怎样从SQL中分析和提取访问的字段信息?| OceanBase实践
当执行任意一条SELECT SQL语句时,我们如何能够分析出所访问的字段信息,并进一步判断结果集中的每一列数据具体来自于哪些数据库、表以及表中的哪些字段呢?本文将会详细阐述针对此问题的技术解决方案。
应用场景
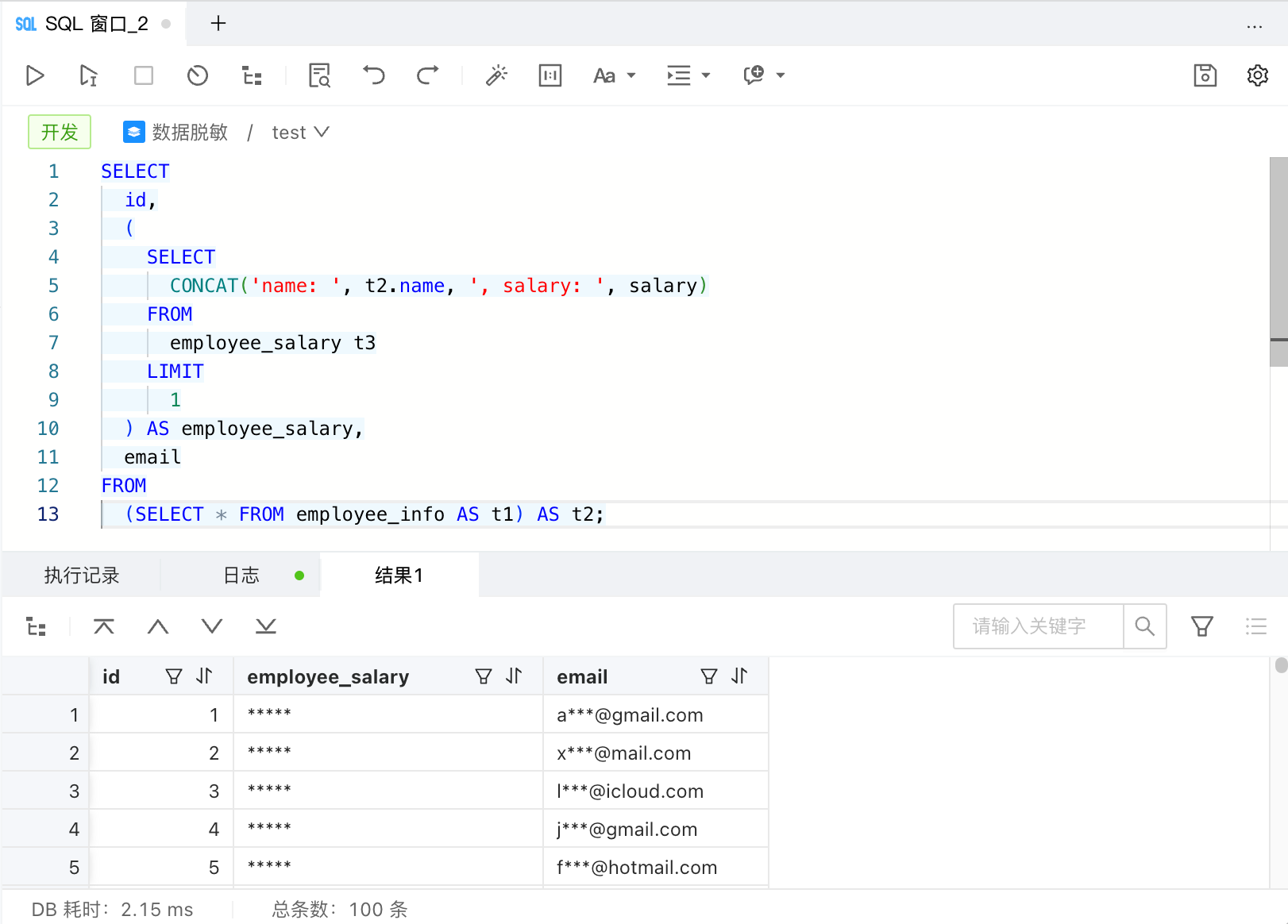
从 SQL 中解析访问的原始字段信息有一定难度,但是非常有用。一个典型的应用就是动态数据脱敏。动态数据脱敏是指数据以明文形式存储在介质中,在查询的时候根据用户权限动态地将敏感数据进行脱敏后展示。例如执行以下 SQL 时,将结果集中涉及员工邮箱和薪资信息的列数据,按照不同列对应的脱敏算法做了脱敏处理。
问题定义
输入:SQL
输出:结果集中的每一列所涉及的数据库、表和字段信息
技术方案
SQL 语法解析
语法解析的目的是将 SQL 文本转化为抽象语法树(Abstract Syntax Tree, AST),方便后续通过编程形式进行分析处理。以 OceanBase MySQL 兼容模式为例,使用 ANTLR4 作为解析器生成器,从 此处 获取 .g4 语法文件。编译生成对应的 Parser,然后就可以基于 Visitor 访问 AST 从 SQL 中提取想要的信息了。举个例子,对于以下 SQL:
SELECT tb.col FROM tb WHERE col1='abc';解析成的 AST 如下: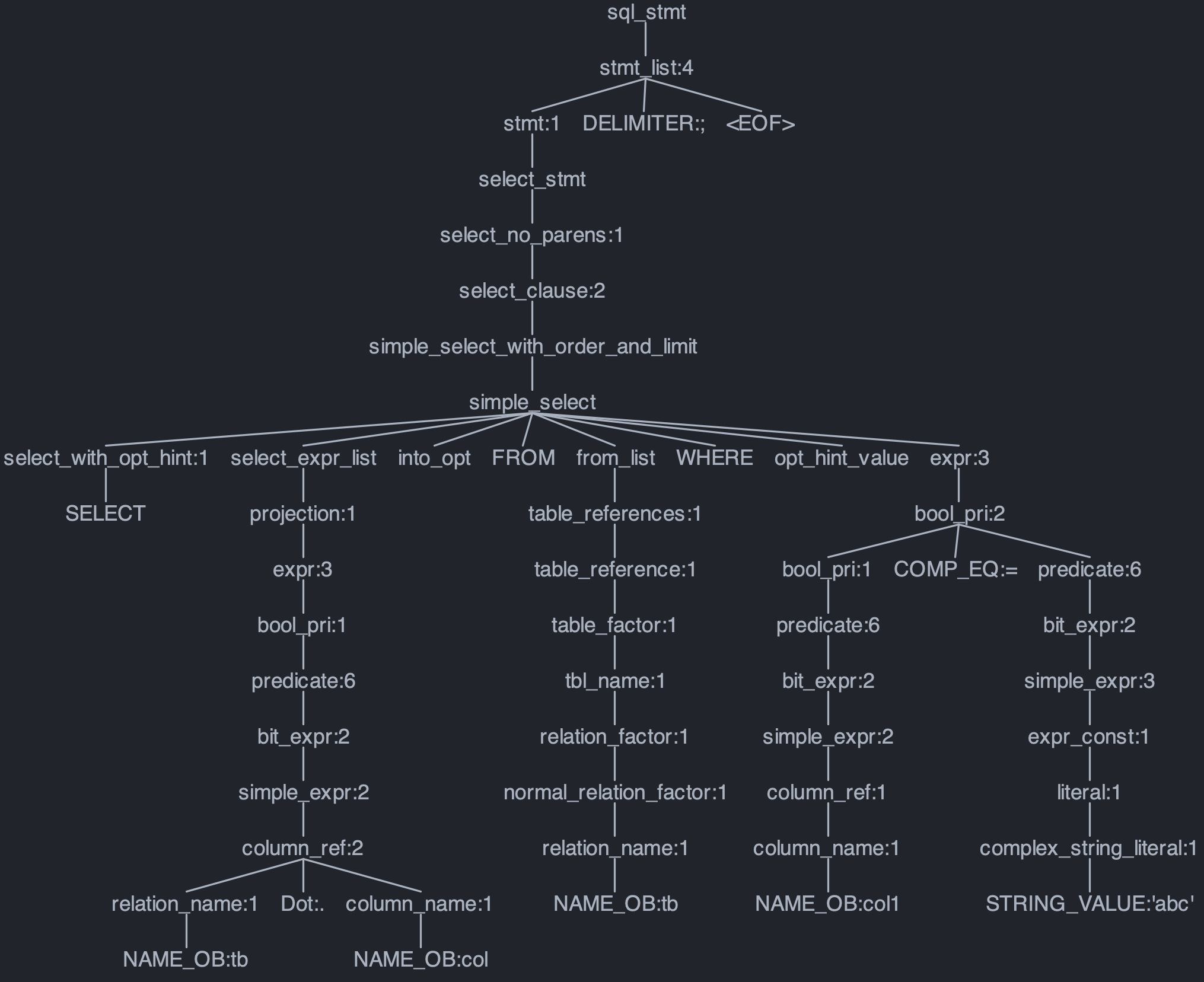 其中,每个节点对应语法文件中定义的一个 Token。例如,语法文件中对 SELECT 子句的起始 Token 定义为
其中,每个节点对应语法文件中定义的一个 Token。例如,语法文件中对 SELECT 子句的起始 Token 定义为select_expr_list,则可以从 select_expr_list 节点的子节点中获取 SELECT 子句中使用的列信息。可以发现,直接访问 AST 来提取 SQL 中的关键信息是比较困难和低效的,因为需要对语法文件和 AST 的结构有清晰的了解。因此,推荐使用 ob-sql-parser。它是开源的基于 ANTLR4 构建的 SQL 解析器,可以将 SQL 文本翻译成 Pojo 类,让程序员可以像操作普通 Java 对象一样处理 SQL。对于上面的 SQL,其处理后的对象结构如下:
SQL Text└──Statement: Select└──selectBody: SelectBody├──selectItems: List<Projection>│ └──Projection| └──column: Expression| └──RelationReference: tb.col├──froms: List<FromReference>│ └──NameReference: tb└──where: Expression└──CompoundExpression: col1='abc'SELECT 字段检测
一条完整的 SELECT 语句中有且仅有以下类型的子句:
- FROM 子句
SELECT * FROM table1;- JOIN 子句
SELECT * FROM table1 JOIN table2;- SELECT 子句
SELECT col1, col2+col3, func(col4, col5) FROM table1;- 子查询
SELECT( SELECT id FROM test_data_masking_1 t1 LIMIT 1 ) > 100 AS subquery
FROMDUAL;- 集合运算
