和使用方法还是需要读者自己灵活选择和搭配。
最后,希望本文介绍的步骤能够对大家搭建 JuiceFS 监控系统带来一定的帮助。如果你有任何疑问,欢迎到 JuiceFS 社区用户群中进行提问和讨论。
相关文章:
如何使用 Grafana 监控文件系统状态
当 JuiceFS 文件系统部署完成并投入生产环境,接下来就需要着手解决一个非常重要的问题 —— 如何实时监控它的运行状态?毕竟,它可能正在为关键的业务应用或容器工作负载提供持久化存储支持,任何小小的故障或性能下降都可能造成不利…...

智能革命:未来人工智能创业的天地
智能革命:未来人工智能创业的天地 一、引言 在这个数字化迅速变革的时代,人工智能(AI)已经从一个边缘科学发展成为推动未来经济和社会发展的关键动力。这一技术领域的飞速进步,不仅影响着科技行业的每一个角落,更是为创业者提供了…...

4月14日总结
java学习 一.多线程 简介:多线程是计算机科学中的一个重要概念,它允许程序同时执行多个任务或操作。在单个程序内部,多线程使得代码可以并行执行,从而提高程序的性能和响应速度。 这里先来介绍一下创建多线程的几种方法。 1.扩展…...

kafka---broker相关配置
一、Broker 相关配置 1、一般配置 broker.id 当前kafka服务的sid(server id),在kafka集群中,该值是唯一的(unique),如果未设置此值,kafka会自动生成一个int值;为了防止自动生成的值与用户设置…...
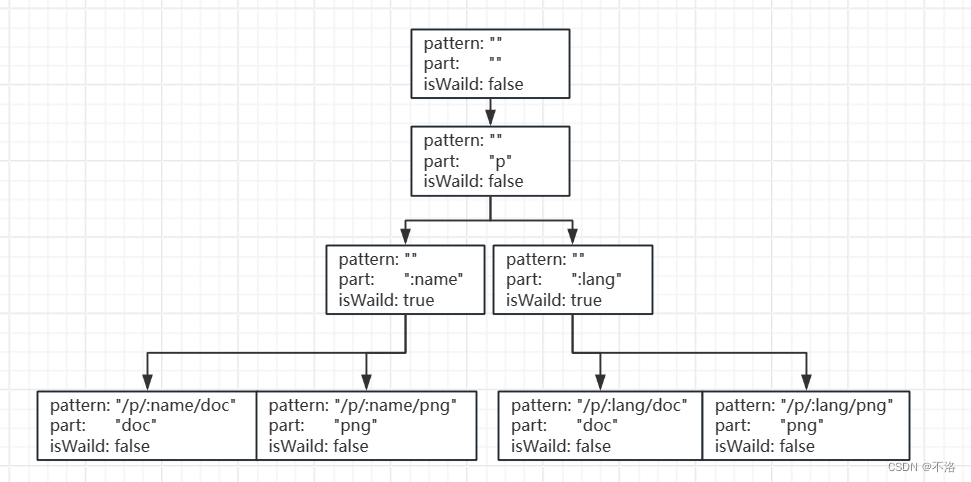
【Golang学习笔记】从零开始搭建一个Web框架(二)
文章目录 模块化路由前缀树路由 前情提示: 【Golang学习笔记】从零开始搭建一个Web框架(一)-CSDN博客 模块化路由 路由在kilon.go文件中导致路由和引擎交织在一起,如果要实现路由功能的拓展增强,那将会非常麻烦&…...

高精度地图导航论文汇总
文章目录 2021基于车载激光点云的高精地图矢量化成图[J] 2022基于高精度地图的智能车辆路径规划与跟踪控制研究[M] 2023一种无人驾驶融合决策方案的设计与实现[M] 2021 基于车载激光点云的高精地图矢量化成图[J] 摘要: 针对车载激光点云中对各特征物提取结果后矢量…...

【域适应】基于域分离网络的MNIST数据10分类典型方法实现
关于 大规模数据收集和注释的成本通常使得将机器学习算法应用于新任务或数据集变得异常昂贵。规避这一成本的一种方法是在合成数据上训练模型,其中自动提供注释。尽管它们很有吸引力,但此类模型通常无法从合成图像推广到真实图像,因此需要域…...

