131. 面试中关于架构设计都需要了解哪些内容?
文章目录
- 一、社区系统架构组件概览
- 1. 系统拆分
- 2. CDN、Nginx静态缓存、JVM本地缓存
- 3. Redis缓存
- 4. MQ
- 5. 分库分表
- 6. 读写分离
- 7. ElasticSearch
- 二、商城系统-亿级商品如何存储
- 三、对账系统-分布式事务一致性
- 四、统计系统-海量计数
- 六、系统设计 - 微软
- 1、需求收集
- 2、顶层设计
- 3、系统核心指标
- 4、数据存储
- 七、如何设计一个微博
一、社区系统架构组件概览
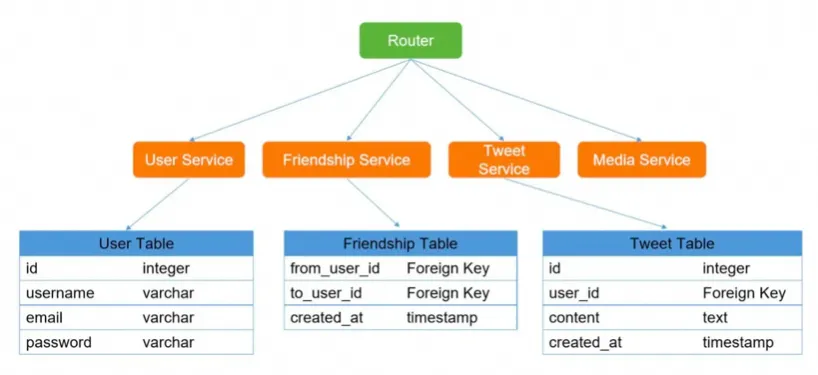
一个非常简易的系统架构大致如下: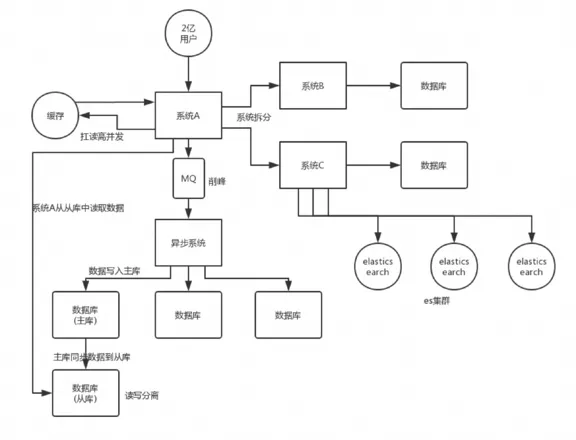
接下来就以上图为例,剖析每个组件的作用。
1. 系统拆分
通过DDD领域模型,对服务进行拆分,将一个系统拆分为多个子系统,做成微服务。微服务设计时要尽可能做到少扇出,多扇入,根据服务器的承载,进行客户端负载均衡,通过对核心服务的上游服务进行限流和降级改造。
一个服务的代码不要太多,1万行左右,两三万撑死了吧。
大部分的系统,是要进行多轮拆分的,第一次拆分,可能就是将以前的多个模块该拆分开来了,比如说将电商系统拆分成订单系统、商品系统、采购系统、仓储系统、用户系统等等吧。
但是后面可能每个系统又变得越来越复杂了,比如说采购系统里面又分成了供应商管理系统、采购单管理系统,订单系统又拆分成了购物车系统、价格系统、订单管理系统。
2. CDN、Nginx静态缓存、JVM本地缓存
利用Java的模板thymeleaf可以将页面和数据动态渲染好,然后通过Nginx直接返回。动态数据可以从redis中获取。其中redis里的数据由一个缓存服务来进行消费指定的变更服务。
商品数据,每条数据是10kb。100条数据是1mb,10万条数据是1g。常驻内存的是 200万条商品数据,占用内存是20g,仅仅不到总内存的50%。目前高峰期每秒就是 3500qps左右的请求量。
3. Redis缓存
Redis cluster,10台机器,5主5从,5个节点对外提供读写服务,每个节点的读写高峰QPS可能可以达到每秒5万,5台机器最多是25万读写请求每秒。
注:一般一台Redis实例最大能承受的QPS在16万左右。
32G内存+ 8核CPU + 1T磁盘,但是分配给Redis进程的是10g内存,一般线上生产环境,Redis的内存尽量不要超过10g,超过10g可能会有问题。
因为每个主实例都挂了一个从实例,所以是高可用的,任何一个主实例宕机,都会自动故障迁移,Redis从实例会自动变成主实例继续提供读写服务。
4. MQ
可以通过消息队列对微服务系统进行解耦,异步调用的更适合微服务的扩展。
同时可以应对秒杀活动中的高并发写请求,比如kafka在毫秒延迟基础上可以实现10w级吞吐量。
同时可以使用消息队列保证分布式系统最终一致性。
5. 分库分表
分库分表,可能到了最后数据库层面还是免不了抗高并发的要求,好吧,那么就 将一个数据库拆分为多个库,多个库来扛更高的并发;然后将一个表拆分为多个 表,每个表的数据量保持少一点,提高sql跑的性能。在通讯录、订单和商城商品模块超过千万级别都应及时考虑分表分库。一般单表保存的数据尽量不要超过4千万,否则查询性能可能受损,数据过大时,及时考虑分表处理,实际在需求初期就应该调研量级,考虑分表方案。
6. 读写分离
读写分离,这个就是说大部分时候数据库可能也是读多写少,没必要所有请求都 集中在一个库上吧,可以搞个主从架构,主库写入,从库读取,搞一个读写分离。读流量太多的时候,还可以加更多的从库。比如统计监控类的微服务通过读写分离,只需访问从库就可以完成统计,例如使用ES完成统计诉求,读从库即可。
