图神经网络实战(10)——归纳学习
图神经网络实战(10)——归纳学习
- 0. 前言
- 1. 转导学习与归纳学习
- 2. 蛋白质相互作用数据集
- 3. 构建 GraphSAGE 模型实现归纳学习
- 小结
- 系列链接
0. 前言
归纳学习 (Inductive learning) 通过基于已观测训练数据,建立一个通用模型,使模型能够对未见过的节点和图进行归纳预测,而转导学习(Transductive learning, 也称直推学习)是基于所有已经观测到的训练和测试数据构建模型,这种方法是通过已经有标记的节点信息来预测无标记数据节点,因此,在图神经网络 (Graph Neural Networks, GNN)、图卷积网络 (Graph Convolutional Network, GCN)、图注意力网络 (Graph Attention Networks,GAT) 和 GraphSAGE 等节中所构建的模型均属于转导学习模型。在本节中,我们将介绍图数据中的归纳学习和多标签分类,使用 GraphSAGE 模型在蛋白质相互作用 (protein-protein interactions) 数据集执行多标签分类任务,并了解归纳学习的优势和实现方法。
1. 转导学习与归纳学习
在图神经网络 (Graph Neural Networks, GNN)中,可以将学习分为两类,转导学习(Transductive learning, 也称直推学习)和归纳学习 (Inductive learning):
- 在归纳学习中,
GNN在训练过程中只看到训练集中的数据,而在测试过程中需要对未见过的数据进行预测,这属于机器学习中典型的监督学习 (supervised learning)。在这种情况下,标签用来调整GNN的参数,模型需要具备良好的泛化能力,能够从有限的样本中推断出普遍适用的规律 - 在转导学习中,
GNN在训练过程中会看到来自训练集和测试集的数据,它通过对已有的样本进行学习来进行预测和分类。模型只从训练集中学习数据,模型会尝试将已有的样本归类到已知的类别中,并根据这些样本的特征进行预测,标签用于信息扩散。转导学习不是直接从训练集中学习出一般性的规律,而是利用图数据间的相似性或连接性进行预测
我们在之前构建的图神经网络 (Graph Neural Networks, GNN) 和图卷积网络 (Graph Convolutional Network, GCN) 属于转导学习情况。而 GraphSAGE 模型可以在训练过程中使用整个图进行预测 (self(batch.x, batch.edge_index)),然后部分屏蔽这些预测,只使用训练数据计算损失并训练模型 (criterion(out[batch.train_mask], batch.y[batch.train_mask]))。
转导学习只能为固定的图生成嵌入,不能泛化到未见过的节点或图。但由于采用了邻居采样,GraphSAGE 可以在局部水平上对经过剪枝的计算图进行预测,这种情况下属于归纳学习框架,可以应用于具有相同特征模式的任何计算图。
2. 蛋白质相互作用数据集
在 GraphSAGE 一节中,我们已经在 PubMed 数据集上构建 GraphSAGE 模型实现了转导学习。接下来,我们将 GraphSAGE 应用于由 Agrawal 等人提出的蛋白质相互作用 (protein-protein interaction, PPI) 网络数据集。该数据集是 24 个图的集合,其中节点( 21,557 个)是人类蛋白质,边( 342,353 条)是人类细胞中蛋白质之间的连接。用 Gephi 制作的 PPI 图数据集可视化结果如下所示:

该数据集的目标是使用 121 个标签进行多标签分类,这意味着每个节点可以具有 0 到 121 个标签。这不同于多类别分类,多类别分类中每个节点只会属于一个类别。接下来,我们使用 PyTorch Geometric (PyG) 实现 GraphSAGE 模型用于对 PPI 数据集执行多标签分类任务。
(1) 将 PPI 数据集加载为三个不同的子集,训练集、验证集和测试集:
import torch
from sklearn.metrics import f1_scorefrom torch_geometric.datasets import PPI
from torch_geometric.data import Batch
from torch_geometric.loader import DataLoader, NeighborLoader
from torch_geometric.nn import GraphSAGE# Load training, evaluation, and test sets
train_dataset = PPI(root=".", split='train')
val_dataset = PPI(root=".", split='val')
test_dataset = PPI(root=".", split='test')
(2) 训练集包含 20 个图,而验证集和测试集只有两个图。对训练集应用邻居采样,为了方便起见,使用 Batch.from_data_list() 将所有训练图统一到一个集合中,然后应用邻居采样:
train_data = Batch.from_data_list(train_dataset)
train_loader = NeighborLoader(train_data, batch_size=2048, shuffle=True, num_neighbors=[20, 10], num_workers=2, persistent_workers=True)
(3) 训练集创建完毕后,使用 DataLoader 类创建批数据,将 batch_size 值定义为 2,与每批图的数量相对应:
val_loader = DataLoader(val_dataset, batch_size=2)
test_loader = DataLoader(test_dataset, batch_size=2)
(4) 定义设备使批处理能够在 GPU 上进行处理。如果计算机中有 GPU,使用 GPU,否则就使用 CPU:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
3. 构建 GraphSAGE 模型实现归纳学习
使用 PyTorch Geometric 的 torch_geometric.nn 模块构建 GraphSAGE 模型。
(1) 使用 GraphSAGE() 类初始化一个两层的 GraphSAGE 模型,其中隐藏维度为 512,此外,还需要使用 to(device) 将模型放置在与数据相同的设备上:
model = GraphSAGE(in_channels=train_dataset.num_features,hidden_channels=512,num_layers=2,out_channels=train_dataset.num_classes,
).to(device)
(2) fit() 函数与 GraphSAGE 一节中使用的函数类似,不同之处在于,我们希望尽可能将数据移动到 GPU 上,并且由于每批数据有两个图,因此将损失乘以 2 (data.num_graphs):
criterion = torch.nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.005)def fit(loader):model.train()total_loss = 0for data in loader:data = data.to(device)optimizer.zero_grad()out = model(data.x, data.edge_index)loss = criterion(out, data.y)total_loss += loss.item() * data.num_graphsloss.backward()optimizer.step()return total_loss / len(loader.data)
由于 val_loader 和 test_loader 包含两个图且 batch_size 值为 2,因此在 test() 函数中,两个图位于同一个批数据中,而无需像训练时那样在加载器中循环。
(3) 使用度量指标 F1 分数代替准确率,F1 分数相当于精确度和召回率的调和平均值。但,模型的预测结果是 121 维的实数向量,我们需要将其转换成二进制向量,使用 out > 0 将它们与 data.y 进行比较:
@torch.no_grad()
def test(loader):model.eval()data = next(iter(loader))out = model(data.x.to(device), data.edge_index.to(device))preds = (out > 0).float().cpu()y, pred = data.y.numpy(), preds.numpy()return f1_score(y, pred, average='micro') if pred.sum() > 0 else 0
