Autodl服务器中Faster-rcnn(jwyang)训练自己数据集(二)
前言
上一章中完成了faster-rcnn(jwyang版本)的复现,本节将在此基础进一步训练自己的数据集~
项目地址:https://github.com/jwyang/faster-rcnn.pytorch/tree/pytorch-1.0
复现环境:autodl服务器+python3.6+cuda11.3+Ubuntu20.04+Pytorch1.10.0
往期回顾
Autodl服务器中Faster-rcnn(jwyang)复现(一)
目录
- 一、数据准备
- 二、修改源代码
- 三、开始训练
- 四、开始测试
- 五、开始推理
一、数据准备
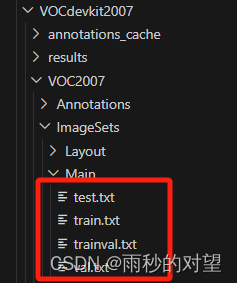
第一步:查看VOC数据集得文件夹tree结构
VOCdevkit2007
└── VOC2007├── Annotations├── ImageSets│ └── Main│ ├── test.txt│ ├── train.txt│ ├── trainval.txt│ └── val.txt└── JPEGImages
其中Annotations内放xml标注文件,JPEGImages内放图片,ImageSets/Main/内的四个txt文件分别是测试集、训练集、训练验证集、验证集。自己数据集依然采用VOC2007数据集的类。
第二步:制作自己数据集
(1)把原来的图片删掉,位置是:
/root/faster-rcnn/data/VOCdevkit2007/VOC2007/JPEGImages
将自己数据集的图片上传至JPEGImages
(2)更改xml文件中属性值
用这个代码可以任意改变xml里的属性值,比如你想把xml文件中类别名称改变,或把图片名称、路径等值改变,参考以下代码
#这里只修改folder部分
import os
import os.path
import xml.dom.minidompath = "/home/zhangxin/faster-rcnn.pytorch/data/VOCdevkit/VOC2007/Annotations/"
files = os.listdir(path) #得到文件夹下所有文件名称for xmlFile in files: #遍历文件夹if not os.path.isdir(xmlFile): #判断是否是文件夹,不是文件夹才打开print(xmlFile)#将获取的xml文件名送入到dom解析dom = xml.dom.minidom.parse(os.path.join(path, xmlFile)) #输入xml文件具体路径root = dom.documentElement#获取标签<name>以及<folder>的值name = root.getElementsByTagName('name')folder = root.getElementsByTagName('folder')#对每个xml文件的多个同样的属性值进行修改。此处将每一个<folder>属性修改为VOC2007for i in range(len(folder)): print(folder[i].firstChild.data)folder[i].firstChild.data = 'VOC2007'print(folder[i].firstChild.data)#将属性存储至xml文件中with open(os.path.join(path, xmlFile),'w') as fh:dom.writexml(fh)print('已写入')
这里修改folder部分,与VOC一样

