头歌-机器学习 第13次实验 特征工程——共享单车之租赁需求预估
第1关:数据探索与可视化
任务描述
本关任务:编写python代码,完成一天中不同时间段的平均租赁数量的可视化功能。
相关知识
为了完成本关任务,你需要掌握:
- 读取数据
- 数据探索与可视化
读取数据
数据保存在./step1/bike_train.csv中,共享单车的训练集数据总共有8709个训练样本,训练样本中有12个特征(其中count为标签)。特征说明如下:
datetime:时间。年月日小时格式season:季节。1:春天;2:夏天;3:秋天;4:冬天holiday:是否节假日。0:否;1:是workingday:是否工作日。0:否;1:是weather:天气。1:晴天;2:阴天;3:小雨或小雪;4:恶劣天气temp:实际温度atemp:体感温度humidity:湿度windspeed:风速casual:未注册用户租车数量registered:注册用户租车数量count:总租车数量
想要读取数据很简单,使用pandas即可,代码如下:
import pandas as pdtrain_df = pd.read_csv('./step1/bike_train.csv')# 打印数据中的前5行print(train_df.head(5))
输出如下图所示:

数据探索与可视化
一般拿到数据之后都需要做数据探索(EDA),因为我们需要看看数据到底长什么样子,有什么特性是可以挖掘出来的。假设我们需要看看数据的大概分布是什么样的。可以用pandas提供的describe()函数。输出如下:
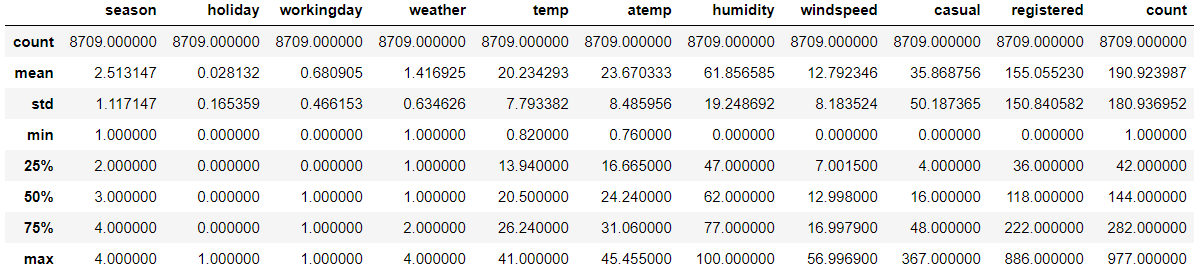
此时我们能看到count的标准差很大,我们可以将count的数据分布可视化出来,代码如下:
import matplotlib.pyplot as pltplt.figure(figsize=(10,10))# 画count的直方图plt.hist(train_df['count'],bins=20)plt.title('count histgram')plt.xlabel('count')
可视化结果如下:
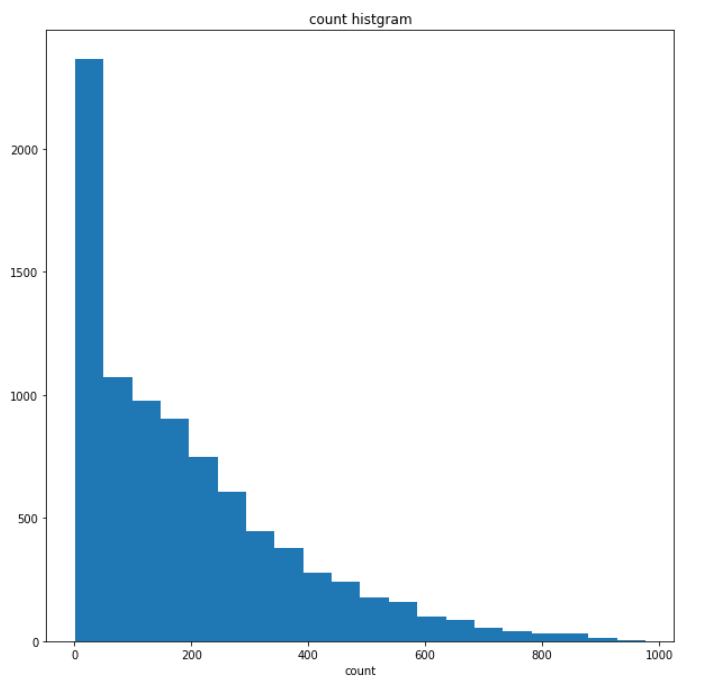
从可视化结果可以看出,count的整体的分布倾斜比较严重,需要处理一下,不然可能过拟合会有点严重。此时我们可以考虑将count的数值在3个标准差之外的样本给扔掉,减少训练集中的噪声,并对count做log变换。代码如下:
import matplotlib.pyplot as pltimport numpy as npimport seaborn as sns# 筛选3个标准差以内的数据train_df=train_df[np.abs(train_df['count']-train_df['count'].mean())<=3*train_df['count'].std()]# log变换y=train_df['count'].valuesy_log=np.log(y)# 可视化sns.distplot(y_log)plt.title('distribution of count after log')
