爬虫基础1
一、爬虫的基本概念
1.什么是爬虫?
请求网站并提取数据的自动化程序
2.爬虫的分类
2.1 通用爬虫(大而全)
功能强大,采集面广,通常用于搜索引擎:百度,360,谷歌
2.2 聚焦爬虫,主题爬虫(小而精)
功能相对单一(只针对特定的网站的特定内容进行爬取)
2.3增量式爬虫(只采集更新后的内容)
爬取更新后的内容,新闻,漫画,视频…(区分新老数据)
3.ROOT协议
什么是robots协议?
3.1 Robots协议的全称是"网络爬虫排除标准" (Robots Exclusion Protocol),简称为Robots协议。
3.2 Robots协议的一个很重要作用就是网站告知爬虫哪些页面可以抓取,哪些不
行。君子协定:指代的是口头上的协议,如果爬取了,可能会出现法律纠纷(商用).
二、爬虫的基本流程
1.发起请求
通过HTTP库向目标站点发起请求,即发起一个Request,请求可以包含额外的headers信息,等待服务器响应。
2.获取响应内容
如果服务器能正常响应,会得到一个Response,Response的内容便是索要获取的页面内容,类型可能有HTML,Json字符串,二进制数据(如图片视频)等类型
3.解析内容
得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析,可能是Json,可以直接转为Json对象解析,可能是二进制数据,可能做保存或进一步处理
4.保存数据
保存形式多样,可以保存为文本,也可保存至数据库或者保存特定格式的文件
三、Request和Response
1.浏览器就发送消息给该网址所在的服务器,这个过程叫做HTTP Request。
2.服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应处理,然
后把消息回传给浏览器。这个过程叫做HTTP Response。
3.浏览器收到服务器的Response信息后,会对信息进行相应处理,然后展示。
4.Request
4.1 主要有GET、POST两种类型
4.2 URL全称统一资源定位符,如一个网页文档、一张图片、一个视频等都可
以用URL唯一来确定。
4.3 包含请求时的头部信息,如User-Agent、Host、Cookies等信息。
4.4 请求时额外携带的数据如表单提交时的表单数据。
5.Reponse
5.1 响应状态
有多种响应状态,如200代表成功、301跳转、404找不到页面、502服务器错误
5.2 响应头
如内容类型、内容长度、服务器信息、设置Cookie等等。
5.3 响应体
最主要的部分,包含了请求资源的内容, 如网页HTML、图片二进制数据等。
注意:在监测的时候用Ctrl+F调出搜索框
四、Requests模块
作用:发送网络请求,或得响应数据
开源地址:https://github.com/kennethreitz/requests![]() https://github.com/kennethreitz/requests
https://github.com/kennethreitz/requests
安装: pip install requests -i https://pypi.douban.com/simple/
中文文档 API: http://docs.python-requests.org/zh_CN/latest/index.html![]() http://docs.python-requests.org/zh_CN/latest/index.html
http://docs.python-requests.org/zh_CN/latest/index.html
官方文档: Requests: 让 HTTP 服务人类 — Requests 2.18.1 文档![]() https://requests.readthedocs.io/projects/cn/zh-cn/latest/
https://requests.readthedocs.io/projects/cn/zh-cn/latest/
1.Requests请求
只能得到一个包的数据
url = 'https://www.baidu.com/'
response = requests.get(url)
print(response)#返回的是一个响应体对象print(response.text)#获取响应体内容print(response.status_code)#响应状态码Get请求
url = 'https://httpbin.org/get'#url = 'https://httpbin.org/get?age=18&&name=zhangsan'data = {'name':'zhangsan','age':19}response = requests.get(url,params=data)#params携带get请求的参数进行传参print(response.text)Post请求
rl = 'https://httpbin.org/post'data = {'name':'zhangsan','age':19}response = requests.post(url,data=data)#data:携带post请求需要的表单数据,在form里面形成print(response.text)自己理解:
对于Get来说,主要在网址输入时即输入URL的时候用到,而POST则是在网页里面,比如翻译时的单词输入等
获取Json数据
url = 'https://httpbin.org/get'result = requests.get(url)result_data = result.json()print(result_data)print(type(result_data))会发现Py里面的Json数据就是字典类型
获取二进制据数据
url = 'https://b.bdstatic.com/searchbox/icms/searchbox/img/ci_boy.png'result = requests.get(url)#print(result.text) #二进制数据转文本会显示乱码,strprint(result.content)#会发现是以b开头的bite类型二进制数据,bytesdata = result.contentwith open('TuPian.png','wb') as f: #wb是写入二进制f.write(data)初步伪装小爬虫——添加headers
浏览器用户身份的标识,缺少的话服务器会认为你不是一个正常的浏览器用户,而是一个爬虫程序
