【mysql】mysql单表查询、多表查询、分组查询、子查询等案例详细解析

✨✨ 欢迎大家来到景天科技苑✨✨
🎈🎈 养成好习惯,先赞后看哦~🎈🎈
🏆 作者简介:景天科技苑
🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。
🏆《博客》:Python全栈,前后端开发,小程序开发,人工智能,js逆向,App逆向,网络系统安全,数据分析,Django,fastapi,flask等框架,linux,shell脚本等实操经验,网站搭建,数据库等分享。所属的专栏:MySQL数据库入门,进阶应用实战必备
景天的主页:景天科技苑
文章目录
- mysql查询操作
- where 条件的使用
- 单表查询案例解析
- 1. 查询部门是sale的所有员工姓名:
- 2. 部门是teacher , 收入大于10000的所有数据
- 3. 收入在1万到2万之间的所有员工姓名和收入
- 4. 收入不在1万到2万之间的所有员工姓名和收入
- 5. 查看岗位描述为NULL的员工信息
- 6. 查看岗位描述不为NULL的员工信息
- 7. 查询收入是3000 ,4000 ,5000,8300 所有员工的姓名和收入
- 8. 查询收入不是3000 ,4000 ,5000,8300 所有员工的姓名和收入
- 9. 以on结尾的员工名搜一下
- 10. 统计员工一年的年薪
- 11. 查询部门的种类,distinct去重
- group by 子句 分组分类
- 聚合函数
- 一、count
- 二、count执行效率
- 三.having
- 四.order by 排序
- 五.limit 限制查询条数 (应用在分页)
- 六.mysql 当中可以使用正则表达式 (不推荐,效率低)
- mysql多表查询操作
- 多表查询案例解析
- 1.内联接 : inner join
- 2.外联接 : left join左联接 / right join 右联接
- (1)left join左联接
- (2)right join右联接
- (3)全联接 : union
- 3.子查询
mysql查询操作
where 条件的使用
功能: 对表中的数据进行帅选和过滤
语法:
- 1.判断的符号
= (!= <>不等于) > >= < <= - 2.拼接不同的条件的关键字
and or not - 3.查询对应的区间值
between 小值 and 大值 [小值,大值] 查询两者之间的范围值 - 4.查询具体在哪个范围中
in(1,21,333,444) 指定范围
between and 与in区别
范围查询:
between and 表示在一个连续的范围内查询
in 可以表示在一个非连续的范围内查询
- 5.模糊查询 like % 通配符 _ 通配符
like “%b” 匹配以b结尾的任意长度的字符串
like “b%” 匹配以b开头的任意长度的字符串
like “%b%” 匹配字符串中含有b的任意长度的内容
like “_b" 匹配总长度为3个字符,任意内容的字符串,并且以b结尾
like "b” 匹配总长度为2个字符,任意内容的字符串,并且以b开头
单表查询案例解析
- 创建表
create table employee(
id int not null unique auto_increment,
emp_name varchar(20) not null,
sex enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一个部门一个屋子
depart_id int
);
#三个部门:教学,销售,运营
insert into employee(emp_name,sex,age,hire_date,post,salary,office,depart_id) values
('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部
('alex','male',78,'20150302','teacher',1000000.31,401,1),
('wupeiqi','male',81,'20130305','teacher',8300,401,1),
('yuanhao','male',73,'20140701','teacher',3500,401,1),
('liwenzhou','male',28,'20121101','teacher',2100,401,1),
('jingliyang','female',18,'20110211','teacher',9000,401,1),
('jinxin','male',18,'19000301','teacher',30000,401,1),
('成龙','male',48,'20101111','teacher',10000,401,1),('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门
('丫丫','female',38,'20101101','sale',2000.35,402,2),
('丁丁','female',18,'20110312','sale',1000.37,402,2),
('星星','female',18,'20160513','sale',3000.29,402,2),
('格格','female',28,'20170127','sale',4000.33,402,2),('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3)
;
查看表结构
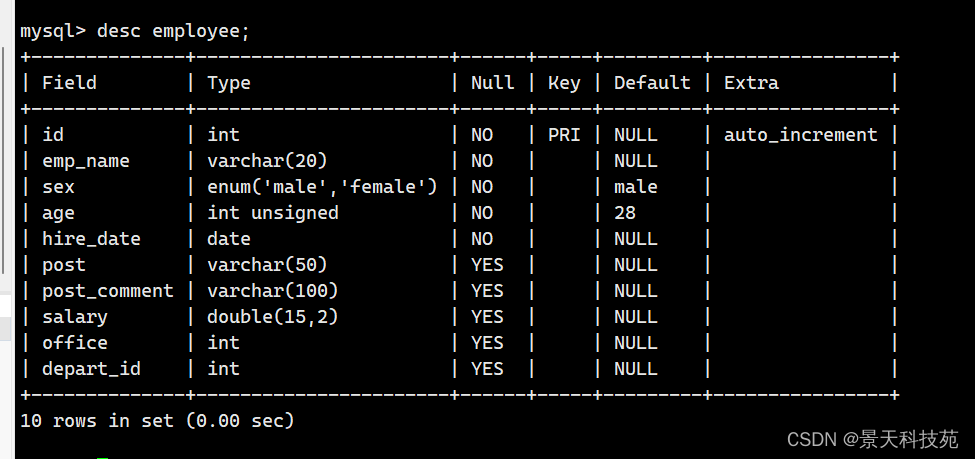
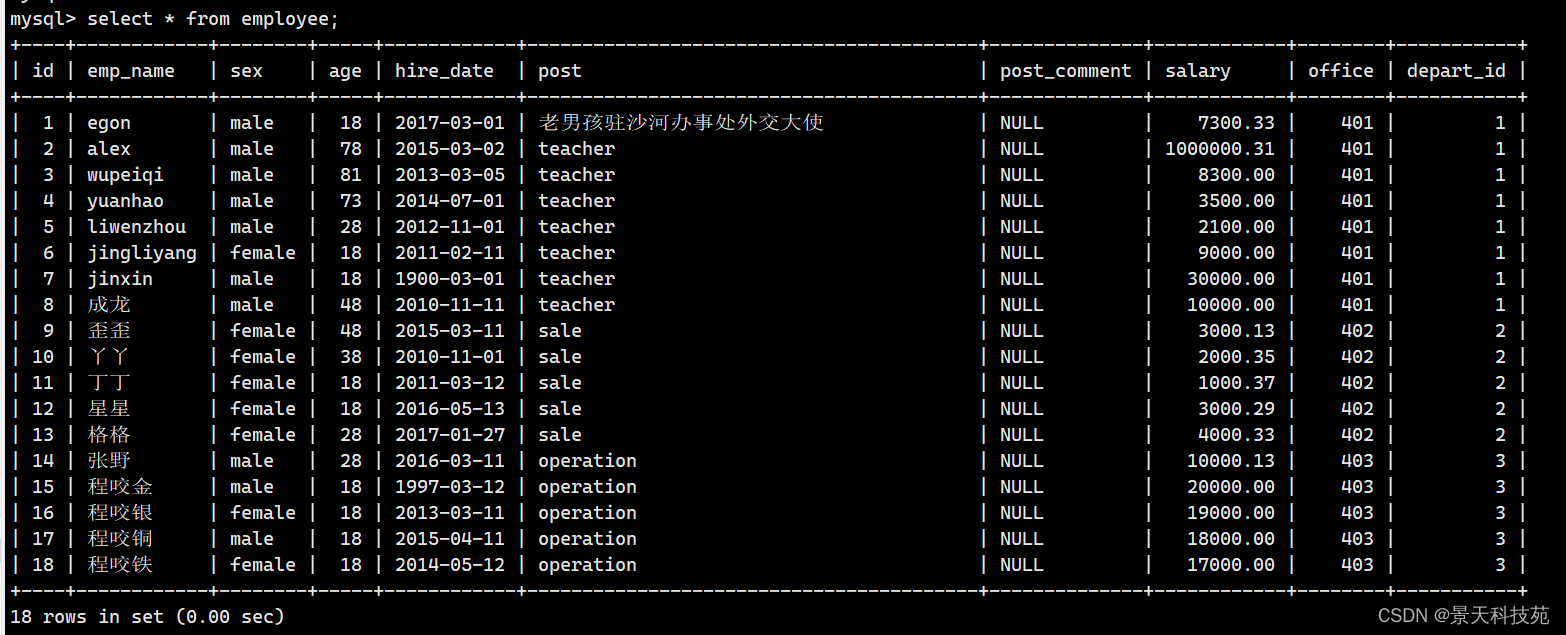
查看表数据
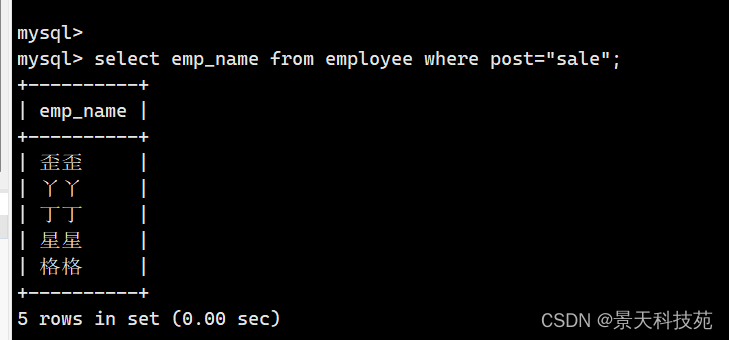
1. 查询部门是sale的所有员工姓名:
select emp_name from employee where post="sale";
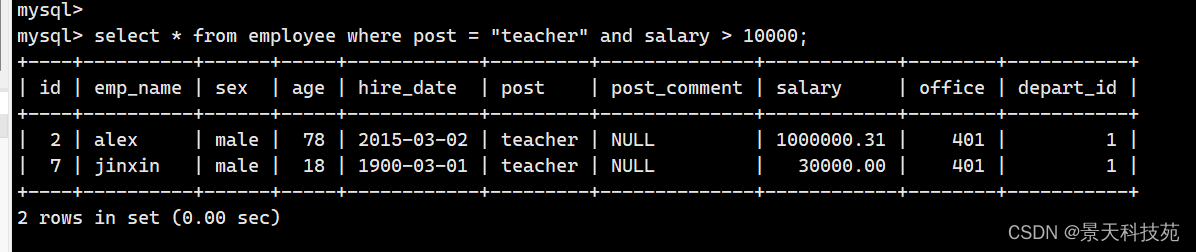
2. 部门是teacher , 收入大于10000的所有数据
select * from employee where post = "teacher" and salary > 10000;
3. 收入在1万到2万之间的所有员工姓名和收入
select emp_name,salary from employee where salary between 10000 and 20000;
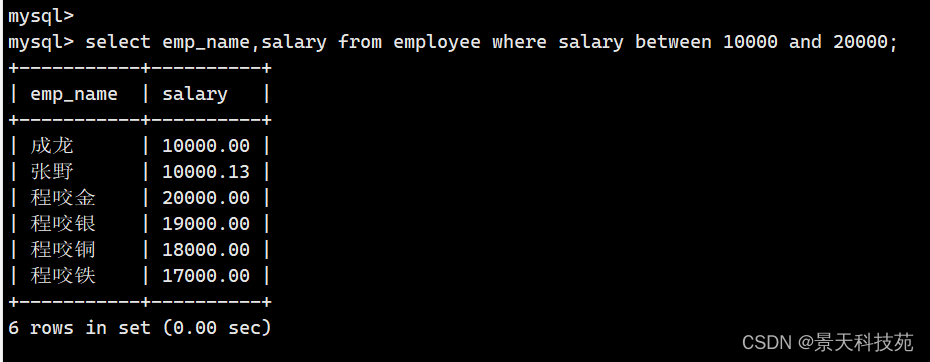
4. 收入不在1万到2万之间的所有员工姓名和收入
范围查询:
between and 表示在一个连续的范围内查询
in 表示在一个非连续的范围内查询
select emp_name,salary from employee where salary not between 10000 and 20000;
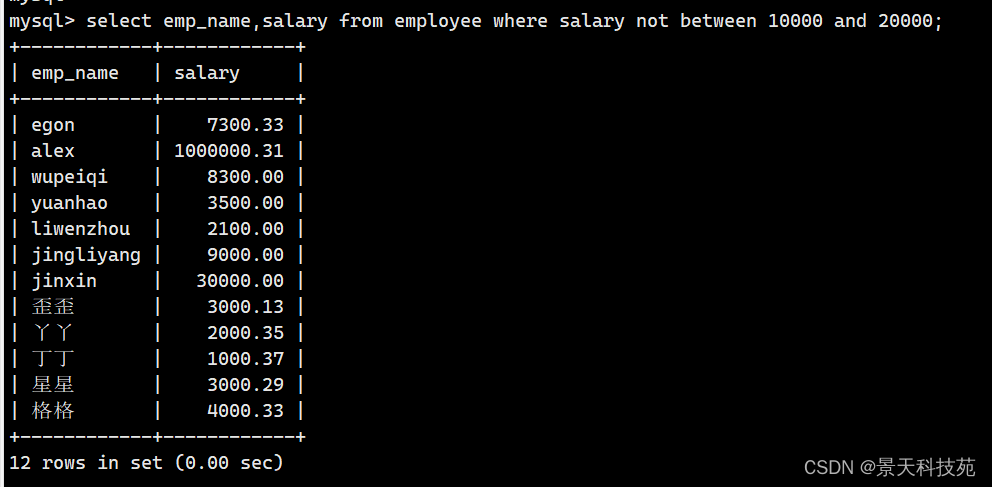
5. 查看岗位描述为NULL的员工信息
select emp_name from employee where post_comment = null;
select emp_name from employee where post_comment = '';
select emp_name from employee where post_comment is null;
为空只能是is null ,= null = ‘’ 都不对,null是mysql的关键字,使用is来作比对
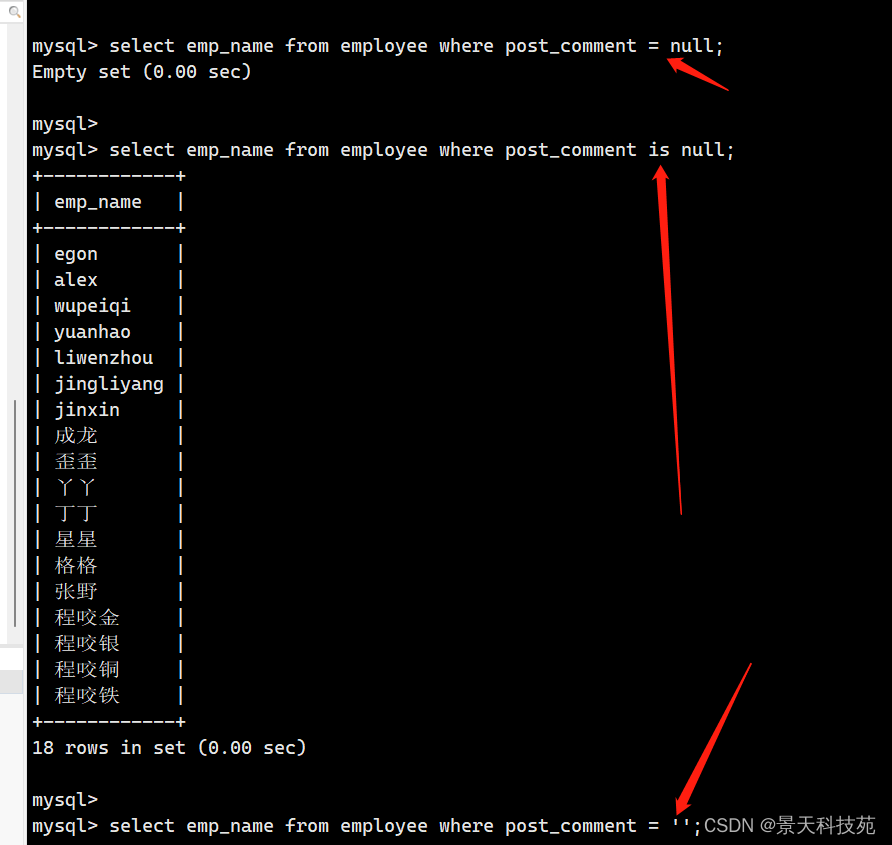
6. 查看岗位描述不为NULL的员工信息
select emp_name from employee where post_comment is not null;

