深度学习-Softmax回归+损失函数+图像分类数据集
目录
- Softmax回归
- 回归 VS 分类
- Kaggle上的分类问题
- 从回归到多类分类
- 回归
- 分类
- 从回归到多类分类-均方损失
- 从回归到多类分类-无校验比例
- 从回归到多类分类-校验比例
- Softmax和交叉熵损失
- 总结
- 损失函数
- 均方损失
- 绝对值损失函数
- 鲁棒损失
- 图像分类数据集
- 通过框架中内置函数将FashionMNIST数据集下载并读取到内存中
- 可视化数据集的函数
- 几个样本的图像及其相应的标签
- 读取一小批量数据,大小为batch_size
- 定义load_data_fashion_mnist函数
- softmax回归的从零实现
- ① 给定一个矩阵X,可以对所有元素求和。
- ②实现softmax
- 实现softmax回归模型
- 交叉熵损失
- 实现交叉熵损失函数
- 将预测类别与真实y元素进行比较(即:预测正确的概率)
- 评估在任意模型net的准确率
- Softmax回归的训练
- 训练函数(完整的数据集通过神经网络一次)
- 定义一个在动画中绘制数据的实用程序类
- 轮次总训练函数
- 对图像进行分类预测
- Softmax回归的简洁实现
- 问题
Softmax回归

回归 VS 分类
回归估计一个连续值
分类预测一个离散类别
例如:
MNIST:手写数字识别(10类)

ImageNet:自然物体分类(1000类)

Kaggle上的分类问题
将人类蛋白质显微镜图片分为28类

将恶意软件分为9个类别

将恶意的Wikipedia评论分成7类
从回归到多类分类
回归
单连续数值输出
自然区间R
跟真实值的区别作为损失

分类
通常多个输出
输出i是预测为第i类的置信度

解释举例说明:



softmax回归原理及损失函数-跟李沐老师动手学深度学习
从回归到多类分类-均方损失
对类别进行一位有效编码

使用均方损失训练
从回归到多类分类-无校验比例
最大值预测

选取i,使得最大化 O i O_i Oi的置信度的值作为预测。其中 O i O_i Oi中的i是预测的标号,叫做one-hot(独热编码)
需要更置信的识别正确类(大余量)

从回归到多类分类-校验比例

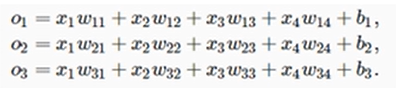
 输出匹配概率(非负,和为1)
输出匹配概率(非负,和为1)
Softmax和交叉熵损失



在Pycharm中损失函数中,它默认的是e为底,log不写参数时的底数取决于具体的上下文和所使用的工具或库。在数学中,通常默认为10;在编程中,可能会因库或语言的不同而有所差异。

需要用到数学中的log公式:


总结
Softmax回归是一个多类分类模型
使用Softmax操作子得到每个类的预测置信度
使用交叉熵来衡量预测和标号的区别
损失函数
损失函数:用来衡量预测值和真实值之间的区别,是机器学习里面一个重要的概念。
三个常用的损失函数 L2 loss、L1 loss、Huber’s Robust loss
均方损失

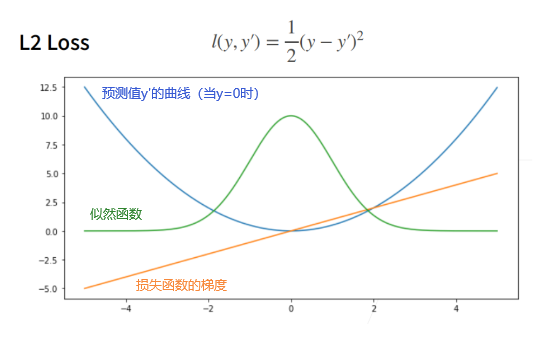
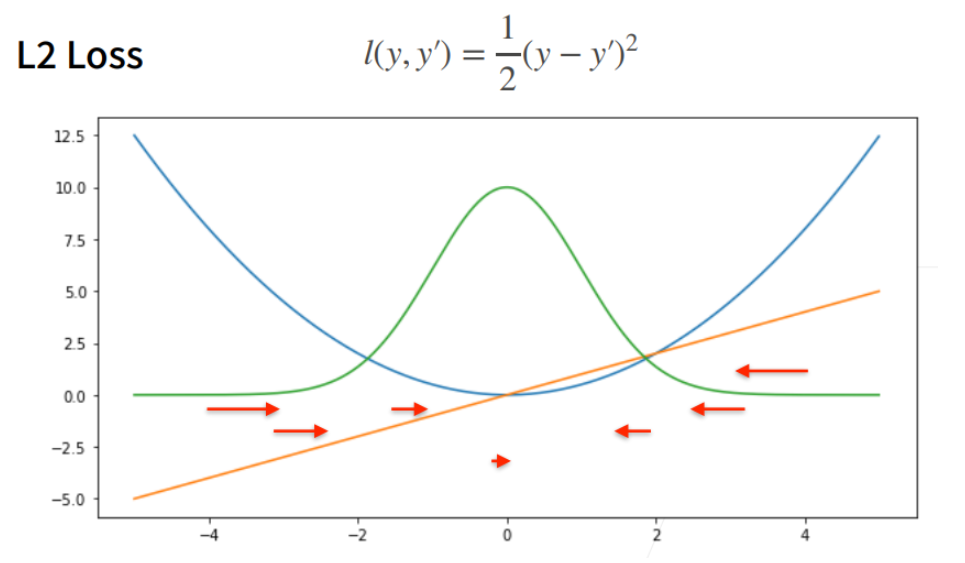
④ 在梯度下降的时候,我们是对负梯度方向来更新我们的参数。所以它的导数就决定我们是如何更新我们的参数的。当预测值y’跟真实值y隔的比较远的时候,(真实值y为0,预测值就是下面的曲线里的x轴),梯度比较大,所以参数更新比较多。
⑤ 随着预测值靠近真实值的时候,梯度越来越小,意味着对参数的更新的幅度越来越小。
当我对于离原点比较远的时候,我不一定想要那么大的梯度来更新我的参数。所以另外一个选择是考虑绝对值损失函数。
绝对值损失函数



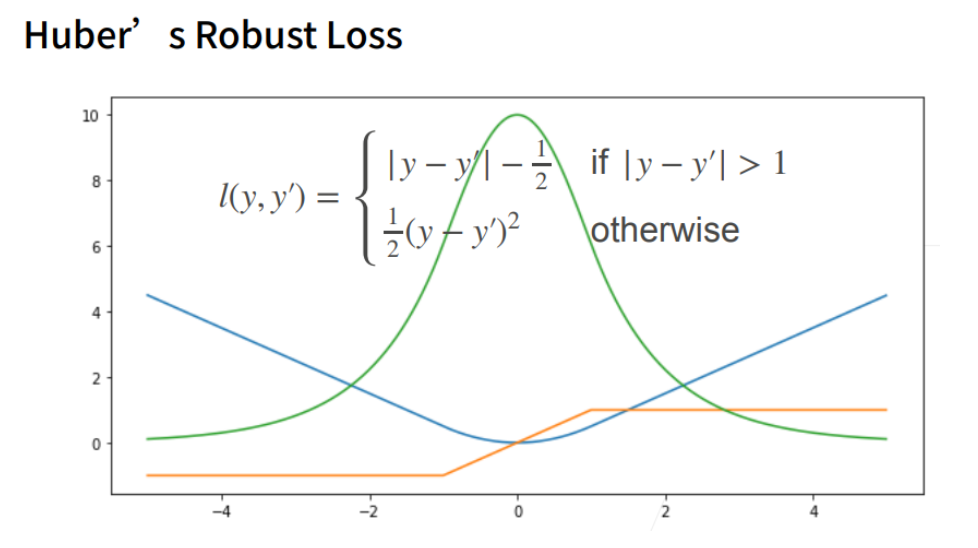
鲁棒损失
① 结合L1 loss 和L2 loss损失。
定义:当预测值和真实值差的比较大时,绝对值大于1的时候是一个绝对值误差。当预测值和真实值靠的比较近的时候就是一个平方误差。
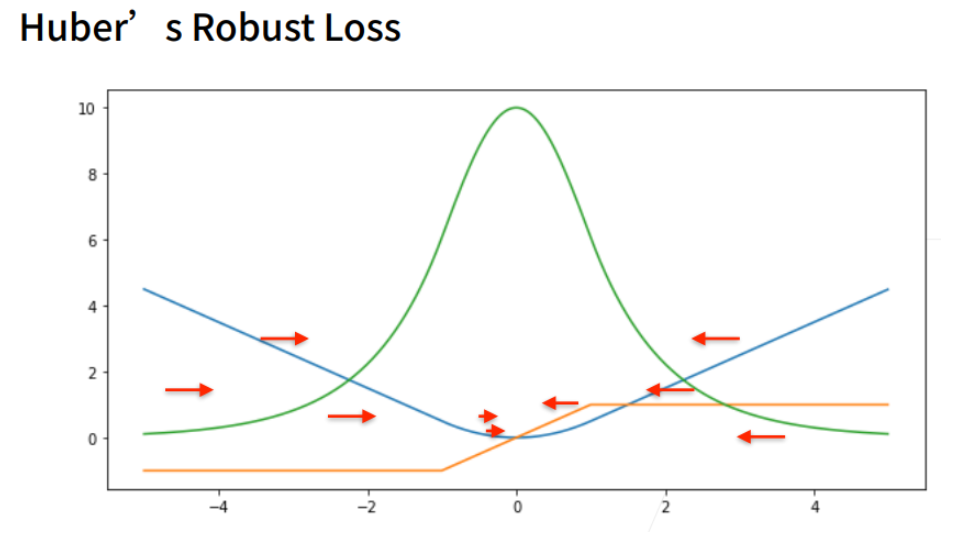
当y’大于1或小于-1的时候,它的导数是常数,在之间的时候是一个渐变的过程。
它的好处:当预测值和真实值差的比较远的时候,梯度比较均匀的力度往回拉。当靠近的时候(优化比较默契的时候),梯度的绝对值会越来越小,从而保证优化的平滑。
图像分类数据集
MNIST数据集是图像分类中广泛使用的数据集之一,但作为基准数据集过于简单。我们将使用类似但更复杂的Fashion-MNIST数据集。
FashionMNIST是一个常用的数据集,它包含70,000个28x28的灰度图片,分为10个类别,每个类别有7,000个样本。其中,60,000个样本用于训练,10,000个样本用于测试。
通过框架中内置函数将FashionMNIST数据集下载并读取到内存中
import torchvision
from torchvision import transforms
from d2l import torch as d2ld2l.use_svg_display()
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式
# 并除以255使得所有像素的数值均在0到1之间,将其归一化到[0.0, 1.0]范围。
trans = transforms.ToTensor()#预处理
#第一个参数数据集的根目录,第二个参数加载训练数据集,第三个参数使用上面定义的转换对象,第四个参数如果数据集不在指定的根目录下,则从互联网上下载。
mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)
print(len(mnist_train)) # 训练数据集长度
print(len(mnist_test)) # 测试数据集长度print(mnist_train[0][0].shape) #第一张图片的形状,黑白图片,所以RGB的channel为1。
print(mnist_train[0][1]) # [0][0]表示第一个样本的图片信息,[0][1]表示该样本对应的标签值
结果:
可视化数据集的函数
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2ldef get_fashion_mnist_labels(labels):"""返回Fashion-MNIST数据集的文本标签"""text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']return [text_labels[int(i)] for i in labels]def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):"""Plot a list of images."""#元组figsize,它表示图形的宽度和高度。图形的宽度是列数(num_cols)乘以一个放缩比例因子(scale),而高度是行数(num_rows)乘以相同的放缩比例因子。# 传进来的图像尺寸,scale 为放缩比例因子figsize = (num_cols * scale, num_rows * scale)#_, axes: 返回的图形对象和子图坐标轴对象的列表分别赋值给_和axes。axes是一个二维数组,其中包含了所有子图的坐标轴对象,可以通过索引来访问和修改它们。_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)print(_)print(axes) # axes 为构建的两行九列的画布#将二维数组转换为一维数组。可以更容易地遍历所有的子图,而不需要考虑它们的原始二维布局。axes = axes.flatten()print(axes) # axes 变成一维数据for i, (ax, img) in enumerate(zip(axes, imgs)):if i < 1:print("i:", i)print("ax,img:", ax, img)if torch.is_tensor(img):# 图片张量ax.imshow(img.numpy())ax.set_title(titles[i])else:# PIL图片ax.imshow(img)d2l.use_svg_display()
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式
# 并除以255使得所有像素的数值均在0到1之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18))) # X,y 为仅抽取一次的18个样本的图片、以及对应的标签值
#show_images用来显示一批图像。.reshape(18, 28, 28) 意味着 X 被重新塑形为一个包含 18 个图像的数据集,每个图像的大小是 28x28 像素。
#2, 9: 这两个参数指定了如何在一个网格中布局显示的图像。在一个 2 行 9 列的网格中显示图像。因此,总共会显示 2x9=18 个图像,与 X.reshape(18, 28, 28) 中的图像数量相匹配。
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y))





