神经网络学习
神经网络学习
- 导语
- 数据驱动
- 驱动方法
- 训练/测试数据
- 损失函数
- 均方误差
- 交叉熵误差
- mini-batch
- 数值微分
- 梯度
- 梯度法
- 神经网络梯度
- 学习算法的实现
- 随机梯度下降
- 2层神经网络实现
- mini-batch实现
- 总结
- 参考文献
导语
神经网络中的学习指从训练数据中自动获取最优权重参数的过程,这个“最优”的定义在不同的应用场景下各有不同。
数据驱动
机器学习最关键的部分即如何对待数据,从数据当中找到模式,找到规律,找到答案。
驱动方法
机器学习的思路是,先从图像中提取特征量(一般由人设计),再用机器学习学习特征量的模式,神经网络的思路是,直接学习数据本身,特征量也是自主学习,区别图如下(来自书):
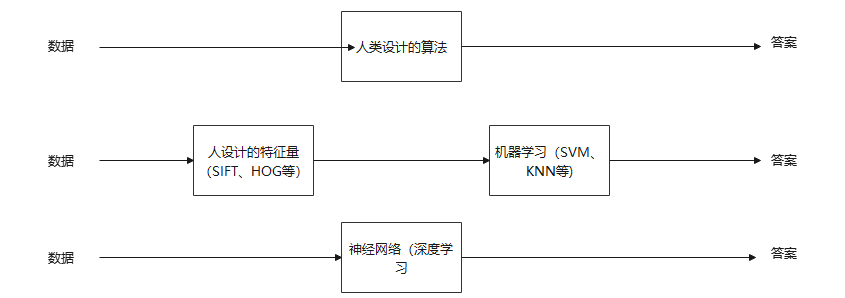 神经网络对所有的问题都用同样的流程解决,有时也被称为端到端机器学习(从输入直接获得输出)。
神经网络对所有的问题都用同样的流程解决,有时也被称为端到端机器学习(从输入直接获得输出)。
训练/测试数据
训练数据用来学习和找到最优的参数,测试数据用来评价模型的泛化能力,判断已训练的模型效果如何。
泛化能力即处理未被观察过的数据(简单说就是训练数据之外的数据)的能力,机器学习的目标就是获得这种能力。
为了提高泛化能力,对一个模型往往使用多个数据集进行考察,如果只使用一个数据集的话,可能会导致模型在这个数据集上表现很好,但是直接拿来检测新的数据时表达很差,这种只对某个数据集过度拟合的状态就是过拟合。
损失函数
为了评估每次训练的结果,神经网络采用了损失函数这一指标,这个损失函数有多种取法,书上给了几种函数及其实现方式。
均方误差
均方误差是常用的损失函数,表达式为(仅两个数据比对): E = 1 2 ∑ k ( y k − t k ) 2 E=\frac{1}{2}\mathop{\sum}\limits_k(y_k-t_k)^2 E=21k∑(yk−tk)2。
y k y_k yk为神经网络输出, t k t_k tk为监督数据, k k k为数据的维数,一般用one-hot表示(正解标签为1,其他为0)。
python实现:
def mean_squared_error(y,t):return 0.5*np/sum((y-t)**2)
交叉熵误差
交叉熵误差表达式为: E = − ∑ k t k l n y k E=-\mathop{\sum}\limits_kt_klny_k E=−k∑tklnyk,也用one-hot标签,python的实现很简单,如下:
def cross_entropy_error(y,t):return -np.sum(t*np.log(y))
这个实现方法看起来没什么问题,但是如果熟悉 l n x lnx lnx曲线的话就会知道,当 y y y存在0项时, l n 0 ln0 ln0的值是无穷大,是无法运算的,因此需要添加一个微小值防止负无穷大,更改之后的函数实现如下:
def cross_entropy_error(y,t):delta=1e-8return -np.sum(t*np.log(y+delta))
mini-batch
上述给出的实现和式子都是只针对只有一个值的情况,实际上,神经网络是一批一批地处理数据的,当要求处理大量数据时,书上以交叉熵误差为例,式子表达为: E = − 1 N ∑ n ∑ k t n k l n y n k E=-\frac{1}{N}\mathop{\sum}\limits_n\mathop{\sum}\limits_kt_{nk}lny_{nk} E=−N1n∑k∑tnklnynk。
其中, t n k t_{nk} tnk表示第 n n n个数据的第 k k k个元素值, y n k y_{nk} ynk是输出, t n k t_{nk} tnk是监督数据。
一般来说,由于数据集的数据量很大,用全部数据来计算损失函数是不适合的,因此mini-batch应运而生(从全部数据随机选出一部分,作为整体的近似),可以理解为现实中的抽样调查。
mini-batch的交叉熵实现:
def cross_entropy_error(y,t):if y.ndim==1:t=t.reshape(1,t.size)y=y.reshape(1,y.size)batch_size=y.shape[0]return -np.sum(t.np.log(y+1e-8))/batch_size#one-hot表示#return -np.sum(np.log(y[np.arange(batch_size),t]+1e-8))/batchsize#非one-hot表示
数值微分
书上在这里介绍了导数(用割线来代替)、求导、偏导等概念,如果有高等数学基础,应该很容易能理解这些,因此跳过,直接从梯度开始。
梯度
梯度是建立在偏导数的基础上的,假设有变量 x 0 , x 1 , . . . . . . x n x_0,x_1,......x_n x0,x1,......xn,然后有偏导数 ∂ f ∂ x 0 , ∂ f ∂ x 1 . . . . . . , ∂ f ∂ x n \frac{\partial f}{\partial x_0},\frac{\partial f}{\partial x_1}......,\frac{\partial f}{\partial x_n} ∂x0∂f,∂x1∂f......,∂xn∂f,由全部变量的偏导数汇成的向量就是梯度,书上python的实现如下:
def numerical_gradient(f,x):h=1e-4grad=np.zeros_like(x)#先生成一个全0数组for idx in range(x.size):#遍历输入tmp_val=x[idx]x[idx]=tmp_val+hfxh1=f(x)#f(x+h)x[idx] = tmp_val - hfxh2 = f(x)#f(x-h)grad[idx]=(fxh1-fxh2)/(2*h)x[idx]=tmp_valreturn grad
梯度指示的方向是各点函数值减小最多的方向,具体证明属于高数知识,略。
梯度法
对于机器学习中的损失函数,我们总是想让其达到最小,但是,损失函数一般很复杂,不能直接得到最小的取值,此时,梯度法就是很好的解决方案。
但梯度法不一定每次都能取到最值,根据高等数学的指示,梯度所指的方向更类似于极值,而非最值(根据寻求最大值和最小值分成梯度下降和梯度上升)。
梯度法的思路很简单,计算当前位置的梯度,然后函数的取值沿着梯度前进一定距离,然后在新的地方求梯度(移动多少书在后面解释了,和学习率有关),循环往复。
梯度法的数学表达式很简单: x = x − η ∂ f ∂ x x=x-η\frac{\partial f}{\partial x} x=x−η∂x∂f, η \eta η是更新量,也就是学习率,决定了每次移动的步长。
像学习率这种参数被称为超参数,因为它并不是神经网络自动学习获得的,在实际的训练过程中,往往需要尝试多个值,学习率过小,则迭代次数过多,训练的时间被无意义浪费,学习率过大,可能步子迈大了扯着蛋,越过了极值或最值。
书上将梯度法式子用python实现:
def gradient_descent(f,init_x,lr=0.01,step_num=100):x=init_x#初始化网络参数for i in range(step_num):grad=numerical_gradient(f,x)#计算梯度x-=lr*grad#向梯度方向移动return x
神经网络梯度
在理解了梯度的概念和用法之后,在神经网络中运用梯度就变得很容易了,将结果矩阵中的每个值对权重秋偏导即可,以一个 2 × 2 2×2 2×2的矩阵为例,表达式如下:
W = ( w 11 w 12 w 21 w 22 ) W= \begin{pmatrix} w_{11}&w_{12}\\ w_{21}&w_{22} \end{pmatrix} W=(w11w21w12w22)
∂ L ∂ W = ( ∂ L ∂ w 11 ∂ L ∂ w 12 ∂ L ∂ w 21 ∂ L ∂ w 22 ) \frac{\partial L}{\partial W}= \begin{pmatrix} \frac{\partial L}{\partial w_{11}}&\frac{\partial L}{\partial w_{12}}\\ & &\\ \frac{\partial L}{\partial w_{21}}&\frac{\partial L}{\partial w_{22}}\\ \end{pmatrix} ∂W∂L= ∂w11∂L∂w21∂L∂w12∂L∂w22∂L
python的实现如下:
def numerical_gradient(f, x):h = 1e-4 # 0.0001grad = np.zeros_like(x)#初始化一个全0数组it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])#设置迭代器#操作对象为多维,操作为读写while not it.finished:idx = it.multi_indextmp_val = x[idx]x[idx] = float(tmp_val) + hfxh1 = f(x) # f(x+h)x[idx] = tmp_val - h fxh2 = f(x) # f(x-h)grad[idx] = (fxh1 - fxh2) / (2*h)x[idx] = tmp_val # 还原值it.iternext() return grad
学习算法的实现
神经网络的学习过程大致包括这几个部分:选出mini-batch,计算梯度,更新参数,循环往复,理解起来很简单,最关键的部分就是前面提到的梯度及其更新的部分。
随机梯度下降
随机梯度下降的概述很简单,在原数据中随机选择mini batch的数据,然后再计算梯度,再根据梯度下降的方向移动,进行下一次运算,循环往复,一般将该函数命名为SGD。
2层神经网络实现
书上实现了一个两层神经网络的类,一些函数在前面已经写过,在此不再赘述,附带注释的代码如下:
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
from common.functions import *
from common.gradient import numerical_gradientclass TwoLayerNet:def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):#输入层神经元数,隐藏层神经元数,输出层神经元数# 初始化权重self.params = {}self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)#随机初始化权重,使用高斯分布self.params['b1'] = np.zeros(hidden_size)#偏置初始化为0self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)#随机初始化权重self.params['b2'] = np.zeros(output_size)def predict(self, x):#推理过程W1, W2 = self.params['W1'], self.params['W2']b1, b2 = self.params['b1'], self.params['b2']a1 = np.dot(x, W1) + b1z1 = sigmoid(a1)a2 = np.dot(z1, W2) + b2y = softmax(a2)return y# x:输入数据, t:监督数据def loss(self, x, t):y = self.predict(x)return cross_entropy_error(y, t)def accuracy(self, x, t):#计算精准度y = self.predict(x)y = np.argmax(y, axis=1)#重新排列成一维数组t = np.argmax(t, axis=1)accuracy = np.sum(y == t) / float(x.shape[0])return accuracy# x:输入数据, t:监督数据def numerical_gradient(self, x, t):#进行梯度下降loss_W = lambda W: self.loss(x, t)#获得损失值grads = {}grads['W1'] = numerical_gradient(loss_W, self.params['W1'])grads['b1'] = numerical_gradient(loss_W, self.params['b1'])grads['W2'] = numerical_gradient(loss_W, self.params['W2'])grads['b2'] = numerical_gradient(loss_W, self.params['b2'])#向梯度减小的方向移动return grads
mini-batch实现
书上以MNIST数据集为基础,用两层神经网络进行了学习,修改和加上注释后,代码和运行结果如下:
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet# 读入数据
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)#加载数据network = TwoLayerNet(input_size=784, hidden_size=100, output_size=10)#创造一个神经网络类,隐藏层数据可以设置其他合理值iters_num = 10000 # 适当设定循环的次数
train_size = x_train.shape[0]
batch_size = 100#抽100个训练
learning_rate = 0.1train_loss_list = []
train_acc_list = []
test_acc_list = []iter_per_epoch = max(train_size / batch_size, 1)for i in range(iters_num):batch_mask = np.random.choice(train_size, batch_size)#选100个随机数x_batch = x_train[batch_mask]#获得下标t_batch = t_train[batch_mask]#获得下标# 计算梯度grad = network.numerical_gradient(x_batch, t_batch)#很慢,不如反向传播# 更新参数for key in ('W1', 'b1', 'W2', 'b2'):network.params[key] -= learning_rate * grad[key]loss = network.loss(x_batch, t_batch)#计算损失train_loss_list.append(loss)if i % iter_per_epoch == 0:#每次算完一小批就输出一次结果train_acc = network.accuracy(x_train, t_train)test_acc = network.accuracy(x_test, t_test)train_acc_list.append(train_acc)test_acc_list.append(test_acc)print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))# 绘制图形
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
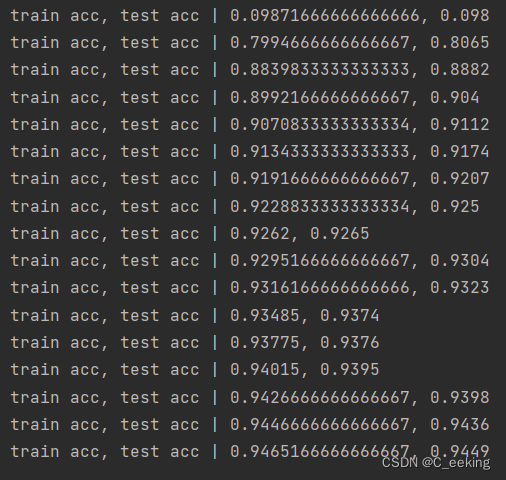
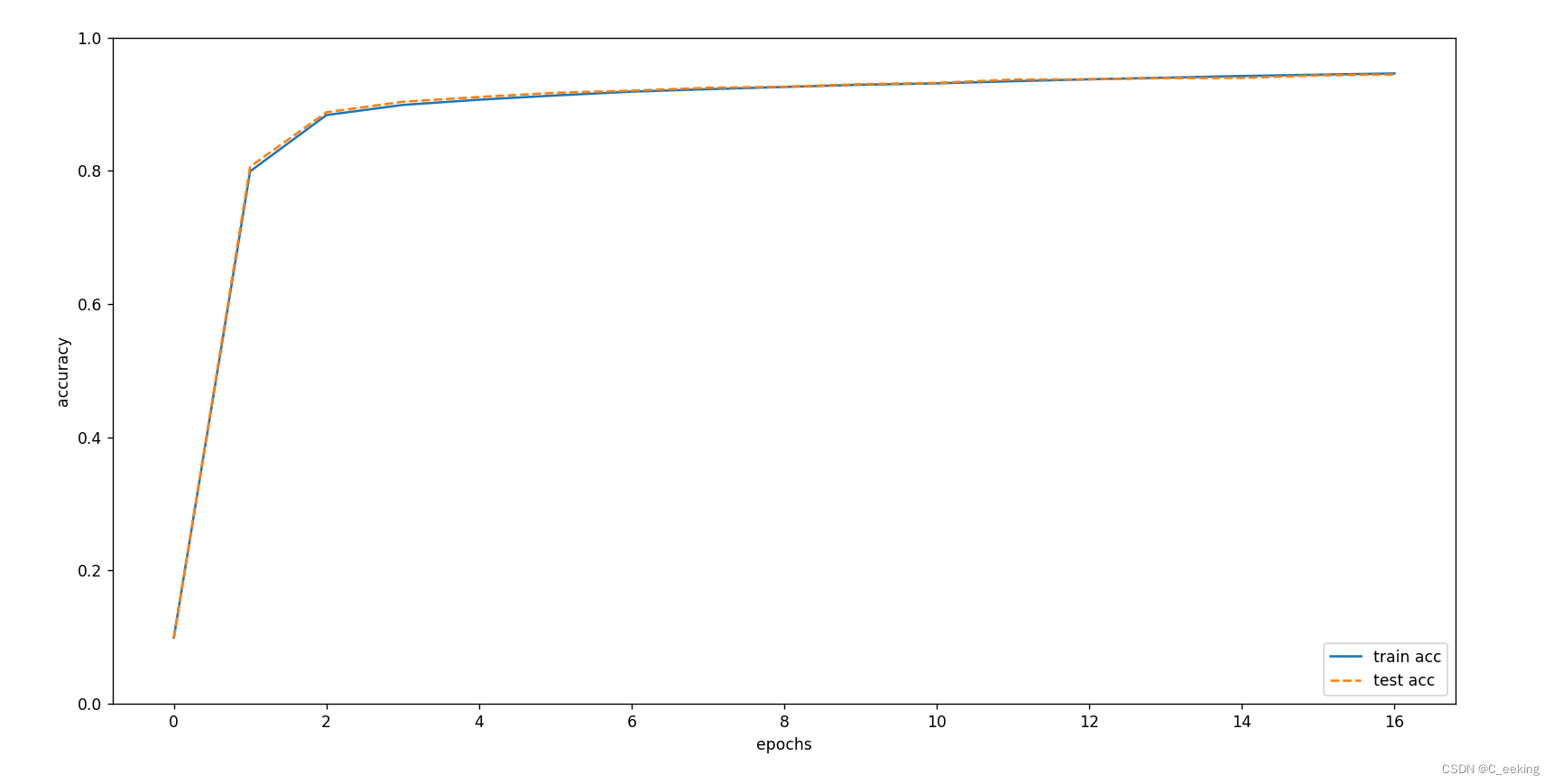
代码循环次数为10000,每一次都随机抽100个进行学习,计算损失函数值,输出一次学习结果,记录准确率,可以明显的看到准确率在逐渐增加,一般来说,准确率的增加也有可能意味着过拟合的出现,但是可以从图中看到,随着学习进行,训练数据和测试数据的精度几乎同步上升,且基本重合,因此可以说没有出现过拟合。
总结
神经网络的学习中有许多重要的概念,如梯度、损失函数、梯度下降等,在弄清楚了这些之后就能更好的理解神经网络的学习过程。
参考文献
- 《深度学习——基于Python的理论实现》
相关文章:
神经网络学习
神经网络学习 导语数据驱动驱动方法训练/测试数据 损失函数均方误差交叉熵误差mini-batch 数值微分梯度梯度法神经网络梯度 学习算法的实现随机梯度下降2层神经网络实现mini-batch实现 总结参考文献 导语 神经网络中的学习指从训练数据中自动获取最优权重参数的过程࿰…...

