【数据库】MySQL
文章目录
- 概述
- DDL
- 数据库操作
- 查询
- 使用
- 创建
- 删除
- 表操作
- 创建
- 约束
- MySqL数据类型
- 数值类型
- 字符串类型
- 日期类型
- 查询
- 修改
- 删除
- DML
- insert
- update
- delete
- DQL
- 基本查询
- 条件查询
- 分组查询
- 分组查询
- 排序查询
- 分页查询
- 多表设计
- 一对多
- 一对一
- 多对多
- 设计步骤
- 多表查询
- 概述
- 内连接
- 外连接
- 子查询
- 标量子查询
- 列子查询
- 行子查询
- 表子查询
- 案例
- 事务
- 语法
- 四大特性(ACID)
- 索引
- 结构
- 语法
概述
关系型数据库(RDBMS):多张相连的二维表组成的数据库
SQL语句:操作关系型数据库的编程语言,是统一标准的。
(1)不区分大小写
(2)单行注释:-- 注释内容; 多行注释:/* 注释内容 */
SQL语句分类:
- DDL:definition,定义对象
- DML:manipulation,操作数据
- DQL:query,查询表记录
- DCL:control,控制用户、数据库权限
DDL
数据库操作
查询
查询所有数据库:show databases;
查询当前数据库:select database();
使用
使用数据库:use 数据库名;
创建
创建数据库:create database [if not exists] 数据库名;
删除
删除数据库:drop database [if exists] 数据库名;
表操作
创建
create table 表名(字段1 字段类型 [约束] [comment 字段1注释],字段2 字段类型 [约束] [comment 字段2注释],......字段n 字段类型 [约束] [comment 字段n注释]
)[comment 表注释];
约束
概念:作用于表中字段上的规则,用于限制存储在表中的数据
目的:保证数据库中的数据的正确性、有效性和完整性。
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段值不能为null | not null |
| 唯一约束 | 保证字段的所有数据都是唯一、不重复的 | unique |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | primary key(auto_increment自增) |
| 默认约束 | 保存数据时,若为指定该字段值,则采用默认值 | default |
| 外键约束 | 让两个表的数据建立联系,保证数据的一致性和完整性 | forign key |
create table tb_user(id int primary key comment 'ID,唯一标识';username varchar(20) not null unique comment '用户名',name varchar(10) not null comment '姓名',age int comment '年龄',gender char(1) default '男' comment '性别'
) comment '用户表';
MySqL数据类型
数值类型
| 类型 | 大小(byte) | 有符号(signed)范围 | 无符号(unsigned)范围 | 描述 |
|---|---|---|---|---|
| tinyint | 1 | (-128,127) | (0,255) | 小整数值 |
| smallint | 2 | (-32768,32767) | (0,65535) | 大整数值 |
| mediumint | 3 | (-8388608,8389607) | (0,16777215) | 大整数值 |
| int | 4 | (-2147483648,2147483647) | (0,4294967295) | 大整数值 |
| bigint | 8 | (-263 ,263-1) | (0,264-1) | 极大整数值 |
| float | 4 | (-3.4028 E+38 ,3.4028 E+38) | 0和(1.1754 E-38,3.4028 E+38) | 单精度浮点数 |
| double | 8 | (-1.7976 E+308 ,1.7976 E+308) | 0和(2.2250 E-308,1.7976 E+308) | 双精度浮点数 |
| decimal | 小数值(精度更高) |
float(5,2),double(5,2),decimal(5,2):5表示整个数字长度,2表示小数位个数。
字符串类型
| 类型 | 大小 | 描述 |
|---|---|---|
| char | 0-255 bytes | 定长字符串 |
| verchar | 0-65535 bytes | 变长字符串 |
char(10)最多只能存10个字符,不足10个字符,占用10个字符空间。【性能高、浪费空间】
varchar(10)最多只能存10个字符,不足10个字符,按照实际长度存储。【性能低、节省空间】
日期类型
| 类型 | 大小(bytes) | 范围 | 格式 | 描述 |
|---|---|---|---|---|
| date | 3 | 1000-01-01 至9999-12-31 | YYYY-MM-DD | 日期值 |
| datetime | 8 | 1000-01-01 00:00:00至于9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
查询
查询当前数据库所有表:show tables;
查询表结构:desc 表名;
查询建表语句:show create table 表名;
修改
添加字段:alter table 表名 add 字段名 类型(长度) [comment 注释] [约束];
修改字段类型:alter table 表名 modify 字段名 新数据类型(长度);
修改字段名和字段类型:alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 注释] [约束];
删除字段:alter table 表名 drop column 字段名;
修改表名:rename table 表名 to 新表名;
例题:在表tb_emp中完成如下操作:
(1)为表tb_emp 添加字段 qq varchar(11)
alter table tb_emp add qq varchar(11) comment 'QQ';
(2)修改 表tb_emp 字段类型 qq varchar(13)
alter table tb_emp modify qq varchar(13) comment 'QQ';
(3)修改 表tb_emp 字段名 qq 为qq_num varchar(13)
alter table tb_emp change qq qq_num varchar(13) comment 'QQ';
(4)删除 表tb_emp 的 qq_num 字段
alter table tb_emp drop column qq_num;
(5)将表tb_emp 表名修改为emp
rename table tb_emp to emp;
删除
删除表:drop table [if exits] 表名;
DML
insert
指定字段添加数据:insert 表名(字段名1,字段名2) values(值1,值2);
全部字段添加数据:insert into 表名 values (值1,值2...);
批量添加数据(指定字段):insert into 表名(字段1,字段名2) values(值1,值2),(值1,值2);
批量添加数据(全部字段):insert into 表名 values(值1,值2,...),(值1,值2,...);
注意:
1.插入数据时,指定的字段顺序需要与值的顺序是一一对应的。
