Elasticsearch集群和Logstash、Kibana部署
1、 Elasticsearch集群部署
-
服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| Elasticsearch | Elk | 10.3.145.14 | centos7.5.1804 | 2核4G |
| Elasticsearch | Es1 | 10.3.145.56 | centos7.5.1804 | 2核3G |
| Elasticsearch | Es2 | 10.3.145.57 | centos7.5.1804 | 2核3G |
-
软件版本:elasticsearch-7.13.2.tar.gz
-
示例节点:10.3.145.14
1、安装配置jdk
可以自行安装,es安装包中自带了jdk
2、安装配置ES
(1)创建运行ES的普通用户
[root@elk ~]# useradd es
[root@elk ~]# echo "******" | passwd --stdin "es"(2)安装配置ES
[root@elk ~]# tar zxvf /usr/local/package/elasticsearch-7.13.2-linux-x86_64.tar.gz -C /usr/local/
[root@elk ~]# mv /usr/local/elasticsearch-7.13.2 /usr/local/es
[root@elk ~]# vim /usr/local/es/config/elasticsearch.yml
cluster.name: bjbpe01-elk
cluster.initial_master_nodes: ["192.168.1.101","192.168.1.102","192.168.1.103"] # 单节点模式这里的地址只填写本机地址
node.name: elk01
node.master: true
node.data: true
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
# 单节点模式下,将discovery开头的行注释
discovery.seed_hosts: ["192.168.1.102","192.168.1.103"]
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping_timeout: 150s
discovery.zen.fd.ping_retries: 10
client.transport.ping_timeout: 60s
http.cors.enabled: true
http.cors.allow-origin: "*"配置项含义
cluster.name 集群名称,各节点配成相同的集群名称。
cluster.initial_master_nodes 集群ip,默认为空,如果为空则加入现有集群,第一次需配置
node.name 节点名称,各节点配置不同。
node.master 指示某个节点是否符合成为主节点的条件。
node.data 指示节点是否为数据节点。数据节点包含并管理索引的一部分。
path.data 数据存储目录。
path.logs 日志存储目录。
bootstrap.memory_lock 内存锁定,是否禁用交换,测试环境建议改为false。
bootstrap.system_call_filter 系统调用过滤器。
network.host 绑定节点IP。
http.port rest api端口。
discovery.seed_hosts 提供其他 Elasticsearch 服务节点的单点广播发现功能,这里填写除了本机的其他ip
discovery.zen.minimum_master_nodes 集群中可工作的具有Master节点资格的最小数量,官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量。
discovery.zen.ping_timeout 节点在发现过程中的等待时间。
discovery.zen.fd.ping_retries 节点发现重试次数。
http.cors.enabled 是否允许跨源 REST 请求,用于允许head插件访问ES。
http.cors.allow-origin 允许的源地址。(3)设置JVM堆大小#7.0默认为4G
[root@elk ~]# sed -i 's/## -Xms4g/-Xms4g/' /usr/local/es/config/jvm.options
[root@elk ~]# sed -i 's/## -Xmx4g/-Xmx4g/' /usr/local/es/config/jvm.options注:确保堆内存最小值(Xms)与最大值(Xmx)的大小相同,防止程序在运行时改变堆内存大小。
如果系统内存足够大,将堆内存最大和最小值设置为31G,因为有一个32G性能瓶颈问题。
堆内存大小不要超过系统内存的50%(4)创建ES数据及日志存储目录
[root@elk ~]# mkdir -p /data/elasticsearch/data
[root@elk ~]# mkdir -p /data/elasticsearch/logs (5)修改安装目录及存储目录权限
[root@elk ~]# chown -R es.es /data/elasticsearch
[root@elk ~]# chown -R es.es /usr/local/es3、系统优化
(1)增加最大文件打开数
[root@elk ~]# echo "* soft nofile 65536" >> /etc/security/limits.conf(2)增加最大进程数
[root@elk ~]# echo "* soft nproc 65536" >> /etc/security/limits.conf或者
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
更多的参数调整可以直接用这个(3)增加最大内存映射数
[root@elk ~]# echo "vm.max_map_count=262144" >> /etc/sysctl.conf
[root@elk ~]# sysctl -p(4)启动遇到下面问题解决办法
memory locking requested for elasticsearch process but memory is not locked
elasticsearch.yml文件
bootstrap.memory_lock : false
/etc/sysctl.conf文件
vm.swappiness=0错误:
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]意思是elasticsearch用户拥有的客串建文件描述的权限太低,知道需要65536个解决:切换到root用户下面,[root@elk ~]# vim /etc/security/limits.conf在最后添加
* hard nofile 65536
* hard nproc 65536
重新启动elasticsearch,还是无效?
必须重新登录启动elasticsearch的账户才可以,例如我的账户名是elasticsearch,退出重新登录。
另外*也可以换为启动elasticsearch的账户也可以,* 代表所有,其实比较不合适启动还会遇到另外一个问题,就是
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
意思是:elasticsearch用户拥有的内存权限太小了,至少需要262114。这个比较简单,也不需要重启,直接执行
sysctl -w vm.max_map_count=262144
就可以了4、启动ES
以ES用户启动
[root@elk ~]# su - es -c "cd /usr/local/es && nohup bin/elasticsearch &"测试:浏览器访问http://10.3.145.14:9200

