Pytorch常用的函数(九)torch.gather()用法
Pytorch常用的函数(九)torch.gather()用法
torch.gather() 就是在指定维度上收集value。
torch.gather() 的必填也是最常用的参数有三个,下面引用官方解释:
input(Tensor) – the source tensordim(int) – the axis along which to indexindex(LongTensor) – the indices of elements to gather
一句话概括 gather 操作就是:根据 index ,在 input 的 dim 维度上收集 value。
1、举例直观理解
# 1、我们有input_tensor如下
>>> input_tensor = torch.arange(24).reshape(2, 3, 4)
tensor([[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]],[[12, 13, 14, 15],[16, 17, 18, 19],[20, 21, 22, 23]]])# 2、我们有index_tensor如下
>>> index_tensor = torch.tensor([[[0, 0, 0, 0],[2, 2, 2, 2]],[[0, 0, 0, 0],[2, 2, 2, 2]]]
) # 3、我们通过torch.gather()函数获取out_tensor
>>> out_tensor = torch.gather(input_tensor, dim=1, index=index_tensor)
tensor([[[ 0, 1, 2, 3],[ 8, 9, 10, 11]],[[12, 13, 14, 15],[20, 21, 22, 23]]])
我们以out_tensor中[0,1,0]=8为例,解释下如何利用dim和index,从input_tensor中获得8。