处理后可视化结果如下:
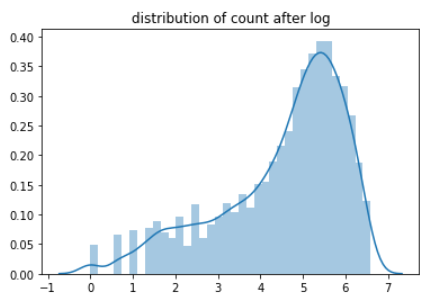
可以从可视化结果看出,转换过后,count的分布倾斜没有那么严重了,差异也变小了。
接下来我们看看其他的一些特征对于共享单车租赁量的影响。
首先来看看季节对于租赁量的影响,代码如下:
day_df=train_df.groupby('date').agg({'season':'mean','casual':'sum', 'registered':'sum','count':'sum','temp':'mean','atemp':'mean','workingday':'mean','holiday':'mean'})season_day_mean=day_df.groupby(['season'],as_index=True).agg({'casual':'mean', 'registered':'mean','count':'mean'})temp_df = day_df.groupby(['season'], as_index=True).agg({'temp':'mean', 'atemp':'mean'})season_day_mean.plot(figsize=(15,9),xticks=range(1,4))plt.title('count in different season')
可视化结果如下:
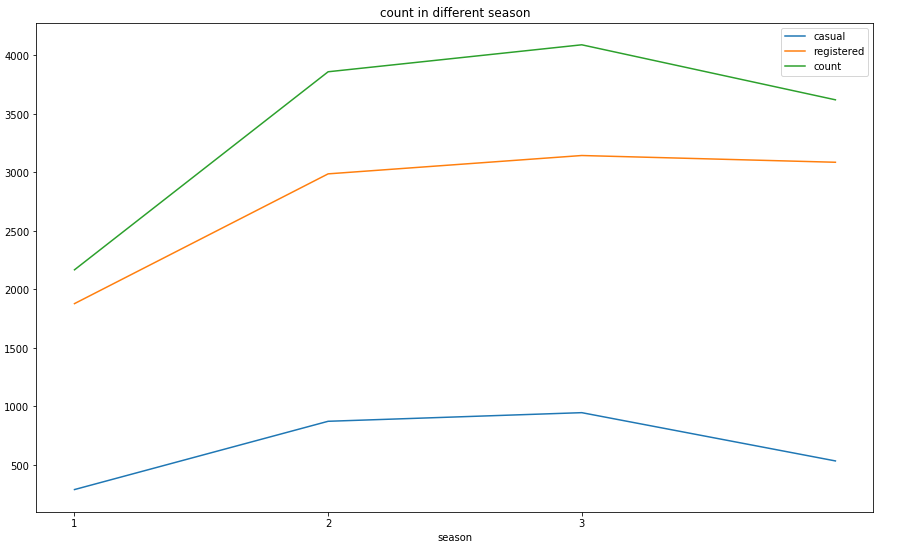
从可视化结果可以看出,临时用户和注册用户用车数量变化趋势大体一致,且两年间都在秋季左右达到了比较高的用车辆,说明美国人也都比较喜欢在这段时间外出游玩。这是符合常理的。
接下来看看天气对租赁数量的影响,代码如下:
weather_group=train_df.groupby(['weather'])weather_count=weather_group[['count','registered','casual']].count()weather_mean=weather_group[['count','registered','casual']].mean()# 不同天气的每小时平均租赁数量weather_mean.plot.bar(stacked=True,title='count per hour in different weather')
可视化结果如下:
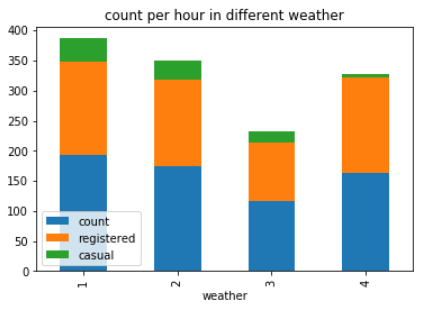
讲道理,天气比较好的时侯,骑共享单车的人才比较多。但上图中像4(恶劣天气)这种天气的租赁数量也比较高,这是不是有点反常呢?我们可以从数据集中找出对应的数据看看,代码如下:
print(train_df.loc[train_df.weather==4])
数据结果如下:

数据的时间是下午6点,刚好是下班的高峰期,所以能够理解为什么这条数据对应的租赁量均值那么高了,这也是符合常理的。
那么一天中不同时间段对于租赁数量有什么样的影响呢?这个就留给你做练习吧。
编程要求
根据提示,在右侧编辑器Begin-End处补充代码,将./step1/bike_train.csv中的数据按照hour这个特征分组,然后求每一组的count的平均值。并使用matplotlib.pyplot绘制折线图,并保存到./step1/result/plot.png。
测试说明
平台会对你生成的折线图与正确答案进行比对,因此请按照以下要求可视化:
- 折线图的
figsize为(10, 10) - 折线图的标题为
average count per hour
测试输入: 预期输出:你的答案与正确答案一致
import pandas as pd
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt#********* Begin *********#
import pandas as pdimport matplotlib.pyplot as plttrain_df = pd.read_csv('./step1/bike_train.csv')train_df['hour'] = train_df.datetime.apply(lambda x:x.split()[1].split(':')[0]).astype('int')group_hour=train_df.groupby(train_df.hour)hour_mean=group_hour[['count','registered','casual']].mean()fig=plt.figure(figsize=(10,10))plt.plot(hour_mean['count'])plt.title('average count per hour')plt.savefig('./step1/result/plot.png')#********* End *********#
第2关:特征工程
任务描述
本关任务:编写python代码,完成时间细化的功能。
相关知识
为了完成本关任务,你需要掌握:
- 相关性分析
- 特征选择
相关性分析
在选择特征之前,我们可以看看各个特征相关性的强弱。代码如下:
# 计算特征对的相关性corr_df=train_df.corr()corr_df1=abs(corr_df)# 画热力图fig=plt.gcf()fig.set_size_inches(30,12)sns.heatmap(data=corr_df1,square=True,annot=True,cbar=True)
相关性热力图如下(其中颜色越亮,代表线性相关性越高):
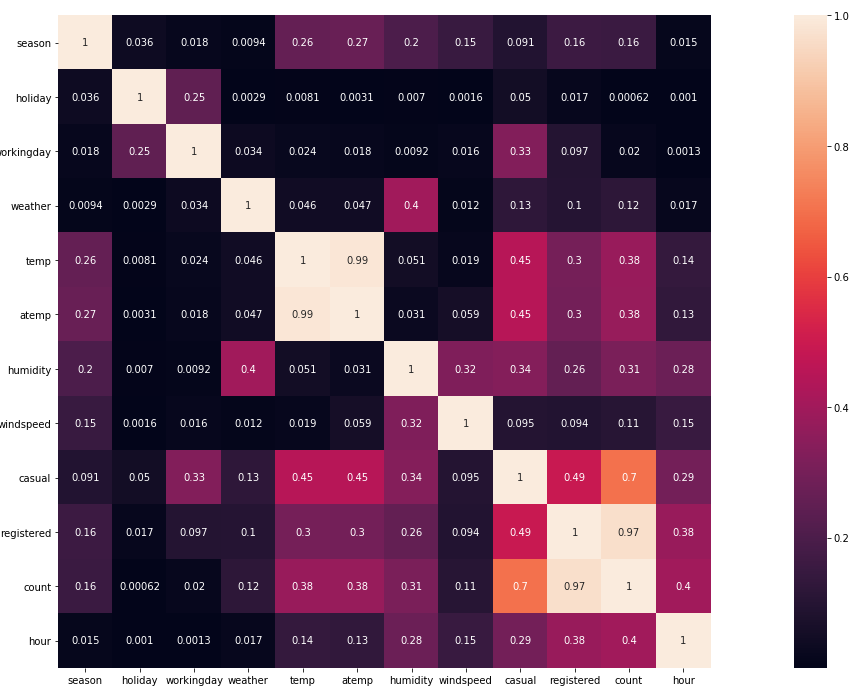
选择特征
在使用相关性这一指标来选择特征时,通常选择相关性较低,也就是颜色较暗的特征。因为如果选择相关性较高的,比如temp和atemp。从图可以看出这两个特征的相关性很高,也就是说在训练模型的时候,这两个特征所对应的权重是成比例的。既然成比例,那么之选其中一个就行了。
根据热力图我们暂且可以选择时段(hour)、温度(temp)、湿度(humidity)、季节(season)、天气(weather)、风速(windspeed)、是否工作日(workingday)、是否假日(holiday 、注册用户租赁数量(registered)作为特征。
编程要求
现在可能觉得datetime这个字段有必要再细化挖掘一下,比如细化成年份、月份、日期、星期几等。
根据提示,在右侧编辑器Begin-End处补充代码,实现transform_data函数。该函数需要你将train_df中的datetime字段进行细化,细化成year(年份)、month(月份)、date(日期)、weekdat(星期几)、hour(小时)。并返回细化后的DataFrame。
例如,原始数据如下:

细化后数据如下:

测试说明
平台会对你返回的DataFrame与答案进行比对,您只需实现transform_data即可。
测试输入: 预期输出:你的答案与正确答案一致。
import pandas as pd
import numpy as np
from datetime import datetimedef transform_data(train_df):'''将train_df中的datetime划分成year、month、date、weekday、hour:param train_df:从bike_train.csv中读取的DataFrame:return:无'''#********* Begin *********#train_df['date'] = train_df.datetime.apply(lambda x:x.split()[0])train_df['hour'] = train_df.datetime.apply(lambda x:x.split()[1].split(':')[0]).astype('int')train_df['year'] = train_df.datetime.apply(lambda x:x.split()[0].split('-')[0]).astype('int')train_df['month'] = train_df.datetime.apply(lambda x: x.split()[0].split('-')[1]).astype('int')train_df['weekday'] = train_df.date.apply(lambda x: datetime.strptime(x, '%Y-%m-%d').isoweekday())return train_df#********* End **********#
第3关:租赁需求预估
任务描述
本关任务:编写python代码,实现租赁需求预估。
相关知识
为了完成本关任务,你需要掌握:
- 独热编码
sklearn机器学习算法的使用- 生成预测结果
独热编码
一般来说,代表类型型的特征我们需要对其进行独热编码。像数据中季节这种类别型的特征,应该使用独热编码。因为如果使用原始的1、2、3、4的话,机器学习算法可能会认为4这个季节更重要。为了防止这种偏见,我们就需要对其进行独热编码。
独热编码其实很简单,就是将待编码的特征的所有可能的取值列出来,然后再在对应的位置上填1,其他位置填0。可以看成是二进制的一种变形。
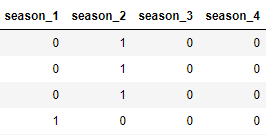
比如有4个样本的season分别为2、2、2、1。如下图所示:

那么将其独热编码后,如下图所示(第1行到第3行的season=2,所以编码后,每行的season_2这一列为1,其他列为0。而第4行的season=1,所以编码后,season_1这一列为1,其他列为0):
代码如下:
import pandas as pd# 将train_df中的season这一列进行独热编码dummies_season = pd.get_dummies(train_df['season'], prefix='season')# 打印print(dummies_season)
sklearn机器学习算法的使用
sklearn中提供了非常多的机器学习算法的接口,例如逻辑回归、弹性网络、随机森林等等。而且使用起来非常简单,只需要fit、predict二连即可。而本关是对共享单车的租赁需求量做预测,所以这是一个回归问题。在这里给出sklearn解决回归问题的示例代码:
from sklearn.linear_model import Ridge# 实例化Ridge回归对象ridge = Ridge(alpha=1.0)# 使用训练集的数据和标签训练ridge.fit(train_df, train_label)# 对测试集数据进行预测pred_result = ridge.predict(test_df)
生成预测结果
想要将预测结果保存到文件中,可以使用pandas来实现,示例代码如下:
import pandas as pd# 构建DataFrame,pred_result为机器学习算法的预测结果result = pd.DataFrame({'count':pred_result})# 将DataFrame保存成result.csv,并且保存时不保留indexresult.to_csv('./result.csv', index=False)
编程要求
根据提示,在右侧编辑器补充代码。代码主要任务如下:
- 读取
./step3/bike_train.csv中的数据作为训练集,读取./step3/bike_test.csv中的数据作为测试集 - 将数据处理成你想要的样子
- 使用
sklearn对训练集数据进行训练,并对测试集进行预测 - 将预测结果保存至
./step3/result.csv
测试说明
平台会计算你保存的./step3/result.csv的r2 score。若r2 score高于0.95视为过关。
测试输入: 预期输出:你的预测结果的r2 score高于0.95
PS:./step3/result.csv中需要两列。一列为datetime,另一列为count。其中datetime为./step3/bike_test.csv中的datetime,count为你的预测结果。如:
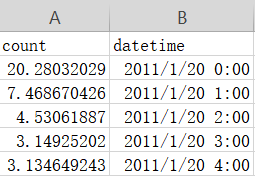
#********* Begin *********#
import pandas as pd
import numpy as np
from datetime import datetime
from sklearn.linear_model import Ridge
train_df = pd.read_csv('./step3/bike_train.csv')
# 舍弃掉异常count
train_df=train_df[np.abs(train_df['count']-train_df['count'].mean())<=3*train_df['count'].std()]
# 训练集的时间数据处理
train_df['date']=train_df.datetime.apply(lambda x:x.split()[0])
train_df['hour']=train_df.datetime.apply(lambda x:x.split()[1].split(':')[0]).astype('int')
train_df['year']=train_df.datetime.apply(lambda x:x.split()[0].split('-')[0]).astype('int')
train_df['month']=train_df.datetime.apply(lambda x:x.split()[0].split('-')[1]).astype('int')
train_df['weekday']=train_df.date.apply( lambda x : datetime.strptime(x,'%Y-%m-%d').isoweekday())
# 独热编码
train_df_back=train_df
dummies_month = pd.get_dummies(train_df['month'], prefix='month')
dummies_year = pd.get_dummies(train_df['year'], prefix='year')
dummies_season = pd.get_dummies(train_df['season'], prefix='season')
dummies_weather = pd.get_dummies(train_df['weather'], prefix='weather')
train_df_back = pd.concat([train_df, dummies_month,dummies_year, dummies_season,dummies_weather], axis = 1)
train_label = train_df_back['count']
train_df_back = train_df_back.drop(['datetime', 'season', 'weather', 'atemp', 'date', 'month', 'count'], axis=1)
test_df = pd.read_csv('./step3/bike_test.csv')
# 测试集的时间数据处理
test_df['date']=test_df.datetime.apply(lambda x:x.split()[0])
test_df['hour']=test_df.datetime.apply(lambda x:x.split()[1].split(':')[0]).astype('int')
test_df['year']=test_df.datetime.apply(lambda x:x.split()[0].split('-')[0]).astype('int')
test_df['month']=test_df.datetime.apply(lambda x:x.split()[0].split('-')[1]).astype('int')
test_df['weekday']=test_df.date.apply( lambda x : datetime.strptime(x,'%Y-%m-%d').isoweekday())
# 独热编码
test_df_back=test_df
dummies_month = pd.get_dummies(test_df['month'], prefix='month')
dummies_year = pd.get_dummies(test_df['year'], prefix='year')
dummies_season = pd.get_dummies(test_df['season'], prefix='season')
dummies_weather = pd.get_dummies(test_df['weather'], prefix='weather')
test_df_back = pd.concat([test_df, dummies_month,dummies_year, dummies_season,dummies_weather], axis = 1)
test_df_back = test_df_back.drop(['datetime', 'season', 'weather', 'atemp', 'date', 'month'], axis=1)
clf = Ridge(alpha=1.0)
# 训练
clf.fit(train_df_back, train_label)
# 预测
count = clf.predict(test_df_back)
# 保存结果
result = pd.DataFrame({'datetime':test_df['datetime'], 'count':count})
result.to_csv('./step3/result.csv', index=False)
#********* End *********#
相关文章:
头歌-机器学习 第13次实验 特征工程——共享单车之租赁需求预估
第1关:数据探索与可视化 任务描述 本关任务:编写python代码,完成一天中不同时间段的平均租赁数量的可视化功能。 相关知识 为了完成本关任务,你需要掌握: 读取数据数据探索与可视化 读取数据 数据保存在./step1/…...
Unity 2D让相机跟随角色移动
相机跟随移动 最简单的方式通过插件Cinemachine 在窗口/包管理器选择全部找到Cinemachine,导入。然后在游戏对象/Cinemachine创建2D Camera。此时层级中创建一个2D相机。选中人物拖入检查器Follow。此时相机跟随人物移动。 修改相机视口距离 在检查器中Lens下调正…...

