Vitis HLS 学习笔记--抽象并行编程模型-控制驱动与数据驱动
目录
1. 简介
2. Takeaways
3. Data-driven Task-level Parallelism
3.1 simple_data_driven 示例
3.2 分析 hls::task 类
3.3 分析通道(Channel)
3.4 注意死锁
4. Control-driven Task-level Parallelism
4.1 理解控制驱动的 TLP
4.2 simple_control_driven 示例
4.3 分析示例
4.4 DATAFLOW 规范形式
4.5 配置 DATAFLOW 的通道
5. 总结
1. 简介
当我们谈论任务级并行度(TLP)时,我们实际上是在讨论如何在应用程序中同时执行多个任务,以提高效率和性能。这就像是一个厨师在厨房里同时烹饪多道菜,而不是一道一道地做,这样可以更快地准备一顿大餐。
Vitis HLS 提供了两种典型的 TLP 模型:控制驱动的任务和数据驱动的任务。
数据驱动的模型就像是一个自动化的流水线,它不断地处理数据,不需要外部的指令或干预。只要有数据输入,它就会工作。这适用于那些不需要与外部存储器交互,且各个函数之间没有数据依赖关系的应用。简单来说,如果你的程序是一系列独立的步骤,每个步骤处理的数据都不会影响其他步骤,那么这种模型就很合适。
控制驱动的模型更像是有一个指挥官,根据需要调度任务和管理数据。如果你的应用程序的不同部分需要相互通信,或者一个任务的输出是另一个任务的输入,那么你就需要这种模型。Vitis HLS是一个工具,它可以帮助确定哪些任务可以同时进行,以及如何最有效地安排它们。
2. Takeaways
如果 HLS 设计为纯数据驱动的设计,且无需与软件应用进行任何交互,那么可以使用数据驱动的 TLP 模型来建模。
此类设计的典型应用场景有:
- 基于简单规则的“防火墙”,且“规则”编译到内核中。
- 快速傅里叶变换,且配置数据编译到内核中。
- FIR 滤波器,且系数编译到内核中。
如果设计需要往来外部存储器执行数据传输,那么可使用控制驱动的 TLP 模型。此类设计的示例有:
- 网络路由器,其中路由表必须完全更新后才能执行内核。
- 使用散列映射向服务器发送数据的负载均衡器,这类负载均衡器必须同时更新服务器列表、服务器映射以及对应的 IP 地址。
大部分设计将混用控制驱动与数据驱动的模型,需要对外部存储器进行部分访问,支持 HLS 内的并行任务与流水打拍任务之间的串流。
- 本文探讨的是函数级建模的方法(任务通道最优化或数据流最优化)。
- 达成良好的吞吐量的另一个关键要素是,指令级并行度。
- 指令级并行度指的是在循环、函数甚至阵列内部有效执行并行运算的能力。
3. Data-driven Task-level Parallelism
3.1 simple_data_driven 示例
#include "hls_task.h"void splitter(hls::stream<int>& in, hls::stream<int>& odds_buf,hls::stream<int>& evens_buf) {int data = in.read();if (data % 2 == 0)evens_buf.write(data);elseodds_buf.write(data);
}void odds(hls::stream<int>& in, hls::stream<int>& out) {out.write(in.read() + 1);
}void evens(hls::stream<int>& in, hls::stream<int>& out) {out.write(in.read() + 2);
}void odds_and_evens(hls::stream<int>& in, hls::stream<int>& out1,hls::stream<int>& out2) {hls_thread_local hls::stream<int, 5> s1; // channel connecting t1 and t2hls_thread_local hls::stream<int, 5> s2; // channel connecting t1 and t3// t1 infinitely runs func1, with input in and outputs s1 and s2hls_thread_local hls::task t1(splitter, in, s1, s2);// t2 infinitely runs func2, with input s1 and output out1hls_thread_local hls::task t2(odds, s1, out1);// t3 infinitely runs func3, with input s2 and output out2hls_thread_local hls::task t3(evens, s2, out2);
}3.2 分析 hls::task 类
对象声明:
- 在源代码中,hls::task 用于声明新对象,并配合 hls_thread_local 限定符使用。
- 这个限定符的关键作用是确保在函数(如 odds_and_evens)的多次实例化调用中,对象及其底层线程保持活跃状态。
- 在数据驱动模型中,无论是 C 语言仿真还是 RTL 仿真,hls_thread_local 都保证了一致的行为。
- 在 RTL 中,函数启动后将持续运行。
- 为了在 C 语言仿真中复现相同的行为,hls_thread_local 确保每个任务只启动一次,并且在多次调用中维持相同状态。
任务对象:
- 任务对象负责隐式地管理持续运行的函数线程。
- 向这些对象传递参数时,只能使用 hls::stream 或 hls::stream_of_blocks 类型。
系统不支持传递其他类型的参数。例如,不能直接将 even 这样的常量值作为函数的参数。如果需要在任务执行过程中使用常量,建议的做法是将相关函数设计为模板函数,并以模板参数的形式传递常量值。
任务主体:
- 提供的函数(例如示例中的 splitter/odds/evens)被称为任务主体。
- 这些函数被隐式无限循环包围,以确保任务保持运行并等待输入。
流水线循环:
- 提供的函数包含流水线循环。但是,为了防止死锁,需要将其设置为可刷新的流水线(FLP)。
- 工具会自动选择适用于给定流水线函数或循环的正确流水线样式。
3.3 分析通道(Channel)
通道由特殊模板化的 hls::stream(或 hls::stream_of_blocks)C++ 类进行建模。
通道具有以下属性:
- 在数据驱动的 TLP 模型中,hls::stream<type,depth> 对象的行为类似于具有指定深度的 FIFO。默认情况下,这些串流的深度为 2,但用户可以覆盖该值。
- 对这些串流的读取和写入是按顺序执行的。一旦从 hls::stream<> 中读取数据项,就无法再次读取该数据项。
- 串流可以在局部或全局范围内定义。全局作用域内定义的串流遵循与其他全局变量相同的规则。
- 对于这些串流(例如示例中的 s1 和 s2),hls_thread_local 限定符也是必需的。它确保在实例化函数(例如示例中的 odds_and_evens)的多次调用之间,相同的串流保持活动状态。
3.4 注意死锁
读取空串流属于阻塞读取,可能引发死锁,以下情况需要注意:
- 设计本身内部的进程的生产和耗用率不平衡,发生死锁。
- 测试激励文件提供的数据太少,不足以生成该测试激励文件在检查计算结果时所需的所有输出,发生死锁。
