DS高阶:B树系列

一、常见的搜索结构
1、顺序查找 时间复杂度:O(N)
2、二分查找 时间复杂度:O(logN)
要求:(1)有序 (2)支持下标的随机访问
3、二叉搜索树(BS树) 时间复杂度:O(logN)——>O(N)
若接近有序的数据插入到BS中,会导致退化成单支树,时间复杂度退化为O(N)
4、平衡搜索树 (AVL树和RB树) 时间复杂度:O(logN)
在BS的基础上,通过一些规则加以限制,通过旋转来限制高度,维持logN的时间复杂度
5、哈希 时间复杂度:O(1)
底层是散列表,要注意解决哈希冲突。综合效率优于平衡搜索树
以上结构适合用于数据量相对不是很大,能够一次性存放在内存中(内查找),进行数据查找的场景。如果数据量很大,比如有100G数据,无法一次放进内存中,那就只能放在磁盘上了,如果放在磁盘上,有需要搜索某些数据,那么如果处理呢?那么我们可以考虑将存放关键字及其映射的数据的地址放到一个内存中的搜索树的节点中,那么要访问数据时,先取这个地址去磁盘访问数据。(B树系列 解决外查找的问题)
根据上面的分析,我们知道B树系列是为了解决外查找的问题而生的,但是你可能会有这样的疑惑:虽然高度下降了,但是由于我的一个节点存储这多个关键字信息,那么我即使找到这个节点,不也是要遍历关键字信息,效率真的能提高么??
答:在磁盘中的搜索来说,定位的效率低,但是如果准确定位到了(节点),后面效率就会很高(顺序遍历节点中的关键字),这个跟磁盘的底层结构有关,具体可以参照下面的文献去理解。

二、B树的概念
1970年,R.Bayer和E.mccreight提出了一种适合外查找的树,它是一种平衡的多叉树,称为B树(后面有一个B的改进版本B+树、B*树,然后有些地方的B树写的的是B-树,注意不要误读成"B减树")。一棵m阶(m>2)的B树,是一棵平衡的M路平衡搜索树,可以是空树或者满足一下性质:
(1)根节点至少有两个孩子
(2)每个分支节点都包含k-1个关键字和k个孩子,其中 ceil(m/2) ≤ k ≤ m ceil是向上取整函数
(3)每个叶子节点都包含k-1个关键字,其中 ceil(m/2) ≤ k ≤ m

(4)所有的叶子节点都在同一层
(5)每个节点中的关键字从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划
分
(6)每个结点的结构为:(n,A0,K1,A1,K2,A2,… ,Kn,An)其中,Ki(1≤i≤n)为关键
字,且Ki<Ki+1(1≤i≤n-1)。Ai(0≤i≤n)为指向子树根结点的指针。且Ai所指子树所有结点中的关键字均小于Ki+1。
(7)实际中M通常会设计得比较大(比如1024)
以上规则可能还有点抽象,我们通过分析B树的插入来剖析具体的过程
三、B树的插入过程分析
为了简单起见,假设M = 3. 即三叉树,每个节点中存储两个数据,两个数据可以将区间分割成三个部分,因此节点应该有三个孩子,为了后续实现简单期间,节点的结构如下:
注意孩子比关键字多一个,并且为了防止越界的问题,我们多开一个空间

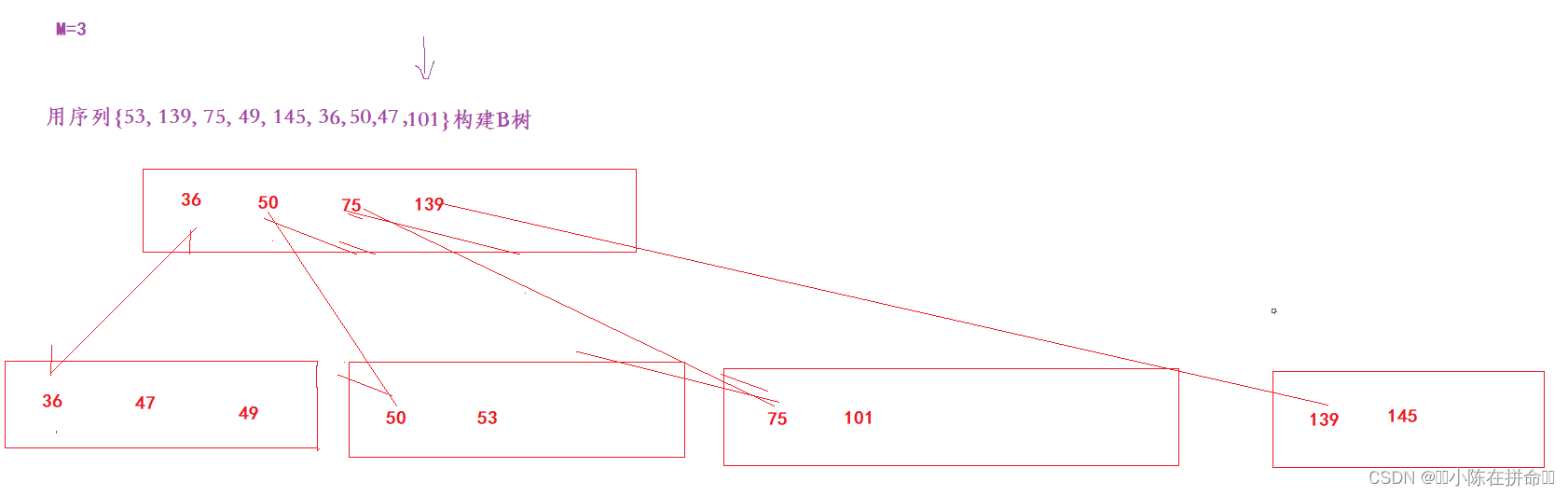
用序列{53, 139, 75, 49, 145, 36, 50,47,101}构建B树的过程如下
(1)插入53
 (2)插入139
(2)插入139

