大模型框架:vLLM
目录
一、vLLM 介绍
二、安装 vLLM
2.1 使用 GPU 进行安装
2.2 使用CPU进行安装
2.3 相关配置
三、使用 vLLM
3.1 离线推理
3.2 适配OpenAI-API的API服务
一、vLLM 介绍
vLLM是伯克利大学LMSYS组织开源的大语言模型高速推理框架。它利用了全新的注意力算法「PagedAttention」,提供易用、快速、便宜的LLM服务。
二、安装 vLLM
2.1 使用 GPU 进行安装
vLLM 是一个Python库,同时也包含预编译的C++和CUDA(12.1版本)二进制文件。
1. 安装条件:
- OS: Linux
- Python: 3.8 – 3.11
- GPU: compute capability 7.0 or higher (e.g., V100, T4, RTX20xx, A100, L4, H100, etc.)
2.使用 pip 安装:
# 使用conda创建python虚拟环境(可选)
conda create -n vllm python=3.11 -y
conda activate vllm# Install vLLM with CUDA 12.1.
pip install vllm
2.2 使用CPU进行安装
vLLM 也支持在 x86 CPU 平台上进行基本的模型推理和服务,支持的数据类型包括 FP32 和 BF16。
1.安装要求:
- OS: Linux
- Compiler: gcc/g++>=12.3.0 (recommended)
- Instruction set architecture (ISA) requirement: AVX512 is required.
2.安装编译依赖:
yum install -y gcc gcc-c++
3.下载源码:
git clone https://github.com/vllm-project/vllm.git
4.安装python依赖:
pip install wheel packaging ninja setuptools>=49.4.0 numpy psutil
# 需要进入源码目录
pip install -v -r requirements-cpu.txt --extra-index-url https://download.pytorch.org/whl/cpu
5.执行安装:
VLLM_TARGET_DEVICE=cpu python setup.py install
2.3 相关配置
1. vLLM默认从HuggingFace下载模型,如果想从ModelScope下载模型,需要配置环境变量:
export VLLM_USE_MODELSCOPE=True
三、使用 vLLM
3.1 离线推理
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams# Initialize the tokenizer
tokenizer = AutoTokenizer.from_pretrained("/data/weisx/model/Qwen1.5-4B-Chat")# Pass the default decoding hyperparameters of Qwen1.5-4B-Chat
# max_tokens is for the maximum length for generation.
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=512)# Input the model name or path. Can be GPTQ or AWQ models.
llm = LLM(model="Qwen/l/Qwen1.5-4B-Chat", trust_remote_code=True)# Prepare your prompts
prompt = "Tell me something about large language models."
messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)# generate outputs
outputs = llm.generate([text], sampling_params)# Print the outputs.
for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")3.2 适配OpenAI-API的API服务
借助vLLM,构建一个与OpenAI API兼容的API服务十分简便,该服务可以作为实现OpenAI API协议的服务器进行部署。默认情况下,它将在 http://localhost:8000 启动服务器。您可以通过 --host 和 --port 参数来自定义地址。请按照以下所示运行命令:
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen1.5-4B-Chat
使用curl与Qwen对接:
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "Qwen/Qwen1.5-4B-Chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me something about large language models."}
]
}'
使用python客户端与Qwen对接:
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)chat_response = client.chat.completions.create(model="Qwen/Qwen1.5-4B-Chat",messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Tell me something about large language models."},]
)
print("Chat response:", chat_response)相关文章:

大模型框架:vLLM
目录 一、vLLM 介绍 二、安装 vLLM 2.1 使用 GPU 进行安装 2.2 使用CPU进行安装 2.3 相关配置 三、使用 vLLM 3.1 离线推理 3.2 适配OpenAI-API的API服务 一、vLLM 介绍 vLLM是伯克利大学LMSYS组织开源的大语言模型高速推理框架。它利用了全新的注意力算法「PagedAtten…...