在 C 语言仿真期间:某个进程周期或者从顶层输入启动的进程链尝试读取空的通道,会导致死锁。
在 C/RTL 协同仿真期间以及在硬件 (HW) 中运行时:写入已满的通道或者读取空的通道,会导致死锁。
当设计包含 hls::task 时,Vitis HLS 工具会自动例化死锁检测器,检测到死锁后停止 C 语言仿真。使用 Vitis HLS GUI 可观察仿真的 hls::tasks 尝试读取空的通道时,所有发生阻塞的具体位置。
4. Control-driven Task-level Parallelism
4.1 理解控制驱动的 TLP
控制驱动的任务级并行(TLP) 是一种用于建模并行性的方法,它依赖于 C++ 中的顺序语义,而不是连续运行的线程。这种模型适用于以下情况:
- 按并发流水方式执行的函数:例如,在循环内部可以同时执行多个函数。
- 搭配实参执行的函数:这些实参不是通道,而是 C++ 中的标量或数组变量。这两种方式都适用于本地存储器和片外DDR存储器。
Vitis HLS 在保留原始 C++ 顺序执行行为的同时,引入了并行度的概念,具有以下特点:
- 后续函数可以在前一个函数完成之前启动。
- 函数可以在完成之前重新启动。
- 可以同时启动两个或两个以上的顺序函数。
控制驱动的 TLP ,也称数据流模型,它使用一系列顺序执行的函数来创建一个并行处理的流水线结构。这个结构允许多个任务同时进行:
任务级流水线架构:就像一个工厂流水线上的不同工位同时工作一样,数据流模型允许多个函数(任务)同时执行,每个函数处理不同的数据部分。
推断并行任务和通道:工具会自动识别哪些任务可以并行执行,并建立它们之间的通信通道。
DATAFLOW 指令:设计人员通过这些指令告诉工具哪些区域(函数体或循环主体)应该以数据流的方式来处理。
通道类型:设计人员可以选择不同类型的通道,比如 FIFO(hls::stream 或 #pragma HLS STREAM)或 PIPO(hls::stream_of_blocks),这些通道决定了数据的传输方式。
4.2 simple_control_driven 示例
#include <hls_stream.h>
#include <hls_vector.h>// Each vector will be 64 bytes (16 x 4 bytes)
typedef hls::vector<uint32_t, NUM_WORDS> vecOf16Words;
typedef unsigned int data_t;extern "C" {void diamond(vecOf16Words* vecIn, vecOf16Words* vecOut, int size) {
// The depth setting is required for pointer to array in the interface.
#pragma HLS INTERFACE m_axi port = vecIn depth = 32
#pragma HLS INTERFACE m_axi port = vecOut depth = 32hls::stream<vecOf16Words> c0, c1, c2, c3, c4, c5;assert(size % 16 == 0);#pragma HLS dataflowload(vecIn, c0, size);compute_A(c0, c1, c2, size);compute_B(c1, c3, size);compute_C(c2, c4, size);compute_D(c3, c4, c5, size);store(c5, vecOut, size);
}
}void load(vecOf16Words* in, hls::stream<vecOf16Words>& out, int size) {
Loop_Ld:for (int i = 0; i < size; i++) {
#pragma HLS performance target_ti = 32
#pragma HLS LOOP_TRIPCOUNT max = 32out.write(in[i]);}
}void compute_A(hls::stream<vecOf16Words>& in, hls::stream<vecOf16Words>& out1,hls::stream<vecOf16Words>& out2, int size) {
Loop_A:for (int i = 0; i < size; i++) {
#pragma HLS performance target_ti = 32
#pragma HLS LOOP_TRIPCOUNT max = 32vecOf16Words t = in.read();out1.write(t * 3);out2.write(t * 3);}
}void compute_B(hls::stream<vecOf16Words>& in, hls::stream<vecOf16Words>& out,int size) {
Loop_B:for (int i = 0; i < size; i++) {
#pragma HLS performance target_ti = 32
#pragma HLS LOOP_TRIPCOUNT max = 32out.write(in.read() + 25);}
}void compute_C(hls::stream<vecOf16Words>& in, hls::stream<vecOf16Words>& out,int size) {
Loop_C:for (data_t i = 0; i < size; i++) {
#pragma HLS performance target_ti = 32
#pragma HLS LOOP_TRIPCOUNT max = 32out.write(in.read() * 2);}
}
void compute_D(hls::stream<vecOf16Words>& in1, hls::stream<vecOf16Words>& in2,hls::stream<vecOf16Words>& out, int size) {
Loop_D:for (data_t i = 0; i < size; i++) {
#pragma HLS performance target_ti = 32
#pragma HLS LOOP_TRIPCOUNT max = 32out.write(in1.read() + in2.read());}
}void store(hls::stream<vecOf16Words>& in, vecOf16Words* out, int size) {
Loop_St:for (int i = 0; i < size; i++) {
#pragma HLS performance target_ti = 32
#pragma HLS LOOP_TRIPCOUNT max = 32out[i] = in.read();}
}4.3 分析示例
void diamond(data_t vecIn[100], data_t vecOut[100])
{data_t c1[100], c2[100], c3[100], c4[100];
#pragma HLS dataflowfuncA(vecIn, c1, c2);funcB(c1, c3);funcC(c2, c4);funcD(c3, c4, vecOut);
}
在以上示例中有 4 个函数:funcA,funcB,funcC 和 funcD。funcB 与 funcC 之间不存在任何数据依赖关系,因此可以并行执行:

funcA 会从非本地存储器 (vecIn) 读取,需首先执行。同样,funcD 写入非本地存储器 (vecOut),因此最后执行。
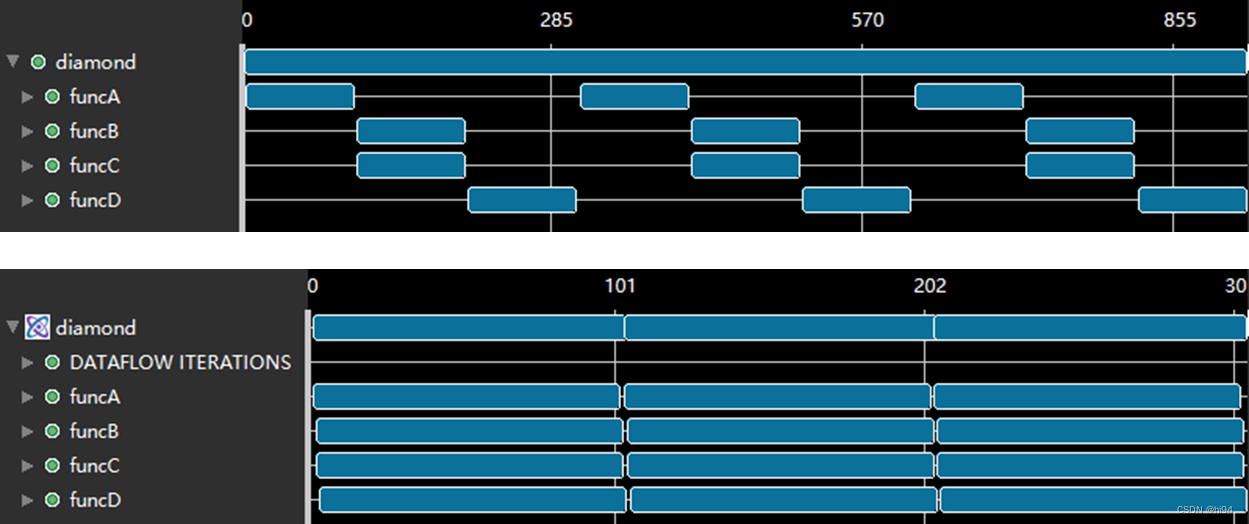
简单回顾:
- 通过 DATAFLOW 指令划定数据流区域。将某个特定区域(例如,函数体或循环主体)识别为要应用数据流模型的区域。
- 创建各通道。HLS 工具解析区域内函数体或循环体,并基于 C++ 变量(例如,标量、阵列或用户定义的通道,如 hls::streams 或 hls::stream_of_blocks)创建各通道,这些变量用于对数据流区域内的数据流动进行建模。
- 非标量变量。对于标量变量而言可能只是简单的 FIFO,而对于非标量变量,则可能是乒乓 (PIPO) 缓冲器,此类非标量变量有阵列、块串流(前提是需将 FIFO 和 PIPO 行为与块的显式锁定加以组合)等。
4.4 DATAFLOW 规范形式
为了增强数据流的可预测性,应遵循特定的代码编写规范。下面简明地概述了这些规范:
- 函数规范:
- 使用#pragma HLS dataflow指令以启用数据流优化。
- 定义的子函数可作为数据流的一部分,但不包括变量初始化和表达式的值传递。
- 确保按照规范格式编写代码,以便Vitis HLS能够有效实现数据流。如有偏差,使用GUI的数据流查看器和协同仿真时间轨迹进行验证。
示例代码:
void dataflow(Input0, Input1, Output0, Output1)
{
#pragma HLS dataflowUserDataType C0, C1, C2; // UserDataType can be scalars or arraysfunc1(Input0, Input1, C0, C1); // read Input0, read Input1, write C0, write C1func2(C0, C1, C2); // read C0, read C1, write C2func3(C2, Output0, Output1); // read C2, write Output0, write Output1
}- 循环内的数据流:
- 循环应仅包含一个函数调用,无其他代码。
- 循环变量应从0开始,以1递增,且上限为非负数。
- 数据流指令应位于循环体内。
示例代码:
void dataflow(Input0, Input1, Output0, Output1)
{for (int i = 0; i < N; i++){#pragma HLS dataflowUserDataType C0, C1, C2; // UserDataType can be scalars or arraysfunc1(Input0, Input1, C0, C1); // read Input0, read Input1, write C0, write C1func2(C0, C0, read C1, C2); // read C0, read C0, read C1, write C2func3(C2, Output0, Output1); // read C2, write Output0, writeOutput1}
}
4.5 配置 DATAFLOW 的通道
- 对于标量,Vitis HLS 将自动推断 FIFO 作为通道类型。
- 对于阵列,且始终顺序访问数据,PIPO/FIFO 均可作为通道。PIPO 从不发生死锁,但需要耗用更多存储器。FIFO 所需存储器较少,但存储深度配置不正确,则存在发生死锁的风险。
- 对于阵列,且需任意顺序访问数据,只能 PIPO 来实现(默认大小是原始阵列的两倍)。
void top ( ... ) {
#pragma HLS dataflowint A[1024];#pragma HLS stream type=pipo variable=A depth=3producer(A, B, …); // producer writes A and Bmiddle(B, C, ...); // middle reads B and writes Cconsumer(A, C, …); // consumer reads A and C
}
5. 总结
任务级并行度(TLP)通过同时执行多个任务提升应用效率和性能。Vitis HLS 提供了数据驱动和控制驱动两种 TLP 模型。数据驱动模型像自动化流水线,适用于无外部存储器交互且函数间无数据依赖的应用;控制驱动模型则更像一个指挥官,适合不同部分需相互通信的应用。数据驱动模型中,任务通过 hls::task 声明,通道通过 hls::stream 模拟,注意避免死锁。控制驱动模型使用 C++ 顺序语义创建并行处理流水线,任务级并行执行函数,需使用 DATAFLOW 编译指示。两者结合,实现高效并行计算。