(4) 对模型进行 300 个 epoch 的训练,并打印训练过程中模型在验证数据集上的 F1 分数:
for epoch in range(301):loss = fit(train_loader)val_f1 = test(val_loader)if epoch % 50 == 0:print(f'Epoch {epoch:>3} | Train Loss: {loss:.3f} | Val F1-score: {val_f1:.4f}')
'''
Epoch 0 | Train Loss: 12.686 | Val F1-score: 0.4866
Epoch 50 | Train Loss: 8.734 | Val F1-score: 0.7963
Epoch 100 | Train Loss: 8.600 | Val F1-score: 0.8098
Epoch 150 | Train Loss: 8.531 | Val F1-score: 0.8202
Epoch 200 | Train Loss: 8.495 | Val F1-score: 0.8230
Epoch 250 | Train Loss: 8.497 | Val F1-score: 0.8255
Epoch 300 | Train Loss: 8.432 | Val F1-score: 0.8290
'''
(5) 最后,计算测试集上的 F1 分数:
print(f'Test F1-score: {test(test_loader):.4f}')# Test F1-score: 0.8527
可以看到,在归纳学习中,模型在 PPI 数据集上训练后的 F1 分数为 0.9360。当增加或减少隐藏维度的大小时,模型的性能会有有大幅改变,我们可以使用不同的值,如 128 和 1,024,并观察训练的后的模型 F1 分数变化。
需要注意的是,在以上代码中,我们并未显式的使用掩码。这是由于实际上,归纳学习是由 PPI 数据集强制实现的;训练数据、验证数据和测试数据位于不同的图和数据加载器中。我们也可以使用 Batch.from_data_list() 将它们合并,然后再使用归纳学习的设定。
小结
在本节中,学习了图神经网络中转导学习(Transductive learning, 也称直推学习)和归纳学习 (Inductive learning) 的区别。其中,图神经网络中的归纳学习通常指的是从给定的训练图数据中学习出一个泛化能力强的模型,以便对未知图数据中的节点或边进行预测或分类,而转导学习通常指的是利用训练图数据和测试图数据之间的关联性进行推断,从而对给定的测试图数据进行预测或分类。并且构建了 GraphSAGE 模型在 PPI 数据集上测试了归纳学习,以执行多标签分类任务。
系列链接
图神经网络实战(1)——图神经网络(Graph Neural Networks, GNN)基础
图神经网络实战(2)——图论基础
图神经网络实战(3)——基于DeepWalk创建节点表示
图神经网络实战(4)——基于Node2Vec改进嵌入质量
图神经网络实战(5)——常用图数据集
图神经网络实战(6)——使用PyTorch构建图神经网络
图神经网络实战(7)——图卷积网络(Graph Convolutional Network, GCN)详解与实现
图神经网络实战(8)——图注意力网络(Graph Attention Networks, GAT)
图神经网络实战(9)——GraphSAGE详解与实现
相关文章:
图神经网络实战(10)——归纳学习
图神经网络实战(10)——归纳学习 0. 前言1. 转导学习与归纳学习2. 蛋白质相互作用数据集3. 构建 GraphSAGE 模型实现归纳学习小结系列链接 0. 前言 归纳学习 (Inductive learning) 通过基于已观测训练数据,建立一个通用模型,使模…...
Python——IO编程
IO在计算机中指Input/Output,也就是输入和输出。由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘、网络等,就需要IO接口。 比如你打开浏览器,访问新浪…...
什么是网络端口?为什么会有高危端口?
一、什么是网络端口? 网络技术中的端口默认指的是TCP/IP协议中的服务端口,一共有0-65535个端口,比如我们最常见的端口是80端口默认访问网站的端口就是80,你直接在浏览器打开,会发现浏览器默认把80去掉,就是…...
CleanMyMac X v4.14.6中文破解版,让您的电脑像新的一样
小编给您带来CleanMyMac X v4.14.6中文破解版,CleanMyMac X破解版是应用在MacOS上的一款Mac系统清理优化工具,使用cleanmymac x 中文破解版只需两个简单步骤就可以把系统里那些乱七八糟的无用文件统统清理掉,节省宝贵的磁盘空间。 CleanMyMa…...
LeetCode 235. 二叉搜索树的最近公共祖先
LeetCode 235. 二叉搜索树的最近公共祖先 1、题目 题目链接:235. 二叉搜索树的最近公共祖先 给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表…...
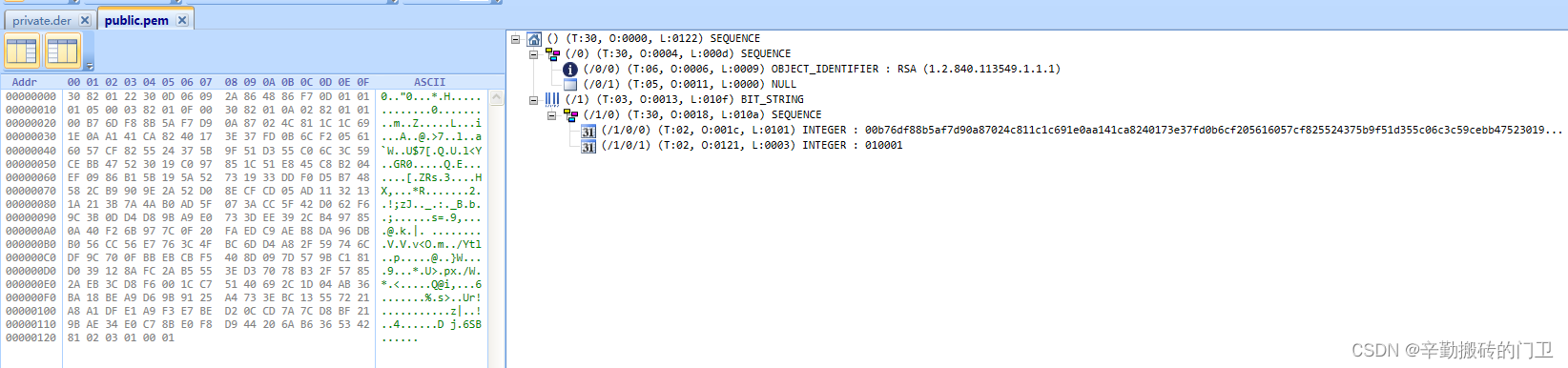
基于ASN.1的RSA算法公私钥存储格式解读
1.概述 RFC5958主要定义非对称密钥的封装语法,RFC5958用于替代RFC5208。非对称算法会涉及到1对公私钥,例如按照RSA算法,公钥是n和e,私钥是d和n。当需要将公私钥保存到文件时,需按照一定的格式保存。本文主要定义公私钥…...