SQL 使用心得【持续更新】
COUNT(字段) 不会统计 NULL 值,但是COUNT(*)会只要有子查询,就需要给子查询定义别名!where 后面的条件表达式中不能存在聚合函数,但是 Having 可以聚合函数基本上都是需要配合 group…...
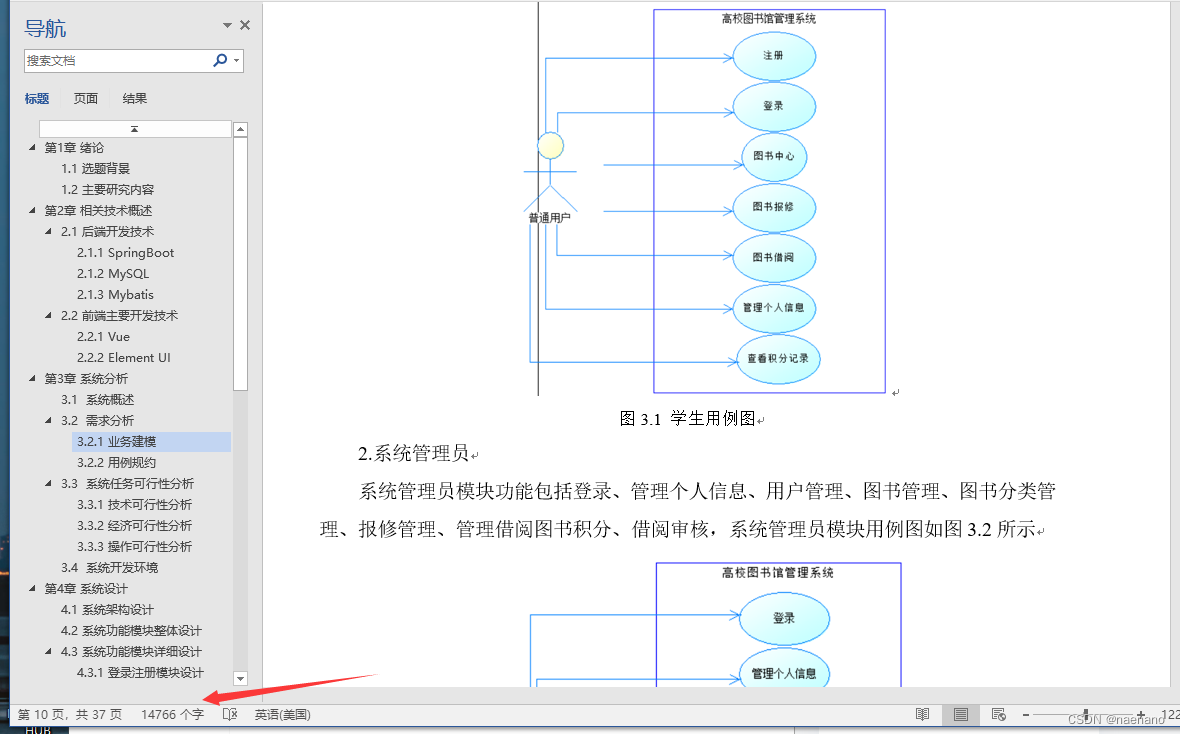
基于Spring Boot的高校图书馆管理系统
项目和论文都有企鹅号2583550535 基于Spring Boot的图书馆管理系统||图书管理系统_哔哩哔哩_bilibili 第1章 绪论... 1 1.1 研究背景和意义... 1 1.2 国内外研究现状... 1 第2章 相关技术概述... 2 2.1 后端开发技术... 2 2.1.1 SpringBoot 2 2.1.2 MySQL.. 2 2.1.3 My…...
 : pip安装使用国内源)
python(4) : pip安装使用国内源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests...

让写书人勇敢穿越纸海的迷雾
坚守纸海:让写书人勇敢穿越纸海的迷雾 你作为一位写书人,在创作过程中你需要坚守初心是非常重要的。在创作的过程中,你会遇到各种挑战和困难,你要勇敢面对迷雾中的挑战,并通过不懈的努力和决心,成功地穿越…...

ROS2学习——节点话题通信(2)
目录 一、ROS2节点 1.概念 2.实例 (1)ros2 run (2)ros2 node list (3)remapping重映射 (4)ros2 node info 二、话题 (1) ros2 topic list …...
【Spring Boot】深度复盘在开发搜索引擎项目中重难点的整理,以及遇到的困难和总结
💓 博客主页:从零开始的-CodeNinja之路 ⏩ 收录文章:【Spring Boot】深度复盘在开发搜索引擎项目中重难点的整理,以及遇到的困难和总结 🎉欢迎大家点赞👍评论📝收藏⭐文章 目录 什么是搜索引…...

配置docker阿里云镜像地址
一、安装docker的步骤: 1.yum install -y yum-utils 2.yum-config-manager --add-repo http://mirrors.aliyun.com/docker- ce/linux/centos/docker-ce.repo --配置阿里云仓库3.yum makecache fast4.yum install docker-ce -y5.docker version …...

ICML 2024 Mamba 论文总结
2024ICML(International Conference on Machine Learning,国际机器学习会议)在2024年7月21日-27日在奥地利维也纳举行 🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀 欢迎大家关注时空探索之旅 …...