相关文章:
Vitis HLS 学习笔记--抽象并行编程模型-控制驱动与数据驱动
目录 1. 简介 2. Takeaways 3. Data-driven Task-level Parallelism 3.1 simple_data_driven 示例 3.2 分析 hls::task 类 3.3 分析通道(Channel) 3.4 注意死锁 4. Control-driven Task-level Parallelism 4.1 理解控制驱动的 TLP 4.2 simple_control_driven 示例 4…...

Python爬取B站视频:封装一下
📚博客主页:knighthood2001 ✨公众号:认知up吧 (目前正在带领大家一起提升认知,感兴趣可以来围观一下) 🎃知识星球:【认知up吧|成长|副业】介绍 ❤️如遇文章付费,可先看…...
Android Low Storage机制之DeviceStorageMonitorService
一、Android 版本 Android 13 二、low storage简介(DeviceStorageMonitorService) 设备存储监视器服务是一个模块,主要用来: 1.监视设备存储(“/ data”)。 2.每60秒扫描一次免费存储空间(谷歌默认值) 3.当设备的存储空间不足…...

1105: 交换二叉树的孩子结点
解法: #include<iostream> using namespace std; struct treeNode {char val;treeNode* left, * right;treeNode(char x) :val(x), left(NULL), right(NULL) {}; }; treeNode* buildtree() {char ch;cin >> ch;if (ch #) return NULL;treeNode* r ne…...

