Kafka之【生产消息】
消息(Record)
在kafka中传递的数据我们称之为消息(message)或记录(record),所以Kafka发送数据前,需要将待发送的数据封装为指定的数据模型:
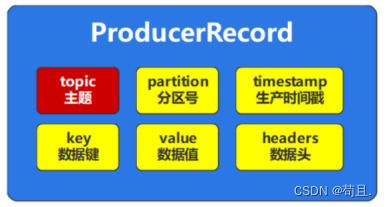
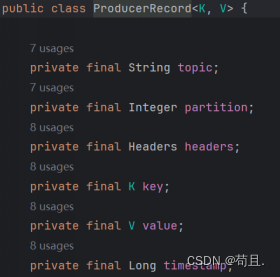
相关属性必须在构建数据模型时指定,其中主题和value的值是必须要传递的。如果配置中开启了自动创建主题,那么Topic主题可以不存在。value就是我们需要真正传递的数据了,而在未指定分区器或者未指定分区得情况下,Key可以用于数据的分区定位。
根据前面提供的配置信息创建生产者对象,通过这个生产者对象向Kafka服务器节点发送数据,而具体的发送是由生产者对象创建时,内部构建的多个组件实现的,多个组件的关系有点类似于生产者消费者模式。
生产者(Producer)是一个关键组件,负责将消息发送到Kafka集群。Kafka生产者主要由三个核心部分组成:
KafkaProducerRecordAccumulatorSender
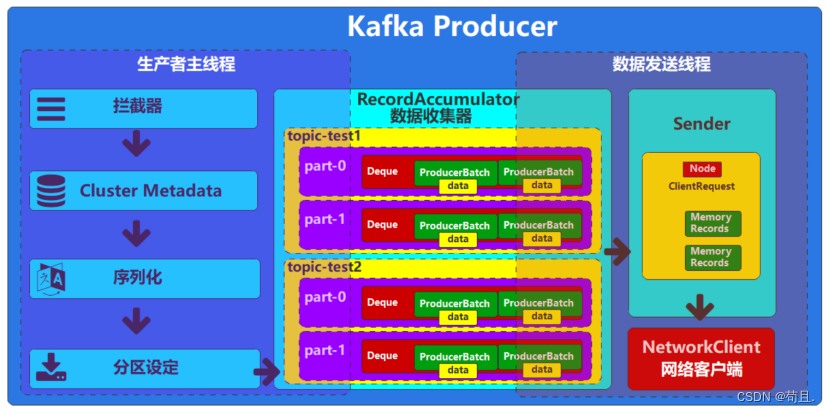
数据生产者(KafkaProducer)
作用:
KafkaProducer是生产者客户端的核心接口,为生产者对象,用于对我们的数据进行必要的转换和处理,将处理后的数据放入到数据收集器中,类似于生产者消费者模式下的生产者,负责提供向Kafka集群发布消息的功能。
组成:
KafkaProducer由以下关键部分组成:
- 配置(ProducerConfig):用于初始化和配置生产者客户端的参数。
- 拦截器(Interceptor):用于在消息发送前后进行自定义处理。如果配置拦截器栈(interceptor.classes),那么将数据进行拦截处理。某一个拦截器出现异常并不会影响后续的拦截器处理。
- 序列化器(Serializer):因为发送的数据为KV数据,所以需要根据配置信息中的序列化对象对数据中Key和Value分别进行序列化处理。
- 分区器(Partitioner):计算数据所发送的分区位置。
工作流程:
- 初始化:根据配置参数初始化客户端,包括序列化器、分区器等。
- 消息发送:消息经过拦截器处理、序列化、分区选择后,放入
RecordAccumulator中。 - 事务支持:处理事务消息的发送和事务边界(如果配置了事务,如幂等)。
数据收集器(RecordAccumulator)
作用:
RecordAccumulator用于收集,转换我们产生的数据,类似于生产者消费者模式下的缓冲区。为了优化数据的传输,Kafka并不是生产一条数据就向Broker发送一条数据,而是通过合并单条消息,进行批量(批次)发送,提高吞吐量,减少带宽消耗。
组成:
RecordAccumulator由以下部分组成:
- 内存缓冲区(BufferPool):管理消息缓冲区的内存分配。
- 消息队列(Deque):每个分区对应一个消息队列,用于存储批次消息。
- 批次(ProducerBatch):用于存储一批待发送的消息。
内部工作:
- 默认情况下,一个发送批次的数据容量为
16K,这个可以通过参数batch.size进行改善。 - 批次是和分区进行绑定的。也就是说
发往同一个分区的数据会进行合并,形成一个批次。 - 将消息追加到对应分区的批次中,如果当前
批次已满或达到时间限制,创建新的批次。 - 这个队列使用的是
Java的双端队列Deque。旧的批次关闭不再接收新的数据,等待发送
重要参数:
- batch.size:每个批次的大小,默认16K。
- linger.ms:发送前的等待时间限制,默认0s。
- buffer.memory:内存缓冲区的总大小默认32M。
数据发送器(Sender)
作用:
Sender是一个后台线程,负责从RecordAccumulator中取出消息批次,向服务节点发送。类似于生产者消费者模式下的消费者。因为是线程对象,所以启动后会不断轮询获取数据收集器中已经关闭的批次数据。对批次进行整合后再发送到Broker节点中
组成:
Sender由以下部分组成:
- 网络客户端(NetworkClient):负责与Kafka Broker进行网络通信。
- 元数据管理(Metadata):获取和更新Kafka集群的元数据信息。
- 请求管理(ClientRequest/ClientResponse):管理发送的请求和接收的响应。
内部工作:
- 因为数据
真正发送的地方是Broker节点,不是分区。所以需要将从数据收集器中收集到的批次数据按照可用Broker节点重新组合成List集合。 - 将组合后的<节点,List<批次>>的数据封装成客户端请求发送到网络客户端对象的缓冲区,由网络客户端对象通过网络发送给Broker节点。
- Broker节点获取客户端请求,并根据请求键进行后续的数据处理:向分区中增加数据。
重要参数:
- retries:重试次数。
- retry.backoff.ms:重试间隔时间。
- request.timeout.ms:请求超时时间。
协作机制
-
消息发送流程:
- 用户通过
KafkaProducer.send()方法发送消息。 - 消息经过序列化、分区选择和拦截器处理后,进入
RecordAccumulator。 RecordAccumulator将消息存入对应分区的消息队列中,形成批次。
- 用户通过
-
消息传输流程:
Sender后台线程不断从RecordAccumulator中取出已准备好的消息批次。Sender通过NetworkClient将消息批次发送到Kafka Broker。- 如果发送成功,
Sender接收响应并通知KafkaProducer;如果发送失败,根据重试策略进行重试。
通过这种协作机制,Kafka生产者实现了高效、可靠的消息发送。KafkaProducer负责接口和配置管理,RecordAccumulator负责消息缓存和批量处理,Sender负责消息的实际传输和重试逻辑。
生产者代码
// TODO 配置属性集合
Map<String, Object> configMap = new HashMap<>();
// TODO 配置属性:Kafka服务器集群地址
configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// TODO 配置属性:Kafka生产的数据为KV对,所以在生产数据进行传输前需要分别对K,V进行对应的序列化操作
configMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
configMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
// TODO 创建Kafka生产者对象,建立Kafka连接
// 构造对象时,需要传递配置参数
KafkaProducer<String, String> producer = new KafkaProducer<>(configMap);
// TODO 准备数据,定义泛型
// 构造对象时需要传递 【Topic主题名称】,【Key】,【Value】三个参数
ProducerRecord<String, String> record = new ProducerRecord<String, String>("test", "key1", "value1"
);
// TODO 生产(发送)数据
producer.send(record);
// TODO 关闭生产者连接
producer.close();
拦截器
生产者API在数据准备好发送给Kafka服务器之前,允许我们对生产的数据进行统一的处理,比如校验,整合数据等等。这些处理我们是可以通过Kafka提供的拦截器完成。因为拦截器不是生产者必须配置的功能,所以可以根据实际的情况自行选择使用。
但是要注意,这里的拦截器是可以配置多个的。执行时,会按照声明顺序执行完一个后,再执行下一个。并且某一个拦截器如果出现异常,只会跳出当前拦截器逻辑,并不会影响后续拦截器的处理。所以开发时,需要将拦截器的这种处理方法考虑进去。

