滴滴三面 | Go后端研发
狠狠的被鞭打了快两个小时… 注意我写的题解不一定是对的,如果你认为有其他答案欢迎评论区留言
bg:23届 211本 社招
1. 自我介绍
2. 讲一个项目的点,因为用到了中间件平台的数据同步,于是开始鞭打数据同步。。
3. 如果同步的时候,插入了新数据怎么处理?
看我们业务对数据实时性的要求
- 如果实时性要求不高,可以设置定时任务,T+1小时、T+30分钟进行同步或者统一处理
- 如果实时性要求高,我们可以监听binlog进行消费,不过要做好
幂等性方面的工作,防止重复消费
4. binlog有什么用?
binlog是存储mysql的数据变更,我们可以通过监听binlog知道数据库发生了哪些变更,通常可以使用binlog进行数据同步、数据备份以及主从复制等等…
6. binlog的数据格式有哪些?
binlog日志有三种数据格式
- STATEMENT:每一条修改数据的
原声 SQL 语句都会被记录到 binlog 中。但有动态函数的问题,比如你用了 uuid 或者 now 这些函数,那么就会导致主库上执行的结果并不是从库执行的结果,这种随时在变的函数就会导致复制前后的数据不一致。 - ROW:
记录行数据最终被修改成什么样了,不会出现 STATEMENT 下动态函数的问题。但 ROW 的缺点是每行数据的变化结果都会被记录,比如执行UPDATE user_user SET a = 1 WHERE id > 100语句,那么有多少行数据产生了变化,日志就会记录多少,这会使 binlog 文件过大,而在 STATEMENT 格式下只会记录一个 update 语句而已; - MIXED:包含了 STATEMENT 和 ROW 模式,
它会根据不同的情况自动使用 ROW 模式和 STATEMENT 模式
7. 如何监听binlog?
一般有两种方案:
- 基于 canal 中间件进行监听binlog
- 基于flinkcdc监听binlog
其实这两种区别不大,业内常用的是flinkcdc来监听。原理就是模拟主从复制,将自身模拟程一个slave节点,向master节点发送dump协议,当master节点收到dump协议请求之后,就开始推送binlog到slave。
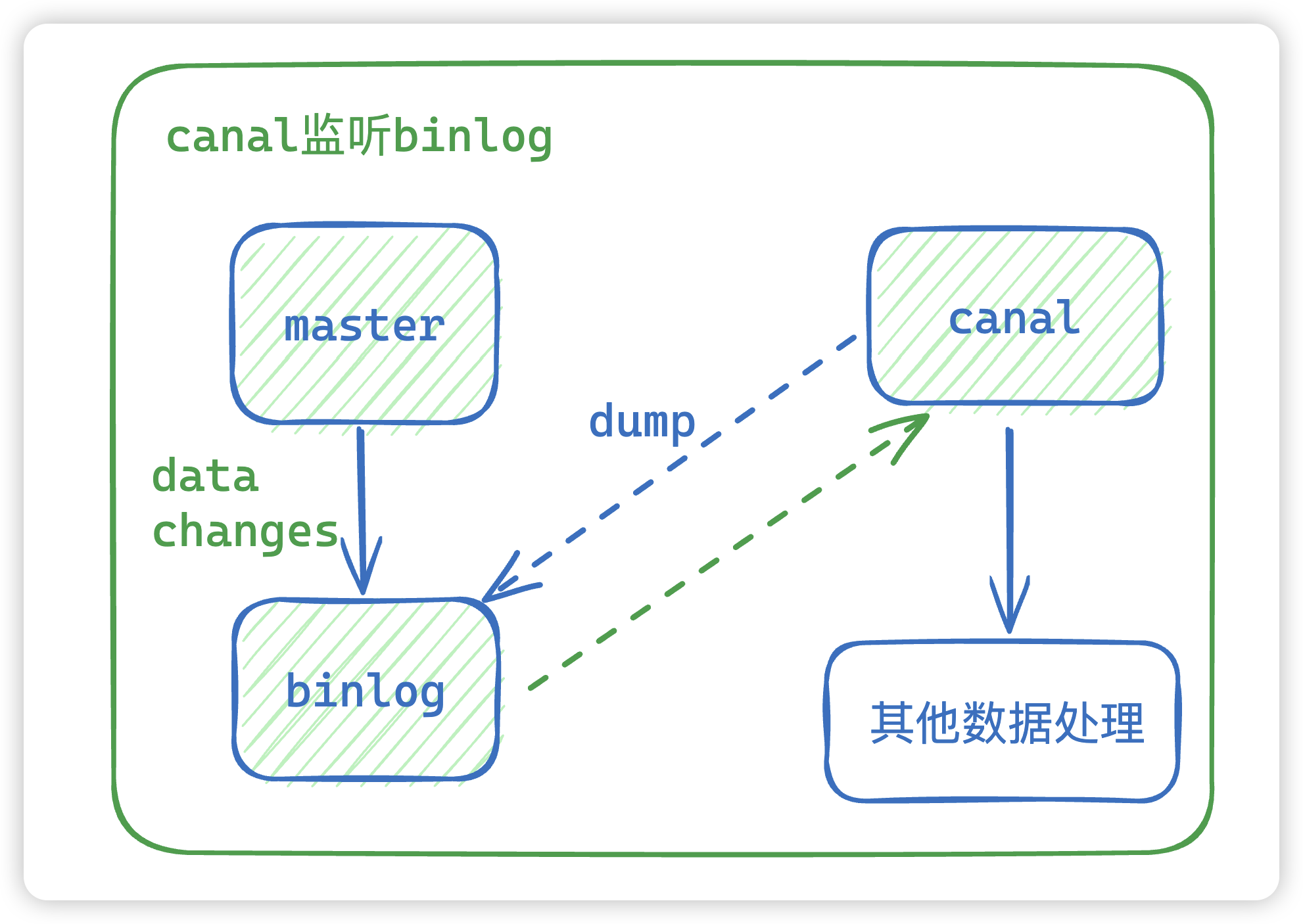
8. mysql dump 之后需要进行什么处理?
一般接受到的是byte流数据,我们需要解析 binary log 对象才能拿到正在的变更后的数据。那么在接收到主服务器上的 dump 数据后,会根据数据的类型(SQL 查询语句或 Binlog)来进行处理,如果是STATEMENT格式就直接执行sql,如果是ROW格式就直接记录数据。(不确定是不是这样)
9. 唯一索引和联合索引有什么区别?
- 唯一索引是指索引列的取值必须是唯一的,索引列中的值
不能重复。如果尝试插入重复值,数据库会抛出唯一性约束错误。 - 联合索引是指
索引包含多个列,通过这些列的组合值进行索引。当查询时涉及到联合索引的所有列,数据库会使用该联合索引进行优化查询,提高多列查询的效率,特别是当这些列经常一起作为查询条件时。联合索引中的列顺序很重要,查询时必须按照最左匹配原则进行查询,否则索引无法生效。
10. 联合索引可以是唯一索引吗?
可以的,这样就意味着索引列的组合值必须是唯一
举个例子:
创建下面一张表结构,如下结构,我们创建了一个联合的唯一索引,username和email作为联合的唯一索引列
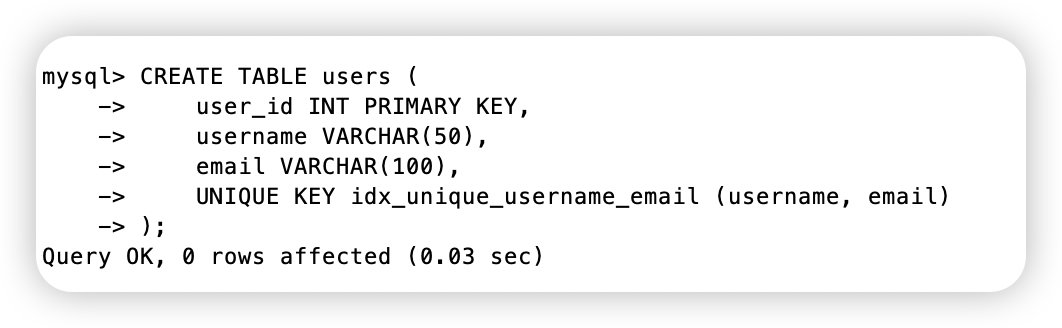
当我们插入数据