CentOS部署NFS
NFS服务端 部署NFS服务端 sudo yum install -y nfs-utils挂载目录 给 NFS 指定一个存储位置,也就是网络共享目录。一般来说,应该建立一个专门的 /data 目录,方便起见使用临时目录 /tmp/nfs: mkdir -p /tmp/nfs #修改权限 chmo…...

JWT使用方法
目录 基础概念 依赖 生成令牌 工具类 控制层 解析令牌 工具类 网关过滤器 效果 基础概念 Json web token (JWT), 是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准((RFC 7519).该token被设计为紧凑且安全的,特别适用于分布式站点…...

使用鱼香肉丝一键安装重新安装ROS后mavros节点报错,.so文件不匹配
解决方案: 1、写在mavros相关软件,共卸载7个包 sudo apt-get remove ros-melodic-mav*2、重新安装mavros,共安装10个包 sudo apt-get remove ros-melodic-mav*...
STM32+CubeMX移植SPI协议驱动W25Q16FLash存储器
STM32CubeMX移植SPI协议驱动W25Q16FLash存储器 SPI简介拓扑结构时钟相位(CPHA)和时钟极性( CPOL) W25Q16简介什么是Flash,有什么特点?W25Q16内部块、扇区、页的划分引脚定义通讯方式控制指令原理图 CubeMX配…...