5.安装配置head监控插件 (只在第一台es部署)
-
服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| Elasticsearch-head-master |
(1)安装node
[root@elk ~]# wget https://npm.taobao.org/mirrors/node/latest-v10.x/node-v10.0.0-linux-x64.tar.gz
[root@elk ~]# tar -zxf node-v10.0.0-linux-x64.tar.gz –C /usr/local
[root@elk ~]# echo "
NODE_HOME=/usr/local/node-v10.0.0-linux-x64
PATH=\$NODE_HOME/bin:\$PATH
export NODE_HOME PATH
" >>/etc/profile
[root@elk ~]# source /etc/profile
[root@elk ~]# node --version #检查node版本号(2)下载head插件
[root@elk ~]# wget https://github.com/mobz/elasticsearch-head/archive/master.zip
[root@elk ~]# unzip -d /usr/local elasticsearch-head-master.zip(3)安装grunt
[root@elk ~]# cd /usr/local/elasticsearch-head-master
[root@elk elasticsearch-head-master]# npm install -g grunt-cli
[root@elk elasticsearch-head-master]# grunt -version #检查grunt版本号(4)修改head源码
[root@elk ~]# vi /usr/local/elasticsearch-head-master/Gruntfile.js +99
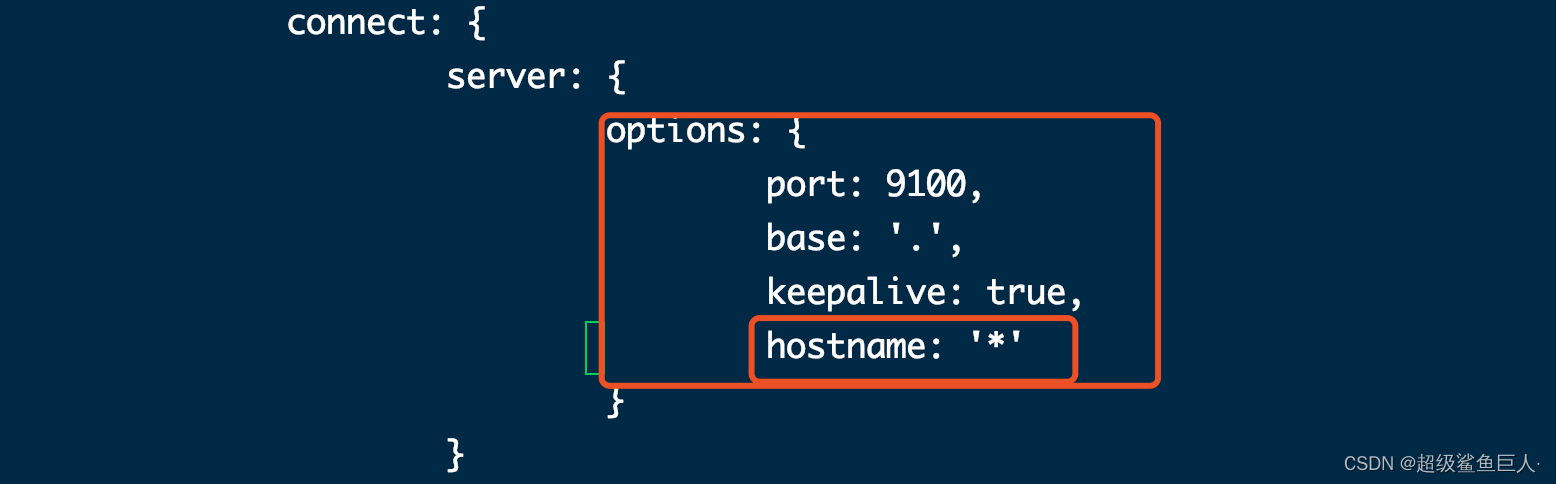
添加hostname,注意在上一行末尾添加逗号,hostname 不需要添加逗号
[root@elk ~]# vim /usr/local/elasticsearch-head-master/_site/app.js +4388