7. ElasticSearch
Elasticsearch,简称es。es是分布式的,分布式天然就可以支撑高并发,因为动不动就可以扩容加机器来扛更高的并发。那么一些比较简单的查询、统计类的操作,比如运营平台上的各地市的汇聚统计,还有一些全文搜索类的操作,比如通讯录和订单的查询,都很适合用es存储。
二、商城系统-亿级商品如何存储
基于Hash取模、一致性Hash实现分库分表。
高并发读可以通过多级缓存应对。
大促销热key读的问题通过 redis集群+本地缓存+限流+key加随机值分布在多个实例中。
高并发写的问题通过基于Hash取模、一致性Hash实现分库分表均匀落盘。
业务分配不均导致的热key读写问题,可以根据业务场景进行range分片,将热点范围下的子key打散。
具体实现: 预先设定主键的生成规则,根据规则进行数据的分片路由,但这种方式会侵入商品各条线主数据的业务规则,更好的方式是基于分片元数据服务器(即每次访问分片前先询问分片元服务器再路由到实际分片),不过会带来复杂性,比如如何保证元数据服务器的一致性和可用性。
三、对账系统-分布式事务一致性
尽量避免分布式事务,单进程用数据库事务,跨进程用消息队列。
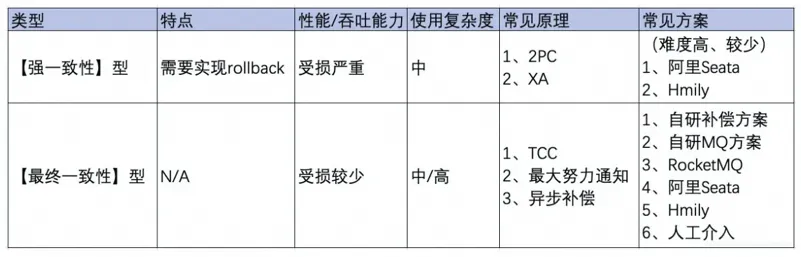
主流实现分布式系统事务一致性的方案:
-
最终一致性:也就是基于
MQ的可靠消息投递的机制, -
基于重试加确认的的最大努力通知方案。
理论上也可以使用(2PC两阶段提交、3PC三阶段提交、TCC短事务、SAGA长事务方案),但是这些方案工业上落地代价很大,不适合互联网的业界场景。针对金融支付等需要强一致性的场景可以通过前两种方案实现。
本地数据库事务原理:undo log(原子性) + redo log(持久性) + 数据库锁(原子性&隔离性) + MVCC(隔离性)
分布式事务原理:全局事务协调器(原子性) + 全局锁(隔离性) + DB本地事务(原子性、持久性)
MQ方式实现一致性应该保证以下两点
- 要求下游MQ消费方一定能成功消费消息。否则转人工介入处理。
- 千万记得实现幂等性。
四、统计系统-海量计数
中小规模的计数服务(万级)
中小规模量级,最常见的计数方案是采用缓存+DB的存储方案。当计数变更时,先变更计数DB,计数加 1,然后再变更计数缓存,修改计数存储的Memcached或Redis。这种方案比较通用且成熟,但在高并发访问场景,支持不够友好。
在互联网社交系统中,有些业务的计数变更特别频繁,比如微博feed的阅读数,计数的变更次数和访问次数相当,每秒十万到百万级以上的更新量,如果用DB存储,会给DB带来巨大的压力,DB就会成为整个计数服务的瓶颈所在。即便采用聚合延迟更新DB的方案,由于总量特别大,同时请求均衡分散在大量不同的业务端,巨大的写压力仍然是DB的不可承受之重。
大型互联网场景(百万级)
百万及以上量级,建议直接把计数全部存储在Redis中,通过 hash 分拆的方式,可以大幅提升计数服务在Redis集群的写性能,通过主从复制,在master后挂载多个从库,利用读写分离,可以大幅提升计数服务在Redis集群的读性能。而且Redis有持久化机制,不会丢数据。
但也不是万无一失的,要以下方面要考虑。
一方面Redis作为通用型存储来存储计数,内存存储效率低。以存储一个key为long(8字节)型id、value为4字节的计数为例,Redis至少需要65个字节左右(以为要记录很多其他元信息),不同版本略有差异。但这个计数理论只需要占用12个字节即可。内存有效负荷只有12/65=18.5%。如果再考虑一个long型id需要存4个不同类型的4字节计数,内存有效负荷只有(8+16)/(65*4)= 9.2%。