gpt-4o考场安排
说明 :经过多次交互,前后花了几个小时,总算完成了基本功能。如果做到按不同层次分配考场,一键出打印结果就完美了。如果不想看中间“艰苦”的过程,请直接跳到“最后结果”及“食用方法”。中间过程还省略了一部分交互&…...
【Unity AR开发插件】四、制作热更数据-AR图片识别场景
专栏 本专栏将介绍如何使用这个支持热更的AR开发插件,快速地开发AR应用。 链接: Unity开发AR系列 插件简介 通过热更技术实现动态地加载AR场景,简化了AR开发流程,让用户可更多地关注Unity场景内容的制作。 “EnvInstaller…”支…...

Spring AOP的实操 + 原理(动态代理)
1 什么是Spring AOP 要想知道Spring AOP那必然是是要先知道什么是AOP了: AOP,全称为 Aspect-Oriented Programming(面向切面编程),是一种编程范式,用于提高代码的模块化,特别是横切关注点(cros…...
16.线性回归代码实现
线性回归的实操与理解 介绍 线性回归是一种广泛应用的统计方法,用于建模一个或多个自变量(特征)与因变量(目标)之间的线性关系。在机器学习和数据科学中,线性回归是许多入门者的第一个模型,它…...
Java进阶学习笔记1——课程介绍
课程适合学习的人员: 1)具备一定java基础的人员; 2)想深刻体会Java编程思想,成为大牛的人员; 学完有什么收获? 1)掌握完整的Java基础技术体系; 2)极强的编…...
【全开源】沃德商协会管理系统源码(FastAdmin+ThinkPHP+Uniapp)
一款基于FastAdminThinkPHPUniapp开发的商协会系统,新一代数字化商协会运营管理系统,以“智慧化会员体系、智敏化内容运营、智能化活动构建”三大板块为基点,实施功能全场景覆盖,一站式解决商协会需求壁垒,有效快速建立…...
)
python毕设项目选题汇总(全)
各位计算机方面的毕业生们,是不是在头疼毕业论文写什么呢,我这给大家提供点思路: 网站系统类 《基于python的招聘数据爬虫设计与实现》 《基于python和Flask的图书管理系统》 《基于照片分享的旅游景点推荐系统》 《基于djangoxadmin的学生信…...