User-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0
import requestsimport fake_useragentua = fake_useragent.UserAgent()ua_fake = ua.chromeurl = 'https://www.jianshu.com/'headers = {#'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0''User-Agent':ua_fake}result = requests.get(url,headers = headers)print(result.text)会话维持
例如爬取简书的收藏的时候,如果不登陆就无法爬取,可以在headers里面增加cookie内容即可,但要注意的是cookie有对应的时间
import requestsimport fake_useragentua = fake_useragent.UserAgent()ua_fake = ua.chromeurl = 'https://www.jianshu.com/'headers = {#'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0''User-Agent':ua_fake,'cookie':''}result = requests.get(url,headers = headers)print(result.text)代理
import requestsp = {'http':'120.41.143.139:21037','https':'120.41.143.139:21037',
}url = 'https://www.jianshu.com/'headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'}result = requests.get(url,headers = headers,proxies=p)print(result.text)注意的是这里的ip无效,后面继续展开
五、正则表达式
1.正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特殊字符以及这些特殊字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种逻辑过滤
2.非Python独有
3.Python里面是使用re模块来实现的,不需要额外进行安装,是内置模块
常见匹配模式
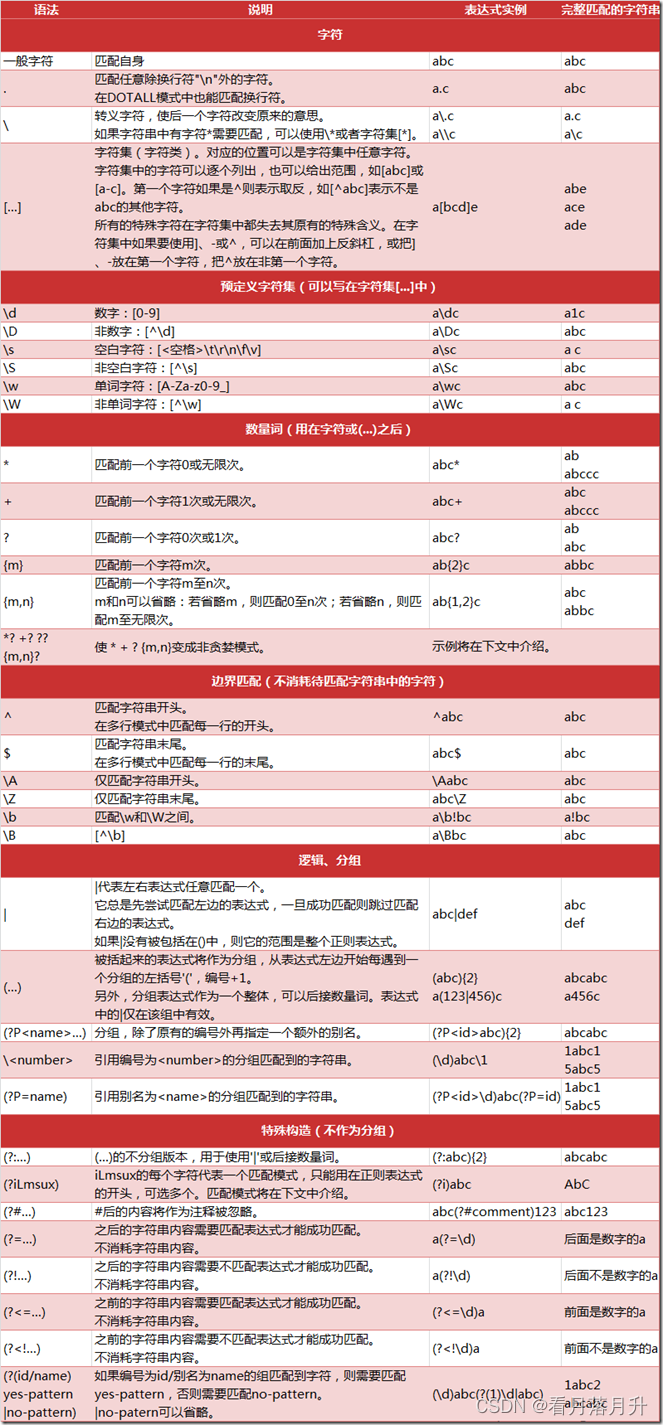
re.match()方法的使用
import re#content = 'Hello 123 456789 World_This is a Regex Demo'#re.match('正则表达式','目标字符串')#result = re.match('Hello\s\d\d\d\s\d{6}\s\w{10}',content)#print(result.group())#result = re.match('H.*Demo',content)#result = re.match('Hello\s(\d{3})\s(\d{6})',content)#print(result.group(1)) #这里0表示最先出现的括号,1表示第二次出现的括号#print(result.group(1,2)) #这是一个元组,后面处理较麻烦#content = 'Hello 123456789 World_This is a Regex Demo'#result = re.match('He.*(\d+).*Demo',content)#因为贪婪模式的存在,在He之后,Demo之前至少有一个数字字符,即9#print(result.group(1)) #打印的为9#加上?后,即为非贪婪#result = re.match('He.*?(\d+).*Demo',content)#print(result.group(1))#content = """Hello 123456789#World_This# is a Regex# Demo"""#result = re.match('He.*?(\d+).*Demo',content,re.S)#re.S忽略换行符#print(result.group())#\转义符,如果对\转义,则需要两个\\,也可以直接写r,再接一个\#content = 'price is $9.99'#result = re.match('price\sis\s\$9.99',content) #$这个在正则表达式有自己的含义#print(result.group())search方法
search全文检索,返回满足表达式的第一个
#result = re.search('<a\s\href="/3.mp3"\ssinger="(.*)">(.*)</a>',html)#print(result.group(1))Findall方法
用一个大列表返回满足所有的正则表达式结果
#result = re.findall('<a\s\href="(.*)"\ssinger="(.*)">(.*)</a>',html)#for i in result:# print(i)Re.sub()
#re.sub('要替换的目标的正则表达式','想要将前面匹配到的数据替换成什么','目标字符串')#sub_html = re.sub('<i.*</i>','',html)#result = re.findall('<a\s\href="(.*)"\ssinger="(.*)">(.*)</a>',sub_html)#for i in result:# print(i)相关文章:
爬虫基础1
一、爬虫的基本概念 1.什么是爬虫? 请求网站并提取数据的自动化程序 2.爬虫的分类 2.1 通用爬虫(大而全) 功能强大,采集面广,通常用于搜索引擎:百度,360,谷歌 2.2 聚焦爬虫&#x…...
vlan综合实验
1、实验拓扑 2、实验要求 1、pc1和pc3所在接口为access;属于vlan 2; pc2/pc4/pc5/pc6处于同一网段;其中pc2可以访问pc4/pc5/pc6; pc4可以访问pc6;pc5不能访问pc6; 2、pc1/pc3与pc2/pc4/pc5/pc6不在同一网段; 3、所有pc通过DHC…...