插入相同索引数据的时候,就会报错了

11. 那mysql索引结构是什么样的?
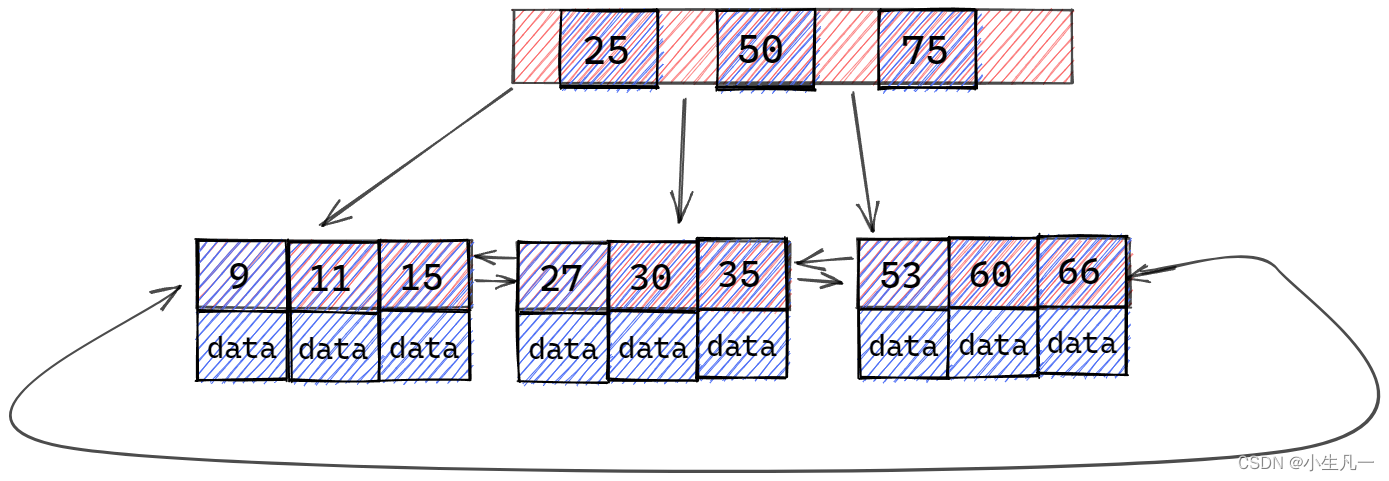
mysql的索引结构是B+树,
- 根节点:包含指向子节点的指针。
- 中间节点:包含
索引键值和指向子节点的指针。 - 叶子节点:包含
索引键值和指向实际数据行的指针。
数据按照索引键值的顺序存储在叶子节点中,这样可以通过在树中进行一系列比较操作来快速定位到所需的数据行。叶子节点之间通过指针连接,形成一个有序的链表,这样可以支持范围查询和排序操作。
12. 一个索引的建立过程是什么样的?
- 插入数据:当插入一个新的数据项时,首先在叶子节点中找到合适的位置插入数据。如果插入后叶子节点的数据项数量超过了阶数的限制,就需要进行
节点分裂操作。 - 节点分裂:当一个节点中的数据项数量超过了阶数的限制时,该节点需要进行分裂。分裂操作会将该节点中的数据项分为两部分,然后将
中间值上移到父节点中,以保持 B+树的平衡性。 - 向上递归:如果父节点也满足不了插入新数据项的条件,就需要继续
向上递归进行节点分裂操作,直到根节点。如果根节点也满了,则根节点会分裂成两个节点,同时树的高度增加一层。 - 更新索引:在每次节点分裂后,需要
更新父节点的索引信息,确保索引的正确性。 - 删除数据:删除数据时,首先在叶子节点中找到要删除的数据项,然后将其删除。如果
删除后导致节点的数据项数量低于阶数要求的最小值,需要进行节点合并操作。 - 节点合并:
当一个节点中的数据项数量低于阶数要求的最小值时,该节点需要与其兄弟节点进行合并操作。合并操作会将两个节点合并成一个节点,并将父节点中的相应索引项删除。
13. 如果我对age字段建立索引,建立的过程是什么样的?
举个age的例子:
最开始的时候是一段链表
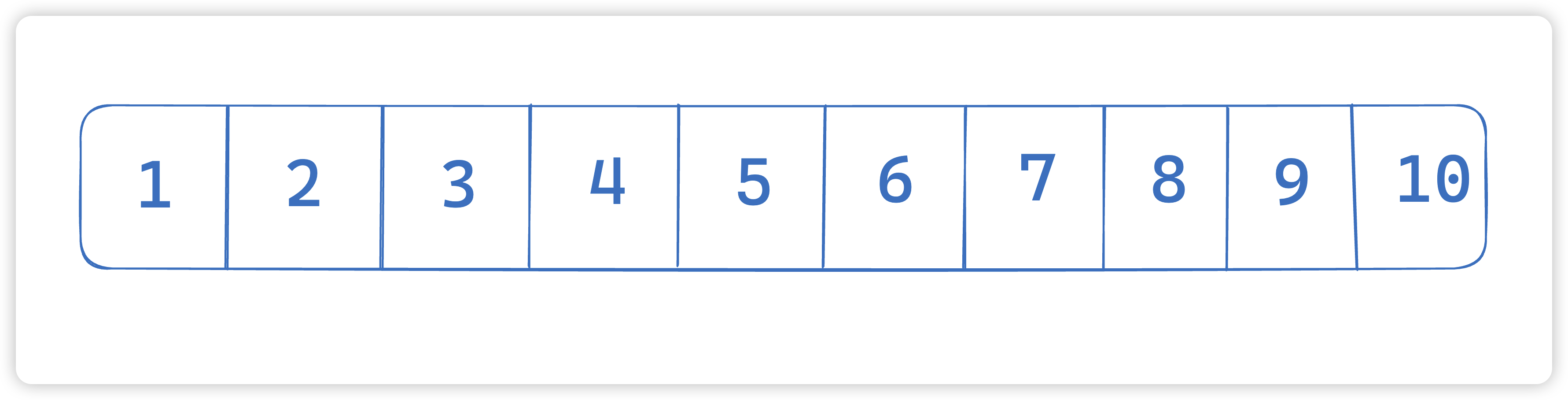
然后当我们数据变多的时候,会对这个链表进行拆分,抽取
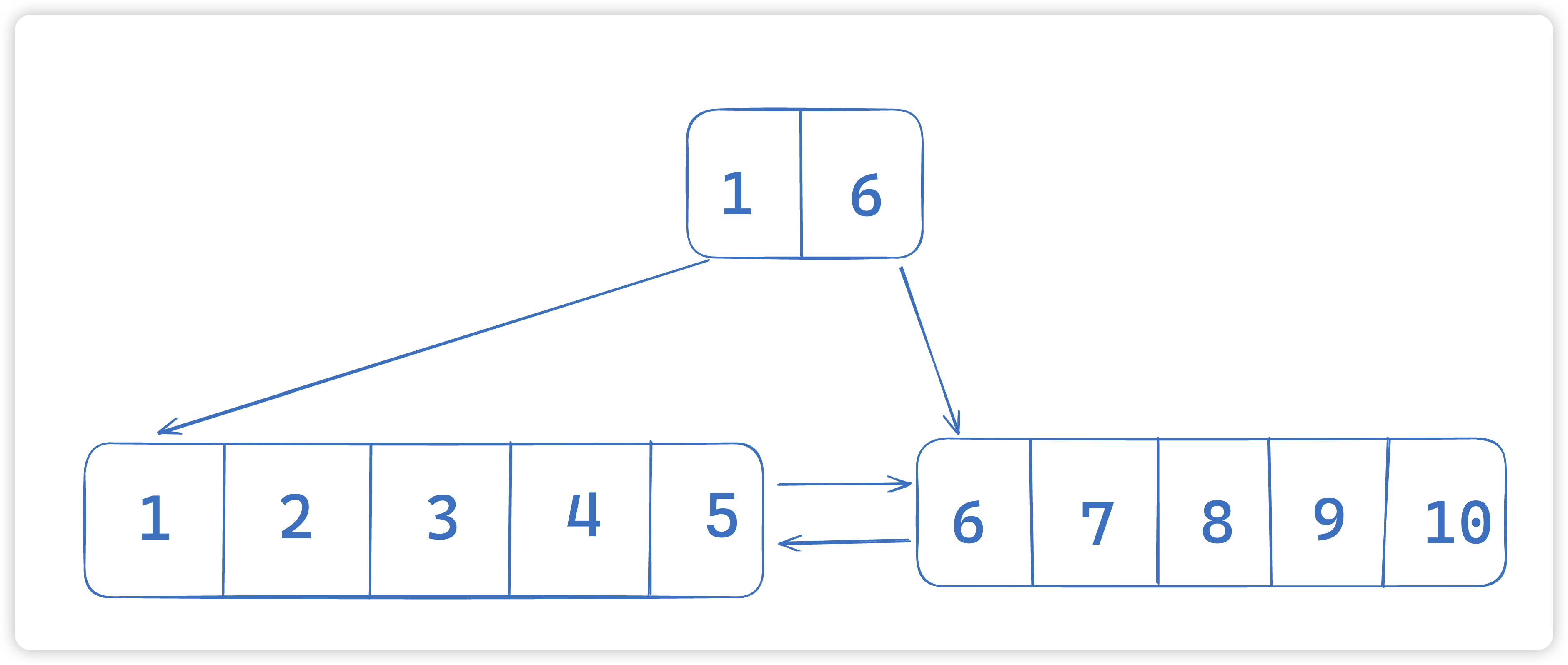
当我们的数据越来越多的时候,会不断向上抽取,一般会抽成三层
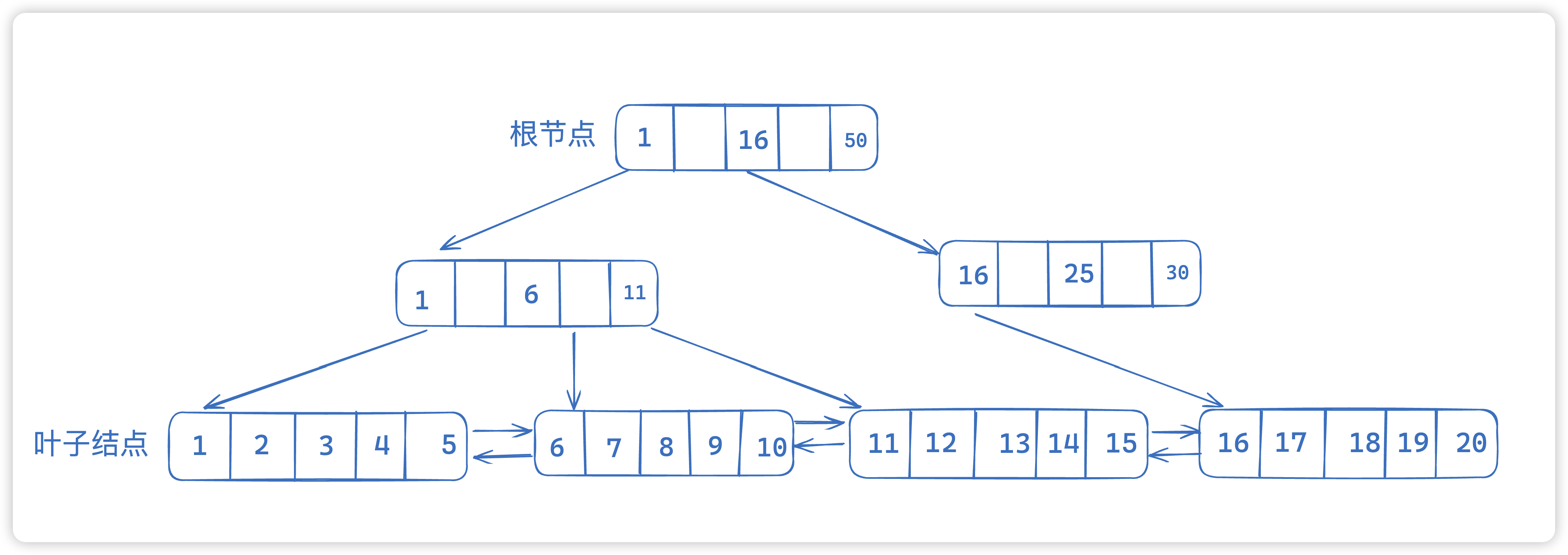
14. 为什么走索引加快了?
- 减少数据扫描:当数据库表中有索引时,MySQL可以通过索引快速定位到符合查询条件的数据行,而
不需要对整个表进行扫描。这样可以大大减少需要扫描的数据量,提高查询速度。 - 加快数据定位:索引使得数据库系统能够更快速地定位到需要的数据行,而
不需要逐行查找。通过索引,MySQL可以跳过大部分数据行,直接定位到目标数据行,从而减少了数据访问的时间。 - 降低磁盘I/O操作:索引可以
减少磁盘I/O操作的次数。由于索引使得数据定位更快速,数据库系统需要读取的数据页数减少,从而减少了磁盘I/O操作,提高了查询效率。
15. 为什么age可以建立索引?sex字段就不行?
sex字段一般是个枚举值0,1,2,那么如果是sex的枚举的话,就会变成
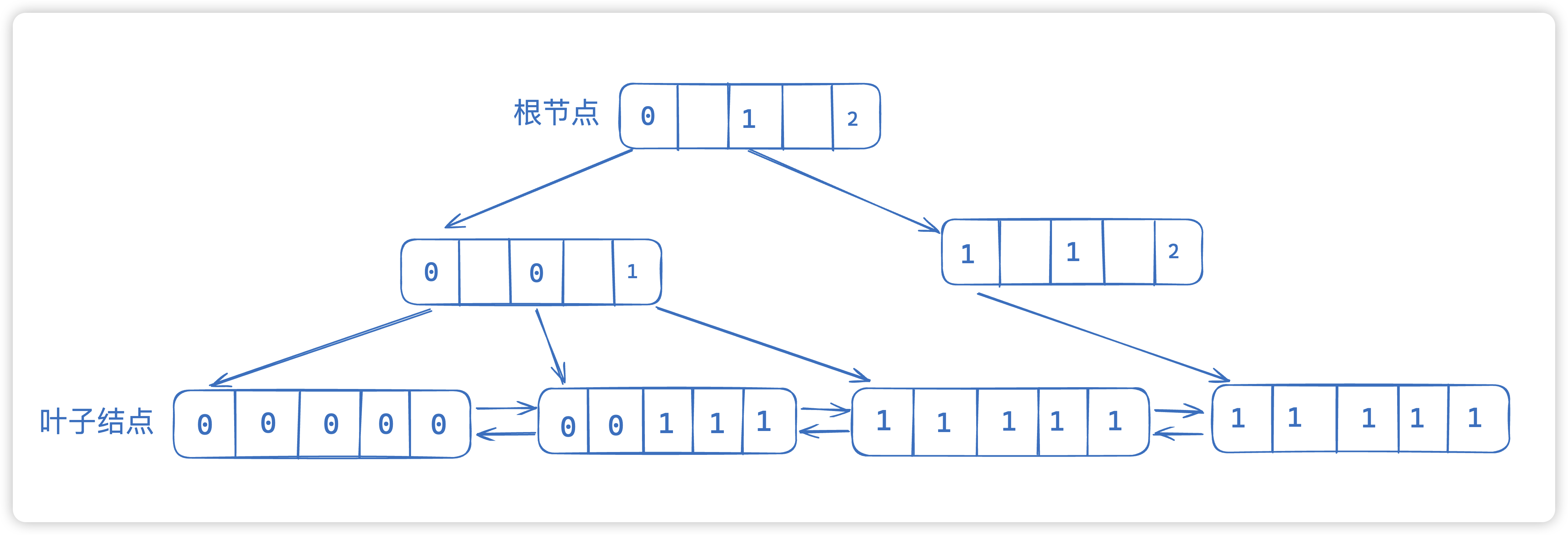
我们最终无法通过索引命中我们需要的节点,所以我们必须扫全表才能找到这条数据
注意一点:
InnoDB中的聚集索引的叶节点就是最终的
数据节点,InnoDB中的非聚集索引叶子节点指向的是相应的主键值。而MyISAM中非聚集索引的主键索引树和二级索引树的叶节仍然是索引节点,但它有一个指向最终数据的指针
16. 为什么sex建立索引还是会扫全表?
性别字段因为可重复所以只能建立非聚集索引,然而因为非聚集索引叶子节点存储的是索引值和聚集索引值,所以非聚集索引不能直接获取到数据,需要通过逻辑指针进行二次查找来获取数据,也就是需要回表的。
那么无论搜索哪个sex字段都可能得到1/3的数据。在这些情况下,还不如不要索引,而且数据库优化器最终很大概率也不会选择走这个索引,因为 MySQL 优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。
17. 如果我订单表达到一定规模之后mysql单表是撑不住了,怎么办?
首先要做好调研工作,根据当前业务的发展情况,去选择合适的技术方案。
- 如果这个业务比较重要(能赚钱),那么我们可以做分库分表,用比较多的人力和精力去维护。
- 如果这个业务相对来说不那么重要(辅助性业务),可以用当前比较热门的分布式数据库做DTS,比如 tidb、ES,减少我们的投入精力。
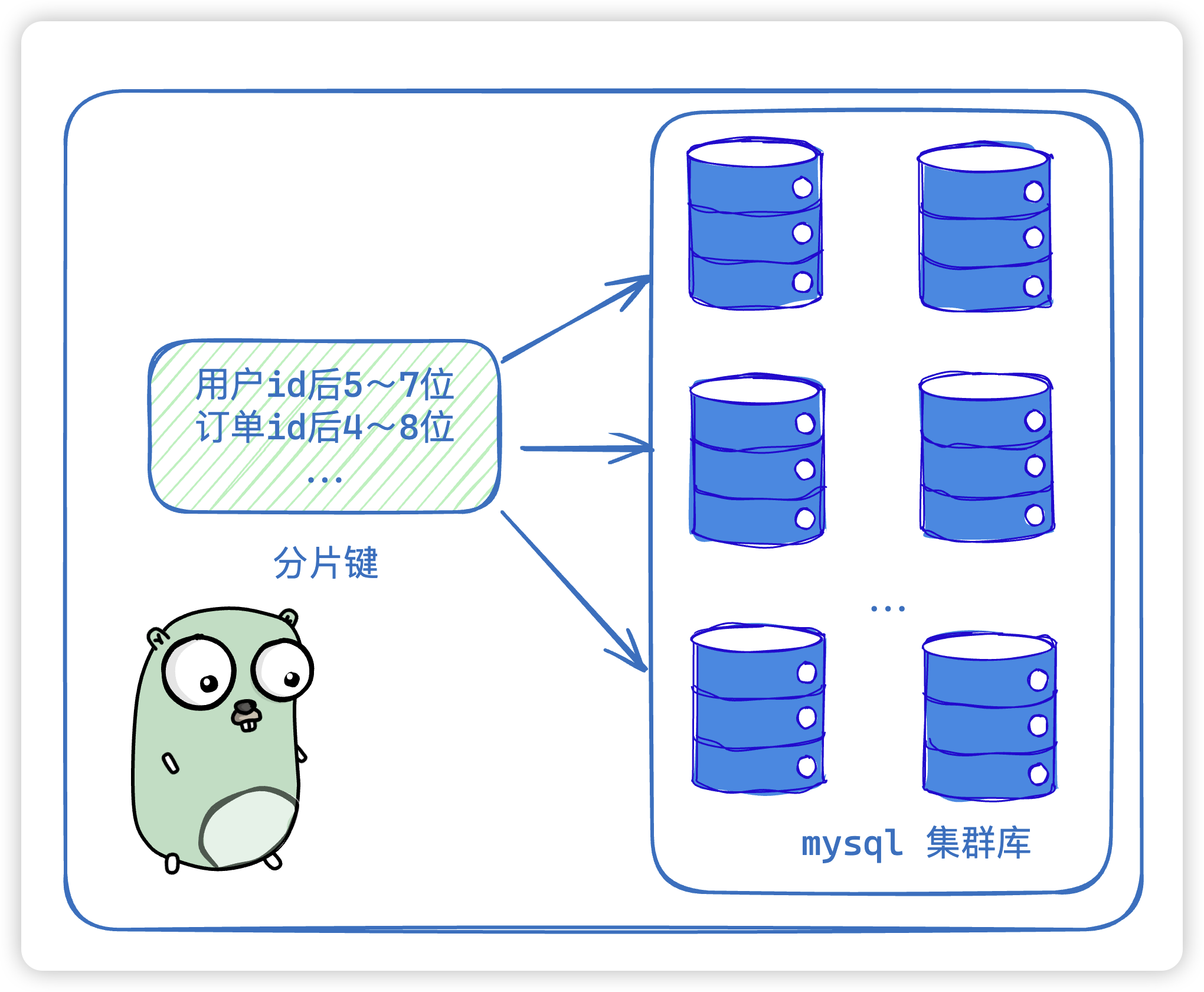
18. 具体你会怎么分库分表?
一般有水平扩展和垂直扩展,然后根据当前业务现状选择合适的分片键
- 水平扩展:根据日期进行分库分表,同一时期分在一个表或者一个库中。
- 垂直扩展:根据分片键进行hash命中哪一个库和表,就存在哪一个库表,分片键一般会
取用户id的后5~7位
19. 分库分表如果进行条件查询?
分片键只是为了路由命中我们要查的数据在哪个库,哪个表,命中之后还是需要带条件走索引查询。
一般会设置多个分片键,以防多个业务场景需要,如果实在没有命中任何库表,会兜底去查分布式数据库,tidb、es之类的,因为tidb、es会有dts进行同步。
20. 同步ES?不使用其他组件,单单是mysql怎么操作,所有表遍历找过去吗?索引会不会失效?