完成后同样把原来的xml删掉,位置是:
/root/faster-rcnn/data/VOCdevkit2007/VOC2007/Annotations
将自己数据集的图片上传至Annotations
(3)自己制作trainval.txt,里面存储自己的待训练图片名称,记住不要带.jpg后缀,代码如下:
# !/usr/bin/python
# -*- coding: utf-8 -*-
import os
import random trainval_percent = 0.8 #trainval占比例多少
train_percent = 0.7 #test数据集占比例多少
xmlfilepath = '/root/faster-rcnn/data/VOCdevkit2007/VOC2007/Annotations/'
txtsavepath = '/root/faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/'
total_xml = os.listdir(xmlfilepath) num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr) ftrainval = open('/root/faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/trainval.txt', 'w')
ftest = open('/root/faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/test.txt', 'w')
ftrain = open('/root/faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/train.txt', 'w')
fval = open('/root/faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/val.txt', 'w') for i in list: name=total_xml[i][:-4]+'\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
生成结果:
二、修改源代码
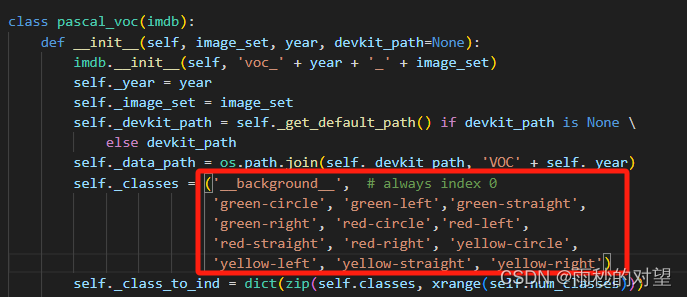
第一步:在lib\datasets\pascal_voc.py中更改self._classes中的类别,添加自己的类
三、开始训练
训练之前一定要激活自己创建的my-env虚拟环境
conda activate my-env
参考:Autodl服务器中Faster-rcnn(jwyang)复现
CUDA_VISIBLE_DEVICES=0 python trainval_net.py \--dataset pascal_voc --net vgg16 \--bs 4 --nw 0 \--lr 0.002 \--cuda
-
报错1
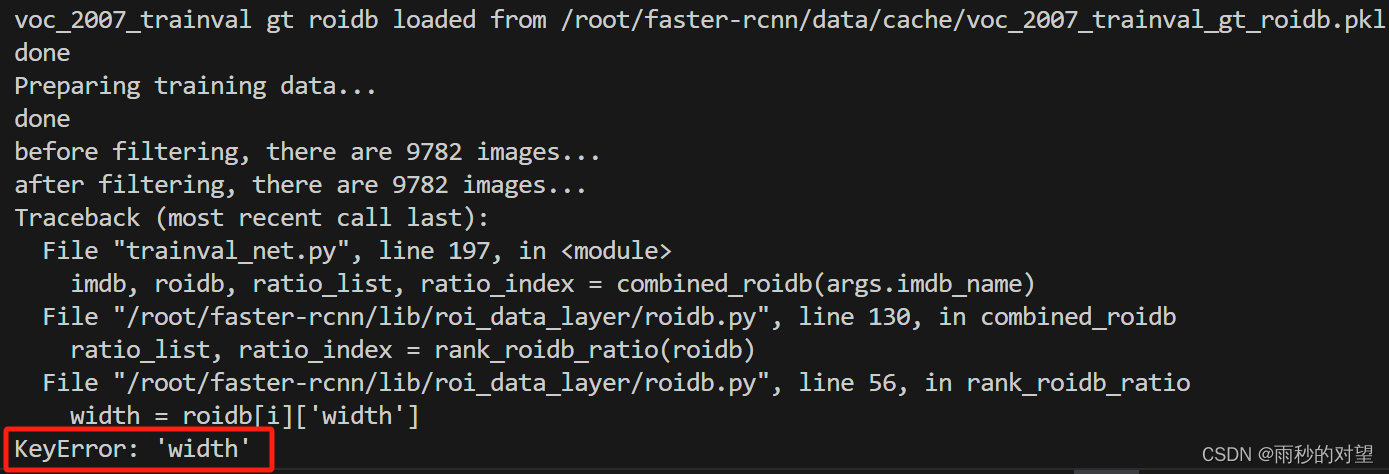
原因:在训练原数据集VOC时,图像数量是5964张(进行了数据增强),这时会保存训练信息至缓存中,文件路径为:/home/mw/faster-rcnn/data/cache/voc_2007_trainval_gt_roidb.pkl
解决:在重新训练新数据集的时候,会读取这个缓存配置,以加快训练,那么此时就入坑了,我的新集合只有994张,所以训练时读的缓存里,需要读的图像还是原来那5964张,那势必会找不到这5964张图像,所以要做的就是,把这个缓存文件voc_2007_trainval_gt_roidb.pkl删除 -
报错2
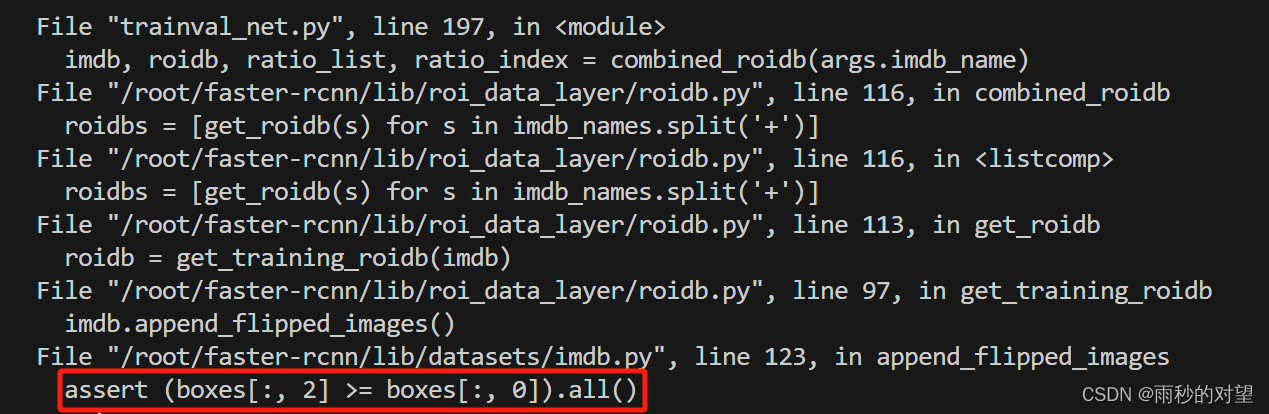
解决过程:https://blog.csdn.net/xzzppp/article/details/52036794
跑通如下:
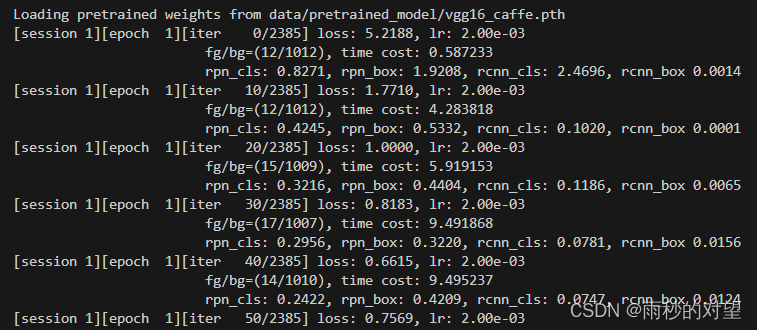
四、开始测试
python test_net.py --dataset pascal_voc --net vgg16 --checksession 1 --checkepoch 3 --checkpoint 2384 --cuda
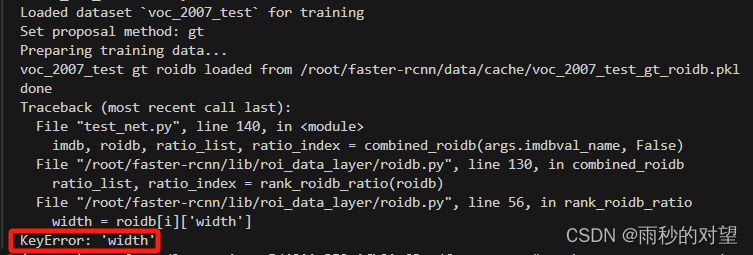
解决:与上述相似,把这个缓存文件/home/mw/faster-rcnn/data/cache/voc_2007_test_gt_roidb.pkl删除
效果如下:

在VOC上12个class的mAP为83.4%
五、开始推理
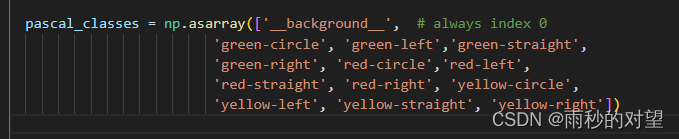
第一步:修改demo.py中pascal_classes类别
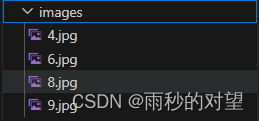
第二步:把几张测试图片放到images中
第三步:运行demo.py
python demo.py --net vgg16 --checksession 1 --checkepoch 3 --checkpoint 2384 --cuda --load_dir models
推理结果如下:

好了,到这一步关于faster-rcnn训练自己的数据集就结束了,完结撒花~
相关文章:
Autodl服务器中Faster-rcnn(jwyang)训练自己数据集(二)
前言 上一章中完成了faster-rcnn(jwyang版本)的复现,本节将在此基础进一步训练自己的数据集~ 项目地址:https://github.com/jwyang/faster-rcnn.pytorch/tree/pytorch-1.0 复现环境:autodl服务器python3.6cuda11.3Ubuntu20.04Pytorch1.10.0…...