TensorFlow.js
什么是 TensorFlow.js? TensorFlow.js 是一个基于 JavaScript 的机器学习库,它是 Google 开发的 TensorFlow 的 JavaScript 版本。它使得开发者能够在浏览器中直接运行机器学习模型,而不需要依赖于后端服务器或云服务。TensorFlow.js 的主要…...
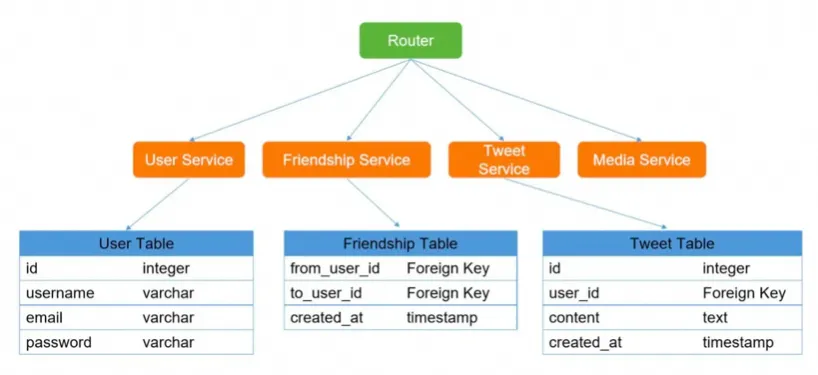
131. 面试中关于架构设计都需要了解哪些内容?
文章目录 一、社区系统架构组件概览1. 系统拆分2. CDN、Nginx静态缓存、JVM本地缓存3. Redis缓存4. MQ5. 分库分表6. 读写分离7. ElasticSearch 二、商城系统-亿级商品如何存储三、对账系统-分布式事务一致性四、统计系统-海量计数六、系统设计 - 微软1、需求收集2、顶层设计3、…...
