NVIDIA: RULER新测量方法让大模型现形
1 引言
最近在人工智能系统工程和语言模型设计方面的进展已经实现了语言模型上下文长度的高效扩展。以前的工作通常采用合成任务,如密钥检索和大海捞针来评估长上下文语言模型(LMs)。然而,这些评估在不同工作中使用不一致,仅揭示了检索能力,无法衡量其他形式的长上下文理解。
在这项工作中,NVIDIA提出了RULER,一个新的基准来评估语言模型的长上下文建模能力。RULER包含四个任务类别,用于测试超出简单上下文检索的行为:
- 检索:该研究扩展了大海捞针(Kamradt, 2023, NIAH)测试,以评估具有不同类型和数量"针"的检索能力。
- 多跳跟踪:该研究提出了变量跟踪,一个指代链解析的最小代理任务,用于检查具有多跳连接的实体跟踪行为。
- 聚合:该研究提出了常见/频繁词提取,摘要的代理任务,用于测试聚合跨越长距离上下文的相关信息的能力。
- 问答:该研究在现有短上下文问答数据集的输入中添加了干扰信息,以评估各种上下文大小下的问答能力。

与现有的真实基准(表1)相比,RULER完全由合成任务组成,提供了控制序列长度和任务复杂性的灵活性。RULER中的合成输入减少了对参数知识的依赖,而参数知识会干扰真实任务中长上下文输入的利用。
使用RULER,该研究对GPT-4和九个开源模型进行了基准测试,上下文长度从4k到128k不等。尽管在原版NIAH测试中取得了接近完美的性能,但随着序列长度的增加,所有模型在RULER的更复杂任务上都表现出了巨大的性能下降。虽然所有模型都声称上下文大小为32k个token或更多,但该研究的结果表明,只有四个模型可以通过超过定性阈值在32k长度上有效处理序列长度。此外,几乎所有模型在达到声称的上下文长度之前都低于该阈值。为了获得细粒度的模型比较,该研究使用两个加权平均分数从4k到128k聚合性能,其中权重模拟了真实使用案例的长度分布。无论选择哪种加权方案,顶级模型-GPT-4、Command-R、Yi-34B和Mixtral始终优于其他模型。
该研究进一步分析了Yi-34B,它声称上下文长度为200k,在开源模型中在RULER上获得第二名。该研究的结果表明,随着输入长度和任务复杂性的增加,Yi的性能出现了很大的下降。在大的上下文大小下,Yi-34B经常返回不完整的答案,无法精确定位相关信息。此外,该研究观察到,随着上下文大小的扩展,多个模型出现了两种行为:对参数知识的依赖增加,以及对非检索任务从上下文中复制的倾向增加。该研究的附加消融实验表明,在更长的序列上训练并不总是在RULER上带来更好的性能,而且更大的模型尺寸与更好的长上下文能力正相关。最后,该研究表明,非Transformer架构,如RWKV和Mamba,在RULER上仍然远远落后于Transformer。
该研究的贡献如下:
- 该研究提出了一个新的基准RULER,用于通过具有灵活配置的合成任务评估长上下文语言模型。
- 该研究引入了新的任务类别,特别是多跳跟踪和聚合,以测试除了从长上下文中检索之外的行为。
- 该研究使用RULER评估了10个长上下文语言模型,并在模型和任务复杂性方面进行了分析。
- 该研究开源了RULER,以激发长上下文语言模型的未来研究。
2 相关工作
长上下文语言模型。由于工程、架构和算法设计方面的进步,最近引入了许多长上下文语言模型。Flash attention和Ring attention显著减少了处理长上下文所需的内存占用。采用了各种稀疏注意力机制,如移位稀疏注意力、膨胀注意力和注意力汇,以实现有效的上下文缩放。提出了新的位置嵌入方法来改进Transformer中的长度外推,包括ALiBi、xPOS和RoPE变体。另一条研究路线集中在减少上下文大小。这可以通过使用递归机制缓存先前的上下文来实现,或通过检索或压缩来保留长上下文中的显著信息。最后,也提出了新的架构,如Mamba和RWKV来有效处理长上下文输入。
长上下文基准和任务。该研究的工作与其他长上下文语言模型基准测试的工作密切相关。ZeroSCROLLS涵盖了十个真实自然语言任务,如长文档问答和(基于查询的)摘要。L-Eval也使用真实数据,这些数据经过手动过滤以确保质量。LongBench包含双语设置中的任务。
InfiniteBench包括长度大于100k个token的任务。
LTM针对长期对话的评估。为了隔离参数知识的影响,先前的工作也提出使用在某个截止日期之后在线发布的文档,或利用极低资源的材料。与真实基准相比,合成任务在控制设置(如序列长度和任务复杂性)方面更加灵活,并且受参数知识的影响较小。最近的工作主要集中在基于检索的合成任务上,只有少数针对其他类型的长上下文使用,包括各种类型的推理和长距离语篇建模。
3 RULER基准
RULER包括四个类别的任务:检索、多跳跟踪、聚合和问答,所有任务都可以配置不同的长度和复杂度(见表2)。
3.1 检索:大海捞针(NIAH)
最近的工作通常采用大海捞针(Kamradt, 2023, NIAH)测试来评估长上下文建模能力。NIAH测试让人联想到广泛研究的联想召回任务,其中需要在给定足够查询的情况下从上下文中检索相关信息。在RULER中,该研究包括多个基于检索的任务,扩展了原版NIAH测试,以根据三个标准评估模型。具体来说,检索能力应该(1)与"针"和"大海"的类型无关,(2)足够强大以忽略硬干扰,(3)当需要检索多个项目时具有高召回率。基于这些标准,该研究开发了四个NIAH任务。每个任务中的"针"是插入到"大海"(长干扰文本)中的键值对。查询位于序列的末尾,用作匹配上下文中的键并随后检索相关值的提示。

