Python数据分析实验四:数据分析综合应用开发
目录
- 一、实验目的与要求
- 二、主要实验过程
- 1、加载数据集
- 2、数据预处理
- 3、划分数据集
- 4、创建模型估计器
- 5、模型拟合
- 6、模型性能评估
- 三、主要程序清单和运行结果
- 四、实验体会
一、实验目的与要求
1、目的:
综合运用所学知识,选取有实际背景的应用问题进行数据分析方案的设计与实现。要求明确目标和应用需求,涵盖数据预处理、建模分析、模型评价和结果展示等处理阶段,完成整个分析流程。
2、要求:
(1)应用Scikit-Learn库中的逻辑回归、SVM和kNN算法对Scikit-Learn自带的乳腺癌(from sklearn.datasets import load_breast_cancer)数据集进行分类,并分别评估每种算法的分类性能。
(2)为了进一步提升算法的分类性能,能否尝试使用网格搜索和交叉验证找出每种算法较优的超参数。
二、主要实验过程
1、加载数据集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
cancer.keys()
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names'])
将数据集转换为DataFram:
import pandas as pd
cancer_data=pd.DataFrame(cancer.data,columns=cancer.feature_names)
cancer_data['target']=cancer.target_names[cancer.target]
cancer_data.head(3).append(cancer_data.tail(3))
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.30010 | 0.14710 | 0.2419 | 0.07871 | ... | 17.33 | 184.60 | 2019.0 | 0.16220 | 0.66560 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | malignant |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.08690 | 0.07017 | 0.1812 | 0.05667 | ... | 23.41 | 158.80 | 1956.0 | 0.12380 | 0.18660 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | malignant |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.19740 | 0.12790 | 0.2069 | 0.05999 | ... | 25.53 | 152.50 | 1709.0 | 0.14440 | 0.42450 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | malignant |
| 566 | 16.60 | 28.08 | 108.30 | 858.1 | 0.08455 | 0.10230 | 0.09251 | 0.05302 | 0.1590 | 0.05648 | ... | 34.12 | 126.70 | 1124.0 | 0.11390 | 0.30940 | 0.3403 | 0.1418 | 0.2218 | 0.07820 | malignant |
| 567 | 20.60 | 29.33 | 140.10 | 1265.0 | 0.11780 | 0.27700 | 0.35140 | 0.15200 | 0.2397 | 0.07016 | ... | 39.42 | 184.60 | 1821.0 | 0.16500 | 0.86810 | 0.9387 | 0.2650 | 0.4087 | 0.12400 | malignant |
| 568 | 7.76 | 24.54 | 47.92 | 181.0 | 0.05263 | 0.04362 | 0.00000 | 0.00000 | 0.1587 | 0.05884 | ... | 30.37 | 59.16 | 268.6 | 0.08996 | 0.06444 | 0.0000 | 0.0000 | 0.2871 | 0.07039 | benign |
6 rows × 31 columns
2、数据预处理
进行数据标准化:
from sklearn.preprocessing import StandardScaler
X=StandardScaler().fit_transform(cancer.data)
y=cancer.target
3、划分数据集
将数据集划分为训练集和测试集:
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33)
4、创建模型估计器
(1)创建逻辑回归模型估计器:
#创建逻辑回归模型估计器
from sklearn.linear_model import LogisticRegression
lgr=LogisticRegression()
(2)创建SVM算法模型估计器:
#创建SVM算法模型估计器
from sklearn.svm import SVC
svc=SVC()
(3)创建kNN算法模型估计器:
#创建kNN算法模型估计器
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier()
5、模型拟合
用训练集训练模型估计器estimator:
#训练逻辑回归模型估计器
lgr.fit(X_train,y_train)
#训练SVM算法模型估计器
svc.fit(X_train,y_train)
#训练kNN算法模型估计器
knn.fit(X_train,y_train)
6、模型性能评估
(1)逻辑回归模型性能评估:
#用模型估计器对测试集数据做预测
y_pred=lgr.predict(X_test)#对模型估计器的学习效果进行评价
print("测试集的分类准确率为:",lgr.score(X_test,y_test))
(2)SVM算法模型性能评估:
#用模型估计器对测试集数据做预测
y_pred=svc.predict(X_test)#对模型估计器的学习效果进行评价
print("测试集的分类准确率为:",svc.score(X_test,y_test))
(3)kNN算法模型性能评估:
#用模型估计器对测试集数据做预测
y_pred=knn.predict(X_test)#对模型估计器的学习效果进行评价
print("测试集的分类准确率为:",knn.score(X_test,y_test))
三、主要程序清单和运行结果
1、逻辑回归用于分类
#加载数据集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()#对数据集进行预处理,实现数据标准化
from sklearn.preprocessing import StandardScaler
X=StandardScaler().fit_transform(cancer.data)
y=cancer.target#将数据集划分为训练集和测试集(要求测试集占25%,随机状态random state设置为33)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33) #创建模型估计器estimator
from sklearn.linear_model import LogisticRegression
lgr=LogisticRegression()#用训练集训练模型估计器estimator
lgr.fit(X_train,y_train)#用模型估计器对测试集数据做预测
y_pred=lgr.predict(X_test)#对模型估计器的学习效果进行评价
#最简单的评估方法:就是调用估计器的score(),该方法的两个参数要求是测试集的特征矩阵和标签向量
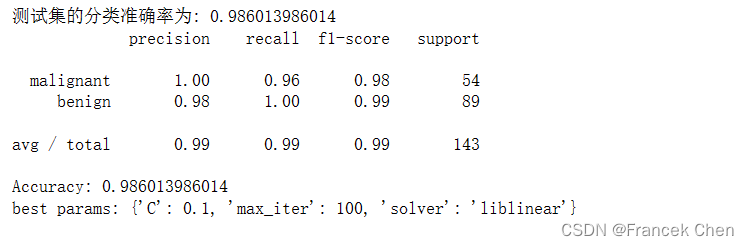
print("测试集的分类准确率为:",lgr.score(X_test,y_test))
from sklearn import metrics
#对于多分类问题,还可以使用metrics子包中的classification_report
print(metrics.classification_report(y_test,y_pred,target_names=cancer.target_names)) #网格搜索与交叉验证相结合的逻辑回归算法分类:
from sklearn.model_selection import GridSearchCV,KFold
params_lgr={'C':[0.01,0.1,1,10,100],'max_iter':[100,200,300],'solver':['liblinear','lbfgs']}
kf=KFold(n_splits=5,shuffle=False)grid_search_lgr=GridSearchCV(lgr,params_lgr,cv=kf)
grid_search_lgr.fit(X_train,y_train)
grid_search_y_pred=grid_search_lgr.predict(X_test)
print("Accuracy:",grid_search_lgr.score(X_test,y_test))
print("best params:",grid_search_lgr.best_params_)
2、支持向量用于分类
#加载数据集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()#对数据集进行预处理,实现数据标准化
from sklearn.preprocessing import StandardScaler
X=StandardScaler().fit_transform(cancer.data)
y=cancer.target#将数据集划分为训练集和测试集(要求测试集占25%,随机状态random state设置为33)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33) #创建模型估计器estimator
from sklearn.svm import SVC
svc=SVC()#用训练集训练模型估计器estimator
svc.fit(X_train,y_train)#用模型估计器对测试集数据做预测
y_pred=svc.predict(X_test)#对模型估计器的学习效果进行评价
#最简单的评估方法:就是调用估计器的score(),该方法的两个参数要求是测试集的特征矩阵和标签向量
print("测试集的分类准确率为:",svc.score(X_test,y_test))
from sklearn import metrics
#对于多分类问题,还可以使用metrics子包中的classification_report
print(metrics.classification_report(y_test,y_pred,target_names=cancer.target_names))#网格搜索与交叉验证相结合的SVM算法分类:
from sklearn.model_selection import GridSearchCV,KFold
params_svc={'C':[0.1,1,10],'gamma':[0.1,1,10],'kernel':['linear','rbf']}
kf=KFold(n_splits=5,shuffle=False)
grid_search_svc=GridSearchCV(svc,params_svc,cv=kf)
grid_search_svc.fit(X_train,y_train)
grid_search_y_pred=grid_search_svc.predict(X_test)
print("Accuracy:",grid_search_svc.score(X_test,y_test))
print("best params:",grid_search_svc.best_params_)