2.字符串和日期型数据应该包含在引号中。
3.插入的数据大小,应该在字段的规定范围内。
例子:表tb_emp中有姓名name和性别gender
(1)为tb_emp表的name,gender字段插入值
insert into tb_emp(name,gender) values('张无忌',1);
(2)为tb_emp表的所有字段插入值。
insert into tb_emp values('周芷若',2);
(3)批量为tb_emp表的username,gender字段插入数据。
inser into tb_emp (username,gender) values ('韦一笑',2),('谢逊',1);
update
修改数据:update 表名 set 字段名1=值1,字段名2=值2,... [where 条件];
修改语句的条件可以有。若没有条件,则修改整张表的所有数据。
delete
删除数据:delete from 表名 [where 条件];
1.删除语句的条件可以有。若没有条件,则删除整张表的所有数据。
2.删除语句不能删除某一个字段的值(若要操作,可以使用update,将该字段的值置为NULL)
DQL
语法:
select 字段列表
from 表名列表where 条件列表
group by 分组字段列表
having 分组后条件列表
order by 排序字段列表
limit 分页参数
基本查询、条件查询(where)、分组查询(group by)、排序查询(order by)、分页查询(limit)
基本查询
查询多个字段:select 字段1,字段2,字段3 from 表名;
查询所有字段(通配符):select * from 表名;
设置别名:select 字段1 [as 别名1],字段2 [as 别名2] from 表名;
去除重复记录:select distinct 字段列表 from 表名;
*号代表查询所有字段,在实际开发中尽量少用(不直观,影响效率)
条件查询
条件查询:select 字段列表 from 表名 where 条件列表;
| 比较运算符 | 功能 |
|---|---|
| between…and… | 在某个范围之间(含最小值、最大值) |
| in(…) | 在in之后的列表中的值,多选一 |
| like 占位符 | 模糊匹配(_匹配单个字符,%匹配任意个字符) |
| is null | 是null |
例子:表tb_emp中有姓名name,性别gender(1为男2为女),职位job,入职时间entrydate.
(1)查询入职时间在’2000-01-01’(包含)到’2010-01-01’(包含)之间 且 性别为女 的员工信息。
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01' and gender=2;
(2)查询 职位为2(讲师),3(学工主管),4(教研主管)的员工信息。
select * from tb_emp where job = 2 or job = 3 or job = 4;
或
select * from tb_emp where job in (2,3,4);
(3)查询 姓名 为两个字的员工信息。
select * fron tb_emp where name like '__';
(4)查询 姓‘张’ 的员工信息
select * from tb_emp where name like '张%';
分组查询
将一列数据作为一个整体,进行纵向计算。
select 聚合函数(字段列表) from 表名;
| 聚合函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
NULL值不参与所有聚合函数运算。
统计数量可以用count(*) count(字段)
例子:表tb_emp中有入职时间entrydate.
(1)统计该企业员工数量
select count(*) from tb_emp;
(2)统计该企业最晚入职的员工
select max(entrydate) from tb_emp;
分组查询
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤过滤条件];
面试题:
where与having 的区别?
1.执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
2.判断条件不同:where不能对聚合函数进行判断,而having可以。
分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无意义。
执行顺序:where>聚合函数>having
例子:表tb_emp中有姓名name,性别gender(1为男2为女),职位job,入职时间entrydate.
(1)根据性别分组,统计男性和女性员工的数量
select gender,count(*) from tb_emp group by gender;
(2)先查询入职时间在’2015-01-01’(包含)以前的员工,并对结果根据职位分组,获取员工数量大于等于2的职位。
select job,count(*) from tb_emp where entrydate <= '2015-01-01' group by job having count(*) >=2;
排序查询
select 字段列表 from 表名 [where 条件列表] [group by 分组字段] order by 字段1 排序方式1,字段2 排序方式2...;
ASC:升序(默认值)
DESC:降序
若是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序。
例子:表tb_emp中入职时间entrydate,更新时间update_time
(1)根据 入职时间 对公司的员工进行 升序排序, 入职时间相同的,再按照 更新时间 进行降序排序。
select * from tb_emp order by entrydate, update_time desc;
分页查询
select 字段列表 from 表名 limit 起始索引,查询记录数;
起始索引从0开始,起始索引=(查询页码-1)*每页显示记录数。
分页查询是数据库的方言,不同数据库有不用的实现,MySQL中是limit.
若查询的是第一页数据,起始索引可以省略,直接简写成limit10.
例子:在表tb_emp中操作:
(1)从 起始索引0 开始查询员工数据,每页展示5条记录
select * from tb_emp limit 0,5;
(2)查询 第2页 员工数据,每页展示5条记录
select * from tb_emp limit 5,5;
多表设计
有一对一,一对多,多对多
一对多
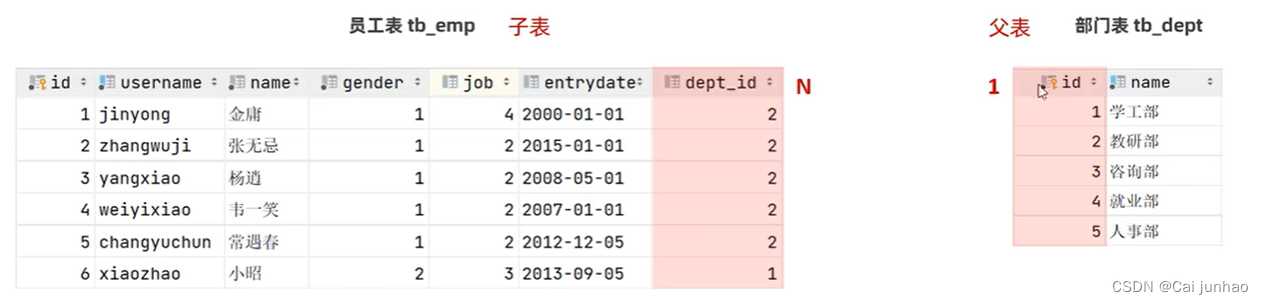
目前上述的两个表,在数据库层面,并未建立关联,所以是无法保证数据的一致性和完整性的。
外键约束
--创建表时指定
create table 表名(字段名 数据类型,...[constraint] [外键名称] foreign key [外键字段名] references 主表(字段名)
);--建完表后,添加外键
alter table 表名 add constraint 外键名 foreign key (外键字段名) references 主表(字段名);
物理外键:使用foreign key定义外键关联另一张表
缺点:影响增删改的效率(需要检查外键关系);仅用于单节点数据库,不适用于分布式、集群场景;容易引发数据库的死锁问题,消耗性能。
逻辑外键:在业务层中,解决外键关联
(推荐!!!)
一对一
多用于单表拆分,将一张表的基础字段放在一张表中,其他字段放在另一张表中,以提高效率.
实现:在任意一方加入外键,关联另一方的逐渐,并且设置外键为唯一的(unique)
案例:用户 与 身份证信息 的关系