【面试题】s += 1 和 s = s + 1的区别
文章目录 1.问题2.发现过程3.解析 1.问题 以下两个程序真的完全等同吗? short s 0; s 1; short s 0; s s 1; 2.发现过程 初看s 1 和 s s 1好像是等价的,没有什么区别。很长一段时间内我也是这么觉得,因为当时学习c语言的时候教科书…...

ARM的学习
点亮流水灯 .text .global _start _start: 使能GPIOE的外设时钟 RCC_MP_AHB4ENSETR 0x50000a28 [4]->1LDR R0,0X50000A28 指定基地址LDR R1,[R0] 将寄存器数据读取出来保存到R1中ORR R1,R1,#(0x3<<4) [4]设置为1ORR R1,R1,#(0x3<<5) [5]设置为1STR …...
)
Restful API接口规范(以Django为例)
Restful API接口规范(以Django为例) Restful API的接口架构风格中制定了一些规范,极大的简化了前后端对接的时间,以及增加了开发效率 安全性保证–使用https路径中带 api标识路径中带版本号数据即资源,通常使用名词操作请求方式决定操作资源…...

AI助力,程序员压力倍增?
讲动人的故事,写懂人的代码 你知道程序员现在在AI辅助编程时最头疼的事情是什么吗?就是怎么在改代码的时候保住小命。 大家都听过程序员因为工作太累导致过劳湿的事情。 无论是写新功能、修bug,还是更改系统配置,都得改代码。 现在有了AI的帮助,本应该轻松很多,为什么…...