RS2227XN功能和参数介绍及PDF资料
RS2227XN是一款模拟开关/多路复用器 品牌: RUNIC(润石) 封装: MSOP-10 描述: USB2.0高速模拟开关 开关电路: 双刀双掷(DPDT) 通道数: 2 工作电压: 1.8V~5.5V 导通电阻(RonVCC): 10Ω 功能:模拟开关/多路复用器 USB2.0高速模拟开关 工作电压范围:1.8V ~ 5…...

机器人非线性阻抗控制系统
机器人非线性控制系统本质上是一个复杂的控制系统,其状态变量和输出变量相对于输入变量的运动特性不能用线性关系来描述。这种系统的形成基于两类原因:一是被控系统中包含有不能忽略的非线性因素,二是为提高控制性能或简化控制系统结构而人为…...
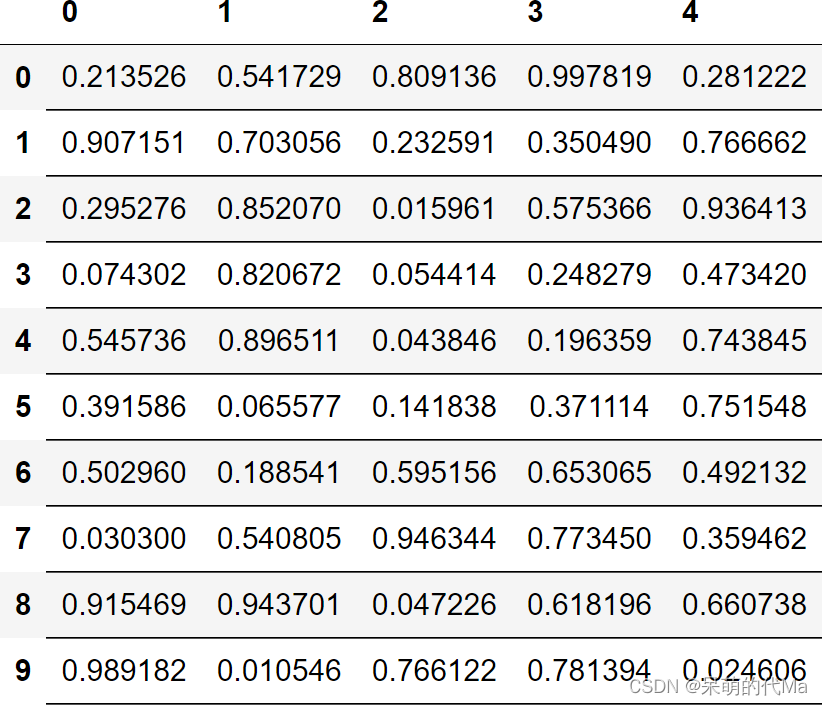
pandas style添加表格边框,或是只添加下边框等自定义边框样式设置
添加表格边框 可以使用如下程序添加表格: import dataframe_image as dfi import pandas as pd import numpy as npdf pd.DataFrame(np.random.random(size(10, 5))) df_style df.style.set_properties(**{text-align: center,border-color: black,border-width…...