(3)插入75
 (4)进行分裂
(4)进行分裂

这里可以解释为什么ceil(m/2) ≤ k ≤ M
假设M是偶数 比如是10 那么后面5个给兄弟,中位数给父亲,自己还剩下4个,兄弟会多一个
假设M是奇数 比如是11 那么后面5个给兄弟,中位数给父亲,自己还剩下5个,正好一样多
(5)插入49
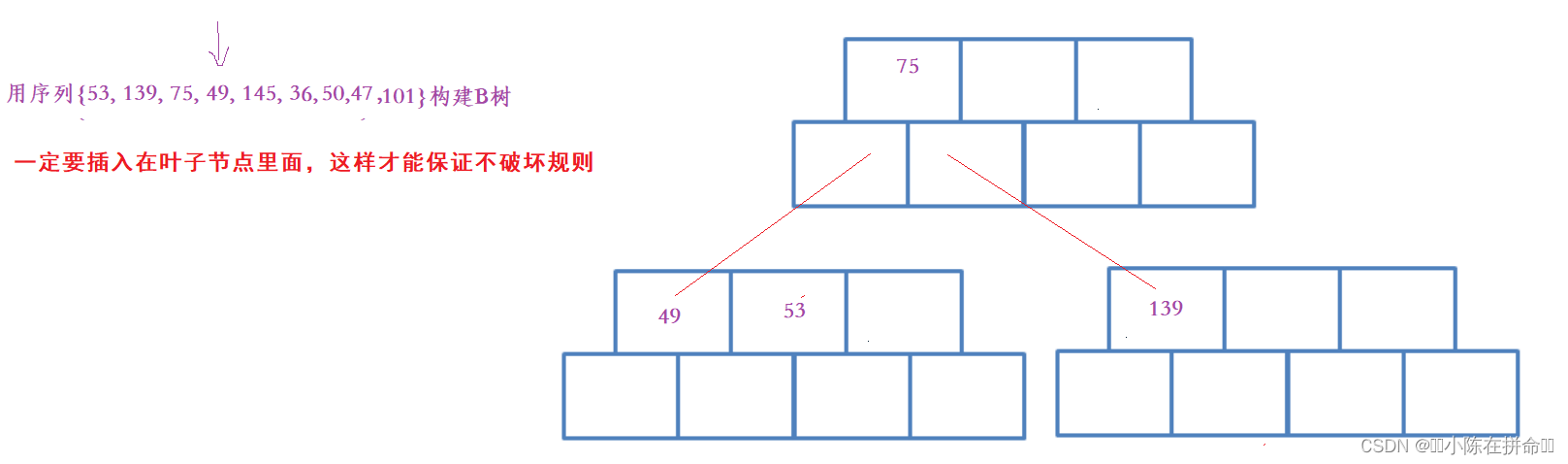
分析以下,当B树有多个叶子节点的时候,如何去选取我们要插入的叶子节点。
答:B树的逻辑是 左-根-左-根-左-根……-右,我们先忽略掉后面这个右子树,把它抽象成一个节点对应一个左子树,在拓展兄弟的时候是向右拓展的,所以我们找的是要左(小)的找。 举个例子,49比75小,那么必然在75左孩子那边,此时可以直接往下走,但是如果139比75大,那么此时不能直接到下一层,而是先往后找,直到找到一个比自己大的节点(如果后面没有,就是当前节点)的左孩子去找。
(6)插入145