安卓手机文件误删或丢失?教你快速找回的方法!
概括 有时我们可能会错误地删除Android设备上的重要文件。更疯狂的是,Android 手机上的文件一夜之间就消失了,我们不知道为什么。我们很遗憾、很恼火,但又不知道。然而,现在学习如何从Android手机恢复已删除的文件已经为时已晚&a…...
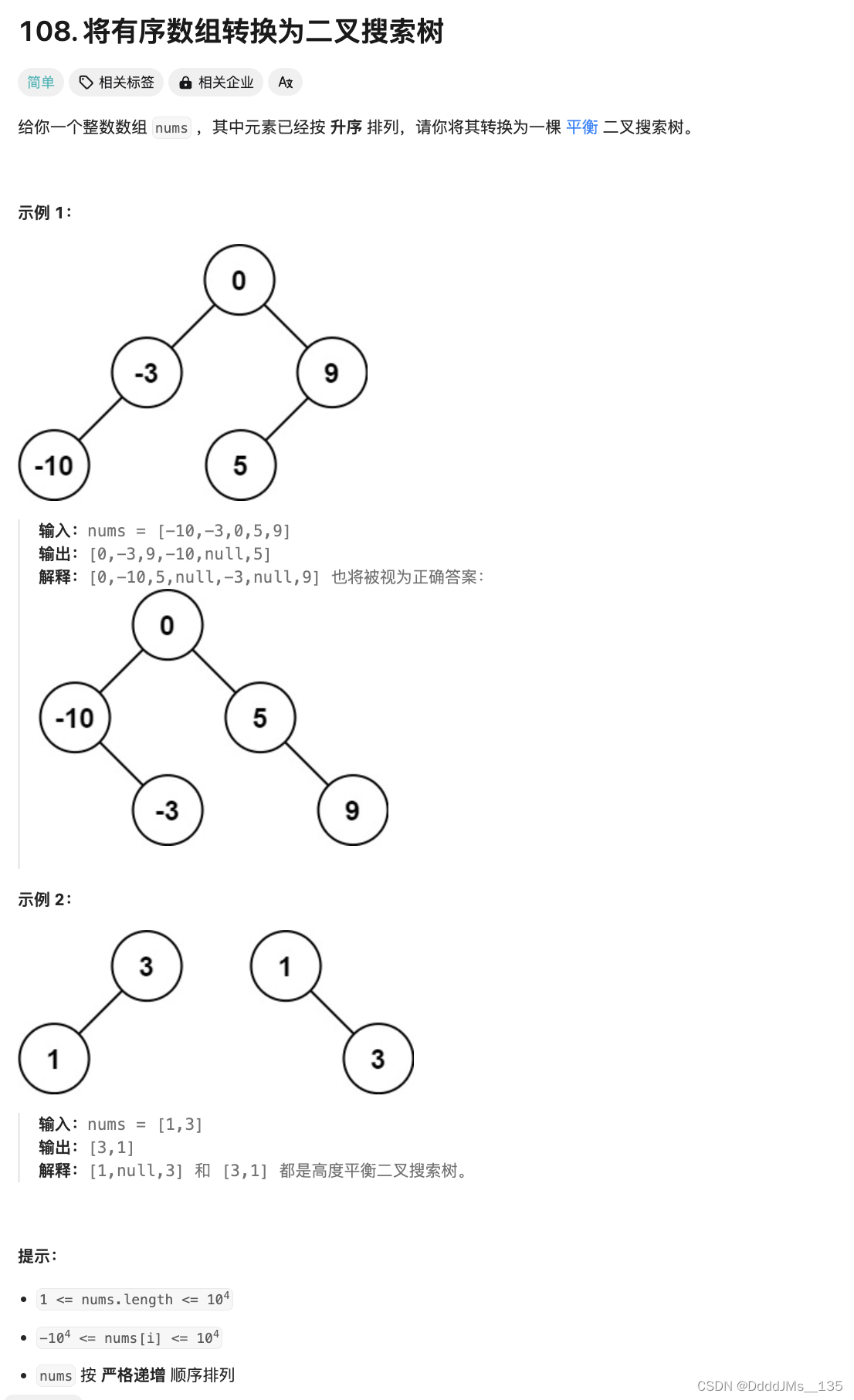
C语言 | Leetcode C语言题解之第108题将有序数组转换为二叉搜索树
题目: 题解: struct TreeNode* helper(int* nums, int left, int right) {if (left > right) {return NULL;}// 选择任意一个中间位置数字作为根节点int mid (left right rand() % 2) / 2;struct TreeNode* root (struct TreeNode*)malloc(sizeo…...
可行性研究的报告)
关于在企业环境中中间人攻击(MITM)可行性研究的报告
这份文件是一篇关于在企业环境中中间人攻击(MITM)可行性研究的报告,由Nobel Ang和Koh Chuen Hia撰写。 以下是其核心内容的概述: 标题: 研究在企业环境中中间人攻击的可行性 作者: Nobel Ang(…...