另一方面,Redis所有数据均存在内存,单存储历史千亿级记录,单份数据拷贝需要10T以上,要考虑核心业务上1主3从,需要40T以上的内存,再考虑多IDC部署,轻松占用上百T内存。就按单机100G内存来算,计数服务就要占用上千台大内存服务器。存储成本太高。
微博、微信、抖音(亿级)
亿级别数据,应该考虑通过以下方式存储
- 定制数据结构,共享
key紧凑存储,提升计数有效负荷率; - 超过阈值后数据保存到
SSD硬盘,内存里存索引; - 冷
key从SSD硬盘中读取后,放入到LRU队列中; - 自定义主从复制的方式,海量冷数据异步多线程并发复制;
六、系统设计 - 微软
1、需求收集
- 确认使用的对象
ToC:高并发ToB:高可用
- 系统的服务场景
- 即时通信:低延迟
- 游戏:高性能
- 购物:秒杀-一致性
- 用户量级
- 万级:双机
- 百万:集群
- 亿级:弹性分布式、容器化编排架构
- 百万读:
3主6从,每个节点的读写高峰QPS可能可以达到每秒5万,可以实现15万,30万读性能 - 亿级读: 通过
CDN、静态缓存、JVM缓存等多级缓存来提高读并发 - 百万写: 通过消息队列削峰填谷,通过
hash分拆,水平扩展分布式缓存 - 亿级写:
redis可以定制数据结构、SSD+内存LRU、冷数据异步多线程复制 - 持久化:
Mysql承受量约为1K的QPS,读写分离提升读并发,分库分表提升写并发
2、顶层设计
核心功能包括什么:
-
写功能:发送微博
-
读功能:热点资讯
-
交互:点赞、关注
3、系统核心指标
-
系统性能和延迟
-
边缘计算 | 动静分离 | 缓存 | 多线程 |
-
可扩展性和吞吐量
-
负载均衡 | 水平扩展 | 垂直扩展 | 异步 | 批处理 | 读写分离
-
可用性和一致性
-
主从复制 | 哨兵模式 | 集群 | 分布式事务
4、数据存储
-
键值存储 :
Redis( 热点资讯 ) -
文档存储 :
MongoDB( 微博文档分类) -
分词倒排:
Elasticsearch(搜索) -
列型存储:
Hbase、BigTable(大数据) -
图形存储:
Neo4j(社交及推荐) -
多媒体:
FastDfs(图文视频微博)
七、如何设计一个微博
实现哪些功能:
筛选出核心功能(Post a Tweet,Timeline,News Feed,Follow/Unfollow a user,Register/Login)
承担多大QPS:
- QPS = 100,那么用我的笔记本作Web服务器就好了
- QPS = 1K,一台好点的Web服务器也能应付,需要考虑单点故障;
- QPS = 1m,则需要建设一个1000台Web服务器的集群,考虑动态扩容、负载分担、故障转移
- 一台SQL Database (Mysql)承受量约为1K的QPS;
- 一台NoSQL Database (Redis) 约承受量是20k的QPS;
- 一台NoSQL Database (Memcache) 约承受量是200k的QPS;
微服务战略拆分
针对不同服务选择不同存储
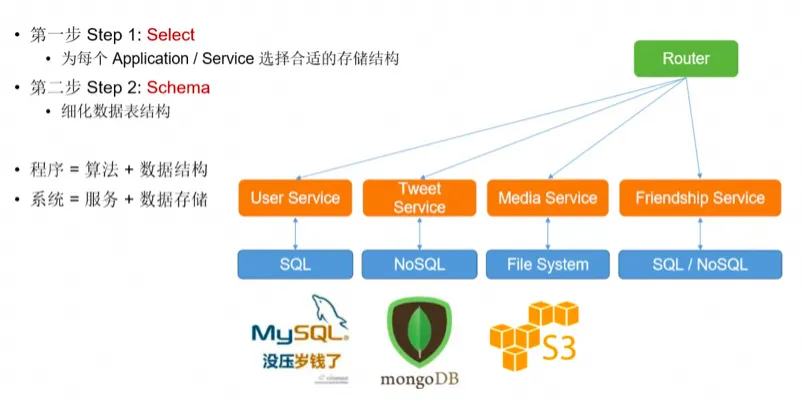
设计数据表的结构
基本差不多就形成了一个解决方案,但是并不是完美的,仍然需要小步快跑的不断的针对消息队列、缓存、分布式事务、分表分库、大数据、监控、可伸缩方面进行优化。
相关文章:
131. 面试中关于架构设计都需要了解哪些内容?
文章目录 一、社区系统架构组件概览1. 系统拆分2. CDN、Nginx静态缓存、JVM本地缓存3. Redis缓存4. MQ5. 分库分表6. 读写分离7. ElasticSearch 二、商城系统-亿级商品如何存储三、对账系统-分布式事务一致性四、统计系统-海量计数六、系统设计 - 微软1、需求收集2、顶层设计3、…...