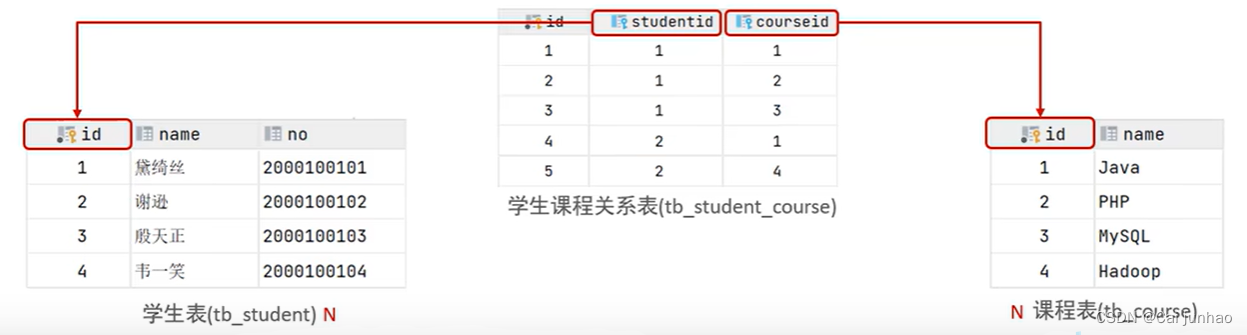
多对多
案例:学生 与 课程 的关系
关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择
实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
设计步骤
(1)分析各个模块涉及到的表结构,及表结构之间的关系
(2)分析各个表结构中的具体字段及约束
多表查询
概述
多表查询:从多张表中查询数据
笛卡尔积:两个集合的所有组合情况(在多表查询时,需要消除无效的笛卡尔积)
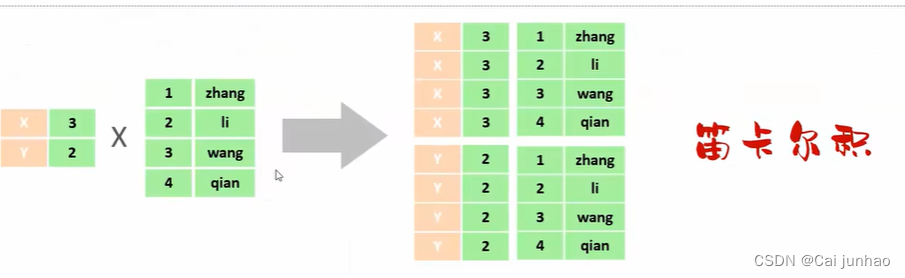
分类:内连接 和 外连接(左外连接和右外连接)
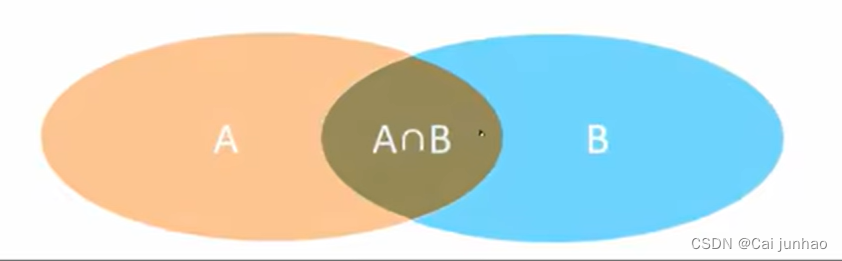
内连接
相当于查询A、B交际部分数据
隐式内连接:select 字段列表 from 表1,表2 where 条件...;
显式内连接:select 字段列表 from 表 [inner] join 表2 on 连接条件;
例子:表tb_emp有员工姓名name,员工的部门编号dept_id ; 表tb_dept有部门名称name,部门编号id
(1)查询员工的姓名,及所属的部门名称(隐式内连接实现)
select tb_emp.name,tb_dept.name
from tb_em,tb_dept
where tb_emp.dept_id=tb_dept.id;-- 起别名
select e.name, d.name
from tb_emp e, tb_dept d
where e.dept_id=d.id;
(2)查询员工的姓名,及所属的部门名称(隐式外连接实现)
select tb_emp.name,tb_dept.name
from tb_emp
inner join tb_dept on tb_emp.dept_id=tb_dept.id;
外连接
左外连接:select 字段列表 from 表1 [outer] join 表2 on 连接条件;
右外连接:select 字段列表 from 表1 [outer] join 表2 on 连接条件;
例子:表tb_emp有员工姓名name,员工的部门编号dept_id; 表tb_dept有部门名称name,部门编号id
(1)查询员工表 所有 员工的姓名,和对应的部门名称(左外连接)
select e.name,d.name
from tb_emp e
left join tb_dept d on e.dept_id=d.id;
(2)查询部门表 所有 部门的名称,和对应的员工名称(右外连接)
select e.name,d.name
from tb_emp e
right join tb_dept d on e.dept_id=d.id;
--等同于
select e.name,d.name
from tb_dept d
left join tb_emp e on e.dept_id=d.id;
子查询
又称嵌套查询,其外部的语句可以是insert/ update/ delete/ select的任何一个,最常见的是select。
select * from t1 where column1 = (select column from t2 ...);
分类:
(1)标量子查询:子查询返回的结果为单个值
(2)列子查询:子查询返回的结果为一列
(3)行子查询:子查询返回的结果为一行
(4)表子查询:子查询返回的结果为多行多列
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式
常用的操作符:= <> > >= < <=
例子:表tb_dept中有部门名name,部门ID id; 表tb_emp中有入职信息entrydate
(1)查询“教研部”所有员工信息
-- a.查询 教研部 的部门ID - tb_dept
select id from tb_dept where name = '教研部';
-- b.再查询该部门ID下的员工信息 -tb_emp
select * from tb_emp where dept_id = (select id from tb_dept where name = '教研部';)
(2)查询在“方东白”入职之后的员工信息
-- a.查询 方东白 的入职时间
select entrydate from tb_emp where name = '方东白';
-- b.查询在“方东白”入职之后的员工信息