3、kNN用于分类
#加载数据集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()#对数据集进行预处理,实现数据标准化
from sklearn.preprocessing import StandardScaler
X=StandardScaler().fit_transform(cancer.data)
y=cancer.target#将数据集划分为训练集和测试集(要求测试集占25%,随机状态random state设置为33)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33) #创建模型估计器estimator
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier()#用训练集训练模型估计器estimator
knn.fit(X_train,y_train)#用模型估计器对测试集数据做预测
y_pred=knn.predict(X_test)#对模型估计器的学习效果进行评价
#最简单的评估方法:就是调用估计器的score(),该方法的两个参数要求是测试集的特征矩阵和标签向量
print("测试集的分类准确率为:",knn.score(X_test,y_test))
from sklearn import metrics
#对于多分类问题,还可以使用metrics子包中的classification_report
print(metrics.classification_report(y_test,y_pred,target_names=cancer.target_names))#网格搜索与交叉验证相结合的kNN算法分类:
from sklearn.model_selection import GridSearchCV,KFold
params_knn={'algorithm':['auto','ball_tree','kd_tree','brute'],'n_neighbors':range(3,10,1),'weights':['uniform','distance']}
kf=KFold(n_splits=5,shuffle=False)
grid_search_knn=GridSearchCV(knn,params_knn,cv=kf)
grid_search_knn.fit(X_train,y_train)
grid_search_y_pred=grid_search_knn.predict(X_test)
print("Accuracy:",grid_search_knn.score(X_test,y_test))
print("best params:",grid_search_knn.best_params_)