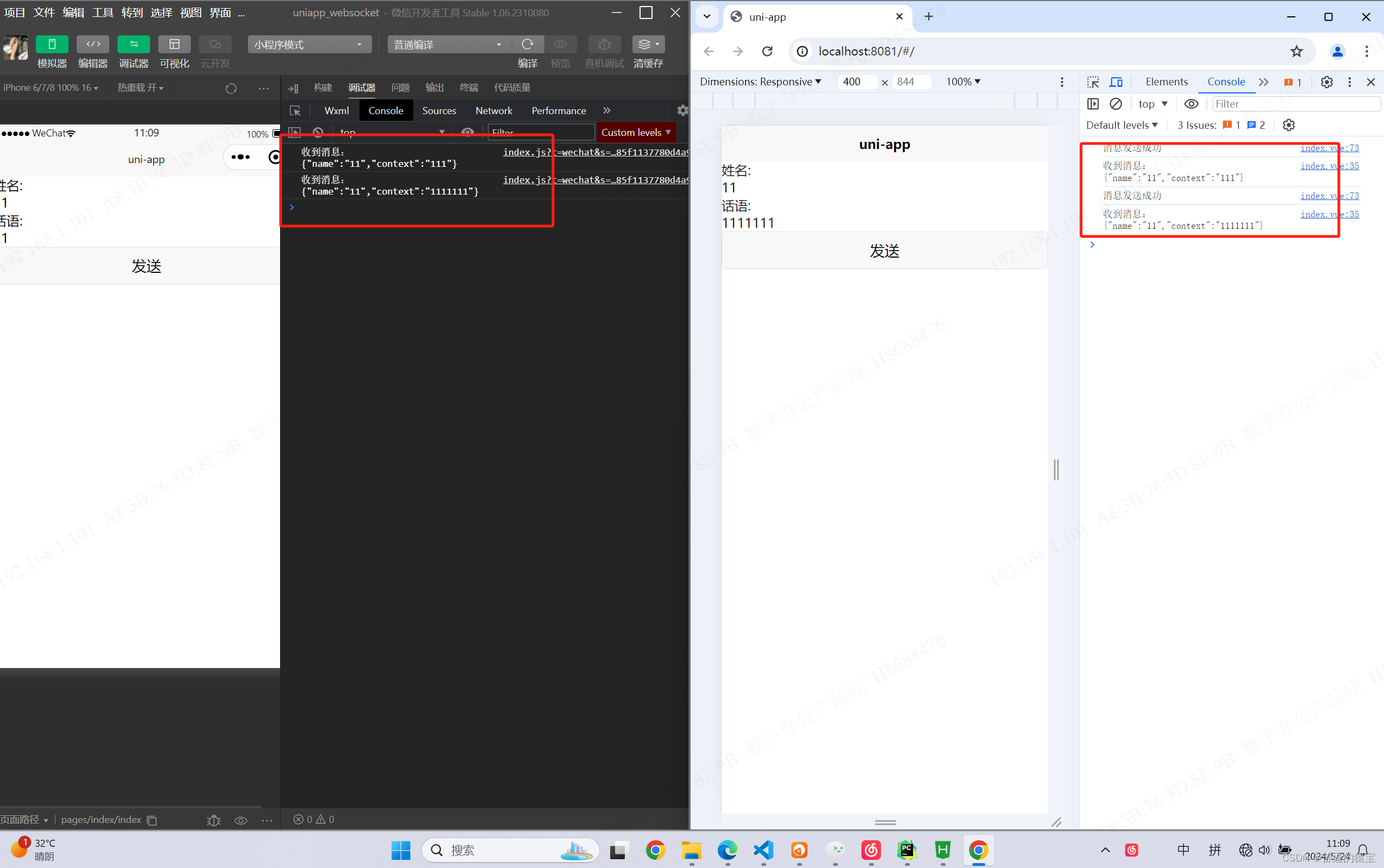
Nodejs+Websocket+uniapp完成聊天
前言 最近想做一个聊天,但是网上的很多都是不能实现的,要么就是缺少代码片段很难实现websocket的链接,更别说聊天了。自己研究了一番之后实现了这个功能。值得注意的是,我想在小程序中使用socket.io,不好使࿰…...
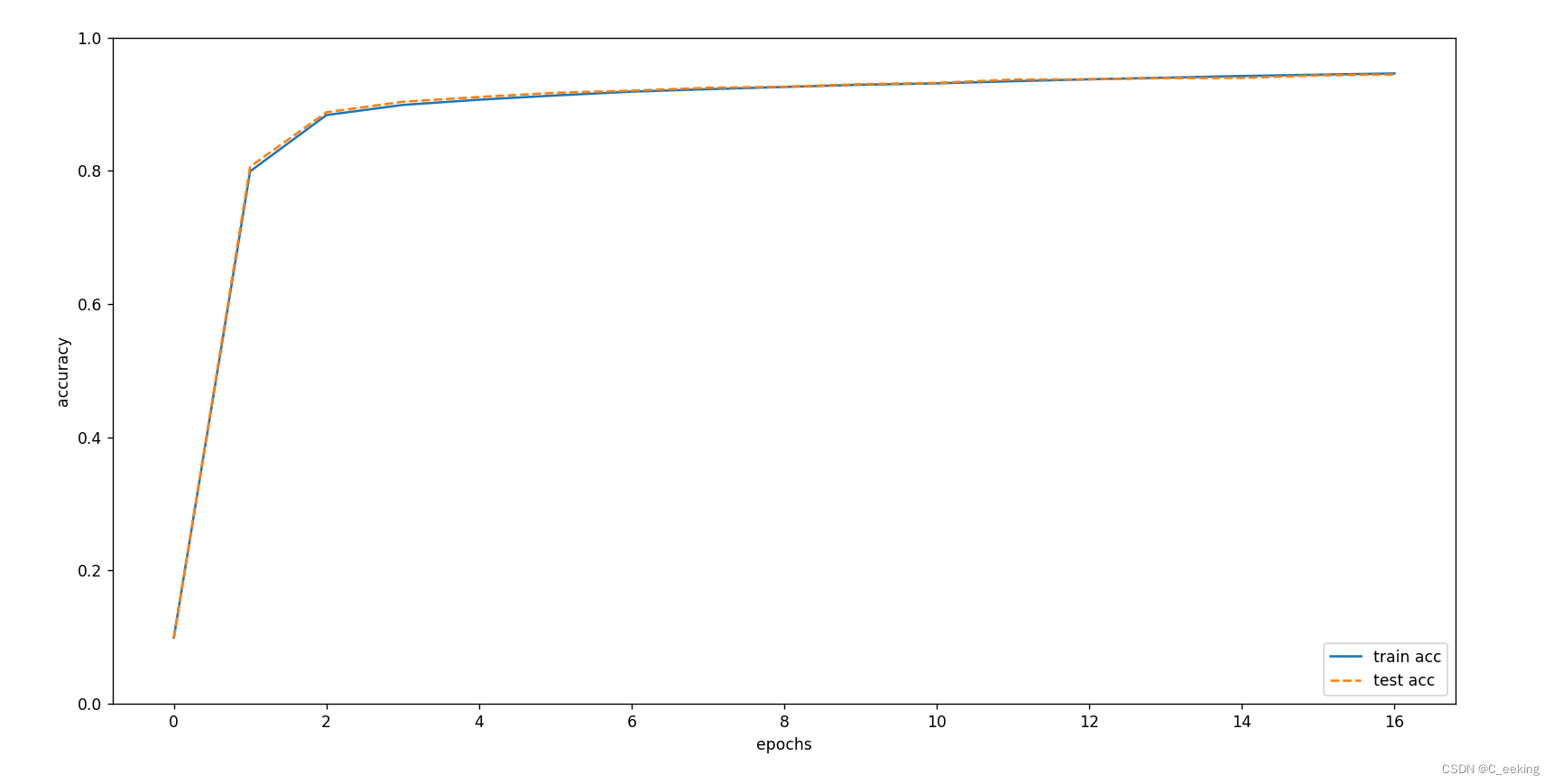
神经网络学习
神经网络学习 导语数据驱动驱动方法训练/测试数据 损失函数均方误差交叉熵误差mini-batch 数值微分梯度梯度法神经网络梯度 学习算法的实现随机梯度下降2层神经网络实现mini-batch实现 总结参考文献 导语 神经网络中的学习指从训练数据中自动获取最优权重参数的过程࿰…...