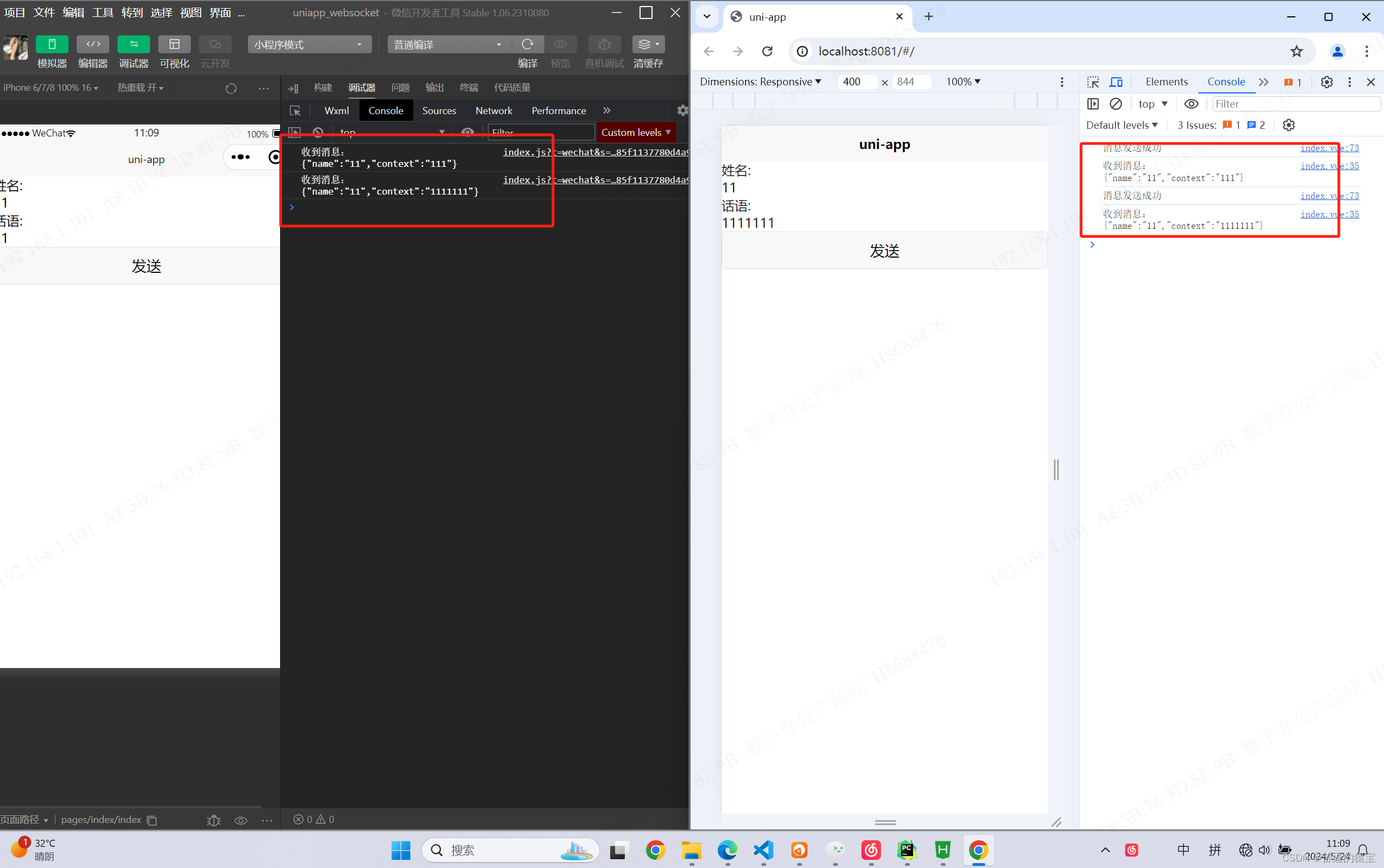
Nodejs+Websocket+uniapp完成聊天
前言 最近想做一个聊天,但是网上的很多都是不能实现的,要么就是缺少代码片段很难实现websocket的链接,更别说聊天了。自己研究了一番之后实现了这个功能。值得注意的是,我想在小程序中使用socket.io,不好使࿰…...
神经网络学习
神经网络学习 导语数据驱动驱动方法训练/测试数据 损失函数均方误差交叉熵误差mini-batch 数值微分梯度梯度法神经网络梯度 学习算法的实现随机梯度下降2层神经网络实现mini-batch实现 总结参考文献 导语 神经网络中的学习指从训练数据中自动获取最优权重参数的过程࿰…...

CentOS部署NFS
NFS服务端 部署NFS服务端 sudo yum install -y nfs-utils挂载目录 给 NFS 指定一个存储位置,也就是网络共享目录。一般来说,应该建立一个专门的 /data 目录,方便起见使用临时目录 /tmp/nfs: mkdir -p /tmp/nfs #修改权限 chmo…...

JWT使用方法
目录 基础概念 依赖 生成令牌 工具类 控制层 解析令牌 工具类 网关过滤器 效果 基础概念 Json web token (JWT), 是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准((RFC 7519).该token被设计为紧凑且安全的,特别适用于分布式站点…...

使用鱼香肉丝一键安装重新安装ROS后mavros节点报错,.so文件不匹配
解决方案: 1、写在mavros相关软件,共卸载7个包 sudo apt-get remove ros-melodic-mav*2、重新安装mavros,共安装10个包 sudo apt-get remove ros-melodic-mav*...
STM32+CubeMX移植SPI协议驱动W25Q16FLash存储器
STM32CubeMX移植SPI协议驱动W25Q16FLash存储器 SPI简介拓扑结构时钟相位(CPHA)和时钟极性( CPOL) W25Q16简介什么是Flash,有什么特点?W25Q16内部块、扇区、页的划分引脚定义通讯方式控制指令原理图 CubeMX配…...

gpt-4o考场安排
说明 :经过多次交互,前后花了几个小时,总算完成了基本功能。如果做到按不同层次分配考场,一键出打印结果就完美了。如果不想看中间“艰苦”的过程,请直接跳到“最后结果”及“食用方法”。中间过程还省略了一部分交互&…...
【Unity AR开发插件】四、制作热更数据-AR图片识别场景
专栏 本专栏将介绍如何使用这个支持热更的AR开发插件,快速地开发AR应用。 链接: Unity开发AR系列 插件简介 通过热更技术实现动态地加载AR场景,简化了AR开发流程,让用户可更多地关注Unity场景内容的制作。 “EnvInstaller…”支…...