四、实验体会
在本次实验中,我使用了Scikit-Learn库中的逻辑回归、支持向量机(SVM)和k最近邻(kNN)算法对乳腺癌数据集进行分类,并对每种算法的分类性能进行了评估。随后,我尝试使用网格搜索和交叉验证来找出每种算法的较优超参数,以进一步提升其分类性能。
首先,我加载了乳腺癌数据集,并将其划分为训练集和测试集。然后,我分别使用逻辑回归、SVM和kNN算法进行训练,并在测试集上进行评估。评估指标包括准确率、精确率、召回率和F1-score等。通过这些指标,我能够了解每种算法在乳腺癌数据集上的分类性能。
接着,我尝试使用网格搜索(Grid Search)和交叉验证(Cross Validation)来找出每种算法的较优超参数。网格搜索是一种通过在指定的超参数空间中搜索最佳参数组合来优化模型的方法。而交叉验证则是一种评估模型性能和泛化能力的方法,它将数据集分成多个子集,在每个子集上轮流进行训练和测试,从而得到更稳健的性能评估结果。
在进行网格搜索和交叉验证时,我根据每种算法的参数范围设置了不同的参数组合,并使用交叉验证来评估每种参数组合的性能。最终,我选择了在交叉验证中性能最优的参数组合作为最终的超参数,并将其用于重新训练模型。
通过这次实验,我学到了如何使用Scikit-Learn库中的机器学习算法进行分类任务,并了解了如何通过网格搜索和交叉验证来优化算法的超参数,提升其分类性能。同时,我也意识到了在实际应用中,选择合适的算法和调优超参数对于获得良好的分类效果至关重要。这次实验为我提供了宝贵的实践经验,对我的机器学习学习之旅有着重要的意义。
相关文章:
Python数据分析实验四:数据分析综合应用开发
目录 一、实验目的与要求二、主要实验过程1、加载数据集2、数据预处理3、划分数据集4、创建模型估计器5、模型拟合6、模型性能评估 三、主要程序清单和运行结果四、实验体会 一、实验目的与要求 1、目的: 综合运用所学知识,选取有实际背景的应用问题进行…...

基于51单片机的盆栽自动浇花系统
一.硬件方案 工作原理是湿度传感器将采集到的数据直接传送到ADC0832的IN端作为输入的模拟信号。选用湿度传感器和AD转换,电路内部包含有湿度采集、AD转换、单片机译码显示等功能。单片机需要采集数据时,发出指令启动A/D转换器工作,ADC0832根…...
SpirngMVC框架学习笔记(一):SpringMVC基本介绍
1 SpringMVC 特点&概述 SpringMVC 从易用性,效率上 比曾经流行的 Struts2 更好 SpringMVC 是 WEB 层框架,接管了 Web 层组件, 比如控制器, 视图, 视图解析, 返回给用户的数据格式, 同时支持 MVC 的开发模式/开发架构SpringMVC 通过注解,…...