OpenHarmony 3GPP协议开发深度剖析——一文读懂RIL
市面上关于终端(手机)操作系统在 3GPP 协议开发的内容太少了,即使 Android 相关的学习文档都很少,Android 协议开发书籍我是没有见过的。可能是市场需求的缘故吧,现在市场上还是前后端软件开发从业人员最多,…...
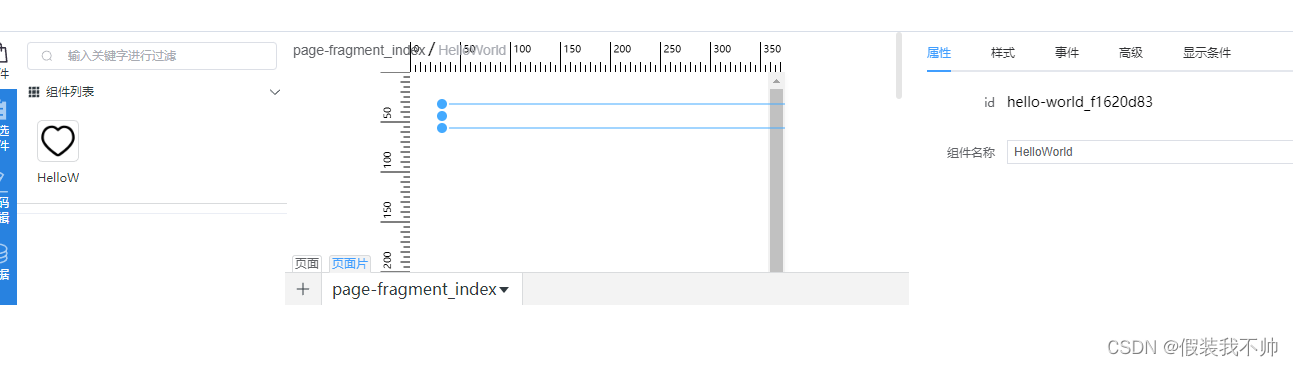
windows部署腾讯tmagic-editor02-Runtime
创建editor项目 将上一教程中的hello-world复制过来,改名hello-editor 创建runtime项目 和hello-editor同级 pnpm create vite删除src/components/HelloWorld.vue 按钮需要用的ts types依赖 pnpm add tmagic/schema tmagic/stage实现runtime 将hello-editor中…...
 函数的构建细节)
“分块”算法的基本要素及 build() 函数的构建细节
【“分块”算法知识点】 ● 分块是用线段树的分区思想改良的暴力法。代码比线段树简单。效率比普通暴力法高。分块适合求解 m=n=10^5 规模的问题,或 m*sqrt(n)≈10^7 的问题。其中,n 为元素个数,m 为操作次数。 ● “分块”算法的基本要素 (1)块的大小用 block 表示。通常…...
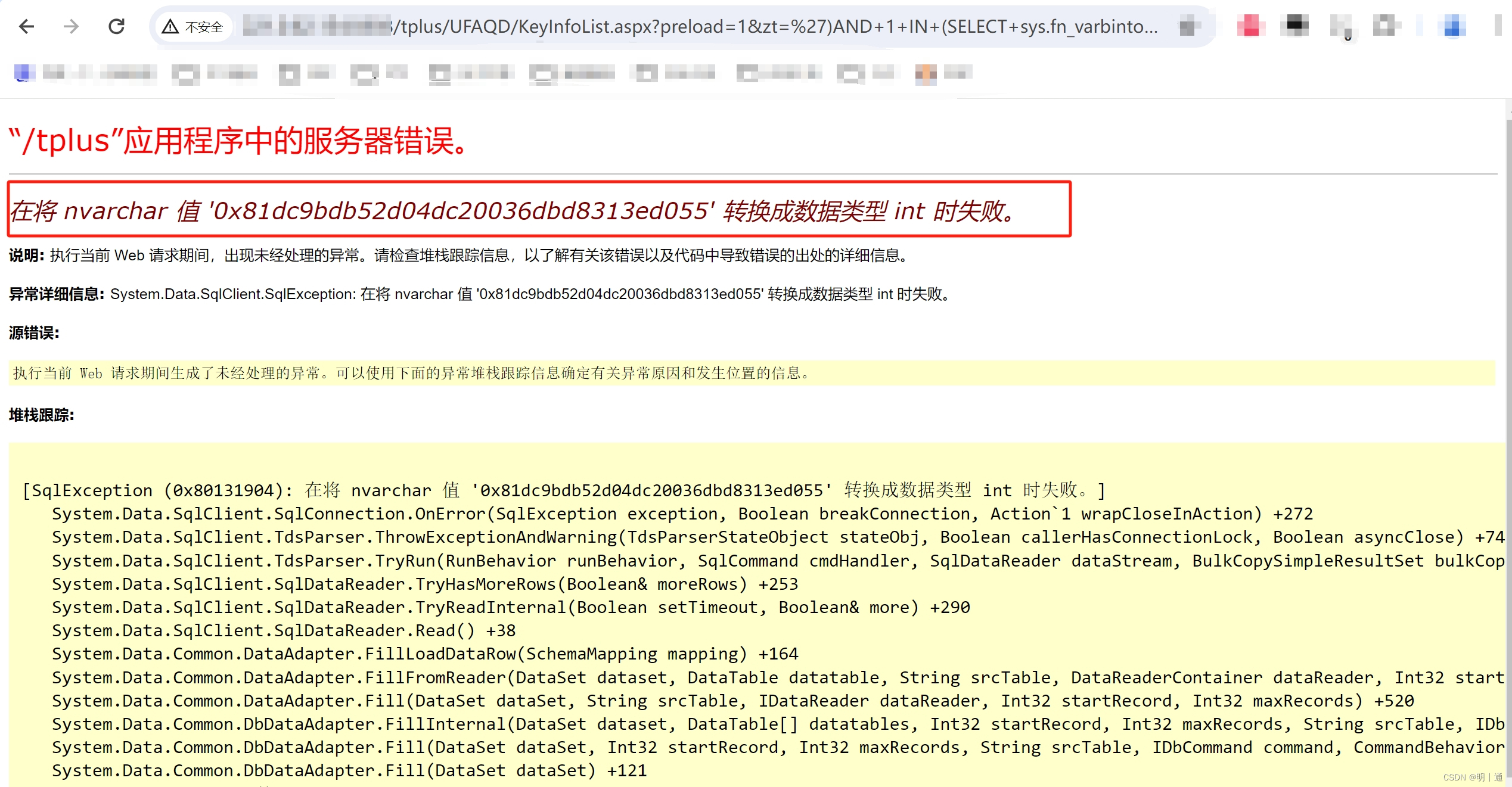
畅捷通TPlus keyEdit.aspx、KeyInfoList.aspx SQL注入漏洞复现
前言 免责声明:请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失,均由使用者本人负责,所产生的一切不良后果与文章作者无关。该文章仅供学习用途使用。 一、产…...
Ubuntu22 下配置 Qt5 环境
1. Qt 简介 Qt5 中的新功能,可以看到各个版本的情况Whats New in Qt 5 | Qt 5.15 Qt 源文件网址Index of /archive/qt 2. 安装 Qt Creator cd 到安装包所在目录,进行软件安装。赋予可执行权限,加上 sudo 权限进入安装,这样会安…...