自定义拦截器
要想自定义拦截器,只需要创建一个类,然后实现Kafka提供的分区类接口ProducerInterceptor,接下来重写方法。这里我们只关注onSend方法即可。
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;import java.util.Map;/*** TODO 自定义数据拦截器* 1. 实现Kafka提供的生产者接口ProducerInterceptor* 2. 定义数据泛型 <K, V>* 3. 重写方法* onSend* onAcknowledgement* close* configure*/
public class KafkaInterceptorMock implements ProducerInterceptor<String, String> {@Override// 数据发送前,会执行此方法,进行数据发送前的预处理public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {return record;}@Override // 数据发送后,获取应答时,会执行此方法public void onAcknowledgement(RecordMetadata metadata, Exception exception) {}@Override// 生产者关闭时,会执行此方法,完成一些资源回收和释放的操作public void close() {}@Override// 创建生产者对象的时候,会执行此方法,可以根据场景对生产者对象的配置进行统一修改或转换。public void configure(Map<String, ?> configs) {}
}
使用拦截器
// 仅需在配置properties的时候,指定自定义拦截器器即可
configMap.put( ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, KafkaInterceptorMock.class.getName());
同步发送和异步发送
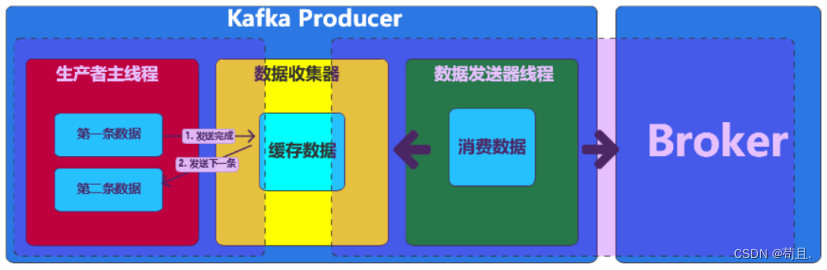
1. 异步发送
如果Kafka通过主线程代码将一条数据放入到缓冲区后,无需等待数据的后续发送过程,就直接发送一下条数据的场合,我们就称之为异步发送。
import org.apache.kafka.clients.producer.*;import java.util.HashMap;
import java.util.Map;public class KafkaProducerASynTest {public static void main(String[] args) {Map<String, Object> configMap = new HashMap<>();configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");configMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");configMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");KafkaProducer<String, String> producer = new KafkaProducer<>(configMap);// TODO 循环生产数据for ( int i = 0; i < 10; i++ ) {// TODO 创建数据ProducerRecord<String, String> record = new ProducerRecord<String, String>("test", "key" + i, "value" + i);// TODO 发送数据producer.send(record, new Callback() {// TODO 回调对象public void onCompletion(RecordMetadata recordMetadata, Exception e) {// TODO 当数据发送成功后,会回调此方法System.out.println("数据发送成功:" + recordMetadata.timestamp());}});// TODO 发送当前数据System.out.println("发送数据");}producer.close();}
}
2. 同步发送
如果Kafka通过主线程代码将一条数据放入到缓冲区后,需等待数据的后续发送操作的应答状态,才能发送一下条数据的场合,我们就称之为同步发送。所以这里的所谓同步,就是生产数据的线程需要等待发送线程的应答(响应)结果。
import org.apache.kafka.clients.producer.*;import java.util.HashMap;
import java.util.Map;public class KafkaProducerASynTest {public static void main(String[] args) throws Exception {Map<String, Object> configMap = new HashMap<>();configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");configMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");configMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");KafkaProducer<String, String> producer = new KafkaProducer<>(configMap);// TODO 循环生产数据for ( int i = 0; i < 10; i++ ) {// TODO 创建数据ProducerRecord<String, String> record = new ProducerRecord<String, String>("test", "key" + i, "value" + i);// TODO 发送数据producer.send(record, new Callback() {// TODO 回调对象public void onCompletion(RecordMetadata recordMetadata, Exception e) {// TODO 当数据发送成功后,会回调此方法System.out.println("数据发送成功:" + recordMetadata.timestamp());}}).get();// TODO 发送当前数据System.out.println("发送数据");}producer.close();}
}
分区器
- 如果
指定了分区,直接使用 - 如果指定了自己的分区器,通过
分区器计算分区编号,如果有效,直接使用 - 如果指定了数据Key,且使用Key选择分区的场合,采用murmur2非加密散列算法(类似于hash)计算数据Key序列化后的值的散列值,然后对主题分区数量模运算取余,最后的结果就是分区编号。
hash(key)%numPartitions = 分区号 - 如果
未指定数据Key,或不使用Key选择分区,那么Kafka会自动分区。
自定义分区器
只需要创建一个类,然后实现Kafka提供的分区类接口Partitioner,接下来重写方法。这里我们只关注partition方法即可,因为此方法的返回结果就是需要的分区编号。
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;import java.util.Map;/*** TODO 自定义分区器实现步骤:* 1. 实现Partitioner接口* 2. 重写方法* partition : 返回分区编号,从0开始* close* configure*/
public class KafkaPartitionerMock implements Partitioner {/*** 分区算法 - 根据业务自行定义即可* @param topic The topic name* @param key The key to partition on (or null if no key)* @param keyBytes The serialized key to partition on( or null if no key)* @param value The value to partition on or null* @param valueBytes The serialized value to partition on or null* @param cluster The current cluster metadata* @return 分区编号,从0开始*/@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {return 0;}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
使用分区器
// 仅需在配置properties的时候,指定自定义分区器即可
configMap.put( ProducerConfig.PARTITIONER_CLASS_CONFIG, KafkaPartitionerMock.class.getName());
消息可靠性(Acknowledgement)
ACK = 0
当生产数据时,生产者对象将数据通过网络客户端将数据发送到网络数据流中的时候,Kafka就对当前的数据请求进行了响应(确认应答),如果是同步发送数据,此时就可以发送下一条数据了。如果是异步发送数据,回调方法就会被触发。
ACK = 1
当生产数据时,Kafka Leader副本将数据接收到并写入到了日志文件后,就会对当前的数据请求进行响应(确认应答),如果是同步发送数据,此时就可以发送下一条数据了。如果是异步发送数据,回调方法就会被触发。
ACK = -1/all (默认) 最可靠
当生产数据时,Kafka Leader副本和Follower副本都已经将数据接收到并写入到了日志文件后,再对当前的数据请求进行响应(确认应答),如果是同步发送数据,此时就可以发送下一条数据了。如果是异步发送数据,回调方法就会被触发。
数据重试导致的数据重复
由于网络或服务节点的故障,Kafka在传输数据时,可能会导致数据丢失,所以我们才会设置ACK应答机制,尽可能提高数据的可靠性。
- 在某些场景中,数据并不是真正地丢失,比如将ACK应答设置为1,Leader副本将数据写入文件后,Kafka就可以对请求进行响应。
- 此时,假设网络故障的原因,Kafka并没有成功将ACK应答信息发送给Producer,那么此时对于Producer来讲,以为kafka没有收到数据,所以就会一直等待响应,一旦超过某个时间阈值,就会发生超时错误,也就是说在Kafka Producer眼里,数据已经丢了
- 所以在这种情况下,kafka Producer会尝试对超时的请求数据进行重试(retry)操作。通过重试操作尝试将数据再次发送给Kafka。
- 如果此时发送成功,Kafka就又收到了数据,两条数据一样,也就是说数据的重复。
数据乱序
数据重试(retry)功能除了可能会导致数据重复以外,还可能会导致数据乱序。
- 假设需要将编号为1,2,3的三条连续数据发送给Kafka。
- 如果在发送过程中,1因为网络原因发送失败,2、3发生成功
- 则此时在Broker的缓存中,为消息2、3
- 生产者重发消息1
- 则此时在Broker的缓存中,为消息2、3、1
这就产生了数据的乱序
幂等