Spring AOP的实操 + 原理(动态代理)
1 什么是Spring AOP 要想知道Spring AOP那必然是是要先知道什么是AOP了: AOP,全称为 Aspect-Oriented Programming(面向切面编程),是一种编程范式,用于提高代码的模块化,特别是横切关注点(cros…...
16.线性回归代码实现
线性回归的实操与理解 介绍 线性回归是一种广泛应用的统计方法,用于建模一个或多个自变量(特征)与因变量(目标)之间的线性关系。在机器学习和数据科学中,线性回归是许多入门者的第一个模型,它…...
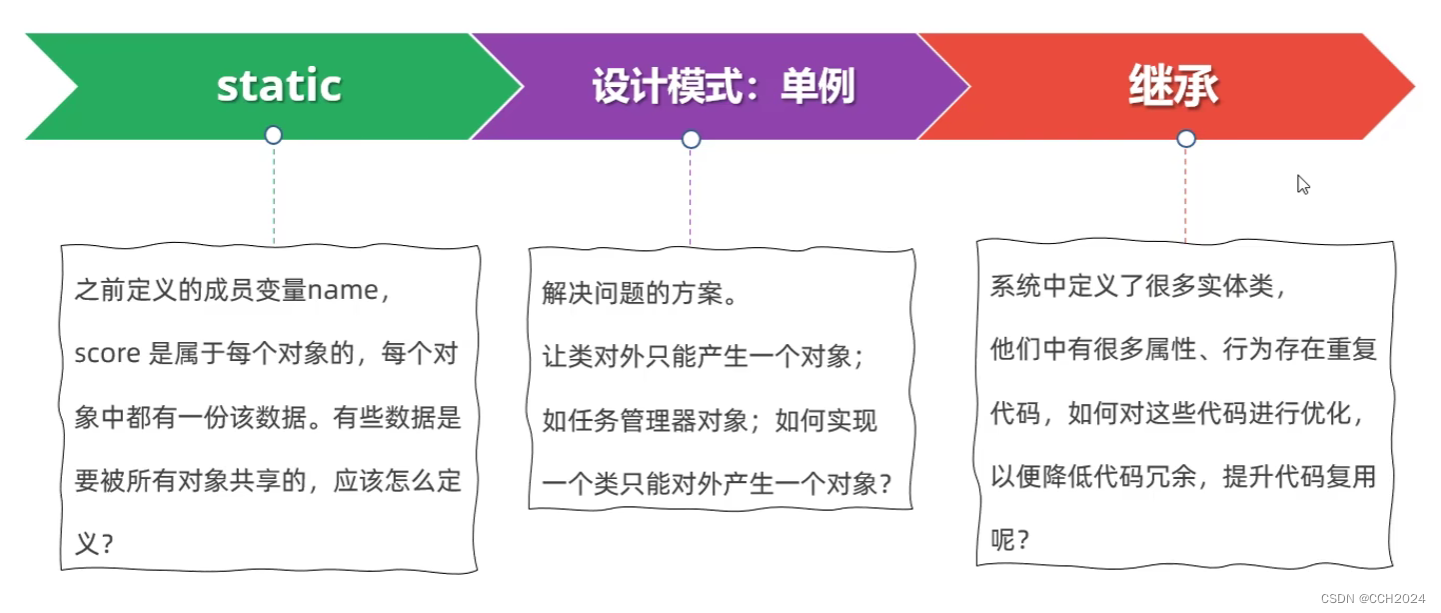
Java进阶学习笔记1——课程介绍
课程适合学习的人员: 1)具备一定java基础的人员; 2)想深刻体会Java编程思想,成为大牛的人员; 学完有什么收获? 1)掌握完整的Java基础技术体系; 2)极强的编…...
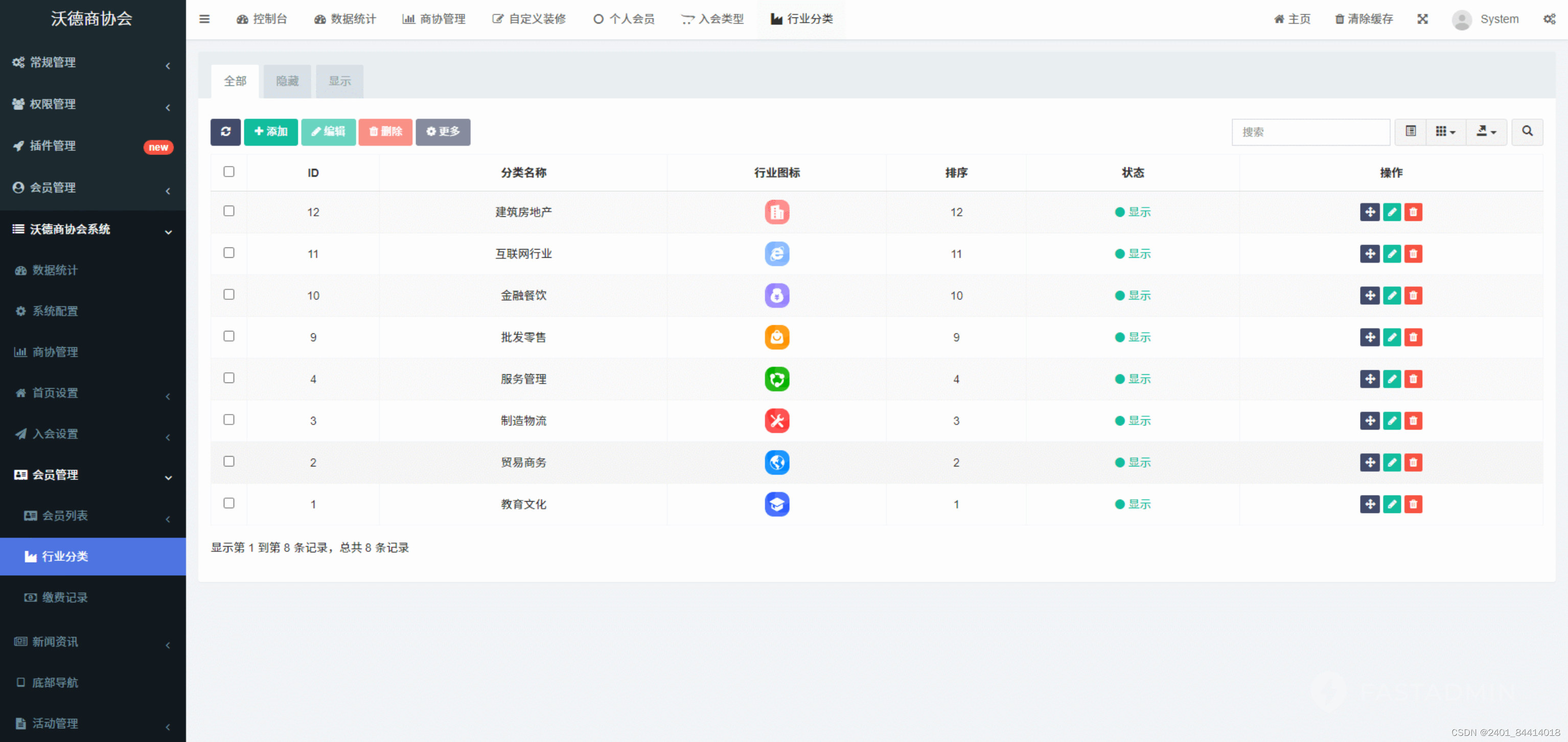
【全开源】沃德商协会管理系统源码(FastAdmin+ThinkPHP+Uniapp)
一款基于FastAdminThinkPHPUniapp开发的商协会系统,新一代数字化商协会运营管理系统,以“智慧化会员体系、智敏化内容运营、智能化活动构建”三大板块为基点,实施功能全场景覆盖,一站式解决商协会需求壁垒,有效快速建立…...
)