如何使用ffmpeg 实现10种特效
相关特效的名字 特效id 特效名 1 向上移动 2 向左移动 3 向下移动 4 颤抖 5 摇摆 6 雨刷 7 弹入 8 弹簧 9 轻微跳动 10 跳动 特效展示(同时汇总相关命令) pad背景显示 pad背景透明 相关命令(一会再讲这些命令,先往下看) # 合成特效语音 ffmpeg -y -loglevel erro…...

C语言如果变量全部在全局内存空间会怎么样
结论先行 应该根据内存使用的生命周期,选择合适的内存空间应该尽量使用连续内存如果不想在设计封装性上付出太多代价,全部放入全局空间也比较可取 空间类型特点全局空间生命周期最久,空间连续,变量分配紧致,但存在浪…...
)
【YOLO改进】换遍MMPretrain主干网络之ConvNeXt-Tiny(基于MMYOLO)
ConvNeXt-Tiny ConvNeXt-Tiny 是一种改进的卷积神经网络架构,其设计目的是在保持传统卷积神经网络优势的同时,借鉴了一些Transformer架构的成功经验。 ConvNeXt-Tiny 的优点 架构优化: ConvNeXt-Tiny 对经典ResNet架构进行了多种优化&#…...
【数据库】MySQL
文章目录 概述DDL数据库操作查询使用创建删除 表操作创建约束MySqL数据类型数值类型字符串类型日期类型 查询修改删除 DMLinsertupdatedelete DQL基本查询条件查询分组查询分组查询排序查询分页查询 多表设计一对多一对一多对多设计步骤 多表查询概述内连接外连接 子查询标量子…...