LoRA微调
论文:LoRA: Low-Rank Adaptation of Large Language Models 实现:microsoft/LoRA: Code for loralib, an implementation of “LoRA: Low-Rank Adaptation of Large Language Models” (github.com) 摘要 自然语言处理的一个重要的开发范式包括&#…...
45.基于SpringBoot + Vue实现的前后端分离-驾校预约学习系统(项目 + 论文)
项目介绍 本站是一个B/S模式系统,采用SpringBoot Vue框架,MYSQL数据库设计开发,充分保证系统的稳定性。系统具有界面清晰、操作简单,功能齐全的特点,使得基于SpringBoot Vue技术的驾校预约学习系统设计与实现管理工作…...

系统思考—时间滞延
“没有足够的时间是所有管理问题的一部分。”——彼得德鲁克 鱼和熊掌可以兼得,但并不能同时获得。在提出系统解决方案时,我们必须认识到并考虑到解决方案的实施通常会有必要的时间滞延。这种延迟有时比我们预想的要长得多,特别是当方案涉及…...

SSM项目转Springboot项目
SSM项目转Springboot项目 由于几年前写的一个ssm项目想转成springboot项目,所以今天倒腾了一下。 最近有人需要毕业设计转换一下,所以我有时间的话可以有偿帮忙转换,需要的私信我或+v:Arousala_ 首先创建一个新的spr…...

VUE3.0对比VUE2.0
vue3.0 与 vue2.0的不同之处有以下几点: 数据响应式原理 3.0基于Proxy的代理实现监测,vue2.0是基于Object.defineProperty实现监测。 vue2.0 通过Object.defineProperty,每个数据属性被定义成可观察的,具有getter和setter方法&…...
车内AR互动娱乐解决方案,打造沉浸式智能座舱体验
美摄科技凭借其卓越的创新能力,为企业带来了革命性的车内AR互动娱乐解决方案。该方案凭借自研的AI检测和渲染引擎,打造出逼真的数字形象,不仅丰富了车机娱乐内容,更提升了乘客与车辆的互动体验,让每一次出行都成为一场…...

OR36 链表的回文结构
描述 对于一个链表,请设计一个时间复杂度为O(n),额外空间复杂度为O(1)的算法,判断其是否为回文结构。 给定一个链表的头指针A,请返回一个bool值,代表其是否为回文结构。保证链表长度小于等于900。 测试样例: 1->…...

【译】微调与人工引导: 语言模型调整中的 SFT 和 RLHF
原文地址:Fine-Tuning vs. Human Guidance: SFT and RLHF in Language Model Tuning 本文主要对监督微调(SFT, Supervised Fine Tuning )和人类反馈强化学习(RLHF, Reinforcement Learning from Human Feedback)进行简…...
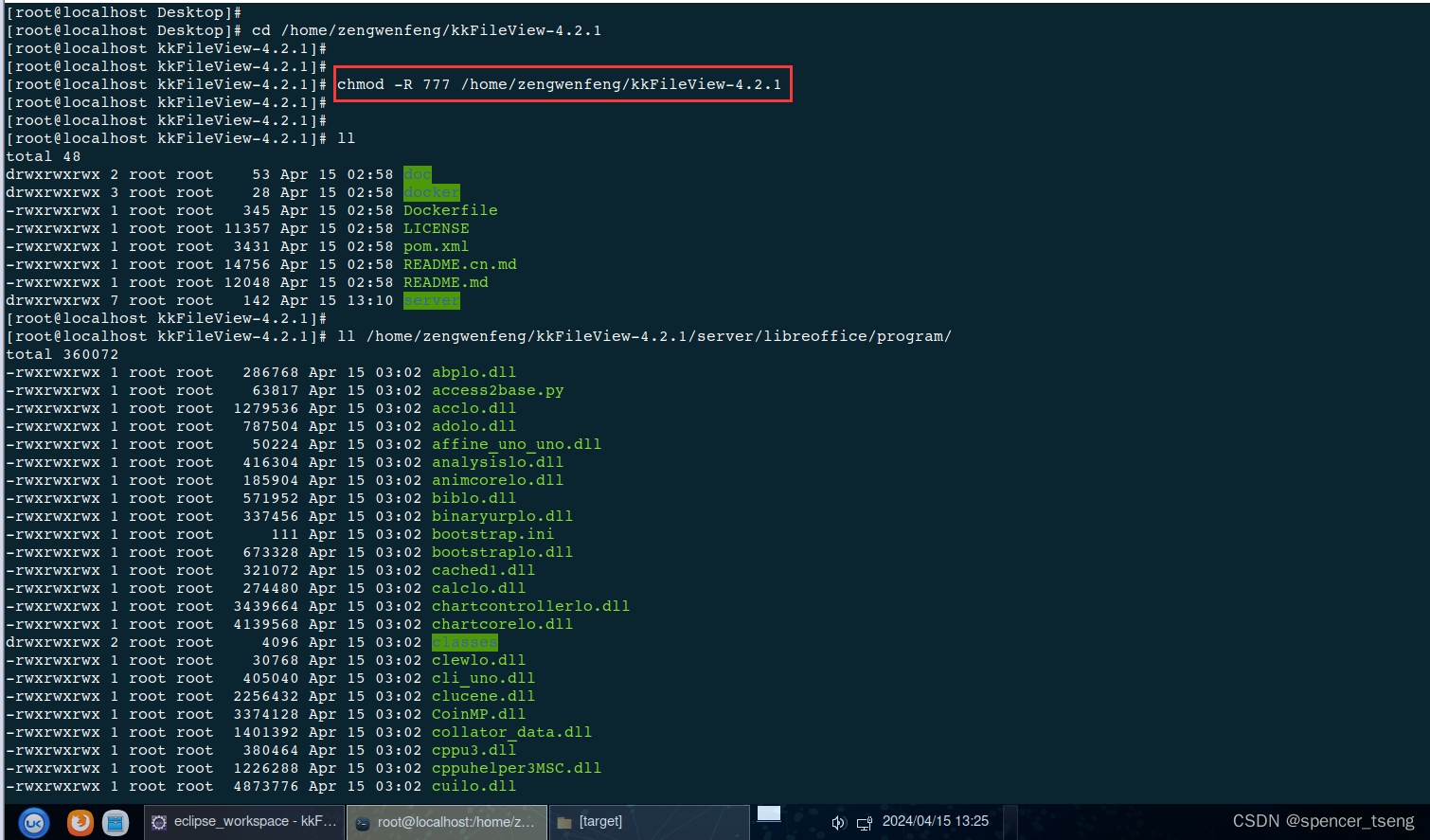
kylin java.io.IOException: error=13, Permission denied
linux centos7.8 error13, Permission denied_linux open error13-CSDN博客 chmod -R 777 /home/zengwenfeng/kkFileView-4.2.1 2024-04-15 13:15:17.416 WARN 3400 --- [er-offprocmng-1] o.j.l.office.LocalOfficeProcessManager : An I/O error prevents us to determine…...