几个样本的图像及其相应的标签
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2ldef get_fashion_mnist_labels(labels):"""返回Fashion-MNIST数据集的文本标签"""text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']return [text_labels[int(i)] for i in labels]def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):"""Plot a list of images."""figsize = (num_cols * scale, num_rows * scale) # 传进来的图像尺寸,scale 为放缩比例因子_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)axes = axes.flatten()for i, (ax, img) in enumerate(zip(axes, imgs)):if torch.is_tensor(img):# 图片张量ax.imshow(img.numpy())ax.set_title(titles[i])ax.axis('off') # 隐藏坐标轴else:# PIL图片ax.imshow(img)d2l.use_svg_display()
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式
# 并除以255使得所有像素的数值均在0到1之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18))) # X,y 为仅抽取一次的18个样本的图片、以及对应的标签值
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y))
d2l.plt.show()#在PyCharm等IDE中可能需要显式调用show()来显示图形
结果:

读取一小批量数据,大小为batch_size
import torch
import torchvision
from torch.utils import data
from torchvision import transformsdef get_fashion_mnist_labels(labels):"""返回Fashion-MNIST数据集的文本标签"""text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']return [text_labels[int(i)] for i in labels]def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):"""Plot a list of images."""#元组figsize,它表示图形的宽度和高度。图形的宽度是列数(num_cols)乘以一个放缩比例因子(scale),而高度是行数(num_rows)乘以相同的放缩比例因子。# 传进来的图像尺寸,scale 为放缩比例因子figsize = (num_cols * scale, num_rows * scale)#_, axes: 返回的图形对象和子图坐标轴对象的列表分别赋值给_和axes。axes是一个二维数组,其中包含了所有子图的坐标轴对象,可以通过索引来访问和修改它们。_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)#将二维数组转换为一维数组。可以更容易地遍历所有的子图,而不需要考虑它们的原始二维布局。axes = axes.flatten()for i, (ax, img) in enumerate(zip(axes, imgs)):if torch.is_tensor(img):# 图片张量ax.imshow(img.numpy())ax.set_title(titles[i])else:# PIL图片ax.imshow(img)def get_dataloader_workers():"""使用4个进程来读取的数据"""return 4# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式
# 并除以255使得所有像素的数值均在0到1之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)
# batch_size用于图像显示
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18))) # X,y 为仅抽取一次的18个样本的图片、以及对应的标签值
# show_images用来显示一批图像。.reshape(18, 28, 28) 意味着 X 被重新塑形为一个包含 18 个图像的数据集,每个图像的大小是 28x28 像素。
# 2, 9: 这两个参数指定了如何在一个网格中布局显示的图像。在一个 2 行 9 列的网格中显示图像。因此,总共会显示 2x9=18 个图像,与 X.reshape(18, 28, 28) 中的图像数量相匹配。
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y))batch_size = 256 #用于模型训练
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers())
timer = d2l.Timer() # 计时器对象实例化,开始计时
for X, y in train_iter: # 遍历一个batch_size数据的时间continue
print(f'{timer.stop():.2f}sec') # 计时器停止时,停止与开始的时间间隔事件
结果: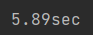
定义load_data_fashion_mnist函数
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2ldef get_dataloader_workers():"""使用4个进程来读取的数据"""return 4# 加载数据集的函数
def load_data_fashion_mnist(batch_size, resize=None):"""下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False, num_workers=get_dataloader_workers())) # 测试集通常不shuffle# 使用函数加载数据
if __name__ == '__main__':batch_size = 256 # 用于模型训练train_iter, test_iter = load_data_fashion_mnist(batch_size)# 计时器部分timer = d2l.Timer()for X, y in train_iter:continueprint(f'{timer.stop():.2f}sec')结果:
softmax回归的从零实现
①我们之前的每张图片是一个长为28宽为28的图片,通道数为1,是个3D的输入,但对于softmax回归来说我的输入相当于向量所以要将图片拉长,拉成一个向量(会损失空间信息–>留给卷积神经网络来继续),28×28=784,所以softmax回归的输入是一个784的向量
② 因为数据集有10个类别,所以网络输出维度为10.
import torchnum_inputs = 784
num_outputs = 10
w = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
print(w.shape)
print(b.shape)① 给定一个矩阵X,可以对所有元素求和。
import torch# 给定一个矩阵X,2*3的矩阵,我们可以按照维度进行元素求和
X = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
#X.sum(0, keepdim=True)其中0是按照第一维度(行)求和,X.sum(1, keepdim=True)按照第二维度(列)求和
#keepdim=True保持是二维矩阵,这个参数用于指定在归并操作后是否保持原始张量的维度。
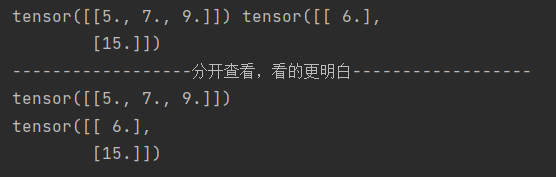
print(X.sum(0, keepdim=True), X.sum(1, keepdim=True))
print("------------------分开查看,看的更明白------------------")
print(X.sum(0, keepdim=True))
print(X.sum(1, keepdim=True))
结果:
②实现softmax

import torchdef softmax(X):X_exp = torch.exp(X) # 每个都进行指数运算partition = X_exp.sum(1, keepdim=True)#按照第二维度,列方向求和(就是对一行求和)return X_exp / partition # 这里应用了广播机制扩展partition的第二个维度以匹配X_exp的形状,从而进行逐元素的除法。# 将每个元素变成一个非负数。此外,依据概率原理,每行总和为1。
X = torch.normal(0, 1, (2, 5)) # 两行五列的数,数符合标准正态分布
X_prob = softmax(X)
print(X_prob) # 形状没有发生变化,还是一个两行五列的矩阵,Softmax转换后所有值为正的
print(X_prob.sum(1)) # 相当于 X_prob.sum(axis=1) 按行求和,概率和为1
结果:

详细分析代码
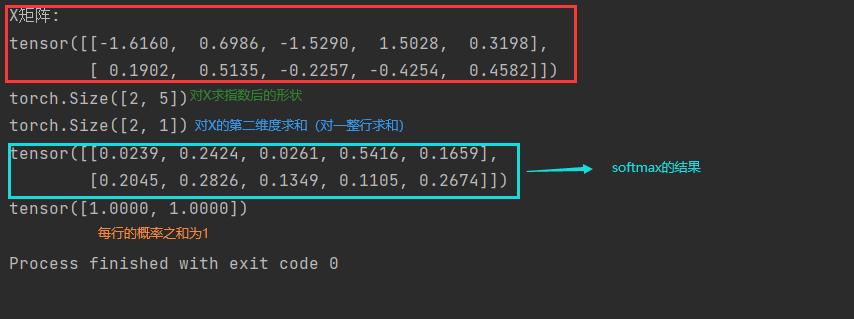
import torchdef softmax(X):X_exp = torch.exp(X) # 每个都进行指数运算print(X_exp.shape) #(batch_size, num_classes)partition = X_exp.sum(1, keepdim=True)#按照第二维度,列方向求和(就是对一行求和)print(partition.shape) #(batch_size, 1)return X_exp / partition # 这里应用了广播机制扩展partition的第二个维度以匹配X_exp的形状,从而进行逐元素的除法。# 将每个元素变成一个非负数。此外,依据概率原理,每行总和为1。
X = torch.normal(0, 1, (2, 5)) # 两行五列的数,数符合标准正态分布
print('X矩阵:')
print(X)
X_prob = softmax(X)
print(X_prob) # 形状没有发生变化,还是一个两行五列的矩阵,Softmax转换后所有值为正的
print(X_prob.sum(1)) # 相当于 X_prob.sum(axis=1) 按行求和,概率和为1
结果:
实现softmax回归模型
import torchdef softmax(X):X_exp = torch.exp(X) # 每个都进行指数运算partition = X_exp.sum(1,keepdim=True)return X_exp / partition # 这里应用了广播机制def net(X):#需要一个批量大小*输入维数的矩阵,reshape成一个2D的矩阵,-1表示自动计算(其实就是批量大小batch_size=256)而w.shape[0]=784#X已经被重新塑形为(batch_size, 784),而w的形状假设为(784, num_classes)(其中num_classes是类别的数量)#所以矩阵乘法的结果将是一个(batch_size, num_classes)的矩阵。即:256*10的矩阵return softmax(torch.matmul(X.reshape((-1, w.shape[0])), w)+b)batch_size = 256
num_inputs = 784
num_outputs = 10
w = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
# 生成模拟输入数据
X = torch.randn(batch_size, num_inputs) # 创建一个形状为(batch_size, num_inputs)的随机数矩阵# 通过网络计算输出
outputs = net(X)
# 验证输出的形状和内容
print("Output shape:", outputs.shape) # 输出 (batch_size, num_outputs),即 (256, 10)# 打印部分输出内容
print("Sample outputs:")
print(outputs[:5]) # 打印前5个样本的输出,每个样本有10个类别的概率# 如果需要的话,也可以检查每行的概率是否加起来为1(接近1,因为浮点数的精度问题)
for i in range(outputs.size(0)):assert torch.allclose(outputs[i].sum(), torch.tensor(1.0),atol=1e-5), "Probabilities in row {} do not sum to 1".format(i)print("All probabilities in each row sum to approximately 1.")
结果:

交叉熵损失
① 创建一个数据y_hat,其中包含2个样本在3个类别的预测概率,使用y作为y_hat中概率的索引。
import torch# 包含两个整数元素:0和2
# 表示两个样本的真实类别标签。第一个样本的真实类别是0,而第二个样本的真实类别是2。
y = torch.tensor([0, 2])# y_hat表示两个一维数组,表示是预测的类型'0','1','2'的概率
# 一维数组的标量大小和位置 对应 类型和概率。比如0.1就是类型’0‘ 的概率为0.1, 0.3表示类型’1‘的概率为0.3, 0.6表示类型’2‘的概率为0.6
# [0.1, 0.3, 0.6]第0个样本的预测值,[0.3, 0.2, 0.5]第1个样本的预测值
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]]) # 两个样本在3个类别的预测概率# 第三行代码是索引,[0,1]是行索引,y是列索引,然后配对,最后取y_hat[0][0],y_hat[1][2]
print(y_hat[[0, 1], y]) # 把第0个样本对应标号"0"的预测值拿出来、第1个样本对应标号"2"的预测值拿出来结果:
实现交叉熵损失函数

解释为什么 ∑ i \sum_{i} ∑i y i y_i yi=1,因为只有当i=t的时 y t y_t yt是真实类别的情况才等于1,其余的都为0.
公式:-log( y ^ y \hat{y}_y y^y)其中 y ^ y \hat{y}_y y^y是预测的类别的概率。
range(len(y_hat))表示行标号、y表示列标号
y_hat[range(len(y_hat)), y]表示根据行标和列标来查找真实类别的预测概率
对于此题的预测的类别的概率是y_hat[行号][列号]
所以公式可以写为:-log( y − h a t [ 行号 ] [ 列号 ] y_-{hat}[行号][列号] y−hat[行号][列号])
import torchdef cross_entropy(y_hat, y):# range(len(y_hat))每一行拿出一个0到n的向量# 其中range(len(y_hat))是生成0和1,也就是只有两个样本,在这两个样本中查找真实标号的预测值# range(y_hat)是所有行,y是真实值所对应的列return -torch.log(y_hat[range(len(y_hat)), y]) # y_hat[range(len(y_hat)),y]为把y的标号列表对应的值拿出来。传入的y要是最大概率的标号# 包含两个整数元素:0和2
# 表示两个样本的真实类别标签。第一个样本的真实类别是0,而第二个样本的真实类别是2。
y = torch.tensor([0, 2])# y_hat表示两个一维数组,表示是预测的类型'0','1','2'的概率
# 一维数组的标量大小和位置 对应 类型和概率。比如0.1就是类型’0‘ 的概率为0.1, 0.3表示类型’1‘的概率为0.3, 0.6表示类型’2‘的概率为0.6
# [0.1, 0.3, 0.6]第0个样本的预测值,[0.3, 0.2, 0.5]第1个样本的预测值
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]]) # 两个样本在3个类别的预测概率# y_hat预测和真实标号y
print(cross_entropy(y_hat, y))结果:
-ln0.1≈-(-2.3026)=2.3026
-ln0.5≈-(-0.6931)=0.6931
将预测类别与真实y元素进行比较(即:预测正确的概率)
import torchdef accuracy(y_hat, y):"""计算预测正确的数量"""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1: y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum()) y = torch.tensor([0, 2])
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
print("accuracy(y_hat,y) / len(y):", accuracy(y_hat, y) / len(y))
代码注释详细说明:
import torchdef accuracy(y_hat, y):"""计算预测正确的数量"""# 第一个判断张量是否大于一维,第二个是判断张量的第二个维度是否大于1if len(y_hat.shape) > 1 and y_hat.shape[1] > 1: # y_hat.shape[1]>1表示不止一个类别,每个类别有各自的概率# y_hat.argmax(axis=1)为求每行数值最大的那列(最大的预测概率)的索引号,y_hat是预测分类的类别y_hat = y_hat.argmax(axis=1)# 输出查看一下是否正确:不出意外索引都是2,因为第一行是0.6最大、第二行是0.5最大print("y_hat:", y_hat)print(y_hat.type(y.dtype)) # 输出:tensor([2, 2])print(y) # 输出:tensor([0, 2])cmp = y_hat.type(y.dtype) == y # 先判断逻辑运算符==,再赋值给cmp,cmp为布尔类型的数据print(cmp) # 输出tensor([False, True]) 下面的cmp.type(y.dtype)就是tensor([0, 1])求和就是1return float(cmp.type(y.dtype).sum()) # 获得y.dtype的类型作为传入参数,将cmp的类型转为y的类型(int型),然后再求和# 包含两个整数元素:0和2
# 表示两个样本的真实类别标签。第一个样本的真实类别是0,而第二个样本的真实类别是2。
y = torch.tensor([0, 2])# y_hat表示两个一维数组,表示是预测的类型'0','1','2'的概率
# 一维数组的标量大小和位置 对应 类型和概率。比如0.1就是类型’0‘ 的概率为0.1, 0.3表示类型’1‘的概率为0.3, 0.6表示类型’2‘的概率为0.6
# [0.1, 0.3, 0.6]第0个样本的预测值,[0.3, 0.2, 0.5]第1个样本的预测值
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]]) # 两个样本在3个类别的预测概率
# print("accuracy(y_hat,y):",accuracy(y_hat,y)) 预测正确的样本数
print("accuracy(y_hat,y) / len(y):", accuracy(y_hat, y) / len(y))结果:

正确的类别是0和1
0对应y_hat的第一行的0.1
1对应y_hat的第二行的0.5
然后使用该函数只预测到第二行的0.5,没用预测到第一行的0.1的概率
评估在任意模型net的准确率
import torch
import torchvision
from torch.utils import data
from torchvision import transformsclass Accumulator:"""在n个变量上累加"""def __init__(self, n):self.data = [0, 0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)] # zip函数把两个列表第一个位置元素打包、第二个位置元素打包....def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]def get_dataloader_workers():"""使用4个进程来读取的数据"""return 4def load_data_fashion_mnist(batch_size, resize=None):"""下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False, num_workers=get_dataloader_workers())) # 测试集通常不shuffledef softmax(X):X_exp = torch.exp(X)partition = X_exp.sum(1,keepdim=True)return X_exp / partition def net(X):return softmax(torch.matmul(X.reshape((-1, w.shape[0])), w)+b)def accuracy(y_hat, y):"""计算预测正确的数量"""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1: y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == y return float(cmp.type(y.dtype).sum()) def evaluate_accuracy(net, data_iter):"""计算在指定数据集上模型的精度"""if isinstance(net, torch.nn.Module): net.eval() metric = Accumulator(2) for X, y in data_iter:metric.add(accuracy(net(X), y), y.numel()) return metric[0] / metric[1] if __name__ == '__main__':batch_size = 256train_iter, test_iter = load_data_fashion_mnist(batch_size) num_inputs = 784num_outputs = 10w = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)b = torch.zeros(num_outputs, requires_grad=True)print(evaluate_accuracy(net, test_iter))
结果: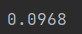
详细代码分析:
import torch
import torchvision
from torch.utils import data
from torchvision import transforms# Accumulator实例中创建了2个变量,用于分别存储正确预测的数量和预测的总数量
class Accumulator:"""在n个变量上累加"""# 初始化一个长度为n的列表,所有元素都是0.0# [0, 0] 是一个包含两个元素(都是0)的列表。def __init__(self, n):self.data = [0, 0] * ndef add(self, *args):# 使用列表推导式和zip函数将self.data中的当前值与args中的对应值相加,并将结果重新赋值给self.data。self.data = [a + float(b) for a, b in zip(self.data, args)] # zip函数把两个列表第一个位置元素打包、第二个位置元素打包....# 通过print函数我们可知将猜测正确样本数(即参数accuracy(net(X), y))和总样本数y.numel()分别累加print(self.data)def reset(self):# 将self.data重置为一个新的列表,长度与原来的self.data相同,但所有元素都是0.0。self.data = [0.0] * len(self.data)def __getitem__(self, idx):# 使用索引来访问self.data中的元素。return self.data[idx]def get_dataloader_workers():"""使用4个进程来读取的数据"""return 4# 加载数据集的函数
# batch_size(用于指定数据加载器加载的批次大小)和 resize(可选参数,用于指定图像在加载前是否需要调整大小,默认为 None,即不进行大小调整)。
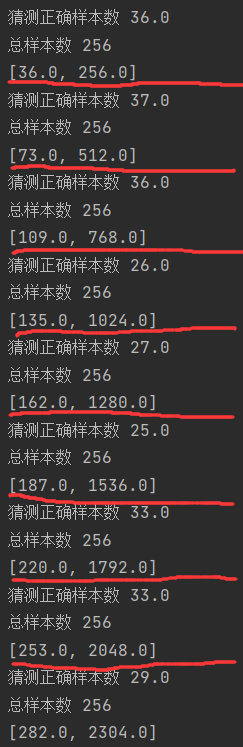
def load_data_fashion_mnist(batch_size, resize=None):"""下载Fashion-MNIST数据集,然后将其加载到内存中"""# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式# 并除以255使得所有像素的数值均在0到1之间# 创建一个列表 trans,其中包含一个 transforms.ToTensor() 实例。这个列表将用于构建图像转换的流水线。trans = [transforms.ToTensor()]# 判断 resize 参数是否有值if resize:# 如果 resize 有值,则在 trans 列表的开头插入一个 transforms.Resize(resize) 实例。这表示在转换为张量之前,先对图像进行大小调整。trans.insert(0, transforms.Resize(resize))# 将 trans 列表中的转换 组合成一个流水线,并重新赋值给 trans 变量。trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)# 使用 data.DataLoader 创建一个数据加载器,用于加载训练集。参数 batch_size 指定批次大小,shuffle=True 表示在训练时打乱数据顺序,# num_workers=get_dataloader_workers() 指定用于数据加载的子进程数return (data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False, num_workers=get_dataloader_workers())) # 测试集通常不shuffledef softmax(X):X_exp = torch.exp(X) # 每个都进行指数运算partition = X_exp.sum(1, keepdim=True)return X_exp / partition # 这里应用了广播机制def net(X):#需要一个批量大小*输入维数的矩阵,reshape成一个2D的矩阵,-1表示自动计算(其实就是批量大小batch_size=256)而w.shape[0]=784#X已经被重新塑形为(batch_size, 784),而w的形状假设为(784, num_classes)(其中num_classes是类别的数量)#所以矩阵乘法的结果将是一个(batch_size, num_classes)的矩阵。即:256*10的矩阵return softmax(torch.matmul(X.reshape((-1, w.shape[0])), w)+b)def accuracy(y_hat, y):"""计算预测正确的数量"""# 第一个判断张量是否大于一维,第二个是判断张量的第二个维度是否大于1if len(y_hat.shape) > 1 and y_hat.shape[1] > 1: # y_hat.shape[1]>1表示不止一个类别,每个类别有各自的概率# y_hat.argmax(axis=1)为求每行数值最大的那列(最大的预测概率)的索引号,y_hat是预测分类的类别y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == y # 先判断逻辑运算符==,再赋值给cmp,cmp为布尔类型的数据return float(cmp.type(y.dtype).sum()) # 获得y.dtype的类型作为传入参数,将cmp的类型转为y的类型(int型),然后再求和# 可以评估在任意模型net的准确率,
def evaluate_accuracy(net, data_iter):"""计算在指定数据集上模型的精度"""# 如果net模型是torch.nn.Module实现的神经网络的话,将它变成评估模式if isinstance(net, torch.nn.Module):net.eval() # 将模型设置为评估模式metric = Accumulator(2) # 正确预测数、预测总数,metric为累加器的实例化对象,里面存了两个数# 对于迭代器中每次拿出一个X和yfor X, y in data_iter:# 通过net(X)算出评测值,accuracy(net(X), y)计算所有猜测正确的样本数, y.numel()是样本的总数print("猜测正确样本数", accuracy(net(X), y)) # 样本数print("总样本数", y.numel()) # 总样本数# 然后放入Accumulator累加器metric.add(accuracy(net(X), y), y.numel()) # net(X)将X输入模型,获得预测值。print("对所有的猜测正确样本数/总样本数=它的准确率")print(metric[0])print(metric[1])return metric[0] / metric[1] # 分类正确的样本数 / 总样本数if __name__ == '__main__':batch_size = 256train_iter, test_iter = load_data_fashion_mnist(batch_size) # 返回训练集、测试集的迭代器# 28×28=784,数据集有10个类别num_inputs = 784num_outputs = 10w = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)b = torch.zeros(num_outputs, requires_grad=True)print(evaluate_accuracy(net, test_iter))结果:




Softmax回归的训练
训练函数(完整的数据集通过神经网络一次)
# 训练函数
def train_epoch_ch3(net, train_iter, loss, updater):# 如果是nn.Module模型的话,则开始训练模式if isinstance(net, torch.nn.Module):net.train()# 用一个长度为3的迭代器累加我们需要的信息metric = Accumulator(3)# 扫一遍我们的数据for X, y in train_iter:y_hat = net(X) # net(X)算出评测值y_hatl = loss(y_hat, y) # 通过交叉熵损失函数来算出预测值 y_hat 和实际值 y 之间的误差l# 更新模型参数(如果使用优化器,updater 是一个 PyTorch 的优化器实例)if isinstance(updater, torch.optim.Optimizer):# 先把梯度设成0updater.zero_grad()l.backward() # 计算梯度updater.step() # 对参数进行一次更新metric.add(# 累加损失、准确率和样本数。float(l) * len(y), accuracy(y_hat, y), y.size().numel())# 更新模型参数(如果未使用优化器,updater 不是优化器实例)else:# 对损失 l 进行求和,然后对求和后的损失进行反向传播。将计算损失关于模型参数的梯度,并将这些梯度存储在模型参数的 .grad 属性中。l.sum().backward()# 传入当前批次的样本数作为参数,手动更新模型参数。updater(X.shape[0])# 这次直接使用l.sum()(没有乘以len(y)),因为已经进行了求和。metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 返回整个训练周期的平均损失和平均准确率return metric[0] / metric[2], metric[1] / metric[2]
定义一个在动画中绘制数据的实用程序类
from IPython import display
from d2l import torch as d2lclass Animator:def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):if legend is None:legend = []d2l.use_svg_display()self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]self.config_axes = lambda: d2l.set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsdef add(self, x, y):if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()display.display(self.fig)display.clear_output(wait=True)轮次总训练函数
import matplotlib.pyplot as plt
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from IPython import display
from d2l import torch as d2l# Accumulator实例中创建了2个变量,用于分别存储正确预测的数量和预测的总数量
class Accumulator:"""在n个变量上累加"""# 初始化一个长度为n的列表,所有元素都是0.0# [0, 0] 是一个包含两个元素(都是0)的列表。def __init__(self, n):self.data = [0, 0] * ndef add(self, *args):# 使用列表推导式和zip函数将self.data中的当前值与args中的对应值相加,并将结果重新赋值给self.data。self.data = [a + float(b) for a, b in zip(self.data, args)] # zip函数把两个列表第一个位置元素打包、第二个位置元素打包....# 通过print函数我们可知将猜测正确样本数(即参数accuracy(net(X), y))和总样本数y.numel()分别累加# print(self.data)def reset(self):# 将self.data重置为一个新的列表,长度与原来的self.data相同,但所有元素都是0.0。self.data = [0.0] * len(self.data)def __getitem__(self, idx):# 使用索引来访问self.data中的元素。return self.data[idx]class Animator:def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):if legend is None:legend = []d2l.use_svg_display()self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]self.config_axes = lambda: d2l.set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsdef add(self, x, y):if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()plt.draw()plt.pause(0.001)display.display(self.fig)display.clear_output(wait=True)def show(self):display.display(self.fig)def get_dataloader_workers():"""使用4个进程来读取的数据"""return 4# 加载数据集的函数
# batch_size(用于指定数据加载器加载的批次大小)和 resize(可选参数,用于指定图像在加载前是否需要调整大小,默认为 None,即不进行大小调整)。
def load_data_fashion_mnist(batch_size, resize=None):"""下载Fashion-MNIST数据集,然后将其加载到内存中"""# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式# 并除以255使得所有像素的数值均在0到1之间# 创建一个列表 trans,其中包含一个 transforms.ToTensor() 实例。这个列表将用于构建图像转换的流水线。trans = [transforms.ToTensor()]# 判断 resize 参数是否有值if resize:# 如果 resize 有值,则在 trans 列表的开头插入一个 transforms.Resize(resize) 实例。这表示在转换为张量之前,先对图像进行大小调整。trans.insert(0, transforms.Resize(resize))# 将 trans 列表中的转换 组合成一个流水线,并重新赋值给 trans 变量。trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)# 使用 data.DataLoader 创建一个数据加载器,用于加载训练集。参数 batch_size 指定批次大小,shuffle=True 表示在训练时打乱数据顺序,# num_workers=get_dataloader_workers() 指定用于数据加载的子进程数return (data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False, num_workers=get_dataloader_workers())) # 测试集通常不shuffledef softmax(X):X_exp = torch.exp(X) # 每个都进行指数运算partition = X_exp.sum(1, keepdim=True)return X_exp / partition # 这里应用了广播机制def cross_entropy(y_hat, y):# range(len(y_hat))每一行拿出一个0到n的向量# 其中range(len(y_hat))是生成0和1,也就是只有两个样本,在这两个样本中查找真实标号的预测值# range(y_hat)是所有行,y是真实值所对应的列return -torch.log(y_hat[range(len(y_hat)), y]) # y_hat[range(len(y_hat)),y]为把y的标号列表对应的值拿出来。传入的y要是最大概率的标号def net(X):#需要一个批量大小*输入维数的矩阵,reshape成一个2D的矩阵,-1表示自动计算(其实就是批量大小batch_size=256)而w.shape[0]=784#X已经被重新塑形为(batch_size, 784),而w的形状假设为(784, num_classes)(其中num_classes是类别的数量)#所以矩阵乘法的结果将是一个(batch_size, num_classes)的矩阵。即:256*10的矩阵return softmax(torch.matmul(X.reshape((-1, w.shape[0])), w)+b)def accuracy(y_hat, y):"""计算预测正确的数量"""# 第一个判断张量是否大于一维,第二个是判断张量的第二个维度是否大于1if len(y_hat.shape) > 1 and y_hat.shape[1] > 1: # y_hat.shape[1]>1表示不止一个类别,每个类别有各自的概率# y_hat.argmax(axis=1)为求每行数值最大的那列(最大的预测概率)的索引号,y_hat是预测分类的类别y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == y # 先判断逻辑运算符==,再赋值给cmp,cmp为布尔类型的数据return float(cmp.type(y.dtype).sum()) # 获得y.dtype的类型作为传入参数,将cmp的类型转为y的类型(int型),然后再求和# 可以评估在任意模型net的准确率,
def evaluate_accuracy(net, data_iter):"""计算在指定数据集上模型的精度"""# 如果net模型是torch.nn.Module实现的神经网络的话,将它变成评估模式if isinstance(net, torch.nn.Module):net.eval() # 将模型设置为评估模式metric = Accumulator(2) # 正确预测数、预测总数,metric为累加器的实例化对象,里面存了两个数# 对于迭代器中每次拿出一个X和yfor X, y in data_iter:# 通过net(X)算出评测值,accuracy(net(X), y)计算所有猜测正确的样本数, y.numel()是样本的总数# print("猜测正确样本数", accuracy(net(X), y)) # 样本数# print("总样本数", y.numel()) # 总样本数# 然后放入Accumulator累加器metric.add(accuracy(net(X), y), y.numel()) # net(X)将X输入模型,获得预测值。# print("对所有的猜测正确样本数/总样本数=它的准确率")# print(metric[0])# print(metric[1])return metric[0] / metric[1] # 分类正确的样本数 / 总样本数# 训练函数(epoch是指一个完整的数据集通过神经网络一次)
def train_epoch_ch3(net, train_iter, loss, updater):# 如果是nn.Module模型的话,则开始训练模式if isinstance(net, torch.nn.Module):net.train()# 用一个长度为3的迭代器累加我们需要的信息metric = Accumulator(3)# 扫一遍我们的数据for X, y in train_iter:y_hat = net(X) # net(X)算出评测值y_hatl = loss(y_hat, y) # 通过交叉熵损失函数来算出预测值 y_hat 和实际值 y 之间的误差l# 更新模型参数(如果使用优化器,updater 是一个 PyTorch 的优化器实例)if isinstance(updater, torch.optim.Optimizer):# 先把梯度设成0updater.zero_grad()l.backward() # 计算梯度updater.step() # 对参数进行一次更新metric.add(# 累加损失、准确率和样本数。float(l) * len(y), accuracy(y_hat, y), y.size().numel())# 更新模型参数(如果未使用优化器,updater 不是优化器实例)else:# 对损失 l 进行求和,然后对求和后的损失进行反向传播。将计算损失关于模型参数的梯度,并将这些梯度存储在模型参数的 .grad 属性中。l.sum().backward()# 传入当前批次的样本数作为参数,手动更新模型参数。updater(X.shape[0])# 这次直接使用l.sum()(没有乘以len(y)),因为已经进行了求和。metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 返回整个训练周期的平均损失和平均准确率return metric[0] / metric[2], metric[1] / metric[2]# 总训练函数
# net: 神经网络模型、train_iter: 训练数据集迭代器、test_iter: 测试数据集迭代器、loss: 损失函数、num_epochs: 训练的轮数(即整个数据集被遍历的次数)、updater: 一个用于更新模型参数的函数
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):# 使用 Animator 工具来绘制训练过程中的指标,设置了x轴标签为“epoch”,x轴的范围从1到num_epochs,y轴的范围从0.3到0.9# 曲线分别有训练损失、训练正确率和测试正确率。animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3,0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs): # 变量num_epochs遍数据train_metrics = train_epoch_ch3(net, train_iter, loss, updater) # 返回两个值,一个总损失、一个总正确率# 在测试数据集上评估模型的精度。这个函数只返回一个值:仅返回测试集上的总正确率。test_acc = evaluate_accuracy(net, test_iter)# 因为通常我们从第1个epoch开始计数,而不是从第0个,所以这里加了1# train_metrics+(test_acc,):这不是将两个正确率相加,而是将训练指标(损失和正确率)的元组与测试正确率合并成一个新的元组。animator.add(epoch+1, train_metrics+(test_acc,)) # train_metrics+(test_acc,) 仅将两个值的正确率相加,train_loss, train_acc = train_metricsanimator.show()lr = 0.1def updater(batch_size):# 调用sgd函数来更新参数w和breturn d2l.sgd([w, b], lr, batch_size)if __name__ == '__main__':batch_size = 256train_iter, test_iter = load_data_fashion_mnist(batch_size) # 返回训练集、测试集的迭代器# 28×28=784,数据集有10个类别num_inputs = 784num_outputs = 10w = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)b = torch.zeros(num_outputs, requires_grad=True)# print(evaluate_accuracy(net, test_iter))num_epochs = 10train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)# d2l.plt.pause(0)d2l.plt.show()结果:

对图像进行分类预测
import matplotlib.pyplot as plt
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from IPython import display
from d2l import torch as d2l# Accumulator实例中创建了2个变量,用于分别存储正确预测的数量和预测的总数量
class Accumulator:"""在n个变量上累加"""# 初始化一个长度为n的列表,所有元素都是0.0# [0, 0] 是一个包含两个元素(都是0)的列表。def __init__(self, n):self.data = [0, 0] * ndef add(self, *args):# 使用列表推导式和zip函数将self.data中的当前值与args中的对应值相加,并将结果重新赋值给self.data。self.data = [a + float(b) for a, b in zip(self.data, args)] # zip函数把两个列表第一个位置元素打包、第二个位置元素打包....# 通过print函数我们可知将猜测正确样本数(即参数accuracy(net(X), y))和总样本数y.numel()分别累加# print(self.data)def reset(self):# 将self.data重置为一个新的列表,长度与原来的self.data相同,但所有元素都是0.0。self.data = [0.0] * len(self.data)def __getitem__(self, idx):# 使用索引来访问self.data中的元素。return self.data[idx]class Animator:def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):if legend is None:legend = []d2l.use_svg_display()self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]self.config_axes = lambda: d2l.set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsdef add(self, x, y):if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()plt.draw()plt.pause(0.001)display.display(self.fig)display.clear_output(wait=True)def show(self):display.display(self.fig)def get_dataloader_workers():"""使用4个进程来读取的数据"""return 4# 加载数据集的函数
# batch_size(用于指定数据加载器加载的批次大小)和 resize(可选参数,用于指定图像在加载前是否需要调整大小,默认为 None,即不进行大小调整)。
def load_data_fashion_mnist(batch_size, resize=None):"""下载Fashion-MNIST数据集,然后将其加载到内存中"""# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式# 并除以255使得所有像素的数值均在0到1之间# 创建一个列表 trans,其中包含一个 transforms.ToTensor() 实例。这个列表将用于构建图像转换的流水线。trans = [transforms.ToTensor()]# 判断 resize 参数是否有值if resize:# 如果 resize 有值,则在 trans 列表的开头插入一个 transforms.Resize(resize) 实例。这表示在转换为张量之前,先对图像进行大小调整。trans.insert(0, transforms.Resize(resize))# 将 trans 列表中的转换 组合成一个流水线,并重新赋值给 trans 变量。trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)# 使用 data.DataLoader 创建一个数据加载器,用于加载训练集。参数 batch_size 指定批次大小,shuffle=True 表示在训练时打乱数据顺序,# num_workers=get_dataloader_workers() 指定用于数据加载的子进程数return (data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False, num_workers=get_dataloader_workers())) # 测试集通常不shuffledef softmax(X):X_exp = torch.exp(X) # 每个都进行指数运算partition = X_exp.sum(1, keepdim=True)return X_exp / partition # 这里应用了广播机制def cross_entropy(y_hat, y):# range(len(y_hat))每一行拿出一个0到n的向量# 其中range(len(y_hat))是生成0和1,也就是只有两个样本,在这两个样本中查找真实标号的预测值# range(y_hat)是所有行,y是真实值所对应的列return -torch.log(y_hat[range(len(y_hat)), y]) # y_hat[range(len(y_hat)),y]为把y的标号列表对应的值拿出来。传入的y要是最大概率的标号def net(X):#需要一个批量大小*输入维数的矩阵,reshape成一个2D的矩阵,-1表示自动计算(其实就是批量大小batch_size=256)而w.shape[0]=784#X已经被重新塑形为(batch_size, 784),而w的形状假设为(784, num_classes)(其中num_classes是类别的数量)#所以矩阵乘法的结果将是一个(batch_size, num_classes)的矩阵。即:256*10的矩阵return softmax(torch.matmul(X.reshape((-1, w.shape[0])), w)+b)def accuracy(y_hat, y):"""计算预测正确的数量"""# 第一个判断张量是否大于一维,第二个是判断张量的第二个维度是否大于1if len(y_hat.shape) > 1 and y_hat.shape[1] > 1: # y_hat.shape[1]>1表示不止一个类别,每个类别有各自的概率# y_hat.argmax(axis=1)为求每行数值最大的那列(最大的预测概率)的索引号,y_hat是预测分类的类别y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == y # 先判断逻辑运算符==,再赋值给cmp,cmp为布尔类型的数据return float(cmp.type(y.dtype).sum()) # 获得y.dtype的类型作为传入参数,将cmp的类型转为y的类型(int型),然后再求和# 可以评估在任意模型net的准确率,
def evaluate_accuracy(net, data_iter):"""计算在指定数据集上模型的精度"""# 如果net模型是torch.nn.Module实现的神经网络的话,将它变成评估模式if isinstance(net, torch.nn.Module):net.eval() # 将模型设置为评估模式metric = Accumulator(2) # 正确预测数、预测总数,metric为累加器的实例化对象,里面存了两个数# 对于迭代器中每次拿出一个X和yfor X, y in data_iter:# 通过net(X)算出评测值,accuracy(net(X), y)计算所有猜测正确的样本数, y.numel()是样本的总数# print("猜测正确样本数", accuracy(net(X), y)) # 样本数# print("总样本数", y.numel()) # 总样本数# 然后放入Accumulator累加器metric.add(accuracy(net(X), y), y.numel()) # net(X)将X输入模型,获得预测值。# print("对所有的猜测正确样本数/总样本数=它的准确率")# print(metric[0])# print(metric[1])return metric[0] / metric[1] # 分类正确的样本数 / 总样本数# 训练函数(epoch是指一个完整的数据集通过神经网络一次)
def train_epoch_ch3(net, train_iter, loss, updater):# 如果是nn.Module模型的话,则开始训练模式if isinstance(net, torch.nn.Module):net.train()# 用一个长度为3的迭代器累加我们需要的信息metric = Accumulator(3)# 扫一遍我们的数据for X, y in train_iter:y_hat = net(X) # net(X)算出评测值y_hatl = loss(y_hat, y) # 通过交叉熵损失函数来算出预测值 y_hat 和实际值 y 之间的误差l# 更新模型参数(如果使用优化器,updater 是一个 PyTorch 的优化器实例)if isinstance(updater, torch.optim.Optimizer):# 先把梯度设成0updater.zero_grad()l.backward() # 计算梯度updater.step() # 对参数进行一次更新metric.add(# 累加损失、准确率和样本数。float(l) * len(y), accuracy(y_hat, y), y.size().numel())# 更新模型参数(如果未使用优化器,updater 不是优化器实例)else:# 对损失 l 进行求和,然后对求和后的损失进行反向传播。将计算损失关于模型参数的梯度,并将这些梯度存储在模型参数的 .grad 属性中。l.sum().backward()# 传入当前批次的样本数作为参数,手动更新模型参数。updater(X.shape[0])# 这次直接使用l.sum()(没有乘以len(y)),因为已经进行了求和。metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 返回整个训练周期的平均损失和平均准确率return metric[0] / metric[2], metric[1] / metric[2]# 总训练函数
# net: 神经网络模型、train_iter: 训练数据集迭代器、test_iter: 测试数据集迭代器、loss: 损失函数、num_epochs: 训练的轮数(即整个数据集被遍历的次数)、updater: 一个用于更新模型参数的函数
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):# 使用 Animator 工具来绘制训练过程中的指标,设置了x轴标签为“epoch”,x轴的范围从1到num_epochs,y轴的范围从0.3到0.9# 曲线分别有训练损失、训练正确率和测试正确率。animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3,0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs): # 变量num_epochs遍数据train_metrics = train_epoch_ch3(net, train_iter, loss, updater) # 返回两个值,一个总损失、一个总正确率# 在测试数据集上评估模型的精度。这个函数只返回一个值:仅返回测试集上的总正确率。test_acc = evaluate_accuracy(net, test_iter)# 因为通常我们从第1个epoch开始计数,而不是从第0个,所以这里加了1# train_metrics+(test_acc,):这不是将两个正确率相加,而是将训练指标(损失和正确率)的元组与测试正确率合并成一个新的元组。animator.add(epoch+1, train_metrics+(test_acc,)) # train_metrics+(test_acc,) 仅将两个值的正确率相加,train_loss, train_acc = train_metricsanimator.show()def predict_ch3(net, test_iter, n=6):# net: 神经网络模型# test_iter: 测试数据集迭代器# n: 需要显示的图像数量,默认为6"""预测标签"""# 取一次数据就结束,因为有breakfor X, y in test_iter:break# 获取真实的标签trues = d2l.get_fashion_mnist_labels(y)# 使用神经网络模型net对取出的X进行预测,net(X) 返回的是每个类别的得分,使用argmax(axis=1)找到得分最高的类别索引,即预测的标签preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))# 创建一个titles列表,其中每个元素都是一个字符串,包含真实的标签和预测的标签# 使用列表推导式和zip函数将trues和preds中的元素配对并格式化字符串# true 和 pred是从 trues 和 preds 列表中提取的元素# zip函数将两个列表元素配对。例如,如果 trues = [1, 2, 3] 且 preds = [0, 2, 1],那么 zip(trues, preds) 将返回 [(1, 0), (2, 2), (3, 1)]。titles = [true + '\n' + pred for true, pred in zip(trues, preds)]# # 使用d2l.show_images函数显示前n个图像,并将对应的标题设置为上面创建的titles列表中的前n个元素# X[0:n]取出的是前n个图像的数据,但需要先reshape为(n, 28, 28)的形式,# 因为原始数据可能是(batch_size, 28*28)的形式d2l.show_images(X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])# X形状可能是 (batch_size, 28*28),其中 batch_size 是批处理中的图像数量,28*28 是单个图像的展平后的像素数量。# 从输入数据 X 中选取前 n 个图像的数据,重新塑形为 (n, 28, 28) 的形状,然后水平排列成一行显示这些图像,并为每个图像附上一个标题(这些标题来自 titles 列表的前 n 个元素)。lr = 0.1def updater(batch_size):# 调用sgd函数来更新参数w和breturn d2l.sgd([w, b], lr, batch_size)if __name__ == '__main__':batch_size = 256train_iter, test_iter = load_data_fashion_mnist(batch_size) # 返回训练集、测试集的迭代器# 28×28=784,数据集有10个类别num_inputs = 784num_outputs = 10w = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)b = torch.zeros(num_outputs, requires_grad=True)# print(evaluate_accuracy(net, test_iter))num_epochs = 10# 必须加上,要么测试predict_ch3无法正确对应train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)# d2l.plt.pause(0)predict_ch3(net, test_iter)d2l.plt.tight_layout() # 调整子图参数,使之填充整个图像区域d2l.plt.show()
结果:

Softmax回归的简洁实现
import torch
import matplotlib.pyplot as plt
from torch import nn
from d2l import torch as d2l
from IPython import display# Accumulator实例中创建了2个变量,用于分别存储正确预测的数量和预测的总数量
class Accumulator:"""在n个变量上累加"""# 初始化一个长度为n的列表,所有元素都是0.0# [0, 0] 是一个包含两个元素(都是0)的列表。def __init__(self, n):self.data = [0, 0] * ndef add(self, *args):# 使用列表推导式和zip函数将self.data中的当前值与args中的对应值相加,并将结果重新赋值给self.data。self.data = [a + float(b) for a, b in zip(self.data, args)] # zip函数把两个列表第一个位置元素打包、第二个位置元素打包....# 通过print函数我们可知将猜测正确样本数(即参数accuracy(net(X), y))和总样本数y.numel()分别累加# print(self.data)def reset(self):# 将self.data重置为一个新的列表,长度与原来的self.data相同,但所有元素都是0.0。self.data = [0.0] * len(self.data)def __getitem__(self, idx):# 使用索引来访问self.data中的元素。return self.data[idx]class Animator:def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):if legend is None:legend = []d2l.use_svg_display()self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]self.config_axes = lambda: d2l.set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsdef add(self, x, y):if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()plt.draw()plt.pause(0.001)display.display(self.fig)display.clear_output(wait=True)def show(self):display.display(self.fig)def accuracy(y_hat, y):"""计算预测正确的数量"""# 第一个判断张量是否大于一维,第二个是判断张量的第二个维度是否大于1if len(y_hat.shape) > 1 and y_hat.shape[1] > 1: # y_hat.shape[1]>1表示不止一个类别,每个类别有各自的概率# y_hat.argmax(axis=1)为求每行数值最大的那列(最大的预测概率)的索引号,y_hat是预测分类的类别y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == y # 先判断逻辑运算符==,再赋值给cmp,cmp为布尔类型的数据return float(cmp.type(y.dtype).sum()) # 获得y.dtype的类型作为传入参数,将cmp的类型转为y的类型(int型),然后再求和# 可以评估在任意模型net的准确率,
def evaluate_accuracy(net, data_iter):"""计算在指定数据集上模型的精度"""# 如果net模型是torch.nn.Module实现的神经网络的话,将它变成评估模式if isinstance(net, torch.nn.Module):net.eval() # 将模型设置为评估模式metric = Accumulator(2) # 正确预测数、预测总数,metric为累加器的实例化对象,里面存了两个数# 对于迭代器中每次拿出一个X和yfor X, y in data_iter:# 通过net(X)算出评测值,accuracy(net(X), y)计算所有猜测正确的样本数, y.numel()是样本的总数# print("猜测正确样本数", accuracy(net(X), y)) # 样本数# print("总样本数", y.numel()) # 总样本数# 然后放入Accumulator累加器metric.add(accuracy(net(X), y), y.numel()) # net(X)将X输入模型,获得预测值。# print("对所有的猜测正确样本数/总样本数=它的准确率")# print(metric[0])# print(metric[1])return metric[0] / metric[1] # 分类正确的样本数 / 总样本数# 训练函数(epoch是指一个完整的数据集通过神经网络一次)
def train_epoch_ch3(net, train_iter, loss, updater):# 如果是nn.Module模型的话,则开始训练模式if isinstance(net, torch.nn.Module):net.train()# 用一个长度为3的迭代器累加我们需要的信息metric = Accumulator(3)# 扫一遍我们的数据for X, y in train_iter:y_hat = net(X) # net(X)算出评测值y_hatl = loss(y_hat, y) # 通过交叉熵损失函数来算出预测值 y_hat 和实际值 y 之间的误差l# 更新模型参数(如果使用优化器,updater 是一个 PyTorch 的优化器实例)if isinstance(updater, torch.optim.Optimizer):# 先把梯度设成0updater.zero_grad()l.backward() # 计算梯度updater.step() # 对参数进行一次更新metric.add(# 累加损失、准确率和样本数。float(l) * len(y), accuracy(y_hat, y), y.size().numel())# 更新模型参数(如果未使用优化器,updater 不是优化器实例)else:# 对损失 l 进行求和,然后对求和后的损失进行反向传播。将计算损失关于模型参数的梯度,并将这些梯度存储在模型参数的 .grad 属性中。l.sum().backward()# 传入当前批次的样本数作为参数,手动更新模型参数。updater(X.shape[0])# 这次直接使用l.sum()(没有乘以len(y)),因为已经进行了求和。metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 返回整个训练周期的平均损失和平均准确率return metric[0] / metric[2], metric[1] / metric[2]# 总训练函数
# net: 神经网络模型、train_iter: 训练数据集迭代器、test_iter: 测试数据集迭代器、loss: 损失函数、num_epochs: 训练的轮数(即整个数据集被遍历的次数)、updater: 一个用于更新模型参数的函数
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):# 使用 Animator 工具来绘制训练过程中的指标,设置了x轴标签为“epoch”,x轴的范围从1到num_epochs,y轴的范围从0.3到0.9# 曲线分别有训练损失、训练正确率和测试正确率。animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3,0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs): # 变量num_epochs遍数据train_metrics = train_epoch_ch3(net, train_iter, loss, updater) # 返回两个值,一个总损失、一个总正确率# 在测试数据集上评估模型的精度。这个函数只返回一个值:仅返回测试集上的总正确率。test_acc = evaluate_accuracy(net, test_iter)# 因为通常我们从第1个epoch开始计数,而不是从第0个,所以这里加了1# train_metrics+(test_acc,):这不是将两个正确率相加,而是将训练指标(损失和正确率)的元组与测试正确率合并成一个新的元组。animator.add(epoch+1, train_metrics+(test_acc,)) # train_metrics+(test_acc,) 仅将两个值的正确率相加,train_loss, train_acc = train_metricsanimator.show()# 初始化神经网络中线性层权重
def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01) # 均值为0,标准差为0.01来初始化权重batch_size = 256
# train_iter:是一个迭代器,用于遍历训练集中的数据。在每次迭代中,它会返回一个小批量的训练样本和对应的标签。
# test_iter:也是一个迭代器,它用于遍历测试集中的数据。在每次迭代中,它同样会返回一个小批量的测试样本和对应的标签。
# batch_size 是一个参数,它指定了每个小批量中应包含的样本数量。
# 例如,如果 batch_size 是 64,那么 train_iter 每次迭代都会返回 64 个训练样本和对应的 64 个标签。
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)# PyTorch不会隐式地调整输入的形状。
# 因此,我们定义了展平层(flatten)在线性层前调整网络输入的形状
# nn.Flatten() 是一个将多维张量展平为一维张量的模块。
# 假设其形状为 [batch_size, channels, height, width]则转换为 [batch_size, channels * height * width]
# 以便可以将其传递给线性层。
# 在Fashion-MNIST数据集中,每个图像都是 28x28 像素的灰度图(没有颜色通道,所以 channels = 1)。
# 因此,一个图像的形状是 [1, 28, 28]经过 nn.Flatten() 后,其形状变为 [784](因为 28*28=784)。
# nn.Linear(784, 10) 接收一个形状为 [784] 的输入(即展平后的图像),并输出一个形状为 [10] 的向量。
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
# 用于将某个函数(这里是 init_weights)应用到神经网络 net 中的所有模块上。
net.apply(init_weights)
# 在交叉熵损失函数中传递未归一化的预测,并同时计算softmax及其对数,使得在训练分类模型时不需要在最后一层之后显式地添加 softmax 层。
loss = nn.CrossEntropyLoss()
# 使用学习率为0.1的小批量随机梯度下降作为优化算法
# torch.optim.SGD 是一个优化器
# 在PyTorch中,模型的参数(如线性层的权重和偏置)通常存储在 nn.Parameter 对象中,这些对象在模型被实例化时自动注册到模型的 parameters() 方法中。
trainer = torch.optim.SGD(net.parameters(), lr=0.1)
# 调用之前定义的训练函数来训练模型
num_epochs = 10
train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
d2l.plt.show()
结果:
问题
1、softlabe训练策略、以及为什么有效。
一位有效表示一个标号,n类的话表示成一个很长的向量,只有正确那一类为1,剩下的所有变成0,然后用一个softmax去逼近这个纯0、1的分布,它的问题是用了指数的话很难用指数逼近1,因为指数变成1的话,你想要它完全变成1的话,你的输出必须几乎接近无穷大,而剩下的都很小,挺难用softmax逼近0和1的极端的数值。所以提出一个方案是说如果是正确的那一类计为0.9,剩下那些不正确的类就是0.1÷ 1 n \frac 1n n1,这就是softlabel。这样的好处是说使得你用softmax真的去完全拟合0.9和那些很小的数的时候是有可能的。
2、softmax回归和logistic回归分析是一样的吗?如果不一样的话,哪些地方不同?
可以认为是一样的,
3、为什么用交叉熵,不用相对熵等其他基于信息量的度量?
相对熵表示的是一个两个概率之间的区别,它比交叉熵的好处是说它是一个对称的关系。不用的原因是不好算。
4、ylog y ^ \hat{y} y^我们为什么只关心正确类,不关心不正确类呢,如果关心不正确类效果有没有可能更好呢?
其实,我们不是不关心不正确的类,是因为y_hat的编码把剩下类的概率变成了0,导致计算的时候可以忽略掉不正确的类,如果我们使用softlable,不正确的类也是有存在非0的概率的情况下,我们确实会关心不正确的类。
5、这样的n分类,对每一个类别来说,是不是可以认为只有1个正类,n-1个负类吗?会不会类别不平衡呢?
会有这样的情况,但相对来说,好处是可以看到损失函数,如果是0、1编码的话,并不关心别的类会怎么样,只关心当前类。其实不用关心类别平不平衡,要关心的是是不是存在一些类,这些类有没有足够多的样本。
6、似然函数是怎么得出来的?有什么参考意义?其他次优解是不是似然值也很高呢?
最小化的损失等价于最大化的一个似然函数,似然函数是指一个模型,在给定数据的情况下,这个所谓的模型就是我的权重,出现的概率有多大。
7、DaTALOADER()的num_workers是并行了吗?
是的,取决于你的实现,pytorch是用进程来实现的。
8、Pytorch训练好模型,测试的时候发现无论batchsize设为1还是更多,测试的总时间都差不多,但正常理解如果设为4不应该是设为1的4倍速度吗?
不是的,不管batch_size是多少,计算量是不会发生变化的,唯一发生变化的是并行度是不是能增加,执行的效率能不能增加。
9、为什么不在accuracy函数中把除以len(y)做完呢?
因为读一个batch的时候,最后那个batch可能读不满,会导致不正确。
10、在计算精度的时候,为什么需要使用new.eval()将模型设置成评估模式?
不设也没有关系,是一个好的习惯,设成eval模式的话是默认不计算梯度。
11、w、b怎么从模型中抽出来,放进updater的?
在trainer = torch.optim.SGD(net.parameters(), lr=0.1)中,net.parameters()是将模型的所有w b参数都放入到updater里面了。
12、在多次迭代之后如果测试精度出现上升后再下降是过拟合了吗?可以提前终止吗?
一直在下降,很可能过拟合了。有其他微调可以避免这些事情。
相关文章:
深度学习-Softmax回归+损失函数+图像分类数据集
目录 Softmax回归回归 VS 分类Kaggle上的分类问题 从回归到多类分类回归分类从回归到多类分类-均方损失从回归到多类分类-无校验比例从回归到多类分类-校验比例 Softmax和交叉熵损失总结损失函数均方损失绝对值损失函数鲁棒损失 图像分类数据集通过框架中内置函数将FashionMNIS…...

【论文解读】Overview of the Scalable Video Coding Extension of the H.264/AVC Standard
介绍 该篇论文是一篇关于H.264/AVC标准可扩展视频编码(SVC)扩展的综述论文,由Heiko Schwarz、Detlev Marpe和Thomas Wiegand撰写,发表在《IEEE Transactions on Circuits and Systems for Video Technology》2007年9月第17卷第9期上。 论文解读 摘要: H.264/AVC视频编…...

【C语言】程序员自我修养之文件操作
【C语言】程序员自我修养之文件操作 🔥个人主页:大白的编程日记 🔥专栏:C语言学习之路 文章目录 【C语言】程序员自我修养之文件操作前言一.文件介绍1.1为什么使用文件1.2文件分类1.3二进制文件和文本文件 二.文件的打开和关闭2.…...

一种获取java代码结构的实现思路
一种获取java代码结构的实现思路 有时,我们需要获取java文件里的代码结构,即,只需要里面的class定义、方法声明、属性定义。不需要额外的方法实现 这里提供一下实现思路: 采用语法解析器Tree-sitter对java代码进行解析,获取里面的方法实现遍历第一步获取到的方法列表,在源…...

MySQL---增删改查
MySQL是一个流行的关系型数据库管理系统,它使用结构化查询语言(SQL)来管理数据库中的数据。以下是MySQL中增删改查(CRUD)操作的基本命令: 创建(Create): 创建新表:CREATE TABLE table_name (column1 datatype,column2 datatype,...PRIMARY KEY (column) );插入数据:…...