select * from tb_emp where entrydate > (select entrydate from tb_emp where name = '方东白');
列子查询
子查询返回的结果是一列(可以是多行)
常用的操作符:in、not in等
例子:表tb_dept中有部门名name,部门ID id; 表tb_emp中有入职信息entrydate
(1)查询“教研部”和“咨询部”的所有员工信息
-- a.查询“教研部”和“咨询部”的部门ID -tb_dept
select id
from tb_dept
where name = '教研部' or name = '咨询部';-- b.根据部门ID,查询该部门下的员工信息 -tb_emp
select *
from tb_emp
where dept_id in (3,2);合并以上:
select * from tb_emp
where dept_id in (select id from tb_dept where name = '教研部' or name = '咨询部');
行子查询
子查询返回的结果是一行(可以是多列)
常见的操作符:= <> in not in
例子:表tb_dept中有部门名name,部门ID id; 表tb_emp中有员工姓名name,入职信息entrydate,职位编号job
(1)查询与“韦一笑”的入职日期 及 职位都相同的员工信息
-- a.查询“韦一笑”的入职信息 及职位
select entrydate, job
from tb_emp
where name = '韦一笑';
-- b.查询与其入职信息 及 职位都相同的员工信息
select *
from tb_emp
where entrydate = '2007-01-01' and job = 2;
或
select *
from tb_emp
where (entrydate,job) = ('2007-01-01',2);合并:
select * from tb_emp
where entrydate = (select entrydate from tb_emp where name = '韦一笑') and job = (select job from tb_emp where name = '韦一笑' );
或
select * from tb_emp
where (entrydate,job) = (select entrydate, job from tb_emp where name = '韦一笑');
表子查询
子查询返回的结果是多行多列,常常作为临时表
常用的操作符:in
例子:表tb_dept中有部门名name,部门ID id; 表tb_emp中有员工姓名name,入职信息entrydate,职位job,部门ID dept_id
(1)查询入职时间是"2006-01-01"之后的员工信息 及其部门名称
-- a.查询入职时间是"2006-01-01"之后的员工信息
select *
from tb_emp
where entrydate > '2006-01-01';
-- b.查询这部分员工信息及其部门名称
select e.*,d.name
from tb_dept e,tb_dept d
where e.dept_id=d.id;-- 合并得:
select e.*,d.name
from (select * from tb_emp where entrydate > '2006-01-01');
案例
如下为四张表及其对应关系
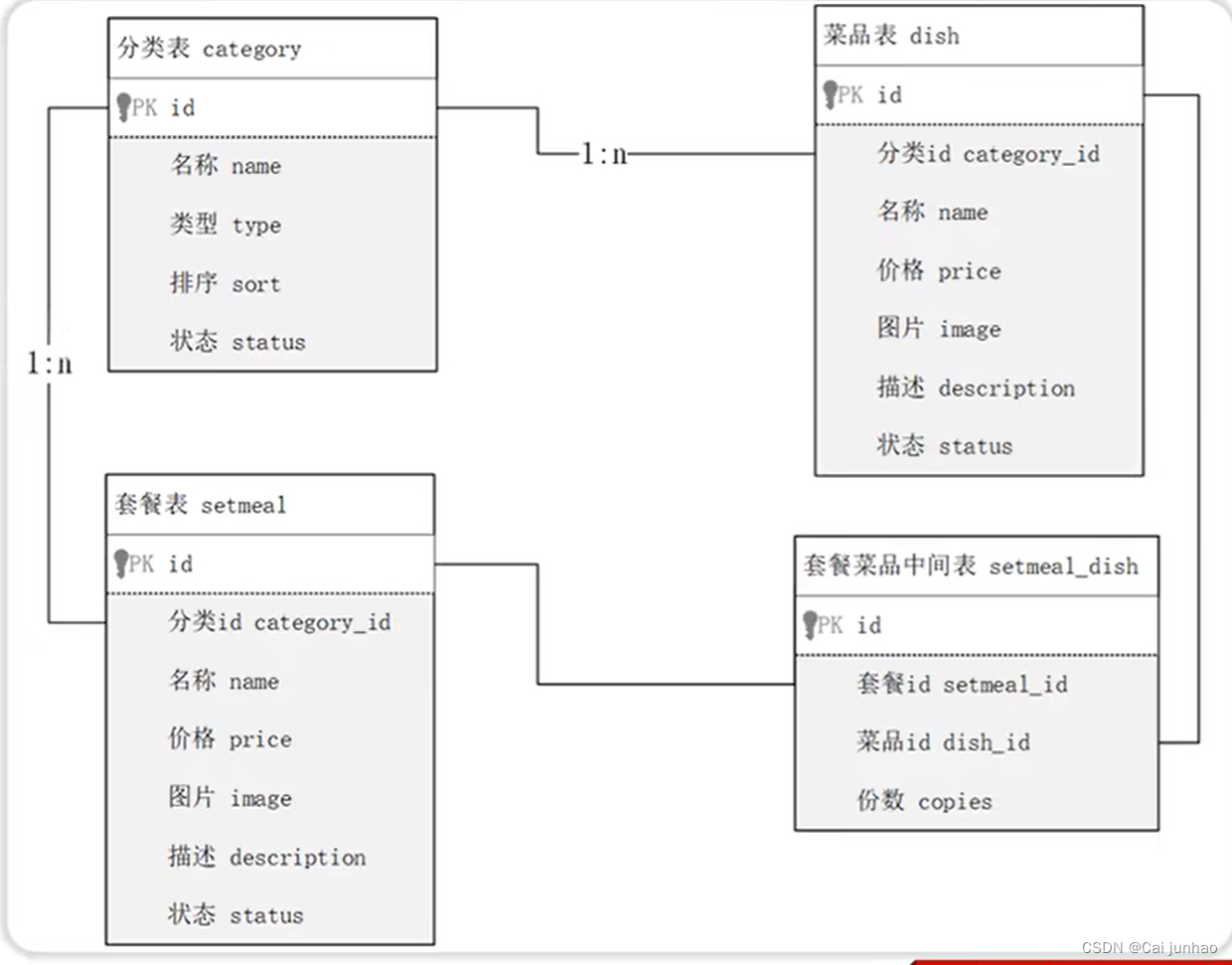
(1)查询价格低于 10元 的菜品的名称、价格 及其 菜品的分类名称
select d.name,d.price,c.name
from dish d,category c
where d.category_id=c.id and d.price<10;
(2)查询所有价格在 10元(含)到50元(含)之间 且 状态为“起售”(为1)的菜品,展示出菜品的名称、价格 及其 菜品的分类名称(即使菜品没有分类,也需要将菜品查询出来)
select d.name, d.price c.name
from dish d
left join category c on c.id = d.category_id
where d.price between 10 and 50
and d.status = 1
(3)查询每个分类下最贵的菜品,展示出分类的名称、最贵的菜品的价格
select c.name,max(d.price)