JVM运行时内存:垃圾回收器(Serial ParNew Parallel )详解
文章目录 1. 查看默认GC2. Serial GC : 串行回收3. ParNew GC:并行回收4. Parallel GC:吞吐量优先 1. 查看默认GC -XX:PrintCommandLineFlags:查看命令行相关参数(包含使用的垃圾收集器)使用命令行指令:ji…...
The Missing Semester of Your CS Education(计算机教育中缺失的一课)
Shell 工具和脚本(Shell Tools and Scripting) 一、shell脚本 1.1、变量赋值 在bash中为变量赋值的语法是foobar,访问变量中存储的数值,其语法为 $foo。 需要注意的是,foo bar (使用空格隔开)是不能正确工作的&…...

如何为ChatGPT编写有效的提示词:软件开发者的指南
作为一名软件开发者,特别是使用Vue进行开发的开发者,与ChatGPT等AI助手高效互动,可以极大地提升你的开发效率。本文将深入探讨如何编写有效的提示词,以便从ChatGPT中获取有用的信息和帮助。 1. 明确目标 在编写提示词之前&#…...

angular插值语法与属性绑定
在 Angular 中,您提供的两种写法都是用来设置 HTML 元素的 title 属性,但它们的工作方式有所不同: 插值语法 (Interpolation) <h1 title"{{ name }}">我的名字</h1> 属性绑定 (Property Binding) <h1 [title]&q…...