7. 查询收入是3000 ,4000 ,5000,8300 所有员工的姓名和收入
select emp_name,salary from employee where salary in(3000,4000,5000,8300);
select emp_name,salary from employee where salary = 3000 or salary=4000 or salary=5000 or salary=8300;
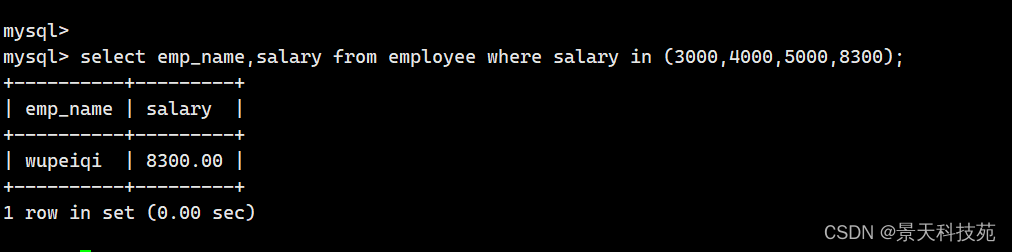
8. 查询收入不是3000 ,4000 ,5000,8300 所有员工的姓名和收入
select emp_name,salary from employee where salary not in(3000,4000,5000,8300);
9. 以on结尾的员工名搜一下
select emp_name from employee where emp_name like "%on";
select emp_name from employee where emp_name like "ji%";
select emp_name from employee where emp_name like "_le_";
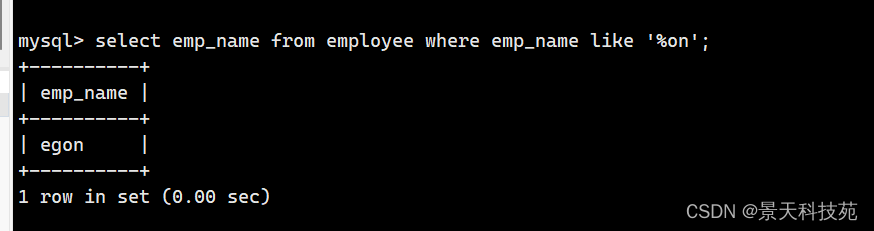
10. 统计员工一年的年薪
select concat(" 姓名: ",emp_name," 收入: ",salary) from employee;
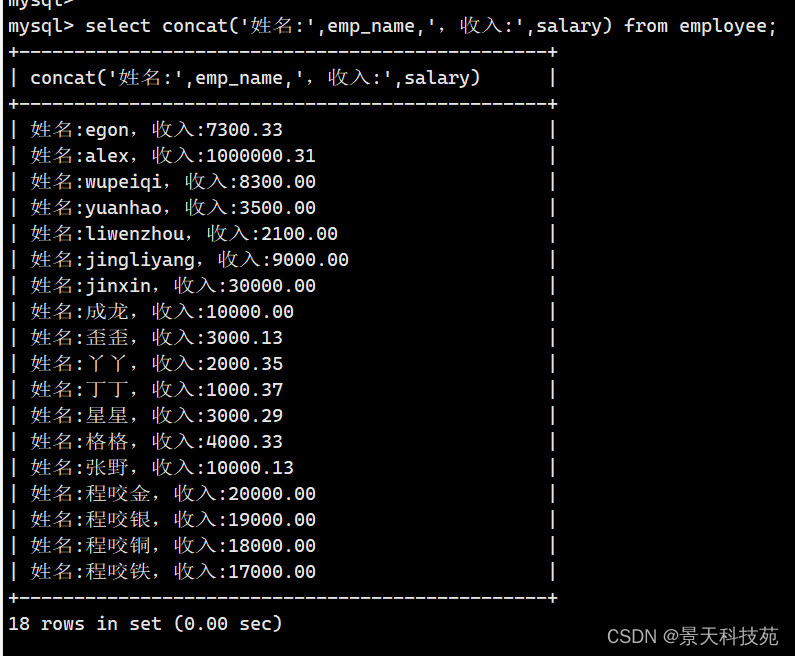
计算年薪,可以在mysql中使用四则运算符 + - * /
select concat(" 姓名: ",emp_name," 收入: ",salary * 12) from employee;
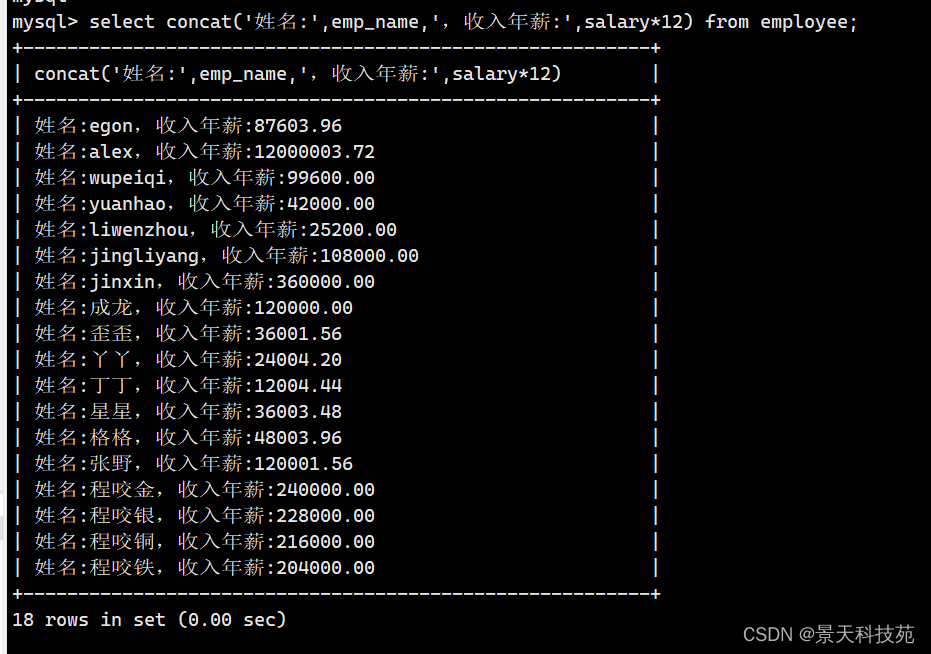
select concat_ws(" : ",emp_name,salary*12 ) from employee;
以 “:” 将字段拼接一起
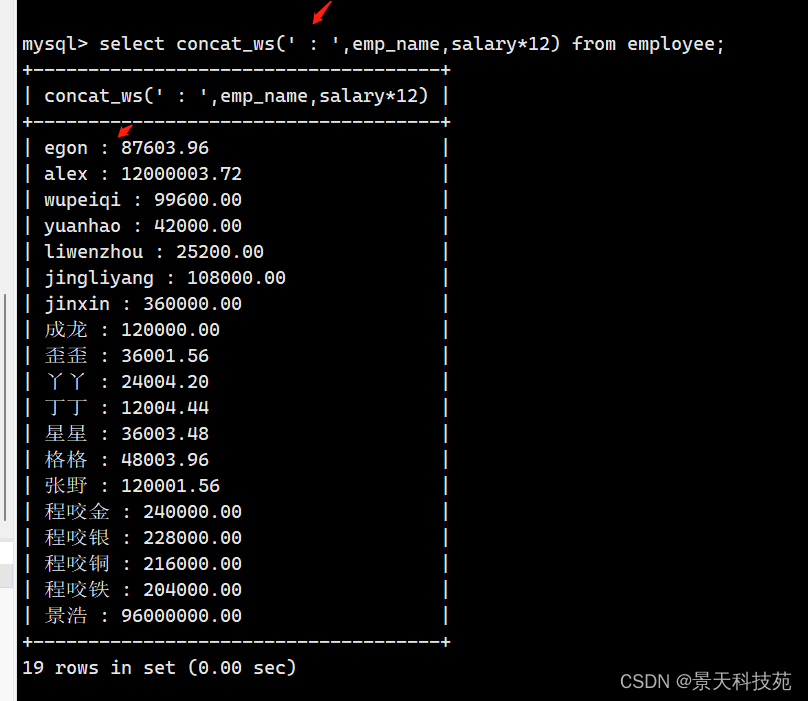
select concat_ws(" : ",emp_name,salary*12 ) from employee;
以 “:” 将字段拼接一起,自己设个单独的拼接符
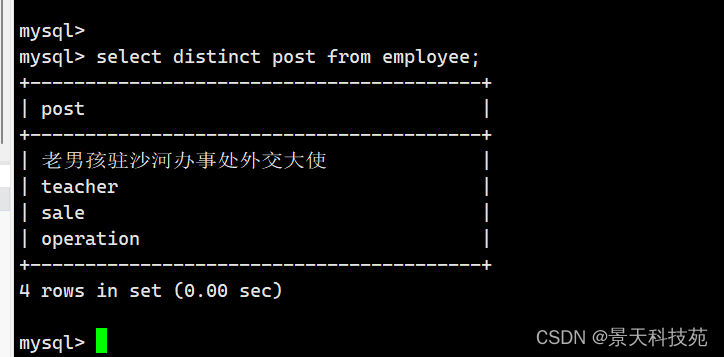
11. 查询部门的种类,distinct去重
distinct 返回唯一不同的值,去重,可以去除重复数据行
select distinct(post) from employee;
group by 子句 分组分类
group by 字段,对数据进行分类, by后面接什么字段,select后面就搜什么字段
分组查询:
分组查询就是将查询结果按照指定字段进行分组,字段中数据相等的分为一组
语法格式:
group by 列名[having 条件表达式][with rollup]
说明:
having条件表达式:用来过滤分组后的数据
在所有记录的最后加上一条数据,显示select查询时聚合函数的统计和计算结果
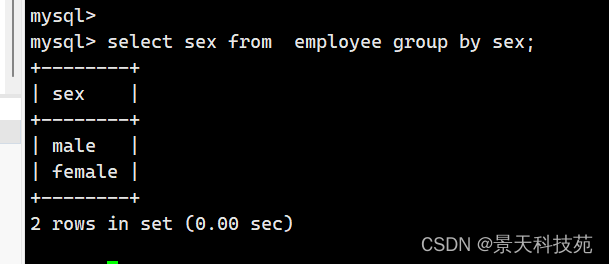
group by的使用: 只能查询指定分组的字段
select sex from employee group by sex;
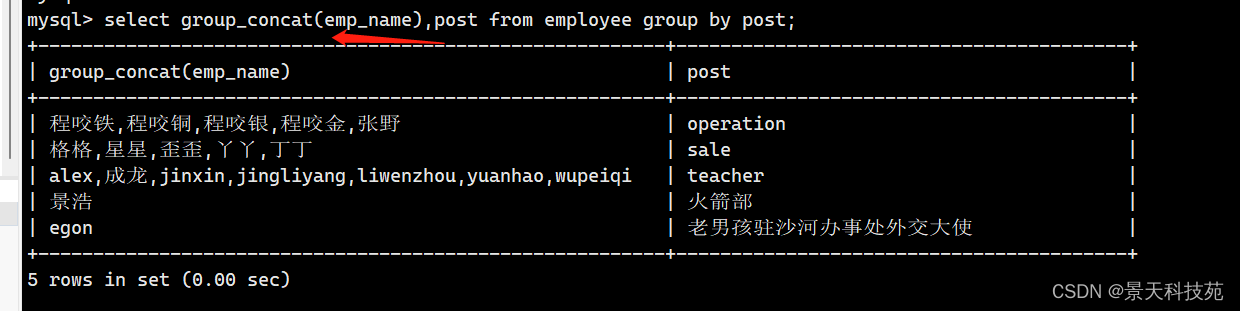
group_concat 按照分组把对应字段拼在一起;
group_concat(字段名):列出每个分组指定字段的总数集合,每个信息之间用逗号隔开
select group_concat(emp_name),post from employee group by post;

聚合函数
聚合函数: 聚合函数不统计空值
聚合函数又叫组函数,通常对表中数据进行统计和计算,一般结合分组group by来使用
用于统计和计算分组数据
常用的聚合函数:
1、count(col)指定列的总行数 当某一列有空值,不做统计 一般统计总行数用count(*)
2、max(col)指定列的最大值
3、min(col)指定列的最小值
4、sum(col)指定列求和
5、avg(col)指定列求平均值
使用group by 时,聚合函数可以直接搜,其他字段不能直接搜,要搜只能按by的字段分组列出来 该分组中指定字段的总和
如下,emp_name没有by,不能直接搜索