如果我们不走ES、TiDB这种并且没有分片键命中的话,那么我们就要在go里面用到协程池去做批量查询的操作了,每张表都用新协程去查询然后聚合结果,同时用协程池进行池化,减少协程的频繁创建与销毁。
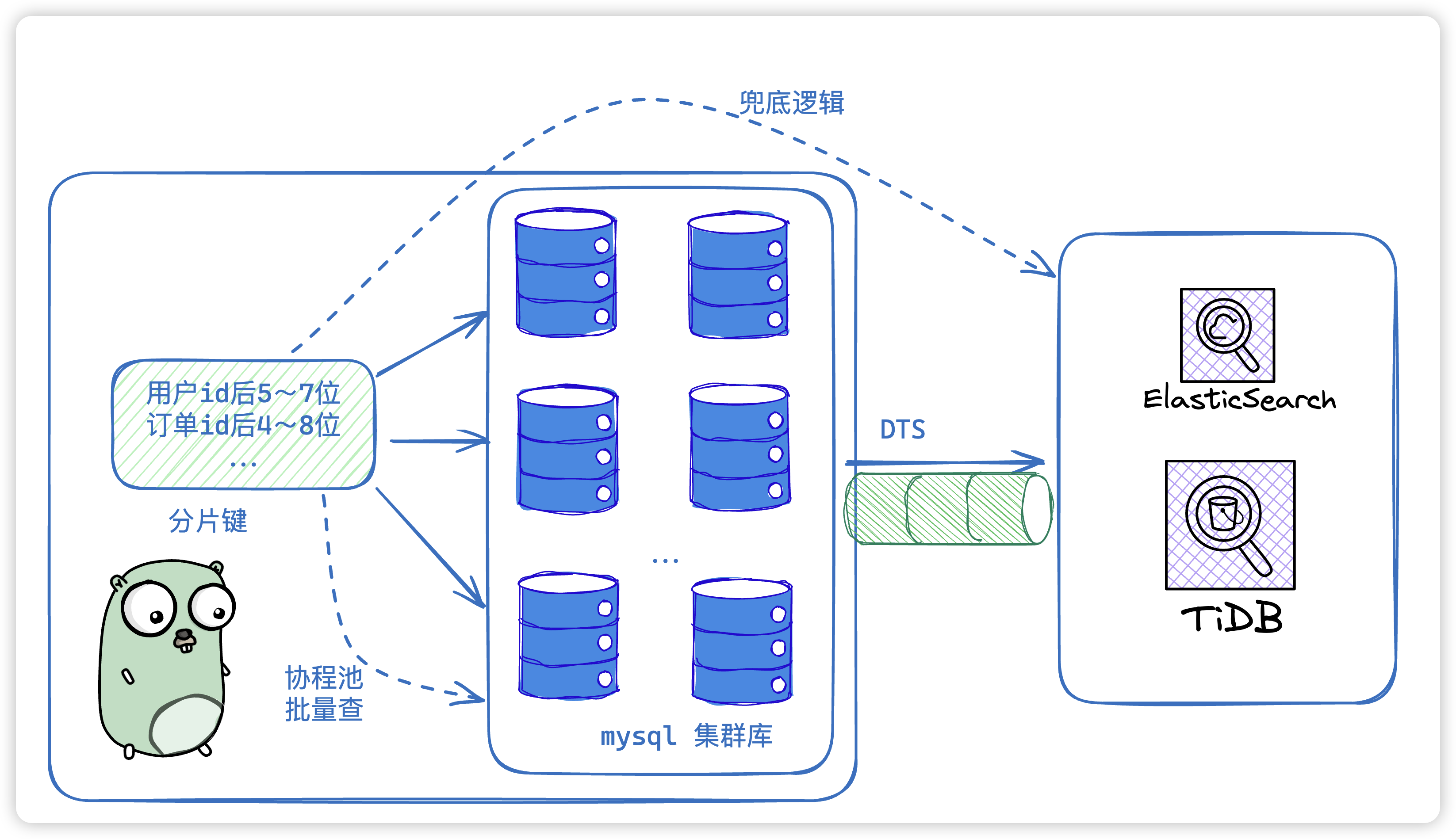
当然其实这种场景是很少的,99%的业务场景都可以使用分片键去处理,如果实在很难用分片键处理,我们一般会和业务沟通,甚至拒掉这个需求。索引是不会失效的,如果索引失效的话,那将会是P2级及以上的bug了。
21. ok,redis源码有了解吗?他的线程模型是什么样的?
其实我们说redis是单线程,说的是只有一个进程处理主线任务,主线任务就是将接受客户端命令,将命令传送到服务端,服务端处理完,再将数据返回给客户端。
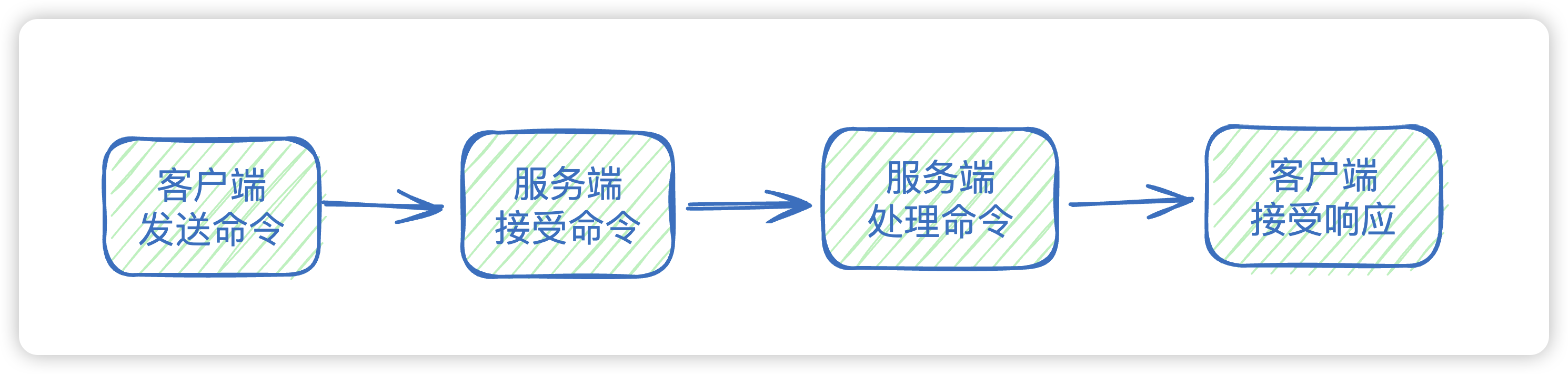
其实redis在启动的时候,是会启动一个后台线程去加载日志数据。
22. redis 有哪些存储日志的形式?同步还是异步?
- RDB持久化就是指的讲当前进程的
全量数据生成快照存入到磁盘中,触发RDB机制又分为手动触发与自动触发。 - AOF 持久化是以独立的日志记录每次写命令,也就是
增量数据,所以AOF主要就是解决持久化的实时性。
是否异步?
- AOF 是同步的
- RDB的save是同步的,bgsave是异步的
AOF和主进程的关系如下:
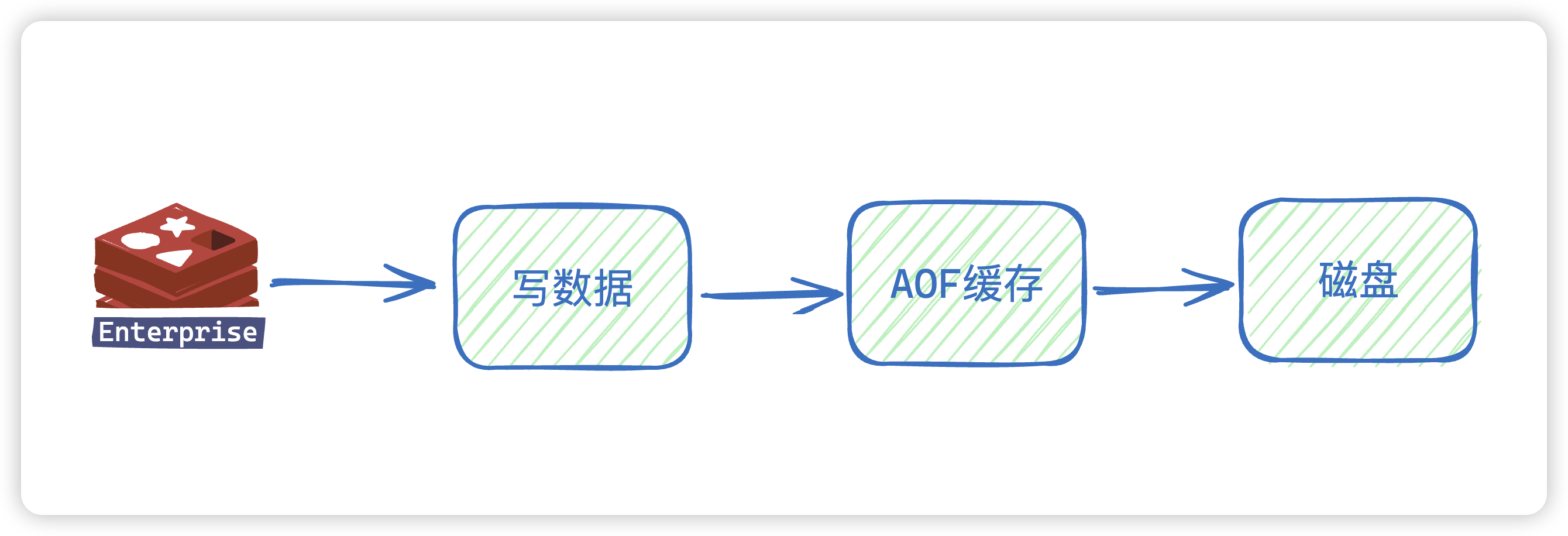
AOF的写入是同步的,AOF写入不会阻塞当前的写命令,但是有可能会阻塞下一个写命令
注意是写命令进行日志写入,读命令才会记录日志
23. 那AOF具体是怎么存储日志的?
- Redis 写操作命令结束后,会将命令重写到
AOF 缓冲区 - 然后通过系统调用,
将 AOF 缓冲区的数据拷贝到了内核缓冲区 - 然后内核会将数据写入硬盘,具体内核缓冲区的数据什么时候写入到硬盘,由内核决定,而这也是数据丢失的一个隐患。
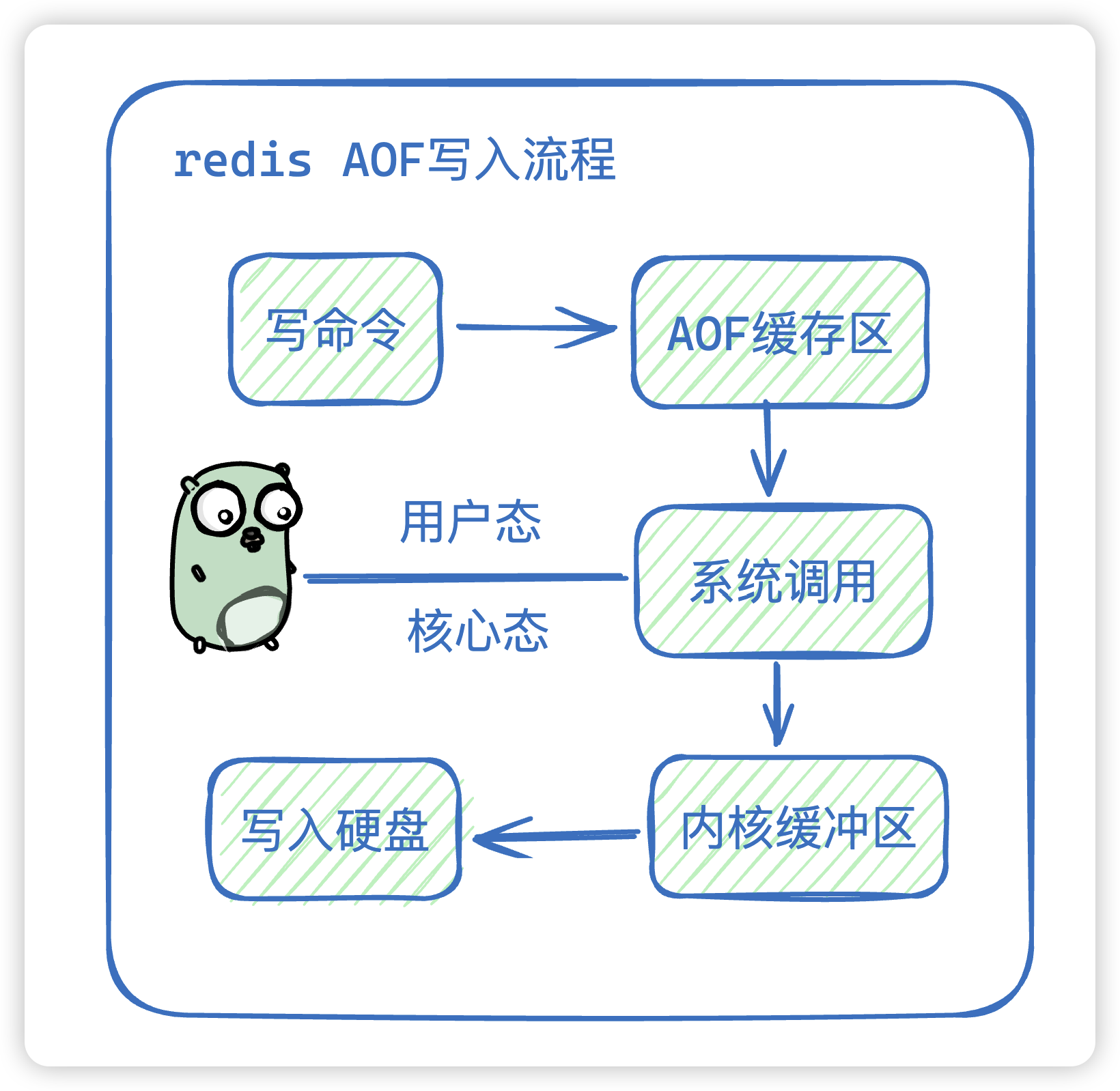
24. AOF不断的写日志不是会有很多的io操作吗?怎么避免?
其实我们业务背景中,redis的读和写的比例一般会是9:1这个状态,写一次redis就意味着这一次请求可能打到DB了。如果是在一些极限的场景,比如滴滴的订单需要频繁的修改状态,那么我们可以设置redis的aof的落盘策略。
- Always:每次写操作命令执行完后,
实时将 AOF 日志数据写回硬盘 - Everysec:每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,然后
每隔一秒将缓冲区里的内容写回到硬盘 - No: Redis 不控制写回硬盘的时间,每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,再
由操作系统决定什么时候将缓冲区内容写回硬盘
如果我们需要极致的性能,选择No就可以了,当然高回报的背后是高风险,由于我们并不知道操作系统会什么时候写入硬盘,所以如果redis宕机了,我们将会丢失这段时间的数据。所以在生产当中我们一般会使用AOF + RDB的组合方式来保证AOF的持久化。
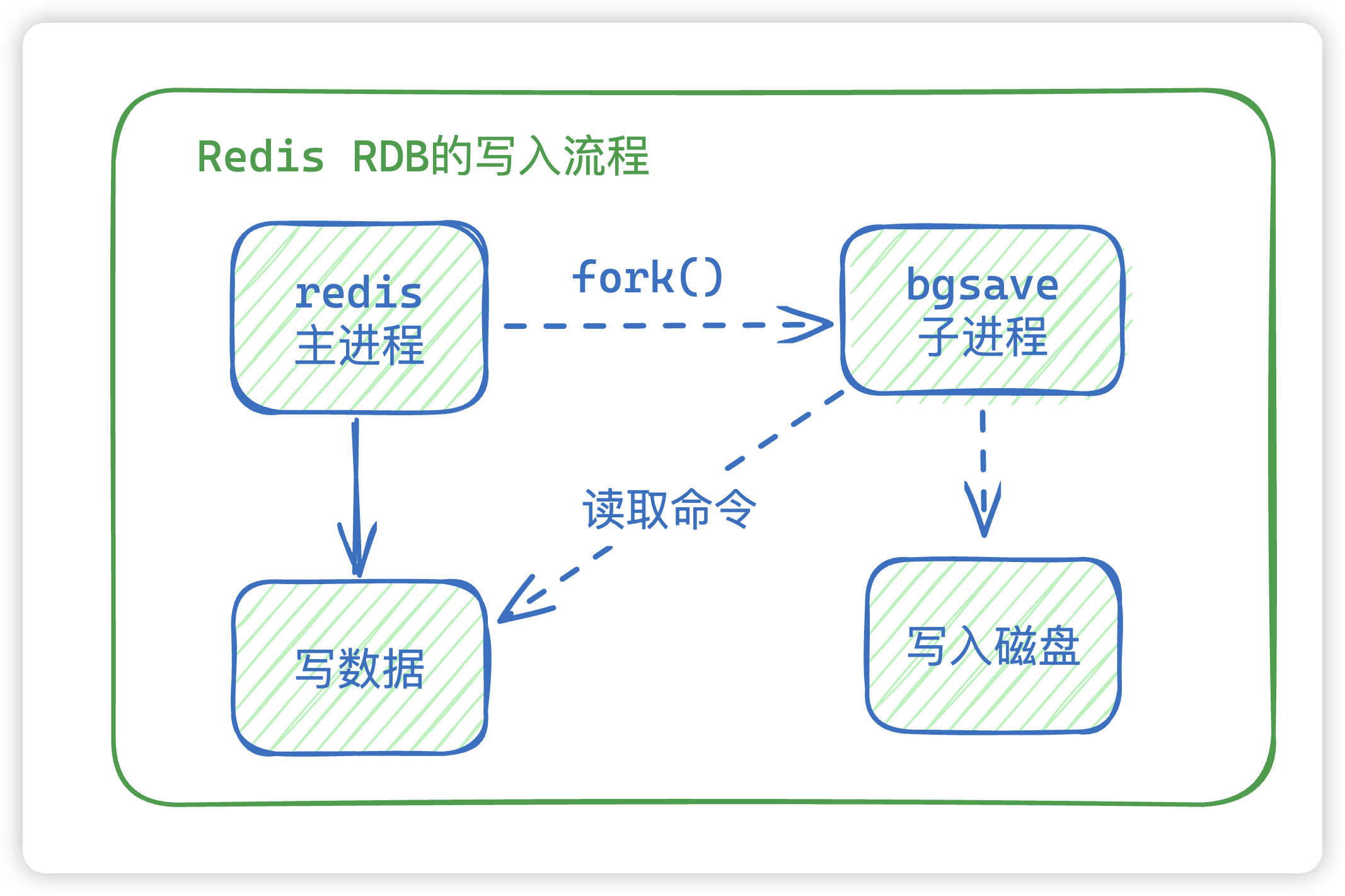
25. RDB是怎么进行操作?
redis 一般会有两个命令生产RDB,一个是save,另一个是bgsave,区别在于是否阻塞主线程
- save 是和操作命令在同一个线程里面,如果有大key写入RDB文件,会造成阻塞。
- bgsave是创建一个子进程来写入RDB文件,不会造成阻塞。
RDB和everysec模式的AOF区别就是一个是全量,一个是增量
那么在bgsave中,通过fork函数创建的子进程会和父进程共享同一片内存数据,因为在fork的时候,子进程会复制父进程的页表数据,而这两个进程的页表数据一摸一样也就表示会指向同一片物理内存地址。 这样是为了减少创建子进程时的性能损耗,加快子进程的创建速度,毕竟创建子进程的过程中,是会阻塞主线程的。
26. 那如果数据库和redis需要缓存一致性怎么解决?
其实我们一般都是先更新数据库再更新redis的,在业务允许的下,可以接受一定时间段的数据不一致,因为我们业务场景都只是要求数据的最终一致性就可以了。
27. 那我不考虑最终一致性,我要强一致性,怎么解决?
- 那我们可以需要牺牲一点性能了,
我们将 redis 和 mysql 的数据绑定在一起,redis 使用 lua 脚本更新,和mysql 的更新数据绑定在一点,要么一起成功,一起失败,如果失败则需要告警,走降级兜底,然后人工快速介入。
- 又或者可以把缓存删掉,然后再更新数据库,此时大量的请求将会打到DB,这时候,我们就需要使用
singlefight这种在缓存失效的时候使用的合并请求的方式减轻DB的压力。
其实无论怎么选型都不会非常完美的,CAP必定会牺牲一个,即使是99.9999%高可用的阿里云也会有宕机的情况。这个一致性如果要深究一篇文章都讲不完…这里不再过度描述…
28. ok,网络这块我也问问。http和https的区别是什么?
http和https其实就是有一个加密的过程,这个加密就是tls、ssl加密。