为了解决Kafka传输数据时,所产生的数据重复和乱序问题,Kafka引入了幂等性操作,所谓的幂等性,就是Producer同样的一条数据,无论向Kafka发送多少次,kafka都只会存储一条。注意,这里的同样的一条数据,指的不是内容一致的数据,而是指的不断重试的数据。
// 幂等需要手动开启
enable.idempotence配置为true
-
开启幂等性后,为了保证数据不会重复,那么就需要给每一个请求批次的数据增加唯一性标识,kafka中,这个标识采用的是连续的序列号数字
sequencenum,但是不同的生产者Producer可能序列号是一样的,所以仅仅靠seqnum还无法唯一标记数据,所以还需要同时对生产者进行区分,所以Kafka采用申请生产者ID(producerid)的方式对生产者进行区分。这样,在发送数据前,我们就需要提前申请producerid以及序列号sequencenum -
Broker中会给每一个分区记录生产者的生产状态:采用队列的方式
缓存最近的5个批次数据。队列中的数据按照seqnum进行升序排列。这里的数字5是经过压力测试,均衡空间效率和时间效率所得到的值,所以为固定值,无法配置且不能修改。 -
如果Borker当前新的请求批次数据在缓存的5个旧的批次中存在相同的,
如果有相同的,那么说明有重复,当前批次数据不做任何处理。
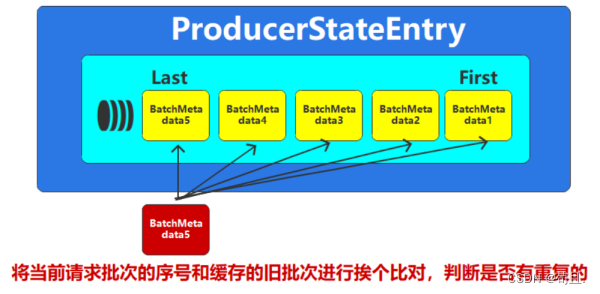
-
如果Broker当前的请求批次数据在缓存中没有相同的,那么
判断当前新的请求批次的序列号是否为缓存的最后一个批次的序列号加1,如果是,说明是连续的,顺序没乱。那么继续,如果不是,那么说明数据已经乱了,发生异常。
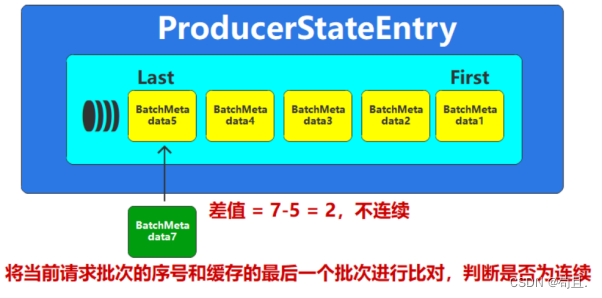
-
Broker根据异常返回响应,通知Producer进行重试。Producer重试前,需要在缓冲区中将数据重新排序,保证正确的顺序后。再进行重试即可。
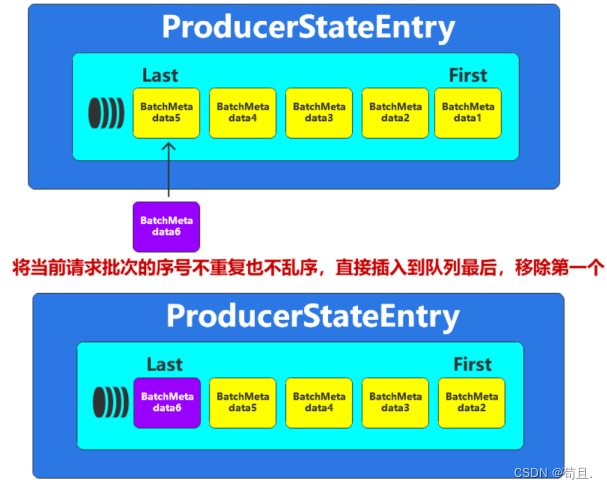
-
如果请求批次不重复,且有序,那么更新缓冲区中的批次数据。将当前的批次放置再队列的结尾,将队列的第一个移除,保证队列中缓冲的数据最多5个。
从上面的流程可以看出,Kafka的幂等性是通过消耗时间和性能的方式提升了数据传输的有序和去重,在一些对数据敏感的业务中是十分重要的。但是通过原理,咱们也能明白,这种幂等性还是有缺陷的:
- 幂等性的producer仅做到单分区上的幂等性,即单分区消息有序不重复,多分区无法保证幂等性。
- 只能保持生产者单个会话的幂等性,无法实现跨会话的幂等性
(也就是说如果一个producer挂掉再重启,那么重启前和重启后的producer对象会被当成两个独立的生产者,从而获取两个不同的独立的生产者ID,导致broker端无法获取之前的状态信息,所以无法实现跨会话的幂等) - 要想解决这个问题,就需要采用事务功能。
什么是生产者事务
在Kafka中,生产者事务(Producer Transactions)允许生产者以原子方式向一个或多个主题写入消息。事务可以确保消息要么全部成功写入,要么全部失败,从而保证数据的一致性。下面详细解释Kafka中生产者事务的原理:
事务组件
在Kafka中,事务涉及以下几个组件:
- Transactional Producer(事务生产者):负责在事务中写入消息。
- Transaction Coordinator(事务协调器):管理事务的生命周期,包括开始事务、提交事务和中止事务。
- Broker(代理):Kafka集群中的服务器,存储消息并协助协调事务。
事务处理的详细步骤
- 初始化事务:事务生产者向事务协调器注册,事务协调器为该生产者分配一个唯一的
Transactional ID和Producer Epoch。 - 开始事务:生产者调用
beginTransaction时,事务协调器记录事务开始状态。 - 发送消息:生产者发送消息时,消息会标记为“待处理”状态并包含事务ID和epoch。
- 提交事务:生产者调用
commitTransaction时,事务协调器将事务状态更新为“提交中”,然后通知所有相关分区代理提交消息。 - 完成提交:所有分区代理确认消息已写入日志后,事务协调器更新事务状态为“已提交”,通知生产者事务完成。
- 中止事务:在任何步骤发生错误时,生产者可以调用
abortTransaction,事务协调器将事务状态更新为“中止中”,通知相关分区代理丢弃消息,最后更新事务状态为“已中止”。
实现事务的要点
- 幂等性:确保消息的幂等性,以避免重复写入。Kafka通过
Producer ID和Sequence Number实现幂等性。 - 协调和日志:事务协调器负责管理事务状态,事务日志记录事务的所有状态变化。
- 原子提交:确保事务提交的原子性,通过两阶段提交协议(2PC)实现。
-
第一阶段:预提交:
- 生产者发送消息时,代理记录Producer ID和Sequence Number。
- 消息标记为“待提交”。
-
第二阶段:提交或中止:
- 当生产者提交事务时,事务协调器通知代理将消息标记为“已提交”。
- 如果事务中止,代理丢弃消息,不进行处理。
-