c#从数据库读取数据到datagridview
从已有的数据库读取数据显示到winform的datagridview控件,具体代码如下: //判断有无表 if (sqliteConn.State ConnectionState.Closed) sqliteConn.Open(); SQLiteCommand mDbCmd sqliteConn.CreateCommand(); m…...
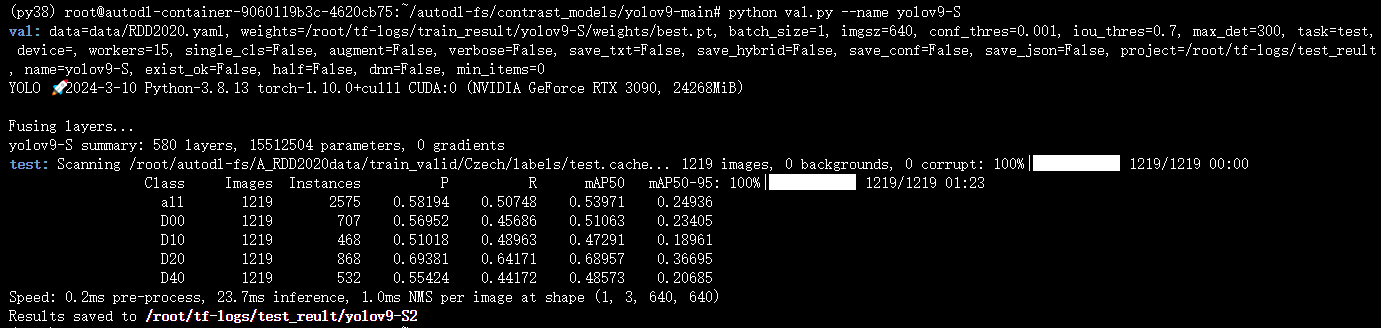
训练YOLOv9-S(注意:官方还没有提供YOLOv9-S的网络,我这是根据网络博客进行的步骤,按照0.33、0.50比例调整网络大小,参数量15.60M,计算量67.7GFLOPs)
文章目录 1、自己动手制造一个YOLOv9-S网络结构1.1 改前改后的网络结构(参数量、计算量)对比1.2 一些发现,YOLOv9代码打印的参数量计算量和Github上提供的并不一致,甚至yolov9-c.yaml代码打印出来是Github的两倍1.3 开始创造YOLOv…...

视觉检测实战项目——九点标定
本文介绍九点标定方法 已知 9 个点的图像坐标和对应的机械坐标,直接计算转换矩阵,核心原理即最小二乘拟合 {𝑥′=𝑎𝑥+𝑏𝑦+𝑐𝑦′=𝑎′𝑥+𝑏′𝑦+𝑐′ [𝑥1𝑦11𝑥2𝑦21⋮⋮⋮𝑥9𝑦91][𝑎𝑎′𝑏𝑏′𝑐𝑐′]=[𝑥1′𝑦…...