实现信号发生控制
1. 信号发生器的基本原理 信号发生器是一种能够产生特定波形和频率的电子设备,常用于模拟信号的产生和测试。 信号发生器的基本原理 信号发生器的工作原理基于不同的技术,但最常见的类型包括模拟信号发生器和数字信号发生器(DDS࿰…...
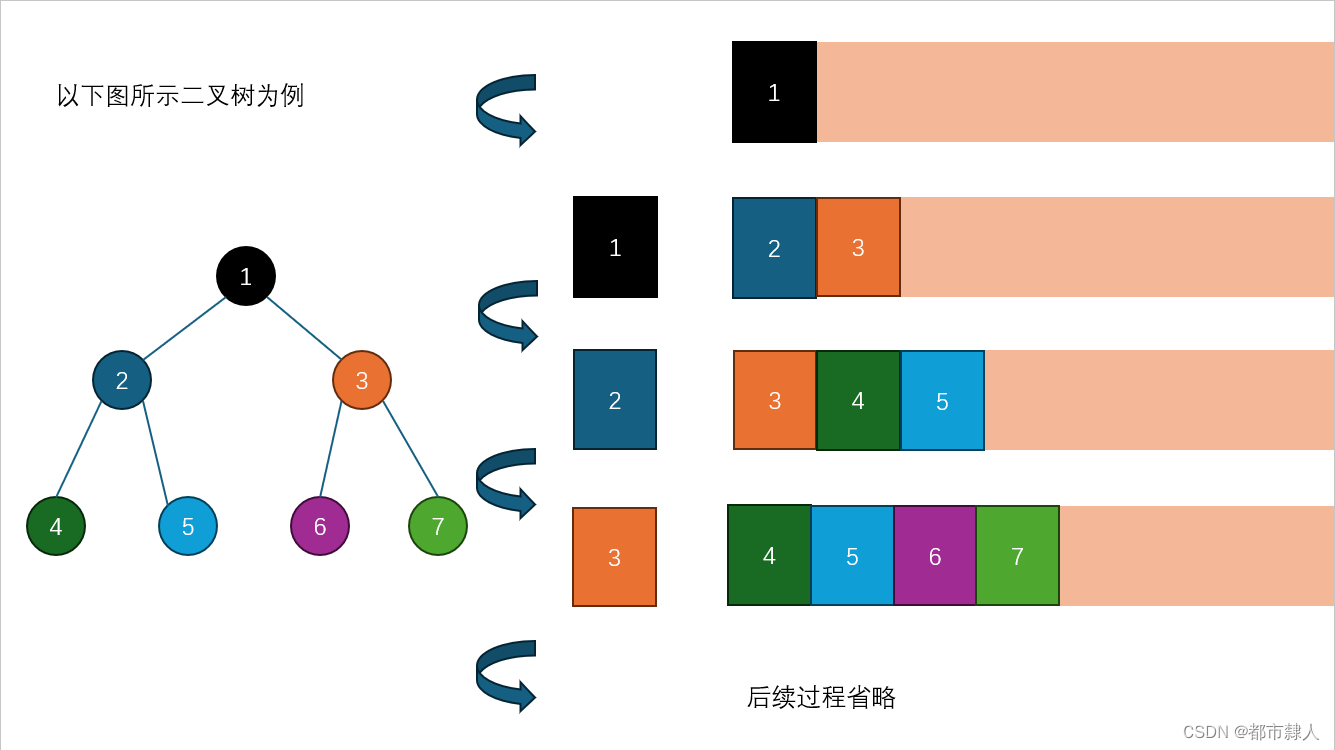
二叉树基于队列实现的操作详解
一、队列知识补充 有关队列的知识请详见博主的另一篇博客:http://t.csdnimg.cn/3PwO4 本文仅仅附上需要的队列操作供读者参考 //结构体定义 typedef struct BinaryTreeNode* QDataType;typedef struct QueueNode {struct QueueNode* next;QDataType val; }QNode;…...