(7)插入36
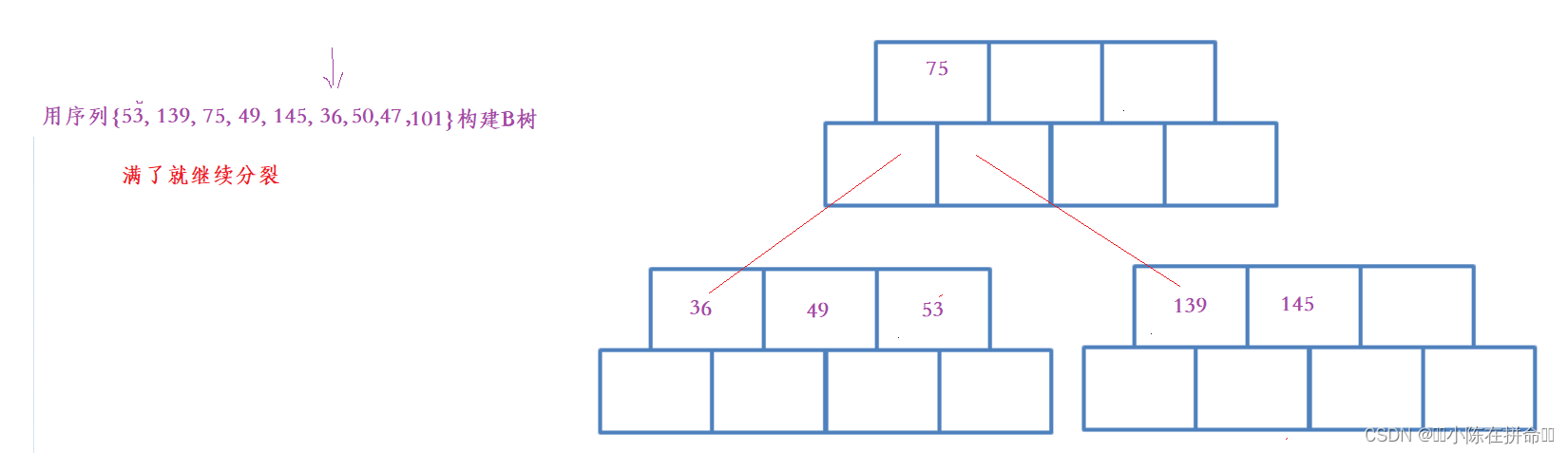
(8)进行分裂

(9)插入50

(10)插入47

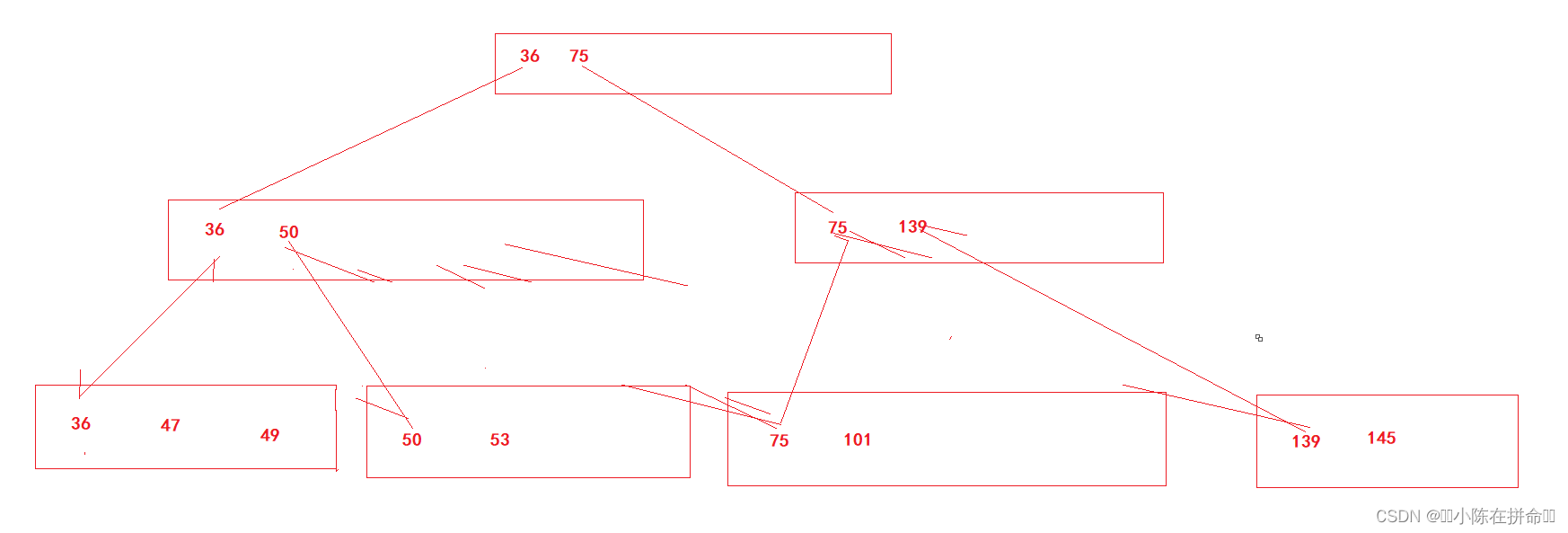
(11)插入101

(12)继续分裂
 (13)二次分裂
(13)二次分裂

四、B树简单模拟实现
4.1 B树的节点设计
template<class K,size_t M>
struct BTreeNode
{BTreeNode(){for (size_t i = 0; i < M; ++i){_keys[i] = K(); //K的默认构造_subs[i] = nullptr;}_subs[M] = nullptr;_parent = nullptr;_n = 0;}//关键字永远比孩子少一个 为了方便插入,我们多开一个空间 预防边界情况K _keys[M]; //M-1个关键字BTreeNode<K, M>* _subs[M + 1];// 孩子的集合 M个孩子BTreeNode<K, M>* _parent;//父亲节点 方便插入的时候向上回溯size_t _n; //实际存了多少节点
};
template<class K, size_t M>
class BTree
{typedef BTreeNode<K, M> Node;
public:private:Node* _root=nullptr;
};1、K代表K类型,一般是表示地址,当然也可以是KV模型
2、M表示这是M路多叉树
3、_subs表示孩子节点的集合,_keys表示关键字的集合,为了防止边界情况的判断,统一多开一个空间。
4、_n表示一共个有效的关键字
5、_parent是父亲节点,维护父亲的原因是我们需要向上传中位数,如果不维护一个父亲节点,会比较难实现,但是增加了一个指针,同时也要十分注意去维护这个指针(容易忽略)。
4.2 B树的查找
在B树不允许键值冗余的情况下,如果我们想插入一个节点,那么我们要保证B树没有该节点,因此我们在实现插入之前,先实现一个查找的函数
pair<Node*, int> Find(const K& key) //查找这个节点以及对应关键字的下标
{Node* cur = _root;Node* parent = nullptr;//如果没找到, 把父亲节点带回来while (cur) //因为i每次都要重头开始算{size_t i = 0; while (i < cur->_n){if (key < cur->_keys[i]) break; //keys[i]的左孩子根他的下标是相等的else if (key > cur->_keys[i]) ++i; //左才会往下跳 比右小i++else return make_pair(cur, i);}//但是有可能走到空都不会结束 找不到就往自己的孩子去跳parent = cur;cur = cur->_subs[i];}return make_pair(parent, -1);
}1、返回值pair<Node*,int> 前一个返回对应的节点,后一个表示对应节点中的下标。
2、parent指针的意义:因为我们在插入之前必须要调用这个查找函数,并且必须插入到相应的叶子节点中去。那么我们可以顺便通过这个返回值返回我们要插入的叶子节点。这样在insert函数中接受find函数的返回值的时就可以直接拿到待插入的叶子节点。
3、因为拓展都是往右拓展的,所以我们必须要确保比key当前元素小,我们才能跳到下一层去找他的左孩子,并且每次都要从第一个位置开始找,如果比当前元素大的话,那么先往后找,而不是直接往该节点的右孩子找!!
4.3 插入key的过程
我们多开一块空间的目的先进行无脑插入,然后再去检查该节点是否满了,如果满了再进行分裂调整,但是我们有些时候可能不光要插入key,还要插入新增的节点。
//每次循环往cur插入newkey和child
void InsertKey(Node* node, const K& key, Node* child)
{int end = node->_n - 1;while (end >= 0) //如果我比你小,你就往后挪 类似插入排序逻辑{if (key < node->_keys[end]) //挪动key 还要挪动右孩子{node->_keys[end + 1] = node->_keys[end];node->_subs[end + 2] = node->_subs[end+1];--end;}else break; //找到了就放}node->_keys[end + 1] = key;node->_subs[end + 2] = child;if (child) child->_parent = node; // 一定要记得反向链接维护parent指针++node->_n;
}1、只有多次分裂的时候才会出现需要链接新增的节点,如果只有一次分裂的话,child就是nullptr,所以在反向链接的时候要注意!!!
2、在插入关键字的时候,我们按照插入排序的逻辑从后开始往前找,不断将比自己大的元素往后挪,挪动的时候要别忘了把他的右子树也跟着往后挪动。
3、end必须设置成int而不能是size_t,因为是从后往前找的,所以end是有可能会出现负数的。
4.4 B树的插入整体实现
bool Insert(const K& key)
{if (_root == nullptr) //如果我为空 那我就让自己成为新的根{_root = new Node;_root->_keys[0] = key;++_root->_n; return true;}//如果不为空 开始执行插入逻辑pair<Node*, int> ret = Find(key);if (ret.second>=0) return false;//如果没有找到,find顺便带回了要插入的叶子节点Node* cur = ret.first;//每次循环往cur插入newkey和childK newKey = key;Node* child = nullptr;while (1){InsertKey(cur, newKey, child);//情况1 没满, 直接结束if (cur->_n < M) return true;Node* brother = new Node;//分裂一半[mid+1,M-1]给兄弟 找到中间那个值size_t mid = M / 2;size_t i = mid + 1;size_t j = 0;for (; i < M; ++i, ++j){//拷贝key和key的左孩子brother->_keys[j] = cur->_keys[i]; brother->_subs[j] = cur->_subs[i]; //节点也拷过去//与父亲建立连接if (cur->_subs[i]) cur->_subs[i]->_parent = brother;//清理一下方便观察cur->_keys[i] = K();cur->_subs[i] = nullptr;}// 还有最后一个右孩子拷过去brother->_subs[j] = cur->_subs[i];if (cur->_subs[i]) cur->_subs[i]->_parent = brother; //孩子如果不是空 那么父亲就得更新一下cur->_subs[i] = nullptr;brother->_n = j;cur->_n -= (brother->_n + 1);//因为还要把中位数往上放K midKey = cur->_keys[mid];cur->_keys[mid] = K();//方便观察//转化成往cur的parent去插入 cur->[mid]和 brother// 说明刚刚分裂是根节点if (cur->_parent == nullptr){_root = new Node; //最坏情况 我的父亲是空,那就造一个新的根出来_root->_keys[0] = midKey;_root->_subs[0] = cur;_root->_subs[1] = brother;_root->_n = 1;//链接起来cur->_parent = _root;brother->_parent = _root;break;}else //如果父亲不是空,还可以向上调整{// 转换成往parent->parent 去插入parent->[mid] 和 brothernewKey = midKey;child = brother;cur = cur->_parent;}}return true;
}1、如果什么也没有,那么自己就成为新的树。
2、通过find函数去找B树中是否存在这个关键字,如果存在就结束,不存在,那就把返回的pair中的first(待插入的叶子节点)提取出来。
3、因为有可能会涉及到多次分裂,所以我们要将插入的函数写在循环里面(通过cur、newkey、child来帮助我们迭代 ),然后每次插入之后就去判断是否还要进行分裂。如果没满就结束,如果满了就分裂。
4、分裂一半的key和节点(要注意节点的反向链接)给自己的兄弟,然后清理一下数据方便我们调试观察,最后有一个右孩子还得再拷贝一次。