python毕设项目选题汇总(全)
各位计算机方面的毕业生们,是不是在头疼毕业论文写什么呢,我这给大家提供点思路: 网站系统类 《基于python的招聘数据爬虫设计与实现》 《基于python和Flask的图书管理系统》 《基于照片分享的旅游景点推荐系统》 《基于djangoxadmin的学生信…...

c#从数据库读取数据到datagridview
从已有的数据库读取数据显示到winform的datagridview控件,具体代码如下: //判断有无表 if (sqliteConn.State ConnectionState.Closed) sqliteConn.Open(); SQLiteCommand mDbCmd sqliteConn.CreateCommand(); m…...
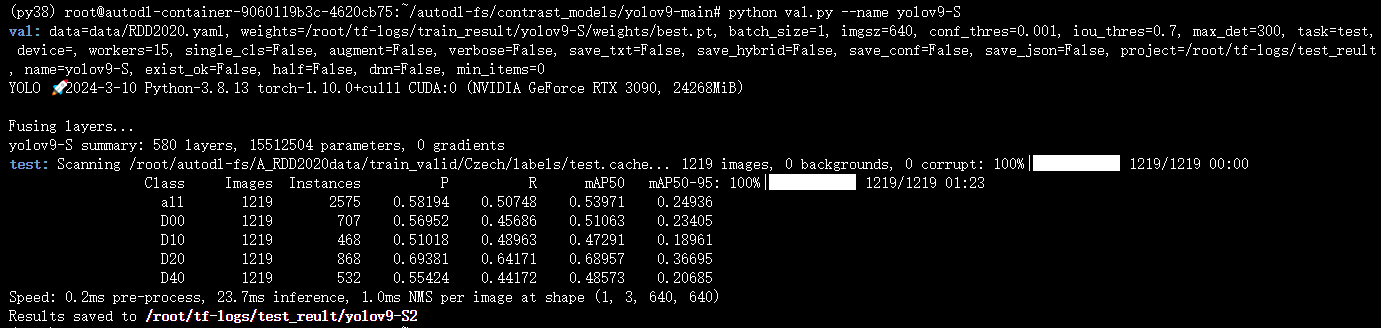
训练YOLOv9-S(注意:官方还没有提供YOLOv9-S的网络,我这是根据网络博客进行的步骤,按照0.33、0.50比例调整网络大小,参数量15.60M,计算量67.7GFLOPs)
文章目录 1、自己动手制造一个YOLOv9-S网络结构1.1 改前改后的网络结构(参数量、计算量)对比1.2 一些发现,YOLOv9代码打印的参数量计算量和Github上提供的并不一致,甚至yolov9-c.yaml代码打印出来是Github的两倍1.3 开始创造YOLOv…...