- 单针NIAH
(S-NIAH):这是原版NIAH测试,其中需要从"大海"中检索单个"针"。查询/键/值可以采用单词、数字(7位)或UUID(32位)的形式。"大海"可以是重复的噪声句子或Paul
Graham的文章。 - 多键NIAH
(MK-NIAH):将多个"针"插入"大海",只需检索其中一个。额外的"针"是硬干扰。最具挑战性的设置是整个"大海"充满干扰针的版本。 - 多值NIAH (MV-NIAH):将多个共享相同键的"针"插入"大海"。需要检索与同一键关联的所有值。
- 多查询NIAH
(MQ-NIAH):将多个"针"插入"大海"。需要检索具有不同键的所有"针"。这与Arora et al.(2024)使用的多查询联想召回任务设置相同。与MV-NIAH一起,这两个任务评估检索能力而不遗漏任何关键信息。

3.2 多跳跟踪:变量跟踪(VT)
有效的语篇理解取决于成功识别新提及的实体并建立整个长上下文中指代同一实体的参照链。该研究开发了一个新任务变量跟踪,以模拟最小的指代链解析任务。该任务检查跟踪相关共现模式和在长输入中绘制跳过连接的行为。具体而言,变量X1被初始化为值V,后面是线性链的变量名绑定语句(例如X2 = X1, X3 = X2, …),它们被插入到输入的各个位置。目标是返回指向相同值V的所有变量名。通过添加更多跳数(即名称绑定的次数)或更多链,可以增加任务复杂性,类似于在MK-NIAH中添加硬干扰。
3.3 聚合:常见词(CWE)和频繁词提取(FWE)
在RULER中,该研究引入了一个新的类别,作为摘要任务的代理,其中相关信息构成上下文的更大部分,目标输出取决于相关输入的准确聚合。具体而言,该研究通过从预定义的(合成)单词列表中采样单词来构造输入序列。在常见词提取任务(CWE)中,单词从离散均匀分布中采样,常见词的数量固定,而非常见词的数量随序列长度增加。在频繁词提取任务(FWE)中,单词从Zeta分布中采样。图1显示了构造输入中单词频率的插图。模型需要返回上下文中最频繁的前K个单词。在CWE中,K等于常见词的数量。在FWE中,该研究将K设置为3,因为即使在小上下文大小下,对大多数模型来说,增加K也会导致性能下降。可以通过改变常见词的数量或Zeta分布的参数来调整任务复杂性。
3.4 问答(QA)
大多数现有的问答数据集都是为基于短段落回答问题而设计的。通过添加干扰信息,这些数据集可以扩展以模拟长上下文输入。在这个任务类别中,该研究将黄金段落(即包含答案的段落)插入从同一数据集中随机采样的段落中。这个类别是NIAH的真实场景改编(Ivgi et al., 2023),其中问题作为查询,"针"是黄金段落,"大海"由干扰段落组成。