from dish d,category c
where c.id=d.category_id
group by c.name;
(4)查询各个分类下 菜品状态为“起售”(为1),并且 该分类下菜品总数量大于等于3 的分类名称
select c.name,count(*)
from category c,dish d
where d.category_id = c.id and d.status = 1
group by c.name
having count(*)>=3
(5)查询出"商务套餐A"中包含了哪些菜品(展示出套餐名称、价格,包含的菜品名称、价格、份数)
select s.name, s.price, d.name, d.price, sd.copies
from setmeal s , dish d, setmeal_dish sd
where s.id=sd.setmeal_id and sd.dish_id = d.id and s.name='商务套餐A';
(6)查询出低于平均价格的菜品信息(展示出菜品名称、菜品价格)
-- a.查询出平均价格
select avg(price)
from dish;-- b.查询菜品信息
select * from dish
where price < (select avg(price) from dish);
事务
场景:学工部 整个部门都解散了,该部门及其部下的员工都需要删除
操作:
删除学工部:delete from tb_dept where id=1;
删除学工部的员工:delete from tb_emp where dept_id =1;
问题:
若删除部门成功了,删除该部门员工时失败了,就造成了数据的不一致。
概念:是一组操作的集合,是不可分割的工作单位。
事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败
语法
开启事务:start transaction; / begin;
提交事务:commit
回滚事务:rollback
则场景的代码可改为:
start transaction;
delete from tb_dept where id=1;
delete from tb_emp where dept_id =1;
commit;
rollback;
commit类似crtl+s保存;rollback类似ctrl+z撤销
注意:MySQL的事务是自动提交的,即当执行一条DML语句,MySQL会立即隐式的提交事务。
四大特性(ACID)
原子性(Atomicity):不可分割的最小单元,要么全部成功,要么全部失败
一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态
隔离性(Isolation):在不受外部并发操作影响的独立环境下运行
持久性(Durability):一旦提交或回滚,对数据库中的数据的改变时永久的。
索引
概念:帮助数据库高效获取数据 的 数据结构
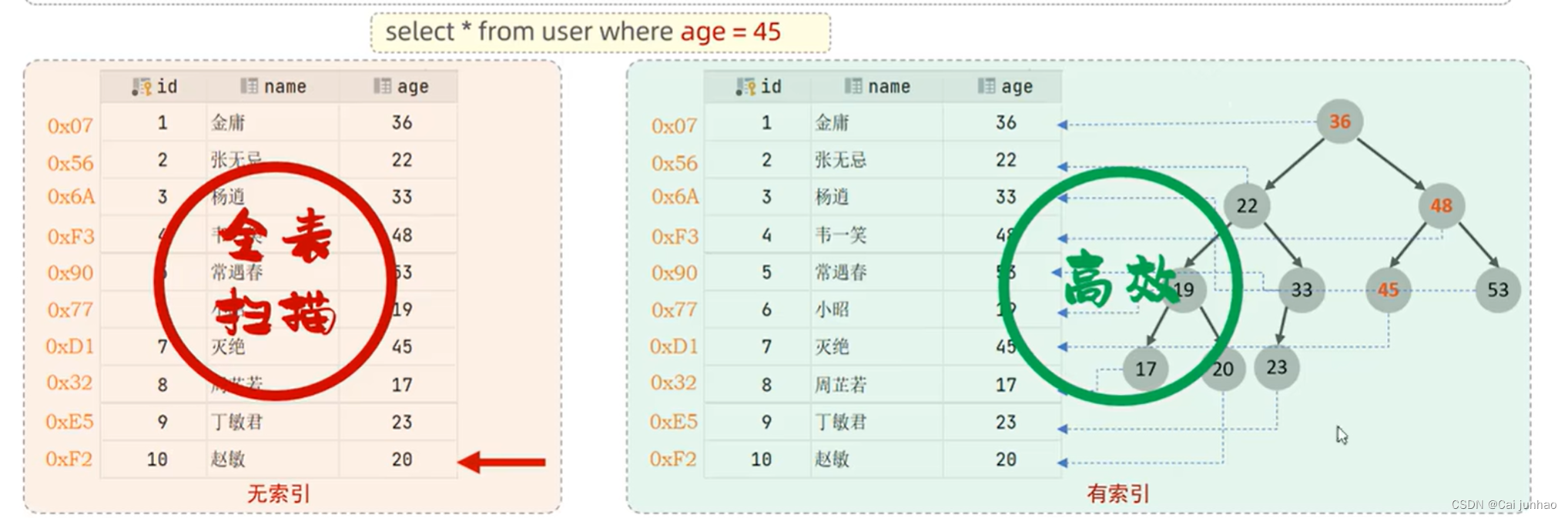
优点:提高数据查询的效率,降低数据库的IO成本;通过索引对数据进行排序,降低数据排序的成本,降低CPU消耗
缺点:索引会占用存储空间;大大提高了查询效率,同时也降低了insert,update,delete的效率
空间换时间
结构
一般是指B+ Tree结构组织的索引。
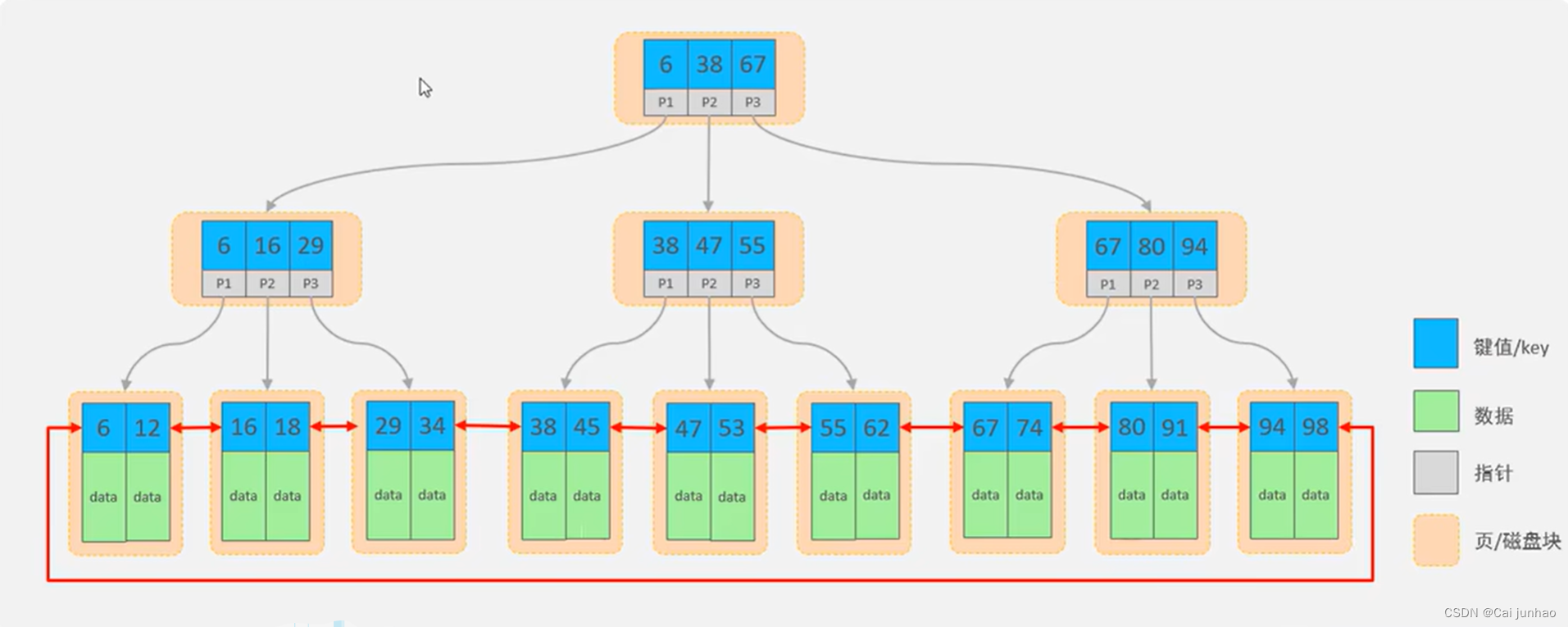
1.每个节点,可以存储多个key(有n个key,就有n个指针)
2.所有的数据都存储在叶子节点,非叶子节点仅用于索引数据。
3.叶子节点形成了一颗双向链表,便于数据的排序及区间范围查询。
语法
创建索引:create [unique] index 索引名 on 表名(字段名...);
查看索引:show index from 表名;
删除索引:drop index 索引名 on 表名;
注意:
主键字段,在建表时,会自动创建主键索引
添加唯一约束时,数据库实际上会添加唯一索引
例子:
为tb_emp表的name字段建立一个索引
create index idx_emp_name on tb_name(name);
相关文章:
【数据库】MySQL
文章目录 概述DDL数据库操作查询使用创建删除 表操作创建约束MySqL数据类型数值类型字符串类型日期类型 查询修改删除 DMLinsertupdatedelete DQL基本查询条件查询分组查询分组查询排序查询分页查询 多表设计一对多一对一多对多设计步骤 多表查询概述内连接外连接 子查询标量子…...