CentOS部署NFS
NFS服务端 部署NFS服务端 sudo yum install -y nfs-utils挂载目录 给 NFS 指定一个存储位置,也就是网络共享目录。一般来说,应该建立一个专门的 /data 目录,方便起见使用临时目录 /tmp/nfs: mkdir -p /tmp/nfs #修改权限 chmo…...

JWT使用方法
目录 基础概念 依赖 生成令牌 工具类 控制层 解析令牌 工具类 网关过滤器 效果 基础概念 Json web token (JWT), 是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准((RFC 7519).该token被设计为紧凑且安全的,特别适用于分布式站点…...

使用鱼香肉丝一键安装重新安装ROS后mavros节点报错,.so文件不匹配
解决方案: 1、写在mavros相关软件,共卸载7个包 sudo apt-get remove ros-melodic-mav*2、重新安装mavros,共安装10个包 sudo apt-get remove ros-melodic-mav*...
STM32+CubeMX移植SPI协议驱动W25Q16FLash存储器
STM32CubeMX移植SPI协议驱动W25Q16FLash存储器 SPI简介拓扑结构时钟相位(CPHA)和时钟极性( CPOL) W25Q16简介什么是Flash,有什么特点?W25Q16内部块、扇区、页的划分引脚定义通讯方式控制指令原理图 CubeMX配…...

gpt-4o考场安排
说明 :经过多次交互,前后花了几个小时,总算完成了基本功能。如果做到按不同层次分配考场,一键出打印结果就完美了。如果不想看中间“艰苦”的过程,请直接跳到“最后结果”及“食用方法”。中间过程还省略了一部分交互&…...
【Unity AR开发插件】四、制作热更数据-AR图片识别场景
专栏 本专栏将介绍如何使用这个支持热更的AR开发插件,快速地开发AR应用。 链接: Unity开发AR系列 插件简介 通过热更技术实现动态地加载AR场景,简化了AR开发流程,让用户可更多地关注Unity场景内容的制作。 “EnvInstaller…”支…...