Sass详解
Sass简介 Sass(Syntactically Awesome Stylesheets)是一种CSS预处理器,它在CSS的语法基础上添加了一些功能和语法糖,提供了更强大和灵活的样式表语言。 Sass可以通过定义变量、嵌套规则、混合、继承等功能,帮助开发者…...

如何实现一个高效的排序算法?
要实现一个高效的排序算法,可以考虑以下几个方面: 1.选择合适的排序算法:根据数据规模和特点选择合适的排序算法。例如,对于小规模的数据可以选择插入排序或选择排序,而对于大规模数据可以选择归并排序或快速排序。 …...
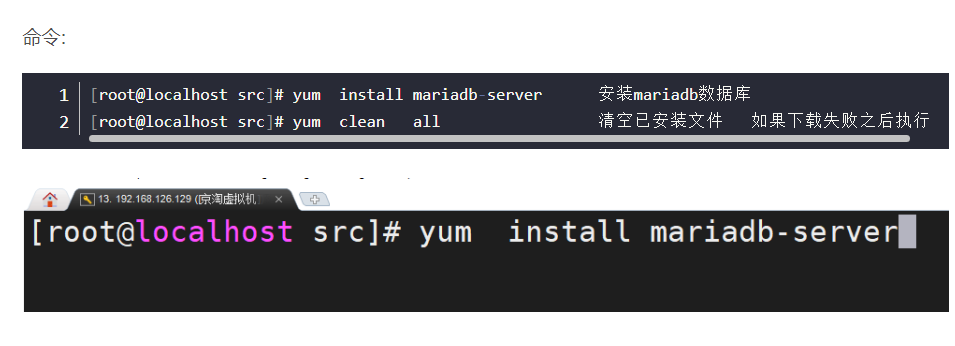
Linux--10---安装JDK、MySQL
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 安装JDK[Linux命令--03----JDK .Nginx. 数据库](https://blog.csdn.net/weixin_48052161/article/details/108997148) 第一步 查询系统中自带的JDK第二步 卸载系统中…...
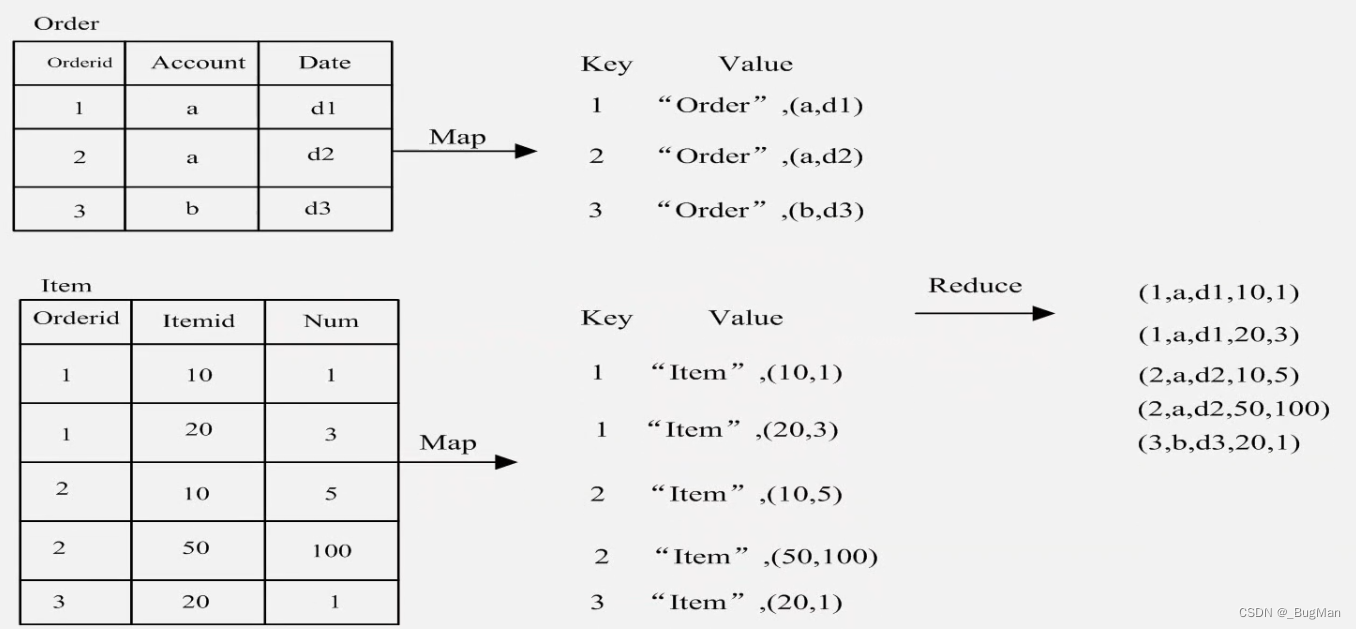
【大数据】MapReduce JAVA API编程实践及适用场景介绍
目录 1.前言 2.mapreduce编程示例 3.MapReduce适用场景 1.前言 本文是作者大数据系列专栏的其中一篇,前文我们依次聊了大数据的概论、分布式文件系统、分布式数据库、以及计算引擎mapreduce核心概念以及工作原理。 书接上文,本文将会继续聊一下mapr…...
)
图像分类和文本分类(传统机器学习和深度学习)
1. 传统机器学习—决策树 1.1 图像分类代码 from sklearn import tree from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split# 加载数据集 iris load_iris() X, y iris.data, iris.target# 划分数据集 X_train, X_test, y_train,…...
基于SpringBoot和Hutool工具包实现的验证码案例
目录 验证码案例 1. 需求 2. 准备工作 3. 约定前后端交互接口 需求分析 接口定义 4. Hutool 工具介绍 5. 实现验证码 后端代码 前端代码 6. 运行测试 验证码案例 随着安全性的要求越来越高,目前项目中很多都会使用验证码,只要涉及到登录&…...