4 实验 & 结果
模型 & 推理设置 该研究选择了10个长上下文语言模型,包括9个开源模型和一个封闭源代码模型(GPT-4),涵盖了不同的模型大小(6B到8x7B,带有MoE架构)和声称的上下文长度(32k到1M)。这些模型的完整信息包含在附录A中。该研究使用vLLM评估所有模型,这是一个具有高效KV缓存内存管理的语言模型服务系统。对于所有模型,该研究在8个NVIDIA A100 GPU上使用BFloat16进行贪婪解码推理。
任务配置 该研究在RULER中的13个任务上测试所有模型,这些任务涵盖了不同的复杂性和四个类别。测试配置(如附录B所示)是基于附录C中描述的任务相关性研究选择的。对于每个任务,该研究使用500个示例评估每个模型,长度从(4k, 8k, 16k, 32k,
64k, 128k)系列中的每个长度生成,同时遵守每个模型必要的聊天模板。为了防止模型拒绝回答查询或生成解释,该研究在任务输入后面附加一个答案前缀,并使用基于召回的准确性检查目标输出的存在。
有效上下文大小 该研究注意到,随着RULER中输入长度的增加,所有模型的性能都出现了大幅下降。为了确定模型可以有效处理的最大上下文大小,该研究使用固定阈值对每个模型进行评分,通过该阈值表明在评估长度上的满意性能。该研究使用Llama2-7b模型在4K上下文长度处的性能作为阈值。该研究在表3中报告了超过阈值的最大长度作为"有效长度",以及"声称的长度"。
模型排名标准 虽然基于阈值的评分揭示了声称长度和有效长度之间的差异,但它缺乏细粒度模型比较的细节。因此,该研究使用加权平均分数来聚合各种上下文大小下的模型性能。该研究在两种加权方案下对模型进行排名:wAvg. (inc)和wAvg. (dec),其中权重随序列长度线性增加和减少。理想情况下,每个长度的权重应由模型使用的长度分布决定,这里该研究选择这两种方案来模拟较长序列(inc)或较短序列(dec)主导分布的情况。
主要结果 该研究在表3中包括了与Llama2-7B基线相比的十个长上下文语言模型的结果。
某个长度下的性能是RULER中所有13个任务的平均值。虽然所有模型都声称有32K个token或更多的有效上下文,但没有一个模型在其声称的长度上保持高于Llama2-7B基线的性能,除了Mixtral,它在声称的32K上下文大小的两倍长度上实现了中等性能。尽管在通行证检索和原版NIAH任务(如附录E所示)中取得了接近完美的性能,但随着序列长度的增加,所有模型在RULER的更复杂任务中都表现出了很大的下降。RULER上表现最好的模型是GPT-4,它在4k长度下具有最高的性能,在将上下文扩展到128K时,表现出最小但非边际的下降(15.4)。开源模型中排名前三的Command-R、Yi-34B和Mixtral都使用RoPE中的大基频,参数大小也大于其他模型。尽管使用1M的上下文大小进行训练,但LWM在4K下的性能甚至比Llama2-7B还差。然而,随着上下文大小的增加,它表现出较小的下降,因此当较长序列获得较大权重时(wAvg. inc),它的排名高于Mistral-7B。这一结果表明,在绝对短序列性能和相对上下文大小缩放下降之间存在评估折衷。
5 任务错误分析
该研究使用增加的输入长度(最长256K)和更复杂的任务评估了Yi-34B-200K,该模型在RULER上在开源模型中排名第二,以了解任务配置和RULER中失败模式的影响。
对"针"类型的非鲁棒性。图2(左)显示,当在标准通行证检索和原版NIAH中使用词-数字对作为针时,Yi几乎达到了完美的性能,但当针采用其他形式时,性能会下降。该研究观察到,在检索UUIDs的任务中,性能下降最大,对于长(>128K)输入上下文,Yi有时无法返回完整的32位数字。
未能忽略干扰 图2(中左)显示,增加干扰针的数量会稳定地降低性能,在极端版本中,Yi在256K处下降了约40分,其中上下文充满了不相关的针(#K=FULL)。错误分析显示,在长输入上下文中,Yi无法有效忽略硬干扰,从而错误地检索与干扰键关联的值。在极端版本中,Yi经常返回目标附近的值,表明范围的粗略匹配,但在目标与噪声分布相同时缺乏精确定位键的能力。
返回不完整信息。与先前的工作(Liu et al., 2024a; Reid et al., 2024)一致,该研究注意到,当模型需要从长输入中检索多个项目时,性能会显著下降。例如,将查询数量从1增加到8会使性能下降约15分(图2右)。当模型需要检索与同一键关联的多个值时(图2中右),Yi经常输出重复的答案而不返回完整的值集,这意味着键和其每个值之间的关联不均匀。