如要搜索,需要结合group_concat()
聚合函数可以直接搜
group by 后面如果是 unique唯一索引或主键 其他字段都可以搜
一、count
1、count(1):可以统计表中所有数据,不统计所有的列,用1代表代码行,在统计结果中包含列字段为null的数据;
2、count(字段):只包含列名的列,统计表中出现该字段的次数,并且不统计字段为null的情况;
3、count(*):统计所有的列,相当于行数,统计结果中会包含字段值为null的列;
二、count执行效率
列名为主键,count(列名)比count(1)快;列名不为主键,count(1)会比count(列名)快;
如果表中多个列并且没有主键,则count(1)的执行效率优于count(*);
如果有主键,则select count(主键)的执行效率是最优的;如果表中只有一个字段,则select count(*)最优。
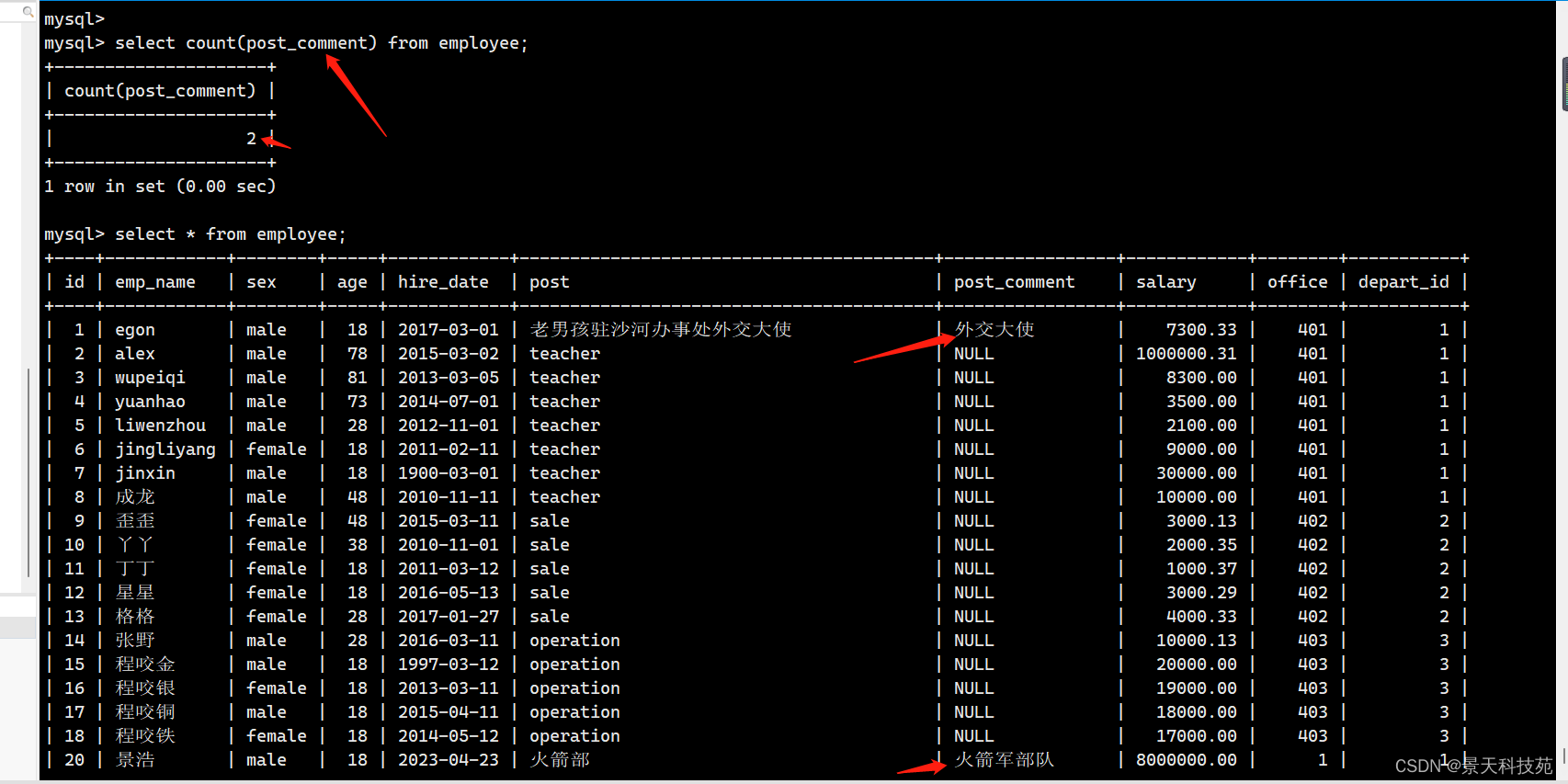
如果某列字段中个别值是空值,直接计算平均值时,会不准确,它只统计非空值的全部数据的平均数 非空值数据和除以非空值个数
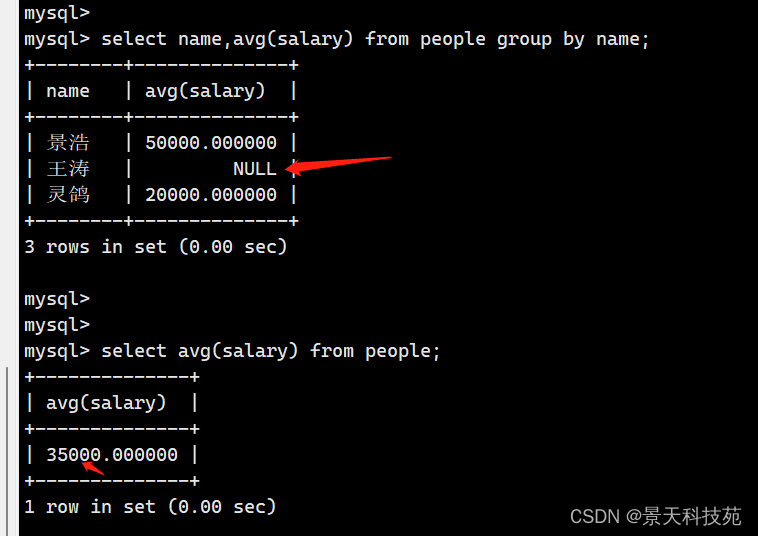
针对空值设为默认值,可以解决这个问题
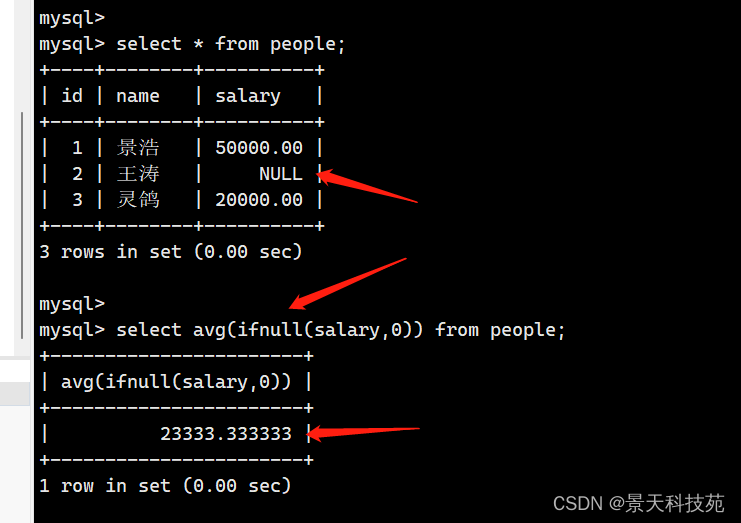
如果遇到某列有空值,avg()是不做统计的,它只统计非空值的全部数据的平均数 非空值数据和除以非空值个数
如果想把空值的个数也算进去,需要用ifnull函数,设个默认值
ave(ifnull(height, 0)),默认空值的数据为0.这样统计出来的就是非空值全部数据的和除以非空值个数加上空值个数
对sum也适用
select sum(ifnull(height, 1.6)) from student;
# count 统计总数 *所有select count(*) from employee;# max 统计最大值select max(salary) from employee;# min 统计最小值select min(salary) from employee;# avg 统计平均值select avg(salary) from employee;# sum 统计总和select sum(salary) from employee;
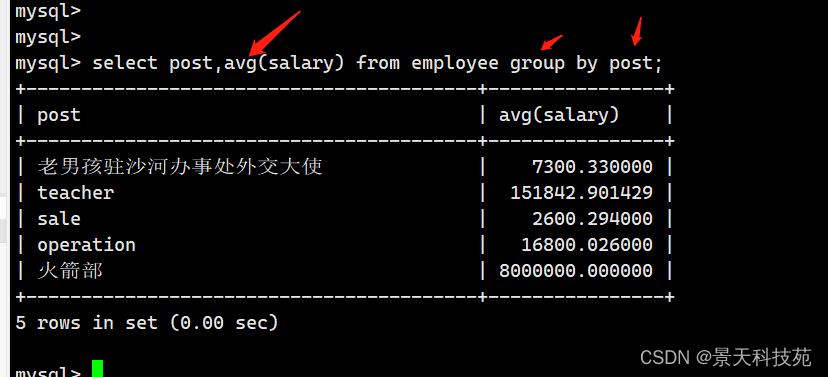
- 查询部门名以及各部门的平均薪资
select avg(salary),post from employee group by post;
- 查询部门名以及各部门的最高薪资
select max(salary),post from employee group by post;
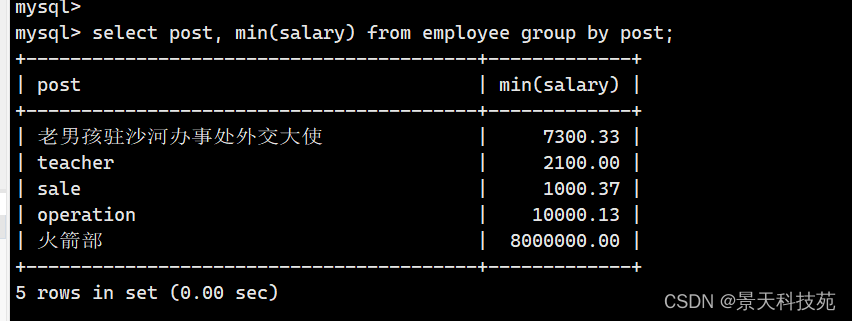
- 查询部门名以及各部门的最低薪资
select min(salary),post from employee group by post;
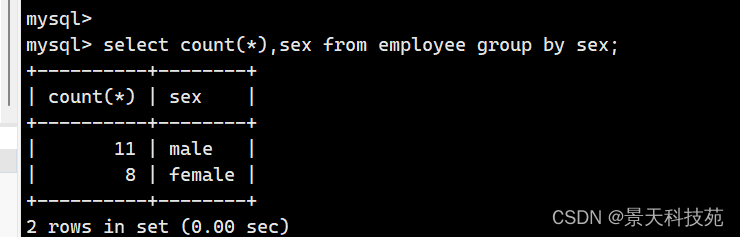
- 查询公司内男员工和女员工的个数
select count(*),sex from employee group by sex;
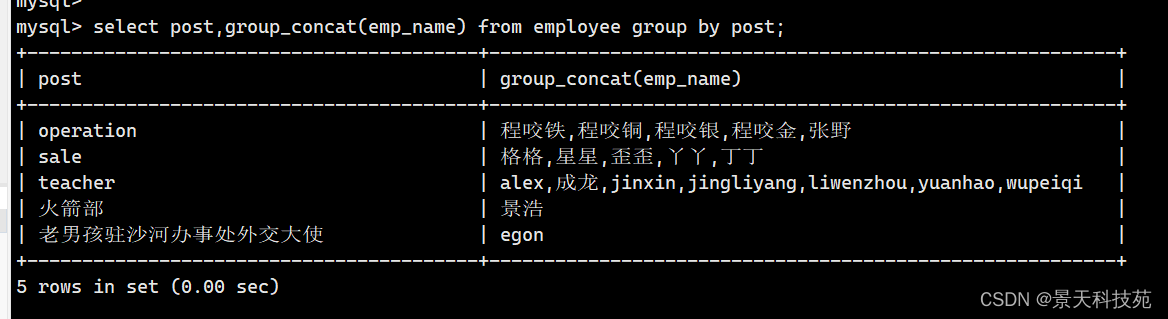
- 查询部门名以及部门包含的所有员工名字
select group_concat(emp_name),post from employee group by post;
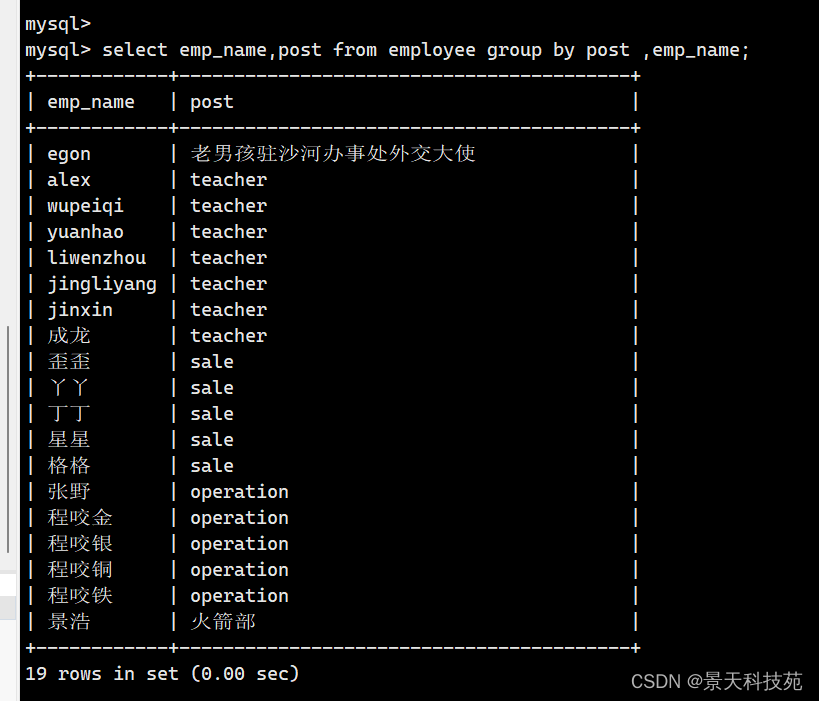
- 可以group by 两个字段,就可以同时搜索两个字段。可以group by 多个字段。by谁 搜谁
select emp_name,post from employee group by post ,emp_name;
三.having
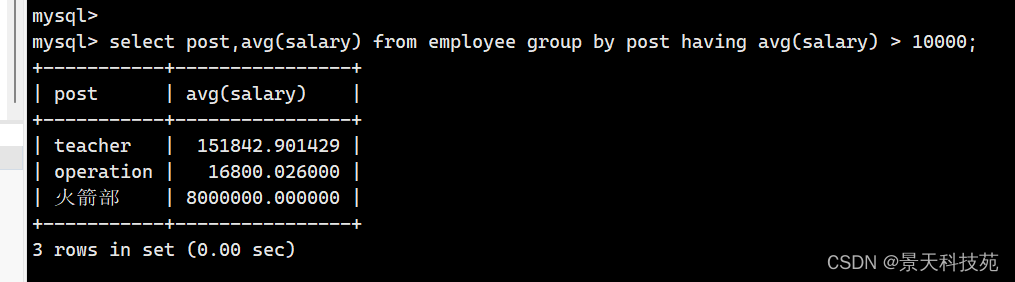
在数据分类分组之后,对数据进行二次过滤,一般配合group by来使用的;
找出各部门平均薪资,并且大于10000
select post , avg(salary) from employee group by post having avg(salary) > 10000
1.查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数
select post , group_concat(emp_name), count(*) from employee group by post having count(*) < 2;
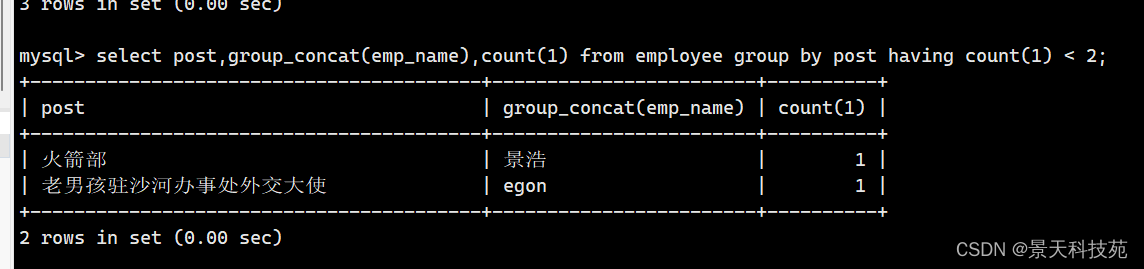
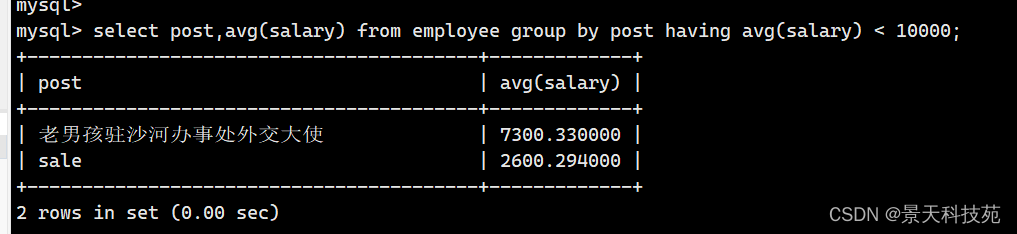
2.查询各岗位平均薪资小于10000的岗位名、平均工资
select post , avg(salary) from employee group by post having avg(salary) < 10000
3.查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资
select post, avg(salary) from employee group by post having avg(salary) between 10000 and 20000