前端面试01总结
1.Js 中!x为true 时,x可能为哪些值 答: 1.false:布尔值false 2.0或-0:数字零 3.""或’或 (空字符串):长度为0的字符串 4.null:表示没有任何值的特殊值 5.undefined:变量未定义时的默认…...

算法--目录
algorithm: 十种排序算法 二分法-各种应用 algorithm: 拓扑排序 算法中的背包问题 最长子序列问题 前缀和-解题集合 差分数组-解题...
ArcGIS Pro 3D建模简明教程
在本文中,我讲述了我最近一直在探索的在 ArcGIS Pro 中设计 3D 模型的过程。 我的目标是尽可能避免与其他软件交互(即使是专门用于 3D 建模的软件),并利用 Pro 可以提供的可能性。 这个短暂的旅程分为三个不同的阶段:…...

24届数字IC设计/验证秋招总结贴——先看这个
文章目录 前言一、经验篇二、知识学习篇三、笔试篇3.1 各大公司笔试真题3.2 华为机试——数字芯片笔试题汇总 四、面试篇4.1 时间节点4.2 提前批4.3 正式批 前言 为方便快速进行查找该专栏的内容,将所有内容链接均放在此篇博客中 整理不易,欢迎订阅~~ …...
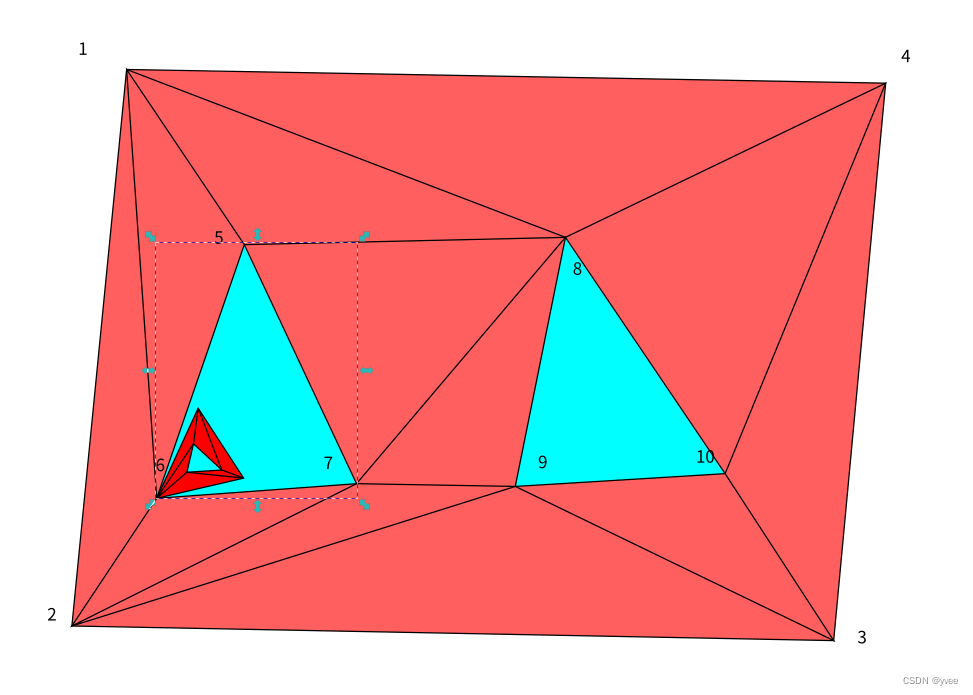
带洞平面三角分割结果的逆向算法
先标不重复点,按最近逐个插入。 只说原理。 不带洞的 1 2 4 2 3 4 两个三角形 结果 1 2 3 4 无重复 无洞 1 2 6 1 2 3 6 1 2 3 7 6 1 2 3 4 7 6 1 2 3 4 5 7 6 1 2 3 4 1 5 7 6 1 2 3 4 1 6 5 7 6 最终结果 1 2 3 4 1 6 5 7 6 按重复分割 1 2 3…...
)
从90%到99%:实战提升Tesseract在C++项目中的识别准确率(附调参技巧)
从90%到99%:实战提升Tesseract在C项目中的识别准确率(附调参技巧) 在工业级文档处理系统中,我们常遇到这样的困境:测试集上的OCR识别准确率卡在90%左右,而业务部门要求必须达到99%以上才能上线。去年负责某…...