SELECT * FROM table1
UNION ALL
SELECT * FROM table2;- 通用表表达式(Common Table Expressions,CTE)
WITH cte (col_1, col_2)
AS (SELECT col1, col2 FROM table1
)
SELECT * FROM cte;下面我们逐个分析这些子句对应的字段提取方案。
FROM 子句
形如 SELECT * FROM t;。此时,只需要访问数据库获取表 t 的字段信息,即可计算出输出列对应的字段。注意点:
- FROM 子句中如果没有显式指定库名,需要使用当前所在库名代替
- 需要对内置
DUAL表做特殊处理
JOIN 子句
形如 SELECT * FROM t1 JOIN t2;。具体语法格式如下:
joined_table: {table_reference {[INNER | CROSS] JOIN | STRAIGHT_JOIN} table_factor [join_specification]| table_reference {LEFT|RIGHT} [OUTER] JOIN table_reference join_specification| table_reference NATURAL [INNER | {LEFT|RIGHT} [OUTER]] JOIN table_factor
}join_specification: {ON search_condition| USING (join_column_list)
}join_column_list:column_name [, column_name] ...对于简单的 JOIN 查询,输出列是由多张表按 JOIN 的顺序拼接而成。此时分别查询表结构,即可计算出输出列对应的字段。对于NATURAL JOIN和JOIN USING (columnList)查询,输出列会根据字段名进行合并。合并后的每个列可能会对应多个原始字段。合并规则如下:
- 同名(或在
columnList中)的列,按照其在左边表中的顺序放在输出列的最左侧 - 不同名的列,按照先左边表后右边表的顺序依次排序
SELECT 子句
形如SELECT col1, col2+col3, func(col4, col5) FROM t;。此时,先单独处理 FROM 子句,即处理 SELECT * FROM t获取输出列,然后处理 SELECT 子句中的内容。注意点:
- SELECT 子句中引用的列名如果能唯一确定,则库名可以省略,否则为语法错误
- SELECT 子句和 FROM 子句中都可以混合使用原名和别名,因此编码时存储的元信息应包括:库名、表名、表别名、列名、列别名
- SELECT 子句中可以使用常数、表达式、函数、子查询等,需要分别专门处理
子查询
子查询可以出现在 SELECT 子句、FROM 子句、WHERE 子句和 HAVING 子句等几乎任何地方。我们可以将子查询分为两类专门处理:
- 非关联子查询,形如
SELECT * FROM (SELECT a FROM t)。可以将其按独立的 SELECT 语句进行处理。 - 关联子查询,形如
SELECT (SELECT CONCAT(t1.a, t2.b) FROM t2 LIMIT 1) FROM t1。子查询中会使用子查询之外的表(外部表),因此需要使用一个变量,存储子查询所在当前外部表层级的中间结果集,形如List<Map<输出列, List<物理库表列>>>。**需要注意的是,子查询的不同层级外部表的别名可以重复,按从内到外的顺序依次匹配,以先匹配到的为准。**子查询外部不能引用子查询内部的中间结果集,所以存储相关信息的变量的结构可以是一个栈,每次完成一个层级子查询的处理后,将相应的外部表信息出栈。