从零实现诗词GPT大模型:pytorch框架介绍
专栏规划: https://qibin.blog.csdn.net/article/details/137728228 因为咱们本系列文章主要基于深度学习框架pytorch进行,所以在正式开始之前,现对pytorch框架进行一个简单的介绍,主要面对深度学习或者pytorch还不熟悉的朋友。 一、安装pytorch 这一步很简单,主要通过p…...

[目标检测] OCR: 文字检测、文字识别、text spotter
概述 OCR技术存在两个步骤:文字检测和文字识别,而end-to-end完成这两个步骤的方法就是text spotter。 文字检测数据集摘要 daaset语言体量特色MTWI中英文20k源于网络图像,主要由合成图像,产品描述,网络广告(淘宝)MS…...

Windows环境下删除MySQL
文章目录 一、关闭MySQL服务1、winR打开运行,输入services.msc回车2、服务里找到MySQL并停止 二、卸载MySQL软件1、打开控制模板--卸载程序--卸载MySQL相关的所有组件 三、删除MySQL在物理硬盘上的所有文件1、删除MySQL的安装目录(默认在C盘下的Program …...

uniapp:uview-plus的一些记录
customStyle 并不是所有的组件都有customStyle属性来设置自定义属性,有的还是需要通过::v-deep来修改内置样式 form表单 labelStyle 需要的是一个对象 :labelStyle"{color: #333333,fontSize: 32rpx,fontWeight: 500}"dateTimePicker选择器设置默认值…...

OLTP 与 OLAP 系统说明对比和大数据经典架构 Lambda 和 Kappa 说明对比——解读大数据架构(五)
文章目录 前言OLTP 和 OLAPSMP 和 MPPlambda 架构Kappa 架构 前言 本文我们将研究不同类型的大数据架构设计,将讨论 OLTP 和 OLAP 的系统设计,以及有效处理数据的策略包括 SMP 和 MPP 等概念。然后我们将了解经典的 Lambda 架构和 Kappa 架构。 OLTP …...
步骤大全:网站建设3个基本流程详解
一.领取一个免费域名和SSL证书,和CDN 1.打开网站链接:https://www.rainyun.com/z22_ 2.在网站主页上,您会看到一个"登陆/注册"的选项。 3.点击"登陆/注册",然后选择"微信登录"选项。 4.使用您的…...
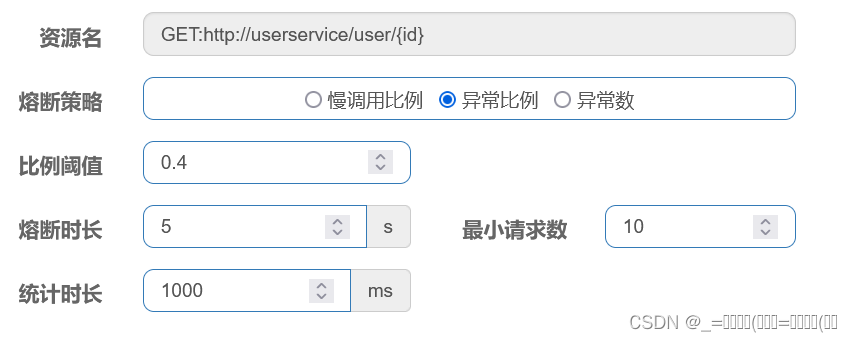
利用Sentinel解决雪崩问题(二)隔离和降级
前言: 虽然限流可以尽量避免因高并发而引起的服务故障,但服务还会因为其它原因而故障。而要将这些故障控制在一定范围避免雪崩,就要靠线程隔离(舱壁模式)和熔断降级手段了,不管是线程隔离还是熔断降级,都是对客户端(调…...

基于springboot的房产销售系统源码数据库
基于springboot的房产销售系统源码数据库 摘 要 随着科学技术的飞速发展,各行各业都在努力与现代先进技术接轨,通过科技手段提高自身的优势;对于房产销售系统当然也不能排除在外,随着网络技术的不断成熟,带动了房产…...