根据上图,我们很直观的了解根据 index ,在 input 的 dim 维度上收集 value的过程。
- 假设
input和index均为三维数组,那么输出 tensor 每个位置的索引是列表[i, j, k],正常来说我们直接取input[i, j, k]作为 输出 tensor 对应位置的值即可; - 但是由于
dim的存在以及input.shape可能不等于index.shape,所以直接取值可能就会报错 ; - 所以我们是将索引列表的相应位置替换为
dim,再去input取值。在上面示例中,由于dim=1,那么我们就替换索引列表第1个值,即[i,dim,k],因此由原来的[0,1,0]替换为[0,2,0]后,再去input_tensor中取值。 - pytorch官方文档的写法如下,同一个意思。
out[i][j][k] = input[index[i][j][k]][j][k] # if dim == 0
out[i][j][k] = input[i][index[i][j][k]][k] # if dim == 1
out[i][j][k] = input[i][j][index[i][j][k]] # if dim == 2
2、反推法再理解
# 1、我们有input_tensor如下
>>> input_tensor = torch.arange(24).reshape(2, 3, 4)
tensor([[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]],[[12, 13, 14, 15],[16, 17, 18, 19],[20, 21, 22, 23]]])# 2、假设我们要得到out_tensor如下
>>> out_tensor
tensor([[[ 0, 1, 2, 3],[ 8, 9, 10, 11]],[[12, 13, 14, 15],[20, 21, 22, 23]]])、# 3、如何知道dim 和 index_tensor呢?
# 首先,我们要记住:out_tensor的shape = index_tensor的shape# 从 output_tensor 的第一个位置开始:
# 此时[i, j, k]一样,看不出来 dim 应该是多少
output_tensor[0, 0, :] = input_tensor[0, 0, :] = 0
# 同理可知,此时index都为0
output_tensor[0, 0, 1] = input_tensor[0, 0, 1] = 1
output_tensor[0, 0, 2] = input_tensor[0, 0, 2] = 2
output_tensor[0, 0, 3] = input_tensor[0, 0, 3] = 3# 我们从下一行的第一个位置开始:
# 这里我们看到维度 1 发生了变化,1 变成了 2,所以 dim 应该是 1,而 index 应为 2
output_tensor[0, 1, 0] = input_tensor[0, 2, 0] = 8
# 同理可知,此时index都为2
output_tensor[0, 1, 1] = input_tensor[0, 2, 1] = 9
output_tensor[0, 1, 2] = input_tensor[0, 2, 2] = 10
output_tensor[0, 1, 3] = input_tensor[0, 2, 3] = 11# 根据上面推导我们易知dim=1,index_tensor为:
>>> index_tensor = torch.tensor([[[0, 0, 0, 0],[2, 2, 2, 2]],[[0, 0, 0, 0],[2, 2, 2, 2]]]
)
3、实际案例
在大神何凯明MAE模型(Masked Autoencoders Are Scalable Vision Learners)源码中,多次使用了torch.gather() 函数。
- 论文链接:https://arxiv.org/pdf/2111.06377
- 官方源码:https://github.com/facebookresearch/mae
在MAE中根据预设的掩码比例(paper 中提倡的是 75%),使用服从均匀分布的随机采样策略采样一部分 tokens 送给 Encoder,另一部分mask 掉。采样25%作为unmasked tokens过程中,使用了torch.gather() 函数。
# models_mae.pyimport torchdef random_masking(x, mask_ratio=0.75):"""Perform per-sample random masking by per-sample shuffling.Per-sample shuffling is done by argsort random noise.x: [N, L, D], sequence"""N, L, D = x.shape # batch, length, dimlen_keep = int(L * (1 - mask_ratio)) # 计算unmasked的片数# 利用0-1均匀分布进行采样,避免潜在的【中心归纳偏好】noise = torch.rand(N, L, device=x.device) # noise in [0, 1]# sort noise for each sample【核心代码】ids_shuffle = torch.argsort(noise, dim=1) # ascend: small is keep, large is removeids_restore = torch.argsort(ids_shuffle, dim=1)# keep the first subsetids_keep = ids_shuffle[:, :len_keep]# 利用torch.gather()从源tensor中获取25%的unmasked tokensx_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))# generate the binary mask: 0 is keep, 1 is removemask = torch.ones([N, L], device=x.device)mask[:, :len_keep] = 0# unshuffle to get the binary maskmask = torch.gather(mask, dim=1, index=ids_restore)return x_masked, mask, ids_restoreif __name__ == '__main__':x = torch.arange(64).reshape(1, 16, 4)random_masking(x)
# x模拟一张图片经过patch_embedding后的序列
# x相当于input_tensor
# 16是patch数量,实际上一般为(img_size/patch_size)^2 = (224 / 16)^2 = 14*14=196
# 4是一个patch中像素个数,这里只是模拟,实际上一般为(in_chans * patch_size * patch_size = 3*16*16 = 768)
>>> x = torch.arange(64).reshape(1, 16, 4)
tensor([[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11],[12, 13, 14, 15],[16, 17, 18, 19], # 4[20, 21, 22, 23],[24, 25, 26, 27],[28, 29, 30, 31],[32, 33, 34, 35],[36, 37, 38, 39],[40, 41, 42, 43], # 10[44, 45, 46, 47],[48, 49, 50, 51], # 12[52, 53, 54, 55], # 13[56, 57, 58, 59],[60, 61, 62, 63]]])
# dim=1, index相当于index_tensor
>>> index
tensor([[[10, 10, 10, 10],[12, 12, 12, 12],[ 4, 4, 4, 4],[13, 13, 13, 13]]])# x_masked(从源tensor即x中,随机获取25%(4个patch)的unmasked tokens)
>>> x_masked相当于out_tensor
tensor([[[40, 41, 42, 43],[48, 49, 50, 51],[16, 17, 18, 19],[52, 53, 54, 55]]])
相关文章:
Pytorch常用的函数(九)torch.gather()用法
Pytorch常用的函数(九)torch.gather()用法 torch.gather() 就是在指定维度上收集value。 torch.gather() 的必填也是最常用的参数有三个,下面引用官方解释: input (Tensor) – the source tensordim (int) – the axis along which to indexindex (Lo…...

用爬虫解决问题
使用Java进行网络爬虫开发是一种常见的做法,它可以帮助你从网站上自动抓取信息。Java语言因为其丰富的库支持(如Jsoup、HtmlUnit、Selenium等)和良好的跨平台性,成为实现爬虫的优选语言之一。下面我将简要介绍如何使用Java编写一个…...

机器学习-有监督学习
有监督学习是机器学习的一种主要范式,其基本思想是从有标签的训练数据中学习输入和输出之间的关系,然后利用学习到的模型对新的输入进行预测或分类。 有监督学习的过程如下: 1. 准备数据:首先,需要准备一组有标签的训练…...