视觉检测实战项目——九点标定
本文介绍九点标定方法 已知 9 个点的图像坐标和对应的机械坐标,直接计算转换矩阵,核心原理即最小二乘拟合 {𝑥′=𝑎𝑥+𝑏𝑦+𝑐𝑦′=𝑎′𝑥+𝑏′𝑦+𝑐′ [𝑥1𝑦11𝑥2𝑦21⋮⋮⋮𝑥9𝑦91][𝑎𝑎′𝑏𝑏′𝑐𝑐′]=[𝑥1′𝑦…...

android git提交代码命令以及常见命令的使用
安装Git Ubuntu: sudo apt-get install git-core创建代码仓库: 配置身份: git config --global user.name "Tony" git confit --global user.email "tonygmail.com"查看身份: git config --global user.…...
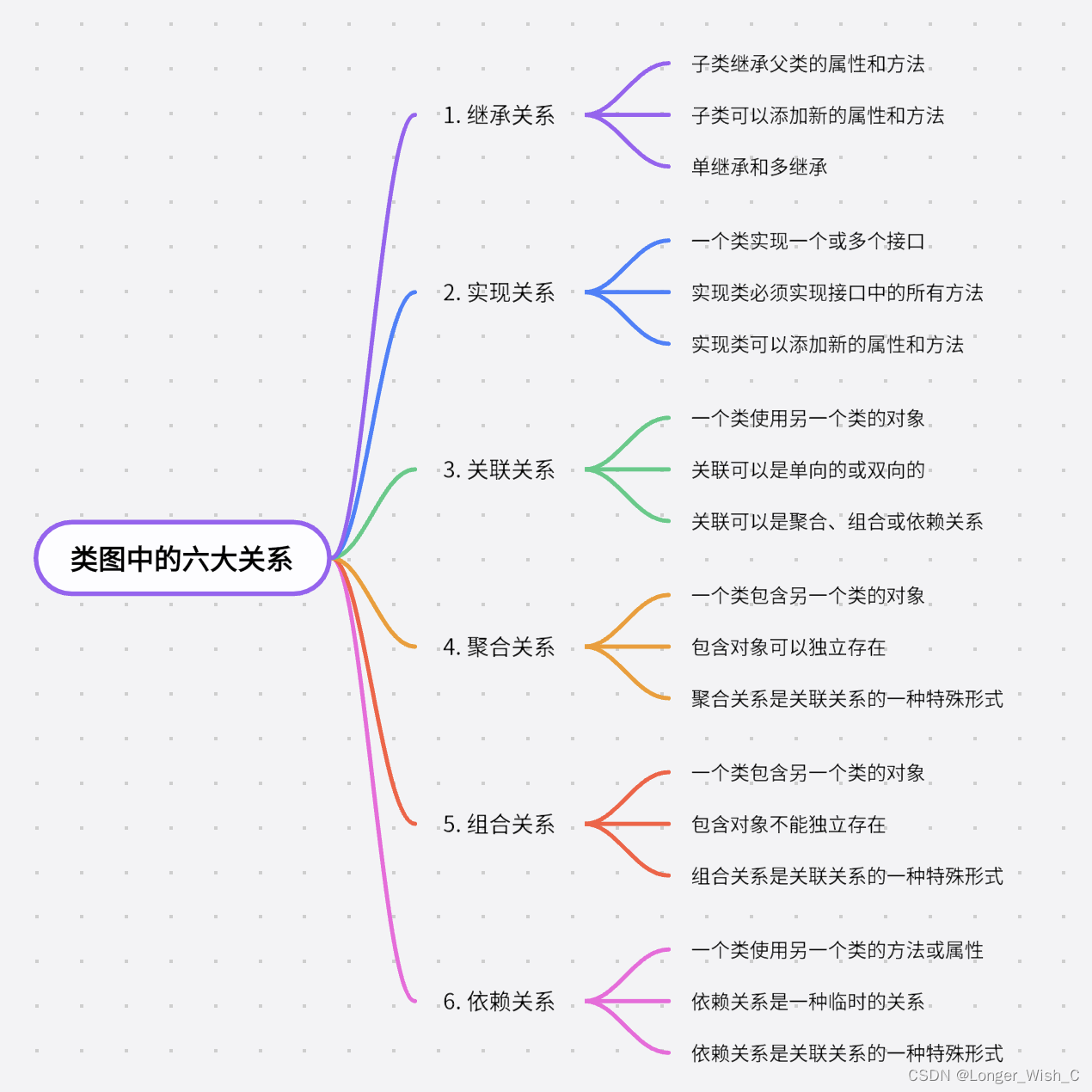
类图的六大关系
类图中的六大关系包括:继承关系、实现关系、关联关系、聚合关系、组合关系和依赖关系。 1. 继承关系 继承是一种类与类之间的关系,表示一种泛化和特化的关系。子类继承父类的特性和行为。 class Animal {void eat() {System.out.println("This an…...