【MATLAB】基于Wi-Fi指纹匹配的室内定位-仿真获取WiFi RSSI数据(附代码)
基于Wi-Fi指纹匹配的室内定位-仿真获取WiFi RSSI数据 WiFi指纹匹配是室内定位最为基础和常见的研究,但是WiFi指纹的采集可以称得上是labor-intensive和time-consuming。现在,给大家分享一下我们课题组之前在做WiFi指纹定位时的基于射线跟踪技术仿真WiFi…...

深圳晶彩智能ESP32-3248S035R使用LovyanGFX实现手写板
深圳晶彩智能ESP32-3248S035R介绍 深圳晶彩智能出品ESP32-3248S035R为3.5寸彩色屏采用分辨率480x320彩色液晶屏,驱动芯片是ST7796。板载乐鑫公司出品ESP-WROOM-32,Flash 4M。型号尾部“R”标识电阻膜的感压式触摸屏,驱动芯片是XPT2046。 Lo…...
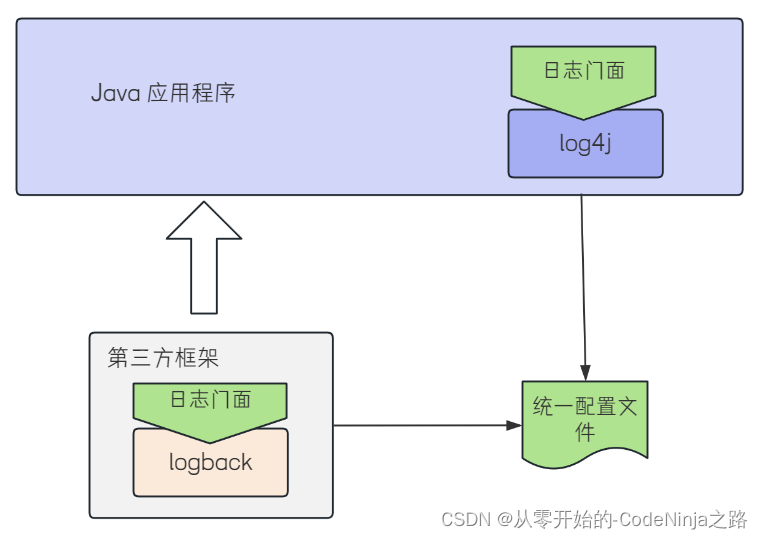
【Spring Boot】深入解密Spring Boot日志:最佳实践与策略解析
💓 博客主页:从零开始的-CodeNinja之路 ⏩ 收录文章:【Spring Boot】深入解密Spring Boot日志:最佳实践与策略解析 🎉欢迎大家点赞👍评论📝收藏⭐文章 目录 Spring Boot 日志一. 日志的概念?…...
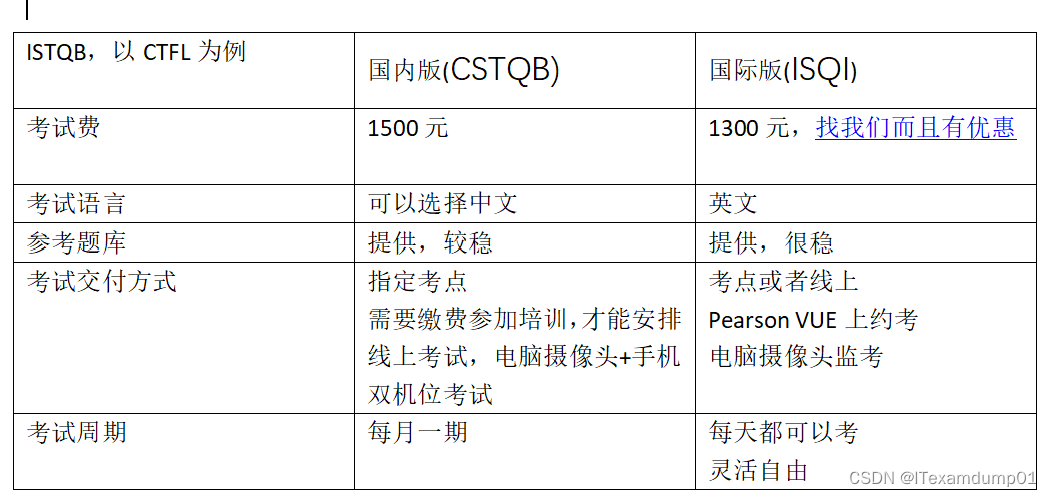
ISTQB选择国内版,还是国际版呢
1, ISTQB简介 ISTQB(International Software Testing Qualifications Board)是一个国际软件测试资格认证机构,旨在提供一个统一的软件测试认证标准。ISTQB成立于2002年,是非盈利性的组织,由世界各地的国家或地区软件测…...