可以参考以下包含多层关联子查询的 SQL 来理解上面的内容:
SELECTCONCAT(name,' - ',(SELECTCONCAT(t2.salary,' - ',(SELECT/* 这里需要注意列匹配顺序:从最里层到最外层逐次匹配1. 虽然 test_data_masking_2 和 test_data_masking_3 都有 id 字段且别名都叫 t2,但是这里的 t2.id 取值是 test_data_masking_3.id2. level 字段只在 test_data_masking_3 存在,因此取值是 test_data_masking_3.level3. t1.name 唯一确定是 test_data_masking_1.name4. name 按从内到外顺序,匹配的是 test_data_masking_3.name*/CONCAT(t2.id, level, ' - ', t1.name, ' - ', name)FROMtest_data_masking_3 t2LIMIT1))FROMtest_data_masking_2 t2LIMIT1)) AS output
FROMtest_data_masking_1 t1;集合运算
集合运算的处理比较简单,将两张表的输出列所对应的物理库表列按以下规则合并即可。需要注意两张中间表的列数必须相同。
| 运算符 | 返回值 |
|---|---|
| UNION | 返回任意查询选择的所有不同行。 |
| UNION ALL | 返回任意查询选择的所有行,并包括所有重复项。 |
| INTERSECT | 返回两个查询都选择的所有不同行。 |
| MINUS | 返回第一个查询选择的所有不同行,但其中不包括出现在第二个查询中的行。 |
通用表表达式(CTE)
CTE 的语法格式如下:
with_clause:WITH [RECURSIVE]cte_name [(col_name [, col_name] ...)] AS (subquery)[, cte_name [(col_name [, col_name] ...)] AS (subquery)] ...其本质上就是在 SELECT 语句执行前引入一些名为cte_name的“临时表”,这些临时表是由 CTE 中的subquery(SELECT 语句)动态生成并仅供在当前 SQL 中引用。因此需要在处理 SELECT 语句前先将 CTE 定义的临时表构建出来。非递归 CTE 的处理方式和普通 SELECT 语句一致。需要注意的是,CTE 定义中可以包含多个临时表的定义,顺序是从前往后,后面的 CTE 可以引用前面已经定义的临时表。另外,临时表定义本身也可以使用 CTE,与嵌套子查询类似,里层的 CTE 定义可以引用外层已经定义的 CTE。
递归 CTE 的subquery包含两个部分:初始化 SELECT 语句和递归 SELECT 语句,二者用UNION ALL或UNION [DISTINCT]分开,形如:
WITH RECURSIVEcte (id, name) AS (SELECT id, name FROM test_data_masking_1 t1 WHERE t1.id = 1UNION ALLSELECT id+1, name FROM cte where id <= 10)