5、传中位数的时候,如果cur没有父亲,那么就直接造一个父亲出来。如果cur有父亲,就更新一下cur、newkey、child,继续往上迭代去走。将问题转化成往父亲节点插入中位数和一个brother节点。
4.5 B树的中序遍历验证
他的整体逻辑是左、根、左、根、左、根……右 所以我们可以将前两个过程抽出来,然后最后再单独处理右。走一个中序遍历的逻辑实现有序。
void _InOrder(Node* cur){if (cur == nullptr) return;// 左 根 左 根 ... 右size_t i = 0;for (; i < cur->_n; ++i){_InOrder(cur->_subs[i]); // 左子树cout << cur->_keys[i] << " "; // 根}_InOrder(cur->_subs[i]); // 最后的那个右子树}void InOrder(){_InOrder(_root);}附上测试用例:
void testBtree()
{BTree<int, 3> t;int a[] = { 53, 139, 75, 49, 145, 36, 101 };for (auto e : a) t.Insert(e);t.InOrder();
}
4.6 整体的代码
#pragma once
#include<iostream>
using namespace std;//K表示存的地址 M表示最多有几个分支
template<class K,size_t M>
struct BTreeNode
{BTreeNode(){for (size_t i = 0; i < M; ++i){_keys[i] = K(); //K的默认构造_subs[i] = nullptr;}_subs[M] = nullptr;_parent = nullptr;_n = 0;}//关键字永远比孩子少一个 为了方便插入,我们多开一个空间 预防边界情况K _keys[M]; //M-1个关键字BTreeNode<K, M>* _subs[M + 1];// 孩子的集合 M个孩子BTreeNode<K, M>* _parent;//父亲节点 方便插入的时候向上回溯size_t _n; //实际存了多少节点
};template<class K, size_t M>
class BTree
{typedef BTreeNode<K, M> Node;
public:pair<Node*, int> Find(const K& key) //查找这个节点以及对应关键字的下标{Node* cur = _root;Node* parent = nullptr;//如果没找到, 把父亲节点带回来while (cur) //因为i每次都要重头开始算{size_t i = 0; while (i < cur->_n){if (key < cur->_keys[i]) break; //keys[i]的左孩子根他的下标是相等的else if (key > cur->_keys[i]) ++i; //左才会往下跳 比右小i++else return make_pair(cur, i);}//但是有可能走到空都不会结束 找不到就往自己的孩子去跳parent = cur;cur = cur->_subs[i];}return make_pair(parent, -1);}//每次循环往cur插入newkey和childvoid InsertKey(Node* node, const K& key, Node* child){int end = node->_n - 1;while (end >= 0) //如果我比你小,你就往后挪 类似插入排序{if (key < node->_keys[end]) //挪动key 还要挪动右孩子{node->_keys[end + 1] = node->_keys[end];node->_subs[end + 2] = node->_subs[end+1];--end;}else break; //找到了就放}node->_keys[end + 1] = key;node->_subs[end + 2] = child;if (child) child->_parent = node; // 要记得向上连接++node->_n;}bool Insert(const K& key){if (_root == nullptr) //如果我为空 那我就让自己成为新的根{_root = new Node;_root->_keys[0] = key;++_root->_n; return true;}//如果不为空 开始执行插入逻辑pair<Node*, int> ret = Find(key);if (ret.second>=0) return false;//如果没有找到,find顺便带回了要插入的叶子节点Node* cur = ret.first;//每次循环往cur插入newkey和childK newKey = key;Node* child = nullptr;while (1){InsertKey(cur, newKey, child);//情况1 没满, 直接结束if (cur->_n < M) return true;Node* brother = new Node;//分裂一半[mid+1,M-1]给兄弟 找到中间那个值size_t mid = M / 2;size_t i = mid + 1;size_t j = 0;for (; i < M; ++i, ++j){//拷贝key和key的左孩子brother->_keys[j] = cur->_keys[i]; brother->_subs[j] = cur->_subs[i]; //节点也拷过去//与父亲建立连接if (cur->_subs[i]) cur->_subs[i]->_parent = brother;//清理一下方便观察cur->_keys[i] = K();cur->_subs[i] = nullptr;}// 还有最后一个右孩子拷过去brother->_subs[j] = cur->_subs[i];if (cur->_subs[i]) cur->_subs[i]->_parent = brother; //孩子如果不是空 那么父亲就得更新一下cur->_subs[i] = nullptr;brother->_n = j;cur->_n -= (brother->_n + 1);//因为还要把中位数往上放K midKey = cur->_keys[mid];cur->_keys[mid] = K();//方便观察//转化成往cur的parent去插入 cur->[mid]和 brother// 说明刚刚分裂是根节点if (cur->_parent == nullptr){_root = new Node; //最坏情况 我的父亲是空,那就造一个新的根出来_root->_keys[0] = midKey;_root->_subs[0] = cur;_root->_subs[1] = brother;_root->_n = 1;//链接起来cur->_parent = _root;brother->_parent = _root;break;}else //如果父亲不是空,还可以向上调整{// 转换成往parent->parent 去插入parent->[mid] 和 brothernewKey = midKey;child = brother;cur = cur->_parent;}}return true;}void _InOrder(Node* cur){if (cur == nullptr) return;// 左 根 左 根 ... 右size_t i = 0;for (; i < cur->_n; ++i){_InOrder(cur->_subs[i]); // 左子树cout << cur->_keys[i] << " "; // 根}_InOrder(cur->_subs[i]); // 最后的那个右子树}void InOrder(){_InOrder(_root);}private:Node* _root=nullptr;
};void testBtree()
{BTree<int, 3> t;int a[] = { 53, 139, 75, 49, 145, 36, 101 };for (auto e : a) t.Insert(e);t.InOrder();
}4.7 B树的性能分析
对于一棵节点为N度为M的B-树,查找和插入需要$log{M-1}N$~$log{M/2}N$次比较,这个很好证明:对于度为M的B-树,每一个节点的子节点个数为M/2 ~(M-1)之间,因此树的高度应该在要
$log{M-1}N$和$log{M/2}N$之间,在定位到该节点后,再采用二分查找的方式可以很快的定位
到该元素。
B-树的效率是很高的,对于N = 62*1000000000个节点,如果度M为1024,则$log_{M/2}N$ <=4,即在620亿个元素中,如果这棵树的度为1024,则需要小于4次即可定位到该节点,然后利用二分查找可以快速定位到该元素,大大减少了读取磁盘的次数。
4.8 B树的删除过程分析
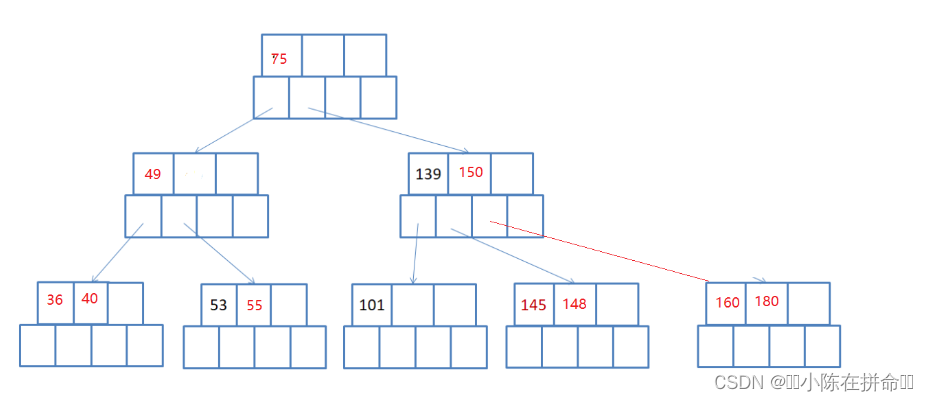 1、删除36
1、删除36