从上下文复制的趋势。该研究注意到,随着输入长度的扩展,Yi有很强的从上下文逐字复制的趋势。这种趋势在变量跟踪(VT)和常见词提取(CWE)中最为明显,在这两个任务中,该研究在序列开头包含一个上下文内演示。在128K的CWE任务中,Yi超过80%的输出只是从一次性示例中复制的字符串,而对于短序列,复制是不存在的。
这种复制行为也存在于LWM模型和LongAlpaca中,但在其他模型(如Mixtral)中不太普遍。这一发现进一步强化了在长输入上下文中测试除检索之外的行为的必要性。
不可靠的上下文内跟踪。对于变量跟踪任务,添加更多链和更多跳数都会导致Yi性能的大幅下降。随着上下文大小的增加,Yi在更多跳数的设置中一致降级(图3左),而在更多链的设置中,降级在大于128K的长度下最为显著(图3中左)。除了前面提到的复制问题,Yi由于错误返回空字符串或来自其他链的变量而出错,这意味着缺乏在长上下文中可靠跟踪同一实体的能力。这些错误也经常在不表现复制行为的模型中观察到。
聚合失败。该研究在聚合任务中注意到两种常见的失败模式:参数知识的不正确使用和不准确的聚合。在CWE任务中不表现出复制问题的模型有时会忽略上下文信息,而是使用参数知识来回答查询,尤其是在大上下文大小下。例如,Mistral (7b-instruct-v0.2)返回高频词,如"the"、“an”、“a”,而不计算上下文中的单词。对于表现出较少复制问题的FWE任务,随着Zeta分布中α的减小,Yi无法正确输出最频繁的词(图3中右)。减小α会导致单词之间的频率差异变小,增加区分最频繁词的难度。
长上下文QA中的频繁幻觉。对于QA任务,随着该研究使用分散的段落扩展上下文,Yi的性能接近其无上下文基线(图3右)。性能下降主要源于幻觉和对上下文信息的依赖减少。该研究注意到,在大上下文大小下,模型预测有时与问题无关,可能与其无上下文基线的答案一致。QA任务中整体较差的性能证实,在长上下文中模糊匹配查询和相关段落比简单的NIAH测试更具挑战性,后者可以在上下文中精确定位键。

6 模型分析
训练上下文长度的影响。使用更大上下文大小训练的模型在RULER上表现更好吗?该研究评估了参数大小固定且训练至不同上下文长度的一系列LargeWorldModels(LWM)。图4(左和中左)显示,更大的上下文大小总体上会带来更好的性能,但对于长序列,排名可能不一致。例如,使用1M上下文大小训练的模型(LWM-1M)在256K长度上比使用512K训练的模型差,这可能是由于训练不足,无法调整RoPE中的新基频。此外,当模型需要外推到看不见的长度时(例如,给定256K输入的LMW-128K),该研究观察到性能突然下降,并且在对数尺度上的最大训练上下文大小内,随着输入长度几乎线性降级。
模型大小的影响 该研究的主要结果中的顶级模型比其他模型大得多。为了消融模型大小的影响,该研究评估了Yi-34B-200k、Yi-9B-200k和Yi-6B-200k,它们都使用相同的数据混合训练至相同的上下文长度。图4(中右)显示,34B模型在RULER上的4K长度性能和相对降级方面都明显优于6B模型,表明扩展模型大小有利于更好的长上下文建模。
架构的影响 该研究评估了两个非Transformer架构模型的有效上下文长度:RWKV-v5(Peng et al., 2023)和Mamba-2.8B-slimpj(Gu & Dao, 2023)。该研究发现,当将上下文大小扩展到8K时,这两个模型都表现出显著的降级,并且在4K的长度上,它们都大大低于Transformer基线Llama2-7B,超过该长度,Llama2表现出较差的长度外推性能(图4右)。
7 结论
该研究提出了RULER,一个用于评估长上下文语言模型的合成基准。RULER包含不同的任务类别,检索、多跳跟踪、聚合和问答,提供了语言模型长上下文能力的灵活且全面的评估。该研究使用RULER对十个长上下文语言模型进行了基准测试,上下文大小从4K到128K不等。尽管在广泛使用的大海捞针测试中取得了完美的结果,但随着输入长度的增加,所有模型在RULER的其他任务中都未能保持其性能。该研究观察到在大上下文大小下的常见失败模式,包括未能忽略干扰和无效利用长上下文(例如,简单地从上下文复制或使用参数知识)。该研究表明,即使对于排名最高的开源模型,随着任务复杂性的增加,RULER也具有挑战性。该研究的分析进一步揭示了RULER上的巨大改进潜力,以及扩展模型大小在实现更好的长上下文能力方面的好处。
我的看法
这篇论文对长上下文语言模型(LMs)的评估提出了新的视角和方法,具有重要的研究价值和实践意义。
- RULER基准的设计思路新颖,涵盖了检索、多跳跟踪、聚合、问答等不同类型的任务,能够全面考察LMs在长上下文理解方面的多种能力,弥补了之前工作的不足。合成任务虽然在真实性上有所欠缺,但能够灵活控制变量,有利于系统性的比较和分析。
- 实验规模较大,评测了包括GPT-4在内的10个主流LMs,上下文长度跨度也比较全面,最长达到128K tokens。这为模型间的横向比较以及不同长度下的性能变化提供了翔实的数据支撑。
- 细致的结果分析给出了富有洞察力的发现,例如目前LMs在面对极长上下文时普遍存在显著的性能下降,且下降趋势因任务而异;模型虽然声称能处理很长的上下文,但实际有效长度远低于此;模型尺寸、训练数据长度、架构等因素对长上下文建模能力有重要影响。
- 作者总结了模型在RULER上的几类典型错误模式,如对干扰信息处理不足、过度依赖参数知识而忽视上下文、از不可靠的多跳推理等,这对后续算法改进具有重要启示作用。
- 研究还具有很好的开放性,论文附录详细说明了评测方法,并开源了RULER基准,有利于研究者基于此开展后续工作。
不足之处:
- RULER目前规模还不够大,任务也以合成数据为主,今后可纳入更多真实场景的长文本任务。
- 抽样分析GPT-4等大模型的错误行为很有意义,但由于它们是黑盒系统,解释性有限。未来可结合可解释性研究,分析模型失误的深层原因。
- 研究主要关注单一长文档理解,对话历史、知识库问答等更复杂的多文档长上下文场景尚未涉及。
- 不同模型的训练数据、计算资源投入差异很大,纵向比较时需考虑这些因素的影响。
这项工作丰富了对LMs长上下文建模能力的认识,为全面评估大语言模型提供了新的视角和工具,对基准的构建、模型的改进以及实际应用都有重要的参考价值。未来进一步扩大评测规模、引入更多真实任务、结合可解释性等方面的研究,有望推动LMs在长文本理解与应用上取得更大突破。
相关文章:
NVIDIA: RULER新测量方法让大模型现形
1 引言 最近在人工智能系统工程和语言模型设计方面的进展已经实现了语言模型上下文长度的高效扩展。以前的工作通常采用合成任务,如密钥检索和大海捞针来评估长上下文语言模型(LMs)。然而,这些评估在不同工作中使用不一致,仅揭示了检索能力,无法衡量其他形式的长上下文理解。 …...