SELECT * FROM cte;可以看到,初始化 SELECT 语句确定了 CTE 定义的临时表的列,这部分按照普通 SELECT 语句处理即可。处理递归 SELECT 语句时,将初始化 SELECT 语句的输出作为递归 SELECT 的额外输入即可。这里需要考虑敏感数据传递的情况,例如: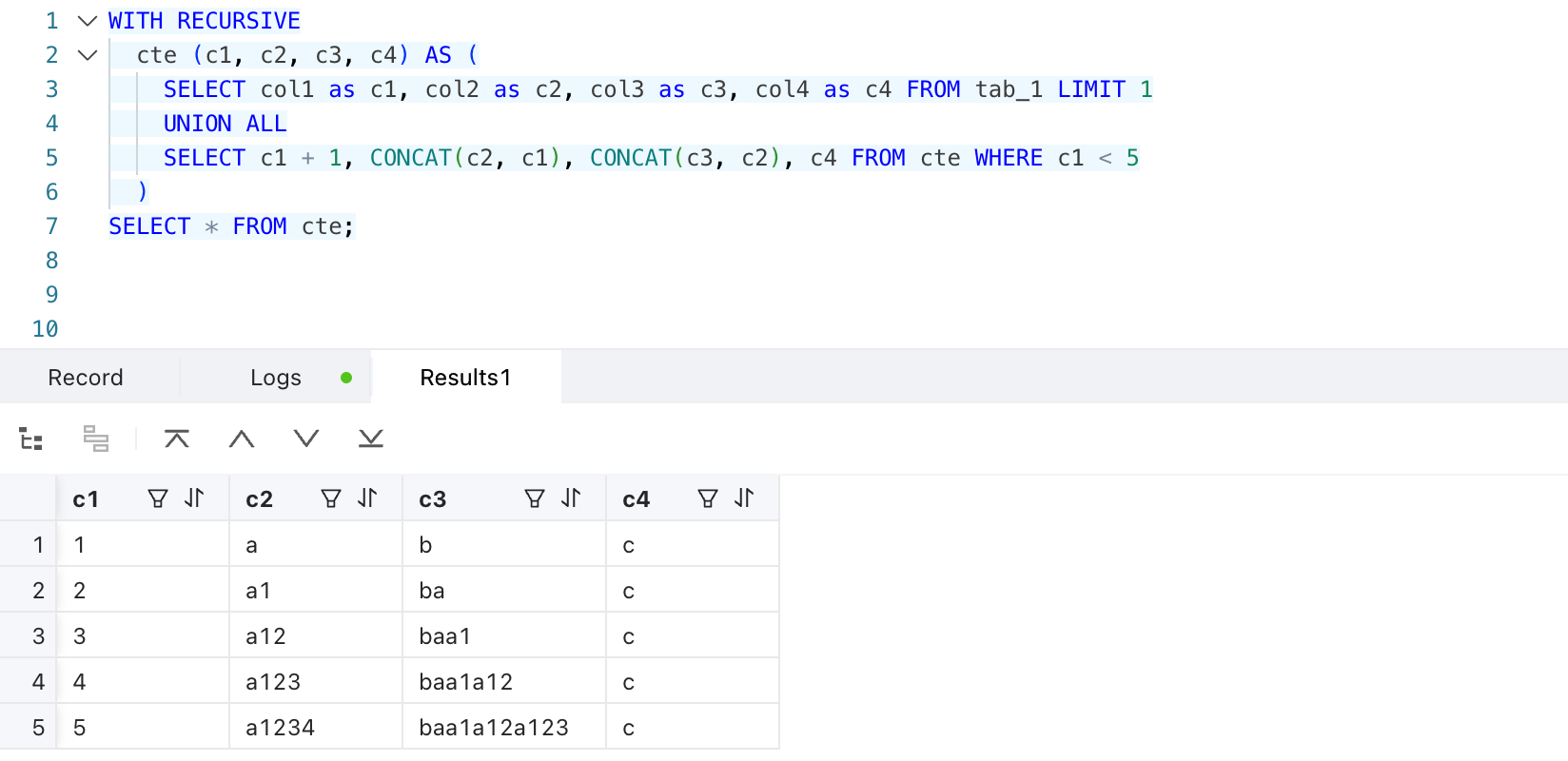 假设
假设tab_1.col1是敏感字段,初始化 SELECT 语句解析完成后,仅c1列包含敏感数据。然后处理递归 SELECT 语句,可以看到,第 1 次递归后(即结果集第 2 行)c2列包含了敏感数据;第 2 次递归后c3列也包含了敏感数据;第 3 次递归后依然只有c1、c2、c3 包含敏感数据。可以得出结论:每次递归之后,敏感列数量要么增加,要么不变。如果敏感列不变,则之后的递归都不会再增加敏感列。
编程实现
基于上述技术方案,本节介绍 Java 的编程实现,可以在 此处 查看完整源码。
首先,也是最最重要的,是对SQL 处理过程中需要记录的字段和临时表做合适的抽象。这里所说的“临时表”并不是数据库系统中的临时表,而是指用来描述子查询、CTE 和 FROM 子句形成的中间计算结果的“表”。每个临时表中包含了多个字段(列),每个字段又由来自不同临时表的字段计算而成。表和表,表和字段,字段和字段之间是相互依赖的。此时,我们可以使用树形结构来描述。
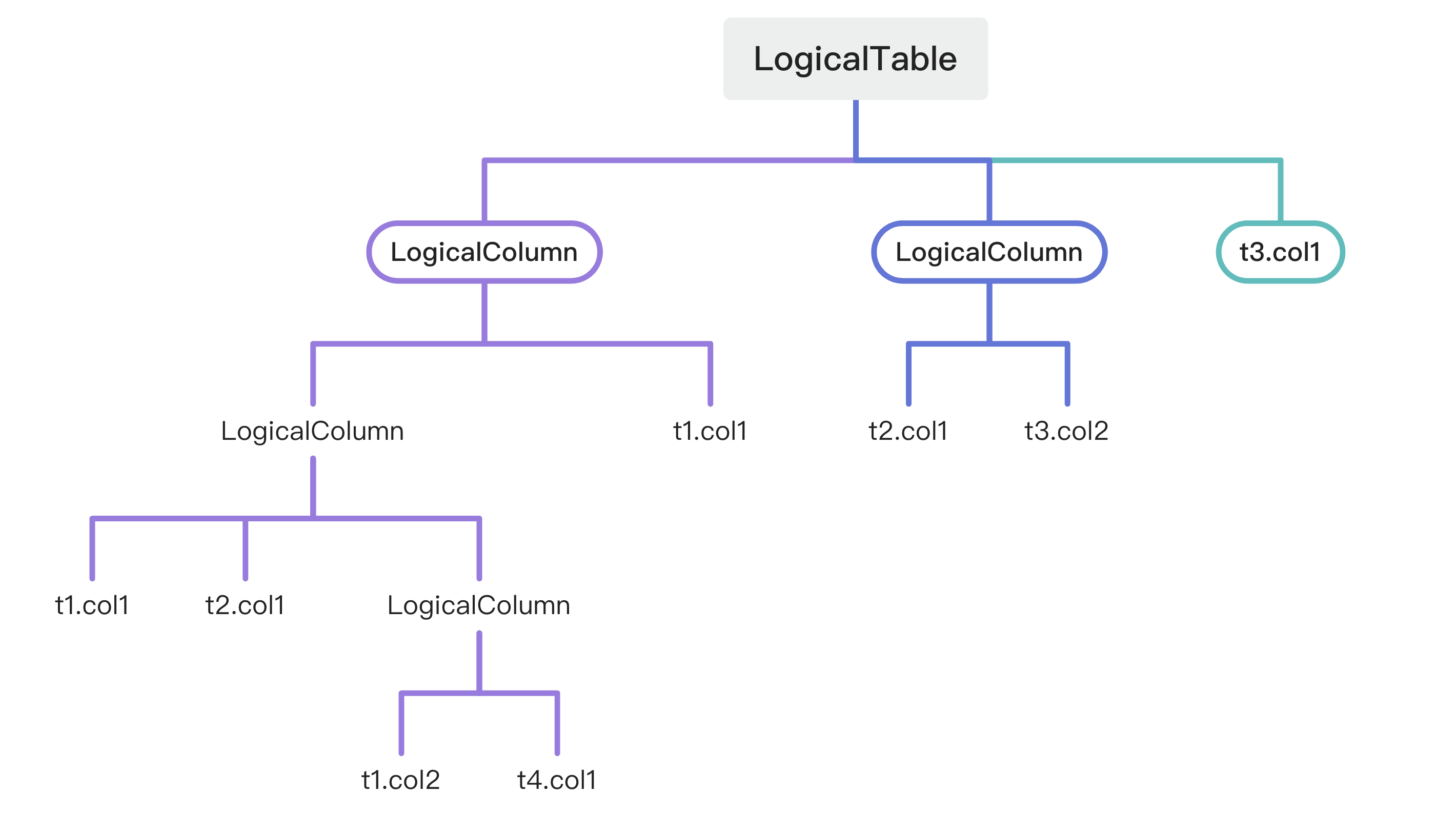
对应的 Java 对象结构如下:
public class LogicalTable {private String name;private String alias;private List<LogicalColumn> columnList;/*** Only used when there is more than one from tables*/private List<LogicalTable> tableList;
}public class LogicalColumn {private String name;private String alias;private ColumnType type;/*** Only used when type is PHYSICAL*/private String databaseName;private String tableName;/*** Only used when type is not PHYSICAL*/private List<LogicalColumn> fromList;
}LogicalTabl用来存储临时表信息,包括表名、表别名和其内部包含的列信息。FROM 子句中可能查询了多张表,虽然这些表中的字段信息在columnList中已经有记录,但是考虑到在外层引用是可能使用表名或表别名,因此需要使用tableList来记录这些表信息。
LogicalColumn用来存储字段信息,包括字段名、字段别名和类型。当该字段对应物理库中的字段时,还需要填充库名和表名信息。当改字段是由其他多个字段计算而成时,则需要使用fromList来存储这类信息。使用枚举类型 ColumnType 来定义字段的类型:
public enum ColumnType {/*** Physical column (Column that actually exist in the database system)*/PHYSICAL,/*** Temporary columns inherited directly from the underlying temporary table*/INHERITANCE,/*** Temporary column formed by the underlying temporary table through computation*/COMPUTATION,/*** Temporary column formed by the underlying temporary table through function call*/FUNCTION_CALL,/*** Temporary column formed by the underlying temporary table through case when*/CASE_WHEN,/*** Temporary column formed by the select body*/SELECT,/*** Temporary column formed by the constant*/CONSTANT,/*** Temporary column formed by the underlying temporary table through join operation*/JOIN,/*** Temporary column formed by the underlying temporary table through union operation*/UNION;public boolean isTemporary() {return this != PHYSICAL;}
}对于 SELECT SQL 各个子句的处理,需要按序依次处理 CTE、FROM 子句、SELECT 子句和集合运算。在处理过程中,需要时刻对照 ob-sql-parser 中对 SELECT 语句的抽象模型,具体如下(参考源码):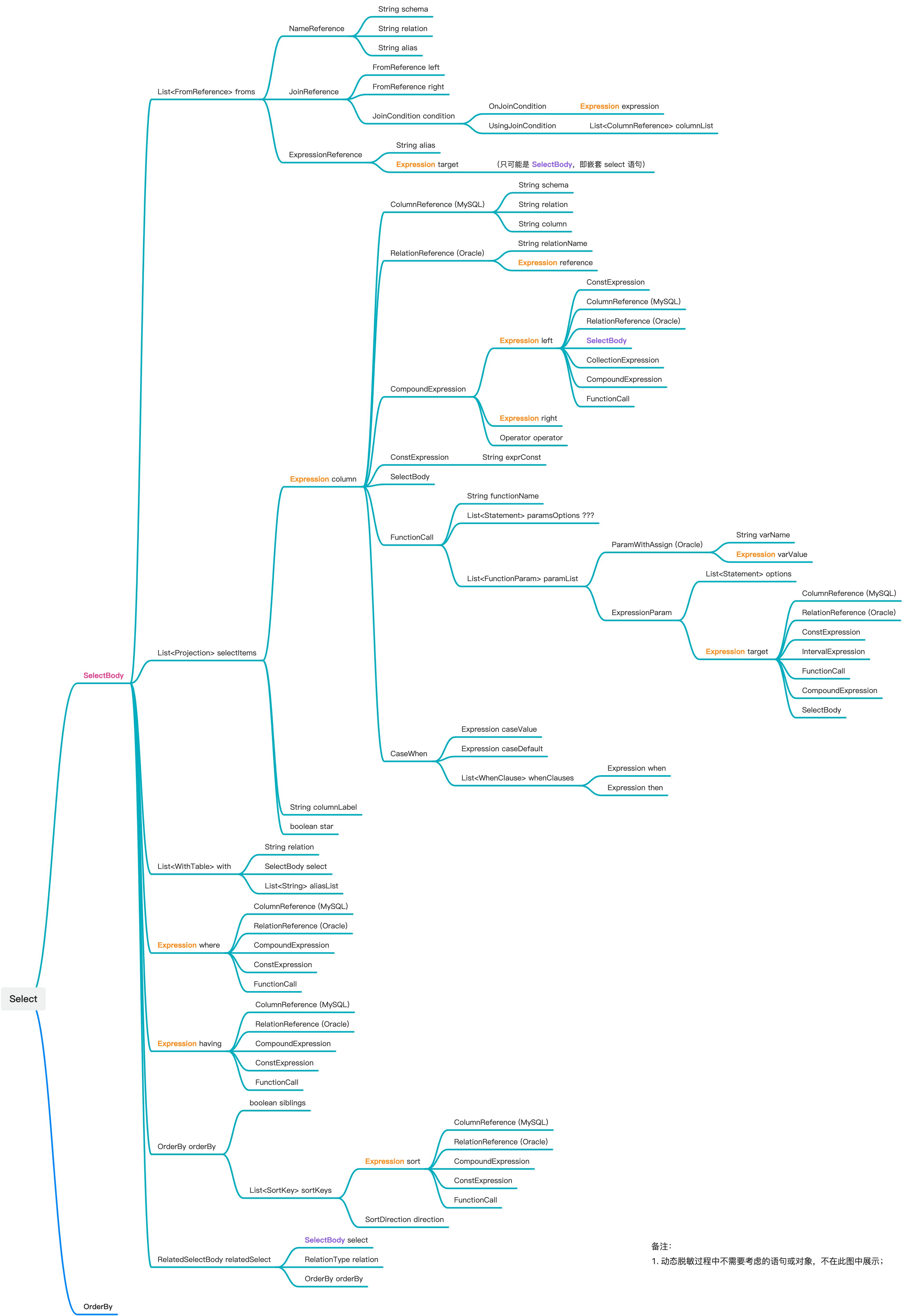
这个思维导图看起来很复杂,穷举每一种情况是几乎不可能完成的。其实,大部分抽象节点的类型是重复的,我们只需要对每一种类型进行处理,然后在编程过程中巧妙的使用递归算法即可。此部分实现的核心 500 行代码在 此处 ,文中不做赘述。
当我们处理完 SELECT SQL 的所有子句,得到上图根节点对应的 LogicalTable 对象后,即可反向计算出 SQL 执行结果集中的每一列所涉及的原始库表列信息。计算方法如下:
- 第一层节点顺序依次对应结果集的每一列,LogicalColumn 的 alias 字段非空时即为列名,否则 name 字段为列名
- 以每个第一层节点作为根节点,遍历树,收集所有 type 为 PHYSICAL 的列,即可得到结果集列关联的原始库表列
💡 本文介绍的技术方案应用在 OceanBase Developer Center 的动态数据脱敏中。获取源码及更多详情,请访问我们的 GitHub 仓库:https://github.com/oceanbase/odc。
相关文章:
怎样从SQL中分析和提取访问的字段信息?| OceanBase实践
当执行任意一条SELECT SQL语句时,我们如何能够分析出所访问的字段信息,并进一步判断结果集中的每一列数据具体来自于哪些数据库、表以及表中的哪些字段呢?本文将会详细阐述针对此问题的技术解决方案。 应用场景 从 SQL 中解析访问的原始字段…...
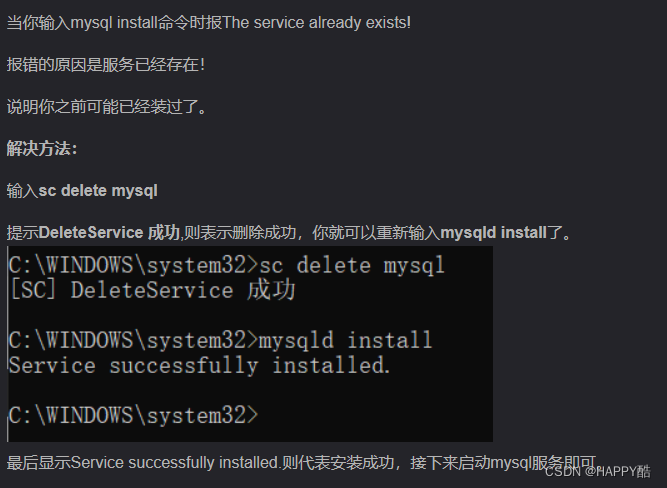
MySQL 服务无法启动
常见原因: 检查端口占用: 使用命令行工具(如netstat)来检查3306端口是否已被其他程序占用,输入netstat -ano(Windows)或netstat -tulnp | grep 3306(Linux/Mac)来查找3306端口的占用情况。如果…...