2、删除40

3、删49
 4、删150
4、删150
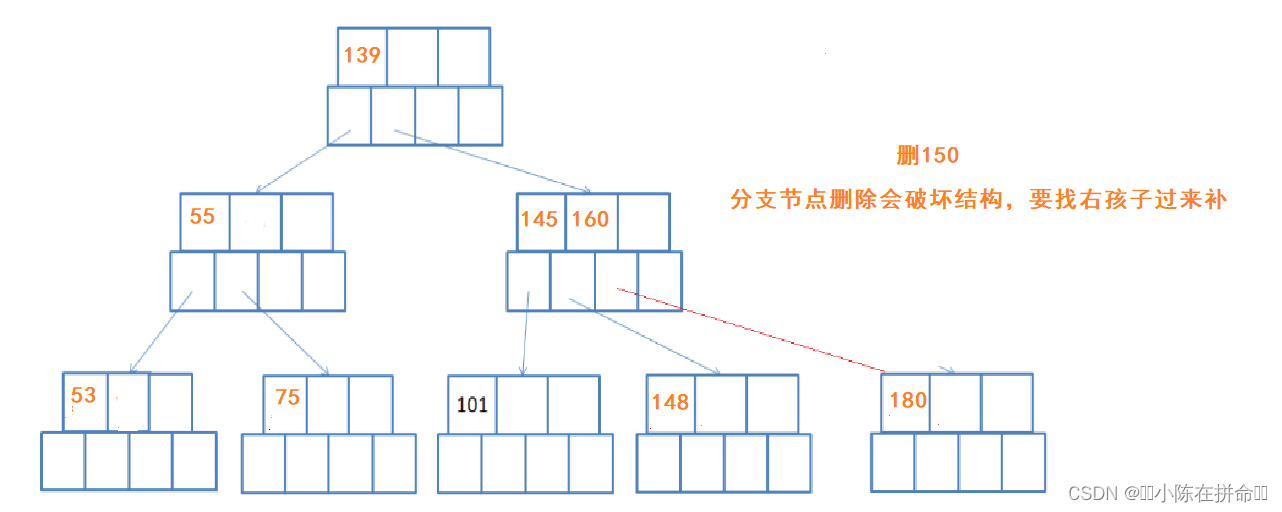
5、删160

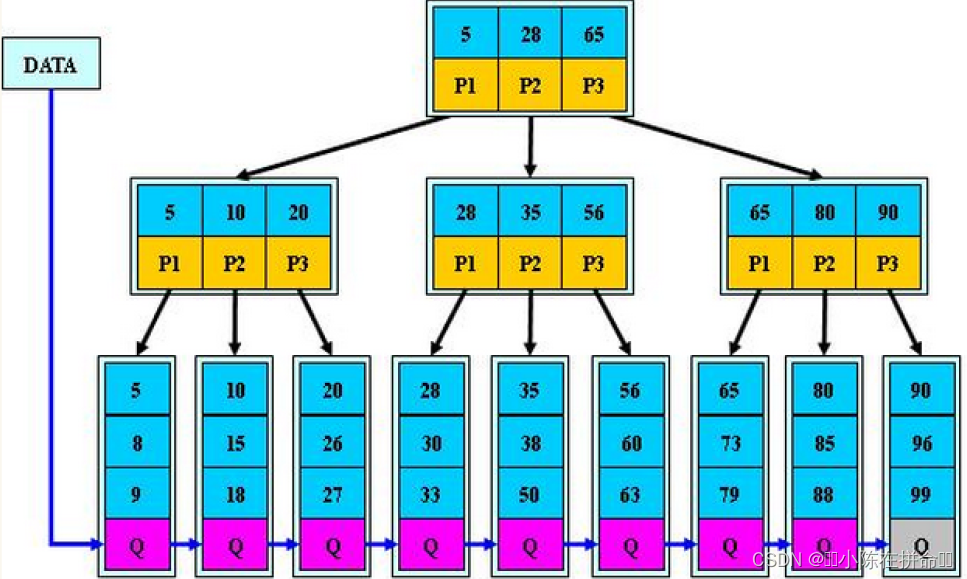
五、B树系列
5.1 B+树
B+树是B树的变形,是在B树基础上优化的多路平衡搜索树,B+树的规则跟B树基本类似,但是又在B树的基础上做了以下几点改进优化:
(1)分支节点的子树指针与关键字个数相同(相当于去掉了左边的子树,相比B树取消了孩子和关键字的包含关系,而是一一对应)

(2)分支节点的子树指针p[i]指向关键字值大小在[k[i],k[i+1])区间之间(和B树一致)
(3) 所有叶子节点增加一个链接指针链接在一起(这样就可以直接找到叶子节点,不一定需要从根去找了!!)
(4)所有关键字及其映射数据都在叶子节点出现(1、分支节点和叶子节点有重复的值,分支节点存的是叶子节点的索引->key.2、父亲中存的是孩子节点中的最小值做索引)
和B树规则区别总结:
1、简化B树孩子比关键字多一个的规则,变成了相等(一一对应)。
2、而key value都存在叶子节点上,一方面是节省空间,一方面是方便遍历查找所有值
B+树的特性:
1. 所有关键字都出现在叶子节点的链表中,且链表中的节点都是有序的。
2. 不可能在分支节点中命中(因为只存k而没有存kv)。
3. 分支节点相当于是叶子节点的索引,叶子节点才是存储数据的数据层
5.2 B+树的插入过程分析
用序列{53, 139, 75, 49, 145, 36, 50,47,101}构建B+树的过程如下:
1、插入53