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.Future;public class ProducerTransactionTest {public static void main(String[] args) {Map<String, Object> configMap = new HashMap<>();configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");configMap.put( ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());configMap.put( ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// TODO 配置幂等性configMap.put( ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);// TODO 配置事务IDconfigMap.put( ProducerConfig.TRANSACTIONAL_ID_CONFIG, "my-tx-id");// TODO 配置事务超时时间configMap.put( ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 5);// TODO 创建生产者对象KafkaProducer<String, String> producer = new KafkaProducer<>(configMap);// TODO 初始化事务producer.initTransactions();try {// TODO 启动事务producer.beginTransaction();// TODO 生产数据for ( int i = 0; i < 10; i++ ) {ProducerRecord<String, String> record = new ProducerRecord<String, String>("test", "key" + i, "value" + i);final Future<RecordMetadata> send = producer.send(record);}// TODO 提交事务producer.commitTransaction();} catch ( Exception e ) {e.printStackTrace();// TODO 终止事务producer.abortTransaction();}// TODO 关闭生产者对象producer.close();}
}
如何确保跨会话中的幂等(生产者崩溃后,事务恢复生产者,即为跨会话)
确保幂等性的过程主要依赖于Kafka的Producer ID、Producer Epoch和Sequence Number机制。以下是详细的过程描述:
1. 初始生产者启动和消息发送
-
生产者初始化:
- 生产者在初始化时,Kafka为其分配一个唯一的Producer ID (PID)。
- Producer ID标识当前生产者实例。
-
开始发送消息:
- 生产者发送消息时,每个消息附带一个Sequence Number。
- Sequence Number在每个分区内是递增的,用于标识消息的顺序。
2. 记录Producer ID和Sequence Number
- Kafka代理(Broker)会记录每个分区的Producer ID和最新的Sequence Number。
- 每条消息发送时,代理会检查当前Producer ID和Sequence Number,确保消息的顺序和唯一性。
3. 生产者崩溃和重启
-
生产者崩溃:
- 假设生产者在事务过程中崩溃。
-
生产者重启:
- 生产者重启后,使用相同的Transactional ID重新初始化。
- Kafka为重启的生产者分配一个新的Producer ID。
- 同时,Producer Epoch递增,标识这是生产者的一个新的会话。
4. 恢复未完成的事务
- 事务协调器:负责管理事务状态,恢复未完成的事务。
- 当生产者重启并调用
initTransactions时,事务协调器会:- 检查与Transactional ID相关的未完成事务。
- 根据事务日志记录,决定是提交还是中止这些事务。
5. 幂等性保障机制
-
新的Producer ID和递增的Producer Epoch:
- Kafka代理识别新的Producer ID和递增的Producer Epoch,确保重启后的生产者实例与之前的实例区分开。
-
更新记录:
- 代理更新记录新的Producer ID和Sequence Number。
- 新的Producer ID和递增的Sequence Number确保消息不重复处理。
-
消息去重:
- 代理通过检查Producer ID和Sequence Number,确保同一个Producer ID的消息不会被处理两次。
- 即使生产者在重启后重新发送消息,代理能够识别并忽略重复的消息。
6. 事务性消息处理
-
第一阶段:预提交:
- 生产者发送消息时,代理记录Producer ID和Sequence Number。
- 消息标记为“待提交”。
-
第二阶段:提交或中止:
- 当生产者提交事务时,事务协调器通知代理将消息标记为“已提交”。
- 如果事务中止,代理丢弃消息,不进行处理。
总结
通过以上机制,Kafka确保生产者在不同会话中的幂等性:
- Producer ID和Producer Epoch:标识生产者实例和会话阶段。
- Sequence Number:确保每个分区中的消息顺序和唯一性。
- 事务协调器:管理事务状态,确保事务的一致性和原子性。
即使生产者崩溃并重启,通过这些机制,Kafka能够保证消息的幂等性和事务一致性,避免重复处理消息,确保数据可靠性和一致性。
相关文章:
Kafka之【生产消息】
消息(Record) 在kafka中传递的数据我们称之为消息(message)或记录(record),所以Kafka发送数据前,需要将待发送的数据封装为指定的数据模型: 相关属性必须在构建数据模型时指定,其中…...
asp.net core接入prometheus
安装prometheus和Grafana 参考之前的文章->安装prometheus和Grafana教程 源代码 dotnet源代码 新建.net core7 web项目 修改Program.cs using Prometheus;namespace PrometheusStu01;public class Program {public static void Main(string[] args){var builder We…...