普通人也能创业!轻资产短视频带货项目,引领普通人实现创业梦想
在这个信息爆炸的时代,创业似乎成为了越来越多人的梦想。然而,传统的创业模式 keJ0277 往往伴随着高昂的资金投入和复杂的管理流程,让许多普通人望而却步。然而,现在有一种轻资产短视频带货项目正在悄然兴起,它以其低…...
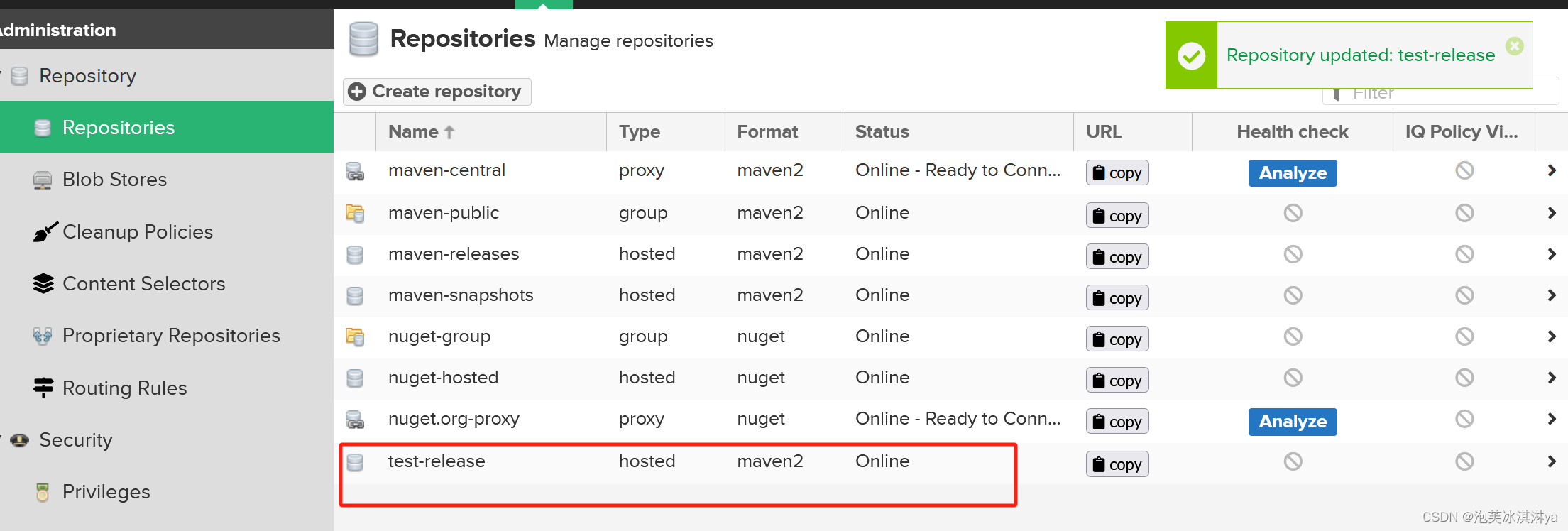
【Maven】Nexus简单使用
1、安装配置介绍Nexus私服: 安装配置指路上一篇详细教程博客 【Maven】Nexus私服简介_下载安装_登录-CSDN博客 简单介绍原有仓库类型: proxy代理仓库:代理远程仓库,访问全球中央仓库或其他公共仓库,将资源存储在私…...

winform嵌入excel 设置父窗体分辨率不是100% 嵌入excel分辨率变成双倍大小
在WinForms应用程序中嵌入Excel时,遇到分辨率问题可能是由于DPI缩放导致的。Windows 10及更高版本默认启用了DPI缩放,以便在高分辨率显示器上显示更清晰的内容。这可能会导致嵌入的应用程序(如Excel)看起来变大或变小。 解决方案 …...