GitHub Actions 自动部署 AWS Lambda
在现代软件开发中,持续集成和持续部署(CI/CD)已经成为必不可少的一部分。借助 GitHub Actions 这个强大的工具,我们可以轻松地实现将代码自动部署到 AWS Lambda 的流程。 在本文中,我们将介绍如何使用 GitHub Actions 将代码部署到 AWS Lambda。我们将涵盖以下步骤: 设置 A…...

【NOIP2013普及组复赛】题4:车站分级
题4:车站分级 【题目描述】 一条单向的铁路线上,依次有编号为 1 , 2 , … , n 1,2,…,n 1,2,…,n 的 n n n 个火车站。每个火车站都有一个级别,最低为 1 1 1 级。现有若干趟车次在这条线路上行驶,每一趟都满足如下要求&#…...

el-table 表格拖拽 + 表头可修改 + 宽度自定义
el-table 表格拖拽 表头可修改 宽度自定义 宽度自定义 header-dragend"headerdragend"操作之后获取最后的宽度 headerdragend(newWidth, oldWidth, column, event) {// 获取当前拖动的是第几个,方便后续检测 DOM 是否已更新var currentColIndex this.t…...

Google发布的CAT3D,在1分钟内,能够从任意数量的真实或生成的图像创建3D场景。
给定任意数量的输入图像,使用以这些图像为条件的多视图扩散模型来生成场景的新视图。生成的视图被输入到强大的 3D 重建管道,生成可以交互渲染的 3D 表示。总处理时间(包括视图生成和 3D 重建)仅需一分钟。 相关链接 论文&#x…...
基于Matlab实现声纹识别系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 一、项目背景与意义 声纹识别,也称为说话人识别,是一种通过声音判别说话人身份的生物识别技…...

【人工智能项目】小车障碍物识别与模型训练(完整工程资料源码)
实物演示效果: 一、绪论: 1.1 设计背景 小车障碍物识别与模型训练的设计背景通常涉及以下几个方面: 随着自动驾驶技术的发展,小车(如无人驾驶汽车、机器人等)需要能够在复杂的环境中自主导航。障碍物识别是实现这一目标的关键技术之一,它允许小车检测并避开路上的障碍物…...

#05【面试问题整理】嵌入式软件工程师
前言 本系列博客主要记录有关嵌入式方面的面试重点知识,本系列已经更新的篇目有如下: 1.1进程线程的基本概念 1.2 并发,同步,异步,互斥,阻塞,非阻塞的理解 1.3 孤儿进程、僵尸进程、守护进程的概念 【本篇】5.1 Linux内核相关 6.0 单片机常见面试题 内容如有错误请在…...
同旺科技 FLUKE ADPT 隔离版发布 ---- 3
所需设备: 1、FLUKE ADPT 隔离版 内附链接; 应用于:福禄克Fluke 12E / 15BMax / 17B Max / 101 / 106 / 107 应用于:福禄克Fluke 15B / 17B / 18B 总体连接: 连接线,根据自己实际需求而定; …...

探索 JavaScript 新增声明命令与解构赋值的魅力:从 ES5 迈向 ES6
个人主页:学习前端的小z 个人专栏:JavaScript 精粹 本专栏旨在分享记录每日学习的前端知识和学习笔记的归纳总结,欢迎大家在评论区交流讨论! ES5、ES6介绍 文章目录 💯声明命令 let、const🍟1 let声明符&a…...

HTML5 历史、地理位置处理、全屏处理
目录 历史HistoryAPI地理位置处理GeolocationAPI全屏处理FullscreenAPIHistoryAPI window.history 对象 window.history 是浏览器提供的一个内置对象,它提供了对浏览器历史记录的访问和操作能力。通过这个对象,开发者可以实现无刷新页面跳转、添加新的浏览历史条目等,从而提…...

打印机驱动程序安装后位置以及注册表中的位置
文件系统中的位置 驱动程序文件:通常位于以下目录: C:\Windows\System32\spool\driversC:\Windows\System32\DriverStore\FileRepository 打印机配置文件:这些文件存储了特定打印机的配置信息: C:\Windows\System32\spool\PRINTER…...

oracle数据库解析过高分析
解析非常高,通过时间模型可以看到解析占比非常高 解析大致可以分为硬解析( hard parse)、软解析( soft parse)和软软解析( soft soft parse)。如,执行一条 SQL 的时候,如…...

Python解析网页-XPath
目录 1、什么是XPath 2、安装配置 3、XPath常用规则 4、快速入门 5、浏览器XPath工具 1.什么是XPath XPath(XML Path Language)是一种用于在XML文档中定位和选择节点的语言。 它是W3C(World Wide Web Consortium)定义的一种标…...