原本是http://localhost:9200,如果head和ES不在同一个节点,注意修改成ES的IP地址
(5)下载head必要的文件
[root@elk ~]# wget https://github.com/Medium/phantomjs/releases/download/v2.1.1/phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@elk ~]# yum -y install bzip2
[root@elk ~]# mkdir /tmp/phantomjs
[root@elk ~]# mv phantomjs-2.1.1-linux-x86_64.tar.bz2 /tmp/phantomjs/
[root@elk ~]# chmod 777 /tmp/phantomjs -R(6)运行head
[root@elk ~]# cd /usr/local/elasticsearch-head-master/
[root@elk elasticsearch-head-master]# npm install
[root@elk elasticsearch-head-master]# nohup grunt server &
[root@elk elasticsearch-head-master]# ss -tnlp
nohup grunt server --allow-root &
npm install 执行错误解析:
npm ERR! code ELIFECYCLE
npm ERR! errno 1
npm ERR! phantomjs-prebuilt@2.1.16 install: `node install.js`
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the phantomjs-prebuilt@2.1.16 install script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.npm ERR! A complete log of this run can be found in:
npm ERR! /root/.npm/_logs/2021-04-21T09_49_34_207Z-debug.log解决:
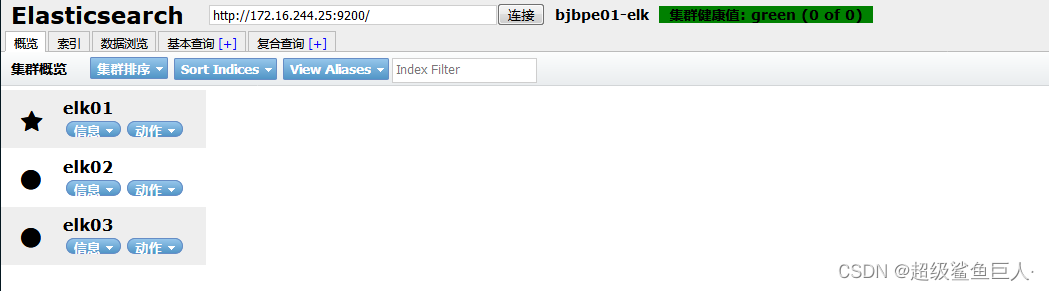
[root@elk elasticsearch-head-master]# npm install phantomjs-prebuilt@2.1.16 --ignore-scripts # 具体的版本按照上述报错修改(7)测试
访问http://10.3.145.14:9100
2. Logstash部署
-
服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| Logstash | Elk | 10.3.145.14 | centos7.5.1804 | 2核4G |
-
软件版本:logstash-7.13.2.tar.gz
1.安装配置Logstash
Logstash运行同样依赖jdk,本次为节省资源,故将Logstash安装在了10.3.145.14节点。
(1)安装