Python贪心算法
贪心算法(Greedy Algorithm)是一种常见的算法设计策略,它在每一步选择当前最优解,希望通过局部最优解最终得到全局最优解。贪心算法通常适用于满足一些特定条件的问题,例如货币找零、活动选择、任务调度等。贪心算法的…...

牛客网刷题 | BC85 牛牛学数列3
目前主要分为三个专栏,后续还会添加: 专栏如下: C语言刷题解析 C语言系列文章 我的成长经历 感谢阅读! 初来乍到,如有错误请指出,感谢! 描述 牛牛准备继续进阶&…...
quartz定时任务
Quartz 数据结构 quartz采用完全二叉树:除了最后一层每一层节点都是满的,而且最后一层靠左排列。 二叉树节点个数规则:每层从左开始,第一层只有一个,就是2的0次幂,第二层两个就是2的1次幂,第三…...
——选择结构与循环结构)
Python基础学习笔记(五)——选择结构与循环结构
目录 程序的组织结构条件选择结构1. 单分支结构2. 双分支结构3. 多分支结构4. 嵌套(分支)结构5. 无内容执行6. 条件表达式 循环结构1. 可迭代对象2. range()函数3. for循环语句4. while循环语句5. 结束语句 程序的组织结构 程序的组织结构主要有以下三种…...