python-找出四位数中的玫瑰花数
【问题描述】玫瑰花数指一个n位数(n>4),其每位上的数字的n次幂之和等于本身。 请求出所有四位数中的玫瑰花数 【输入形式】 【输出形式】 【样例输入】 【样例输出】1634 8208 9474 【样例说明】 【评分标准】 完整代码如下: for n in ra…...

Linux-命令上
at是一次性的任务,crond是循环的定时任务 如果 cron.allow 文件存在,只有在文件中出现其登录名称的用户可以使用 crontab 命令。root 用户的登录名必须出现在 cron.allow 文件中,如果这个文件存在的话。系统管理员可以明确的停止一个用户&am…...
青鸟云报修系统:实现高效、便捷的维修申请处理
在日常生活和工作中,故障报修难免会遇到,售后报修服务则成为了解决问题的关键。纸质化售后报修维修申请单,作为报修流程中的重要一环,在一定程度上能够记录和追踪售后报修维修流程,但在实际操作过程中却存在着诸多弊端…...

Python解析网页
目录 1、Beautiful Soup 2、解析数据 3、遍历文档树 4、搜索文档树 一、Beautiful Soup 1、什么是Beautiful Soup 定义:Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库. 功能:它能够通过你喜欢的转换器实现惯用的文档导航,查找,修…...

IDEA连接MySQL后如何管理数据库
上一节讲解了IDEA如何连接MySQL数据库管理系统,接下来我们就可以在IDEA里使用MySQL来管理数据库了。那么如果我们现在还没有创建需要的数据库怎么办?本节就来教大家如何在IDEA连接MySQL后管理数据库(创建/修改/删除数据库、创建/修改/删除表、插入/更新/…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...

Raspberry Pi Debug Probe:RP2040嵌入式开发的调试利器与实战指南
1. 项目概述:为什么你需要一个Raspberry Pi Debug Probe?如果你玩过树莓派Pico或者任何基于RP2040芯片的开发板,肯定遇到过这样的场景:写好的代码,点一下“上传”,然后……就没有然后了。板子上的LED没按你…...

统信UOS浏览器书签同步难题?一招搞定所有新用户默认书签配置
统信UOS浏览器书签批量配置:系统管理员的高效部署指南在企业或教育机构的IT运维工作中,统信UOS作为国产操作系统的代表,其浏览器书签的统一管理常常成为系统管理员面临的挑战。想象一下,每当有新员工入职或学生入学,都…...

【大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型?】
大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型? 随着大模型技术的快速发展,越来越多的企业开始将 AI 能力融入到业务流程中。然而,面对市场上众多的大模型产品,企业往往面临着 “选择困难…...
P2P聊天程序)
基于C#实现(WinForm)P2P聊天程序
♻️ 资源 大小: 29.8MB ➡️ 资源下载:https://download.csdn.net/download/s1t16/87430269 p2p聊天程序 一、功能介绍 1.1 登录 用户凭用户名和密码登录系统,可以更换服务器 IP 和端口,以防网络不畅通,连接服务…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...

前馈补偿技术:用数字预失真驯服放大器非线性失真
1. 项目概述:用前馈补偿驯服放大器失真在音频发烧友和硬件工程师的圈子里,追求“高保真”几乎是一种信仰。我们总希望从扬声器里传出的声音,是录音现场或音乐制作人意图的完美复刻,纤毫毕现,不带一丝杂质。然而&#x…...