头歌-机器学习 第11次实验 softmax回归
第1关:softmax回归原理 任务描述 本关任务:使用Python实现softmax函数。 相关知识 为了完成本关任务,你需要掌握:1.softmax回归原理,2.softmax函数。 softmax回归原理 与逻辑回归一样,softmax回归同样…...

解决 Claude Code 频繁封号问题之转向 Taotoken 稳定服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决 Claude Code 频繁封号问题之转向 Taotoken 稳定服务 对于依赖 Claude Code 进行开发的工程师而言,账号访问权限的…...

社区团购系统源码推荐:为什么越来越多团队开始关注 LikeShop 社区团购系统?
如果你最近在研究:社区团购系统源码社区团购平台搭建团长分销系统私域社区团购社区自提系统你会发现一个现象:越来越多人开始提到:“LikeShop社区团购系统”。尤其是在:生鲜团购社区零售社群团购县域电商社区便利店私域卖货这些场…...

资源受限场景下基于强化学习的自适应AI安全框架设计与实践
1. 项目概述:当AI安全遇上资源与伦理的双重挑战最近和几位在非洲做技术援助的朋友聊起他们的工作,他们提到一个很有意思的困境:在乌干达这样的地区,网络安全监测的需求日益增长,但本地计算资源极其有限,网络…...

别再花钱买板卡了!手把手教你用NI-MAX虚拟PCI6224玩转LabVIEW数字IO
零成本玩转LabVIEW数字IO:NI-MAX虚拟设备全攻略 在工程教育与原型开发领域,硬件成本往往是阻碍学习进程的第一道门槛。一块标准的NI PCI-6224数字IO板卡市场价超过万元,而学生和独立开发者可能需要反复实验数十次才能掌握基础操作。但鲜为人知…...

谷歌seo搜索引擎优化教程有吗?资深SEO总结的15个高效提速工具
很多企业主每年在独立站开发上投入超过 10 万人民币,但网站上线半年,每天的自然访问量依然是个位数。面对“谷歌seo搜索引擎优化教程有吗?”这种疑问,行业内的真实情况是:绝大部分公开课都在讲十年前的套路,…...

告别外部中断!用STM32定时器输入捕获实现EC11编码器的高效解码
STM32定时器输入捕获实现EC11编码器的高效解码方案 在嵌入式开发中,旋转编码器作为人机交互的重要组件,广泛应用于工业控制、智能家居和消费电子等领域。EC11作为常见的机械编码器,其稳定性和低成本使其成为许多项目的首选。然而,…...

避开这些坑:在MATLAB中用DQN做LKA时,我的并行训练为什么失败了?
避开这些坑:在MATLAB中用DQN做LKA时,我的并行训练为什么失败了? 当你第一次在MATLAB中启用UseParalleltrue选项时,可能满怀期待地以为训练速度会直线上升。但现实往往很骨感——要么直接报错终止,要么训练效率反而比串…...

机电一体化系统设计的核心挑战与跨学科协同
1. 机电一体化系统设计的核心挑战与机遇十年前我第一次参与工业机器人控制系统开发时,机械团队和电气团队还在用纸质图纸传递设计变更。某个周五下午的机械结构改动,直到下周一才通知到电气组,导致整个控制柜布局需要返工。这种割裂的开发模式…...

Arm编译器浮点运算实现与优化实践
1. Arm编译器中的浮点运算实现机制在嵌入式开发领域,浮点运算的实现质量直接影响着数值计算的精度和系统性能。Arm编译器通过深度整合IEEE 754标准,为开发者提供了可靠的浮点运算支持。让我们先看一个典型场景:当使用printf输出浮点数时&…...

MiGPT终极指南:如何将小爱音箱改造成AI语音助手
MiGPT终极指南:如何将小爱音箱改造成AI语音助手 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 在智能家居日益普及的今天࿰…...