C++ 变量类型与转换
C 变量类型与转换 文章目录 C 变量类型与转换变量int_tsize_t与ssize_tpid_ttime_t typenametypeid关键字类型转换编译期类型转换std::static_cast注意事项运行时类型转换std::dynamic_cast 变量 int_t 它是通过typedef定义的,而不是一种新的数据类型。 - int8_t…...
【杂七杂八】Huawei Gt runner手表系统降级
文章目录 Step1:下载安装修改版华为运动与健康Step2:在APP里进行配置Step3:更新固件(时间会很长) 目前在使用用鸿蒙4 111版本的手表系统,但是感觉睡眠检测和运动心率检测一言难尽,于是想到是否能回退到以前的版本&…...

FMEA做不出来的原因究竟是什么?——FMEA软件
免费试用FMEA软件-免费版-SunFMEA FMEA(Failure Mode and Effects Analysis)即故障模式与影响分析,是一种旨在识别并预防潜在问题的方法。然而,尽管其重要性被广泛认知,但在实际应用中,却常常遇到FMEA难以…...

pandas ExcelWriter写excel报错openpyxl.utils.exceptions.IllegalCharacterError
一直使用pandas写excel,本次写的数据有大字段,每次写到该字段就报错,代码如下: with pd.ExcelWriter(r".\提数_20240523\tq_type3_doc.xlsx", engineopenpyxl) as writer: df.to_excel(writer,indexFalse, sheet_namesh…...
Golang创建文件夹
方法 package zdpgo_fileimport ("os" )// AddDir 创建文件夹 func AddDir(dir string) error {if !IsExist(dir) {return os.MkdirAll(dir, os.ModePerm)}return nil }测试 package zdpgo_fileimport "testing"func TestAddDir(t *testing.T) {data : […...
所学的全部课程的学生)
头歌OpenGauss数据库-I.复杂查询第5关:至少学了某位学生(Oliver)所学的全部课程的学生
本关任务:根据提供的表和数据,查询至少学了Oliver同学所学的全部课程的其他同学的信息(学号s_id,姓名`s_name)。 student表数据: s_ids_names_sex01Mia女02Riley男03Aria女04Lucas女05Oliver男06Caden男07Lily女08Jacob男course表数据: c_idc_namet_id01Chinese0202Math…...