[root@elk ~]# tar zxf /usr/local/package/logstash-7.13.2.tar.gz -C /usr/local/(2)测试文件
标准输入=>标准输出及es集群
1、启动logstash
2、启动后直接在终端输入数据
3、数据会由logstash处理后返回并存储到es集群中
input {tcp {port => 8888}
}
filter {grok {match => {"message" => "%{DATA:key} %{NUMBER:value:int}"} }
}
output {stdout {codec => rubydebug}elasticsearch {hosts => ["10.3.145.14","10.3.145.56","10.3.145.57"]index => 'logstash-debug-%{+YYYY-MM-dd}'}
}(3)启动
[root@elk ~]# cd /usr/local/logstash-7.13.2
[root@elk ~]# nohup bin/logstash -f etc/conf.d/ --config.reload.automatic &3、Kibana部署
-
服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| Kibana | Elk | 10.3.145.14 | centos7.5.1804 | 2核4G |
| 软件版本:nginx-1.14.2、kibana-7.13.2-linux-x86_64.tar.gz |
1. 安装配置Kibana
(1)安装
[root@elk ~]# tar zxf kibana-7.13.2-linux-x86_64.tar.gz -C /usr/local/(2)配置
[root@elk ~]# echo '
server.port: 5601
server.host: "192.168.181.128"
elasticsearch.hosts: ["http://192.168.181.128:9200"]
kibana.index: ".kibana"
i18n.locale: "zh-CN"
'>>/usr/local/kibana-7.13.2-linux-x86_64/config/kibana.yml含义:
server.port kibana服务端口,默认5601
server.host kibana主机IP地址,默认localhost
elasticsearch.url 用来做查询的ES节点的URL,默认http://localhost:9200
kibana.index kibana在Elasticsearch中使用索引来存储保存的searches, visualizations和dashboards,默认.kibana(3)启动
[root@elk ~]# cd /usr/local/kibana-7.13.2-linux-x86_64/
[root@elk ~]# nohup ./bin/kibana &
./bin/kibana --allow-root4、Filebeat部署
为什么用 Filebeat ,而不用原来的 Logstash 呢?
原因很简单,资源消耗比较大。
由于 Logstash 是跑在 JVM 上面,资源消耗比较大,后来作者用 GO 写了一个功能较少但是资源消耗也小的轻量级的 Agent 叫 Logstash-forwarder。