LabVIEW常用开发架构有哪些
LabVIEW常用开发架构有多种,每种架构都有其独特的特点和适用场合。以下是几种常用的开发架构及其特点和适用场合: 1. 单循环架构 特点: 简单易用适用于小型应用将所有代码放在一个循环中 适用场合: 简单的数据采集和处理任务…...
)
告别 Dart 中的 Future.wait([])
作为 Dart 开发人员,我们对异步编程和 Futures 的强大功能并不陌生。过去,当我们需要同时等待多个 future 时,我们依赖 Future.wait([]) 方法,该方法返回一个 List<T>。然而,这种方法有一个显着的缺点࿱…...

Cisco ASA防火墙抓包命令Capture
在日常运维中,遇到故障时经常需要在ASA上抓包进行诊断。 从抓包中可以看到流量是否经过ASA流量是否被ASA放行,或block,匹配的哪一条ACL capture在Firepower平台上同样适用,无论跑的是ASA还是FTD 1 抓包命令 capture 2 配置方…...

Linux网络编程:HTTP协议
前言: 我们知道OSI模型上层分为应用层、会话层和表示层,我们接下来要讲的是主流的应用层协议HTTP,为什么需要这个协议呢,因为在应用层由于操作系统的不同、开发人员使用的语言类型不同,当我们在传输结构化数据时&…...

HTTP 协议中 GET 和 POST 有什么区别?分别适用于什么场景?
HTTP 协议中 GET 和 POST 是两种常用的请求方法,它们的区别如下: 1. 参数传递方式不同 GET 请求参数是在 URL 中以键值对的形式传递的,例如:http://www.example.com/?key1value1&k ey2value2。 而 POST 请求参数是在请求体中以键值对的…...
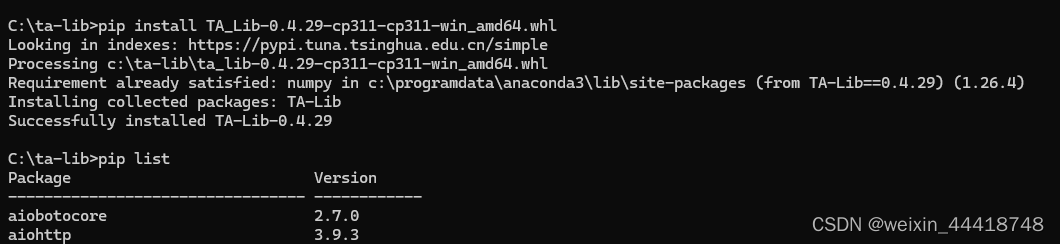
talib 安装
这里写自定义目录标题 talib 安装出错 talib 安装出错 https://github.com/cgohlke/talib-build/releases 这里找到轮子 直接装。...
echarts-树图、关系图、桑基图、日历图
树图 树图主要用来表达关系结构。 树图的端点也收symbol的调节 树图的特有属性: 树图的方向: layout、orient子节点收起展开:initialTreeDepth、expandAndCollapse叶子节点设置: leaves操作设置:roam线条:…...
04Django项目基本运行逻辑及模板资源套用
对应视频链接点击直达 Django项目用户管理及模板资源 对应视频链接点击直达1.基本运行逻辑Django的基本运行路线:视图views.py中的 纯操作、数据返回、页面渲染 2.模版套用1.寻找一个好的模版2.模板部署--修改适配联动 OVER,不会有人不会吧不会的加Q1394…...

安徽大学数学科学学院教授陈昌昊
男,本(2005-2009)、硕(2009-2012)学位都在湖北大学获得,博士学位在芬兰获得(2012-2016),博士后分别在澳大利亚(2016-2019)、香港(2020…...

com.alibaba.fastjson.JSONObject循环给同一对象赋值会出现“$ref“:“$[0]“现象问题
1、问题描述 有些场景下,我们会选择用JSONObject代替Map来处理业务逻辑,但是使用JSONObject时有一个需要注意的地方:在处理JSONObject对象时,引用的com.alibaba.fastjson.JSONObject,在一个集合中,循环给这…...