JVM运行时内存:垃圾回收器(Serial ParNew Parallel )详解
文章目录 1. 查看默认GC2. Serial GC : 串行回收3. ParNew GC:并行回收4. Parallel GC:吞吐量优先 1. 查看默认GC -XX:PrintCommandLineFlags:查看命令行相关参数(包含使用的垃圾收集器)使用命令行指令:ji…...
The Missing Semester of Your CS Education(计算机教育中缺失的一课)
Shell 工具和脚本(Shell Tools and Scripting) 一、shell脚本 1.1、变量赋值 在bash中为变量赋值的语法是foobar,访问变量中存储的数值,其语法为 $foo。 需要注意的是,foo bar (使用空格隔开)是不能正确工作的&…...

如何为ChatGPT编写有效的提示词:软件开发者的指南
作为一名软件开发者,特别是使用Vue进行开发的开发者,与ChatGPT等AI助手高效互动,可以极大地提升你的开发效率。本文将深入探讨如何编写有效的提示词,以便从ChatGPT中获取有用的信息和帮助。 1. 明确目标 在编写提示词之前&#…...

angular插值语法与属性绑定
在 Angular 中,您提供的两种写法都是用来设置 HTML 元素的 title 属性,但它们的工作方式有所不同: 插值语法 (Interpolation) <h1 title"{{ name }}">我的名字</h1> 属性绑定 (Property Binding) <h1 [title]&q…...