select post, avg(salary) from employee group by post having avg(salary) > 10000 and avg(salary) < 20000;
四.order by 排序
按照某字段排序。可以接多个字段,前面的排序相同,再按后面字段来排序
order by age asc (升序) order by age desc (降序)
按照年龄从小到大排序,默认升序
select * from employee order by age;
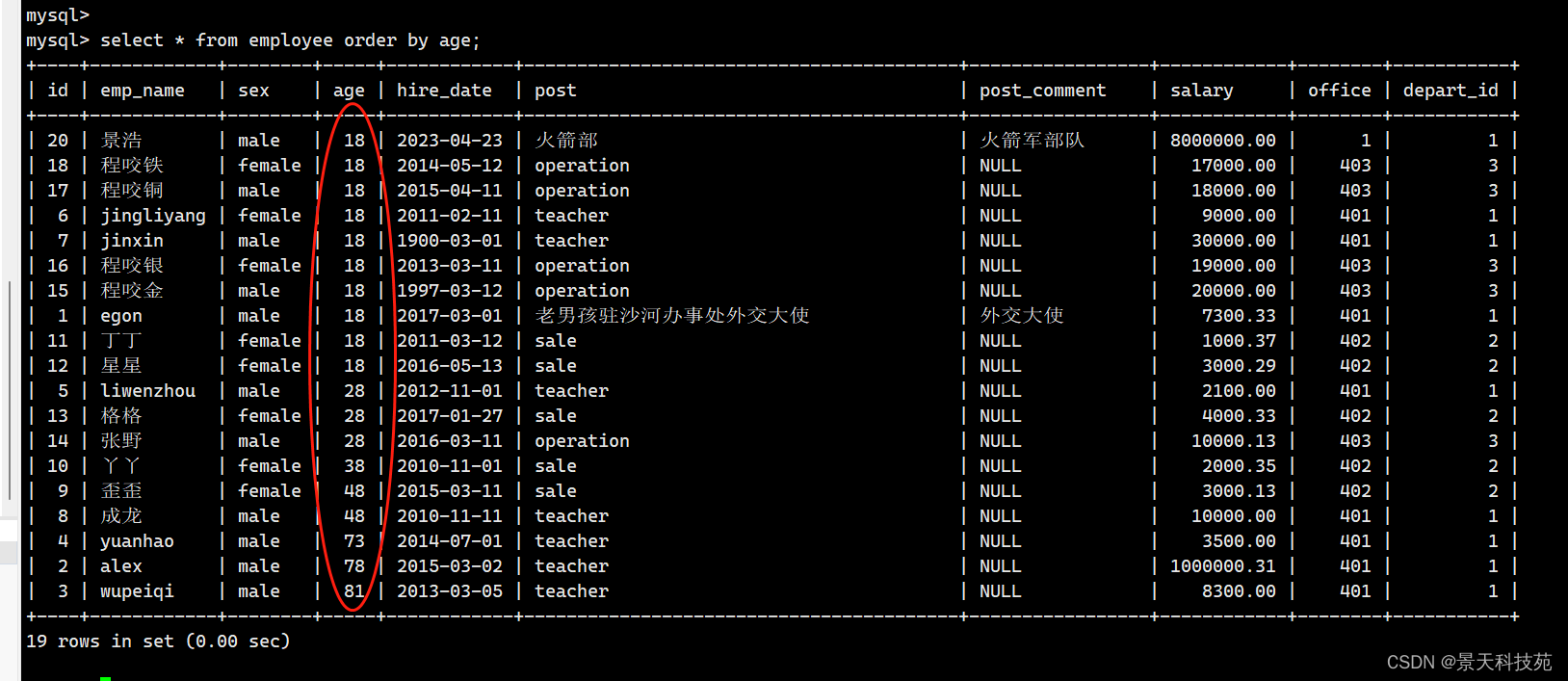
按照年龄从大到小排序
select * from employee order by age desc;
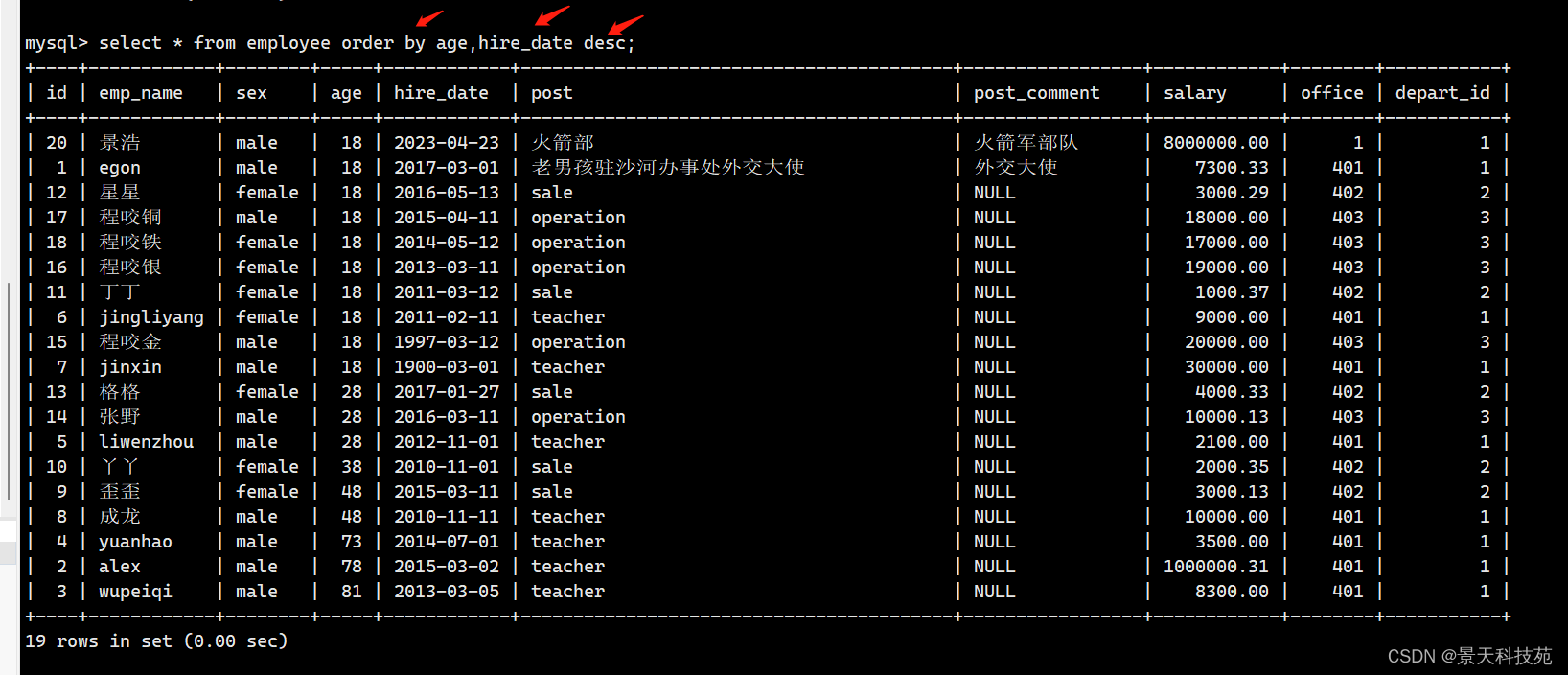
- 查询所有员工信息,先按照age升序排序,如果age相同则按照hire_date降序排序
select * from employee order by age asc , hire_date desc;
- 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资升序排列
select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) asc
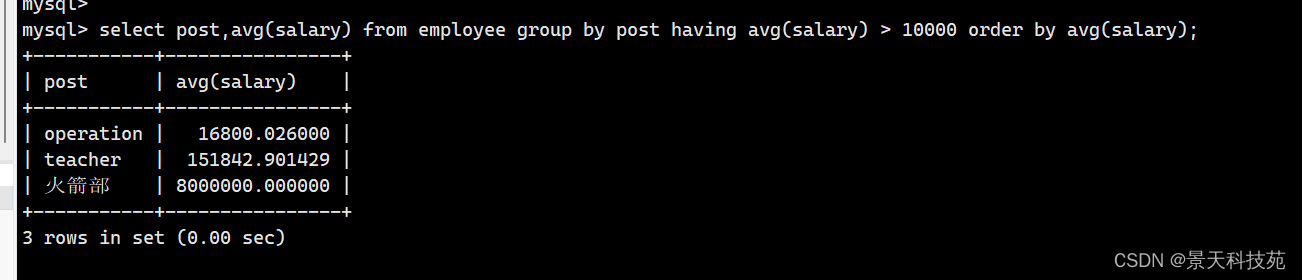
- 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资降序排列
select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) desc
五.limit 限制查询条数 (应用在分页)
limit m,n m代表从第几条数据开始查, n 代表查几条 m=0 代表的是第一条数据,默认m从0开始
select * from employee limit 0,10 # 0代表的是第一条数据开始
select * from employee limit 10,10 # 10代表的是第十一条数据
select * from employee limit 20,10 # 20代表的是第二十一条数据
搜索前10条
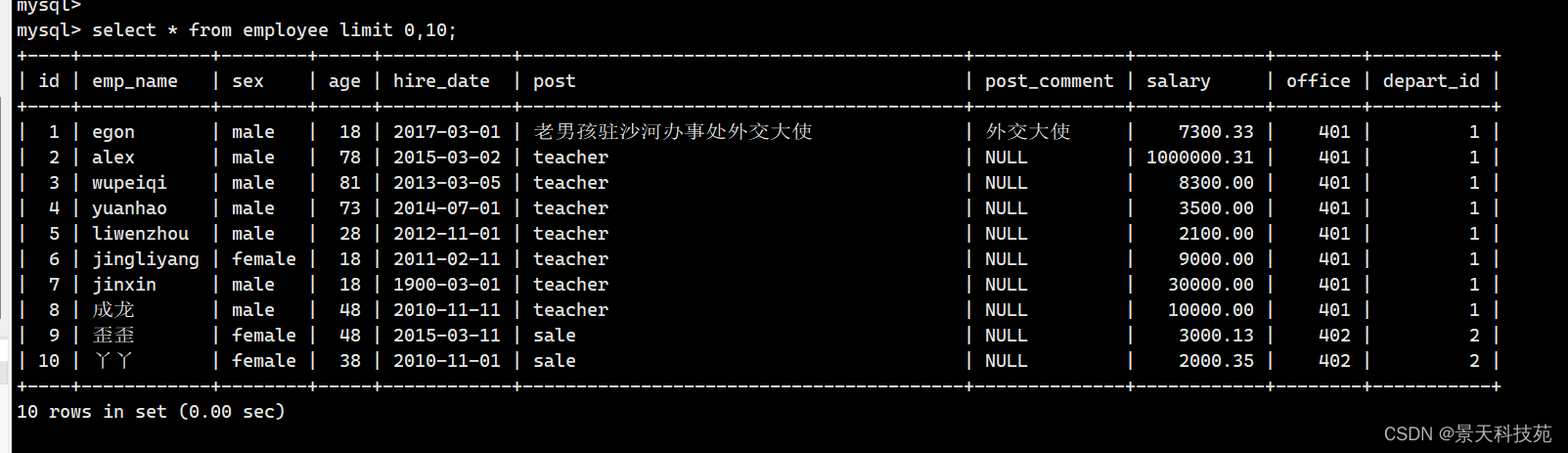
limit + num num => 搜索的条数据
select * from employee limit 1
搜索一条数据

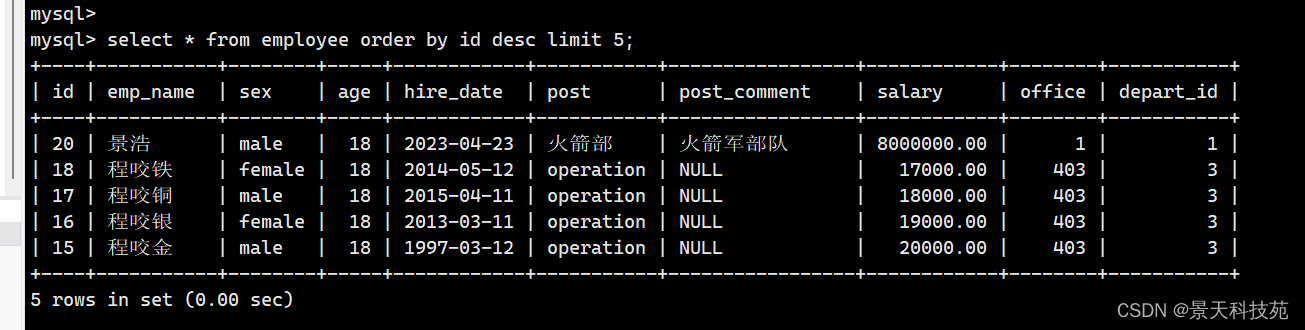
搜索这个表里面最后一条数据
select * from employee order by id desc limit 1
搜索这个表里面最后五条数据
select * from employee order by id desc limit 5
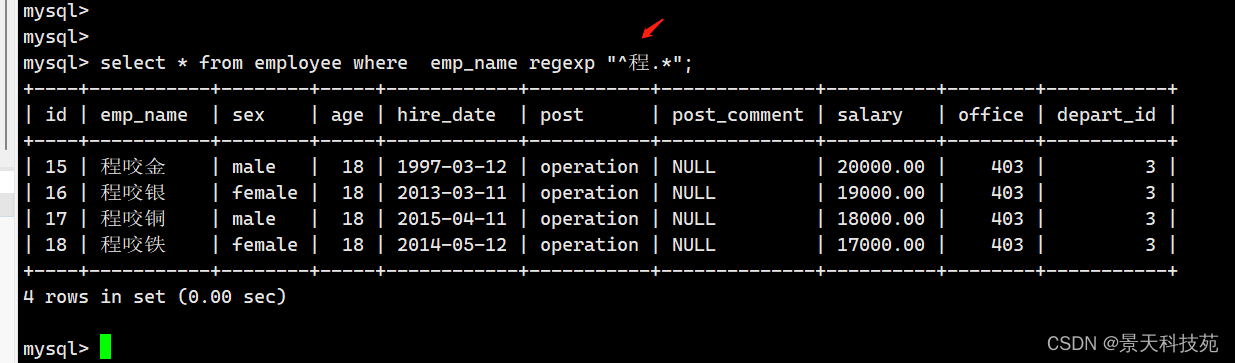
六.mysql 当中可以使用正则表达式 (不推荐,效率低)
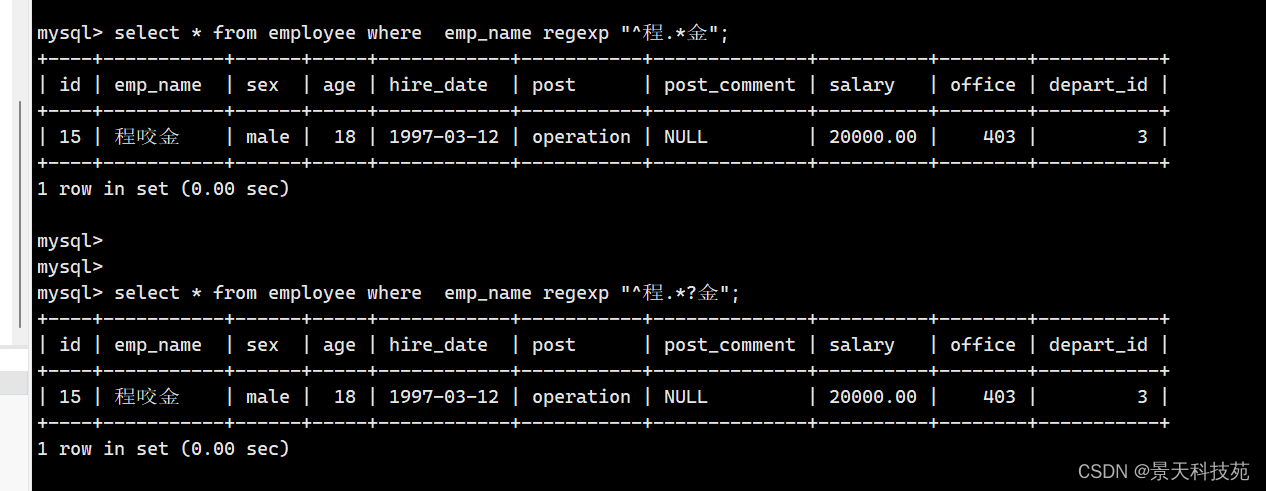
select * from employee where emp_name regexp ".*on$"; # mysql中无法识别?