【数据结构】哈夫曼树和哈夫曼编码
一、哈夫曼树 1.1 哈夫曼树的概念 给定一个序列,将序列中的所有元素作为叶子节点构建一棵二叉树,并使这棵树的带权路径长度最小,那么我们就得到了一棵哈夫曼树(又称最优二叉树) 接下来是名词解释: 权&a…...

深入探索微软Edge:领略新一代浏览器的无限可能
深入探索微软Edge:领略新一代浏览器的无限可能 在当今数字化时代,网络浏览器已经成为我们日常生活中不可或缺的一部分。而随着技术的不断进步,浏览器的功能和性能也在不断提升。微软Edge作为微软推出的全新一代浏览器,引领着浏览…...

JavaScript表达式和运算符
表达式 表达式一般由常量、变量、运算符、子表达式构成。最简单的表达式可以是一个简单的值。常量或变量。例:var a10 运算符 运算符一般用符号来表示,也有些使用关键字表示。运算符由3中类型 1.一元运算符:一个运算符能够结合一个操作数&…...
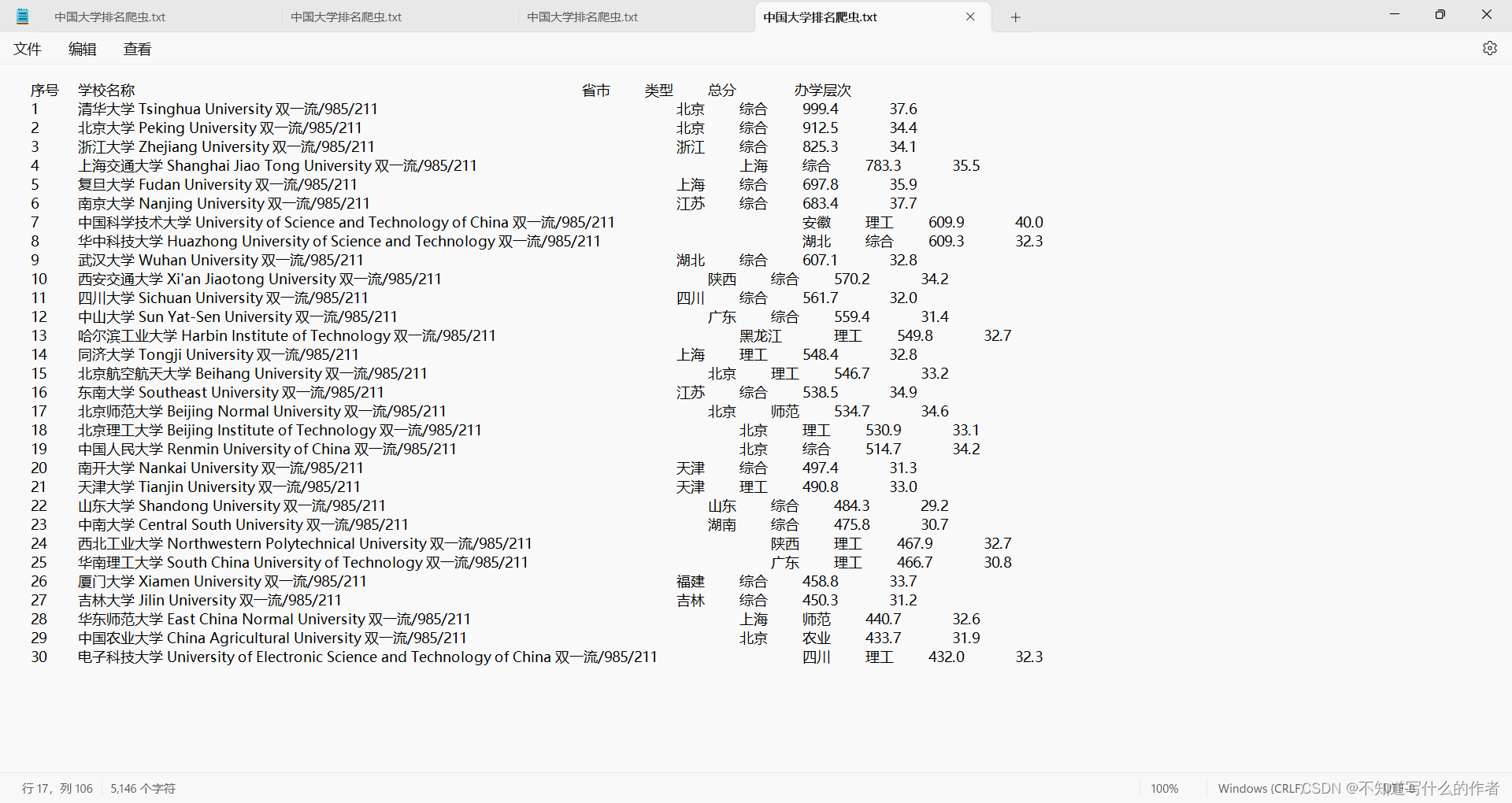
爬虫实训案例:中国大学排名
近一个月左右的时间学习爬虫,在用所积累的知识爬取了《中国大学排名》这个网站,爬取的内容虽然只是可见的文本,但对于初学者来说是一个很好的练习。在爬取的过程中,通过请求数据、解析内容、提取文本、存储数据等几个重要的内容入…...

C++ IO流
C标准IO流 使用cout进行标准输出,即数据从内存流向控制台(显示器)使用cin进行标准输入,即数据通过键盘输入到程序中使用cerr进行标准错误的输出使用clog进行日志的输出 C文件IO流 文件流对象 ofstream:只写 ofstream 是 C 中用于输出文件…...

debian nginx upsync consul 实现动态负载
1. consul 安装 wget -O- https://apt.releases.hashicorp.com/gpg | sudo gpg --dearmor -o /usr/share/keyrings/hashicorp-archive-keyring.gpg echo "deb [signed-by/usr/share/keyrings/hashicorp-archive-keyring.gpg] https://apt.releases.hashicorp.com $(lsb_r…...