Python ❀ 使用代码解决今天中午吃什么的重大生存问题
1. 环境安装 安装Python代码环境参考文档 2. 代码块 import random# 准备一下你想吃的东西 hot ["兰州拉面", "爆肚面", "黄焖鸡", "麻辣香锅", "米线", "麻食", "羊肉泡馍", "肚丝/羊血汤&qu…...
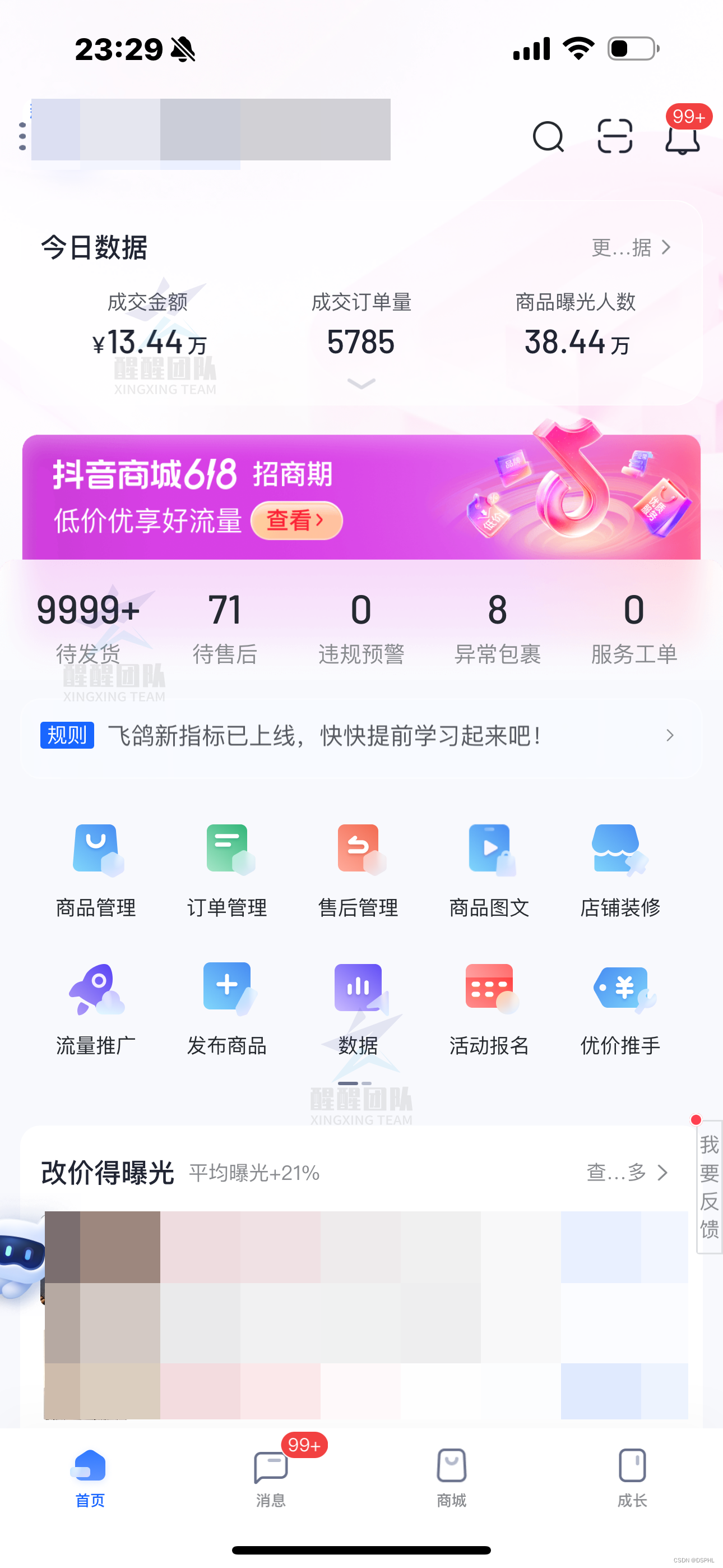
做抖音小店需要清楚的5个核心点!
大家好,我是喷火龙。 不管你是在做抖音小店,还是在做其他的电商平台,如果已经做了一段时间了,但还是没有拿到什么结果,我所指的结果不是什么大结果,而是连温饱都解决不了,甚至说还在亏钱。 有…...

文件流下载优化:由表单提交方式修改为Ajax请求
如果想直接看怎么写的可以跳转到 解决方法 节! 需求描述 目前我们系统导出文件时,都是通过表单提交后,接收文件流自动下载。但由于在表单提交时没有相关调用前和调用后的回调函数,所以我们存在的问题,假如导出数据需…...