Vue插槽solt如何传递具名插槽的数据给子组件?
在Vue中,你可以通过作用域插槽(scoped slots)来传递数据给子组件。这同样适用于具名插槽。首先,你需要在子组件中定义一个具名插槽,并通过v-slot指令传递数据。例如: 子组件(ChildComponent.vu…...
小程序-收货地址管理模块实现
页面结构代码: address-form.vue --->新建地址和修改地址页面 <template><view class"content"><form><!-- 表单内容 --><view class"form-item"><text class"label">收货人</text>…...
)
【星海随笔】微信小程序(三)
网络数据请求 1.小程序中网络数据请求的限制 出于安全性方面的考虑,小程序官方对 数据接口的请求 做出了如下 两个限制: ① 只能请求 HTTPS 类型的接口 ② 必须将 接口的域名 添加到 信任列表 中 微信小程序只能请求 https 类型的接口 且需要请求的域名必须提前进行设置后,才可…...
pip(包管理器) for Python
pip是什么 pip是Python的包安装程序,即python包管理器。您可以使用 pip 从Python包索引和其他索引安装包。 1. pip 安装 python 包 pip install 包名 例如:pip install pymssql : 使用pip安装数据库驱动包 pymssql 2.pip 卸载 python 包 pi…...

Ubuntu上安装Maven
在Ubuntu上安装Maven的步骤如下: 更新包索引: sudo apt update 安装Maven: sudo apt install maven 验证安装是否成功: mvn -version 以上步骤将会安装Maven并添加到系统路径中,你可以通过运行mvn -version来验…...
java中使用svnkit实现文件的版本管理
java中使用svnkit实现文件的版本管理 一、引入svnKit依赖二、初始化仓库工厂类二、使用svnkit创建本地存储仓库三、svn基本原子操作四、通过原子方法实现简单svn相应操作 一、引入svnKit依赖 <dependency><groupId>org.tmatesoft.svnkit</groupId><artifa…...
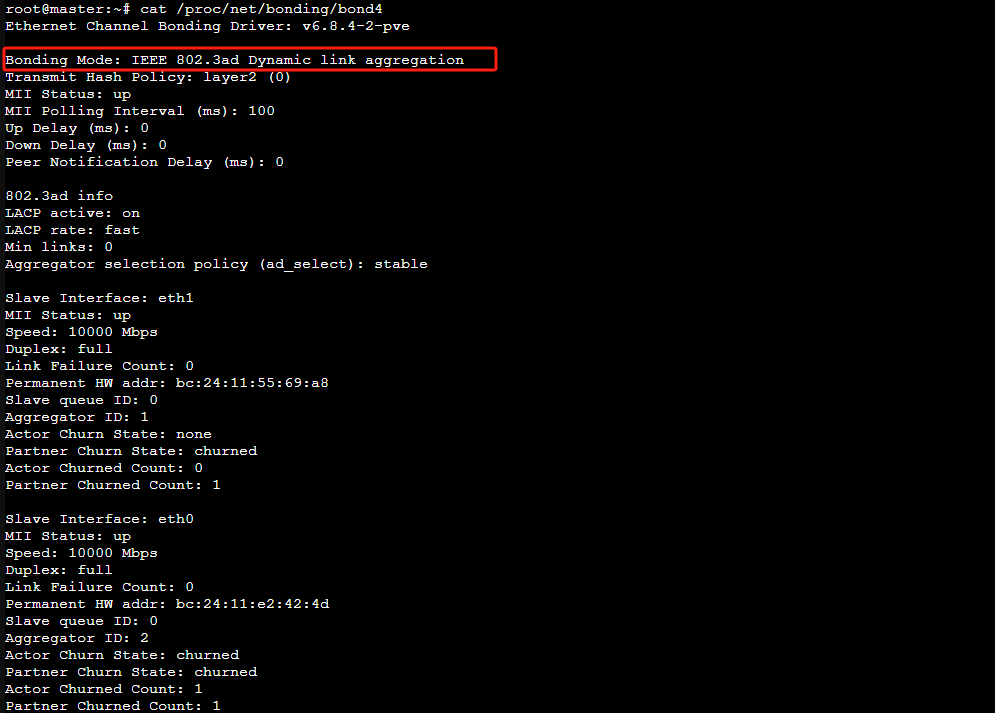
了解 Linux 网络卡绑定:提高网络性能与冗余性
在现代 IT 基础设施中,网络性能和可靠性至关重要。对于许多企业和个人用户来说,确保网络的高可用性和冗余性是首要任务之一。Linux 提供了一个强大的解决方案——网络卡绑定(Network Interface Card Bonding,简称 NIC Bonding&…...