2024数学-微积分和线性代数/本科研究生专业考试/考研/论文/重点公式考点汇总/最难公式投票
## 整体公式汇总列表 http://www.deepnlp.org/equation/category/math #### 微积分 ## 几何级数http://www.deepnlp.org/equation/arithmetic-and-geometric-progressions ## 级数收敛http://www.deepnlp.org/equation/convergence-of-series ## 二项式展开 http://www.dee…...
:Leetcode1005、134、135(难得有一天能完全独立做出题目))
代码随想录训练营Day33(贪心算法):Leetcode1005、134、135(难得有一天能完全独立做出题目)
Leetcode1005: 题目描述: 给你一个整数数组 nums 和一个整数 k ,按以下方法修改该数组: 选择某个下标 i 并将 nums[i] 替换为 -nums[i] 。 重复这个过程恰好 k 次。可以多次选择同一个下标 i 。 以这种方式修改数组后,返回数…...
Flutter笔记:Widgets Easier组件库(12)使用消息吐丝(Notify Toasts)
Flutter笔记 Widgets Easier组件库(12)使用消息吐丝(Notify Toasts) - 文章信息 - Author: 李俊才 (jcLee95) Visit me at CSDN: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 29114848416…...

从《春色寄情人》学习如何面对死亡
经典台词,很震撼又很实用,记录一下。 ❤️01 有的时候好人不长命百岁,是因为老天爷觉得他们太累,让他们提前休息了! ❤️02 跟我们亲近的人离世,有可能是老天给我们发的信号,提醒我们ÿ…...