【详细介绍下Visual Studio】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...

【Golang】实现 Excel 文件下载功能
在当今的网络应用开发中,提供数据导出功能是一项常见的需求。Excel 作为一种广泛使用的电子表格格式,通常是数据导出的首选格式之一。在本教程中,我们将学习如何使用 Go 语言和 Gin Web 框架来创建一个 Excel 文件,并允许用户通过…...

设计模式2——原则篇:依赖倒转原则、单一职责原则、合成|聚合复用原则、开放-封闭原则、迪米特法则、里氏代换原则
设计模式2——设计原则篇 目录 一、依赖倒转原则 二、单一职责原则(SRP) 三、合成|聚合复用原则(CARP) 四、开放-封闭原则 五、迪米特法则(LoD) 六、里氏代换原则 七、接口隔离原则 八、总结 一、依赖…...

深入探讨布隆过滤器算法:高效的数据查找与去重工具
在处理海量数据时,我们经常需要快速地进行数据查找和去重操作。然而,传统的数据结构可能无法满足这些需求,特别是在数据量巨大的情况下。在这种情况下,布隆过滤器(Bloom Filter)算法就显得尤为重要和有效。…...

基于STC12C5A60S2系列1T 8051单片机实现一主单片机与一从单片机进行双向串口通信功能
基于STC12C5A60S2系列1T 8051单片机实现一主单片机与一从单片机进行双向串口通信功能 STC12C5A60S2系列1T 8051单片机管脚图STC12C5A60S2系列1T 8051单片机串口通信介绍STC12C5A60S2系列1T 8051单片机串口通信的结构基于STC12C5A60S2系列1T 8051单片机串口通信的特殊功能寄存器…...

ubuntu18.04安装docker容器
Ubuntu镜像下载 https://mirrors.huaweicloud.com/ubuntu-releases/ docker安装 # 第一步、卸载旧版本docker sudo apt-get remove docker docker-engine docker.io containerd runc# 第二步、更新及安装软件 luhost:~$ curl -fsSL https://get.docker.com -o get-docker.sh …...
等级考试试卷(二级))
202212青少年软件编程(Python)等级考试试卷(二级)
第 1 题 【单选题】 运行下列程序, 最终输出的结果是? ( ) info = {1:小明, 2:小黄,3:小兰}info[4] = 小红info[...

单播、组播、广播
概念 单播(Unicast) 单播是网络中最常用、最基本的通信方式。在单播通信中,数据包从一个节点发送到特定的另一个节点。换句话说,发送端和接收端之间建立一对一的连接,然后进行数据传输。 例如&#x…...