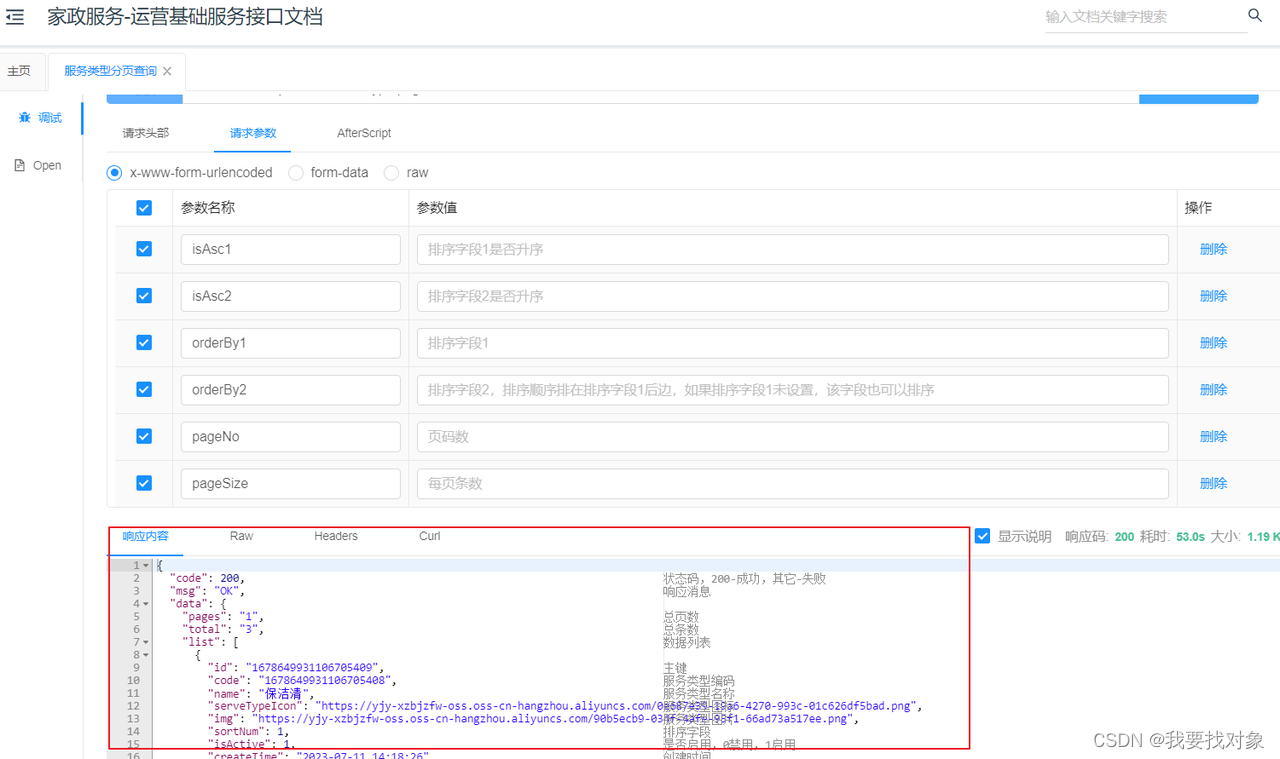
家政项目day2 需求分析(模拟入职后熟悉业务流程)
目录 1 项目主体介绍1.1 项目背景1.2 运营模式1.3 项目业务流程 2 运营端需求2.1 服务类型管理2.2 服务项目(服务)管理2.3 区域管理2.4 区域服务管理2.5 相关数据库表的管理2.6 设计工程结构2.7 测试接口(接口断点查看业务代码) 3…...

机器学习与深度学习在地球物理勘探中的应用:基于电阻率数据预测极化率模型
1. 项目概述与核心价值在花岗岩这类地质条件复杂的地区搞勘探,最头疼的就是地下情况“看不清”。传统的电阻率(ERT)和激发极化(IP)联合反演,就像用一把刻度模糊的尺子去量一块表面坑洼不平的石头——面对高…...

内网环境下Win7系统批量离线补丁部署实战指南
1. 内网Win7补丁部署的挑战与解决方案老旧Win7系统在内网环境中的安全隐患就像漏雨的屋顶,看似不影响日常使用,但随时可能引发严重后果。我经手过几十家单位的系统加固项目,发现这些场景存在三个典型痛点:首先是补丁来源问题&…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

如何高效批量下载音乐歌词:智能歌词管理完整指南
如何高效批量下载音乐歌词:智能歌词管理完整指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX ZonyLrcToolsX 是一款专业的跨平台歌词下载工具,…...

OpenClaw用户如何快速接入Taotoken并开始Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw用户如何快速接入Taotoken并开始Agent工作流 对于使用OpenClaw框架构建AI智能体的开发者而言,快速接入稳定、多…...
)
Windows10下V-REP教育版安装保姆级教程(附百度网盘资源与避坑点)
Windows10系统V-REP教育版完整安装指南:从下载到实战避坑在机器人仿真和自动化控制领域,V-REP(现更名为CoppeliaSim)作为一款功能强大的跨平台机器人仿真软件,已经成为众多工科学生和研究人员的首选工具。特别是其教育…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...

脉冲神经网络加速器设计与边缘计算优化
1. 脉冲神经网络加速器的设计挑战与突破在边缘计算领域,脉冲神经网络(SNN)正以其独特的生物启发特性引发新一轮技术变革。与传统人工神经网络(ANN)相比,SNN通过离散的脉冲信号传递信息,模拟生物神经元的工作机制,理论上可实现超低…...

HoRain云--CLAUDE.md 使用指南
🎬 HoRain云小助手:个人主页 🔥 个人专栏: 《Linux 系列教程》《c语言教程》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!…...
)
DeepSeek代码风格检查避坑指南(内部审计报告首次披露:37个被忽略的合规红线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码风格检查的合规性本质与审计背景 DeepSeek代码风格检查并非单纯的技术偏好约束,而是嵌入研发治理链条中的合规性控制节点。其本质是将编程实践与组织级安全策略、行业监管要求&…...