C#编程-.NET Framework使用工具类简化对象之间的属性复制和操作
在C#编程中,对象之间的属性复制和操作是一个常见的需求。为此,.NET Framework提供了多种实用工具库,如AutoMapper、ValueInjecter和ExpressMapper。这些库通过简化代码,提高了开发效率。本文将介绍这些工具库,比较它们…...

爬虫基本原理及requests库用法
文章目录 一、爬虫基本原理1、什么是爬虫2、爬虫的分类3、网址的构成4、爬虫的基本步骤5、动态【异步】页面和静态【同步】页面6、请求头 二、requests基本原理及使用1、chrome 抓包按钮详解1.1 Elements1.2 元素定位器1.3 Network1.4 All1.5 XHR1.6 Preserve log1.7 手机模式1…...
spring和springboot、springcloud版本关系
进入新公司,看底层框架代码时,想了解spring的版本,很好奇这些版本之间时怎么对应的,因为不同版本应该有依赖关系,用得不对可能代码会有隐藏问题。 Spring、SpringBoot和SpringCloud的版本不一致,并且需要搭…...
视频监控汇聚平台LntonCVS通过GB/T28181国标协议实现视频监控平台的级联方案
近年来,随着网络视频监控应用范围的拓展,越来越多的政府部门和跨区域行业单位对视频监控的需求已经不局限于本地联网监控。他们正在探索在原有的本地联网监控基础上,建设省级乃至全国范围内的跨区域监控联网,以全面打造数据共享平…...

【精品】使用 v-md-editor 上传图片
简介 v-md-editor 是基于 Vue 开发的 markdown 编辑器组件,即支持vue2也支持vue3。 gitee:https://gitee.com/ckang1229/vue-markdown-editor文档:https://code-farmer-i.github.io/vue-markdown-editor/zh/ 服务器端代码 RestController…...

STM32——DAC篇(基于f103)
技术笔记! 一、DAC简介(了解) 1.1 DAC概念 传感器信号采集改变电信号,通过ADC转换成单片机可以处理的数字信号,处理后,通过DAC转换成电信号,进而实现对系统的控制。 1.2 DAC的特性参数 1.3…...

突然提示由于找不到msvcr120.dll,无法继续执行代码有什么办法可以解决?
msvcr120.dll是Microsoft Visual C 2013 Redistributable Package的一部分,它包含了运行时库,用于支持使用Visual C 2013开发的应用程序。如果电脑突然提示由于找不到msvcr120.dll,无法继续执行代码有什么办法可以解决?以下是关于msvcr120.dl…...

swig4.2.1压缩包中里面没有找到swig.exe
官网:Simplified Wrapper and Interface Generator C转 C# 采用Swig.exe 打开Example示例的解决方案:sln 生成 即可查看如何调用和使用.i文件 但是:迅雷不管下载哪个版本都是没有exe 官网说了自带。很迷很迷~ 下载其他版本的时候发现&…...

Vue文本溢出如何自动换行
css新增 word-break: break-all; word-wrap: break-word;...

【系统架构师】-论文-系统安全性与保密性设计
1、摘要: 2018 年初,我所在的公司为一票务公司开发开票业务平台的建设。我在该项目中担任系统架构设计师的职务,主要负责设计平台系统架构和安全体系架构。该平台以采用 B/S 架构服务用户,采用”平台应用”的模式解决现有应用单机独立开票的模…...

Cisco Catalyst 9000 9200 9300 9400 IOS software upgrade
1 背景 从Catalyst 3650 ,3850,Catalyst 9000开始, 更准确的说是IOS XE的交换机的系统镜像安装方式分为2种 Bundle mode Install mode 这2种方工啥区别? Bundle mode 传统方式利用boot system flash:c9k.xx16.bin方式引导 Install mode 将bin文…...
Web Server项目实战2-Linux上的五种IO模型
上一节内容的补充:I/O多路复用是同步的,只有调用某些API才是异步的 Unix/Linux上的五种IO模型 a.阻塞 blocking 调用者调用了某个函数,等待这个函数返回,期间什么也不做,不停地去检查这个函数有没有返回,…...
Docker | 基础指令
环境:centos8 参考: 安装 Docker | Docker 从入门到实践https://vuepress.mirror.docker-practice.com/install/ 安装Docker 卸载旧版本,安装依赖包,添加yum软件源,更新 yum 软件源缓存,安装 docker-ce…...
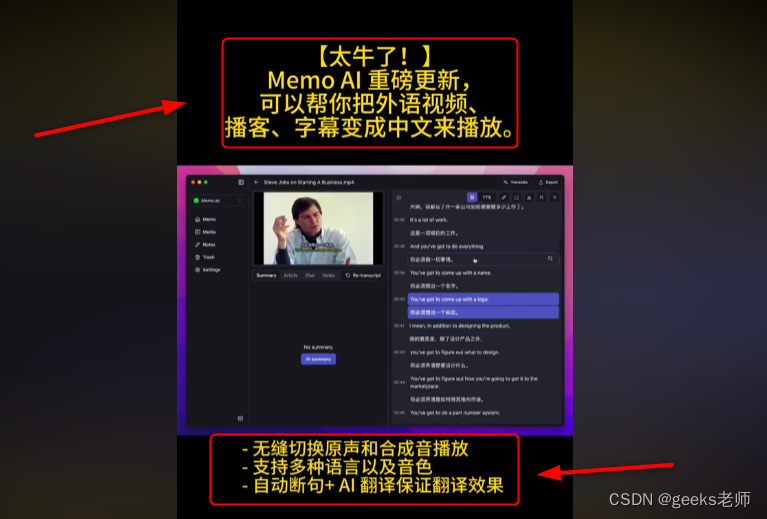
10款手机黑科技app,每款都好用到爆!
AI视频生成:小说文案智能分镜智能识别角色和场景批量Ai绘图自动配音添加音乐一键合成视频https://aitools.jurilu.com/ 1. 计划程序应用 —— Android Auto Text Android Auto Text(前身为 Do It Later)是一款简单易用的日程安排应用程序&am…...

tomcat请求数据解析过程
前面提到tomcat请求处理的io交互过程,现在开始看下经过io交互后tomcat是怎么处理请求数据的。首先到AbstractProtocol.java中的process方法,注意这个方法是在tomcat线程池分配的线程调用的。生成用来对请求字节流数据进行解析的Http11Processor。 public…...

COCO数据集到底怎么用?从PyTorch和TensorFlow加载到可视化标注的完整代码示例
COCO数据集实战指南:从数据加载到可视化标注的全流程解析 计算机视觉领域的研究者和开发者们,当你开始构建目标检测或图像分割模型时,COCO数据集无疑是你最重要的训练资源之一。这个由微软发起的大规模数据集已经成为行业标准,但许…...

Mythos模型的技术本质:执行态建模与终端状态感知
1. 这不是一次普通模型发布:Mythos背后的真实技术分水岭 “Claude Mythos Preview”这七个字,最近在安全圈和AI工程一线引发的震动,远超多数人最初预估。它不是又一个参数堆叠的“更大模型”,也不是一次常规的SOTA刷新——它是一次…...

PowerToys中文汉化:让Windows效率工具真正为你所用
PowerToys中文汉化:让Windows效率工具真正为你所用 【免费下载链接】PowerToys-CN PowerToys Simplified Chinese Translation 微软增强工具箱 自制汉化 项目地址: https://gitcode.com/gh_mirrors/po/PowerToys-CN 你是否曾经面对微软PowerToys的强大功能却…...

3D-LLM:面向可制造性的三维语言模型技术解析
1. 项目概述:当大语言模型开始“看见”三维空间“From Text to Tangible: 3D-LLM Unleashes Language Models into the 3D World”——这个标题不是科幻小说的副标题,而是2024年真实出现在CVPR和ICML顶会workshop上的技术路线宣言。我第一次在arXiv上读到…...

LLM语言大模型的企业应用案例
本文系统梳理 2025-2026 年国内外 7 款主流大语言模型(LLM)在企业中的成功部署案例,覆盖金融、汽车、旅游、政务、医疗五大行业,每个案例均包含部署步骤、数据准备、改善效果数字及经验教训,为企业 AI 落地提供可借鉴的…...

深度掌握GB28181视频监控API:构建高效国标协议的3个核心技巧
深度掌握GB28181视频监控API:构建高效国标协议的3个核心技巧 【免费下载链接】wvp-GB28181-pro 基于GB28181-2016、部标808、部标1078标准实现的开箱即用的网络视频平台。自带管理页面,支持NAT穿透,支持海康、大华、宇视等品牌的IPC、NVR接入…...

网页视频抓取终极指南:猫抓工具让你轻松收藏全网精彩内容
网页视频抓取终极指南:猫抓工具让你轻松收藏全网精彩内容 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为网页上的精彩视频无法保…...

历史性突破,OpenAI模型搞定人类科学家80年未破难题,能发顶刊了
OpenAI 7个月前曾因虚假数学突破被同行嘲笑。 智东西5月21日报道,今日,OpenAI宣布,其一款未对外发布的内部通用推理模型,独立完成了一份原创数学证明。该证明推翻了匈牙利数学家保罗埃尔德什(Paul Erdős)…...

可观测性告警:及时发现和响应系统异常
可观测性告警:及时发现和响应系统异常 一、可观测性告警概述 1.1 可观测性告警的定义 可观测性告警是指基于系统的指标、日志和追踪数据,通过预设的规则和阈值,自动检测系统异常并发送通知的机制。它帮助运维人员及时发现问题,快速…...

国家数据局印发《2026年数字经济发展工作要点》:八项任务背后的数据治理信号
大家好,我是独孤风。5月19日,国家数据局印发《2026年数字经济发展工作要点》。这不是一份泛泛谈数字经济的文件,而是对 2026 年数字经济工作的重点部署。从文件内容看,2026 年数字经济工作的关键词并不只是“上云、用数、用 AI”&…...