吴恩达深度学习笔记:深度学习的 实践层面 (Practical aspects of Deep Learning)1.13-1.14
目录 第二门课: 改善深层神经网络:超参数调试、正 则 化 以 及 优 化 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)第一周:深度学习的 实践层面 (Practical aspects of Deep Learning)1.13 梯度检验&#…...
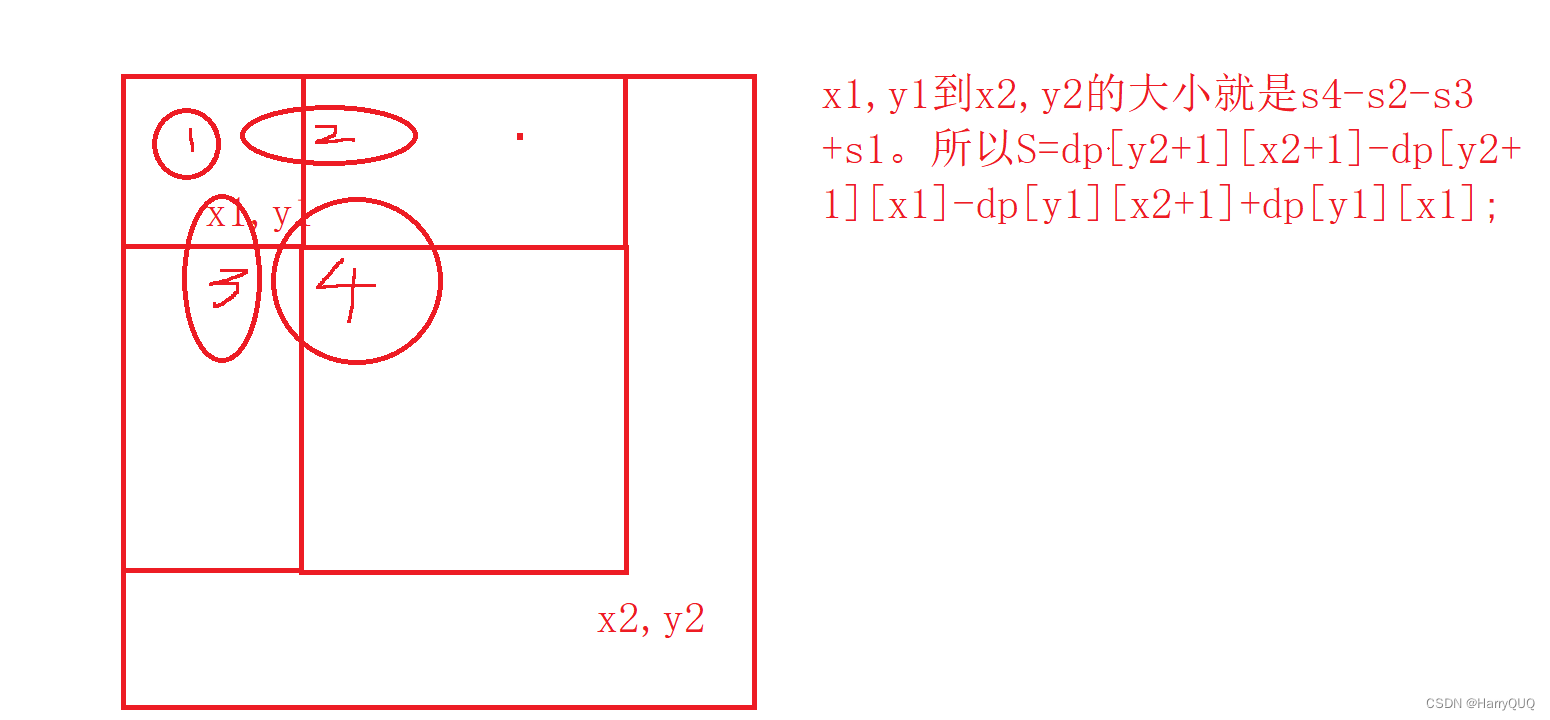
笔试强训未触及题目(个人向)
1.DP22 最长回文子序列 1.题目 2.解析 这是一个区间dp问题,我们让dp[i][j]表示在区间[i,j]内的最长子序列长度,如图: 3.代码 public class LongestArr {//DP22 最长回文子序列public static void main(String[] args) {Scanner…...
)
【YOLO改进】换遍MMDET主干网络之EfficientNet(基于MMYOLO)
EfficientNet EfficientNet是Google在2019年提出的一种新型卷积神经网络架构,其设计初衷是在保证模型性能的同时,尽可能地降低模型的复杂性和计算需求。EfficientNet的核心思想是通过均衡地调整网络的深度(层数)、宽度࿰…...

uniapp下拉选择组件
uniapp下拉选择组件 背景实现思路代码实现配置项使用尾巴 背景 最近遇到一个这样的需求,在输入框中输入关键字,通过接口查询到结果之后,以下拉框列表形式展现供用户选择。查询了下uni-app官网和项目中使用的uv-ui库,没找到符合条…...

高斯数据库创建函数的语法
CREATE FUNCTION 语法格式 •兼容PostgreSQL风格的创建自定义函数语法。 CREATE [ OR REPLACE ] FUNCTION function_name ( [ { argname [ argmode ] argtype [ { DEFAULT | : | } expression ]} [, …] ] ) [ RETURNS rettype [ DETERMINISTIC ] | RETURNS TABLE ( { column_…...