后来作者加入 elastic.co 公司, Logstash-forwarder 的开发工作给公司内部 GO 团队来搞,最后命名为 Filebeat。
Filebeat 需要部署在每台应用服务器上,可以通过 Salt 来推送并安装配置。
-
服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| filebeat | Kafka3 | 10.3.145.43 | centos7.5.1804 | 1核2G |
-
软件版本 filebeat-7.13.2-x86_64.rpm
(1)下载
[root@kafka3 ~]# curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.13.2-x86_64.rpm(2)解压
[root@kafka3 ~]# yum install -y filebeat-7.13.2-x86_64.rpm(3)修改配置
修改 Filebeat 配置,支持收集本地目录日志,并输出日志到 Kafka 集群中
[root@kafka3 ~]# vim filebeat.yml
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/nginx/access.log
output.logstash:hosts: ["10.3.145.14:5000"]output.kafka: hosts: ["10.3.145.41:9092","10.3.145.42:9092","10.3.145.43:9092"]topic: 'nginx'# 注意,如果需要重新读取,请删除/data/registry目录 (4)启动
[root@kafka3 ~]# ./filebeat -e -c filebeat.yml相关文章:
Elasticsearch集群和Logstash、Kibana部署
1、 Elasticsearch集群部署 服务器 安装软件主机名IP地址系统版本配置ElasticsearchElk10.3.145.14centos7.5.18042核4GElasticsearchEs110.3.145.56centos7.5.18042核3GElasticsearchEs210.3.145.57centos7.5.18042核3G 软件版本:elasticsearch-7.13.2.tar.gz 示…...
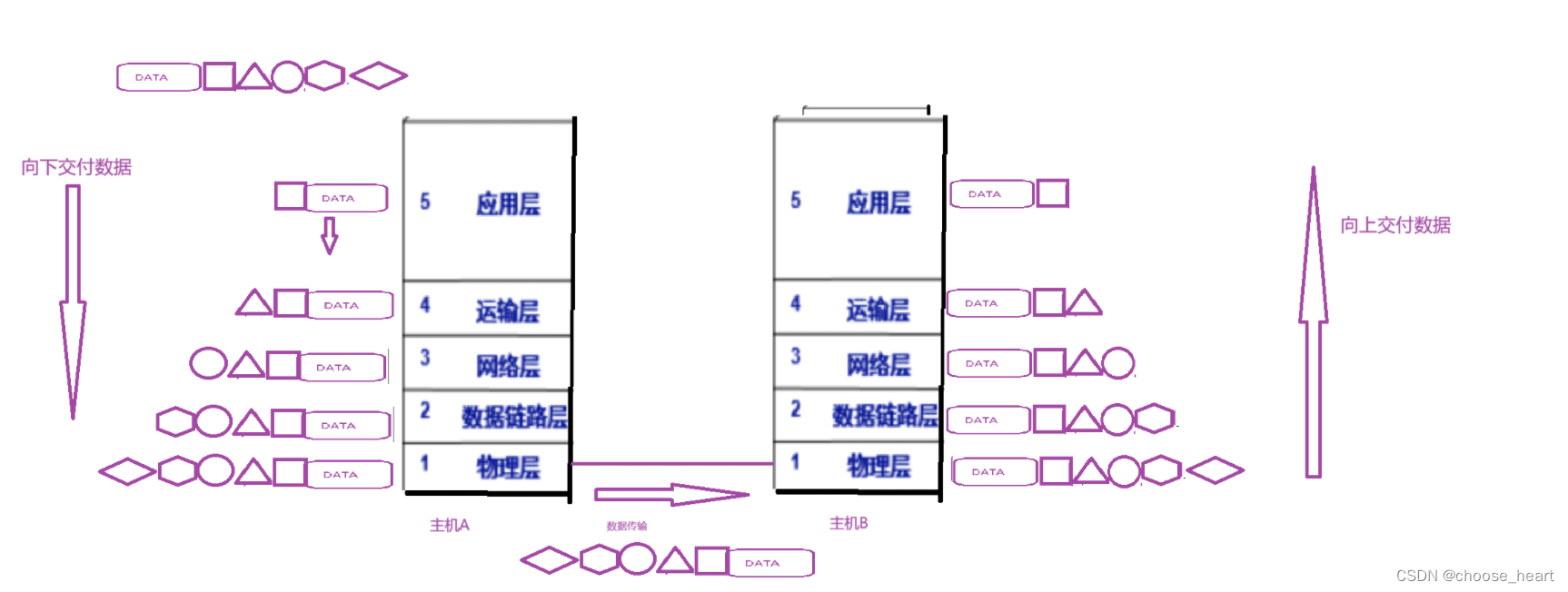
网络的基础理解
文章目录 网络的基础认识 网络协议协议分层OSI七层模型TCP/IP 五层/四层 模型 网络的基础认识 先来看下面几个问题 什么是网络? 网络就是有许多台设备包括计算机单不仅限于计算机,这些设备通过相互通信所组成起来系统,我们称之为网络所以如…...
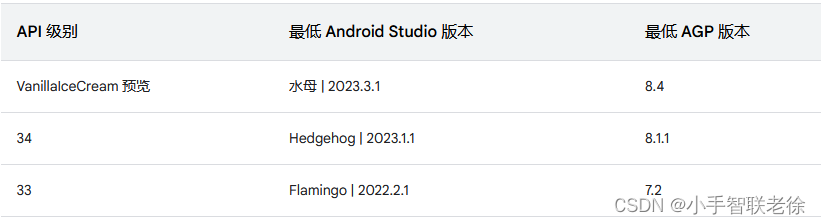
Android Studio 与 Gradle 及插件版本兼容性
Android Studio 开始新项目时,会自动创建其中部分文件,并为其填充合理的默认值。 项目文件结构布局: 一、Android Gradle 及插件作用: Android Studio 构建系统以 Gradle 为基础,并且 Android Gradle 插件 (AGP) 添加…...