使用moveit控制机械臂
在这篇博客中,我们将详细探讨如何利用Python和Robot Operating System(ROS)配合MoveIt! 控制机械臂执行精确的抓取任务。机械臂技术在工业自动化、医疗服务以及研究领域扮演着越来越关键的角色。本文将通过介绍安装必要的软件、编写控制脚本以…...
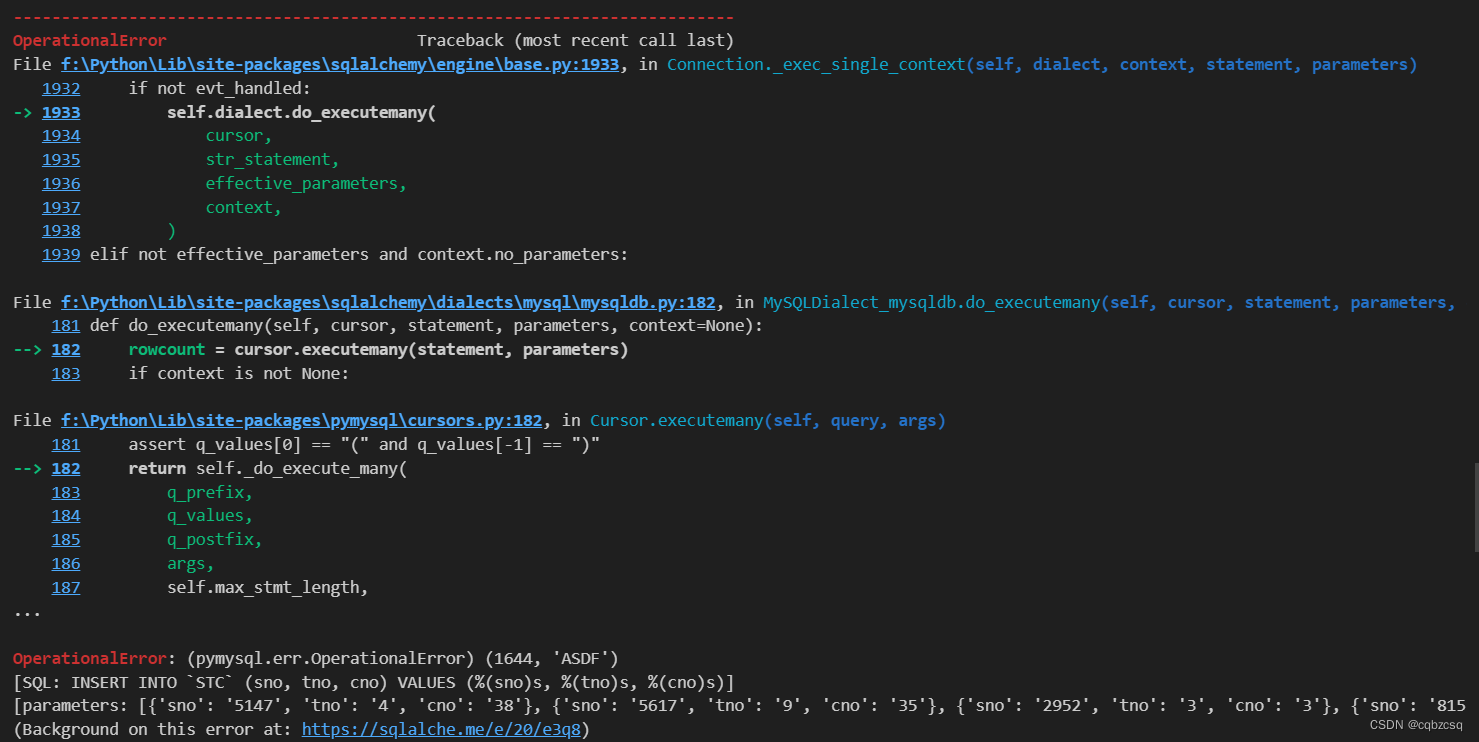
Mysql报错红温集锦(一)(ipynb配置、pymysql登录、密码带@、to_sql如何加速、触发器SIGNAL阻止插入数据)
一、jupyter notebook无法使用%sql来添加sql代码 可能原因: 1、没装jupyter和notebook库、没装ipython-sql库 pip install jupyter notebook ipython-sql 另外如果是vscode的话还需要安装一些相关的插件 2、没load_ext %load_ext sql 3、没正确的登录到mysql…...