android git提交代码命令以及常见命令的使用
安装Git Ubuntu: sudo apt-get install git-core创建代码仓库: 配置身份: git config --global user.name "Tony" git confit --global user.email "tonygmail.com"查看身份: git config --global user.…...
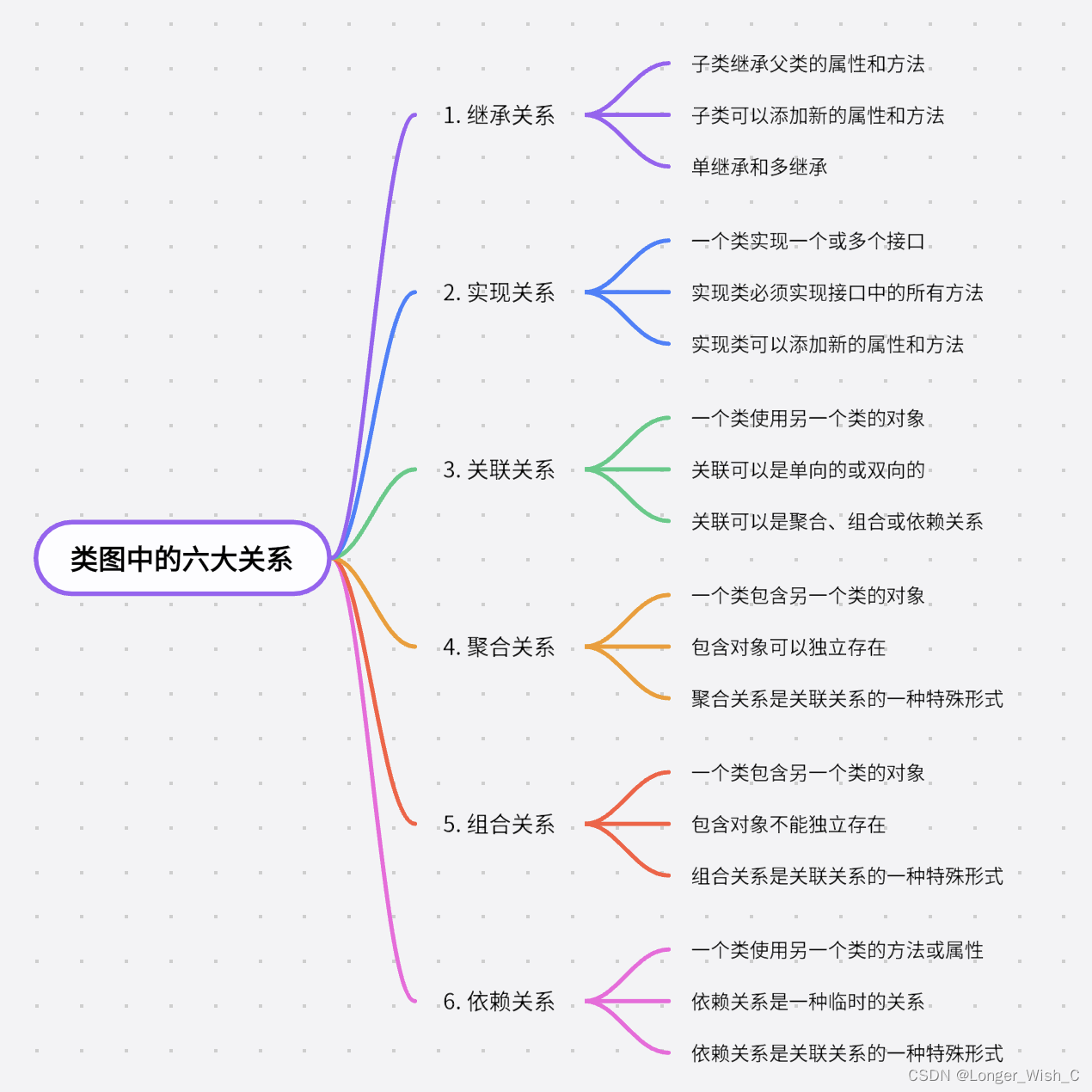
类图的六大关系
类图中的六大关系包括:继承关系、实现关系、关联关系、聚合关系、组合关系和依赖关系。 1. 继承关系 继承是一种类与类之间的关系,表示一种泛化和特化的关系。子类继承父类的特性和行为。 class Animal {void eat() {System.out.println("This an…...
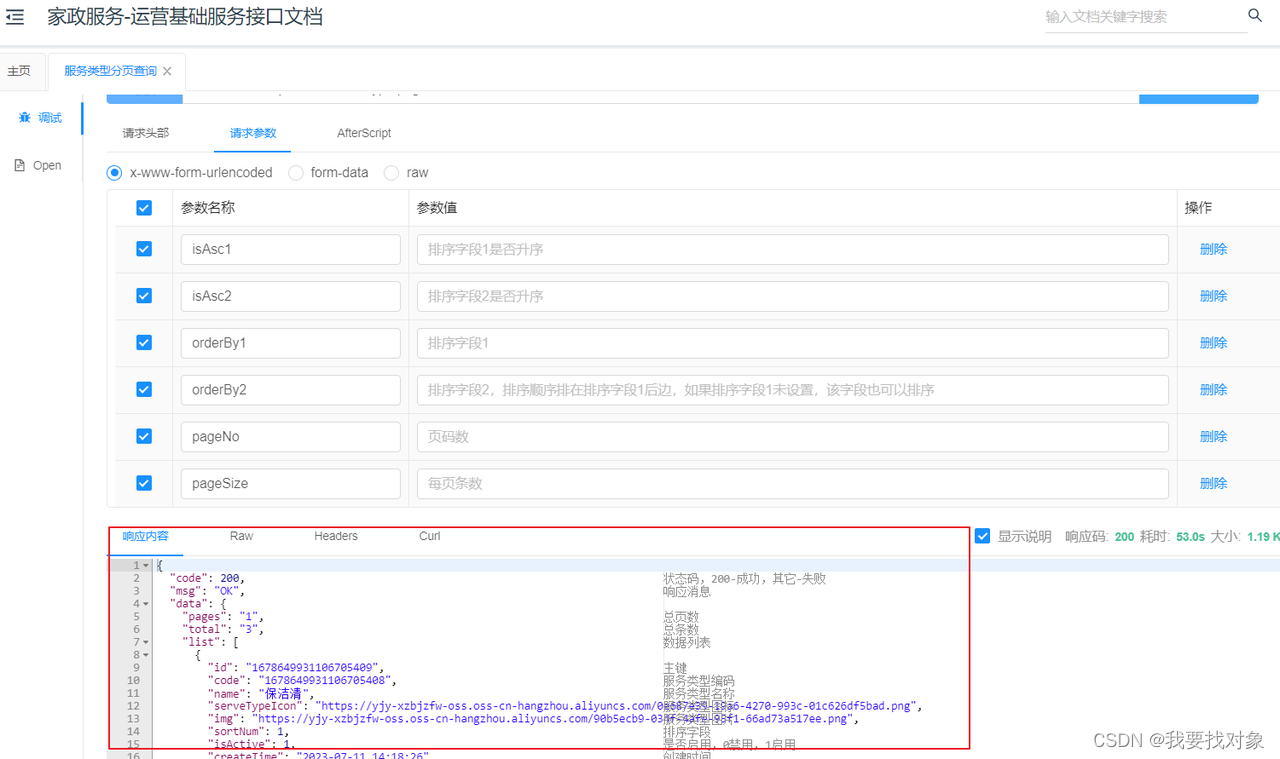
家政项目day2 需求分析(模拟入职后熟悉业务流程)
目录 1 项目主体介绍1.1 项目背景1.2 运营模式1.3 项目业务流程 2 运营端需求2.1 服务类型管理2.2 服务项目(服务)管理2.3 区域管理2.4 区域服务管理2.5 相关数据库表的管理2.6 设计工程结构2.7 测试接口(接口断点查看业务代码) 3…...