新版的mysql8.0支持.*?

select * from employee where emp_name regexp "^程.*";
select * from employee where emp_name regexp "^程.*金";
查询姓名以 程 开头的记录
新版的mysql支持.*?
mysql多表查询操作
连接查询:
连接查询可以实现多个表的查询,当查询的字段数据来自于不同的表,就可以使用连接查询
连接查询分为:
内连接查询 inner join 取的就是两张表的交集
左连接查询 left join 左外连接:左边的是主表,左表数据全部显示,右表显示符合ON后的条件的数据,不符合的用NULL代替。
右连接查询 right join 右外连接:右边边的是主表,右边表数据全部显示,左边表显示符合ON后的条件的数据,不符合的用NULL代替。
全连接查询 union 全连接查询的是 左表所有的数据 加上 右表所有的数据 并去重。
多表查询案例解析
建表
create table department(
id int,
name varchar(20)
);create table employee(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
插入数据
insert into department values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营');insert into employee(name,sex,age,dep_id) values
('egon','male',18,200),
('alex','female',48,201),
('wupeiqi','male',38,201),
('yuanhao','female',28,202),
('liwenzhou','male',18,200),
('jingliyang','female',18,204)
;
# 查询:
# 一.找出平均年龄大于25岁以上的部门
# 二.查看技术部门员工姓名
# 三.查看哪个部门没员工
# 四.查询大于平均年龄的员工名与年龄
# 五.把大于其本部门平均年龄的员工名和姓名查出来
# 六.查询每个部门最新入职的那位员工 # 利用上一套数据表进行查询;
# 七.带EXISTS关键字的子查询
1.内联接 : inner join
两表或者多表之间,把满足条件的所有数据查询出来 (多表之间共同拥有的数据会被查询出来)
两表联查
select 字段 from 表1 inner join 表2 on 必要的关联条件
多表联查
select 字段 from 表1 inner join 表2 on 必要的关联条件1 inner join 表3 on 必要的关联条件2
select * from employee inner join department on employee.dep_id = department.id;
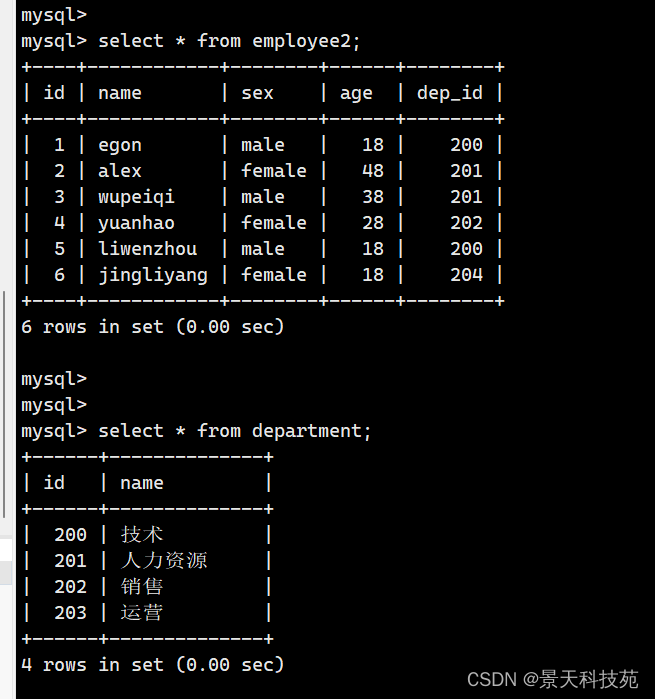
内连接查询:查询的是的就是两张表的交集
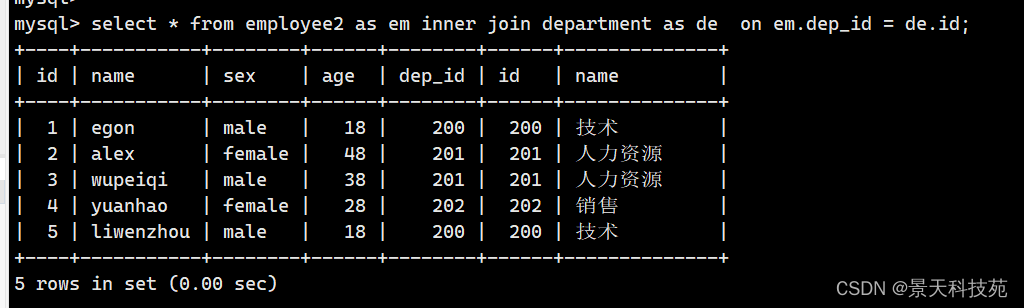
as 起别名
select * from employee as e inner join department as d on e.dep_id = d.id;
也可以省略as (不推荐)
select * from employee e inner join department d on e.dep_id = d.id;
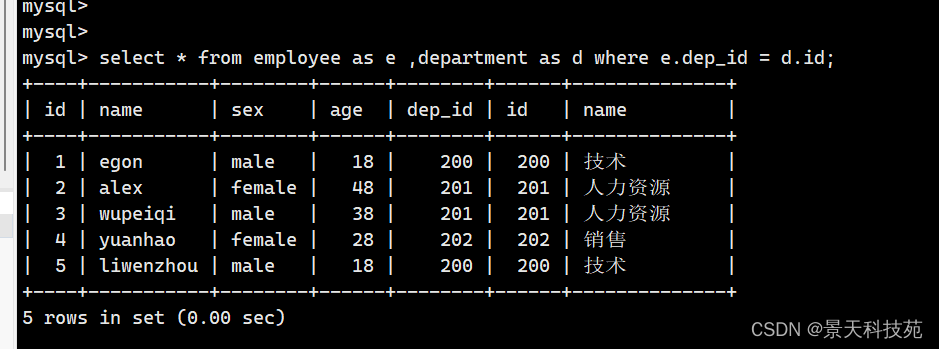
where 写法默写是内联接( 等同于inner join )
select * from employee,department where employee.dep_id = department.id;
select * from employee as e ,department as d where e.dep_id = d.id;
2.外联接 : left join左联接 / right join 右联接
(1)left join左联接
以左表为主,右表为辅,完整查询左表所有数据,右表没有的数据补null
select * from employee left join department on employee.dep_id = department.id;
右表department没有id为204的字段,所以以null补充
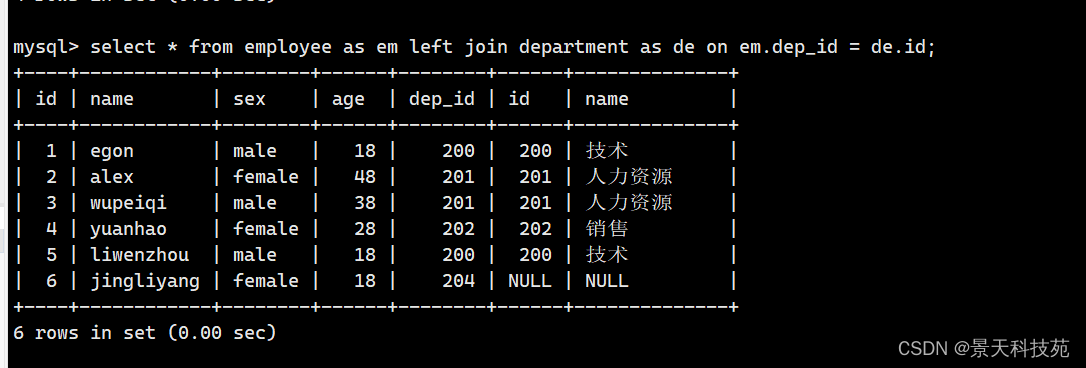
(2)right join右联接
以右表为主,左表为辅,完整查询右表所有数据,左表没有的数据补null
select * from employee right join department on employee.dep_id = department.id;
左表没有dep_id为203的字段,右连接查询,所以左边表没有的数据以null填充
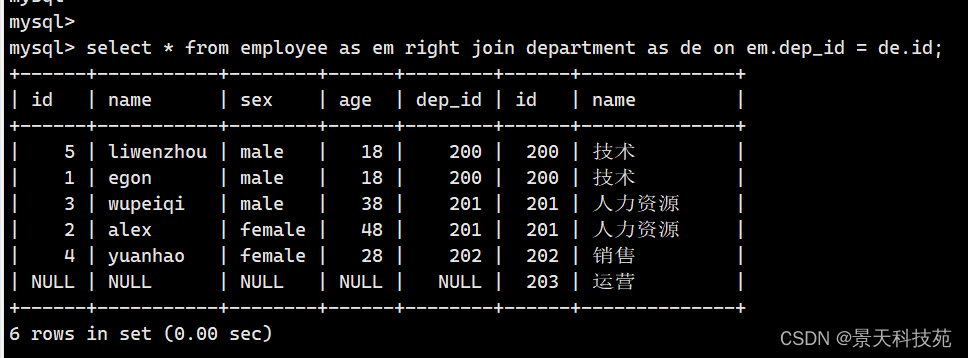
(3)全联接 : union
全连接查询的是 左表所有的数据 加上 右表所有的数据
select * from employee left join department on employee.dep_id = department.id
union
select * from employee right join department on employee.dep_id = department.id;
左连接与右连接的并集
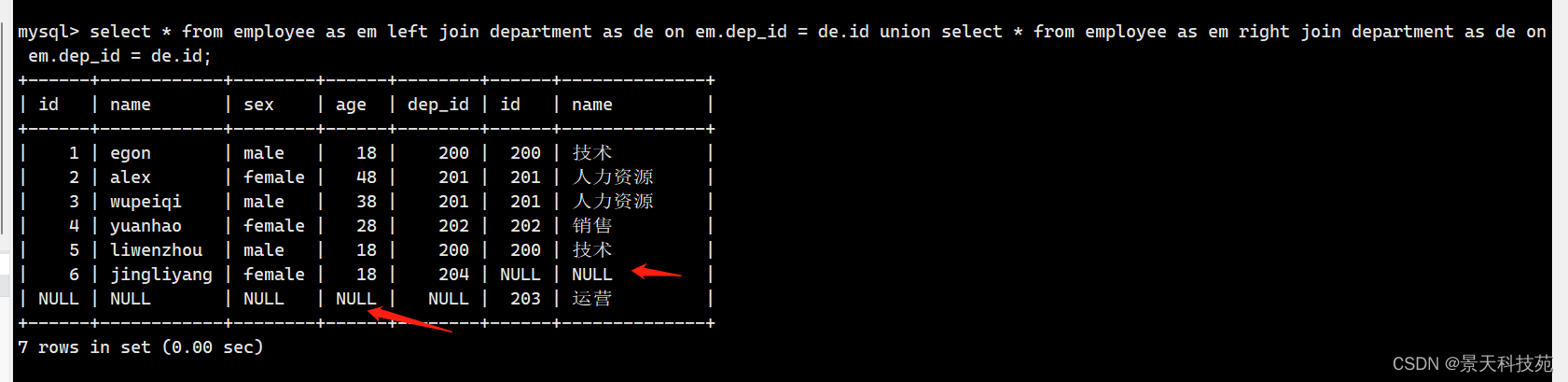
3.子查询
子查询: 嵌套查询(1) sql语句当中又嵌套了另外一条sql,用括号()进行包裹,表达一个整体(2) 一般用在from子句,where子句... 身后,表达一个条件或者一个表(3) 速度快慢: 单表查询 > 联表查询 > 子查询;
一.找出平均年龄大于25岁以上的部门
(1) where
select d.id,d.name
from employee as e ,department as d
wheree.dep_id = d.id
group by d.id,d.name
havingavg(e.age) > 25

(2) inner join
select d.id,d.name
from employee as e inner join department as d on e.dep_id = d.id
group by d.id,d.name
havingavg(e.age) > 25
(3) 子查询
1.先找出平均年龄大于25岁的部门id
select dep_id from employee group by employee.dep_id having avg(age)>25; # 201 202
2.通过部门的id找部门的名字
select name from department where id in (201,202);
3.综合拼接:
select id , name from department where id in (select dep_id from employee group by employee.dep_id having avg(age)>25);
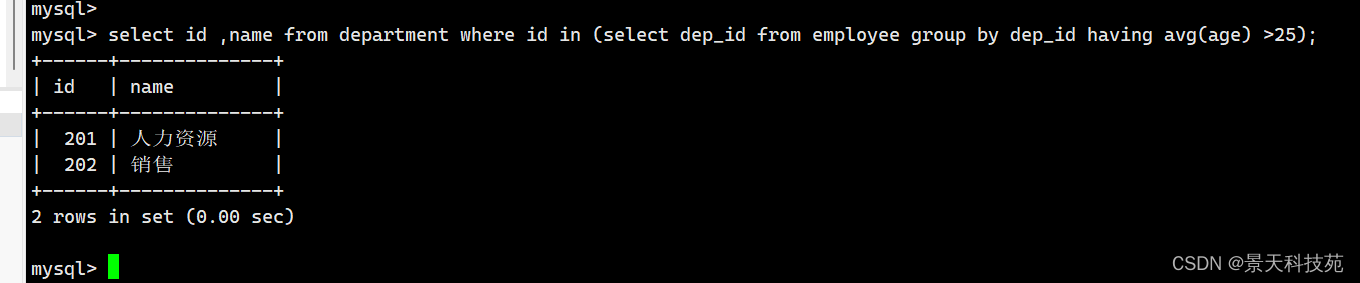
二.查看技术部门员工姓名
(1) 普通的where 查询
select e.id,e.name
fromemployee as e,department as d
wheree.dep_id = d.idandd.name = "技术"
(2) inner join
select e.id,e.name
fromemployee as e inner join department as d on e.dep_id = d.id
whered.name = "技术"
(3)子查询
(1) 找技术部门对应的id
select id from department where name = "技术";
(2) 通过id找员工姓名
select name from employee where dep_id = 200;
(3) 综合拼接
select id,name from employee where dep_id = (select id from department where name = "技术");
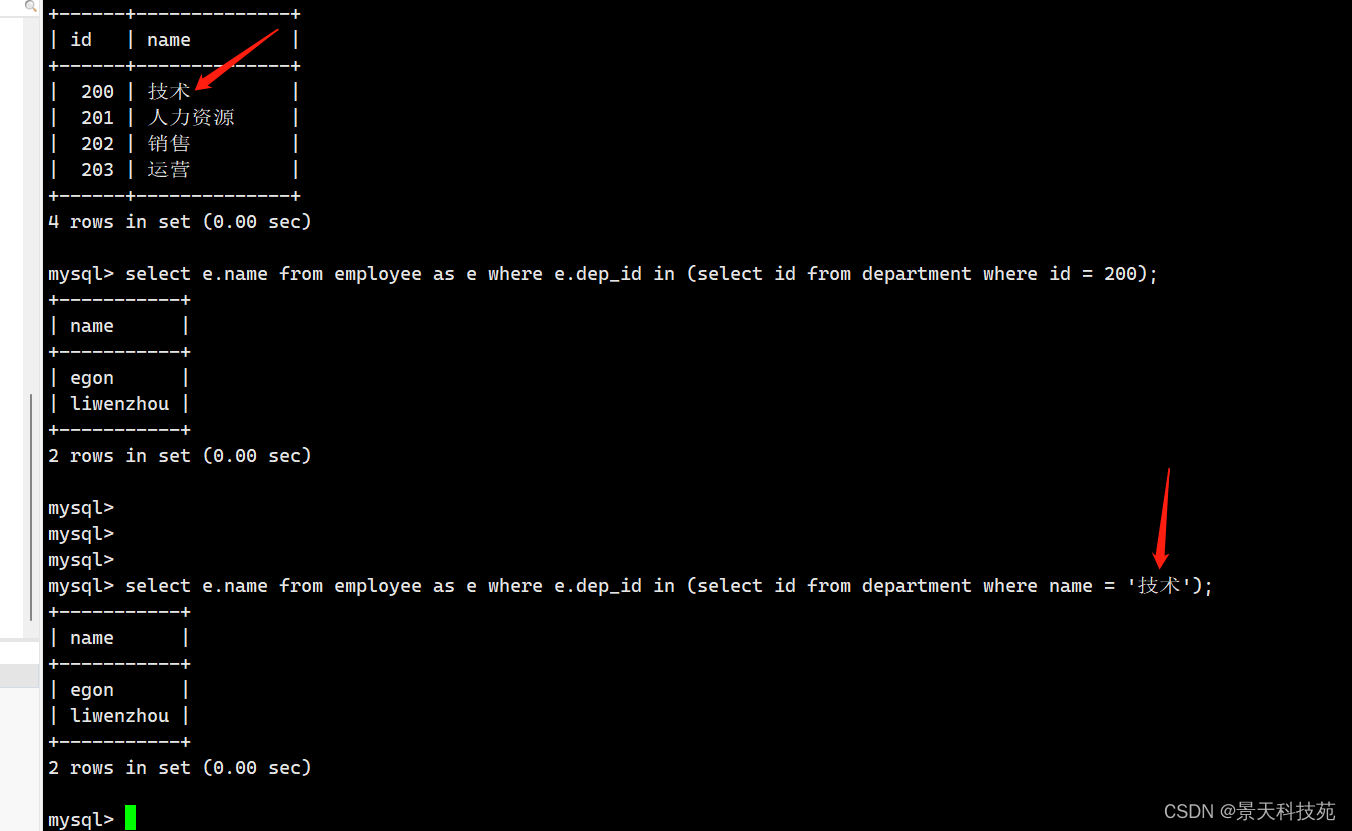
三.查看哪个部门没员工
联表写法
selectd.id,d.name
fromdepartment as d left join employee as e on d.id = e.dep_id
wheree.dep_id is null
1.找员工在哪些部门 (200 201 202 204)
select dep_id from employee group by dep_id
2.把不在该部门的员工找出来
select id from department where id not in (200,201,202,204);
3.综合拼接
select id,name from department where id not in (select dep_id from employee group by dep_id);
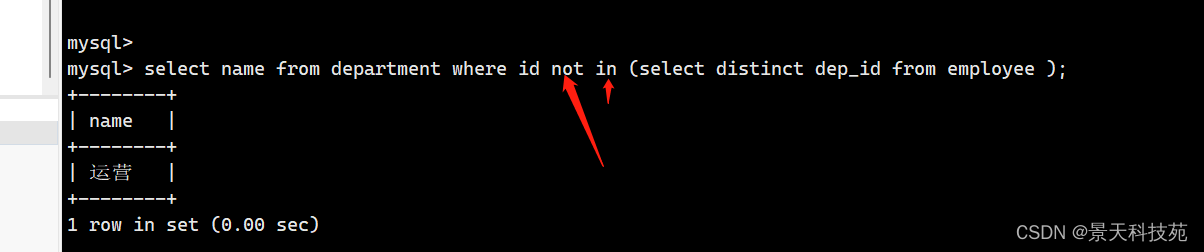
四.查询大于平均年龄的员工名与年龄
假设已经知道了平均年龄;
select name,age from employee where age > 30;
计算平均年龄
select avg(age) from employee;
综合拼接
select name,age from employee where age > (select avg(age) from employee);
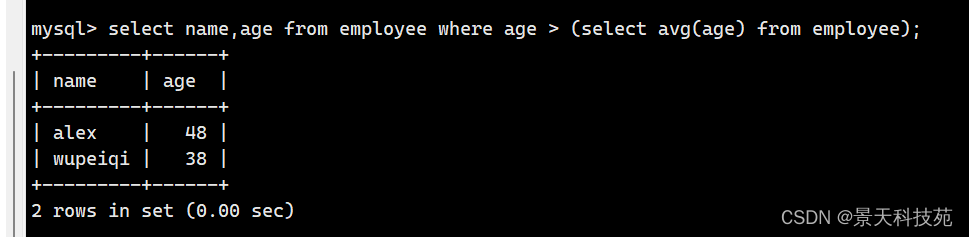
五.把大于其本部门平均年龄的员工名和姓名查出来
1.先计算本部门的平均年龄是多少
select dep_id , avg(age) from employee group by dep_id;
+--------+----------+
| dep_id | avg(age) |
+--------+----------+
| 200 | 18.0000 |
| 201 | 43.0000 |
| 202 | 28.0000 |
| 204 | 18.0000 |
+--------+----------+
2.把查询的各部门平均年龄和employee进行联表,变成一张大表,最后做单表查询
select *
fromemployee as t1 inner join (1号查询出来的数据) as t2 on t1.dep_id = t2.dep_id
3.综合拼装
select *
fromemployee as t1 inner join (select dep_id , avg(age) as avg_age from employee group by dep_id) as t2 on t1.dep_id = t2.dep_id
4.最后做一次单表查询,让age > 平均值
select *
fromemployee as t1 inner join (select dep_id , avg(age) as avg_age from employee group by dep_id) as t2 on t1.dep_id = t2.dep_id
where age >avg_age
使用连接查询,变成一张大表。单表用连接查询,要创建别名,不然查询失败
子查询作为一张表,必须创建别名
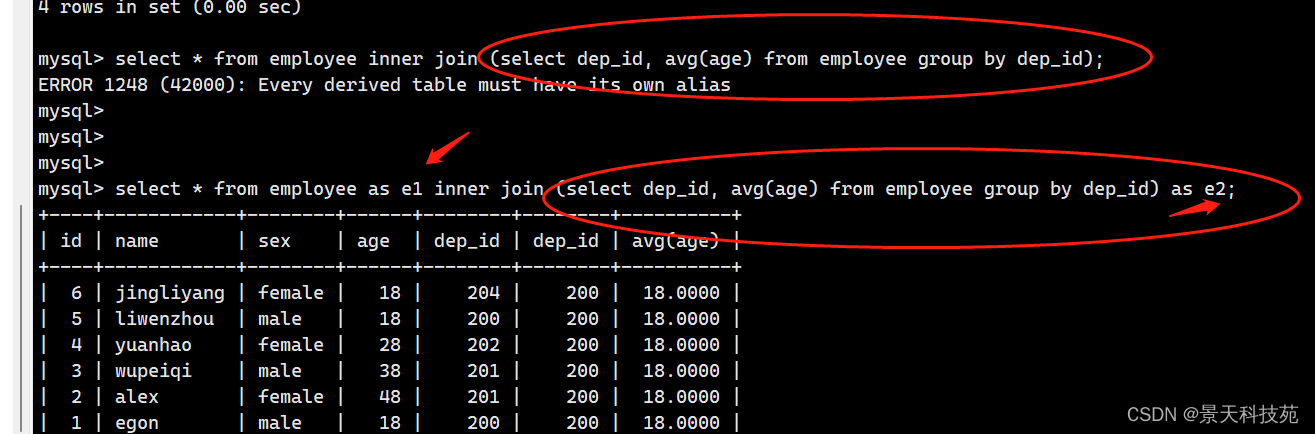
字段也要用别名