ASP.NET Core SignalR 配置与集成测试究极指南
这篇文章也可以在我的博客中查看 前言 哥们最近都在埋头苦干,沉默是金,有一段时间没更新博客了。然而今儿SignalR集成测试实属是给我整破防了。虽说SignalR是.NET官方维护的实时通信库,已经开发了有十几年,甚至已经编入至了core…...
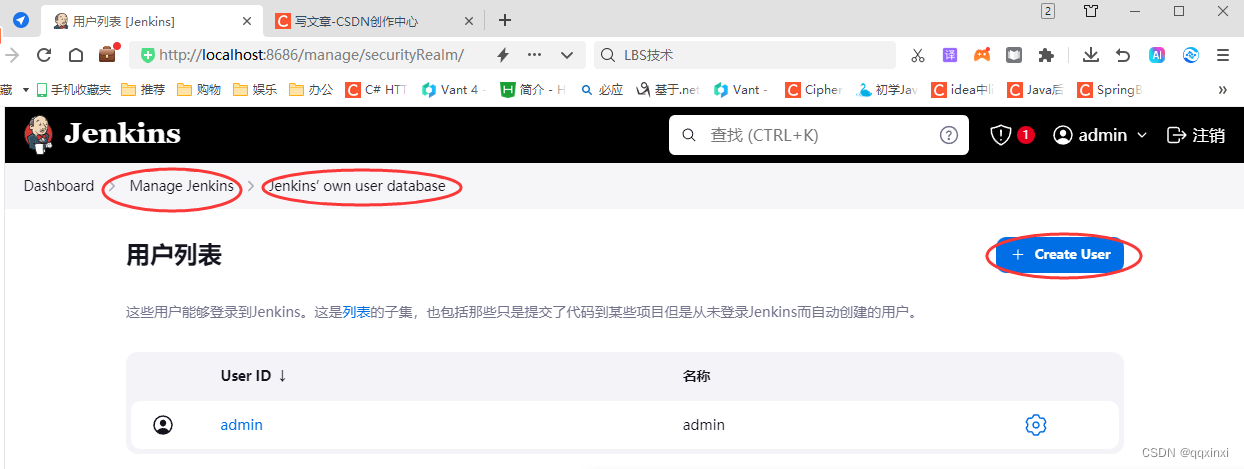
JENKINS 安装,学习运维从这里开始
Download and deployJenkins – an open source automation server which enables developers around the world to reliably build, test, and deploy their softwarehttps://www.jenkins.io/download/首先点击上面。下载Jenkins 为了学习,从windows开始&#x…...

大语言模型从Scaling Laws到MoE
1、摩尔定律和伸缩法则 摩尔定律(Moores law)是由英特尔(Intel)创始人之一戈登摩尔提出的。其内容为:集成电路上可容纳的晶体管数目,约每隔两年便会增加一倍;而经常被引用的“18个月”…...

四级英语翻译随堂笔记
降维表达:中译英,英译英 没有强调主语,没有说明主语:用被动 但如果实在不行,再增添主语 不会就不翻译,不要乱翻译 以xxx为背景:against the backdrop of the xxx eg:against the backdrop of…...

Nacos支持的配置格式及其在微服务架构中的应用
今天,我想和大家探讨一下Nacos这一重要的微服务组件,特别是它所支持的配置格式以及这些格式在微服务架构中的应用。 一、Nacos简介 Nacos是阿里巴巴开源的一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。它提供了服务发现、配置管理…...
-OD统一考试(C卷D卷))
2024年华为OD机试真题-小明找位置-(C++)-OD统一考试(C卷D卷)
题目描述: 小朋友出操,按学号从小到大排成一列;小明来迟了,请你给小明出个主意,让他尽快找到他应该排的位置。 算法复杂度要求不高于nLog(n);学号为整数类型,队列规模<=10000; 输入描述: 1、第一行:输入已排成队列的小朋友的学号(正整数),以”,”隔开; …...
机器人系统ros2内部接口介绍
内部 ROS 接口是公共 C API ,供创建客户端库或添加新的底层中间件的开发人员使用,但不适合典型 ROS 用户使用。 ROS客户端库提供大多数 ROS 用户熟悉的面向用户的API,并且可能采用多种编程语言。 内部API架构概述 内部接口主要有两个&#x…...

跟随Facebook的足迹:社交媒体背后的探索之旅
在当今数字化时代,社交媒体已经成为了人们日常生活中不可或缺的一部分。而在这庞大的社交媒体网络中,Facebook作为其中的巨头,一直在引领着潮流。从创立之初的一个大学社交网络到如今的全球性平台,Facebook的发展历程承载了无数故…...

面试题分享之Java并发篇
注意:文章若有错误的地方,欢迎评论区里面指正 🍭 系列文章目录 面试题分享之Java集合篇(三) 面试题分享之Java集合篇(二) 面试题分享之Java基础篇(三) 前言 今天给小…...

bpmn-js 多实例配置MultiInstanceLoopCharacteristics实现或签会签
使用bpmn-js流程图开发过程中会遇到会签和或签的问题,这个时候我们就需要使用多实例配置来实现BPMN 2.0的配置实现了,多实例任务,是从流程编辑概念之初也就是Activiti时期就存在的一个方式。所谓的多实例任务也就是字面意思,一个任务由多个人完成,常见于我们的审批流程的或…...
【gpedit.msc】组策略编辑器的安装,针对windows家庭版,没有此功能
创建一个记事本文件然后放入以下内容 echo offpushd "%~dp0"dir /b %systemroot%\Windows\servicing\Packages\Microsoft-Windows-GroupPolicy-ClientExtensions-Package~3*.mum >gp.txtdir /b %systemroot%\servicing\Packages\Microsoft-Windows-GroupPolicy-…...
带EXCEL附件邮件发送相关代码
1.查看生成的邮件 2.1 非面向对象的方式(demo直接copy即可) REPORT Z12. DATA: IT_DOCUMENT_DATA TYPE SODOCCHGI1,IT_CONTENT_TEXT TYPE STANDARD TABLE OF SOLISTI1 WITH HEADER LINE,IT_PACKING_LIST TYPE TABLE OF SOPCKLSTI1 WITH HEADER LIN…...