基础3 探索JAVA图形编程桌面:逻辑图形组件实现
在一个宽敞明亮的培训教室里,阳光透过窗户柔和地洒在地上,教室里摆放着整齐的桌椅。卧龙站在讲台上,面带微笑,手里拿着激光笔,他的眼神中充满了热情和期待。他的声音清晰而洪亮,传遍了整个教室:…...
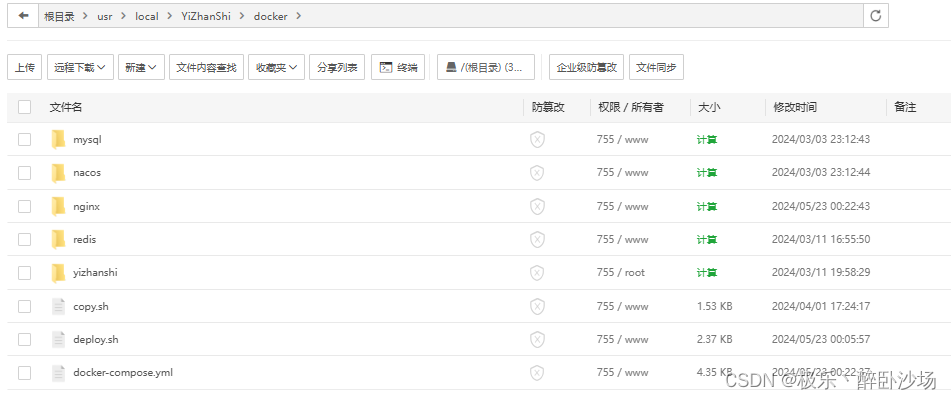
前后端部署笔记
windows版: 如果傻呗公司让用win电脑部署,类似于我们使用笔记本做局域网服务器,社内使用。 1.安装win版的nginx、mysql、node、jdk等 2.nginx开机自启参考Nginx配置及开机自启动(Windows环境)_nginx开机自启动 wind…...
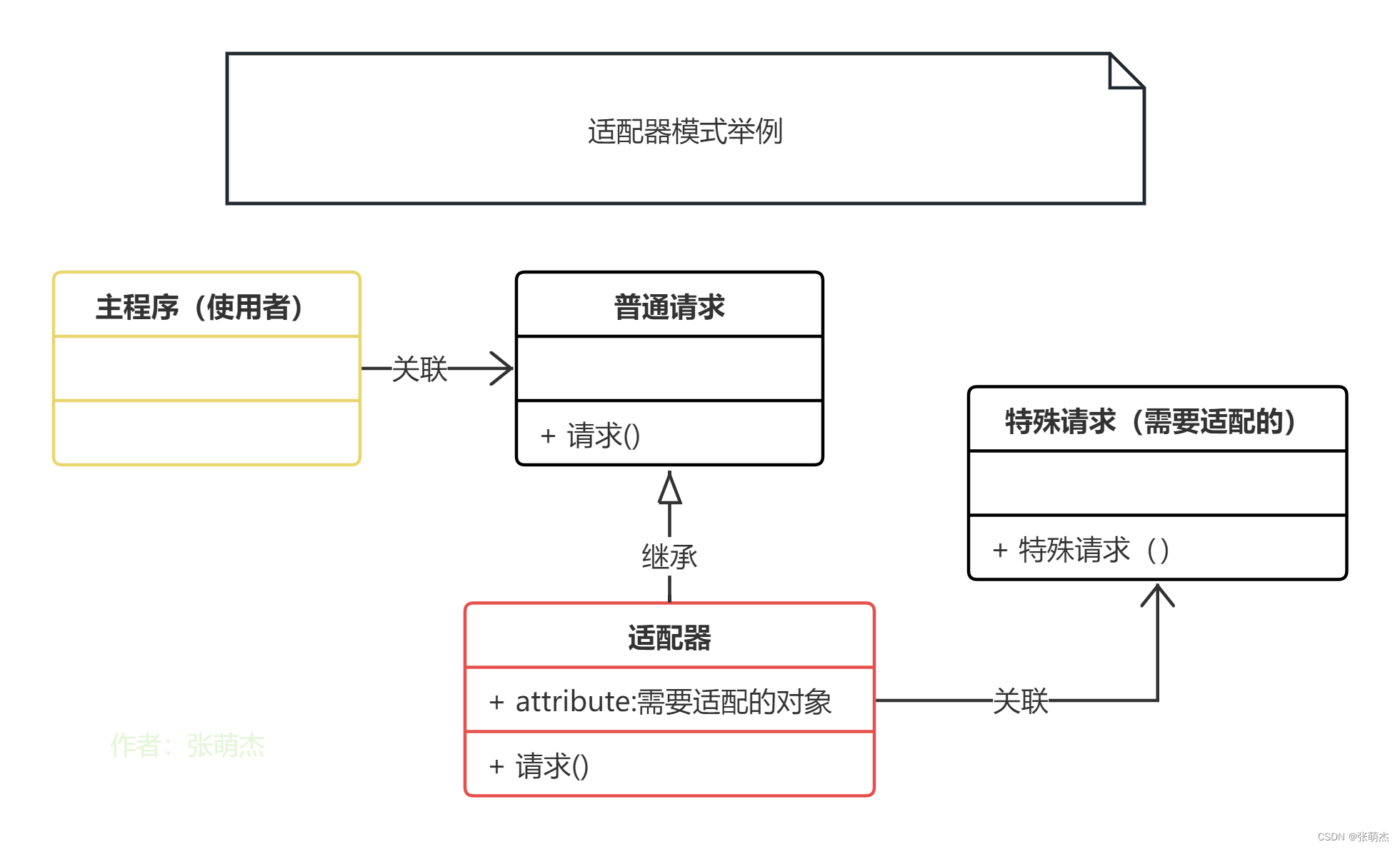
设计模式9——适配器模式
写文章的初心主要是用来帮助自己快速的回忆这个模式该怎么用,主要是下面的UML图可以起到大作用,在你学习过一遍以后可能会遗忘,忘记了不要紧,只要看一眼UML图就能想起来了。同时也请大家多多指教。 适配器模式(Adapte…...