29. https是怎么建立连接的?先建立什么?再建立什么?
先建立tcp连接再建立ssl、tls连接
30. 具体是怎么建立的ssl tls加密?
- 客户端 Hello:客户端向服务器发送一个Client Hello消息,其中包含支持的
加密算法、协议版本、随机数等信息。 - 服务器 Hello:服务器收到Client Hello后,选择
加密算法和协议版本,并向客户端发送一个Server Hello消息。 - 证书验证:服务器还会发送自己的
数字证书给客户端,客户端会验证证书的有效性,包括证书是否由受信任的证书颁发机构颁发。 - 密钥交换:如果证书验证通过,客户端生成一个随机数,使用服务器的公钥(从证书中提取)加密后发送给服务器,服务器使用自己的私钥解密得到该随机数,用于生成对称加密的会话密钥。
- 完成握手:握手阶段完成后,客户端和服务器都知道如何加密通信,并且共享一个会话密钥用于加密和解密数据。
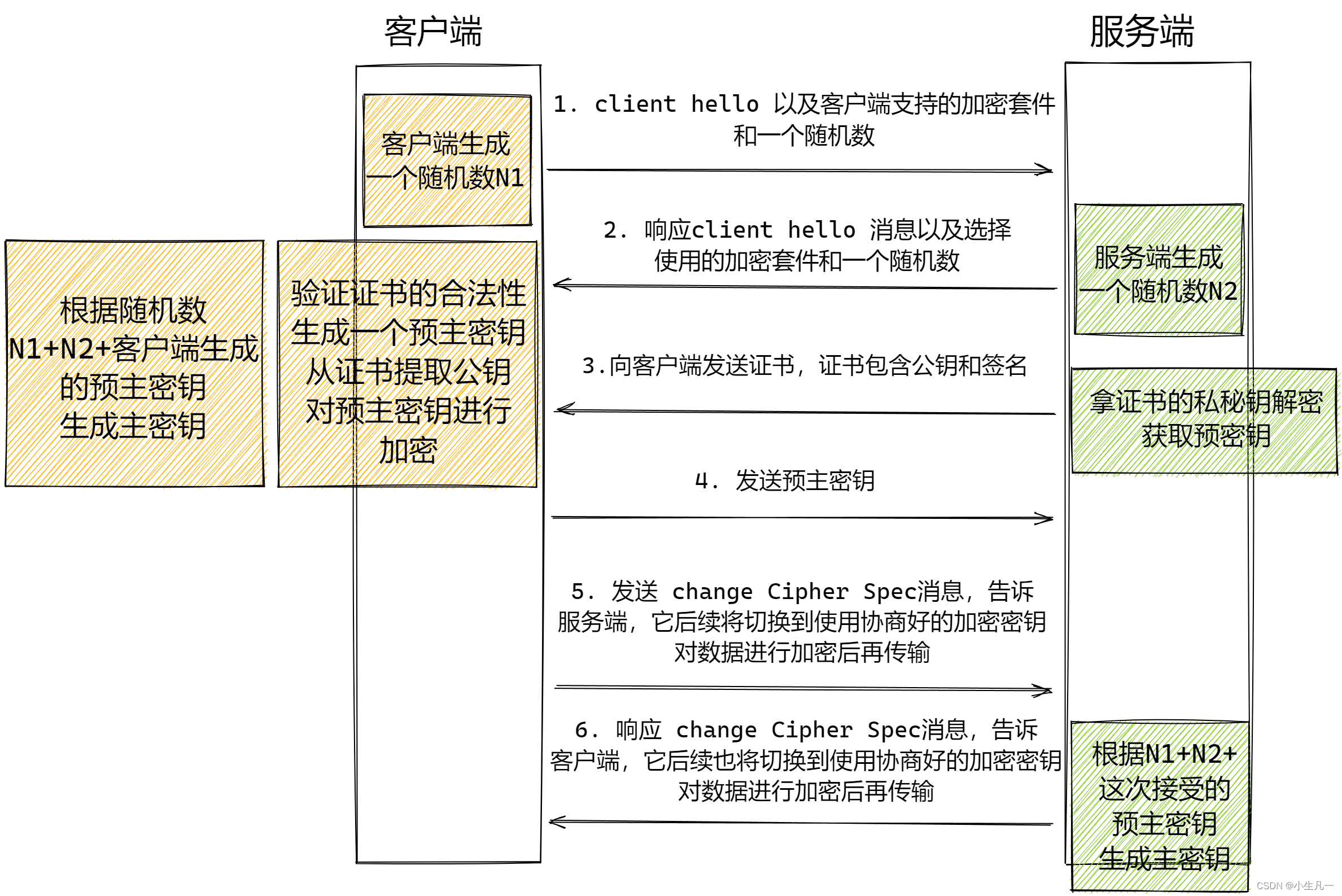
四次握手主要是交换以下信息:
-
数字证书:该证书包含了公钥等信息,一般是由服务器发给客户端,接收方通过验证这个证书是不是由信赖的CA签发,或者与本地的证书相对比,来判断证书是否可信;假如需要双向验证,则服务器和客户端都需要发送数字证书给对方验证;
-
三个随机数:这三个随机数构成了后续通信过程中用来对数据进行对称加密解密的
对话密钥。- 首先客户端先发第一个随机数N1,然后服务器回了第二个随机数N2(这个过程同时把之前
提到的证书发给客户端),这两个随机数都是明文的; - 而第三个随机数N3(预主密钥),客户端用
数字证书的公钥进行非对称加密,发给服务器,服务器用只有自己知道的私钥来解密,获取第三个随机数。 - 服务端和客户端都有了三个随机数N1+N2+N3,然后两端就使用这三个随机数来生成“对话密钥”,
在此之后的通信都是使用这个“对话密钥”来进行对称加密解密。因为这个过程中,服务端的私钥只用来解密第三个随机数,从来没有在网络中传输过,这样的话,只要私钥没有被泄露,那么数据就是安全的。
- 首先客户端先发第一个随机数N1,然后服务器回了第二个随机数N2(这个过程同时把之前
-
加密通信协议:就是双方商量使用哪一种加密方式,假如两者支持的加密方式不匹配,则无法进行通信;
一句话概括也就是用非对称加密来生成对称加密的密钥
31. http的请求头和响应头一般有什么信息,有什么用?
-
HTTP请求头(Request Headers):
- Host:指定请求的目标主机。
- User-Agent:标识发起请求的客户端软件。
- Accept:指定客户端能够接受的内容类型。
- Content-Type:指定请求体的MIME类型。
- Authorization:用于身份验证的信息。
- Cookie:包含客户端发送给服务器的Cookie信息。
- Referer:指示请求的来源页面的URL。
- Cache-Control:指定缓存行为。
- Connection:指定是否保持持久连接。
- Accept-Encoding:指定客户端支持的内容编码方式。
-
HTTP响应头(Response Headers):
- Content-Type:指定响应体的MIME类型。
- Content-Length:指定响应体的长度。
- Server:指定响应的服务器软件。
- Set-Cookie:在响应中设置Cookie。
- Cache-Control:指定缓存行为。
- Location:指定重定向的URL。
- Expires:指定响应过期的时间。
- Last-Modified:指定资源的最后修改时间。
- Access-Control-Allow-Origin:指定允许跨域请求的来源。
32. ok,页的概念你清楚吗?
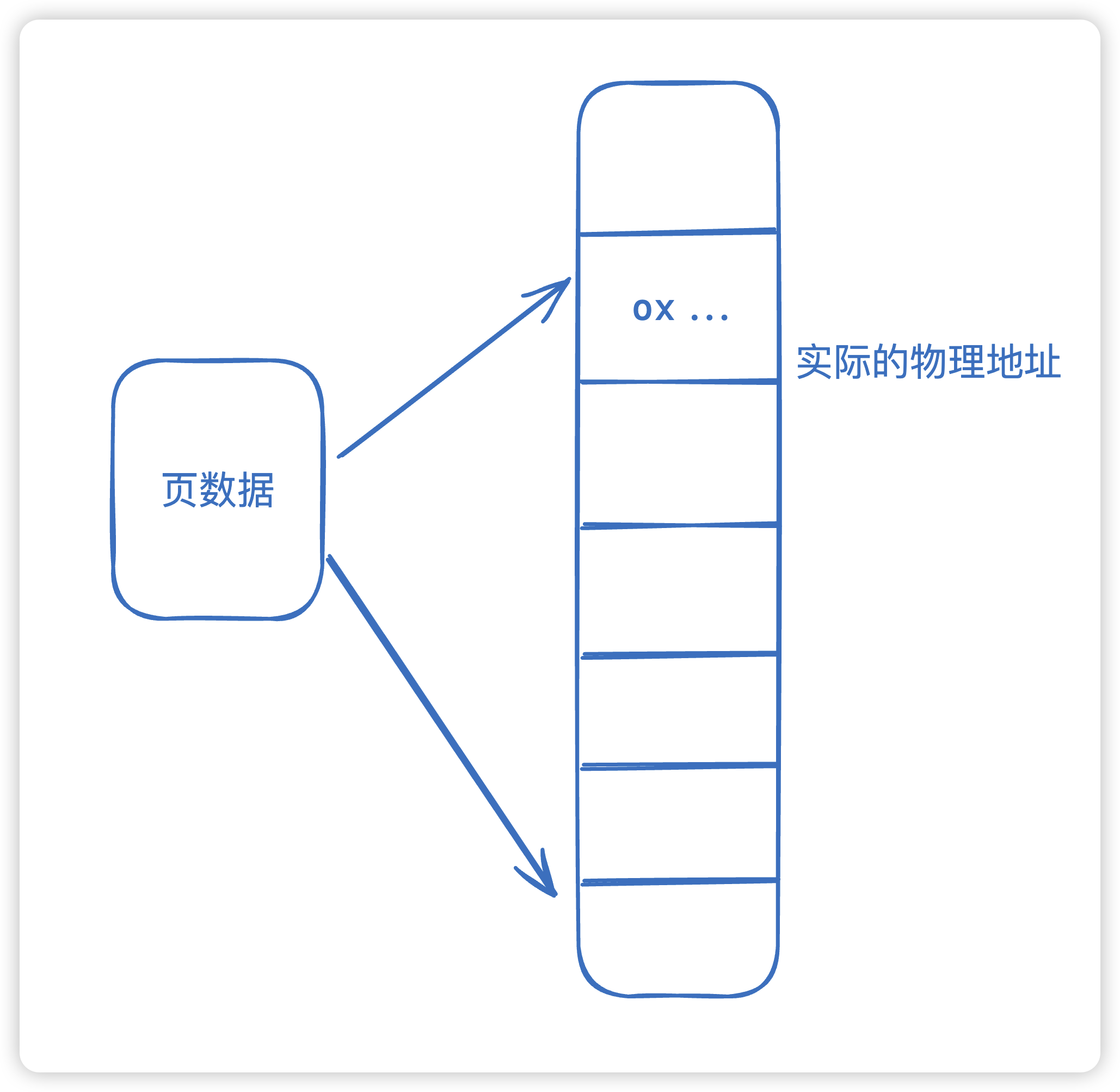
对于进程来说,使用的都是虚拟地址, 虚拟地址空间划分为多个固定大小的虚拟页(VP),物理地址空间划分为多个固定大小的物理页(PP),虚拟页和物理页的大小是一样,通常为4KB。页的主要功能是做出虚拟地址对物理地址的映射。
- 页表:每个进程维护一个单独的页表,页表是一种数组结构,
存放着各虚拟页的状态,是否映射,是否缓存。 - 页表项:页表中的每个条目称为页表项,其中包含了
虚拟页号和物理页框号之间的映射关系。 - 页面调度:当程序访问一个虚拟地址,而对应的物理页不在内存中时,会发生页面调度,操作系统会从磁盘中将相应的页面加载到内存中。
- 页面置换:当内存中的页面不足时,操作系统需要选择一个页面进行置换(page replacement),将其写回磁盘并加载新的页面。
通过使用页面和页表,操作系统可以实现虚拟内存管理,提高内存利用率和程序的运行效率。虚拟内存技术允许程序看到一个比实际物理内存更大的地址空间,同时可以将不常用的页面置换到磁盘上,从而提高系统的整体性能和稳定性。
33. 页碎是什么?
页碎片是指在虚拟内存系统中,由于分配和释放内存的过程中导致的页面不连续、零散的现象。
在虚拟内存管理中,内存通常被划分为固定大小的页面,而应用程序请求的内存空间可能不是页面大小的整数倍,这就导致了页面的碎片化。
而大量的页碎可能会导致以下问题:
- 分配性能下降:当系统需要分配大块连续内存时,如果内存中存在大量碎片,系统可能需要进行