【BUG】Edge|联想电脑 Bing 搜索报错“Ref A: 乱码、 Ref B:乱码、Ref C: 日期” 的解决办法
文章目录 省流版前言解决办法 详细解释版前言问题描述与排查过程解决办法与总结 省流版 我原以为我解决了,才发的博客,晚上用了一下其他设备发现还是会出现这个问题… 这篇博客并未解决该问题,如果评论里有人解决了这个问题不胜感激&#x…...

深度学习小车操作手册全
深度学习小车_操作手册_全 资源链接 分享文件:深度学习小车_操作手册_全.pdf 链接:https://pan.xunlei.com/s/VNy-KXPDZw64RqQGXiWVEDMRA1?pwdymu4# 复制这段内容后打开手机迅雷App,查看更方便智能车简介 2019 年的特斯拉自动驾驶开放日上…...

Python实现天气数据采集
Python实现天气数据采集 一、需求介绍二、完整代码一、需求介绍 本次天气数据采集的需求是获取每日的最高温、最低温、风力、风向、天气状况、AQI指数,如图所示,完整代码附后: 本次采集的目标网址是2345天气网: 上图的URL中,beijing是城市名称的缩写,54511即为城市代码…...
05 JavaSE-- 异常、IOStream、多线程、反射、Annotation、泛型、序列化
Exception 异常 异常也是对象,也有自己的体系,在这个体系中,所有异常对象的根类是 throwable 接口。异常和 error 错误是不同的概念。 错误是严重的 JVM 系统问题,一般不期待程序员去捕获、处理这些错误,同时…...

c++/c语法基础【2】
目录 1.memset 数组批量赋值 2.字符数组 编辑输入输出: 字符数组直接输入输出%s: gets! string.h 1.strlen:字符串去掉末尾\0的长度...

python 庆余年2收视率数据分析与可视化
为了对《庆余年2》的收视率进行数据分析与可视化,我们首先需要假设有一组收视率数据。由于实际数据可能无法直接获取,这里我们将使用模拟数据来演示整个过程。 以下是一个简单的步骤,展示如何使用Python(特别是pandas和matplotli…...

yolov8训练自己数据集时出现loss值为nan。
具体原因目前暂未寻找到。 解决办法 将参数amp改成False即可。 相关资料: https://zhuanlan.zhihu.com/p/165152789 https://github.com/ultralytics/ultralytics/issues/1148...

[Chapter 5]线程级并行,《计算机系统结构》,《计算机体系结构:量化研究方法》
文章目录 一、互连网络1.1 互连网络概述1.1 互连函数1.1.1 互连函数1.1.2 几种基本的互连函数1.1.2.1 恒等函数1.1.2.2 交换函数1.1.2.3 均匀洗牌函数1.1.2.4 碟式函数1.1.2.5 反位序函数1.1.2.6 移数函数1.1.2.7 PM2I函数 1.2 互连网络的结构参数与性能指标1.2.1 互连网络的结…...
首发!飞凌嵌入式FETMX6ULL-S核心板已适配OpenHarmony 4.1
近日,飞凌嵌入式在FETMX6ULL-S核心板上率先适配了OpenHarmony 4.1,这也是业内的首个应用案例,嵌入式核心板与OpenHarmony操作系统的结合与应用,将进一步推动千行百业的数智化进程。 飞凌嵌入式FETMX6ULL-S核心板基于NXP i.MX 6ULL…...
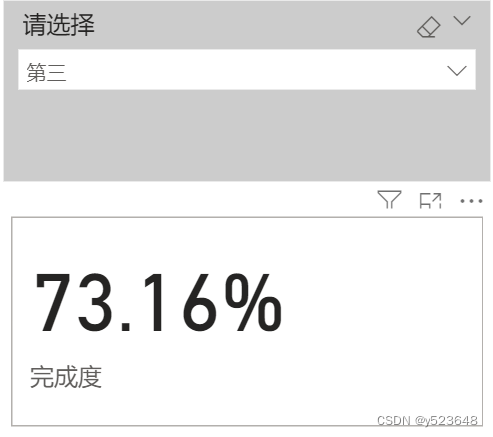
Power BI实现动态度量值
假设有一张销售数据表Sale: 报表上有一个切片器(Slicer)(下拉框样式), 当选择"第一"时,计算列[FirstSale]与列[Target]的百分比, 选择"第二"时,计算列[SecondSale]与列[Target]的百分比 选择"第三&qu…...

给大家分享一套非常棒的python机器学习课程
给大家分享一套非常棒的python机器学习课程——《AI小天才:让小学生轻松掌握机器学习》,2024年5月完结新课,提供配套的代码笔记软件包下载!学完本课程,可以轻松掌握机器学习的全面应用,复杂特征工程&#x…...

免费,Python蓝桥杯等级考试真题--第6级(含答案解析和代码)
Python蓝桥杯等级考试真题–第6级 一、 选择题 答案:D 解析:4411*4,超出范围,故答案为D。 答案:B 解析:5<8<10,故答案为B。 答案:A 解析:先比较a,然后…...

Spring Boot:SpringBoot 如何优雅地定制JSON响应数据返回
一、前言 目前微服务项目中RESTful API已经是前后端对接数据格式的标配模式了,RESTful API是一种基于REST(Representational State Transfer,表述性状态转移)原则的应用程序编程接口(Application Programming Interfac…...

c++中的constexpr 与decltype
constexpr constexpr 是 C11 引入的关键字,用于声明可以在编译时求值的常量表达式。constexpr 函数可以在编译时被计算,从而可以提高程序的性能并允许进行一些在运行时无法完成的优化。 在 C 中,constexpr 可以用于以下两种情况:…...
苹果MacOS系统使用微软远程桌面连接Windows电脑桌面详细步骤
文章目录 前言1. 测试本地局域网内远程控制1.1 Windows打开远程桌面1.2 局域网远程控制windows 2. 测试Mac公网远程控制windows2.1 在windows电脑上安装cpolar2.2 Mac公网远程windows 3. 配置公网固定TCP地址 前言 日常工作生活中,有时候会涉及到不同设备不同操作系…...