【.NET Core】你认识Attribute之CallerMemberName、CallerFilePath、CallerLineNumber三兄弟
你认识Attribute之CallerMemberName、CallerFilePath、CallerLineNumber三兄弟 文章目录 你认识Attribute之CallerMemberName、CallerFilePath、CallerLineNumber三兄弟一、概述二、CallerMemberNameAttribute类三、CallerFilePathAttribute 类四、CallerLineNumberAttribute 类…...

ubuntu删除opencv
要完全删除OpenCV 3.4.5版本,你可以按照以下步骤进行操作: 卸载OpenCV库: 首先,你需要卸载OpenCV 3.4.5版本。可以使用以下命令卸载OpenCV库: sudo apt-get purge libopencv*这将删除OpenCV库及其相关文件。 删除O…...
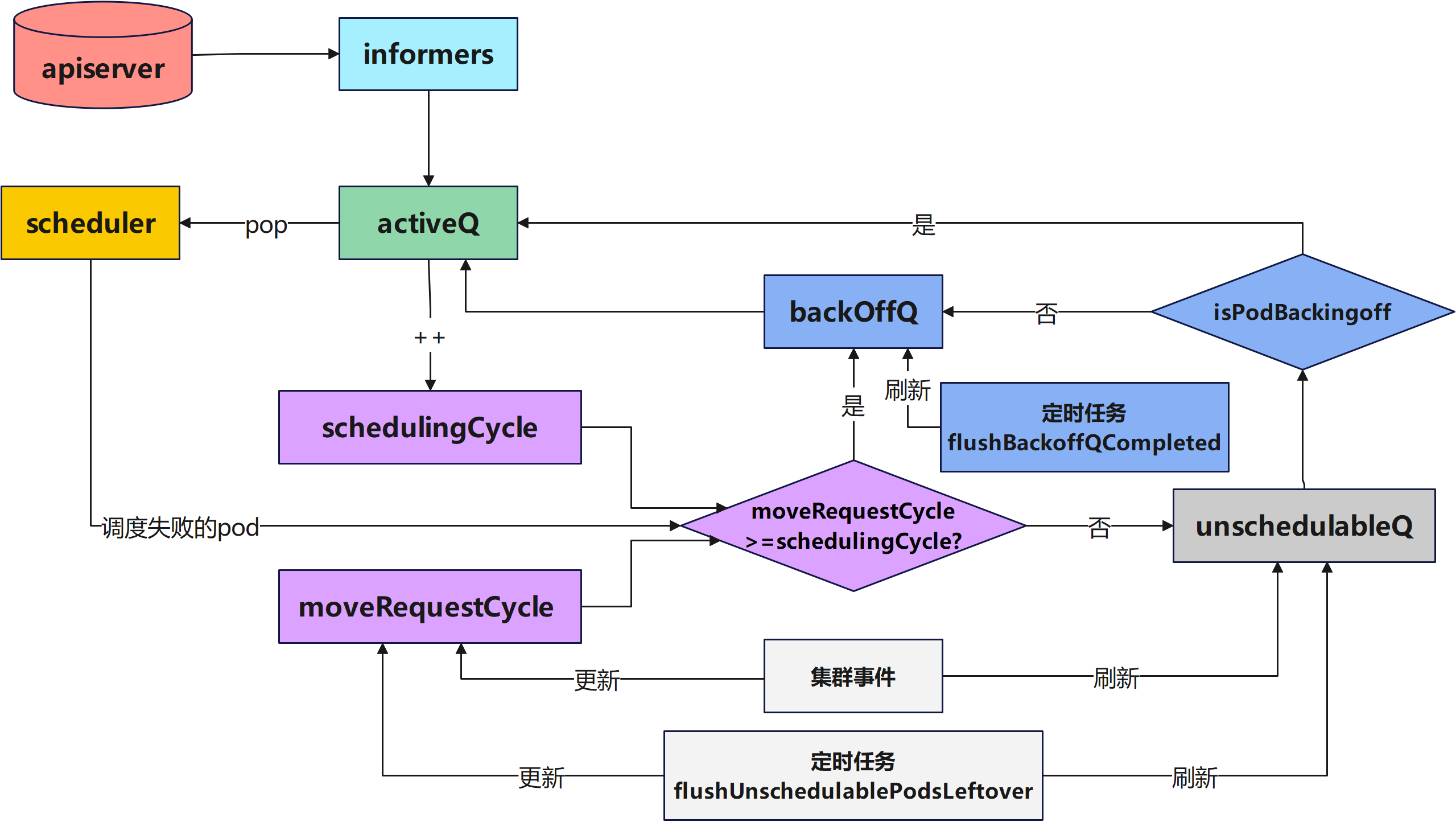
K8s源码分析(二)-K8s调度队列介绍
本文首发在个人博客上,欢迎来踩! 本次分析参考的K8s版本是 文章目录 调度队列简介调度队列源代码分析队列初始化QueuedPodInfo元素介绍ActiveQ源代码介绍UnschedulableQ源代码介绍**BackoffQ**源代码介绍队列弹出待调度的Pod队列增加新的待调度的Podpod调…...
)
OpenGL ES 面试高频知识点(二)
说说纹理常用的采样方式? 最邻近点采样(GL_NEAREST)和双线性采样(GL_LINEAR)。 GL_NEAREST 采样是 OpenGL 默认的纹理采样方式,OpenGL 会选择中心点最接近纹理坐标的那个像素,纹理放大的时候会有锯齿感或者颗粒感。 **GL_LINEAR 采样会基于纹理坐标附近的纹理像素,计…...