作比较的时候不能用avg(age),小括号是一种特殊的符号,不能作比较
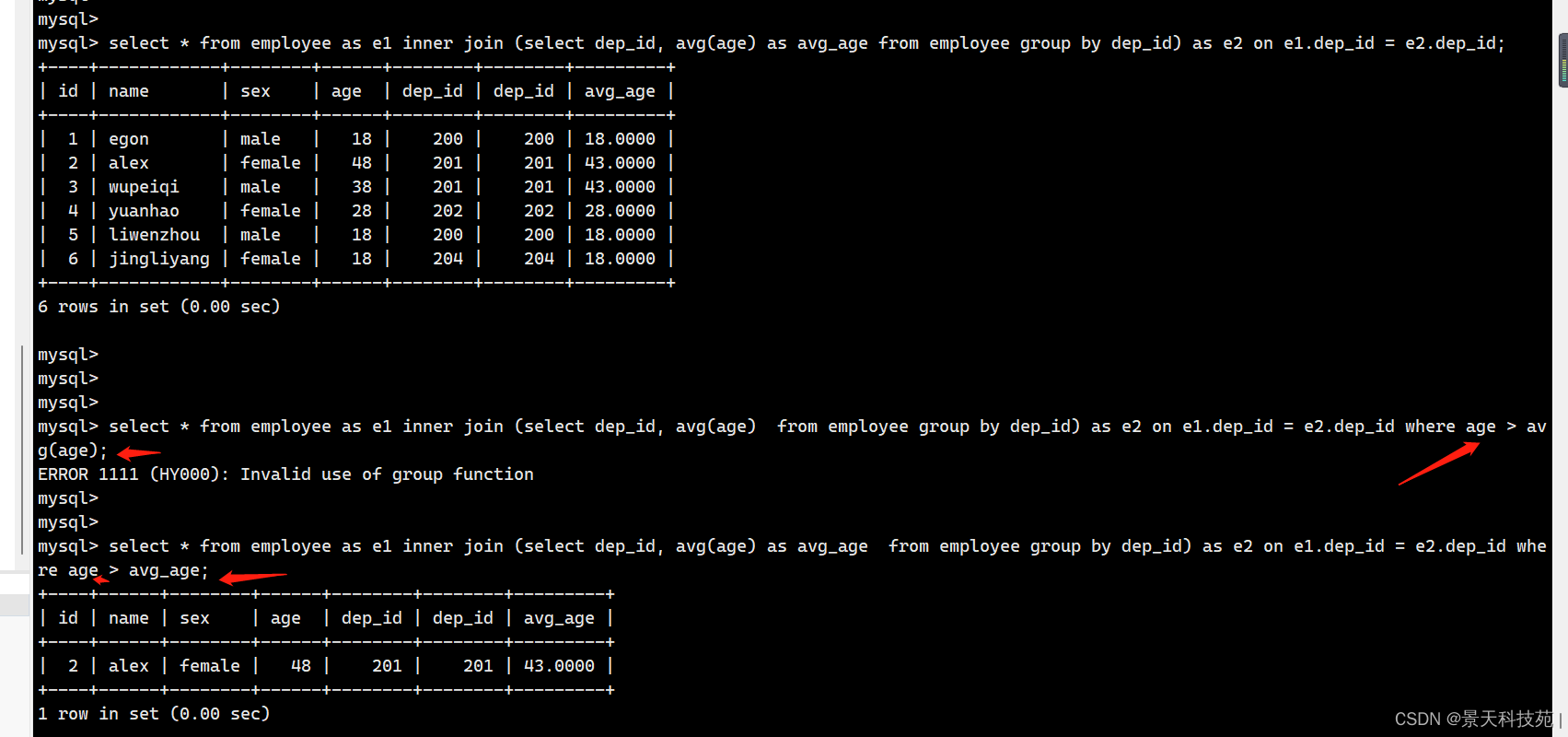
别名都创建好,可以正常查询

六.查询每个部门最新入职的那位员工 # 利用上一套数据表进行查询;
employee
+----+------------+--------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+
| id | emp_name | sex | age | hire_date | post | post_comment | salary | office | depart_id | max_date
+----+------------+--------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+
| 1 | egon | male | 18 | 2017-03-01 | 老男孩驻沙河办事处外交大使 | | 7300.33 | 401 | 1 | 2017-03-01
| 2 | alex | male | 78 | 2015-03-02 | teacher | NULL | 1000000.31 | 401 | 1 | 2015-03-02
| 3 | wupeiqi | male | 81 | 2013-03-05 | teacher | NULL | 8300.00 | 401 | 1 | 2015-03-02
| 4 | yuanhao | male | 73 | 2014-07-01 | teacher | NULL | 3500.00 | 401 | 1 | 2015-03-02
| 5 | liwenzhou | male | 28 | 2012-11-01 | teacher | NULL | 2100.00 | 401 | 1 | 2015-03-02
| 6 | jingliyang | female | 18 | 2011-02-11 | teacher | NULL | 9000.00 | 401 | 1 | 2015-03-02
| 7 | jinxin | male | 18 | 1900-03-01 | teacher | NULL | 30000.00 | 401 | 1 | 2015-03-02
| 8 | 成龙 | male | 48 | 2010-11-11 | teacher | NULL | 10000.00 | 401 | 1 | 2015-03-02
| 9 | 歪歪 | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 | 2017-01-27
| 10 | 丫丫 | female | 38 | 2010-11-01 | sale | NULL | 2000.35 | 402 | 2 | 2017-01-27
| 11 | 丁丁 | female | 18 | 2011-03-12 | sale | NULL | 1000.37 | 402 | 2 | 2017-01-27
| 12 | 星星 | female | 18 | 2016-05-13 | sale | NULL | 3000.29 | 402 | 2 | 2017-01-27
| 13 | 格格 | female | 28 | 2017-01-27 | sale | NULL | 4000.33 | 402 | 2 | 2017-01-27
| 14 | 张野 | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 | 2016-03-11
| 15 | 程咬金 | male | 18 | 1997-03-12 | operation | NULL | 20000.00 | 403 | 3 | 2016-03-11
| 16 | 程咬银 | female | 18 | 2013-03-11 | operation | NULL | 19000.00 | 403 | 3 | 2016-03-11
| 17 | 程咬铜 | male | 18 | 2015-04-11 | operation | NULL | 18000.00 | 403 | 3 | 2016-03-11
| 18 | 程咬铁 | female | 18 | 2014-05-12 | operation | NULL | 17000.00 | 403 | 3 | 2016-03-11
+----+------------+--------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+
1.找各部门的最新入职的时间
select post,max(hire_date) as max_date from employee group by post+-----------------------------------------+------------+
| post | max_date |
+-----------------------------------------+------------+
| operation | 2016-03-11 |
| sale | 2017-01-27 |
| teacher | 2015-03-02 |
| 老男孩驻沙河办事处外交大使 | 2017-03-01 |
+-----------------------------------------+------------+
2.把子查询搜索出来的结果作为一张表和employee这个表做联表,把max_date拼接在employee这个表中,变成一张大表,最后做一次单表查询
select *
fromemployee as t1 inner join (1号数据) as t2 on t1.post = t2.post
wheret1.hire_date = t2.max_date
3.综合拼装
select emp_name , max_date
fromemployee as t1 inner join (select post,max(hire_date) as max_date from employee group by post) as t2 on t1.post = t2.post
wheret1.hire_date = t2.max_date

七.带EXISTS关键字的子查询
exists 关键字 , 表达存在 , 应用在子查询中如果内层sql , 能够查到数据, 返回True , 外层sql执行相应的sql语句如果内层sql , 不能查到数据, 返回False , 外层sql不执行sql语句
select * from employee where exists (select * from employee where id = 1);
select * from employee where exists (select * from employee where id = 100000);
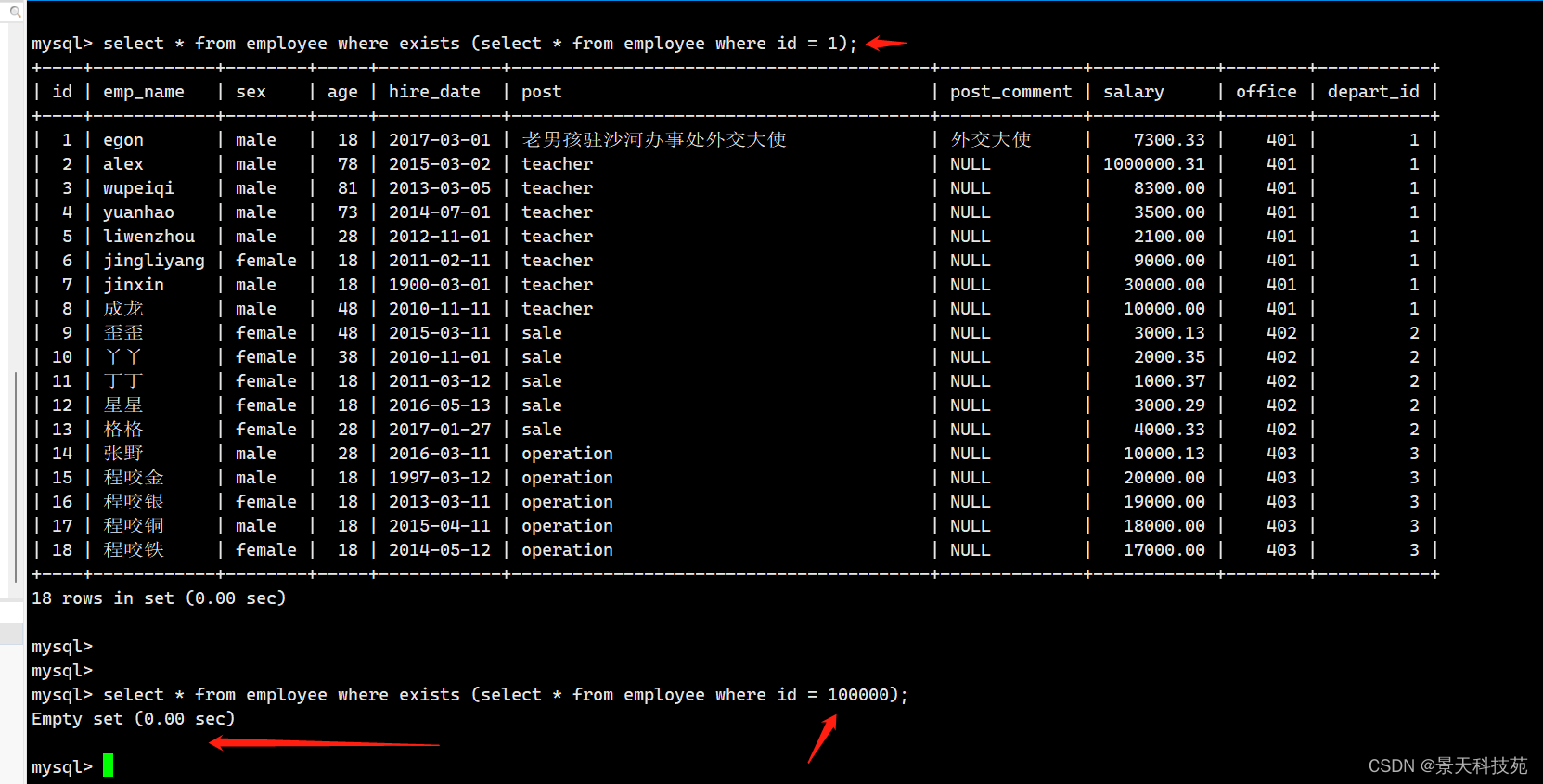
总结:
子查询可以单独作为临时数据,作为一张表或者一个字段,通过()进行包裹,表达一个整体;
一般用在from,where,select.子句的后面
可以通过查询出来的数据和 另外的表做联表变成更大一张表,
最后做单表查询,达到目的;
相关文章:
【mysql】mysql单表查询、多表查询、分组查询、子查询等案例详细解析
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...
【Gateway远程开发】0.5GB of free space is necessary to run the IDE.
【Gateway远程开发】0.5GB of free space is necessary to run the IDE. 报错 0.5GB of free space is necessary to run the IDE. Make sure that there’s enough space in following paths: /root/.cache/JetBrains /root/.config/JetBrains 原因 下面两个路径的空间不…...