【C++】详解AVL树——平衡二叉搜索树
个人主页:东洛的克莱斯韦克-CSDN博客 祝福语:愿你拥抱自由的风 目录 二叉搜索树 AVL树概述 平衡因子 旋转情况分类 左单旋 右单旋 左右双旋 右左双旋 AVL树节点设计 AVL树设计 详解单旋 左单旋 右单旋 详解双旋 左右双旋 平衡因子情况如…...
《计算机网络微课堂》2-2 物理层下面的传输媒体
请大家注意,传输媒体不属于计算机网络体系结构的任何一层,如果非要将它添加到体系结构中,那只能将其放在物理层之下。 传输媒体可分为两类:一类是导引型传输媒体,另一类是非导引型传输媒体。 在导引型传输媒体…...
【算法设计与分析】基于Go语言实现动态规划法解决TSP问题
本文针对于最近正在学习的Go语言,以及算法课实验所需内容进行Coding,一举两得! 一、前言 由于这个实验不要求向之前的实验一样做到那种连线的可视化,故可以用图形界面不那么好实现的语言进行编写,考虑到Go语言的…...
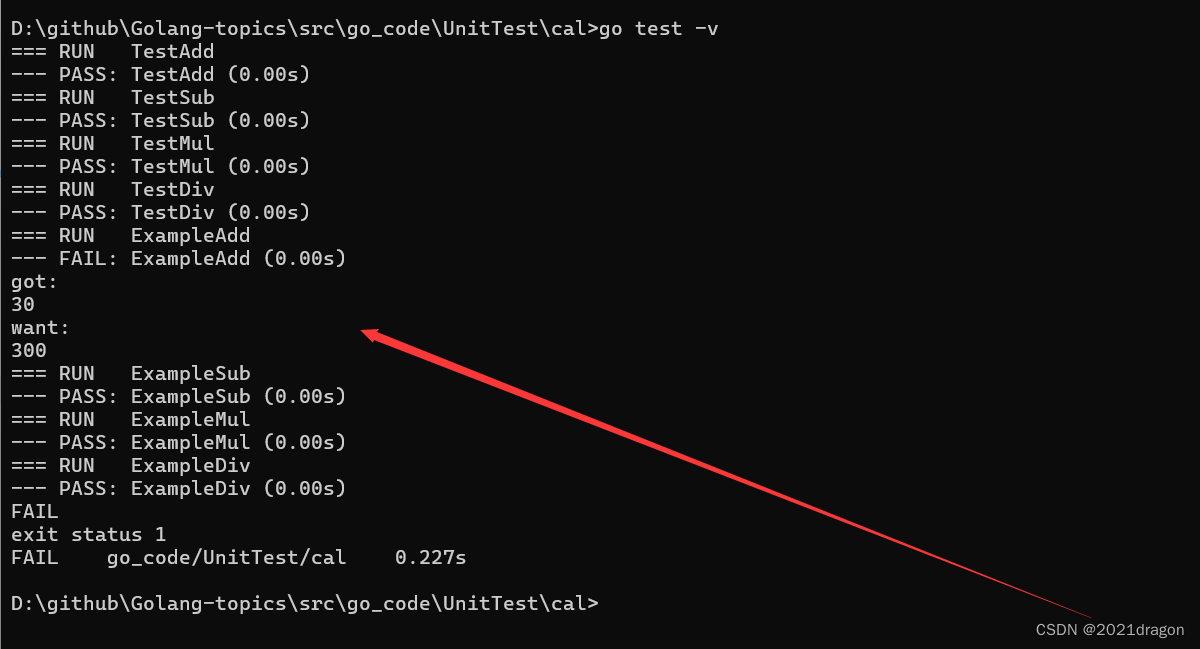
Golang单元测试
文章目录 传统测试方法基本介绍主要缺点 单元测试基本介绍测试函数基准测试示例函数 传统测试方法 基本介绍 基本介绍 代码测试是软件开发中的一项重要实践,用于验证代码的正确性、可靠性和预期行为。通过代码测试,开发者可以发现和修复潜在的错误、确保…...
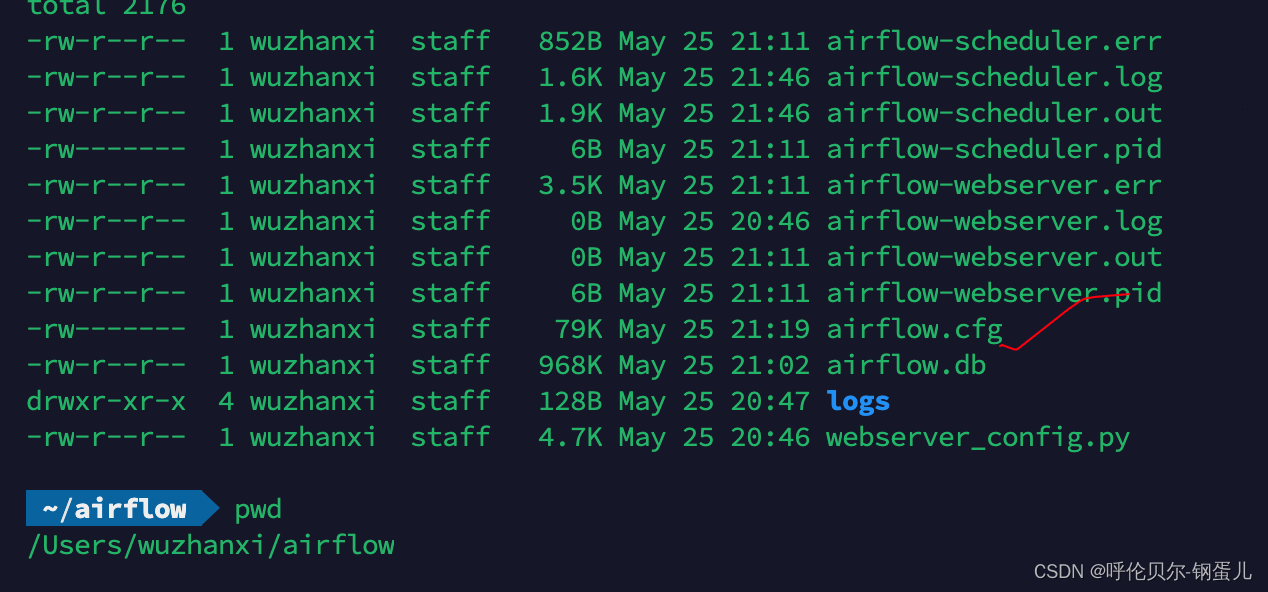
mac下安装airflow
背景:因为用的是Mac的M芯片的电脑,安装很多东西都经常报错,最近在研究怎么把大数据集群上的crontab下的任务都配置到一个可视化工具中,发现airflow好像是个不错的选择,然后就研究怎么先安装使用起来,后面再…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...