2、插入139
 3、插入75
3、插入75
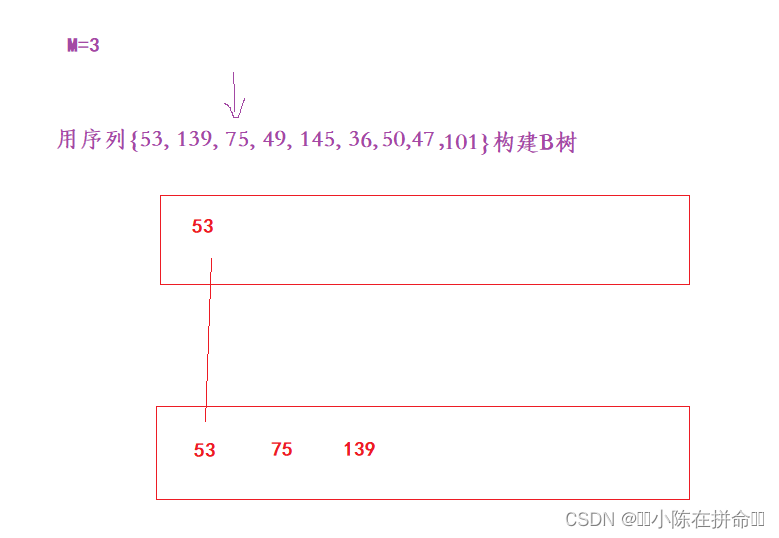
4、插入49
 5、分裂
5、分裂

6、插入145
 7、插入36
7、插入36
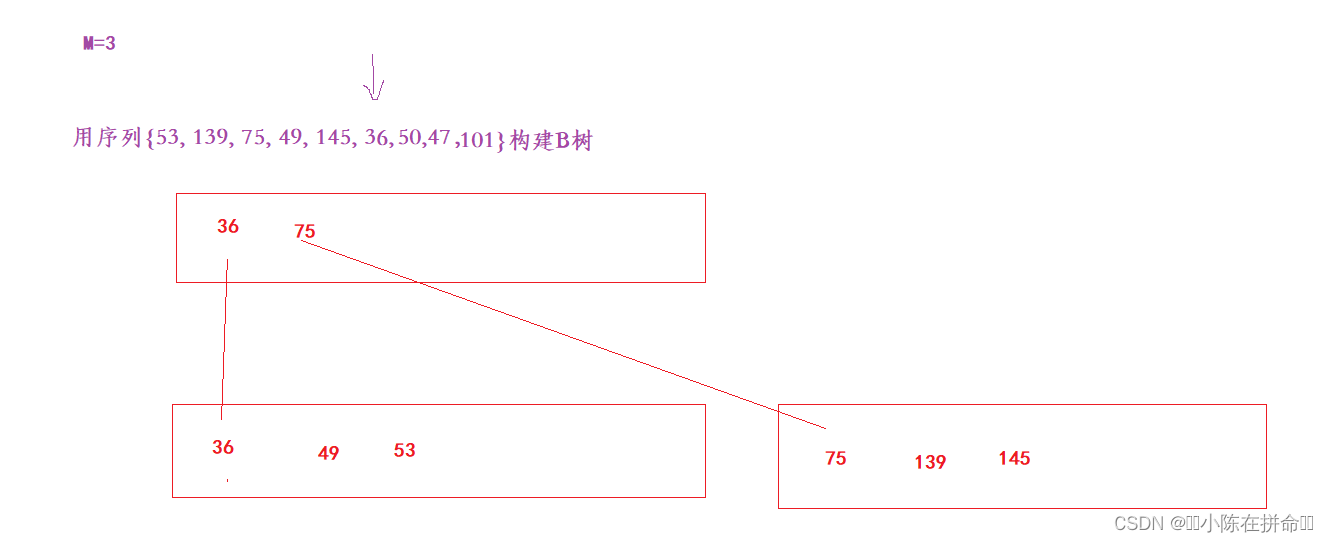
8、插入50

9、分裂
 10、插入47
10、插入47

11、插入101
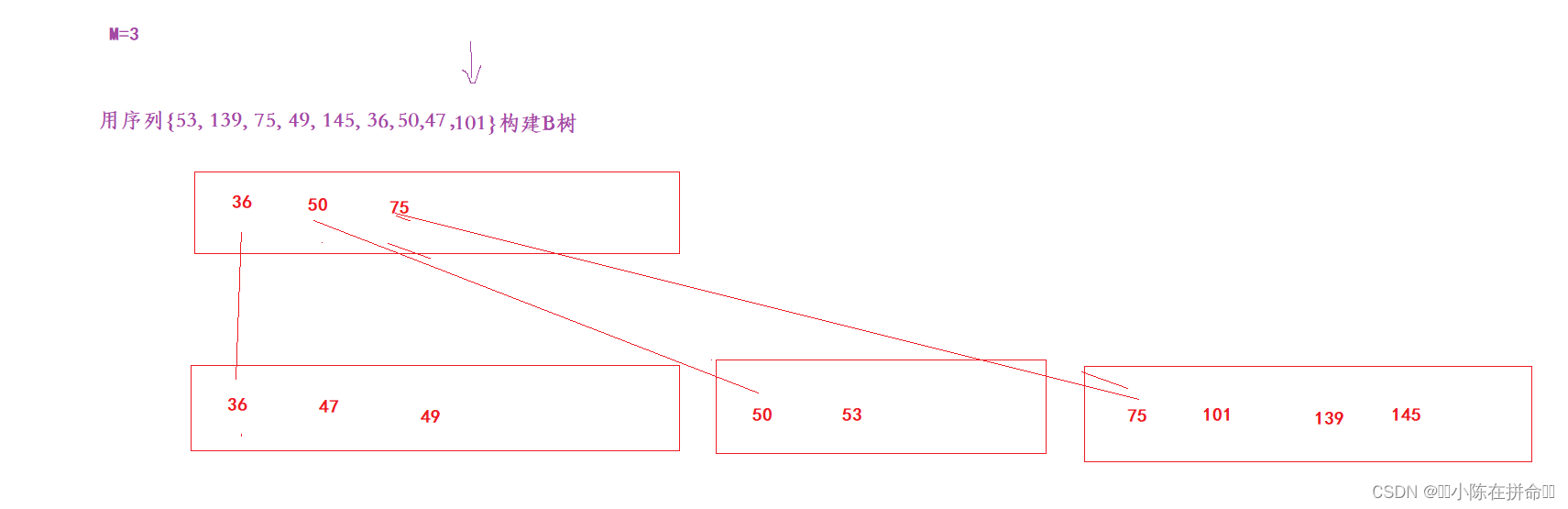 12、分裂
12、分裂
13、二次分裂
和B树插入的区别:
1、一开始创建的是两层,一层做根,一层做分支
2、父亲节点存的是孩子节点中的最小值做索引,如果最小值更新了,那么往上的索引值都要全部更新
3、孩子不再是比key多一个(包含关系),而是和key相等(一一对应关系)
4、分裂的时候,不再是把中位数往上拿,而是把分裂出来的兄弟节点的最小值往上拿
5.3 B*树
B*树是B+树的变形,在B+树的非根和非叶子节点再增加指向兄弟节点的指针。 为什么B*树的非叶子节点需要指向兄弟节点的指针呢?而B+树不需要呢? 究竟想达到什么目的?
为什么B*树的非叶子节点需要指向兄弟节点的指针呢?而B+树不需要呢? 究竟想达到什么目的?
B+树的分裂:
当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针。
B*树的分裂:
当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。(所以B*树的关键字和孩子数量->[2/3M——M])
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
5.3 B树系列总结
B树:有序数组+平衡多叉树;
B+树:有序数组链表+平衡多叉树;
B*树:一棵更丰满的,空间利用率更高的B+树。