普通组件的注册-局部注册和全局注册
目录 一、局部注册和全局注册-概述 二、局部注册的使用示例 三、全局注册的使用示例 一、局部注册和全局注册-概述 组件注册有两种方式: 局部注册:只能在注册的组件内使用。使用方法:创建.vue文件,在使用的组件内导入并注册。…...

Apache Dubbo知识点表格总结
Dubbo是一个高性能的Java RPC框架,它提供了一系列的功能来支持分布式系统的开发。通常用于微服务之间的服务调用,顺便提一下也是用于微服务之间调用的OpenFeign,OpenFeign是Spring Cloud体系中的一个声明式HTTP客户端,用于简化HTT…...

电路板/硬件---器件
电阻 电阻作用 电阻在电路中扮演着重要的角色,其作用包括: 限制电流:电阻通过阻碍电子流动的自由而限制电流。这是电阻最基本的功能之一。根据欧姆定律,电流与电阻成正比,电阻越大,通过电阻的电流就越小。…...
STC15W1K16S和VC6.0串口通讯收发测试实例
/********************************************* STC USB 串口板 2014 4 7 20:12 发送接收数据 使用STC串口调试助手通讯正常,L161 **********************************************/ #include "reg51.h" #include "intrins.h" #define…...
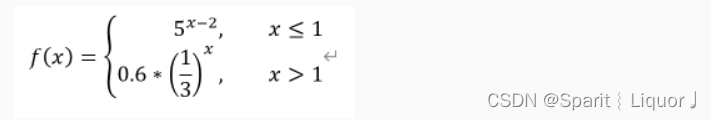
Python程序设计 函数(三)
练习十一 函数 第1关: 一元二次方程的根 定义一个函数qg,输入一元二次方程的系数a,b,c 当判别式大于0,返回1和两个根 当判别式等于0,返回0和两个根 当判别式小于0,访问-1和两个根 在主程序中,根据函数返回…...
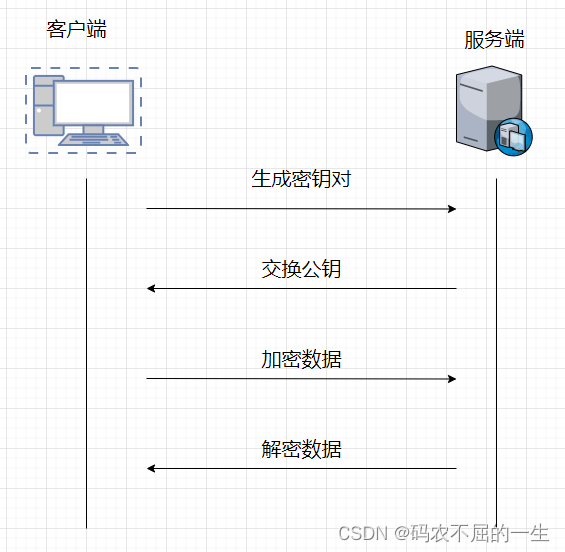
linux之ssh
SSH远程连接协议 SSH远程管理 定义 SSH(Secure Shell )是一种安全通道协议,主要用来实现字符界面的远程的登录、远程复制等功能。 SSH协议对通信双方的数据传输进行了加密处理,其中包括用户登录时输入的用户口令。因此SSH协议具…...
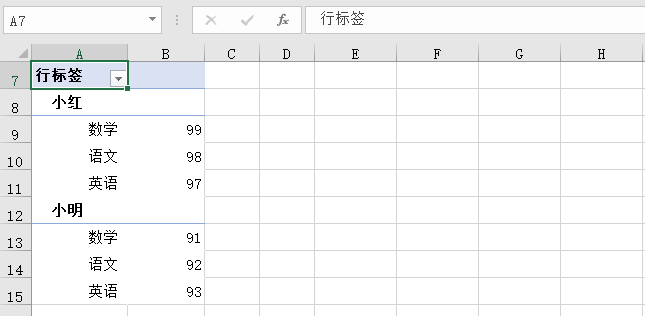
excel如何将多列数据转换为一列?
这个数据整理借用数据透视表也可以做到: 1.先将数据源的表头补齐,“姓名” 2.点击插入选项卡,数据透视表,在弹出对话框中,数据透视位置选择 现有工作表,(实际使用时新建也没有问题)…...

【Java 刷题记录】前缀和
前缀和 25. 一维前缀和 示例1: 输入: 3 2 1 2 4 1 2 2 3输出: 3 6import java.util.Scanner;// 注意类名必须为 Main, 不要有任何 package xxx 信息 public class Main {public static void main(String[] args) {Scanner in new Scanner(S…...

NVIDIA: RULER新测量方法让大模型现形
1 引言 最近在人工智能系统工程和语言模型设计方面的进展已经实现了语言模型上下文长度的高效扩展。以前的工作通常采用合成任务,如密钥检索和大海捞针来评估长上下文语言模型(LMs)。然而,这些评估在不同工作中使用不一致,仅揭示了检索能力,无法衡量其他形式的长上下文理解。 …...

2024数学-微积分和线性代数/本科研究生专业考试/考研/论文/重点公式考点汇总/最难公式投票
## 整体公式汇总列表 http://www.deepnlp.org/equation/category/math #### 微积分 ## 几何级数http://www.deepnlp.org/equation/arithmetic-and-geometric-progressions ## 级数收敛http://www.deepnlp.org/equation/convergence-of-series ## 二项式展开 http://www.dee…...
:Leetcode1005、134、135(难得有一天能完全独立做出题目))
代码随想录训练营Day33(贪心算法):Leetcode1005、134、135(难得有一天能完全独立做出题目)
Leetcode1005: 题目描述: 给你一个整数数组 nums 和一个整数 k ,按以下方法修改该数组: 选择某个下标 i 并将 nums[i] 替换为 -nums[i] 。 重复这个过程恰好 k 次。可以多次选择同一个下标 i 。 以这种方式修改数组后,返回数…...
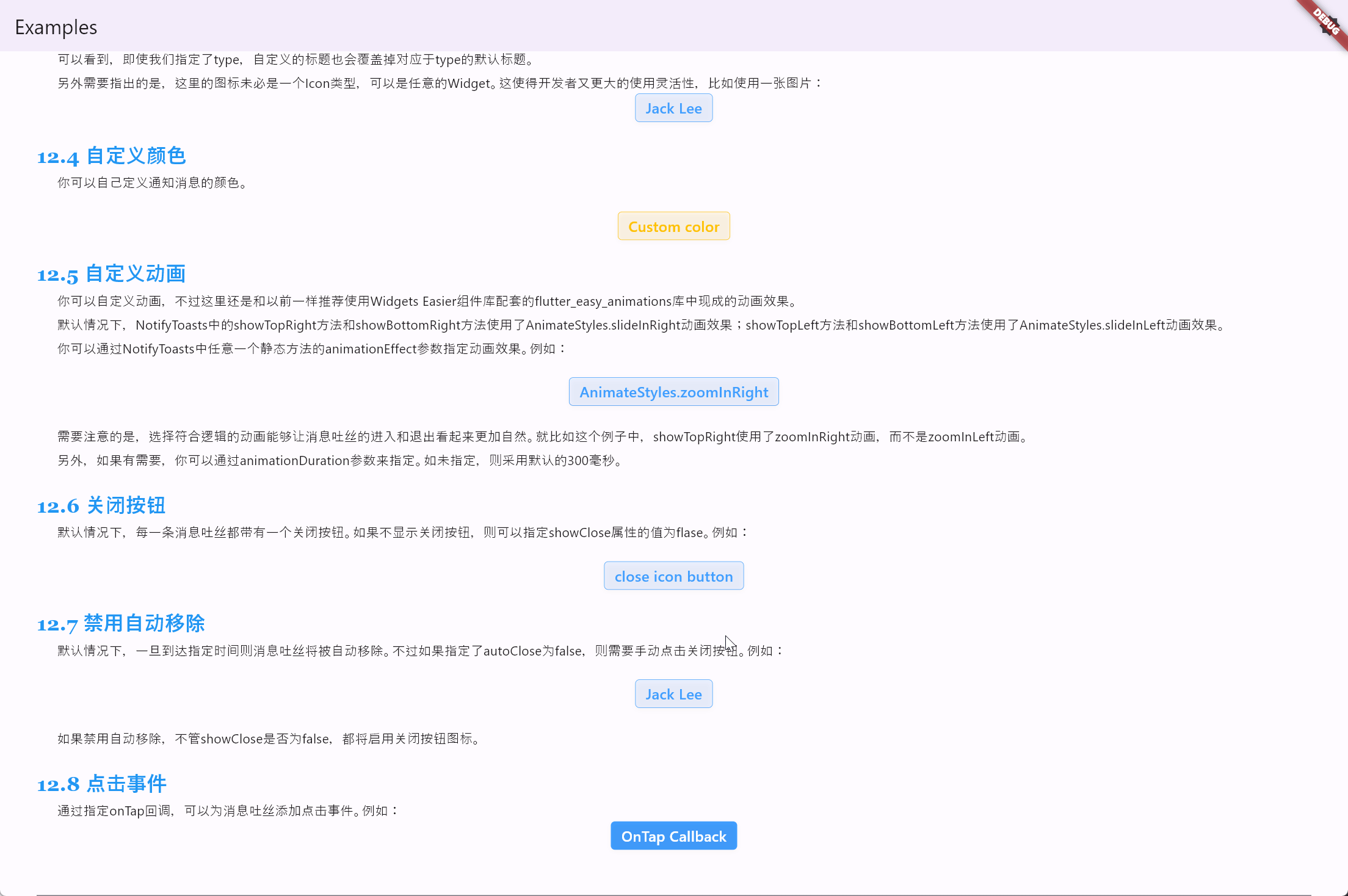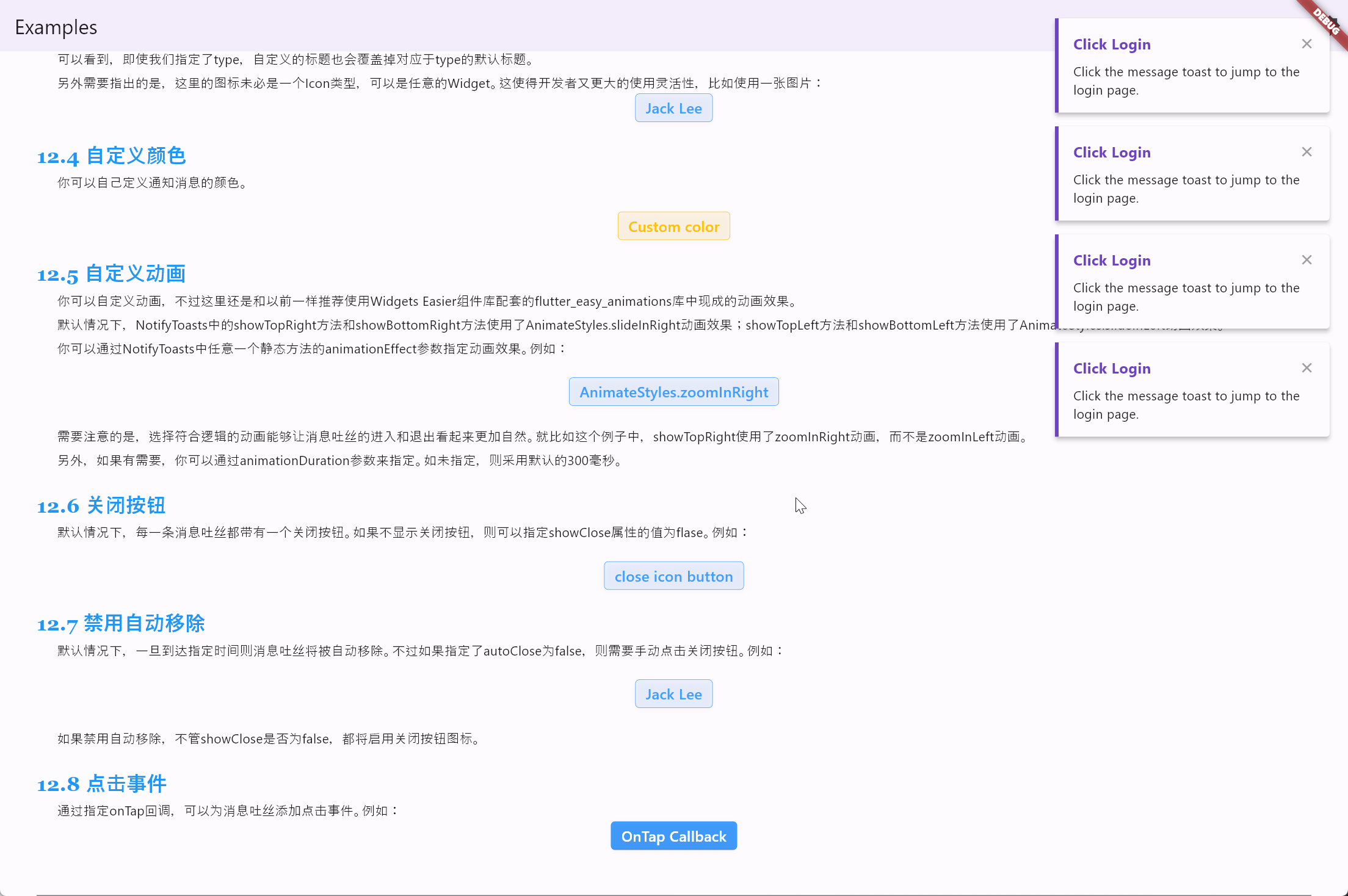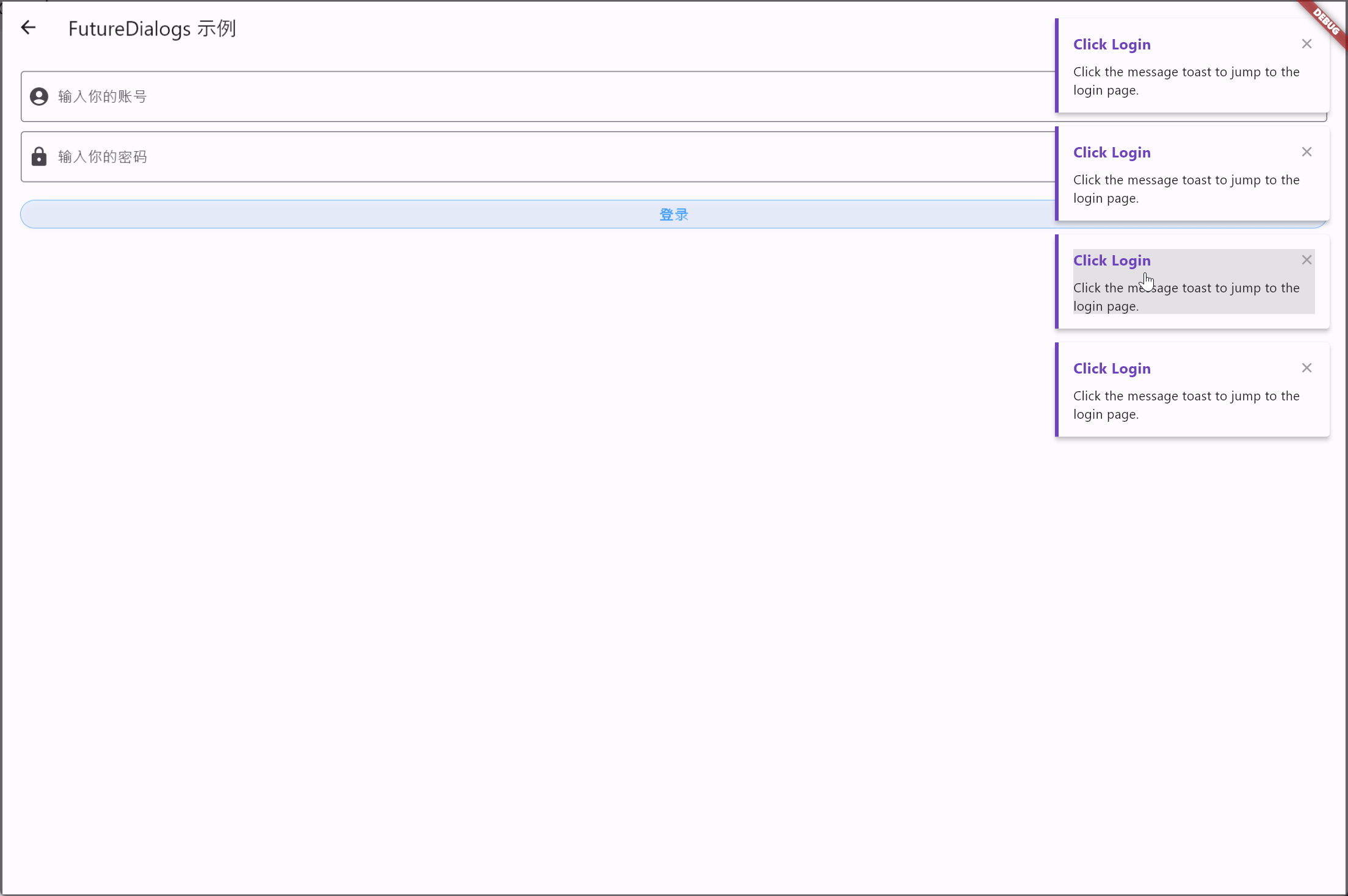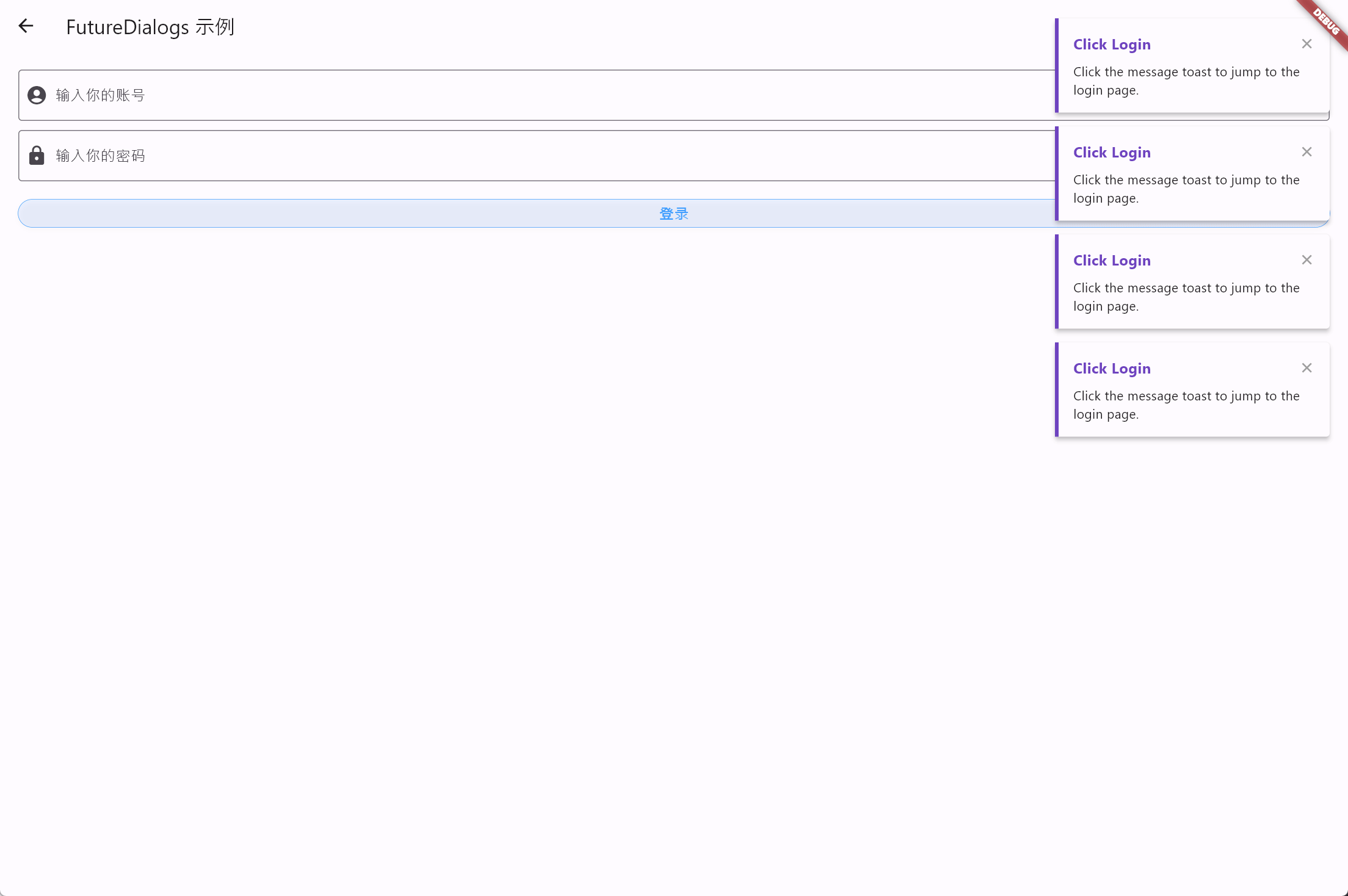
Flutter笔记:Widgets Easier组件库(12)使用消息吐丝(Notify Toasts)
Flutter笔记 Widgets Easier组件库(12)使用消息吐丝(Notify Toasts) - 文章信息 - Author: 李俊才 (jcLee95) Visit me at CSDN: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 29114848416…...