Spring AOP的实操 + 原理(动态代理)
1 什么是Spring AOP 要想知道Spring AOP那必然是是要先知道什么是AOP了: AOP,全称为 Aspect-Oriented Programming(面向切面编程),是一种编程范式,用于提高代码的模块化,特别是横切关注点(cros…...
16.线性回归代码实现
线性回归的实操与理解 介绍 线性回归是一种广泛应用的统计方法,用于建模一个或多个自变量(特征)与因变量(目标)之间的线性关系。在机器学习和数据科学中,线性回归是许多入门者的第一个模型,它…...
Java进阶学习笔记1——课程介绍
课程适合学习的人员: 1)具备一定java基础的人员; 2)想深刻体会Java编程思想,成为大牛的人员; 学完有什么收获? 1)掌握完整的Java基础技术体系; 2)极强的编…...
【全开源】沃德商协会管理系统源码(FastAdmin+ThinkPHP+Uniapp)
一款基于FastAdminThinkPHPUniapp开发的商协会系统,新一代数字化商协会运营管理系统,以“智慧化会员体系、智敏化内容运营、智能化活动构建”三大板块为基点,实施功能全场景覆盖,一站式解决商协会需求壁垒,有效快速建立…...
)
python毕设项目选题汇总(全)
各位计算机方面的毕业生们,是不是在头疼毕业论文写什么呢,我这给大家提供点思路: 网站系统类 《基于python的招聘数据爬虫设计与实现》 《基于python和Flask的图书管理系统》 《基于照片分享的旅游景点推荐系统》 《基于djangoxadmin的学生信…...

c#从数据库读取数据到datagridview
从已有的数据库读取数据显示到winform的datagridview控件,具体代码如下: //判断有无表 if (sqliteConn.State ConnectionState.Closed) sqliteConn.Open(); SQLiteCommand mDbCmd sqliteConn.CreateCommand(); m…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行
BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

【审计专栏】【财务领域】 第四十九篇 人在企业中的核心资产和核心利益01
编号 类型 企业 (行业/企业产品/企业利益链/生态位与层级) 业务领域 企业性质 企业中人的角色/岗位/利益矩阵 人在企业中的核心资产/附属资产 资产的业务-财务数学模型及数字/数值 关联知识 1 核心经营性资产(如IP、数据、品牌) 行业:人工智能 产品:工业视觉检…...

构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学
构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学 【免费下载链接】scdl Soundcloud Music Downloader 项目地址: https://gitcode.com/gh_mirrors/sc/scdl 在流媒体音乐主导的时代,音乐爱好者面临着一种矛盾:我们享受着…...
)
从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表)
更多请点击: https://codechina.net 第一章:从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表) 向事件驱动架构(EDA)演进不是功能迭代&…...

模拟电路实现自主循线机器人:无MCU的硬件逻辑设计
1. 项目概述:用最纯粹的模拟电路,造一台会“思考”的机器人每次看到那些在赛道上灵巧穿梭的循线小车,你是不是也手痒,想自己动手做一个?但一听到“单片机”、“编程”、“Arduino”这些词,又觉得门槛太高&a…...

Cesium动态数据可视化实战:CallbackProperty结合setInterval打造实时运动轨迹
Cesium动态数据可视化实战:CallbackProperty结合setInterval打造实时运动轨迹 在三维地理信息系统中,实时数据可视化一直是开发者面临的挑战之一。想象一下,当我们需要在地球表面追踪一架正在飞行的无人机,或者监控城市中数百辆出…...

别只盯着主控芯片!拆解STM32最小系统板:电源、时钟、复位三大支柱电路深度解析
STM32最小系统板设计进阶:电源、时钟与复位电路的工程实践 在嵌入式系统开发中,我们常常将注意力集中在主控芯片的功能实现上,却忽略了支撑系统稳定运行的三大基础电路——电源、时钟和复位。这些看似简单的电路模块,实则是整个系…...

如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器
如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为想和朋友一起玩游戏却只有一台电脑而烦…...

Diablo Edit2:3步掌握暗黑破坏神2存档修改的终极秘籍
Diablo Edit2:3步掌握暗黑破坏神2存档修改的终极秘籍 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 还在为暗黑破坏神2中刷装备的漫长过程感到疲惫吗?Diablo Edit2这款免费…...