前端系列-4 promise与async/await与fetch/axios使用方式
背景: 本文介绍promise使用方式,以及以Promise为基础的async/await用法和fetch/axios使用方式,主要以案例的方式进行。 1.promise 1.1 promise介绍 javascript是单线程执行的,异步编程的本质是事件机制和函数回调。当执行阻塞…...

微信公众号自定义分销商城小程序源码系统 带完整的安装代码吧以及系统部署搭建教程
系统概述 微信公众号自定义分销商城小程序源码系统是一款功能强大的电商解决方案,它集成了商品管理、订单处理、支付接口、分销管理等多种功能。该系统支持自定义界面设计,商家可根据自身需求调整商城的页面布局和风格,打造独特的品牌形象。…...
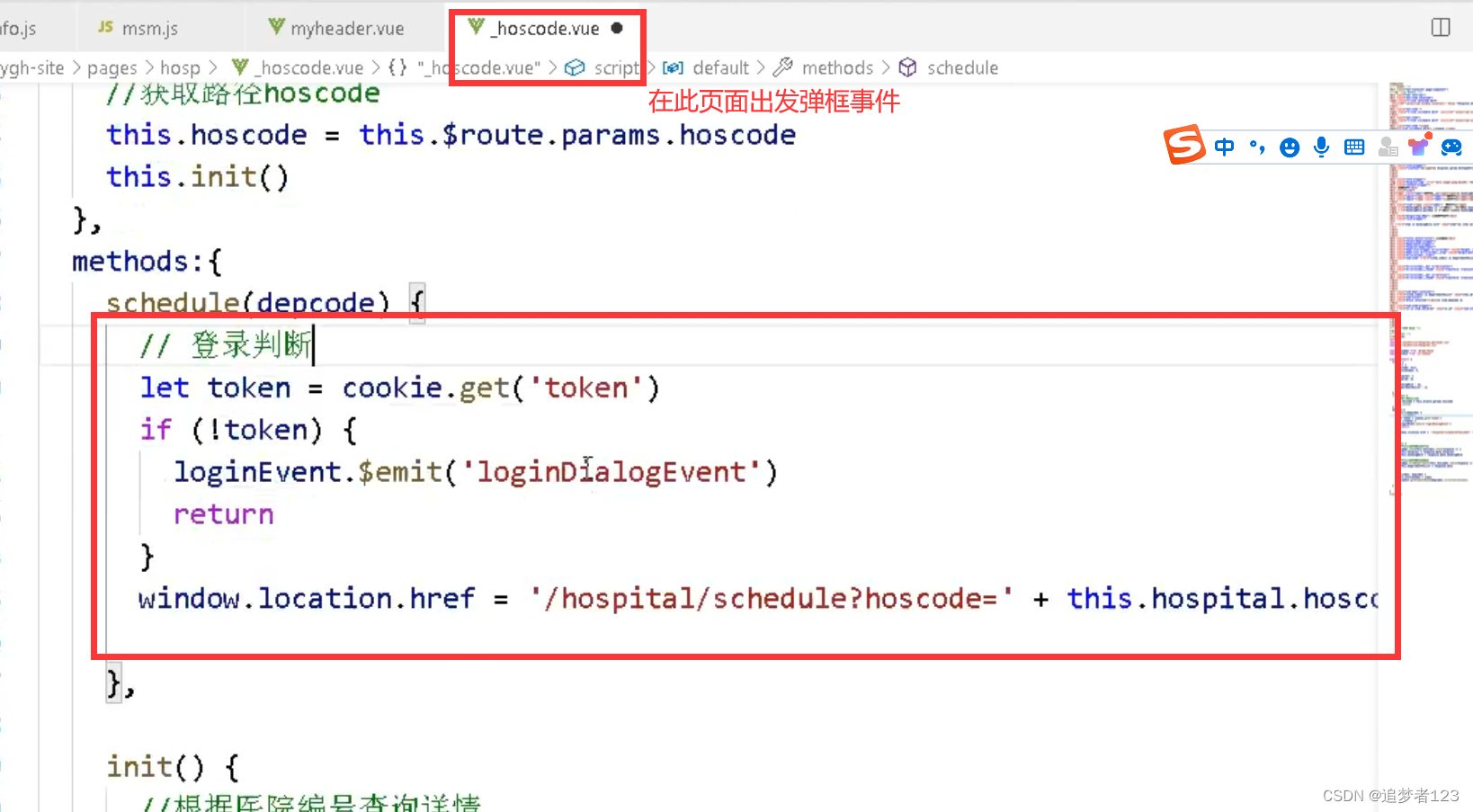
在另外一个页面,让另外一个页面弹框显示操作(调佣公共的弹框)vue
大概意思是,登录弹框在另外一个页面中,而当前页面不存在,在当前页面中判断如果token不存在,就弹框出登录的弹框 最后一行 window.location.href … 如果当前用户已登录,则执行后续操作(注意此处,可不要)...