额外的合并操作,降低了分配性能。 - 缓存失效率增加:页面碎片化也可能导致缓存的失效率增加,因为数据分散存储在不同的页面中,需要更多的缓存行加载,降低了缓存的效率。
- 内存利用率下降:由于页面被分割成小块或者存在空隙,导致
实际可用内存空间比总内存空间要少。 - 缓存失效率增加:页面碎片化也可能导致缓存的失效率增加,因为数据分散存储在不同的页面中,需要更多的缓存行加载,降低了缓存的效率。
通常会采取一些策略来优化内存分配和释放,比如使用内存池、动态内存分配算法、碎片整理等技术来减少碎片化,提高内存利用率和系统性能。
34. 为什么需要内存对齐?
内存对齐,就是将数据存放到一个是字的整数倍的地址指向的内存之中。处理器在执行指令去操作内存中的数据,这些数据通过地址来获取。为了能让复杂数据结构对齐,编译器一般会对数据结构做一些填充。
内存对齐总的来说就是两个原因:提升效率和避免出错。
- 某些处理器只能存取对齐的数据,存取非对齐的数据可能会引发异常;
- 某些处理不能保证在
存取非对齐数据的时候的操作是原子操作; - 相比于存取对齐的数据,存取
非对齐数据需要额外花费更多的时钟周期; - 有些处理器虽然支持非对齐数据访问,但是会引发
对齐陷阱; - 某些处理只支持简单数据指令非对齐存取,不支持复杂数据指令非对齐存取。
而我们可能需要进行类型转换、位运算、使用特定平台的指令、内存拷贝这些额外的操作取非对齐的数据,而这也需要额外的指令来访问和处理这些数据,也造成了不必要的开销。
35. go里面怎么样会发生死锁?死锁的场景具体有哪些?
我们了解一下死锁的必要条件:互斥、请求与保持、不可抢占、循环等待
- 相互等待资源:两个或多个goroutine相互持有对方需要的资源而无法释放,例如,goroutine A持有资源X并等待资源Y,而goroutine B持有资源Y并等待资源X。
- 未释放锁:一个goroutine获取了一个锁,但在释放之前就阻塞了,导致其他goroutine无法获取该锁。
- 未缓冲的通道:当一个goroutine试图向一个
未缓冲的通道发送数据,但没有接收者时,它会被阻塞,这可能导致死锁。 - 使用互斥锁的顺序问题:如果多个goroutine以
不同的顺序获取多个互斥锁,可能会导致死锁。 - 等待超时不处理:如果goroutine在
等待资源时没有设置超时或者没有处理超时情况,可能会导致永久等待。
36. 内存泄漏有哪些场景?怎么排查?
内存泄漏是指程序在动态分配内存后,由于某种原因未能释放或回收这些内存,导致系统中的可用内存持续减少,最终可能耗尽系统资源。
- 未释放资源:动态分配的内存或其他资源(如文件流、响应流、数据库连接等)在使用完后
未被释放。 - 循环引用:两个或多个对象相互引用,导致它们之间形成
循环引用,即使程序不再需要这些对象,它们也无法被垃圾回收机制回收。 - 缓存未及时清理:缓存中的对象长时间
未被清理或更新,导致不再需要的对象仍然占用内存。 - 大对象未释放:大对象(如大型数组、大文件等)在使用完后
未被及时释放,占用大量内存。
在go语言里面,其实内存泄漏不太好排查,因为gc和编辑器做的优化都太好了,不怎么容易发生内存泄漏。那么如果发生了内存泄露,我们可以采取以下方法:
- 内存分析工具:使用
内置或第三方的内存分析工具(如Go语言中的pprof工具)来检测程序的内存使用情况,查看内存分配情况和对象生命周期。 - 代码审查:仔细审查代码,查找可能导致内存泄漏的地方,例如
未释放资源、循环引用等。 - 日志和监控:
添加日志和监控,记录程序的内存使用情况,以便及时发现内存泄漏问题。 - 压力测试:进行压力测试,
模拟程序长时间运行,观察内存使用情况是否持续增长。 - Heap Dump:在发生内存泄漏时,生成
Heap Dump文件,用于分析程序中的对象和内存使用情况。
37. goruntine 泄漏的场景有哪些?怎么排查?
Goroutine泄漏指的是创建的goroutine没有被正确释放或终止,导致这些goroutine继续存在而不被使用,最终可能导致系统资源的浪费,影响程序的并发执行能力。
- 未等待goroutine完成:在启动goroutine后没有正确等待goroutine执行完成,
导致goroutine未被正确处理而继续存在并且没有被gc回收。 - 阻塞导致无法退出:某些情况下,
goroutine可能会被阻塞而无法正常退出,例如等待通道操作、锁操作等。 - 循环/递归创建goroutine:在循环中创建goroutine,但未控制goroutine的数量和生命周期,导致大量无法及时销毁的goroutine。在
没有终止条件或终止条件不正确的情况下递归,导致goroutine的无限增长。
排查:
- 使用go vet工具:Go提供了
go vet工具,可以静态分析检查代码。 - 使用pprof工具:pprof工具可以分析程序的性能和资源使用情况,包括goroutine的使用情况。
预防:
- 监控日志告警:添加监控,日志和告警,以便及时发现异常情况。
- 代码审查:仔细审查代码,特别是涉及goroutine启动和结束的地方,确保每个goroutine都能被正确处理。
- 限制goroutine数量:在创建goroutine时,可以考虑限制goroutine的数量,比如使用