Python ❀ 使用代码解决今天中午吃什么的重大生存问题
1. 环境安装 安装Python代码环境参考文档 2. 代码块 import random# 准备一下你想吃的东西 hot ["兰州拉面", "爆肚面", "黄焖鸡", "麻辣香锅", "米线", "麻食", "羊肉泡馍", "肚丝/羊血汤&qu…...
做抖音小店需要清楚的5个核心点!
大家好,我是喷火龙。 不管你是在做抖音小店,还是在做其他的电商平台,如果已经做了一段时间了,但还是没有拿到什么结果,我所指的结果不是什么大结果,而是连温饱都解决不了,甚至说还在亏钱。 有…...

文件流下载优化:由表单提交方式修改为Ajax请求
如果想直接看怎么写的可以跳转到 解决方法 节! 需求描述 目前我们系统导出文件时,都是通过表单提交后,接收文件流自动下载。但由于在表单提交时没有相关调用前和调用后的回调函数,所以我们存在的问题,假如导出数据需…...

基础3 探索JAVA图形编程桌面:逻辑图形组件实现
在一个宽敞明亮的培训教室里,阳光透过窗户柔和地洒在地上,教室里摆放着整齐的桌椅。卧龙站在讲台上,面带微笑,手里拿着激光笔,他的眼神中充满了热情和期待。他的声音清晰而洪亮,传遍了整个教室:…...
前后端部署笔记
windows版: 如果傻呗公司让用win电脑部署,类似于我们使用笔记本做局域网服务器,社内使用。 1.安装win版的nginx、mysql、node、jdk等 2.nginx开机自启参考Nginx配置及开机自启动(Windows环境)_nginx开机自启动 wind…...
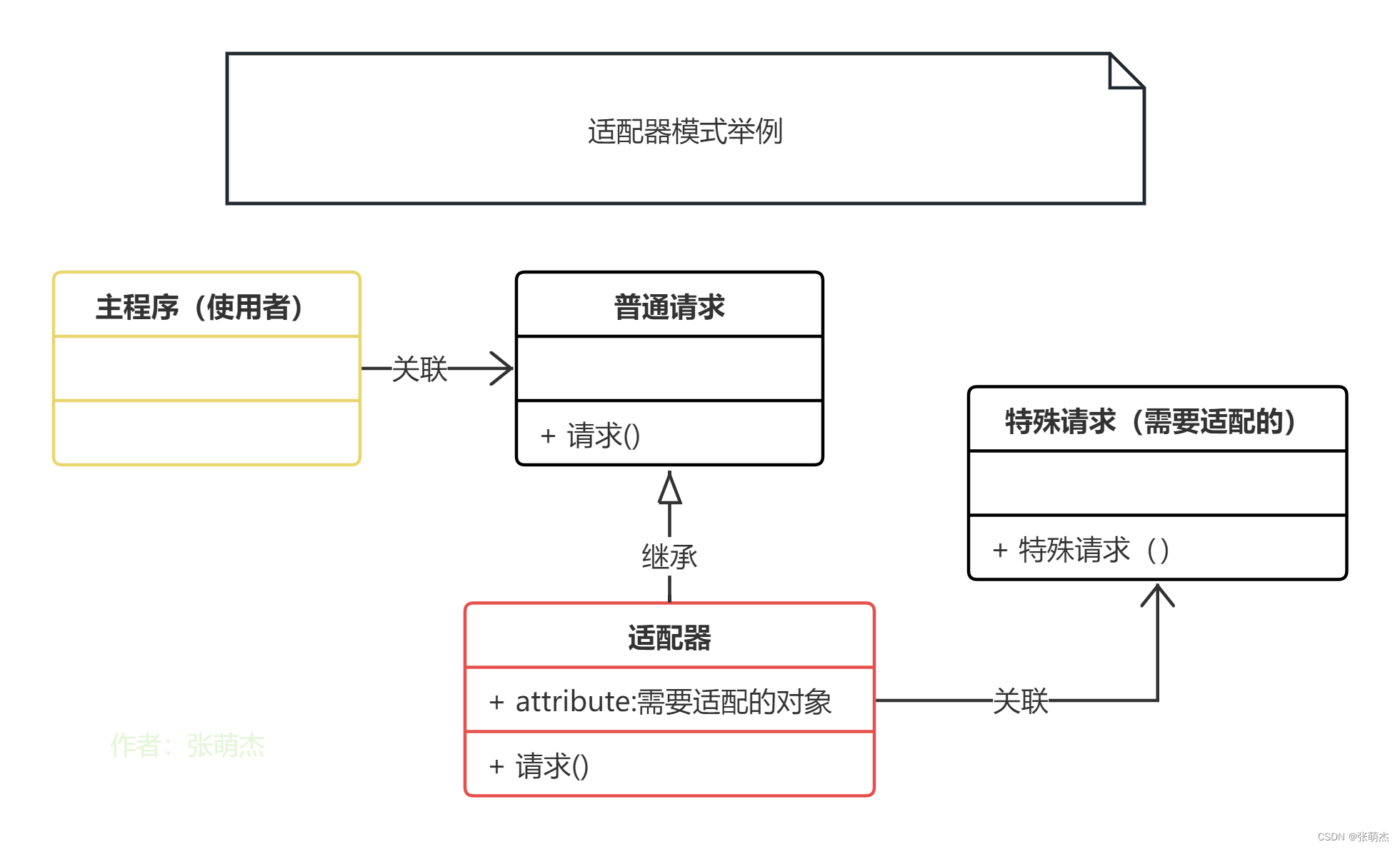
设计模式9——适配器模式
写文章的初心主要是用来帮助自己快速的回忆这个模式该怎么用,主要是下面的UML图可以起到大作用,在你学习过一遍以后可能会遗忘,忘记了不要紧,只要看一眼UML图就能想起来了。同时也请大家多多指教。 适配器模式(Adapte…...

一文了解基于ITIL的运维管理体系框架
本文来自腾讯蓝鲸智云社区用户:CanWay ITIL(Information Technology Infrastructure Library)是全球最广泛使用的 IT 服务管理方法,旨在帮助组织充分利用其技术基础设施和云服务来实现增长和转型。优化IT运维,作为企业…...

Web前端开发技术-格式化文本 Web页面初步设计
目录 Web页面初步设计 标题字标记 基本语法: 语法说明: 添加空格与特殊符号 基本语法: 语法说明: 特殊字符对应的代码: 代码解释: 格式化文本标记 文本修饰标记 计算机输出标记 字体font标记 基本语法: 属…...
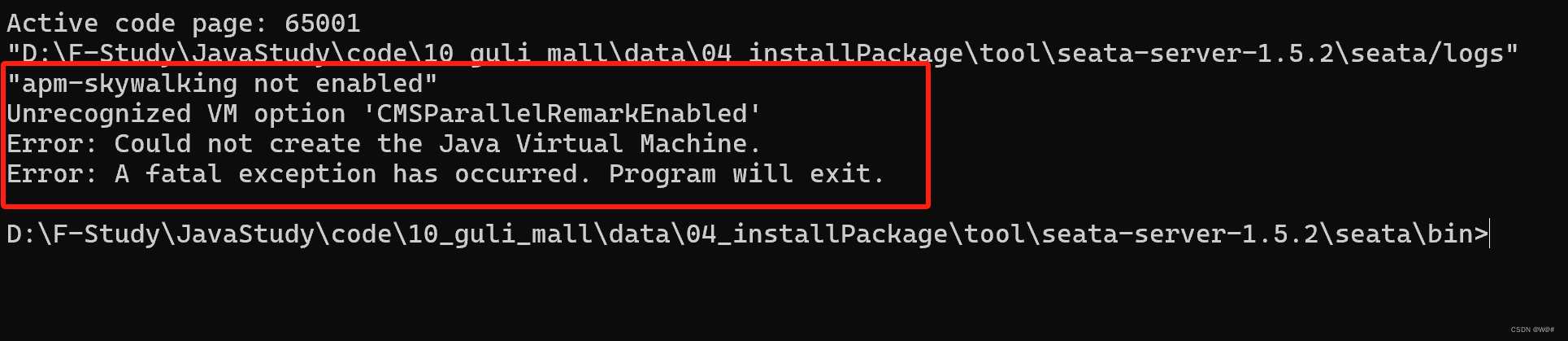
Windows下部署Seata1.5.2,解决Seata无法启动问题
目录 1. 版本说明 2. Windows下部署Seata1.5.2 2.1 创建回滚日志表undo_log 2.2 创建Seata服务端需要的四张表 2.3 在nacos创建seata命名空间,添加seataServer.yml配置 2.4 修改本地D:/tool/seata-server-1.5.2/seata/conf/applicaltion.yml文件 2.5 启动Seat…...