2024年618购物狂欢节即将来袭!精选五款超值入手数码好物!
618购物狂欢盛宴即将落幕,是时候展现我们的购物智慧了!在追求价格优惠的同时,我们更应看重商品的品质与实用性。面对琳琅满目的选择,如何筛选出真正值得拥有的好物呢?为了让大家的购物之旅更加轻松愉快,以下…...

中国AI独角兽资本大冒险
成立不过一年多时间,月之暗面已然成为中国大模型赛道上,最炙手可热的明星公司。 5月21日,华尔街见闻获悉,月之暗面将按照投前估值30亿美元(合217.3亿人民币)进行融资,完成后依然会是当前中国估…...
项目十二:简单的python基础爬虫训练
许久未见,甚是想念,今日好运,为你带好运。ok,废话不多说,希望这门案例能带你直接快速了解并运用。🎁💖 基础流程 第一步:安装需要用到的requests库,命令如下 pip inst…...

OpenGL学习入门及开发环境搭建
最近学习OpenGL开发,被各种openGL库搞得晕头转向,什么glut, glew glfw glad等等。 可以参考这边博客:OpenGL 下面的 glut freeglut glfw 都是个啥_glx wgl的中文-CSDN博客 glfw是glut的升级版,跨平台的主要处理窗口 事件相关。 glad是glew…...

three.js能实现啥效果?看过来,这里都是它的菜(08)
在Three.js中实现旋转动画的原理是通过修改对象的旋转属性来实现的,通常使用渲染循环(render loop)来更新对象的旋转状态,从而实现动画效果。 具体的原理包括以下几个步骤: 创建对象:首先创建一个需要旋转…...
之整合mybatis)
SpringBoot(九)之整合mybatis
SpringBoot(九)之整合mybatis 文章目录 SpringBoot(九)之整合mybatisSpring整合mybatis回顾1. 引入依赖2. mybatis-config.xml SpringBoot整合mybatis1.引入依赖2. 配置数据源和 MyBatis 属性3. 配置 Mapper 接口4. 配置mapper.xm…...

【实战教程】使用Spring AOP和自定义注解监控接口调用
一、背景 随着项目的长期运行和迭代,积累的功能日益繁多,但并非所有功能都能得到用户的频繁使用或实际上根本无人问津。 为了提高系统性能和代码质量,我们往往需要对那些不常用的功能进行下线处理。 那么,该下线哪些功能呢&…...

Tiger框架深度剖析:从依赖注入到组件管理的完整指南
Tiger框架深度剖析:从依赖注入到组件管理的完整指南 【免费下载链接】tiger 项目地址: https://gitcode.com/gh_mirrors/ti/tiger Tiger框架是一个基于Java的依赖注入框架,专为Android和Java应用设计,提供了一套完整的组件管理解决方…...

保姆级教程:5分钟快速搭建你的DNC服务器,实现Fanuc/西门子数控程序远程传输与管理
数控机床程序远程管理实战:5分钟构建企业级DNC服务 在金属加工车间里,老师傅们弯腰在机床控制面板上手动输入程序的场景正逐渐成为历史。当车间里同时运行着发那科、西门子和三菱等不同品牌的数控设备时,如何高效管理这些设备的加工程序&…...
)
别再怪PoE不稳定了!手把手教你排查网线、供电、配置三大坑(附真实监控项目踩坑实录)
PoE稳定性实战指南:从网线到供电的深度排查手册 凌晨三点,监控室突然响起警报——某重要区域的摄像头集体离线。值班工程师的第一反应往往是"设备又坏了",但真实情况可能藏在那些容易被忽略的细节里:一根劣质网线在低温…...

2026头部GEO服务商哪家实力强?服务质量效果深度测评,合作优选榜单
随着生成式AI全面接管大众信息检索与商业决策场景,GEO生成式引擎优化已然成为企业品牌智能化布局的核心刚需。相较于传统SEO的页面排名逻辑,GEO主打适配大模型语义推理、信源采信、答案生成规则,帮助品牌成为AI问答中的核心推荐信源。当下多数…...

Java 读写 Excel 公式:从基础到高级的实战总结
做数据处理的朋友应该都遇到过这种场景:需要批量生成带公式的Excel报表,或者读取现有表格中的公式进行二次计算。以前我都是手动在Excel里写公式,后来发现用Java代码来处理更高效,尤其是数据量大的时候。 今天整理一下平时用得比较…...

电子供应链服务转型:从元器件分销到技术赋能与韧性构建
1. 项目概述:从“卖货”到“赋能”的供应链服务转型在电子元器件分销这个看似传统的行业里,我从业十几年,亲眼见证了从“电话传真报价”到“线上实时库存”的变迁。最近和一位行业老友,也是某知名分销商的资深销售总监聊天&#x…...

告别手动启动:在Windows Server上把Gitblit配置成稳定可靠的后台服务
Windows Server生产环境Gitblit服务化部署全指南 在团队协作开发中,代码仓库的稳定性和可靠性直接影响着整个研发流程的效率。对于使用Windows Server作为基础架构的企业来说,将Gitblit从简单的命令行工具转变为系统服务,是实现7x24小时不间断…...

今天不学这5个专业级Refinement技巧,你的ChatGPT文章永远过不了主编终审关
更多请点击: https://codechina.net 第一章:Refinement技巧在ChatGPT内容生产中的战略价值 Refinement(精炼)并非简单的二次润色,而是以目标导向的迭代式提示工程策略——它通过结构化反馈、上下文锚定与语义约束&…...

FanControl终极指南:3个核心模块助你打造完美风扇控制方案
FanControl终极指南:3个核心模块助你打造完美风扇控制方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

Qwen-Image-2512+LoRA:构建Godot 4.x原生像素编译工作流
1. 这不是“AI画图”,而是一次像素艺术工作流的底层重构你有没有试过在Godot 4.x里导入一张Stable Diffusion生成的“像素风”图,结果放大一看全是模糊的伪像素、边缘发虚、色阶溢出,连8-bit调色板都对不上?我去年帮三个独立游戏团…...