【paper】基于分布式采样的多机器人编队导航信念传播模型预测控制
Distributed Sampling-Based Model Predictive Control via Belief Propagation for Multi-Robot Formation NavigationRAL 2024.4Chao Jiang 美国 University of Wyoming 预备知识 马尔可夫随机场(Markov Random Field, MRF) 马尔可夫随机场ÿ…...

代码随想录算法训练营第二天| 977.有序数组的平方 、209.长度最小的子数组、 59.螺旋矩阵II
977. 有序数组的平方 题目链接:977. 有序数组的平方 文档讲解:代码随想录 状态:so easy 刚开始看到题目第一反应就是平方之后进行排序,数据量在 1 0 4 10^4 104,可以使用O(nlogn)的排序。但是更好的方式是使用双指针&a…...

美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训
https://www.mckinsey.com/mgi/our-research/At-250-sustaining-Americas-competitive-edge 美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训 这一切始于一场惊天动地的反抗行动。 1776年7月,来自13…...

解锁你的音乐宝藏:ncmdump让网易云音乐文件自由播放
解锁你的音乐宝藏:ncmdump让网易云音乐文件自由播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 当你精心收藏的网易云音乐只能在特定客户端播放时,那种被束缚的感觉是否让你感到无奈?想象一下…...
)
别再死记硬背了!用MATLAB手把手教你画根轨迹图(附代码与避坑指南)
MATLAB实战:从零绘制根轨迹图的完整指南与避坑技巧 在控制系统的设计与分析中,根轨迹图是理解系统动态特性的重要工具。传统教学中,学生往往被要求死记硬背绘制规则,却难以理解其实际应用价值。本文将彻底改变这一现状——通过MAT…...

深度解析Scarab:空洞骑士模组管理器的专业实现与架构设计
深度解析Scarab:空洞骑士模组管理器的专业实现与架构设计 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 空洞骑士模组管理器Scarab为玩家提供了高效、专业的模组…...

5分钟掌握小红书无水印下载:让内容保存效率提升300%
5分钟掌握小红书无水印下载:让内容保存效率提升300% 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&#…...

Obsidian智能模板终极指南:3步打造高效笔记自动化系统
Obsidian智能模板终极指南:3步打造高效笔记自动化系统 【免费下载链接】Templater A template plugin for obsidian 项目地址: https://gitcode.com/gh_mirrors/te/Templater Templater插件是Obsidian生态系统中功能最强大的智能模板解决方案,它能…...

【ElevenLabs情绪模拟技术白皮书】:基于2,147小时情感语音标注数据集的11类基础情绪迁移模型验证报告
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术白皮书概述 ElevenLabs的情绪模拟技术并非简单调节音高或语速,而是基于多模态情感表征学习(Multimodal Affective Representation Learning, MARL&#x…...

OpenClaw实战教程:声明式配置驱动的高效数据抓取方案
1. 项目概述:一个关于“OpenClaw”的实战教程 最近在GitHub上看到一个挺有意思的项目,叫“OpenClawTuto”。光看名字,你可能会有点摸不着头脑,这“OpenClaw”到底是个啥?是某种开源机械爪?还是一个代号&…...

Arm Cortex-A35 Cycle Model技术解析与SoC集成实战
1. Arm Cortex-A35 Cycle Model技术解析在SoC设计领域,虚拟平台验证已成为不可或缺的关键环节。作为Armv8-A架构中的能效比优化核心,Cortex-A35处理器通过Cycle Model提供了RTL级精度的硬件行为模拟能力。我在多个车载SoC项目中验证发现,其Cy…...

动态提示词工程:让AI提示词具备上下文学习能力的实践指南
1. 项目概述:当提示词遇上上下文学习最近在折腾大语言模型应用时,我反复遇到一个痛点:精心设计的提示词(Prompt)在特定任务上效果拔群,但换个场景或数据,效果就大打折扣。每次都得重新调整、测试…...