我加入了C++交流社区
最近,我决定加入了一个C交流社区,这是一个专注于C编程语言的在线平台。加入这个社区的初衷是为了提升我的编程技能,与其他对C感兴趣的人交流经验和知识。 加入这个社区后,我发现了许多有趣的讨论和资源。每天都有各种各样的话题&…...

Vue从入门到实战Day11
一、为什么要学Vue3 Vue3官网:简介 | Vue.js 1. Vue3的优势 2. Vue2选项式API vs Vue3组合式API 示例: 二、create-vue搭建Vue3项目 1. 认识create-vue create-vue是Vue官方新的脚手架工具,底层切换到了vite(下一代构建工具),为…...
day15|各种遍历的应用
相关题目: 层次遍历会一打十 反转二叉树 对称二叉树 层次遍历会一打十 自底向上的层序遍历 实现思路:层次遍历二叉树,将遍历后的结果revers即可 public List<List<Integer>> levelOrderBottom(TreeNode root) {List<List&l…...

第12周作业--HLS入门
目录 一、HLS入门 二、HLS入门程序编程 创建项目 1、点击Vivado HLS 中的Create New Project 2、设置项目名 3、加入文件 4、仿真 3、综合 一、HLS入门 1. HLS是什么?与VHDL/Verilog编程技术有什么关系? HLS(High-Level Synthesis,…...

WorkManager使用技巧及各Android版本适配
WorkManager使用技巧及各Android版本适配 WorkManager是Android Jetpack中用于处理异步任务的库,它能够保证任务即使在应用关闭或设备重启后也能被执行。以下是WorkManager的使用技巧和代码示例,以及不同Android版本的适配方法。 1. 初始化WorkManager…...

鼠标滚轮使用时上下跳动的解决方法
前阵子鼠标滚轮使用时总会出现上下跳动比如向下滚动会往上反弹或者是在当前框架卡住但颤动的情况,这个问题困扰了我很久,试过了很多设置和驱动方面的办法都没解决,因此大概率是滚轮那有脏东西了。最后终于在一个答复下面看到了一种不用拆开修…...

ANI-RSS自定义扩展技术深度解析:架构设计与高级定制方案
ANI-RSS自定义扩展技术深度解析:架构设计与高级定制方案 【免费下载链接】ani-rss 基于RSS自动追番、订阅、下载、刮削、洗版 项目地址: https://gitcode.com/gh_mirrors/an/ani-rss ANI-RSS作为一款基于RSS的自动化追番解决方案,其技术架构提供了…...

企业级应用如何利用Taotoken实现多模型灾备与负载均衡
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何利用Taotoken实现多模型灾备与负载均衡 1. 场景与挑战 在企业级应用中,大模型API的调用已成为许多核心…...

5分钟搞定RK3588开发板Ubuntu系统:从零到完美的终极配置指南
5分钟搞定RK3588开发板Ubuntu系统:从零到完美的终极配置指南 【免费下载链接】ubuntu-rockchip Ubuntu for Rockchip RK35XX Devices 项目地址: https://gitcode.com/gh_mirrors/ub/ubuntu-rockchip 还在为RK3588开发板的系统安装头疼吗?别担心&a…...

Irony Mod Manager:终极Paradox游戏模组冲突解决方案完全指南
Irony Mod Manager:终极Paradox游戏模组冲突解决方案完全指南 【免费下载链接】IronyModManager Mod Manager for Paradox Games. Official Discord: https://discord.gg/t9JmY8KFrV 项目地址: https://gitcode.com/gh_mirrors/ir/IronyModManager 你是否曾经…...

* LangChain4j中的会话记忆ChatMemory
在构建 AI 志愿填报顾问时,一个很自然的期望是它能记住我们之前聊过什么,而不是每次都像第一次见面一样。大模型本身是无状态的,每次调用都是独立的,要实现“记忆”,唯一的方法就是把聊天历史连同新问题一起发给模型。…...

2026 年 AI 工具聚合站:从模型入口到开发基础设施的进化之路
在 2026 年的 AI 开发生态中,开发者正面临一个矛盾的现状:一方面是 GPT-5.5、Claude 4.7、Gemini 3.1 等大模型的能力持续突破,带来了前所未有的技术红利;另一方面,模型碎片化、接口异构化、成本高企等问题,…...

Windows平台苹果USB网络共享驱动自动化部署方案
Windows平台苹果USB网络共享驱动自动化部署方案 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh_mirrors/ap/Apple-Mob…...

【全新 v 2.7.5 版本】Open Claw 本地环境一键部署教程
前言 2026 年开源圈爆火的「数字员工」OpenClaw(昵称小龙虾),GitHub 星标狂揽 28 万 ,凭「本地运行 零代码操作 自动干活」的核心优势圈粉无数!很多人误以为它是普通聊天 AI,实则是能真正操控电脑的自动…...

如何快速一键获取Steam游戏清单?Onekey工具完整使用指南
如何快速一键获取Steam游戏清单?Onekey工具完整使用指南 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 你是否曾经为了获取Steam游戏的清单文件而花费大量时间查找App ID、配置解锁…...

BurpBounty配置文件完全解析:从API密钥到SQL注入检测
BurpBounty配置文件完全解析:从API密钥到SQL注入检测 【免费下载链接】BurpBounty Burp Bounty (Scan Check Builder in BApp Store) is a extension of Burp Suite that allows you, in a quick and simple way, to improve the active and passive scanner by mea…...