协程池进行池化,避免无限制地创建goroutine。
38. 进程、线程、协程有什么区别?
略
39. 协程能被 kill 掉吗?
不能,kill 作用对象是进程,是进程管理的常用命令,实施对象是操作系统。
40. 那协程应该怎么处理?
协程如果要实现“被kill”的效果,可以使用context包进行timeout处理,这样如果到了一定时间如果还没执行完就进行context cancel了。
41. 那context一般有什么信息?有什么用途?
42. 那如果我要 clone 一个context,子context 和 父context 是一摸一样吗?为什么?
41、42 另外开一期讲讲context吧
43. singleflight 是什么?什么时候用的?
缓存失效,合并请求的时候用的
44. 如果这个goruntine超时怎么办?
45. doChan方法具体是怎么实现的?
43-45 也单独开一期讲讲 singleflight 。
46. 为什么会有饥饿模式?
互斥锁在设计上主要有两种模式: 正常模式和饥饿模式。
之所以引入了饥饿模式,是为了保证goroutine获取互斥锁的公平性。 所谓公平性,其实就是多个goroutine在获取锁时,goroutine获取锁的顺序,和请求锁的顺序一致,则为公平。
- 正常模式下,所有阻塞在等待队列中的goroutine会按顺序进行锁获取,当唤醒一个等待队列中的goroutine时,此goroutine并不会直接获取到锁,而是会和新请求锁的goroutine竞争。 通常新请求锁的goroutine更容易获取锁, 这是因为
新请求锁的goroutine正在占用cpu片执行,大概率可以直接执行到获取到锁的逻辑 - 饥饿模式下, 新请求锁的goroutine不会进行锁获取,而是加入到队列尾部阻塞等待获取锁。
47. 什么时候会让出时间片?
- 时间片用尽:当进程或线程的时间片用尽时,操作系统会
强制进行上下文切换,将CPU资源分配给其他就绪状态的进程或线程。 - 阻塞操作:当进程或线程执行阻塞操作 (如等待I/O操作完成、等待信号量、等待锁等) 时,它会让出CPU时间片,以便其他就绪状态的进程或线程能够执行。
- 显式让出:进程或线程可以通过系统调用或特定的API显式让出CPU时间片,例如在 Golang 进程会有一个
全局监控协程 monitor g的存在,这个 g 会越过 p 直接与一个 m 进行绑定,不断轮询对所有 p 的执行状况进行监控. 倘若发现满足抢占调度的条件,则会从第三方的角度出手干预,主动发起该动作。 - 优先级调度:如果有更高优先级的进程或线程需要执行,当前进程或线程可能会让出时间片,以便高优先级任务能够及时执行。
- 信号处理:当进程接收到信号并需要处理时,它可能会让出CPU时间片来处理信号。毕竟信号也可以在多线程中传递信息。
48. IO密集型和计算密集型的区别?
在计算机科学中,我们通常将任务分为两类:IO密集型和计算密集型。
-
IO密集型任务:
- 这类任务主要涉及大量的输入/输出操作,如从
磁盘读取数据、网络通信、数据库查询等。在执行过程中,任务会频繁地进行IO操作,而不是大量的计算操作。 - IO密集型任务的特点是CPU通常会大部分时间处于空闲状态,等待IO操作完成。因此,是非阻塞的。
- 这类任务主要涉及大量的输入/输出操作,如从
-
计算密集型任务:
- 这类任务主要涉及大量的计算操作,例如
复杂的数学运算、图像处理、加密算法等。在执行过程中,任务会消耗大量的CPU资源进行计算操作。 - 计算密集型任务的特点是CPU会长时间处于繁忙状态,执行大量的计算操作,因此是阻塞的。
- 这类任务主要涉及大量的计算操作,例如
最后是几道代码题,飞书文档看着代码,不使用任何编辑器。
这段代码会发生什么?为什么?具体是怎么溢出的?
var a uint = 1
var b uint = 2
fmt.Println(a-b)
这个uint类型的溢出我就不过多赘述了。
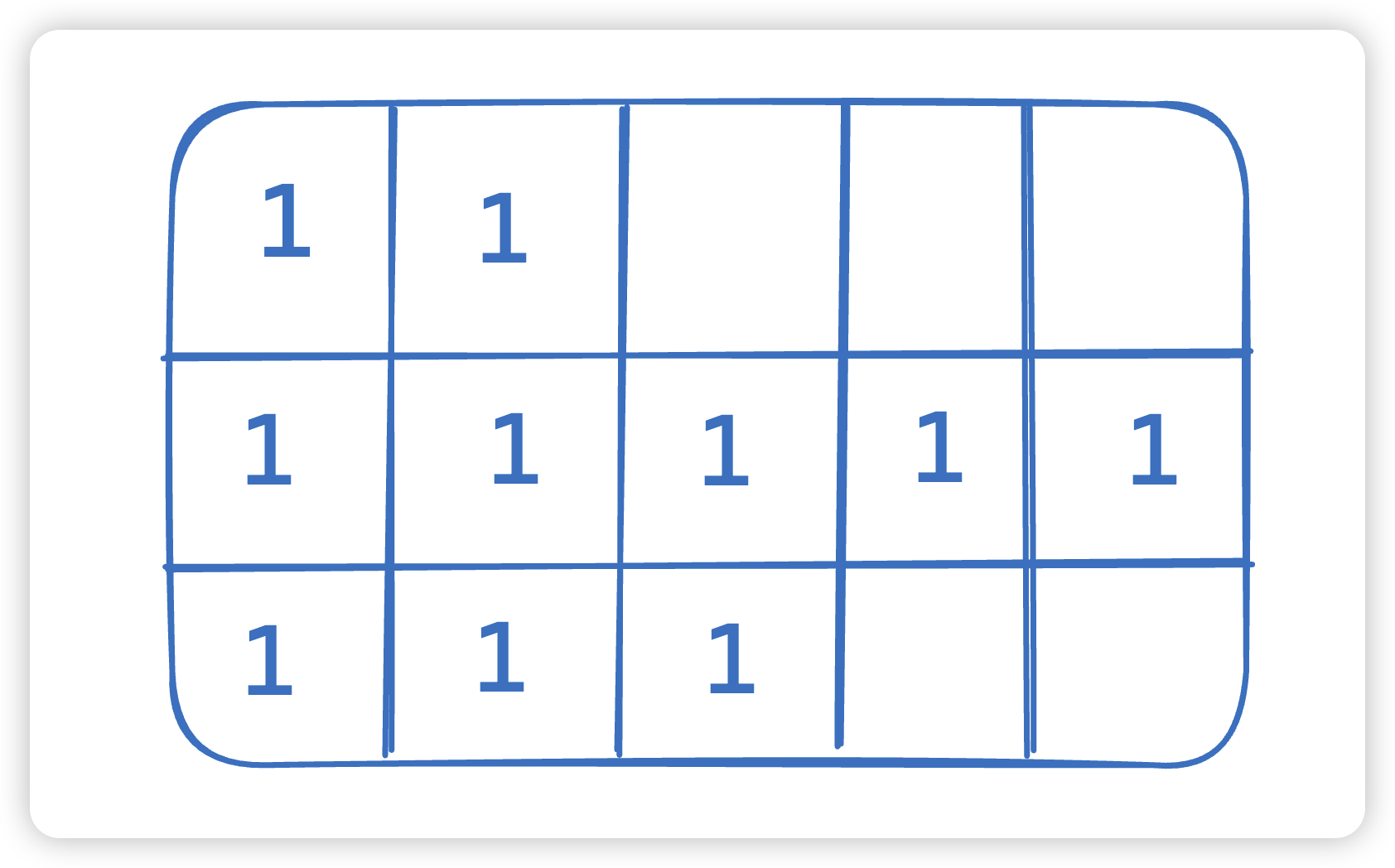
说出以下输出结果?为什么?
func TestSlicePrint(t *testing.T) {a := []byte("AAAA/BBBBB")index := bytes.IndexByte(a, '/')b := a[:index]c := a[index+1:]b = append(b, "CCC"...)fmt.Println(string(a))fmt.Println(string(b))fmt.Println(string(c))
}
结果:
AAAACCC
CCBBB
AAAACCCBBB
切片是对底层数组的引用,因此对切片的修改会影响原始的切片。
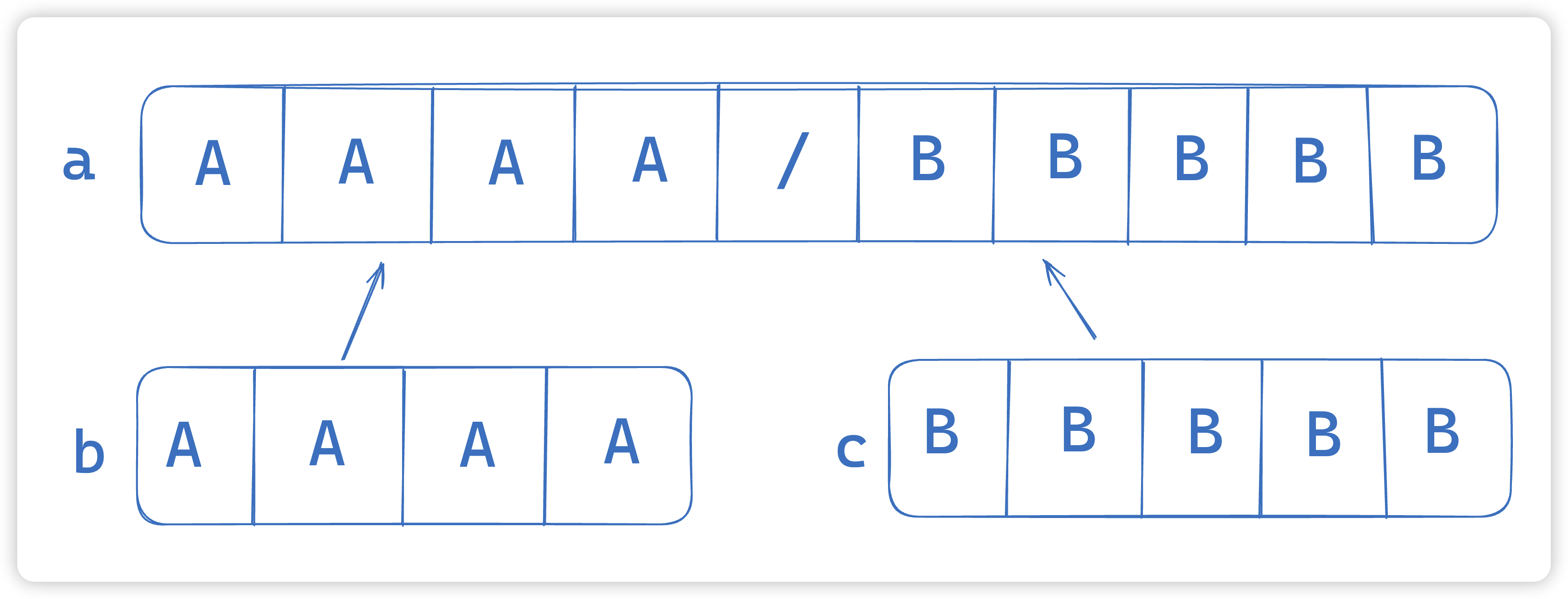
当一个切片被用做一个append函数调用中的基础切片时:
- 如果添加的元素数量大于
此(基础)切片的冗余元素槽位的数量,则一个新的底层内存片段将被开辟出来并用来存放结果切片的元素。 这时,基础切片和结果切片不共享任何底层元素。
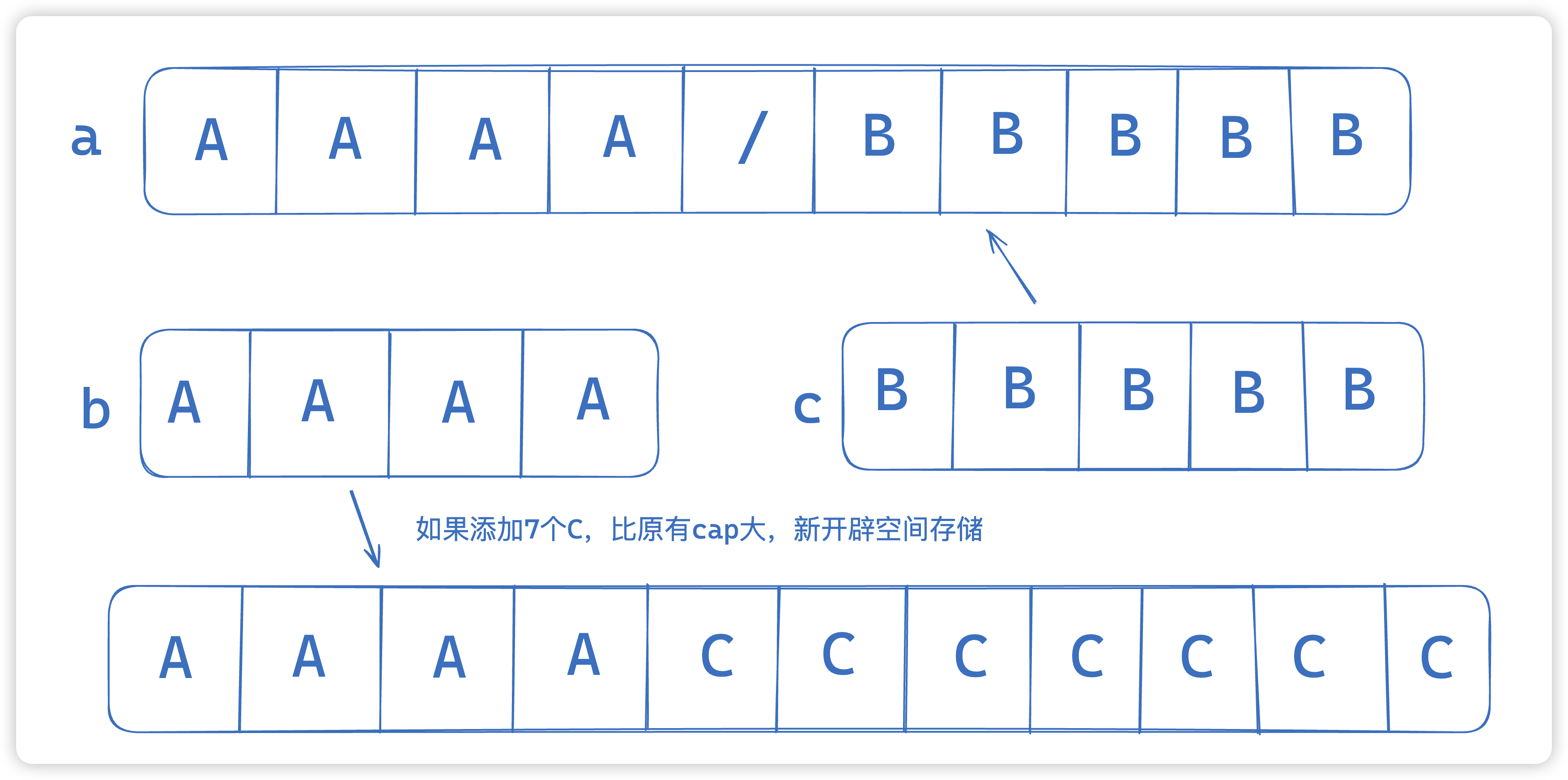
- 否则,不会有底层内存片段被开辟出来。这时,基础切片中的所有元素也同时属于结果切片。两个切片的元素都
存放于同一个内存片段上。