CANoe诊断测试没CDD文件怎么办?手把手教你用Fault Memory窗口和CAPL脚本读取解析DTC故障码
CANoe诊断测试无CDD文件的实战解决方案:从Fault Memory到CAPL脚本全解析当CDD文件缺失或定义不清晰时,诊断测试工程师常常陷入困境。本文将深入探讨如何利用Fault Memory窗口的基础功能,并通过CAPL脚本实现更灵活、更强大的故障码读取与解析方…...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...

NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台
NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经面对Minecraft世界文件…...

Git Bash 中无法启动 Claude Code ?
最近需要在 git bash 中跑 Claude Code 。git bash 是随 git for windows 套件安装的,很久没更新了,结果启动 Claude Code 报错:Warning: no stdin data received in 3s, proceeding without it. If piping from a slow command, redirect st…...

用PyTorch复现FactorVAE:一个能同时预测收益和风险的量化模型实战教程
用PyTorch实战FactorVAE:构建收益与风险双预测的量化模型 在量化投资领域,传统线性因子模型正逐渐被非线性机器学习方法所取代。然而金融数据特有的低信噪比特性,使得直接从市场数据中提取有效因子成为一项艰巨挑战。本文将深入探讨如何利用P…...

ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现
ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 在机器人操作系统(ROS)开发领域,硬件依赖和测试成本一直是制约算法迭代效率的…...

Lovable电商网站搭建,为什么92%的初创团队在第3周就遭遇性能雪崩?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署。其核心基于 Vue 3(Composition API&a…...

别再只会用--nogpgcheck了!手把手教你安全修复PostgreSQL yum源的GPG密钥问题
企业级PostgreSQL部署:安全解决GPG密钥验证的完整方案 当你在生产环境中部署PostgreSQL时,遇到GPG签名验证错误直接使用--nogpgcheck绕过检查,就像因为门锁打不开就直接把门拆掉一样危险。本文将带你深入理解GPG验证机制,并提供一…...