一文了解基于ITIL的运维管理体系框架
本文来自腾讯蓝鲸智云社区用户:CanWay ITIL(Information Technology Infrastructure Library)是全球最广泛使用的 IT 服务管理方法,旨在帮助组织充分利用其技术基础设施和云服务来实现增长和转型。优化IT运维,作为企业…...

Web前端开发技术-格式化文本 Web页面初步设计
目录 Web页面初步设计 标题字标记 基本语法: 语法说明: 添加空格与特殊符号 基本语法: 语法说明: 特殊字符对应的代码: 代码解释: 格式化文本标记 文本修饰标记 计算机输出标记 字体font标记 基本语法: 属…...
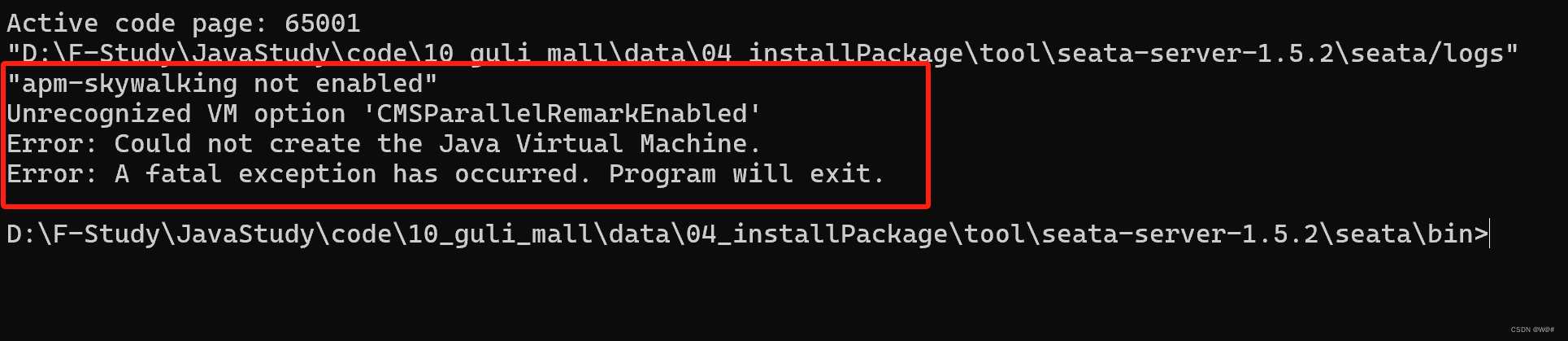
Windows下部署Seata1.5.2,解决Seata无法启动问题
目录 1. 版本说明 2. Windows下部署Seata1.5.2 2.1 创建回滚日志表undo_log 2.2 创建Seata服务端需要的四张表 2.3 在nacos创建seata命名空间,添加seataServer.yml配置 2.4 修改本地D:/tool/seata-server-1.5.2/seata/conf/applicaltion.yml文件 2.5 启动Seat…...