这个锁是什么用的?这段代码有什么问题?
func TestNumPrint(t *testing.T) {wg := sync.WaitGroup{}lock := new(sync.Mutex)var a int32 = 0var b int32 = 2for i := 0; i < 5; i++ {go func() {if a > b {fmt.Println("done")return}lock.Lock()defer lock.Unlock()a++fmt.Printf("i: %d a: %d \n", i, a)}()}wg.Wait()
}
我个人觉得有三点:
- wg没有add(1)导致主进程结束了,子进程还没开始。但这个被面试官否掉啦,“你就当主进程一直阻塞就好了”
- 这个i的变量有问题,都将会是最后一个数也就是5的这个值。也被否掉了,“go最新版里面这个不是问题,你就当是最新版吧”
- 还有就是这个锁有问题,虽然锁住了
a的自增,但是没锁住a的读取,int 类型本身并不是并发安全的,我们必须加锁才能保证原子性,那么如果我们不加锁,还可以使用atomic.AddInt32()进行原子操作。但是这里锁的粒度出现了问题,锁应该是对变量的读取和修改都进行锁,上面只锁住了修改,锁应该要锁出一段逻辑操作,而不是一个变量,所以只需要将锁提到if a>b的前面。
最后手撕一题:整数反转。直接在飞书文档上写,写的真难受…
面试官在我写的过程依次提示考虑正数、负数、正数溢出、负数溢出?正数溢出和负数溢出是不是一样的?
这题是全场最简单的了,略,具体思路就是先计算这个整数的位数,然后反着来相乘再相加就好了。相加的过程中注意正数的溢出,如果是负数的话,做个标识,让负数变正数,最后再把符合加上就好了
参考资料
[1] https://www.jianshu.com/p/67600a8ddb8c
[2] https://zh.m.wikipedia.org/wiki/数据结构对齐
[3] https://www.cnblogs.com/rjzheng/p/12557314.html
[4] https://golang.design/under-the-hood/
相关文章:
滴滴三面 | Go后端研发
狠狠的被鞭打了快两个小时… 注意我写的题解不一定是对的,如果你认为有其他答案欢迎评论区留言 bg:23届 211本 社招 1. 自我介绍 2. 讲一个项目的点,因为用到了中间件平台的数据同步,于是开始鞭打数据同步。。 3. 如果同步的时候…...