【算法作业】均分卡牌,购买股票
问题描述 John 有两个孩子,在 John病逝后,留下了一组价值不一定相同的魔卡, 现在要求你设计一种策略,帮John的经管人将John的这些遗产分给他的两个孩子,使得他们获得的遗产差异最小(每张魔卡不能分拆&#…...

ARM ETM10硬件追踪系统设计与信号完整性优化
1. ARM ETM10硬件追踪系统设计精要在嵌入式系统开发领域,ARM ETM10(Embedded Trace Macrocell)作为一款高性能硬件追踪模块,为开发者提供了处理器指令和数据流的实时可视性。不同于软件调试工具,ETM10通过在芯片内部直…...

从NOIP到CSP:信息学奥赛初赛这15年真题,我帮你划出了重点考点变迁
信息学奥赛初赛15年考纲演进:从NOIP到CSP的考点变迁与备考策略 翻开2007年NOIP普及组的初赛试卷,再对比2022年CSP-J/S的真题,你会惊讶地发现:同样是"入门级"考试,题目考察的维度和深度已经发生了翻天覆地的变…...

OBS遮罩插件深度指南:15种特效解决直播画面优化的5大痛点
OBS遮罩插件深度指南:15种特效解决直播画面优化的5大痛点 【免费下载链接】obs-advanced-masks Advanced Masking Plugin for OBS 项目地址: https://gitcode.com/gh_mirrors/ob/obs-advanced-masks OBS高级遮罩插件(OBS Advanced Masksÿ…...

Python在气象与海洋中的实践技术应用
Python是功能强大、免费、开源,实现面向对象的编程语言,能够在不同操作系统和平台使用,简洁的语法和解释性语言使其成为理想的脚本语言。除了标准库,还有丰富的第三方库,并且能够把用其他语言(C/C、Fortran…...

5大核心功能揭秘:MoneyPrinterPlus如何实现AI短视频自动化批量生产
5大核心功能揭秘:MoneyPrinterPlus如何实现AI短视频自动化批量生产 【免费下载链接】MoneyPrinterPlus AI一键批量生成各类短视频,自动批量混剪短视频,自动把视频发布到抖音,快手,小红书,视频号上,赚钱从来没有这么容易过! 支持本地语音模型chatTTS,fasterwhisper,G…...

生成式 AI 的成本暗礁:FinOps 如何照亮从试点到规模化的全链路
前言 全球大模型市场正呈现爆发式增长态势。2025年全球大语言模型市场规模约140亿美元,预计到2032年将接近6910亿美元,未来六年年复合增长率(CAGR)高达74.9%。2026年第一季度,全球LLM月活跃用户已突破38亿人ÿ…...

Univer开源项目部署完整指南:从零到生产环境
Univer开源项目部署完整指南:从零到生产环境 【免费下载链接】univer Build AI-native spreadsheets. Univer is a full-stack framework for creating and editing spreadsheets on both web and server. With Univer Platform, Univer Spreadsheets is driven dir…...

从汽车电子到工业控制:手把手教你用STM32CubeMX和HAL库玩转CAN总线多节点通信
从零构建工业级CAN总线通信系统:基于STM32CubeMX的实战指南 1. CAN总线技术基础与工业应用场景 在现代工业控制系统中,CAN总线因其高可靠性和实时性已成为设备间通信的事实标准。不同于普通串行通信,CAN采用差分信号传输和先进的错误检测机…...

Rdkit实战:从2D到3D,解锁分子构象生成与优化的全流程
1. 从2D到3D:分子构象生成的基础概念 第一次接触分子构象生成时,我完全被各种术语搞晕了——距离几何、ETKDG、MMFF这些名词听起来就像天书。直到用RDKit实际操作了几次,才发现这个过程其实就像搭积木:先有个平面设计图ÿ…...

AI 系统多模型路由与降级架构设计:从流量调度到无感切换的工程实践
背景 / 现象 在一个典型的 AI 应用系统中,主模型(如 GPT-4o、Claude 3.5 等)通常承担核心推理任务。但在生产环境中,主模型可能因额度耗尽、响应超时、服务不可用或突发限流等原因导致调用失败。此时,用户侧可能表现为…...