面试总结之:socket线路切换
"socket线路切换"通常指的是在网络通信过程中,根据当前网络状态或策略来动态更换数据传输路径的技术。这种技术可以提高通信的可靠性和性能。 在实际应用中,线路切换可能涉及到多种技术,例如: 负载均衡:根据每条路径的当前负载情况,动态地选择一条较为空闲的路…...

002 递归评论 mongodb websocket消息推送
文章目录 商品评论CommentController.javaComment.javaCommentServiceImpl.javaCommentRepository.javaCommentService.javaWebSocketConfig.javaWebSocketProcess.javaapplication.yamlproductReview.htmlindex.htmlindex.jsindex.css 订单评论EvaluateMapper.xmlEvaluateMapp…...

ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题
ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vari…...

从入门到上岗,Java+AI 复合型人才养成攻略
当下编程行业格局正在悄然改变,纯 Java 后端岗位内卷日趋严重,薪资增长逐步放缓;纯粹的 AI 算法岗门槛居高不下,对学历、数理功底要求严苛,普通开发者很难入局。 而Java+AI 复合型开发顺势成为行业刚需岗位,既依托成熟的 Java 体系承接业务开发,又能融入人工智能技术实…...

软阴影:那个让虚拟世界“温柔起来“的光影小秘密
一、从一只小猫的影子说起 前几天我在朋友家做客,他家养了一只胖乎乎的橘猫,正趴在阳台的窗边晒太阳。我无意间瞥了一眼那只猫脚边的影子,突然被一个细节震撼了—— 那只猫的影子——并不是一片均匀的黑。 仔细看——猫肚子紧贴地板的地方——…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...
)
保姆级教程:Windows系统下Arcgis 10.2从下载、安装到汉化一次搞定(附常见License启动失败解决方案)
Windows系统下Arcgis 10.2完整安装与汉化实战指南第一次接触Arcgis的新手往往会被复杂的安装流程和神秘的License Manager搞得晕头转向。作为一款功能强大的地理信息系统软件,Arcgis在科研、城市规划、环境监测等领域有着广泛应用,但它的安装过程确实会让…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

TorchDynamo与TorchInductor:PyTorch编译器生态的完整解析
TorchDynamo与TorchInductor:PyTorch编译器生态的完整解析 【免费下载链接】torchdynamo A Python-level JIT compiler designed to make unmodified PyTorch programs faster. 项目地址: https://gitcode.com/gh_mirrors/to/torchdynamo TorchDynamo 是一个…...

打造XBEE封装BLE112蓝牙模块:硬件设计、射频布局与调试全攻略
1. 项目概述:为什么我们需要一个“XBEE格式”的蓝牙模块?在嵌入式开发和物联网项目中,无线通信模块的选择往往决定了项目的成败。对于很多工程师和创客来说,Silicon Labs(芯科科技)的BLE112/113模块是蓝牙4…...

Keil µVision反汇编窗口内容导出方案与调试技巧
1. 问题背景与需求解析在嵌入式开发过程中,调试环节往往占据大量时间。Keil Vision作为业界广泛使用的集成开发环境(IDE),其调试器功能强大但某些细节功能仍有提升空间。最近我在使用C251架构开发汽车电子控制单元时,就遇到了一个看似简单却影…...