Vue 3入门指南
title: Vue 3入门指南 date: 2024/5/23 19:37:34 updated: 2024/5/23 19:37:34 categories: 前端开发 tags: 框架对比环境搭建基础语法组件开发响应式系统状态管理路由配置 第1章:Vue 3简介 1.1 Vue.js的历史与发展 Vue.js由前谷歌工程师尤雨溪(Eva…...
Arcpy安装和环境配置
一、前言 ArcPy 是一个以成功的arcgisscripting 模块为基础并继承了arcgisscripting 功能进而构建而成的站点包。目的是为以实用高效的方式通过 Python 执行地理数据分析、数据转换、数据管理和地图自动化创建基础。该包提供了丰富纯正的 Python 体验,具有代码自动…...

Swagger2 和 Swagger3 的不同
Swagger2 和 Swagger3 的不同 SpringBoot 整合 Swagger3 和 Swagger2 的主要区别如下: 区别一:引入不同的依赖 如果使用的是 Swagger 3 <dependency><groupId>io.springfox</groupId><artifactId>springfox-boot-starter<…...

ComfyUI-Impact-Pack:AI图像精细化增强的3大突破性技术革命
ComfyUI-Impact-Pack:AI图像精细化增强的3大突破性技术革命 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址: htt…...

基于qstock的北向资金量化分析框架构建与策略应用
基于qstock的北向资金量化分析框架构建与策略应用 【免费下载链接】qstock qstock由“Python金融量化”公众号开发,试图打造成个人量化投研分析包,目前包括数据获取(data)、可视化(plot)、选股(stock)和量化回测(策略b…...

CANN 容器化部署:Docker 与 K8s 实战
一、为什么需要容器化 1.1 容器化优势 裸机部署:环境依赖复杂,版本冲突扩缩容困难,手动运维资源隔离差,互相影响容器化部署:环境一致性,开箱即用弹性扩缩容,自动运维资源隔离,互不影响版本管理,…...

WarcraftHelper:如何快速解决魔兽争霸3在现代电脑上的三大兼容问题?
WarcraftHelper:如何快速解决魔兽争霸3在现代电脑上的三大兼容问题? 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典…...

机器学习实战地形图:从问题定义到模型监控的端到端闭环
1. 项目概述:这不是一本“速成手册”,而是一张机器学习领域的实操地形图 “Machine Learning A-Z Briefly Explained”——光看标题,很多人第一反应是“又一本入门书?”、“是不是那种翻两页就堆满公式、第三章就开始推导梯度下降…...

ENSP实验避坑指南:搭建园区网时,VLAN间通信、MSTP负载分担、VRRP主备切换这些细节你配对了吗?
ENSP园区网实战排错手册:从VLAN间通信到VRRP主备切换的深度解析 刚完成ENSP园区网搭建实验的网络工程师小王盯着屏幕,眉头紧锁——所有配置明明都按照教程一步步操作,可VLAN间的PC就是无法互通,MSTP负载分担也没生效。这种"…...

从Hugging Face模型到可部署服务:我的fast-whisper中文识别项目踩坑与优化实录
从Hugging Face模型到可部署服务:我的fast-whisper中文识别项目踩坑与优化实录 去年夏天接手了一个智能客服系统的语音模块改造项目,客户要求实现高准确率的中文语音实时转写。当我第一次在会议室演示原型时,背景杂音导致转写结果出现了&quo…...

解锁智能电网通信:libiec61850如何重塑电力自动化架构
解锁智能电网通信:libiec61850如何重塑电力自动化架构 【免费下载链接】libiec61850 Official repository for libIEC61850, the open-source library for the IEC 61850 protocols 项目地址: https://gitcode.com/gh_mirrors/li/libiec61850 在电力系统自动…...

如何高效使用COMET翻译评估工具:专业用户实战指南
如何高效使用COMET翻译评估工具:专业用户实战指南 【免费下载链接】COMET A Neural Framework for MT Evaluation 项目地址: https://gitcode.com/gh_mirrors/com/COMET 在机器翻译快速发展的今天,你如何准确评估翻译质量?传统的人工…...

暗黑破坏神2角色编辑革命:Diablo Edit2如何彻底改变你的游戏体验
暗黑破坏神2角色编辑革命:Diablo Edit2如何彻底改变你的游戏体验 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾因重复刷装备而疲惫,却依然无法获得心仪的属性组合…...