相关文章:
DS高阶:B树系列
一、常见的搜索结构 1、顺序查找 时间复杂度:O(N) 2、二分查找 时间复杂度:O(logN) 要求:(1)有序 (2)支持下标的随机访问 3、二叉搜索树(BS树) 时间复杂…...

第五百零三回
文章目录 1. 概念介绍2. 使用方法2.1 普通路由2.2 命名路由 3. 示例代码4. 内容总结 我们在上一章回中介绍了"使用get显示Dialog"相关的内容,本章回中将介绍使用get进行路由管理.闲话休提,让我们一起Talk Flutter吧。 1. 概念介绍 我们在本章…...
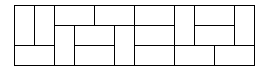
[动态规划] 完美覆盖
描述 一张普通的国际象棋棋盘,它被分成 8 乘 8 (8 行 8 列) 的 64 个方格。设有形状一样的多米诺牌,每张牌恰好覆盖棋盘上相邻的两个方格,即一张多米诺牌是一张 1 行 2 列或者 2 行 1 列的牌。那么,是否能够把 32 张多米诺牌摆放…...
redis深入理解之实战
1、SpringBoot整合redis 1.1 导入相关依赖 <dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId> </dependency> <dependency><groupId>org.springframework.boot</groupId><artifactId&g…...

python设计模式---工厂模式
定义了一个抽象类Animal,并且让具体的动物类(Dog、Cat、Duck)继承自它,并实现了speak方法。然后创建了AnimalFactory工厂类,根据传入的参数来决定创建哪种动物的实例。 from abc import abstractmethod, ABCclass Anim…...

探索Vue 3.0中的v-html指令
探索Vue 3.0中的v-html指令 一、什么是v-html指令?1、 在Vue 3.0中使用v-html2、 注意事项 二、结语 一、什么是v-html指令? Vue.js作为一款流行的JavaScript框架,不断地演进着。随着Vue 3.0的发布,开发者们迎来了更加强大和灵活…...

anaconda 环境配置
官方网站下载地址: https://www.anaconda.com/download/ 国内清华镜像下载地址: https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/ 配置国内环境: conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ …...

DS:顺序表、单链表的相关OJ题训练(2)
欢迎各位来到 Harper.Lee 的学习世界! 博主主页传送门:Harper.Lee的博客主页 想要一起进步的uu欢迎来后台找我哦! 一、力扣--141. 环形链表 题目描述:给你一个链表的头节点 head ,判断链表中是否有环。如果链表中有某个…...
上传到 PyPI
将软件包上传到 PyPI(Python Package Index),您需要遵循以下步骤: 准备软件包:确保您的软件包满足以下要求: 包含一个 setup.py 文件,用于描述软件包的元数据和依赖项。包含软件包的源代码和必要…...
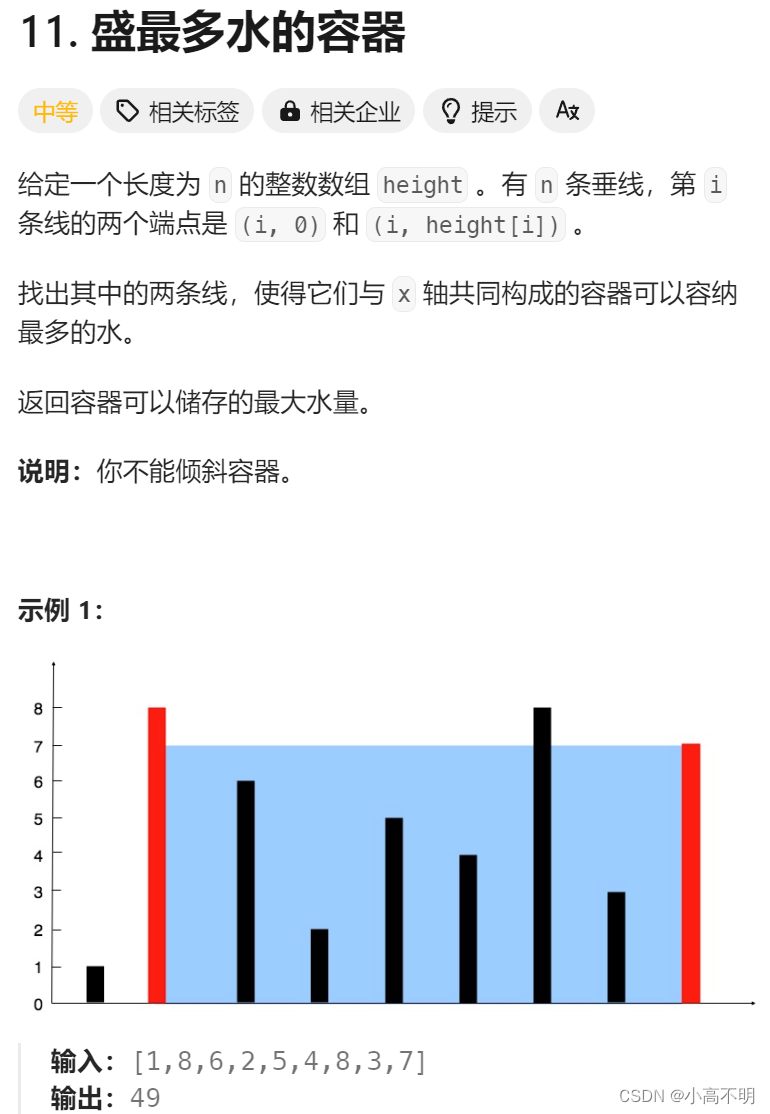
盛最多水的容器(双指针)
解题思路: 1,暴力解法(超时) 我们可以使用两层for循环进行遍历。找到那个最大的面积即可,这里我就不写代码了,因为写了也是超时。 2,双指针法 先定义两个指针一个在最左端,一个在…...
【深度学习】实验3 特征处理
特征处理 python 版本 3.7 scikit-learn 版本 1.0.2 1.标准化 from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import MinMaxScaler from matplotlib import gridspec import numpy as np import matplotlib.pyplot as plt cps np.random.…...
MoneyPrinter国内版改造
背景: MoneyPrinter 是一个自动生成短视频的开源项目。只需要输入短视频主题,然后就可以生成视频。 在国内环境运行时,框架中使用的youtube、抖音文字转语音等功能无法使用,需要对框架进行国内版改造,使其使用国内网络…...