智慧树自动刷课神器Autovisor:3分钟极速上手的完整指南
智慧树自动刷课神器Autovisor:3分钟极速上手的完整指南 【免费下载链接】Autovisor 2025智慧树刷课脚本 基于Python Playwright的自动化程序 [有免安装版] 项目地址: https://gitcode.com/gh_mirrors/au/Autovisor 还在为智慧树平台的繁琐操作而烦恼吗&#…...

避坑指南:Unity游戏在Linux上运行报错?OpenCV依赖和文件权限问题排查实录
Unity游戏Linux部署避坑指南:从权限修复到OpenCV依赖全解析 当你在Ubuntu上双击那个刚导出的Unity游戏.x86_64文件时,屏幕却弹出一行冰冷的错误信息——这种从云端跌入谷底的体验,每个跨平台开发者都经历过。不同于Windows的一键运行…...

【ElevenLabs情绪模拟技术白皮书】:基于2,147小时情感语音标注数据集的11类基础情绪迁移模型验证报告
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术白皮书概述 ElevenLabs的情绪模拟技术并非简单调节音高或语速,而是基于多模态情感表征学习(Multimodal Affective Representation Learning, MARL&#x…...

基于Nginx-Lua镜像构建高性能可编程网关的实践指南
1. 项目概述:一个为现代Web架构而生的Nginx镜像如果你和我一样,长期在容器化环境中部署和管理Web服务,那么你一定对Nginx的灵活性和Lua脚本的强大能力印象深刻。但将这两者结合,并打包成一个稳定、安全、功能齐全的Docker镜像&…...

Docker容器MCP服务镜像:AI安全运维与自动化实践
1. 项目概述:一个为Docker容器提供MCP服务的镜像最近在折腾一些自动化工作流,发现很多工具都开始支持一种叫做MCP(Model Context Protocol)的协议。简单来说,MCP就像是一个标准化的“插座”,让各种AI模型&a…...

Deep Lake:AI数据湖与向量数据库一体化管理实践
1. 项目概述:当数据湖遇上深度学习如果你正在构建一个AI应用,无论是图像识别、自然语言处理还是多模态模型,数据管理绝对是你绕不开的“硬骨头”。数据分散在各个文件夹、云存储、数据库里,格式五花八门,加载速度慢&am…...

Git Worktree CLI工具:告别分支切换焦虑,实现高效并行开发
1. 项目概述与核心价值如果你和我一样,长期在多个Git分支间穿梭,同时维护着几个不同的功能特性或修复补丁,那你一定对那种在分支间反复切换、代码状态混乱、甚至不小心提交到错误分支的“切分支焦虑症”深有体会。传统的git checkout或git sw…...
pydantic-settings、核心BaseModel、字段约束Field()、FastAPI)
Python Pydantic介绍(数据校验、自动类型转换、结构化数据建模、序列化JSON、配置管理)pydantic-settings、核心BaseModel、字段约束Field()、FastAPI
文章目录Python 数据校验神器:Pydantic 完全指南一、什么是 Pydantic二、Pydantic 能解决什么问题1)数据校验(Validation)2)自动类型转换(Parsing)3)结构化数据建模4)序列…...

数据模型代码生成器:从OpenAPI/Schema自动生成Python类型安全模型
1. 项目概述:当数据模型遇上代码生成如果你经常和数据模型打交道,无论是OpenAPI规范、JSON Schema,还是数据库的DDL,那你一定体会过手动编写对应数据类(Data Class)或Pydantic模型的繁琐。一个字段类型写错…...

3分钟快速上手:m4s-converter让B站缓存视频秒变MP4格式
3分钟快速上手:m4s-converter让B站缓存视频秒变MP4格式 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在当今数字内容时代ÿ…...