从《春色寄情人》学习如何面对死亡
经典台词,很震撼又很实用,记录一下。 ❤️01 有的时候好人不长命百岁,是因为老天爷觉得他们太累,让他们提前休息了! ❤️02 跟我们亲近的人离世,有可能是老天给我们发的信号,提醒我们ÿ…...

使用moveit控制机械臂
在这篇博客中,我们将详细探讨如何利用Python和Robot Operating System(ROS)配合MoveIt! 控制机械臂执行精确的抓取任务。机械臂技术在工业自动化、医疗服务以及研究领域扮演着越来越关键的角色。本文将通过介绍安装必要的软件、编写控制脚本以…...
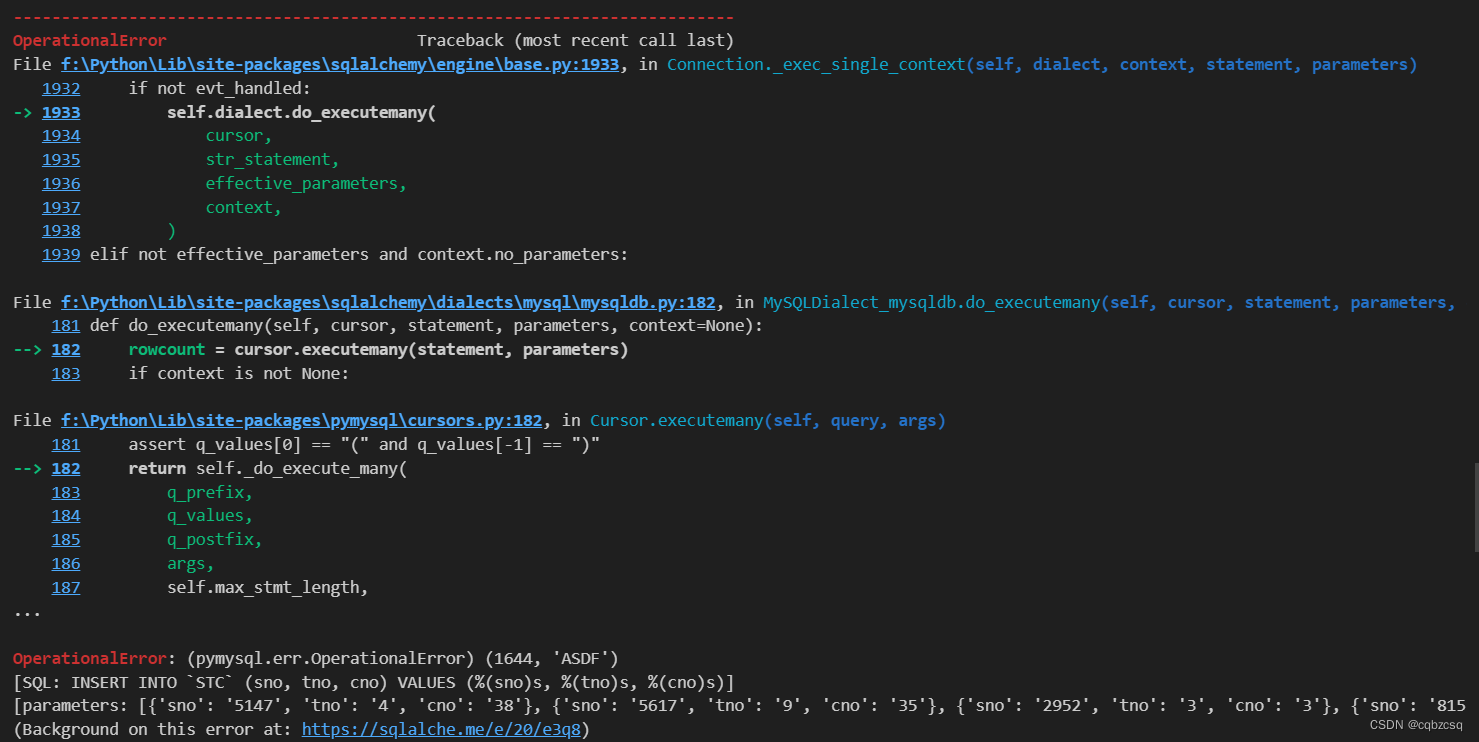
Mysql报错红温集锦(一)(ipynb配置、pymysql登录、密码带@、to_sql如何加速、触发器SIGNAL阻止插入数据)
一、jupyter notebook无法使用%sql来添加sql代码 可能原因: 1、没装jupyter和notebook库、没装ipython-sql库 pip install jupyter notebook ipython-sql 另外如果是vscode的话还需要安装一些相关的插件 2、没load_ext %load_ext sql 3、没正确的登录到mysql…...

ASP.NET Core SignalR 配置与集成测试究极指南
这篇文章也可以在我的博客中查看 前言 哥们最近都在埋头苦干,沉默是金,有一段时间没更新博客了。然而今儿SignalR集成测试实属是给我整破防了。虽说SignalR是.NET官方维护的实时通信库,已经开发了有十几年,甚至已经编入至了core…...
JENKINS 安装,学习运维从这里开始
Download and deployJenkins – an open source automation server which enables developers around the world to reliably build, test, and deploy their softwarehttps://www.jenkins.io/download/首先点击上面。下载Jenkins 为了学习,从windows开始&#x…...

大语言模型从Scaling Laws到MoE
1、摩尔定律和伸缩法则 摩尔定律(Moores law)是由英特尔(Intel)创始人之一戈登摩尔提出的。其内容为:集成电路上可容纳的晶体管数目,约每隔两年便会增加一倍;而经常被引用的“18个月”…...

初次使用 Taotoken 从注册获取 Key 到完成第一次 API 调用的全过程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用 Taotoken 从注册获取 Key 到完成第一次 API 调用的全过程 对于初次接触大模型 API 的开发者来说,从一个新平台…...
)
Adams新手避坑指南:从Box到拉伸体,教你正确给几何模型‘赋予灵魂’(含质量设置)
Adams新手避坑指南:从几何体到动力学构件的关键转换 在Adams中创建几何模型时,许多新手用户会遇到一个令人困惑的现象:明明已经画好了精致的Box、Cylinder等几何体,但进行动力学仿真时,这些模型要么纹丝不动࿰…...

Windows 环境 OpenClaw 部署详解|从安装到使用全流程
OpenClaw(小龙虾)Windows 一键部署教程|10 分钟搭建自动化数字员工 前言 OpenClaw(俗称小龙虾)是 2026 年热门的开源 AI 智能体,GitHub 星标突破 28 万,主打本地运行、低门槛、自动化执行。本…...

3步掌握Windows 11任务栏自定义神器:Taskbar11完全指南
3步掌握Windows 11任务栏自定义神器:Taskbar11完全指南 【免费下载链接】Taskbar11 Change the position and size of the Taskbar in Windows 11 项目地址: https://gitcode.com/gh_mirrors/ta/Taskbar11 还在为Windows 11僵化的任务栏设置而烦恼吗…...

弹簧工业设备联网数字化管理平台解决方案
在“智能制造”的转型道路上,大量企业卡在同一个困境里:设备买了不少,自动化也上了,但车间依然像一个“数据黑箱”——设备状态靠猜、效率损失靠估、问题根源靠找。对于弹簧部件加工这类多工序、高精度的制造场景,OEE&…...

基于ENVI、eCognition与ArcGIS的南京江北新区土地利用变化监测与驱动分析
1. 南京江北新区土地利用变化监测的技术路线 我第一次接触南京江北新区土地利用监测项目时,被这个区域的快速发展震撼到了。作为国家级新区,这里从2015年设立至今,土地利用格局发生了翻天覆地的变化。要准确捕捉这些变化,我们采用…...

N_m3u8DL-RE:跨平台流媒体下载终极指南
N_m3u8DL-RE:跨平台流媒体下载终极指南 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE 在当今数字时…...

10个必须知道的simplex-noise.js实战技巧:从基础到高级应用
10个必须知道的simplex-noise.js实战技巧:从基础到高级应用 【免费下载链接】simplex-noise.js A fast simplex noise implementation in Javascript / Typescript. 项目地址: https://gitcode.com/gh_mirrors/si/simplex-noise.js simplex-noise.js是一个快…...

探索商业成功的奥秘:BABOK Guide v3深度解析
探索商业成功的奥秘:BABOK Guide v3深度解析 【下载地址】商业分析知识体系指南BABOKGuidev3 《商业分析知识体系指南(BABOK Guide v3)》是业界权威的商业分析专业标准,深受全球专业人士的认可与信赖。本指南经过严密的共识驱动开…...

百度季报图解:营收321亿 AI业务占比首次过半 DAA重塑AI价值标准
雷递网 雷建平 5月18日百度集团(纳斯达克:BIDU及香港联交所:9888(港元柜台)及89888(人民币柜台))今天公布其截至2026年3月31日止第一季度的未经审计财务业绩,财报显示&am…...