C++ 派生类的引入与特性
一 继承与派生 从上面的例子可以看出: 继承:一旦指定了某种事物父代的本质特征,那么它的子代将会自动具有哪些性质。这就是一种朴素的可重用的概念。 派生:而且子代可以拥有父代没有的特性,这是可扩充的概念。 1 C 的…...
Poe是什么?怎样订阅Poe?
Poe(全称“开放探索平台”,Platform for Open Exploration)是一款由Quora开发的移动应用程序,于2022年12月推出。该应用程序内置建基于AI技术的聊天机器人,可供用户向机器人询问专业知识、食谱、日常生活,甚…...

基于FPGA的视频矩阵切换方案
一、单个显示设备的系统方案:会议室只有1个显示设备 会议室的信号源有很多,但是显示设备只有1个,这个时候最佳方案是使用切换器。 (1)切换器(控制方式:遥控器、软件、机箱面板、中控ÿ…...

.NET周刊【5月第1期 2024-05-05】
国内文章 一个开源轻量级的C#代码格式化工具(支持VS和VS Code) https://www.cnblogs.com/Can-daydayup/p/18164905 CSharpier是一个开源、免费的C#代码格式化工具,特点是轻量级且依赖Roslyn引擎重构代码格式。支持的IDE包括Visual Studio …...
springcloud -nacos实战
一、nacos 功能简介 1.1.什么是Nacos? 官方简介:一个更易于构建云原生应用的动态服务发现(Nacos Discovery )、服务配置(Nacos Config)和服务管理平台。 Nacos的关键特性包括: 服务发现和服务健康监测动态配置服务动态DNS服务服务及其元数…...

第十五章 数据管理成熟度评估练习
单选题 (每题1分,共19道题) 1、 [单选] 下列选项中属于数据管理成熟度2级特征的选项是? A:很少或没有治理;有限的工具集;单个竖井(系统)内定义角色;控件(如果有的话的应用完全不一致);未解决的数据质量问题 B:治理开始出现;引入一致的工具集;定义了一些角色和…...

tcpdump速查表
tcpdump 速查表 -D 列出网络设备 ~]$ sudo tcpdump -D1.eth02.nflog (Linux netfilter log (NFLOG) interface)3.nfqueue (Linux netfilter queue (NFQUEUE) interface)4.any (Pseudo-device that captures on all interfaces)5.lo [Loopback]-i 指定网卡 前面列出的设备可以…...

单元测试与集成测试:软件质量的双重保障
目录 概述 单元测试 集成测试 单元测试的方法 白盒测试 黑盒测试 白盒测试的方法和用例设计 代码审查 集成测试 单元测试工具 结语 在软件开发中,测试是一个不可或缺的环节,它能够帮助我们发现和修复缺陷,确保软件的质量和可靠性。…...

手把手教你学Simulink——基于 PWM 加相移混合控制的双向 DC-DC 变换器仿真
目录 手把手教你学Simulink——基于 PWM 加相移混合控制的双向 DC-DC 变换器仿真 摘要 Abstract 1. 引言 1.1 研究背景 1.2 本文目标 2. 混合控制机理 2.1 拓扑选择:双有源桥(DAB) 2.2 混合控制自由度 3. Simulink 主电路建模 3.1…...

2026实测:能耗管控场景下的AI工具数据分析能力横向对比,实在Agent如何通过ISSUT打破数据孤岛?
【摘要】 步入2026年,全球能源结构转型进入深水区。随着数据中心耗电量突破1000太瓦时(TWh)以及工业领域对“双碳”目标的刚性对标,能耗管控场景已成为企业运营的战略核心。然而,企业在推进自动化能效管理时࿰…...

3步快速上手AnotherRedisDesktopManager:Redis桌面管理终极指南
3步快速上手AnotherRedisDesktopManager:Redis桌面管理终极指南 【免费下载链接】AnotherRedisDesktopManager 🚀🚀🚀A faster, better and more stable Redis desktop manager [GUI client], compatible with Linux, Windows, Ma…...

长期使用Taotoken服务在稳定性与响应速度上的综合体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken服务在稳定性与响应速度上的综合体验 在持续数月的日常开发与测试工作中,我们团队将多个项目的大模型…...

用Logisim搞定Educoder交通灯实训:从数码管驱动到状态机集成的保姆级避坑指南
用Logisim征服Educoder交通灯实训:从零搭建到联调的全链路实战手册 第一次打开Educoder平台的交通灯实训项目时,我盯着那些闪烁的数码管和错综复杂的线路图,感觉像在破解某种外星密码。三小时后,当我的第一个状态机模块终于通过测…...

用ZYNQ和LWIP搞定8路ADS8681数据采集:从Vivado Block Design到上位机TCP通信的完整流程
ZYNQ与LWIP构建的8通道高速数据采集系统实战指南 在工业自动化、测试测量和科研领域,多通道高精度数据采集系统正变得越来越重要。本文将详细介绍如何利用Xilinx ZYNQ SoC和LWIP协议栈,构建一个支持8路ADS8681同步采集的实时数据传输系统。不同于简单的代…...

OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统
OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是…...

Windows驱动清理终极指南:用DriverStore Explorer安全释放数十GB磁盘空间
Windows驱动清理终极指南:用DriverStore Explorer安全释放数十GB磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你的Windows电脑是否经常提示C盘空间不足ÿ…...

GURU-Ai:面向开发者的AI命令行工具集,提升代码理解与运维效率
1. 项目概述:一个面向开发者的AI助手工具集最近在GitHub上看到一个挺有意思的项目,叫“Guru322/GURU-Ai”。光看名字,你可能会觉得这又是一个大而全的AI模型或者聊天机器人,但点进去仔细研究后,我发现它的定位其实非常…...

Qdrant客户端库实战:从向量数据库连接到生产级应用开发
1. 项目概述:从向量数据库到应用落地的桥梁如果你最近在折腾大模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率绕不开一个词:向量数据库。简单来说,它就像一个能理解“意思”的超级搜索引擎,不…...