Context Engineering 实战:别再往 context 里塞东西了
Context Engineering 实战:别再往 context 里塞东西了 为什么 token 塞满反而让 LLM 变蠢?四种核心策略 Python 代码实现 Agent 跑到第 15 步,突然开始做蠢事。 它把已经检查过的文件又检查了一遍,给出了和第 3 步完全矛盾的结论…...

架构解密:如何通过FastExcel流式处理引擎重塑Java Excel操作效率标准
架构解密:如何通过FastExcel流式处理引擎重塑Java Excel操作效率标准 【免费下载链接】fastexcel Generate and read big Excel files quickly 项目地址: https://gitcode.com/gh_mirrors/fas/fastexcel 在当今数据驱动的企业环境中,Excel文件处理…...

从B站视频到高品质音频:BilibiliDown音频提取全攻略
从B站视频到高品质音频:BilibiliDown音频提取全攻略 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/…...

IDM试用期总在倒计时?这个开源脚本让你告别30天限制的烦恼
IDM试用期总在倒计时?这个开源脚本让你告别30天限制的烦恼 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 想象一下这样的场景:你刚刚找到…...

如何在Hermes Agent项目中自定义Provider接入Taotoken多模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何在Hermes Agent项目中自定义Provider接入Taotoken多模型服务 Hermes Agent 是一个功能强大的AI代理框架,它允许开发…...

Frida+Fart实战:在ART Dex加载临界点精准dump二代壳内存Dex
1. 这不是“又一个脱壳教程”,而是对Android加固演进逻辑的现场解剖你打开一个市面上主流的金融类App,用adb shell pm list packages | grep bank随手一搜,发现它被某知名商业加固厂商打了“二代壳”——启动慢、内存占用高、关键so文件加密、…...

BilibiliDown音频提取技术指南:Java实现与配置深度解析
BilibiliDown音频提取技术指南:Java实现与配置深度解析 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/…...

戴尔G15散热控制终极指南:免费开源工具TCC-G15告别过热降频
戴尔G15散热控制终极指南:免费开源工具TCC-G15告别过热降频 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 你是否为戴尔G15笔记本在游戏或高强度工…...

读写锁:高并发场景的“读写分离“利器
在电商大促期间,商品详情页的访问量是平时的100倍,但商品信息每小时只更新一次。如何让成千上万的用户同时浏览商品,又能在管理员更新价格时保证数据一致性?答案就是:读写锁。 一、读写锁:为什么它能提升10…...

[特殊字符] TCP/IP四层协议栈解析——互联网通信的“底层逻辑“
📅 发布时间:2026年5月 | 🏷️ 标签:TCP/IP、网络协议、网络架构、互联网原理、网络层 🔍 SEO关键词:TCP/IP协议栈、四层模型、ARP协议、IP协议、网络通信原理开篇暴击:你正在看这篇文章&#x…...