揭秘HunterPie:如何用现代化覆盖层技术革新《怪物猎人:世界》体验
揭秘HunterPie:如何用现代化覆盖层技术革新《怪物猎人:世界》体验 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_m…...

用好外勤数据,一年能帮你省下多少管理成本?
很多公司买外勤软件的初衷很简单:知道业务员在哪里,有没有去客户那边。打卡、定位、签到——这三件事做到了,觉得系统就发挥作用了。 一年过去,后台积累了几万条拜访记录、几千个停留点位、每个人每天的行动轨迹。这些数据安静地躺…...

宝塔面板登录教程
1买个服务器2连接ssh-宝塔或者xshell都行3在xshell下载宝塔面板4在服务器主页--在哪里订购的就在有个管理点进去-加入安全组或者添加nat转发。如果不行用bt命令重置端口号再访问,最后重置之后重启一下-bt 15使用nat转发的要用外网端口,宝塔显示的是内网的…...

AI代理协作平台Run402:基于看板与微支付的自动化任务管理
1. 项目概述:一个面向AI代理的协作与支付平台最近在开源社区里,我注意到一个挺有意思的项目,叫musfoner/run402。乍一看,它的描述非常简洁,甚至可以说有些“神秘”,只有“yonathan estudio”几个字。但结合…...

《Java 100 天进阶之路》第1篇:编程语言类型有哪些?我心中的TOP1编程语言,什么是Java跨平台性?
第1篇:编程语言类型有哪些?我心中的TOP1编程语言,什么是Java跨平台性? 一、核心知识点 编程语言的三大类型:机器语言、汇编语言、高级语言Java为什么是“一次编写,到处运行”(跨平台原理&…...

不开刀、少痛苦!拱墅区这家公立肿瘤专科,中西医结合守护生命希望
面对肿瘤,你是否还在恐惧开刀创伤、担忧放化疗副作用?杭州市拱墅区人民中西医结合医院肿瘤一科,作为公立二级甲等医院重点专科,以 “微创消瘤、中西扶正” 为核心,走出一条低损伤、高疗效的抗癌新路,为无数…...

[CAN BUS] 从开源到商用:USB-CAN适配器选型避坑指南与稳定性深度剖析
1. 为什么USB-CAN适配器选型这么重要? 如果你正在开发汽车电子、工业控制或者机器人项目,大概率会用到CAN总线。作为嵌入式工程师,我最开始接触CAN总线时,天真地以为随便买个USB转CAN的工具就能搞定。结果在实际项目中踩了不少坑—…...

ARM架构FPU识别与FPSID寄存器详解
1. ARM浮点系统识别基础在ARM架构中,浮点运算单元(FPU)的实现经历了从VFPv1到VFPv4的演进过程。FPSID寄存器作为浮点系统的"身份证",提供了识别FPU实现特性的标准方式。这个32位寄存器包含了多个关键字段,每个字段都承载着特定的识…...

NPYViewer:5分钟上手的数据可视化神器,告别NumPy数组查看烦恼
NPYViewer:5分钟上手的数据可视化神器,告别NumPy数组查看烦恼 【免费下载链接】NPYViewer Load and view .npy files containing 2D and 1D NumPy arrays. 项目地址: https://gitcode.com/gh_mirrors/np/NPYViewer 还在为NumPy二进制文件头疼吗&a…...