深度学习之基于Yolov3的行人重识别
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 一、项目背景 行人重识别(Person Re-Identification,简称ReID)是计算机视觉领域…...

防火墙最新技术汇总
防火墙技术持续发展,以应对日益复杂的网络安全威胁。以下是防火墙领域的一些最新技术汇总: 下一代防火墙(NGFW):NGFW结合了传统防火墙的分组过滤和状态检测功能,还集成了深度包检测(DPI…...

PikaUnsafe upfileupload
1.client check 客户端检测,前端js检测,禁用js和修改后缀名即可。 php格式不能上传,我们修改后缀上传。 蚁剑成功连接。 2.MIME type 这个就是 content-type 规定上传类型,上面的方法也能成功,也可以修改 conten-ty…...

git拉取项目前需要操作哪些?
1.输入 $ ssh-keygen -t rsa -C "秘钥说明" 按enter键 2.出现 ssh/id_rsa:(输入也可以不输入也可以) 然后按enter键 3.出现empty for no passphrase:(输入也可以不输入也可以) 然后按enter键 4.出现same passphrase again: (输入也可以不输入也…...
报名开启!2024 开源之夏丨Serverless Devs 课题已上线!
Serverless 是近年来云计算领域热门话题,凭借极致弹性、按量付费、降本提效等众多优势受到很多人的追捧,各云厂商也在不断地布局 Serverless 领域。 Serverless Devs 是一个由阿里巴巴发起的 Serverless 领域的开源项目,其目的是要和开发者们…...

DataBinding viewBinding(视图绑定与数据双向绑定)简单案例 (kotlin)
先上效果: 4个view的文字都是通过DataBinding填充的。交互事件:点击图片,切换图片 创建项目(android Studio 2023.3.1) Build.gradle(:app) 引入依赖库(完整源码) buildFeatures { vie…...

TensorFlow基于anaconda3快速构建
基于python构建太累 Installing Packages - Python Packaging User Guide 使用 pip 安装 TensorFlow 有兴趣自己学,我放弃了 -------------------------------------------------------- 下面基于anaconda 1、下载 Index of /anaconda/archive/ | 清华大学开…...

力扣72-编辑距离
题目链接 记忆化搜索: 解题关键:每次仅考虑两字符串word1、word2分别从0 - i修改成0-j下标的完全匹配(下标表示) 临界条件:当 i 或 j 小于0时,表示该字符串为空,编辑距离确定为 y1 或 x1 int dp[501][501…...

K8S 删除pod的正确步骤
在日常的k8s运维过程中,避免不了会对某些pod进行剔除,那么如何才能正确的剔除不需要的pod呢? 首先,需要查出想要删除的pod # 可通过任意方式进行查询 kubectl get pods -A |grep <podname> kubectl get pods -n <names…...

羊大师分析,羊奶健康生活的营养源泉
羊大师分析,羊奶健康生活的营养源泉 羊奶,作为一种古老的饮品,近年来因其独特的营养价值和健康益处而备受关注。今天,羊大师就来探讨一下羊奶与健康之间的紧密联系。 羊奶富含蛋白质、脂肪、维生素和矿物质等多种营养成分。羊奶…...

刷屏一天GPT-4o,发现GPT4用的都还不熟练?戳这儿
以ChatGPT、LLaMA、Gemini、DALLE、Midjourney、Stable Diffusion、星火大模型、文心一言、千问为代表AI大语言模型带来了新一波人工智能浪潮,可以面向科研选题、思维导图、数据清洗、统计分析、高级编程、代码调试、算法学习、论文检索、写作、翻译、润色、文献辅助…...

力扣HOT100 - 139. 单词拆分
解题思路: 动态规划 class Solution {public boolean wordBreak(String s, List<String> wordDict) {Set<String> wordDictSet new HashSet(wordDict);boolean[] dp new boolean[s.length() 1];dp[0] true;for (int i 1; i < s.length(); i) {…...

rush 功能特性梳理
Rush 可以让 JavaScript 开发者更轻松地同时构建、发布多个 NPM 包,即将多个包或项目放到一个大仓库下管理。 仅需一次 NPM 安装 仅需一步,Rush 便可以将你项目的所有依赖安装到一个公共文件夹下,该文件夹并不像 “package.json” 一样位于项…...

算法分析与设计复习__递归方程与分治
总结自:【算法设计与分析】期末考试突击课_哔哩哔哩_bilibili 1.递归,递归方程 1.1递归条件: 1.一个问题的解可以分解为几个子问题的解; 2.这个问题与分解之后的子问题,除了数据规模不同,求解思路完全一样; 3.存在…...

apk-parse包信息解析
最近公司做项目,需要解析apk包的基本信息,上网找了好多资料,最终决定使用apk-parse。 .yml文件 引入jar包 <dependency> <groupId>net.dongliu</groupId> <artifactId>apk-parser</artifactId> <version&…...

AI绘画进阶工具ComfyUI 傻瓜整合包安装教程!模型共享,一键安装!
哈喽大家好,今天给大家分享一下AI绘画工具Stable Diffusion的另一种UI界面,常见的有: 窗口式界面的WebUI 节点式工作流的ComfyUI ComfyUI更加进阶一些,是一个节点式工作流的AI绘画界面,它高度可定制、自定义编辑Ai生…...
无人机摄影测量数据处理、三维建模及在土方量计算
原文链接:无人机摄影测量数据处理、三维建模及在土方量计算https://mp.weixin.qq.com/s?__bizMzUzNTczMDMxMg&mid2247603776&idx2&snd96440e116900a46a71c45ff77316896&chksmfa8217a7cdf59eb15da39dd6366378b98ca39b9c836b76a473ff292b67ee37a6ff6…...
)
大模型平台后端开发(xiaomi)
文章目录 算法题 算法题 1 三数之和 (注意去重的边界条件,过几天再刷几次) 2 长度最小的子数组 (代码随想录题目,滑动窗口) 3 用链表实现栈 package mainimport ("errors""fmt" )// Node 定义链表节点 type…...

性能测试工具—jmeter的基础使用
1.Jmeter三个重要组件 1.1线程组的介绍: 特点: 模拟用户,支持多用户操作多个线程组可以串行执行,也可以并行执行 线程组的分类: setup线程组:前置处理,初始化普通线程组:编写…...

如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富!
如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富! 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/Gi…...

LLM Notebooks:从零构建RAG问答系统的实践指南
1. 项目概述:一个面向大语言模型实践的“笔记本”仓库最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫qianniuspace/llm_notebooks。光看名字,llm_notebooks,大语言模型笔记本,这指向性就非常明确了。这大…...

AI应用开发利器:ai-devkit工具包核心功能与工程实践指南
1. 项目概述与核心价值最近在折腾AI应用开发,发现一个挺有意思的项目,叫codeaholicguy/ai-devkit。乍一看名字,你可能会觉得这又是一个“AI开发工具包”,市面上类似的工具已经多如牛毛了。但深入用下来,我发现它不太一…...

Ix开源平台:基于Kubernetes的私有云与家庭实验室一体化管理方案
1. 项目概述与核心价值最近在折腾一个叫Ix的开源项目,它来自ix-infrastructure这个组织。乍一看这个名字,你可能觉得有点抽象,但如果你对自托管、家庭实验室、私有云或者想找一个更现代、更易用的 TrueNAS 替代品感兴趣,那这个项目…...

SyntaxUI:基于原子设计与Web组件的现代UI库开发实践
1. 项目概述:一个为开发者而生的现代UI组件库 如果你是一名前端开发者,或者正在构建一个需要用户界面的应用,那么你肯定经历过这样的场景:为了一个按钮的样式、一个表格的交互,或者一个模态框的动画,反复在…...

从零构建Go Web框架:解析the0极简框架的设计原理与实现
1. 项目概述:一个极简主义Web框架的诞生在Web开发的世界里,我们常常面临一个选择:是拥抱功能齐全但略显臃肿的“巨无霸”框架,还是追求极致轻量与灵活的自定义方案?对于许多追求性能、热爱掌控感,或是需要构…...

3步强力清理:Pearcleaner让你轻松解决Mac应用残留文件问题
3步强力清理:Pearcleaner让你轻松解决Mac应用残留文件问题 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾删除Mac应用后,发…...

Go语言构建开发者命令行工具箱:navis项目架构与实现解析
1. 项目概述:一个为开发者打造的“导航”工具箱最近在GitHub上看到一个挺有意思的项目,叫navis,作者是NaveenBuidl。光看名字,你可能会联想到“导航”或者“航行”,没错,这个项目的核心定位就是一个为开发者…...
)
【2026年阿里巴巴集团暑期实习- 5月16日-算法岗-第一题- 分组计数】(题目+思路+JavaC++Python解析+在线测试)
题目内容 给定 nnn 个人的权值序列 a1,a2,…,ana_1,a_2,\dots,a_na...

AXI Crossbar设计解析:从总线互联原理到SoC集成实战
1. 项目概述:AXI Crossbar,不仅仅是“总线交叉开关”在复杂的数字系统设计,尤其是SoC(片上系统)和FPGA应用中,我们常常面临一个核心问题:多个主设备(Master,如CPU、DMA控…...