我加入了C++交流社区
最近,我决定加入了一个C交流社区,这是一个专注于C编程语言的在线平台。加入这个社区的初衷是为了提升我的编程技能,与其他对C感兴趣的人交流经验和知识。 加入这个社区后,我发现了许多有趣的讨论和资源。每天都有各种各样的话题&…...

Playwright×CoPilot:用自然语言驱动UI自动化的新范式
1. 这不是“写代码”,而是让AI替你“看屏幕、点按钮、填表单”“Playwright CoPilot:UI自动化的超级加速器”——这个标题里藏着一个正在悄悄改变测试和RPA工作流的事实:我们正从“手写定位器硬编码断言”的时代,跨入“用自然语言…...

3步解锁Beyond Compare 5专业版:Python密钥生成器终极指南
3步解锁Beyond Compare 5专业版:Python密钥生成器终极指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 还在为Beyond Compare 5的30天试用期而烦恼吗?想免费使用这款强…...

米哈游游戏字体库终极指南:轻松获取11款精美架空文字字体资源
米哈游游戏字体库终极指南:轻松获取11款精美架空文字字体资源 【免费下载链接】HoYo-Glyphs Constructed scripts by HoYoverse 米哈游的架空文字 项目地址: https://gitcode.com/gh_mirrors/ho/HoYo-Glyphs 想要为你的设计作品注入《原神》、《崩坏…...

插电式混合动力公交车工况预测与智能能量管理策略【附程序】
✨ 长期致力于插电式混合动力系统、行驶工况构建、工况预测、预测能量管理策略、智能能量管理策略研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)自组…...

基于微信小程序的疫苗预约管理系统的设计与实现
第1章 绪 论本章对疫苗预约管理系统的背景进行了研究和分析,并且对目前疫苗预约管理系统所存在的问题做了简单的分析,接着论述了选题的重要性以及现实意义,通过研究疫苗预约管理系统类系统的发展历程,给后面系统需求分析和设计打下…...

Appium环境搭建实战手册:解决JDK、Android SDK与Node.js兼容性问题
1. 为什么Appium环境搭建总让人卡在第一步?——不是工具不行,是路径没走对“Appium环境搭好了吗?”这句话我过去三年在测试团队晨会里至少听过27次。不是新人问的,是干了五年自动化测试的老同事皱着眉甩出来的。他刚重装系统&…...

京东自动抢购工具:5分钟快速上手指南,轻松抢购心仪商品
京东自动抢购工具:5分钟快速上手指南,轻松抢购心仪商品 【免费下载链接】autobuy-jd 使用python语言的京东平台抢购脚本 项目地址: https://gitcode.com/gh_mirrors/au/autobuy-jd 还在为心仪商品秒杀时手速不够快而烦恼吗?Autobuy-JD…...

仅剩最后47个印尼语专属Voice ID配额!ElevenLabs企业版印尼语音定制通道即将关闭——附2024Q3合规接入白皮书
更多请点击: https://codechina.net 第一章:印尼语Voice ID配额告急与企业定制通道关闭预警 近期,多家使用印尼语(Bahasa Indonesia)语音身份验证(Voice ID)服务的企业客户收到平台侧自动通知&…...

2021年5月AI工程化三大关键突破:Deformable DETR、REALM与WB Model Registry
1. 项目概述:这不是一份榜单,而是一份2021年5月AI领域真实水位的切片报告“The AI Monthly Top 3 — May 2021”这个标题乍看像一份轻量级资讯简报,但在我连续追踪AI领域动态超过十年、亲手部署过从BERT-base到GPT-3早期API调用、从YOLOv3训练…...

Unity ASE全屏风沙Shader实战:从光学建模到跨平台优化
1. 这不是“加个粒子就完事”的风沙——为什么全屏风沙在Unity里是个硬骨头“Unity之ASE实现全屏风沙效果”——看到这个标题,很多刚接触Shader Graph或Amplify Shader Editor(ASE)的美术向程序员第一反应是:“不就是叠个噪波UV动…...