前端基础入门三大核心之HTML篇 —— 同源策略的深度解析与安全实践
前端基础入门三大核心之HTML篇 —— 同源策略的深度解析与安全实践 一、同源策略:定义与起源1.1 定义浅析1.2 何为“源”?1.3 起源与意义 二、同源策略的运作机制2.1 限制范围2.2 安全边界 三、跨越同源的挑战与对策3.1 JSONP3.2 CORS3.3 postMessage 四…...

go 微服务框架 kratos 日志库使用方法及原理探究
一、Kratos 日志设计理念 kratos 日志库相关的官方文档:日志 | Kratos Kratos的日志库主要有如下特性: Logger用于对接各种日志库或日志平台,可以用现成的或者自己实现Helper是在您的项目代码中实际需要调用的,用于在业务代码里…...

VC++位移操作>>和<<以及逻辑驱动器插拔产生的掩码dbv.dbcv_unitmask进行分析的相关代码
VC位移操作>>和<<以及逻辑驱动器插拔产生的掩码dbv.dbcv_unitmask进行分析的相关代码 一、VC位移操作符<<和>>1、右位移操作符 >>:2、左位移操作符 <<: 二、逻辑驱动器插拔产生的掩码 dbv.dbcv_unitmask 进行分析的…...

查看gpu
## 查看gpu信息 if_cuda torch.cuda.is_available() print("if_cuda",if_cuda)gpu_count torch.cuda.device_count() print("gpu_count",gpu_count)...

CSS与表格设计
在网页设计中,表格是一种不可或缺的元素,用于展示和组织数据。虽然HTML提供了基本的表格结构,但通过CSS(层叠样式表)的应用,我们可以极大地提升表格的外观和用户体验。本文将探讨如何利用CSS来设计既美观又…...

阴影映射(线段树)
实时阴影是电子游戏中最为重要的画面效果之一。在计算机图形学中,通常使用阴影映射方法来实现实时阴影。 游戏开发部正在开发一款 2D 游戏,同时希望能够在 2D 游戏中模仿 3D 游戏的光影效果,请帮帮游戏开发部! 给定 x-y 平面上的…...

抖音内容高效管理方案:批量下载与智能文件组织
抖音内容高效管理方案:批量下载与智能文件组织 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音…...

终极M3U8视频下载指南:5个技巧轻松掌握开源工具
终极M3U8视频下载指南:5个技巧轻松掌握开源工具 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 想要下载在线视频却总是失败?面对M3U8格式束手无策&#x…...

3步掌握DownKyi:让你的B站视频收藏效率提升300%
3步掌握DownKyi:让你的B站视频收藏效率提升300% 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等)…...

ToastFish:Windows通知栏背单词神器,碎片化时间高效记忆方案
ToastFish:Windows通知栏背单词神器,碎片化时间高效记忆方案 【免费下载链接】ToastFish 一个利用摸鱼时间背单词的软件。 项目地址: https://gitcode.com/GitHub_Trending/to/ToastFish ToastFish是一款创新的Windows桌面应用程序,专…...

XHS-Downloader:小红书内容采集的技术架构与多模式部署方案
XHS-Downloader:小红书内容采集的技术架构与多模式部署方案 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接…...

2026年想做美缝施工?专业靠谱的美缝施工究竟哪家好?
在装修领域,美缝施工虽看似是小工程,却对家居整体美观度和实用性影响重大。然而,美缝行业乱象丛生,让众多业主在选择美缝施工团队时犯了难。2026年若想做美缝施工,怎样才能选到专业靠谱的团队呢?下面为大家…...

设计模式之建造者
问题:构造函数参数太多(「伸缩构造」),或步骤必须按顺序、且步骤组合多变。做法:Director(可选)规定步骤顺序;Builder 提供 setA()、setB()… 最后 build() 返回产品。C 要点&#x…...

WTEW的操作记录
WTEW的操作记录WTEW事务代码的操作记录WTEW事务代码的操作记录 1、查询贸易合同信息 如果是自己创建可以使用WB21、WB22、WB23事务码,如果是税码更新用WBRP更新价格 2、创建后续单据,采购TC创建采购订单,销售TC创建销售订单,注…...
)
告别ifconfig!用ip命令和ethtool搞定Linux网卡状态排查(附实战案例)
告别ifconfig!用ip命令和ethtool搞定Linux网卡状态排查(附实战案例) 在Linux服务器运维中,网络故障排查是最常见的任务之一。记得去年深夜处理一次线上事故时,面对一台突然失联的数据库服务器,我习惯性地敲…...

专栏导读:为什么需要从 MM 理解 HMM
一个真实的困境 假设你是一个 GPU 计算框架的开发者。用户写了这样一段代码: float *data malloc(1GB); // ... 填充数据 ... gpu_kernel<<<grid, block>>>(data); // 希望 GPU 直接访问 data在传统编程模型下,这不可能工作——GPU …...